On the Use of a Spectral Glottal Model for the Source-filter Separation of Speech
The estimation of glottal flow from a speech waveform is a key method for speech analysis and parameterization. Significant research effort has been made to dissociate the first vocal tract resonance from the glottal formant (the low-frequency resona…
Authors: Olivier Perrotin, Ian Vince McLoughlin
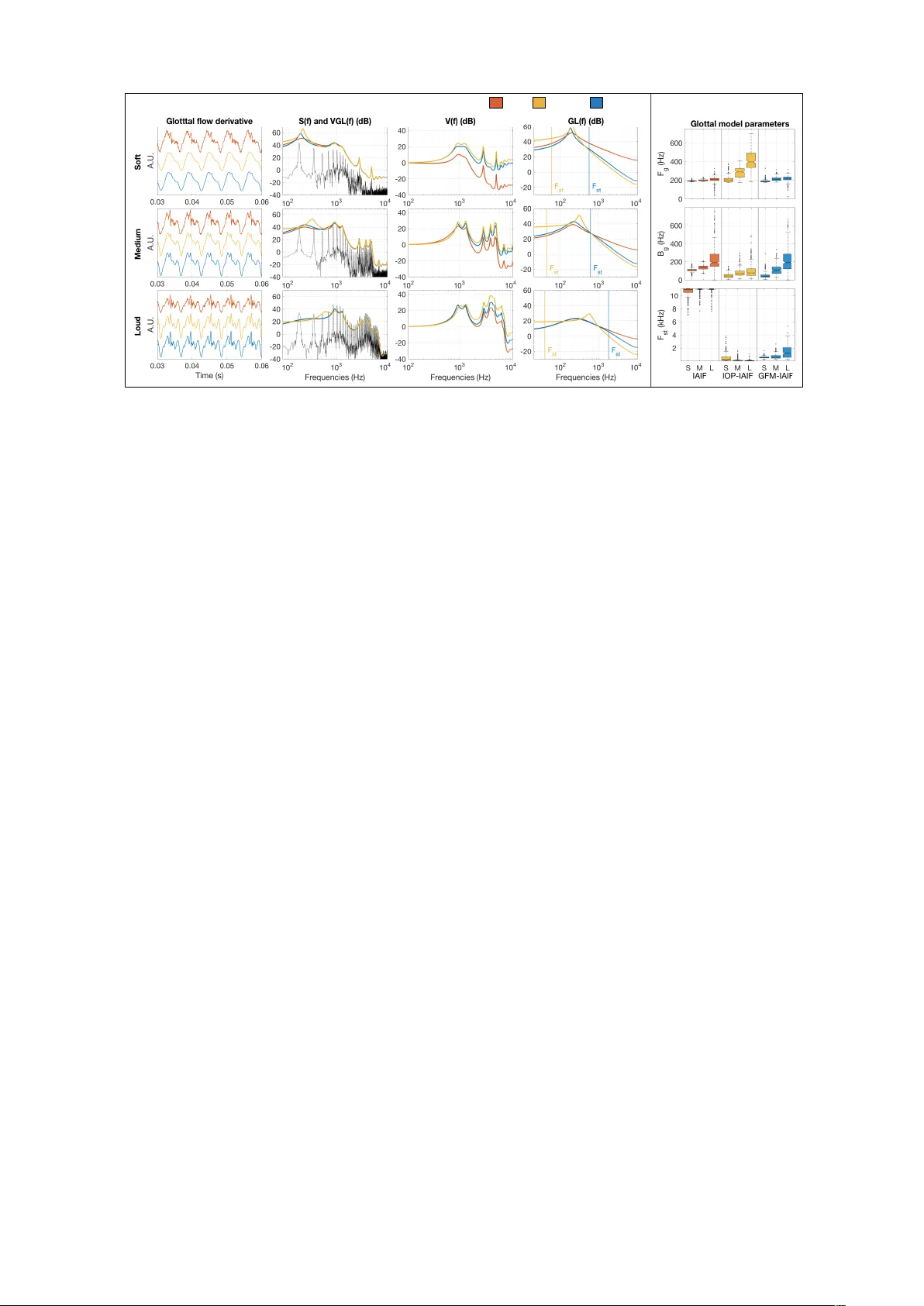
On the Use of a Sp ectral Glottal Mo del for the Source-filter Separation of Sp eec h Olivier P errotin and Ian V. McLoughlin, Senior member, IEEE ∗ Decem b er 22, 2017 Abstract The estimation of glottal flo w from a sp eech w a veform is a k ey metho d for speech analysis and parameterization. Significant researc h effort has b een made to disso ciate the first vocal tract resonance from the glottal formant (the low-frequency resonance describing the op en-phase of the vocal fold vibration). Ho wev er few metho ds cop e with estimation of high-frequency spectral tilt to describ e the return-phase of the vocal fold vibration, which is crucial to the p erception of v o cal effort. This paper prop oses an improv ed version of the well-kno wn Iterativ e Adaptive In verse Filtering (IAIF) called GFM-IAIF. GFM-IAIF includes a full sp ectral mo del of the glottis that incorp orates b oth glottal formant and sp ectral tilt features. Comparisons with the standard IAIF metho d show that while GFM-IAIF main tains goo d p erformance on vocal tract remov al, it significan tly impro ves the perceptive timbral v ariations asso ciated to v o cal effort. 1 In tro duction Sp eec h communication is the combination of a linguistic comp onent which con veys messages through the articulation of phonemes, and a proso dic comp onent whic h enco des sp eec h expression through v ariations of pitch, intensit y , rhythm and timbre. The widely used linear mo del of source production [1] mo dels those components independently , in four parts; an excitation combining pulse train and with noise to conv ey information on pitch, in tensity , and breathiness; a glottis filter mo deling the vibration shap e of the vocal folds to conv ey information on v oice quality (i.e. tim bre); a vocal tract (VT) filter mo deling the oral and nasal cavit y resonances resp onsible for the p erception of phonemes; and a lip radiation filter which mainly has the effect of a deriv ative filter. In the frequency domain the sp eec h is then computed as S ( ω ) = E ( ω ) G ( ω ) V ( ω ) L ( ω ), where S, E are the sp ectra of the sp eech and excitation, and G, V , L are the frequency resp onses of the glottis, VT, and lip radiation filters, resp ectiv ely . G and L are often combined to pro vide a glottal flow deriv ative rather than a glottal flow. A typical non-intrusiv e approach to study eac h component is glottal inv erse filtering (GIF) [2]. This relies on accurate estimation of the glottis and VT filters from the acoustic signal, and deconv olv es the VT filter from the latter. Unfortunately , while the sp ectral characteristics of the glottis are broadband, most curren t metho ds asso ciate the lo wer part of the sp ectrum with the glottis and the higher part with the VT. High-frequency glottis features are thus generally assigned to V rather than G . While this approximation works for applications inv olving mo derate speech, it breaks down at the extremes of voice quality where high frequency v ariations reflect glottal b eha viour changes due to v o cal effort. This letter propose s an improv ed version of the well-kno wn Iterative Adaptive In verse Filtering (IAIF) metho d for GIF, to extract the full sp ectral characteristics of the glottis filter. 2 Review of glottal in v erse filtering metho ds 2.1 Sp ectral mo del of v oice pro duction 2.1.1 Glottis One p eriod of vocal fold vibration starts with an opening phase, where the folds are pulled apart by sub-glottal pressure. When the pressure b ecomes weak er than the elasticity of the v o cal folds, the latter are drawn closer to even tually close the trachea ap erture. This is the closing phase. The folds ∗ O. Perrotin and I.V. McLoughlin are with the Sc ho ol of Computing, Universit y of Kent, Medwa y , UK, e-mail: ofmp@ken t.ac.uk 1 0 Glottal Flow Open phase Closed phase Opening Closing 0 T 0 Time -E 0 Glottal Flow Derivative (GFD) F g F st Frequencies -90 -80 -70 -60 -50 -40 -30 -20 GFD Spectrum magnitude (dB) +20 dB/dec. -20 dB/dec. -40 dB/dec. Figure 1: LF-model. T op-left: Glottal flo w mo del; Bottom-left: Glottal flow deriv ative mo del; Right: Glottal flow deriv ative spectrum then remain closed un til the sub-glottal pressure b ecomes large enough to trigger a new op ening phase. The left part of Fig. 1 depicts one vocal flow p eriod (top) and its deriv ative (b ottom) from the widely used LF-mo del [3]. It has b een shown that op en and closed phases are represented b y distinct regions of the frequency sp ectrum [4]. In particular, the oscillation prov ok ed by the op en phase leads to a ma jor p eak near the fundamen tal frequency often called the “glottal formant”. This is easily mo deled b y a second-order all-p ole resonant filter with a ± 20 dB/decade slop e (see right panel of Fig. 1). The p osition F g and bandwidth B g of the glottal forman t are linked to the relative duration of the op en phase ov er a p erio d and, the glottal pulse asymmetry [5, 6]. The abruptness of the closing phase relates to the high frequencies of the spectrum. The smo other the closure, the lo wer the cutting frequency F st of the sp ectral tilt, and the more attenuated the high frequencies. A supplementary − 20 dB/decade first order lo w-pass filter accounts for this. In summary , the glottal flow deriv ative can be mo deled b y a third order filter with a complex conjugate p ole pair { a, a ∗ } (glottal formant) and one real p ole b (spectral tilt): G ( z ) = 1 (1 − az − 1 )(1 − a ∗ z − 1 )(1 − bz − 1 ) (1) Man y studies describe v oice quality through this mo del. F or instance, a tensed v oice has a higher and wider glottal formant and smaller sp ectral tilt than a breathy voice [7]. A close correlation has also b een found b et ween v o cal effort and sp ectral tilt [8, 9]. These results motiv ate the use of the 3-p ole glottal flo w mo del for v oice quality mo dification [10, 11] and expressiv e singing or sp eec h syn thesis [12, 13]. 2.1.2 V ocal tract The oral cavit y introduces resonances (p oles) in the glottal flow sp ectrum while the nasal cavit y atten uates certain regions (zeros). Nev ertheless, the VT is often simplified by neglecting the nasal con tribution (or by appro ximating it with a pair of additional resonances [14]), and expressed as an auto-regressiv e mo del comp osed of N v pairs of complex conjugate p oles { c i , c i ∗ } : V ( z ) = 1 Q N v i =1 (1 − c i z − 1 )(1 − c i ∗ z − 1 ) (2) 2.1.3 Lip radia tion Airflo w radiation at the lips is often mo deled as a deriv ative filter with co efficien t d close to 1 [15], L ( z ) = 1 − dz − 1 2.2 Glottal in v erse filtering metho ds Glottal in verse filtering has been inv estigated for the past 60 y ears [16], [17] with the most straight- forw ard metho ds using linear prediction to extract the VT after pre-emphasis of the sp eec h signal. Assuming that the glottis filter can b e reduced to the glottal formant contribution and that the a co efficien t in the G filter is close to the d co efficien t in the L filter, the con tribution of GL can b e 2 remo ved b y a simple first-order high-pass filter [18]. IAIF uses 1 st order LPC analysis to define the pre-emphasis filter [19], although more thorough pre-emphasis filter estimation has b een prop osed [20]. Another wa y to remov e the effect of the glottis is to apply linear prediction to the VT during the closed-phase [21]. This requires accurate detection of the closed phase instants. Mixed-phase decomp osition assumes that the glottal forman t is anticausal ( | a | > 1) and that the sp ectral tilt and VT are causal ( | b | < 1 and | c | < 1). Therefore, separation of the minimum phase and maxim um phase comp onen ts through the zeros of the Z transform [22], or the complex cepstrum of sp eec h [23], leads to the extraction of the glottal formant on one hand, and the VT plus sp ectral tilt on the other hand. Both pre-emphasized linear prediction and mixed-phase decomp osition model the source as only a glottal forman t. Therefore the sp ectral tilt remains in the VT filter and the GIF is not exhaustive. T o mo del the full glottis in the GIF pro cess, other techniques use a glottal mo del in the estimation pro cess. Joint optimization of VT and glottal mo dels has b een suggested [24, 25], considering sp eec h as an autoregressive mo del with parametric glottal excitation. Although the estimation quality is high, the technique has high computational complexit y and suffers from con vergence issues. Finally , by com bining pre-emphasis with a glottal mo del, some metho ds estimate a glottal mo del from the signal, decon volv e the mo del to the signal, and apply linear prediction to estimate the VT. Glottal mo del co debo oks ha ve been prop osed [26] while other authors estimate glottis parameters directly from the signal [27, 28]. Optimization tec hniques are required to estimate the glottis parameters. IAIF is probably the most p opular metho d, combining straigh tforward computation (no estimation or optimization needed) with no requirement for a priori knowledge of the signal. It is also noise robust, th us suitable for low-qualit y recordings [29]. Despite this p opularit y , it do es not encompass the sp ectral tilt of the glottis filter, whic h is important for conv eying the p erception of vocal effort. A recen t attem pt to encompass sp ectral tilt has b een prop osed in the IOP-IAIF metho d [30]. This uses unconstrained high-order filtering for signal pre-emphasis and, when ev aluated for a sp oken /a/ at v arious levels of vocal effort, impro ved separation of voice qualities. W e b eliev e that while the extension of IAIF is merited, the unconstrained filter endows the glottal mo del with to o m uch complexity , and is not straigh tforward to implemen t. Instead, we propose extending the first order glottal mo del of IAIF to a third order filter based on evidence that third order mo dels are sufficient [7, 10 – 12]. The b enefits of a third order sp ectral glottal mo del in eqn. 1 are tw ofold: (1) w e will demonstrate that it is significan tly better than IAIF at conv eying vocal effort and (2) it enables the extraction and mo dification of simple sp ectral parameters (e.g. F g , B g and F st ), essen tial for voice transformation and synthesis. 3 Glottal in v erse filtering W e prop ose Iterative Adaptive Inv erse Filtering with Glottal Flow Mo del (GFM-IAIF) to replace the simple IAIF mo del pre-emphasis filter with a 3 rd order glottal mo del. T raditional IAIF [19] is accomplished in four steps: 1. Gross glottis and lip filters estimation (1 st order LPC). 2. a. Remov e glottis and lip filters from sp eech signal. b. Gross VT estimation (high order LPC). 3. a. Remov e VT and lip filters from sp eech signal. b. Fine estimation of the glottis (high order LPC). 4. a. Remov e glottis and lip filters from sp eech signal. b. Fine estimation of the VT (high order LPC). Step (1) is critical to giv e the global shap e to the glottis. Step (2) then encompasses the remaining sp ectral v ariations within the VT filter. Although the order of the fine estimation of the glottis filter is high, the estimated shape of the glottis sp ectrum will be globally close to that in step (1). As stated ab o v e, IAIF assumes that the glottis can b e mo deled as the glottal formant only , by mo deling the glottis and lip radiation filters as a first order filter. GFM-IAIF is prop osed as sho wn in Fig. 2. The architecture extends on IAIF b y estimating the glottal flow (eqn. 1) during the gross estimation pro cess as a 3 rd order filter. Moreo ver, it is essential during gross estimation of the glottis not to mo del an y VT forman ts. F or this sake, the estimation is accomplished b y three successiv e first order iterations. While IAIF join tly estimated the glottis and lip 3 Gross Source Estimation Gross Vocal Tract Estimation Fine Source Estimation Fine Vocal Tract Estimation s(n) LPC-analysis Order 1 LPC-analysis Order 1 LPC-analysis Order 1 G 11 (z) G 12 (z) G 13 (z) Inverse filtering G 11 -1 Inverse filtering G 11 -1 x G 12 -1 LPC-analysis Order N v Inverse filtering G 1 -1 V 1 (z) LPC-analysis Order 3 Integration L -1 Inverse filtering V 1 -1 Integration L -1 LPC-analysis Order N v Integration L -1 Inverse filtering G 2 -1 G 2 (z) V 2 (z) X G 1 (z) X Figure 2: Flo wc hart of the GFM-IAIF metho d radiation filters, GFM-IAIF first integrates the signal to remo ve the lip radiation con tribution, then estimates the glottis indep enden tly . The resulting glottis filter has three real p oles, and its frequency resp onse can b e st ylized with slopes of 0, − 20, − 40 and − 60 dB/decade. In practice, the tw o first p oles tend to ha ve cutting frequencies close to each other at the p osition of the glottal formant. The VT gross estimation phase follo ws IAIF: the gross glottis and lip radiation filters are deconv olved from the original signal and VT autoregressive coefficients then estimated through high order linear prediction. A third order LPC is then used during the fine estimation of the glottis to ensure that the final glottis filter follows equation 1. The VT fine estimation is identical to the metho d in IAIF. 4 Ev aluation GIF ev aluation is complicated b y the lack of glottal flow ground truth. Ho wev er, as the glottal source is expected to con vey voice quality information [31], Drugman et. al ev aluated GIF based on its abilit y to enco de voice qualit y . The b etter the GIF metho d, the b etter voice qualit y is conv ey ed [29]. W e will use the same database and criteria as the ab o v e authors to ev aluate GFM-IAIF, namely , 12 differen t v ow els uttered at three v o cal effort levels (soft, medium, loud) b y a single German female sp eak er from the de7 diphone database [32, 33]. Each vo wel w as rep eated from 18 to 23 times with the same vocal effort, leading to 825 stimuli, sampled at 22.05 kHz. IAIF (using the CO V AREP toolb o x [34]), the recently published IOP-IAIF [30] and GFM-IAIF metho ds are compared. Eac h metho d uses the IAIF default parameters of lip co efficient d = 0 . 99 and VT LPC order N v = F s / 1000 + 4 = 26. The glottis LPC order for fine estimation was set to N g = 3 to match the sp ectral glottal mo del, for all metho ds. 4.1 Glottal in v erse filtering Fig. 3 explores the three GIF metho ds for v ow el /a/ uttered with the three v oice qualities. Glottal flo w deriv atives all exhibit some ripples resulting from incomplete forman t extraction, commonly observed with IAIF [29, 35]. Nev ertheless, IOP-IAIF and GFM-IAIF sho w b etter v ariability across the three v oice qualities. Glottis extraction (4 th column) sho ws that while GFM-IAIF exhibits stronger v ariations of band- width with a narrow er glottal formant for soft v oice than IAIF, IOP-IAIF provides extremely high glottal formant p ositions and low bandwidths for all voice qualities. Moreov er, the sp ectral tilt is not equally balanced b et ween glottis and VT spectral env elop es across methods. The glottal sp ectral tilt for IAIF is low and constan t for all voice qualities, resulting in high tilt v ariations in the VT. Conv ersely , 4 Vo w e l / a / All stimuli IAIF $ $ $$$IOP-IAIF$$$$$$ $ $ $ $ $ $ $$GFM-IAIF$ Figure 3: Plots of decomp osed signals for IAIF (orange), IOP-IAIF (yello w) and GFM-IAIF (blue) for vo wel /a/ for soft (S): top row; medium (M): middle row and loud (L): b ottom row stimuli. The righ t-hand column plots the distribution of the glottal forman t frequency (top); glottal formant bandwidth (middle) and sp ectral tilt cutting frequency (b ottom) for all stim uli dep ending on the metho d and v oice qualities. GFM-IAIF assigns most of the sp ectral tilt v ariations in the glottis. The sp ectral tilt cutting frequency increases for louder voices, leading to less tilt v ariation in the VT. As for the IOP-IAIF metho d, it seems the spectral tilt is maximum for all voice qualities, causing larger tilt v ariations in the VT en velope compared to GFM-IAIF. The distributions of F g , B g and F st displa yed on Fig. 3 (righ t column) suggest these trends are v alid for all stim uli. A Wilco xon rank-sum test assessed the difference b etw een distributions relativ ely to v oice qualit y (soft vs. medium; medium vs. large; small vs. large). All pairs were significantly different ( p < 10 − 3 ) except for the medium vs. loud distributions of B g extracted by IOP-IAIF, and the small vs. medium distributions of F st extracted b y GFM-IAIF. T o summarize, GFM-IAIF features glottal forman t parameters with the same order of magnitude as IAIF, with greater v ariability betw een voice qualities and in line with the literature [4]. IOP-IAIF provides unexpectedly high formant positions and low bandwidths for medium/loud voices. Additionally , only GFM-IAIF provides the exp ected relationship b et ween sp ectral tilt cutting frequency and v oice quality [9]. The main difference b etw een IOP-IAIF and GFM-IAIF is the order of the gross estimation of the glottis. This is unconstrained in the former, reaching an LPC order of 19 for some of these stim uli. When restrained to a low er third order during fine estimation, IOP-IAIF encompasses the maximum slop e in the glottis by keeping the sp ectral tilt cutting frequency low and narro wing the formant bandwidth. 4.2 V oice qualit y classification W e ha ve seen ho w GFM-IAIF leads to glottal parameter v ariations that are more representativ e of v oice qualit y , but is voice qualit y more predictable from the glottal flow deriv ative in GFM-IAIF than in other metho ds? Glottal flo w deriv ative can b e described by several frequency-domain features [29]. The amplitude difference b et ween first and second harmonics H1-H2 is linked to the glottal formant p osition [5, 36]; The closer it is to the first harmonic, the higher is H1-H2 . The harmonic richness factor HRF is a measure of the quan tity of harmonics in the sp ectrum, defined as the ratio b et w een the sum of the 2 nd to n th harmonic amplitudes (in dB) ov er the fundamental frequency amplitude [7]. Finally , sp ectral tilt ST (in dB/decade) is computed from a linear regression of the n first harmonic amplitudes on a log-frequency scale. W e c hose n to select harmonics b elo w 5 kHz only [34]. As the v oice b ecomes louder, smaller H1-H2 and higher HRF and ST v alues are exp ected [5, 7, 9]. Fig. 4 displays the distribution of these three parameters (top to b ottom left) dep ending on v oice qualit y and estimation metho d. W e actually observe decreasing H1-H2 and increasing HRF and ST v alues with increasing vocal effort. A non-parametric Wilcoxon rank-sum test assessed the significance b et w een different pairs of distributions (soft vs. medium; medium vs. large; small vs. large). Giv en the large sample size, all differences w ere assessed significan t ( p < 10 − 3 ). 5 Figure 4: Sp ectral parameters (top: H1-H2; middle: HRF; b ottom: glottis ST). Left: distributions by extraction metho d and v oice quality (S: soft; M: medium; L: loud). Right: normalized distribution rank-sum compared pairwise by v oice quality for eac h parameter and metho d. The rank-sum calculated from eac h pair w as normalized and display ed in Fig. 4 (right c olumn). 0 indicates non-o verlapping distributions while 1 indicates similarity . Hence, lo wer v alues denote more distinct distributions and greater lik eliho o d the parameter could b e used for voice qualit y discrimination. H1-H2 reflects the b eha viour of F g observ ed previously . As IOP-IAIF provides higher v ariations of F g , this affects H1-H2 , giving more distinct distributions across voice qualities than for IAIF or GFM-IAIF and low er normalized rank-sum v alues. How ev er, as F g v alues w ere unexp ectedly high for IOP-IAIF, one ma y question the relev ance of H1-H2 as a discriminative parameter for this method. IAIF and GFM-IAIF show similar performance and a goo d discriminative p o wer for soft vs. loud v oice qualities. The lack of formant bandwidth v ariation with IOP-IAIF leads to the p oorest HRF discriminativ e p erformance. GFM-IAIF shows the b est discriminativ e p o w er b et ween soft vs. medium, and soft vs. loud. Moreo ver, the GFM-IAIF HRF distributions are more spread than for IAIF. GFM-IAIF ST distributions also sho w b etter spread with voice qualit y . Nev ertheless, IAIF sho ws as m uch discriminativ e p o wer as GFM-IAIF. Although IAIF did not pro vide a v ariation of sp ectral tilt cutting frequencies, glottal formant bandwidth has an influence on ST and justifies the discriminative p erformance of the latter. Finally , IOP-IAIF has the p oorest p erformance as b oth glottal bandwidth and sp ectral tilt cutting frequency w ere wrongly detected. Ov erall, it seems that GFM-IAIF can b e sligh tly more discriminativ e than other metho ds regarding v oice quality . 5 Conclusion This pap er prop oses a new metho d for glottal in verse filtering, GFM-IAIF, ha ving a third order filter in the pre-emphasis step, in line with s pectral glottis source mo dels. This mo dels b oth the glottal formant and the sp ectral tilt effectively; tw o glottis sp ectral features resp onsible for the p erception of v oice qualit y . Ev aluation of GFM-IAIF against the standard IAIF and IOP-IAIF shows that GFM-IAIF pro vides the best estimation of glottal formant frequency and bandwidth, and sp ectral tilt cutting frequency dep ending on v oice quality v ariations, according to literature [4, 7 – 9]. By ensuring a reduced set of parameters (frequency and bandwidth of glottal formant and cutting frequency of sp ectral tilt), GFM-IAIF also eases intuitiv e voice qualit y analysis and synthesis. References [1] G. F ant, A c oustic The ory of Sp e e ch Pr o duction . Mouton, 1970. [2] T. Drugman, P . Alku, A. Alwan, and B. Y egnanara yana, “Glottal source pro cessing: F rom analysis to applications,” Computer Sp e e ch & L anguage , vol. 28, no. 5, pp. 1117–1138, 2014. 6 [3] G. F an t, J. Liljencrants, and Q. Lin, “A four-parameter mo del of glottal flow,” Roy al Institute of T ec hnologies - Dept. for Sp eec h, Music and Hearing, Quarterly Progress and Status Rep ort 4, 1985. [4] B. Dov al, C. d’Alessandro, and N. Henric h, “The sp ectrum of glottal flow mo dels,” A cta A custic a unite d with A custic a , vol. 92, no. 6, pp. 1026–1046, 2006. [5] G. F ant, “The lf-mo del revisited. transformations and frequency domain analysis,” Roy al Institute of T ec hnologies - Dept. for Sp eec h, Music and Hearing, Quarterly Progress and Status Report 2-3, 1995. [6] N. Henric h, C. d’Alessandro, and B. Dov al, “Sp ectral correlates of voice open quotient and glottal flo w asymmetry: Theory , limits and exp erimen tal data,” in Pr o c e e dings of Eur osp e e ch , Aalb org, Denmark, September 3-7 2001, pp. 47–50. [7] D. G. Childers, “V ocal quality factors: Analysis, synthesis and perception,” The Journal of the A c oustic al So ciety of Americ a , vol. 90, no. 5, pp. 2394–2410, 1991. [8] C. Harw ardt, “Comparing the impact of raised v o cal effort on v arious spectral parameters,” in Pr o c e e dings of Intersp e e ch , Florence, Italy , August 28-31 2011, pp. 2941–2944. [9] S. Duvvuru and M. Erickson, “The effect of change in sp ectral slope and forman t frequencies on the p erception of loudness,” Journal of V oic e , vol. 27, no. 6, pp. 691–697, 2013. [10] C. d’Alessandro and B. Do v al, “Exp eriments in voice quality mo dification of natural sp eech signals: the sp ectral approac h,” in ISCA Sp e e ch Synthesis Workshop , Jenolan Cav es House, Blue Moun tains, Australia, No vem b er 26-29 1998, pp. 277–282. [11] O. Perrotin and C. d’Alessandro, “V o cal effort modification in singing synthesis,” in Pr o c e e dings of Intersp e e ch , San F rancisco, CA, USA, Septem b er 8-12 2016, pp. 1235–1239. [12] L. F eug ` ere, C. d’Alessandro, B. Dov al, and O. Perrotin, “Can tor digitalis: Chironomic parametric syn thesis of singing,” EURASIP Journal on Audio, Sp e e ch, and Music Pr o c essing , 2017. [13] C. Gobl and A. N ´ ı Chasaide, “The role of voice qualit y in communicating emotion, mo od and attitude,” Sp e e ch Communic ation , vol. 40, no. 1, pp. 189–212, April 2003. [14] D. O’Shaughnessy , “Linear predictiv e co ding,” IEEE Potentials , vol. 7, no. 1, pp. 29–32, F ebruary 1988. [15] I. V. McLoughlin, Sp e e ch and Audio Pr o c essing: a MA TLAB-b ase d appr o ach . Cam bridge Univ ersity Press, 2016. [16] G. Degottex, “Glottal source and vocal-tract separation: Estimation of glottal parameters, voice transformation and synthesis using a glottal mo del,” Ph.D. dissertation, Univ ersit´ e Pierre et Marie Curie (UPMC), Nov em b er 16 2010. [17] P . Alku, “Glottal in verse filtering analysis of h uman voice production – a review of estimation and parameterization metho ds of the glottal excitation and their applications,” Sadhana , vol. 36, no. 5, pp. 623–650, Oct 2011. [18] B. Dov al, C. d’Alessandro, and B. Diard, “Spectral methods for v oice source parameters estimation,” in Pr o c e e dings of Eur osp e e ch , Rho des, Greece, September 22-25 1997, pp. 533–536. [19] P . Alku, “Glottal wa ve analysis with pitc h synchronous iterative adaptive inv erse filtering,” Sp e e ch Communic ation , v ol. 11, no. 2–3, pp. 109–118, June 1992. [20] O. O. Ak ande and P . J. Murph y , “Estimation of the vocal tract transfer function with application to glottal wa v e analysis,” Sp e e ch Communic ation , vol. 46, no. 1, pp. 15–36, May 2005. [21] D. W ong, J. Mark el, and A. Gra y , “Least squares glottal inv erse filtering from the acoustic sp eech w av eform,” IEEE T r ansactions on A c oustics, Sp e e ch, and Signal Pr o c essing , vol. 27, no. 4, pp. 350–355, Aug 1979. [22] B. Bozkurt, B. Dov al, C. d’Alessandro, and T. Dutoit, “Zeros of z-transform representation with application to source-filter separation in sp eech,” IEEE Signal Pr o c essing L etters , v ol. 12, no. 4, pp. 344–347, April 2005. 7 [23] T. Drugman, B. Bozkurt, and T. Dutoit, “Causal–an ticausal decomp osition of speech using complex cepstrum for glottal source estimation,” Sp e e ch Communic ation , vol. 53, no. 6, pp. 855–866, July 2011. [24] P . Hedelin, “A glottal lp c-v o coder,” in IEEE International Confer enc e on A c oustics, Sp e e ch, and Signal Pr o c essing (ICASSP) , San Diego, CA, USA, March 19-21 1984, pp. 21–24. [25] D. Vincent, O. Rosec, and T. Chonav el, “A new metho d for sp eec h synthesis and transformation based on an arx-lf source-filter decomp osition and hnm mo deling,” in IEEE International Confer- enc e on A c oustics, Sp e e ch, and Signal Pr o c essing (ICASSP) , v ol. 4, Honolulu, Haw aii, USA, April 15-20 2007, pp. 525–528. [26] Y.-L. Sh ue, J. Kreiman, and A. Alwan, “A no vel codeb o ok search tec hnique for estimating the op en quotien t,” in Pr o c e e dings of Intersp e e ch , Brighton, UK, Septem b er 6-10 2009, pp. 2895–2898. [27] J. P . Cabral, K. Richmond, J. Y amagishi, and S. Renals, “Glottal sp ectral separation for sp eec h syn thesis,” IEEE Journal of Sele cte d T opics in Signal Pr o c essing , vol. 8, no. 2, pp. 195–208, F ebruary 2013. [28] G. Degottex, P . Lanchan tin, A. Ro eb el, and X. Ro det, “Mixed source mo del and its adapted v o cal tract filter estimate for v oice transformation and synthesis,” Sp e e ch Communic ation , v ol. 55, no. 2, pp. 278–294, F ebruary 2013. [29] T. Drugman, B. Bozkurt, and T. Dutoit, “A comparative study of glottal source estimation tec hniques,” Computer Sp e e ch & L anguage , v ol. 26, no. 1, pp. 20–34, 2012. [30] P . Mokhtari and H. Ando, “Iterative optimal preemphasis for improv ed glottal-flow estimation by iterativ e adaptiv e in verse filtering,” in Pr o c e e dings of Intersp e e ch , Sto c kholm, Sweden, August 21-24 2017, pp. 1044–1048. [31] C. d’Alessandro, “V oice source parameters and proso dic analysis,” Metho d in Empiric al Pr oso dy R ese ar ch , pp. 63–88, 2006. [32] “http://tcts.fpms.ac.be/synthesis/m brola/dba/de7/de7.zip.” [33] M. Schroder and M. Grice, “Expressing vocal effort in concatenativ e synthesis,” in International Congr ess of Phonetic Scienc es (ICPhS) , Barcelona, Spain, August 3-9 2003, pp. 2589–2592. [34] G. Degottex, J. Kane, T. Drugman, T. Raitio, and S. Scherer, “Cov arep – a collab orativ e voice analysis rep ository for sp eech tec hnologies,” in IEEE International Confer enc e on A c oustics, Sp e e ch, and Signal Pr o c essing (ICASSP) , Florence, Italy , May 4-9 2014, pp. 960–964. [35] N. Sturmel, C. d’Alessandro, and B. Dov al, “A comparative ev aluation of the zeros of z transform represen tation for voice source estimation,” in Pr o c e e dings of Intersp e e ch , Ant werp, Belgium, August 27-31 2007, pp. 558–561. [36] D. H. Klatt and L. C. Klatt, “Analysis, synthesis, and p erception of v oice quality v ariations among female and male talkers,” The Journal of the A c oustic al So ciety of Americ a , v ol. 87, no. 2, pp. 820–857, 1990. 8
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment