Predicting Network Controllability Robustness: A Convolutional Neural Network Approach
Network controllability measures how well a networked system can be controlled to a target state, and its robustness reflects how well the system can maintain the controllability against malicious attacks by means of node-removals or edge-removals. T…
Authors: Yang Lou, Yaodong He, Lin Wang
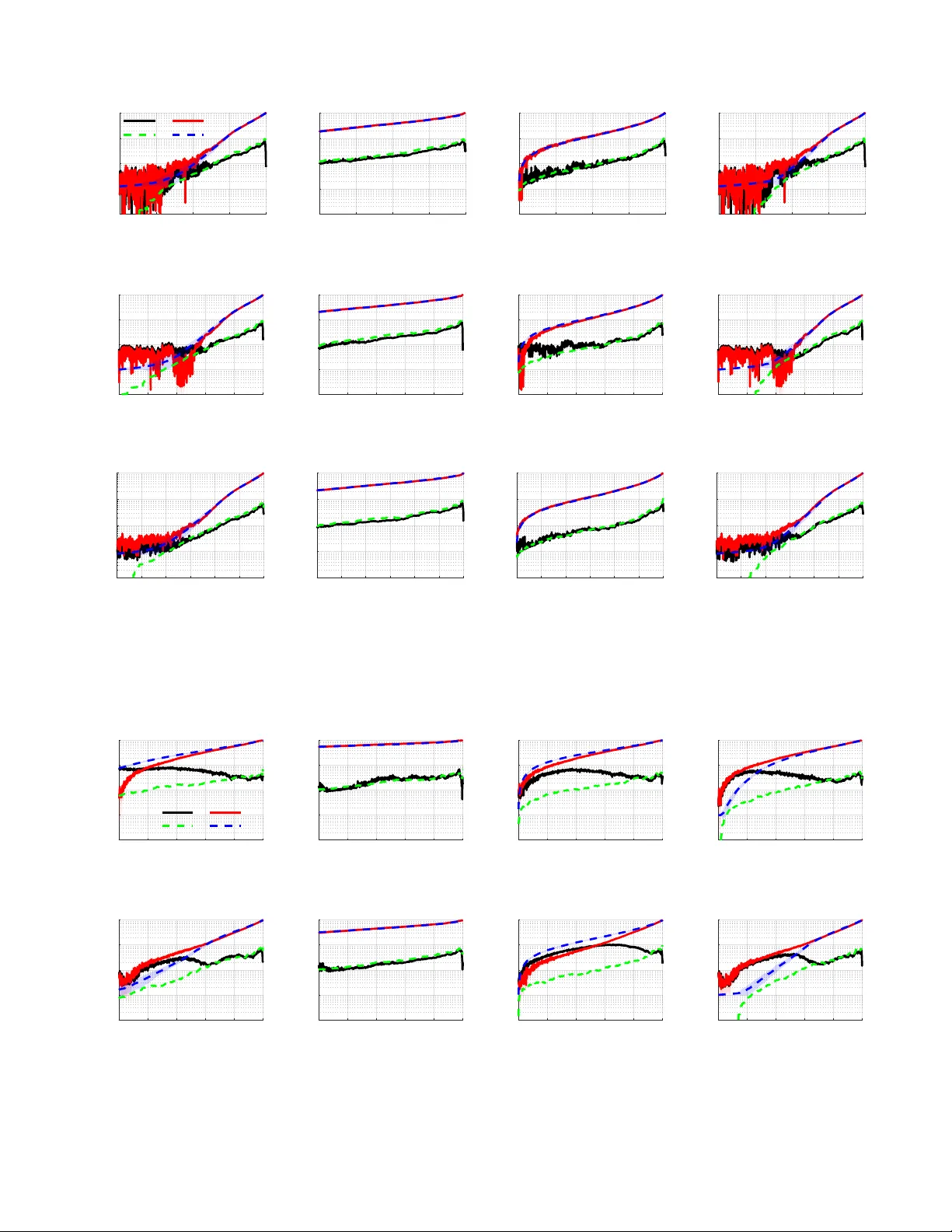
HTTPS://DOI.ORG/10.1109/TCYB.2020.3013251 (SEPTEMBER 2020) 1 Predicting Network Controllability Rob ustness: A Con v olutional Neural Network Approach Y ang Lou, Y aodong He, Lin W ang, Senior Member , IEEE, and Guanrong Chen, Life F ellow , IEEE Abstract —Network controllability measur es how well a net- worked system can be controlled to a target state, and its robust- ness reflects how well the system can maintain the controllability against malicious attacks by means of node-remov als or edge- remo vals. The measure of network controllability is quantified by the number of external control inputs needed to recover or to retain the controllability after the occurrence of an unexpected attack. The measure of the network controllability rob ustness, on the other hand, is quantified by a sequence of values that record the r emaining controllability of the network after a sequence of attacks. T raditionally , the controllability r obustness is determined by attack simulations, which is computationally time consuming. In this paper , a method to predict the controllability robustness based on machine learning using a conv olutional neural network is proposed, moti vated by the observ ations that 1) there is no clear correlation between the topological features and the controllability robustness of a general network, 2) the adjacency matrix of a netw ork can be regarded as a gray-scale image, and 3) the con volutional neural network technique has proved successful in image processing without human intervention. Under the new framework, a fairly large number of training data generated by simulations are used to train a con volutional neural network for predicting the controllability rob ustness according to the input network-adjacency matrices, without performing con ventional attack simulations. Extensive experimental studies were carried out, which demonstrate that the proposed framework for predict- ing controllability robustness of different network configurations is accurate and reliable with very low overheads. Index T erms —Complex network, con volutional neural net- work, controllability , robustness, performance prediction. I . I N T R O D U C T I O N C OMPLEX networks ha ve gained wide popularity and rapid development during the last two decades. Scientific research on this subject was pursued with great efforts from various scientific and engineering communities, which has literally become a self-contained discipline interconnecting network science, systems engineering, statistical physics, ap- plied mathematics and social sciences alike [ 1 ]–[ 3 ]. Recently , the network controllability issue has become a focal topic in complex network studies [ 4 ]–[ 13 ], where the Y . Lou, Y . He, and G. Chen are with the Department of Electrical Engi- neering, City University of Hong Kong (e-mails: felix.lou@my .cityu.edu.hk; yaodonghe2-c@my .cityu.edu.hk; eegchen@cityu.edu.hk). L. W ang is with the Department of Automation, Shanghai Jiao T ong Univ ersity , Shanghai 200240, China, and also with the Key Laboratory of System Control and Information Processing, Ministry of Education, Shanghai 200240, China (e-mail: wanglin@sjtu.edu.cn). This research was supported in part by the National Natural Science Foundation of China under Grant 61873167, and in part by the Natural Science Foundation of Shanghai under Grand 17ZR1445200. ( Corr esponding author: Guanr ong Chen. ) This paper has been published in IEEE T ransactions on Cybernetics . https://doi.org/10.1109/TCYB.2020.3013251 concept of contr ollability refers to the ability of a network in moving from any initial state to any target state under an admissible control input within a finite duration of time. It was shown that identifying the minimum number of exter- nal control inputs (recalled driv er nodes) to achie v e a full control of a directed network amounts to searching for the maximum matching of the network, known as the structural contr ollability [ 4 ]. Along the same line of research, in [ 5 ], an efficient tool to assess the state contr ollability of a large-scale network is suggested. In [ 7 ], it reveals that random networks are controllable by an infinitesimal fraction of dri ver nodes, if both of its minimum in-degree and out-degree are greater than two. In [ 6 ], it demonstrates that clustering and modularity hav e no discernible impact on the network controllability , while degree correlations have certain effects. The network controllability of some canonical graph models is studied quite thoroughly in [ 14 ]. Moreover , the controllability of multi- input/multi-output networked systems is studied in [ 9 ], [ 15 ]. A comprehensive overvie w of the subject is a v ailable in the recent survey papers [ 16 ], [ 17 ]. Meanwhile, malicious attacks on comple x netw orks is a main concerned issue today [ 18 ]–[ 23 ]. Reportedly , degree- based node attacks, by means of removing nodes with high degrees, are more destructiv e than random attacks on net- work controllability over directed random-graph and scale- free networks [ 24 ]. The underlying hierarchical structure of such a network leads to the effecti ve random upstream (or downstream) attack, which remov es the hierarchical upstream (or downstream) node of a randomly picked one, since this attack remov es more hubs than a random attack [ 21 ]. Both random and intentional edge-removal attacks have also been studied by man y . In [ 25 ], for example, it shows that the intentional edge-remov al attack by remo ving highly-loaded edges is very effecti ve in reducing the network controllability . It is moreover observed (e.g., in [ 26 ]) that intentional edge- based attacks are usually able to trigger cascading failures in scale-free netw orks but not necessarily in random-graph networks. These observations have motiv ated some recent in- depth studies of the robustness of network controllability [ 27 ]. In this regard, both random and intentional attacks as well as both node- and edge-removal attacks were in vestig ated in the past fe w years. In particular, it was found that redundant edges, which are not included in any of the maximum matchings, can be rewired or re-directed so as to possibly enlarge a maximum matching such that the needed number of dri v er nodes is reduced [ 28 ], [ 29 ]. Although the correlation between network topology and network controllability has been in v estigated, there is no HTTPS://DOI.ORG/10.1109/TCYB.2020.3013251 (SEPTEMBER 2020) 2 prominent theoretical indicator or performance index that can well describe the controllability robustness with this measure. Under different attack methods, the controllability robustness behav es dif ferently . The essence of different attack methods leads to dif ferent definitions of importance of nodes (or edges). Generally , degree and betweenness are commonly used measures for importance [ 24 ]. In [ 21 ], a control centrality is defined to measure the importance of nodes, discovering that the upstream (or downstream) neighbors of a node are usually more (or less) important than the node itself. Interestingly , it was recently found that the existence of special motifs such as rings and chains is beneficial for enhancing the controllability robustness [ 27 ], [ 30 ], [ 31 ]. On the other hand, in machine learning, deep neural net- works ha v e sho wn po werful capability in performing clas- sification and regression tasks. Compared to the canonical neural networks that inv olv e human-defined features, deep neural networks entirely ignore these requirements, thus lower down the risk of being misled by possibly biased human interference. For example, given an image classification task, a deep neural network w orks based only on the results of processing the raw image pixels, rather than human-defined features such as colors and te xtures. Conv olutional neural network (CNN) is a kind of effecti v e deep neural network. In a CNN, the con volutional layer consists of a set of learnable filters (called kernels) [ 32 ], and through a forward pass the well-trained filters are con v olved with the input image maps. This structure is able to automatically analyze inner features of a dataset without human interference. Successful real- world applications of CNNs include te xt recognition and classification [ 33 ]–[ 35 ], speech recognition [ 36 ], [ 37 ], and question answering [ 38 ], [ 39 ] in natural language processing; image and video classifications [ 40 ], [ 41 ], face recognition and detection [ 42 ], and person re-identification [ 43 ], [ 44 ] for performing vision tasks. Applications of CNNs hav e also been extended to biomedical image segmentation [ 45 ], patient- specific electrocardiogram classification [ 46 ], etc. In the literature, the measure of network controllability is quantified by the number of external controllers needed to recov er or to retain the controllability after the occurrence of a malicious attack. The measure of the network controllability robustness is quantified by a sequence of values that record the remaining controllability of the network after a sequence of attacks. Usually , the controllability rob ustness is determined by attack simulation, which howe ver is computationally time con- suming. In this paper , a method to predict the controllability robustness using a CNN is proposed, based on the observ ations that there is no clear correlation between the topological features and the controllability robustness of a network, and the CNN technique has been successful in image processing without human intervention while a network adjacency matrix can be represented as a gray-scale image. Specifically , for a giv en adjacency matrix with 0-1 elements, representing an un- weighted network, it is first con verted to a black-white image; while for a weighted network with real-v alued elements in the adjacency matrix, a gray-scale image is plotted. Examples of the conv erted images for both weighted and unweighted images are sho wn in Fig. 1 , where different network topologies show distinguished patterns. The resulting images are then processed (for either training or testing) by a CNN, where the input is the raw image (adjacency matrix) and the output is referred to as a contr ollability curve against the probability of attacks. Giv en an N -node network, a controllability curve is used to indicate the controllability of the remaining net- work after i ( i = 1 , 2 , . . . , N − 1 ) nodes (or edges) were remov ed. No feature of the adjacency matrix is assumed to hav e any correlation with the controllability robustness. Given a sufficiently large number of training samples, the CNN can be well trained for the purpose of prediction. Each sample (either for training or testing) consists of an input-output pair, i.e., a pair of an adjacency matrix and a controllability curve. Compared to the traditional network attack simulations, the proposed method costs significantly less time to obtain an accurate controllability rob ustness measure of a giv en netw ork, of an y size and any type, with low o verheads in training. The performance of the proposed frame w ork is also very encouraging, as further discussed in the experiments section below . The rest part of the paper is or ganized as follows. Sec- tion II revie ws the network controllability and controllability robustness against various attacks. Section III introduces the con v olutional neural network used in this work. In Section IV , experimental study is performed and analyzed. Finally , Section V concludes the inv estigation. I I . N E T W O R K C O N T RO L L A B I L I T Y Giv en a linear time-in v ariant (L TI) networked system de- scribed by ˙ x = A x + B u , where A and B are constant matrices of compatible dimensions, the system is state controllable if and only if the controllability matrix [ B AB A 2 B · · · A N − 1 B ] has a full row-rank, where N is the dimension of A . The concept of structural contr ollability is a slight generalization dealing with two parameterized matrices A and B , in which the parameters characterize the structure of the underlying networked system. If there are specific parameter values that can ensure the L TI system described by the two parameterized matrices be state controllable, then the underlying networked system is structurally controllable. The network controllability is measured by the density of the driver nodes, n D , defined by n D ≡ N D / N , (1) where N D is the number of driver nodes needed to retain the network controllability after the occurrence of an attack to the network, and N is the current network size, which does not change during an edge-remov al attack but would be reduced by a node-removal attack. Under this measure, the smaller the n D value is, the more robust the network controllability will be. Recall that a network is sparse if the number of edges M (or the number of nonzero elements of the adjacency matrix) is much less than the possible maximum number of edges, M max . For a directed network, M max can be calculated by M max = N · ( N − 1) . (2) HTTPS://DOI.ORG/10.1109/TCYB.2020.3013251 (SEPTEMBER 2020) 3 (a) unweighted ER (b) unweighted SF (c) unweighted QSN (d) unweighted SW (e) weighted ER (f) weighted SF (g) weighted QSN (h) weighted SW Fig. 1: An example of adjacency matrix con verting images for both weighted and unweighted images. The network size N = 50 with av erage degree h k i = 5 . In each image, a black pixel represents a 0 element in the adjacency matrix; a white pixel represents a 1 element in the unweighted network. For an weighted network, the non-zero elements are normalized ∈ (0 , 1] to form a gray-scale image. Practically , if M / M max ≤ 0 . 05 , then it is considered as a sparse network. For state controllability , if the adjacency matrix A of the network is sparse, the number N D of driv er nodes can be calculated by [ 5 ] N D = max { 1 , N − rank ( A ) } . (3) If it has a full rank, then the number of driv er nodes is N D = 1 ; otherwise, N D = N − rank ( A ) div er nodes are needed, which should be properly assigned (to fill the deficiency of the matrix rank). As for structural controllability , according to the minimum inputs theor em [ 4 ], when a maximum matching is found, the number of dri ver nodes N D is determined by the number of unmatched nodes, i.e., N D = max { 1 , N − | E ∗ |} , (4) where | E ∗ | is the cardinal number of elements in the maximum matching E ∗ . In a directed netw ork, a matching is a set of edges that do not share common start or end nodes. A maximum matching is a matching that contains the lar gest possible number of edges, which cannot be further extended. A node is matched if it is the end of an edge in the matching; otherwise, it is unmatched. A perfect matching is a matching that matches all nodes in the network. If a network has a perfect matching, then the number of driv er nodes is N D = 1 and the driv er node can be any node; otherwise, the needed N D = N − | E ∗ | control inputs should be put at those unmatched nodes. The robustness of both state and structural controllabilities is reflected by the value of n D calculated according to Eq. ( 1 ) and recorded after each node or edge is removed. In this paper , for brevity , only node-remov al attacks are discussed. I I I . C O N V O L U T I O NA L N E U R A L N E T W O R K S The CNN to be used for controllability performance pre- diction consists of an embedding layer , sev eral groups of con- volutional layers, and some fully connected layers. Rectified linear unit (ReLU) is employed as the activ ation function and max pooling is used to reduce the dimensions of datasets. T ABLE I: Parameter settings of the sev en groups of conv olu- tional layers. Group Layer Kernel size Stride Output channel Group 1 Con v7-64 7x7 1 64 Max2 2x2 2 64 Group 2 Con v5-64 5x5 1 64 Max2 2x2 2 64 Group 3 Con v3-128 3x3 1 128 Max2 2x2 2 128 Group 4 Con v3-128 3x3 1 128 Max2 2x2 2 128 Group 5 Con v3-256 3x3 1 256 Max2 2x2 2 256 Group 6 Con v3-256 3x3 1 256 Max2 2x2 2 256 Group 7 Con v3-512 3x3 1 512 Max2 2x2 2 512 The framew ork of CNN is shown in Fig. 2 . The detailed parameter settings of the 7 groups of con volutional layers are gi ven in T able I . Here, the CNN architecture follo ws the V isual Geometry Group (VGG) 1 ) architecture [ 47 ]. Compared with the original CNN architectures, the VGG architecture incorporates a smaller kernel size and a greater network depth. Thus, in this architecture, most kernels have small sizes ( 2 × 2 or 3 × 3 ). The con v olution stride is set to 1 and the pooling stride is set to 2 . 1 http://www .robots.ox.ac.uk/ ∼ vgg/ HTTPS://DOI.ORG/10.1109/TCYB.2020.3013251 (SEPTEMBER 2020) 4 embedding sparse data N × N dense data N × N FM 1 N 1 × N 1 × 64 FM 2 N 2 × N 2 × 64 FM 3 N 3 × N 3 × 128 FM 4 N 4 × N 4 × 128 FM 5 N 5 × N 5 × 256 FM 6 N 6 × N 6 × 256 FM 7 N 7 × N 7 × 512 FC 1 1 × N FC 1 FC 2 1 × N FC 2 prediction 1 × ( N − 1) convolution and ReLU max pooling concatenation fully connected and ReLU Fig. 2: The architecture of the CNN used for controllability rob ustness prediction, where FM is an abbreviation for feature map , and FC for fully connected . The data size N i = d N / ( i + 1) e , for i = 1 , 2 , . . . , 7 . The concatenation layer reshapes the matrix to a vector , from FM 7 to FC 1 , i.e., N F C 1 = N 7 × N 7 × 512 . N F C 2 is a hyperparameter and N F C 2 ∈ ( N F C 1 , N − 1) . Set N F C 2 = 4096 for N = 800 , 1000 , and 1200 , in this paper . Giv en the input as an N × N sparse matrix with less than 5% of non-zero elements but more than 95% zeros. If the network is unweighted then further assume that the input to the CNN is a sparse one-hot matrix, namely a 0-1 matrix that contains less than M max × 5% 1-elements. According to [ 48 ], howe ver , deep neural network performs poorly on this type of data, and thus the input data will be con verted to normal dense data via the embedding layer for better performances. An embedding layer is a randomly generated normalized matrix, which has a size N × N here. The conv erted matrix A 0 = AD becomes a dense one, where A is the original sparse (one-hot) matrix and D is the embedding matrix. As shown in Fig. 2 , following the preprocessing embedding layer , there are 7 feature map (FM) processing layers, denoted as FM 1 to FM 7 . Each FM processing layer consists of a con v olution layer , a ReLU, and a max pooling layer . Con v olutional layers are used in the hidden layers because they can more efficiently deal with large-scale datasets (e.g., 1000 × 1000 pixel images), while fully-connected layers are more suitable for small-sized datasets such as MNIST 2 images (an MNIST image has 28 × 28 pixels). The size of a real complex network generally varies from hundreds (e.g., there are 279 non-pharyngeal neurons in the sensory system of the worm C. ele gans [ 49 ]) to billions (e.g., 5 . 5 billions of pages in the W orld W ide W eb 3 ). In Section IV , the network size for simulation will be set to 1000 , and thus the con volutional lay- ers are employed instead of fully-connected layers. Compared to the fully-connected layers, using the con v olutional layers can significantly reduce the number of parameters. Meanwhile, the number of FM groups will be set to 7 , since the input size is around 1000 × 1000 in the following experiments. The number of FM groups should be set to be greater for a larger input dataset, and vice versa. ReLU provides a commonly-used activ ation function that defines the non-negati v e part of a set of inputs. It has been prov ed performing the best on 2 D data [ 50 ]. The formation 2 http://yann.lecun.com/exdb/mnist/ 3 https://www .worldwidewebsize.com/ (Accessed: 20 May , 2020) of ReLU to be used here is f ( x ) = max { 0 , x } . The output of each hidden layer, i.e., a multiplication of weights, is summed up and rectified by a ReLU for the next layer . Pooling layers reduce the dimensions of the datasets for the input of the following layer . There are two commonly- used pooling methods, namely the max pooling and average pooling. The former uses the maximum value (a greater value represents a brighter pixel in a gray-scale image) within the current window , while the latter uses the av erage value. Max pooling is useful when the background of the image is dark. Since the interest here is only in the lighter pixels, the max pooling is adopted. Follo wing the 7 con volutional groups, there are two fully- connected layers. The last feature map, FM 7 , is concatenated to FC 1 , and thus the input size of FC 1 is equal to the number of elements of the FM 7 output, which is N 7 × N 7 × 512 . The size of FC 2 is a hyper-parameter that should be set to be within the range N F C 2 ∈ ( N F C 1 , N − 1) . The loss function used is equal to the mean-squared error between the predicted vector (referred to as a controllability curve) and the true vector , as follows: L = 1 N − 1 N − 1 X i =1 || pv i − tv i || , (5) where || · || is the Euclidean norm, pv i is the i th element of the predicted curve, and tv i is the i th element of the true controllability curve. The training process for the CNN aims to minimize the loss function ( 5 ). Source codes of this work are available for the public 4 . I V . E X P E R I M E N TA L S T U DY Four representativ e directed networks, each has weighted or unweighted edges, are examined. They are Erd ¨ os-R ´ enyi random graph (ER) [ 51 ], generic scale-free (SF) network [ 24 ], [ 52 ], [ 53 ], q -snapback netw ork (QSN) [ 27 ], and Newman– W atts small-world (SW) network [ 54 ]. 4 https://fylou.github .io/sourcecode.html HTTPS://DOI.ORG/10.1109/TCYB.2020.3013251 (SEPTEMBER 2020) 5 Specifically , the edges in the ER network are added com- pletely at random, where the direction of each edge is e venly- randomly assigned. The edges of SF network are generated according to their weights defined by w i = ( i + θ ) − σ , i = 1 , 2 , . . . , N , (6) where σ ∈ [0 , 1) and θ N . T wo nodes i and j ( i 6 = j , i, j = 1 , 2 , ..., N ) are randomly picked with a probability proportional to the weights w i and w j , respectiv ely . Then, an edge A ij from i to j is added (if the two nodes are already connected, do nothing). The resulting SF network has a po wer- law distribution k − γ , where k is the degree v ariable, with constant γ = 1 + 1 σ , which is independent of θ . In this paper, σ is set to 0.999, such that the power -la w distribution has a reasonable scaling exponent γ = 2 . 001 . The QSN has one layer , r q , generated with a backbone chain and multiple snap- back edges created for each node i = r q + 1 , r q + 2 , . . . , N , which connects backward to the previously-appeared nodes i − l × r q ( l = 1 , 2 , . . . , b i/r q c ), with the same probability q ∈ [0 , 1] [ 27 ]. The SW network is initiated by a directed ring with K = 2 nearest-neighbors connected, i.e., a node i is connected to nodes i − 1 , i + 1 , i − 2 and i + 2 , via edges A i − 1 ,i , A i,i +1 , A i − 2 ,i and A i,i +2 . Then, adding or removing edges, until the predefined number of edges is reached. For each network topology , unweighted networks are stud- ied in Subsection IV -A and weighted networks are studied in Subsection IV -B . The adjacency matrix is represented by A i,j = ( 0 , no edge connecting i to j, e, otherwise . (7) where e = rand (0 , 1] representing a random real value for a weighted network; e = 1 for a unweighted network. Examples of images that are conv erted from weighted or unweighted networks are shown in Fig. 1 . Resizing (upsampling or subsampling) is commonly used for CNNs to process inputs with different sizes. Howe ver , therein the application scenario is dif ferent. For example, portrait photos can be properly resized, without disturbing the task of object recognition. Ho we ver , a pixel here represents an edge in the network, and thus resizing will change the original topology , thereby misleading the task of prediction. There are a fe w works that deal with different network sizes by using the same CNN, with additional assumptions. For example, in [ 55 ], to generate an input sequence for a network of any size, a sequence of nodes that covers large parts of the network should be searched first, and moreov er the local neighborhood structure has to be assumed. In this paper, CNNs are used to process both raw and complete structures of complex netw orks, without any assumption or prior knowledge on network structural features, and thus the input size is fixed to be same as the size of the input network. Due to space limitation, only node-removal attacks are considered in this paper . The node-remov al attack methods include: 1) random at- tack (RA) that removes randomly-selected nodes; 2) targeted betweenness-based attack (TB A) that remo ves nodes with maximum betweenness; and 3) targeted degree-based attack (TD A) that remov es nodes with maximum node degree. For TB A and TDA, when two or more nodes hav e the same max- imum value of betweenness or degree, one node is randomly picked to remove. The e xperiments are run on a PC with 64-bit operation system, installed Intel i7-6700 (3.4 GHz) CPU, GeForce GTX 1080 Ti GPU. The CNN is implemented in T ensorFlow 5 that is a Python-friendly open source library . A. Controllability Curve Prediction First, unweighted networks of size N = 1000 are consid- ered. For each network topology , four av erage (out-)degree values are set, namely h k i = 2 , h k i = 5 , h k i = 8 , and h k i = 10 . Since the networks are unweighted, only the structural controllability (see Eq. ( 4 )) is discussed here. In Subsection IV -B , state controllability (see Eq. ( 3 )) is measured for the weighted networks discussed therein. The reason is that the structural controllability is independent of the edge weights, while the state controllability depend on them. For CNN training and testing, with each of the three attack methods, there are 1000 randomly generated instances for each network configuration, amongst which 800 instances are used for training, 100 instances for cross validation, and the other 100 instances for testing. T aking RA for example, there are 4( topologies ) × 4( h k i values ) × 800 instances used for CNN training; 4 × 4 × 100 instances used for cross validation; and 4 × 4 × 100 instances used for testing. The number of training epochs is empirically set to 10 in these simulations. For each training epoch, the CNN is trained by the full set of training data in a shuffled order . T o prev ent over -fitting, after running an epoch, the trained CNN is ev aluated by the full set of validation data. The best-performing structure on the v alidation data is then selected as the optimum structure. The Adam optimizer [ 56 ] is used to optimize the CNN, i.e., to minimize the loss function defined in Eq. ( 5 ). The learning rate of Adam is set to 0 . 005 . The first momentum, the second momentum and the of Adam follow the recommended settings, which are 0 . 9 , 0 . 999 and 1 × 10 − 8 , respectively . Figure 3 sho ws the testing results on RA. The results of TB A and TD A are sho wn in Figs. S1 and S2 of the supplementary information (SI) 6 . In these figures, results of the same topology with different average degrees are aligned in a row . The av erage degree increases from left to right on each row . The red curve shows the predicted value ( pv ) giv en by the CNN; the dotted blue line represents the true value ( tv ) obtained from simulations; the black curve shows the error ( er ) between the prediction and the true value; and the green dotted line represents the standard deviation of the true value ( st ), used as reference. For each curve of pv , tv , and er , the shaded shadow in the same color sho ws the standard deviation, while the standard deviation curve st does not contain such a shadow . It can be seen from these figures that dif ferent network topologies show dif ferent controllability curves against the same attacks. For QSN and SW , since there is a directed-chain 5 https://www .tensorflow .org/ 6 https://fylou.github .io/pdf/pcrsi.pdf HTTPS://DOI.ORG/10.1109/TCYB.2020.3013251 (SEPTEMBER 2020) 6 in QSN and a connected global loop in SW , the initial number of needed external controllers is 1, hence the controllability curves start from 10 − 3 . In contrast, there is no such a structure in ER or SF , thus their curves start from much higher than 10 − 3 . From left to right, as the average degree increases, 1) the positions of all curves become lo wer , which means less controllers are needed, and the controllability consequently becomes better , throughout the entire attack process; 2) the initial positions of ER and SF curves become lo wer , but for QSN and SW , their initial positions remain the same at 10 − 3 . Generally , both er and st increase as the number of remo ved nodes increases. The two curves er and st generally match each other , which means that the prediction error and the standard deviation of the testing data roughly have the same magnitude. Ev en in some cases, er is less than st mostly throughout the attack process (e.g., shown by Fig. 3 (f)), when the tv and pv values approach 1, both er and st curves drop drastically . The predicted controllability curves become rugged for the tw o homogeneous random graphs, ER and SW , in the initial stage of RA. As h k i increases, the ruggedness of controllability curves increase as well. This is because the topological characteristics (the unknown features abstracted by CNN itself) of the homogeneous networks can only be mildly influenced by the change of a v erage degree. In the latter stage of RA, the predicted controllability curves match the true curves smoothly . In contrast, SF is a heterogeneous network while QSN has a uniform degree distribution; both topologies hav e stronger topological characteristics and thus the predicted curves and true curves are matched smoothly . As shown in the con verted gray-scale image examples (see Fig. 1 ), SF images have a strong characteristic, where the light pixels (representing edges) are conv er ged in the upper-left corner . Except for the black upper-right triangle and the backbone- chain, the rest light pixels in QSN are uniformly randomly distributed. Similarly , except for the backbone directed trian- gles, the rest light pixels in SW are also uniformly randomly distributed. There are substantial numbers of light pixels in ER, QSN, and SW , which are uniformly randomly distributed in the images. Figures S1 and S2 in SI show the results on TBA and TD A, respectively . Similarly , the predicted curves and the true curves are smoothly matched for both SF and QSN, while the predicted curves are rugged for both ER and SW in the initial stage of an attack, especially as h k i increases. It is worth mentioning that in Figs. S1(c), S1(d), S1(n), S1(o), S1(p), and Figs. S2(c), S2(d), S2(m), S2(n), S2(o), S2(p), the pv curves cannot well match the tv curves at the very beginning of the process, i.e., at the initial positions. This means that the controllability robustness of homogeneous networks are more difficult to predict than that on heterogeneous networks and QSN, which hav e stronger topological features. Meanwhile, the controllability performance prediction on TBA and TD A is also slightly more difficult than that on RA. Although the er values in the rugged part is relativ ely small (compared to the other parts of the curve), they are nevertheless greater than the st values. Note that, during CNN training, networks with different topologies and different average degrees are trained together . The controllability performance prediction is not specified for any particular network topology with a specified a verage degree. As for an attack method, it can also be integrated into the training data. Ho we ver , here the focus is on predicting the controllability curves, rather than predicting the attack method, hence different attack methods are trained and tested separately . As shown in Figs. 3 , and Figs. S1 and S2 in SI that the value of er is visibly as small as the standard deviation of the testing data, which include 100 testing samples. In T able II , the mean error is compared to the mean standard deviation of the testing data under RA. The mean error ¯ er is further averaged over the 999 data points, i.e., ¯ er equals the average value of a whole er curve. The mean standard de viation ¯ σ is the mean of the standard deviations calculated on P N = i ( i = 1 , 2 , . . . , N − 1 , N = 1000 ), i.e., the a verage value of a whole st curve. As can be seen from the table, the ¯ er v alues are less than or equal to the ¯ σ values in most cases, indicating that the overall prediction error is very small, thus the prediction of the CNN is very precise. The comparisons under TBA and TD A are presented in T able S1 of SI. T ABLE II: The mean error of prediction vs. the mean standard deviation of the testing data for the unweighted networks under RA. h k i = 2 h k i = 5 h k i = 8 h k i = 10 RA ER ¯ er 0.017 0.017 0.013 0.011 ¯ σ 0.019 0.017 0.015 0.013 SF ¯ er 0.018 0.020 0.023 0.024 ¯ σ 0.021 0.024 0.026 0.026 QSN ¯ er 0.015 0.014 0.013 0.012 ¯ σ 0.018 0.016 0.014 0.013 SW ¯ er 0.015 0.013 0.013 0.011 ¯ σ 0.015 0.015 0.014 0.012 B. Extension of Experiments The pre vious subsection has demonstrated that the (struc- tural) controllability robustness performance of various net- works, with different average degrees under different attacks, can be well predicted. Here, the experiments are further extended to predict state controllability curv es of weighted networks, with network size set to N = 800 , 1000 , and 1200 , respectively . For each network size setting, a new CNN is trained. The a v erage de gree is fix ed to h k i = 10 . The CNN structure and configurations remain the same as in the experiments reported in Subsection IV -A , where only the input and output sizes are modified. The experimental results are shown in Fig. 4 and T able III . Fig. 4 shows that the prediction error er remains low when the network size is varied from 800 , to 1000 , then to 1200 . Once again, in T able III the comparison between the mean error ¯ er of the results and the mean standard deviation ¯ σ of the testing data shows very high precision of the prediction. The extensibility of the trained CNN is in v estigated, when the networks of the training and testing sets hav e different av erage degrees. The CNN trained in Subsection IV -A (for RA) is reused here without further training, where unweighted HTTPS://DOI.ORG/10.1109/TCYB.2020.3013251 (SEPTEMBER 2020) 7 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA ER - h k i =2 er st pv tv (a) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA ER - h k i =5 (b) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA ER - h k i =8 (c) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA ER - h k i =10 (d) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA SF - h k i =2 (e) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA SF - h k i =5 (f) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA SF - h k i =8 (g) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA SF - h k i =10 (h) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA QSN - h k i =2 (i) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA QSN - h k i =5 (j) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA QSN - h k i =8 (k) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA QSN - h k i =10 (l) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA SW - h k i =2 (m) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA SW - h k i =5 (n) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA SW - h k i =8 (o) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA SW - h k i =10 (p) Fig. 3: [Color online] Results of CNN controllability curve prediction under random attacks. P N represents the number of nodes having been removed from the network; n D is calculated by Eqs. ( 1 ) and ( 4 ). T ABLE III: The mean error of prediction vs. the mean standard deviation of the testing data for the weighted networks. N = 800 N = 1000 N = 1200 RA ER ¯ er 0.013 0.014 0.010 ¯ σ 0.014 0.013 0.011 SF ¯ er 0.025 0.022 0.021 ¯ σ 0.031 0.028 0.025 QSN ¯ er 0.014 0.014 0.011 ¯ σ 0.016 0.014 0.012 SW ¯ er 0.014 0.012 0.010 ¯ σ 0.013 0.012 0.011 networks with a verage degrees h k i = 2 , 5 , 8 , and 10 respec- tiv ely , are employed. Then, the CNN is used to predict the controllability robustness for the networks with h k i = 3 and 7 respectiv ely . The network size is N = 1000 and the structural controllability is calculated. Compared to Fig. 3 , where the training and testing data are drawn from the same distribution, when the training and testing data have different distributions, the prediction performances of ER (Figs. 5 (a) and (e)), QSN (Figs. 5 (c) and (g)), and SW (Figs. 5 (d) and (h)) are clearly worse. In contrast, the controllability robustness of SF (Figs. 5 (b) and (f)) can be well predicted. T able IV shows that, for ER, QSN, and SW , the mean errors of prediction ¯ er are about 2 to 4 times greater than the mean standard de viations ¯ σ of the testing data; while for SF , the prediction reaches a very low mean error that is close to ¯ σ . It is remarked that, when the training and testing data are drawn from different distributions, a more suitable machine learning technique might be transfer learning [ 57 ]. Finally , consider dif ferent sizes of training data in the HTTPS://DOI.ORG/10.1109/TCYB.2020.3013251 (SEPTEMBER 2020) 8 0 200 400 600 800 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA ER - h k i =10 er st pv tv (a) weighted ER N = 800 0 200 400 600 800 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA SF - h k i =10 (b) weighted SF N = 800 0 200 400 600 800 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA QSN - h k i =10 (c) weighted QSN N = 800 0 200 400 600 800 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA SW - h k i =10 (d) weighted SW N = 800 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA ER - h k i =10 (e) weighted ER N = 1000 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA SF - h k i =10 (f) weighted SF N = 1000 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA QSN - h k i =10 (g) weighted QSN N = 1000 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA SW - h k i =10 (h) weighted SW N = 1000 0 200 400 600 800 1000 1200 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA ER - h k i =10 (i) weighted ER N = 1200 0 200 400 600 800 1000 1200 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA SF - h k i =10 (j) weighted SF N = 1200 0 200 400 600 800 1000 1200 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA QSN - h k i =10 (k) weighted QSN N = 1200 0 200 400 600 800 1000 1200 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA SW - h k i =10 (l) weighted SW N = 1200 Fig. 4: [Color online] Results of CNN controllability curve prediction on weighted networks under different attacks. P N represents the number of nodes having been removed from the network; n D is calculated by Eqs. ( 1 ) and ( 3 ). 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA ER - h k i =3 er st pv tv (a) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA SF - h k i =3 (b) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA QSN - h k i =3 (c) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA SW - h k i =3 (d) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA ER - h k i =7 (e) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA SF - h k i =7 (f) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA QSN - h k i =7 (g) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D RA SW - h k i =7 (h) Fig. 5: [Color online] Results of CNN controllability curve prediction on unweighted networks with h k i = 3 and 7 respectiv ely , under random attacks. The CNN is trained in the same way as that in Fig. 3 ( h k i = 2 , 5 , 8 , and 10 ). P N represents the number of nodes removed from the network; n D is calculated by Eqs. ( 1 ) and ( 4 ). HTTPS://DOI.ORG/10.1109/TCYB.2020.3013251 (SEPTEMBER 2020) 9 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D ER - h k i =8 (40%) (a) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D ER - h k i =8 (60%) (b) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D ER - h k i =8 (80%) (c) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D ER - h k i =8 (100%) (d) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D SF - h k i =8 (40%) (e) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D SF - h k i =8 (60%) (f) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D SF - h k i =8 (80%) (g) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D SF - h k i =8 (100%) (h) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D QSN - h k i =8 (40%) (i) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D QSN - h k i =8 (60%) (j) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D QSN - h k i =8 (80%) (k) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D QSN - h k i =8 (100%) (l) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D SW - h k i =8 (40%) (m) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D SW - h k i =8 (60%) (n) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D SW - h k i =8 (80%) (o) 0 200 400 600 800 1000 P N 10 -4 10 -3 10 -2 10 -1 10 0 n D SW - h k i =8 (100%) (p) Fig. 6: [Color online] Results of CNN controllability curve prediction under random attacks. The size of training data is set to 40% , 60% , 80% , and 100% of the data size used in the paper , where 100% represents a training set of 800 instances. The av erage degree is set to h k i = 8 . T ABLE IV: The mean error of prediction vs. the mean standard deviation, where the training and testing data have different av erage degrees. h k i = 3 h k i = 7 RA ER er 0.058 0.023 ¯ σ 0.020 0.016 SF ¯ er 0.025 0.022 ¯ σ 0.024 0.027 QSN ¯ er 0.044 0.063 ¯ σ 0.016 0.015 SW ¯ er 0.037 0.026 ¯ σ 0.015 0.014 settings of Subsection IV -A , where 800 training instances are employed for each topology with a giv en h k i . Next, the size of training data is reduced to 40% , 60% , and 80% of that, respectiv ely . Meanwhile, the data sizes of cross validation set and testing set remain the same. Figure 6 shows the prediction results when h k i = 8 . It can be seen that a smaller size of training data does not influence the prediction performance for SF and QSN, but clearly influ- ences the results for ER and SW . This is because SF and QSN hav e strong topological characteristics. A full set of prediction results for the four network topologies with h k i = 2 , 5 , 8 , and 10 , are shown in Figs. S3–S6, respectively . The av erage error comparison is presented in T able S2. It is revealed that, if a network has strong topological characteristics (e.g., SF and QSN), or if its average degree is low (e.g., h k i = 2 ), then a small training data size can be used; otherwise, a setting as in HTTPS://DOI.ORG/10.1109/TCYB.2020.3013251 (SEPTEMBER 2020) 10 Subsection IV -A is recommended. C. Computational Costs 0 1.28 2.56 3.84 5.12 6.4 7.68 8.96 10.24 11.52 12.8 10 -2 10 -1 10 0 10 1 10 2 Loss Value ep1 ep2 ep3 ep4 ep5 ep6 ep7 ep8 ep9 ep10 (a) RA 10 3 0 1.28 2.56 3.84 5.12 6.4 7.68 8.96 10.24 11.52 12.8 10 -2 10 -1 10 0 10 1 10 2 Loss Value ep1 ep2 ep3 ep4 ep5 ep6 ep7 ep8 ep9 ep10 (b) TBA 10 3 0 1.28 2.56 3.84 5.12 6.4 7.68 8.96 10.24 11.52 12.8 Training 10 -2 10 -1 10 0 10 1 10 2 Loss Value ep1 ep2 ep3 ep4 ep5 ep6 ep7 ep8 ep9 ep10 (c) TDA 10 3 Fig. 7: The con ver gence process of loss value calculated by Eq. ( 5 ) during the CNN training of (a) RA; (b) TBA; and (c) TD A. The horizontal axis ‘Training’ represents the number of instances trained. The red curve represents the exponentially weighted averages (with β = 0 . 9 ) for reference. There are 10 epochs in total. In each epoch, 4 × 4 × 800 = 12800 instances are trained. Giv en an N -node network without self-loops and multiple links, there could be N · ( N − 1) directed edges at most. For sparse networks considered here, with a small av erage degree h k i = a , there are aN edges in total, with N · ( N − 1) aN possible combinations. This shows the impossibility of e xhausti v ely enumerating all possible networks with fixed size and av erage degree. Further , with a giv en adjacency matrix at hand, the simulation to measure its controllability rob ustness is non- trivial. The simulation process should be iterated for N − 1 times. At each time step t , when t nodes have been removed, the major computational cost includes: 1) to find the node with the maximum betweenness or degree among the present N − t nodes; 2) to calculate the current controllability , using Eq. ( 3 ) or Eq. ( 4 ), both are time-consuming in traditional simulation. Empirically , given a PC with configuration as introduced abov e, the elapsed time is about 90 seconds for a QSN with N = 1000 and h k i = 10 under the attack by TD A, to collect a controllability robustness curve by simulation. In contrast, it needs less than 0.2 seconds to get a controllability robustness predicted curve by a well-trained CNN. The training overhead is also low , which costs less than 5 hours to train a CNN using 4 × 4 × 800 samples. The con v ergence process of loss values is plotted in Fig. 7 . An example of run time comparison is av ailable with source codes 7 . In summary , it is not only effecti ve, b ut also ef ficient to train a CNN and then use it to predict the network controllability robustness. 7 https://fylou.github .io/sourcecode.html V . C O N C L U S I O N S Network controllability robustness, which reflects how well a networked system can maintain a full control under various malicious attacks, can be measured via attack simulations, which returns the true values of the controllability robustness but is computationally costly and time consuming in con- ventional approaches. In this paper , the con volutional neural network is employed to predict the controllability robustness, which returns encouraging results, in the sense that the predic- tion error is of the same magnitude as the standard de viation of the data samples, with attractiv ely low computational costs. Con v olutional neural network is adopted in this study , for the following reasons: 1) no netw ork topological features ha v e been found and reported in the literature, to provide a clear correlation with the controllability robustness measure; 2) the adjacency matrix of a complex network can be processed as a gray-scale image; 3) con volutional neural network technique has been successfully applied to image processing where no clear feature-label correlations are gi ven in advance. The present study has confirmed that conv olutional neural network is indeed an excellent choice for predicting the complex network controllability robustness. In this study , extensi ve experimental simulations were carried out to predict the con- trollability robustness of four typical network topologies, in both weighted and unweighted settings, with different network sizes and av erage degrees. F or all cases, the con v olutional neural network tool is proved to provide accurate and reliable predictions of the controllability robustness for all simulated networks under different kinds of malicious attacks. Future research aims to develop analytic methods for in-depth studies of the controllability robustness and other related issues in general complex networks. R E F E R E N C E S [1] A.-L. Barab ´ asi, Network Science . Cambridge Univ ersity Press, 2016. [2] M. E. Newman, Networks: An Intr oduction . Oxford University Press, 2010. [3] G. Chen, X. W ang, and X. Li, Fundamentals of Complex Networks: Models, Structur es and Dynamics , 2nd ed. John W iley & Sons, 2014. [4] Y .-Y . Liu, J.-J. Slotine, and A.-L. Barab ´ asi, “Controllability of complex networks, ” Nature , vol. 473, no. 7346, pp. 167–173, 2011. [5] Z. Z. Y uan, C. Zhao, Z. R. Di, W .-X. W ang, and Y .-C. Lai, “Exact controllability of complex networks, ” Natur e Communications , vol. 4, p. 2447, 2013. [6] M. P ´ osfai, Y .-Y . Liu, J.-J. Slotine, and A.-L. Barab ´ asi, “Effect of correlations on network controllability , ” Scientific Reports , vol. 3, p. 1067, 2013. [7] G. Menichetti, L. Dall’Asta, and G. Bianconi, “Network controllability is determined by the density of low in-degree and out-degree nodes, ” Physical Review Letters , vol. 113, no. 7, p. 078701, 2014. [8] A. E. Motter , “Networkcontrology , ” Chaos: An Interdisciplinary Journal of Nonlinear Science , vol. 25, no. 9, p. 097621, 2015. [9] L. W ang, X. W ang, G. Chen, and W . K. S. T ang, “Controllability of networked mimo systems, ” Automatica , vol. 69, pp. 405–409, 2016. [10] Y .-Y . Liu and A.-L. Barab ´ asi, “Control principles of complex systems, ” Review of Modern Physics , vol. 88, no. 3, p. 035006, 2016. [11] L. W ang, X. W ang, and G. Chen, “Controllability of networked higher- dimensional systems with one-dimensional communication channels, ” Royal Society Philosophical T ransactions A , vol. 375, no. 2088, p. 20160215, 2017. [12] L.-Z. W ang, Y .-Z. Chen, W .-X. W ang, and Y .-C. Lai, “Physical con- trollability of complex networks, ” Scientific Reports , vol. 7, p. 40198, 2017. HTTPS://DOI.ORG/10.1109/TCYB.2020.3013251 (SEPTEMBER 2020) 11 [13] Y . Zhang and T . Zhou, “Controllability analysis for a networked dynamic system with autonomous subsystems, ” IEEE T ransactions on Automatic Contr ol , vol. 62, no. 7, pp. 3408–3415, 2016. [14] E. W u-Y an, R. F . Betzel, E. T ang, S. Gu, F . Pasqualetti, and D. S. Bassett, “Benchmarking measures of network controllability on canonical graph models, ” Journal of Nonlinear Science , pp. 1–39, 2018. [15] Y . Hao, Z. Duan, and G. Chen, “Further on the controllability of networked MIMO L TI systems, ” International Journal of Robust and Nonlinear Contr ol , vol. 28, no. 5, pp. 1778–1788, 2018. [16] L. Xiang, F . Chen, W . Ren, and G. Chen, “ Adv ances in network controllability , ” IEEE Circuits and Systems Magazine , vol. 19, no. 2, pp. 8–32, 2019. [17] G. W en, X. Y u, W . Y u, and J. L ¨ u, “Coordination and control of complex network systems with switching topologies: A survey , ” IEEE T ransactions on Systems, Man, and Cybernetics: Systems , 2020, doi:10.1109/TSMC.2019.2961753. [18] P . Holme, B. J. Kim, C. N. Y oon, and S. K. Han, “ Attack vulnerability of complex networks, ” Physical Review E , vol. 65, no. 5, p. 056109, 2002. [19] B. Shargel, H. Sayama, I. R. Epstein, and Y . Bar-Y am, “Optimization of robustness and connectivity in complex networks, ” Physical Review Letters , vol. 90, no. 6, p. 068701, 2003. [20] C. M. Schneider , A. A. Moreira, J. S. Andrade, S. Havlin, and H. J. Herrmann, “Mitigation of malicious attacks on networks, ” Proceedings of the National Academy of Sciences , vol. 108, no. 10, pp. 3838–3841, 2011. [21] Y .-Y . Liu, J.-J. Slotine, and A.-L. Barab ´ asi, “Control centrality and hierarchical structure in complex networks, ” PLOS ONE , vol. 7, no. 9, p. e44459, 2012. [22] A. Bashan, Y . Berezin, S. Buldyrev , and S. Havlin, “The extreme vulnerability of interdependent spatially embedded networks, ” Natur e Physics , vol. 9, pp. 667–672, 2013. [23] Y .-D. Xiao, S.-Y . Lao, L.-L. Hou, and L. Bai, “Optimization of ro- bustness of network controllability against malicious attacks, ” Chinese Physics B , vol. 23, no. 11, p. 118902, 2014. [24] C.-L. Pu, W .-J. Pei, and A. Michaelson, “Robustness analysis of network controllability , ” Physica A: Statistical Mechanics and its Applications , vol. 391, no. 18, pp. 4420–4425, 2012. [25] S. Nie, X. W ang, H. Zhang, Q. Li, and B. W ang, “Robustness of controllability for networks based on edge-attack, ” PLoS One , vol. 9, no. 2, p. e89066, 2014. [26] S. Buldyrev , R. Parshani, G. Paul, H. Stanley , and S. Havlin, “Catas- trophic cascade of failures in interdependent networks, ” Natur e , vol. 464, p. 1025, 2010. [27] Y . Lou, L. W ang, and G. Chen, “T oward stronger robustness of network controllability: A snapback network model, ” IEEE T r ansactions on Cir cuits and Systems I: Regular P aper s , vol. 65, no. 9, pp. 2983–2991, 2018. [28] J. Xu, J. W ang, H. Zhao, and S. Jia, “Improving controllability of complex networks by rewiring links regularly , ” in Chinese Contr ol and Decision Conference (CCDC) , 2014, pp. 642–645. [29] L. Hou, S. Lao, B. Jiang, and L. Bai, “Enhancing comple x network con- trollability by rewiring links, ” in International Conference on Intelligent System Design and Engineering Applications (ISDEA) . IEEE, 2013, pp. 709–711. [30] G. Chen, Y . Lou, and L. W ang, “ A comparativ e study on controllability robustness of complex networks, ” IEEE Tr ansactions on Cir cuits and Systems II: Express Briefs , vol. 66, no. 5, pp. 828–832, 2019. [31] Y . Lou, L. W ang, and G. Chen, “Enhancing controllability robustness of q -snapback networks through redirecting edges, ” Resear ch , vol. 2019, no. 7857534, 2019. [32] J. Schmidhuber, “Deep learning in neural networks: An ov erview , ” Neural Networks , vol. 61, pp. 85–117, 2015. [33] T . W ang, D. J. Wu, A. Coates, and A. Y . Ng, “End-to-end text recog- nition with convolutional neural networks, ” in International Conference on P attern Recognition (ICPR 2012) . IEEE, 2012, pp. 3304–3308. [34] S. Lai, L. Xu, K. Liu, and J. Zhao, “Recurrent conv olutional neural networks for te xt classification, ” in AAAI Confer ence on Artificial Intelligence , 2015, pp. 2267–2273. [35] X. Zhang, J. Zhao, and Y . LeCun, “Character-le v el con v olutional networks for text classification, ” in Advances in Neural Information Pr ocessing Systems (NIPS 2015) , 2015, pp. 649–657. [36] O. Abdel-Hamid, A.-r . Mohamed, H. Jiang, and G. Penn, “ Applying con volutional neural networks concepts to hybrid NN-HMM model for speech recognition, ” in International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2012, pp. 4277–4280. [37] O. Abdel-Hamid, A.-R. Mohamed, H. Jiang, L. Deng, G. Penn, and D. Y u, “Conv olutional neural networks for speech recognition, ” IEEE/ACM T ransactions on Audio, Speech, and Language Processing , vol. 22, no. 10, pp. 1533–1545, 2014. [38] W . Y in, H. Sch ¨ utze, B. Xiang, and B. Zhou, “ ABCNN: Attention-based con volutional neural network for modeling sentence pairs, ” T ransactions of the Association for Computational Linguistics , vol. 4, pp. 259–272, 2016. [39] X. Qiu and X. Huang, “Con volutional neural tensor network architec- ture for community-based question answering, ” in International Joint Confer ence on Artificial Intelligence , 2015, pp. 1305–1311. [40] A. Krizhevsky , I. Sutskev er , and G. E. Hinton, “Imagenet classification with deep conv olutional neural networks, ” in Advances in Neural Infor- mation Pr ocessing Systems (NIPS 2012) , 2012, pp. 1097–1105. [41] A. Karpathy , G. T oderici, S. Shetty , T . Leung, R. Sukthankar, and L. Fei-Fei, “Large-scale video classification with convolutional neural networks, ” in IEEE Confer ence on Computer V ision and P attern Recog- nition (CVPR) , 2014, pp. 1725–1732. [42] H. Li, Z. Lin, X. Shen, J. Brandt, and G. Hua, “ A conv olutional neural network cascade for face detection, ” in IEEE Conference on Computer V ision and P attern Recognition (CVPR) , 2015, pp. 5325–5334. [43] E. Ahmed, M. Jones, and T . K. Marks, “ An improv ed deep learning architecture for person re-identification, ” in IEEE Conference on Com- puter V ision and P attern Recognition (CVPR) , 2015, pp. 3908–3916. [44] S. Zhou, J. W ang, J. W ang, Y . Gong, and N. Zheng, “Point to set similarity based deep feature learning for person re-identification, ” in IEEE Confer ence on Computer V ision and P attern Recognition (CVPR) , 2017, pp. 3741–3750. [45] O. Ronneberger , P . Fischer, and T . Brox, “U-Net: Conv olutional net- works for biomedical image segmentation, ” in International Confer ence on Medical Image Computing and Computer-Assisted Intervention . Springer , 2015, pp. 234–241. [46] S. Kiranyaz, T . Ince, and M. Gabbouj, “Real-time patient-specific ecg classification by 1-d con v olutional neural networks, ” IEEE T ransactions on Biomedical Engineering , vol. 63, no. 3, pp. 664–675, 2015. [47] K. Simonyan and A. Zisserman, “V ery deep conv olutional networks for large-scale image recognition, ” arXiv Pr eprint: 1409.1556 , 2014. [48] T . Mikolov , K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space, ” arXiv pr eprint: 1301.3781 , 2013. [49] G. Y an, P . E. V ´ ertes, E. K. T owlson, Y . L. Chew , D. S. W alker , W . R. Schafer , and A.-L. Barab ´ asi, “Network control principles predict neuron function in the caenorhabditis elegans connectome, ” Natur e , vol. 550, no. 7677, p. 519, 2017. [50] X. Glorot, A. Bordes, and Y . Bengio, “Deep sparse rectifier neural networks, ” in International Confer ence on Artificial Intelligence and Statistics , 2011, pp. 315–323. [51] P . Erd ¨ os and A. R ´ enyi, “On the strength of connectedness of a random graph, ” Acta Mathematica Hungarica , vol. 12, no. 1-2, pp. 261–267, 1964. [52] K.-I. Goh, B. Kahng, and D. Kim, “Univ ersal behavior of load distri- bution in scale-free networks, ” Physical Revie w Letters , vol. 87, no. 27, p. 278701, 2001. [53] F . Sorrentino, “Effects of the network structural properties on its con- trollability , ” Chaos: An Interdisciplinary Journal of Nonlinear Science , vol. 17, no. 3, p. 033101, 2007. [54] M. E. Newman and D. J. W atts, “Renormalization group analysis of the small-world network model, ” Physics Letters A , vol. 263, no. 4-6, pp. 341–346, 1999. [55] M. Niepert, M. Ahmed, and K. Kutzkov , “Learning con volutional neural networks for graphs, ” in International Confer ence on Machine Learning (ICML) , 2016, pp. 2014–2023. [56] D. P . Kingma and J. Ba, “ Adam: A method for stochastic optimization, ” arXiv Preprint: 1412.6980 , 2014. [57] S. J. Pan and Q. Y ang, “ A survey on transfer learning, ” IEEE T r ansac- tions on Knowledge and Data Engineering , vol. 22, no. 10, pp. 1345– 1359, 2009.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment