secml: A Python Library for Secure and Explainable Machine Learning
We present \texttt{secml}, an open-source Python library for secure and explainable machine learning. It implements the most popular attacks against machine learning, including test-time evasion attacks to generate adversarial examples against deep n…
Authors: Maura Pintor, Luca Demetrio, Angelo Sotgiu
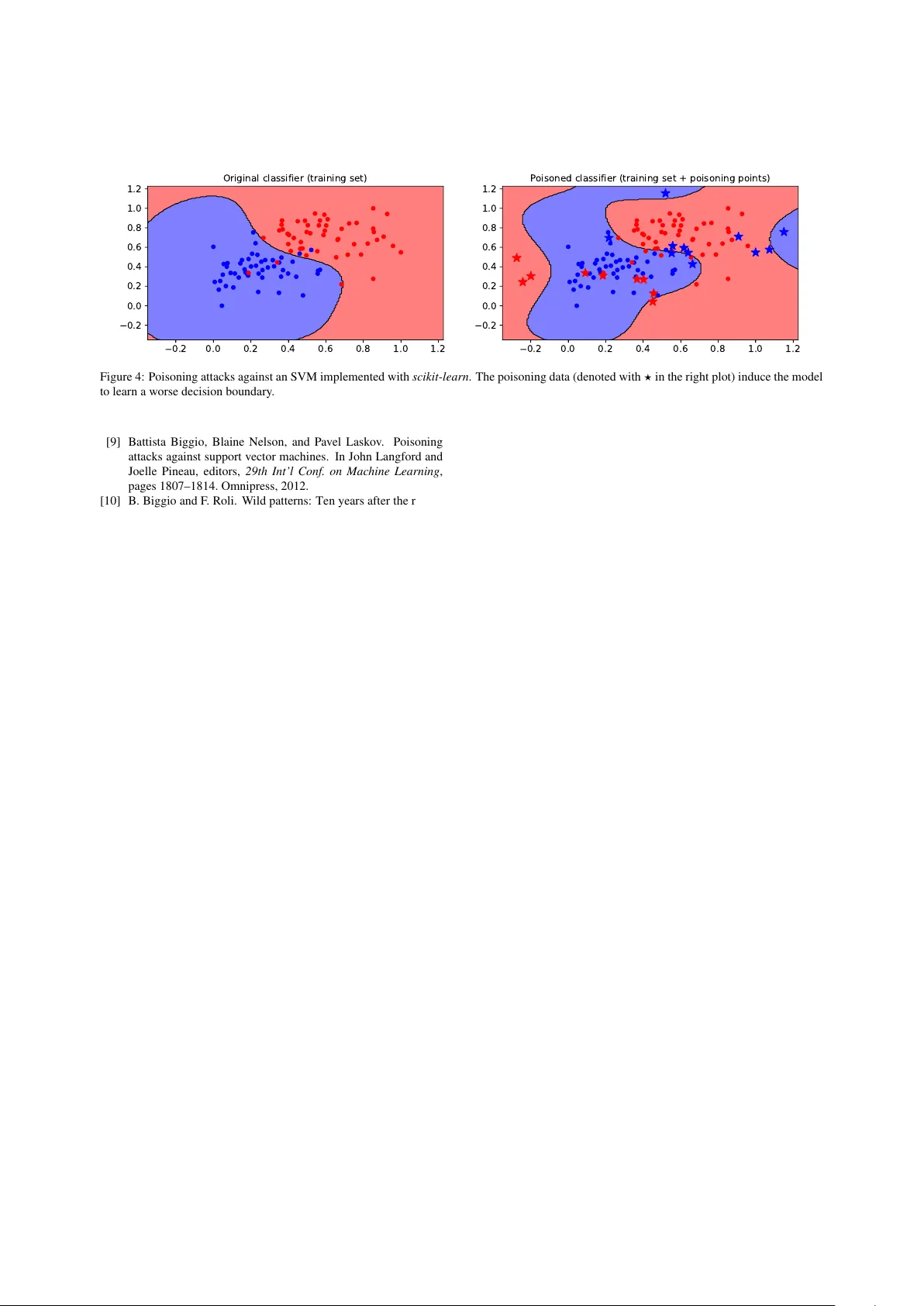
secml : Secure and Explainable Machine Learning in Python Maura Pintor a,b , Luca Demetrio a,b , Angelo Sotgiu a,b , Marco Melis a , Ambra Demontis a , Battista Biggio a,b a DIEE, University of Cagliari, V ia Mar engo, Cagliari (IT) b Pluribus One, V ia V incenzo Bellini, 9, Cagliari (IT) Abstract W e present secml , an open-source Python library for secure and explainable machine learning. It implements the most popular attacks against machine learning, including test-time e vasion attacks to generate adversarial examples against deep neural networks and training-time poisoning attacks against support v ector machines and many other algorithms. These attacks enable e v aluating the security of learning algorithms and the corresponding defenses under both white- box and black-box threat models. T o this end, secml provides b uilt-in functions to compute security e v aluation curves, showing ho w quickly classification performance decreases against increasing adv ersarial perturbations of the input data. secml also includes explainability methods to help understand why adversarial attacks succeed against a giv en model, by visualizing the most influential features and training prototypes contributing to each decision. It is distributed under the Apache License 2.0 and hosted at https://github.com/pralab/secml . K e ywor ds: Machine Learning, Security, Adversarial Attacks, Explainability, Python3 1. Introduction Machine learning is vulnerable to well-crafted at- tacks. At test time, the attacker can stage ev asion at- tacks (i.e., adversarial e xamples) [1, 2, 3, 4, 5], sponge examples [6], model stealing [7], and membership in- ference [8] attacks to violate system integrity , av ail- ability , or even its confidentiality . Similarly , at train- ing time, the attacker may target either system in- tegrity or a vailability via poisoning [9, 10] and backdoor attacks[11]. The most studied attacks, namely ev asion and poisoning, firstly explored by Biggio et al. [9, 2], are formalized as constrained optimization problems, solved through gradient-based or gradient-free algo- rithms [10, 12], depending on whether the attacker has white- or black-box access to the target system. Many libraries implement the former, howe ver , they do not allow dev elopers to assess machine learning models’ security easily . Hence, we present secml , an open- source Python library that serves as a complete tool for ev aluating and assessing the performance and robust- ness of machine-learning models. T o this end, secml implements: ( i ) a methodology for the empirical se- curity ev aluation of machine-learning algorithms under di ff erent ev asion and poisoning attack scenarios; and ( ii ) explainable methods to help understand why and how these attacks are successful. W ith respect to other popular libraries that implement attacks almost solely against Deep Neural Networks (DNNs) [13, 14, 15], secml also implements training-time poisoning attacks and computationally-e ffi cient test-time e v asion attacks against many di ff erent algorithms, including support vector machines (SVMs) and random forests (RFs). It also incorporates both the feature-based and prototype- based explanation methods proposed by [16, 17, 18]. 2. Software Description secml has a modular architecture oriented to code reuse. W e hav e defined abstract interfaces for all com- ponents, including loss functions, regularizers, optimiz- ers, classifiers, and attacks. By separating the definition of the optimization problem from the algorithm used to solve it, one can easily define novel attacks or clas- sifiers (in terms of constrained optimization problems) and then use di ff erent optimizers to obtain a solution. This is a great advantage with respect to other libraries like CleverHans [13], F oolbox [14, 19], and ART [15] as, we can switch from white-box to black-box attacks by just changing the optimizer (from a gradient-based to a gradient-free solver), without re-defining the entire optimization problem. secml integrates di ff erent components via well- designed wrapper classes. W e integrate sev eral attack implementations from CleverHans and F oolbox , by ex- Goals Integrity A vailability Knowledge White-box Black-box Capabilities Generic feature-space & W indows Programs manipulations (a) (b) Figure 1: Features av ailable in secml . On the left, the supported threat models; on the right, the structure of the packages, and the supported strategies. tending them to also track the v alues of the loss function and the intermediate points optimized during the attack iterations, as well as the number of function and gra- dient e valuations. This is useful to debug and compare di ff erent attacks, e.g., by checking their con ver gence to a local optimum and properly tuning their hyperparam- eters (e.g., step size and number of iterations). secml supports DNNs via a dedicated PyT or c h wrapper, which can be extended to include other popular deep-learning framew orks, like T ensorFlow and Ker as , and it nati vely supports scikit-learn classifiers as well. This allows us to run attacks that are implemented in CleverHans and F oolbox to universally run on both PyT orc h and scikit- learn models. Main packages. The library supports di ff erent threat models (Fig. 1a), and it is organized in di ff erent pack- ages (Fig. 1b). The adv package implements di ff er - ent adversarial attacks and provides the functionalities to perform security ev aluations. It includes target and untargeted e v asion attacks pro vided by Cle verHans and F oolbox as well as our implementations of ev asion and poisoning attacks [10]. These attacks target the feature space of a model, re gardless of its domain of application (e.g. attacking Android malware detection 1 ). Hence, dev elopers can encode ad-hoc manipulations that corre- spond to perturbations in the input space of a targeted domain (e.g. W indo ws programs [20]), and then use the algorithms included inside secml to optimize the attack. All the included attacks are listed in Fig. 1b. The ml package imports classifiers from scikit-learn and DNNs from PyT or ch . W e have extended scikit- learn classifiers with the gradients required to run ev a- 1 https://github.com/pralab/secml/blob/master/ tutorials/13- Android- Malware- Detection.ipynb sion and poisoning attacks, which have been imple- mented analytically . Our library also supports chain- ing di ff erent modules (e.g., scalers and classifiers) and can automatically compute the corresponding end-to- end gradient via the chain rule. The explanation package implements the feature- and prototype-based explanation methods [16, 17, 18]. The optim pack- age provides an implementation of the projected gra- dient descent (PGD) algorithm, and a more e ffi cient version of it that runs a bisect line search along the gradient direction (PGD-LS) to reduce the number of gradient ev aluations [21]. Finally , data provides data loaders for popular datasets, integrating those provided by scikit-learn and PyT or ch ; array provides a higher- lev el interface for both dense ( numpy ) and sparse ( scipy ) arrays, enabling the e ffi cient execution of attacks on sparse data representations; figure implements some advanced plotting functions based on matplotlib (e.g., to visualize and debug attacks); and utils provides func- tionalities for logging and parallel code execution. W e also pro vide a model zoo, av ailable on GitHub as well, 2 that contains pre-trained models to rapidly test newly implemented attacks and utilities. W e recap the main functionalities of secml in T a- ble 1, where we also compare it with other relev ant li- braries. Notably , our library is the sole that provides attack loss inspection plots to choose the appropriate at- tacks’ hyperparameters, and security ev aluation plots, to ease the complexity of assessing the robustness of machine learning models. Moreov er , the features of- fered by secml are not only related to attacking ma- chine learning models, but they are gathered to elev ate secml as a complete tool for attacking, inspecting, and 2 https://github.com/pralab/secml- zoo 2 DL frameworks support scikit-learn support Built-in attack algorithms Wraps adversarial frame works Dense / Sparse data support Security ev aluation plots Attack loss inspection plots Loss separated from Optimizer Explainability Model zoo Comprehensiv e tutorials secml X X X X X X X X X X X F oolbox X x X x x ∼ x x x X ∼ ART X X X x x x x x x x X CleverHans X x X x x x x x x x x T able 1: Comparison of secml and the other adversarial machine learning libraries. W e show whether the library o ff er full ( X ), partial ( ∼ ) or no ( x ) support of a particular feature. assessing the performances of machine learning models. T esting and documentation. W e have run extensi ve tests on macOS X, Ubuntu 16.04, Debian 9 and 10, through the GitHub Actions infrastracture, 3 with also experimental support on W indows 10 platforms. The user documentation is av ailable at https://secml. readthedocs.io/en/v0.15/ , along with a basic de- veloper guide detailing ho w to extend the ml package with other classifiers and deep-learning frameworks. The complete set of unit tests is av ailable in our repos- itory . A comprehensi ve vie w of the functionalities av ailable in secml is included in tutorials available as Jupyter notebooks. 3. Impact W e now o ff er two examples e xtracted from secml to showcase its impact: ev asion attacks against DNNs, and a poisoning attack against an SVM. Evasion attacks. W e sho w here how to use secml to run di ff erent ev asion attacks against ResNet-18, a DNN pretrained on ImageNet, av ailable from tor c hvi- sion . This example demonstrates how secml enables running CleverHans attacks (implemented in T ensor - Flow ) against PyT or ch models. Our goal is perturb- ing the image of a race car to be misclassified as a tiger , using the ` 2 -norm targeted Carlini-W agner (CW) attack (from CleverHans ), the ` 2 PGD attack imple- mented in secml , and PGD-patch, where the attacker can only change the pixels corresponding to the license plate [22]. W e run all the attacks for 50 iterations, we set the con- fidence parameter of the CW attack κ = 10 6 to generate 3 https://docs.github.com/en/actions/ automating- builds- and- tests race car tiger (CW) tiger (PGD) tiger (PGD-patch) explanations Figure 2: Adversarial images (CW , PGD, and PGD-patch) represent- ing a race car misclassified as a tiger . For PGD-patch, we also report explanations via integrated gradients. high-confidence misclassifications, and c = 0 . 4, yield- ing an ` 2 perturbation size = 1 . 87. W e bound PGD to create an adversarial image with the same perturbation size. For PGD-patch, we do not bound the perturbation size for the pixels that can be modified. The resulting adversarial images are sho wn in Fig. 2. For PGD-patch, we also highlight the most relev ant pix- els used by the DNN to classify this image as a tiger , using the inte gr ated gradients explanation method. The most relev ant pix els are found around the perturbed re- gion containing the license plate, un veiling the presence 3 0 10 20 30 40 50 iteration 0.0 0.2 0.4 0.6 0.8 1.0 loss CW PGD PGD-patch 0 10 20 30 40 50 iteration 0.0 0.2 0.4 0.6 0.8 1.0 confidence Figure 3: Attack optimization. Left : loss minimization; Right : confi- dence of source class ( race car , dashed lines) vs confidence of target class ( tiger , solid lines), across iterations. of potential adversarial manipulations. W e also visualize the performances of the attack in Fig. 3. The leftmost plot shows how the attack losses (scaled linearly in [0 , 1] to enable comparison) iteration- wise, while the rightmost plot shows ho w the confidence assigned to class race car (dashed line) decreases in fa- vor of the confidence assigned to class tiger (solid line) for each attack, across di ff erent iterations. By inspect- ing them, we can understand if these attacks have been correctly configured. For instance, by looking at the loss curves on the left, we can understand if the attacks reached conv er gence or not, thus facilitating tuning of either the step size or the number of iterations. Also, by looking at the plot on the right, it is clear that all the attacks are successful since the confidence of the target class exceeds the score of the original one. Poisoning attacks. W e also show the e ff ect of a poi- soning attack provided by secml applied to an SVM classifier implemented in scikit-learn . The experimen- tal setting and code are av ailable in one of our tutorials on GitHub 4 . Results of the successful attack are repre- sented in Fig. 4., highlighting the flexibility of secml in applying di ff erent strategies to third-party models as well, without the need of customizing them on a partic- ular framew ork. 4 https://github.com/pralab/secml/blob/master/ tutorials/05- Poisoning.ipynb 4. Conclusions and Future W ork The secml project was born more than fi ve years ago and we open-sourced it in August 2019. Thanks to an emerging community of users and developers from our GitHub repository , we firmly believ e that secml will soon become a reference tool to e valuate the security of machine-learning algorithms. W e are constantly work- ing to enrich it with new functionalities, by adding novel defenses, wrappers for other third-party libraries, and more pretrained models to the secml zoo. Acknowledgements This work has been partly supported by the PRIN 2017 project RexLearn, funded by the Italian Min- istry of Education, Univ ersity and Research (grant no. 2017TWNMH2); by the project ALOHA, under the EU’ s H2020 programme (grant no. 780788); and by the project TEST ABLE (grant no. 101019206), under the EU’ s H2020 research and innovation programme. References [1] L. Huang, A. D. Joseph, B. Nelson, B. Rubinstein, and J. D. T ygar . Adversarial machine learning. In 4th ACM W orkshop on Artificial Intelligence and Security (AISec 2011) , pages 43–57, Chicago, IL, USA, 2011. [2] B. Biggio, I. Corona, D. Maiorca, B. Nelson, N. ˇ Srndi ´ c, P . Laskov , G. Giacinto, and F . Roli. Evasion attacks against machine learning at test time. In Hendrik Blockeel, Kris- tian Kersting, Siegfried Nijssen, and Filip ˇ Zelezn ´ y, editors, Machine Learning and Knowledge Discovery in Databases (ECML PKDD), P art III , volume 8190 of LNCS , pages 387– 402. Springer Berlin Heidelberg, 2013. [3] Christian Szegedy , W ojciech Zaremba, Ilya Sutskev er , Joan Bruna, Dumitru Erhan, Ian Goodfello w , and Rob Fer gus. In- triguing properties of neural networks. In International Confer- ence on Learning Repr esentations , 2014. [4] Nicolas Papernot, P atrick McDaniel, Somesh Jha, Matt Fredrik- son, Z. Berkay Celik, and Ananthram Swami. The limitations of deep learning in adversarial settings. In Pr oc. 1st IEEE Eu- r opean Symposium on Security and Privacy , pages 372–387. IEEE, 2016. [5] Nicholas Carlini and David A. W agner. T o wards ev aluating the robustness of neural networks. In IEEE Symposium on Security and Privacy , pages 39–57. IEEE Computer Society , 2017. [6] Ilia Shumailov , Yiren Zhao, Daniel Bates, Nicolas Papernot, Robert Mullins, and Ross Anderson. Sponge examples: Energy- latency attacks on neural networks. In 2021 IEEE Eur opean Symposium on Security and Privacy (EuroS & P) , pages 212– 231. IEEE, 2021. [7] Florian T ram ` er , Fan Zhang, Ari Juels, Michael K Reiter, and Thomas Ristenpart. Stealing machine learning models via pre- diction APIs. In 25th USENIX Security Symposium (USENIX Security 16) , pages 601–618, 2016. [8] Reza Shokri, Marco Stronati, Congzheng Song, and V italy Shmatikov . Membership inference attacks against machine learning models. In 2017 IEEE Symposium on Security and Pri- vacy (SP) , pages 3–18. IEEE, 2017. 4 0.2 0.0 0.2 0.4 0.6 0.8 1.0 1.2 0.2 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Original classifier (training set) 0.2 0.0 0.2 0.4 0.6 0.8 1.0 1.2 0.2 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Poisoned classifier (training set + poisoning points) 0.2 0.0 0.2 0.4 0.6 0.8 1.0 1.2 0.2 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Accuracy on test set: 94.00% Original classifier (test set) 0.2 0.0 0.2 0.4 0.6 0.8 1.0 1.2 0.2 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Accuracy on test set: 88.00% Poisoned classifier (test set) Figure 4: Poisoning attacks against an SVM implemented with scikit-learn . The poisoning data (denoted with ? in the right plot) induce the model to learn a worse decision boundary . [9] Battista Biggio, Blaine Nelson, and Pa vel Laskov . Poisoning attacks against support vector machines. In John Langford and Joelle Pineau, editors, 29th Int’l Conf. on Machine Learning , pages 1807–1814. Omnipress, 2012. [10] B. Biggio and F . Roli. W ild patterns: Ten years after the rise of adversarial machine learning. P attern Recognition , 84:317–331, 2018. [11] Tianyu Gu, Kang Liu, Brendan Dolan-Gavitt, and Siddharth Garg. Badnets: Ev aluating backdooring attacks on deep neu- ral networks. IEEE Access , 7:47230–47244, 2019. [12] Anthony D. Joseph, Blaine Nelson, Benjamin I. P . Rubinstein, and J.D. T ygar . Adversarial Mac hine Learning . Cambridge Uni- versity Press, 2018. [13] Nicolas Papernot, Fartash Faghri, Nicholas Carlini, Ian Good- fellow , Reuben Feinman, Alexey Kurakin, Cihang Xie, Y ash Sharma, T om Bro wn, Aurko Roy , Alexander Matyasko, V ahid Behzadan, Karen Hambardzumyan, Zhishuai Zhang, Y i-Lin Juang, Zhi Li, Ryan Sheatsley , Abhibhav Gar g, Jonathan Ue- sato, Willi Gierke, Yinpeng Dong, Da vid Berthelot, Paul Hen- dricks, Jonas Rauber, and Rujun Long. T echnical report on the clev erhans v2.1.0 adversarial examples library . arXiv pr eprint arXiv:1610.00768 , 2018. [14] Jonas Rauber, W ieland Brendel, and Matthias Bethge. Fool- box: A Python toolbox to benchmark the robustness of machine learning models. In Reliable Machine Learning in the W ild W orkshop, 34th International Confer ence on Machine Learning , 2017. [15] Maria-Irina Nicolae, Mathieu Sinn, Minh Ngoc Tran, Beat Buesser , Ambrish Raw at, Martin W istuba, V alentina Zant- edeschi, Nathalie Baracaldo, Bryant Chen, Heiko Ludwig, et al. Adversarial robustness toolbox v1. 0.0. arXiv preprint arXiv:1807.01069 , 2018. [16] Marco T ulio Ribeiro, Sameer Singh, and Carlos Guestrin. “Why should I trust you?”: Explaining the predictions of an y classifier . In 22nd ACM SIGKDD Int’l Conf. Knowl. Disc. Data Mining , KDD ’16, pages 1135–1144, New Y ork, NY , USA, 2016. A CM. [17] Mukund Sundararajan, Ankur T aly , and Qiqi Y an. Axiomatic attribution for deep networks. In International Conference on Machine Learning , pages 3319–3328. PMLR, 2017. [18] Pang W ei K oh and Percy Liang. Understanding black-box pre- dictions via influence functions. In International Confer ence on Machine Learning , pages 1885–1894. PMLR, 2017. [19] Jonas Rauber, Roland Zimmermann, Matthias Bethge, and W ieland Brendel. Foolbox nativ e: Fast adversarial attacks to benchmark the robustness of machine learning models in py- torch, tensorflow , and jax. Journal of Open Sour ce Softwar e , 5(53):2607, 2020. [20] Luca Demetrio and Battista Biggio. Secml-malware: Pentest- ing windows malware classifiers with adversarial EXEmples in Python. arXiv pr eprint arXiv:2104.12848 , 2021. [21] Ambra Demontis, Marco Melis, Maura Pintor, Matthew Jagiel- ski, Battista Biggio, Alina Oprea, Cristina Nita-Rotaru, and Fabio Roli. Why do adversarial attacks transfer? Explain- ing transferability of evasion and poisoning attacks. In 28th USENIX Security Symposium (USENIX Security 19) . USENIX Association, 2019. [22] Marco Melis, Ambra Demontis, Battista Biggio, Gavin Brown, Giorgio Fumera, and F abio Roli. Is deep learning safe for robot vision? Adversarial examples against the iCub humanoid. In IC- CVW V ision in Practice on Autonomous Robots (V iP AR) , pages 751–759. IEEE, 2017. 5
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment