Universal Adversarial Perturbations for CNN Classifiers in EEG-Based BCIs
Multiple convolutional neural network (CNN) classifiers have been proposed for electroencephalogram (EEG) based brain-computer interfaces (BCIs). However, CNN models have been found vulnerable to universal adversarial perturbations (UAPs), which are …
Authors: Zihan Liu, Lubin Meng, Xiao Zhang
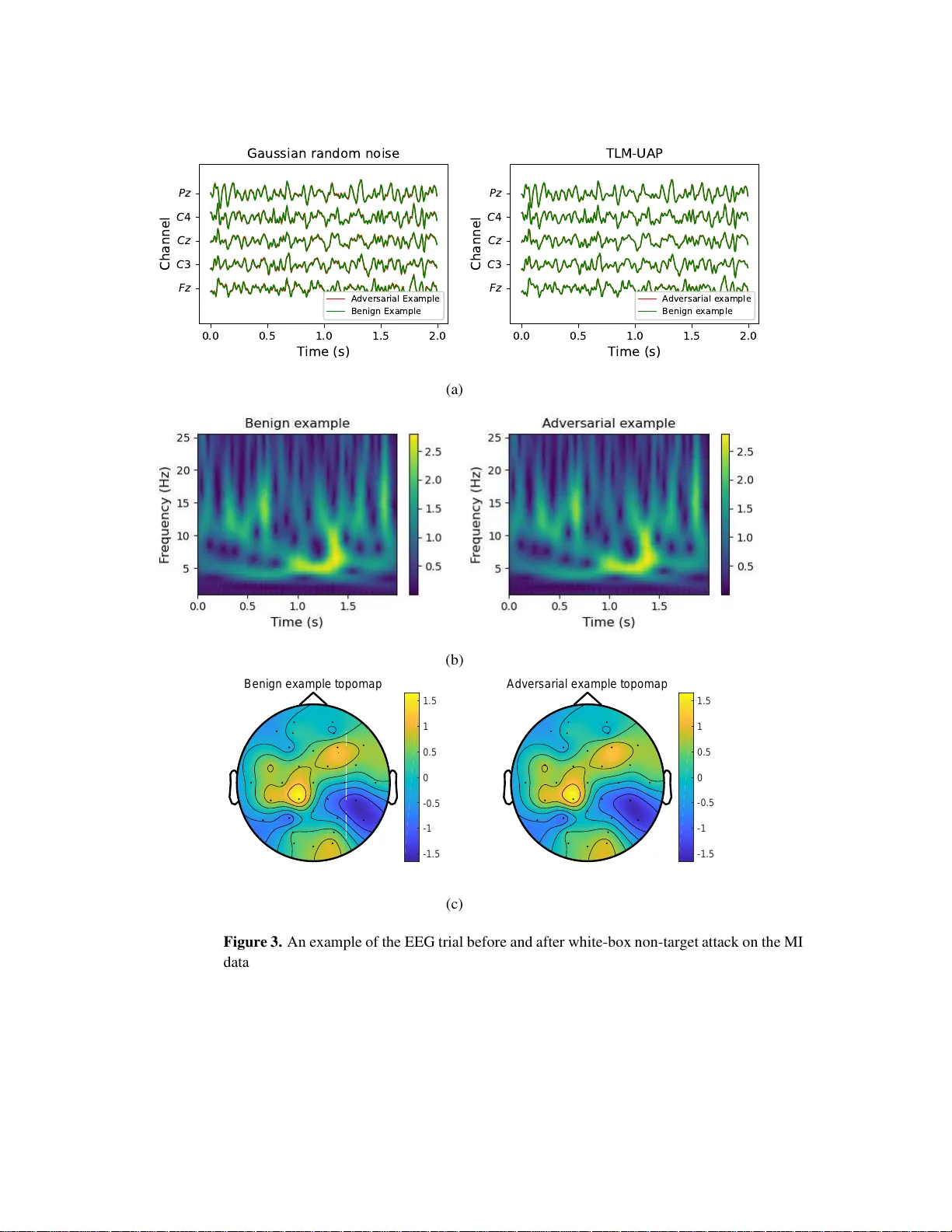
Universal Adversarial P erturbat io ns f or C NN Cla ssifiers in EEG-Base d BCIs Zihan Liu 1 , 4 , Lubin Meng 1 , 4 , Xiao Zhang 1 , W eili Fang 2 and Dongrui W u 1 , 3 1 Ke y Laboratory of the Ministry of Education f or Image Pr ocessing and I ntelligent Con trol, School o f Artificial Intelligence an d Automation, Hu azhong Un iv ersity of Science and T echnology , W uh an 43 0074, Chin a. 2 School o f Design and En vironmen t, National University of Singapore , 11756 6 Singapore. 3 Zhejiang Lab, Han gzhou 3 11121 , China. 4 These authors contributed equally to this work. E-mail: zhl iu95@hust.ed u.cn, lubinmeng@hu st.edu.cn, xiao zhang@hust.e du.cn, bdgfw@nus. edu.sg, drwu@hust.edu.cn. Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 2 Abstract. Multiple con volutional n eural network (CNN) classifiers have been propo sed for electroencep halogra m (EEG) based brain-compu ter interfaces (BCIs). Howe ver , CNN models have been f ound vulnerab le to universal adversarial per turbation s (U APs), which are sma ll and example-ind ependen t, yet powerful eno ugh to d egra de the perf o rmance of a CNN model, when added to a benign example. This p a p er propo ses a novel total lo ss m inimization (TLM) approa c h to gen erate U APs for EEG-ba sed BCIs. Experime ntal results dem o nstrated the effecti veness of TL M on three popular CNN classifiers for both target an d non- target attacks. W e also verified the transfer a b ility of U APs in E EG-based BCI system s. T o our knowledge, this is the first study on UAPs of CNN classifiers in EEG-based BCIs. U APs are ea sy to construct, and can attack BCIs in real-time, exp o sing a p otentially critical security con cern o f BCIs. K ey wor ds : Brain-computer interface, con v olutional neural network, electroencephalogram, univ ersal adversarial perturbati on 1. Introduct ion A brain-computer interface (BCI) enables peop l e to interact directly with a computer u s ing brain sign als. Due to it s low-cost and con venience, electroencephalogram (EEG), which records the brain’ s electrical activities from t he scalp, has b ecome the most widely used in p ut signal in BCIs. There are sev eral popular paradigms in EEG-based BCIs, e.g., P300 ev oked potentials [1 – 4], motor imagery (MI) [5], steady-state visual ev oked potentials (SSVEP) [6], etc. Deep learning, wh ich eliminates manual feature eng i neering, has become increasingly popular in d ecodi ng EEG sig n als in BCIs. Mul tiple con v olutional neural network (CNN) classifiers ha ve been proposed for EEG-based BCIs. Lawhern et al. [7] propos ed EEGNet , a compact CNN model demonst rati ng promisin g performance in sev eral EEG-based BCI tasks . Schirrmeister et al. [8] proposed a deep CNN m odel (DeepCNN) and a shallow CNN model (ShallowC NN) for EEG classification. There were also studies that con verted EEG signals to spectrograms or topo p lots and then fed them into deep learning classifiers [9 – 11]. This paper focuses on CNN class ifiers whi ch take raw EEG signals as the input, but our approach shou l d also be extendable to other forms of inputs. Albeit their promising performance, it was foun d that deep learning models are vulnerable to adversarial attacks [12, 13], in wh i ch deliberately designed tiny perturbations can significantly degra de the m o del performance. M any successful adversar ial attacks ha ve been reported in image classi fication [14 – 17], speech recognition [18] , malw are detection [19], etc. According t o the purpo s e of the attacker , adversarial attacks can be categorized into two types: non-target attacks and t ar get attacks. In a n on-targe t attack, th e attacker wants the mod el output t o an adversarial example (after adding the adversarial perturbation) to be wrong, but do es no t force it int o a particular class. T w o typical non-target attack approaches are DeepFool [20] and uni versal adversarial perturbation ( U AP) [21]. In a target attack, the m odel outp ut to an adversarial example should always be biased into a s pecific w ron g Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 3 class. Some typical target attack approaches are t he iterativ e least-likely class method [15], adversarial transformation networks [22], and projected gradient d escent (PGD) [23]. There are also approaches t hat can be used in bot h n o n-tar get and target attacks, e.g., L-BFGS [12], the fast gradient sign method (FGSM) [14], the C&W m ethod [24], the basic iterative method [15], etc. An EEG-based BC I system us ually consists of four parts: signal acquis ition, signal preprocessing, machine learning, and control action. Zhang and W u [25 ] explored the vulnerability of CNN class ifiers under adversarial attacks in EEG-based BCIs, and discovered that adversarial examples do exist there. They inj ected a jammi n g modul e between signal preprocessing and m achine learning to perform the adversarial attack, as shown in Fig. 1. They s uccessfully attacked t hree CNN classifiers (EEGNet, DeepCNN, and ShallowCNN) in three differe nt scenarios (white-box, gray-box, and black-box). Their results exposed a critical security problem in EEG-based BCIs, which had not been in vestigated before. As pointed out in [25], “ EEG-based BCIs coul d be used to contr ol wheelchairs or e xoskeleton for the disabled [2 6], wher e adversarial attacks could ma ke the wheelc hair or exosk el eto n malfunction. The consequence coul d range fr om mer ely user confusion and frustration , to significantl y r educing the user’ s quality of life, and even to hurting the user by driving him/her into d anger on pu rpose. In cli nical app lications of BCIs in awar eness e valuation/detectio n for disor der of consciousness pati ent s [26], adversarial attac ks could lead to misdiagnosis. ” Figure 1. Attac k ing an EEG-based BCI system [25]. Albeit their su ccess, Zhang and W u’ s approaches [25] had the following limitations: (i) An adversarial perturbation needs to be com p uted specifically for each input E E G trial, which is inconv enient. (ii) T o compute the adve rsarial perturbation, the attacker needs to wait for the complete EEG trial to be collected; howe ver , by that tim e the EEG trial has gone, and the perturbation cannot be actually added t o it. So, Zhang and W u’ s approaches are theoretically important, but may not be easily implem ent able in practice. For bet t er practicability , we should be able to perform the attack as soon as an EEG trial starts. This paper introduces U AP for BCIs, wh i ch is a u niv ersal perturbatio n template Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 4 computed offl ine and added to any EEG trial in real-tim e. Compared with Zhang and W u’ s approaches [25], it has two corresponding adva ntages: (i) A U AP is computed once and applicable to any EEG trial, instead of being computed specifically for each in put EEG trial. (ii) A U AP can be added as soon as an EE G trial starts , o r anywhere during an EEG trial, thus the attacker does not need to know the number of EEG channels, the starting time, and the l ength of a trial. So, it relieve s the two limitati ons of [25] simult aneou s ly , making the attack more practical ‡ . Studies on U APs appeared in the literature very recently . Moos a vi-Dezfooli et al. [21] discovered the existence of U APs, and verified that they can fool state-of-the-art machine learning models in image classification. Their method for crafting the U APs, based on DeepFool [20], s olves a compl ex optimi zation problem. The same idea was later used i n attacking speech recognition syst em s [28 ]. Behjati et al. [29] prop osed a gradient projection based approach for genera ting U APs in text classification. Mopuri et al. [30] proposed a generalizable and data-free approach for crafting U APs, which is independent of th e underlying task. All these approaches were for non-target attacks. T arget attacks using U APs are more challenging, because the perturbation needs t o be bo t h u n iv ersal and t ar geting at a particular class. T o our knowledge, th e only study on U APs for tar get at t acks w as [31 ], where Hirano et al . integrated a simp le iterativ e method for generating no n -tar get U APs and FGSM for target attacks to generate U APs for target attacks. This paper i n vestigates U A Ps in EEG-based BCIs. W e m ake t he following three contributions: (i) T o our knowledge, thi s i s th e first st u dy on U APs for EEG-based BCIs, which make adversarial attacks in BCIs more conv eni ent and more practical. (ii) W e propose a nov el to t al loss minimization (TLM) approach for generating a U AP for EEG t ri al s , which can achi eve better att ack performance wi th a smaller perturbation, compared with the traditional DeepFool b ased approach. (iii) Ou r proposed TLM can perform both non-t arget att acks and target at t acks. T o our knowledge, no one has studied optimi zation based U APs for tar g et attacks before. The remainder of this paper is organized as follows: Section 2 introduces two approaches to generate U APs for EEG trials. Section 3 describes our e xperimental setting. Sections 4 and 5 present the experimental results on non-targe t attacks and tar get attacks, respectiv ely . Finally , Section 6 draws conclusions and point s out se veral future research directions. ‡ A very rece nt resear ch [2 7] also developed ad versarial perturb ation templates to accommo date casuality , but it consider ed traditional P300 an d SSVEP b ased BCI speller pipelines, which p erform feature extraction and classification separately , wh ereas in th is paper th e U APs are d ev eloped fo r en d-to-en d deep lear ning classifiers in P3 00 and M I tasks. Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 5 2. Universal Adver sarial Perturbations (U APs) This section first introduces an iterative algorithm for crafting a U AP for EEG trials, then presents the det ail s of our proposed TLM approach. Al l source code can be downloaded at https:// g ithub .com /ZihanLiu95/ U AP EEG. W e dist inguish between two types of attacks: • T ar get attac ks , in which the attacke r wants all adversarial examples to be classified int o a specific class. For example, for 3-class MI (left-hand, right-hand , and feet), the attacker may want all left-hand and right-hand adversarial trials to be mis classified as feet trials. • Non-targ et attacks , in which the attacker wants the adversarial exa mples to be misclassified, but does no t care which class they are classified into . In the above example, a left-hand adversarial trial could b e misclassified as a righ t-hand trial, or a feet trial. 2.1. Pr ob l em Setup T o attack a BCI syst em, the adversarial perturbations need to be added to benig n EEG signals in real-time. Let X i ∈ R C × T be the i -th raw EEG trial ( i = 1 , ..., n ), where C is the number of EEG channels and T the number of time domain sampl es. Let x ∈ R C · T × 1 be th e vector form of X i , which concatenates all columns of X i into a single col u mn. Let k ( x i ) be the estim ated label from the target CNN model, v ∈ R C ˙ T × 1 be the U AP , and ˜ x i = x i + v be the adv ersarial EEG trial after addin g t he U AP . Then, v needs to satisfy: 1 n P n i =1 I ( k ( x i + v ) 6 = k ( x i )) ≥ δ k v k p ≤ ξ ) , (1) where k · k p is the L p norm, and I ( · ) is t h e indicator function which equals 1 if i ts ar gument is true, and 0 otherwise. The parameter δ ∈ (0 , 1] determines the desired attack success rate (ASR), and ξ cons trains the magnitude of v . Briefly speaking, the first constraint requires the U AP to achie ve a d esired ASR, and th e second constraint ensures the U AP is smal l . Next, we describe how a U AP can be crafted for EEG data. W e first introduce DeepFool [20], a white-box attack (the attacker has access to all information of the victi m model, includi n g its architecture, parameters, and tra ining da ta) approach for crafting an adversarial perturbation for a singl e inp ut example, and then extend it t o crafting a UAP for multiple examples. Finally , we propose a novel TLM approach t o craft U AP , which can be applied to bot h non-target attacks and target attacks. 2.2. DeepF ool -Based U AP DeepFool is an approach for crafting an adversarial perturbation for a singl e input example. Consider a binary classi fication problem, where the labels are {− 1 , 1 } . Let x be an input example, and f an affine classification function f ( x ) = w T x + b . T h en, the predicted label is k ( x ) = sign f ( x ) . The mi nimal adversarial perturbati o n r ∗ should m ove x to the decision Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 6 hyperplane F = { x ∗ : w T x ∗ + b = 0 } , i.e., r ∗ = − f ( x ) k w k 2 2 w . (2) CNN classifiers are nonl i near . So, an it erative procedure [20] is used to identify the adversarial perturbati on, by approximately linearizing f ( x t ) ≈ f ( x t ) + ∇ f ( x t ) T r t around x t at Iteration t , where ∇ is t he g radi ent of f ( x t ) . Then, the minimal perturbation at Iteration t is computed as: min r t k r t k , s.t. f ( x t ) + ∇ f ( x t ) T r t = 0 . (3) The perturbation r t at Iteration t is computed u sing the closed-form solution in (2), and then x t +1 = x t + r t is used in the next iteratio n . The it eration stops when x t +1 starts to change the classi fication label. The pseudocode is giv en in Al gorithm 1. Algorithm 1 : DeepFool [20] for generating an adversarial perturbati on for a s ingle input example. Input: x , an input example; f , the classi fication funct i on. Output: r ∗ , the adversarial perturbation. x 0 = x ; t = 0 ; while sign f ( x t ) = sign f ( x 0 ) do r t = − f ( x t ) k∇ f ( x t ) k 2 2 ∇ f ( x t ) ; x t +1 = x t + r t ; t = t + 1 ; end r ∗ = P t i =0 r i . Algorithm 1 can be extended to mu l ti-class classification by using the o ne-versus-all scheme to find the closest hyperplane. Experiments in [20 ] demonstrated that DeepF ool can achie ve com parable attack performance as FGSM [14], but the magnitude of the perturbation is smaller , whi ch is more desirable. U APs were recently discovered in image classification by Moosavi-Dezfooli et a l . [21], who showed t hat a fixed adv ersarial per turbation can fool multiple state-of-the-art CNN classifiers on mult iple images. They developed a DeepF ool-based iterati ve algorithm t o craft the U AP , which sati sfies (1). A U AP i s designed by proceeding iteratively over all examples in the dataset X = { x i } n i =1 . In each it eration, DeepFool is used to compute a m inimum perturbation △ v i for the current perturbed point x i + v , and t hen △ v i is aggregated into v . More specifically , if th e current universal perturbation v cannot fool the classi fier on x i , then a min i mum extra perturbatio n △ v i that can fool x i is computed by solving the following optimizatio n problem: min △ v i k △ v i k 2 , s.t. k ( x i + v + △ v i ) 6 = k ( x i ) . (4) Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 7 T o ensure the constraint k v k p ≤ ξ is satisfied, the updated univer sal perturbation v is further projected onto the ℓ p ball of radius ξ centered at 0. The projection operator P p,ξ is defined as: P p,ξ ( v ) = arg min k v ′ k p ≤ ξ k v − v ′ k 2 . (5) Then, the U AP can be updated by v = P p,ξ ( v + △ v i ) in each iteration. Th i s p rocess is repeated on the entire dataset unt i l the maxim um number of iteratio ns is reached, or the ASR on the perturbed dataset X v = { x i + v } n i =1 exceeds the tar get ASR threshol d δ ∈ (0 , 1] , i.e., AS R ( X v , X ) = 1 n n X i =1 I ( k ( x i + v ) 6 = k ( x i )) ≥ δ . (6) The pseudo-code of t h e DeepFool-based algorithm is given in Al g orithm 2. Algorithm 2: DeepFool-based algorithm for generating a U AP [21]. Input: X = { x i } n i =1 , n inpu t examples; k , t h e classi fier; ξ , the maxi mum ℓ p norm of the U AP; δ , the desired ASR; M , the maxim um number of iterations. Output: v , a U AP . v = 0 ; X v = X ; f or m = 1 , ..., M do if AS R ( X v , X ) < δ then f or Each x i ∈ X do if k ( x i + v ) == k ( x i ) then Use DeepFool to compute the mi nimal perturbation △ v i in (4); Update the perturbation by (5): v ← P p,ξ ( v + △ v i ) ; end end X v = { x i + v } n i =1 ; else Break; end end Return v . 2.3. Our Proposed TLM-Based U AP Diffe rent from the DeepFool-based algori t hm, TLM directly optimi zes an objective function w .r .t. the U AP by batch gradient descent. In white-box attacks, the parameters o f the victim Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 8 model are known and fixed, and hence we can vie w the U AP as a variable to minim ize an objective function on th e entire training set. Specifically , we solve the following optim ization problem by gradient descent: min v E x ∼ D l ( x + v , y ) + α · C ( x , v ) , s.t. k v k p ≤ ξ , (7) where l ( x + v , y ) is a l oss fu n ct i on, which ev aluates the eff ect of the U AP o n the tar get model. C ( x , v ) is the cons traint on the perturbation v , and α th e regularization coefficient. Our proposed approach is highly flexible, as the attacker can choose diff erent o p t imizers, l oss functions, and/or constraint s, according to the specific task. For non-target attacks, the l o ss function l can be defined as l ( x , y ) = log( p y ( x )) , in which y is the t rue label of x . This l oss function forces the U AP to make the model to have minimum confidence on t he true label y . TLM optimizes t he perturbation by increasing th e expected loss of the mo del on the traini n g data D as m u ch as possible. When U AP can aff ect enough samples in the dataset, and the distribution difference between the test d ata and D is small, UAP wil l h a ve a high probabi lity of affecting the test data. In practice, we could also use arg max j p j ( x ) , i.e., the predicted label, to replace y if the true label is not av ail able. For t ar get att acks, the loss function s h ould force the U AP to maximize the model’ s confidence on the target l abel y t specified by attacker; hence, l can be defined as l ( x , y t ) = − log ( p y t ( x )) . In fact, both l ( x , y ) and l ( x , y t ) are ess entially the negativ e cross-entropy . There are als o v arious options for the const raint function C ( x , v ) . In most cases, we can simply set C ( x , v ) as L1 or L2 regularization on the U AP v ; howe ver , it can also be a more sophisticated function, e.g., a metric function to detect whether the inpu t is an adversarial example or not. When a new metric function for detecting adversar ial e xamples is proposed, our approach can also be util i zed to test it s reli abi lity: we set C as the metric function to check whether we can stil l find an adversarial example. Give n the diversity of metric functions , we only consider L1 or L2 regularization in this paper . Other metric functions and defense strategies for TLM-U AP will be considered in our futu re research. T o ensure the constraint k v k p ≤ ξ , we can project the U AP v into the l p ball of radius ξ centered at 0 by the projectio n function in (5) after each optimization iteration, or simply clip its amplitu d e into [ − ξ , ξ ] , which is equivalent to u s ing the l ∞ ball. The latter was used in th is paper for its si mplicity . Due t o the transferabilit y of adversarial examples, i.e., adversarial examples generated by one m odel may also be used t o attack anoth er one, we can perform TLM-U A P attacks in a gray-box attack scenario. In this case, t he attacker only has access to the training set of t h e victim mod el, instead of its architecture and parameters. The attacker can train a sub s titute model on the known traini ng s et to generate a U AP , wh ich can then be used to attack the victim model. The TLM -U AP can als o be s i mplified, e.g., the same perturbation is design ed for all EEG channels, or a mini TLM-U AP is added to an arbitrary location of an EEG t rail. The corresponding experimental results are shown in Sections 4.2 and 5. The pseudo-code of ou r proposed TLM approach i s given in Algorit h m 3. Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 9 Algorithm 3: The propo s ed TLM approach for generating a U AP . Input: X train = { x train,i } n i =1 , n traini n g examples; X val = { x val , i } m i =1 , m validation examples; k , t h e classi fier; ξ , the maxi mum ℓ p norm of the U AP; α , the regularization coefficient; δ , the desired ASR; M , the maxim um number of epochs; Output: v best , a U AP . v = 0 ; r = 0 ; f or m = 1 , ..., M do f or Each mini-batch D ∈ X train do Update v in (7) for D with an optim izer; Constrain v by (5): v ← P p,ξ ( v ) , or directly clip v into [ − ξ , ξ ] ; end X val , v = { x val , i + v } n i =1 ; if AS R ( X val , v , X val ) > r then r = AS R ( X val , v , X val ) ; v best = v ; end if r > δ then Break; end end Return v best . 3. Experimental Settings This section introdu ces the experimental settings for validating the performance of our proposed TLM approach. 3.1. The Thre e BCI Dat a sets The following three BCI datasets were us ed in our experiments, as in [25, 3 2]: P300 evok ed potentials (P300) : The P300 dataset, first introduced in [33], contained eight subjects . In the experiment, each subject faced a laptop on w h i ch six im ages were flashed random l y t o elicit P300 responses. The goal was to classify whether t he im age was a tar get or non-tar get. The 32-channel EEG data was downsampled to 256Hz, b and p ass filtered to [1 , 4 0] Hz, and epoched to [0 , 1] s after each image onset. Then, we normalized the data using x − mean ( x ) 10 , and clipp ed the result ing values t o [ − 5 , 5] . Each subj ect had about 3, 3 00 trials. Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 10 Fe edback err or -r elated negativity (ERN) : Th e ERN dataset [34] was used in a Kaggle challenge § . The EEG signals were collected from 26 subjects and consisted of two classes (bad-feedback and good-feedback). The enti re dataset was partitioned into a traini n g set (16 subjects) and a test set (10 su b jects). W e used all 26 subjects in th e experiments. The 56- channel EEG signals were downsampled t o 2 00Hz, bandpass filtered to [1 , 4 0] Hz, epoched to [0 , 1 . 3 ] s after each sti mulus, and z -normali zed. Each sub j ect had 340 trials. Motor imagery (MI) : The MI dataset was Dataset 2A k in BCI Competi tion IV [35]. The EEG signals were collected from nine subjects and consist ed of four classes: the imagined movements of the left hand, right hand, both feet, and tongue. The 22-channel EEG signals were downsampled t o 128Hz, bandpass filtered t o [4 , 40] Hz, epoched to [0 , 2] s after each imagination prompt , and standardized using an exponential moving average w i ndow with a decay factor of 0.999, as i n [7]. Each subject had 576 trials, wi t h 144 in each class. 3.2. The Thre e CNN Model s The following three CNN models were used in our experiments, as in [25, 32]: EEGNet : EEGNet [7] is a compact CNN architecture for EEG-based BCIs. It consists of t wo con v olutional blo cks a nd a classification block. T o reduce the number o f model parameters, EEGNet uses depthwi se and separable con volutions [36] instead of traditi o n al con volutions. DeepCNN : DeepCNN [8] consists of four conv olut i onal blocks and a softmax layer for classification, which is deeper than EEGNet. Its first con volutional block is specially designed to handle EEG inputs, and the other th ree are standard con volutional blocks. ShallowCNN : Inspi red by filter bank comm o n spatial patterns [37], ShallowCNN [8] is specifically tailored to decode band power features. Compared with DeepCNN, ShallowCNN uses a larger kernel i n t em poral conv oluti on, and t hen a spati al filter , squaring nonlinearity , a mean pooli n g layer and logarithmi c activ atio n function. 3.3. The T wo Experimental Settings W e consid ered two experimental sett ings: Within- subject experiments : W ithin-su bject 5-fold cross-validation was us ed in the experiments. For each individual subject, all EEG trials were divided into 5 non-ov erlapping blocks. Three blo cks were selected for training, one for validation, and the remaining one for test. W e m ade sure each blo ck was used in test once, and reported the avera ge results. Cr oss-subject experiments : For each dataset, leave-one-subject-out cross-validation was performed. Assu me a dataset had N subj ects , and the N -th s ubject was selected as the t est s ubject. In train i ng, trials from the first N − 1 sub j ects were mixed, and divided into 75% for train i ng and 25% for validation in early stoppi n g. When training the victim mod els on the first t wo dat asets , we applied weights to d i f ferent classes to accommodate th e class imbalance, according to t he inv erse of its proportion in the § h ttps://www .kaggle.c om/c/inria-b ci-challenge k http ://www .bbci.de/co mpetition/iv/ Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 11 training set. W e used the cross entropy loss function and Adam opt imizer [38]. Early s t opping was used to reduce overfitting. The parameters for generating DF-U AP and T L M -U AP are shown in T abl e 1. It should be noted that TLM-U AP was trained with no constraint, and we set δ t o 1 . 0 and used early stopping (patience=10) to decide whether to stop the iteration or not. W e replaced the t rue labels y in (7) wit h the p redi cted ones, as in real-world appl i cations we d o no t have the true labels. T able 1. Parameters for gene r ating DF-UAP and TLM-U AP . k v k ∞ was used in com puting the norm of the UAPs. ξ δ M α Constraint DF-U AP 0.2 0.8 10 - - TLM-UAP 0.2 1.0 500 0 No 3.4. The T wo P erformance Measur es Both raw classification accurac y (RCA) and balanced classification accurac y (BCA) [3] w ere used as the performance measures. The RCA is th e ratio of the number of correctly classified samples to the num b er of t otal sampl es, and the BCA is the av erage of the individual RCAs of different class es. The BCA is necessary , b ecause some BCI paradigms (e.g., P300) hav e intrinsic significant class im balance, and hence using RCA alon e may be misleading sometimes. 4. Non-T arget Attack Results This sectio n p resents the experimental results in non-target attacks on the t h ree BCI datasets . Recall that a non-target attack forces a mo d el t o misclassify an adver sarial example to any class, instead of a specific class. For notation con venience, we denote the U AP generated by the DeepFool-based algorithm (Algorit h m 2) as DF -UAP , and the U AP generated by the proposed TLM (Algorithm 3) as TLM-U AP . 4.1. Baseline P e rformances W e compared the U AP attack performance with two baselines: 4.1.1. Clean Bas el i ne W e eva luated the baseline performances of th e three CNN models on the clean (unperturbed) EEG data, as shown in the first part of T able 2. For all three dat aset s and all three classifiers, generally RCAs and BCAs of the within-subject e xperiments were higher than t h eir counterparts in the cross-subject experiments, which is reasonable, si nce individual differences cause inconsis t ency among EEG tri al s from differ ent subjects. Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 12 T able 2. T h e r atio of the number of correctly classified samples to the number of total samples (RCAs), an d the mean RCAs of different classes (BCAs), of the three CNN classifiers in different no n-target attack scenarios on the thre e datasets ( ξ = 0 . 2 ). For eac h attack ty pe on each CNN model and each dataset, th e best p erforma nces are mar ked in bold . Statistically significantly different RCAs/BCAs between DF-UAP and TLM-UAP were marked with ‘ *’ (non- parametric Mann-Whitney U test; p < 0 . 01 ). Experiment Dat aset V ictim Model RCA/BCA Baseline White-Box Attack Gray-Box Attack Clean Noisy DF-UAP TLM-U AP Substitute Model (DF-UAP ) Substitute Model (TLM-UAP) EEGNet DeepCNN ShallowCNN EEGNet DeepCNN ShallowCNN P300 EEGNet . 81 / . 7 9 . 8 0 /. 79 . 18 /. 51 . 17 ∗ /. 50 ∗ . 21 /. 52 . 21 /. 52 . 40 /. 62 . 17 ∗ /. 20 ∗ . 19 ∗ /. 50 ∗ . 25 ∗ /. 54 ∗ DeepCNN . 82 /. 78 . 82 /. 78 . 20 /. 5 1 . 19 ∗ /. 50 ∗ . 33 /. 58 . 24 /. 53 . 49 /. 65 . 20 ∗ /. 51 ∗ . 20 ∗ /. 51 ∗ . 30 ∗ /. 57 ∗ ShallowCNN . 80 /. 75 . 80 /. 74 . 4 6 /. 62 . 20 ∗ /. 51 ∗ . 62 /. 69 . 56 /. 67 . 58 /. 66 . 44 ∗ /. 62 ∗ . 43 ∗ /. 61 ∗ . 29 ∗ /. 54 ∗ W ithin ERN EEGNet . 76 / . 7 3 . 6 9 /. 64 . 32 /. 51 . 30 /. 50 . 58 /. 6 4 . 56 /. 63 . 69 /. 67 . 45 ∗ /. 57 ∗ . 53 /. 61 . 62 ∗ /. 66 ∗ -Subject DeepCNN . 69 /. 65 . 69 /. 65 . 44 /. 5 5 . 40 /. 52 . 65 /. 64 . 60 /. 62 . 66 /. 62 . 60 ∗ /. 62 ∗ . 59 /. 61 . 64 /. 62 ShallowCNN . 70 /. 68 . 69 /. 67 . 5 2 /. 57 . 40 ∗ /. 53 ∗ . 66 /. 65 . 65 /. 65 . 62 /. 62 . 66 /. 66 . 64 /. 65 . 57 ∗ /. 61 ∗ MI EEGNet . 61 / . 6 1 . 4 7 /. 48 . 29 /. 29 . 25 ∗ /. 25 ∗ . 37 /. 38 . 36 /. 36 . 38 /. 3 8 . 34 /. 34 . 31 ∗ /. 31 ∗ . 34 /. 34 DeepCNN . 50 /. 50 . 47 /. 47 . 35 /. 3 5 . 26 ∗ /. 26 ∗ . 47 /. 47 . 41 /. 41 . 44 /. 44 . 49 /. 49 . 32 ∗ /. 32 ∗ . 39 /. 39 ShallowCNN . 74 /. 74 . 68 /. 68 . 2 9 /. 29 . 25 ∗ /. 25 ∗ . 55 ∗ /. 55 ∗ . 40 /. 40 . 32 /. 3 2 . 64 /. 63 . 35 ∗ /. 35 ∗ . 27 ∗ /. 27 ∗ P300 EEGNet . 68 / . 6 3 . 6 9 /. 63 . 19 /. 51 . 17 ∗ /. 50 ∗ . 22 /. 52 . 29 /. 54 . 27 /. 5 4 . 17 ∗ /. 50 ∗ . 17 ∗ /. 50 ∗ . 18 ∗ /. 50 ∗ DeepCNN . 69 /. 64 . 70 /. 64 . 20 /. 5 1 . 18 ∗ /. 50 ∗ . 24 /. 52 . 22 /. 52 . 28 /. 5 4 . 18 ∗ /. 50 ∗ . 18 ∗ /. 50 ∗ . 18 ∗ /. 50 ∗ ShallowCNN . 67 /. 62 . 66 /. 62 . 2 7 /. 54 . 19 ∗ /. 50 ∗ . 32 /. 55 . 35 /. 57 . 32 /. 5 5 . 20 ∗ /. 51 ∗ . 20 ∗ /. 51 ∗ . 18 ∗ /. 50 ∗ Cross ERN EEGNet . 67 / . 6 8 . 6 7 /. 65 . 31 /. 51 . 29 /. 50 ∗ . 53 /. 59 . 60 /. 58 . 43 /. 5 9 . 29 ∗ /. 50 ∗ . 31 ∗ /. 50 ∗ . 29 ∗ /. 50 ∗ -Subject DeepCNN . 69 /. 69 . 71 /. 70 . 34 /. 5 2 . 31 /. 50 . 49 /. 54 . 41 /. 53 . 3 6 /. 53 . 29 ∗ /. 50 ∗ . 31 ∗ /. 50 ∗ . 29 ∗ /. 50 ∗ ShallowCNN . 69 /. 69 . 68 /. 68 . 3 8 /. 55 . 29 ∗ /. 50 ∗ . 60 /. 63 . 65 /. 62 . 42 /. 5 6 . 35 ∗ /. 54 ∗ . 38 ∗ /. 55 ∗ . 29 ∗ /. 50 ∗ MI EEGNet . 44 / . 4 4 . 3 8 /. 38 . 30 /. 30 . 25 ∗ /. 25 ∗ . 30 /. 30 . 34 /. 34 . 30 /. 3 0 . 29 /. 29 . 29 ∗ /. 29 ∗ . 25 ∗ /. 25 ∗ DeepCNN . 47 /. 47 . 44 /. 44 . 33 /. 3 3 . 25 ∗ /. 25 ∗ . 38 /. 38 . 32 /. 32 . 28 /. 28 . 40 /. 40 . 30 /. 30 . 26 /. 26 ShallowCNN . 47 /. 47 . 43 /. 43 . 2 7 /. 27 . 25 ∗ /. 25 ∗ . 31 ∗ /. 31 ∗ . 26 /. 26 . 30 /. 30 . 35 /. 35 . 29 /. 29 . 26 ∗ /. 26 ∗ 4.1.2. Noisy Baseline W e added clip p ed Gaussian random noise ξ · max( − 1 , min(1 , N (0 , 1 ))) to the ori g inal EEG data, which had the same maximum amplitu de ξ as the U AP and sat i s- fied th e constraint k v k p ≤ ξ after clipping. If the random noise und er the sam e magnitu d e constraint can significantly degrade the classification performance, then there is no need to compute a U AP . The results are shown in T abl e 2. Random n o ise with the same amplitud e as the UAP did not degrade the classification performance in mos t cases, except sometimes on the MI dataset. This suggests t hat the three CNN classifiers are generally rob ust to rando m noise, therefore we should deliberately design the adversarial perturbations . 4.2. White-Box Non-targ et Attack P erformances First consider white-box attacks, wh ere we hav e access to all information of the vict i m model, including its architecture, parameters, and traini n g data. T h e performances of DF-U AP and TLM-U AP in white-box no n -tar get attacks are shown in th e second part of T able 2. W e also performed non-parametric Mann-Whitn ey U tests [39] on the RCAs (BCAs) of DF-U AP and TLM-U AP to check if there were statistically significant dif ferences bet w een them (m arked with ‘*’; p < 0 . 01 ). Observe that: (i) After adding DF-U AP or TL M -U AP , both the RCAs and the BCAs were significantly reduced, suggestin g the effecti veness of DF-U AP and TL M -U AP attacks. (ii) In most cases, TLM-U AP significantly outperformed DF-U AP . This may be due to the Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 13 fact that, as s h own in (7), TLM-U AP optimizes the ASR directly o n the entire dataset, whereas DF-U AP considers each s am ple i ndividually , wh ich m ay be easily t rapped into a local mi nimum. (iii) Th e BCAs of the P300 and ERN dataset s were close to 0 . 5 after DF-U AP or TLM -U AP attacks, whereas the RCAs were lower than 0 . 5 , im p lying that most test EEG trials were classified into th e mi nority class to achieve t he best attack performance. Fig. 2 shows the number of EEG trials in each class on the three datasets, class ified by EEGNet before and after applyi ng TLM-U AP . Generally , the trials origi nally classified into th e majo ri t y class were misclassified into the m inority cl ass in binary classi fication after applying TLM-U AP . This is reasonable. Assu me t h e mi nority class cont ain s p % ( p < 50 ) of the trials. Then, m isclassifying all minority class trials int o the majority class gives an ASR of p % , whereas misclassifyi ng all majorit y class trials into the minority class giv es an ASR of (100 − p )% . Clearly , the latter i s lar ger . Similarly , the trials were mi s classified into a minori ty class (but not necessarily the smallest clas s ) in multi -class classification. Be fo r e T L M - U A P Aft e r T L M - UAP 0 1 0 0 0 2 0 0 0 3 0 0 0 Nu m b e r o f tr i a l s N o n - T a r g e t T a r g e t (a) Be fo r e T L M - UAP A ft e r T L M - U A P 0 1 0 0 2 0 0 3 0 0 Nu m b e r o f tr i a l s Ba d - F e e d b a c k Go o d - F e e d b a c k (b) Be fo r e T LM - UAP A ft e r T L M - U A P 0 2 0 0 4 0 0 6 0 0 Nu m b e r o f tr i a l s Le ft h a n d R i g h t h a n d F e e t T o n g u e (c) Figure 2. Numb er of EEG trials in each class (cla ssified by EE GNet), before and after applying T LM-U AP in white-b ox non -target attack. a) P300 ; b) ERN; and, c) MI. An example of the EEG trial before and after apply i ng Gaus sian rando m noise and TLM - U AP in the time domain is shown in Fig. 3(a). The s ignal distortio n caused by the Gaussian random nois e was greater than that caused by TLM -U AP under t he same maximum am plitude, indicating the ef fecti veness of the cons traint on t h e TLM-U AP amplitude d u ring optim ization. Fig. 3(b) shows t he spectrogram of the EEG trial before and after applying TLM-U AP . The TLM-U AP was s o small in both the time domain and t he frequency domain that it is barely visible, and hence dif ficult to detect. W e further show the topopl ots of an EEG trial before and after white-box n o n-tar get TLM-U AP attack in Fig. 3(c). The difference is again very small, which may not be detectable by human eyes or a computer program. W e also in vestigated an easily implement abl e channel-in variant TLM -U AP attack, wh i ch added the same perturbation to all E E G channels . The white-box attack resul t s are shown in T able 3. Compared wi th the clean and noi sy baselines in T able 2, the RCAs and BCAs in T able 3 are smaller , i.e., the attacks were ef fective; h owev er , the attack performances were worse than those o f DF-U AP and TLM-U AP in T able 2, which i s intu i tiv e, as the channel- in variant TLM-U AP had more con straints. Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 14 0 . 0 0 . 5 1 . 0 1 . 5 2 . 0 T i m e ( s) F z C 3 C z C 4 Pz C h a n n e l G a u ssi a n r a n d o m n o i se A d v e r sa r i a l E x a m p l e Be n i g n E x a m p l e 0 . 0 0 . 5 1 . 0 1 . 5 2 . 0 T i m e ( s) F z C 3 C z C 4 Pz C h a n n e l T L M - UA P A d v e r sa r i a l e x a m p l e Be n i g n e x a m p l e (a) (b) Benign example topomap -1.5 -1 -0.5 0 0.5 1 1.5 Adversarial example topomap -1.5 -1 -0.5 0 0.5 1 1.5 (c) Figure 3. An example of the EEG trial before an d after white- b ox non-target attack o n the MI dataset ( ξ = 0 . 2 ). (a) time doma in ; (b) frequen cy domain; ( c) to poplot. Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 15 T able 3. T h e r atio of the number of correctly classified samples to the number of total samples (RCAs) and the a verag e of the individual RCAs of different classes (BCAs) of the three CNN classifiers after channel-inv ariant TLM - U AP attacks on the three datasets ( ξ = 0 . 2 ). Experime nt Dataset V ictim Model RCA/BCA Baseline TLM-UAP Channel-inv ariant Clean Noise TLM-UAP P300 EEGNet . 81 /. 79 . 80 / . 7 9 . 1 7 /. 50 . 47 /. 66 DeepCNN . 82 /. 78 . 82 / . 78 . 1 9 /. 50 . 60 /. 7 2 ShallowCNN . 80 /. 75 . 80 /. 74 . 20 /. 51 . 64 / . 7 2 W ithin ERN EEGNet . 76 /. 73 . 69 / . 6 4 . 3 0 /. 50 . 48 /. 58 -Subject DeepCNN . 69 /. 65 . 69 / . 65 . 4 0 /. 52 . 53 /. 5 9 ShallowCNN . 70 /. 68 . 69 /. 67 . 40 /. 53 . 56 / . 6 1 MI EEGNet . 61 /. 61 . 47 / . 4 8 . 2 5 /. 25 . 36 /. 37 DeepCNN . 50 /. 50 . 47 / . 47 . 2 6 /. 26 . 52 /. 5 1 ShallowCNN . 74 /. 74 . 68 /. 68 . 25 /. 25 . 74 / . 7 4 P300 EEGNet . 61 /. 61 . 47 / . 4 8 . 2 5 /. 25 . 36 /. 57 DeepCNN . 69 /. 64 . 70 / . 64 . 1 8 /. 50 . 40 /. 5 8 ShallowCNN . 67 /. 62 . 66 /. 62 . 19 /. 50 . 49 / . 6 1 Cross ERN EEGNet . 67 /. 68 . 67 / . 6 5 . 2 9 /. 50 . 53 /. 62 -Subject DeepCNN . 69 /. 69 . 71 / . 70 . 3 1 /. 50 . 46 /. 5 6 ShallowCNN . 69 /. 69 . 68 /. 68 . 29 /. 50 . 57 / . 6 1 MI EEGNet . 44 /. 44 . 38 / . 3 8 . 2 5 /. 25 . 33 /. 33 DeepCNN . 47 /. 47 . 44 / . 44 . 2 5 /. 25 . 33 /. 3 3 ShallowCNN . 47 /. 47 . 43 /. 43 . 25 /. 25 . 38 / . 3 8 4.3. Generalization of TLM-U AP on T raditional Clas s ification Models It’ s also interesting to ev aluate the generalization performance of the proposed TLM-U AP approach on t raditional BCI classification models. W e used the TLM-U AP generated from CNN models to attack som e traditional non-CNN models, i.e., xD A WN [40] spatial filtering and Logisti c Regression (LR) for P300 and ERN, and common spatial pattern (CSP) [41] filtering and LR classi fier for MI. TLM-U APs with three different am p l itudes were generated by t hree CNN models, and then used to attack the traditional models. Th e results are shown in T able 4. Observe t h at: (i) Generally , TL M-U APs generated by CNN models were more effecti ve t o degrade the performance of the traditi o n al m odels than random Gaussian noi s e, i.e., TLM-U AP can generalize to tradit ional non-CNN models. (ii) The amplit u de of TLM-U AP heavily af fected the attack performance. Intuitively , a larger amplitude resulted in a greater model performance reduction . (iii) Di f ferent models may h a ve different resistance to TLM-U APs. Compared wit h the att ack performances on CNN models in T abl e 2, the traditi onal model was more robust than CNN models on the ERN dataset, but less robust o n the MI dataset. Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 16 T able 4. T h e r atio of the number of correctly classified samples to the number of total samples (RCAs), and the mean RCAs of different cla sses ( BCAs), of the traditional classifiers afte r TLM-UAP attack s with d ifferent ξ on the th ree datasets. Dataset V ictim M odel ξ RCA/BCA Baseline Generation Mo del Clean Noise EEGNet DeepCNN ShallowCNN P300 x D A WN+LR 0 . 05 . 73 / . 7 3 . 75 /. 7 3 . 66 /. 71 . 61 /. 7 0 . 71 / . 73 0 . 1 . 73 /. 73 . 75 / . 73 . 56 / . 68 . 48 /. 65 . 6 6 /. 71 0 . 2 . 73 /. 73 . 74 / . 73 . 38 / . 60 . 30 /. 56 . 5 7 /. 68 ERN xD A WN+LR 0 . 05 . 67 / . 6 5 . 67 /. 6 5 . 66 /. 64 . 65 /. 6 4 . 66 / . 65 0 . 1 . 67 /. 65 . 66 / . 65 . 64 / . 65 . 64 /. 64 . 6 5 /. 65 0 . 2 . 67 /. 65 . 67 / . 65 . 64 / . 64 . 62 /. 64 . 6 3 /. 64 MI CSP+LR 0 . 05 . 58 / . 5 8 . 57 / 57 . 47 /. 47 . 52 /. 5 2 . 42 / . 42 0 . 1 . 58 /. 58 . 42 / . 42 . 31 / . 31 . 32 /. 32 . 2 8 /. 28 0 . 2 . 58 /. 58 . 27 / . 27 . 30 / . 30 . 26 /. 26 . 2 7 /. 27 4.4. T ransferability of UAP in Gray-Box Att ac ks T ransferabili ty is one of the most threatening properties of adversarial examples, which m eans that adversarial examples generated b y on e m odel may also be abl e to attack another one. This section explores the transferability of DF-U AP and TLM-U AP . A gray-box att ack scenario was considered: the attacker only has access to the training set of the vi ctim model, inst ead of its architecture and parameters. In thi s s ituation, the attacker can train a substitute model on th e same training set to generate a U AP , wh ich was then used to attack t he vi ctim model. The results are shown in the last part of T able 2. W e can observe that: (i) The classification performances degraded after gray-box att acks, verifying the transferability of bot h DF-U AP and TLM -U AP . (ii) In most cases, TLM-U AP led to lar ger classification performance d egradation of th e RCA and BCA than DF-U AP , sug g esting that ou r proposed TLM -U AP was more eff ectiv e than DF-U AP . 4.5. Characteristics of U A P Additional experiments were performed in th is subsecti on to analyze the characteristics of TLM-U AP . 4.5.1. Signal-to-P erturbation Ratio (SPR) W e comput ed SPRs of the perturbed EEG trials, including applying random no i se, DF-U AP and TLM-U AP in wh i te-box attacks. W e treated the original EEG trials as clean sig nals, and comp u ted the SPRs in cross-su bject e xperiments. The r esults are shown in T able 5. In most cases, the SPR s of the adve rsarial examples perturbed by TLM-U AP were high er than those perturbed by DF-U AP , i.e., the U AP crafted Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 17 by TLM had a smaller magnitude, and hence m ay be mo re dif ficult to detect. This is because in addition to k v k p ≤ ξ , TLM-U AP is also bounded by t h e cons t raint functi o n C ( x , v ) in (7). T able 5. SP Rs (dB) of EEG trials perturbed by DF-U AP an d TLM-UAP in white- b ox non - target attacks ( ξ = 0 . 2 ). Dataset EEGNet DeepCNN Sh allowCNN P300 16 . 99 17 . 00 17 . 85 DF-U AP ERN 16 . 22 16 . 73 17 . 73 MI 21 . 71 13 . 08 14 . 57 P300 21 . 17 19 . 92 20 . 58 TLM-UAP ERN 21 . 03 21 . 67 17 . 72 MI 23 . 48 17 . 85 17 . 80 4.5.2. Spectr ogram In order to analyze the tim e-frequency characteristics of UAP , we compared the spectrograms of DF-U AP and TLM-U AP for the three classifiers in white-box attacks. The results are shown in Fig. 4. (a) (b) Figure 4. Spectro g rams of DF- UAPs and TLM-U APs on the P300 dataset in white-box no n- target within-sub ject experimen ts. Channel C z was used . (a) DF-U AP; ( b) TLM - U AP . DF-U APs and TLM-U APs share similar spectrogram patterns: for EEGNet and DeepCNN, the energy was mainly concentrated in the l ow-f requency areas, whereas it wa s more s cattered for ShallowC NN. T h ere were also some significant di fferences. For EEGNet, the energy of DF-U AP was concentrated i n [0 . 1 , 0 . 9 ] s and [0 , 7] Hz, wh ereas t he energy of TLM-U AP was concentrated in [0 . 1 , 0 . 8] s and [3 , 8] Hz. For DeepCNN, TLM-U AP seemed Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 18 to affec t a lo n ger period o f signals, i.e., [0 . 4 , 0 . 8] s. For ShallowCNN, TLM-UAP mainly perturbed the high-frequency areas, which were less uniform than DF-U AP . These results also explained the cross -subject transferability results of TLM-U AP o n the P300 dataset i n T able 2: TLM-U APs generated from EEGNet and DeepCNN were m ore similar than th o se from ShallowCNN, so TLM-U AP generated from E E G N et (DeepCNN) was more ef fecti ve in attacking DeepCNN (EEGNet), and their RCAs and BCAs were close. 4.5.3. Hidden-Layer F eature Map Section 4.2 sho ws t hat there i s no big dif ference b etween the EEG trial before and after TLM-U AP attack in the time dom ain and the frequency domain, and on the topoplot. Fig. 5 visu alizes the feature m ap from t h e last con volution layer of EEGNet before and after adding the TLM-U AP to a clean MI EEG trial. The s mall perturbation was ampli fied by the compl ex nonli n ear t ransformation of EEGNet, and hence the hidden layer feature maps were significantly d i f ferent. This is intui t iv e, as otherwise the output of EEGNet would no t chang e much. Be n i g n fe a t u r e m a p 0 1 2 3 4 5 6 A d v e r sa r i a l f e a tu r e m a p 0 5 1 0 1 5 2 0 2 5 Figure 5. Feature map of EEGNet befo re a nd after white-box non -target within-subject TLM- U AP attack on the MI dataset ( ξ = 0 . 2 ). 4.6. Hyper-P arameter Sensit i vity This subsection analyzes the sensitivity of TLM -U AP to its h y per -parameters. 4.6.1. The Magnitude of TLM-U AP ξ is an important parameter in Algorith m 3, wh i ch directly boun ds the magnitude of the perturbatio n . W e ev alu ated t h e TLM -U AP attack performance with respect to di f ferent ξ . As shown in Fig. 6, the RCA decreased rapidly as ξ increased and con ver ged at ξ = 0 . 2 in most cases, suggesting th at a sm all U AP i s powerful enough to attack the victim model. 4.6.2. T raining Set Size It’ s int eresti ng to study i f the traini ng set size affects the performance of TLM-U AP . Fig. 7 shows the white-box non-target att ack perf ormance of TLM-U AP , which were trained wi th dif ferent numbers of EEG trials in cross-subject Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 19 0 . 0 0 . 2 0 . 4 0 . 6 ξ 0 . 2 0 . 4 0 . 6 0 . 8 R C A E E GNe t De e p C NN S h a l l o w C NN (a) 0 . 0 0 . 2 0 . 4 0 . 6 ξ 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 R C A E E G Ne t De e p C NN S h a l l o w C NN (b) 0 . 0 0 . 2 0 . 4 0 . 6 ξ 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 R C A E E G Ne t De e p C NN S h a l l o w C NN (c) Figure 6. RCAs o f the v ictim m odel af ter white-box no n-target within-sub ject TLM-UAP attack, with respect to d ifferent ξ . (a) P300 dataset; (b) ERN da taset; and, ( c ) MI dataset. experiments o n the M I dataset. It seems that we d o not need a large training set to o b tain an effe ctiv e TLM-U AP . The same ph enomenon was also observed in [21]. E E G N e t De e p C N N S h a l l o w C N N 0 2 0 4 0 6 0 8 0 1 0 0 A S R ( % ) 5 0 1 0 0 2 0 0 5 0 0 1 0 0 0 A l l Figure 7. ASRs in white-box n on-target cro ss-subject experim e nt on the MI dataset, with respect to different tr aining set sizes. ‘ All’ means all 4,60 8 train ing EEG trials in the MI dataset were u sed in Alg o rithm 3 . 4.6.3. Const raint W e als o compared differe nt constraint C in (7): No const rain t , L1 regularization ( α = 10 / 10 / 5 for EEGNet/DeepCNN/ShallowCNN), and L2 regularization ( α = 100 ). The SPRs on t he three datasets are shown in T abl e 6. Albeit si m ilar att ack performances, TLM-U AP trained wit h constraints led to a l ar ger SPR (th e SPRs i n t h e ‘L1’ and ‘L2’ rows are lar ger than tho s e in the correspondi ng ‘No’ ro w). Fig. 8 shows that add i ng diffe rent constraints significantly changed the wa veforms of TLM-U AP . L1 regularization introduced sparsity , whereas L2 regularization reduced the perturbation magnitu de. W e may also generate a TLM-U AP which satisfies other requirements by changing the constraint functio n C , such as perturbing certain EEG channels, or even against a metric function which is used to detect adversarial examples. W e will leav e these to our future Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 20 T able 6. Mean RCAs (%) and SPRs (dB) on the three datasets using different constraints in white-box n on-target attacks ( ξ = 0 . 2 ). Dataset Constraint Mean RCA SPR o f TLM-U AP EEGNet DeepCNN ShallowC NN P300 No 17 . 18 14 . 89 14 . 71 14 . 45 L1 17 . 36 18 . 39 17 . 82 17 . 16 L2 17 . 85 21 . 17 19 . 92 20 . 58 ERN No 30 . 96 19 . 91 20 . 70 17 . 02 L1 29 . 24 21 . 45 22 . 05 17 . 11 L2 30 . 66 21 . 03 21 . 67 17 . 72 MI No 25 . 05 22 . 88 15 . 46 16 . 11 L1 25 . 08 23 . 35 53 . 76 16 . 88 L2 25 . 06 23 . 48 17 . 85 17 . 80 0 . 0 0 0 . 0 5 0 . 1 0 0 . 1 5 0 . 2 0 0 . 2 5 0 . 3 0 T i m e ( s) F z C z Pz C h a n n e l No L 1 L 2 Figure 8. TLM-U AP trained with d ifferent constraints o n the MI dataset in white-b ox non - target attacks. Ch a nnels P z , C z and F z were used. research. 4.7. Influence of the Batch Size Mini-batch gradient descent was us ed to optimize TLM-U AP . T able 7 s h ows the change of RCAs and BCAs w .r .t. diffe rent batch sizes. Generally , the proposed TLM-U AP is i nsensitive to batch size w i thin [16 , 64 ] . 5. T arget Attack Results Our TLM approach is also capable of performing tar get attacks, which can be easily achie ved by changing th e los s function l in (7). W e performed white-box target attacks in cross -subject experiments on the three datasets and ev aluated th e tar get rate , wh ich is the number of samples classi fied to the target class Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 21 T able 7. T h e r atio of the number of correctly classified samples to the number of total samples (RCAs), and the mean RCAs of different c lasses (BCAs), of the three CNN classifiers after TLM-UAP attack s with d ifferent batch sizes o n the th ree datasets. Dataset V ictim M odel RCA/BCA Batch Size 16 Batch Size 3 2 Batch Size 6 4 P300 EEGNet . 17 /. 50 . 17 /. 50 . 17 /. 5 0 DeepCNN . 17 /. 50 . 17 /. 50 . 19 /. 5 0 ShallowCNN . 21 / . 51 . 20 /. 51 . 20 /. 51 ERN EEGNet . 31 /. 50 . 31 /. 50 . 30 /. 5 0 DeepCNN . 41 /. 52 . 40 /. 52 . 40 /. 5 2 ShallowCNN . 38 / . 51 . 38 /. 51 . 40 /. 53 MI EEGNet . 25 /. 25 . 25 /. 25 . 25 /. 2 5 DeepCNN . 29 /. 29 . 29 /. 29 . 26 /. 2 6 ShallowCNN . 26 / . 26 . 26 /. 26 . 25 /. 25 divided by the number of total samples. The resul ts are sho wn in T able 8. TLM-U APs had close to 100% target rates in white-box tar get attacks, in dicating that our approach can manipulate the BCI systems to output whateve r the attacker wants, which m ay be more dangerous than non-target attacks. For example, in a BCI-drive n wheelchair , a t arget TLM- U AP attack may force all com mands to be interpreted as a specific comm and (e.g., going forward), and hence run the user into danger . T o further simplify the implementation of TLM-U AP , we also consi d ered smaller template si ze, i.e., mini TLM-U AP wit h a sm all number of channels and time dom ain samples, which can b e added anywhere to an EEG trail. Mini TLM-U APs are more practical and flexible, because they do not require th e attacker to k now the exact num ber of EEG channels and the exact length and starting tim e of an EEG trial. During optimization , we randomly placed th e mi n i TLM-U AP at di f ferent locatio n s (both channel-wise and time-wise) of EEG trials and tried to make t he at t acks successful. During test, the mini TLM-U AP was randomly added t o 30 dif ferent locations o f each EEG trail. The results are shown in Fig. 9. Generally , all mini TLM-U APs were effecti ve. Howe ver , their ef fecti veness decreased when the number of used channels ( C m ) and/or the template length ( T m ) decreased, which i s intuitive . These results sug gest that a mini TLM-U AP may be used to achie ve a better comprom ise between the attack performance and the implementati on dif ficulty . 6. Conclusions and Futur e Resear ch Multiple CNN classifiers ha ve been proposed for EEG-based BCIs. Howe ver , CNN models are vulnerable to U APs, whi ch are sm all and example-independent perturbations, yet power ful enough to significantly degrade the performance of a CNN mo d el when added to a benign example. This paper has proposed a nove l TLM approach to g enerate U AP for E E G-based BCI systems. Experimental results demonstrated its ef fectiveness in attacking three p opular CNN classifiers for both non-target and target attacks. W e also verified t he transferabili t y Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 22 T able 8. T arget rates o f the three CNN classifiers in cro ss-subject white-box target TLM-UAP attacks on the th ree datasets ( ξ = 0 . 2 ). Dataset V ictim Mo del T arget Class Baseline TLM-UAP Clean Noisy Attack P300 EEGNet Non-target . 6627 . 6463 . 9 629 T a rget . 3373 . 3510 . 9572 DeepCNN Non-target . 6755 . 6637 . 9 416 T a rget . 3245 . 3116 . 9373 ShallowCNN Non-target . 6505 . 6597 . 8 904 T a rget . 3495 . 3499 . 8306 ERN EEGNet Bad . 3537 . 3741 . 99 80 Good . 6463 . 630 0 . 9971 DeepCNN Bad . 3770 . 3309 . 99 12 Good . 6230 . 673 9 . 9976 ShallowCNN Bad . 3033 . 2910 . 97 41 Good . 6967 . 716 0 . 9888 MI EEGNet Left . 3152 . 1350 . 9821 Right . 2830 . 205 6 . 9850 Feet . 1545 . 1954 . 9994 T o ngue . 2473 . 5380 1 . 00 0 DeepCNN Left . 2535 . 1765 . 8839 Right . 3491 . 220 7 . 9238 Feet . 2282 . 3155 . 9659 T o ngue . 1692 . 2544 . 993 8 ShallowCNN Left . 2872 . 1952 . 9151 Right . 2537 . 174 6 . 9443 Feet . 2647 . 2838 . 9819 T o ngue . 2124 . 3673 . 998 3 E E G Ne t De e p C N N S h a l l o w C NN 0 2 0 4 0 6 0 8 0 1 0 0 T a rg e t r a t e ( % ) ( 3 2 , 1 0 0 ) ( 3 2 , 5 0 ) ( 2 0 , 1 0 0 ) ( 1 0 , 1 0 0 ) (a) E E G N e t De e p C NN S h a l l o w C N N 0 2 0 4 0 6 0 8 0 1 0 0 T a rg e t r a t e ( % ) ( 5 6 , 1 0 0 ) ( 5 6 , 5 0 ) ( 2 0 , 1 0 0 ) ( 1 0 , 1 0 0 ) (b) E E G N e t De e p C NN S h a l l o w C N N 0 2 0 4 0 6 0 8 0 1 0 0 T a rg e t r a t e ( % ) ( 2 2 , 1 0 0 ) ( 2 2 , 5 0 ) ( 2 0 , 1 0 0 ) ( 1 0 , 1 0 0 ) (c) Figure 9. T arget rates of cro ss-subject mini TLM- U AP target attacks, with different U AP template size ( C m , T m ) , wh ere C m is the number of EEG chan nels and T m the number of time d omain samples. The origin a l tr ial sizes of P30 0/ERN/MI datasets were (32 , 2 56) / (56 , 260) / (2 2 , 256) , respectively . ( a) P3 00 dataset, non-target class; (b) ERN dataset, bad-feed back class; (c) MI d ataset, lef t-hand class. Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 23 of the U APs in EEG-based BCI system s. T o our knowledge, this is the first study on U APs of CNN classifiers in EEG-based BCIs. It exposes a potentiall y critical security p rob lem in BCIs, and hopefully wi l l lead to the d esign of safer BCIs. Our future research will enhance the transferabilit y of TLM-U AP in deep learning, and also consider how to attack traditi o nal m achine learning models i n EEG-based BCIs. More importantly , we wil l design ef fective st rategies to defend against U AP attacks. Multiple approaches, e.g., adversarial training [14], defensive distillation [42], ens em ble adversarial training [43], a nd so on [23, 4 4 – 46], ha ve been proposed to defend against adversarial examples in other application domains. As TLM is a perturbation based first-order gradient optimizatio n approach, PGD [23] training may be used to defend against it. Refer ences [1] Samu e l Sutton, Margery Brar en, Joseph Zubin, and E. R. John. Ev oked-potential corre late s of stimu lus uncertainty . Science , 150(3 700):1 187–1188, 1965 . [2] LA Farwell and E Donchin. T alking off the top of your h ead: Toward a mental prosthesis utilizing ev ent-related b rain potentials. Electr oencepha lography and Clinical Neur oph ysiology , 70(6):51 0–523 , December 1988. [3] Don grui W u. Onlin e and offline domain adaptation fo r reducing BCI calibratio n ef fort. IEEE T rans. on Human-Ma chine Sy stems , 47 (4):550 –563 , 2 017. [4] Don grui W u, V ern on J. Lawhern , W . D. Hairston , and Bren t J. Lance . Switching EEG headsets made easy: Reducin g offline calibratio n effort using active weigh ted adaptation regularization . IEEE T rans. on Neural Systems and Reha bilitation Eng ineering , 24 (11):11 25–1 137 , 20 16. [5] G. Pfur tscheller and C. Neupe r . Mo tor imagery and d irect brain-c o mputer com munication . P r oc. I EEE , 89(7) :1123– 1134, Jul 200 1. [6] Danh ua Zhu, Jor di Bieger , Gar y Garcia Molina, and Ronald M Aar ts. A survey of stimulation meth ods used in SSVEP- based BCIs. Comp utationa l In telligence and Neur oscien ce , pag e 70 2357, 2 010. [7] V erno n J. Lawhern, Amelia J. Solo n, Nicholas R. W ay towich, Stephen M. Go rdon, Chou P . Hung, and Brent J. Lance. EEGNet: A co mpact con volutional neural network for EEG-based brain-co mputer interfaces. Journal of Neural En gineering , 1 5 (5):05 6013, June 2018. [8] Robin T ibor Sch ir rmeister , Jost T obias Sp r ingenbe rg, L ukas Dominiqu e Josef Fiederer, Mar tin Glasstetter, Katharina Eggensperger, Michael T an g ermann , Frank Hutter , W olfram Burgard , and T onio Ball. Deep learning with con v olutional neural netw orks for EEG decod ing and visualizatio n. Human B rain Mapping , 38(11) :5391– 5420, 201 7. [9] Pouy a Bashiv an, Irina Rish, Moham med Y ea sin , and No el Codella. Learnin g representations from EE G with deep recu rrent-co nvolutional ne u ral network s. I n Pr oc. In t’l Co nf. on Learning Rep r esenta tions , San Juan, Puerto Rico, May 20 16. [10] Y ou sef Rezaei T abar and Ugur Halici. A novel d eep learning approach fo r classification of E EG motor imagery signals. Journal of Neural Enginee rin g , 14(1) :01600 3, 2017 . [11] Zied T ayeb , Juri Fedjaev , Nejla Ghaboo si, Christoph Richter , Lukas Everding, Xingwe i Qu , Y ingy u W u, Gordon Cheng, an d J ¨ org Conr adt. V alida tin g deep neur al n etworks for o nline decod in g of m otor imager y movements from EEG sign als. Sen sors , 19(1 ):210, January 2019 . [12] Chr istian Szegedy , W ojciech Zar e mba, Ilya Sutskever , Joan Brun a, Dum itru Erh an, Ian J. Goodfellow , an d Rob Fergus. Intr ig uing p roperties of neur al network s. In Pr o c . Int’l Conf. on Learning Representations , Banff, Canada, April 2014 . [13] Battista Bigg io, Igino Corona , Davide Maiorca, Blaine Nelson, Nedim ˇ Srndi ´ c, Pa vel Laskov , Giorgio Giacinto, and Fabio Roli. E vasion attacks against mach ine learnin g at test time. In Pr oc. Joint Eu r opea n Conf. on Machine Learning and Knowledge Discovery in Data bases , page s 3 87–40 2, Berlin, Germany , September 2013. Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 24 [14] Ia n J. Go odfellow , Jonathon Shlens, an d Ch r istian Szegedy . Explain ing and har nessing adversar ia l examples. I n Pr oc. In t’l Conf. on Learning Repr e sen tations , San Diego, CA, May 2015. [15] Alexey Kurakin, Ian J. Goodfellow , and Samy Beng io. Adversarial examples in the ph ysical world. In Pr oc. Int’l Conf. on Learn ing Rep r esenta tions , T oulon, France, Ap ril 2 017. [16] T om B. Brown, Dan delion Man ´ e, Aurko Roy , Ma r t´ ın Abadi, a nd Justin Gilmer . Adversarial patc h . CoRR , abs/1712 .09665 , 2017. [17] An ish Athalye, Log an Eng strom, Andrew Ilyas, and Ke vin Kwok. Synthesizing robust ad versarial examples. In Pr oc . 35th Int’l Conf. on Ma chine Lea rning , pag es 284–29 3, Stock holm, Sweden , July 2018. [18] Nich olas Carlini and David A. W agn er . Audio adversarial examples: T argeted attacks on speech- to-text. In Pr oc. IEEE Symp osium on Security and Privacy , pages 1–7, San Francisco, CA, May 20 1 8. [19] Kath rin Gr osse, Nicolas Paperno t, Praveen Mano h aran, Michael Backes, and Patrick McDaniel. Adversarial perturba tions again st deep neu ral networks fo r malw are classification. CoRR , abs/1606 .04435 , 2016. [20] Seyed- M ohsen Moo sa vi-Dezfoo li, Alhussein Fawzi, and Pascal Fro ssard. Deep fool: A simp le and accu rate method to fool deep neu ral n etworks. In Pr oc. IEEE Con f. on Computer V ision and P attern Recognition , pages 2574– 2582 , Las V egas, NV , June 2016 . [21] Seyed- M ohsen Moosavi-Dezfooli, Alh ussein Fa wzi, Omar Fawzi, and Pascal Fro ssard. Universal adversarial pertu rbations. In Pr oc. IEE E Conf. on Computer V ision an d P attern Recognition , pag e s 1765– 1773, Honolulu , HI, July 2 017. [22] Shu meet Baluja and Ian Fischer . Adversar ia l tra n sformation network s: Learn ing to g enerate adversarial examples. Co R R , abs/1703. 0 9387 , 2017. [23] Alek sander Madry , Aleksandar Makelov , Ludwig Sch midt, Dimitris Tsipras, a nd Adrian Vladu. T o wards deep lea r ning m odels resistant to adversarial a ttac k s. In Pr oc. Int’l. Conf. on Learning R epr e sen tations , V ancouver, Canada, May 2018. [24] Nich olas Carlini and David W ag ner . T ow ar ds ev aluatin g th e robustness o f n eural networks. In Pr oc. IEEE Symposium on Security a nd Privacy , p ages 3 9–57, San Jose, CA, May 20 1 7. IEEE. [25] X. Zhang and D. W u . On th e vulnerab ility of CNN classifiers in EEG-ba sed BCIs. I EEE T rans. on Neural Systems a nd Rehabilita tio n Enginee rin g , 27(5) :814–8 25, May 2019 . [26] Jun dong Li, K ewei Cheng, Suhan g W ang, Fred Morstatter, Robert P . T revino, Jiliang T ang , an d Huan Liu. Feature selection: A data perspec ti ve. CoRR , abs/16 01.07 9 96, 2 016. [27] Xiao Zhang , Dong rui W u , Lieyun Ding, Hanbin L uo, Chin-T eng L in, Tzyy- Ping Jun g , an d Ricardo Chav arr iaga. T iny noise, big mistakes: Adversarial p erturbatio ns indu ce erro r s in brain-co mputer interface spellers. National Science Review , 8( 4), 202 1 . [28] Paarth Neek h ara, Shehzeen Hussain, Pr akhar Pandey , Shlomo Dubnov , Julian J. McAu ley , a n d Farinaz Koushanfar . Universal adversarial perturbations fo r speech recognition sy stems. CoRR , abs/1905 .03828 , 2019. [29] Melik a Behjati, Seyed-Mohsen Moosavi-Dezfoo li, Mahdieh Soleymani Baghsh a h, and Pascal Frossard. Universal a d versarial attacks on text classifiers. In P r oc. IEEE Int’l Conf. on Acoustics, Sp eech and Signal Pr ocessing , pag es 7345 –7349 , Brighto n , United King dom, May 20 1 9. [30] Konda Reddy Mopuri, Ad itya Ganeshan, and V en k atesh Bab u Radhakr ish nan. Generalizable d ata-free objective for c r afting universal adversarial pe r turbation s. IEEE T rans. on P attern Analysis a nd Machine Intelligence , 41( 10):24 5 2–24 65, Oc tober 2 019. [31] Ho kuto Hiran o and Kazu hiro T akemoto. Simple it erativ e method for gen erating targeted universal adversarial per turbation s. In Pr oc. o f 25th Int’l. Sympo sium o n Artificial Life a nd Robotics , page s 426 – 430, Beppu, Jap an, January 2020. [32] Xu e Jiang , Xiao Zhan g , and Don grui W u. Active learning f or blac k -box ad versarial attacks in EEG-based brain-co mputer interfaces. In Pr oc. IEEE Sympo sium S eries on Computation al Inte lligence , X ia m en, China, December 2019. [33] Ulric h Hoffmann, Jean - Marc V esin, T ouradj Ebrahimi, a nd Karin Disere ns. A n efficient P30 0-based brain- computer interface for disab led subjects. Journal of Neur oscience Methods , 167(1 ):115–1 25, Janu ary Universal Adversarial P erturbation s for CNN Clas s ifiers in EEG-Based BCIs 25 2008. [34] Perr in Margaux, Ma b y Emmanue l, Dalig ault S ´ ebastien, Ber tr and Olivier , and Matto ut J ´ er ´ emie. Ob jectiv e and subjective e valuation of online error co rrection durin g P300-based spelling. Advances in Human- Computer Interaction , 201 2(578 295):1 3, Octo ber 20 12. [35] Mich ael T angermann, Klaus-Rob ert M ¨ uller, Ad Aertsen, Niels Birb a u mer, Christoph Braun , Clemen s Brunner, Rob ert Leeb, Carsten M ehring, Kai Miller, Gernot Mueller-Putz, Guido Nolte, Gert Pfurtscheller, Huber t Preissl, Gerwin Schalk, Alois Sch l ¨ ogl, Carmen V idaurre, Stephan W alde r t, and Benjamin Blankertz. Revie w of the BCI Competition IV. F r ontiers in Neur o scien ce , 6:5 5, 20 12. [36] Fran cois Chollet. Xceptio n: Deep le a r ning with depthwise separable con volutions. I n Pr oc. IEEE Conf. on Computer V ision and P attern Recogn ition , pages 1800– 1807, Hono lulu, HI, July 2017 . [37] Kai K eng Ang, Zheng Y an g Chin, Haihong Zhang , and Cun tai Guan . Filter bank comm on spatial pattern (FBCSP) in brain- compu ter interface. In Pr oc. I EEE In t’l Joint Conf. o n Neural Networks , Hong K ong, China, June 2008. [38] Died erik P . Kingma and Jimmy Ba. Adam: A method for stochastic op timization. CoRR , abs/141 2 .6980 , 2014. [39] Hen ry B Man n and Donald R Wh itn ey . On a test of wheth er on e of two r a ndom variables is stochastically larger than the other . Th e a nnals o f mathematical statistics , pag es 50–6 0, 19 47. [40] B. Ri vet, A. Soulou miac, V . Attin a, and G. Gibert. x D A WN algorith m to enhance e voked po tentials: application to br ain-comp uter interface. IE E E T rans. on Biomedical Engineering , 56 (8):203 5–20 4 3, 2009. [41] Her bert Ramoser, Jo hannes Muller-Gerkin g , an d Gert Pfurtsche ller . Optimal spatial filtering of single trial E EG dur in g imagined h and m ovement. IE EE T rans. o n Reh abilitation Engin e ering , 8(4):441 –446 , 2000. [42] Nico las Papernot, Patrick McDaniel, Xi W u, Somesh Jha, and Ananth ram Swami. Distillation as a de fense to adversarial perturbatio ns against de e p neu ral networks. In Pr oc. IEEE Symposium o n Sec urity a nd Privacy , pages 5 82–59 7, San Jose, CA, M ay 2016. IEEE. [43] Flor ian T ram ` er, Alexey Kurakin, Nicolas Papernot, Ian Good f ellow , Dan Boneh, and Patrick McDaniel. Ensemble adversarial trainin g: Attacks an d defenses. I n Pr oc. In t’l Con f. on Learnin g Representations , V ancouver, Canada, May 2018. [44] Cihan g Xie, Jianyu W ang, Z hishuai Z h ang, Zhou Ren, and Alan Y u ille. Mitigating adversarial effects throug h ran d omization. In Pr oc. I n t’l Conf. on Learnin g Repres entations , V an couver, Canada, May 2018. [45] Chu an G u o, Mayank Rana, Mo u stapha Ciss ´ e, and Lau r ens van der Maaten. Counte r ing adversar ial imag es using input transformatio ns. CoRR , abs/17 1 1.001 17, 2 017. [46] Naveed Akh tar , Jian Liu, an d Ajmal Mian. De f ense against un i versal adversarial perturbation s. I n Pr oc. IEEE Conf. on Computer V ision and P attern Recognitio n , pages 338 9–339 8, Salt Lake City , U T , Ju ne 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment