A Fully Time-domain Neural Model for Subband-based Speech Synthesizer
This paper introduces a deep neural network model for subband-based speech synthesizer. The model benefits from the short bandwidth of the subband signals to reduce the complexity of the time-domain speech generator. We employed the multi-level wavel…
Authors: Azam Rabiee, Geonmin Kim, Tae-Ho Kim
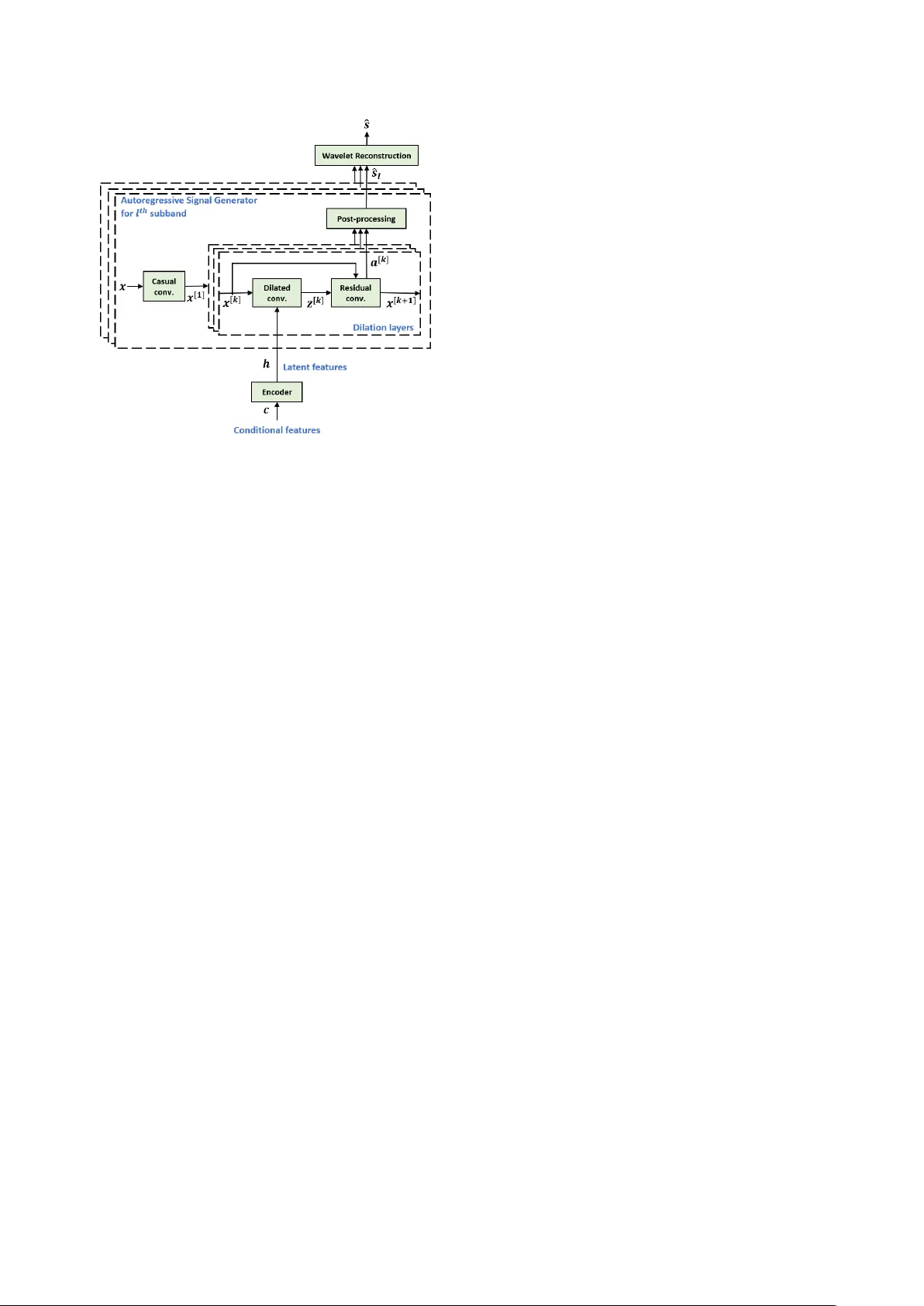
A Fully T ime-domain Neural Model f or Subband-based Speech Synthesizer Azam Rabiee 1 , Geonmin Kim 2 , T ae-Ho Kim 1 , Soo-Y oung Lee 1 1 KAIST Institute for Artificial Intelligence 2 Department of Electrical Engineering K orea Adv anced Institute of Science and T echnology , Daejeon, K orea azrabiee@kaist.ac.kr, gmkim90@gmail.com, ktho22@kaist.ac.kr, sy-lee@kaist.ac.kr Abstract This paper introduces a deep neural network model for subband-based speech synthesizer . The model benefits from the short bandwidth of the subband signals to reduce the complexity of the time-domain speech generator . W e employed the multi- lev el w av elet analysis/synthesis to decompose/reconstruct the signal into subbands in time domain. Inspired from the W av eNet, a con v olutional neural network (CNN) model pre- dicts subband speech signals fully in time domain. Due to the short bandwidth of the subbands, a simple network architecture is enough to train the simple patterns of the subbands accurately . In the ground truth experiments with teacher-forcing, the sub- band synthesizer outperforms the fullband model significantly in terms of both subjecti ve and objective measures. In addi- tion, by conditioning the model on the phoneme sequence us- ing a pronunciation dictionary , we hav e achiev ed the fully time- domain neural model for subband-based text-to-speech (TTS) synthesizer , which is nearly end-to-end. The generated speech of the subband TTS sho ws comparable quality as the fullband one with a slighter network architecture for each subband. Index T erms : deep learning, speech synthesis, text-to-speech, wa velet transforms, W aveNet 1. Introduction T ext-to-speech (TTS) techniques ha ve been started from con- catenativ e synthesis [1], [2] to statistical parametric speech syn- thesis [3][5], and eventually end-to-end fully neural network based models [6], [7]. Recent speech synthesizers have em- ployed giant neural networks and high configuration GPUs to achiev e remarkable success in more natural and f ast speech gen- eration. Of such models, W aveNet [8] has achiev ed the most natural generated speech that significantly closes the gap with human. As a deep generativ e network, W aveNet directly mod- els the raw audio wav eform, which has changed the existing paradigms. It made a paradigm to absorb a tremendous amount of attention for sequential modeling [9], speech enhancement [10], [11], and vocoder , which is the wav e synthesizer from acoustic features [12][16]. Thanks to its conv olutional structure, W a veNet benefits from parallel computing in train. Ho wev er , the generation is still a sequential sample-by-sample process. Thus, due to the very high temporal resolution of speech signals (at least 16000 samples per second), the v anilla W aveNet suf fers from the long generation time. Therefore, fast [17], parallel [18], [19], and glow-based [20] models are introduced. The fast model is an efficient implementation that removes redundant con volutional operations by caching them. While parallel and glo w-based models utilized distillation and normalizing flow , respectively , which lead to the speech synthesis faster than real-time. Unlike the huge network required in the parallel and glow- based models, some studies benefit from subband decomposi- tion to reduce the complexity . Previously , a hybrid TTS [21] applied HMM-based and wav eform-based synthesis for lo w and high frequencies, respectively . Howe v er , the TTS suffers from the drawbacks of the HMM-based models and the overall per- formance is not satisfying. In addition, a subband W av eNet vocoder [22] is presented using a frequency filterbank analy- sis. Howe ver , to hav e a TTS based on the subband vocoder , separate acoustic and linguistic models are required. Similar to [22], the aim of this research is to break down the W a veNet architecture into smaller networks for each sub- band of the speech signal. The benefits of the subband model is the reduced computational complexity and the feasibility of training accurately for each subband due to their short band- width. Unlike the frequency domain filterbank used in [21] and [22], wa velet decomposition is used in this study . In addition, the similar morphological structure of the dilated conv olutions in W av eNet and the wav elet transform has inspired us to use the wa velet. Thus, the inno vation is utilizing the w av elet analy- sis to decompose the time-domain speech signal s ( t ) into sub- bands s l ( t )( l = 1 , , L ) . Then, an integrated model generates each subband signal in parallel. The subband signal generator is based on the fast W a veNet [17]. Even though many recent studies utilized the W av eNet as a vocoder , we belie ve that con v erting the spectrogram informa- tion to wa veform is an inv erse spectrogram process and may not necessarily need such a huge architecture. Instead, our hy- pothesis is that the W aveNet is able to perform some parts of the TTS front stage, as well. In addition, a single integrated model is likely to be more stable empirically and less-sensitiv e for parameter tuning than a multi-stage model, in which sepa- rate parameter tuning is required for each stage and the errors may add up [6], [23]. Hence, another contribution of this pa- per is that by simply conditioning the proposed model on the phoneme sequence and benefitting from an encoder, we have achiev ed the fully time-domain neural model for subband-based TTS. Section 2 describes the proposed subband speech synthe- sizer . Section 3 explains our experiments and results. Finally , conclusion comes in Section 4. 2. Proposed subband speech synthesizer The aim of this paper is to reduce the complexity of the time- domain TTS by decomposing the fullband speech signal s into the subbands s l ( l = 1 , ..., L ) using the wavelet analysis (de- tailed in Subsection 2.1). Due to the short bandwidth of the sub- bands, the structure of each subband generator is much slighter than the fullband one. Moreover , our hypothesis is that subband generators are more accurate as they are trained for the local- ized frequency patterns. Furthermore, our designed model ben- efits from the parallel processing in subband signal generators. When the subband signals are generated according to the corre- sponding conditional features using the localized TTS, then the Figure 1: Schematic diagram of the pr oposed time-domain subband-based speech synthesizer . The model is trained to es- timate subband signals s l conditioning on the latent variable h extr acted from conditional features c and the pr evious time sam- ples of the subband signal x . Linguistic and acoustic featur es can feed to the model as the conditional featur es for TTS. wa velet synthesis reconstructs the fullband signal. In the designed model depicted in Figure 1, given the con- ditional features c , an encoder extracts the latent variables h for generating samples conditioning on them (detailed in Sub- section 2.2). If the conditional features are linguistic features such as character or phoneme sequence, then the latent features would be linguistic features to make the model as a TTS. The main part of the model is the autoregressi v e signal gen- erators, shown by the outer dashed blocks in Figure 1. Each generator is in charge of modeling the probability distribution of each subband similar to the W a veNet (detailed in Subsection 2.3). In the training phase, the loss is defined by summation of the subband losses, which is the cross-entropy of the estimated and target subband signal, as loss = − L X l =1 E p l [log q l ] , (1) in which p l and q l are the probability distribution of s l ( t ) and ˆ s l ( t ) , respectiv ely . Since it is a probabilistic model, the generation model estimates the t th sample of each subband by sampling the learned probability distribution. W ith such a loss, the shared module, i.e. encoder , can train ef ficiently according to all the frequenc y bins. In addition, it is not timely ef ficient to train a separate network per sub- band, and then combine them. The integrated model in Figure 1 benefits from the parallel computation, along with any pos- sible future subband integration via more shared modules for additional attrib utes such as speaker identity , prosody , speaking style, recording channel and noise lev els. 2.1. Subband decomposition/reconstruction A set of analysis filters can decompose speech signal s ( t ) into subbands s l ( t ) , and their paired synthesis filters are able to re- construct back the fullband signal. The proposed synthesizer utilizes multi-lev el orthogonal time-domain w av elet as follo ws, ( u l ( t ) = u l − 1 ( t ) ∗ ϕ l ( t ) s l ( t ) = u l − 1 ( t ) ∗ ψ l ( t ) (2) where ϕ l ( t ) and ψ l ( t ) are Daubechies scaling (low-pass) and mother wavelet (high-pass) functions [24], respectiv ely . Moreov er , l = 1 , ..., L refers to the wav elet le vel and u 0 ( t ) = s ( t ) . The do wnsampling is omitted in e very level of the wa velet transform because the downsampling widens the bandwidth, which needs more complex network to train. In addition, it de- creases the size of the dataset. As there is no data like more data for the training, we ignored the downsampling after each layer . Reasons for selecting the wavelet transform rather than the short time Fourier transform (STFT) filterbank are as follows. First, the wav elet transform is very robust for reconstruction [25]. Corruption of the wa velet coefficients will only affect the reconstructed signal locally near the perturbed position, while the STFT will spread out the error ev erywhere in time. Sec- ond, output of the Fourier analysis filters are complex. Most of the spectrogram-based speech synthesizers ignore modeling the phase spectrogram [6], while the F ourier synthesis filters are sensitiv e to phase errors. Therefore, compared to the wa velet, the STFT models are unable to reconstruct the phase correctly . Third, the logarithmic spectral resolution of the wa velet are more compatible with the nature of speech compared to the uni- form tiling of the spectrogram. Due to the nonlinear bandwidth divisions of the w av elet, high frequencies (e.g. above 4 kHz for 16 kHz sampling rate) fall in one subband. Whereas, there are fine di visions for the lo w frequencies. Later in the experiments, we will see the signal-to-noise ratio (SNR) of the consecuti ve decomposition and reconstruction is about 41 dB, in which the noise is hardly sensible by the human ear . 2.2. Conditional/latent features A variety of conditional features can be fed to the model for different possible applications such as v ocoder or TTS. Of such features, we use phoneme sequence produced by a te xt normal- ization and lexicon to have a TTS model. The text normaliza- tion contains 1) con v erting to the lower -case characters, 2) re- moving the special symbols, and 3) con v erting numbers to te xt. The phoneme sequence speeds up the training [26]. As shown in Figure 1 by the encoder block, a number of con v olutional layers along time axis can extract the linguistic features implic- itly . The acti vation of the last layer , denoted by latent features h , is used for the generators. In fact, the encoder plays the role of the linguistic model for TTS, which is significant as shown in Figure 2. W e have examined the fullband model without the encoder , which is in fact the original W aveNet conditioning on phoneme sequence; but the results were worse as the features were not enough for the training. Comparing fullband synthe- sis with and without the encoder module shows the importance of the module for automatic linguistic feature extraction in the proposed model. 2.3. Subband autoregressiv e signal generator The subband generator has a similar architecture as the W av eNet. Unlike the W a veNet, our autore gressi ve signal gener - ator is in charge of generating subband signals. The model es- timates the posterior probability of each subband time-sample x t conditioned on the previous samples, x
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment