QubitHD: A Stochastic Acceleration Method for HD Computing-Based Machine Learning
Machine Learning algorithms based on Brain-inspired Hyperdimensional(HD) computing imitate cognition by exploiting statistical properties of high-dimensional vector spaces. It is a promising solution for achieving high energy efficiency in different …
Authors: Samuel Bosch, Alex, er Sanchez de la Cerda
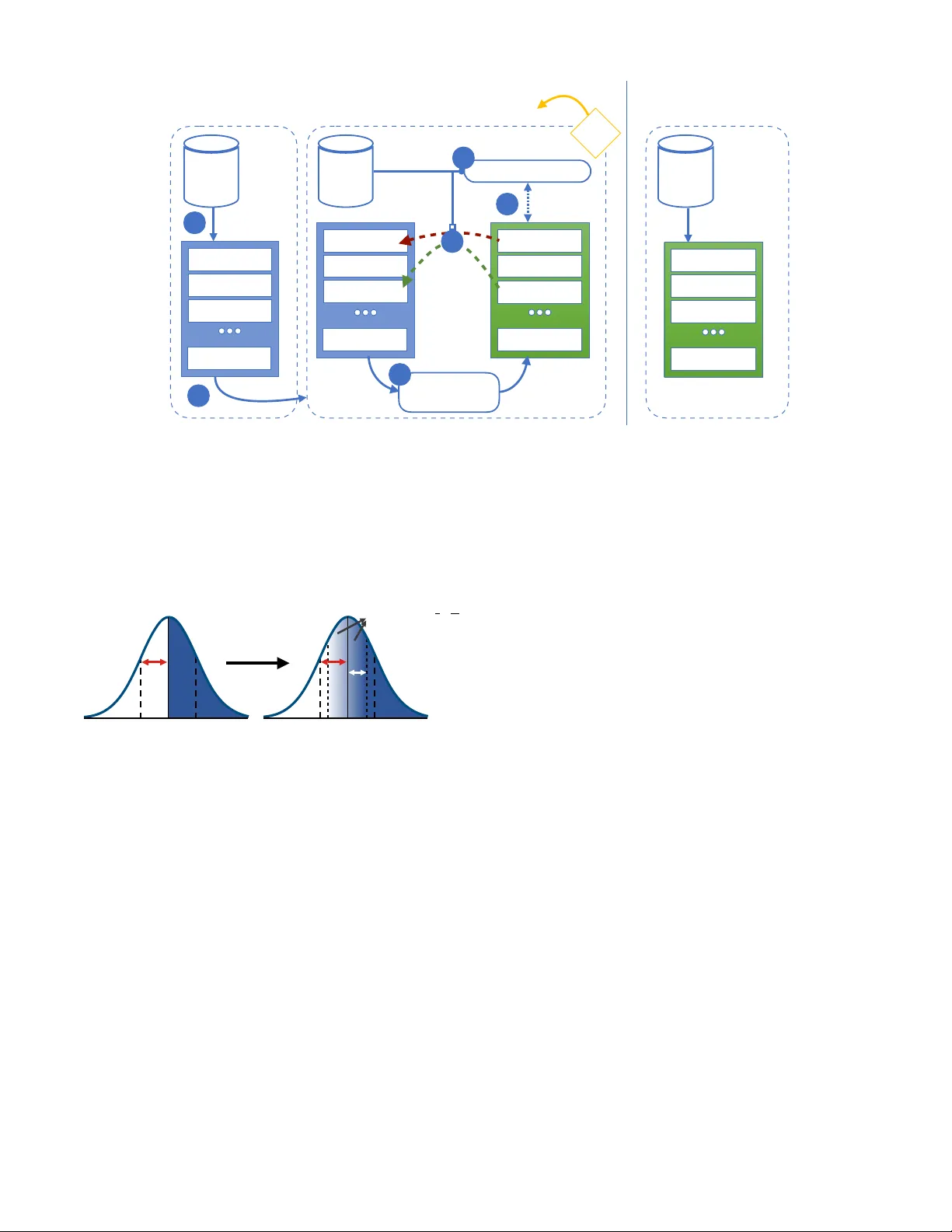
QubitHD: A Sto c hastic Acceleration Metho d for HD Computing-Based Mac hine Learning Sam uel Bosch, 1 , ∗ Alexander Sanchez de la Cerda, 2 Mohsen Imani, 3 T a jana ˇ Sim uni´ c Rosing, 4 and Giov anni De Micheli 5 1 Massachusetts Institute of T e chnolo gy, Cambridge, MA 02139, USA 2 Harvar d University, Cambridge, MA 02138, USA 3 University of California Irvine, Irvine, CA 92697, USA 4 University of California San Die go, L a Jol la, CA 92093, USA 5 ´ Ec ole p olyte chnique f´ ed´ er ale de L ausanne, L ausanne, VD 1015, Switzerland (Dated: October 12, 2022) Mac hine Learning algorithms based on Brain-inspired Hyp erdimensional (HD) computing imitate cognition b y exploiting statistical prop erties of high-dimensional v ector spaces. It is a promising solution for ac hieving high energy efficiency in differen t machine learning tasks, suc h as classifica- tion, semi-sup ervised learning, and clustering. A weakness of existing HD computing-based ML algorithms is the fact that they hav e to b e binarized to achiev e very high energy efficiency . A t the same time, binarized models reach lo wer classification accuracies. T o solv e the problem of the trade-off betw een energy efficiency and classification accuracy , we propose the QubitHD algorithm. It sto chastically binarizes HD-based algorithms, while maintaining comparable classification accu- racies to their non-binarized coun terparts. The FPGA implemen tation of QubitHD provides a 65% impro vemen t in terms of energy efficiency , and a 95% impro vemen t in terms of training time, as compared to state-of-the-art HD-based ML algorithms. It also outp erforms state-of-the-art low-cost classifiers (such as Binarized Neural Netw orks) in terms of sp eed and energy efficiency by an order of magnitude during training and inference. I. INTR ODUCTION: With the rise of data science and the In ternet of Things (IoT), the amount of pro duced data on a daily basis has increased to a lev el w e are barely able to handle [1]. As the amount of data that needs to b e pro cessed is often significantly larger than small-scale and battery- p o w ered devices can handle, so many of these devices are forced to connect to the internet to pro cess the data in the cloud. Deep Neural Netw orks (DNNs) are used for complex classification tasks, suc h as text and image recognition [2], translation, and ev en medical applica- tions [3]. How ev er, the complexity of DNNs makes them impractical for some real-w orld applications, suc h as classification tasks on small battery-p ow ered devices. Engineers often face a trade-off b et w een energy efficiency and the ac hiev ed classification accuracy . Therefore, we need to create light w eigh t classifiers, which can p erform inference on small-scale op erating devices. Brain-inspired Hyp erdimensional (HD) computing [4] has b een prop osed as a ligh tw eigh t learning algorithm and metho dology . The principles gov erning HD com- puting are based on the fact that the brain computes with p atterns of neur al activities which are not directly asso ciated with n um b ers [4]. Mac hine learning algo- rithms based on Brain-inspired HD computing imitate cognition b y exploiting statistical prop erties of very high- dimensional vector spaces. Recently , architectures such ∗ sbosch@mit.edu as L o okHD [5] hav e been prop osed, which enable real- time HDC learning on low-pow er edge devices. The first step in HD computing is to map each data p oint into a high-dimensional space (e.g., 10 , 000 dimensions). Dur- ing training, HD computing linearly com bines the en- co ded hypervectors to create a hypervector representing eac h class. During the inference, classification is done b y calculating the cosine similarity b et ween the enco ded query hypervector and all class h yp erv ectors. The algo- rithm then predicts the class with the highest similarity score. In the case of multiple classes with high similarity , the algorithm is likewise suited to express confidence in the correctness of a prediction. Man y publications on Brain-inspired HD computing argue that for most practical applications, HD comput- ing has to b e trained and tested using floating-p oin t, or at least integer v alues [6, 7]. Binarized HD computing mo dels pro vided low classification accuracies. Often to o lo w for practical applications. An algorithm called QuantHD [8] rev ealed the existence of a metho d to impro ve the classification accuracies of binarized and ternarized models significantly . Nev ertheless, there still exists a large gap b et w een the classification ac- curacy of non-binarized and binarized HD computing classifiers. Also, such metho ds increase the required training time and are unstable as they tend to get stuc k in local minima during training. In this pap er, w e prop ose a new metho d that can, both, reduce this classification accuracy gap by b et w een a third and a half whilst simultaneously improving energy efficiency during training by 60% , on av erage. It also mak es the training more stable by introducing randomness. W e call this technique QubitHD , as it is based on the 2 principle of information b eing stored in a quantum bit (Qubit) b efore its measuremen t. The floating-p oin t v alues represen t the quan tum state, while the binarized v alues represent the quantum state after a measuremen t has b een p erformed. The main contributions of the pap er are the following: • W e decreased the gap in classification accuracy b e- t ween binarized and non-binarized state-of-the-art HD computing-based ML algorithms by 38.8% , on a verage. • W e decrease the conv ergence time in the range of 30-50% (for different datasets). In tro ducing ran- domness in the algorithm preven ts it from getting stuc k in lo cal minima, and incites the algorithm to quic kly mov e tow ards the optimal v alue. The rea- son wh y the authors of [8] had problems with slow con vergence was precisely this: lack of randomness. • QubitHD p erforms a similarity chec k b y calculating the Hamming distance betw een the h yp erv ectors instead of calculating the costly cosine similarity . • W e implemented the algorithm on FPGA, which accelerates training and inference. W e also ev alu- ated sev eral classification problems, including hu- man activity , face, and text recognition. When lo oking at energy efficiency and sp eed, the FPGA implemen tation of QubitHD provides, on av erage, a 56 × and 8 × energy efficiency improv emen t and sp eedup during training, as compared to state-of- the-art HD computing algorithms [9]. F or com- parison purp oses, the authors of [8] only achiev e 34.1 × and 4.1 × energy efficiency improv ement and sp eedup during the training against the same state-of-the-art HD computing algorithms. When comparing QubitHD with multi-la y er p erceptron (MLP) and binarized neural netw ork (BNN) clas- sifiers, we observe that QubitHD can pro vide 56 × and 52 × faster computing in training and testing resp ectiv ely , while providing similar classification accuracies (see T able I I I). I I. HYPERDIMENSIONAL COMPUTING The applications of brain-inspired HD computing in mac hine learning are div erse. In this publication, w e only fo cus on sup ervised classification tasks, but a recen t pub- lication indicated that HD computing-based ML algo- rithms can b e applied to clustering and semi-sup ervised learning as well [10]. The basis of QubitHD is describ ed in Figure 2. The core difference to QuantHD is the bi- narization step that is discussed in Section I II. The non- binarized algorithm with retraining consists of the fol- lo wing steps: FIG. 1: Av erage classification accuracies during differen t retraining iterations of QubitHD compared to binary QuantHD , for datasets listed in table (I I). It is clear that QubitHD conv erges faster than QuantHD , as a result of the sto chastic binarization pro cess. It do es so without utilizing additional hardware resources. T able (I I) also lists the maximum accuracies ach ieved with a large num b er ( ≥ 1000) of training iterations for the individual datasets. A. Enco ding The training dataset is pre-pro cessed by con verting all data p oin ts into very high-dimensional vectors (hyper- v ectors). W e used hypervectors of length D = 10 , 000 in this pap er, as it is the standard baseline for all HD computing-based machine learning algorithms. Like ex- plained in [8], the original data is assumed to hav e n features: f = { f 1 , . . . f n } . The ob jectiv e is enco ding eac h feature that corresp onds to each datap oint into the h yp erv ector of dimension D ( D = 10 , 000 in this pa- p er). Eac h feature v ector ”memorizes” the v alue and p osition of the relev an t feature. In order to take in to accoun t the p osition of each feature, we use a set of randomly generated base h yp erv ectors { B i , B 2 , . . . , B n } , where n is the total n umber of features in each data p oin t ( B i ∈ {− 1 , 1 } D ). Since the base-hypervectors are uni- formly generated at random (with equal probability for − 1 and 1), they are approximately mutually orthogo- nal. The cosine pro duct b etw een h yp erv ectors ranges b et w een cos( H 1 , H 2 ) ∈ − 1 , 1 . The exp ected cosine pro duct of indep enden t and randomly generated base- h yp erv ectors is E [cos( B i , B j )] = 0, whereas the v ariance is V [cos( B i , B j )] = 1 √ D ≈ 0 for D >> n (random walk) for i 6 = j . Thereby , the hypervectors are almost orthog- onal. This is true only when the num ber of randomly generated base-hypervectors is significantly smaller than the dimension of the entire vector space D . F or compar- ison of the binarized hypervectors, we use the Hamming 3 T est Data Classification Overview Encoding Base V ectors Query a) T rain # Data Encoder b) Encoder T raining Minimum Distance Similarity Query h D h 1 Discretization Feature V ector f 1 f 2 f n C 2D C 1D C 11 C 21 Class 1 Class 2 C kD C k1 Class k Base V ectors ID 1 vector ID 2 vector Base V ectors ID n vector × × × + + Query Compare Non-binary Binary 6 FIG. 2: Ov erview of a simple HD computing-based machine learning algorithm for classification on the left. The enco ding scheme used in this publication is illustrated on the right. distance. Therefore: E [ δ ( B i , B j )] = D / 2 ( f or i 6 = j ) . Here δ is the Hamming distance similarit y b etw een the t wo binarized base-hypervectors. B. Initial training The first training round is p erformed by s umming up all hypervectors p ertaining to the same class. That is, w e abstract all hypervectors with the same lab els. This metho d is called one-shot learning and is, at the momen t, the most widespread wa y of using HD computing in ma- c hine learning [9, 11 – 14]. W e now hav e one matrix C of size m × D ( C ∈ R m × D ), where m is the n umber of existing classes and D is the length of the h yp erv ectors. C. Retraining The classification accuracy of the current mo del during the inference is lo w [8]. F or this reason, we hav e to do retraining. As display ed in Figure 3, retraining is done in the following w ay . W e go through the entire dataset of enco ded data p oin ts and test them to ascertain if they are correctly classified by the current mo del C . F or every misclassified data p oin t, we hav e to make additional im- pro vemen ts to the mo del. Let us assume that the correct lab el of a data p oin t is k , but it was incorrectly classified as l . W e now add the erroneously classified hypervec- tor to its corresponding row C k . (to mak e them more similar). W e also subtract the incorrectly classified hy- p erv ector from the ro w corresponding to the inaccurately predicted class C l (to make them more distinct). T o de- crease the con vergence of time and noise, it is common practice to introduce a learning rate of α in this step as illustrated in Figure 3a [15]. This pro cess is rep eated sev eral times. D. Inference During the inference, w e predict the class to whic h the data point b elongs. This data p oint is enco ded as describ ed in I I A, and then compared to all the class hy- p erv ectors. The algorithm then predicts the class with the largest cosine similarity . E. Binarization: So far, we describ ed in the algorithm that the trained mo del has non-binarized elements. Man y existing HD computing metho ds [16 – 18] bina- rize the class hypervectors to eliminate costly c osine op erations used for the asso ciativ e search ( C ∈ R m × D → C binariz ed ∈ {− 1 , 1 } m × D ). Binary hy- p erv ectors do not provide sufficiently high classification accuracies on many (if not most) real-w orld applications. The usual wa y of binarizing class h yp erv ectors is making all p ositive v alues equal to +1 and negative v alues equal to − 1. This metho d suffers from a significant loss of information ab out the trained mo del. T o the b est of our kno wledge, [8] was the first publication demonstrating a metho d of achieving high classification accuracy while using a binarized (or quantized) HD mo del. Instead of just ”blindly” binarizing the class hypervectors after ev ery retraining iteration, QuantHD trains the mo del in a wa y that is optimized for binarized hypervectors. That is, during every single retraining iteration, they create an additional binarized mo del. Doing so requires no additional computational p o wer, as the binary rep- resen tation of n um b ers in usual computer architectures reserv es the first bit for the sign (0 stands for p ositiv e, 1 4 for negativ e). The QuantHD algorithm retrains on the predictions of the binarized mo del, while up dating the non-binarized mo del as describ ed in subsection I I C and Figure 3. The binarized mo del achiev es, after several iterations, v ery high classification accuracies. They are significan tly higher than they would b e without binary-optimized retraining. I II. STOCHASTIC BINARIZA TION Our goal is to create a binarized mo del whose exp ected v alue is equal to the non-binarized mo del. This idea w as inspired b y the wa y in which quantum bits (or qubits) are measured – hence the name QubitHD . In other words, we wan t E C binarized ≈ C non binarized . The QuantHD algorithm uses the following (v ery trivial) binarization function: bin ( x ) = ( 1 , if x ≥ 0 − 1 , otherwise (1) W e prop ose using the following metho d instead: q bin ( x ) = 1 , if x > b 1 , if | x | ≤ b , then with probability 1 2 + x 2 b − 1 , if | x | ≤ b , otherwise − 1 , if x < − b (2) where b is the cutoff v alue defined as a fixed fraction of the standard deviation σ of the data. It is discussed in greater detail in subsection IV A. The adv antage of doing so is the fact that the exp ected v alue of q bin ( x ) for x ∈ − b, b is prop ortional to x: E q bin ( x ) = (+1)( 1 2 + x 2 b ) + ( − 1)( 1 2 − x 2 b ) = x b IV. PR OPOSED QUBITHD ALGORITHM Motiv ation The QuantHD algorithm still leav es us with a signif- ican t gap betw een the maximum classification accuracy of the floating-p oin t mo del and the binarized one. Also, the QuantHD retraining metho d describ ed in [8] tends to get ”stuck” in lo cal minima. F urther, their algorithm almost doubles the av erage con v ergence rate, whic h here- after increases energy consumption during training. T o summarize, here are the main problems with the QuantHD algorithm, which the QubitHD algorithm can either solve or improv e: 1. There still exists a significant gap b etw een the bi- narized mo del and non-binarized mo del accuracy 2. The algorithm can sometimes get stuck in lo cal minima , which makes it unreliable. 3. The con vergence time of QuantHD algorithm is almost twice as slow as compared to the other state- of-the-art HD computing algorithms with retrain- ing A. F ramework of the QubitHD algorithm In this section, we present the QubitHD algorithm. It enables efficient binarization of the HD mo del with a mi- nor impact on classification accuracy . The algorithm is based on QuantHD and consists of four main steps: 1) Enco ding : This part is describ ed in detail in Subsection I I A and Figure 2b 2) Initial training : QubitHD trains the class hyper- v ectors by summing all the enco ded data p oints corre- sp onding to the same class as seen in Figure 3a It is evident from Figure 3a that ev ery accum u- lated hypervector represents one class. As explained in [8], in an application with k classes, the initially trained HD mo del contains k non-binarized hypervectors { C 1 , . . . , C k } , where C i ∈ N D 1 . 3) Sto chastic binarization : This part is the main c hange with resp ect to the QuantHD algorithm. A given class hypervector is created by summing together random h yp erv ectors h of the type h ∈ {− 1 , 1 } D . Every element C ij in a class hypervector C i (of class i) is the pro duct of a ”random w alk”. In other w ords, its distribution follo ws a binomial distribution with a probability mass function (pmf ): p ( C ij = k ) = n k p k (1 − p ) n − k = n k 1 2 n (3) where p = 1 2 (as we hav e equal probabilities for h j = − 1 and h j = +1), n is the num ber of randomly summed h yp erv ectors for class i, and k is a p ossible v alue C ij can tak e. Note that C ij ∈ {− n, ..., 0 , ..., n } . Assuming that the num ber of hypervectors correspond- ing to every class in the dataset is large enough, the nor- mal distribution is a go od approximation for mo deling the binomial distribution In previous publications, [8], the w ay of binarizing a mo del C w as describ ed by Equation 1. W e instead pro- p ose using Equation 2 shown in Figure 4. Implement- ing this change requires almost no additional resources (the random flips ha ve to b e p erformed only once per retraining round), but leads to significant improv ements in terms of accuracy , reliability , sp eed, and energy ef- ficiency . The accuracy improv emen t is due to the fact that the exp ected v alue of this sto c hastically binarized mo del is equal to the non-binarized mo del. The reliabil- it y and speed improv emen t are because the mo del quickly 5 C 1 bin C 2 bin C 3 bin C k bin Quantized C miss + 𝛼 𝗛 non - binary C correct C matched - 𝛼 𝗛 C k Encoded Dataset 1 Encoded Dataset C 1 non - binary Initial T r aining Retr aining Binarization 2 Stochastic binarization 6 Update Model Δ E< ε 4 5 Similarity Comparison next iteration 𝗛 B Encoded Dataset Infer ence Similarity Comparison a) b) 3 C 2 C 3 C k C 1 bin C 2 bin C 3 bin C k bin Quantized rapid inference through utilization of binary model 1 FIG. 3: (a) QubitHD framework ov erview (including the initial training and the retraining of the non-binarized mo del based on the binarized mo del). (b) Efficient inference from mo del ”jumps” out of local minima, as opp osed to getting stuc k for several iterations. The energy c onsumption during training dep ends on the num ber of retraining iterations, whic h are significantly reduced. -1 +1 𝞼 b { + 𝟏𝒘𝒊𝒕𝒉𝒑 = 𝟏 𝟐 + 𝒙 𝟐𝒃 − 𝟏𝒐𝒕𝒉𝒆𝒓𝒘𝒊𝒔𝒆 -1 +1 𝞼 QuantHD QubitHD FIG. 4: On the left side, we ha ve a visualization of equation 1 from QuantHD . On the right side, we hav e a visualization of equation 2 from QubitHD . White represen ts − 1, blue +1, and the colors b etw een represen t a sto chastic selection. Just as w e ha ve demonstrated, the enco ded data w e are pro cessing is (approximately) normally distributed. T o b e able to use Equation 2 for the binarization pro cess, w e hav e to define a ”cutoff” v alue b . That is, everything ab o v e + b will b ecome +1, and everything b elow − b will b ecome − 1. Only v alues b et ween − b and + b will b e b etter approximated through Equation 2. In most cases, b has to b e smaller than the standard deviation of the data distribution σ . If we would use b >> σ , our mo del w ould b ecome almost completely random, as most of the v alues are con tained in the − σ, + σ in terv al (68% to b e precise). The reason why the q bin ( x ) binarization works b etter than the bin ( x ) lies in the fact that taking into accoun t the exp ected v alue of the binarized mo del, it is equal to actual v alues in the non-binarized mo del, with the exception of v alues b elo w − b and ab ov e + b . Empirically , w e also noticed that the randomness of q bin ( x ) preven ts the algorithm from getting stuck in lo cal minima during training, which reduces the conv ergence time by 50% , on av erage. V. POSSIBLE FPGA IMPLEMENT A TION It is kno wn that HD computing-based machine learn- ing algorithms can b e implemented in a wide range of differen t hardware platforms, such as CPUs, GPUs, and FPGAs. As most of the training and all of the infer- ence relies on bit-wise op erations, it was prop osed in [8] that FPGAs would b e a suitable candidate for efficien t hardw are acceleration. The same hardware can b e used for implementing b oth, the QuantHD and the QubitHD algorithm. This is also one of the ma jor adv an tages of QubitHD , as it do esn’t require costly hardware upgrades from previous mo dels. VI. EV ALUA TION A. Exp erimen tal Setup The training and inference of the algorithm w ere im- plemen ted and verified using V erilo g and the co de w as syn thesized on the Kintex-7 FPGA KC705 Evaluation Kit . The Vivado XPower to ol has b een used to estimate the device p ow er. Additionally , for testing purp oses, all parts of the QubitHD algorithm hav e b een implemen ted on the CPU. W e also implemented the algorithm on an 6 T ABLE I: Datasets ( n : num ber of features, k : n umber of classes). n K Data Size T rain Size T est Size Description ISOLET 617 26 19MB 6,238 1,559 V oice Recognition [21] UCIHAR 561 12 10MB 6,213 1,554 Activity recognition(Mobile)[22] MNIST 784 10 220MB 60,000 10,000 Handwritten digits [23] F ACE 608 2 1.3GB 522,441 2,494 F ace recognition[24] EXTRA 225 4 140MB 146,869 16,343 Phone p osition recognition[25] em b edded device ( R asb erry Pi 3 ) with an ARM Cortex A54 CPU. T o make an accurate and fair comparison, w e use the follo wing FPGA-implemented algorithms as baselines: • The QuantHD algorithm from [8], on whic h QubitHD is based • Other state-of-the-art HD computing-based ma- c hine learning algorithms [6, 9, 15] • A multi-lev el perceptron (MLP) [19] (see T able I I I) • A binary neural netw ork (BNN) [20] (see T able I I I) T o show the adv an tage of the QubitHD and the previous [8] algorithm, we used the datasets summarized in T able I. The datasets range from small datasets lik e UCIHAR and ISOLET (frequently used in IoT devices, for which QubitHD is sp ecially created), to larger datasets lik e face recognition. B. Accuracy The ev aluation of the baseline HD mo del provides high-classification accuracy when using non-binarized h y- p erv ectors for classification. The problem, ho wev er, is that retraining and inference with a non-binary class hy- p erv ector is very costly , as it requires calculating cosine similarities. That is, for k -bit in tegers or floating-point n umbers O ( D k 2 ) basic op erations need to b e p erformed through every step. These are costly and impractical on small-scale and battery-p o wered devices. Similarly , during inference, the asso ciative search b e- t ween a query and a trained mo del requires the calcu- lation of the costly cosine similarities. T o address this issue, many HD computing-based mac hine learning al- gorithms binarize their mo dels [9]. That wa y , the cosine similarit y is replaced b y a simple Hamming distanc e sim- ilarit y c heck. The key problem with this approac h is that it leads to a significan t decrease in classification accuracy , as shown in T able I I. The authors of [8] already show ed the existence of a partial solution to this problem, which inv olv es simulta- neously retraining the non-binarized mo del, while updat- ing the binarized mo del. W e already listed the problems with this mo del in subsection IV. What esp ecially mo- tiv ated us to create a stable and more reliable QubitHD algorithm, is the fact that the QuantHD algorithm’s re- training is unstable and unreliable. After extensiv ely testing the QubitHD algorithm, we conclude that it, on av erage, closes the gap of classification accuracy by 38.8% as compared to the baseline HD computing-based mac hine learning algorithms in [9] using the Quan tHD framew ork (See T able I I). Additionally , we observe that the accuracies of the QubitHD algorithm, using a binary mo del, are 1.2% and 60% higher than the classification accuracies of the base- line HD computing-based algorithm using non-quan tized and binary resp ectively . Figure 1 compares the classifica- tion accuracy of QubitHD and QuantHD during differen t training iterations. It is clear that QubitHD conv erges m uch faster than QuantHD , as a result of the sto c hastic binarization pro cess. C. T raining Efficiency The training efficiency of HD-based algorithms is c har- acterized by initial training of the mo del and subsequent retraining. Figure 5 shows the energy consumption and execution time of QubitHD during retraining. • Algorithms in this t yp e all consume the same en- ergy during the generation of the initial training mo del • The significant cost is the retraining: compared to the non-binarized mo del, QuantHD uses fewer op- erations when calculating the hypervector similari- ties (step 4 in Figure 3). • No complex c osine similarity has to b e computed as calculating the Hamming distance is sufficien t to determine whether there w as a correct classification or not • The impro vemen t of QubitHD lies in the faster con- v ergence to a high classification accuracy , which is 30-50% faster than in QuantHD and also decreases the energy consumption after the initial training prop ortionally . • The QubitHD mo dification has a dual b enefit. It mak es it p ossible to sav e energy and time during training, whilst achieving the same or b etter clas- sification accuracies during testing dep ending on whether the goal is rapid conv ergence or high clas- sification accuracy . D. Inference Efficiency Compared to QuantHD, there is no gain or loss in the time execution or energy efficiency , since the mo dels b e- ha ve identically once they are trained. So w e rep ort the same 44 × energy efficiency improv emen t and 5 × sp eedup as compared to the non-binarized HD algorithm. 7 T ABLE I I: Comparison of QubitHD classification accuracies with the state-of-the-art HD computing. Baseline HD QuantHD QubitHD Non-Quantize d Binary Non-Quantized Binary Binary with r andomize d flip ISOLET 91.1% 88.1% 95.8% 94.6% 95.3% UCIHAR 93.8% 77.4% 95.9% 93.0% 94.1% MNIST 88.1% 32.70% 91.2% 87.1% 88.3% F ACE 95.9% 68.4% 96.2% 94.6% 95.4% Mean 92.23% 65.9% 94.78% 92.33% 93.28 T ABLE I II: Comparison of QubitHD with MLP and BNN in terms of accuracy , efficiency , and mo del size [8] MLP/BNN T op ologies Accuracy CPU T raining (s) FPGA Inference ( µ s) Mo del Size MLP BNN QubitHD MLP BNN QubitHD MLP BNN QubitHD MLP BNN QubitHD ISOLET 617-512-256-26 95.8% 96.1% 95.3% 2.08 17.69 0.19 27.39 5.24 0.28 1.81MB 56.7KB 65.0KB UCIHAR 561-512-256-12 97.3% 95.9% 94.1% 1.04 8.32 0.08 21.43 5.18 0.27 1.68MB 52.7KB 30.0KB F A CE 608-512-256-2 96.1% 96.1% 95.4% 0.56 4.30 0.03 17.68 5.11 0.24 1.77MB 55.3KB 5.0KB Baseline HD QuantHD QubitHD 30 10 11 30 9 9.7 31 9.5 10 26 8.6 8.8 ISOLET UCIHAR MNIST F ACE Energy consumption (µJ) 1 10 100 1000 ISOLET UCIHAR MNIST F ACE Initial T raining (one shot) QuantHD (retraining) QuantHD (retraining) QuantHD r etraining QubitHD 450 220 405 194 427.5 200 387 176 ISOLET UCIHAR MNIST F ACE T raining Time (µs) on FPGA 1 10 100 ISOLET UCIHAR MNIST F ACE 2 FIG. 5: Energy consumption and execution time of initial training, QuantHD retraining and QubitHD retraining on a FPGA E. QubitHD comparison with MLP and BNN QubitHD is a classifier in tended to run on low-pow ered devices, specifically with the goal of lo w energy consump- tion and fast and efficient execution in mind. As suc h, w e set out to compare QubitHD , not only to Quan tHD but also to other non-HD ligh tw eigh t classifiers. In our analysis, we compared QubitHD accuracy and efficiency with the state-of-the-art ligh tw eigh t classifiers, includ- ing Multi-La yer Perceptron (MLP) and Binarized Neural Net work (BNN). F or MLP and BNN, w e aimed to use the same metric as employ ed in [20] with the small mo difica- tion in input and output lay ers in order to run different applications. The results of this, presented in T able I I I, indicate that QubitHD , while ha ving similar classification accuracies to v ery ligh t w eight classifier BNNs and M LPs, drastically reduces CPU usage during training and exe- cution time during the inference. In particular, compared to MLPs QubitHD uses 12 × less CPU during training and is 84 × faster during the inference on FPGAs. Com- pared with BNNs, QubitHD uses a factor of 101 × less CPU time during training and is still 20 × faster during the inference. VI I. CONCLUSION Mac hine learning algorithms, based on Brain-inspired Hyp erdimensional (HD) computing, imitate cognition b y exploiting statistical prop erties of very high-dimensional v ector spaces. They are a promising solution for energy- efficien t classification tasks. A weakness of existing HD computing-based ML algorithms is the fact that they ha ve to b e binarized to achiev e very high energy effi- ciency . A t the same time, binarized mo dels reac h low er classification accuracies. In order to solv e the problem of the trade-off b et ween energy efficiency and classifica- tion accuracy , we prop ose the QubitHD algorithm. With QubitHD , it is p ossible to use binarized HD computing- based ML algorithms, which provide virtually the same classification accuracies as their non-binarized counter- parts. The algorithm is inspired by stochastic quan- tum state measurement tec hniques. The improv emen t of QubitHD is a duality and is reflected in the quick er con vergence, and the higher and more stable classifica- tion accuracy achiev ed, as compared to QuantHD . 8 [1] J. Gubbi, R. Buyya, S. Marusic, and M. Palanisw ami, In ternet of things (iot): A vision, arc hitectural elemen ts, and future directions, F uture generation computer sys- tems 29 , 1645 (2013). [2] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. F ei- F ei, Imagenet: A large-scale hierarc hical image database, in 2009 IEEE c onfer enc e on c omputer vision and p attern r e c o gnition (Ieee, 2009) pp. 248–255. [3] E. Mu, S. Jabbour, A. V. Dalca, J. Guttag, J. Wiens, and M. W. Sjoding, Augmenting existing deterioration indices with chest radiographs to predict clinical deteri- oration, Plos one 17 , e0263922 (2022). [4] P . Kanerv a, Hyp erdimensional computing: An intro- duction to computing in distributed representation with high-dimensional random vectors, Cognitiv e Computa- tion 1 , 139 (2009). [5] M. Imani, Z. Zou, S. Bosch, S. A. Rao, S. Salamat, V. Kumar, Y. Kim, and T. Rosing, Revisiting hyper- dimensional learning for fpga and low-pow er arc hitec- tures, in 2021 IEEE International Symp osium on High- Performanc e Computer Ar chite ctur e (HPCA) (IEEE, 2021) pp. 221–234. [6] J. Morris, M. Imani, S. Bosch, A. Thomas, H. Shu, and T. Rosing, Comphd: Efficient h yp erdimensional comput- ing using model compression, in 2019 IEEE/A CM Inter- national Symp osium on Low Power Ele ctr onics and De- sign (ISLPED) (IEEE, 2019) pp. 1–6. [7] M. Imani, S. Salamat, B. Khaleghi, M. Samragh, F. Koushanfar, and T. Rosing, Sparsehd: Algorithm- hardw are co-optimization for efficient high-dimensional computing, in 2019 IEEE 27th Annual International Symp osium on Field-Pr o gr ammable Custom Computing Machines (FCCM) (IEEE, 2019) pp. 190–198. [8] M. Imani, S. Bosc h, S. Datta, S. Ramakrishna, S. Sala- mat, J. M. Rabaey , and T. S. Rosing, Quanthd: A quan ti- zation framew ork for hyperdimensional computing, IEEE T ransactions on Computer-Aided Design of In tegrated Circuits and Systems (TCAD) (2019). [9] A. Rahimi, P . Kanerv a, and J. M. Rabaey , A robust and energy-efficien t classifier using brain-inspired h yper- dimensional computing, in Pr o c e e dings of the 2016 In- ternational Symp osium on L ow Power Ele ctr onics and Design (A CM, 2016) pp. 64–69. [10] M. Imani, S. Bosch, M. Jav aheripi, B. Rouhani, X. W u, F. Koushanfar, and T. S. Rosing, Semihd: Semi- sup ervised learning using hyperdimensional comput- ing, IEEE/A CM International Conference On Computer Aided Design (ICCAD) , 1 (2019). [11] H. Li, T. F. W u, A. Rahimi, K.-S. Li, M. Rusch, C.-H. Lin, J.-L. Hsu, M. M. Sabry , S. B. Eryilmaz, J. Sohn, W.-C. Chiu, M.-C. Chen, T.-T. W u, J.-M. Shieh, W.-K. Y eh, J. M. Rabaey , S. Mitra, and W. H.-S. Philipa, Hy- p erdimensional computing with 3d vrram in-memory k er- nels: Device-architecture co-design for energy-efficient, error-resilien t language recognition, in 2016 IEEE Inter- national Ele ctr on Devic es Me eting (IEDM) (IEEE, 2016) pp. 16–1. [12] T. F. W u, H. Li, P .-C. Huang, A. Rahimi, G. Hills, B. Ho dson, W. Hw ang, J. M. Rabaey , H.-S. P . W ong, M. M. Sh ulaker, and S. Mitra, Hyp erdimensional com- puting exploiting carb on nanotub e fets, resistive ram, and their monolithic 3d in tegration, IEEE Journal of Solid-State Circuits 53 , 3183 (2018). [13] A. Rahimi, S. Benatti, P . Kanerv a, L. Benini, and J. M. Rabaey , Hyp erdimensional biosignal pro cessing: A case study for emg-based hand gesture recognition, in R eb o ot- ing Computing (ICRC), IEEE International Confer enc e on (IEEE, 2016) pp. 1–8. [14] T. W u, P . Huang, A. Rahimi, H. Li, J. Rabaey , P . W ong, and S. Mitra, Brain-inspired computing exploiting car- b on nanotub e fets and resistive ram: Hyp erdimensional computing case study , in IEEE Intl. Solid-State Cir cuits Confer enc e (ISSCC) (IEEE, 2018). [15] M. Imani, J. Morris, S. Bosch, H. Shu, G. De Micheli, and T. Rosing, Adapthd: Adaptive efficient training for brain-inspired hyperdimensional computing, in 2019 IEEE Biome dical Cir cuits and Systems Confer enc e (Bio- CAS) (IEEE, 2019) pp. 1–4. [16] A. Rahimi, S. Datta, D. Kleyko, E. P . F rady , B. Olshausen, P . Kanerv a, and J. M. Rabaey , High- dimensional computing as a nanoscalable paradigm, IEEE T ransactions on Circuits and Systems I: Regular P ap ers 64 , 2508 (2017). [17] M. Imani, A. Rahimi, D. Kong, T. Rosing, and J. M. Rabaey , Exploring hyperdimensional asso cia- tiv e memory , in High Performanc e Computer Ar chite c- tur e (HPCA), 2017 IEEE International Symp osium on (IEEE, 2017) pp. 445–456. [18] A. Rahimi, A. Tchouprina, P . Kanerv a, J. d. R. Mill´ an, and J. M. Rabaey , Hyp erdimensional computing for blind and one-shot classification of eeg error-related p oten tials, Mobile Netw orks and Applications , 1 (2017). [19] H. Sharma, J. Park, D. Maha jan, E. Amaro, J. K. Kim, C. Shao, A. Mishra, and H. Esmaeilzadeh, F rom high- lev el deep neural models to fpgas, in Micr o ar chite ctur e (MICRO), 2016 49th Annual IEEE/ACM International Symp osium on (IEEE, 2016) pp. 1–12. [20] Y. Um uroglu, N. J. F raser, G. Gam bardella, M. Blott, P . Leong, M. Jahre, and K. Vissers, Finn: A frame- w ork for fast, scalable binarized neural net work inference, in Pr o c e e dings of the 2017 ACM/SIGD A International Symp osium on Field-Pr o gr ammable Gate Arr ays (ACM, 2017) pp. 65–74. [21] Uci machine learning repository , http://archive.ics. uci.edu/ml/datasets/ISOLET . [22] D. Anguita, A. Ghio, L. Oneto, X. Parra, and J. L. Rey es-Ortiz, Human activit y recognition on smartphones using a multiclass hardware-friendly supp ort vector ma- c hine, in International workshop on ambient assiste d liv- ing (Springer, 2012) pp. 216–223. [23] Y. LeCun, C. Cortes, and C. J. Burges, Mnist hand- written digit database, A T&T Labs [Online]. Av ailable: h ttp://yann. lecun. com/exdb/mnist (2010). [24] Y. Kim, M. Imani, and T. Rosing, Orc hard: Visual ob ject recognition accelerator based on approximate in-memory pro cessing, in Computer-Aide d Design (ICCAD), 2017 IEEE/ACM International Confer enc e on (IEEE, 2017) pp. 25–32. [25] Y. V aizman, K. Ellis, and G. Lanckriet, Recognizing de- tailed human context in the wild from smartphones and smart watc hes, IEEE Perv asive Computing 16 , 62 (2017).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment