Distributed Adaptive Newton Methods with Global Superlinear Convergence
This paper considers the distributed optimization problem where each node of a peer-to-peer network minimizes a finite sum of objective functions by communicating with its neighboring nodes. In sharp contrast to the existing literature where the fast…
Authors: Jiaqi Zhang, Keyou You, Tamer Bac{s}ar
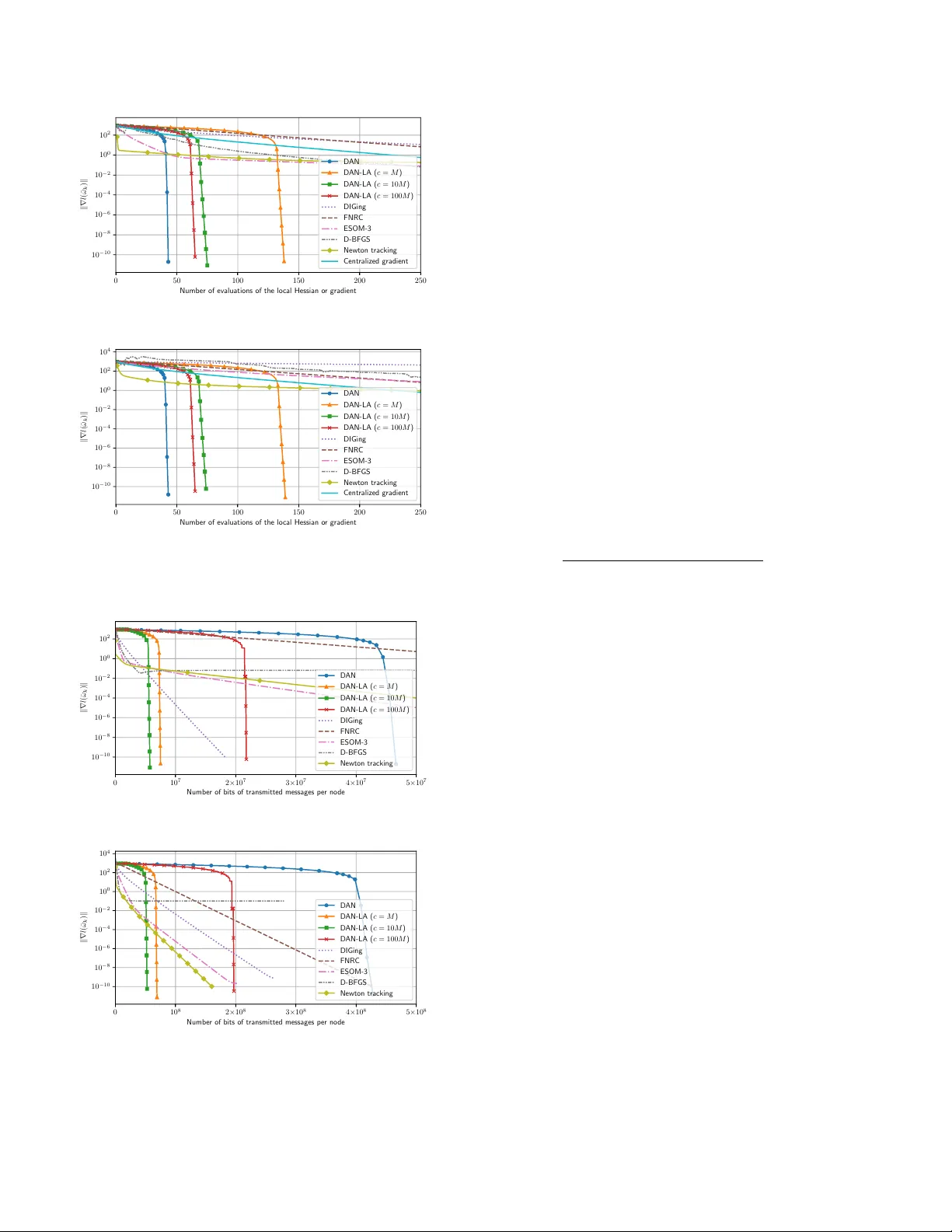
Distributed A daptiv e Newton Metho ds with Global Sup erlinear Con v ergence ? Jiaqi Zhang a , Key ou Y ou a , ∗ , T amer Başar b a Dep artment of Automation, and BNR ist, Tsinghua University, Beijing 100084, China. b Co or dinate d Scienc e L abor atory, University of Il linois at Urb ana-Champ aign, Urb ana, IL 61801 USA. Abstract This pap er considers the distributed optimization problem where each node of a p eer-to-p eer netw ork minimizes a finite sum of ob jectiv e functions by comm unicating with its neighboring no des. In sharp contrast to the existing literature where the fastest distributed algorithms con v erge either with a global linear or a lo cal sup erlinear rate, we prop ose a distributed adaptiv e Newton (DAN) algorithm with a glob al quadr atic con vergence rate. Our k ey idea lies in the design of a finite-time set- consensus metho d with Poly ak’s adaptive stepsize. Moreo v er, w e introduce a low-rank matrix approximation (LA) tec hnique to compress the innov ation of Hessian matrix so that eac h node only needs to transmit message of dimension O ( p ) (where p is the dimension of decision vectors) p er iteration, which is essen tially the same as that of first-order methods. Nev ertheless, the resulting D AN-LA con verges to an optimal solution with a glob al sup erline ar rate. Numerical experiments on logistic regression problems are conducted to v alidate their adv antages o ver existing methods. Key wor ds: distributed optimization; Newton metho d; low-rank appro ximation; sup erlinear conv ergence. 1 In tro duction Distributed optimization en tails solving the follo wing problem o ver a p eer-to-p eer netw ork system minimize x 1 ,..., x n F ( x 1 , . . . , x n ) , n X i =1 f i ( x i ) sub ject to x 1 = · · · = x n ∈ R p (1) where each node i priv ately holds a lo cal ob jectiv e func- tion f i and up dates its decision vector x i via comm uni- cating with its neigh b oring no des. Our goal is to design efficien t distributed algorithms to find an optimal solu- tion of ( 1 ). Many efforts hav e b een devoted along this line, see e.g., Nedić et al. ( 2017 ), Xin & Khan ( 2019 ), ? This work was supp orted by the National Natural Science F oundation of China under grant no. 62033006, a grant from the Guo qiang Institute, T singh ua Univ ersity , and in part b y the ARL under coop erative agreement W911NF-17-2-0196. The material in this pap er w as partially presented at the 59th IEEE Conference on Decision and Control. ∗ Corresp onding author Email addr esses: zjq16@mails.tsinghua.edu.cn (Jiaqi Zhang), youky@tsinghua.edu.cn (Keyou Y ou), basar1@illinois.edu (T amer Başar). Scaman et al. ( 2017 ), Qu & Li ( 2019 ). It is known that the fastest rate for first-order metho ds is linear ( Nes- tero v 2018 ), and second-order metho ds are una voidable for the sup erlinear conv ergence. Unfortunately , the existing distributed metho ds cannot ac hieve glob al sup erline ar con vergence rates. In con trast, our paper proposes tw o Newton-based distributed al- gorithms with global quadratic and superlinear con ver- gence rates, respectively . A direct comparison with the existing literature can b e found in T able 1 . F or second- order metho ds in Mokhtari et al. ( 2017 ), Manso ori & W ei ( 2020 , 2017 ), T utunov et al. ( 2019 ) and Zargham et al. ( 2014 ), an inexact penalization reformulation as an unconstrained optimization problem is adopted to solv e ( 1 ). Their sup erlinear rate is restricted to a limited re- gion, which does not include an optimal solution, and then reduced to a linear rate. Even though the inexact issue has b een resolved in Eisen et al. ( 2017 , 2019 ) and V aragnolo et al. ( 2016 ), their con vergence rates are still linear. Under a master-slav e net work configuration, some dis- tributed quasi-Newton methods hav e b een prop osed in Shamir et al. ( 2014 ), W ang et al. ( 2018 ), Zhang & Lin ( 2015 ), and So ori et al. ( 2020 ). Though the master no de of this setting uses all the information from the slav e Preprin t submitted to Automatica 17 Jan uary 2022 no des, the algorithms in Shamir et al. ( 2014 ), Zhang & Lin ( 2015 ) and W ang et al. ( 2018 ) still conv erge linearly , and only So ori et al. ( 2020 ) achiev es a lo c al sup erlinear con vergence rate if the starting p oint is sufficien tly close to an optimal solution. T o ac hieve a global sup erlinear con vergence rate, tw o b ottlenec ks ha ve to be resolved. The first is the use of the linear consensus algorithm whose con vergence rate is at most linear. Th us, the resulting second-order metho ds are still constrained to the linear con vergence rate. Simi- lar to this work, finite-time consensus metho ds ha ve b een adopted in Qu et al. ( 2019 ) to achiev e lo cal quadratic con vergence b y using the pure Newton direction. The second bottleneck lies in the design of a backtrac k- ing line searc h metho d to distributedly tune stepsizes of the second-order metho ds. Ev en though the pure New- ton direction with a unit stepsize is k ey to the sup erlin- ear con vergence, it may lead to div ergence if the algo- rithm is far from an optimal solution ( Boyd & V anden- b erghe 2004 ). In fact, the line searc h in the early stage is vital to the global conv ergence of second-order meth- o ds and usually requires no des to ev aluate the ob jective function of F multiple times in a single iteration, whic h is not p ossible in our distributed setting as eac h node i can only access its individual ob jectiv e function f i . T o circum ven t this problem, local line searc h methods hav e b een designed in Zargham et al. ( 2012 ) and Jadbabaie et al. ( 2009 ) for net work flow problems, and fixed step- sizes ha ve been used in Mokhtari et al. ( 2017 ), Manso ori & W ei ( 2020 , 2017 ), T utunov et al. ( 2019 ), Mokh tari et al. ( 2016 ), Eisen et al. ( 2019 ), V aragnolo et al. ( 2016 ). Ho wev er, they are to o conserv ativ e to ac hiev e superlin- ear con vergence. In this w ork, w e resolv e the ab ov e issues and design dis- tributed algorithms with global sup erlinear conv ergence rates. Building on the distributed flo o ding (DF) algo- rithm ( Liu et al. 2007 , Dias & Bruno 2013 , Li et al. 2017 ), w e prop ose a distributed selective flo o ding (DSF) algorithm to achiev e exact consensus in a finite n um- b er of local comm unication rounds and improv es the DF with prov ably low er comm unication complexity . Pre- cisely , nodes in the DSF ac hiev e consensus with at most n − 1 rounds of lo cal communication rather than n + d G − 1 in the DF, where d G is the diameter of the net work with n no des. By running the DSF at eac h iteration, the con- sensus ac hievemen t is no longer a b ottlenec k for sup er- linear con vergence. Then, we leverage the adaptive stepsize in P olyak & T remba ( 2019 ), which is esp ecially amenable to the dis- tributed setting, and prop ose the Distributed A daptive Newton algorithm (D AN) to maintain the quadratic con- v ergence rate from an y starting p oint. In D AN, eac h no de i computes the gradient and Hessian of f i , and then transmits to its neigh b ors to p erform the DSF, af- ter whic h the Newton direction and the adaptiv e stepsize are computed for updates. Note that Poly ak & T remba ( 2019 ) do es not address any distributed issue. T o explicitly reduce the comm unication cost p er iter- ation, w e further prop ose a Low-rank Approximation (LA) tec hnique to design a communication-efficien t D AN-LA. The idea builds on the observ ation that the rank-1 matrix appro ximation of a symmetric matrix W ∈ R p × p with resp ect to (w.r.t.) the spectral norm can b e expressed as s · ww T , where s ∈ {− 1 , 1 } and w ∈ R p . As first-order methods ( Shi et al. 2015 , Nedić et al. 2017 , Scaman et al. 2017 , Qu & Li 2019 , Zhang & Y ou 2019 b ), using suc h an appro ximation of W only requires transmitting a v ector of dimension O ( p ) . Then, w e apply this idea to the “innov ation” of Hessian, whic h is defined as the difference betw een the true Hessian and its estimate. Noticeably different from the quasi- Newton metho ds (e.g., BF GS ( Nesterov 2018 , No cedal & W right 2006 )), here we can control the appro ximation error to co-design stepsizes to ensure global sup erlin- ear con vergence. Note that the truncation method in Mokh tari et al. ( 2017 ) cannot achiev e a global sup erlin- ear con vergence rate. Finally , we test DAN and D AN- LA on a logistic regression problem o v er the Cov ertype dataset. The results confirm the adv an tages of DAN and D AN-LA and v alidate our theoretical results. The rest of this pap er is organized as follo ws. Section 2 form ulates the problem. Section 3 in tro duces the finite- time DSF with theoretical guarantees. Section 4 first re- views the Newton metho d and P olyak’s adaptiv e step- size, and then prop oses D AN. Section 5 presen ts D AN- LA with lo w-rank matrix approximation metho ds. W e test the tw o algorithms in Section 6 on a logistic regres- sion problem, and conclude the pap er in Section 7 . A conference v ersion of this paper app ears in Zhang et al. ( 2020 ), where none of the pro ofs ha ve been included and the DSF metho d in Section 3.2 do es not app ear. Notation: x T denotes the transp ose of x . k · k de- notes the l 2 -norm for v ectors and the sp ectral norm for matrices. |X | denotes the cardinalit y of set X . ∇ f and ∇ 2 f denote the gradient and Hessian of f , resp ec- tiv ely . O ( · ) denotes the big-O notation. A B means A − B is non-negative definite. The ceiling function d x e returns the least in teger greater than or equal to x . A sequence { e k } con verges to 0 with a Q -linear rate if lim k →∞ | e k +1 | / | e k | = γ for some γ ∈ (0 , 1) , a Q -sup erlinear rate if lim k →∞ | e k +1 | / | e k | = 0 , and a Q -quadratic rate if lim k →∞ | e k +1 | / | e 2 k | = γ for some γ > 0 . A sequence { ε k } con verges R -linearly (sup erlin- early , quadratically) if there exists a Q -linearly (sup er- linearly , quadratically) conv ergent sequence { e k } suc h that | ε k | ≤ | e k | , ∀ k . In this pap er, the con vergence rates are alw ays in the sense of R -rate. 2 T able 1 A brief summary of distributed second-order metho ds. Literature Con v ergence rates Main features Manso ori & W ei ( 2017 , 2020 ) T utunov et al. ( 2019 ), Zargham et al. ( 2014 ) Mokh tari et al. ( 2017 ) Linear a , inexact b Appro ximate the Hessian of a p enalty function of ( 1 ) with truncated T a ylor series Mokh tari et al. ( 2016 ), Eisen et al. ( 2017 , 2019 ) Linear Primal-dual metho ds V aragnolo et al. ( 2016 ), Zhang et al. ( 2021 ) Linear Asymptotic a v erage consensus Shamir et al. ( 2014 ), W ang et al. ( 2018 ) Linear Master-sla v e net w orks So ori et al. ( 2020 ) Sup erlinear, lo c al c Master-sla v e net w orks Qu et al. ( 2019 ) Quadratic, lo c al c Finite-time av erage consensus D AN of this w ork Quadratic A daptiv e stepsize and finite-time consensus D AN-LA of this w ork Sup erlinear Lo w-rank appro ximation to compress Hessians a Sup erlinear rate may happ en in a region that does not include the optimal solution, and then the rate reduces to linear. b Cannot conv erge to an exact optimal solution c The starting p oint should be sufficiently close to the optimal solution 2 Problem F orm ulation The comm unication netw ork among no des is mo deled b y a directed netw ork G = ( V , E ) , where V = { 1 , · · · , n } denotes the set of nodes and E ⊆ V × V is the set of edges with ( i, j ) ∈ E if and only if no de i can directly send messages to j . Let N i in = { j | ( j, i ) ∈ E } denote the set of in-neighbors and N i out = { j | ( i, j ) ∈ E } is the set of out-neigh b ors of node i . If G is undirected, i.e., ( i, j ) ∈ E implies ( j, i ) ∈ E , w e simply denote by N i the neighbors of node i . A path from no de i to no de j is a sequence of consecutively directed edges from i to j . W e say G is str ongly c onne cte d if there exists a directed path b etw een an y pair of nodes. The distance b etw een t wo no des in G is the n umber of edges in a shortest path connecting them, and the diameter d G of G is the largest distance b et ween an y pair of no des. A tr e e is an undirected net work that is strongly connected without any cycle. Essen tially , ( 1 ) is equiv alent to the following optimiza- tion problem minimize x ∈ R p f ( x ) , n X i =1 f i ( x ) . (2) W e inv oke the follo wing assumptions in the pap er. Assumption 1 (a) f is twic e c ontinuously differ en- tiable and µ -str ongly c onvex, i.e., ther e exists a p os- itive µ > 0 such that ∇ 2 f ( x ) µI , ∀ x . (b) f has L -Lipschitz c ontinuous Hessian, i.e., k∇ 2 f ( x ) − ∇ 2 f ( y ) k ≤ L k x − y k , ∀ x , y . Assumption 2 (a) The c ommunic ation network is str ongly c onne cte d. (b) Each no de has a unique identifier. Assumption 1 is standard in the second-order meth- o ds ( Boyd & V andenberghe 2004 ), whic h implies that f has a unique global minimum point x ? , i.e., f ( x ? ) = min x f ( x ) . Assumption 2 is com mon to handle directed net works ( Xie et al. 2018 , Xi et al. 2018 ) and is eas- ily satisfied. F or example, nodes are generally equipped with netw ork interface cards (NIC) for comm unication, and eac h card is assigned to a unique MAC address. The MA C address then naturally serv es as an identifier. 3 Distributed Finite-time Set-consensus This section first in tro duces the concept of distributed finite-time set-consensus that pla ys a crucial role in b oth D AN and DAN-LA. F ollowing that, w e propose a Dis- tributed Selective Flo o ding (DSF) algorithm that im- pro ves the communication efficiency of the existing DF. 3.1 Distribute d Finite-time Set-c onsensus Set-consensus aims to ensure that all nodes reac h con- sensus on a set of v alues among nodes, whic h is differ- en t from v alue-consensus to agree on some v alue. Finite- time consensus ac hieves the consensus goal only after a finite n umber of rounds of comm unication with neigh- b ors. Until no w, most distributed algorithms ( Shi et al. 2015 , Nedić et al. 2017 , Scaman et al. 2017 , Qu & Li 2019 , Zhang & Y ou 2019 b ) to solv e ( 1 ) ha ve b een built on asymptotic a verage-consensus metho ds with linear it- erations, which can only attain linear conv ergence and b ecome a bottleneck for the design of superlinearly con- v ergent algorithms. T o resolv e this issue, we design the DSF to achiev e set-consensus, which improv es the DF in Liu et al. ( 2007 ), Dias & Bruno ( 2013 ), Li et al. ( 2017 ). 3 3.2 The Distribute d Sele ctive Flo o ding Algorithm The DSF is giv en in Algorithm 1 , where I i ( t ) con tains the information that no de i has received after t com- m unication rounds, and is updated iterativ ely . The im- plemen tation for undirected and directed net works are sligh tly differen t. W e first fo cus on the former case. Let S i b e the information to b e shared b y no de i , whic h can b e a scalar, a vector, a matrix, or a set. Each no de i ini- tializes a set I i (0) = {S i } . At the k -th round, for eac h neigh b or j , no de i selects an elemen t e ∈ I i ( k − 1) suc h that (a) no de i has not sent e to no de j , and (b) no de i has not received e from no de j b efore. Then, no de i sends e to no de j (Line 3 ). Mean while, it receives an elemen t e j from no de j and copies to I i ( k − 1) , i.e., I i ( k ) = I i ( k − 1) ∪ { e j | j ∈ N i } (Line 6 ). W e sho w in Theorem 1 that eac h no de i of DSF obtains a set con taining the information of all no des after n − 1 rounds of communication, i.e., I i ( n − 1) = {S u | u ∈ V } . That is, nodes reach set-consensus in finite time. In DSF, eac h message sen t from no de i to no de j is ‘new’ to no de j , and hence no messages shall b e repeatedly trans- mitted ov er any link ( i, j ) . T o this end, unique identi- fiers are needed to distinguish messages (c.f. Assumption 2 (b)), whic h requires additional d log 2 ( n ) e bits of mem- ory for eac h message than iterative consensus methods (e.g. Olfati-Saber & Murra y ( 2004 )). On a positive note, ho wev er, it is less than 16 bits ev en for n ≤ 6 × 10 5 . F or directed netw orks, the in-neighbors of a no de can b e differen t from its out-neighbors. It is infeasible to c heck whether an element e has b een receiv ed from an out- neigh b or j . Then, the DSF is modified and a no de selects e that is not sent to its out-neighbor j , i.e., Line 3 is replaced b y Line 5 in Algorithm 1 . Ho wev er, this slo ws do wn the consensus seeking and duplicate transmissions ma y happ en. In fact, the DSF in this case reduces to the DF, see Remark 3 for details. Theorem 1 Supp ose Assumption 2 holds. If G is a tr e e, then e ach no de in Algorithm 1 obtains a set c ontaining al l no des’ messages after n − 1 r ounds of lo c al c ommu- nic ation with its neighb ors, i.e., I i ( n − 1) = {S u | u ∈ V } , ∀ i ∈ V . If G is dir e cte d, then the maximum numb er of c ommunic ation r ounds is n + d G − 1 . The pro of is relegated to App endix B . Although The- orem 1 only considers undirected trees, the result also holds for other t yp es of undirected netw orks where we can first construct a spanning tree in a distributed man- ner and then apply the DSF on the selected tree. Remark 1 A sp anning tr e e c an b e c onstructe d in a dis- tribute d way via a simple br e adth-first se ar ch, se e e.g. Lynch ( 1996 , Se ction 4.2), wher e O ( d G ) c ommunic ation r ounds ar e ne e de d and the total numb er of c ommunic ation bits of al l no des is at most O ( |E | log ( n )) for undir e cte d Algorithm 1 The DSF — from the viewp oint of no de i Input: A message S i , whic h can b e a scalar, a vector, a matrix, or a set, and let I i (0) = {S i } . 1: for k = 1 , 2 , · · · , n − 1 do 2: if G is undirected then 3: F or eac h no de j ∈ N i , no de i selects an element e ∈ I i ( k − 1) suc h that (a) node i has not sent e to no de j , and (b) no de i has not received e from no de j b efore. Then, no de i sends e to node j . 4: else if G is directed then 5: F or eac h node j ∈ N i out , no de i selects an ele- men t e ∈ I i ( k − 1) that has not been sen t to no de j from no de i , and sends e to no de j . 6: No de i receiv es an elemen t e j from eac h neighbor j and copies to I i ( k − 1) , i.e., I i ( k ) = I i ( k − 1) ∪ { e j | j ∈ N i } . Output: Each no de obtains a set I i ( n − 1) = {S u | u ∈ V } , ∀ i ∈ V which contains messages of all no des. gr aphs. Sinc e we fo cus on static networks, the tr e e only ne e ds to b e c onstructe d onc e. The DSF is also r esilient against dr opping some e dges if the r esulting time-varying gr aphs always c ontain a fixe d sp anning tr e e. As The or em 1 dictates, the essential r e quir ement of the gr aph lies in the existenc e of a sp anning tr e e. Whether the network c onditions c an b e r elaxe d to those supp orting iter ative c onsensus ( Olfati-Sab er & Murr ay 2004 ) is not addr esse d in this work. Remark 2 (Optimalit y for trees) Sinc e ther e exists at le ast one no de with only one neighb or in a tr e e, such a no de has to r e c eive n − 1 tr ansmissions fr om its neighb or to achieve set-c onsensus. Thus, the set-c onsensus ne e ds at le ast n − 1 numb er of tr ansmissions, showing the op- timality of The or em 1 . Remark 3 (Impro vemen t ov er the DF) The DF is designe d for dir e cte d networks and is e quivalent to our DSF for dir e cte d networks. However, the DSF impr oves the DF on undir e cte d networks by eliminating the du- plic ate tr ansmissions of the same message over an e dge. Sinc e the diameter of a line network is d G = n − 1 , the DSF only r e quir es a half numb er of c ommunic ations than that of the DF. Despite the widespr e ad use of the DF, its minimum numb er of c ommunic ation r ounds has only r e c ently b e en establishe d ( Oliva et al. 2017 , The or em 1). 4 The Distributed A daptive Newton Method W e first review the cen tralized Newton method with a backtrac king line search, and rev eals its difficult y in the distributed setting. Then, we in tro duce an adap- tiv e Newton method ( P olyak & T remba 2019 ), whic h do es not require an y line searc h while main taining a quadratic con v ergence rate. Finally , we in tegrate the 4 adaptiv e Newton metho d with the DSF to propose the Distributed A daptive Newton metho d (D AN) and pro- vide its con v ergence result. 4.1 The Newton Metho d The Newton metho d has the following update rule x k +1 = x k − α k ( ∇ 2 f ( x k )) − 1 ∇ f ( x k ) . (3) If the stepsize α k = 1 , then ( 3 ) is the pur e Newton metho d, whic h con verges quadratically only when the starting p oin t x 0 is sufficien tly close to x ? , i.e., k x 0 − x ? k ≤ µ 2 /L ( Nestero v 2018 ). If x 0 is far from x ? , the pure Newton metho d may div erge. T o ensure global conv ergence, α k in ( 3 ) is usually de- termined b y a backtrac king line search method. F or ex- ample, the popular Armijo rule chooses α k = β l where β ∈ (0 , 1) and l is the smallest nonnegative integer sat- isfying f ( x k + β l d k ) − f ( x k ) ≤ γ β l ∇ f ( x k ) T d k (4) where γ ∈ (0 , 1) and d k = ( ∇ 2 f ( x k )) − 1 ∇ f ( x k ) is the Newton direction. Ev en though this often promises a global superlinear conv ergence rate, it needs at least O (( l + 1)( n − 1)) comm unication rounds in the dis- tributed setting per iteration, leading to a h uge com- m unication o verhead. If x k is far aw ay from an optimal p oin t x ? , then l in ( 4 ) is often large, and thus the line searc h is not suitable for distributed implemen tation. 4.2 The Polyak’s A daptive Newton Metho d In P olyak & T rem ba ( 2019 ), a damped Newton method with adaptiv e stepsizes has b een proposed to solve non- linear equations, and has a basic form as follows α k = min n 1 , µ 2 L k∇ f ( x k ) k o x k +1 = x k − α k ( ∇ 2 f ( x k )) − 1 ∇ f ( x k ) (5) where µ and L are defined in Assumption 1 . The idea in ( 5 ) is v ery natural. When x k is far from the optimal p oint x ? , the algorithm is in the damp ed Newton phase with the stepsize in versely prop ortional to the size of ∇ f ( x k ) . When x k is close to x ? , then ( 5 ) switc hes to the pure Newton metho d. Ev en though it does not in volv e any line search, it still achiev es a global quadratic con vergence rate. P articularly , the n umber of iterations to achiev e k x k − x ? k ≤ is O log 2 log 2 (1 / ) , which matc hes the theoretical rate of the Newton metho d with line searc h in Bo yd & V andenberghe ( 2004 ). Algorithm 2 The Distributed A daptive Newton metho d (DAN) — from the view of node i Input: Starting p oint x 0 i = x 0 , ∀ i . 1: for k = 0 , 1 , 2 , · · · do 2: Compute g ( i ) k = ∇ f i ( x ( i ) k ) and H ( i ) k = ∇ 2 f i ( x ( i ) k ) . 3: Obtain S = { ( g ( u ) k , H ( u ) k ) , u ∈ V } by p erforming the DSF (Algorithm 1 ) via n − 1 communication rounds with neigh b ors. 4: Compute the global gradient and Hessian ¯ g k = P n u =1 g ( u ) k and ¯ H k = P n u =1 H ( u ) k . 5: Let α ( i ) k = min n 1 , µ 2 L k ¯ g k k o and up date x ( i ) k +1 = x ( i ) k − α ( i ) k ( ¯ H k ) − 1 ¯ g k . 4.3 The Distribute d A daptive Newton Metho d W e use the DSF to extend the abov e idea to prop ose D AN in Algorithm 2 to solve the distributed optimiza- tion problem. At each iteration, eac h no de i computes the lo cal gradien t and Hessian of f i (Line 2 ), and then runs the DSF to obtain the gradien t and Hessian of f (Lines 3 and 4 ). Finally , eac h node uses the aggregated gradien t and Hessian to perform a Newton step with the adaptiv e Poly ak’s stepsize (Line 5 ). F or brevit y , all no des are assumed to start from the same p oint x 0 , whic h can b e relaxed by adding a finite-time v alue-consensus step. Theorem 2 Supp ose that Assumptions 1 and 2 hold. Then, al l se quenc es { x ( i ) k } , i ∈ V in A lgorithm 2 c onver ge to an optimal p oint x ? , and k∇ f ( x ( i ) k ) k is monotonic al ly de cr e asing. Mor e over, let k 0 = max 0 , l 2 L µ 2 k∇ f ( x 0 ) k m − 2 , γ = L 2 µ 2 k∇ f ( x 0 ) k − k 0 4 ∈ [0 , 1 2 ) . Then, it holds that k∇ f ( x ( i ) k ) k ≤ k∇ f ( x 0 ) k − µ 2 2 L k , k ≤ k 0 2 µ 2 L γ 2 ( k − k 0 ) , k > k 0 and k x ( i ) k − x ? k ≤ µ L ( k 0 − k + 2 γ 1 − γ ) , k ≤ k 0 , 2 µγ 2 ( k − k 0 ) L (1 − γ 2 ( k − k 0 ) ) , k > k 0 . Pr o of. One can use mathematical induction to easily sho w that x (1) k = · · · = x ( n ) k for all k , i.e., all nodes’ states 5 are identical at an y time. Let ¯ x k , x (1) k = · · · = x ( n ) k . Then, each node actually performs the follo wing update α k = min n 1 , µ 2 L k∇ f ( ¯ x k ) k o ¯ x k +1 = ¯ x k − α k ( ∇ 2 f ( ¯ x k )) − 1 ∇ f ( ¯ x k ) whic h is exactly P olyak’s adaptiv e Newton metho d ( 5 ). Th us, the result follows from Poly ak & T rem ba ( 2019 , Theorem 4.1). By Theorem 2 , k∇ f ( x ( i ) k ) k and k x ( i ) k − x ? k in eac h node of DAN decrease by at least a constant positive v alue at each iteration when k ≤ k 0 , after whic h the decreas- ing rate b ecomes quadratic. Specifically , the n umber of iterations for k x ( i ) k − x ? k ≤ in each node is given b y k 0 + log 2 log (1 /γ ) 4 µ/L = O log 2 log 2 (1 / ) . It is worth noting that the abov e quadratic rate is glob al and exact , whic h is in sharp contrast with the exist- ing distributed second-order metho ds ( Qu et al. 2019 , Mokh tari et al. 2017 , Mansoori & W ei 2020 , 2017 , T u- tuno v et al. 2019 , Zargham et al. 2014 ). Remark 4 (Comm unication complexity) Although e ach no de in DAN involves n − 1 r ounds of c ommuni- c ating messages of size O ( p 2 ) p er iter ation, the over al l c ommunic ation c omplexity c ould b e much lower than that of first-or der algorithms. In p articular, the c ommunic a- tion c omplexity in e ach no de to achieve k x ( i ) k − x ? k ≤ is O np 2 log 2 log 2 (1 / ) for DAN and is O ( d G p log 2 1 / ) for the optimal first-or der algorithm ( Sc aman et al. 2017 ). The latter is higher than the former if a high pr e- cision is desir e d, i.e., ≤ O (2 − np d G ) . A similar analysis c an also b e made for the c omputational c omplexity. Despite the global quadratic conv ergence, DAN ma y progress relatively slow in the early stage due to the use of small stepsizes in the damp ed Ne wton phase ( k ≤ k 0 ) and the DSF in Line 3 of Algorithm 2 . In practice, w e can start at a first-order metho d for a few itera- tions and then switc h to DAN for quadratic conv er- gence afterwards, whic h is similar to the practical use of the Newton metho d. In Section 5 , we prop ose a nov el comm unication-efficient DAN with lo w rank appro xima- tion. 5 The Comm unication-efficient D AN-LA In this section, we prop ose a no vel communication- efficien t v ersion of DAN in Algorithm 3 that reduces the transmitted Hessian to a vector of size O ( p ) . This reduction is significant in applications with high di- mensional decision vectors. Since it main tains a global sup erlinear conv ergence rate, it is muc h faster than the existing distributed Newton-type algorithms ( Mokhtari et al. 2017 , Manso ori & W ei 2020 , 2017 , T utunov et al. 2019 , Mokh tari et al. 2016 , Eisen et al. 2019 , V aragnolo et al. 2016 ). T o this end, w e in tro duce t wo nov el ideas in Algorithm 3 : (a) a symmetric rank- 1 matrix in R p × p can b e repre- sen ted b y the outer pro duct of a v ector in R p and itself with only a possible sign c hange; and (b) instead of di- rectly compressing the Hessian, w e appro ximate its in- novation b y a symmetric rank-1 matrix. If the decision v ectors do not v ary m uch betw een tw o consecutiv e iter- ations, the innov ation is exp ected to b e “small”, which suggests that a rank- 1 matrix appro ximation might not lose m uch information. Sp ecifically , supp ose that each node has the same esti- mate of the Hessian of f in ( 2 ) at the ( k − 1) -th iter- ation, say ˆ H ( i ) k − 1 , and an estimate H ( i ) k − 1 of the Hessian of f i suc h that ˆ H ( i ) k − 1 = P n i =1 H ( i ) k − 1 , whic h can be easily satisfied when k = 1 , e.g., let ˆ H ( i ) 0 = H ( i ) 0 = 0 , ∀ i ∈ V . A t the next iteration, node i computes a lo cal Hessian ∇ 2 f i ( x ( i ) k ) and approximates its innov ation via a rank-1 matrix, i.e., ∇ 2 f i ( x ( i ) k ) − H ( i ) k − 1 ≈ s ( i ) k · h ( i ) k ( h ( i ) k ) T where s ( i ) k and h ( i ) k are solved b y the Ec k art-Y oung- Mirsky Theorem ( Mark ovsky 2012 , Theorem 2.23). P articularly , let λ i b e the i -th largest eigen v alue of ∇ 2 f i ( x ( i ) k ) − H ( i ) k − 1 in magnitude and w i b e the asso- ciated normalized right eigenv ector, i.e., ( ∇ 2 f i ( x ( i ) k ) − H ( i ) k − 1 ) w i = λ i w i and k w i k = 1 . Then, h ( i ) k = p | λ 1 | w 1 , s ( i ) k = sign ( λ 1 ) , r ( i ) k = | λ 2 | (Line 2 ). Clearly , this can b e computed by the eigen v alue decomp osition with complexity O ( p 3 ) or a truncated singular v alue de- comp osition (SVD) with a c omplexit y of O ( p 2 ) in some cases ( Allen-Zhu & Li 2016 ). Ov erall, the complexit y is comparable to that of computing a Newton direction. Moreo ver, no de i up dates an estimate of the lo cal Hes- sian as H ( i ) k = H ( i ) k − 1 + s ( i ) k · h ( i ) k ( h ( i ) k ) T (Line 3 ). Via only comm unicating s ( i ) k and h ( i ) k in the DSF (Line 4 ), it is able to compute an estimate of the Hessian of f b y ˆ H ( i ) k = ˆ H ( i ) k − 1 + n X i = u s ( u ) k · h ( u ) k ( h ( u ) k ) T (Line 5 ) . The Newton direction is then computed based on the estimates ˆ H ( i ) k and ˆ g ( i ) k . 6 Another challenge is how to handle the error in approxi- mating the Hessian of f . In tuitively , if the error is large, a pure Newton may lead to divergence, and we adap- tiv ely turn to a higher rank approximation for a b etter estimate. Otherwise, w e can safely run a Newton up date. T o achiev e it, eac h no de i computes an upper b ound on the estimation error ˆ r ( i ) k (Line 5 ). If the error is smaller than the explicit threshold r in ( 7 ) (Line 6 ), it updates via an adaptiv e Newton step ( 8 ) with our nov el step- size (Line 7 ). Note that the inv ertibility of ˆ H ( i ) k in ( 8 ) alw ays holds, since k ˆ H ( i ) k − ∇ 2 f ( x ( i ) k ) k ≤ r ≤ µ/ 3 and ∇ 2 f ( x ( i ) k ) µI (c.f. Assumption 1 (a)). More specifically , if α ( i ) k = 0 at the k -th iteration, then x ( i ) k +1 = x ( i ) k and w e obtain from Lines 2 - 3 in Algo- rithm 3 that in the ( k + 1) -th iteration, ∇ 2 f i ( x ( i ) k ) − H ( i ) k − 1 + s ( i ) k h ( i ) k ( h ( i ) k ) T ≈ s ( i ) k +1 h ( i ) k +1 ( h ( i ) k +1 ) T . Since h ( i ) k and h ( i ) k +1 are tw o linearly indep enden t vectors, it implies that ∇ 2 f i ( x ( i ) k ) − H ( i ) k − 1 is in fact approximated b y a rank-2 matrix s ( i ) k h ( i ) k ( h ( i ) k ) T + s ( i ) k +1 h ( i ) k +1 ( h ( i ) k +1 ) T , and the approximation error is strictly reduced, i.e., r ( i ) k +1 < r ( i ) k . Join tly with Lines 4 - 5 , there must exist a smallest nonnegativ e in teger m ≤ p − 1 such that ˆ r ( i ) k + m ≤ r which implies that α ( i ) k + m > 0 , and even tually x ( i ) k is up dated to a new vector. One can easily see that the ab ov e is equiv alent to the direct use of rank- ( m + 1) appro ximation in ( 6 ). W e pro ve the conv ergence of D AN-LA under the stan- dard assumption in quasi-Newton methods, see e.g. No- cedal & W right ( 2006 ). Assumption 3 The Hessian of f in ( 2 ) is upp er b ounde d by M , i.e., ∇ 2 f ( x ) M I , ∀ x ∈ R p . Theorem 3 Supp ose Assumptions 1 - 3 hold, and let { x ( i ) k } b e gener ate d by DAN-LA. F or any c > 0 in Line 6 of A lgorithm 3 and any i ∈ V , k x ( i ) k − x ? k c onver ges sup erline arly to 0, wher e x ? is the optimal p oint of ( 2 ) . Similar to quasi-Newton metho ds ( Nocedal & W right 2006 ), it is v ery difficult to explicitly quantify its con v er- gence rate. Some remarks are provided after the proof. Pr o of of The or em 3 . W e first pro ve the conv ergence of { x ( i ) k } and { r ( i ) k } , and then in vok e Dennis-Moré Theo- rem ( Dennis & Moré 1974 ) to pro ve global sup erlinear con vergence. Step 1: A k ey inequality . It can readily b e obtained b y mathematical induction that x (1) k = · · · = x ( n ) k , x k , ˆ g (1) k = · · · = ˆ g ( n ) k = g k = ∇ f ( x k ) , α (1) k = · · · = α ( n ) k , α k and ˆ H (1) k = · · · = ˆ H ( n ) k , ˆ H k . That is, all agen ts actually p erform identical up dates with aid of the set- consensus algorithm, and ( 8 ) b ecomes x k +1 = x k − α k ( ˆ H k ) − 1 g k . (9) Moreo ver, it implies that ˆ H k = P n i =1 H ( i ) k (c.f. Lines 3 and 5 ). By the Ec k art-Y oung-Mirsky The- orem ( Marko vsky 2012 , Theorem 2.23), we ha ve k∇ 2 f i ( x k ) − H ( i ) k k = r ( i ) k and k∇ 2 f ( x k ) − ˆ H k k = n X i =1 ∇ 2 f i ( x k ) − H ( i ) k ≤ n X i =1 k∇ 2 f i ( x k ) − H ( i ) k k = ˆ r ( i ) k . (10) Recall that g k = ∇ f ( x k ) , and let z k = x k +1 − x k = − α k ( ˆ H k ) − 1 g k . (11) Then, w e ha ve g k +1 = g k + Z 1 0 ∇ 2 f ( x k + t z k ) z k dt = g k + Z 1 0 ∇ 2 f ( x k + t z k ) − ˆ H k z k dt + ˆ H k z k = (1 − α k ) g k + Z 1 0 ∇ 2 f ( x k ) − ˆ H k z k dt + Z 1 0 ∇ 2 f ( x k + t z k ) − ∇ 2 f ( x k ) z k dt (12) W e no w show that α k ∈ (0 , 1] b y proving that φ in ( 7 ) is p ositiv e. Let ˜ φ ( r ) , L 2( µ − r ) 2 φ = µ M + µ − r µ − r . Then, ˜ φ ( r ) is strictly decreasing on (0 , µ ) . Since r = 1 3 p M 2 c + 3 µ 2 − M c 3 = µ 2 / ( p M 2 c + 3 µ 2 + M c ) < µ 2 / ( M + 2 µ ) < µ , then ˜ φ ( r ) > ˜ φ ( µ 2 M +2 µ ) = 0 , i.e., φ > 0 . It follo ws from ( 12 ) that k g k +1 k ≤ (1 − α k ) k g k k + k∇ 2 f ( x k ) − ˆ H k kk z k k + Z 1 0 ∇ 2 f ( x k + t z k ) − ∇ 2 f ( x k ) k z k k dt ≤ (1 − α k ) k g k k + ˆ r ( i ) k k z k k + L 2 k z k k 2 (13) where we used ( 10 ) and Assumption 1 in the last in- equalit y . Step 2: pro ve that lim k →∞ { α k } = 1 and { x k } con- v erges. Let K = { k l : l ≥ 0 } be an increasing sequence suc h that k ∈ K if and only if α k > 0 at iteration k , whic h follows from ( 7 ) that ˆ r ( i ) k ≤ r . 7 Algorithm 3 The DAN-LA — from the view of node i Input: Starting p oint x ( i ) 0 = x 0 , g ( i ) 0 = ∇ f i ( x 0 ) , ˆ H ( i ) − 1 = H ( i ) − 1 = 0 , c > 0 , and µ, L, M in Assumptions 1 and 3 . 1: for k = 0 , 1 , 2 , · · · do 2: Let λ j b e the j -th largest eigen v alue in magnitude of ∇ 2 f i ( x ( i ) k ) − H ( i ) k − 1 , w j b e the asso ciated unit eigen vector and h ( i ) k = p | λ 1 | w 1 , s ( i ) k = sign ( λ 1 ) , r ( i ) k = | λ 2 | . (6) 3: Compute H ( i ) k = H ( i ) k − 1 + s ( i ) k h ( i ) k ( h ( i ) k ) T and g ( i ) k = ∇ f i ( x ( i ) k ) . % H ( i ) k is the r ank-1 appr oximation of ∇ 2 f i ( x ( i ) k ) 4: Run Algorithm 1 to obtain S = DSF ( r ( i ) k , s ( i ) k , g ( i ) k , h ( i ) k ) , where S = { ( r ( u ) k , s ( u ) k , g ( u ) k , h ( u ) k ) | u ∈ V } . % Finite-time set-c onsensus 5: Use S to compute ˆ g ( i ) k = P n u =1 g ( u ) k , ˆ H ( i ) k = ˆ H ( i ) k − 1 + P n u =1 s ( u ) k h ( u ) k ( h ( u ) k ) T , and ˆ r ( i ) k = P n u =1 r ( u ) k . % ˆ H ( i ) k is an appr oximation of ∇ 2 f ( x ( i ) k ) and ˆ r ( i ) i b ounds the appr oximation err or 6: Let M c = M + c . Set the stepsize % Up date only if the appr oximation err or is smal l α ( i ) k = ( min n 1 , φ k ˆ g ( i ) k k o , where φ , 2 µ ( µ − r ) 2 L ( M + µ ) − 2 r ( µ − r ) L > 0 , if ˆ r ( i ) k ≤ r , 1 3 p M 2 c + 3 µ 2 − M c 3 0 , otherwise. (7) 7: If α ( i ) k = 0 , set x ( i ) k +1 = x ( i ) k . Otherwise, up date % A daptive Newton step x ( i ) k +1 = x ( i ) k − α ( i ) k ( ˆ H ( i ) k ) − 1 ˆ g ( i ) k . (8) W e sho w that k l +1 − k l ≤ p and x k l +1 = x k l +2 = · · · = x k l +1 , where p is the dimension of x k . F or an y k l < k < k l +1 , it follows from ( 9 ) and α k = 0 that x k +1 = x k , and the second part follows b y induction. Supp ose that there exists an l suc h that k l +1 − k l > p . Let λ ( j ) k , j = 1 , · · · , p b e the j -th largest eigenv alue of ∇ 2 f i ( x ( i ) k ) − H ( i ) k − 1 in magnitude and w ( j ) k b e the corre- sp onding unit eigen vector. Define λ ( j ) k = 0 for an y j > p . Since ∇ 2 f i ( x ( i ) k ) = ∇ 2 f i ( x k +1 ) for any k l < k < k l +1 , it follo ws from ( 6 ) that ∇ 2 f i ( x k +1 ) − H ( i ) k = ∇ 2 f i ( x k ) − H ( i ) k − 1 − λ (1) k w (1) k ( w (1) k ) T = p X j =2 λ ( j ) k w ( j ) k ( w ( j ) k ) T , and hence λ ( j ) k +1 = λ ( j +1) k for all j > 0 , whic h further implies that | λ ( j ) k +1 | ≤ | λ ( j ) k | . Then, for an y k ∈ [ k l + p, k l +1 ) 6 = ∅ , w e hav e r ( i ) k = | λ (2) k | ≤ | λ (2) k l + p | = | λ ( p +1) k l +1 | = 0 , ∀ i . Thus, ˆ r ( i ) k = P n i =1 r ( i ) k = 0 and w e must hav e α k > 0 , and hence k ∈ K , which leads to a con tradiction. Next, w e study the sequence {k g k l k : k l ∈ K} . Consider the first stage that α k l = φ/ k ˆ g ( i ) k l k ≤ 1 . It follows from ( 10 ) and the definition of K that k∇ 2 f ( x k l ) − ˆ H k l k ≤ ˆ r ( i ) k l ≤ r = r α k l k ˆ g ( i ) k l k φ (14) whic h jointly with Assumption 3 implies that k ˆ H k l k ≤ k∇ 2 f ( x k l ) k + r ≤ M + r . Thus, it follows from ( 11 ) that k z k l k = α k l k ( ˆ H k l ) − 1 g k l k = α k l q ( g k l ) T ( ˆ H k l ) − 2 g k l ≥ α k l k g k l k / ( M + r ) which, together with ( 14 ), implies that ˆ r ( i ) k l ≤ r α k l k ˆ g ( i ) k l k φ ≤ r ( M + r ) k z k l k φ . (15) Com bining ( 15 ) and ( 13 ) yields that k g k l +1 k = k g k l +1 k ≤ (1 − α k l ) k g k l k + L 2 + r ( M + r ) φ k z k l k 2 ≤ k g k l k − α k l k g k l k + Lφ + 2 r ( M + r ) 2 φ ( µ − r ) 2 ( α k l k g k l k ) 2 = k g k l k − φ + Lφ + 2 r ( M + r ) 2( µ − r ) 2 φ (16) where the first equalit y follows from x k l +1 = x k l +2 = · · · = x k l +1 , the second inequalit y follo ws from ( 11 ) and ( 14 ), and the last equality follo ws from the definition of the first stage. Let θ = µ/ ( M + µ ) . The definition of φ implies that Lφ 2( µ − r ) 2 = θ − r µ − r . (17) Let q ( r ) , − r µ − r + r ( M + r ) ( µ − r ) 2 = 2 r 2 +( M − µ ) r ( µ − r ) 2 whic h is strictly increasing on [0 , µ ) . Notice that q (0) = 0 and q ( r 0 ) = 1 / 2 with r 0 = 1 / 3 · ( p M 2 + 3 µ 2 − M ) . Since 8 0 < r < r 0 , w e ha ve q ( r ) < q ( r 0 ) = 1 / 2 . Since M ≥ µ , it join tly with ( 17 ) implies that Lφ + 2 r ( M + r ) 2( µ − r ) 2 < µ M + µ + 1 2 ≤ 1 . By ( 16 ), w e obtain that k g k l +1 k ≤ k g k l k − 1 − Lφ + 2 r ( M + r ) 2( µ − r ) 2 φ. (18) Th us, the sequence {k g k l k} is monotonically decreasing b y at least a constant at eac h step in the first stage. ( 18 ) implies that there exists a k l suc h that the algorithm en ters the second stage where α k l = 1 , i.e., k g k l k ≤ φ . Similar to ( 16 ), it follows from ( 13 ) that k g k l +1 k = k g k l +1 k ≤ ˆ r ( i ) k k z k l k + L 2 k z k l k 2 ≤ r µ − r k g k l k + L 2( µ − r ) 2 k g k l k 2 . (19) Let e k l = k g k l k /φ ≤ 1 . Then, it implies that e k l +1 ≤ r µ − r e k l + Lφ 2( µ − r ) 2 ( e k l ) 2 ≤ r µ − r + Lφ 2( µ − r ) 2 e k l . (20) Recall from ( 17 ) that r µ − r + Lφ 2( µ − r ) 2 = θ ≤ 1 2 , (21) whic h, combined with ( 20 ), shows that { e k l } and {k g k l k} are monotonically decreasing and con verge to 0 at least linearly at the second stage. This also concludes that k g k k will remain in the second stage for all k ≥ k l , and hence lim k →∞ α k = 1 . Com bining all ab o ve, it implies that {k g k l k : k l ∈ K} con verges to 0. Since k l +1 − k l ≤ p and x k l +1 = · · · = x k l +1 , then k g k k con verges to 0 as well. Since k x k − x ? k ≤ 1 µ k g k k , w e ha ve th us prov ed that x k con verges to x ? . Step 3: pro v e the conv ergence of { r ( i ) k } to 0. W e now sho w that the approximation error { r ( i ) k } con v erges to 0 for all i . Denote b y σ j ( A ) the j -th largest singular v alue of A ∈ R p × p . Let E k = ∇ 2 f i ( x ( i ) k ) − H ( i ) k − 1 and ε k = k E k k ∗ , where k A k ∗ = P p j =1 σ j ( A ) ≥ 0 is the nuclear norm of A . Since the algorithm will enter the second stage after a finite num b er of iterations, it is sufficient to fo cus only on this stage. Denote by k l ∈ K the first time step when the algorithm enters it. Then, ε k l +1 ≤ ε k l +1 = k∇ 2 f i ( x ( i ) k l +1 ) − H ( i ) k l k ∗ = k∇ 2 f i ( x ( i ) k l +1 ) − ∇ 2 f i ( x ( i ) k l ) + ∇ 2 f i ( x ( i ) k l ) − H ( i ) k l k ∗ ≤ k∇ 2 f i ( x ( i ) k l ) − H ( i ) k l k ∗ + k∇ 2 f i ( x ( i ) k l +1 ) − ∇ 2 f i ( x ( i ) k l ) k ∗ ≤ p X j =2 σ j ( E k l ) + p k∇ 2 f i ( x ( i ) k l +1 ) − ∇ 2 f i ( x ( i ) k l ) k ≤ ε k l − σ 1 ( E k l ) + pL µ − r k g k l k ≤ (1 − 1 p ) ε k l + pL µ − r k g k l k (22) where we used k A k ∗ ≤ p k A k , Assumption 1 , the rank- 1 approximation prop erty , and 0 ≤ ε k ≤ pσ 1 ( E k ) . Note that ( 19 )-( 21 ) sho w that k g k l k , k l ∈ K conv erges to 0 at least linearly . Then, it follo ws from ( 22 ) that lim k →∞ ε k = 0 . The conv ergence of { r ( i ) k } to 0 follo ws immediately b y noticing ε k ≥ r ( i ) k . Step 4: pro v e the superlinear con vergence. Now w e study the sequence ˆ H k . It follows from ( 10 ) and As- sumption 1 that k ˆ H k − ∇ 2 f ( x ? ) k ≤ k ˆ H k − ∇ 2 f ( x k ) k + L k x k − x ? k ≤ n X i =1 r ( i ) k + L k x k − x ? k . Since we ha ve already sho wn that b oth k x k − x ? k and P n i =1 r ( i ) k con verge to 0, then ˆ H k con verges to ∇ 2 f ( x ? ) . In view of ( 9 ), it follo ws from Lemma 1 that the sup er- linear con vergences of k x k − x ? k and k∇ f ( x k ) k . Remark 5 (Relation with BF GS) Even though D AN-LA is also a quasi-Newton metho d, it do es not imply that we c an c ombine DSF and other quasi-Newton metho ds (e.g. BF GS ( Nester ov 2018 , No c e dal & W right 2006 )) to achieve the glob al sup erline ar c onver genc e. As it usual ly r e quir es using a line-se ar ch scheme, one of the main chal lenges lies in the design of stepsizes in the distribute d setting. A striking differ enc e fr om BF GS is that the Hessian appr oximation err or in D AN-LA c an b e explicitly c ontr ol le d, which is essential to our stepsize c o-design (Line 6 ). In fact, BFGS has b e en original ly adopte d to avoid c om- puting a Hessian, wher e as the Hessian appr oximation in DAN-LA aims to r e duc e the c ommunic ation c ost and no des stil l ne e d to c ompute the Hessian. Remark 6 (The effect of parameter c ) The p ar am- eter c in Line 6 aims to b alanc e the c ommunic ation 9 c ost and the c omputational c ost. Sp e cific al ly, fr om ( 7 ) , a lar ger c me ans a b etter appr oximation of the Hessian of f and also suggests a lar ger stepsize. However, it may r esult in a lar ger numb er of un-up date d iter ations. How the p ar ameter c affe cts the glob al c onver genc e r ate is r elate d to the network b andwidth, p ar ameters in As- sumption 1 , etc. In fact, DAN-LA r e duc es to D AN if c tends to infinity, and it is also fe asible to set c = 0 if M is strictly lar ger than µ . W e wil l empiric al ly show its effe ct in Se ction 6 . Remark 7 (Comparison with D AN) Comp ar e d to D AN, DAN-LA r e duc es the tr ansmitte d messages’ size fr om O ( p 2 + p ) to O (2 p + 1) p er iter ation, which is es- sential ly identic al to existing first-or der metho ds, e.g., Ne dić et al. ( 2017 ) r e quir es no des to tr ansmit messages with size O (2 p ) . Nevertheless, DAN-LA may r e quir e mor e iter ations than DAN to achieve the same level of ac cur acy. It is difficult to c onclude which one is always b etter fr om a the or etic al p oint of view. In our exp er- iments, we find that the numb er of total tr ansmitte d messages in bits of DAN-LA is much smal ler than that of DAN to achieve the same level of ac cur acy, while the c omputation incr e ases. Remark 8 (Imp ortance of set-consensus) A lthough the finite-time set-c onsensus step in D AN c an b e r eplac e d by a finite-time a verage c onsensus (e.g. Char alamb ous & Hadjic ostis 2018 , W ang & Ong 2018 , Y uan et al. 2013 ) to r e duc e memory size, it is indisp ensable in DAN- LA. In Line 5 of A lgorithm 3 , no des ne e d to c ompute the summation 1 n P n i =1 s ( i ) k h ( i ) k ( h ( i ) k ) T , which r e quir es tr ansmitting messages in size O ( p 2 ) to their neighb ors if iter ative c onsensus metho ds ar e adopte d. In c ontr ast, the tr ansmitte d messages ar e of size O ( p ) in the DSF. Remark 9 Similar to DAN, it is suggeste d to initial ly p erform sever al iter ations of first-or der metho ds to achieve a go o d starting p oint for D AN-LA. In view of Line 5 , the c omplexity of obtaining the inverse in ( 8 ) c an b e r e duc e d fr om O ( p 3 ) to O ( np 2 ) if n < p by invok- ing the Sherman-Morrison-W o o dbury formula ( Horn & Johnson 2012 , Se ction 0.7.4). 6 Numerical Examples In this section, we test D AN and DAN-LA b y train- ing a binary logistic regression classifier for the Co v er- t yp e datatset from the UCI machine learning rep ository ( Dheeru & Karra T aniskidou 2017 ), where the samples in Classes 3 and 7 are used. The optimization problem in volv ed has the following form: min. l ( ω ) , − m X i =1 y i ln σ ( z i )+(1 − y i ) ln(1 − σ ( z i ))+ ρ 2 k ω k 2 where ω ∈ R 55 and m = 56264 is the num b er of samples; z i = ω T x i where x i ∈ R 55 is the feature of the i -th sam- ple with each en try normalized to [ − 1 , 1] , and y i ∈ { 0 , 1 } is the corresp onding label. The regularization parame- ter is c hosen as ρ = 0 . 01 m . The gradient and Hessian are respectively ∇ l ( ω ) = P m i =1 x i ( σ ( z i ) − y i ) + r ω and ∇ 2 l ( ω ) = P m i =1 x i x T i σ ( z i )(1 − σ ( z i )) + r I . F or distributed training, we randomly partition the dataset ov er n = 10 or n = 100 no des with each one priv ately holding a lo cal subset. W e compare our al- gorithms with the four second-order metho ds: FNR C ( V aragnolo et al. 2016 ), ESOM-3 ( Mokhtari et al. 2016 ), Newton trac king ( Zhang et al. 2021 ), D-BFGS ( Eisen et al. 2017 ), and a first-order metho d: DIGing ( Nedić et al. 2017 ). An undirected communication net work is constructed b y adopting the Erdős-Rén yi mo del ( Erdős & Rényi 1960 ), i.e., each pair of no des is connected with probabilit y 2 ln n/n . F or comparison, the edge weigh ts are generated by the Metrop olis metho d ( Nedić et al. 2017 , Shi et al. 2015 ). W e also implemen t the centralized gradien t descent metho d as a baseline, where the training is conducted on a single no de. In all algorithms, we set µ = 0 . 02 m, L = m and M = 0 . 04 m in Assumptions 1 and 3 to guide the selection of stepsizes. F or example, the stepsize in the cen tralized gradien t method is set to the optimal one 2 / ( µ + L ) ( Nestero v 2018 ) and the stepsize used in DIG- ing is a/L with a determined by a grid searc h. If the theoretical suggestions are not clear, w e manually tune the stepsizes to obtain the n umerically b est one. The con vergence behaviors of these algorithms are depicted in Figs. 1 and 2 . Fig. 1 plots the con vergence rates for the cases of n = 10 and n = 100 , resp ectively . The rate is measured b y the decreasing sp eed of the global gradien t’s norm versus the n umber of ev aluations of the local gradien t or Hessian. It sho ws that b oth DAN and DAN-LA achiev e sup erlinear con vergence and outp erform DIGing, FNRC, D-BFGS, Newton trac king, and ESOM-3. Though they progress slo w in the early stages, they rapidly outpace others in the pure Newton phase as exp ected. In practice, one can adopt some first-order metho ds initially and then switch to DAN or DAN-LA (c.f. Remark 9 ). Fig. 1 v alidates Re- mark 6 where a larger c leads to a better appro ximation qualit y of the global Hessian and a larger stepsize. Fig. 2 sho ws the con vergence rates versus the a v eraged transmitted bits of a n o de (a num b er is stored and trans- mitted in 64-bit floating-point format). The D AN and D AN-LA behav e similarly as in Fig. 1 . Moreo ver, the transmission of Hessians results in large comm unication o verhead of DAN b efore it enters the pure Newton phase. Th us, DAN seems more suitable for net works with high bandwidth in modest size, and DAN-LA with an appro- priate c is muc h more comm unication efficien t. 10 0 50 100 150 200 250 Numb er of evaluations of the lo cal Hessian o r gradient 10 − 10 10 − 8 10 − 6 10 − 4 10 − 2 10 0 10 2 k∇ l ( ¯ ω k ) k D AN D AN-LA ( c = M ) D AN-LA ( c = 10 M ) D AN-LA ( c = 100 M ) DIGing FNRC ESOM-3 D-BF GS Newton tracking Centralized gradient (a) n = 10 0 50 100 150 200 250 Numb er of evaluations of the lo cal Hessian o r gradient 10 − 10 10 − 8 10 − 6 10 − 4 10 − 2 10 0 10 2 10 4 k∇ l ( ¯ ω k ) k D AN D AN-LA ( c = M ) D AN-LA ( c = 10 M ) D AN-LA ( c = 100 M ) DIGing FNRC ESOM-3 D-BF GS Newton tracking Centralized gradient (b) n = 100 Fig. 1. The conv ergence rates w.r.t. the n umber of ev alua- tions of lo cal Hessian or gradient. 0 10 7 2 × 10 7 3 × 10 7 4 × 10 7 5 × 10 7 Numb er of bits of transmitted messages p er no de 10 − 10 10 − 8 10 − 6 10 − 4 10 − 2 10 0 10 2 k∇ l ( ¯ ω k ) k D AN D AN-LA ( c = M ) D AN-LA ( c = 10 M ) D AN-LA ( c = 100 M ) DIGing FNRC ESOM-3 D-BF GS Newton tracking (a) n = 10 0 10 8 2 × 10 8 3 × 10 8 4 × 10 8 5 × 10 8 Numb er of bits of transmitted messages p er no de 10 − 10 10 − 8 10 − 6 10 − 4 10 − 2 10 0 10 2 10 4 k∇ l ( ¯ ω k ) k D AN D AN-LA ( c = M ) D AN-LA ( c = 10 M ) D AN-LA ( c = 100 M ) DIGing FNRC ESOM-3 D-BF GS Newton tracking (b) n = 100 Fig. 2. The conv ergence rate w.r.t. the transmitted bits. 7 Conclusion This pap er has prop osed tw o distributed second-order optimization algorithms with global sup erlinear conv er- gence. The striking features lie in the use of (a) a finite- time set-consensus metho d, (b) an adaptive version of Newton metho d for global conv ergence, and (c) the low- rank matrix appro ximation methods to compress the Hessian for efficien t communication. F uture works can fo cus on async hronous v ersions of the prop osed algo- rithms as in ( Zhang & Y ou 2019 b , a ), the in tegration of the prop osed algorithms with quasi-Newton metho ds, and dev eloping more comm unication-efficient ones. A T ec hnical Lemma Lemma 1 ( Dennis & Moré 1974 ) Supp ose f is twic e c ontinuously differ entiable and ∇ 2 f ( x ? ) is nonsingular for some x ? . L et { B k } b e a se quenc e of nonsingular ma- tric es, and for some x 0 let the se quenc e { x k } c onver ge to x ? , wher e x k +1 = x k − α k ( B k ) − 1 ∇ f ( x k ) . Then, { x k } c onver ges sup erline arly to x ? and ∇ f ( x ? ) = 0 if and only if lim k →∞ α k = 1 and lim k →∞ k [ B k − ∇ 2 f ( x ? )]( x k +1 − x k ) k k x k +1 − x k k = 0 . B Pro of of Theorem 1 The pro of for directed netw orks is given in Oliv a et al. ( 2017 , Theorem 1), and here w e just deal with undirected trees. Consider a tree with the ro ot an arbitrary node. Let U v ( k ) = { u |S u ∈ I v ( k ) } b e the set of no des whose messages arriv e at no de v in k iterations, R v b e the set of desc endants of v (not including v ), and e U v ( k ) = U v ( k ) ∩ R v b e the set of descendan ts of v whose messages are in U v ( k ) . It follo ws from the definition that e U v ( k ) ⊆ R v and e U v ( k ) ⊆ U v ( k ) , and R v = ∅ for a leaf no de v . Claim 1: If v is not a leaf and u is a child of v , then |U v ( k ) ∩ R u | ≤ k − 1 . Pr o of: Since G is a tree, no de v can get the messages of no des in R u only from no de u . Note that no de u sends the message of itself to no de v at the first iteration. The result then follo ws from that only k − 1 iterations can b e used to transmit the messages of no des in R u , and each iteration only transmits one message. Claim 2: | e U v ( k ) | ≥ min {|R v | , k } for all v ∈ V and k ∈ N . Pr o of: W e prov e it b y mathematical induction. It is clear that | e U v (0) | = 0 for all v ∈ V . Suppose that | e U v ( t ) | ≥ min {|R v | , t } for all v ∈ V , and w e next sho w that | e U v ( t + 1) | ≥ min {|R v | , t + 1 } . F or some node v , if | e U v ( t ) | > t 11 or | e U v ( t ) | = |R v | , then the result follows immediately . No w consider | e U v ( t ) | = t < |R v | , which means that v cannot b e a leaf. It follo ws that there exists a child u of no de v and a nonempt y subset R 0 ⊂ R u suc h that all elemen ts in R 0 are not con tained in U v ( k ) , i.e., U v ( k ) ∩ R 0 = ∅ (otherwise | e U v ( t ) | = |R v | ). Then, the h yp othesis implies that |R u | ≥ | e U u ( t ) | ≥ min {|R u | , t } . If | e U u ( t ) | = |R u | , then R 0 ⊂ U u ( t ) . Note that the selective op eration ensures that no messages are transmitted more than once o ver a link ( u, v ) , which implies that an element in R 0 will b e sen t to node v at iteration t + 1 , and hence |U v ( t + 1) | ≥ t + 1 . If | e U u ( t ) | ≥ t , which means |R u | ≥ t , then it follo ws from Claim 1 that there must exist a no de in e U u ( k ) whose message is not contained in U v ( k ) , and hence this elemen t will be sent to no de v from node u at iteration t + 1 due to the selective op eration. Therefore, |U v ( t + 1) | ≥ t + 1 . F or any node i , let k = n − 1 and designate i as the ro ot. Then, it follo ws from Claim 2 that | e U i ( n − 1) | ≥ n − 1 and R i ⊆ U i ( n − 1) , whic h prov es the result. References Allen-Zh u, Z. & Li, Y. (2016), LazySVD: even faster SVD decomp osition y et without agonizing pain, in ‘A dv ances in Neural Information Processing Systems’, pp. 974–982. Bo yd, S. & V anden b erghe, L. (2004), Convex Optimiza- tion , Cam bridge Univ ersity Press. Charalam b ous, T. & Hadjicostis, C. N. (2018), Laplacian-based matrix design for finite-time a veazge consensus in digraphs, in ‘IEEE Conference on Deci- sion and Con trol’, IEEE, pp. 3654–3659. Dennis, J. E. & Moré, J. J. (1974), ‘A characteriza- tion of superlinear conv ergence and its application to quasi-newton methods’, Mathematics of Computation 28 (126), 549–560. Dheeru, D. & Karra T aniskidou, E. (2017), ‘UCI ma- c hine learning repository’. URL: http://ar chive.ics.uci.e du/ml Dias, S. S. & Bruno, M. G. (2013), ‘Coop erative tar- get tracking using decen tralized particle filtering and RSS sensors’, IEEE T r ansactions on Signal Pr o c ess- ing 61 (14), 3632–3646. Eisen, M., Mokhtari, A. & Rib eiro, A. (2017), ‘Decen- tralized quasi-newton metho ds’, IEEE T r ansactions on Signal Pr o c essing 65 (10), 2613–2628. Eisen, M., Mokh tari, A. & Rib eiro, A. (2019), ‘A primal- dual quasi-Newton metho d for exact consensus op- timization’, IEEE T r ansactions on Signal Pr o c essing 67 (23), 5983–5997. Erdős, P . & Rén yi, A. (1960), ‘On the evolution of random graphs’, Publ. Math. Inst. Hung. A c ad. Sci 5 (1), 17–60. Horn, R. A. & Johnson, C. R. (2012), Matrix analysis , Cam bridge Universit y Press. Jadbabaie, A., Ozdaglar, A. & Zargham, M. (2009), A distributed Newton metho d for netw ork optimiza- tion, in ‘IEEE Conference on Decision and Control held join tly with Chinese Con trol Conference’, IEEE, pp. 2736–2741. Li, T., Corc hado, J. M. & Prieto, J. (2017), ‘Con- v ergence of distributed flo o ding and its application for distributed Ba yesian filtering’, IEEE T r ansactions on Signal and Information Pr o c essing over Networks 3 (3), 580–591. Liu, H., Jia, X., W an, P .-J., Liu, X. & Y ao, F. F. (2007), ‘A distributed and efficient flo o ding scheme using 1-hop information in mobile ad ho c netw orks’, IEEE T r ansactions on Par al lel and Distribute d Sys- tems 18 (5), 658–671. Lync h, N. A. (1996), Distribute d algorithms , Elsevier. Manso ori, F. & W ei, E. (2017), Sup erlinearly con- v ergent asynchronous distributed net work Newton metho d, in ‘Conference on Decision and Control’, IEEE, pp. 2874–2879. Manso ori, F. & W ei, E. (2020), ‘A fast dis- tributed async h ronous Newton-based optimization al- gorithm’, IEEE T r ansactions on Automatic Contr ol 65 (7), 2769–2784. Mark ovsky , I. (2012), L ow R ank Appr oximation : Algo- rithms, Implementation, Applic ations , Springer, Lon- don New Y ork. Mokh tari, A., Ling, Q. & Rib eiro, A. (2017), ‘Net work Newton distributed optimization metho ds’, IEEE T r ansactions on Signal Pr o c essing 65 (1), 146–161. Mokh tari, A., Shi, W., Ling, Q. & Rib eiro, A. (2016), ‘A decen tralized second-order metho d with exact linear con vergence rate for consensus optimization’, IEEE T r ansactions on Signal and Information Pr o c essing over Networks 2 (4), 507–522. Nedić, A., Olshevsky , A. & Shi, W. (2017), ‘A chieving ge- ometric con vergence for distributed optimization ov er time-v arying graphs’, SIAM Journal on Optimization 27 (4), 2597–2633. Nestero v, Y. (2018), L e ctur es on c onvex optimization , V ol. 137, Springer. No cedal, J. & W righ t, S. (2006), Numeric al optimization , Springer Science & Business Media. Olfati-Sab er, R. & Murra y , R. M. (2004), ‘Consensus problems in netw orks of agen ts with switc hing topol- ogy and time-dela ys’, IEEE T r ansactions on A uto- matic Contr ol 49 (9), 1520–1533. Oliv a, G., Setola, R. & Hadjicostis, C. N. (2017), ‘Dis- tributed finite-time a verage-consensus with limited computational and storage capability’, IEEE T r ans- actions on Contr ol of Network Systems 4 (2), 380–391. P olyak, B. & T rem ba, A. (2019), ‘New versions of New- ton metho d: step-size choice, con vergence domain and under-determined equations’, Optimization Metho ds and Softwar e pp. 1–32. Qu, G. & Li, N. (2019), ‘A ccelerated distributed nesterov gradien t descent’, IEEE T r ansactions on Automatic Contr ol 65 (6), 2566–2581. Qu, Z., W u, X. & Lu, J. (2019), Finite-time-consensus- 12 based metho ds for distributed optimization, in ‘Chi- nese Con trol Conference’, IEEE, pp. 5764–5769. Scaman, K., Bac h, F., Bub eck, S., Lee, Y. T. & Mas- soulié, L. (2017), Optimal algorithms for smooth and strongly con vex distributed optimization in net works, in ‘In ternational Conference on Machine Learning’, pp. 3027–3036. Shamir, O., Srebro, N. & Zhang, T. (2014), Comm unication-efficient distributed optimization using an approximate Newton-t yp e method, in ‘In ternational Conference on Mac hine Learning’, pp. 1000–1008. Shi, W., Ling, Q., W u, G. & Yin, W. (2015), ‘EXTRA: An exact first-order algorithm for decentralized con- sensus optimization’, SIAM Journal on Optimization 25 (2), 944–966. So ori, S., Mishchenk o, K., Mokhtari, A., Dehna vi, M. M. & Gurbuzbalaban, M. (2020), DA v e-QN: A dis- tributed av eraged quasi-Newton metho d with lo cal su- p erlinear con vergence rate, in ‘In ternational Confer- ence on Artificial Intelligence and Statistics’, PMLR, pp. 1965–1976. T utunov, R., Bou-Ammar, H. & Jadbabaie, A. (2019), ‘Distributed Newton method for large-scale consensus optimization’, IEEE T r ansactions on Automatic Con- tr ol 64 (10), 3983–3994. V aragnolo, D., Zanella, F., Cenedese, A., Pillonetto, G. & Sc henato, L. (2016), ‘Newton-Raphson consensus for distributed conv ex optimization’, IEEE T r ansac- tions on Automatic Contr ol 61 (4), 994–1009. W ang, S., Roosta-Khorasani, F., Xu, P . & Mahoney , M. W. (2018), GIANT: Globally impro v ed approxi- mate Newton metho d for distributed optimization, in ‘A dv ances in Neural Information Processing Systems’, pp. 2332–2342. W ang, Z. & Ong, C. J. (2018), ‘Sp eeding up finite- time consensus via minimal polynomial of a weigh ted graph: A n umerical approach’, Automatic a 93 , 415– 421. Xi, C., Mai, V., Xin, R., Ab ed, E. & Khan, U. (2018), ‘Linear conv ergence in optimization ov er directed graphs with ro w-sto chastic matrices’, IEEE T r ansac- tions on Automatic Contr ol 63 (10), 3558–3565. Xie, P ., Y ou, K., T empo, R., Song, S. & W u, C. (2018), ‘Distributed con vex optimization with in- equalit y constrain ts o ver time-v arying un balanced di- graphs’, IEEE T r ansactions on A utomatic Contr ol 63 (12), 4331–4337. Xin, R. & Khan, U. A. (2019), ‘Distributed heavy-ball: A generalization and acceleration of first-order metho ds with gradient trac king’, IEEE T r ansactions on Auto- matic Contr ol 65 (6), 2627–2633. Y uan, Y., Stan, G.-B., Shi, L., Barahona, M. & Goncalv es, J. (2013), ‘Decentralised minimum-time consensus’, Automatic a 49 (5), 1227–1235. Zargham, M., Rib eiro, A. & Jadbabaie, A. (2012), A distributed lin e search for netw ork optimization, in ‘American Con trol Conference’, IEEE, pp. 472–477. Zargham, M., Ribeiro, A., Ozdaglar, A. & Jadbabaie, A. (2014), ‘A ccelerated dual descent for netw ork flo w op- timization’, IEEE T r ansactions on Automatic Contr ol 59 (4), 905–920. Zhang, J., Ling, Q. & So, A. M.-C. (2021), ‘A Newton trac king algorithm with exact linear con vergence for decen tralized consensus optimization’, IEEE T r ansac- tions on Signal and Information Pr o c essing over Net- works 7 , 346–358. Zhang, J. & Y ou, K. (2019 a ), ‘AsySP A: An exact asyn- c hronous algorithm for conv ex optimization ov er di- graphs’, IEEE T r ansactions on A utomatic Contr ol 65 (6), 2494–2509. Zhang, J. & Y ou, K. (2019 b ), ‘F ully asynchronous dis- tributed optimization with linear conv ergence in di- rected net works’, arXiv pr eprint arXiv:1901.08215 . Zhang, J., Y ou, K. & Başar, T. (2020), A c hieving glob- ally sup erlinear conv ergence for distributed optimiza- tion with adaptiv e newton metho d, in ‘IEEE Confer- ence on Decision and Con trol’, IEEE, pp. 2329–2334. Zhang, Y. & Lin, X. (2015), Disco: Distributed opti- mization for self-concordant empirical loss, in ‘In- ternational conference on machine learning’, PMLR, pp. 362–370. 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment