PHOTONAI -- A Python API for Rapid Machine Learning Model Development
PHOTONAI is a high-level Python API designed to simplify and accelerate machine learning model development. It functions as a unifying framework allowing the user to easily access and combine algorithms from different toolboxes into custom algorithm …
Authors: Ramona Leenings, Nils Ralf Winter, Lucas Plagwitz
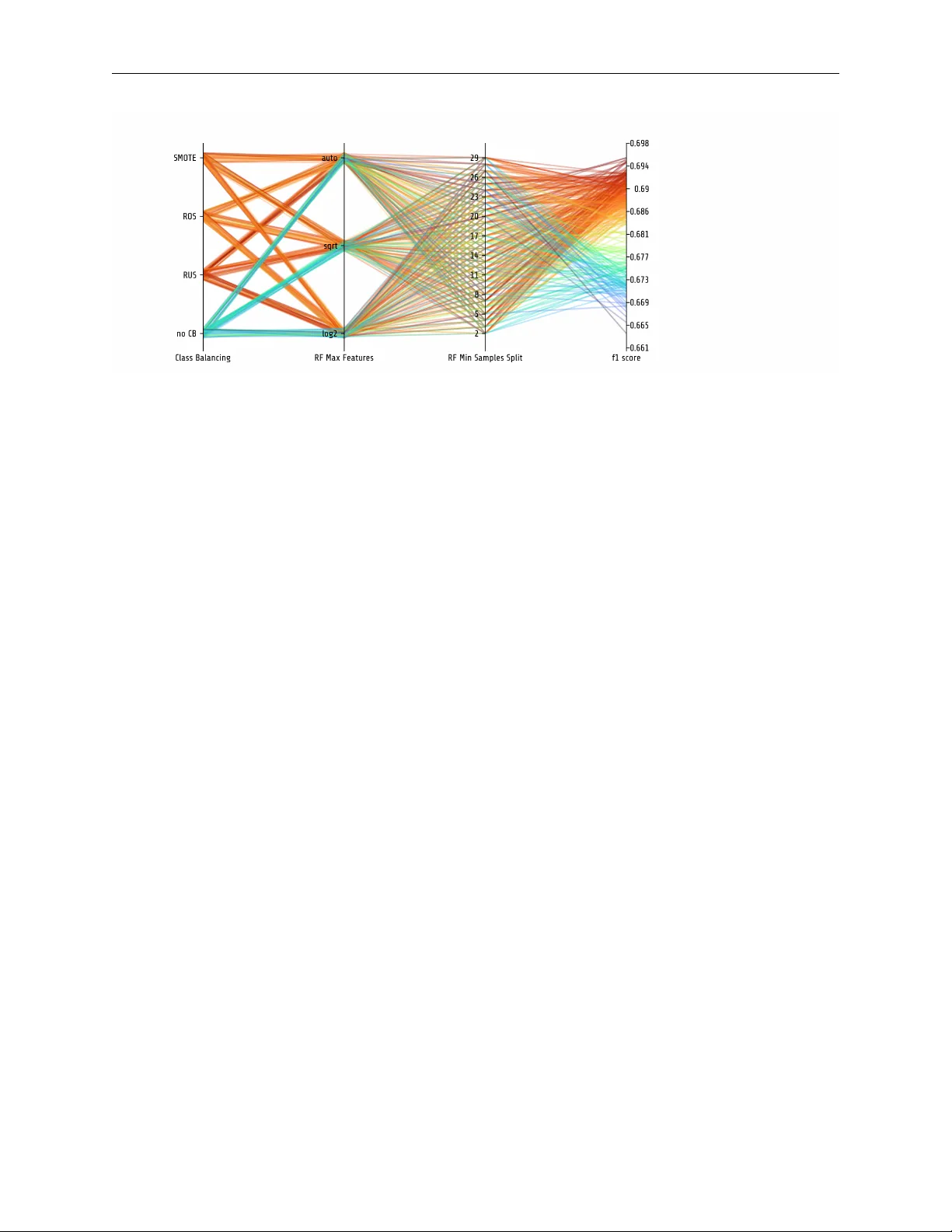
P H OT O NA I - A P Y T H O N A P I F O R R A P I D M A C H I N E L E A R N I N G M O D E L D E V E L O P M E N T Ramona Leenings 1,2 ∗ Nils Ralf Winter 1 * Lucas Plagwitz 1 V incent Holstein 1 Jan Er nsting 1,2 Kelvin Sarink 1 Lukas Fisch 1 Jak ob Steenweg 1 Leon Kleine-V ennekate 1 Julian Gebker 1 Daniel Emden 1 Dominik Grotegerd 1 Nils Opel 1 Benjamin Risse 2 Xiaoyi Jiang 2 Udo Dannlowski 1 Tim Hahn 1 A B S T R AC T PHO TON AI is a high-le vel Python API designed to simplify and accelerate machine learning model dev elopment. It functions as a unifying frame work allo wing the user to easily access and combine algorithms from different toolboxes into custom algorithm sequences. It is especially designed to support the iterati ve model de velopment process and automates the repetiti ve training, hyperparameter optimization and e v aluation tasks. Importantly , the w orkflow ensures unbiased performance estimates while still allo wing the user to fully customize the machine learning analysis. PHO TON AI extends existing solutions with a nov el pipeline implementation supporting more complex data streams, feature combinations, and algorithm selection. Metrics and results can be con veniently visualized using the PHOT ON AI Explorer and predictiv e models are shareable in a standardized format for further external v alidation or application. A growing add-on ecosystem allo ws researchers to offer data modality specific algorithms to the community and enhance machine learning in the areas of the life sciences. Its practical utility is demonstrated on an exemplary medical machine learning problem, achie ving a state-of-the-art solution in few lines of code. Source code is publicly av ailable on Github, while examples and documentation can be found at www .photon-ai.com. 1 Introduction In recent years, the interest in machine learning for medical, biological, and life science research has significantly increased. T echnological adv ances dev elop with breathtaking speed. The basic workflo w to construct, optimize and ev aluate a machine learning model, howe ver , has remained virtually unchanged. In essence, it can be framed as the (systematic) search for the best combination of data processing steps, learning algorithms, and hyperparameter v alues under the premise of unbiased performance estimation. ∗ * These authors contributed equally . 1 - Institute for T ranslational Psychiatry , University of Münster , Germany . 2 - Faculty of Mathematics and Computer Science, Uni versity of Münster , Germany . PHO TON AI - A Python API for Rapid Machine Learning Model Dev elopment P R E P R I N T Subject to the iterativ ely optimized workflo w is a machine learning pipeline, which in this context is defined as the sequence of algorithms subsequently applied to the data. T o begin with, the data is commonly prepared by successively applying se veral processing steps such as normalization, imputation, feature selection, dimensionality reduction, data augmentation, and others. The altered data is then forwarded to one or more learning algorithms which internally deri ve the best fit for the learning task and finally yield predictions. In practice, researchers select suitable preprocessing and learning algorithms from dif ferent toolboxes, learn toolbox- specific syntaxes, decide for a training and testing scheme, manage the data flo w and, ov er time, iterati vely optimize their choices. Importantly , all of this is done while prev enting data leakage, calculating performance metrics, adhering to (nested) cross-validation best practices, and searching for the optimal (h yperparameter-) configuration. A multitude of high-quality and well-maintained open-source toolboxes of fer specialized solutions, each for a particular subdomain of machine learning-related (optimization) problems. 1.1 Existing solutions: Specialized open-source toolboxes In the field of (deep) neural networks, libraries such as T ensorflow , Theano , Caffe and PyT or ch [ 1 , 2 , 3 , 4 ] of fer domain-specific implementations for nodes, layers, optimizers, as well as e valuation and utility functions. On top of that, higher lev el Application Programming Interfaces (APIs) such as K eras and fastai [ 5 , 6 ] offer e xpressiv e syntaxes for accelerated and enhanced dev elopment of deep neural network architectures. In the same manner , the scikit-learn [ 7 ] toolbox, has evolv ed as one of the major resources of the field, covering a very broad range of regression, classification, clustering, and preprocessing algorithms. It has established the de-facto standard interface for data processing and learning algorithms, and, in addition, offers a wide range of utility functions, such as cross-validation schemes and model e valuation metrics. Next to these general frameworks, other libraries in the software landscape offer functionalities to address more specialized problems. Prominent examples are the imbalanced-learn toolbox [ 8 ], which provides numerous ov er- or under-sampling methods, or modality-specific libraries such as nilearn and nibabel [ 9 , 10 ] which offer utility functions for accessing and preparing neuroimaging data. On top of that, the software landscape is complemented by se veral hyperparameter optimization packages, each implementing a different strate gy to find the most effecti ve hyperparameter combination. Ne xt to Bayesian approaches, such as Scikit-optimize or SMA C [ 11 , 12 ], there are packages implementing e volutionary strategies [ 13 ] or packages approximating gradient descent within the hyperparameter space [ 14 , 15 ]. Each package requires specific syntax and unique hyperparameter space definitions. Finally , there are approaches uniting all these components into algorithms that automatically derive the best model architecture and hyperparameter settings for a gi ven dataset. Libraries such as auto-sklearn , TPO T , AutoW eka , Auto- ker as , AutoML , A uto-Gluon and others optimize a specific set of data-processing methods, learning algorithms and their respectiv e hyperparameters [ 16 , 17 , 18 , 19 , 20 , 21 , 22 ]. While very intriguing, these libraries aim at full automation - neglecting the need for customization and foregoing the opportunity to incorporate high-le vel domain kno wledge in the model architecture search. Especially the complex and often high-dimensional data structure nativ e to medical and biological research requires the integration and application of modality-specific processing and often entails the dev elopment of nov el algorithms. 1.2 Current shortcoming: Manual integration of cross-toolbox algorithm sequences Currently , iterativ e model dev elopment approaches across different toolboxes as well as design and optimization of custom algorithm sequences are barely supported. For a start, scikit-learn has introduced the concept of pipelines, which successi vely apply a list of processing methods (referred to as transformers) and a final learning algorithm (called estimator) to the data. The pipeline directs the data from one algorithm to another and can be trained and ev aluated in 2 PHO TON AI - A Python API for Rapid Machine Learning Model Dev elopment P R E P R I N T (simple) cross-validation schemes, thereby significantly reducing programmatic ov erhead. Scikit-learn’ s consistent usage of standard interfaces enables the pipeline to be subject to scikit-learn’ s inherent hyperparameter optimization strategies based on random- and grid-search. While being a simple and ef fective tool, se veral limitations still remain. For one, hyperparameter optimization requires a nested cross-validation scheme, which is not inherently enforced. Second, a standardized solution for easy integration of custom or third-party algorithms is not considered. In addition, sev eral repetitive tasks, such as metric calculations, logging, and visualization lack automation and still need to be handled manually . Finally , the pipeline can not handle adjustments to the target v ector , thereby excluding algorithms for e.g. data augmentation or handling class imbalance. 1.3 Major contributions of PHO TON AI: Supporting a con venient dev elopment workflow T o address these issues, we propose PHO TON AI as a high-le vel Python API that acts as a mediator between dif ferent toolboxes. Established solutions are con veniently accessible or can be easily added. It combines an automated supervised machine learning workflo w with the concept of custom machine learning pipelines. Thereby it is able to considerably accelerate design iterations and simplify the e valuation of nov el analysis pipelines. In essence, PHO TON AI ’ s major contributions are: Increased Accessibility . By pre-registering data processing methods, learning algorithms, hyperparameter optimiza- tion strategies, performance metrics, and other functionalities, the user can effortlessly access established machine learning implementations via simple ke ywords. In addition, by relying on the established scikit-learn object API [ 23 ], users can easily integrate an y third-party or custom algorithm implementation. Extended Pipeline Functionality . A simple to use class structure allows the user to arrange selected algorithms into single or parallel pipeline sequences. Extending the pipeline concept of scikit-learn [ 7 ], we add novel functionality such as flexible positioning of learning algorithms, target vector manipulations, callback functions, specialized caching, parallel data-streams, Or-Operations, and other features as described belo w . A utomation. PHO TON AI can automatically train, (hyperparameter-) optimize and ev aluate any custom pipeline. Importantly , the user designs the training and testing procedure by selecting (nested) cross-v alidation schemes, hyper- parameter optimization strategies, and performance metrics from a range of pre-integrated or custom-built options. Thereby , dev elopment time is significantly decreased and conceptual errors such as information leakage between training, validation, and test set are av oided. Training information, baseline performances, hyperparameter optimization progress, and test performance ev aluations are persisted and can be visualized via an interacti ve, browser-based graphical interface (PHO TON AI Explorer) to facilitate model insight. Model Sharing. A standardized format for saving, loading, and distributing optimized and trained pipeline architec- tures enables model sharing and external model v alidation e ven for non-expert users. 2 Methods In the follo wing, we will describe the automated supervised machine learning workflo w implemented in PHOT ON AI. Subsequently , we will outline the class structure, which is the core of its expressi ve syntax. At the same time, we will highlight its current functionalities, and finally , provide a hands-on example to introduce PHO TON AI’ s usage. Lastly , we close with discussing current challenges and future dev elopments. 2.1 Software Ar chitecture and W orkflow PHO TON AI automatizes the supervised machine learning workflo w according to user -defined parameters (see pseu- docode in Listing 1). In a nutshell, cross-validation folds are deri ved to iterativ ely train and ev aluate a machine learning 3 PHO TON AI - A Python API for Rapid Machine Learning Model Dev elopment P R E P R I N T pipeline following the hyperparameter optimization strate gy’ s current parameter v alue suggestions. Performance metrics are calculated, the progress is logged and finally , the best hyperparameter configuration is selected to train a final model. The training, testing, and optimization workflo w is automated, howe ver , it is important to note that it is parameterized by user choices and therefore fully customized. In order to achieve an efficient and expressi ve customization syntax, PHO TON AI’ s class architecture captures all workflo w- and pipeline-related parameters into distinct and combinable components (see Fig 1). A central management class called Hyperpipe - short for hyperparameter optimization pipeline - handles the setup of the pipeline and ex ecutes the training and test procedure according to user choices. Basis to the data flow is a custom Pipeline implementation, which streams data through a sequence of PipelineElement objects, the latter of which represent either established or custom algorithm implementations. In addition, clear interfaces and se veral utility classes allow the integration of custom solutions, adjust the training and test procedure and build parallel data streams. In the following, PHO TON AI’ s core classes and their respectiv e features will be further detailed. Figure 1: Class architecture The PHOT ON AI framework is built to accelerate and simplify the design of machine learning models. It adds an abstraction layer to existing solutions and is thereby able to simplify , structure, and automate the training, optimization, and testing workflo w . Importantly , the pipeline and the workflo w are subject to user choices as the user selects a sequence of processing and learning algorithms and parameterizes the optimization and validation workflo w . The here depicted class diagram sho ws PHO TON AI’ s core structure. The central element is the Hyperpipe class, short for hyperparameter optimization pipeline, which manages a pipeline and the associated training, optimization, and testing workflow . The Pipeline streams data through a sequence of n PipelineElements . PHO TON AI relies on the established scikit-learn [ 7 ] object API, to integrate established or custom algorithms ( BaseElements ) into the workflo w . PipelineElements can hav e n hyperparameters which are subject to optimization by a hyperparameter optimization strategy . 2.1.1 Core Framew ork - The Hyperpipe Class PHO TON AI’ s core functionality is encapsulated in a class called Hyperpipe , which controls all workflow and pipeline- related parameters and manages the cross-validated training and testing procedure (see Listing ?? ). In particular , it partitions the data according to the cross-validation splits, requests hyperparameter configurations, trains and ev aluates the pipeline with the giv en configuration, calculates performance metrics, and coordinates the logging of all results and metadata such as e.g. computation time. In addition, the Hyperpipe ranks all tested hyperparameter configurations based on a user-selected performance metric and yields a final (optimal) model trained with the best performing 4 PHO TON AI - A Python API for Rapid Machine Learning Model Dev elopment P R E P R I N T Algorithm 1 Pseudocode for PHO TON AI’ s training, hyperparameter optimization and testing workflo w as implements in the Hyperpipe class Input: (1) Pipeline, sequence of algorithms, pipeline (2) Performance metrics, metrics (3) Hyperparameter Optimization Strategy , hpo (4) Outer Cross-V alidation Strate gy , ocv (5) Inner Cross-V alidation Strate gy , icv (6) Features X and T argets y , data (7) Performance Expectations, performance_constraints 1: for outer _ f ol d = 1 , 2 , . . . T ocv .split ( data ) do 2: outer_fold_data = data[outer_fold T ] 3: dummy_performance = apply_dummy_heuristic(outer_fold_data) 4: 5: hpo.initialize_hyperparameter_space(pipeline) 6: for hp_config in hpo.ask() do 7: for inner _ f ol d = 1 , 2 , ..V icv .spl it ( outer _ f old _ data ) do 8: inner_data = outer_fold_data[inner_fold V ] 9: hp_performance = train_and_test(pipeline, hp_config, 10: metrics, inner_data) 11: hpo.tell(hp_performance) 12: if performance_constraints then 13: if hp_performance < performance_constraints then 14: break 15: end if 16: end if 17: end for 18: val_performance = mean([hp_performance 1 , . . . , hp_performance V ]) 19: if hp_config_performance > best_performance then 20: best_outer_fold_configT = hp_config 21: end if 22: end for 23: test_performance = train_and_test(pipeline, best_outer_fold_config, 24: metrics, outer_fold_data) 25: end for 26: ov erall_best_performance = argmax([test_performance 1 , . . . , test_performance T ]) 27: ov erall_best_config = [best_outer_configs 1 , . . . , 28: best_outer_config T ][ov erall_best_performance] 29: pipeline.set_params(ov erall_best_config) 30: pipeline.fit(X, y) 31: pipeline.sav e() 5 PHO TON AI - A Python API for Rapid Machine Learning Model Dev elopment P R E P R I N T 1 pipe = Hyperpipe ( ’example_project’ , 2 optimizer= ’sk_opt’ , 3 optimizer_params={ ’n_configurations’ : 25}, 4 metrics=[ ’accuracy’ , ’precision’ , ’recall’ ], 5 best_config_metric= ’accuracy’ , 6 outer_cv=KFold(n_splits=3), 7 inner_cv=KFold(n_splits=3)) Listing 1: Setting the parameters to control the training, hyperparameter optimization and testing workflo w using the Hyperpipe class. hyperparameter configuration. Further , a baseline performance is established by applying a simple heuristic [ 24 ]. This aids in assessing model performance and facilitates interpretation of the results. 2.1.2 The PHO TON AI Pipeline - Extended Pipeline F eatures The Hyperpipe relies on a custom pipeline implementation that is conceptually related to the scikit-learn pipeline [ 25 ] but e xtends it with four core features. First, it enables the positioning of learning algorithms at an arbitrary position within the pipeline. In case a PipelineElement is identified that a) provides no transform method and b) yet is followed by one or more other PipelineElements , it automatically calls pr edict and delivers the output to the subsequent pipeline elements. Thereby , learning algorithms can be joined to ensembles, used within sub pipelines, or be part of other custom pipeline architectures without interrupting the data stream. Second, it allo ws for a dynamic transformation of the target vector anywhere within the data stream. Common use-cases for this scenario include data augmentation approaches - in which the number of training samples is increased by applying transformations (e.g. rotations to an image) - or strategies for an imbalanced dataset, in which the number of samples per class is equalized via e.g. under- or o versampling. Third, numerous use-cases rely on data not contained in the feature matrix at runtime, e.g. when aiming to control for the ef fect of cov ariates. In PHO TON AI, additional data can be streamed through the pipeline and is accessible for all pipeline steps while - importantly - being matched to the (nested) cross-validation splits. Finally , PHOT ON AI implements pipeline callbacks which allow for liv e inspection of the data flowing through the pipeline at runtime. Callbac ks act as pipeline elements and can be inserted at any point within the pipeline. The y must define a function deleg ate which is called with the same data that the next pipeline step wi ll receiv e. Thereby , a dev eloper may inspect e.g. the shape and values of the feature matrix after a sequence of transformations has been applied. Return values from the delegate functions are ignored so that after returning from the delegate call, the original data is directly passed to the next processing step. 2.1.3 The Pipeline Element - Con veniently access cr oss-toolbox algorithms In order to integrate a particular algorithm into the pipeline’ s data stream, PHO TON AI implements the PipelineElement class. This can either be a data processing algorithm, in reference to the scikit-learn interface also called transformer , or a learning algorithm, also referred to as estimator . By selecting and arranging PipelineElements , the user designs the ML pipeline. T o facilitate this process, it enables con venient access to v arious established implementations from state-of-the-art machine learning toolboxes: With an internal registration system that instantiates class objects from a keyword, import, access, and setup of different algorithms is significantly simplified (see Listing 2). Relying on the established scikit-learn object API [ 23 ], users can inte grate any third-party or custom algorithm implementation. Once registered, custom code fully integrates with all PHO TON AI functionalities thus being compatible with all other 6 PHO TON AI - A Python API for Rapid Machine Learning Model Dev elopment P R E P R I N T 1 # add two preprocessing algorithms to the data stream 2 pipe += PipelineElement ( ’PCA’ , 3 hyperparameters={ ’n_components’ : 4 FloatRange(0.5, 0.8, step=0.1)}, 5 test_disabled=True) 6 7 pipe += PipelineElement ( ’ImbalancedDataTransformer’ , 8 hyperparameters={ ’method_name’ : 9 [ ’RandomUnderSampler’ , ’SMOTE’ ]}, 10 test_disabled=True) Listing 2: Algorithms can be accessed via keywords and are represented together with all potential hyperparameter values. algorithms, hyperparameter optimization strategies, PHO TON AI’ s pipeline functionality , nested cross-validation, and model persistence. 2.2 Hyperparameter Optimization Strategies Hyperparameters directly control the behavior of algorithms and may hav e a substantial impact on model performance. Therefore, unlike classic h yperparameter optimization, PHO TON AI’ s hyperparameter optimization encompasses the hyperparameters of the entire pipeline - not only the learning algorithm’ s hyperparameters as is usually done. The PipelineElement provides an expressi ve syntax for the specification of hyperparameters and their respectiv e value ranges (see Listing 2). In addition, PHOT ON AI conceptually extends the hyperparameter search by adding an on and off switch (a parameter called test_disabled ) to each PipelineElement , allowing the h yperparameter optimization strategy to check if skipping an algorithm improv es model performance. Representing algorithms together with their hyperparameter settings enables seamless switching between different hyperparameter optimization strategies, ranging from (random) grid search to more advanced approaches such as Bayesian or e volutionary optimization [ 11 , 12 , 13 ] Custom hyperparameter optimization strategies can be integrated via an extended an ask- and tell-interface or by accepting an objectiv e function defined by PHO TON AI. 2.3 Parallel Data Str eaming 2.3.1 The Switch element - Optimizing algorithm selection Building ML pipelines inv olves comparing different pipelines with each other . While in most state-of-the-art ML toolboxes the user has to define and benchmark each pipeline manually , in PHO TON AI it is possible to ev aluate sev eral possibilities at once. Specifically , the Switch object is interchanging se veral algorithms at the same pipeline position, representing an OR-Operation (see Fig 2). W ith data processing steps, learning algorithms and their hyperparameters intimately entangled, this enables algorithm selection to be part of the hyperparameter optimization process. For an example usage of the Switc h element see example code on github. 2.3.2 The Stack element - Combining data streams The Stack object acts as an AND-Operation. It allows sev eral algorithms to share a particular pipeline position, streams the data to each element and horizontally concatenates the respective outputs (see Fig 2 and Listing 3 or demo code on github). Thus, new feature matrices can be created by processing the input in dif ferent ways and like wise, ensembles can be built by training se veral learning algorithms in parallel. 7 PHO TON AI - A Python API for Rapid Machine Learning Model Dev elopment P R E P R I N T Figure 2: Parallel Pipeline Elements A: The Switch class represents an OR-Operation and can be placed anywhere in the sequence to interchange and compare dif ferent algorithms at the same pipeline position. B: The Stack represents an AND-Operation and contains se veral algorithms to share a particular pipeline position. It streams the data to each element and horizontally concatenates the respecti ve outputs (see Listing 3). Next to generating new feature matrices through sev eral processing steps at runtime or building classifier ensembles, it can, in addition, be used in combination with the branch element. 1 2 # set up two learning algorithms in an ensemble 3 ensemble = Stack ( ’estimators’ , use_probabilities=True) 4 ensemble += PipelineElement ( ’DecisionTreeClassifier’ , 5 criterion= ’gini’ , 6 hyperparameters={ ’min_samples_split’ : 7 IntegerRange(2, 4)}) 8 ensemble += PipelineElement ( ’LinearSVC’ , 9 hyperparameters={ ’C’ : FloatRange(0.5, 25)}) 10 11 pipe += ensemble Listing 3: Using the Stack object, two learning algorithms can be trained in parallel resulting in various predictions that can e.g. to be fed into a subsequent meta-learner to create an ensemble. 2.3.3 The Branch element - Building nested pipelines Finally , the Branc h class constitutes a parallel sub-pipeline containing a distinct sequence of PipelineElements. It can be used in combination with the Switch and Stack elements enabling the creation of complex pipeline architectures integrating parallel sub-pipelines in the data flo w (see usage example on github). This could be particularly useful when deriving distinct predictions from se veral data subdomains, such as dif ferent brain regions, and further apply a voting strategy to the respecti ve outputs. 2.4 Increasing w orkflow efficiency 2.4.1 Accelerated Computation Sev eral computational shortcuts are implemented in order to most efficiently use av ailable resources. PHOT ON AI allows specifying lo wer or upper bounds which the performance of a hyperparameter configuration has to exceed. Only 8 PHO TON AI - A Python API for Rapid Machine Learning Model Dev elopment P R E P R I N T then, the configuration is further ev aluated in the remaining cross-validation folds, thereby accelerating hyperparameter search [ 16 ]. In addition, PHOT ON AI can compute outer cross-validation folds in parallel relying on the python library dask [ 26 ]. It is compatible with an y custom parallelized model implementation, e.g. for training a multi GPU model. Finally , PHO TON AI is able to reuse data already calculated: It implements a caching strategy that is specifically adapted to handle the varying datasets evolving from the nested cross-validation data splits as well as partially ov erlapping hyperparameter configurations. 2.4.2 Model distribution After identifying the optimal hyperparameter configuration, the Hyperpipe trains the pipeline with the best configuration on all av ailable data. The resulting model including all transformers and estimators is persisted as a single file in a standardized format, suffix ed with ’.photon’ . It can be reloaded to make predictions on ne w , unseen data. The .photon format facilitates model distrib ution, which is crucial for external model v alidation and thus at the heart of ML best practice, we also created a dedicated online model repository to which users can upload their models to make them publicly av ailable. If the model is persisted in the .photon-format, others can do wnload the file and make predictions without extensi ve system setups or the need to share data. 2.4.3 Logging and visualization PHO TON AI pro vides extensiv e result logging including both performances and metadata generated through the hyperparameter optimization process. Each hyperparameter configuration tested is archiv ed including all performance metrics and complementary information such as computation time and the training, validation, and test indices. Finally , all results can be visualized by uploading the JSON output file to a JavaScript web application called Explorer. It provides a visualization of the pipeline architecture, analysis design, and performance metrics. Confusion matrices (for classification problems) and scatter plots (for regression analyses) with interactiv e per-fold visualization of true and predicted values are sho wn. All e valuated hyperparameter configurations can be sorted and are searchable. In addition, the course of the hyperparameter optimization strategy o ver time is visualized (see Fig 3). 3 Example Usage In the following, we will pro vide a hands-on example for using PHO TON AI to predict heart failure from medical data. T o run the example, do wnload the data a v ailable on kaggle [ 27 ] and install PHO TON AI either by cloning it from Github or installing it via pip using: 1 p i p i n s t a l l p h o t o n a i The complete example code can be do wnloaded from Github using this link. Heart Failur e Data In the following, we will de velop a model to predict mortality in the context of heart failure based on medical records [ 27 , 28 ]. The dataset consists of data from 299 patients (105 female, 194 male) in the age between 40 and 95. It provides 13 features per subject: age and gender , se veral clinical blood markers, information about body functions as well as the presence of comorbidities (anemia, diabetes), and lifestyle impacts (smoking). Finally , a boolean value indicates whether a subject died during the follow-up period, which spans 4 to 285 days. In approximately 68 percent of cases the patients surviv ed while approximately 32 percent of the patients die due to heart failure. 9 PHO TON AI - A Python API for Rapid Machine Learning Model Dev elopment P R E P R I N T Figure 3: PHO TON AI Explorer Example plots of PHO TON AI’ s result visualization tool called Explorer. A: User- defined performance metrics, here accuracy , precision and recall, for both training (blue) and test (dark) set. The horizontal line indicates a baseline performance stemming from a simple heuristic. B: For re gression problems, true and predicted values are visualized in a scatter plot on both train (left) and test (right) set. The values are generated by the best model found in each outer folds, respectiv ely . C: Hyperparameter optimization progress is depicted ov er time for each outer fold. D: Pipeline elements and their arrangement is visualized including the best hyperparameter v alue of each item. Hyperpipe Setup First, we will define the training, optimization, and ev aluation workflow in an initial call to the Hyperpipe class. The python code in Listing 4 sho ws the PHOT ON AI code defining both the data flo w and the training and test procedure. After importing the rele vant packages and loading the data, we instantiate a Hyperpipe and choose the workflow parameters as follows: • For the outer cross-v alidation loop, we specify 100 shuffled iterations each holding out a test set of 20 percent. For the inner cross-v alidation loop, we select a ten-fold cross-v alidation. (lines 13-14). • T o measure model performance, we specify that f1 score, Matthews correlation coefficient, balanced accuracy , as well as sensitivity and specificity are to be calculated (lines 16-17). • W e optimize the pipeline for f1 score, as it maximizes both sensiti ve and specific predictions, which is particularly important in medical contexts. (line 18). • T o save computational resources and time, we enable caching by specifying a cache folder (line 22). This is particularly useful in examples where there are a lot of partially o verlapping hyperparameters to be tested. 10 PHO TON AI - A Python API for Rapid Machine Learning Model Dev elopment P R E P R I N T • Finally , we specify a folder to which the output is written (line 21) and set the verbosity of the console log to 1. At this verbosity level, information on ev ery tested hyperparameter configuration and its respective performance estimate is printed to the console. After the hyperpipe has been defined, we can design the flow of the data by adding algorithms and respecti ve hyperparameters to the pipeline. • First, data is normalized using scikit-learn’ s StandardScaler which both centers the data and scales it to unit variance (line 26). • Second, we impute missing values with the mean v alues per feature of the training set by calling scikit-learn’ s SimpleImputer (line 27). Of note, we consider use cases 1 to 3 (see belo w) to be exploratory analyses. W e believe this simulates a naturalistic workflo w of machine learning projects where different algorithms, feature preprocessing and hyperparameters are tested in a manual fashion. Ho wev er , if done incorrectly , this inevitably leads to a manual ov er-fitting to the data at hand, which is especially troublesome in high-stake medical problems with small datasets. In this context, manual ov er-fitting happens implicitly when data scientists optimize algorithms and hyperparameters by repeatedly looking at cross-v alidated test performance. In PHO TON AI, this problem can easily be av oided by setting the Hyperpipe parameter use_test_set to F alse . This way , PHO TON AI will still apply nested cv but will only report validation performances from the inner cv loop, not the outer cv test data. In the final use case 4, use_test_set is set to T rue to estimate final model performance and generalizability on the actual test sets. 3.1 Use case 1 - Estimator selection Although some rules of thumb for selecting the correct algorithm do exist, kno wing the optimal learning algorithm for a specific task a priori is impossible (no free lunch theorems [ 29 ]). Therefore, the possibility to automatically e valuate multiple algorithms within nested cross-v alidation is crucial to ef ficient and unbiased machine learning analyses. In this example, we first train a machine learning pipeline and consider three dif ferent learning algorithms that we find appropriate for this learning problem. These algorithms are added to the PHOT ON AI Hyperpipe in addition to the scaling and imputing preprocessing steps defined abov e. 3.1.1 Setup • T o compare different learning algorithms, an Or-Element called Switch is added to the pipeline that toggles between se veral learning algorithms (see Listing 5). Here, we compare a random forest (RF), gradient boosting (GB), and a support vector machine (SVM) against each other . Again, all algorithms are imported from scikit-learn, and for e very element we specify algorithm-specific hyperparameters that are automatically optimized. • T o efficiently optimize hyperparameters of different learning algorithms, the switch optimizer in PHO TON AI can be used which optimizes each learning algorithm in an individual hyperparameter space (line 19 in Listing 4). W e apply Bayesian optimization to each space respecti vely and limit the number of tested configurations to 10 (line 20 in Listing 4). Finally , we can start the training, optimization, and test procedure by calling Hyperpipe.fit() . After the pipeline opti- mization has finished, we extract not only the overall best hyperparameter configuration and its respecti ve performance, but also the best configuration performance per learning algorithm (RF , GB, SVM, see line 21 in Listing 5). 11 PHO TON AI - A Python API for Rapid Machine Learning Model Dev elopment P R E P R I N T 1 import pandas as pd 2 from sklearn.model_selection import KFold, ShuffleSplit 3 from photonai.base import Hyperpipe , PipelineElement , Switch 4 from photonai.optimization import FloatRange, IntegerRange, MinimumPerformanceConstraint 5 6 # load data 7 df = pd.read_csv( ’./heart_failure_clinical_records_dataset.csv’ ) 8 X = df.iloc[:, 0:12] 9 y = df.iloc[:, 12] 10 11 # setup training and test workflow 12 pipe = Hyperpipe ( ’heart_failure’ , 13 outer_cv=ShuffleSplit(n_splits=100, test_size=0.2), 14 inner_cv=KFold(n_splits=10, shuffle=True), 15 use_test_set=False, 16 metrics=[ ’balanced_accuracy’ , ’f1_score’ , ’matthews_corrcoef’ , 17 ’sensitivity’ , ’specificity’ ], 18 best_config_metric= ’f1_score’ , 19 optimizer= ’switch’ , 20 optimizer_params={ ’name’ : ’sk_opt’ , ’n_configurations’ : 10}, 21 project_folder= ’./tmp’ , 22 cache_folder= ’./cache’ , 23 verbosity=1) 24 25 # arrange a sequence of algorithms subsequently applied 26 pipe += PipelineElement ( ’StandardScaler’ ) 27 pipe += PipelineElement ( ’SimpleImputer’ ) 28 29 # learning algorithm’s will be added here 30 ... 31 # 32 33 # start the training, optimization and test procedure 34 pipe.fit(X, y) Listing 4: PHO TON AI code to define an initial training, optimization and test proecdure for the heart f ailure dataset. The pipeline normalizes the data and imputes missing values. 12 PHO TON AI - A Python API for Rapid Machine Learning Model Dev elopment P R E P R I N T 1 # compare different learning algorithms in an OR_Element 2 estimators = Switch ( ’estimator_selection’ ) 3 4 estimators += PipelineElement ( ’RandomForestClassifier’ , 5 criterion= ’gini’ , 6 bootstrap=True, 7 hyperparameters={ ’min_samples_split’ : IntegerRange(2, 30), 8 ’max_features’ : [ ’auto’ , ’sqrt’ , ’log2’ ]}) 9 10 estimators += PipelineElement ( ’GradientBoostingClassifier’ , 11 hyperparameters={ ’loss’ : [ ’deviance’ , ’exponential’ ], 12 ’learning_rate’ : FloatRange(0.001, 1, 13 "logspace" )}) 14 estimators += PipelineElement ( ’SVC’ , 15 hyperparameters={ ’C’ : FloatRange(0.5, 25), 16 ’kernel’ : [ ’linear’ , ’rbf’ ]}) 17 pipe += estimators 18 19 pipe.fit(X, y) 20 21 pipe.results_handler.get_mean_of_best_validation_configs_per_estimator() Listing 5: PHO TON AI code to define three learning algorithms that are tested by PHO TON AI automatically through an OR-element, the PHO TON AI Switch. 3.1.2 Results The results of the initial estimator selection analysis are gi ven in the first line of T able 1. W e observe an f1 score of 75% and a Matthews correlation coefficient of 65%. The best config found by the hyperparameter optimization strategy applied the Random Forest classifier , which thus in this case outperforms gradient boosting and the Support V ector Machine. T able 1: V alidation perf ormance metrics for thr ee different pipeline setups. Pipeline f1 matthews corr BA CC sens spec Estimator selection pipeline 0.7504 0.6583 0.8217 0.9144 0.7289 + Lasso feature selection 0.7496 0.6570 0.8211 0.7300 0.9123 + class balancing 0.7644 0.6619 0.8384 0.8210 0.8557 Notes : matthews corr = Matthe ws correlation coefficient, B A CC = balanced accuracy , sens = sensitivity , spec = specificity 3.2 Use case 2 - Featur e selection Next, we will ev aluate the effect of an additional feature selection step. This can be done, e.g., by analyzing a linear model’ s normalization coefficients. While low coef ficient features are interpreted detrimental to the learning process since they might induce error v ariance into the data, high coefficient features are interpreted as important information to solve learning problem. A frequently used feature selection approach is based on the Lasso algorithm, as the Lasso implements an L1 regularization norm that penalizes non-sparsity of the model and thus pushes unnecessary model weights to zero. The Lasso coefficients can then be used to select the most important features. 13 PHO TON AI - A Python API for Rapid Machine Learning Model Dev elopment P R E P R I N T 1 pipe += PipelineElement ( ’LassoFeatureSelection’ , 2 hyperparameters={ ’percentile’ : FloatRange(0.1, 0.5), 3 ’alpha’ : FloatRange(0.5, 5, 4 range_type= "logspace" )}) Listing 6: Code for adding a feature selection pipeline element that uses Lasso coefficients to rank and remov e features. 1 pipe += PipelineElement ( ’ImbalancedDataTransformer’ , 2 hyperparameters={ ’method_name’ : [ ’RandomUnderSampler’ , 3 ’RandomOverSampler’ , 4 ’SMOTE’ ]}) Listing 7: Code for adding class balancing algorithms to the pipeline and optimizing the concrete class balancing strategy . 3.2.1 Setup The Lasso implementation is imported from scikit-learn, and in order to prepare it as a feature selection tool, accessed via a simple wrapper class provided in PHO TON AI. The wrapper sorts the fitted model’ s coefficients and only features falling in the top k percentile are kept. Both the Lasso’ s alpha parameter as well as the percentile of features to keep can be optimized. W e add the pipeline element LassoF eatureSelection as gi ven in Listing 6 between the SimpleImputer pipeline element and the estimator switch. Again, we run the analysis and e valuate only the v alidation set ( Hyperpipe parameter use_test_set is set to F alse ). 3.2.2 Results The performance metrics for the pipeline with Lasso Feature Selection are gi ven in T able 1. W e see a minor performance decrease of approximately 1%. Apparently , linear feature selection is unhelpful indicating that the learning problem is rather under - than ov er-described by the features gi ven. Interestingly , while 90% of the subjects are correctly identified as surviv ors (specificity of 91%), a notable amount of actual deaths are missed (sensitivity of 73%). The lower sensitivity in relation to a high specificity might be due to the class imbalance present in the data with more subjects surviving than dying (68%), which we will no w inv estigate in use case 3. Use case 3 - Handling class imbalance As a next step, we will try to enhance predicti ve accuracy and balance the trade-of f between specificity and sensitivity by decreasing class imbalance. 3.2.3 Setup In order to con veniently access class balancing algorithms, PHO TON AI offers a wrapper calling o ver- and under - sampling (or a combination of both) techniques implemented in the imbalanced-learn package. W e remov e the LassoF eatur eSelection pipeline element and substitute it with an ImbalancedDataT ransformer pipeline element as shown in Listing 7. As a hyperparameter , we optimize the specific class balancing method itself by ev aluating random undersampling, random ov ersampling, and a combination of both called SMO TE. 14 PHO TON AI - A Python API for Rapid Machine Learning Model Dev elopment P R E P R I N T 3.2.4 Results Rerunning the analysis with a class balancing algorithm yields a slightly better performance (f1 score = 0.76, Matthe ws correlation coef ficient = 0.66, see line 3 in T able 1). The optimal class balancing method was found to be SMO TE, a combination of under- and over -sampling. More importantly , a greater balance between sensiti vity (82%) and specificity (86%) was reached which also resulted in a higher balanced accuracy compared to the two pre vious pipelines (BA CC = 84%). 3.3 Use case 4 - Estimating final model performance From the results of use cases 2 and 3, we can see that only class balancing but not feature selection slightly increased the classification performance in this specific dataset. Additionally , when we examine the results of the three learning algorithms of the class balancing pipeline, we can further see that the Random Forest (f1 = 0.76) is still outperforming gradient boosting and the Support V ector Machine (see T able 2). Therefore, we restrict our final machine learning pipeline to a class balancing element and a Random Forest classifier . T able 2: Differ ent estimator’ s av erage best validation perf ormance for the class balancing pipeline. Estimator f1 matthews corr BA CC sens spec Random Forest 0.7623 0.6602 0.8368 0.8161 0.8575 Gradient Boosting 0.7393 0.6233 0.8192 0.7949 0.8435 SVM 0.7017 0.5717 0.7895 0.7445 0.8344 Notes : matthews corr = Matthe ws correlation coefficient, B A CC = balanced accuracy , sens = sensitivity , spec = specificity 3.3.1 Setup In this last step, we finish model de velopment and estimate the final model performance. W e remov e the estimator switch from the pipeline and substitute it by a single Random Forest pipeline element. In addition, we decide to thoroughly inv estigate the hyperparameter space and therefore change the hyperparameter optimizer to grid search (see line 3-4 in Listing 8). In addition, we use the previously calculated v alidation metrics as a rough guide to specify a lower performance bound that promising hyperparameter configurations must outperform. Specifically , we apply a MinimumP erformanceConstraint on f1 score, meaning that inner fold calculations are aborted when the mean performance is belo w 0.7 (see line 5-7 in Listing 8). Thereby , less promising configurations are dismissed early and computational resources are sa ved. Importantly , we will now set use_test_set to T rue to make sure that PHO TON AI will ev aluate the best hyperparameter configurations on the outer cv test set. 3.3.2 Results The final model performance on the test set is giv en in T able 3. All metrics remained stable when being e valuated on the previously unused test set. As a comparison, Chicco et al. (2020) [ 30 ] trained several learning algorithms to the heart failure dataset used in this example (see row 2 of T able 11 in Chicco et al. [ 30 ]). PHOT ON AI is able to outperform the best model of Chicco et al. which was trained on all av ailable features in a similar fashion (see T able 3). For the f1 score, the PHO TON AI pipeline reaches 0.746. Also, sensitivity and specificity appears to be more balanced in comparison to Chicco et al. Fig 4 shows a parallel plot of the hyperparameter space PHO TON AI has explored in this final analysis. Since we have used a grid search optimizer , all possible hyperparameter combinations hav e been ev aluated. Interestingly , when looking 15 PHO TON AI - A Python API for Rapid Machine Learning Model Dev elopment P R E P R I N T 1 pipe = Hyperpipe (... 2 use_test_set=True, 3 optimizer= ’grid_search’ , 4 optimizer_params = {}, 5 performance_constraints=MinimumPerformanceConstraint( ’f1_score’ , 6 threshold=0.7, 7 strategy= "mean" ) 8 ...) 9 ... 10 pipe += PipelineElement ( ’RandomForestClassifier’ , 11 criterion= ’gini’ , 12 bootstrap=True, 13 hyperparameters={ ’min_samples_split’ : IntegerRange(2, 30), 14 ’max_features’ : [ ’auto’ , ’sqrt’ , ’log2’ ]}) 15 ... 16 pipe.fit(X,y) Listing 8: Changes made to the PHO TON AI script to generate the final model at Figure 4, a clear disadv antage becomes evident when no class balancing algorithm is used, random under -sampling appears to provide generally better model performance. T able 3: T est perf ormance metrics for the final model. f1 matthews corr BA CC sens spec Chicco et al. 0.714 0.607 0.818 0.780 0.856 Final PHO TON AI model 0.746 0.619 0.818 0.813 0.823 Notes : matthews corr = Matthe ws correlation coefficient, B A CC = balanced accuracy , sens = sensitivity , spec = specificity 4 Discussion W e introduced PHO TON AI, a high-le vel Python API for rapid machine learning model dev elopment. As demonstrated in the example abo ve, both the pipeline and the training and test procedure, as well the inte gration of hyperparameter optimization can be implemented in a few lines of code. In addition, experimenting with different algorithm sequences, hyperparameter optimization strategies, and other workflow-related parameters was realized by adding single lines of code or changing a few keyw ords. Through the automation of the training, validation and test procedure, data transformation and feature selection steps are restricted to the v alidation set only , thus strictly av oiding data leakage ev en when used by non-e xperts. Interestingly , this fundamentally important separation between training and test data w as apparently not implemented for the feature selection analyses in Chicco et al., as they seem to ha ve selected the most important features on the whole dataset which has most likely inflated their final model performance. Examples like this again highlight the importance of easy-to-use nested cross-validation frame works that guarantee an unbiased estimate of the predictiv e performance and generalization error , which is key to, e.g., the dev elopment of reliable machine learning applications in the medical domain. Finally , the toolbox automatically identified the best hyperparameter configurations, yielded in-depth information about both v alidation and test set performance, and of fered con venient estimator comparison tools. PHO TON AI is de veloped with common scientific use cases in mind, for which it can significantly decrease programmatic ov erhead and support rapid model prototyping. Howe ver , use cases that substantially differ in the amount of av ailable 16 PHO TON AI - A Python API for Rapid Machine Learning Model Dev elopment P R E P R I N T Figure 4: Parallel plot showing hyperparameter exploration. All three hyperparameters used in the final model are sho wn on the x-axis. They include the class balancing algorithm and two hyperparameters of the Random F orest classifier (maximum number of features and minimum samples per split). Each line represents a specific combination of all hyperparameters. The line color reflects the corresponding model performance based on the f1 score. Higher model performance is sho wn in dark red while lower model performance is sho wn in blue. Random under-sampling appears to increase model performance slightly while using no class balancing algorithm decreases o verall model performance. CB = class balancing, R US = random under-sampling, R OS = random ov er-sampling, SMO TE = synthetic minority ov ersampling technique, RF = Random Forest. data or in the computational resources required to train the model, might require a different model de velopment workflo w . For example, while all kinds of neural networks can be inte grated in PHO TON AI, dev eloping and optimizing extremely comple x and specialized deep neural networks with specialized architecture optimization protocols might be cumbersome within the PHO TON AI framew ork. In addition, unbiased performance ev aluation in massi ve amounts of data might significantly relax the need for strict cross-validation schemes. In addition, cross-toolbox access to algorithms comes at the cost of manually pre-registrating the algorithms with the PHO TON AI Registry system. In addition, if the algorithm does not inherently adheres to the scikit-learn object API, the user needs to manually write a wrapper class calling the algorithm according to the fit-predict-transform interface. Howe ver , this process is only required once and can afterwards be shared with the community , thereby enabling con venient access for other researchers without further effort. Furthermore, once registered, all integrated algorithms are instantaneously compatible with all other functionalities of the PHO TON AI framework, for e xample, can they be optimized with an y hyperparameter optimization algorithm of choice. In the future, we intend to extend both functionality and usability . First, we will incorporate additional hyperparameter optimization strategies. While this area has seen tremendous progress in recent years, these algorithms are often not readily a vailable to data scientists, and studies systematically comparing them are e xtremely scarce. Second, we seek to extend automatic ensemble generation to fully exploit the v arious models trained during the hyperparameter optimization process. Generally , we striv e to pre-re gister more of the arising ML utility packages, so that accessibility is facilitated and functionality can be used within PHO TON AI as a unified framew ork. Finally , we would like to improv e our con venience functions for model performance assessment and visualization. In addition to these core functionalities, we aim to establish an ecosystem of add-on modules simplifying ML analyses for dif ferent data types and modalities. For example, we will add a neuroimaging module as a means to directly use multimodal Magnetic Resonance Imaging (MRI) data in ML analyses. In addition, a graph module will integrate existing graph analysis functions and provide specialized ML approaches for graph data. Likewise, modules integrating 17 PHO TON AI - A Python API for Rapid Machine Learning Model Dev elopment P R E P R I N T additional data modalities such as omics data would be of great value. More generally , PHO TON AI would benefit from modules making nov el approaches to model interpretation (i.e. Explainability) av ailable. 5 Conclusion In summary , PHOT ON AI is especially well-suited in contexts requiring rapid and iterative ev aluation of novel approaches such as applied ML research in medicine and the Life Sciences. In the future, we hope to attract more de velopers and users to establish a thriving, open-source community . Acknowledgments This work was supported by grants from the Interdisciplinary Center for Clinical Research (IZKF) of the medical faculty of Münster (grant MzH 3/020/20 to TH and grant Dan3/012/17 to UD) and the German Research F oundation (DFG grants HA7070/2-2, HA7070/3, HA7070/4 to TH). Competing interests W e hereby declare no financial or non-financial competing interests in behalf of all contributing authors. 18 PHO TON AI - A Python API for Rapid Machine Learning Model Dev elopment P R E P R I N T References [1] Mart’in Abadi, Ashish Agarw al, Paul Barham, Eugene Bre vdo, Zhifeng Chen, Craig Citro, GregS.Corrado, AndyDavis, Jeffre yDean, MatthieuDevin, SanjayGhemawat, Ian Goodfellow , Andrew Harp, Geoffrey Irving, Michael Isard, Y angqing Jia, Raf al Jozefo wicz, Lukasz Kaiser , Manjunath Kudlur , Josh Lev enberg, Dandelion Mané, Rajat Monga, Sherry Moore, Derek Murray , Chris Olah, Mike Schuster , Jonathon Shlens, Benoit Steiner , Ilya Sutske ver , Kunal T alwar , Paul T ucker , V incent V anhoucke, V ijay V asude van, Fernanda V iégas, Oriol V inyals, Pete W arden, Martin W attenberg, Martin Wick e, Y uan Y u, and Xiaoqiang Zheng. T ensorFlow: Large-Scale Machine Learning on Heterogeneous Systems, 2015. [2] The Theano Development T eam, Rami Al-Rfou, Guillaume Alain, Amjad Almahairi, Christof Angermueller, Dzmitry Bahdanau, Nicolas Ballas, Frédéric Bastien, Justin Bayer , Anatoly Belikov , and Others. Theano: A Python Frame work for Fast Computation of Mathematical Expressions. arXiv pr eprint arXiv:1605.02688 , 2016. [3] Y angqing Jia, Ev an Shelhamer , Jeff Donahue, Ser gey Karayev , Jonathan Long, Ross Girshick, Ser gio Guadarrama, and T rev or Darrell. Caf fe: Con volutional Architecture For F ast Feature Embedding. In Pr oceedings of the 22nd A CM international confer ence on Multimedia , pages 675–678, 2014. [4] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer , James Bradbury , Gregory Chanan, T rev or Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, and Others. PyT orch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Pr ocessing Systems , pages 8024–8035, 2019. [5] François Chollet and Others. Keras, 2015. [6] Jeremy How ard and Others. fastai, 2018. [7] Fabian Pedregosa, Ron W eiss, Matthieu Brucher, Gaël V aroquaux, Ale xandre Gramfort, V incent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron W eiss, V incent Dubourg, Jake V anderplas, Alexandre P assos, David Cournapeau, Matthieu Brucher , Matthieu Perrot, and Édouard Duchesnay . Scikit-learn: Machine Learning in Python. Journal of Machine Learning Resear ch , 12(Oct):2825–2830, 2011. [8] Guillaume Lemaitre, Fernando Nogueira, and Christos K Aridas. Imbalanced-learn: A Python T oolbox to T ackle the Curse of Imbalanced Datasets in Machine Learning. Journal of Machine Learning Resear ch , 18(17):1–5, 2017. [9] Alexandre Abraham, F abian Pedregosa, Michael Eickenber g, Philippe Gervais, Andreas Mueller , Jean K ossaifi, Alexandre Gramfort, Bertrand Thirion, and Gaël V aroquaux. Machine learning for neuroimaging with scikit-learn. F r ontiers in Neur oinformatics , 8, 2014. [10] Matthew Brett, Christopher J Markie wicz, Michael Hanke, Marc-Alexandre Côté, Ben Cipollini, Paul McCarthy , Dorota Jarecka, Christopher P Cheng, Y aroslav O Halchenko, Michiel Cottaar, Eric Larson, Satrajit Ghosh, Demian W assermann, Stephan Gerhard, Gregory R Lee, Hao-T ing W ang, Erik Kastman, Jakub Kaczmarzyk, Roberto Guidotti, Or Duek, Jonathan Daniel, Ariel Rokem, Cindee Madison, Brendan Moloney , Félix C Morency , Mathias Goncalves, Ross Mark ello, Cameron Riddell, Christopher Burns, Jarrod Millman, Ale xandre Gramfort, Jaakko Leppäkangas, Anibal Sólon, Jasper J F van den Bosch, Robert D V incent, Henry Braun, Krish Subramaniam, Krzysztof J Gorgole wski, Pradeep Reddy Raamana, Julian Klug, B Nolan Nichols, Eric M Baker , Soichi Hayashi, Basile Pinsard, Christian Haselgrov e, Mark Hymers, Oscar Esteban, Serge K oudoro, Fernando Pérez-García, Nikolaas N Oosterhof, Bago Amirbekian, Ian Nimmo-Smith, L y Nguyen, Samir Reddigari, Samuel St-Jean, Egor Panfilov , Eleftherios Garyfallidis, Gael V aroquaux, Jon Haitz Legarreta, Ke vin S Hahn, Oliv er P Hinds, Bennet Fauber , Jean-Baptiste Poline, Jon Stutters, Kesshi Jordan, Matthew Cieslak, Miguel Estev an Moreno, V alentin Haenel, Y annick Schw artz, Zvi Baratz, Benjamin C Darwin, Bertrand Thirion, Carl Gauthier , Dimitri Papadopoulos Orfanos, Igor Solov ey , Ivan Gonzalez, Jath Palasubramaniam, Justin Lecher , Katrin Leinweber , K onstantinos Raktiv an, Markéta Calábková, Peter Fischer, Philippe Gervais, Syam Gadde, Thomas Ballinger, Thomas Roos, V enkateswara Reddy Reddam, and Freec84. nibabel, 2020. 19 PHO TON AI - A Python API for Rapid Machine Learning Model Dev elopment P R E P R I N T [11] T im Head, MechCoder , Gilles Louppe, Iarosla v Shcherbatyi, Fcharras, Zé V inícius, Cmmalone, Christopher Schröder , Nel215, Nuno Campos, T odd Y oung, Stef ano Cereda, Thomas Fan, Rene-rex, K ejia (KJ) Shi, Justus Schwabedal, Carlosdanielcsantos, Hvass-Labs, Mikhail Pak, SoManyUsernamesT aken, Fred Callaway , Loïc Estève, Lilian Besson, Mehdi Cherti, Karlson Pfannschmidt, Fabian Linzberger , Christophe Cauet, Anna Gut, Andreas Mueller , and Alexander F abisch. Scikit-optimize, 2018. [12] Frank Hutter, Holger H Hoos, and Ke vin Leyton-Brown. Sequential Model-Based Optimization for General Algorithm Configuration. In International Conference on Learning and Intellig ent Optimization , pages 507–523. Springer , 2011. [13] J Rapin and O T eytaud. Nev ergrad - A gradient-free optimization platform. https://GitHub.com/ FacebookResearch/Nevergrad , 2018. [14] Fabian Pedregosa. Hyperparameter Optimization with Approximate Gradient. T echnical report, Département Informatique de l’École Normale Supérieure, Paris, 2016. [15] Samantha Ando w Emilio Arroyo-Fang Irene Dea Johann George Melissa Grueter Basil Hosmer Stef fi Stumpos Alanna T empest Shannon Y ang Kartik Chandra Erik Meijer. Gradient Descent: The Ultimate Optimizer. T echnical report, Stanford Univ ersity , Palo Alto, California - USA F acebook, Menlo Park, California, USA, 2019. [16] Matthias Feurer , Aaron Klein, Katharina Eggensperger , Jost T obias Springenberg, Manuel Blum, and Frank Hutter . Auto-sklearn: Efficient and Rob ust Automated Machine Learning. pages 113–134. 2019. [17] Randal S. Olson and Jason H. Moore. TPO T : A T ree-Based Pipeline Optimization T ool for Automating Machine Learning. pages 151–160. 2019. [18] Lars K otthoff, Chris Thornton, Holger H Hoos, Frank Hutter , and Ke vin Leyton-Bro wn. Auto-WEKA 2.0: Automatic Model Selection and Hyperparameter Optimization in WEKA. Journal of Machine Learning Resear ch , 18(1):826–830, 2017. [19] Haifeng Jin, Qingquan Song, and Xia Hu. Auto-Keras: An Efficient Neural Architecture Search System. In Pr oceedings of the 25th ACM SIGKDD International Confer ence on Knowledge Discovery & Data Mining - KDD ’19 , pages 1946–1956, New Y ork, New Y ork, USA, 2019. A CM Press. [20] Barret Zoph and Quoc V . Le. Neural Architecture Search with Reinforcement Learning. no v 2016. [21] Hieu Pham, Melody Y . Guan, Barret Zoph, Quoc V . Le, and Jeff Dean. Ef ficient Neural Architecture Search via Parameter Sharing. feb 2018. [22] Nick Erickson, Jonas Mueller , Alexander Shirkov , Hang Zhang, Pedro Larroy , Mu Li, and Alexander Smola. AutoGluon-T abular: Robust and Accurate AutoML for Structured Data. mar 2020. [23] Lars Buitinck, Gilles Louppe, Mathieu Blondel, Fabian Pedregosa, Andreas Mueller , Olivier Grisel, Vlad Niculae, Peter Prettenhofer , Alexandre Gramfort, Jaques Grobler , Robert Layton, Jake V anderplas, Arnaud Joly , Brian Holt, and Gaël V aroquaux. API Design For Machine Learning Software: Experiences From the scikit-learn Project. sep 2013. [24] Fabian Pedregosa, Ron W eiss, Matthieu Brucher, Gaël V aroquaux, Alexandre Gramfort, V incent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron W eiss, V incent Dubourg, Jake V anderplas, Alexandre P assos, David Cournapeau, Matthieu Brucher , Matthieu Perrot, and Édouard Duchesnay . DummyClas- sifier , 2020. [25] Fabian Pedregosa, Ron W eiss, Matthieu Brucher, Gaël V aroquaux, Alexandre Gramfort, V incent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron W eiss, V incent Dubourg, Jake V anderplas, Alexandre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot, and Édouard Duchesnay . Pipeline, 2020. [26] Matthe w Rocklin. Dask: Parallel computation with block ed algorithms and task scheduling. In Pr oceedings of the 14th python in science confer ence , number 130-136. Citeseer , 2015. 20 PHO TON AI - A Python API for Rapid Machine Learning Model Dev elopment P R E P R I N T [27] T anvir Ahmad. Heart Failure Prediction, 2020. [28] T anvir Ahmad, Assia Munir , Sajjad Haider Bhatti, Muhammad Aftab, and Muhammad Ali Raza. Surviv al analysis of heart failure patients: A case study. PLOS ONE , 12(7):e0181001, jul 2017. [29] Alan J. Lockett. No free lunch theorems. Natural Computing Series , 1(1):287–322, 2020. [30] Davide Chicco and Giuseppe Jurman. Machine learning can predict surviv al of patients with heart failure from serum creatinine and ejection fraction alone. BMC Medical Informatics and Decision Making , 20(1):16, dec 2020. 21
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment