BANANAS: Bayesian Optimization with Neural Architectures for Neural Architecture Search
Over the past half-decade, many methods have been considered for neural architecture search (NAS). Bayesian optimization (BO), which has long had success in hyperparameter optimization, has recently emerged as a very promising strategy for NAS when i…
Authors: Colin White, Willie Neiswanger, Yash Savani
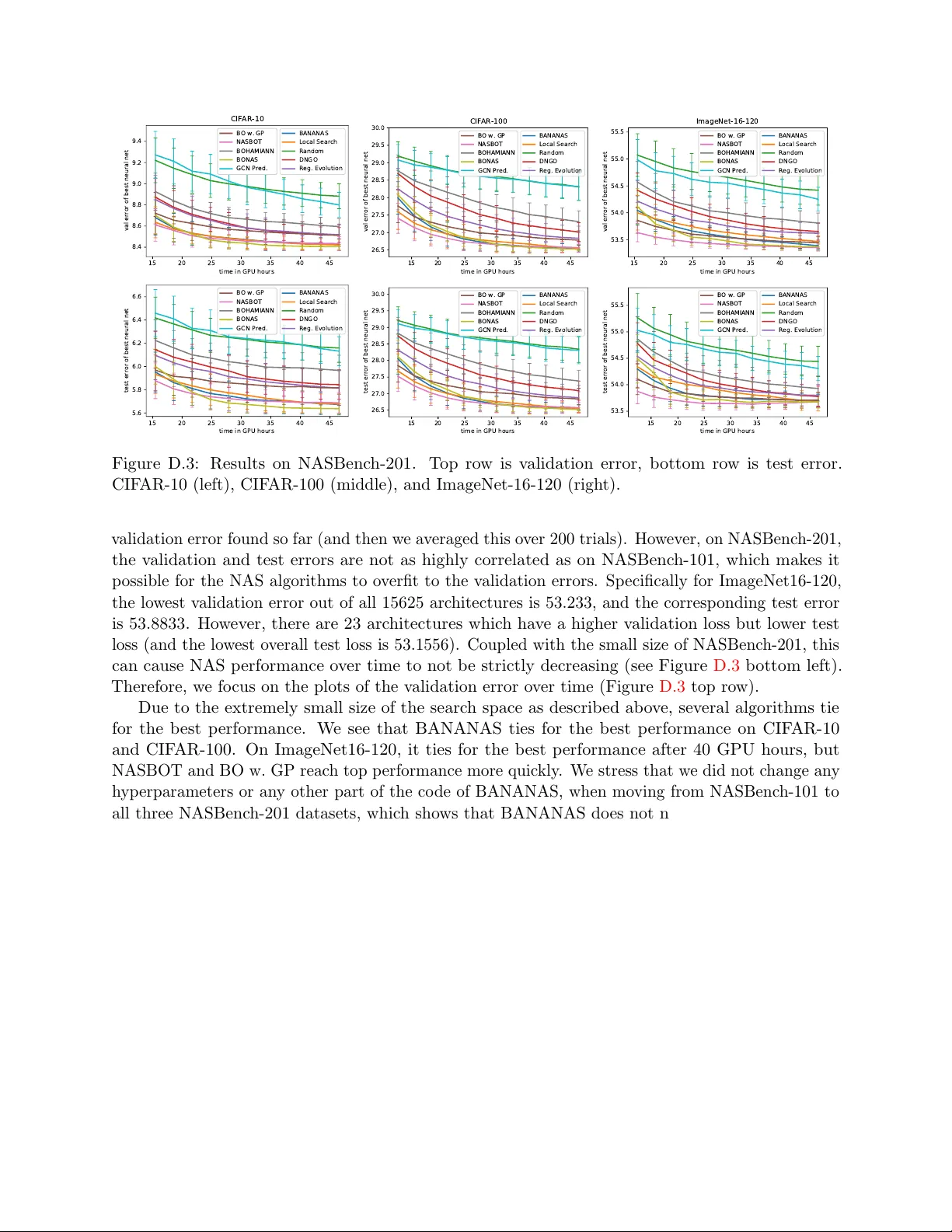
BANANAS: Ba y esian Optimization with Neural Arc hitectures for Neural Arc hitecture Searc h Colin White Abacus.AI colin@abacus.ai Willie Neisw anger Stanford Univ ersity and P etuum Inc. neiswanger@cs.stanford.edu Y ash Sa v ani Abacus.AI yash@abacus.ai Abstract Ov er the past half-decade, many metho ds ha v e b een considered for neural architecture searc h (NAS). Ba yesian optimization (BO), which has long had success in hyperparameter optimization, has recently emerged as a v ery promising strategy for NAS when it is coupled with a neural predictor. Recen t work has prop osed different instantiations of this framework, for example, using Ba yesian neural netw orks or graph conv olutional netw orks as the predictiv e mo del within BO. How ever, the analyses in these pap ers often fo cus on the full-fledged NAS algorithm, so it is difficult to tell whic h individual comp onen ts of the framework lead to the b est p erformance. In this work, we giv e a thorough analysis of the “BO + neural predictor” framew ork by iden tifying fiv e main components: the arc hitecture encoding, neural predictor, uncertaint y calibration metho d, acquisition function, and acquisition optimization strategy . W e test sev eral differen t methods for each comp onen t and also develop a nov el path-based enco ding scheme for neural architectures, which we sho w theoretically and empirically scales b etter than other enco dings. Using all of our analyses, we develop a final algorithm called BANANAS, which ac hieves state-of-the-art p erformance on NAS search spaces. W e adhere to the NAS research c hecklist (Lindauer and Hutter 2019) to facilitate b est practices, and our co de is av ailable at https://github.com/naszilla/naszilla . 1 In tro duction Since the deep learning revolution in 2012, neural netw orks hav e b een gro wing increasingly more complex and sp ecialized [ 25 , 17 , 57 ]. Dev eloping new state-of-the-art arc hitectures often takes a v ast amount of engineering and domain knowledge. A rapidly dev eloping area of research, neural arc hitecture search (NAS), seeks to automate this pro cess. Since the p opular work by Zoph and Le [ 79 ], there has b een a flurry of researc h on NAS [ 34 , 42 , 35 , 21 , 10 , 19 ]. Man y metho ds hav e b een prop osed, including ev olutionary search, reinforcement learning, Bay esian optimization (BO), and gradien t descent. In certain settings, zeroth-order (non-differentiable) algorithms suc h as BO are of particular interest ov er first-order (one-shot) techniques, due to adv an tages such as simple parallelism, joint optimization with other hyperparameters, easy implementation, p ortabilit y to div erse architecture spaces, and optimization of other/m ultiple non-differentiable ob jectiv es. BO with Gaussian processes (GPs) has had success in deep learning h yp erparameter optimization [ 14 , 11 ], and is a leading metho d for efficient zeroth order optimization of exp ensiv e-to-ev aluate functions in Euclidean spaces. Ho wev er, initial approaches for applying GP-based BO to NAS came with challenges that limited its ability to ac hieve state-of-the-art results. F or example, initial 1 approac hes required specifying a distance function b et ween architectures, which inv olv ed cum bersome h yp erparameter tuning [ 21 , 19 ], and required a time-consuming matrix inv ersion step. Recen tly , Bay esian optimization with a neural predictor has emerged as a high-performing framew ork for NAS. This framework av oids the aforementioned problems with BO in NAS: there is no need to construct a distance function b et w een architectures, and the neural predictor scales far b etter than a GP mo del. Recent work has prop osed differen t instantiations of this framework, for example, Bay esian neural netw orks with BO [ 53 ], and graph neural netw orks with BO [ 48 , 36 ]. Ho wev er, the analyses often fo cus on the full-fledged NAS algorithm, making it challenging to tell whic h comp onen ts of the framework lead to the b est p erformance. In this work, we start b y p erforming a thorough analysis of the “BO + neural predictor” framew ork. W e iden tify five ma jor comp onen ts of the framework: architecture enco ding, neural predictor, uncertain ty calibration metho d, acquisition function, and acquisition optimization strategy . F or example, graph conv olutional netw orks, v ariational auto enco der-based net works, or feedforw ard net works can be used for the neural predictor, and Ba yesian neural netw orks or different t yp es of ensem bling metho ds can b e used for the uncertain ty calibration metho d. After conducting exp erimen ts on all comp onents of the BO + neural predictor framew ork, w e use this analysis to define a high-performance instan tiation of the framew ork, which w e call BANANAS: Bay esian optimization with neural architectures for NAS. In order for the neural predictor to ac hiev e the highest accuracy , we also define a no v el path-based arc hitecture enco ding, which we call the path enco ding. The motiv ation for the path enco ding is as follo ws. Eac h architecture in the search space can b e represen ted as a lab eled directed acyclic graph (D AG) – a set of no des and directed edges, together with a list of the op erations that each no de (or edge) represen ts. How ev er, the adjacency matrix can b e difficult for the neural net work to in terpret [ 78 ], since the features are highly dep endent on one another. By contrast, eac h feature in our path enco ding scheme represents a unique path that the tensor can take from the input lay er to the output lay er of the arc hitecture. W e show theoretically and exp erimen tally that this enco ding scales b etter than the adjacency matrix enco ding, and allows neural predictors to ac hieve higher accuracy . W e compare BANANAS to a host of popular NAS algorithms including random search [ 30 ], D AR TS [ 35 ], regularized evolution [ 44 ], BOHB [ 11 ], NASBOT [ 21 ], lo cal searc h [ 66 ], TPE [ 4 ], BONAS [ 48 ], BOHAMIANN [ 53 ], REINFOR CE [ 67 ], GP-based BO [ 50 ], AlphaX [ 62 ], ASHA [ 30 ], GCN Predictor [ 64 ], and DNGO [ 52 ]. BANANAS achiev es state-of-the-art p erformance on NASBenc h-101 and is comp etitive on all NASBench-201 datasets. Subsequen t work has also sho wn that BANANAS is comp etitive on NASBenc h-301 [ 49 ], ev en when compared to first-order metho ds such as DAR TS [ 35 ], PC-D AR TS [ 69 ], and GD AS [ 8 ]. Finally , to promote repro ducibility , in App endix E we discuss how our exp eriments adhere to the NAS b est practices chec klist [ 33 ]. In particular, we exp eriment on w ell-known search spaces and NAS pip elines, run enough trials to reach statistical significance, and release our co de. Our con tributions. W e summarize our main contributions. • W e analyze a simple framework for NAS: Bay esian optimization with a neural predictor, and we thoroughly test five comp onents: the enco ding, neural predictor, calibration, acquisition function, and acquisition optimization. • W e prop ose a nov el path-based enco ding for arc hitectures, whic h impro ves the accuracy of neural predictors. W e give theoretical and exp erimental results showing that the path enco ding scales b etter than the adjacency matrix enco ding. 2 • W e use our analyses to dev elop BANANAS, a high p erformance instantiation of the ab ov e framew ork. W e empirically show that BANANAS is state-of-the-art on p opular NAS b enchmarks. 2 So cietal Implications Our work gives a new metho d for neural arc hitecture searc h, with the aim of improving the p erformance of future deep learning research. Therefore, we ha ve muc h less con trol ov er the net impact of our work on so ciety . F or example, our work ma y b e used to tune a deep learning optimizer for reducing the carb on fo otprint of large p ow er plants, but it could just as easily b e used to impro ve a deep fake generator. Clearly , the first example w ould hav e a p ositiv e impact on so ciety , while the second example may hav e a negativ e impact. Our work is one lev el of abstraction from real applications, but our algorithm, and more generally the field of NAS, ma y b ecome an imp ortan t step in adv ancing the field of artificial intelligence. Because of the recent push for explicitly reasoning ab out the impact of research in AI [ 16 ], we are hop eful that neural architecture search will b e used to b enefit so ciet y . 3 Related W ork NAS has been studied since at least the 1990s and has gained significant atten tion in the past few y ears [ 22 , 56 , 79 ]. Some of the most p opular recen t techniques for NAS include evolutionary algorithms [ 37 ], reinforcement learning [ 79 , 42 ], BO [ 21 ], and gradient descent [ 35 ]. F or a survey of neural arc hitecture search, see [ 10 ]. Initial BO approaches defined a distance function b etw een arc hitectures [ 21 , 19 ]. There are sev eral works that predict the v alidation accuracy of neural netw orks [ 23 , 6 , 18 , 74 , 1 ]. A few recent pap ers hav e used Ba yesian optimization with a graph neural net work as a predictor [ 36 , 48 ], how ever, they do not conduct an ablation study of all comp onents of the framew ork. In this work, we do not claim to inv en t the BO + neural predictor framew ork, how ev er, we giv e the most in-depth analysis that w e are aw are of, which we use to design a high-p erformance instantiation of this framework. There is also prior w ork on using neural netw ork mo dels in BO for hyperparameter optimization [ 52 , 53 ], The explicit goal of these pap ers is to improv e the efficiency of Gaussian pro cess-based BO from cubic to linear time, not to dev elop a different type of prediction mo del in order to improv e the p erformance of BO with resp ect to the num b er of iterations. Recen t pap ers hav e called for fair and repro ducible exp eriments [ 30 , 72 ]. In this vein, the NASBenc h-101 [ 72 ], -201 [ 9 ], and -301 [ 49 ] datasets were created, which contain tens of thousands of pretrained neural architectures. W e provide additional related work details in App endix A . Subsequen t w ork. Since its release, several pap ers ha ve included BANANAS in new exp eriments, further sho wing that BANANAS is a comp etitiv e NAS algorithm [ 24 , 49 , 40 , 45 , 63 ]. Finally , a recen t pap er conducted a study on sev eral enco dings used for NAS [ 65 ], concluding that neural predictors p erform well with the path enco ding. 3 4 BO + Neural Predictor F ramew ork In this section, w e giv e a background on BO, and w e describ e the BO + neural predictor framew ork. In applications of BO for deep learning, the t ypical goal is to find a neural architecture and/or set of h yp erparameters that lead to an optimal v alidation error. F ormally , BO seeks to compute a ∗ = arg min a ∈ A f ( a ), where A is the search space, and f ( a ) denotes the v alidation error of arc hitecture a after training on a fixed dataset for a fixed num b er of ep o chs. In the standard BO setting, o v er a sequence of iterations, the results from all previous iterations are used to model the top ology of { f ( a ) } a ∈ A using the p osterior distribution of the mo del (often a GP). The next arc hitecture is then chosen by optimizing an acquisition function such as exp ected improv emen t (EI) [ 38 ] or Thompson sampling (TS) [ 59 ]. These functions balance exploration with exploitation during the search. The chosen arc hitecture is then trained and used to up date the mo del of { f ( a ) } a ∈ A . Ev aluating f ( a ) in each iteration is the b ottleneck of BO (since a neural net work must b e trained). T o mitigate this, parallel BO metho ds typically output k arc hitectures to train in each iteration, so that the k architectures can b e trained in parallel. BO + neural predictor framework. In each iteration of BO, we train a neural net work on all previously ev aluated architectures, a , to predict the v alidation accuracy f ( a ) of unseen architectures. The arc hitectures are represented as lab eled D AGs [ 72 , 9 ], and there are differen t metho ds of enco ding the D AGs b efore they are passed to the neural predictor [ 72 , 65 ], whic h we describ e in the next section. Choices for the neural predictor include feedforw ard netw orks, graph con volutional net works (GCN), and v ariational auto enco der (V AE)-based netw orks. In order to ev aluate an acquisition function, w e also compute an uncertaint y estimate for eac h input datap oint. This can b e accomplished by using, for example, a Ba yesian neural netw ork or an ensemble of neural predictors. Giv en the acquisition function, an acquisition optimization routine is then carried out, which returns the next architecture to b e ev aluated. In the next section, we giv e a thorough analysis of the choices that m ust b e made when instantiating this framework. 5 Analysis of the F ramew ork in out 1x1 3x3 3x3 MP MP in out 1x1 MP in out 1x1 3x3 MP in out 3x3 3x3 MP in out 3x3 3 0 3 1 3 2 3 3 3 4 3 5 length of path encoding 5.85 5.90 5.95 6.00 6.05 6.10 6.15 6.20 test error after 150 evaluations BANANAS with path encoding of different lengths Figure 5.1: Example of the path enco ding (left). Perfor mance of BANANAS with the path enco ding truncated to different lengths (right). Since each no de has 3 c hoices of op erations, the “natural” cutoffs are at p ow ers of 3. 4 In this section, w e give an extensive study of the BO + neural predictor framework. First, we discuss architecture enco dings, and w e define a no vel featurization called the path enco ding. Then w e conduct an analysis of different choices of neural predictors. Next, w e analyze differen t metho ds for ac hieving calibrated uncertaint y estimates from the neural predictors. After that, we conduct exp erimen ts on different acquisition functions and acquisition optimization strategies. Finally , we use these analyses to create our algorithm, BANANAS. Throughout this section, w e run exp eriments on the NASBench-101 dataset (exp eriments on additional search spaces are given in Section 6 ). The NASBench-101 dataset [ 72 ] consists of o ver 423,000 neural architectures from a cell-based searc h space, and each arc hitecture comes with precomputed v alidation and test accuracies on CIF AR-10. The search space consists of a D AG with 7 no des that can each tak e on three different operations, and there can b e at most 9 edges b etw een the no des. W e use the op en source version of the NASBenc h-101 dataset [ 72 ]. W e give the full details ab out the use of NASBench-101 in App endix D . Our co de is av ailable at https://github.com/naszilla/naszilla . Arc hitecture enco dings. The ma jority of existing work on neural predictors use an adjacency matrix representation to enco de the neural architectures. The adjacency matrix enco ding giv es an arbitrary ordering to the no des, and then giv es a binary feature for an edge b etw een no de i and no de j , for all i < j . Then a list of the op erations at each no de must also b e included in the enco ding. This is a challenging data structure for a neural predictor to in terpret b ecause it relies on an arbitrary indexing of the no des, and features are highly dep endent on one another. F or example, an edge from the input to no de 2 is useless if there is no path from no de 2 to the output. And if there is an edge from no de 2 to the output, this edge is highly correlated with the feature that describ es the op eration at no de 2 (conv 1x1, p o ol 3x3, etc.). A con tinuous-v alued v ariant of the adjacency matrix enco ding has also b een tested [ 72 ]. W e in tro duce a nov el encoding whic h w e term the p ath enc o ding , and w e sho w that it substan tially increases the p erformance of neural predictors. The path enco ding is quite simple to define: there is a binary feature for eac h path from the input to the output of an arc hitecture cell, given in terms of the op erations (e.g., input → con v 1x1 → p o ol 3x3 → output). T o enco de an arc hitecture, we simply chec k which paths are present in the arc hitecture, and set the corresponding features to 1s. See Figure 5.1 . Intuitiv ely , the path enco ding has a few strong adv an tages. The features are not nearly as dep enden t on one another as they are in the adjacency matrix enco ding, since each feature represen ts a unique path that the data tensor can take from the input no de to the output no de. F urthermore, there is no longer an arbitrary no de ordering, whic h means that eac h neural arc hitecture maps to only one enco ding (whic h is not true for the adjacency matrix enco ding). On the other hand, it is possible for multiple architectures to map to the same path enco ding (i.e., the enco ding is well-defined, but it is not one-to-one). How ev er, subsequen t work sho wed that arc hitectures with the same path enco ding also ha ve v ery similar v alidation errors [ 65 ], which is b eneficial in NAS algorithms. The length of the path enco ding is the total n umber of p ossible paths in a cell, P n i =0 q i , where n denotes the num b er of no des in the cell, and q denotes the num b er of op erations for each no de. Ho wev er, we present theoretical and exp erimen tal evidence that substantially truncating the path enco ding, even to length smaller than the adjacency matrix enco ding, do es not decrease its p erformance. Many NAS algorithms sample architectures by randomly sampling edges in the D AG sub ject to a maximum edge constraint [ 72 ]. In tuitively , the v ast ma jority of paths ha ve a very 5 lo w probability of o ccurring in a cell returned by this pro cedure. Therefore, by simply truncating the least-lik ely paths, our enco ding scales line arly in the size of the cell, with an arbitrarily small amoun t of information loss. In the following theorem, let G n,k,r denote a DA G architecture with n no des, r c hoices of op erations on each no de, and where each p otential forward edge ( n ( n − 1) 2 total) w as chosen with probability 2 k n ( n − 1) (so that the exp ected num b er of edges is k ). Theorem 5.1 ( informal ) . Given inte gers r , c > 0 , ther e exists an N such that ∀ n > N , ther e exists a set of n p aths P 0 such that the pr ob ability that G n,n + c,r c ontains a p ath not in P 0 is less than 1 n 2 . F or the formal statement and full pro of, see App endix C . This theorem says that when n is large enough, with high probability , w e can truncate the path enco ding to a size of just n without losing information. Although the asymptotic nature of this result makes it a pro of of concept, we empirically show in Figure 5.1 that in BANANAS running on NASBenc h-101, the path enco ding can b e truncated from its full size of P 5 i =0 3 i = 364 bits to a length of just twenty bits, without a loss in p erformance. (The exact exp erimen tal setup for this result is describ ed later in this section.) In fact, the p erformance after truncation actually impr oves up to a certain p oint. W e b elieve this is b ecause with the full-length enco ding, the neural predictor ov erfits to very rare paths. In App endix D , we sho w a similar result for NASBench-201 [ 9 ]: the full path enco ding length of P 3 i =0 5 i = 156 can b e truncated to just 30, without a loss of p erformance. Neural predictors. No w w e study the neural predictor, a crucial comp onent in the BO + neural predictor framew ork. Recall from the previous section that a neural predictor is a neural netw ork that is rep eatedly trained on the current set of ev aluated neural architectures and predicts the accuracy of unseen neural architectures. Prior work has used GCNs [ 48 , 36 ] or V AE-based arc hitectures [ 75 ] for this task. W e ev aluate the p erformance of standard feedfow ard neural net works with either the adjacency matrix or path-based enco ding, compared to V AEs and GCNs in predicting the v alidation accuracy of neural architectures. The feedforward neural netw ork we use is a sequential fully-connected netw ork with 10 la yers of width 20, the Adam optimizer with a learning rate of 0 . 01, and the loss function set to mean absolute error (MAE). W e use op en-source implementations of the GCN [ 76 ] and V AE [ 75 ]. See App endix D for a full description of our implemen tations. In Figure 5.2 (left), we compare the differen t neural predictors b y training them on a set of neural arc hitectures drawn i.i.d. from NASBenc h-101, along with v alidation accuracies, and then computing the MAE on a held-out test set of size 1000. W e run 50 trials for differen t training set sizes and a verage the results. The b est-p erforming neural predictors are the feedforward netw ork with the path enco ding (with and without truncation) and the GCN. The feedforw ard netw orks also had shorter runtime compared to the GCN and V AE, ho wev er, the run time of the full NAS algorithm is dominated by ev aluating neural arc hitectures, not by training neural predictors. Uncertain t y calibration. In the previous section, we ev aluated standalone neural predictors. T o incorp orate them within BO, for any datap oin t, neural predictors need to output b oth a prediction and an uncertain ty estimate for that prediction. Two p opular wa ys of achieving uncertainties are by using a Bay esian neural net work (BNN), or by using an ensem ble of neural predictors. In a BNN, we infer a p osterior distribution o ver netw ork weigh ts. It has b een demonstrated recen tly that accurate prediction and uncertaint y estimates in neural netw orks can b e ac hieved using Hamiltonian Mon te Carlo [ 53 ]. In the ensemble approach, we train m neural predictors using differen t random weigh t 6 1 0 2 1 0 3 size of the training set (logscale) 1 2 3 4 5 mean absolute error on test set Feedforward (Adj. Enc.) Feedforward (Path Enc.) Feedforward (Trunc. Path Enc.) Bayesian Neural Net GCN VAE 1 0 2 1 0 3 size of the training set (logscale) 0.0 0.2 0.4 0.6 0.8 1.0 RMSCE on the test set Feedforward (Adj. Enc.) Ensemble Feedforward (Path Enc.) Ensemble Feedforward (Trunc. Path Enc.) Ensemble Bayesian Neural Net GCN Ensemble VAE Ensemble 10 20 30 40 time in TPU hours 5.8 6.0 6.2 6.4 6.6 6.8 7.0 test error of best neural net Feedforward (Path Enc.) Ensemble Feedforward (Trunc. Path Enc.) Ensemble Feedforward (Adj. Enc.) Ensemble Bayesian Neural Net GCN Ensemble VAE Ensemble Figure 5.2: P erformance of neural predictors on NASBenc h-101: predictive ability (left), accuracy of uncertain ty estimates (middle), p erformance in NAS when combined with BO (right). initializations and training set orders. Then for any datap oin t, we can can compute the mean and standard deviation of these m predictions. Ensembles of neural netw orks, ev en of size three and fiv e, hav e b een shown in some cases to give more reliable uncertain ty estimates than other leading approac hes such as BNNs [ 28 , 3 , 5 , 51 , 73 ]. W e compare the uncertaint y estimate of a BNN with an ensemble of size fiv e for each of the neural predictors describ ed in the previous section. W e use the BOHAMIANN implemen tation for the BNN [ 53 ], and to ensure a fair comparison with the ensem bles, we train it for five times longer. The exp erimen tal setup is similar to the previous section, but we compute a standard measure of calibration: ro ot mean squared calibration error (RMSCE) on the test set [ 26 , 60 ]. See Figure 5.2 (middle). In tuitively , the RMSCE is low if a metho d yields a well-calibrated predictiv e estimate (i.e. predicted cov erage of interv als equals the observ ed cov erage). All ensemble-based predictors yielded b etter uncertain ty estimates than the BNN, consisten t with prior work. Note that RMSCE only measures the quality of uncertaint y estimates, agnostic to prediction accuracy . W e must therefore lo ok at prediction (Figure 5.2 left) and RMSCE (Figure 5.2 middle) together when ev aluating the neural predictors. Finally , we ev aluate the p erformance of each neural predictor within the full BO + neural predictor framew ork. W e use the approach describ ed in Section 4 , using indep endent Thompson sampling and m utation for acquisition optimization (describ ed in more detail in the next section). Eac h algorithm is giv en a budget of 47 TPU hours, or ab out 150 neural architecture ev aluations on NASBenc h-101. That is, there are 150 iterations of training a neural predictor and choosing a new architecture to ev aluate using the acquisition function. The algorithms output 10 architectures in eac h iteration of BO for b etter parallelization, as describ ed in the previous section. After each iteration, we return the test error of the arc hitecture with the b est v alidation error found so far. W e run 200 trials of eac h algorithm and av erage the results. This is the same exp erimen tal setup as in Figure 5.1 , as well as exp eriments later in this section and the next section. See Figure 5.2 (righ t). The t wo b est-p e rforming neural predictors are an ensem ble of GCNs, and an ensemble of feedforw ard neural netw orks with the path enco ding, with the latter having a sligh t edge. The feedforw ard netw ork is also desirable b ecause it requires less hyperparameter tuning than the GCN. Acquisition functions and optimization. No w we analyze the BO side of the framework, namely , the choice of acquisition function and acquisition optimization. W e consider four common acquisition functions that can b e computed using a mean and uncertain ty estimate for eac h input datap oin t: exp ected improv ement (EI) [ 38 ], probability of impro vemen t (PI) [ 27 ], upp er confidence 7 b ound (UCB) [ 54 ], and Thompson sampling (TS) [ 59 ]. W e also consider a v arian t of TS called indep enden t Thompson sampling. First we give the formal definitions of eac h acquisition function. Supp ose w e hav e trained an ensemble of M predictiv e mo dels, { f m } M m =1 , where f m : A → R . Let y min denote the low est v alidation error of an architecture discov ered so far. F ollowing previous w ork [ 39 ], we use the follo wing acquisition function estimates for an input architecture a ∈ A : φ EI ( a ) = E [ 1 [ f m ( a ) > y min ] ( y min − f m ( a ))] (5.1) = Z y min −∞ ( y min − y ) N ˆ f , ˆ σ 2 dy φ PI ( x ) = E [ 1 [ f m ( x ) > y min ]] (5.2) = Z y min −∞ N ˆ f , ˆ σ 2 dy φ UCB ( x ) = ˆ f − β ˆ σ (5.3) φ TS ( x ) = f ˜ m ( x ) , ˜ m ∼ Unif (1 , M ) (5.4) φ ITS ( x ) = ˜ f x ( x ) , ˜ f x ( x ) ∼ N ( ˆ f , ˆ σ 2 ) (5.5) In these acquisition function definitions, 1 ( x ) = 1 if x is true and 0 otherwise, and we are making a normal appro ximation for our mo del’s p osterior predictive density , where w e estimate parameters ˆ f = 1 M M X m =1 f m ( x ) , and ˆ σ = s P M m =1 ( f m ( x ) − ˆ f ) 2 M − 1 . In the UCB acquisition function exp eriments, we set the tradeoff parameter β = 0 . 5. W e tested eac h acquisition function within the BO + neural predictor framework, using mutation for acquisition optimization and the b est neural predictor from the previous section - an ensemble of feedforw ard netw orks with the path enco ding. The exp erimen tal setup is the same as in previous sections. See Figure 6.1 (left). W e see that the acquisition function do es not hav e as big an effect on p erformance as other comp onents, though ITS p erforms the b est ov erall. Note also that b oth TS and ITS ha ve adv an tages when running parallel exp eriments, since they are sto c hastic acquisition functions that can b e directly applied in the batc h BO setting [ 20 ]. Next, we test different acquisition optimization strategies. In each iteration of BO, our goal is to find the neural architecture from the search space whic h minimizes the acquisition function. Ev aluating the acquisition function for every neural arc hitecture in the searc h space is computationally infeasible. Instead, w e create a set of 100-1000 architectures (p oten tially in an iterativ e fashion) and c ho ose the arc hitecture with the v alue of the acquisition function in this set. The simplest strategy is to draw 1000 random architectures. How ever, it can b e b eneficial to generate a set of arc hitecture that are close in edit distance to arc hitectures in the training set, since the neural predictor is more likely to giv e accurate predictions to these arc hitectures. F urthermore, lo cal optimization metho ds suc h as mutation, ev olution, and lo cal search ha ve b een shown to b e effectiv e for acquisition optimization [ 2 , 21 , 68 ]. In “mutation”, we simply m utate the arc hitectures with the b est v alidation accuracy that we ha ve found so far by randomly changing one op eration or one edge. In lo cal search, we iteratively tak e the architectures with the curren t highest acquisition function v alue, and compute the acquisition function of all architectures in their neighborho o d. 8 Input Architectures Path Encodings Ensemble of feedforward networks Accuracy Predictions and Uncertainty Estimates 100 0 100 0 100 0 Figure 5.3: Diagram of the BANANAS neural predictor. In ev olution, we iteratively maintain a p opulation b y mutating the architectures with the highest acquisition function v alue and killing the architectures with the lo west v alues. W e give the full details of these metho ds in App endix D . The exp erimental setup is the same as in the previous sections. See Figure 6.1 (middle). W e see that mutation p erforms the b est, whic h indicates that it is b etter to consider architectures with edit distance closer to the set of already ev aluated arc hitectures. BANANAS: Ba y esian optimization with neural arc hitectures for NAS. Using the b est comp onen ts from the previous sections, we construct our full NAS algorithm, BANANAS, comp osed of an ensem ble of feedforward neural net works using the path enco ding, ITS, and a mutation acquisition function. See Algorithm 1 and Figure 5.3 . Note that in the previous sections, we conducted exp erimen ts on each comp onent individually while keeping all other comp onents fixed. In App endix D , we give further analysis v arying all comp onen ts at once, to ensure that BANANAS is indeed the optimal instantiation of this framework. F or the loss function in the neural predictors, w e use mean absolute p ercentage e rror (MAPE) b ecause it gives a higher weigh t to architectures with low er v alidation losses: L ( y pred , y true ) = 1 n n X i =1 y ( i ) pred − y LB y ( i ) true − y LB − 1 , (5.6) where y ( i ) pred and y ( i ) true are the predicted and true v alues of the v alidation error for architecture i , and y LB is a global lo wer b ound on the minimum true v alidation error. T o parallelize Algorithm 1 , in step iv. we simply choose the k arc hitectures with the smallest v alues of the acquisition function and ev aluate the architectures in parallel. 6 BANANAS Exp erimen ts In this section, we compare BANANAS to man y other p opular NAS algorithms on three search spaces. T o promote repro ducibility , w e discuss our adherence to the NAS research chec klist [ 33 ] in 9 Algorithm 1 BANANAS Input: Search space A , dataset D , parameters t 0 , T , M , c, x , acquisition function φ , function f ( a ) returning v alidation error of a after training. 1. Draw t 0 arc hitectures a 0 , . . . , a t 0 uniformly at random from A and train them on D . 2. F or t from t 0 to T , i. T rain an ensemble of neural predictors on { ( a 0 , f ( a 0 )) , . . . , ( a t , f ( a t )) } using the path enco ding to represen t each architecture. ii. Generate a set of c candidate architectures from A b y randomly m utating the x arc hitectures a from { a 0 , . . . , a t } that hav e the low est v alue of f ( a ). iii. F or eac h candidate architecture a , ev aluate the acquisition function φ ( a ). iv. Denote a t +1 as the candidate architecture with minimum φ ( a ), and ev aluate f ( a t +1 ). Output: a ∗ = argmin t =0 ,...,T f ( a t ). 5 10 15 20 25 30 35 40 45 time in TPU hours 5.8 5.9 6.0 6.1 6.2 6.3 6.4 6.5 6.6 test error of best neural net Ind. Thompson Sampling Expected Improvement Probability of Improvement Thompson Sampling Upper Confidence Bound 10 20 30 40 time in TPU hours 6.0 6.2 6.4 6.6 6.8 test error of best neural net Mutation Mutation+Random Random Local Search Evolution 10 20 30 40 time in TPU hours 5.8 6.0 6.2 6.4 6.6 6.8 7.0 7.2 test error of best neural net BANANAS Reg. Evolution Local Search BO w. GP NASBOT Random AlphaX BOHAMIANN REINFORCE GCN Pred. BONAS DNGO BOHB TPE BONAS DNGO BOHB TPE Figure 6.1: Performance of different acquisition functions (left). Performance of different acquisition optimization strategies (middle). Performance of BANANAS compared to other NAS algorithms (righ t). See App endix D for the same results in a table. App endix E . In particular, we release our co de, we use a tabular NAS dataset, and we run many trials of each algorithm. W e run exp eriments on NASBenc h-101 described in the previous section, as well as NASBenc h-201 and the DAR TS search space. The NASBench-201 dataset [ 71 ] consists of 15625 neural arc hitectures with precomputed v alidation and test accuracies for 200 ep o c hs on CIF AR-10, CIF AR-100, and ImageNet-16-120. The search space consists of a complete directed acyclic graph on 4 no des, and eac h edge can tak e on five differen t op erations. The DAR TS search space [ 35 ] is size 10 18 . It consists of tw o cells: a conv olutional cell and a reduction cell. Each cell has four no des that hav e t wo incoming edges which take on one of eight op erations. P erformance on NASBench search spaces. W e compare BANANAS to the most popular NAS algorithms from a v ariety of paradigms: random searc h [ 30 ], regularized evolution [ 44 ], BOHB [ 11 ], NASBOT [ 21 ], lo cal searc h [ 66 ], TPE [ 4 ], BOHAMIANN [ 53 ], BONAS [ 48 ], REINF ORCE [ 67 ], GP-based BO [ 50 ], AlphaX [ 62 ], GCN Predictor [ 64 ], and DNGO [ 52 ]. As muc h as p ossible, we use the co de directly from the op en-source rep ositories, without changing the h yp erparameters (but with a few exceptions). F or a description of each algorithm and details of the implemen tations we used, see App endix D . The exp erimen tal setup is the same as in the previous section. F or results on NASBenc h-101, 10 T able 1: Comparison of NAS algorithms on the DAR TS searc h space. The run time unit is total GPU-da ys on a T esla V100. NAS Algorithm Source Avg. T est error Runtime Metho d Random searc h [ 35 ] 3 . 29 4 Random Lo cal search [ 66 ] 3 . 49 11 . 8 Lo cal search D AR TS [ 35 ] 2 . 76 5 Gradien t-based ASHA [ 30 ] 3 . 03 9 Successiv e halving Random searc h WS [ 30 ] 2 . 85 9 . 7 Random D AR TS Ours 2 . 68 5 Gradien t-based ASHA Ours 3 . 08 9 Successiv e halving BANANAS Ours 2.64 11 . 8 BO + neural predictor see Figure 6.1 (righ t). The top three algorithms in order, are BANANAS, lo cal search, and BONAS. In App endix D , we also sho w that BANANAS achiev es strong p erformance on the three datasets in NASBenc h-201. P erformance on the D AR TS search space. W e test BANANAS on the search space from D AR TS. Since the DAR TS search space is not a tabular dataset, w e cannot fairly compare to other metho ds which use substantially different training and testing pip elines [ 33 ]. W e use a common test ev aluation pip eline which is to train for 600 ep o chs with cutout and auxiliary tow er [ 35 , 30 , 70 ], where the state of the art is around 2.6% on CIF AR-10. Other pap ers use different test ev aluation settings (e.g., training for man y more ep o chs) to ac hieve lo wer error, but they cannot be fairly compared to other algorithms. In our exp eriments, BANANAS is given a budget of 100 ev aluations. In each ev aluation, the c hosen architecture is trained for 50 ep o c hs and the a verage v alidation error of the last 5 ep o chs is recorded. T o ensure a fair comparison by controlling all hyperparameter settings and hardware, we re-trained the arc hitectures from prior work when they were av ailable. In this case, we rep ort the mean test error o ver five random seeds of the b est architecture found for each metho d. W e compare BANANAS to DAR TS [ 35 ], random search [ 35 ], lo cal search [ 66 ], and ASHA [ 30 ]. See T able 1 . Note that a new surrogate b enchmark on the D AR TS searc h space [ 49 ], called NASBenc h-301 w as recen tly introduced, allo wing for fair and computationally feasible exp eriments. Initial exp eriments sho wed [ 49 ] that BANANAS is comp etitive with nine other p opular NAS algorithms, including D AR TS [ 35 ] and t wo improv emen ts of DAR TS [ 69 , 8 ]. 7 Conclusion and F uture W ork W e conduct an analysis of the BO + neural predictor framework, which has recently emerged as a high-p erformance framework for NAS. W e test sev eral metho ds for each main comp onent: the enco ding, neural predictor, calibration metho d, acquisition function, and acquisition optimization strategy . W e also prop ose a no vel path-based enco ding scheme, which impro ves the p erformance of neural predictors. W e use all of this analysis to develop BANANAS, an instan tiation of the BO + neural predictor framework which achiev es state-of-the-art p erformance on p opular NAS search spaces. Interesting follow-up ideas are to develop multi-fidelit y or successiv e halving v ersions of 11 BANANAS. Incorp orating these approaches with BANANAS could result in a significant decrease in the runtime without sacrificing accuracy . Ac kno wledgmen ts W e thank Jeff Schneider, Na veen Sundar Go vindara julu, and Liam Li for their help with this pro ject. 12 References [1] Bo wen Bak er, Otkrist Gupta, Ramesh Rask ar, and Nikhil Naik. Accelerating neural arc hitecture searc h using p erformance prediction. arXiv pr eprint arXiv:1705.10823 , 2017. [2] Maximilian Balandat, Brian Karrer, Daniel R Jiang, Sam uel Daulton, Benjamin Letham, Andrew Gordon Wilson, and Eytan Bakshy . Botorc h: Programmable bay esian optimization in p ytorch. arXiv pr eprint arXiv:1910.06403 , 2019. [3] William H Beluch, Tim Genewein, Andreas N ¨ urn b erger, and Jan M K¨ ohler. The p ow er of ensem bles for activ e learning in image classification. In Pr o c e e dings of the IEEE Confer enc e on Computer Vision and Pattern R e c o gnition , 2018. [4] James S Bergstra, R´ emi Bardenet, Y osh ua Bengio, and Bal´ azs K ´ egl. Algorithms for hyper- parameter optimization. In Pr o c e e dings of the Annual Confer enc e on Neur al Information Pr o c essing Systems (NIPS) , 2011. [5] Y oungwon Choi, Y ongchan Kwon, Hanb yul Lee, Beom Jo on Kim, Myunghee Cho Paik, and Jo ong-Ho W on. Ensem ble of deep conv olutional neural netw orks for prognosis of ischemic strok e. In International Workshop on Br ainlesion: Glioma, Multiple Scler osis, Str oke and T r aumatic Br ain Injuries , 2016. [6] Bo yang Deng, Junjie Y an, and Dahua Lin. P eephole: Predicting netw ork p erformance b efore training. arXiv pr eprint arXiv:1712.03351 , 2017. [7] T obias Domhan, Jost T obias Springenberg, and F rank Hutter. Sp eeding up automatic hy- p erparameter optimization of deep neural net w orks by extrap olation of learning curves. In Twenty-F ourth International Joint Confer enc e on Artificial Intel ligenc e , 2015. [8] Xuan yi Dong and Yi Y ang. Searching for a robust neural arc hitecture in four gpu hours. In Pr o c e e dings of the IEEE Confer enc e on c omputer vision and p attern r e c o gnition , pages 1761–1770, 2019. [9] Xuan yi Dong and Yi Y ang. Nas-bench-201: Extending the scop e of repro ducible neural arc hitecture searc h. In Pr o c e e dings of the International Confer enc e on L e arning R epr esentations (ICLR) , 2020. [10] Thomas Elsken, Jan Hendrik Metzen, and F rank Hutter. Neural architecture search: A survey . arXiv pr eprint arXiv:1808.05377 , 2018. [11] Stefan F alkner, Aaron Klein, and F rank Hutter. Bohb: Robust and efficient hyperparameter optimization at scale. In Pr o c e e dings of the International Confer enc e on Machine L e arning (ICML) , 2018. [12] Dario Floreano, Peter D ¨ urr, and Claudio Mattiussi. Neuro evolution: from architectures to learning. Evolutionary intel ligenc e , 1(1):47–62, 2008. [13] P eter I F razier. A tutorial on bay esian optimization. arXiv pr eprint arXiv:1807.02811 , 2018. 13 [14] Daniel Golovin, Benjamin Solnik, Subho deep Moitra, Greg Ko chanski, John Karro, and D Sculley . Go ogle vizier: A service for black-box optimization. In Pr o c e e dings of the 23r d A CM SIGKDD International Confer enc e on Know le dge Disc overy and Data Mining , pages 1487–1495. A CM, 2017. [15] Ja vier Gonz´ alez, Zhenw en Dai, Philipp Hennig, and Neil La wrence. Batc h bay esian optimization via lo cal p enalization. In Pr o c e e dings of the International Confer enc e on A rtificial Intel ligenc e and Statistics (AIST A TS) , 2016. [16] Bren t Hec ht, Lauren Wilcox, Jeffrey P Bigham, Johannes Sc h¨ oning, Ehsan Ho que, Jason Ernst, Y onatan Bisk, Luigi De Russis, Lana Y arosh, Bushra Anjum, Danish Con tractor, and Cathy W u. It’s time to do something: Mitigating the negative impacts of computing through a change to the p eer review pro cess. ACM F utur e of Computing Blo g , 2018. [17] Gao Huang, Zhuang Liu, Laurens V an Der Maaten, and Kilian Q W einberger. Densely connected con volutional netw orks. In Pr o c e e dings of the IEEE Confer enc e on Computer Vision and Pattern R e c o gnition , 2017. [18] Ro xana Istrate, Florian Sc heidegger, Giov anni Mariani, Dimitrios Nikolopoulos, Costas Bek as, and A Cristiano I Malossi. T apas: T rain-less accuracy predictor for architecture search. In Pr o c e e dings of the AAAI Confer enc e on Artificial Intel ligenc e , 2019. [19] Haifeng Jin, Qingquan Song, and Xia Hu. Auto-keras: Efficient neural architecture searc h with net work morphism. arXiv pr eprint arXiv:1806.10282 , 2018. [20] Kirthev asan Kandasamy , Akshay Krishnamurth y , Jeff Sc hneider, and Barnab´ as P´ oczos. P ar- allelised bay esian optimisation via thompson sampling. In Pr o c e e dings of the International Confer enc e on Artificial Intel ligenc e and Statistics (AIST A TS) , 2018. [21] Kirthev asan Kandasamy , Willie Neisw anger, Jeff Sc hneider, Barnabas Poczos, and Eric P Xing. Neural arc hitecture search with ba yesian optimisation and optimal transp ort. In A dvanc es in Neur al Information Pr o c essing Systems , pages 2016–2025, 2018. [22] Hiroaki Kitano. Designing neural net works using genetic algorithms with graph generation system. Complex systems , 4(4):461–476, 1990. [23] Aaron Klein, Stefan F alkner, Jost T obias Springenberg, and F rank Hutter. Learning curv e prediction with bay esian neural netw orks. ICLR 2017 , 2017. [24] Chepuri Shri Krishna, Ashish Gupta, Himanshu Rai, and Sw arnim Nara yan. Neural arc hitecture searc h with reinforce and masked attention autoregressive density estimators. arXiv pr eprint arXiv:2006.00939 , 2020. [25] Alex Krizhevsky , Ilya Sutsk ever, and Geoffrey E Hinton. Imagenet classification with deep con volutional neural net works. In Pr o c e e dings of the Annual Confer enc e on Neur al Information Pr o c essing Systems (NIPS) , 2012. [26] V olo dymyr Kuleshov, Nathan F enner, and Stefano Ermon. Accurate uncertainties for deep learning using calibrated regression. arXiv pr eprint arXiv:1807.00263 , 2018. 14 [27] Harold J Kushner. A new metho d of lo cating the maxim um p oint of an arbitrary multipeak curv e in the presence of noise. Journal of Basic Engine ering , 86(1):97–106, 1964. [28] Bala ji Lakshminaray anan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictiv e uncertaint y estimation using deep ensem bles. In A dvanc es in Neur al Information Pr o c essing Systems , pages 6402–6413, 2017. [29] Kevin Alexander Laub e and Andreas Zell. Prune and replace nas. arXiv pr eprint arXiv:1906.07528 , 2019. [30] Liam Li and Ameet T alwalk ar. Random searc h and repro ducibility for neural architecture searc h. arXiv pr eprint arXiv:1902.07638 , 2019. [31] Lisha Li, Kevin Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet T alwalk ar. Hy- p erband: A nov el bandit-based approac h to h yp erparameter optimization. arXiv pr eprint arXiv:1603.06560 , 2016. [32] Han wen Liang, Shifeng Zhang, Jiacheng Sun, Xingqiu He, W eiran Huang, Kechen Zh uang, and Zhenguo Li. Darts+: Impro ved differentiable architecture searc h with early stopping. arXiv pr eprint arXiv:1909.06035 , 2019. [33] Marius Lindauer and F rank Hutter. Best practices for scientific research on neural arc hitecture searc h. arXiv pr eprint arXiv:1909.02453 , 2019. [34] Chenxi Liu, Barret Zoph, Maxim Neumann, Jonathon Shlens, W ei Hua, Li-Jia Li, Li F ei-F ei, Alan Y uille, Jonathan Huang, and Kevin Murph y . Progressive neural architecture searc h. In Pr o c e e dings of the Eur op e an Confer enc e on Computer Vision (ECCV) , pages 19–34, 2018. [35] Hanxiao Liu, Karen Simony an, and Yiming Y ang. Darts: Differentiable architecture searc h. arXiv pr eprint arXiv:1806.09055 , 2018. [36] Lizheng Ma, Jiaxu Cui, and Bo Y ang. Deep neural arc hitecture search with deep graph bay esian optimization. In 2019 IEEE/WIC/A CM International Confer enc e on Web Intel ligenc e (WI) , pages 500–507. IEEE, 2019. [37] Krzysztof Maziarz, Andrey Khorlin, Quen tin de Laroussilhe, and Andrea Gesmundo. Ev olutionary-neural hybrid agen ts for architecture searc h. arXiv pr eprint arXiv:1811.09828 , 2018. [38] Jonas Mo ˇ ckus. On bay esian metho ds for seeking the extrem um. In Optimization T e chniques IFIP T e chnic al Confer enc e , pages 400–404. Springer, 1975. [39] Willie Neisw anger, Kirthev asan Kandasam y , Barnabas P o czos, Jeff Sc hneider, and Eric Xing. Prob o: a framework for using probabilistic programming in bay esian optimization. arXiv pr eprint arXiv:1901.11515 , 2019. [40] V u Nguyen, T am Le, Makoto Y amada, and Michael A Osb orne. Optimal transp ort kernels for sequen tial and parallel neural arc hitecture search. arXiv pr eprint arXiv:2006.07593 , 2020. [41] Ji ˇ r ´ ı O ˇ cen´ a ˇ sek and Josef Sch warz. The parallel bay esian optimization algorithm. In The State of the A rt in Computational Intel ligenc e . Springer, 2000. 15 [42] Hieu Pham, Melo dy Y Guan, Barret Zoph, Quo c V Le, and Jeff Dean. Efficien t neural arc hitecture search via parameter sharing. arXiv pr eprint arXiv:1802.03268 , 2018. [43] Carl Edw ard Rasm ussen. Gaussian pro cesses in machine learning. In Summer Scho ol on Machine L e arning , pages 63–71. Springer, 2003. [44] Esteban Real, Alok Aggarwal, Y anping Huang, and Quo c V Le. Regularized ev olution for image classifier architecture search. In Pr o c e e dings of the aaai c onfer enc e on artificial intel ligenc e , v olume 33, pages 4780–4789, 2019. [45] Binxin Ru, Xingc hen W an, Xiao wen Dong, and Michael Osb orne. Neural architecture search using bay esian optimisation with weisfeiler-lehman kernel. arXiv pr eprint arXiv:2006.07556 , 2020. [46] Christian Sciuto, Kaic heng Y u, Martin Jaggi, Claudiu Musat, and Mathieu Salzmann. Ev aluat- ing the search phase of neural architecture search. arXiv pr eprint arXiv:1902.08142 , 2019. [47] Sy ed Asif Raza Shah, W enji W u, Qiming Lu, Liang Zhang, Sa jith Sasidharan, Phil DeMar, Chin Guok, John Macauley , Eric P ouyoul, Jin Kim, et al. Amo ebanet: An sdn-enabled net work service for big data science. Journal of Network and Computer Applic ations , 119:70–82, 2018. [48] Han Shi, Renjie Pi, Hang Xu, Zhenguo Li, James T Kwok, and T ong Zhang. Multi-ob jectiv e neural architecture searc h via predictive net work p erformance optimization. arXiv pr eprint arXiv:1911.09336 , 2019. [49] Julien Siems, Lucas Zimmer, Arb er Zela, Jovita Luk asik, Margret Keup er, and F rank Hutter. Nas-b enc h-301 and the case for surrogate b enc hmarks for neural architecture searc h. arXiv pr eprint arXiv:2008.09777 , 2020. [50] Jasp er Sno ek, Hugo Laro c helle, and Ryan P Adams. Practical bay esian optimization of mac hine learning algorithms. In Pr o c e e dings of the Annual Confer enc e on Neur al Information Pr o c essing Systems (NIPS) , 2012. [51] Jasp er Sno ek, Y aniv Ov adia, Emily F ertig, Bala ji Lakshminaray anan, Sebastian No wozin, D Sculley , Josh ua Dillon, Jie Ren, and Zachary Nado. Can you trust your mo del’s uncertaint y? ev aluating predictive uncertaint y under dataset shift. In Pr o c e e dings of the Annual Confer enc e on Neur al Information Pr o c essing Systems (NIPS) , 2019. [52] Jasp er Snoek, Oren Ripp el, Kevin Sw ersky , Ryan Kiros, Nadath ur Satish, Naray anan Sundaram, Mostofa P atw ary , Mr Prabhat, and Ryan Adams. Scalable bay esian optimization using deep neural net works. In International c onfer enc e on machine le arning , pages 2171–2180, 2015. [53] Jost T obias Springenberg, Aaron Klein, Stefan F alkner, and F rank Hutter. Bay esian optimization with robust bay esian neural netw orks. In A dvanc es in Neur al Information Pr o c essing Systems , pages 4134–4142, 2016. [54] Niranjan Sriniv as, Andreas Krause, Sham M Kak ade, and Matthias Seeger. Gaussian pro- cess optimization in the bandit setting: No regret and exp erimen tal design. arXiv pr eprint arXiv:0912.3995 , 2009. 16 [55] P antelimon Stanica. Go o d lo wer and upp er b ounds on binomial co efficients. Journal of Ine qualities in Pur e and Applie d Mathematics , 2001. [56] Kenneth O Stanley and Risto Miikkulainen. Ev olving neural net works through augmenting top ologies. Evolutionary c omputation , 10(2):99–127, 2002. [57] Christian Szegedy , Sergey Ioffe, Vincent V anhouck e, and Alexander A Alemi. Inception-v4, inception-resnet and the impact of residual connections on learning. In Thirty-First AAAI Confer enc e on Artificial Intel ligenc e , 2017. [58] Mingxing T an and Quo c V Le. Efficien tnet: Rethinking mo del scaling for con volutional neural net works. arXiv pr eprint arXiv:1905.11946 , 2019. [59] William R Thompson. On the likelihoo d that one unknown probability exceeds another in view of the evidence of tw o samples. Biometrika , 25(3/4):285–294, 1933. [60] Kevin T ran, Willie Neiswanger, Junw o ong Y o on, Qingyang Zhang, Eric Xing, and Zac hary W Ulissi. Metho ds for comparing uncertain ty quantifications for material prop ert y predictions. Machine L e arning: Scienc e and T e chnolo gy , 1(2):025006, 2020. [61] Linnan W ang, Saining Xie, T eng Li, Ro drigo F onseca, and Y uandong Tian. Sample-efficien t neural arc hitecture search by learning action space. arXiv pr eprint arXiv:1906.06832 , 2019. [62] Linnan W ang, Yiyang Zhao, Y uu Jinnai, and Ro drigo F onseca. Alphax: exploring neu- ral arc hitectures with deep neural net works and monte carlo tree searc h. arXiv pr eprint arXiv:1805.07440 , 2018. [63] Chen W ei, Chuang Niu, Yiping T ang, and Jimin Liang. Np enas: Neural predictor guided ev olution for neural architecture searc h. arXiv pr eprint arXiv:2003.12857 , 2020. [64] W ei W en, Hanxiao Liu, Hai Li, Yiran Chen, Gabriel Bender, and Pieter-Jan Kindermans. Neural predictor for neural architecture search. arXiv pr eprint arXiv:1912.00848 , 2019. [65] Colin White, Willie Neiswanger, Sam Nolen, and Y ash Sa v ani. A study on enco dings for neural arc hitecture searc h. In Pr o c e e dings of the Annual Confer enc e on Neur al Information Pr o c essing Systems (NIPS) , 2020. [66] Colin White, Sam Nolen, and Y ash Sav ani. Lo cal search is state of the art for nas b enc hmarks. arXiv pr eprint arXiv:2005.02960 , 2020. [67] Ronald J Williams. Simple statistical gradien t-following algorithms for connectionist reinforce- men t learning. Machine le arning , pages 229–256, 1992. [68] James Wilson, F rank Hutter, and Marc Deisenroth. Maximizing acquisition functions for ba yesian optimization. In A dvanc es in Neur al Information Pr o c essing Systems , pages 9884– 9895, 2018. [69] Y uhui Xu, Lingxi Xie, Xiaop eng Zhang, Xin Chen, Guo-Jun Qi, Qi Tian, and Hongk ai Xiong. Pc-darts: Partial channel connections for memory-efficien t arc hitecture searc h. In International Confer enc e on L e arning R epr esentations , 2019. 17 [70] Shen Y an, Y u Zheng, W ei Ao, Xiao Zeng, and Mi Zhang. Do es unsup ervised architecture represen tation learning help neural arc hitecture search? arXiv pr eprint arXiv:2006.06936 , 2020. [71] An toine Y ang, Pedro M Esp eran¸ ca, and F abio M Carlucci. Nas ev aluation is frustratingly hard. In Pr o c e e dings of the International Confer enc e on L e arning R epr esentations (ICLR) , 2020. [72] Chris Ying, Aaron Klein, Esteban Real, Eric Christiansen, Kevin Murph y , and F rank Hutter. Nas-b ench-101: T ow ards repro ducible neural architecture searc h. arXiv pr eprint arXiv:1902.09635 , 2019. [73] Shehery ar Zaidi, Arb er Zela, Thomas Elsk en, Chris Holmes, F rank Hutter, and Y ee Wh ye T eh. Neural ensem ble search for p erformant and calibrated predictions. arXiv pr eprint arXiv:2006.08573 , 2020. [74] Chris Zhang, Mengye Ren, and Raquel Urtasun. Graph hypernetw orks for neural arc hitecture searc h. In Pr o c e e dings of the International Confer enc e on L e arning R epr esentations (ICLR) , 2018. [75] Muhan Zhang, Shali Jiang, Zhic heng Cui, Roman Garnett, and Yixin Chen. D-v ae: A v ariational auto enco der for directed acyclic graphs. In Pr o c e e dings of the Annual Confer enc e on Neur al Information Pr o c essing Systems (NIPS) , 2019. [76] Y uge Zhang. Neural predictor for neural architecture search. GitHub r ep ository ultmas- ter/neur alpr e dictor.pytor ch , 2020. [77] Hongp eng Zhou, Minghao Y ang, Jun W ang, and W ei Pan. Bay esnas: A ba yesian approach for neural arc hitecture search. arXiv pr eprint arXiv:1905.04919 , 2019. [78] Jie Zhou, Ganqu Cui, Zhengyan Zhang, Cheng Y ang, Zhiyuan Liu, and Maosong Sun. Graph neural net works: A review of metho ds and applications. arXiv pr eprint arXiv:1812.08434 , 2018. [79] Barret Zoph and Quo c V. Le. Neural arc hitecture search with reinforcemen t learning. In Pr o c e e dings of the International Confer enc e on L e arning R epr esentations (ICLR) , 2017. 18 A Related W ork Con tinued Ba y esian optimization. Ba yesian optimization is a leading tec hnique for zeroth order optimiza- tion when function queries are exp ensive [ 43 , 13 ], and it has seen great success in hyperparameter optimization for deep learning [ 43 , 14 , 31 ]. The ma jorit y of Ba yesian optimization literature has fo cused on Euclidean or categorical input domains, and has used a GP mo del [ 43 , 14 , 13 , 50 ]. There are tec hniques for parallelizing Ba yesian optimization [ 15 , 20 , 41 ]. There is also prior w ork on using neural netw ork mo dels in Bay esian optimization for h yp er- parameter optimization [ 52 , 53 ]. The goal of these pap ers is to improv e the efficiency of Gaussian Pro cess-based Bay esian optimization from cubic to linear time, not to develop a different t yp e of prediction model in order to improv e the p erformance of BO with resp ect to the n umber of iterations. In our w ork, we presen t tec hniques whic h deviate from Gaussian Pro cess-based Bay esian optimization and see a p erformance b o ost with resp ect to the n umber of iterations. Neural architecture search. Neural architecture searc h has been studied since at least the 1990s [ 12 , 22 , 56 ], but the field w as revitalized in 2017 [ 79 ]. Some of the most p opular tec hniques for NAS include evolutionary algorithms [ 47 , 37 ], reinforcement learning [ 79 , 42 , 34 , 58 , 61 ], Bay esian optimization [ 21 , 19 , 77 ], gradient descent [ 35 , 32 , 29 ], tree search [ 62 , 61 ], and neural predictors [ 48 , 64 ]. F or a survey on NAS, see [ 10 ]. Recen t pap ers hav e called for fair and repro ducible exp eriments [ 30 , 72 ]. In this vein, the NASBenc h-101 [ 72 ], -201 [ 9 ], and -301 [ 49 ] datasets were created, which contain tens of thousands of pretrained neural architectures. Initial BO approaches for NAS defined a distance function b et ween architectures [ 21 , 19 ]. A few recen t pap ers hav e used Bay esian optimization with a graph neural netw ork as a predictor [ 36 , 48 ], ho wev er, they do not conduct an ablation study of all comp onents of the framework. In this work, w e do not claim to inv en t the BO + neural predictor framework, how ever, w e give the most in-depth analysis that we are a ware of, which w e use to design a high-performance instan tiation of this framew ork. Predicting neural net w ork accuracy . There are several approac hes for predicting the v alidation accuracy of neural netw orks, suc h as a lay er-wise enco ding of neural netw orks with an LSTM algorithm [ 6 ], and a lay er-wise enco ding and dataset features to predict the accuracy for neural net work and dataset pairs [ 18 ]. There is also w ork in predicting the learning curve of neural net works for h yp erparameter optimization [ 23 , 7 ] or NAS [ 1 ] using Bay esian tec hniques. None of these metho ds ha ve predicted the accuracy of neural netw orks drawn from a cell-based D AG searc h space such as NASBench or the DAR TS search space. Another recen t work uses a h yp ernetw ork for neural net work prediction in NAS [ 74 ]. Other recent works for predicting neural netw ork accuracy include AlphaX [ 62 ], and three pap ers which use GCN’s to predict neural netw ork accuracy [ 36 , 48 , 64 ]. Ensem bling of neural net works is a p opular approach for uncertaint y estimates, shown in man y settings to b e more effective than all other metho ds suc h as Bay esian neural netw orks even for an ensem ble of size five [ 28 , 3 , 5 , 51 ]. Subsequen t w ork. Since its release, several pap ers hav e indep endently shown that BANANAS is a comp etitiv e algorithm for NAS [ 24 , 49 , 40 , 45 , 63 ]. F or example, one pap er sho ws that BANANAS outp erforms other algorithms on NASBenc h-101 when giv en a budget of 3200 ev aluations [ 24 ], and 19 one pap er shows that BANANAS outp erforms man y p opular NAS algorithms on NASBench-301 [ 49 ]. Finally , a recent pap er conducted a study on several enco dings used for NAS [ 65 ], concluding that neural predictors perform w ell with the path enco ding, and also impro ved up on the theoretical results presen ted in Section 5 . B Preliminaries Con tin ued W e give background information on three key ingredien ts of NAS algorithms. Searc h space. Before deplo ying a NAS algorithm, we must define the space of neural netw orks that the algorithm can search through. Perhaps the most common type of search space for NAS is a c el l-b ase d se ar ch sp ac e [ 79 , 42 , 35 , 30 , 46 , 72 ]. A c el l consists of a relatively small section of a neural net work, usually 6-12 no des forming a directed acyclic graph (D AG). A neural arc hitecture is then built b y rep eatedly stac king one or tw o different cells on top of eac h other sequentially , p ossibly separated b y sp ecialized lay ers. The la yout of cells and sp ecialized la yers is called a hyp er-ar chite ctur e , and this is fixed, while the NAS algorithm searc hes for the b est cells. The search space ov er cells consists of all p ossible D AGs of a certain size, where each no de can b e one of several op erations such as 1 × 1 conv olution, 3 × 3 conv olution, or 3 × 3 max p o oling. It is also common to set a restriction on the n umber of total edges or the in-degree of each no de [ 72 , 35 ]. In this work, w e fo cus on NAS o ver conv olutional cell-based search spaces, though our metho d can b e applied more broadly . Searc h strategy . The searc h strategy is the optimization metho d that the algorithm uses to find the optimal or near-optimal neural architecture from the searc h space. There are man y v aried searc h strategies, such as Bay esian optimization, ev olutionary search, reinforcement learning, and gradien t descent. In Section 5 , we introduced the searc h strategy we study in this pap er: Ba yesian optimization with a neural predictor. Ev aluation metho d. Man y types of NAS algorithms consist of an iterative framework in whic h the algorithm chooses a neural netw ork to train, computes its v alidation error, and uses this result to guide the choice of neural netw ork in the next iteration. The simplest instantiation of this approac h is to train each neural net work in a fixed wa y , i.e., the algorithm has blac k-b ox access to a function that trains a neural net work for x ep o chs and then returns the v alidation error. Algorithms with black-box ev aluation metho ds can b e compared b y returning the architecture with the lo west v alidation error after a certain n umber of queries to the black-box function. There are also multi-fidelit y metho ds, for example, when a NAS algorithm chooses the num b er of training ep o chs in addition to the architecture. C P ath Enco ding Theory In this section, we give the full details of Theorem 5.1 from Section 5 , whic h shows that with high probabilit y , the path enco ding can b e truncated significan tly without losing information. Recall that the size of the path enco ding is equal to the n umber of unique paths, whic h is P i =0 n r i , where n is the num b er of nodes in the cell, and r is the num b er of operations to c ho ose from 20 at eac h no de. This is at least r n . By con trast, the adjacency matrix enco ding scales quadratically in n . Ho wev er, the v ast ma jority of the paths rarely show up in any neural arc hitecture throughout a full run of a NAS algorithm. This is b ecause many NAS algorithms can only sample arc hitectures from a random pro cedure or mutate architectures drawn from the random pro cedure. Now we will giv e the full details of Theorem 5.1 , showing that the v ast ma jorit y of paths hav e a very low probabilit y of o ccurring in a cell outputted from random spec() , a p opular random pro cedure used b y man y NAS algorithms [ 72 ], including BANANAS. Our results sho w that by simply truncating the least-lik ely paths, the path enco ding scales line arly in the size of the cell, with an arbitrarily small amoun t of information loss. W e back this up with exp erimen tal evidence in Figures 5.1 and D.4 , and T able 3 . W e start by defining random spec() , the pro cedure to output a random neural architecture. Definition C.1. Giv en integers n, r , and k < n ( n − 1) / 2 , a random graph G n,k,r is generated as follo ws: (1) Denote n no des by 1 to n . (2) Lab el each no de randomly with one of r op erations. (3) F or all i < j , add edge ( i, j ) with probability 2 k n ( n − 1) . (4) If there is no path from no des 1 to n , goto (1) . The probabilit y v alue in step (3) is chosen so that the exp ected num b er of edges after this step is exactly k . Recall that we use ‘path’ to mean a path from no de 1 to no de n . W e restate the theorem formally . Denote P as the set of all p ossible paths from no de 1 to no de n that could o ccur in G n,k,r . Theorem 5.1 (formal). Given inte gers r , c > 0 , ther e exists N such that for al l n > N , ther e exists a set of n p aths P 0 ⊆ P such that P ( ∃ p ∈ G n,n + c,r ∩ P \ P 0 ) ≤ 1 n 2 . This theorem says that when k = n + c , and when n is large enough compared to c and r , then w e can truncate the path enco ding to a set P 0 of size n , b ecause the probabilit y that random spec() outputs a graph G n,k,r with a path outside of P 0 is v ery small. Note that there are tw o cav eats to this theorem. First, BANANAS ma y mutate architectures dra wn from Definition C.1 , and Theorem 5.1 do es not show the probabilit y of paths from mutated arc hitectures is small. Ho wev er, our experiments (Figures 5.1 and D.4 ) giv e evidence that the m utated architectures do not change the distribution of paths to o m uch. Second, the most common paths in Definition C.1 are not necessarily the paths whose existence or non-existence giv e the most entrop y in predicting the v alidation accuracy of a neural arc hitecture. Again, while this is tec hnically true, our exp eriments back up Theorem 5.1 as a reasonable argumen t that truncating the path enco ding do es not sacrifice p erformance. Denote by G 0 n,k,r the random graph outputted b y Definiton C.1 without step (4). In other w ords, G 0 n,k,r is a random graph that could ha ve no path from no de 1 to no de n . Since there are n ( n − 1) 2 pairs ( i, j ) suc h that i < j , the exp ected num b er of edges of G 0 n,k,r is k . F or reference, in the NASBenc h-101 dataset, there are n = 7 no des and r = 3 op erations, and the maximum n umber of edges is 9. W e choose P 0 as the n shortest paths from no de 1 to no de n . The argument for Theorem 5.1 relies on a simple concept: the probabilit y that G n,k,r con tains a long path (length > log r n ) is m uch lo wer than the probability that it contains a short path. F or example, the probabilit y that G 0 n,k,r 21 con tains a path of length n − 1 is v ery low, b ecause there are Θ( n 2 ) p oten tial edges but the exp ected n umber of edges is n + O (1). W e start by upp er b ounding the length of the n shortest paths. Lemma C.2. Given a gr aph with n no des and r no de lab els, ther e ar e fewer than n p aths of length less than or e qual to log r n − 1 . Pr o of. The num b er of paths of length ` is r ` , since there are r c hoices of lab els for each no de. Then 1 + r + · · · + r d log r n e− 1 = r d log r n e − 1 r − 1 = n − 1 r − 1 < n. T o contin ue our argument, we will need the follo wing well-kno wn b ounds on binomial co efficients, e.g. [ 55 ]. Theorem C.3. Given 0 ≤ ` ≤ n , we have n ` ` ≤ n ` ≤ en ` ` . No w w e define a n,k,` as the exp ected n umber of paths from no de 1 to no de n of length ` in G 0 n,k,r . F ormally , a n,k,` = E [ | p ∈ P | | | p | = ` ] . The following lemma, which is the driving force b ehind Theorem 5.1 , sho ws that the v alue of a n,k,` for small ` is muc h larger than the v alue of a n,k,` for large ` . Lemma C.4. Given inte gers r, c > 0 , then ther e exists n such that for k = n + c , we have n − 1 X ` =log r n a n,k,` < 1 n 3 and a n,k, 1 > 1 n . Pr o of. W e hav e that a n,k,` = n − 2 ` − 1 2 k n ( n − 1) ` . This is because on a path from no de 1 to n of length ` , there are n − 2 ` − 1 c hoices of in termediate no des from 1 to n . Once the no des are chosen, we need all ` edges b etw een the no des to exist, and eac h edge exists indep enden tly with probabilit y 2 n ( n − 1) · k . When ` = 1, we hav e n − 2 ` − 1 = 1. Therefore, a n,k, 1 = 2 k n ( n − 1) ≥ 1 n , for sufficien tly large n . Now we will derive an upp er b ound for a n,k,` using Theorem C.3 . 22 a n,k,` = n − 2 ` − 1 2 k n ( n − 1) ` ≤ e ( n − 2) ` − 1 ` − 1 2 k n ( n − 1) ` ≤ 2 k n ( n − 1) 2 ek ( n − 2) ( ` − 1) n ( n − 1) ` − 1 ≤ 4 n 4 e ` − 1 ` − 1 The last inequality is true b ecause k / ( n − 1) = ( n + c ) / ( n − 1) ≤ 2 for sufficiently large n . No w we ha ve n − 1 X ` =log r n a n,k,` ≤ n − 1 X ` =log r n 4 n 4 e ` − 1 ` − 1 ≤ n − 1 X ` =log r n 4 e ` − 1 ` − 1 ≤ n − 1 X ` =log r n 4 e log r n ` − 1 ≤ 4 e log r n log r n n − log r n X ` =0 4 e log r n ` ≤ ( e ) 3 log r n 1 log r n log r n · 2 (C.1) ≤ 2 ( n ) 3 1 n log r log r n (C.2) ≤ 1 n log r log r n − 4 ≤ 1 n 3 . In inequalit y C.1 , we use the fact that for large enough n , 4 e log r n < 1 2 , therefore, n − log r n X ` =0 4 e log r n ` ≤ n − log r n X ` =0 1 2 ` ≤ 2 In inequalit y C.2 , we use the fact that (log n ) log n = e log log n log n = e log n log log n = n log log n 23 No w we can prov e Theorem 5.1 . Pr o of of The or em 5.1 . Recall that P denotes the set of all p ossible paths from no de 1 to no de n that could b e present in G n,k,r , and let P 0 = { p | | p | < log r n − 1 } . Then by Lemma C.2 , |P | < n . In Definition C.1 , the probabilit y that we return a graph in step (4) is at least the probability that there exists an edge from no de 1 to no de n . This probability is ≥ 1 n from Lemma C.4 . Now we will compute the probability that there exists a path in P \ P 0 in G n,k,r b y conditioning on returning a graph in step (4). The p enultimate inequality is due to Lemma C.4 . P ( ∃ p ∈ G n,k,r ∩ P \ P 0 ) = P ( ∃ p ∈ G 0 n,k,r ∩ P \ P 0 | ∃ q ∈ G 0 n,k,r ∩ P ) = P ( ∃ p ∈ G 0 n,k,r ∩ P \ P 0 ) P ( ∃ q ∈ G 0 n,k,r ∩ P ) ≤ 1 n 3 / 1 n ≤ 1 n 2 D Additional Exp erimen ts and Details In this section, we present details and supplementary exp eriments from Sections 5 and 6 . In the first subsection, we give a short description and implementation details for all 15 of the NAS algorithms w e tested in Section 6 , as well as additional details from Section 6 . Next, w e giv e an exhaustive exp erimen t on the BO + neural predictor framew ork. After that, w e ev aluate BANANAS on the three datasets in NASBenc h-201. Then, we discuss the NASBench-101 API and conduct additional exp erimen ts. Finally , w e study the effect of the length of the path enco ding on the p erformance of BANANAS on NASBench-201. D.1 Details from Section 6 Here, w e give more details on the NAS algorithms we compared in Section 6 . Regularized ev olution. This algorithm consists of iteratively m utating the b est achitectures out of a sample of all arc hitectures ev aluated so far [ 44 ]. W e used the [ 72 ] implementation although w e changed the p opulation size from 50 to 30 to account for fewer total queries. W e also found that in eac h round, removing the arc hitecture with the w orst v alidation accuracy p erforms b etter than remo ving the oldest architecture, so this is the algorithm we compare to. (T ec hnically this would mak e the algorithm closer to standard ev olution.) Lo cal search. Another simple baseline, lo cal search iteratively ev aluates all architectures in the neigh b orho o d of the architecture with the lo west v alidation error found so far. F or NASBenc h-101, the “neighborho o d” means all architectures whic h differ from the curren t arc hitecture b y one op eration or one edge. W e used the implemen tation from White et al. [ 66 ], who show ed that lo cal searc h is a state-of-the-art approac h on NASBench-101 and NASBench-201. Ba y esian optimization with a GP mo del. W e set up Ba yesian optimization with a Gaussian pro cess mo del and UCB acquisition. In the Gaussian pro cess, we set the distance function b et ween t wo neural net works as the sum of the Hamming distances b et ween the adjacency matrices and the list of op erations. W e use the ProBO implemen tation [ 39 ]. 24 NASBOT. Neural arc hitecture search with Bay esian optimization and optimal transp ort (NASBOT) [ 21 ] w orks by defining a distance function b etw een neural net works by computing the similarities b etw een lay ers and then running an optimal transp ort algorithm to find the minimum earth-mo ver’s distance b etw een the tw o arc hitectures. Then Ba yesian optimization is run using this distance function. The NASBOT algorithm is sp ecific to macro NAS, and we put in a go o d-faith effort to implemen t it in the cell-based setting. Sp ecifically , w e compute the distance b et ween tw o cells by taking the earth-mo ver’s distance b et ween the set of row-sums, column-sums, and no de op erations. This is a version of the OTMANN distance [ 21 ], defined for the cell-based setting. Random searc h. The simplest baseline, random search, draws n arc hitectures at random and outputs the architecture with the low est v alidation error. Despite its simplicit y , multiple pap ers ha ve concluded that random search is a comp etitive baseline for NAS algorithms [ 30 , 46 ]. In T able 1 , w e also compared to Random Search with W eight-Sharing, which uses shared weigh ts to quickly compare orders of magnitude more architectures. AlphaX. AlphaX casts NAS as a reinforcement learning problem, using a neural net work to guide the search [ 62 ]. Each iteration, a neural net work is trained to select the b est action, suc h as making a small change to, or growing, the current architecture. W e used the op en-source implemen tation of AlphaX as is [ 62 ]. BOHAMIANN. Ba yesian Optimization with Hamiltonian Monte Carlo Artificial Neural Net works (BOHAMIANN) [ 53 ] is an approac h which fits in to the “BO + neural predictor” framew ork. It uses a Bay esian neural netw ork (implemented using Hamiltonian Mon te Carlo) as the neural predictor. W e used the BOHAMIANN implementation of the Bay esian neural netw ork [ 53 ] with our o wn outer BO wrapp er, so that w e could accurately compare different neural predictors within the framew ork. REINF OR CE. W e use the NASBenc h-101 implemen tation of REINFOR CE [ 67 ]. Note that this w as the b est reinforcement learning-based NAS algorithm released by NASBenc h-101, outp erforming other p opular approaches such as a 1-lay er LSTM controller trained with PPO [ 72 ]. GCN Predictor. W e implemented a GCN predictor [ 64 ]. Although the co de is not op en- sourced, we found an op en-source implementation online [ 76 ]. W e used this implemen tation, keeping the h yp erparameters the same as in the original pap er [ 64 ]. BONAS. W e implemen ted BONAS [ 48 ]. Again, the co de w as not op en-sourced, so we used the same GCN implementation as ab ov e [ 76 ], using our own co de for the outer BO wrapp er. DNGO. Deep Netw orks for Global Optimization (DNGO) is an implementation of B a yesian optimization using adaptive basis regression using neural netw orks instead of Gaussian pro cesses to a void the cubic scaling. W e used the op en-source co de [ 52 ]. BOHB. Ba yesian Optimization Hyp erBand (BOHB) com bines multi-fidelit y Bay esian optimiza- tion with principled early-stopping from Hyperband [ 11 ]. W e use the NASBenc h implementation [ 72 ]. TPE. T ree-structured Parzen estimator (TPE) is a BO-based h yp erparameter optimization algorithm based on adaptive Parzen windows. W e use the NASBench implemen tation [ 72 ]. D AR TS. D AR TS [ 35 ] is a p opular first-order (sometimes called “one-shot”) NAS algorithm. In DAR TS, the neural netw ork parameters and the architecture hyperparameters are optimized sim ultaneously using alternating steps of gradient descent. In T able 1 , w e rep orted the published n umbers from the pap er, and then w e retrained the architecture published b y the DAR TS pap er, fiv e times, to account for differences in hardware. ASHA. Asyncrhonous Successiv e Halving Algorithm (ASHA) is an algorithm that uses asyn- c hronous parallelization and early-stopping. As with DAR TS, we rep orted b oth the published 25 T able 2: Comparison of the arc hitectures with the low est test error (av eraged o ver 200 trials) returned b y NAS algorithms after 150 arc hitecture ev aluations on NASBench-101. NAS Algorithm Source Metho d T est Error REINF ORCE [ 67 ] Reinforcemen t learning 6.436 TPE [ 4 ] BO (P arzen windows) 6.415 BOHB [ 11 ] BO (successiv e halving) 6.356 Random searc h [ 30 ] Random searc h 6.341 GCN Pred. [ 64 ] GCN 6.331 BO w. GP [ 50 ] BO (Gaussian pro cess) 6.267 NASBOT [ 21 ] BO (Gaussian pro cess) 6.250 AlphaX [ 62 ] Mon te Carlo tree searc h 6.233 Reg. Ev olution [ 44 ] Ev olution 6.109 DNGO [ 52 ] BO (neural netw orks) 6.085 BOHAMIANN [ 53 ] BO (Ba yesian NN) 6.010 BONAS [ 48 ] BO (GCN) 5.954 Lo cal search [ 66 ] Lo cal search 5.932 BANANAS Ours BO (path enco ding) 5.923 c _ { k - 2 } 0 s k i p _ c o n n e c t 1 s e p _ c o n v _ 5 x 5 2 s k i p _ c o n n e c t 3 s e p _ c o n v _ 3 x 3 c _ { k - 1 } s e p _ c o n v _ 3 x 3 s e p _ c o n v _ 5 x 5 s e p _ c o n v _ 5 x 5 s k i p _ c o n n e c t c _ { k } c _ { k - 2 } 0 m a x _ p o o l _ 3 x 3 1 m a x _ p o o l _ 3 x 3 c _ { k - 1 } s e p _ c o n v _ 3 x 3 n o n e 3 s e p _ c o n v _ 3 x 3 2 d i l _ c o n v _ 3 x 3 c _ { k } s e p _ c o n v _ 5 x 5 s e p _ c o n v _ 5 x 5 Figure D.1: The b est neural architecture found by BANANAS in the DAR TS space. Normal cell (left) and reduction cell (right). n umber and the num b ers we achiev ed by retraining the published architecture on our hardw are. Additional notes from Section 6 . W e give the results from Figure 6.1 (righ t) into a table (T able 2 ). In the main NASBenc h-101 exp eriments, Figure 6.1 , w e added an isomorphism-remo ving subroutine to any algorithm that uses the adjacency matrix enco ding. This is b ecause multiple adjacency matrices can map to the same architecture. With the path enco ding, this is not necessary . Note that without the isomorphism-removing subroutine, algorithms using the adjacency matrix enco ding ma y p erform significan tly worse (e.g., we found this to b e true for BANANAS with the adjacency matrix enco ding). This is another strength of the path enco ding. In Section 6 , w e describ ed the details of running BANANAS on the DAR TS search space, which resulted in an architecture. W e show this architecture in Figure D.1 . 26 25 30 35 40 45 time in TPU hours 5.94 5.96 5.98 6.00 6.02 6.04 test error of best neural net Path_ITS_Mutation Trunc_ITS_Mutation GCN_ITS_Mutation Path_UCB_Mutation Trunc_UCB_Mutation GCN_UCB_Mutation Path_EI_Mutation Trunc_EI_Mutation GCN_EI_Mutation 25 30 35 40 45 time in TPU hours 5.94 5.96 5.98 6.00 6.02 6.04 test error of best neural net Path_ITS_Mut+Rand Trunc_ITS_Mut+Rand GCN_ITS_Mut+Rand Path_UCB_Mut+Rand Trunc_UCB_Mut+Rand GCN_UCB_Mut+Rand Path_EI_Mut+Rand Trunc_EI_Mut+Rand GCN_EI_Mut+Rand Figure D.2: A more exhaustive study of the differen t comp onents in the BO + neural predictor framew ork. D.2 Exhaustiv e F ramew ork Exp eriment In Section 5 , we conducted exp erimen ts on each comp onen t individually while k eeping all other comp onen ts fixed. How ever, this exp erimental setup implicitly assumes that all comp onents are linear with resp ect to p erformance. F or example, we show ed GCN p erforms worse than the path enco ding with ITS, and UCB p erforms worse than ITS using the path enco ding, but we never tested GCN together with UCB – what if it outp erforms ITS with the path enco ding? In this section we run a more exhaustive exp eriment by testing the 18 most promising configura- tions. W e take all combinations of the highest-p erforming comp onen ts from Section 5 ). Sp ecifically , w e test all combinations of { UCB, EI, ITS } , { m utation, mutation+random } , and { GCN, path enc., trunc. path enc.) } as acquisition function, acquisition optimization strategy , and neural predictor. W e use the same exp erimental setup as in Section 5 , and we run 500 trials of each algorithm. See Figure D.2 . The o verall b est-p erforming algorithm was Path-ITS-Mutation, which was the same conclusion reached in Section 5 . The next b est com binations are Path-ITS-Mut+Rand and T runc-ITS-Mut+Rand. Note that there is often very little difference b etw een the path enco ding and truncated path enco ding, all else b eing equal. The results sho w that each comp onent has a fairly linear relationship with resp ect to p erformance: mutation outp erforms mutation+random; ITS outp erforms UCB which outp erforms EI; and b oth the path and truncated path enco dings outp erform GCN. D.3 Results on NASBenc h-201 W e describ ed the NASBenc h-201 dataset in Section 6 . The NASBench-201 dataset is similar to NASBenc h-101. Note that NASBenc h-201 is m uch smaller ev en than NASBenc h-101: it is originally size 15625, but it only contains 6466 unique arc hitectures after all isomorphisms are remov ed [ 9 ]. By con trast, NASBench-101 has ab out 423,000 architectures after remo ving isomorphisms. Some pap ers ha ve claimed that NASBench-201 may b e to o small to effectively b enc hmark NAS algorithms [ 66 ]. Ho wev er, one upside of NASBench-201 is that it contains three image datasets instead of just one: CIF AR-10, CIF AR-100, and ImageNet-16-120. Our exp erimental setup is the same as for NASBench-101 in Section 6 . See Figure D.3 . As with NASBenc h-101, at each p oint in time, we plotted the test error of the architecture with the b est 27 15 20 25 30 35 40 45 time in GPU hours 8.4 8.6 8.8 9.0 9.2 9.4 val error of best neural net CIFAR-10 BANANAS Local Search Random DNGO Reg. Evolution BO w. GP NASBOT BOHAMIANN BONAS GCN Pred. BO w. GP NASBOT BOHAMIANN BONAS GCN Pred. 15 20 25 30 35 40 45 time in GPU hours 26.5 27.0 27.5 28.0 28.5 29.0 29.5 30.0 val error of best neural net CIFAR-100 BANANAS Local Search Random DNGO Reg. Evolution BO w. GP NASBOT BOHAMIANN BONAS GCN Pred. BO w. GP NASBOT BOHAMIANN BONAS GCN Pred. 15 20 25 30 35 40 45 time in GPU hours 53.5 54.0 54.5 55.0 55.5 val error of best neural net ImageNet-16-120 BANANAS Local Search Random DNGO Reg. Evolution BO w. GP NASBOT BOHAMIANN BONAS GCN Pred. BO w. GP NASBOT BOHAMIANN BONAS GCN Pred. 15 20 25 30 35 40 45 time in GPU hours 5.6 5.8 6.0 6.2 6.4 6.6 test error of best neural net BANANAS Local Search Random DNGO Reg. Evolution BO w. GP NASBOT BOHAMIANN BONAS GCN Pred. BO w. GP NASBOT BOHAMIANN BONAS GCN Pred. 15 20 25 30 35 40 45 time in GPU hours 26.5 27.0 27.5 28.0 28.5 29.0 29.5 30.0 test error of best neural net BANANAS Local Search Random DNGO Reg. Evolution BO w. GP NASBOT BOHAMIANN BONAS GCN Pred. BO w. GP NASBOT BOHAMIANN BONAS GCN Pred. 15 20 25 30 35 40 45 time in GPU hours 53.5 54.0 54.5 55.0 55.5 test error of best neural net BANANAS Local Search Random DNGO Reg. Evolution BO w. GP NASBOT BOHAMIANN BONAS GCN Pred. BO w. GP NASBOT BOHAMIANN BONAS GCN Pred. Figure D.3: Results on NASBench-201. T op row is v alidation error, b ottom ro w is test error. CIF AR-10 (left), CIF AR-100 (middle), and ImageNet-16-120 (right). v alidation error found so far (and then w e av eraged this o ver 200 trials). Ho wev er, on NASBench-201, the v alidation and test errors are not as highly correlated as on NASBench-101, which makes it p ossible for the NAS algorithms to ov erfit to the v alidation errors. Sp ecifically for ImageNet16-120, the low est v alidation error out of all 15625 architectures is 53.233, and the corresp onding test error is 53.8833. How ev er, there are 23 architectures which hav e a higher v alidation loss but low er test loss (and the lo west ov erall test loss is 53.1556). Coupled with the small size of NASBench-201, this can cause NAS p erformance o ver time to not b e strictly decreasing (see Figure D.3 b ottom left). Therefore, w e fo cus on the plots of the v alidation error ov er time (Figure D.3 top row). Due to the extremely small size of the search space as describ ed ab ov e , sev eral algorithms tie for the best p erformance. W e see that BANANAS ties for the b est p erformance on CIF AR-10 and CIF AR-100. On ImageNet16-120, it ties for the best p erformance after 40 GPU hours, but NASBOT and BO w. GP reac h top p erformance more quickly . W e stress that we did not c hange any h yp erparameters or an y other part of the co de of BANANAS, when moving from NASBench-101 to all three NASBench-201 datasets, which shows that BANANAS do es not need to b e tuned. D.4 NASBenc h-101 API In the NASBench-101 dataset, each architecture w as trained to 108 ep o chs three separate times with different random seeds. The original pap er conducted exp eriments by ( 1 ) choosing a random v alidation error when ev aluating each architecture, and then rep orting the mean test error at the conclusion of the NAS algorithm. The most realistic setting is: ( 2 ) c ho osing a random v alidation error when ev aluating each architecture, and then rep orting the corresp onding test error, and an appro ximation of this is ( 3 ) using the mean v alidation error in the search, and rep orting the mean test error at the end. How ever, ( 2 ) is currently not p ossible with the NASBench-101 API, so our options are ( 1 ) or ( 3 ), neither of which is perfect. ( 3 ) do es not capture the uncertaint y in real NAS exp eriments, while ( 1 ) do es not giv e as accurate results b ecause of the differences b et ween 28 10 20 30 40 time in TPU hours 6.0 6.2 6.4 6.6 6.8 7.0 7.2 test error of best neural net BANANAS Random search Reg. evolution BO w. GP prior REINFORCE DNGO NASBOT DNGO NASBOT 3 1 3 2 3 3 3 4 length of path encoding 5.6 5.7 5.8 5.9 6.0 6.1 6.2 test error after 150 evaluations BANANAS with path encoding of different lengths Figure D.4: NAS exp erimen ts with random v alidation error (left). Performance of BANANAS on NASBenc h-201 with CIF AR-10 with the path enco ding truncated to differen t lengths (right). random v alidation errors and mean test errors. W e used ( 3 ) for Figure 6.1 , and now we use ( 1 ) in Figure D.4 . W e found the ov erall trends to b e the same in Figure D.4 (in particular, BANANAS still distinctly outp erforms all other algorithms after 40 iterations), but the Ba yesian optimization-based metho ds p erformed b etter at the v ery start. D.5 P ath enco ding length In Section 5 , we gav e theoretical results which suggested that truncating the path enco ding ma y not decrease p erformance of NAS algorithms such as BANANAS. W e back ed this up by plotting p erformance of BANANAS vs. truncation length of the path enco ding (Figure 5.1 . Sp ecifically , we ran BANANAS up to 150 ev aluations for truncation lengths of 3 0 , 3 1 , . . . , 3 5 and plotted the results. No w, we conduct the same exp eriment for NASBench-201. W e run BANANAS up to 150 ev aluations on CIF AR-10 on NASBenc h-201 for truncation lengths of 1, 2, 5, 7, 10, 15, 20, 30, 60, and 155 (where 155 is the total num b er of paths for NASBench-201). See Figure D.4 . W e see that truncating from 155 down to just 30 has no decrease in p erformance. In fact, similar to NASBenc h-101, the p erformance after truncation actually impr oves up to a certain p oint. W e b eliev e this is b ecause with the full-length enco ding, the neural predictor ov erfits to v ery rare paths. Next, w e give a table of the probabilities of paths by length from NASBench-101 generated from random spec() (i.e., Definition C.1 ). These probabilities were computed exp erimentally by making 100000 calls to random spec() . See T able 3 . This table giv es further exp erimental evidence to supp ort Theorem 5.1 , b ecause it sho ws that the longest paths are exceedingly rare. E Best practices c hec klist for NAS research The area of NAS has seen problems with repro ducibility , as well as fair empirical comparisons. F ollowing calls for fair and repro ducible NAS research [ 30 , 72 ], a b est practices chec klist was recen tly created [ 33 ]. In order to promote fair and repro ducible NAS researc h, w e address all p oin ts on the chec klist, and we encourage future pap ers to do the same. Our co de is a v ailable at https://github.com/naszilla/naszilla . • Co de for the tr aining pip eline use d to evaluate the final ar chite ctur es. W e used three of the most 29 T able 3: Probabilities of path lengths in NASBench-101 using random spec() . P ath Length Probabilit y T otal num. paths Expected num. paths 1 0 . 200 1 0 . 200 2 0 . 127 3 0 . 380 3 3 . 36 × 10 − 2 9 0 . 303 4 3 . 92 × 10 − 3 27 0 . 106 5 1 . 50 × 10 − 4 81 1 . 22 × 10 − 2 6 6 . 37 × 10 − 7 243 1 . 55 × 10 − 4 p opular search spaces in NAS research, the NASBenc h-101 and NASBenc h-201 search spaces, and the D AR TS searc h space. F or NASBench-101 and 201, the accuracy of all arc hitectures w ere precomputed. F or the D AR TS search space, we released our fork of the DAR TS rep o, whic h is fork ed from the D AR TS rep o designed sp ecifically for repro ducible exp eriments [ 30 ], making trivial changes to account for pytorc h 1 . 2 . 0. • Co de for the se ar ch sp ac e. W e used the p opular and publicly av aliable NASBenc h and D AR TS searc h spaces with no c hanges. • Hyp erp ar ameters use d for the final evaluation pip eline, as wel l as r andom se e ds. W e left all h yp erparameters unc hanged. W e trained the architectures found b y BANANAS, ASHA, and D AR TS five times eac h, using random seeds 0, 1, 2, 3, 4. • F or al l NAS metho ds you c omp ar e, did you use exactly the same NAS b enchmark, including the same dataset, se ar ch sp ac e, and c o de for tr aining the ar chite ctur es and hyp erp ar ameters for that c o de? Y es, we did this b y virtue of the NASBench-101 and 201 datasets. F or the D AR TS exp erimen ts, we used the rep orted architectures (found using the sam e searc h space and dataset as our metho d), and then we trained the final architectures using the same co de, including hyperparameters. W e compared different NAS metho ds using exactly the same NAS b enc hmark. • Did you c ontr ol for c onfounding factors? Y es, we used the same setup for all of our NASBench- 101 and 201 exp erimen ts. F or the DAR TS search space, we compared our algorithm to t wo other algorithms using the same setup (pytorc h version, CUDA version, etc). Across training o ver 5 seeds for each algorithm, we used differen t GPUs, which we found to hav e no greater effect than using a different random seed. • Did you run ablation studies? Y es, in fact, ablation studies guided our en tire decision pro cess in constructing BANANAS. Section 5 is devoted entirely to ablation studies. • Did you use the same evaluation pr oto c ol for the metho ds b eing c omp ar e d? Y es, we used the same ev aluation proto col for all metho ds and we tried multiple ev aluation proto cols. • Did you c omp ar e p erformanc e over time? Y es, all of our plots are p erformance ov er time. • Did you c omp ar e to r andom se ar ch? Y es. 30 • Did you p erform multiple runs of your exp eriments and r ep ort se e ds? W e ran 200 trials of our NASBenc h-101 and 201 exp eriments. Since we ran so many trials, w e did not rep ort random seeds. W e ran four total trials of BANANAS on the DAR TS search space. Curren tly we do not hav e a fully deterministic version of BANANAS on the DAR TS searc h space (which would b e harder to implemen t as the algorithm runs on 10 GPUs). Ho wev er, the av erage final error across trials was within 0.1%. • Did you use tabular or surr o gate b enchmarks for in-depth evaluations Y es, we used NASBench- 101 and 201. • Did you r ep ort how you tune d hyp erp ar ameters, and what time and r esour c es this r e quir e d? W e performed ligh t h yp erparameter tuning at the start of this pro ject, for the num b er of la yers, lay er size, learning rate, and n umber of ep o chs of the meta neural net work. W e did not p erform an y hyperparameter tuning when we ran the algorithm on NASBench-201 for all three datasets, or the DAR TS search space. This suggests that the curren t hyperparameters w ork well for most new searc h spaces. • Did you r ep ort the time for the entir e end-to-end NAS metho d? W e rep orted time for the en tire end-to-end NAS metho d. • Did you r ep ort al l details of your exp erimental setup? W e rep orted all details of our exp eri- men tal setup. 31
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment