Edit wars in Wikipedia
We present a new, efficient method for automatically detecting severe conflicts `edit wars' in Wikipedia and evaluate this method on six different language WPs. We discuss how the number of edits, reverts, the length of discussions, the burstiness of…
Authors: Robert Sumi, Taha Yasseri, Andras Rung
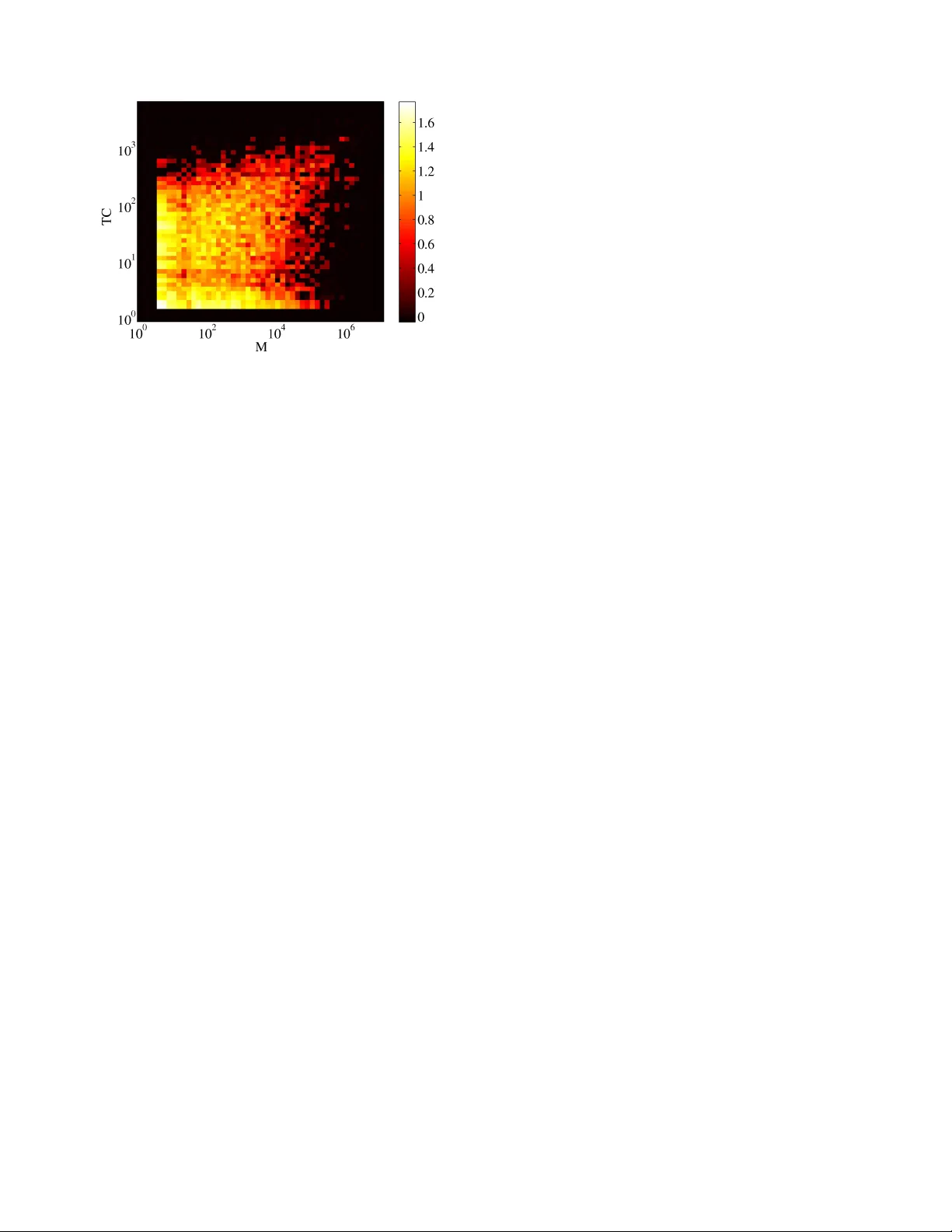
Edit wars in W ikipedia R ´ obert Sumi, T aha Y asseri, Andr ´ as Rung Institute of Physics Budapest Univ ersity of T echnology and Economics H-1111 Budapest Budafoki u 8 Email: { rsumi,yasseri,runga } @phy .bme.hu Andr ´ as K ornai J ´ anos K ert ´ esz Institute of Mathematics and Institute of Physics Budapest Univ ersity of T echnology and Economics H-1111 Budapest Budafoki u 8 Email: kornai@math.bme.hu, kertesz@phy .bme.hu Abstract —W e pr esent a new , efficient method for automatically detecting se vere conflicts, ‘edit wars’ in Wikipedia and ev aluate this method on six different language W ikipedias. W e discuss how the number of edits and r everts deviate in such pages from those follo wing the general workflow , and argue that earlier work has significantly over -estimated the contentiousness of the Wikipedia editing process. I . I N T RO D U C T I O N The dev elopment of W ikipedia (WP) articles is not always a peaceful and collaborativ e process. This has long been rec- ognized by the WP community , which calls extreme cases of disagreement over the contents of an article an edit war , 1 . WP has dev eloped specific guidelines for dealing with edit warring, such as the three revert rule , offers a v ariety of tags to warn about disputes , and even has a humorous listing of the lamest edit wars . Perhaps the easiest way human readers can detect pages affected by w arring (in the English WP , which is the one discussed unless explicitly stated otherwise) is to read through the discussion page (also known as the talk page ) associated to each content page looking for telltale signs such as notices requesting cleanup, swearwords and name-calling. When the discussion gro ws heated, the length of the talk page can exceed the length of the article many times over , so that older discussions must be archiv ed. Another way to detect controv ersy is to view the history of the page, which can show many war-like acts, in particular editors r everting the work of other editors. Schneider et al [1] estimate that among highly edited or highly viewed articles (these notions are strongly correlated, see [2]) about 12% of discussions is de voted to re verts and vandalism, suggesting that the WP development process is highly contentious. In fact, once the great bulk of WP articles is considered, we find the editorial process far more peaceful: as we shall see, around 24k articles, i.e. less than 1% of the 3m articles av ailable in the November 2009 English WP dump, can be called controversial. T o sustain such far-reaching conclusions we can no longer rely on manual checking, so our primary interest is with the automatic detection of edit wars. Since our interest is with the entire WP process, of which the English WP is just the largest (and most mature) instance, we 1 In the electronic version of this paper hyperlinks are direct references to WP . In the printed version, these are given in typewriter font are primarily interested in language- and culture-independent methods that can be applied uniformly across the range of WPs. Therefore, our methods are based entirely on the history page, as opposed to the more human-readable talk page. Previous works (including our own) aimed at the automatic detection of editorial conflict and edit wars is summarized in Section II. In Section III we discuss other indicators of controv ersiality and ev aluate these in comparison to ours. W e offer our conclusions in Section IV. I I . A U T O M A T I C C O N FL I C T D E T E C T I O N Conflicts in WP were studied already both on the article and on the user level. Kittur [3] et al. computed article controversy from dif ferent page metrics (number of reverts, number of revisions etc.), V uong et al. [4] counted the number of deleted words between users and used their “Mutual Reinforcement Principle” to measure how controv ersial a gi ven article is. Both teams counted how many times dispute tags appeared in the history of an article, and used this as ground truth. While this is an excellent test in one direction (certainly recognition of controv ersiality by the participants is as good as the same recognition coming from an outsider), it is too narro w , as there can be quite significant wars that the community is unaware of or at least do not tag, as, e.g., in the articles on Gda ´ nsk or Euthanasia . Note that by applying more lax criteria (i.e. not requiring the presence of overt conflict tags) our method will, if anything, overestimate the e xtent of controversy , strengthening our conclusion that there is much less conflict in WP than appears from sampling highly edited/viewed pages. There are sev eral papers which try to measure the negativ e links between WP editors in a gi ven article and, based on this, attempt to classify editors into groups. The main idea of the method used by Kittur et al. [3], [5] is to count how many times an editor pair rev erted each other . The more two editors rev erted each other, the larger the conflict between them. As we shall see shortly , reverts are indeed central to the assess- ment of controversiality , but one needs to take into account not just the number of (presumably hostile) interactions, but also the seniority of the participants. Brandes et al. [6] assumed that users who do not agree with each other react very fast to edits by the others. The reciprocal v alue of the time elapsed between two consecutiv e edits increases the controv ersy between the two authors. In a more recent paper Brandes [7] counted the number of deleted words between editors and used this as a measure of controversy . W est et. al. and also Adler et. al. have dev eloped v andalism detection methods based on temporal patterns of edits [8], [9]. In both works the main assumption is that offensi ve edits are reverted much faster than normal edits, therefore by considering the time interval between an arbitrary edit and its subsequent re verts, one can classify v andalized versions with high precision. Our o wn work (for a preliminary report, see [10]) was seeded by a manual sample of 40 articles, 20 selected for high controversiality , and 20 for low . T able I summarizes the number of reverts as detected in the text and in the comments 2 (most rev erts are detected by both methods). T ABLE I N U MB E R O F R EV E RT S D E T EC T E D . T H E U P P ER PA RT C O RR E S P ON D S T O A G RO U P O F PAG E S W I TH S E V ER E C ON FL I C TS ( E XC E P T T H O SE I N italics ) ; B E LO W T H E H O RI Z O N T A L L I N E T H ER E A R E P E AC E F UL PAG E S ( E XC E P T T H OS E I N italics ) . Both txt Only Only Article and cmt in txt in cmt titlee 4103 930 328 Global warming 2375 478 142 Homosexuality 1847 617 201 Abortion 1494 260 35 Benjamin F ranklin 1425 437 130 Elvis Presley 1396 233 67 Nuclear power 1298 536 104 Nicolaus Copernicus 1071 211 51 T iger 1036 248 58 Euthanasia 937 204 58 Alzheimer’ s disease 870 192 50 Gun politics 836 172 23 Sherlock Holmes 689 213 49 Arab-Israeli conflict 659 496 138 Israel and the apartheid analogy 652 387 88 Liancourt Rocks 642 250 39 Schizophrenia 516 164 472 Gaza war 431 186 30 1948 Arab-Israeli war 416 73 9 Pumpkin 380 284 58 Gda ´ nsk 318 158 20 SQL 162 24 10 Password 116 26 3 Henry Cav endish 109 29 4 Pension 81 29 4 Mexican drug war 74 37 10 Hungarians in Romania 70 14 4 Markov chain 70 12 1 Mentha 47 20 6 Foucault pendulum 40 5 6 Indian cobra 32 15 1 Harmonium 30 9 1 Infrared photography 29 4 1 Bohrium 24 34 5 Anyos Jedlik 11 6 2 Hungarian forint 10 3 1 Hendrik Lorentz 9 3 1 1980s oil glut 7 1 0 Deutsches Museum 4 0 0 Ara (genus) 0 0 0 Schlenk flask Giv en the number and distribution of false positives and negati ves (typeset in italics) it is clear from T able I that the 2 Each edit could be accompanied by a descriptive comment as Edit summary . raw revert statistics do not yield a clear cutoff-point we could use to distinguish contro versial from non-contro versial articles. Rather than building a complex b ut arbitrary formula that includes different factors that are expected to correlate with controv ersiality , our goal is to base the decision on very fe w parameters – ideally , just one. Let . . . , i − 1 , i, i + 1 , . . . , j − 1 , j, j + 1 , . . . be stages in the history of an article. If the text of revision j coincides with the text of revision i − 1 , we considered this a revert between the editor of re vision j and i respectiv ely . W e are interested in disputes where editors hav e dif ferent opinions about the topic, and do not reach consensus easily . Let us denote by N i the total number of edits in the gi ven ar - ticle of that user who edited the revision i . W e characterize re- verts by pairs ( N d i , N r j ) , where r denotes the editor who makes the re vert, and d refers to the rev erted editor (self-re verts are excluded). Fig.1 represents the re vert map of the non- controv ersial Benjamin Franklin and the highly con- trov ersial Israel and the apartheid analogy arti- cles. Each mark corresponds to one or more reverts. The coordinates of the marks are the total number of edits of the rev erter ( N r ) and the reverted editor ( N d ). Clearly , the disputed article contains more reverts between editors having large edit numbers than the uncontroversial article. Fig. 1. Rev ert maps of the articles Benjamin Franklin (left) and Israel and the apartheid analogy (right). N r and N d are the total number of edits of the rev erter and rev erted editor respectiv ely . The size of the mark is proportional to the number of reverts between them. Fig. 2. Maps of mutual rev erts in the same articles as in Fig. 1. The rev ert maps already distinguish disputed and non- disputed articles, and we can improv e the results by consider- ing only the cases, in which two editors rev ert each other mutually , hereafter called mutual reverts. This causes little change in disputed articles (compare the right panels of Fig.1 to that of Fig.2), but has great impact on non-disputed articles (compare left panels). Based on the rank (total edit number within an article) of editors, two main rev ert types can be distinguished: when one or both of the editors have few edits to their credit (these are typically reverts of v andalism since v andals do not get a chance to achiev e a large edit number as they get banned by experienced users) and when both editors are experienced (created many edits). In order to express this distinction numerically , we use the lesser of the coordinates N d and N r , so that the total count includes vandalism-related reverts as well, but with a much smaller weight. Thus we define our raw measure of controversiality as M r = X ( N d i ,N r j ) min ( N d i , N r j ) Once we developed our first autodetection algorithm based on M r , we iterati vely refined the contro versial and the noncon- trov ersial seeds on multiple languages by manually checking pages scoring very high or v ery low . In this process, we improv ed M r in two w ays: first, by multiplying with the number of editors E who ever rev erted mutually (the larger the armies, the larger the war) and define M i = E × M r and second, by censuring the topmost mutually rev erting editors (eliminating cases with conflicts between two persons only). Our final measure of controv ersiality M is thus defined by M = E × X ( N d i ,N r j ) 1 , 000 for cutoff, which yields a very high controversy population, but if we were truly intent on optimizing the threshold we would probably go down to about M = 200 to see as much vandalism as pure edit warring. As a shortcut, we therefore plotted the second best classifier against M (see Fig. 3), and sampled from the quadrants where they make dif ferent predictions. On the whole, articles with lo w tag count b ut high M appear to be quite controversial, ev en if the participants themselves fail to tag the article for controv ersy . The opposite situation, with low M and high TC, is found v ery rarely . Besides an inherently lower precision and recall, there are some mechanical reasons why counting controversial tags is not a perfect method to detect disputes. There are many dispute- related tags and one has to decide which tags to count on a per-language basis. Page [11] contains all disputed tags, Fig. 3. Scatter plot of article T ag Count (TC) vs. M . Color coding is proportional to the logarithm of the number of articles lying within each cell but some may indicate more serious conflict than others (for example compare {{ Unreferenced }} to {{ Disputed }} ). The limitations of the earlier proposals such as [3] and [4] are evident if we check the results. For example, [4] concluded that in the Podcast article “a significant amount of dispute occurred between the two pairs of users: (a) user 210.213.171.25 and user Jamadagni; and (b) user 68.121.146.76 and user Y amamoto Ichiro”. A closer look at the article reveals that user 210.213.171.25 edited the giv en article only once, and his edit was a vandalism, because he multiplied sev eral time the text of the article, creating a revision which was 20 times larger than the previous one. Jamadagni simply rev erted, generating this way a large number of deleted words between them. Real, recurrent disputes cannot produce this large amount of deleted words, therefore they remain hidden. (This is not an extreme example, user 68.121.146.76 is another vandal, who edited the article only once.) I V . C O N C L U S I O N , F U T U R E D I R E C T I O N S W e proposed a new way to measure how disputed a WP article is. W e did this because existing models hav e drawbacks, and only a small fraction of WP articles were analyzed with them. W e analyzed the whole WP for different language ver- sions, and ranked articles according to their controversy lev el. Altogether , the proposed measure M fares considerably better than earlier proposals both for precision and recall, though this fact would not be evident to the observer restricted to the top 30 articles of the English WP . For example, in Romanian even TC fails rather spectacularly . Based on the results obtained by our classifier, we conclude that in most cases, the process of dev elopment of the articles is considerably peaceful and the number of conflict cases have been overestimated in pre vious works, compared to our estimation of less than 1% of articles to be a candidate for a serious conflict. Besides being a robust language- and culture-independent classifier , our method also yields a numerical ranking, which agrees well with human judgment. While our method does well in separating out edit w ars from vandalism at the high end, much work remains to be done for lower M . Researchers interested in a better controversiality measure may go back to the other indicators of contro versiality and mix these into the measure: the largest limiting factor is the number of manually truthed examples one is willing to create for training and testing, but if resources are pooled across teams or the judgement task could be automated (e.g. by the Mechanical T urk) this limitation can be ov ercome. Our future goals include detection of pure (non-war -like) vandalism, a task made all the more important by the high degree of vandalism we see. Another goal is the prediction of impending edit wars by monitoring the dynamics of M – once a reasonable predictor is provided it will be possible to tag pages for impending conflict by robots. A C K N O W L E D G M E N T This work was supported by the EU’ s 7th Framework Pro- grams FET -Open within ICT eCollecti ve project no. 238597. K ornai also acknowledges support from O TKA grants #77476 (Algebra and algorithms) and #82333 (Semantic language technologies). Special thanks to Santo Fortunato for discus- sions and his help with data at early stages of this work. R E F E R E N C E S [1] Schneider , Jodi and Passant, Alexandre and Breslin, John A Quali- tativ e and Quantitativ e Analysis of How Wikipedia T alk Pages Are Used Pr oceedings of W ebSci10 26-27 April, Raleigh, NC, 2010 http://journal.webscience.org/373 [2] J. Ratkiewicz, S. Fortunato, A. Flammini, F . Menczer and A. V espignani Characterizing and modeling the dynamics of online popularity Physical Revie w Letters 105, article no. 158701, 2010. [3] Aniket Kittur , Bongwon Suh, Bryan A. Pendleton, and Ed H. Chi. He says, she says: conflict and coordination in Wikipedia. In CHI ’07: Pr oceedings of the SIGCHI confer ence on Human factors in computing systems , pages 453–462, New Y ork, NY , USA, 2007. A CM. [4] Ba-Quy V uong, Ee-Peng Lim, Aixin Sun, Minh-T am Le, and Hady Wira wan Lauw . On ranking controversies in wikipedia: models and ev aluation. In Proceedings of the international confer ence on W eb sear ch and web data mining , WSDM ’08, pages 171–182, New Y ork, NY , USA, 2008. ACM. [5] Bongwon Suh, E.H. Chi, B.A. Pendleton, and A. Kittur . Us vs. them: Understanding social dynamics in wikipedia with rev ert graph visualizations. V isual Analytics Science and T echnology , 2007. V AST 2007. IEEE Symposium on , pages 163–170, 30 2007-Nov . 1 2007. [6] Ulrik Brandes and J ¨ urgen Lerner . V isual analysis of controversy in user- generated encyclopedias. Information V isualization , 7:34–48, March 2008. [7] Ulrik Brandes, Patrick Kenis, J ¨ urgen Lerner, and Denise van Raaij. Network analysis of collaboration structure in wikipedia. In Proceedings of the 18th international conference on W orld wide web , WWW ’09, pages 731–740, New Y ork, NY , USA, 2009. ACM. [8] Andrew G. W est, Sampath Kannan, and Insup Lee. Detecting wikipedia vandalism via spatio-temporal analysis of revision metadata? In Pro- ceedings of the Third European W orkshop on System Security , EU- R OSEC ’10, pages 22–28, New Y ork, NY , USA, 2010. ACM. [9] B. Thomas Adler, Luca de Alfaro, and Ian Pye. Detecting Wikipedia V andalism using W ikiT rust: Lab Report for P AN at CLEF 2010 In Notebook P apers of CLEF 2010 LABs and W orkshops, 22-23 September, Padoa, Italy , 2010. ISBN 978-88-904810-0-0. [10] R. Sumi, T . Y asseri, A. Rung, A. Kornai, and J. K ert ´ esz. Characterization and prediction of W ikipedia edit wars In Pr oceedings of the ACM W ebSci’11 June 14-17, Koblenz, Germany , 2011. [11] http://en.wikipedia.org/wiki/Wikipedia:Template_ messages/Disputes
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment