Multimodal active speaker detection and virtual cinematography for video conferencing
Active speaker detection (ASD) and virtual cinematography (VC) can significantly improve the remote user experience of a video conference by automatically panning, tilting and zooming of a video conferencing camera: users subjectively rate an expert …
Authors: Ross Cutler, Ramin Mehran, Sam Johnson
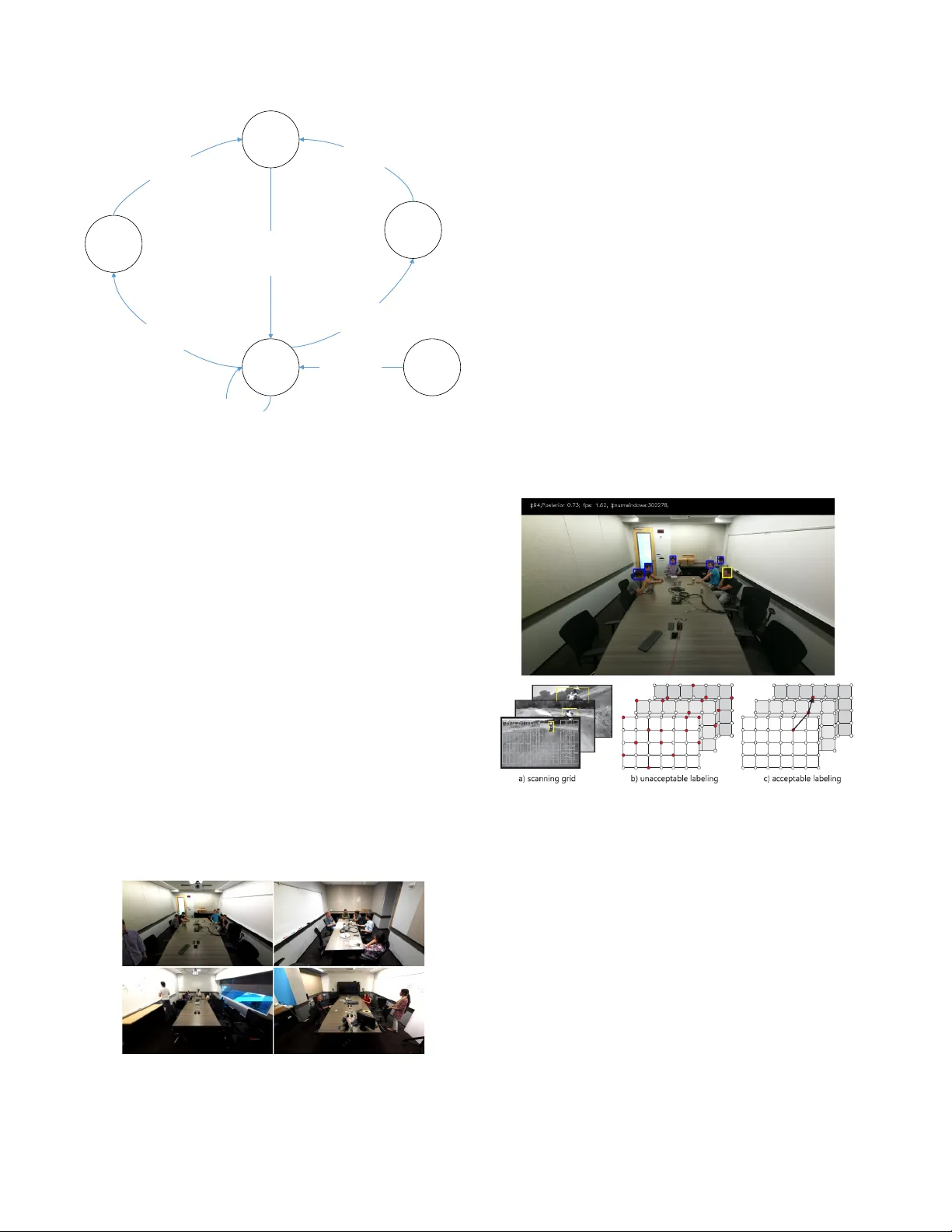
Multimodal active speaker detection and virtual cinematography for video conferencing Ross Cutler 1 , Ramin Mehran 2* , Sam Johnson 3* , Cha Zhang 1 , Adam Kirk 4* , Oliver Whyte 4* , Adarsh Kowdle 5* 1 Microsoft Corp, Redmond, WA 2 Zillow, Seattle, WA 3 Facebook, Menlo Park, CA 4 Omnivor, Seattle, WA 5 perceptiveIO, San Francisco, CA {rcutler,chazhang}@microsoft.com, {rmehran,sammoj,adam.g.kirk,oawhyte,adarsh.kp}@gmail.com ABSTRACT Active speaker detecti on (ASD) and virtual cine matography (VC) can significantly improve the remote user experience of a video conference by automatically panning, tilting and zooming of a video conferencing camera: users subjectively rate an ex pert video cinematographer ’s vi deo significantly higher t han unedited video. We describe a new autom ated ASD and VC tha t performs withi n 0.3 MOS of an expert cin ematogr apher based on subjec tive rat ings wit h a 1 - 5 sca le. This system uses a 4K wide - FOV camera, a dep th camera, and a microphone array ; it extracts features from each modalit y and trai ns an ASD us ing an AdaBoo st mac hine l earnin g system that is very efficient and runs in real - time. A VC is similarly trained using mach ine learning to optimize the subjective quality of the overall experience . T o avoi d dis tracting the room part icipants and reduce switching latency the system has no moving parts – the VC works by cro pping and zo oming the 4K wid e - FOV video stream. The system was tuned and evaluated using extensive crowdsourcing techniques and evalu ated on a datas et with N= 100 meeting s , each 2 - 5 minutes in length . Index Terms — Ac tive speaker detection, virtual cinematograph y, video conferencing, machine learni ng, computer vision, sound source localization, multimodal fusion, crowdsourcing 1. INTRODUCTION Video conferenc ing is widely used for remote collaborat ion , and m any conference rooms in businesses have a video conferenci ng system installed to help facilitate remote collaboration for employees. A few commercial video conferenci ng systems (e.g., [1] , [2]) have active speaker detection (A SD) to track th e active speaker and give an enhanced video experience to the far - end (e.g., [3] , [4] , [5] ) but the vast majority of video conferencing systems do not. ASD allows the far - end participants to see who is currently speaking, which is especiall y use ful when t he con ference room is large or t he remote video is rendered on a small display due to small screen size , small render size, or limited bandwidth. For example, in Fi gure 1 a 480p vide o strea m is viewed remotely on a smartphone, captured from a 2160p video confer encing camera. If the original video is scaled to display at 480p or even in the 2160p video is show n on a smartphone , the faces are too small to recognize reliably, greatly diminishing the value of video for remote collaboration. In contrast, the cropped video stream is much more informative. * Work do ne whil e at Mi crosoft Corp. Some of the limitat ions of existin g ASD solutions are ( 1) available commercial systems have high latency ( e.g., >2s) , (2) the systems use multi ple mechanical pan - tilt - zoom (PTZ) cameras and /or large 2D microphone arr ays, which can be distract ing, (3) the systems are expensive, li miting the number of deployments. In this paper, we describe a new vide o conferencing system wit h ASD that addresses these issues. In particular, (1) our system achieves <200ms A SD +VC latency (2) the system contains no moving parts or large 2D mic rophone arrays; it levera ges a dept h camera to reduce physical size and noise, thus avoidi ng distractions withi n the conference r oom, and (3) the s ystem uses a single 4K wide - FOV camera t o replace multiple expens ive PTZ cameras, which significantly reduced cost , and (4) our system achieves subjecti ve performance within 0.3 MOS (using a 1 - 5 scale) of an expert virtual cinematographer . Figure 1 : Left : Original 2160p video; Right : Cropped 480p image from a video conference 2. RELATED WORK The ASD and VC devel oped by Zhang et. al [5] is the most related work to ours. In that work , a one - dimensional ASD and VC were trained using AdaBoos t. However , that system only had to estimate azimuth, not zoom or el evation, which greatly simplifie d the problem. Co mmercially avail able systems such as [1] and [2] solve the P TZ problem us ing large two - dimensional microp hone arrays to estimate elevation and depth. However , these systems have significant delays in changing to the active speaker (>2s). Our system requirements are to switch to the active speaker < 200ms with no se con dary camera nor lar ge 2D microphone array . Syst ems with digital PTZ such as [1] and [6] also have significant delays (>2s) and do not handle large rooms . An early work in multimodal ASD used TDNN [7] , and the re h as been signific ant recent wor k usin g DNN - based ASD ( e.g., [8] , [9] , [10] , [11] , [12] , [13] , [14] ) . There is now a large dataset creat ed for this task [15] with an ASD competition [10] . However , we are not aware of any ASD (DNN or otherwise) that does low - latency accurate PTZ witho ut lar ge 2D SLL ar rays . In addition, this is the first study we are aware of that provides a subjective evaluation of the VC perform ance compared to a human expert . 3. SYSTEM OVERVIEW Our syst em uses t he foll owing mult imodal s ensors: • A 4 - element linear microphone array loga rithmically spaced as shown in Figure 4 with a total width of 215 mm . • A d epth camera with a 512x 424 resoluti on and 0.5 - 10m working range. • A 4K (384 0x2160) RGB vi deo camera with a 100 ° HFOV. The micropho ne array use s unidirectional micro phones and is sampled at 16 kHz. The depth camera and RGB camera are synchronized with the same start - of - frame signal. Video and audio frames use a common timestamp to facilitate synchronization between audio/video modal ities. The system da taflow is shown in Figure 2 . The microphone array is processed with the s ound s ource localization (SSL) method described in [17] . SSL features are estimated from the SSL probability distribution function (PDF). A set of 15 such features are defined using local 𝐿 ! and global 𝐿 " mi nima and maxima o ver the PDF, described in Table 1 . The depth camera is used to estimate the location of the conference room table to limit the range for the PTZ locations . In addition , depth features based on Haar - like wavelets ( Figure 5 ) and short and long - range motion features as estimated in [5] are estimated from t he depth camera. Finally , the depth camera is used to estimate the zoom used in the VC. The RGB video camera is used to estimate similar motion and video features; in additional a face detector is used to estimate face rectangles. All the above features are fed into an AdaB oost - based ASD . The syste m architect ure is shown in Figure 3 . The system runs on a single - core of a 2 GHz Intel i5 CPU based embedded PC. There are 4 threads in t he A SD an d VC t hat process the features and evalu ate the trained AdaB oost ASD and state - machine VC. The VC is implemented as a state - machine descri bed in Figure 6 . The VC has f our states : (1) st ationary, (2) update target f or a global view (zoom out), (3) update t he target f or a cut (pan/tilt/zoom), and (4) update the window. The par ameters have been t uned to maximize user rating s as d escribe d in l ater s e ctions. Figure 2 : System dataflow Figure 3 : System Architecture Figure 4 : Sound Source Localiz ation PDF 1. # 𝒎𝒂𝒙 𝒍 $# 𝒎𝒊𝒏 𝒈 # 𝒎𝒂𝒙 𝒈 $# 𝒎𝒊𝒏 𝒈 % ()* + &% (,- . % ()* . &% (,- . 2. " # 𝒎𝒊𝒏 𝒍 $# 𝒎𝒊𝒏 𝒈 # 𝒎𝒂𝒙 𝒈 $# 𝒎𝒊𝒏 𝒈 3. # 𝒂𝒗𝒈 𝒍 $# 𝒎𝒊𝒏 𝒈 # 𝒎𝒂𝒙 𝒈 $# 𝒎𝒊𝒏 𝒈 4. # 𝒎𝒊𝒅 𝒍 $# 𝒎𝒊𝒏 𝒈 # 𝒎𝒂𝒙 𝒈 $# 𝒎𝒊𝒏 𝒈 5. # 𝒎𝒂𝒙 𝒍 # 𝒎𝒊𝒏 𝒍 6. # 𝒎𝒂𝒙 𝒍 # 𝒂𝒗𝒈 𝒍 7. " # 𝒎𝒊𝒏 𝒍 # 𝒂𝒗𝒈 𝒍 8. # 𝒎𝒊𝒏 𝒍 # 𝒂𝒗𝒈 𝒍 9. " # 𝒎𝒂𝒙 𝒍 $# 𝒎𝒊𝒏 𝒍 # 𝒂𝒗𝒈 𝒍 10. # 𝒎𝒂𝒙 𝒍 # 𝒎𝒂𝒙 𝒈 11. # 𝒎𝒊𝒏 𝒍 # 𝒎𝒂𝒙 𝒈 12. # 𝒂𝒗𝒈 𝒍 # 𝒎𝒂𝒙 𝒈 13. # 𝒎𝒊𝒅 𝒍 # 𝒎𝒂𝒙 𝒈 14. # 𝒎𝒂𝒙 𝒍 $# 𝒎𝒊𝒏 𝒍 # 𝒎𝒂𝒙 𝒈 15. 𝐿 '() * − 𝐿 +,- ! < "𝜖 Table 1 : Audio SSL features ! Figure 5 : Example video features, H aar - like wavelets Depth Camera RGB Camera Mi cro pho ne Ar ray SS L PD F Learn in g Featur es Table Geometry Mo tion Fa ce Visual features Dep th features Sensor s Active Speaker Dete ctio n Virtua l Cinematograph er D ecisio n Ma king Main Thre ad Audi o 20ms fr ames 25FPS Video 640x 36 0 @5FPS Thre ad Face Rectangles @5FPS Thre ad Depth 512x 424 @5FPS VAD SSL Motio n Acti ve Speaker Detector Virtua l Cinematographer ASD Repo rter Audi o Audi o Video Video 5FPS Depth 5FPS Face Rectang les Reques t 30FPS VAD flag 20m s 25F PS SSL PDF 20m s 25FPS Motion 5FPS Speake r Rectang le 30FPS AS Recta ngle Upda tes 5FPS SSL A n g l e ( de g ) Fr e q u e n c y Likelihood of Active Speaker 38mm 29mm 148mm ! Figure 6 : Virtual Cinematograph er state machine 4. DATA COLLECTION The system we have designe d requires a signif icant amount of training and test data for supervised learning of the ASD and VC. The primary goal for the data capture of meetings is to c apture a large variet y of meeting da ta, similar to that whic h the devi ce wil l see in actual usage . We estima ted base d on previou s work [5] that we wo uld need at least 100 meetings of 5 minutes e ach for the training and testing of the ASD and VC (we late r use d cros s - validation t o check it was sufficient). The requirements for the collection are: • Coverage of the spa ce of dif ferent: o Rooms and mee ting type s o Distrib ution an d number o f people o Speaker variatio ns and distracti ons o Lighting an d appearance variations • V ideo frame s must be label ed with : o Bounding box es around all heads in view o Current a ctive spe aker An example set of meeting s fro m this dataset are shown in Figure 7. Figure 7 : Example meeting s in the dataset We la bel ed the dataset at 5 FPS , giving 150 K total frames to label . Assuming 15 seconds to la bel the 4 - 20 heads in each frame this would be 26 strai ght days of l abeling. To sp eed this up we use d crowdsourcing for labeling . The key challenge in thi s solution is getting high - quality output from unskil led workers at low pay ($0.03/frame). We take the following process to maximize worker quality: (1) offline training with feedback , (2) q ualification of raters , (3) o nline training with feedback , (4) o nline spam checking . Finally , we take multiple annotatio ns per frame, repeating until 2 users agree for each box . Many fr ames of vi deo a re es senti ally the same – most meeting part icipant s move very l ittle . We use a sta te - of - the - art tracker to interpolate the location of pa rticipants b etween labeled frames ( Figure 8 ). Worki ng on an acti ve learning approach we: (1) s tart with a very sparse label set , (2) t rack forward and backward , (3) w hen the tracker posterior drops below a set threshold for any frame, we request labeling . For the 150 K frames of collected data , we al so wis h to know who i s act ively speakin g at that moment. We follow the same approach as for bounding boxes. Here we sho w annotators a 4 - second video with the middle frame being the fr ame of interest . Annota tors are asked to pick the speaker a t the moment bounding boxes are flashe d . Figure 8 : The tracker used in crow dsourced labeling of data 5. TRAINING AND TESTING The system was trained and tested using cros s - validation. To determine whether various components needed further improveme nts we substituted those components with ground truth data to check if there were any overall im provements. For e xample, to determine if the SSL algorithm needed improvemen t we substituted the estimated SSL with the ground truth SSL and measured the sy stem per formance diffe rence (there was little difference) . The same was do ne for the ASD and face detect or. The statisti cs of th e ASD feat ures used are given in Figur e 9 . This shows that the depth ( and the “normalized” depth which imputes missin g valu es) do minates the number of Ad aBoost featu res. Rdiff is the long - ter m image diffe rences, and Diff is the short - term image differences. Trans ition : Updating Actua l Win dow Updating Target Window For Cut Trans ition : Updating Target Window for Glob al V iew Stat ionary Initial Stat e Atomic: Save !"# start of stationary mode Stationary Test Fail & Global View Test Pass: $%&'#()*++,)-'.#+/ 012345 : 6(7 #'/8(# 9 #8# ( # ) # *= # 012345 : 6(7 #'/8(# 9 #8# ( # ) # *= # Atomic: $%&'#():.#;'<) 9 a "(𝑡)= f( 9 a "(𝑡-1),𝑊 tgt "(𝑡*) Save !"# start of stationary mode Stationary Test Fail & Cut test Pass: 9 t ( #=)"6(7)>(.# Stationary Test Pass : 9 ' "(𝑡)=𝑊 ') (𝑡 ?@= Figure 9 : Statistics of used features in Ada Boost ASD 6. RESULTS AND DISCUSSION To evaluate the system we utilize both ob jective and subjective metric s. For the objectiv e metrics , we defined four key performance indicators (KPIs) that characterize the perform ance of the ASD and VC. These KPIs are defined below: • ASD Speaker Det ection Rat e (SDR): Out of fram es containing speakers, how often the ASD found a s peaker • ASD Person Det ection Rate ( PDR): Out of fr ames contai ning speakers, how often the ASD found a p erson • ASD Fals e Negat ive Rat e (FNR) : Out of all f rames containing speakers , how often the ASD did n't f ire while someone was speaking • VC Accep table Speaker Rate (ASR): How oft en the VC produced a n “acceptabl e” crop. The crop should show a speaker, or show a person if no one is speaking The results are shown in Table 2. Small rooms fit 6 or fewer people, medium rooms fit 7-16 people, and large rooms a re >1 6 people. O verall the ASD detects the corre ct speaker 98.3% of the time, and when someone i s speaking a person is selected 99.2% of the time (a non - person i s sele cted jus t 0.8% of the time). The VC performance is better for small rooms ( VC ASR = 96.5% ) than large rooms (VC ASR = 90.4%), which is expected . Room ASD SDR ASD PDR ASD FNR VC ASR Small 97.1% 98.5% 0.1% 96.5% Medium 99.4% 99.5% 2.5% 91.5% Large 97.6% 99.0% 0.5% 90.4% Total 98.3% 99.2% 1.3% 91.4% Table 2 : ASD and VC results To deter mine what KPI cr iteria is neede d to be subje ctively good enough w e performed a subjective test using crow dsourcing. A selection of N=100 one minute videos was edited by an expert cinematographer and these videos were compared with the VC edited videos using the survey form shown in Figure 10 . Th e results are shown in Table 3 and show that the VC gets within 0.3 Mean Opinion Score ( MO S ) [18] of an expert cinematographer , which was sufficient for our requirements . Most of th e compla ints in t he VC subjective test had to do with the mishand ling of meeti ngs when the whit eboard was use d, i n whi ch the V C did not show what the remote person was writing , unlike the expert cinematographer. Figure 10 : Survey form used to rate the V C for subjective evaluation MOS Expert Cinemat ographer 4.1 ± 0.1 VC 3.8 ± 0.1 Table 3 : VC subjective results with 95% confi dence int erval 7. CONCLUSIONS We ha ve de scri bed an end - to - end system for an ASD and VC that uses multisensory input to perform wit hin 0.3 MO S of a human expert cinematographer. This is done wi th lo w late ncy and in a compact form factor with no moving parts to distract the near - end participants. Future enhancements can be made to improve the performance including: • Improving the voice activity detector to re duce incorrect jumps to, for example, squ eaky chairs, paper shu ffling, etc. • Improving whiteboard h andling to include the last say o ne minute of what was w ritten on the whiteboard in addition to the person writing on the whiteboard • Using deep learning f or bette r audio/v ideo featu res into AdaBoost, and perhaps using a DNN inst ead of AdaBoos t for improved perf ormance. 12 . REFER ENCES De pth (n orm) De pth Vid eo Rdi ff Audio Diff [1] “Poly Studio X Series,” en . [Online]. Available : https://www.polycom.com/hd - video - conferencing/room - video - systems/poly - studio -x - series.html. [2] “Cisco TelePresence SpeakerTrac k 60 - Cisco.” [Online]. Availabl e: https://www.cisco.com/c/en/ us/products/collaborati on - endpoints/telepresence - speaker - track - 60/index.html. [3] C. B. Se rgi et al. , “Smart Room: Part icipant And Sp eaker Localizatio n And Identi fication,” in Proc. I EEE Int. C onf. on Acoustics, Speech and S ignal Process ing , 2005. [4] R. Cutler et al. , “Distributed Mee tings: A Meet ing Capture and Broadcasting System,” ACM Int. Conf. Multimed . , pp. 503 – 512, Dec. 2002. [5] C. Zhang et al. , “Boosting - Based Multimodal Spe aker Detect ion for Distributed Meeting V ideos,” IEEE Trans. Multime d. , vol. 10, no. 8, pp. 1541 – 1552, Dec. 2008, doi: 10.1109/TMM.2008.2007344. [6] “Logitech MeetUp Video Conference Camera for Huddle Rooms.” [Onl ine]. Ava ilable: https:// www.logitech. com/en - us/product /meetup - conferencecam. [Accessed: 22 - Oct - 2019]. [7] R. Cutler and L. Davis, “Lo ok Who’s Tal king: Speak er Detectio n Using Video and Audio Cor relation ,” prese nted at the ICME, 200 0. [8] J. S. Chung and A. Zisserman, “Out of Time: Auto mated Lip Sync in the Wi ld,” in Compute r Vision – ACCV 2016 Worksho ps , vol. 10117, C. - S. Chen, J. Lu, and K. - K. Ma, Eds. Cham: Sp ringer Int ernational Publishing, 2017, pp. 251 – 263. [9] P. Chakravarty an d T. Tuytelaars, “Cross - modal S upervis ion for Learning Active Spe aker Detectio n in Video,” ArXiv160308907 Cs , Mar. 2016. [10] M. Sh ahid, C. Be yan, and V. Murin o, “Vo ice A ctivi ty Detectio n by Upper Body Mot ion Analy sis and Unsupervis ed Domain Adap tation, ” present ed at t he IEEE I nternati onal Conference on Computer Vision, 2 019. [11] R . Tapu, B. M ocanu, and T . Zaharia, “DE EP - HEAR: A Multi modal Subtit le Po siti oning Syste m Dedic ated to De af and Hearing - Impaired People,” IE EE Access , vol. 7, pp. 88150 – 88162, 2019, doi: 10.1109/ACCESS.2019.2925806. [12] W. He , P. Motl icek, and J. - M. Odobez , “Deep Neural Networks for Mult iple Spe aker Detec tion and Localiz ation,” 2018 IEEE Int. Conf. Robot. Aut om. ICRA , pp. 74 – 79, May 2018, doi: 10.1109/ICRA.2018.8461267. [13] I. Ariav, D. Dov, and I. Cohen, “A deep architecture for audio - visual voice activit y detection in the presence of transients,” Signal Process. , vol. 142, pp. 69 – 74, Jan. 2018, doi: 10.1016/j.sigpr o.2017.07.006. [14] S. Thermos and G. Potamianos, “Audio - visual s peech activity detection in a t wo - speaker scenario incorpo rating depth information from a profile or frontal view ,” in 2016 IEEE Spoken Language Technology Workshop (SLT) , San Diego, CA, 2016, pp. 579 – 584, doi: 10.1109/SLT.2016.7846321. [15] J. Roth et al. , “AVA - ActiveSpeaker : An Audi o - Visual Dataset for Acti ve Speake r Detecti on,” ArXiv 190101342 Cs Eess , Jan. 2019. [16] J. S. Chung, “Naver at ActivityNet Challenge 2019 -- Task B Active S peaker Det ection (AVA),” ArXiv 190610555 Cs Ees s , Jun. 2019. [17] C. Zhang, Z. Zhang, and D. Florencio, “Maximum Like lihood Sound Source Localiz ation f or Multiple Dir ectional Microp hones, ” in 2007 IEEE International Confere nce on Acoustics, Speech and S ignal Process ing - ICASSP ’07 , Honolulu, HI, 20 07, pp. I - 125 -I– 128, doi: 10.1109/ICASSP.2007.366632. [18] “ITU - T P.800: Metho ds for subj ective dete rminati on of transmission qua lity,” 1996.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment