Block Factor-width-two Matrices and Their Applications to Semidefinite and Sum-of-squares Optimization
Semidefinite and sum-of-squares (SOS) optimization are fundamental computational tools in many areas, including linear and nonlinear systems theory. However, the scale of problems that can be addressed reliably and efficiently is still limited. In th…
Authors: Yang Zheng, Aivar Sootla, Antonis Papachristodoulou
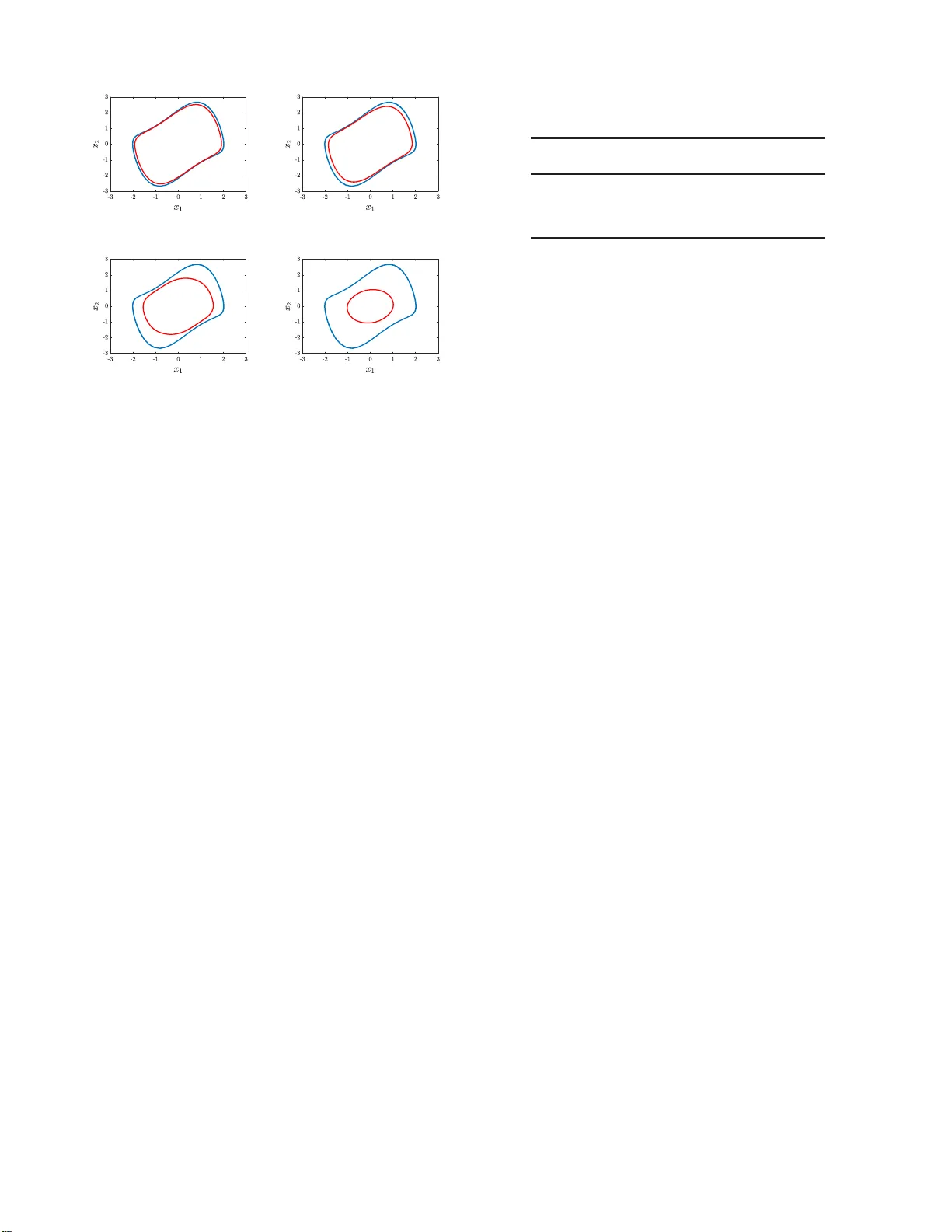
1 Block F actor -width-tw o Matric es and T h eir Applications to Semidefinite and Sum-of-squares Optimizati on Y ang Zheng, Member , IEEE, Aiv ar Sootla, and An tonis Papachristodou lou , F ellow , IEEE Abstract —Semidefinite and sum-of-squares (SOS) opti mization are fundamental comput ation al tools in many ar eas, inclu ding linear and nonlinear systems theory . Howe ver , the scale of problems that can b e add ressed r eliably and efficientl y is still limited. In this paper , we introduce a new notion of bloc k factor- width-two matrices and build a new hierarch y of inner and outer approximations of the cone of positive semidefinite (PS D) matri- ces. This n otion i s a bl ock extension of the standard factor -width- two matrices, and allows fo r an improv ed in n er -approximation of the PSD cone. In th e context of SOS optimization, this leads to a b lock extension of the scaled diago nally dominant sum-of- squares (SDSOS) polynomials. By v arying a matrix partition, the notion of block factor -width-t wo matrices can balance a trade- off between the computation scalability and solution qu ality for solving semidefin ite an d SOS optimization problems. Numerical experiments on a range of larg e-scale instances confirm our theoretical findin gs. Index T erms —Semidefini te optimization, Sum-of-squares poly- nomials, M atrix decomposition, Large-sca le systems. I . I N T R O D U C T I O N S EMIDEFINITE prog rams (SDPs) are a class of conve x problem s over th e co ne of positive semide finite ( PSD) matrices [2], wh ich is one o f the major co mputation al too ls in linear co ntrol th eory . Many an alysis an d synthesis p roblems in line a r systems can be ad dressed via solving certain SDPs; see [3] fo r an overview . The later development of sum-of - squares (SOS) optimization [4], [5] extends the applications of SDPs to nonlinea r problem s inv olving polyn omials, an d thus, allows ad dressing m any non linear con tr ol problem s sys- tematically , e.g. , certifying asym ptotic stability o f equilibriu m points of n onlinear systems [6], [ 7], appro ximating region of attraction [8]– [10], an d providing bo unds o n infinite-time av erages [11]. A. Motivation In theory , SDPs can be solved up to any arbitrar y pre- cision in polyno mial time u sing secon d-ord e r interio r-point methods ( IPMs) [ 2]. From a p ractical v iewpoint, however , the com putational speed a nd reliability of the curren t SDP The first two authors co ntribu ted equally to this w ork. A prelimi nary version of part of this work appeared in [1]. T his work is supported by the E PSRC Grant EP/M002454/ 1. Y . Zheng is with the Depa rtment of Electri cal and Computer Engine ering, Uni versit y of Ca lifornia San Diego, CA 92093. (email: z hengy@eng .ucsd.edu) A. Sootla and A. Papachristo doulou are with Department of Engineering Science , Uni versity of Oxford, Parks Road, Oxfor d, O X1 3PJ, U.K. (emails: { ai v ar .sootla, antonis } @e ng.ox.ac.uk) solvers be comes worse f or many large-scale pro blems of practical interest. Con sequently , d ev eloping fast and r eliable SDP solvers for large-scale problem s has receiv ed considerab le attention in the literatu r e. For instanc e , a ge n eral pur pose first-order solver based on the altern ating direction m ethod of multipliers (ADM M) was dev eloped in [12]. For SDP progr ams with chordal spar sity (a spa r sity pattern m odeled by ch ordal gr aphs [1 3]), fast ADMM-based alg orithms were propo sed in [14], and efficient IPMs w e re sug gested in [15], [16]. Chord al spar sity in the con text of SOS o ptimization was also exploited in [1 7]–[19]. T he un derlying idea in these sparsity exploiting appro a ches is to equivalently decomp ose a large sparse PSD constra in t into a num ber of smaller PSD constraints, leading to significant com p utational savings f o r sparse problems. Since the approac h es in [ 14]–[19] ar e only suitable for sufficiently sp a r se problems, an alternative app roach to speed- up semid efinite and SOS op timization was pr oposed in [20] f or general SDPs, wh ere th e au thors suggested to appro x imate the PSD cone S n + with the con e o f factor-width-two ma trices [2 1], denoted as F W n 2 ( n is the matrix dimension) . A matrix has a factor-width two if it can be repr esented as a sum o f PSD matrices of rank at most two [21], and thus it is also PSD. The cone of F W n 2 can be eq uiv alently written as a number of seco n d-ord er cone constraints, an d thus linear optimization over F W n 2 can b e addr essed by a seco nd-ord er cone prog ram (SOCP), which is much more scalable in terms of memory requirem ents an d tim e consump tio n compared to SDPs. Th is feature of scalability is demonstrated in a wide range of applications [20]. W e note th a t F W n 2 is the same as th e set of symmetric scaled diagonally dominan t ( SDD) matrices [21], and th e au thors in [2 0] ad o pted the termino logy SDD instead of factor-width-two . As alread y poin ted out in [20], app roximatin g the PSD co ne S n + by th e cone of factor-width-two matrices F W n 2 is conser- vati ve. Consequently , the r e stricted problem may be infeasible or the op timal solution of th e prog r am with F W n 2 may be significantly different from that of th e o riginal SDP . Ther e are se veral approac h es to bridge the gap between F W n 2 and S n + , such as the basis pursuit algo rithm in [22]. As d iscussed in [20, Section 5], on e may also em ploy the notion of factor-width- k matrices (denoted as F W n k ) that can be decomposed in to a sum o f PSD matrices of rank at most k . Howe ver , enforc in g this constraint is pro blematic d ue to a large n umber of k × k PSD co nstraints, which gr ows in a com binatorial fashion as n or k inc reases (e.g . , when k = 3 , the nu mber of small PSD 2 constraints is alread y O ( n 3 ) ). Ther efore, th e co mputation al burden ma y actually inc rease using factor-width- k matrices compare d to the orig in al SDP , while also being con servati ve. It is n ontrivial to u se factor-width- k ma tr ices to app roximate SDPs in a practical way . W e no te that the autho r s in [2 3] ha ve provided quantification f or the approxim ation quality of the PSD cone using the d u al o f F W n k for any factor-width k . B. Contributions In th is paper, we take a different appr oach to en rich the cone of factor-width-two matr ices for the appr oximation of the PSD co n e: we take inspir ation from SDD m a tr ices and consider their block extensions. Ou r key idea is to partition a matrix into a set of non-intersecting b locks of en tries and to e nforce SDD constrain ts on these blo c ks instead o f th e individual entries. In th is way , w e c a n reduce the nu mber of small block s sign ificantly compa r ed to F W n k with k ≥ 3 , while still imp roving the ap proxim a tion quality compare d to F W n 2 . Precisely , the contr ibutions of this paper are: • W e in troduce a new class of b lock factor-width-two matrices, which can be d ecompo sed into a sum of PSD matrices who se r ank is b ound e d by th e corr espondin g block sizes. One notable feature of block factor-width- two m atrices is that they are less conservativ e than F W n 2 and more scalable than F W n k ( k ≥ 3) . This new class of matrice s f orms a pr oper cone, an d v ia coarsenin g th e partition, we can b uild a new hierar chy o f in n er and outer approx imations o f the PSD con e. • Motiv ated by [23], we p rovide lower an d up per bound s on the d istance between the class of blo ck factor-width- two matrices and the PSD co ne after some normalization. Our results explicitly show th at reducin g the n umber o f partitions can improve the ap proxim a tion quality . This agrees with the resu lts in [23] that req uire to increase the factor-width k . W e h ighlight that re d ucing the n umber of partitions is num e r ically mor e efficient in practice since the number of d ecompo sition b ases is reduced a s well. In addition, we id entify a class o f sp arse PSD matr ices that belong to the cone of blo ck factor-width-two matrices. • W e app ly the notion of b lock factor-width-two matrices in both sem id efinite a nd SOS optimization . W e first define a new blo ck facto r-width-two co ne pr ogram , w h ich is able to retur n a n upp er bound to th e corresp onding SDP f aster . Then, in the co ntext of SOS o ptimization, ap plying the notion o f block factor-width-two matrices natu rally leads to a bloc k extension of the so-called SDSOS polyno mi- als [20]. A n ew hierar chy of in ner appro ximations of SOS polyn omials is d eriv ed accordin g ly . W e also show that a natural partition exists in the co ntext of SOS matrices. Numerica l tests from large- scale SDPs an d SOS optimization sho w promising results in balancing a trade- off b etween compu tation scalability and solutio n quality using our notio n of bloc k factor-width-two matrices. C. Related work Dev eloping efficient and reliable method s to make SDPs scalable is a very activ e resear ch ar e a. Th e r e are extensiv e results in the literatur e , and we h ere overview som e r epresen- tati ve techniques on improving scalability for SDPs (see [24]– [27] for excellent surveys). One main class of appro a ches is to exploit pro blem structure (such as sparsity [14], [26] and sym- metry [28]) to enhanc e scalability . Ano th er class of m ethods aims to g enerate low-rank solutions to SDPs which pro mises to reduce comp u tational time and storag e require m ents; see the celebrated Burer -Mon teiro alg o rithm [ 29]. Also, there exists increasing resear c h attention on de veloping efficient first-order algorithm s fo r SDPs which in g e neral trade off scalab ility with accuracy [12], [30], [31]. An iterative algorithm based on the Augmente d Lagrangian method has bee n dev eloped in [32]. Finally , another category o f app roaches is to impose stru c tural approx imations of the PSD co ne and trad e off scalability with conservatism. One typical techniqu e is th e afo remention ed factor-width-two approxima tio n [20], [22]. Our result on bloc k factor-width-two matrices falls into the last category and extends the techniqu e in [20]. It will be interesting to co mbine different approache s for fur ther scalability imp rovements o f solving SDPs. D. P aper structur e and no tation The rest of this p aper is organized as fo llows. In Sec- tion II, we briefly r evie w some necessary preliminar ies on matrix th eory . Sectio n III introduces the new class of blo ck factor-width-two matrices and a new hierarchy of inner/o uter approx imations of th e PSD cone. The appro ximation q uality of block facto r-width-two matrices is discussed in Sec tio n IV. W e pr esent app lications in semid efinite and SOS o ptimization in Section V, a n d nu merical exper iments are repo rted in Section VI. W e conclu de the pap er in Sectio n VII. Notation: Thro ughou t this p aper, we use N = { 1 , 2 , . . . } to denote the set of positive integers, and R to d enote the set of real number s. Given a matrix A ∈ R n × n , we den ote its transpose by A T . W e write S n for the set of n × n symmetric matr ic e s, and the set of n × n positive semid efinite (PSD) matrice s is denoted as S n + . Whe n the dimensions are clear from the context, we a lso use X 0 to deno te a PSD matrix. W e use I k to denote an identity matrix of size k × k , and 0 to denote a zero block with appr opriate dimensions that shall b e clear fr om the context. A block- diagona l matrix with D 1 , . . . , D p on its diago nal en tries is denoted as diag ( D 1 , . . . , D p ) . I I . P R E L I M I NA R I E S In th is section, we present some pr eliminaries on m atrix theory , in cluding b lock-par titioned matrices, factor-width- k matrices, and sparse PSD matr ic e s. A. Block-partitioned matrices an d two linear maps Giv en a matrix A ∈ R n × n , we say a set o f integers α = { k 1 , k 2 , . . . , k p } with k i ∈ N ( i = 1 , . . . , p ) is a partition o f matrix A if P p i =1 k i = n , and A is pa r titioned as A 11 A 12 . . . A 1 p A 21 A 22 . . . A 2 p . . . . . . . . . . . . A p 1 A p 2 . . . A pp , 3 (a) (b) (c) Fig. 1: Different partitions for a 6 × 6 matrix: (a) α = { 4 , 2 } , (b) β = { 2 , 2 , 2 } , (c) γ = { 1 , 1 , 1 , 1 , 1 , 1 } . Here, each black square represents a real number . From ri ght to left, we ge t coarser partitions, i.e. γ ⊑ β ⊑ α . with A ij ∈ R k i × k j , ∀ i, j = 1 , . . . , p . Throu ghou t th is paper, we assume the nu mber of blocks in a p artition is no le ss than two, i.e., p ≥ 2 . Obviou sly , a matrix A ∈ R n × n admits many par titions, an d one trivial partitio n is α = { 1 , 1 , . . . , 1 } . W e say α = { k 1 , . . . , k p } is ho mogeneous , if we have k i = k j , ∀ i, j = 1 , . . . , p , whe r e the matrix dimen sio n satisfies n = p k 1 . Next, we d efine a coa r ser/finer relation b etween two partitions α and β f or matr ices in R n × n . Definition 1: Gi ven two p a rtitions α = { k 1 , k 2 , . . . , k p } and β = { l 1 , l 2 , . . . , l q } with p < q and P p i =1 k i = P q i =1 l i , we say β is a sub-p artition of α , de n oted as β ⊑ α , if the re exist integers { m 1 , m 2 , . . . , m p +1 } with m 1 = 1 , m p +1 = q + 1 , m i < m i +1 , i = 1 , . . . , p such that k i = m i +1 − 1 X j = m i l j , ∀ i = 1 , . . . , p. Essentially , a subp a rtition of α = { k 1 , k 2 , . . . , k p } is a finer partition that br eaks so m e b locks of α into sma ller blocks. For example, given thr ee partitions α = { 4 , 2 } , β = { 2 , 2 , 2 } and γ = { 1 , 1 , 1 , 1 , 1 , 1 } , we h av e γ ⊑ β ⊑ α. Fig. 1 illustrates these thr ee pa rtitions for a matrix in R 6 × 6 . Given a partition α = { k 1 , . . . , k p } with P p i =1 k i = n , we deno te E α i = 0 . . . I k i . . . 0 ∈ R k i × n , which forms a par tition of the identity matrix of size n × n , I n = I k 1 I k 2 . . . I k p = E α 1 E α 2 . . . E α p . (1) W e also denote E α ij = ( E α i ) T ( E α j ) T T ∈ R ( k i + k j ) × n , i 6 = j. (2) More g enerally , f or a set o f distinct in dices C = { i 1 , . . . , i m } and 1 ≤ i 1 < . . . < i m ≤ p , we d efine E α C = ( E α i 1 ) T ( E α i 2 ) T . . . ( E α i m ) T T ∈ R |C |× n , where |C | = P i ∈C k i . For a tr i vial partition α = { 1 , 1 , . . . , 1 } , notations E α i , E α ij , E α C are simplified as E i , E ij , E C , respec- ti vely . No te that E i is the i -th standar d un it vector in R n . For a block m a tr ix A with p artition α = { k 1 , . . . , k p } , th e matrix E α C with set C = { i 1 , . . . , i m } can b e u sed to defin e two linear maps: • 1) T run cation op erator , which selects a princip le subma- trix from A , i.e. , Y := E α C A ( E α C ) T = A i 1 i 1 . . . A i 1 i m A i 2 i 1 . . . A i 2 i m . . . . . . . . . A i m i 1 . . . A i m i m ∈ R |C |×|C | . • 2) Lift operator , which creates an n × n matrix from a matrix of dimension |C | × |C | , i.e. , ( E α C ) T Y E α C ∈ R n × n , for a giv en matrix Y ∈ R |C |×|C | . Finally , we defin e a block permutatio n matrix with r espect to a partition α : consider an n × n identity matrix partitioned as (1). A block α - p ermutation matr ix P α is a matrix ob tained by permu ting the bloc k-wise rows o f I n in (1) accor ding to some permu tation of the numb ers 1 to p . For instance, if α = { k 1 , k 2 } , then P α is in one of the f o llowing forms I k 1 I k 2 , I k 2 I k 1 . B. F actor-width- k matrices W e now intro duce the co ncept of fa c tor-wi dth- k matrices , originally defined in [21]. Definition 2 : The facto r width o f a PSD matrix X is the smallest in teger k such that there exists a matrix V where A = V V T and each column of V has at m ost k non-ze ros. Equiv alently , the factor-width of X is th e smallest integer k f or whic h X can be written as the sum of PSD matrices that are non- zero o nly on a single k × k p rincipal su bmatrix. W e use F W n k to denote the set o f n × n matrices of factor- width no greater th an k . Then, we have the fo llowing inner approx imations o f S n + , F W n 1 ⊆ F W n 2 ⊆ . . . ⊆ F W n n = S n + . (3) It is not difficult to see that Z ∈ F W n k if and only if th ere exist Z i ∈ S k + such that Z = s X i =1 E T C i Z i E C i , (4) where C i is a set of k distinct integers from 1 to n and s = n k . W e say (4) is a factor-wdith- k d ecompo sition of Z . The dual o f F W n k with respec t to the trace inner p roduct is ( F W n k ) ∗ = X ∈ S n | E C i X E T C i ∈ S k + , ∀ i = 1 , . . . , s . Then, we also hav e a hierarchy of ou te r app roximatio n s o f the PSD cone S n + S n + = ( F W n n ) ∗ ⊆ . . . ⊆ ( F W n 2 ) ∗ ⊆ ( F W n 1 ) ∗ . Particularly , an interesting case is F W n 2 , which is the same as the set of symmetric scaled diag onally d ominan t ma tri- ces [21]. Linear optimization over F W n 2 can b e eq uiv a lently conv erted into an SOCP , for which efficient algorith ms exist. This feature o f scalability is the main moti vation o f th e so- called SDSOS op tim ization in [20] that u tilizes F W n 2 . For completen e ss, the d efinition of scaled diagonally domin ant matrices is given as follows. 4 Definition 3: A sym metric matrix A ∈ S n with entries a ij is diagonally domin ant (DD) if a ii ≥ X j 6 = i | a ij | , ∀ i = 1 , . . . , n. A symmetric matrix A ∈ S n is scaled diagonally dominant (SDD) if there exists a diagonal matrix D with p ositi ve diagona l entries such that D AD is d iagonally dominan t. W e deno te the set o f n × n DD and SDD matrices as DD n and SDD n , r espectively . I t is not difficult to see th at DD n ⊆ S DD n ⊆ S n + . Also, it is proved in [2 1] that S DD n = F W n 2 . C. Sparse P SD matrices This section covers some n otation on spar se PSD matrices. Here, we u se an undirected grap h to describe the sparsity pattern of a symmetric matrix X ∈ S n with partition α = { k 1 , k 2 , . . . , k p } . A gr a ph G ( V , E ) is defined by a set of vertices V = { 1 , 2 , . . . , p } and a set o f edg e s E ⊆ V × V . Here, we o nly consider grap h s with no self-loop s, i.e ., ( i, i ) / ∈ E . A graph G ( V , E ) is u ndirected if ( i, j ) ∈ E ⇒ ( j, i ) ∈ E . Giv en a partition α = { k 1 , k 2 , . . . , k p } , we define a set of sparse block matrices defined by a g raph G ( V , E ) as S n α ( E , 0) = { X ∈ S n | X ij = 0 , if ( i, j ) / ∈ E , i 6 = j } , where X ij ∈ R k i × k j . The set of sparse block PSD matrices is defined as S n α, + ( E , 0) = S n α ( E , 0) ∩ S n + , and the set of PSD com pletable m atrices is defined as S n α, + ( E , ?) = P S n α ( E , 0) S n + , where P S n α ( E , 0) ( · ) den otes a projection onto the space of S n α ( E , 0) with respect to the usual Frob enius matr ix n orm, i.e., it replaces the blocks outside E with zeros. For any undirected graph G ( V , E ) , the cones S n α, + ( E , 0) an d S n α, + ( E , ?) are du al to ea ch oth e r with r espect to the trace inner produ c t. For a tri vial partition α = { 1 , 1 , . . . , 1 } , notations S n α ( E , 0) , S n α, + ( E , 0) , S n α, + ( E , ?) are simp lified as S n ( E , 0) , S n + ( E , 0) , S n + ( E , ?) , r espectiv ely . One imp ortant feature of S n α, + ( E , 0) an d S n α, + ( E , ?) is that they allow an e q uiv alent decomp osition when th e grap h G ( V , E ) is chordal. Recall tha t an undirected gr aph is called chorda l if every cycle of length g reater than th r ee has at lea st one chord [ 13]. A chord is an edge that co nnects two non- consecutive no d es in a cycle (see [26] for d etails). Befo re introdu c ing the decomp osition of S n α, + ( E , 0) and S n α, + ( E , ?) , we need to define an other c o ncept of cliq u es: a cliqu e C is a subset o f vertices whe r e ( i, j ) ∈ E , ∀ i, j ∈ C , a nd it is called a maximal clique if it is n ot contained in anoth er cliqu e . Theor em 1 ( [33]–[35]): Given a chordal gr a ph G ( V , E ) with maximal cliques C 1 , . . . , C g and a partition α = { k 1 , k 2 , . . . , k p } , we have • X ∈ S n α, + ( E , ?) if and on ly if E α C i X ( E α C i ) T ∈ S |C i | + , i = 1 , . . . , g . • Z ∈ S n α, + ( E , 0) if and only if there exist a set of matrices Z i ∈ S |C i | + , i = 1 , . . . , g , such that Z = g X i =1 ( E α C i ) T Z i ( E α C i ) . (5) For the trivial p artition α = { 1 , 1 , . . . , 1 } , Theor em 1 was originally proved in [33], [34]. Th e extension to an ar bitrary partition α = { k 1 , k 2 , . . . , k p } was g iven in [35, Chapter 2.4]. W e no te that th is deco mposition underp ins m any r ecent algorithm s on exploiting sparsity in semidefin ite pr ograms; see e.g. , [14], [26]. Remark 1 (F actor-width decompo sition and sparse chordal decompo sition): I t is clear that the factor-width decompo si- tion (4) and the sparse chor dal deco mposition (5) ar e in the same decomposition f orm b ut with two distinctiv e d ifferences: 1) the numb er of co mpone n ts is a co m binatorial num ber n k in (4), while th e n umber is boun ded by the number of max imal cliques in ( 5 ); 2) th e size of each com ponen t in (4) is fixed as the factor-width k while the size is de te r mined b y th e correspo n ding max imal cliqu e in (5). Note that F W n k is an inner appr oximation o f S n + while the d ecompo sition (5) is necessary and suf ficient for th e cone S n α, + ( E , 0) with a ch o rdal sparsity pattern E . I I I . B L O C K FAC T O R - W I D T H - T W O M AT R I C E S Since there are a co mbinator ial number n k of smaller matrices of size k × k , a complete para m eterization of F W n k is not a lways prac tical u sing (4). In o ther words, even though F W n k is an inner approximatio n of S n + , it does not n ecessarily mean that checkin g the mem b ership of F W n k is always com - putationally cheaper than that of S n + . For instan c e, optim izing over F W n 3 requires O ( n 3 ) PSD constrain ts of size 3 × 3 , which is proh ibitiv e for ev en moderate n . It appears that the only practical case is F W n 2 which is the same as S DD n , where we have Z ∈ F W n 2 ⇔ Z = n − 1 X i =1 n X j = i +1 E T ij Z ij E ij with Z ij ∈ S 2 + . This constraint Z ∈ F W n 2 can be furthe r reformu lated into O ( n 2 ) second-o rder cone constrain ts, for which efficient solvers are a vailable. Howe ver , the gap b etween F W n 2 and S n + might be unaccep table in some app lica tio ns. T o b ridge this gap, we in troduce a new class of b lo ck factor- width-two matrices in th is section. W e show that this class o f matrices is le ss conservati ve than F W n 2 and more scalable than F W n 3 ( k ≥ 3) for the inn er app roximatio n of S n + . A. Definition and a new hierar chy of inner/ou ter ap pr ox ima- tions of the PSD con e The class of b lock factor-width-two matrices is d efined as follows. Definition 4: A sy mmetric matrix Z ∈ S n with pa r tition α = { k 1 , k 2 , . . . , k p } belong s to the class o f block factor- width-two matr ices, d enoted as F W n α, 2 , if and on ly if Z = p − 1 X i =1 p X j = i +1 ( E α ij ) T X ij E α ij (6) 5 = + + Fig. 2: Block factor -width-two decomposition ( 6) for a PS D matri x with partition α = { k 1 , k 2 , k 3 } , where each summand is required to be P SD. The ( i, j ) black square represents a subma trix of dimension k i × k j , i, j = 1 , 2 , 3 . for some X ij ∈ S k i + k j + and with E α ij defined in (2). Fig. 2 demonstrates this definition for a PSD m atrix with partition α = { k 1 , k 2 , k 3 } . This set o f matrices has stron g topolog ical pr operties with a n easy characterization of its dual cone, as shown b elow . Pr op osition 1: For any ad missible α , the dual of F W n α, 2 with respect to the trace inne r p r oduct is ( F W n α, 2 ) ∗ = { X ∈ S n | E α ij X ( E α ij ) T 0 , 1 ≤ i < j ≤ p } . Furthermo re, b oth F W n α, 2 and ( F W n α, 2 ) ∗ are proper co nes, i.e. , they are conve x, closed, solid, and po inted co nes. Pr oo f: The du al is compu ted by d irect compu tation. N ow , ∀ X 1 , X 2 ∈ ( F W n α, 2 ) ∗ and θ 1 , θ 2 ≥ 0 , it is straightfo r ward to verify θ 1 X 1 + θ 2 X 2 ∈ ( F W n α, 2 ) ∗ . Thus, ( F W n α, 2 ) ∗ is a co n vex con e. The co ne ( F W n α, 2 ) ∗ is pointed because X ∈ ( F W n α, 2 ) ∗ , − X ∈ ( F W n α, 2 ) ∗ implies that X = 0 . Also, I n ∈ ( F W n α, 2 ) ∗ is an interio r point. It is closed because it can be expressed as th e intersection of infinite closed half spaces in S n : X ∈ ( F W n α, 2 ) ∗ if and o nly if x T ij E α ij X ( E α ij ) T x ij ≥ 0 , ∀ x ij ∈ R k i + k j , 1 ≤ i < j ≤ p. Note that each constant vector x ij ∈ R k i + k j defines a linear constraint on the variable X , co rrespon ding to a half spa ce in S n . Now it is clear th a t ( F W n α, 2 ) ∗ is prop e r . Theref ore, the dual of ( F W n α, 2 ) ∗ is F W n α, 2 , which is also pro per . Besides these topolo gical prop erties, ou r n o tion o f block factor-width-two matr ice s offers a tunin g mechanism to build hierarchies of these cones. Intu iti vely , changin g the matrix par- tition shou ld allow a trade-off between app roximatio n qu ality and scalability o f co mputation s. In particu lar , the following theorem is the main result o f th is section. Theor em 2: Given three p a r titions α = { k 1 , . . . , k p } , β = { l 1 , . . . , l q } and γ = { n 1 , n 2 } , where P p i =1 k i = P q i =1 l i = n 1 + n 2 = n and α ⊑ β , we ha ve the following inn er approx imations of S n + : F W n 2 = F W n 1 , 2 ⊆ F W n α, 2 ⊆ F W n β , 2 ⊆ F W n γ , 2 = S n + , as well as the following outer appro ximations of S n + S n + = ( F W n γ , 2 ) ∗ ⊆ ( F W n β , 2 ) ∗ ⊆ ( F W n α, 2 ) ∗ ⊆ ( F W n 1 , 2 ) ∗ where 1 = { 1 , . . . , 1 } den otes the tr ivial partition. Pr oo f: First, F W n 2 = F W n 1 , 2 and F W n γ , 2 = S n + are true by d efinition. W e o nly need to p rove F W n α, 2 ⊂ F W n β , 2 when α ⊑ β , since we always have 1 = { 1 , . . . , 1 } ⊑ α fo r a non-tr ivial par titio n α . As we will show in Corollar y 2, F W n α, 2 is in variant with respect to b lo ck α -pe rmutation. Th erefore , to prove F W n α, 2 ⊂ F W n β , 2 when α ⊑ β , it is sufficient to consider the case α = { k 1 , . . . , k p − 1 , k p , k p +1 } , β = { k 1 , . . . , k p − 1 , k p + k p +1 } , (7) where th e partition β is formed by merging th e last two blocks in α and keeping the other b locks uncha n ged. All th e other cases α ⊑ β can be form ed re cursively by combin ing th e construction (7) with some block α -p ermutation . W e now prove F W n α, 2 ⊂ F W n β , 2 for ( 7). Ou r pro o f is constructive: for any X ∈ F W n α, 2 , we show that X ∈ F W n β , 2 . Let E α ij , 1 ≤ i < j ≤ p + 1 b e the decompo sition bases for th e α -partition, a nd E β ij , 1 ≤ i < j ≤ p be d ecompo sition bases for the β - partition. By definition (2), we have E β ij = E α ij , 1 ≤ i < j ≤ p − 1 , since the fir st p − 1 blocks are th e same fo r α and β . Gi ven any X ∈ F W n α, 2 , there exist X ij ∈ S k i + k j + such that X = p X i =1 p +1 X j = i +1 ( E α ij ) T X ij E α ij = p − 1 X i =1 p − 1 X j = i +1 ( E α ij ) T X ij E α ij + p − 1 X i =1 ( E α ip ) T X ip E α ip + p X i =1 ( E α i ( p +1) ) T X i ( p +1) E α i ( p +1) . (8) W e procee d with constructing ˆ X ij such that X can b e decomp o sed as X = p − 1 X i =1 p X j = i +1 ( E β ij ) T ˆ X ij E β ij . (9) Since the first p − 1 blocks are the same in both p artitions, we can choose ˆ X ij = X ij , 1 ≤ i < j ≤ p − 1 . (10) Comparing (8) with (9), it remain s to construct ˆ X ip , i = 1 , . . . , p − 1 such that p − 1 X i =1 ( E β ip ) T ˆ X ip E β ip = p − 1 X i =1 ( E α ip ) T X ip E α ip + p X i =1 ( E α i ( p +1) ) T X i ( p +1) E α i ( p +1) . (11) Consider the matrices X ij ∈ S k i + k j + , 1 ≤ i ≤ p − 1 , j = p, p + 1 , in (11), and we split th em according to its partitio n X ij = X ij, 1 X ij, 2 ⋆ X ij, 3 6 Fig. 3: Boundry of the set of x and y for which the 6 × 6 symmetric matrix I 6 + xA + y B belongs to F W 6 α, 2 , F W 6 β , 2 , and F W 6 γ , 2 , where α = { 4 , 2 } , β = { 2 , 2 , 2 } , γ = { 1 , 1 , 1 , 1 , 1 , 1 } . The relation γ ⊑ β ⊑ α i s reflected i n the inclusion of SDD 6 = F W 6 γ , 2 ⊂ F W 6 β , 2 ⊂ F W 6 α, 2 = S 6 + . with X ij, 1 ∈ S k i + , X ij, 3 ∈ S k j + and ⋆ denotin g the symmetric part. T h en, b ased on som e d irect calculations, it can b e verified that (11) holds when cho osing ˆ X ip , 1 ≤ i ≤ p − 1 as follows ˆ X ip = 1 p − 1 0 0 0 0 X p ( p +1) , 1 X p ( p +1) , 2 0 ⋆ X p ( p +1) , 3 + X i ( p +1) , 1 0 X i ( p +1) , 2 0 0 0 ⋆ 0 X i ( p +1) , 3 + X ip, 1 X ip, 2 0 ⋆ X ip, 3 0 0 0 0 . (12) This completes the pro o f of the hierarchy of inner approx ima- tions using F W α 2 . Finally , the hierarchy of outer ap p roximatio ns using ( F W α 2 ) ∗ holds by standard duality argume n ts. W e now co mpare the block f actor-width-two matrices F W n α, 2 and the standard factor-width k m atrices F W n k . First, it is easy to no tice that when α = { k , . . . , k } and n = k p ( for which we call the partition is h o mogeneous ), we have F W n α, 2 ⊆ F W n 2 k , ( F W n 2 k ) ∗ ⊆ ( F W n α, 2 ) ∗ . Second, bo th F W n α, 2 and F W n k can be used to constru ct a hierar chy of inner/o uter appr o ximations of S n + . One major difference lies in the number of ba sis m atrices. In F W n k , we need n k basis matrices fo r a complete parameterization , as shown in (4), wh ic h is u sually proh ibitiv e in prac tice. Instead, in F W n α, 2 , we build a sequence of coarser partitions, and the number of basis matrices h as been redu ced to p ( p − 1) 2 , whic h is mo r e practica l fo r num erical co mputation when the size of each bloc k is moderate. Ther efore, the co nes F W n α, 2 are often more scalab le in term s of th e nu mber of variables ( see Sections V and VI for ap plications an d experiments). Example 1: W e here illustrate th e ap proxim ation quality o f the cone F W n α, 2 using Fig. 3, where we plo t the bou ndary of the set of x an d y for which the 6 × 6 symmetric matrix I 6 + xA + y B belongs to F W 6 α, 2 , F W 6 β , 2 , and F W 6 γ , 2 , where the parti- tions are th e sam e as the example in Fig. 1, i.e. , α = { 4 , 2 } , β = { 2 , 2 , 2 } , γ = { 1 , 1 , 1 , 1 , 1 , 1 } . I n this case, F W 6 α, 2 , F W 6 γ , 2 are the same as PSD, and SDD, respectively . Here, the matrices A an d B were generated randomly with indepen d ent a n d identically d istributed entries sampled fo rm the standard norm a l distribution. As expected by Theorem 2, the re la tio n γ ⊑ β ⊑ α is r e flec ted in th e inclu sion of SDD 6 = F W 6 γ , 2 ⊂ F W 6 β , 2 ⊂ F W 6 α, 2 = S 6 + . Example 2: W e co nsider a n other example to f urther illus- trate Theorem 2: X = 6 8 − 2 − 2 8 16 1 1 − 2 1 10 − 1 − 2 1 − 1 24 . It can b e verified that X ∈ F W 4 α, 2 with partition α = { 1 , 1 , 1 , 1 } , and the matr ic e s in the decomp osition (6) can b e chosen as follows X 12 = 4 . 5 8 8 14 . 5 , X 13 = 1 − 2 − 2 6 , X 14 = 0 . 5 − 2 − 2 12 , X 23 = 1 1 1 2 , X 24 = 0 . 5 1 1 6 , X 34 = 2 − 1 − 1 6 . Here, we no te that the off-diago nal elements of X ij are the same with the corresponding off-diago n al elemen ts of X . Th is fact motiv ates our a lternative ch aracterizations of F W n α, 2 in Theorem 3. If we collapse the last two blocks into one single block and obtain a coarser partition β = { 1 , 1 , 2 } , then The orem 2 confirms X ∈ F W 4 β , 2 . Indeed, following the con structions in (10) and (12), we can ch oose ˆ X 12 = X 12 and obtain ˆ X 13 = 1 . 5 − 2 − 2 − 2 7 − 0 . 5 − 2 − 0 . 5 15 , ˆ X 23 = 1 . 5 1 1 1 3 − 0 . 5 1 − 0 . 5 9 . B. Another characterization and its cor ollaries As discussed in Ex ample 2, the decomp o sition matrices X ij use the actual o ff-diagonal values of th e matr ix X . T his observation allows us to d e riv e an alternative descr iption o f F W n α, 2 , offering a ne w interp r etation of block factor-width- two matrices in terms of scaled diago nally dom inance. Theor em 3: Given a partition α = { k 1 , . . . , k p } with P p i =1 k i = n , we have A ∈ F W n α, 2 if and only if th ere exist Z ij ∈ S k i + , i, j = 1 , . . . , p, i 6 = j , such that A ii p X j =1 ,j 6 = i Z ij , ∀ i = 1 , . . . , p (13a) Z ij A ij ⋆ Z j i 0 , ∀ 1 ≤ i < j ≤ p, (13b) where ⋆ denotes the symmetric cou nterpart. Pr oo f: ⇒ : Suppose A ∈ F W n α, 2 . By definition , we h ave A = p − 1 X i =1 p X j = i +1 ( E α ij ) T X ij E α ij (14) 7 for so m e X ij ∈ S k i + k j + . L et X ij ∈ S k i + k j + in (14) be partitioned as X ij = X ij, 1 X ij, 2 ⋆ X ij, 3 0 , (15) with X ij, 1 ∈ S k i + , X ij, 3 ∈ S k j + . By constru ction, we kn ow A ij = X ij, 2 , ∀ 1 ≤ i < j ≤ p, A ii = X ij X j i, 3 , ∀ i = 1 , . . . , p. Now we set Z ij = ( X ij, 1 , if i < j, X j i, 3 , if i > j, which naturally satisfy (13 a) and (1 3b). ⇐ : Suppose we hav e (13a) and (13b). W e next constru ct X ij ∈ S k i + k j + , 1 ≤ i < j ≤ p o f th e f orm ( 15) th at satisfy (1 4). W e first let Q ii = A ii − p X j =1 ,j 6 = i Z ij 0 , i = 1 , . . . , p. Now , ∀ 1 ≤ i < j ≤ p , we set X ij, 1 = Z ij + 1 p − 1 Q ii , X ij, 2 = A ij , X ij, 3 = Z j i + 1 p − 1 Q j j . Since we have ( 13b), we know X ij ∈ S k i + k j + , 1 ≤ i < j ≤ p are in the form (15). Also, by co n struction, we h ave (14) is satisfied. Thus, A ∈ F W n α, 2 . For illustration, we r emark that f or a partitio n with two blocks, i.e. , α = { k 1 , k 2 } with k 1 + k 2 = n , Th eorem 3 simply enforc e s a PSD p r operty o n m atrix A , i.e. , A = A 11 A 12 ∗ A 22 0 if and only if there exists Z 12 ∈ S k 1 + , Z 21 ∈ S k 2 + such that A 11 Z 12 , A 22 Z 21 , Z 12 A 12 ⋆ Z 21 0 . This rep resentation for a 2 × 2 block -partition e d matrix is just to illustrate (13a)-(13b) in Theo r em 3, but we note th a t it is not useful for scalable num e rical c omputatio n . Remark 2 (Block scaled d iagonal do minance) : Th eorem 3 shows that the class of block factor-width-two matrices can be considered as a block extension of the SDD ma trices. It can be interprete d that th e d iagonal b lo ck A ii should d o minate the sum of the off-diagonal b locks A ij in terms o f p ositiv e semidefiniteness. The co nditions (13 a) and (13b) were derived using a blo ck generalizatio n of the strategies fo r the SDD matrices in [36], [37]. In deed, (1 3a) and (13b) red uce to the con dition of scaled d iag onal domin a nce in the tr ivial pa r tition case, i.e. , α = { 1 , . . . , 1 } , A = [ a ij ] ∈ S n . I n this c a se, (1 3a) and (1 3b) become a ii ≥ n X j =1 ,j 6 = i z ij , ∀ i = 1 , . . . , n, ( 16a) | a ij | ≤ √ z ij z j i , ∀ 1 ≤ i < j ≤ n, (16b) z ij ≥ 0 , ∀ i, j = 1 , . . . , n, i 6 = j. ( 1 6c) W e h av e the following resu lt. Cor ollary 1: Given a symmetric matrix A = [ a ij ] ∈ S n , the following statements are eq u iv alen t. 1) A ∈ F W n 2 ; 2) There exists z ij ≥ 0 satisfying (16a) – (16c); 3) A ∈ SDD n . Corollary 1 is proved in Append ix A and presen ts another proof for the equivalence that S DD n = F W n 2 . T his equiva- lence was o riginally proved in [21] which relies on expressing a d iagonally dom in ant matrix A as a sum of rank-1 matrices. The alternative descr ip tion of F W n α, 2 in Theor em 3 allo ws for ded ucing a f ew useful prop erties of b lock factor-width- two matrices. Cor ollary 2: Giv en a partition α = { k 1 , . . . , k p } with P p i =1 k i = n , we h av e the following statements: 1) A ∈ F W n α, 2 if and o nly if D AD T ∈ F W n α, 2 for any in- vertible block- d iagonal matrix D = diag ( D 1 , . . . , D p ) , where D i ∈ R k i , i = 1 , . . . , p . 2) For any X ∈ S n , there exist A, B ∈ F W n α, 2 such that X = A − B . 3) F W n α, 2 is inv ariant with respec t to block α -p ermutation , i.e. , A ∈ F W n α, 2 if and only if P α AP T α ∈ F W n α, 2 . Pr oo f: Statement 1: Suppose A ∈ F W n α, 2 . By Theorem 3, there exist Z ij ∈ S k i + , i, j = 1 , . . . , p, i 6 = j , such that ( 13a) and (13b) hold . Then we h ave D i A ii D T i p X j =1 ,j 6 = i D i Z ij D T i , ∀ i = 1 , . . . , p and D i D j Z ij A ij ⋆ Z j i D i D j T = D i Z ij D T i D i A ij D T j ⋆ D j Z j i D T j 0 , ∀ 1 ≤ i < j ≤ p . Thus, setting ˆ Z ij = D i Z ij D T i proves D AD T ∈ F W n α, 2 . The conv erse follows by ob serving that D AD T ∈ F W n α, 2 ⇒ A = D − 1 D AD T ( D − 1 ) T ∈ F W n α, 2 . Statement 2: Given X = [ X ij ] ∈ S n with partition α , we can cho ose A = X + λI n and B = λI n , wh ich satisfies X = A − B , ∀ λ ∈ R . Since B is d iagonal and the off- diagona l elemen ts are zero, the co nstraints (1 3a) and (13b) can be natura lly satisfied ∀ λ > 0 , and thus B ∈ F W n α, 2 . Meanwhile, the diago nal elements of A can be chosen large enoug h by considerin g a large λ > 0 , such that th e d iagonal elements of Z ij in (1 3a) are large enou gh to satisfy ( 13b). From Theorem 3, it is n ow clear that there exists a λ > 0 such that A, B ∈ F W n α, 2 . Statement 3: Follows directly from the fact that (13a) and (13b) are indep endent of blo ck α -permutatio n. Statement 2 of Cor ollary 2 can b e u sed to provid e addition al results fo r the difference of conve x (DC) deco mposition of nonco nvex po lynomials that was in itially prop osed in [38]. W e will not discu ss furthe r this ap p lication, but mention that it remains to establish h ow F W n α, 2 matrices can be used in this co ntext. The blo ck inv ariant pro p erty in Statement 3 of 8 Corollary 2 h as been used in the p roof of Theo rem 2. Finally , we no te that the con e F W n α, 2 is not inv ariant with respect to the no rmal permutatio n, unless α = { 1 , 1 , . . . , 1 } . In o ther words, given a nontr i vial partition α and A ∈ F W n α, 2 , we may have P AP T / ∈ F W n α, 2 , where P is a standard n × n permutatio n matrix. I V . A P P RO X I M AT I O N Q UA L I T Y O F B L O C K FAC T O R - W I D T H - T WO M A T R I C E S For any partition α , we have F W n α, 2 ⊆ S n + ⊆ ( F W n α, 2 ) ∗ , that is to say F W n α, 2 and its dual ( F W n α, 2 ) ∗ serve as inner and outer ap proxim ations of the PSD cone S n + , r e sp ectiv ely . In this section, we aim to analy z e how well F W n α, 2 and ( F W n α, 2 ) ∗ approx imate the PSD cone. W e f ocus on two cases: 1 ) general dense matrices, wher e w e present upper and lower bou n ds on the distance be twe e n F W n α, 2 (or ( F W n α, 2 ) ∗ ) a n d S n + after some no rmalization; 2) a class of sp arse block PSD matrice s, for which th ere is no ap proxim ation err or to use o ur notio n of block factor-width-two m atrices. A. Upper and lower bou nds Our resu lts in this section ar e motiv ated by [23], wh ere the au thors quantified th e ap p roximatio n qu ality fo r the PSD cone using the du al cone of factor-width- k matr ices ( F W n k ) ∗ . In our context, there are two cases: • For the case of F W n α, 2 ⊆ S n + , we consid e r the matr ix in S n + that is farthest from F W n α, 2 . • For the case o f S n + ⊆ ( F W n α, 2 ) ∗ , we consider the m atrix in ( F W n α, 2 ) ∗ that is farthest from the PSD con e S n + . The distance between a matrix M an d a set D (where D = S n + or F W n α, 2 ) is measured as dist ( M , D ) := inf N ∈D k M − N k F , where k · k F denotes the Frobeniu s no rm. Sim ilar to [23], we consider the following n o rmalized Fro b enius d istan ces: • The largest distance between a unit-n o rm matrix M in S n + and the con e F W n α, 2 : dist ( S n + , F W n α, 2 ) := sup M ∈ S n + , k M k F =1 dist ( M , F W n α, 2 ) . • The largest distance between a unit-n o rm matrix M in ( F W n α, 2 ) ∗ and th e PSD cone S n + : dist (( F W n α, 2 ) ∗ , S n + ) := sup M ∈ ( F W n α, 2 ) ∗ , k M k F =1 dist ( M , S n + ) . W e aim to chara c terize th e b ound s for d ist ( S n + , F W n α, 2 ) and dist (( F W n α, 2 ) ∗ , S n + ) . 1) Upper bound : W e first show that th e distance between ( F W n α, 2 ) ∗ (or F W n α, 2 ) and the PSD con e is at most p − 2 p , where p is the nu mber of partitions. Pr op osition 2: For any partition α = { k 1 , k 2 , . . . , k p } , we have dist ( S n + , F W n α, 2 ) ≤ p − 2 p , dist (( F W n α, 2 ) ∗ , S n + ) ≤ p − 2 p . The p r oof is pr ovided in Appen d ix-B . W e note that the block factor-width-two ap proxim a tion becom es exact when p = 2 . As expected , this u pper bo und rough ly go es from 0 to 1 as the numb e r of partition s p goes fro m 2 to n . W e note that the normalized distance b etween ( F W n k ) ∗ and S n + has an upper bound as [23] dist (( F W n k ) ∗ , S n + ) ≤ n − k n + k − 2 . (17) From the upper bou nds in Propo sition 2 and ( 17), it is explicitly shown that red ucing the n umber o f partitio ns p o r increasing the factor-width k can improve the appr oximation quality f or the PSD cone. W e no te that reducing the n umber of partitions is more efficient in numerical com putation, since the decomp o sition basis in (6) is redu ced, while th e d ecompo sition basis for ( F W n k ) ∗ is a combin atorial numb er n k . 2) Lower b ound: W e next provid e a lower boun d on dist (( F W n α, 2 ) ∗ , S n + ) for a c lass of blo ck matrices with h o - mogene o us partition α . Pr op osition 3: Given a h omogen eous p artition α , we have dist (( F W n α, 2 ) ∗ , S n + ) ≥ 1 q 4 n p 2 − 4 p + 1 p − 2 p . The proof is adapted from [23] and is provided in Append ix -C for co mpleteness. For homog eneous partitions, the up per bound in Proposition 2 matches well with the lower bound in Pro position 3. Given a homogeneo us p a r tition α , we have ( F W n 2 k ) ∗ ⊆ ( F W n α, 2 ) ∗ with p = n/ k , and dist (( F W n 2 k ) ∗ , S n + ) ≤ p − 2 p + 2 − 2 /k , which shows that the distances dist (( F W n 2 k ) ∗ , S n + ) , dist (( F W n α, 2 ) ∗ , S n + ) are growing increasingly close with growing k . Also, tr i vially dist (( F W n α, 2 ) ∗ , ( F W n 2 k ) ∗ ) ≤ p − 2 p . Estimating a tighter boun d, however , is a challen ging ta sk . Remark 3: Propositions 2 and 3 present an explicit qu antifi- cation of the appro x imation quality whe n varying the nu mber of blo ck par titions. Intuitively , the block sizes in a partition will affect the app roximation qu a lity a s well; however , es- timating ap proxima tio n bo unds in terms o f d ifferent bloc k sizes is challengin g . W e note that choosing the block sizes may be prob lem dep endent. For example, in networked contro l applications, each block size may correspond to the d imension of eac h subsy stem [ 39]. In Section V -C, we show that ther e exists a natural block partition for a class o f polyno mial optimization prob lems. B. Sparse b lo ck factor-width-two ma trices Here, we iden tify a cla ss o f sparse PSD matrice s that always belongs to F W n α, 2 , wh ich means ther e is no appro ximation error for this class of PSD matrices. First, Theor em 3 allows us to deal with the sparsity of the matrix A in an efficient way , a s sh own in the following r esult. Cor ollary 3 : Giv en A ∈ F W n α, 2 , let E = { ( i, j ) | k A ij k 2 6 = 0 } , then we have A = X ( i,j ) ∈E ,i 0 such that | m ii | d 2 i ≥ n X j =1 ,j 6 = i m j i d 2 j , ∀ i = 1 , . . . , n. ( 3 4) Pr oo f: Step 1 : T he matrix M is either irredu c ible or M can be conjugated into a blo c k-diago nal matr ix P M P − 1 = M 1 . . . M t , where P is a perm utation matrix, and each blo ck entry M i is irreducib le, i = 1 , . . . , t . Step 2 : W e define a new matr ix ˆ M = M + ξ I n , wh ere ξ = max i =1 ,...,n | m ii | , which imp lies that ˆ M has only no nnegative entries. Further more, since M 1 = 0 , whe r e 1 is a vector of ones, we have that ˆ M 1 = ξ 1 . Accordin g to Step 1, we h av e either ˆ M is irre ducible, or P ˆ M P − 1 = ˆ M 1 . . . ˆ M t , where ˆ M i , i = 1 , . . . , t ar e irred ucible non- n egati ve m atrices. Note that 1 is permutation inv ariant (i.e. , P 1 = P − 1 1 = 1 ) , ˆ M i 1 = ξ 1 and ˆ M i is non-n egati ve and irreducib le for each i . As 1 is a positive eig en-vector, accordin g to Perro n-Frobe n ius theorem, ξ is th e sp ectral radius and th e e igen value of ˆ M i for each i . Th is implies th a t ξ is also the spec tr al radius and an eigenv a lu e f or the matrix ˆ M . Step 3 : Accordin g to the Perr on Frobenius theorem, ξ is the spectral radius of ˆ M i , an d th e co rrespond ing left eigen-vectors can be cho sen to be positive elem ent-wise. Th us, by stacking the positive lef t eigen-vectors of ˆ M i , there exists d = d 2 1 d 2 2 . . . d 2 n T with po siti ve scalar s d i , i = 1 , . . . , n such that d T ˆ M = d T ξ , leading to d T M = 0 , which implies (3 4). This comp letes the proof . Now are read y to p rove Corollary 1. 1 ⇔ 2 simply f ollows Th eorem 3 with α = { 1 , 1 , . . . , 1 } . W e now pr ove 2 ⇔ 3 . 2 ⇒ 3 : W e first define a matrix M = [ m ij ] ∈ R n × n as in ( 3 3). Without loss of gener ality , we can assume M has a symmetr ic n onzero pattern . This is because the con - straint (16b) allows us to set z j i = 0 whe n ev er z ij = 0 . According to Lemm a 2, there exist positiv e scalars d i > 0 such that | m ii | d 2 i ≥ n X j =1 ,j 6 = i m j i d 2 j , ∀ i = 1 , . . . , n. ( 3 5) Note that x + y ≥ 2 √ xy , ∀ x ≥ 0 , y ≥ 0 . (36) Thus, we have th at n X j =1 ,j 6 = i d j d i | a ij | ≤ n X j =1 ,j 6 = i s m j i d 2 j d 2 i m ij ≤ 1 2 n X j =1 ,j 6 = i m j i d 2 j d 2 i + m ij ! = 1 2 n X j =1 ,j 6 = i m ij + 1 2 d 2 i n X j =1 ,j 6 = i m j i d 2 j ≤ 1 2 | m ii | + 1 2 d 2 i | m ii | d 2 i ≤ a ii . (37) In (37), the fir st in equality co mes fr om (16b), th e secon d inequality is the fact (36), the second to last inequ ality is from (3 4), and the last ineq u ality comes fr om (16 a). Thus, D AD is diagon ally do m inant with D = diag ( d 1 , d 2 , . . . , d n ) , i.e. , A ∈ SDD n . 3 ⇒ 2 : Supp ose A ∈ SDD n . By definitio n, there exist positive d i , such that d i a ii ≥ P n j =1 ,j 6 = i | a ij | d j , i = 1 , . . . , n. Now we choose z ij = d j d i | a ij | ≥ 0 , ∀ i, j = 1 , . . . , n, i 6 = j, which naturally satisfy the cond itions in ( 1 6a)-(16c). B. Pr oo f of P r oposition 2 T o facilitate o ur analysis, we define the distance between ( F W n α, 2 ) ∗ and F W n α, 2 as the largest distance between a un it- norm matrix M in ( F W n α, 2 ) ∗ and the cone F W n α, 2 : dist (( F W n α, 2 ) ∗ , F W n α, 2 ) := sup M ∈ ( F W n α, 2 ) ∗ , k M k F =1 dist ( M , F W n α, 2 ) . By definition, it is easy to see th at dist (( F W n α, 2 ) ∗ , F W n α, 2 ) ≥ dist (( F W n α, 2 ) ∗ , S n + ) , dist (( F W n α, 2 ) ∗ , F W n α, 2 ) ≥ dist ( S n + , F W n α, 2 ) . (38) The following strategy is m otiv a ted by [2 3]. Con sider a matrix M ∈ ( F W n α, 2 ) ∗ with k M k F = 1 . W e co nstruct a n ew ˆ M ∈ F W n α, 2 . By definitio n , the p rincipal bloc k submatrices of M are M ij := E α ij M ( E α ij ) T 0 , 1 ≤ i < j ≤ p. Then, we construc t a new matrix as ˆ M := X 1 ≤ i
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment