ForkNet: Multi-branch Volumetric Semantic Completion from a Single Depth Image
We propose a novel model for 3D semantic completion from a single depth image, based on a single encoder and three separate generators used to reconstruct different geometric and semantic representations of the original and completed scene, all shari…
Authors: Yida Wang, David Joseph Tan, Nassir Navab
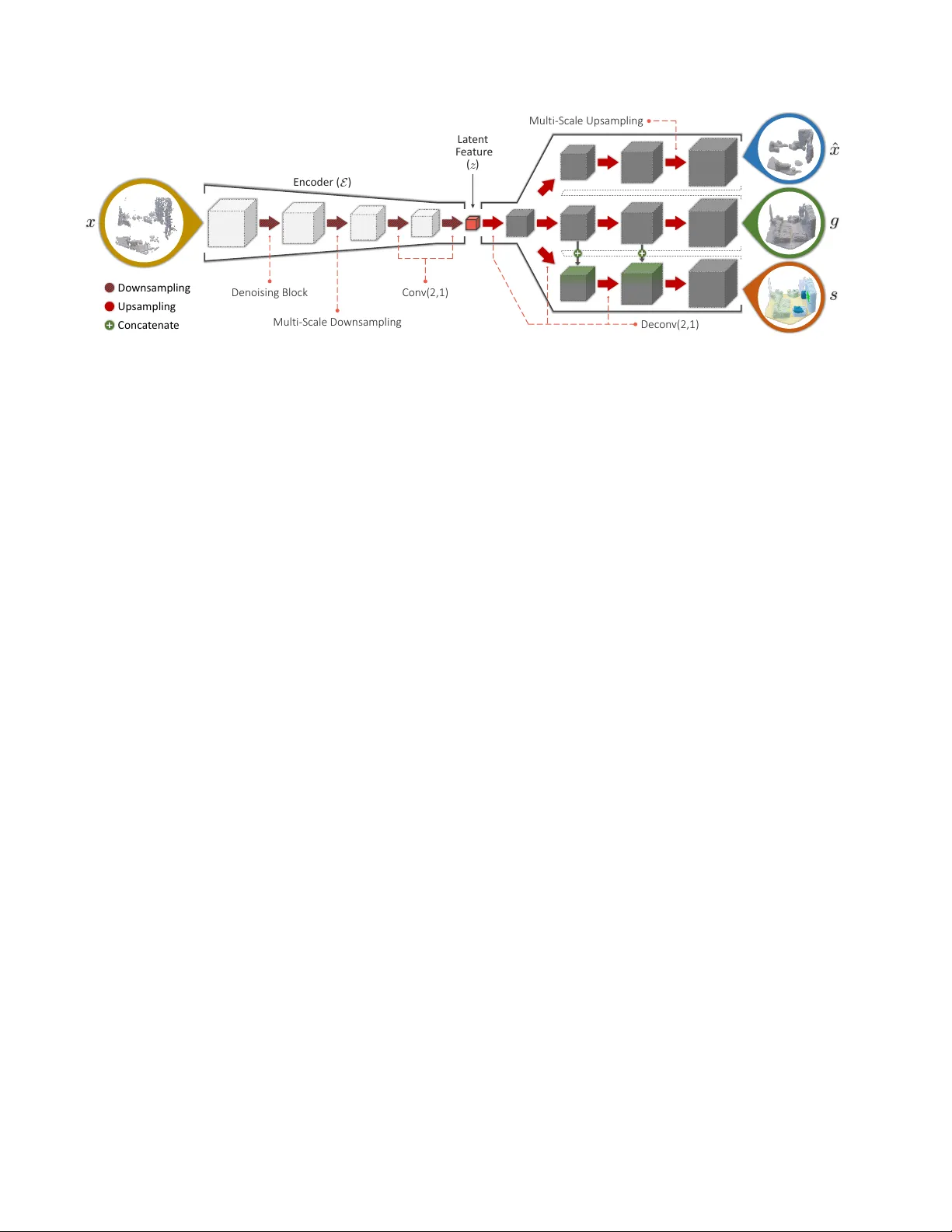
F orkNet: Multi-branch V olumetric Semantic Completion fr om a Single Depth Image Y ida W ang 1 , David Joseph T an 2 , Nassir Nav ab 1 , Federico T ombari 1,2 1 T echnische Univ ersit ¨ at M ¨ unchen 2 Google Inc. (a) Dep th Imag e (NYU) (b) Gr ound T rut h (c) SS CNe t (d) Pr oposed Me thod Ceiling Floo r W all Win dow Chair Bed So f a T able TV s Ob jec ts Furn it ur e Figure 1: Our 3D semantic completion model (right-most) generates realistic yet accurate volumetric scene representations from a single depth image (left-most) affected by occlusion and noise, e ven if acquired from a real depth sensor . Abstract W e pr opose a novel model for 3D semantic completion fr om a single depth image , based on a single encoder and thr ee separ ate gener ators used to reconstruct differ ent ge- ometric and semantic r epr esentations of the original and completed scene, all sharing the same latent space . T o transfer information between the geometric and semantic branc hes of the network, we intr oduce paths between them concatenating featur es at corr esponding network layers. Motivated by the limited amount of training samples fr om r eal scenes, an interesting attribute of our ar chitectur e is the capacity to supplement the existing dataset by generat- ing a new tr aining dataset with high quality , r ealistic scenes that even includes occlusion and r eal noise. W e build the new dataset by sampling the features dir ectly from latent space which gener ates a pair of partial volumetric surface and completed volumetric semantic surface. Mor eover , we utilize multiple discriminator s to incr ease the accur acy and r ealism of the r econstructions. W e demonstrate the benefits of our appr oach on standar d benc hmarks for the two most common completion tasks: semantic 3D scene completion and 3D object completion. 1. Introduction The increasing abundance of depth data, thanks to the widespread presence of depth sensors on devices such as robots and smartphones, has recently fostered big advance- ments in 3D processing for augmented reality , robotics and scene understanding, unfolding ne w applications and tech- nology that relies on the geometric rather than just the ap- pearance information. Since 3D devices sense the environ- ment from one specific vie wpoint, the geometry that can be captured in one shot is only partial due to occlusion caused by foreground objects as well as self-occlusion from the same object. As for many applications, this partial 3D information is insufficient to rob ustly carry-out 3D tasks such as object de- tection and tracking or scene understanding. A recent re- search direction has emerged that leverages deep learning to “complete” the depth images acquired by a 3D sensor, i.e . filling in the missing geometry that the sensor could not capture due to occlusion. The capability of deep learning to determine a latent space that captures the global context from the training samples proved useful in regressing com- pleted 3D scenes and 3D shapes ev en when big portion of the geometry are missing [ 3 , 4 , 28 , 30 , 39 ]. Also, some of these approaches have been extended to jointly learn how to infer geometry and semantic information, in what is re- ferred to as semantic 3D scene completion [ 4 , 30 , 34 ]. Nev- ertheless, current approaches are still limited by different factors, including the difficulty of regressing fine and sharp details of the completed geometry , as well as to general- ize to shapes that significantly dif fer from those seen during training. W all T able TV s Gr ound T rut h F orkN e t (Pr oposed Me thod ) F orkN e t with out Comp le ti on Br anch Figure 2: This figure shows the ground truth reconstruc- tion where we notice the incorrect labels from SUNCG [ 30 ] dataset on the TVs, i.e . enclosed in the black box. In this work, we aim to tackle 3D completion from a sin- gle depth image based on a novel learned model that relies on a single encoder and multiple generators, each trained to regress a different 3D representation of the input data: ( i ) a vox elized depth map, ( ii ) a geometric completed volume, ( iii ) a semantic completed v olume. This particular architec- ture aims at two goals. The first is to supplement the lack of paired input-output data, i.e . a depth map and the associ- ated completed v olumetric scene, with no vel pairs directly generated from the latent space, i.e . by means of ( i ) and ( iii ). The second goal is to o vercome a common limitation of av ailable benchmarks that provide imprecise semantic la- bels, by letting the geometric completion remain unaffected from it, i.e . by means of ( i ) and ( ii ). By means of specific connections between corresponding neural layers in the dif- ferent branches, we let the semantic completion model be conditioned on geometric reconstruction information, this being beneficial to generate accurate reconstructions with aligned semantic information. Overall, the proposed learning model uses a mix of su- pervised and unsupervised training stages which lev erage the power of generative models in addition to the annota- tions provided by benchmark datasets. Additionally , we propose to further improve the ef fectiveness of our gener - ativ e model by employing discriminators able to increase the accuracy and realism of the produced output, yielding completed scenes with high level details e ven in the pres- ence of strong occlusion, as witnessed by Fig. 1 that reports an example from a real dataset (NYU [ 24 ]). Our contributions can be summarized as follows: ( i ) a nov el architecture, dubbed ForkNet, based on a single en- coder and three generators built upon the same shared latent space, useful to generate additional paired training samples; ( ii ) the use of specific connections between generators to let geometric information condition and driv e the completion process over the often imprecise ground truth annotations (see Fig. 2 ); and, ( iii ) the use of multiple discriminators to regress fine details and realistic completions. W e demon- strate the benefits of our approach on standard benchmarks for the two most common completion tasks: semantic 3D scene completion and 3D object completion. For the for- mer , we rely on SUNCG [ 30 ] (synthetic) and NYU [ 24 ] (real). For the latter , instead, we test on ShapeNet [ 1 ] and 3D-RecGAN [ 38 ]. Notably , we outperform the state of the art for both scene reconstruction and object completion on the real dataset. 2. Related w ork Semantic scene completion. 3D semantic scene comple- tion starts from a depth image or a point cloud to pro vide an occlusion-free 3D reconstruction of the visible scene within the viewpoint’ s frustrum while labeling each 3D ele- ment with a semantic class from a pre-defined category set. Scene completion could be in principle achiev ed by exploit- ing simple geometric cues such as plane consistency [ 23 ] or object symmetry [ 17 ]. Moreover , meshing approaches such as Poisson reconstruction [ 16 ] as well as purely geometric works [ 7 ] can also be employed for this goal. Recent approaches suggested to lev erage deep learning to predict how to fill-in occluded parts in a globally coher- ent way with respect to the training set. SSCNet [ 30 ] carries out semantic scene completion from a single depth image using dilated con volution [ 40 ] to capture 3D spatial infor - mation at multiple scales. They rely on a volumetric repre- sentation to represent both input and output data. Based on SSCNet, VVNet [ 12 ] applies view-based 3D con volutions as a replacement for SDF back-projections, this resulting more ef fective in extracting geometric information from the input depth image. SaTNet [ 21 ] relies on the RGB-D im- ages. They initially predict the 2D semantic segments with the RGB. The depth image then back-projects the seman- tically labelled pixels to a 3D volume which goes through another architecture for 3D scene completion. ScanCom- plete [ 4 ] also targets semantic scene completion but, in- stead of starting from a single depth image, they assume to process a large-scale reconstruction of a scene acquired via a consumer depth camera. They suggest a coarse-to- fine scheme based on an auto-regressi ve architecture [ 27 ], where each level predicts the completion and the per-v oxel semantic labeling at a different vox el resolution. The work in [ 34 ] proposes to use GANs for the task of semantic scene completion from a single depth image. In particular , it pro- poses to use adversarial losses applied on both the output and latent space to enforce realistic interpolation of scene parts. The work in [ 34 ] proposes to use GANs for the task of semantic scene completion from a single depth image. In particular , it proposes to use adversarial losses applied on both the output and latent space to enforce realistic interpo- lation of scene parts. P artially related to this field, the work in [ 31 ] le verages input object proposals in the form of 2D bounding boxes to e xtract the layout of a 3D scene from a single RGB image, while estimating the pose of the objects therein. A similar task is tackled by [ 9 ] starting from an ( ) La t en t F ea tur e Denoising Bloc k Con v(2, 1) Dec on v (2,1 ) Multi - Sc ale Ups ampling Multi - Sc ale Do wnsampling Up sampl ing Do wnsamp li ng Conc a t ena t e Enc oder ( ) Figure 3: ForkNet – the proposed volumetric netw ork architecture for semantic completion relies on a shared latent space encoded from SDF volume x reconstructed from the input depth image. The two decoding paths are trained to generate, respectiv ely , incomplete surface geometry ( ˆ x ), completed geometric volume ( g ) and completed semantic volumes ( s ). RGB-D image. Object completion. 3D object completion aims at obtain- ing a full 3D object representation from either a single depth or RGB image. While several RGB-based approaches hav e been recently proposed [ 2 , 6 , 35 ], in this section, we will focus only on those based on depth images as input since they are more related to the scope of this work. The work in [ 28 ] uses a hybrid architecture based on a CNN and an autoencoder to learn completing 3D shapes from a single depth map. 3D-RecGAN [ 38 , 39 ] proposes to complete an observed object from a single depth image using a network based on skip connections [ 29 ] between the encoder and the generator so to fetch more spatial information from the input depth image to the generator . 3D-EPN [ 3 ] performs shape completion based on a latent feature concatenated with object classification information via one-hot coding, so that this additional semantic information could dri ve an accurate extrapolation of the missing shape parts. Han et al . [ 13 ] complete shapes with multiple depth images fused via LSTM Fusion [ 19 ] and process the fused data using a 3D fully con volutional approach. MarrNet [ 35 ] reconstructs the 3D shape by applying reprojection consistenc y between 2.5D sketch and 3D shape. GANs for 3D shapes. Although the use of GANs for 3D semantic scene completion tasks is almost an unexplored territory , GANs have been frequently employed in recent proposals for the task of learning a latent space for 3D shapes, useful for object completion as well as for tasks such as object retriev al and object part segmentation. For instance, 3D-V AE-GAN [ 36 ] trains a volumetric GAN in an unsupervised way from a dataset of 3D models, so to be able to generate realistic 3D shapes by sampling the learned latent space. ShapeHD [ 37 ] tackles the difficult problem of reconstructing 3D shapes from a single RGB image and suggests to overcome the 2D-3D ambiguity by adversari- ally learning a regularizer for shapes. PrGAN [ 8 ] learns to generate 3D volumes in an unsupervised way , trained by a discriminator that distinguishes whether 2D images pro- jected from a generated 3D volume are realistic or fake. 3D- ED-GAN [ 33 ] transforms a coarse 3D shape into a more complete one using a Long Short-term Memory (LSTM) Network by interpreting 3D volumes as sequences of 2D images. 3. Proposed semantic completion T aking the depth image as input, we reconstruct the vis- ible surface by back-projecting each pixel onto a vox el of the volumetric data. Denoted as x , we represent the surface reconstruction from the depth image as a signed distance function (SDF) [ 25 ] with n l × n w × n h vox els such that the value of the v oxel approaches zero when it is closer to the visible surface. Our task then is to produce the completed reconstruction of the scene with a semantic label for each voxel. Hav- ing N object categories, the class labels are assigned as C = { c i } N i =0 where c 0 is the empty space. Thus, denoted as s , we represent the resulting semantic volume as a one-hot encoding [ 22 ] with N + 1 dimensional feature. Similarly , we define g as the completed reconstruction of the scene without the semantic information by setting N to 1. 3.1. Model architecture W e assemble an encoder -generator architecture [ 36 ] that builds the completed semantic v olume from the partial scene derived from a single depth image. As illustrated in Fig. 3 , the encoder E ( · ) is composed of 3D con volutional operators where the spatial resolutions are decreased by a factor of tw o in each layer . In ef fect, this continuously re- duces the volume into its simplest form, denoted by the la- tent feature z such that z = E ( x ) . Conc a t R es3D( 1,1) R es3D( 1,2) R es3D( 1,2) R es3D( 1,2) Con v(2,1 ) (b) Mul ti - sc ale Do wnsampl in g Conc a t R es3D( 1,1) R es3D( 1,2) De c on v (2,1) (c ) Mul ti - sc ale Up sampl in g R es3D (1,1 ) P oo ling Con v(2, 1) Con v(1,1 ) (a ) Den oisi ng Block R es3D(1,1) R es3D(1,1) Figure 4: (a-b) Downsam- pling and (c) upsampling con volutional layers in our architecture (see Fig. 3 ). Note that the two parameters ( s, d ) in all the functions are the stride and dilation while the kernel size is set to 3. In detail, the encoder is composed of four downsampling operators. The first aims at denoising [ 30 ] the SDF volumes as illustrated in Fig. 4 (a). This in volv es a combination of a 3D con volutional operator, se veral 3D ResNet blocks [ 14 ], denoted as Res3D ( s, d ) where s is the stride while d is the dilation, and a pooling layer . The second layer aims at including different objects in the scene ev en with varying sizes by concatenating the output of four sequentially con- nected 3D ResNet blocks in Fig. 4 (b). Consequently , the information from the smaller objects are captured on the first Res3D ( · , · ) while the larger object are captured on the subsequent blocks. Notably , the first block is parameterized with a dilation of 1 while the other three with dilations of 2. The concatenated result is then downsampled by a 3D con volutional operator . In the final two layers, we further downsample the volume with 3D con volutional operators until we form the latent feature with a size of 16 × 5 × 3 × 5 . Branching from the same latent feature, we design three generators that reconstructs: (i) the SDF volume ( ˆ x ) which, with respect to x , formu- lates as an autoencoder; (ii) the completed volume ( g ) which focuses on recon- structing the geometric structure of the scene; and, (iii) the completed semantic volume ( s ) which is the de- sired outcome. W e assign these generators as the functions G ˆ x ( · ) , G g ( · ) and G s ( · ) , respecti vely . Notably , we distinguish x , which is the SDF volume obtained from the input depth image, from ˆ x , which is the inferred SDF volume obtained from the gen- erator . The structure of each generator is composed of 3D decon volutional operators that increases the spatial resolu- tion by two in each layer . While the first 3 conv olutional upsampling layers in the generators are composed of 3D deconv olutional operators as shown in Fig. 3 , the last layer is a multi-scale upsam- pling which is sketched in Fig. 4 (c). This layer is similar to the multi-scale downsampling of the encoder where the goal is to consider the variation of sizes from different objects. In this case, we concatenate the results of two sequentially connected 3D ResNet blocks then end with a 3D deconv o- lution operator . With the same operations as the other gen- erators, the generator that builds the completed semantical volume G s additionally incorporates the data from the gen- erator of the geometric scene reconstruction G g as sho wn in Fig. 3 by concatenating the results from the second and the third layers. Since the resulting ˆ x , g and s have dif ferent number of channels, only the dimension of the output from the deconv olutional operator in the last layer changes for each structure. Giving a holistic perspecti ve, we can simplify the sketch of the architecture in Fig. 3 to Fig. 5 by plotting the relation of the variables x , ˆ x , g , s and z . When we focus on cer- tain structures, we notice that we have an autoencoder that builds an SDF volume in Fig. 5 (a), the reconstruction of the scene in Fig. 5 (b) and the v olumetric semantic completion in Fig. 5 (c), where all of these structures branch out from the same latent feature. Later in Sec. 3.2 , these plots are used to explain the loss terms in training. The rationale of having multiple generators is twofold. First, in contrast to the typical encoder-decoder architecture, we introduce the connection that relates the two generators. T aking the output from the G ˆ x in each layer , we concatenate the results to the data from G s as sho wn in Fig. 3 . By estab- lishing this relation, we incorporate the SDF reconstruction from the G ˆ x into the semantic completion in order to capture the geometric information of the observed scene. Second, the latent feature can generate a pair of SDF and completed semantic volumes. Through this set of paired volumes, we can supplement the learning dataset in an un- supervised manner . This becomes a significant component in ev aluating the NYU dataset [ 24 ] in Sec. 4.1 where the amount of learning dataset is limited because, since they use a consumer depth camera to capture real scenes, annotation becomes difficult. Howe ver , ev aluating on this dataset is more essential compared to the synthetic dataset because it brings us a step closer to real applications. Relying on this idea in Sec. 3.2 , we propose an unsupervised loss term that optimizes the entire architecture based on its o wn learning dataset. Discriminators. Inspired by GANs [ 11 , 26 ], we intro- duce the discriminator D x that e valuates whether the gener- ated SDF volumes from G ˆ x are realistic or not by comparing them to the learning dataset. Here, D x is constructed by a St arting P oin t Fir s t R out e Sec ond R out e Not U sed St art St art St art St art Unsup e r vis e d Su pe r vi sed Su pe r vi sed Unsup e r vis e d Figure 5: Graphical models of the 4 data flo ws (and the associated loss terms) used during training and derived from Fig. 3 . sequentially connected 3D con volutional operators with the kernel size of 3 × 3 × 3 and stride of 2. This implies that the resolution of the input volume is sequentially decreased by a factor of two after each operation. T o capture the local information of the volume [ 5 ], the results from D x is set to a resolution of 5 × 3 × 5. W ith a similar architecture as D x , we also introduce a second discriminator D s that ev aluates the authenticity of the generated volume s . Notably , the two discriminators are ev aluated in the loss terms in Sec. 3.2 to optimize the generators. 3.2. Loss terms Lev eraging on the forward passes of smaller architec- tures in Fig. 5 , we can optimize the entire architecture by simultaneously optimizing different paths. W e also opti- mize the architecture of the two discriminators that distin- guishes whether the generated volumes are realistic or not. During training, the learning dataset is giv en by a set of the pairs { ( x, s gt ) } , where we distinguish s gt as the ground truth from the generated s . Note that the ground truth for the geometric completion g gt is the binarized summation of non-empty space in s gt and an occupancy volume from the SDF surface. SDF autoencoder . Motiv ated to reconstruct as similar SDF volume from the generator G ˆ x as the original input, we define the loss function L auto ( E , G ˆ x ) = kG ˆ x ( E ( x )) − x k 2 (1) for the autoencoder in Fig. 5 (a) in order to minimize the difference between the observ ed x and the inferred ˆ x . Geometric completion. In Fig. 5 (b), a conditional gen- erativ e model combines the encoder E ( · ) and the generator G g ( · ) in order to reconstruct the scene ( i.e . without the se- mantic labels). Since the reconstruction is a two-channel volume that represents the empty and non-empty cate gory , we use a binary cross-entropy loss L recon ( E , G g ) = 1 X i =0 ( ( G g ( E ( x )) , g gt )) (2) to train the inference network, where ( · , · ) is the per - category error ( q , r ) = − λr log q − (1 − λ )(1 − r ) log(1 − q ) . (3) In ( 3 ), λ , which ranges from 0 to 1, weighs the importance of reconstructing true positiv e regions in the volume. If λ = 1 , the penalty for the false positive predictions will not be considered; while, if λ is set to 0, the false negati ves will not be corrected. Semantic completion. Similar to ( 2 ), in Fig. 5 (c), we train a conditional generati ve model that is composed of the encoder E ( · ) and generator G s ( · ) linking x and s . Hence, we also use a binary cross-entropy loss L pred ( E , G s ) = N X i =0 ( ( G s ( E ( x )) , s gt )) (4) where N is the number of categories in the semantic scene. Discriminators on the architecture. In relation to the ar - chitecture, we use two discriminators to optimize the gen- erators [ 36 ] through L gen- ˆ x G ˆ x = − log ( D x ( G ˆ x ( z ))) L gen- s G s = − log ( D s ( G s ( z ))) . (5) In this manner , we optimize the two generativ e models in- cluding both the SDF encoder and the semantic scene gener- ator by randomly sampling the latent features. On the other hand, when we update the parameters of both discrimina- tors, we optimize the loss functions L dis- x ( D x ) = − log( D x ( x )) − log (1 − D x ( G ˆ x ( z ))) L dis- s ( D s ) = − log( D s ( s gt )) − log (1 − D s ( G s ( z ))) . (6) During training, we apply the set of equations in ( 5 ) and ( 6 ) alternatingly to optimize the generators and the discrimina- tors separately . Note that we use the KL-di vergence from the v ariational inference [ 10 , 15 ] to penalize the de viation (a ) SDF V olume (b) Comp le t ed Seman ti c Scene Figure 6: An example of the generated SDF volume and the corresponding completed semantic scene parameterized from the latent feature, which are used to supplement the existing learning dataset. between the distribution of E ( x ) and a normal distribution with zero mean and identity variance matrix. The adv an- tage of such is the capacity to easily sample from the latent space in the generativ e model, which becomes helpful in the succeeding loss term. SDF-Semantic consistency . Since the generators are trained to produce SDF v olumes and semantic scenes while being optimized to produce realistic data by the discrimi- nator , we can build a new set of paired volumes to act as the learning dataset in order to supplement the existing one. Thus, we propose to generate paired volumes directly from the latent feature in order to optimize the architecture in an unsupervised learning. Exploiting the latent space, we reconstruct the set of pairs { ( G ˆ x ( z ) , G s ( z )) } , where z is randomly sampled from a Gaussian distribution centered on the average of latent fea- tures of a batch of samples. Follo wing the inference model in Fig. 5 (c), we formulate a similar loss function as ( 4 ) but with the newly acquired data such that L consistency ( E , G ˆ x , G s ) = N X i =0 ( ( G s ( E ( G ˆ x ( z ))) , G s ( z ))) . (7) By drawing the data flow of the first term G s ( E ( G ˆ x ( z ))) in Fig. 5 (d), we observe that the loss term in ( 7 ) optimizes the entire architecture. Interestingly , when we take a closer look at the newly generated pairs { ( G ˆ x ( z ) , G s ( z )) } in Fig. 6 , we can easily notice the realistic results. The SDF volume in Fig. 6 (a) considers missing regions due to the camera position while the semantic scene in Fig. 6 (b) generates lifelike structures and reasonable positions of the objects in the scene ( e .g . the bed in red). By adding the newly generated pairs, we nu- merically show in Sec. 4.1 that there is a significant boost in performance when e v aluating the NYU dataset [ 24 ] where the size of the learning dataset is small. Optimization. W ith all the loss terms given, achie ving the optimum parameters in our architecture requires us to simultaneously minimize them. W e start by optimizing ( 1 ), ( 2 ), ( 4 ) and ( 5 ) altogether . Then, the loss functions in ( 6 ) for the two discriminators are optimized alternativ ely ( i.e . batch-by-batch) with ( 1 ), ( 2 ), ( 4 ) and ( 5 ). In practice, we employ the Adam optimizer [ 18 ] with a learning rate of 0.0001. For the data flo ws, Fig. 5 (a) and (d) are both un- supervised while Fig. 5 (b) and (c) are supervised. In addi- tion, for the discriminators, ( 5 ) is unsupervised while ( 6 ) is supervised. 4. Experiments There are two tasks at hand – (1) 3D semantic scene completion; and, (2) 3D object completion. Although they perform similar tasks in reconstructing from a single vie w , the former completes the structure of a scene with semantic labels while the latter requires a more detailed completion with the assumption of a single category . Metric. For each of the N classes, the accuracy of the pre- dicted volumes is measured based on the Intersection over Union (IoU). Analogously to the e valuation carried out by other methods, the a verage IoU is taken from all the cate- gories except for the empty space. Implementation details. W e learn our model with an Nvidia Titan Xp with a batch size of 8. W e applied batch normalization after ev ery con volutional and decon vo- lutional operations except for the con volutional operations in the last decon volutional layers in 3 generators. Leaky ReLU with a negati ve slope of 0.2 is applied on the out- put of each conv olutional layer in the Res3D ( · , · ) modules in Fig. 4 . In addition, ReLU is applied on the output of de- con volutional operations in the generators except for the last decon volution operation in the Multi-Scale Upsampling. Fi- nally , the sigmoid operation is applied to the last deconv olu- tion layer of the generators for the geometric and semantic completion. Notably , the factor λ from ( 3 ) is set to be 0.5 for the geometric completion in ( 2 ). For the semantic com- pletion, it is initially set to 0.9 in ( 4 ). Ho wev er , when the network is capable of rev ealing objects from the depth im- age, more and more false positiv e predictions in the empty space appears. Due to this, we set λ to 0.6 after fi ve epochs. 4.1. Semantic scene completion The SUNCG [ 30 ] and NYU [ 24 ] datasets are currently the most relev ant benchmarks for semantic scene comple- tion, and include a paired depth image and the correspond- ing semantically labeled volume. While SUNCG comprises synthetically rendered depth data, NYU includes real scenes acquired with a Kinect depth sensor . This makes the e v al- uation of NYU more challenging, due to the presence of real nuisances, as well as due to a limited training set of ceil. floor w all win. chair bed sofa table tvs furn. objs. A vg. SSCNet [ 30 ] (observed) 97.7 94.5 66.4 30.0 36.9 60.2 62.5 56.3 12.1 46.7 33.0 54.2 Proposed Method (observed) 98.2 96.9 67.8 37.4 35.9 72.9 69.6 48.8 20.5 48.4 32.4 57.2 W ang et al . [ 34 ] 41.4 37.7 45.8 26.5 26.4 21.8 25.4 23.7 20.1 16.2 5.7 26.4 3D-RecGAN [ 38 ] 79.9 75.2 48.2 28.9 20.2 64.4 54.6 25.7 17.4 33.7 24.4 43.0 SSCNet [ 30 ] 96.3 84.9 56.8 28.2 21.3 56.0 52.7 33.7 10.9 44.3 25.4 46.4 VVNet [ 12 ] 98.4 87.0 61.0 54.8 49.3 83.0 75.5 55.1 43.5 68.8 57.7 66.7 SaTNet [ 21 ] 97.9 82.5 57.7 58.5 45.1 78.4 72.3 47.3 45.7 67.1 55.2 64.3 Proposed Method 95.0 85.9 73.2 54.5 46.0 81.3 74.2 42.8 31.9 63.1 49.3 63.4 – without completion branc h 94.1 83.5 68.2 49.6 43.1 80.5 77.7 41.8 33.8 61.7 51.7 62.3 – without scene consistency 89.6 79.5 63.4 46.3 39.0 77.5 73.2 37.7 29.8 57.4 46.7 58.2 T able 1: Semantic scene completion results on the SUNCG test set with depth map for IoU (in %). ceil. floor wall win. chair bed sofa table tvs furn. objs. A vg. SSCNet [ 30 ] (observed) 37.7 91.9 75.4 64.0 29.0 51.1 63.3 43.7 29.7 73.3 54.5 50.8 Proposed Method (observed) 41.5 90.8 69.6 54.8 27.7 53.1 66.3 44.4 27.1 74.7 57.5 55.2 Lin et al . [ 20 ] (NYU only) 0.0 11.7 13.3 14.1 9.4 29.0 24.0 6.0 7.0 16.2 1.1 12.0 3D-RecGAN [ 38 ] 35.3 70.3 24.1 3.8 11.9 47.4 43.1 11.4 16.9 30.6 7.2 27.5 Geiger and W ang [ 9 ] (NYU only) 10.2 62.5 19.1 5.8 8.5 40.6 27.7 7.0 6.0 22.6 5.9 19.6 SSCNet [ 30 ] 15.1 94.6 24.7 10.8 17.3 53.2 45.9 15.9 13.9 31.1 12.6 30.5 VVNet [ 12 ] 19.3 94.8 28.0 12.2 19.6 57.0 50.5 17.6 11.9 35.6 15.3 32.9 SaTNet [ 21 ] 17.3 92.1 28.0 16.6 19.3 57.5 53.8 17.7 18.5 38.4 18.9 34.4 Proposed Method 36.2 93.8 29.2 18.9 17.7 61.6 52.9 23.3 19.5 45.4 20.0 37.1 – without completion branc h 35.8 94.1 28.9 19.2 16.8 61.4 53.5 23.0 14.0 45.6 18.9 36.5 – without scene consistency 36.8 91.7 28.0 18.3 8.3 58.8 49.5 13.0 16.7 42.6 17.6 34.7 T able 2: Semantic scene completion results on the NYU test set with depth map for IoU (in %). SUNCG NYU Lin et al . [ 20 ] – 36.4 3D-RecGAN [ 38 ] 72.1 51.3 Geiger and W ang [ 9 ] – 44.4 SSCNet [ 30 ] 73.5 56.6 VVNet [ 12 ] 84.0 61.1 SaTNet [ 21 ] 78.5 60.6 Proposed Method 86.9 63.4 – without completion branc h 82.3 62.6 – without scene consistency 82.0 61.1 T able 3: Scene completion results on the SUNCG and the NYU test set in terms of IoU (in % ). less than 1000 samples. W e compare our method against W ang et al . [ 34 ], Lin et al . [ 20 ], 3D-RecGAN [ 38 ], Geiger and W ang [ 9 ], SSCNet [ 30 ], VVNet [ 12 ], and SaTNet [ 21 ]. The resolution of our input volume is given in the scale of 80 × 48 × 80 vox els. While [ 9 , 12 , 20 , 21 , 30 ] produce 60 × 36 × 60 semantic volumes for e valuation, [ 34 , 38 ] and us produce a slightly higher resolution of 80 × 48 × 80. Follo wing SUNCG [ 30 ], the semantic categories include 12 classes of varying shapes and sizes, i.e .: empty space , ceiling , floor , wall , window , c hair , bed , sofa , table , tvs , fur - nitur e and other objects . W e follow two types of e valua- tion as introduced by [ 30 ]. One ev aluates the semantic seg- mentation accuracy on the observed surf ace reconstruction, while the other considers the semantic segmentation of the predicted full volumetric reconstruction. SUNCG dataset. Based on an online interior design plat- form, the ev aluation of SUNCG contains more than 130,000 paired depth images and vox el-wise semantic labels taken from 45,622 houses with realistic rooms and furniture lay- outs [ 30 ]. Focusing on the semantic segmentation on the observed surface, our approach performs at an IoU of 57.2% which is 3.0% higher than SSCNet [ 30 ]. On the other hand, when we ev aluate the IoU measure on the entire volume in T able 1 , our method reaches an average IoU of 63.4% which is significantly better than W ang et al . [ 34 ], 3D- RecGAN [ 38 ] and SSCNet [ 30 ] but slightly worse than VVNet [ 12 ] and SaTNet [ 21 ]. NYU dataset (real). The NYU dataset [ 24 ] is composed of 1,449 indoor depth images captured with a Kinect depth sensor . Like SUNCG, each image is also annotated with bench chair couch table A vg. V arley et al . [ 32 ] 65.3 61.9 81.8 67.8 69.2 3D-EPN [ 3 ] 75.8 73.9 83.4 77.2 77.6 Han et al . [ 13 ] 54.4 46.9 48.3 56.0 51.4 3D-RecAE [ 38 ] 73.3 73.6 83.2 75.0 76.3 3D-RecGAN [ 38 ] 74.5 74.1 84.4 77.0 77.5 Proposed Method 79.1 80.6 92.4 84.0 84.1 – without scene consistency 76.3 76.4 87.5 81.2 80.4 T able 4: Object completion results on the ShapeNet test set in terms of IoU (in % ). The resolution for V arley et al . [ 32 ] and 3D-EPN [ 3 ]: 32 × 32 × 32, for others: 64 × 64 × 64. 3D semantic labels. Due to its size, training our network on this dataset alone is insufficient. As a solution already used in [ 30 ], we take the network trained on the SUNCG then refine it by supplementing the training data from NYU with 1,500 randomly selected samples from SUNCG in each epoch of training. Although we achie ved slightly worse results than VVNet [ 12 ] and SaTNet [ 21 ] on the synthetic dataset, we performed better than the state of the art on the real images, reaching an IoU measure of 37.1% as shown in T able 2 . Consequently , we attain a 4.2% improvement compared to VVNet [ 12 ] and 2.7% to SaTNet [ 21 ]. Looking at the other approaches, we achieve even more significant improvements with at least 6.6% increase in IoU. For the ev aluation on the semantic labels on the observed surface, we gained 4.4% increase in IoU against SSCNet. Notably , our approach outperforms other works not only on the av erage IoU but also on indi vidual object categories. In addition, we also achiev e similar improv ements in the scene completion task in T able 3 with approximately 2.8% better in IoU compared to SaTNet [ 21 ]. Moreov er , while the re-implementation SSCNet [ 30 ] in our experiments does not fit into an y of our contrib utions, we used it in order to qualitati vely compare our results with them (see Fig. 1 ). Ablation study for loss terms. In T ables 1 and 2 , we in vestigate the contribution of L recon from the supervised learning and L consistency from the unsupervised learning. Our ablation study indicates that L consistency prompts the highest boost in IoU with 5.2% in T able 1 . When using the L recon in the geometric completion, it improves by 1.1% on the SUNCG dataset. A similar conclusion for the loss terms is presented in T able 1 for NYU. 4.2. 3D object completion Adapting the assessment data and strategy from 3D- RecGAN [ 38 ], we use ShapeNet [ 1 ] to generate the training and test data for 3D object completion, wherein each re- constructed object surface x is paired with a corresponding ground truth vox elized shape with a size of 64 × 64 × 64. The dataset comprises four object classes: bench , chair , couch bench chair couch table A vg. Han et al . [ 13 ] 18.4 14.8 10.1 12.6 14.0 3D-RecAE [ 38 ] 23.1 17.8 10.7 14.8 16.6 3D-RecGAN [ 38 ] 23.0 17.4 10.9 14.6 16.5 Proposed Method 32.7 24.1 15.9 22.5 23.8 – without scene consistency 26.1 21.5 14.9 18.6 20.3 T able 5: Object completion results on the real-world test set provided by 3D-RecGAN [ 38 ] in terms of IoU (in % ). The resolution for all methods is 64 × 64 × 64. and table . [ 38 ] prepared an ev aluation for both synthetic and real input data. Notably , for both synthetic and real test data, we can express the same conclusions as the ablation studies in Sec. 4.1 (see T ables 4 and 5 ). Synthetic test data. W e perform two ev aluations in T a- ble 4 . The first is a single category test [ 38 ] such that each category is trained and tested separately while the second considers the categories in order to label the vox els. W e compare our results against [ 3 , 13 , 32 , 38 ]. In the single category test, we achie ve the best results with 84.1%. This result is 6.5% higher than 3D-EPN [ 3 ], 6.6% higher than 3D-RecGAN [ 38 ], 7.8% higher than 3D- RecAE [ 38 ], 32.7% higher than Han et al . [ 13 ] and 14.9% higher than V arle y et al . [ 32 ]. Moreov er , this table also shows the we achie ve the best results across all categories. Real test data. Using the single category test in T able 5 , we also ev aluate the 3D object completion task on the real world test data provided by [ 38 ]. In this ev aluation, we generate the state-of-the art results with 23.8% IoU mea- sure, which is higher than 3D-RecAE [ 38 ] by 7.2%, 3D- RecGAN [ 38 ] by 7.3% and Han et al . [ 13 ] by 9.8%. 5. Conclusion W e propose F orkNet, a novel architecture for volumetric semantic 3D completion that lev erages a shared embedding encoding both geometric and semantic surf ace cues, as well as multiple generators designed to deal with limited paired data and imprecise semantic annotations. Experimental re- sults numerically demonstrate the benefits of our approach for the two tasks of scene and object completion, as well as the effecti veness of the proposed contributions in terms of architecture, loss terms and use of discriminators. How- ev er , since we compress the input SDF volume into a lo wer resolution through the encoder then increase the resolution through the generator , small or thin structures such as the legs of the chair or TVs tend to disappear during compres- sion. This is an aspect we plan to improve in the future work. In addition, for 3D scene understanding, the volumet- ric representations are typically memory and power -hungry , we also plan to e xtend our model for completion of efficient and sparse representations such as point clouds. Acknowledgment The authors would like to thank Shun-Cheng W u for the fruitful discussions and support in preparation of this w ork. References [1] Angel X Chang, Thomas Funkhouser , Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Sav arese, Manolis Savv a, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3d model repository . arXiv pr eprint arXiv:1512.03012 , 2015. 2 , 8 [2] Christopher B Choy , Danfei Xu, JunY oung Gwak, Ke vin Chen, and Silvio Sav arese. 3d-r2n2: A unified approach for single and multi-vie w 3d object reconstruction. In Eur opean confer ence on computer vision (ECCV) . Springer , 2016. 3 [3] Angela Dai, Charles Ruizhongtai Qi, and Matthias Nießner . Shape completion using 3d-encoder-predictor cnns and shape synthesis. In Pr oc. IEEE Conf . on Computer V ision and P attern Recognition (CVPR) , volume 3, 2017. 1 , 3 , 8 [4] Angela Dai, Daniel Ritchie, Martin Bokeloh, Scott Reed, J ¨ urgen Sturm, and Matthias Nießner . Scancomplete: Large- scale scene completion and semantic segmentation for 3d scans. In Pr oc. IEEE Conf. on Computer V ision and P attern Recognition (CVPR) , v olume 1, 2018. 1 , 2 [5] Ugur Demir and G ¨ ozde B. ¨ Unal. Patch-based image inpainting with generativ e adversarial networks. CoRR , abs/1803.07422, 2018. 5 [6] Haoqiang Fan, Hao Su, and Leonidas J Guibas. A point set generation network for 3d object reconstruction from a single image. In Pr oc. IEEE Conf. on Computer V ision and P attern Recognition (CVPR) , v olume 2, 2017. 3 [7] Michael Firman, Oisin Mac Aodha, Simon Julier, and Gabriel J Brostow . Structured prediction of unobserved vox- els from a single depth image. In Pr oc. IEEE Conf. on Com- puter V ision and P attern Recognition (CVPR) , 2016. 2 [8] Matheus Gadelha, Subhransu Maji, and Rui W ang. 3d shape induction from 2d views of multiple objects. In International Confer ence on 3D V ision (3D V) . IEEE, 2017. 3 [9] Andreas Geiger and Chaohui W ang. Joint 3d object and lay- out inference from a single r gb-d image. In German Con- fer ence on P attern Recognition (GCPR) . Springer , 2015. 2 , 7 [10] Zoubin Ghahramani and Matthew J Beal. V ariational infer- ence for bayesian mixtures of factor analysers. In Advances in Neural Information Pr ocessing Systems (NIPS) , 2000. 6 [11] Ian Goodfellow , Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David W arde-Farle y , Sherjil Ozair , Aaron Courville, and Y oshua Bengio. Generativ e adversarial nets. In Advances in Neural Information Pr ocessing Systems (NIPS) , 2014. 4 [12] Y uxiao Guo and Xin T ong. V iew-volume network for se- mantic scene completion from a single depth image. In Pr o- ceedings of the International Joint Confer ence on Artificial Intelligence (IJCAI) . AAAI Press, 2018. 2 , 7 , 8 [13] Xiaoguang Han, Zhen Li, Haibin Huang, Evangelos Kalogerakis, and Y izhou Y u. High-resolution shape com- pletion using deep neural networks for global structure and local geometry inference. In Proceedings of IEEE Interna- tional Confer ence on Computer V ision (ICCV) , 2017. 3 , 8 [14] Kensho Hara, Hirokatsu Kataoka, and Y utaka Satoh. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In Proc. IEEE Conf. on Computer V ision and P attern Recognition (CVPR) , pages 6546–6555, 2018. 4 [15] Matthew D Hoffman, Da vid M Blei, Chong W ang, and John Paisle y . Stochastic v ariational inference. The Journal of Ma- chine Learning Resear ch , 14(1):1303–1347, 2013. 6 [16] Michael Kazhdan and Hugues Hoppe. Screened poisson sur- face reconstruction. ACM T ransactions on Graphics (T oG) , 32(3):29, 2013. 2 [17] Y oung Min Kim, Niloy J Mitra, Dong-Ming Y an, and Leonidas Guibas. Acquiring 3d indoor en vironments with variability and repetition. A CM T ransactions on Graphics (TOG) , 31(6):138, 2012. 2 [18] Diederick P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In International Conference on Learning Repr esentations (ICLR) , 2015. 6 [19] Zhen Li, Y ukang Gan, Xiaodan Liang, Y izhou Y u, Hui Cheng, and Liang Lin. Lstm-cf: Unifying context modeling and fusion with lstms for rgb-d scene labeling. In European Confer ence on Computer V ision (ECCV) . Springer , 2016. 3 [20] Dahua Lin, Sanja Fidler , and Raquel Urtasun. Holistic scene understanding for 3d object detection with rgbd cameras. In Pr oc. IEEE Conf. on Computer V ision and P attern Recogni- tion (CVPR) , 2013. 7 [21] Shice Liu, YU HU, Y iming Zeng, Qiankun T ang, Beibei Jin, Y inhe Han, and Xiaowei Li. See and think: Disentangling semantic scene completion. In S. Bengio, H. W allach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Pr ocessing Systems 31 , pages 263–274. Curran Associates, Inc., 2018. 2 , 7 , 8 [22] Pauline Luc, Camille Couprie, Soumith Chintala, and Jakob V erbeek. Semantic se gmentation using adversarial networks. CoRR , abs/1611.08408, 2016. 3 [23] Aron Monszpart, Nicolas Mellado, Gabriel J Brostow , and Niloy J Mitra. Rapter: rebuilding man-made scenes with reg- ular arrangements of planes. A CM T rans. Graph. , 34(4):103– 1, 2015. 2 [24] Pushmeet Kohli Nathan Silberman, Derek Hoiem and Rob Fergus. Indoor segmentation and support inference from rgbd images. In Eur opean Confer ence on Computer V ision (ECCV) , 2012. 2 , 4 , 6 , 7 [25] Stanley Osher and Ronald Fedkiw . Level set methods and dynamic implicit surfaces , volume 153. Springer Science & Business Media, 2006. 3 [26] Alec Radford, Luke Metz, and Soumith Chintala. Un- supervised representation learning with deep con volu- tional generati ve adversarial networks. arXiv pr eprint arXiv:1511.06434 , 2015. 4 [27] Scott Reed, A ¨ aron van den Oord, Nal Kalchbrenner , Ser- gio G ´ omez Colmenarejo, Ziyu W ang, Y utian Chen, Dan Belov , and Nando de Freitas. Parallel multiscale autoregres- siv e density estimation. In Proceedings of the 34th Interna- tional Conference on Machine Learning (ICML) . JMLR. org, 2017. 2 [28] Dario Rethage, Federico T ombari, Felix Achilles, and Nassir Nav ab . Deep learned full-3d object completion from single view . CVPR ’16 Scene Understanding W orkshop (SUNw) , 2016. 1 , 3 [29] Olaf Ronneberger , Philipp Fischer , and Thomas Brox. U- net: Con volutional networks for biomedical image segmen- tation. In International Confer ence on Medical image com- puting and computer -assisted intervention . Springer , 2015. 3 [30] Shuran Song, Fisher Y u, Andy Zeng, Angel X Chang, Mano- lis Sa vva, and Thomas Funkhouser . Semantic scene comple- tion from a single depth image. In Pr oc. IEEE Conf. on Com- puter V ision and P attern Recognition (CVPR) . IEEE, 2017. 1 , 2 , 3 , 6 , 7 , 8 [31] Shubham Tulsiani, Saurabh Gupta, David Fouhe y , Alexei A Efros, and Jitendra Malik. F actoring shape, pose, and layout from the 2d image of a 3d scene. In Pr oc. IEEE Conf. on Computer V ision and P attern Recognition (CVPR) , 2018. 2 [32] Jacob V arley , Chad DeChant, Adam Richardson, Joaqu ´ ın Ruales, and Peter Allen. Shape completion enabled robotic grasping. In IEEE/RSJ International Conference on Intelli- gent Robots and Systems (IR OS) . IEEE, 2017. 8 [33] W . W ang, Q. Huang, S. Y ou, C. Y ang, and U. Neumann. Shape inpainting using 3d generativ e adversarial network and recurrent con volutional networks. In IEEE International Confer ence on Computer V ision (ICCV) , Oct 2017. 3 [34] Y . W ang, D. J. T an, N. Nav ab, and F . T ombari. Adversarial semantic scene completion from a single depth image. In 2018 International Conference on 3D V ision (3D V) , 2018. 1 , 2 , 7 [35] Jiajun W u, Y ifan W ang, T ianfan Xue, Xingyuan Sun, Bill Freeman, and Josh T enenbaum. Marrnet: 3d shape recon- struction via 2.5 d sketches. In Advances in neural informa- tion pr ocessing systems (NIPS) , 2017. 3 [36] Jiajun W u, Chengkai Zhang, T ianfan Xue, Bill Freeman, and Josh T enenbaum. Learning a probabilistic latent space of ob- ject shapes via 3d generati ve-adv ersarial modeling. In Ad- vances in Neural Information Pr ocessing Systems (NIPS) , 2016. 3 , 5 [37] Jiajun W u, Chengkai Zhang, Xiuming Zhang, Zhoutong Zhang, W illiam T Freeman, and Joshua B T enenbaum. Learning 3D Shape Priors for Shape Completion and Re- construction. In Eur opean Conference on Computer V ision (ECCV) , 2018. 3 [38] Bo Y ang, Stefano Rosa, Andre w Markham, Niki Trigoni, and Hongkai W en. Dense 3d object reconstruction from a single depth view . IEEE transactions on pattern analysis and ma- chine intelligence , 2018. 2 , 3 , 7 , 8 [39] Bo Y ang, Hongkai W en, Sen W ang, Ronald Clark, Andrew Markham, and Niki Trigoni. 3d object reconstruction from a single depth view with adversarial learning. In Proceedings of the IEEE International Confer ence on Computer V ision (ICCV) , 2017. 1 , 3 [40] Fisher Y u and Vladlen K oltun. Multi-scale context aggregation by dilated con volutions. arXiv pr eprint arXiv:1511.07122 , 2015. 2
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment