Integration of Neural Network-Based Symbolic Regression in Deep Learning for Scientific Discovery
Symbolic regression is a powerful technique that can discover analytical equations that describe data, which can lead to explainable models and generalizability outside of the training data set. In contrast, neural networks have achieved amazing leve…
Authors: Samuel Kim, Peter Y. Lu, Srijon Mukherjee
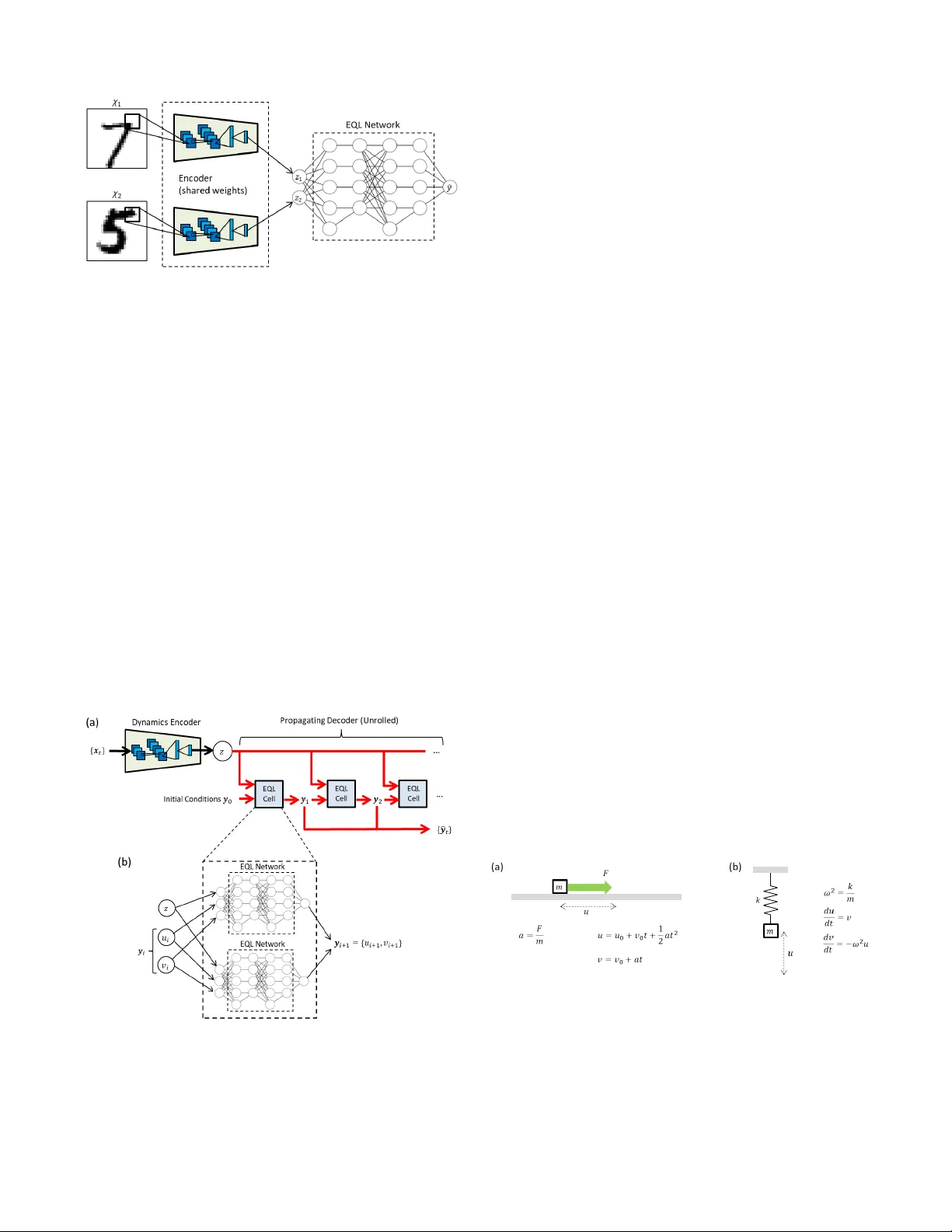
1 Inte gration of Neural Network-Based Symbolic Re gression in Deep Learning for Scientific Disco v ery Samuel Kim 1 ,a , Peter Lu 2 , Srijon Mukherjee 2 , Michael Gilbert 1 , Li Jing 2 , Vladimir ˇ Ceperi ´ c 3 , Marin Solja ˇ ci ´ c 2 Abstract —Symbolic regr ession is a powerful technique that can discover analytical equations that describe data, which can lead to explainable models and generalizability outside of the training data set. In contrast, neural networks ha ve achiev ed amazing levels of accuracy on image recognition and natural language processing tasks, but are often seen as black-box models that are difficult to interpret and typically extrapolate poorly . Her e we use a neural network-based architectur e for symbolic r egression called the Equation Learner (EQL) network and integrate it with other deep learning architectur es such that the whole system can be trained end-to-end through backpr opagation. T o demonstrate the power of such systems, we study their performance on several substantially different tasks. First, we sho w that the neural network can perform symbolic regression and learn the form of several functions. Next, we pr esent an MNIST arithmetic task where a separate part of the neural network extracts the digits. Finally , we demonstrate prediction of dynamical systems where an unknown parameter is extracted through an encoder . W e find that the EQL-based architecture can extrapolate quite well outside of the training data set compared to a standard neural network-based ar chitecture, paving the way for deep learning to be applied in scientific exploration and discovery . Index T erms —Symbolic Regression, Neural Netw ork, Kinemat- ics, Simple Harmonic Oscillator , ODE, Discov ery I . I N T RO D U C T I O N Many complex phenomena in science and engineering can be reduced to general models that can be described in terms of relatively simple mathematical equations. For example, classical electrodynamics can be described by Maxwell’ s equa- tions and non-relativistic quantum mechanics can be described by the Schr ¨ odinger equation. These models elucidate the underlying dynamics of a particular system and can provide general predictions over a very wide range of conditions. On the other hand, modern machine learning techniques hav e become increasingly po werful for many tasks including image recognition and natural language processing, but the neural network-based architectures in these state-of-the-art techniques are black-box models that often make them dif ficult for use in scientific exploration. In order for machine learning to be widely applied to science, there is a need for interpretable and generalizable models that can extract meaningful information 1 Department of Electrical Engineering and Computer Science, Mas- sachusetts Institute of T echnology , Cambridge, MA, USA 2 Department of Ph ysics, Massachusetts Institute of T echnology , Cambridge, MA, USA 3 Faculty of Electrical Engineering and Computing, Univ ersity of Zagreb, Zagreb, Croatia a E-mail: samkim@mit.edu from complex datasets and extrapolate outside of the training dataset. Symbolic regression is a type of regression analysis that searches the space of mathematical expressions to find the best model that fits the data. It is much more general than linear regression in that it can potentially fit a much wider range of datasets and does not rely on a set of predefined features. Assuming that the resulting mathematical expression correctly describes the underlying model for the data, it is easier to in- terpret and can extrapolate better than black-box models such as neural networks. Symbolic regression is typically carried out using techniques such as genetic programming, in which a tree data structure representing a mathematical expression is optimized using ev olutionary algorithms to best fit the data [1]. T ypically in the search for the underlying structure, model accuracy is balanced with model complexity to ensure that the result is interpretable and does not overfit the data. This approach has been used to extract the underlying laws of physical systems from experimental data [2]. Ho wever , due to the combinatorial nature of the problem, genetic programming does not scale well to large systems and can be prone to ov erfitting. Alternativ e approaches to finding the underlying laws of data ha ve been explored. For e xample, sparsity has been com- bined with regression techniques and numerically-ev aluated deriv ativ es to find partial differential equations (PDEs) that describe dynamical systems [3]–[5]. There has also been significant work on designing neural network architectures that are either more interpretable or more applicable to scientific exploration. Neural networks with unique activ ation functions that correspond to functions common in science and engineering ha ve been used for finding mathematical expressions that describe datasets [6], [7]. A deep learning architecture called the PDE-Net has been proposed to predict the dynamics of spatiotemporal systems and produce interpretable dif ferential operators through con- strained con volutional filters [8], [9]. [10] propose a neural net- work module called the Neural Arithmetic Logic Unit (N ALU) that introduces inductiv e biases in deep learning towards arithmetic operations so that the architecture can extrapolate well on certain tasks. Neural network-based architectures ha ve also been used to extract relev ant and interpretable parameters from dynamical systems and use these parameters to predict the propagation of a similar system [11], [12]. Additionally , [13] use symbolic regression as a separate module to discover kinematic equations using parameters extracted from videos 2 Fig. 1. Example of the Equation Learner (EQL) network for symbolic regression using a neural network. Here we sho w only 4 activation functions (identity or “id”, square, sine, and multiplication) and 2 hidden layers for visual simplicity , but the network can include more functions or more hidden layers to fit a broader class of functions. of balls under various types of motion. Here we present a neural network architecture for sym- bolic regression that is integrated with other deep learning architectures so that it can take adv antage of powerful deep learning techniques while still producing interpretable and generalizable results. Because this symbolic regression method can be trained through backpropagation, the entire system can be trained end-to-end without requiring multiple steps. Source code is made publicly av ailable 1 . I I . E Q L A R C H I T E C T U R E The symbolic regression neural network we use is similar to the Equation Learner (EQL) network proposed in [6], [7]. As shown in Figure 1, the EQL network is based on a fully- connected neural network where the i th layer of the neural network is described by g i = W i h i − 1 h i = f ( g i ) where W i is the weight matrix of the i th layer and h 0 = x is the input data. The final layer does not have an activ ation function, so for a network with L hidden layers, the output of the network is described by y = h L +1 = W L +1 h L The activ ation function f ( g ) , rather than being the usual choices in neural networks such as ReLU or tanh, may consist of a separate function for each component of g (such as sine or the square function) and may include functions that take 1 https://github .com/samuelkim314/DeepSymReg two or more arguments while producing one output (such as the multiplication function): f ( g ) = f 1 ( g 1 ) f 2 ( g 2 ) . . . f n h ( g n g − 1 , g n g ) (1) Note that an additi ve bias term can be absorbed into f ( g ) for con venience. These activ ation functions in (1) are analogous to the primitiv e functions in symbolic regression. Allowing func- tions to take more than one ar gument allows for multiplicati ve operations inside the network. While the schematic in Figure 1 only shows 4 activ a- tion functions in each hidden layer for visual simplicity , f ( g ) in 1 can include other functions including exp ( g ) and sigmoid ( g ) = 1 1+ e − g . Additionally , we allow for activ ation functions to be duplicated within each layer . This reduces the system’ s sensitivity to random initializations and creates a smoother optimization landscape so that the network does not get stuck in local minima as easily . This also allows the EQL network to fit a broad range of functions. More details can be found in Appendix A. By stacking multiple layers (i.e. L ≥ 2 ), the EQL archi- tecture can fit complex combinations and compositions of a variety of primitive functions. L is analogous to the maximum tree depth in genetic programming approaches and sets the upper limit on the comple xity of the resulting e xpression. While this model is not as general as con ventional symbolic regression, it is powerful enough to represent most of the functions that are typically seen in science and engineering. More importantly , because the EQL network can be trained by backpropagation, it can be integrated with other neural network-based models for end-to-end training. A. Sparsity A ke y ingredient of making the results of symbolic re gres- sion interpretable is enforcing sparsity such that the system finds the simplest possible equation that fits the data. The goal of sparsity is to set as many weight parameters to 0 as possible such that those parameters are inactiv e and can be remov ed from the final e xpression. Enforcing sparsity in neural networks is an active field of research as modern deep learning architectures using millions of parameters start to become computationally prohibitiv e [14]–[16]. [17] ev aluates several recent dev elopments in neural network sparsity techniques. A straightforward and popular way of enforcing sparsity is adding a re gularization term to the loss function that is a function of the neural network weight matrices: L q = L +1 X i =0 k W i k q (2) where k W i k q is the element-wise norm of the matrix: k W i k q = X j,k | w j,k | q 3 Fig. 2. (a) L 0 . 5 and (b) L ∗ 0 . 5 regularization, as described in (2) and (3), respectiv ely . The threshold for the plot of (3) is set to a = 0 . 1 for easy visualization, but we use a threshold of a = 0 . 01 in our experiments. Setting q = 0 in (2) results in L 0 regularization, which pe- nalizes weights for being non-zero regardless of the magnitude of the weights and thus drives the solution to wards sparsity . Howe ver , L 0 regularization is equiv alent to a combinatorics problem that is NP-hard, and is not compatible with gradi- ent descent methods commonly used for optimizing neural networks [18]. Recent works have explored training sparse neural networks with a relaxed version of L 0 regularization through stochastic gate variables, allowing this regularization to be compatible with backpropagation [14], [19]. A much more popular and well-kno wn sparsity technique is L 1 regularization, which is used in the original EQL network [6]. Although it does not push solutions to wards sparsity as strongly as L 0 regularization, L 1 regularization is a conv ex optimization problem that can be solved using a wide range of optimization techniques including gradient descent to driv e the weights tow ards 0. Howe ver , while L 1 is kno wn to push the solution towards sparsity , it has been suggested that L 0 . 5 en- forces sparsity more strongly without penalizing the magnitude of the weights as much as L 1 [20], [21]. L 0 . 5 regularization is still compatible with gradient descent (although it is no longer con vex) and has been applied to neural networks [22], [23]. Experimental studies suggest that L 0 . 5 regularization performs no worse than other L q regularizers for 0 < q < 0 . 5 , so L 0 . 5 is optimal for sparsity [21]. Our experiments with L 0 . 3 and L 0 . 7 regularizers show no significant ov erall improvement compared to the L 0 . 5 regularizer , in agreement with this study . In addition, our experiments show that L 0 . 5 driv es the solution tow ards sparsity more strongly than L 1 and produces much simpler expressions. In particular, we use a smoothed L 0 . 5 proposed in [23], and we label their approach as L ∗ 0 . 5 . The original L 0 . 5 regulariza- tion has a singularity in the gradient as the weights go to 0, which can make training dif ficult for gradient descent-based methods. T o av oid this, the L ∗ 0 . 5 regularizer uses a piece wise function to smooth out the function at small magnitudes: L ∗ 0 . 5 ( w ) = | w | 1 / 2 | w | ≥ a − w 4 8 a 3 + 3 w 2 4 a + 3 a 8 1 / 2 | w | < a (3) A plot of the L 0 . 5 and L ∗ 0 . 5 regularization are shown in Figure 2. The smoothed L ∗ 0 . 5 regularization av oids the extreme gradient values to impro ve training conv ergence. In our exper- iments, we set a = 0 . 01 . When the EQL network is integrated with other deep learning architectures, the regularization is only applied to the weights of the EQL network. W e hav e also implemented an EQL network with the relax ed L 0 regularization proposed by [14], the details of which can be found in Appendix B. I I I . E X P E R I M E N T S A. Symbolic Regr ession T o validate the EQL network’ s ability to perform symbolic regression, we first test the EQL network on data generated by analytical functions such as exp − x 2 or x 2 1 + sin (2 πx 2 ) . The data is generated on the domain x i ∈ [ − 1 , 1] . Because of the network’ s sensitivity to random initialization of the weights, we run 20 trials for each function. W e then count the number of times the network has conv erged to the correct answer ignoring small terms and slight v ariations in the coefficients from the true value. Additionally , equiv alent answers (such as sin(4 π + x ) instead of sin(2 π + x ) ) are counted as correct. These results are shown in Appendix A. The network only needs to be able to find the correct answer at least once o ver a reasonable number of trials, as one can construct a system that picks out the desired equation from the different trials by a combination of equation simplicity and generalization ability . The generalization ability is measured by the equation error e valuated on the domain x i ∈ [ − 2 , 2] . This extrapolation error of the correct equation tends to be orders of magnitude lower than that of other equations that the network may find, making it simple to pick out the correct answer . The network is still able to find the correct answer when 10% noise is added to the data. W e also test an EQL network with 3 hidden layers which still finds the correct expression and is able to find even more complicated expressions such as ( x 1 + x 2 x 3 ) 3 . B. MNIST Arithmetic In the first experiment, we demonstrate the ability to com- bine symbolic regression and image recongition through an arithmetic task on MNIST digits. MNIST , a popular dataset for image recognition, can be notated as D = { χ, ψ } , where χ are 28 × 28 greyscale images of handwritten digits and ψ ∈ { 0 , 1 , ..., 9 } is the integer-v alue label. Here, we wish to learn a simple arithmetic function, y = ψ 1 + ψ 2 , with the corresponding images { χ 1 , χ 2 } as inputs, and train the system end-to-end such that the system learns ho w to “add” two images together . The deep learning architecture is sho wn in Figure 3. The input to the system consists of two MNIST digits, x = { χ 1 , χ 2 } . During training, χ i is randomly drawn from the MNIST training dataset. Each of { χ 1 , χ 2 } are fed separately into an encoder to produce single-dimensional latent variables { z 1 , z 2 } that are not constrained and can take on any real value, z 1 , 2 ∈ R . Alternatively , one can think of the system as having a separate encoder for each digit, where the two encoders share the same weights, as illustrated in Figure 3. The encoder consists of two conv olutional layers with max pooling layers follo wed by two fully-connected layers and a 4 Fig. 3. Schematic of the MNIST addition architecture. An encoder consisting of con volutional layers and fully-connected layers operate on each MNIST image and extract a single-dimensional latent v ariable. The two encoders share the same weights. The two latent variables are then fed into the EQL network. The entire system is fed end-to-end and without pre-training. batch normalization layer at the output. More details on the encoder can be found in Appendix C. The latent variables { z 1 , z 2 } are then fed as inputs into the EQL network. The EQL network has a single scalar output ˆ y which is compared to the true label y = ψ 1 + ψ 2 . The entire network is trained end-to-end using a mean- squared error loss between the predicted label ˆ y and the true label y . In other words, the encoder is not trained separately from the EQL network. Note that the encoder closely resem- bles a simple con volutional neural network used for classifying MNIST digits except that it outputs a scalar value instead of logits that encode the digit. Additionally , there is no constraint on the properties of z 1 , 2 , but we expect that it has a one-to-one mapping to the true label ψ 1 , 2 . C. Dynamical System Analysis Fig. 4. (a) Architecture to learn the equations that propagate a dynamical system. (b) Each EQL cell in the propagating decoder consists of a separate EQL network for each dimension of y to be predicted. In our case, y = { u, v } where u is the position and v is velocity , so there are 2 EQL networks in each EQL cell. A potentially po werful application of deep learning in science exploration and discovery is discovering parameters in a dynamical system in an unsupervised way and using these parameters to predict the propagation of a similar sys- tem. For e xample, [11] uses multilayer perceptrons to extract relev ant properties from a system of bouncing balls (such as the mass of the balls or the spring constant of a force between the balls) and simultaneously predict the trajectory of a dif ferent set of objects. [12] accomplishes a similar goal but using a dynamics encoder (DE) with con volutional layers and a propagating decoder (PD) with deconv olutional layers to enable analysis and prediction of spatiotemporal systems such as those governed by PDEs. This architecture is designed to analyze spatiotemporal systems that may ha ve an uncontrolled dynamical parameter that varies among different instances of the dataset such as the diffusion constant in the diffusion equation. The parameters encoded in a latent variable are fed into the PD along with a set of initial conditions, which the PD propagates forward in time based on the extracted physical parameter and learned dynamics. Here, we present a deep learning architecture sho wn in Figure 4 which is based on the DE-PD architecture. The DE takes in the full input series { x t } T x t =0 and outputs a single- dimensional latent variable z . Unlike the original DE-PD architecture presented in [12], the DE here is not a V AE. The DE here consists of se veral conv olutional layers follo wed by fully-connected layers and a batch normalization layer . More details are giv en in Appendix C. The parameter z and an initial condition y 0 are fed into the PD which predicts the future time steps { ˆ y t } T y t =1 based on the learned dynamics. The PD consists of a “EQL cell” in a recurrent structure, such that each step in the recurrent structure predicts a single time step forward. The EQL cell consists of separate EQL networks for each of feature, or dimension, in ˆ y t . The full architecture is trained end-to-end using a mean- squared error loss between the predicted dynamics { ˆ y t } T y t =1 and the target series { y t } T y t =1 . Similar to the architecture in Section III-B, the DE and PD are not trained separately , and there is no additionaly restriction or bias placed on the latent variable z . The datasets are derived from two different physical systems (kinematics and simple harmonic oscillator) as described in the following sections. Fig. 5. (a) Kinematics describes the dynamics of an object where a force F is applied to a mass m . (b) Simple harmonic oscillator describes a mass m on a spring with spring constant k . In both cases, u is the displacement of the mass and v is the velocity . 1) Kinematics: Kinematics describes the motion of objects and is used in physics to study how objects move under an applied force. A schematic of a physical scenario described by kinematics is sho wn in Figure 5(a) in which an object on a frictionless surface has a force applied to it where the direction 5 of the force is parallel to the surface. The rele vant parameter to describe the object’ s motion can be reduced to a = F m for a constant force F and object mass m . Giv en position u i and velocity v i at time step i , the object’ s state at time step i + 1 are giv en by u i +1 = u i + v i ∆ t + 1 2 ∆ t 2 v i +1 = v i + a ∆ t (4) Acceleration a varies across different instances of the dataset. In our simulated dataset, we draw initial state and acceleration from uniform distributions: u 0 , v 0 , a ∼ U ( − 1 , 1) W e set ∆ t = 1 . The initial parameters u 0 , v 0 are fed into the propagator , and the dynamics encoder output is expected to correlate with a . 2) Simple Harmonic Oscillator (SHO): The second phys- ical system we analyze to demonstrate the dynamic system analysis architecture is the simple harmonic oscillator (SHO), a ubiquitous model in physics that can describe a wide range of physical systems including springs, pendulums, particles in a potential, or electric circuits. In general, the dynamics of the SHO can be giv en by the coupled first-order ordinary differential equation (ODE) du dt = v dv dt = − ω 2 u (5) where u is the position, v is the velocity , and ω is the resonant frequency of the system. In the case of a spring as sho wn in Figure 5(b), ω = p k /m where k is the spring constant and m is the mass of the object on the end of the spring. The SHO system can be solved for numerically using a finite-difference approximation for the time deriv ativ es. For example, the Euler method for integrating Eqs. 5 gives: u i +1 = u i + v ∆ t v i +1 = v i − ω 2 u ∆ t (6) In our experiments, we generate data with parameters drawn from uniform distributions: u 0 , v 0 ∼ U ( − 1 , 1) ω 2 ∼ U (0 . 1 , 1) The state v ariables u and v are measured at a time step of ∆ t = 0 . 1 to allow the system to find the finite-difference solution. Because of this small time step, we also need to propagate the solution for more time steps to find the right equation (otherwise the system learns the identity function). T o a void problems of the recurrent structure predicting a solution that explodes oward ±∞ , we start the training with propagating only 1 time step, and add more time steps as the training continues. This is a similar strategy as [9] except that we are not restarting the training. The initial parameters u 0 , v 0 are fed into the propagator, and the dynamics encoder output is e xpected to correlate with ω 2 . Fig. 6. The ability of the encoder to differentiate between digits as measured by the latent v ariable z versus the true digit ψ for digits χ drawn from the MNIST (a) training dataset and (b) test dataset. The correlation coef ficients are − 0 . 985 and − 0 . 988 , respectively . The ability of the entire architecture to fit the label y as measured by the predicted sum ˆ y versus the true sum y for digits χ drawn from the MNIST (c) training dataset and (d) MNIST test dataset. D. T raining The neural network is implemented in T ensorFlow [24]. The network is trained using backpropagation with the RMSProp optimizer [25] and the following loss function: L = 1 N X ( y i − ˆ y i ) 2 + λL ∗ 0 . 5 where N is the size of the training dataset and λ is a hyperparameter that balances the regularization versus the mean-squared error . Similar to [6], we introduce a multi-phase training schedule. In an optional first phase, we train with a small value of λ , allowing for the parts of the network apart from the EQL to ev olve freely and extract the latent parameters during training. In the second phase, λ is increased to a point where it forces the EQL network to become sparse. After this second phase, weights in the EQL netw ork belo w a certain threshold α are set to 0 and frozen such that they stay 0, equiv alent to fixing the L 0 norm. In the final phase of training, the system continues training without L ∗ 0 . 5 regularization (i.e. λ = 0 ) and with a reduced maximum learning rate in order to fine-tune the weights. Specific details for each experiment are listed in Appendix C. I V . R E S U LT S A. MNIST Arithmetic Figure 6(b) plots the latent variable z versus the true label ψ for each digit after the entire network has been trained. Note that the system is trained on digits drawn from the MNIST training dataset and we also e valuate the trained network’ s performance on digits drawn from the MNIST test dataset. W e see a strong linear correlation for both datasets, sho wing that the encoder has successfully learned a linear mapping to the digits despite not having access to the digit label ψ . Also note that there is a constant scaling factor between z and ψ 6 due to the lack of constraint on z . A simple linear regression shows that the relation is ψ = − 1 . 788 z + 4 . 519 (7) T ABLE I M N IS T A R I TH M E TI C E X P EC T E D A N D E X T R AC TE D E Q UA T I ON S T rue y = ψ 1 + ψ 2 Encoder ˆ y = − 1 . 788 z 1 − 1 . 788 z 2 + 9 . 04 EQL ˆ y = − 1 . 809 z 1 − 1 . 802 z 2 + 9 The extracted equation from the EQL network for this result is shown in T able I. The “Encoder” equation is what we expect based on the encoder result in Equation 7. W e conclude that the EQL network has successfully extracted the additi ve nature of the function. Plotted in Figure 6(c-d) are the predicted sums ˆ y versus the true sums y . The mean absolute errors of prediction for the system drawing digits from the MNIST training and test datasets are 0.307 and 0.315, respectiv ely . While the architecture is trained as a regression problem using a mean square loss, we can still report accuracies as if it is a classification task since the labels y are integers. T o calculate accuracy , we first round the predicted sum ˆ y to the nearest integer and then compare it to the label y . The trained system achieves accuracies of 89.7% and 90.2% for digits drawn from the MNIST training and test datasets, respectiv ely . T o demonstrate the generalization of this architecture to data outside of the training dataset, we train the system using a scheme where MNIST digit pairs χ 1 , χ 2 are randomly sampled from the MNIST training dataset and used as a training data point if they follo w the condition ψ 1 + ψ 2 < 15 . Otherwise, the pair is discarded. In the test phase, MNIST digit pairs χ 1 , χ 2 are randomly sampled from the MNIST training dataset and kept in the ev aluation dataset if ψ 1 + ψ 2 ≥ 15 . Otherwise, the pair is discarded. For comparison, we also test the generalization of the en- coder by following the abo ve procedures but drawing MNIST digit pairs χ 1 , χ 2 from the MNIST test dataset. T ABLE II M N IS T A R I TH M E TI C G E N ER A L I ZAT IO N R E SU LT S Accuracy [%] Source of w i to form x = { w 1 , w 2 } Network after the encoder y < 15 y ≥ 15 MNIST training dataset EQL 92 87 ReLU 93 0 . 8 MNIST test dataset EQL 91 83 ReLU 92 0 . 6 Generalization results of the network are shown in T able II. In this case, the EQL network has learned the equation ˆ y = − 1 . 56 z 1 − 1 . 56 z 2 + 8 . 66 . First, the most significant result is the difference between the accuracy ev aluated on pairs y < 15 and pairs y ≥ 15 . For the architecture with the EQL network, the accuracy drops by a few percentage points. Ho wev er , for the architecture where the EQL network is replaced by the commonly used fully-connected network with ReLU acti vation functions (which we label as “ReLU”), the accuracy drops to below 1% sho wing that the results of the EQL is able to generalize reasonably well in a regime where the ReLU cannot generalize at all. It is not necessarily an issue with the encoder since the system sees all digits 0 through 9. Second, the accuracy drops slightly when digits are drawn from the MNIST test dataset versus when the digits are drawn from the MNIST training dataset, as expected. W e did not optimize the hyperparameters of the digit extraction network since the drop in accuracy is small. Therefore, this could be optimized further if needed. Finally , the accuracy drops slightly for pairs y < 15 when using the EQL versus the ReLU network. This is unsurprising since the larger size and symmetric activ ation functions of the ReLU network constrains the network less than the EQL and may make the optimization landscape smoother . B. Kinematics Fig. 7. (a) Latent parameter z of the dynamic encoder architecture after training plotted as a function of the true parameter a . W e see a strong linear correlation. (b,c) Predicted propagation { ˆ y i } = { ˆ u i , ˆ v i } with the EQL cell and a con ventional network using ReLU activations. “True” refers to the true propagation { y i } . Figure 7(a) shows the extracted latent parameter z plotted as a function of the true parameter a . W e see a linear correlation with correlation coef ficient close to − 1 , sho wing that the dynamics encoder has extracted the relev ant parameter of the system. Again, there is a scaling relation between z and a : a = − 0 . 884 z − 0 . 091 (8) An example of the equations found by the EQL network after training is sho wn in T able III. The “DE” equation is what we expect based on latent variable extracted with the relation in Equation 8. These results match closely with what we expect. The predicted propagation { ˆ y i } is plotted in Figure 7(c-d). “T rue” is the true solution that we want to fit, and “EQL” is the solution propagated by the EQL network. For comparison, we also train a neural network with a similar architecture to the 7 T ABLE III K I NE M A T I CS E X P E CT E D A N D E X TR AC T E D E Q UA T I O NS T rue u i +1 = u i + v i + 1 2 a v i +1 = v i + a DE ˆ u i +1 = u i + v i − 0 . 442 z − 0 . 045 ˆ v i +1 = v i − 0 . 884 z − 0 . 091 EQL ˆ u i +1 = 1 . 002 u i + 1 . 002 v i − 0 . 475 z ˆ v i +1 = 1 . 002 v i − 0 . 918 z − 0 . 102 one shown in Figure 4 but where the EQL cell is replaced by a standard fully-connected neural network with 2 hidden layers of 50 neurons each and ReLU activ ation functions (which we label as “ReLU”). While both networks match the true solution very closely in the training regime (left of the dotted line), the ReLU network quickly div erges from the true solution outside of the training regime. The EQL cell is able to match the solution reasonably well for sev eral more time steps, showing how it can extrapolate beyond the training data. C. SHO Fig. 8. Results of training on the SHO system. (a) Latent parameter z of the dynamic encoder architecture after training plotted as a function of the true parameter ω 2 . W e see a good linear correlation. (b) Position u and (c) velocity v as a function of time for various models. “True” refers to the analytical solution. “EQL” refers to the propagation equation discovered by the EQL network. “ReLU” refers to propagation by a conv entional neural network that uses ReLU activ ation functions. “Euler” refers to finite-difference solution using the Euler method. The plot of the latent v ariable z as a function of the true parameter ω 2 is shown in Figure 8(a). Note that there is a strong linear correlation between z and ω 2 as opposed to between z and ω . This reflects the fact that using ω 2 requires fewer operations in the propagating equations than ω , the latter of which would require a squaring function. Additionally , the system was able to find that ω 2 is the simplest parameter to describe the system due to the sparsity re gularization on the EQL cell. W e see a strong linear correlation with a correlation coefficient of − 0 . 995 , showing that the dynamics encoder has successfully extracted the rele vant parameter of the SHO system. A linear regression sho ws that the relation is: ω 2 = − 0 . 927 z + 0 . 464 (9) T ABLE IV S H O E X P E CT E D A N D E X TR AC T E D E Q UA T I O NS T rue u i +1 = u i + 0 . 1 v i v i +1 = v i − 0 . 1 ω 2 u i DE ˆ u i +1 = u i + 0 . 1 v i ˆ v i +1 = v i − 0 . 0464 u i + 0 . 0927 u i z DE, 2nd Order ˆ u i +1 = u i + 0 . 1 v i ˆ v i +1 = 0 . 998 v i − 0 . 0464 u i + 0 . 0927 u i z + 0 . 0046 v i z EQL ˆ u i +1 = 0 . 994 u i + 0 . 0992 v i − 0 . 0031 ˆ v i +1 = 0 . 995 v i − 0 . 0492 d + 0 . 084 u i z + 0 . 0037 v i z + 0 . 0133 z 2 The equations extracted by the EQL cell (consisting of 2 EQL networks) are shown in T able IV. The “DE” equation is what we expect based on the dynamics encoder result in Equation 9. Immediately , we see that the expression for ˆ u i +1 and the first three terms of ˆ v i +1 match closely with the Euler method approximation using the latent variable relation extracted by the dynamics encoder . An interesting point is that while we normally use the first-order approximation of the Euler method for integrating ODEs: v i +1 = v i + ∆ t dv dt t = i + O (∆ t 2 ) it is possible to e xpand the approximation to find higher-order terms. If we expand the Euler method to its second-order approximation, we get: v i +1 = v i + ∆ t dv dt t = i + 1 2 ∆ t 2 d 2 v dt 2 t = i + O (∆ t 3 ) ≈ v i − ∆ tω 2 u i − 1 2 ∆ t 2 ω 2 v i The expected equation based on the dynamics encoder result and assuming the 2nd order expansion is labeled as “DE, 2nd Order” in T able IV. It appears that the EQL network in this case has not only found the first-order Euler finite- difference method, it has also added on another small term that corresponds to second-order term in the T aylor expansion of v i +1 . The last term found by the EQL network, 0 . 0133 z 2 is likely from either cross-terms inside the network or a lack of con vergence to exactly 0 and would likely disappear with another thresholding process. The solution propagated through time is shown in Figure 8(b-c). As before, “ReLU” is the solution propagated by an architecture where the EQL network is replaced by a con ven- tional neural network with 4 hidden layers of 50 units each and ReLU activ ation functions. For an additional comparison, we hav e also calculated the finite-difference solution using Euler’ s method to integrate the true ODEs which is labeled as “Euler”. W ithin the training regime, all of the methods fit the true solution reasonably well. Howe ver , the conv entional neural 8 network with ReLU activ ation functions completely fails to extrapolate beyond the training regime and essentially re- gresses to noise around 0. The Euler method and the EQL network are both able to e xtrapolate reasonably well beyond the training regime, although they both start to diver ge from the true solution due to the lar ge time step and the accumulated errors. A more accurate method such as the Runge-Kutta method almost e xactly fits the analytical solution, which is not surprising due to its small error bound. Howe ver , it is more complex than the Euler method and would likely require a larger EQL network to find an expression similar to the Runge- Kutta method. Interestingly , the EQL network solution has a smaller error than the Euler solution, demonstrating that the EQL network w as able to learn higher-order corrections to the first-order Euler method. This could possibly lead to discovery of more efficient integration schemes for dif ferential equations that are difficult to solve through finite-difference. V . C O N C L U S I O N W e hav e shown how we can integrate symbolic regression with deep learning architectures and train the entire system end-to-end to take advantage of the powerful deep learning training techniques that have been dev eloped in recent years. Namely , we show that we can learn arithmetic on MNIST digits where the system must learn to identify the images in an image recognition task while simultanesouly extracting the mathematical expression that relates the digits to the answer . Additionally , we sho w that we can simultaneously e xtract an unkno wn parameter from a dynamical system e xtract the propagation equations. In the SHO system, the results suggest that we can discov er new techniques for integrating ODEs, potentially paving the way for improv ed integrators, such as integrators for stiff ODEs that may be difficult to solve with numerical methods. One direction for future work is to study the role of random initializations and make the system less sensiti ve to random initializations. As seen by the benchmark results of the EQL network in Appendix A, the EQL network is not always able to find the correct mathematical expression. This is because there are a number of local minima in the EQL network that the network can get stuck in, and gradient-based optimization methods are only guaranteed to find local minima rather than global minima. Local minima are not typically a concern for neural networks because the local minima are typically close enough in performance to the global minimum [26]. Howe ver , for the EQL network, we often want to find the true global minimum. In this work, we have alleviated this issue by increasing stochasticity through large learning rates and by decreasing the sensitivity to random initializations by duplicating activ ation functions. Additionally , we run multiple trials and find the best results, either manually or through an automated system [6], [7]. In future work, it may be possible to find the true global minimum without resorting to multiple trials as it has been shown that o ver -parameterized neural networks with certain types of acti vation functions are able to reach the global minimum through gradient descent in linear time regardless of the random initialization [27]. Other directions for future work include expanding the types of deep learning architectures that the EQL network can integrate with. For example, supporting spatio-temporal systems can lead to PDE discovery . The spatial deri vati ves could be calculated using known finite-difference approxi- mations or learnable kernels [8]. Another possible extension is to introduce parametric dependence in which unknown parameters ha ve a time-dependence, which has been studied in PDE-discovery using group sparsity [28]. Additionally , the encoder can be expanded to capture a wider variety of data such as videos [13], audio signals, and text. A P P E N D I X A E Q L N E T W O R K D E TA I L S The activ ation functions in each hidden layer consist of: [1( × 2) , g ( × 4) , g 2 ( × 4) , sin(2 π g )( × 2) , e g ( × 2) , sigmoid (20 g )( × 2) , g 1 ∗ g 2 ( × 2)] where the sigmoid function is defined as: sigmoid ( g ) = 1 1 + e − g and the ( × i ) indicated the number of times each activ a- tion function is duplicated. The sin and sigmoid functions hav e multipliers inside so that the functions more accurately represent their respectiv e shapes inside the input domain of x ∈ [ − 1 , 1] . Unless otherwise stated, these are the acti vation functions used for the other experiments as well. The exact number of duplications is arbitrary and does not hav e a sig- nificant impact on the system’ s performance. Future work may include experimenting with a lar ger number of duplications. W e use two phases of training, where the first phase has a learning rate of 10 − 2 and regularization weight 5 × 10 − 3 for 2000 iterations. Small weights are frozen and set to 0 after the first phase. The second phase of training has a learning rate of 10 − 3 for 10000 iterations. T o benchmark our symbolic regression system, we choose a range of trial functions that our architecture can feasibly construct, train the network through 20 trials, and count how many times it reaches the correct answer . Benchmarking results are shown in T able V. As mentioned in section III-A, we only need the network to find the correct equation at least once since we can construct a system that automatically picks out the correct solution based on equation simplicity and test error . A. Computational Efficiency W ith respect to the task of symbolic regression, we should note that this algorithm does not offer an asymptotic speedup ov er conv entional symbolic regression algorithms, as the prob- lem of finding the correct expression requires a combinatorial search ov er the space of possible e xpressions and is NP- hard. Rather , the advantage here is that by solving symbolic regression problems through gradient descent, we can inte grate symbolic regression with deep learning architectures. Experiments are run on an Nvidia GTX 1080 Ti. T raining the EQL network with 2 hidden layers ( L = 2 ) for 20,000 9 T ABLE V B E NC H M A RK R E S ULT S F O R T H E E Q L N E T WO R K . Success Rate Function L 0 . 5 L 0 x 1 1 x 2 0 . 6 0 . 75 x 3 0 . 3 0 . 05 sin(2 π x ) 0 . 45 0 . 85 xy 0 . 8 1 1 1+ e − 10 x 0 . 3 0 . 55 xy 2 + z 2 0 . 05 0 . 95 exp( − x 2 ) 0 . 05 0 . 15 x 2 + sin(2 πy ) 0 . 2 0 . 8 x 2 + y − 2 z 0 . 6 0 . 9 epochs takes 37 seconds, and training the EQL network with 3 hidden layers ( L = 3 ) takes 51 seconds. In general, the computational complexity of the EQL net- work itself is the same as that of a con ventional fully- connected neural network. The only difference are the activ a- tion functions which are applied by iterating ov er g and thus takes O ( n ) time where n is the number of nodes in each layer . Howe ver , the computational complexity of a neural network is dominated by the weight matrix multiplication which takes O ( n 2 ) time for both the EQL network and the conv entional fully-connected neural network. A P P E N D I X B R E L A X E D L 0 R E G U L A R I Z A T I O N W e ha ve also implemented an EQL network that uses a re- laxed form of L 0 regularization for neural networks introduced by [14]. W e briefly re view the details here, but refer the reader to [14] for more details. The weights W of the neural network are reparameterized as W = ˜ W z where ideally each element of z , z j,k , is a binary “gate”, z j,k ∈ { 0 , 1 } . Howe ver , this is not differentiable and so we allow z j,k to be a stochastic v ariable drawn from the hard concrete distribution: u ∼ U (0 , 1) s = sigmoid ([log u − log(1 − u ) + log α j,k ] /β ) ¯ s = s ( ζ − γ ) + γ ) z j,k = min(1 , max(0 , ¯ s )) where α j,k is a trainable variable that describes the location of the hard concrete distrib ution, and β , ζ , γ are hyperparameters that describe the distribution. In the case of binary gates, the regularization penalty would simply be the sum of z (i.e., the number of non-zero elements in W . Howe ver , in the case of the hard concrete distribution, we can calculate an analytical form for the e xpectation of the regularization penalty over the distribution parameters. The total loss function is then L = 1 N X ( y i − ˆ y i ) 2 + X j,k sigmoid log α j,k − β log − γ ζ The advantage of L 0 regularization is that it enforces spar- sity without placing a penalty on the magnitude of the weights. This also allows us to train the system without needing a final stage where small weights are set to 0 and frozen. While the reparameterization by [14] requires us to double the number of trainable parameters in the neural network, the regularization is only applied to the EQL network which is small compared to the rest of the architecture. In our experiments, we use the hyperparameters for the L 0 regularization suggested by [14], although these can be optimized in future work. Additionally , while [14] apply group sparsity to the rows of the weight matrices with the goal of computational efficiency , we apply parameter sparsity with the goal fo simplifying the symbolic expression. W e benchmark the EQL network using L 0 regularization with the aforemen- tioned trial functions and list the results in T able V. The success rates appear to be as good or better than the network using L 0 . 5 regularization for most of the trial functions that we hav e picked. W e ha ve also integrated the EQL network using L 0 regularization into the MNIST arithmetic and kinematics architectures, and ha ve found similar results as the EQL network using L 0 . 5 regularization. A P P E N D I X C E X P E R I M E N T D E T A I L S A. MNIST Arithmetic The encoder network consists of a con volutional layer with 32 5 × 5 filters followed by a max pooling layer, another con volutional layer with 64 5 × 5 filters followed by a max pooling layer, and 2 fully-connected layers with 128 and 16 units each with ReLU activ ation units. The max pooling layers hav e pool size of 2 and stride length of 2. The fully-connected layers are follo wed by 1-unit layer with batch normalization. The output of the batch normalization layer is divided by 2 such that the standard deviation of the output is 0.5. This decreases the range of the inputs to the EQL network since the EQL network was constructed assuming an input domain of x ∈ [ − 1 , 1] . Additionally , the output of the EQL network, ˆ y ∗ , is scaled as ˆ y = 9 ˆ y ∗ + 9 before being fed into the loss function so as the normalize the output against the range of expected y (this is equi valent to normalizing y to the range [ − 1 , 1] ). The ReLU network that is trained in place of the EQL network for comparison consists of two hidden layers with 50 units each and ReLU activ ation. W e use two phases of training, where the first phases uses a learning rate of 10 − 2 and regularization weight λ = 0 . 05 . The second phase uses a learning rate of 10 − 4 and no regularization. The small weights are frozen between the first and second phase with a threshold of α = 0 . 01 . Each phase is trained for 10000 iterations. B. Kinematics T o generate the kinematics dataset, we sample 100 values for a and generate a time series { x t } T x − 1 t =0 and { y t } T y t =0 for each a . The input series is propagated for T x = 100 time steps. 10 The dynamics encoder consists of 2 1D con volutional layers with 16 filters of length 5 in each layer . These are followed by a hidden layer with 16 nodes and ReLU activ ation function, an output layer with one unit, and a batch normalization layer with standard deviation 0.5. The ReLU network that is trained in place of the EQL network for comparison is the same as that of the MNIST task. W e use two phases of training, where the first phase uses a learning rate of 10 − 2 and a re gularization weight of λ = 10 − 3 for a total of 5000 iterations. The system is trained on T y = 1 time step for the first 1000 iterations, and then T y = 5 time steps for the remainder of the training. The small weights are frozen between the first and second phase with a threshold of α = 0 . 1 . The second phase uses a base learning rate of 10 − 3 and no regularization for 10000 iterations. C. SHO T o generate the SHO dataset, we sample 1000 datapoints values for ω 2 and generate time series time series { x t } T x − 1 t =0 and { y t } T y t =0 for each ω 2 . The input series is propagated for T x = 500 time steps with a time step of ∆ t = 0 . 1 . The output series is propagated for T y = 25 time steps with the same time step. The dynamics encoder is the same architecture as used in the kinematics experiment. Due to the greater number of time steps that the system needs to propagate, the EQL network does not duplicate the activ ation functions for all functions. The functions in each hidden layer consist of: [1( × 2) , g ( × 2) , g 2 , sin(2 π g ) , e g , 10 g 1 ∗ g 2 ( × 2)] The ReLU network that is trained in place of the EQL network for comparison consists of four hidden layers with 50 units each and ReLU activ ation functions. W e use three phases of training, where the first phase uses a learning rate of 10 − 2 and a regularization weight of λ = 4 × 10 − 5 for a total of 2000 iterations. The system starts training on T y = 1 time steps for the first 500 time steps and then add 2 more time steps e very 500 iterations for a total of T y = 7 time steps. In the second phase of training, we increase the number of time steps to T y = 25 , decrease the base learning rate to 2 × 10 − 3 , and increase the regularization weight to λ = 2 × 10 − 4 . The small weights are frozen between the second and third phase with a threshold of α = 0 . 01 . The third and final phase of training uses a base learning rate of 10 − 3 and no regularization. A P P E N D I X D A D D I T I O NA L M N I S T A R I T H M E T I C D A TA The results presented in Figure 6 and T able I are drawn from one of se veral trials, where each in each trial the network is trained from a dif ferent random initialization of the network weights. Due to the random initialization, the EQL does not reach the same equation ev ery time. Here we present results from additional trials to demonstrate the v ariability in the system’ s behavior as well as the system’ s robustness to the random initializations. Fig. 9. The ability of the encoder to differentiate between digits as measured by the latent v ariable z versus the true digit ψ for digits χ drawn from the MNIST (a) training dataset and (b) test dataset. The ability of the entire architecture to fit the label y as measured by the predicted sum ˆ y v ersus the true sum y for digits χ drawn from the MNIST (c) training dataset and (d) MNIST test dataset. The experimental details are described in Section III-B where digits χ 1 , 2 are drawn from the entire MNIST training dataset. W e refer to the results sho wn in Figure 6 and T able I as T rial 1. The results for T rial 2 are shown in Figure 9. Similar to T rial 1, Trial 2 produces a linear relationship between the true digit φ and the latent variable z , although there is a positi ve instead of negati ve correlation. As previously mentioned, there is no bias placed on the latent variable z so whether there is a positiv e or negativ e correlation is arbitrary and depends on the random initialization of the weights. The trained architecture produced the following expression from the EQL network: ˆ y = 1 . 565 z 1 + 1 . 558 z 2 + 9 (10) Note the positi ve coef ficients in (10) which reflects the positi ve correlation shown in Figure 9(a-b). As shown in Figure 9(c-d), the network is still able to accurately predict the sum y . The results for T rial 3 are shown in Figure 10. Note that in this case, the relationship between φ and z is no longer linear . Howe ver , the encoder still finds a one-to-one mapping between φ and z , and the EQL network is still able to extract the information from z such that it can predict the correct sum as shown in Figure 10(c-d). The equation found by the EQL network is: ˆ y = − 4 . 64 sin(2 . 22 z 1 ) − 4 . 63 sin(2 . 21 z 2 ) + 9 (11) This is consistent with the insight that the curve in Figure 10(a-b) represents an inv erse sine function. Thus, (11) is first in verting the transformation from φ to z to produce a linear mapping and then adding the two digits together . So while the EQL network does not always gi ve the exact equation we expect, we can still gain insight into the system from analyzing the latent variable and the resulting equation. 11 Fig. 10. The ability of the encoder to differentiate between digits as measured by the latent v ariable z versus the true digit ψ for digits χ drawn from the MNIST (a) training dataset and (b) test dataset. The ability of the entire architecture to fit the label y as measured by the predicted sum ˆ y v ersus the true sum y for digits χ drawn from the MNIST (c) training dataset and (d) MNIST test dataset. A C K N O W L E D G M E N T W e would like to ackno wledge Joshua T enenbaum, Max T egmark, Jason Fleischer , Ale xander Alemi, Jasper Snoek, Stjepan Picek, Rumen Dango vski, and Ilan Mitnik ov for fruitful con versations. This research is sponsored in part by the Army Research Office and under Cooperative Agreement Number W911NF-18-2-0048, by the Department of Defense through the National Defense Science & Engineering Grad- uate Fellowship (NDSEG) Program, by the MITSenseTime Alliance on Artificial Intelligence, by the Defense Advanced Research Projects Agency (D ARP A) under Agreement No. HR00111890042. Research was also sponsored in part by the United States Air F orce Research Laboratory and w as accom- plished under Cooperativ e Agreement Number F A8750-19-2- 1000. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the United States Air Force or the U.S. Government. The U.S. Gov ernment is authorized to reproduce and distrib ute reprints for Gov ernment purposes notwithstanding any copy- right notation herein. R E F E R E N C E S [1] J. Koza, “Genetic programming as a means for programming computers by natural selection, ” Statistics and Computing , vol. 4, no. 2, pp. 87–112, jun 1994. [Online]. A vailable: http://link.springer .com/10.1007/ BF00175355 [2] M. Schmidt and H. Lipson, “Distilling free-form natural laws from experimental data.” Science (New Y ork, N.Y .) , vol. 324, no. 5923, pp. 81–5, apr 2009. [Online]. A vailable: http://www .ncbi.nlm.nih.gov/ pubmed/19342586 [3] S. L. Brunton, J. L. Proctor, and J. N. Kutz, “Discovering gov erning equations from data by sparse identification of nonlinear dynamical systems.” Proceedings of the National Academy of Sciences of the United States of America , vol. 113, no. 15, pp. 3932–7, apr 2016. [On- line]. A vailable: http://www .ncbi.nlm.nih.gov/pubmed/27035946http: //www .pubmedcentral.nih.gov/articlerender .fcgi?artid=PMC4839439 [4] S. H. Rudy , S. L. Brunton, J. L. Proctor , and J. N. Kutz, “Data-driven discovery of partial differential equations, ” Science Advances , vol. 3, no. 4, p. e1602614, apr 2017. [5] H. Schaeffer , “Learning partial differential equations via data discovery and sparse optimization, ” Proceedings of the Royal Society A , vol. 473, no. 2197, 2017. [Online]. A vailable: http://rspa.royalsocietypublishing. org/content/royprsa/473/2197/20160446.full.pdf [6] G. Martius and C. H. Lampert, “Extrapolation and learning equations, ” oct 2016. [Online]. A vailable: http://arxiv .org/abs/1610.02995 [7] S. S. Sahoo, C. H. Lampert, and G. Martius, “Learning Equations for Extrapolation and Control, ” jun 2018. [Online]. A vailable: https://arxiv .org/abs/1806.07259 [8] Z. Long, Y . Lu, X. Ma, and B. Dong, “PDE-Net: Learning PDEs from Data, ” in Pr oceedings of Machine Learning Resear ch , jul 2018, pp. 3208–3216. [Online]. A vailable: http://proceedings.mlr .press/v80/ long18a.html [9] Z. Long, Y . Lu, and B. Dong, “PDE-Net 2.0: Learning PDEs from Data with A Numeric-Symbolic Hybrid Deep Network, ” nov 2018. [Online]. A vailable: http://arxiv .org/abs/1812.04426 [10] A. Trask, F . Hill, S. Reed, J. Rae, C. Dyer , and P . Blunsom, “Neural Arithmetic Logic Units, ” aug 2018. [11] D. Zheng, V . Luo, J. W u, and J. B. T enenbaum, “Unsupervised learning of latent physical properties using perception-prediction networks, ” in 34th Confer ence on Uncertainty in Artificial Intelligence 2018, U AI 2018 , vol. 1. Association For Uncertainty in Artificial Intelligence (A UAI), 2018, pp. 497–507. [12] P . Y . Lu, S. Kim, and M. Solja ˇ ci ´ c, “Extracting Interpretable Physical Parameters from Spatiotemporal Systems using Unsupervised Learning, ” jul 2019. [Online]. A vailable: http://arxiv .org/abs/1907.06011 [13] P . Chari, C. T alegaonkar , Y . Ba, and A. Kadambi, “V isual Physics: Discovering Physical La ws from V ideos, ” nov 2019. [Online]. A vailable: http://arxiv .org/abs/1911.11893 [14] C. Louizos, M. W elling, and D. P . Kingma, “Learning Sparse Neural Networks through $L 0$ Regularization, ” dec 2017. [Online]. A vailable: https://arxiv .org/abs/1712.01312 [15] D. Molchanov , A. Ashukha, and D. V etrov , “V ariational dropout sparsi- fies deep neural networks, ” in 34th International Conference on Mac hine Learning, ICML 2017 , vol. 5. International Machine Learning Society (IMLS), 2017, pp. 3854–3863. [16] M. Zhu and S. Gupta, “T o prune, or not to prune: exploring the efficacy of pruning for model compression, ” oct 2017. [Online]. A vailable: http://arxiv .org/abs/1710.01878 [17] T . Gale, E. Elsen, and S. Hooker , “The State of Sparsity in Deep Neural Networks, ” feb 2019. [Online]. A vailable: http: //arxiv .org/abs/1902.09574 [18] B. K. Natarajan, “Sparse Approximate Solutions to Linear Systems, ” SIAM Journal on Computing , vol. 24, no. 2, pp. 227–234, apr 1995. [On- line]. A vailable: http://epubs.siam.org/doi/10.1137/S0097539792240406 [19] S. Srinivas, A. Subramanya, and R. V . Babu, “Training Sparse Neural Networks, ” in 2017 IEEE Conference on Computer V ision and P attern Recognition W orkshops (CVPRW) . IEEE, jul 2017, pp. 455–462. [Online]. A vailable: http://ieeexplore.ieee.org/document/8014795/ [20] Z. Xu, H. Zhang, Y . W ang, X. Chang, and Y . Liang, “L 1/2 regularization, ” Science China Information Sciences , v ol. 53, no. 6, pp. 1159–1169, jun 2010. [Online]. A vailable: http://link.springer .com/10. 1007/s11432- 010- 0090- 0 [21] Z.-B. Xu, H.-L. Guo, Y . W ang, and H. Zhang, “Representative of L1/2 Regularization among Lq (0 < q ≤ 1) Regularizations: an Experimental Study Based on Phase Diagram, ” Acta Automatica Sinica , v ol. 38, no. 7, pp. 1225–1228, jul 2012. [Online]. A vailable: https://www .sciencedirect.com/science/article/pii/S1874102911602930 [22] Q. Fan, J. M. Zurada, and W . W u, “Conver gence of online gradient method for feedforward neural networks with smoothing L1/2 regularization penalty, ” Neur ocomputing , vol. 131, pp. 208–216, may 2014. [Online]. A vailable: https://www .sciencedirect.com/science/ article/pii/S0925231213010825 [23] W . Wu, Q. Fan, J. M. Zurada, J. W ang, D. Y ang, and Y . Liu, “Batch gradient method with smoothing L1/2 regularization for training of feedforward neural networks, ” Neural Networks , vol. 50, pp. 72–78, feb 2014. [Online]. A vailable: https://www .sciencedirect.com/science/ article/pii/S0893608013002700 [24] M. Abadi, A. Agarwal, P . Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, S. Ghemaw at, I. Goodfello w , A. Harp, G. Irving, M. Isard, Y . Jia, R. Jozefowicz, L. Kaiser, M. Kudlur, J. Levenber g, D. Man ´ e, R. Monga, S. Moore, D. Murray , C. Olah, M. Schuster, J. Shlens, B. Steiner, I. Sutskev er, K. T alwar , P . T ucker , V . V anhoucke, V . V asudev an, F . V i ´ egas, O. V inyals, P . W arden, M. W attenberg, M. Wicke, Y . Y u, and X. Zheng, “T ensorFlow: Large-scale machine learning on heterogeneous systems, ” 12 2015, software av ailable from tensorflow .org. [Online]. A vailable: http://tensorflow .org/ [25] T . Tieleman and G. Hinton, “Lecture 6.5-rmsprop: Di vide the gradient by a running average of its recent magnitude, ” COURSERA: Neural networks for machine learning , vol. 4, no. 2, pp. 26–31, 2012. [26] A. Choromanska, M. Henaff, M. Mathieu, G. B. Arous, and Y . LeCun, “The loss surfaces of multilayer networks, ” in Journal of Machine Learning Resear ch , vol. 38. Microtome Publishing, 2015, pp. 192– 204. [27] S. S. Du, J. D. Lee, H. Li, L. W ang, and X. Zhai, “Gradient Descent Finds Global Minima of Deep Neural Networks, ” nov 2018. [Online]. A vailable: http://arxiv .org/abs/1811.03804 [28] S. Rudy , A. Alla, S. L. Brunton, and J. N. Kutz, “Data-driven identi- fication of parametric partial differential equations, ” SIAM Journal on Applied Dynamical Systems , vol. 18, no. 2, pp. 643–660, apr 2019.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment