DNN-HMM based Speaker Adaptive Emotion Recognition using Proposed Epoch and MFCC Features
Speech is produced when time varying vocal tract system is excited with time varying excitation source. Therefore, the information present in a speech such as message, emotion, language, speaker is due to the combined effect of both excitation source…
Authors: Md. Shah Fahad, Jainath Yadav, Gyadhar Pradhan
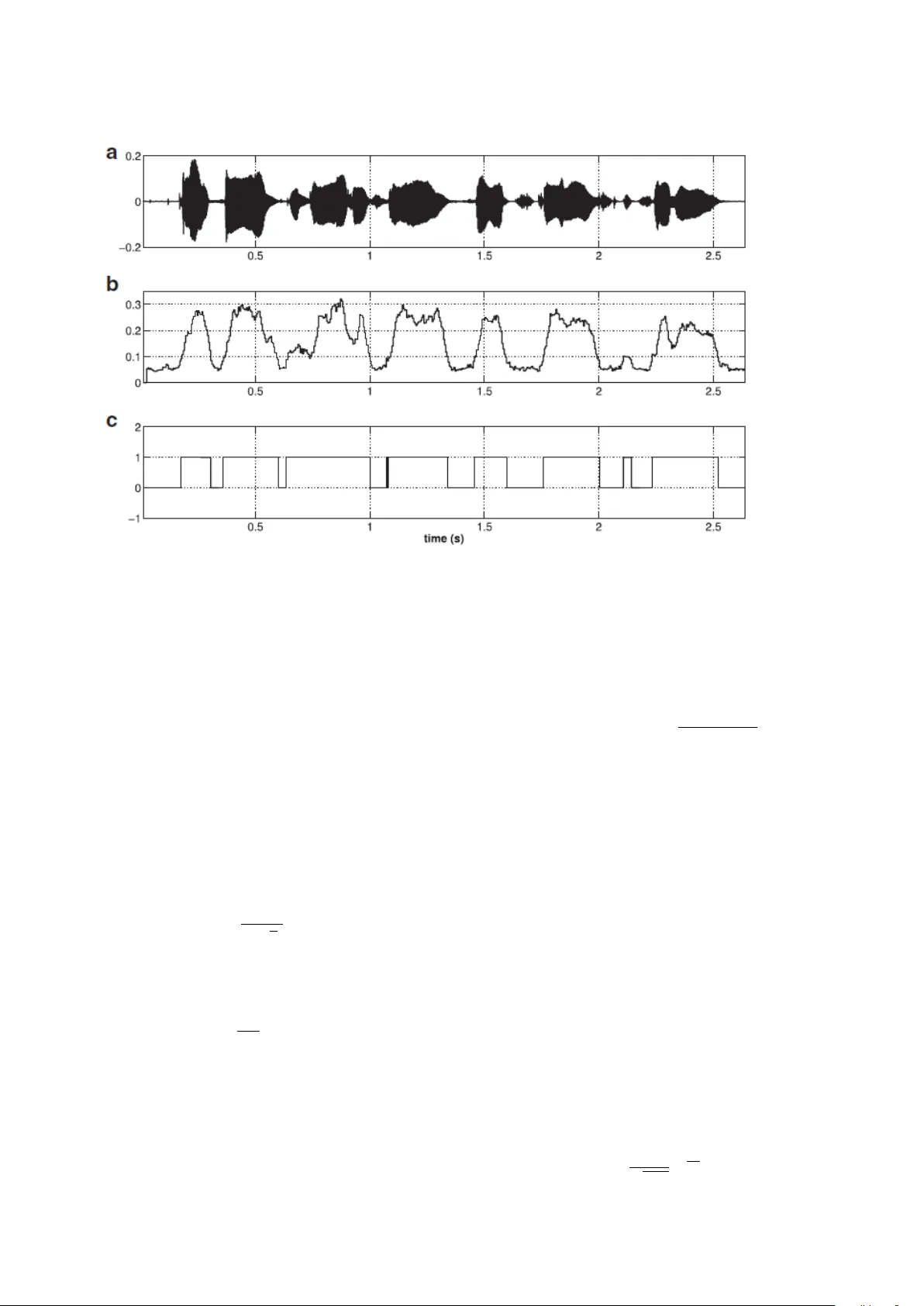
DNN-HMM based Speaker Adapti ve Emotion Recognition using Proposed Epoch and MFCC Features Md. Shah Fahad a , Jainath Y adav b , Gyadhar Pradhan a , Akshay Deepak a a Department of Computer Science, National Institute of T echnology P atna, India b Department of Computer Science, Central Univer sity of South Bihar , P atna, India Abstract Speech is produced when time v arying vocal tract system is excited with time varying excitation source. Therefore, the information present in a speech such as message, emotion, language, speaker is due to the combined e ff ect of both excitation source and vocal tract system. Howe ver , there is very less utilization of e xcitation source features to recognize emotion. In our earlier w ork, we ha ve proposed a novel method to extract glottal closure instants (GCIs) kno wn as epochs. In this paper , we have explored epoch features namely instantaneous pitch, phase and strength of epochs for discriminating emotions. W e ha ve combined the e xcitation source features and the well known Male-frequency cepstral coe ffi cient (MFCC) features to dev elop an emotion recognition system with improv ed performance. DNN-HMM speaker adaptiv e models ha ve been de veloped using MFCC, epoch and combined features. IEMOCAP emotional database has been used to evaluate the models. The average accuracy for emotion recognition system when using MFCC and epoch features separately is 59.25% and 54.52% respectiv ely . The recognition performance improv es to 64.2% when MFCC and epoch features are combined. K eywor ds: Emotion Recognition, Epoch Features, Deep Neural Network(DNN), Gaussian Mixture Model (GMM), Hidden Morkov Model(HMM), Zero T ime W indowing (ZTW) 1. Intr oduction Automatic emotion recognition from speech signal has fas- cinated the research community in the recent years due to its applicability in real-life. Human beings use a lot of emo- tions along with textual messages to con vey the intended in- formation. Emotions impro ve human computer interactions (HCI) system such as interactiv e movies [1], story telling and E-tutoring applications [2], and, retriev al and indexing of the video / audio files [3]. Emotion recognition system assists to im- prov e the quality of service of call attendants at call centers [4]. Automatic emotion detection could be helpful in the psycholog- ical treatment as used in references [[5],[6],[7]]. It can also be useful in the case of surveillance systems [8]. Modern speech- based systems are designed largely using neutral speech. Here, the components of emotions can be used as an add-on to im- prov e the accuracy in practical applications. Excitation source features are not much exploited to recog- nize emotions. Observation from the literature reveals that the majority of the previous works used prosodic and system fea- tures for emotion recognition using speech [[9, 10]]. The sys- tem features MFCCs, Linear Predictive Cepstral Coe ffi cients (LPCCs) and their deriv ativ es reflect the emotion specific in- formation. Prosodic features such as fundamental frequency , duration, energy and intonation are also used for emotion recog- nition. Combinations of prosodic and system features are also Email addr esses: shah.cse16@nitp.ac.in (Md. Shah Fahad), jainath@cub.ac.in (Jainath Y adav), gdp@nitp.ac.in (Gyadhar Pradhan), akshayd@nitp.ac.in (Akshay Deepak) widely used for emotion recognition. Reference [11] uses supra-segmental features such as energy , F0, formant locations, energy , dynamics of F0 and formant contours for emotion clas- sification. The statistical parameters of F0 like maximum, min- imum, and median values, and the slopes of F0 contours hav e emotion specific information [12]. Howe ver , not much work has been done in using excitation source features for emotion recognition. Reference [9] combined 55 features (24 MFCCs, 25 prosodic and 6 formant frequencies) for recognizing six emotions. Prosodic and spectral features are combined in reference [10] for emotion classification. It is prov en from literature that a combination of di ff erent complement features improve the ac- curacy of emotion recognition system. Most of the features are extracted from speech based on the assumption that the speech signal is stationary in the small speech segment. Howe ver , the speech features – either source features or system features – vary rapidly in emotional speech because of the rapid changes in the vibration of the vocal cords. In reference [13], emotion recognition model is de veloped using a combination of epoch and MFCC features. The proposed model used zero frequency filter (ZFF) method for extracting epoch features. The accurac y of epoch detection using ZFF decreases for emotional speech because it requires a priory pitch period to detect epoch lo- cation. Howe ver , the pitch period of emotional speech v aries frequently in an utterance. The emotion recognition model (in reference [13]) was dev eloped using auto-associative neu- ral networks (AANN) and support vector machines (SVM) on IITKGP-SESC database. Pr eprint submitted to Elsevier J une 5, 2018 In our earlier work [14], we proposed a robust method to detect epoch locations. In this paper , epoch features namely in- stantaneous pitch, phase and strength of excitation (SOE) are extracted. These features are explored for di ff erent emotions and combined with MFCCs for classifying four emotions. Us- ing this method, a significant increase in the accuracy of emo- tion recognition model was observed. The av erage accurac y for emotion recognition system when using MFCC and epoch features separately is 59.25% and 54.52% respectiv ely . This improv es to 64.2% when MFCC and epoch features are com- bined. The rest of the paper is organized as follows. Section 2 con- tains the description of speech databases, Sec. 3 describes de- tection of epoch features and Sec. 4 briefly discusses MFCC and de velopment of emotion recognition models. The results are discussed in Sec. 5. Section 6 concludes the paper . 2. Databases Our proposed model has been e valuated on IEMOCAP (In- teractiv e emotional dyadic motion capture database)[15] and IITKGP:SEHSC (Indian Institute of T echnology Kharagpur: Simulated Emotion Hindi Speech Corpus) [16]. IEMOCAP database is a multi-modal database which contains audio, video, text and gesture information of con versations arranged in dyadic sessions. The database is recorded with ten actors (fiv e male and fi ve female) in fi ve sessions. In each session, there are con versations of two actors, one from each gender , on two subjects. The con versation of one session is approximately fi ve minutes long. The contents of the database are recorded in both scripted and spontaneous scenarios. The total number of utter- ances in the database are 10,039, where 4,784 utterances are from the spontaneous sessions and 5,225 are from the scripted sessions. The average duration of an utterance is 4.5 seconds while the average word count per utterance is 11.4 words. The duration of the database is about 12 hours. The database is la- beled as per the two popular schemes: discrete cate gorical label (i.e, labeled as happy , anger , neutral and sad) and continuous dimensional label (i.e, valence, acti vation and dominance). W e hav e only used the audio tracks and the corresponding discrete categorical labels for emotion recognition. In IITKGP-SESC, fifteen emotionally neutral Hindi text prompts were used for recording the emotion in multiple ses- sions to capture di versity . In each session, 15 sentences in eight basic emotions are uttered by each artist. Recording was done with the help of SHURE dynamic cardioid microphone C660N at 16 kHz sampling frequency . The Hindi emotional speech database has 10 speakers (fiv e males and five females) and 15 sentences were recorded for eight emotions (Neutral, Happy , Angry , Sad, Disgust, Sarcastic, Surprise and Fear). There are a total of 12000 speech utterances (10 speakers x 15 sentences x 8 emotions x 10 sessions) in the Hindi emotional speech database. There are 1500 articulations for each emotions. The number of syllables and words in the sentences lie in the range of 9-17 and 4-7 respectiv ely . 3. Extraction of Epoch features using Zero time W indow- ing method In our method, voiced regions are detected using the phase of zero frequency filtered speech signal [17]. After that, Zero T ime Windo wing (ZTW) method [18] is applied to get Hilbert en velope of the Numerator Group Delay (HNGD) spectra of each of the voiced segments. The amplitude of the sum of the three prominent peaks is obtained from each spectrum of the HNGD. The resulting output reproduces the instantaneous en- ergy profile of the windowed signal. The spectral energy pro- file, obtained from HNGD spectrum, shows high energy at the epoch locations because of high SNR (signal to noise ratio) at these locations. Further , the spectral energy profile is normal- ized using mean smooth filter . The normalized spectral energy profile is then con volved with a Gaussian filter to highlight the peaks. The positiv e peaks – selected after removing the spuri- ous peaks – are considered as epochs. Ne xt, each of the above step is described in detail. 3.1. V oiced Activity Detection (V AD) Epochs are present in the voiced regions due to vibration of the vocal cords. Hence, we first di vide the speech into voiced and unv oiced re gions based on its characteristics. In the present paper , voiced regions are detected [17] using the phase of Zero Frequency Filtered Signal (ZFFS). The ZFFS of a speech ut- terance is obtained by using zero frequency resonator [19]. The phase of a ZFFS is determined using the Hilbrert trans- formation. Further , the phase-signal is split into frames of size 30 ms with frame shift of 5 ms and each frame is con volved with Hanning-window . The amplitude spectrum of Hanning- windowed frame is computed. Thereafter , the sum of the first 10 harmonics is computed. The decision of voiced and non- voiced regions is taken based on the appropriate threshold of global maxima of the sum of phase harmonics (SPH) because the global maxima of the SPH of v oiced regions is significantly higher than un voiced regions. V oiced and un voiced regions of a speech signal are detected by setting the threshold of 0.08 for global maxima of SPH of each and ev ery frame as sho wn in Fig. 1. Fig. 1(a) shows the the speech signal. The corresponding global maxima of SPH is shown in Fig. 1(b), which is separated as voiced and un voiced speech in Fig. 1(c) through rectangular wa veform. Here, voiced speech is labeled 1(high) and un voiced speech is labeled 0 (low). 3.2. Sequence of Steps for Epoc h extraction The steps to detect epoch locations are described next. 1. The voiced segment is detected using the phase of zero frequency filtered speech signal [17]. 2. The voiced speech signal is di ff erentiated to remove any low frequency bias in the speech signal using the formula y [ n ] = s [ n ] − s [ n − 1] (1) where: y [ n ] is the di ff erentiated signal at n th sample 2 Fig. 1: Detection of voiced and un voiced re gions using the phase of ZFFS. (a) Speech signal. (b) its corresponding global maxima of SPH. (c) un voiced and voiced regions correspond to lo w and high amplitude respectively . s [ n ] is the actual speech signal at n th sample, and, s [ n − 1] is the actual speech signal at ( n − 1) th sample 3. Three milliseconds segments of the di ff erentiated speech signal (resulting in M = 48 samples) were taken at each sampling point. These were appended with N − M (2048- 48) zeros to obtain su ffi cient resolution in the frequency domain. 4. The time domain signal is multiplied with the square of window function h 1 (defined below) to achieve the smoothened spectrum by integration in the frequency do- main. h 1 [ n ] = 0 n = 0 h 1 [ n ] = 1 4 sin 2 ( π n N ) n = 1 , 2 , .., N − 1 (2) 5. The ripple e ff ect due to truncation is reduced by multiply- ing the signal of the pre vious step with the window h 2 , which is defined as: h 2 [ n ] = 4 co s 2 ( π n 2 M ) , n = 0 , 1 , 2 ..., M − 1 (3) The resultant signal x [ n ] is called windo wed signal. 6. T o highlight the spectral features, the numerator of group delay of windowed signal, denoted g [ k ], is computed as: g [ k ] = X R [ k ] Y R [ k ] + X I [ k ] Y R [ k ] , k = 0 , 1 , 2 ..., N − 1 (4) The resultant signal is known as DNGD signal. 7. Hilbert en velope of the DNGD spectrum is computed to prominently highlight the spectral peaks. The Hilbert en- velope h e [ k ] of DNGD signal g [ k ] is computed as: h e [ k ] = q g 2 [ k ] + g 2 h [ k ] (5) where g h [ k ] is the Hilbert transformation of the sequence g [ k ]. It is computed as: g h [ k ] = I DF T E h ( w ) (6) where E ( ω ) is the DTFT of the sequence g ( k ). It is defined as: E h ( ω ) = − j E ( ω ) , 0 < ω < π jE ( ω, − π < ω < 0 (7) 8. The sum of the three most prominent peaks of the HNGD spectrum is determined at each sampling instant. The resultant amplitude shows high SNR around glottal clo- sure. Further , the amplitude contour is smoothened using 5-point mean smoothing filter to eliminate any outliers. 9. The sum of the three prominent peaks obtained from each HNGD spectra is called spectral energy profile. The spec- tral energy profile is con volved with a Gaussian filter of size, av erage pitch period of that segment. A Gaussian fil- ter of length L is giv en by G [ n ] = 1 √ 2 πσ e − n 2 2 σ 2 , n = 1 , 2 , ..., L (8) 3 The standard deviation σ used in the abov e formula is 1 4 th of the Gaussian filter length. 10. The spurious peaks are eliminated by using follo wing sub steps: (a) First, the spurious peaks are eliminated on the basis that the di ff erence between successive peaks should not be less than 2 ms. This is because 2ms is the minimum range of the pitch period. If two successiv e peaks ha ving a di ff erence of less than 2ms are found, the peak location with less amplitude is remov ed. (b) T wo successive peaks bound a ne gative region be- tween them. This criteria also eliminates some spu- rious peak locations. 11. The positi ve peaks in epoch e vidence plot represent epoch locations. Epoch detection using ZTW method is shown in Fig. 2. The angry emotional speech segment is shown in Fig. 2(a) and its di ff erentiated EGG signal is sho wn in Fig. 2(b). The spectral energy profile obtained from HNGD spectrum of the speech signal using ZTW analysis is plotted in Fig. 2(c). The epoch evidence plot after con volving spectral energy profile with a Gaussian window of 2 m sec is shown in Fig. 2(d). Epoch locations are shown in Fig. 2(e). -0.5 0 0.5 (a) -0.02 0 0.02 (b) 0 5 Amplitude 10 8 (c) -2 0 2 (d) 0 20 40 60 80 100 Time (ms) 0 0.5 1 (e) Fig. 2: Epoch extraction using proposed method. (a) Angry speech segment. (b) Di ff erentiated EGG signal. (c) Spectral ener gy profile obtained from HNGD spectrum. (d) Epoch evidence plot. (e) Epoch locations. ZTW method for epoch detection is rob ust for emotional speech [14]. This method is based on spectral peak energy , therefore, it preserves the ener gy of the signal. 3.3. Epoch F eatures The epoch features such as instantaneous pitch, strength of the epoch, slope of the strength of the epoch, the change of phase at the epoch are specific to each emotion [13]. The abo ve mentioned features are determined by the epoch signal obtained by ZTW method [14]. The advantage of this method is that the v alue at epoch location is actually the sum of the glottal formants. Therefore, the epochs retain both time and spectral information. 3.3.1. Instantaneous F r equency Instantaneous Period (IP) is the duration between two suc- cessiv e epoch locations; instantaneous frequency , denoted ∆ f , is computed as the reciprocal of IP [20, 21]: ∆ f = 1 t ( i ) − t ( i + 1) , i = 1 , 2 , .... ( n − 1) (9) where t ( i ) represents i th epoch location. 3.3.2. Str ength Of Excitation The Strength Of Excitation (SOE) is computed as the di ff er- ence between two successi ve epoch values [22]: y ( i ) = x ( i ) − x ( i + 1) , i = 1 , 2 , .... ( n − 1) (10) where x ( i ) is the epoch strength at i th epoch. 3.3.3. Instantaneous Phase The instantaneous phase of a glottal signal is obtained by the cosine of the phase function of the corresponding analytical signal. • The analytic signal g a ( n ) corresponding to glottal signal g ( n ) is giv en by g a ( n ) = g ( n ) + jg h ( n ) (11) • where g h ( n ) is the Hilbert transformation of g ( n ), and is obtained by g h [ n ] = I DF T g h ( w ) (12) where g h ( w ) is defined as: g h ( ω ) = − jG ( ω ) , 0 < ω < π jG ( ω, − π < ω < 0 (13) G ( ω ) is the DTFT of the sequence g ( n ) and IDFT denotes In verse Discrete Fourier T ransform and • The Hilbert en velope of glottal signal g ( n ) is calculated as: h e [ n ] = q g 2 [ n ] + g 2 h [ n ] (14) • The cosine of the phase of the analytic signal g a ( n ) is giv en by co s Φ ( n ) = Reg a ( n ) | g a ( n ) | = g ( n ) h e [ n ] (15) where g ( n ) is glottal signal deriv ed from speech signal s ( n ) using ZTW method. 4 In Fig. 3., instantaneous frequency and SOE values of same speech utterance by same speaker in di ff erent emotions are plot- ted. Figure 3(a) shows instantaneous pitch for two emotions: angry and sad. Red color indicates angry emotion while black indicates Sad emotion. It is clear from Fig. 3(a) that the range of instantaneous pitch varies from 250-400 Hz for angry emotion while for sad it v aries from 100-200 Hz. The instantaneous pith contour for same arousal emotion (happy and angry) is same but their variation with time is di ff erent. This property of instanta- neous pitch contour is well captured with dynamic model like Hidden Morkov Model (HMM) or Long Short T erm Memory (LSTM) network. Figure 3(b) shows SOE for two emotions: anger and sad. The v ariation of SOE is higher in angry emotion than sad emotion. The v ariation of SOE is quite less in the case of sad emotion. 3(b) sho ws the phase of glottal signal, it is high for sad compared than angry . The two features SOE and glottal phase also discriminate between same arousal emotion (happy and angry). 4. Development of Emotion Recognition System Emotion recognition system is an outcome of two principal stages. In the first stage, training is performed using the features extracted form the known emotional speech utterances. In the second stage, i.e., the testing phase, e valuation of the trained model is carried out on unseen emotional speech utterances. The schematic diagram of the proposed emotion recognition system is sho wn in Fig. 4. W e combined the MFCC features with the epoch features namely instantaneous pitch, instanta- neous phase and strength of epoch (SOE). The excitation source and system features have complementary information for rec- ognizing emotions, hence, the combined features significantly improv e the accuracy of emotion recognition. 4.1. MFCC F eatur e e xtraction Mel Frequency Cepstral Coe ffi cients (MFCCs) features also hav e emotion specific information. W e combine MFCC fea- tures with epoch features in our model for recognizing emo- tions. Gradual spectral variations are captured using 13 MFCCs extracted from speech signal. The speech signal is segmented into frames of size 20 ms, where each frame is overlapped by 10 ms with the adjacent frame. For each frame, 13 MFCC features are extracted. T o minimize spectral distortion at the beginning and at the end of each frame, Hamming windo w is superimposed on each frame segment. MFCC features are ex- tracted from these frames using the MFCC algorithm given in [23]. Recording variations are countered by subtracting cep- stral mean and normalizing variance of MFCCs at the utterance lev el. The schematic diagram of the proposed feature extraction and transformation is shown in Fig. 5. 4.2. DNN-HMMs In our work, the emotion recognition system has been devel- oped using Hidden morkov model (HMM) [24] – a dynamic modeling approach. It captures the temporal dynamic charac- teristics of di ff erent epoch features of corresponding emotions. In conv entional HMM, the observ ation probabilities of HMM states are estimated by Gaussian mixture models (GMMs). The GMMs used in such a con ventional HMM are statistically inef- ficient to model non-linear data in the feature space. Therefore, we have replaced the GMMs with DNN to estimate the obser- vation probabilities of observing input sequence at each state in the training phase. In this w ork, we hav e developed four HMMs for four discrete emotions. Emotion label is assigned for an un- known speech utterance using V iterbi algorithm. The procedure for training and recognition of DNN-HMM is followed as men- tioned in [[25], [26]]. T o the best of our knowledge, this is the first time that such a model is being used in an emotion recog- nition system. For providing class labels to DNN, we used a GMM-HMM model with five states for each emotion class. Specifically , for each speech utterance in the raining set, viterbi algorithm is applied to find an optimal state sequence. The optimal state se- quence is stored in the state-label mapping table, which is used to assign a label to each state. The training speech utterances, combined with their labeled state sequences, are then fed as input to the DNN. The output of the DNN is the posterior prob- abilities of the 20 output units. The observation probability of each state, denoted p ( i t | qt ), is calculated using Bayes theorem as follows: p ( i t | qt ) = p ( q t | i t ) ∗ p ( i t ) p ( q t ) (16) Where I = ( i 1 , i 2 , ....... i T ) is the input sequence and p ( q t | it ) is the posterior probability obtained as output from the DNN. Dur- ing decoding, for an unseen speech utterance, the probability of each emotion is estimated and the utterance is assigned the class whose estimated probability is maximum. p ( q t ) is computed from the initial state lev el alignment of the training set. p ( i t ) remains constant because input feature vectors are assumed to be mutually independent. 5. Experimental Results and Discussion Three models were de veloped for emotion recognition: us- ing system (MFFCCs) features, using source (epoch) features, and by combining MFCC and epoch features. The model on combined features has significantly higher accuracy compared to indi vidual models. The experiments were performed on IEMOCAP and IITKGP:SEHSC databases. Howe ver , we have conducted experiments for only four emotions, namely angry , happy , sad and neutral. Three-fourth part of the database is used for training purpose and the rest one-fourth of the database is used for ev aluating the model. W e hav e used MA TLAB tool for feature extraction and KALDI toolkit [27] for dev eloping the system. For the emotion recognition system de veloped us- ing MFCC features, 13 MFCCs are extracted from each frame. Cepstral mean variance normalization (CMVN) [28] is per- formed at utterance level to mitigate the recording v ariations. W e have also taken the deri vati ve and double deriv ativ e of the normalized MFCCs as features. Therefore, the total number of MFCC features for each frame is 39. T o preserve the con- textual information, we have used the triphone model approach 5 0 200 400 Frequency(Hz) (a) 0 0.02 0.04 Amplitude (b) 0 0.5 1 1.5 2 2.5 Time (sec) -1 0 1 Phase (c) Fig. 3: Instantaneous pitch and SOE contours of angry and sad speech signal using proposed method. (a) Instantaneous pitch contour , (b) SOE contour, and (c) Instantaneous phase contour of angry and sad speech signal. Labelled Emotional Utterances MFCC Features Extraction Epoch Features Extraction Combined Features FeatureTransformation (LDA+MLLT+fMLLR) DNN ‐ HMM Models Unlabelled Emotional Utterances Voiced Region Identification Identified Emotion Fig. 4: Schematic diagram of the proposed emotion recognition model. used in speech recognition where each frame is spliced with the left four frames and the right four frames. A significant im- prov ement in emotion recognition accuracy is observed using the triphone model. Feature transformation is applied on the top of 9 spliced frame features. These features are projected into lower dimensional space using Linear Discriminant Anal- ysis (LDA). Then, diagonalizing Maximum Likelihood Linear T ransform (MLL T) [[29, 30]] is applied to further improve the result. Speaker Adapti ve Training (SA T) is also used to further enhance the accuracy of the emotion recognition model. For speaker adaptiv e training Feature Space Maximum Likelihood Linear Re gression (fMLLR) transformation is used during both training and testing phases. Thus, accuracy of system is fur- ther improved using (LD A + MLL T + SA T)[31]. Four di ff erent DNN-HMM models corresponding to each emotion class are built using the transformed feature v ectors. The DNN architecture used is: 80:512x5:20, where 80 is the number of transformed input features to the DNN and 512x5 represents 512 nodes in each of the 5 hidden layers. This DNN configuration was found to be optimal after experiment- ing with di ff erent sized configurations. The results discussed in this paper have been obtained on optimal DNN configu- ration only . There are 20 output classes in the DNN model (20 = 4x5, where 4 denotes the number of emotion classes and 5 denotes the number of states in HMM). These output classes are treated as ”ground-truth” states and are obtained by GMM- HMM based viterbi algorithm. The initial learning rate of 0.005 is gradually decreased to 0.0005 after 25 epochs. Additional 20 epochs are performed after this. The batch size for training is 512. The training of DNN is performed in three stages as in [32]: (i) unsupervised pre-training consisting in layer-wise training of Restricted Boltzmann Machines (RBM) by Con- trastiv e Div ergence algorithm; (ii) frame classification training based on mini-batch Stochastic Gradient Descent (SGD), opti- mizing frame cross-entropy; and (iii) sequence discriminati ve training consisting in SGD with per-sentence updates, optimiz- ing state Minimum Bayes Risk (MBR). In our study , we have considered four categorical (class) la- 6 Splicing LDA MLLT fMLLR MFCC+Epoch(69x1) 39x1 MFCC 30x1 Epoch dx621 dxd dx(d+1) dx1 features Emotional Speech Fig. 5: Schematic diagram of the proposed feature extraction and transformation. beled emotions namely angry , happy , sad and neutral. The num- bers of utterances in each class are 1103, 595, 1084 and 1708 respectiv ely with a total of 4490. The IEMOCAP database is imbalanced. The model was trained in a speaker independent fashion. W e used four sessions as training data and the remain- ing one session for testing. W e follo wed the approach of leav e- one-speaker -out cross-validation to generalize the model. The test dataset is also imbalanced corresponding to the emotion classes, hence, we calculated both weighted accurac y(W A) and unweighted accuracy(UW A). W eighted accuracy is calculated by dividing the total number of correct classified test examples with the total number of test samples. Unweighted accuracy is calculated for each emotion category and the average accuracy of all emotions class is taken. The unweighted accuracy is also called class accuracy . Similarly , for epcoh features, the emotion recognition system is de veloped using three epoch features namely instantaneous pitch, phase and the strength of epoch. These features are ex- tracted using ZTW method. W e hav e taken frames of size 20 ms – same as MFCC features – to extract epoch features. The number of epoch features are di ff erent for each frame. T o fix the length of epoch-feature vector , we hav e taken length as 10 – the maximum number of epochs encountered in an y frame. If the size of the feature vector is less than 10, we pad the remain- ing length with zeros. There are no adverse e ff ects of padding to train the network because we transform the input feature vec- tors (using LDA + MLL T). Therefore, the total number of epoch feature per frame is 30 (10 epochs × 3 features per epoch). W e dev eloped the DNN-HMM model for each emotion using these 30 epoch features. Finally , we combined the epoch and MFCC features to im- prov e the performance of emotion recognition system. After combining the MFCC and epoch features, the length of the fea- ture vector becomes 69. W e ha ve developed baseline GMM-HMM system using (1) monophone training, (2) triphone training with M F CC + ∆ + ∆ 2 , and (3) triphone training with LD A + MLL T . W e dev el- oped the DNN-HMM system with LDA + MLL T . In T able 1 we hav e sho wn the result of emotion recognition system us- ing only MFCC and its deriv ative features. W e have also ap- plied LDA + MLL T transformation on MFCC and its deri va- tiv e features. Our system is trained using both monophone and triphone training. T riphone system giv es better result than monophone because it captures the contextual information. W e also estimate the observ ation probability using DNN instead of GMM as described in pre vious section. Our system giv es best results in the case of DNN-HMM. The av erage accuracy increases approximately 3.5% when observation probability of HMM models is calculated by DNN instead of GMM. The con- fusion matrix for experiments done using only M F CC + ∆ + ∆ 2 features with LD A + MLL T transformation on DNN-HMM sys- tem is sho wn in T able 2. From the result it is clear that there is more confusion between angry and happy emotions because both are high arousal emotions. The sad and neutral emotions also show confusion because both are lo w arousal emotions. T able 1: Emotion classification performance (%) using the MFCC features on IEMOCAP database Featur es Model UW A ( %) MFCC(monophone) GMM-HMM 44.70 M FC C + ∆ + ∆ 2 (triphone) GMM-HMM 47.70 MFCC(LD A + MLL T) GMM-HMM 51.25 MFCC(LD A + MLL T) DNN-HMM 54.35 T able 2: Emotion recognition performance on IEMOCAP Database, based on MFCC feature vector of voiced region using DNN-HMM. Abbreviations: A- Anger , H-Happy , N-Neutral, S-Sad MFCC feature vector(A verage: 59.58) A H N S Anger 60.21 23.29 9.45 7.05 Happy 26.56 58.17 8.70 7.57 Neutral 8.13 11.43 59.71 20.73 Sadness 8.3 8.45 23.00 60.25 Similarly , we also de veloped the system for epoch features. The av erage recognition rate for the model developed using MFCC features only is 54.35%. The average recognition rate for the model dev eloped using epoch features only is 54.15 %. The confusion matrix in T able 3 sho ws the recognition per- formance for each emotions using Epoch features. The diago- nal elements of the confusion matrix sho ws the recognition per- formance for individual emotions using epoch features. From 7 T able 3: Emotion recognition performance on IEMOCAP Database, based on Epoch feature vector of voiced region. Abbreviations: A-Anger, H-Happy , N- Neutral, S-Sad Epoch feature vector(A verage: 54.52) A H N S Anger 57.21 15.29 22.45 5.05 Happy 13.56 52.24 21.70 12.5 Neutral 15.23 14.40 53.71 16.66 Sadness 7.00 9.05 29.00 54.95 experimental result it is clear that epoch features discriminate well between angry and happy emotions compared to MFCC features. The av erage recognition rate for the model developed using the combination of MFCC and epoch features is 60.14%. The performance of the model for each emotion using MFCC features, epoch features and combination of MFCC and epoch features is compared in T able 4. The combined features signif- icantly improv es the accuracy of emotion recognition. T able 4: Emotion classification performance (%) using the Epoch, MFCC and Combined(MFCC + Epoch) features on IEMOCAP database Featur es Model UW A ( %) Epoch Features + LD A + MLL T(triphone) GMM-HMM 50.25 Epoch Features + LD A + MLL T(triphone) DNN-HMM 54.15 Epoch Features + MFCC + ∆ + ∆ 2 (LD A + MLL T) GMM-HMM 57.25 Epoch Features + MFCC + ∆ + ∆ 2 (LD A + MLL T) DNN-HMM 60.14 5.1. Speaker Adaptation Adaptation is a necessary task for emotion recognition. In general, we train our model with limited dataset but in real en- vironment there may be di ff erent types of speakers and noise. There must be a robust method to adapt trained model in real en vironment. In this paper, we have applied Cepstral mean variance normalization (CMVN) at utterance lev el to mitigate the recording variations. fMLLR transformation is applied per speaker to adapt the emotion v ariation of di ff erent speak- ers. After the LDA-MLL T transformation of a feature vector , we transform this matrix into feature space using constraint maximum likelihood linear regression(CMLLR). The model is dev eloped using the strategy of leav e-one-speaker-out cross- validation where each time two speakers – that were not a part of the training dataset – are used for testing. There is signif- icant improvement in recognition rate after applying speaker adaptiv e training for MFCC features. It is mentioned in the T able 5 that after applying fMLLR the emotion recognition rate increases up to 4 % for MFCC features b ut there is no improv ement for epoch features. Therefore, we can say that T able 5: Emotion classification performance (%) using the Epoch, MFCC and Combined(MFCC + Epoch) features on IEMOCAP database Featur es Model UW A(%) MFCC(LD A + MLL T) DNN-HMM 54.35 Epoch(LD A + MLL T) DNN-HMM 54.15 MFCC + Epoch(LD A + MLL T) DNN-HMM 60.14 MFCC(LD A + MLL T + SA T) DNN-HMM 59.58 Epoch (LD A + MLL T + SA T) DNN-HMM 54.52 MFCC + Epoch(LD A + MLL T + SA T) DNN-HMM 64.20 epoch features are speaker independent features for which no speaker adaptiv e technique is required. The bar graph in Fig. 6 Sho ws that emotion recognition accuracy is higher for com- bined (MFCC + Epoch) set of features than using each feature- set alone. The a verage performance of combined features is in- creased by 5.34% compared to the emotion recognition model dev eloped using MFCC features only . This result proves that both system features and excitation source features hav e com- plementary information for emotion recognition. W e e valuate our proposed approach on two databases IEMO- CAP and IITKGP:SEHSC database. The bar graph corre- sponding to MFCC, Epoch and combined feature set for each database is sho wn in Fig.7. In both databases, the accuracy increased for combined features. The accurac y is more in IITKGP:SEHSC database because it is a scripted database. IEMOCAP database contains both scripted and spontaneous sessions, and is more natural. It is also text independent database. The utterance length in IITKGP:SEHSC database is almost equal whereas large variation in utterance length is ob- served in IEMOCAP database. W e compare our result with the prior work on IEMOCAP database. In [33], DNN was used to extract the features from speech segment and further utterance level features were con- structed and fed to the Extreme Learning Machine(ELM). In [34], raw spectrogram and Low Level Descriptors(LLDs) fea- tures were modeled with attentive LSTM. The accuracy is more for LLDs compared to spectrogram. In [35] Con volutional Neural network(CNN) was used for feature e xtraction from speech frame and these features was fed to the dense neural network. [36], Long Short T erm Memory (LSTM) network was used to preserve the contextual information of CNN-based fea- tures. CNN-based features are fully data driv en. It extracts features from the raw spectrogram which are the representation of speech but it does not contain temporal resolution properly . T o achieve temporal resolution, we hav e to restrict frequency resolution. All the methods used spectrogram for speech repre- sentation but it can mislead the accuracy . Our feature e xtraction approach is not data driv en, we are identifying desired tem- poral and spectral features using signal processing technique. The HMM model captures the contextual information of epoch features. As can be seen from the T able 6 both the weighted and unweighted accuracy outperform from the other methods. Our result prov es that MFCC and source features(epoch) con- tain complimentary information. 8 Angry Happy Neutral Sad Average 0 20 40 60 80 100 Accuracy(%) MFCC Features Epoch Features MFCC+Epoch Features Fig. 6: Emotion classification performance (%) using the Epoch, MFCC and Combined(MFCC + Epoch) features on IEMOCAP database T able 6: Comparision of Emotion classification performance (%) reported in the prior work on IEMOCAP database Model Featur es W A(%) UW A ( %) DNN + ELM [33] MFCC features, pitch-based fea- tures and their deriv ativ es 54.3 48.00 LSTM with attention [34] Local level de- scriptor and Spectrogram 63.5 58.8 CNN [35] Spectrogram 64.78 60.89 CNN + LSTM [36] frame-level Spec- trogram 68.8 59.4 DNN-HMM Epoch (Proposed) 58.60 54.52 DNN-HMM MFCC (proposed) 64.3 59.58 DNN-HMM MFCC + Epoch (Proposed) 69.5 64.2 IEMOCAP Database IITKGP-SEHSC Database 0 20 40 60 80 100 Accuracy(%) MFCC Features Epoch Features MFCC+Epoch Features Fig. 7: Emotion classification performance (%) using the Epoch, MFCC and Combined(MFCC + Epoch) features on IEMOCAP and IITKGP-SEHSC databases 6. SUMMAR Y AND CONCLUSION The paper highlights the rob ust characteristic of ZTW method for extracting epoch features. The DNN-HMM model is developed for each emotion using epoch features such as in- stantaneous pitch, strength of epoch (SOE). The average emo- tion recognition rate of the proposed model using epoch fea- tures is 54.52%. The model dev eloped using epoch features is further combined with the model developed using MFCC fea- ture vectors. The observed accuracy of the proposed model us- ing MFCC and epoch features together is 64.20%. The experi- mental results show that the epoch feature set is complementary to the MFCC feature set for emotion classification. Our future work is to use LSTM network to capture the contextual infor- mation of epoch feature and to explore epoch features in the other applications of speech processing such as speaker identi- fication, speech recognition and, synthesis and language identi- fication. 9 References References [1] R. Nakatsu, J. Nicholson, N. T osa, Emotion recognition and its ap- plication to computer agents with spontaneous interactive capabilities, Knowledge-Based Systems 13 (7) (2000) 497–504. [2] D. V erveridis, C. Kotropoulos, A state of the art review on emotional speech databases, in: Proceedings of 1st Richmedia Conference, Citeseer , 2003, pp. 109–119. [3] T . Sagar, Characterisation and synthesis of emotionsin speech using prosodic features, Ph.D. thesis, Masters thesis, Dept. of Electronics and communications Engineering, Indian Institute of T echnology Guwahati (2007). [4] C. M. Lee, S. S. Narayanan, T ow ard detecting emotions in spoken dialogs, Speech and Audio Processing, IEEE T ransactions on 13 (2) (2005) 293– 303. [5] K. E. B. Ooi, L.-S. A. Low , M. Lech, N. Allen, Early prediction of major depression in adolescents using glottal w ave characteristics and teager en- ergy parameters, in: Acoustics, Speech and Signal Processing (ICASSP), 2012 IEEE International Conference on, IEEE, 2012, pp. 4613–4616. [6] L.-S. A. Low , N. C. Maddage, M. Lech, L. B. Sheeber, N. B. Allen, De- tection of clinical depression in adolescents speech during f amily interac- tions, IEEE T ransactions on Biomedical Engineering 58 (3) (2011) 574– 586. [7] Y . Y ang, C. Fairbairn, J. F . Cohn, Detecting depression severity from vocal prosody , IEEE Transactions on A ff ectiv e Computing 4 (2) (2013) 142–150. [8] C. Clav el, I. V asilescu, L. Devillers, G. Richard, T . Ehrette, Fear-type emotion recognition for future audio-based surveillance systems, Speech Communication 50 (6) (2008) 487–503. [9] Y . W ang, L. Guan, An inv estigation of speech-based human emotion recognition, in: Multimedia Signal Processing, 2004 IEEE 6th W orkshop on, IEEE, 2004, pp. 15–18. [10] J. Nicholson, K. T akahashi, R. Nakatsu, Emotion recognition in speech using neural networks, Neural computing & applications 9 (4) (2000) 290–296. [11] D. V erveridis, C. K otropoulos, I. Pitas, Automatic emotional speech clas- sification, in: Acoustics, Speech, and Signal Processing, 2004. Pro- ceedings.(ICASSP’04). IEEE International Conference on, V ol. 1, IEEE, 2004, pp. I–593. [12] F . Dellaert, T . Polzin, A. W aibel, Recognizing emotion in speech, in: Spo- ken Language, 1996. ICSLP 96. Proceedings., Fourth International Con- ference on, V ol. 3, IEEE, 1996, pp. 1970–1973. [13] S. R. Krothapalli, S. G. Koolagudi, Characterization and recognition of emotions from speech using excitation source information, International journal of speech technology 16 (2) (2013) 181–201. [14] J. Y adav , M. S. Fahad, K. S. Rao, Epoch detection from emotional speech signal using zero time windowing, Speech Communication. [15] C. Busso, M. Bulut, C.-C. Lee, A. Kazemzadeh, E. Mo wer, S. Kim, J. N. Chang, S. Lee, S. S. Narayanan, Iemocap: Interactive emotional dyadic motion capture database, Language resources and ev aluation 42 (4) (2008) 335. [16] S. G. K oolagudi, R. Reddy , J. Y ada v , K. S. Rao, Iitkgp-sehsc: Hindi speech corpus for emotion analysis, in: Devices and Communications (ICDeCom), 2011 International Conference on, IEEE, 2011, pp. 1–5. [17] S. S. Kumar , K. S. Rao, V oice / non-voice detection using phase of zero frequency filtered speech signal, Speech Communication 81 (2016) 90– 103. [18] Y . Bayya, D. N. Go wda, Spectro-temporal analysis of speech signals us- ing zero-time windowing and group delay function, Speech Communica- tion 55 (6) (2013) 782–795. [19] K. S. R. Murty , B. Y egnanarayana, Epoch extraction from speech signals, IEEE T ransactions on Audio, Speech, and Language Processing 16 (8) (2008) 1602–1613. [20] S. G. K oolagudi, R. Reddy , K. S. Rao, Emotion recognition from speech signal using epoch parameters, in: Signal Processing and Communica- tions (SPCOM), 2010 International Conference on, IEEE, 2010, pp. 1–5. [21] N. Narendra, K. S. Rao, Robust voicing detection and f { 0 } estimation for hmm-based speech synthesis, Circuits, Systems, and Signal Processing 34 (8) (2015) 2597–2619. [22] P . Gangamohan, S. R. Kadiri, S. V . Gangashetty , B. Y egnanarayana, Ex- citation source features for discrimination of anger and happy emotions., in: INTERSPEECH, 2014, pp. 1253–1257. [23] L. Rabiner , B.-H. Juang, Fundamentals of speech recognition. [24] L. Rabiner , B. Juang, An introduction to hidden markov models, ieee assp magazine 3 (1) (1986) 4–16. [25] L. Li, Y . Zhao, D. Jiang, Y . Zhang, F . W ang, I. Gonzalez, E. V alentin, H. Sahli, Hybrid deep neural network–hidden mark ov model (dnn-hmm) based speech emotion recognition, in: A ff ectiv e Computing and Intelli- gent Interaction (A CII), 2013 Humaine Association Conference on, IEEE, 2013, pp. 312–317. [26] G. Hinton, L. Deng, D. Y u, G. E. Dahl, A.-r. Mohamed, N. Jaitly , A. Se- nior , V . V anhoucke, P . Nguyen, T . N. Sainath, et al., Deep neural netw orks for acoustic modeling in speech recognition: The shared vie ws of four re- search groups, IEEE Signal Processing Magazine 29 (6) (2012) 82–97. [27] D. Pov ey , A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P . Motlicek, Y . Qian, P . Schwarz, et al., The kaldi speech recognition toolkit, in: IEEE 2011 workshop on automatic speech recog- nition and understanding, no. EPFL-CONF-192584, IEEE Signal Pro- cessing Society , 2011. [28] O. V iikki, K. Laurila, Cepstral domain segmental feature vector nor- malization for noise robust speech recognition, Speech Communication 25 (1-3) (1998) 133–147. [29] M. J. Gales, Maximum lik elihood linear transformations for hmm-based speech recognition, Computer speech & language 12 (2) (1998) 75–98. [30] M. J. Gales, Semi-tied covariance matrices for hidden markov models, IEEE transactions on speech and audio processing 7 (3) (1999) 272–281. [31] S. P . Rath, D. Povey , K. V esel ` y, J. Cernock ` y, Impro ved feature processing for deep neural networks., in: Interspeech, 2013, pp. 109–113. [32] K. V esel ` y, A. Ghoshal, L. Burget, D. Pov ey , Sequence-discriminative training of deep neural networks., in: Interspeech, 2013, pp. 2345–2349. [33] K. Han, D. Y u, I. T ashev , Speech emotion recognition using deep neural network and extreme learning machine, in: Fifteenth Annual Conference of the International Speech Communication Association, 2014. [34] S. Mirsamadi, E. Barsoum, C. Zhang, Automatic speech emotion recog- nition using recurrent neural networks with local attention, in: Acoustics, Speech and Signal Processing (ICASSP), 2017 IEEE International Con- ference on, IEEE, 2017, pp. 2227–2231. [35] H. M. Fayek, M. Lech, L. Cavedon, Evaluating deep learning architec- tures for speech emotion recognition, Neural Networks 92 (2017) 60–68. [36] A. Satt, S. Rozenberg, R. Hoory , E ffi cient emotion recognition from speech using deep learning on spectrograms, Proc. Interspeech 2017 (2017) 1089–1093. 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment