Gradient-Consensus: Linearly Convergent Distributed Optimization Algorithm over Directed Graphs
In this article, we propose a new approach, optimize then agree for minimizing a sum $ f = \sum_{i=1}^n f_i(x)$ of convex objective functions over a directed graph. The optimize then agree approach decouples the optimization step and the consensus st…
Authors: Vivek Khatana, Govind Saraswat, Sourav Patel
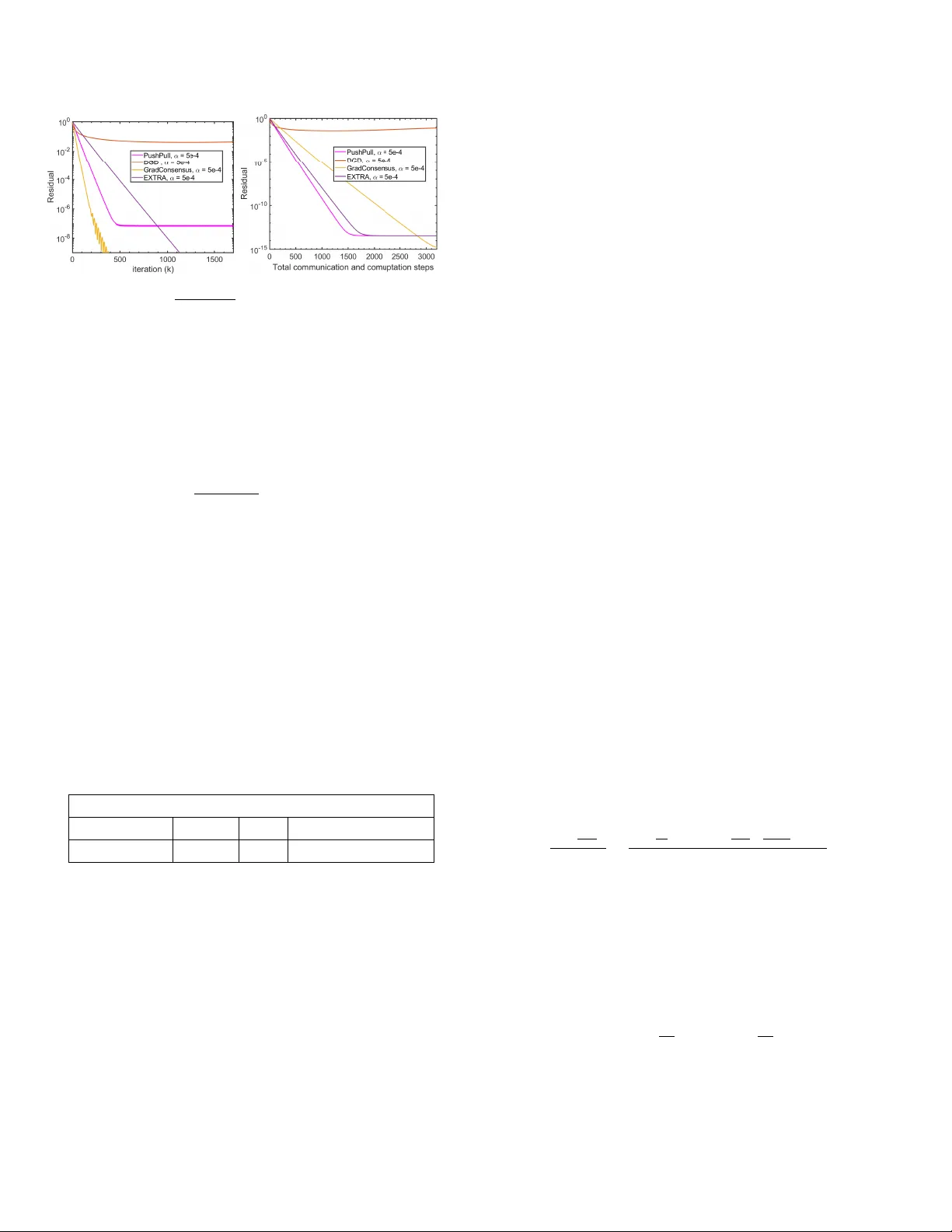
Gradien t-Consensus: Linearly Con v ergen t Distributed Optimization Algorithm o v er Directed Graphs ? Viv ek Khatana a , Go vind Saraswat b , Soura v Patel a , Murti V. Salapak a a a Dep artment of Ele ctric al and Computer Engine ering, University of Minnesota, Minne ap olis, USA b National R enewable Ener gy L ab or atory (NREL), Golden, CO, USA Abstract In this article, we propose a new approach, optimize then agr e e for minimizing a sum, f = P n i =1 f i , of con v ex ob jectiv e functions f i ’s, where, f i is only a v ailable lo cally to the agen t i , o v er a directed graph of n agen ts. The optimize then agr e e approac h decouples the optimization step and the consensus step in a distributed optimization framework. One of the key motiv ations for optimize then agr e e is to guaran tee that the disagreement b etw een the estimates of the agen ts during every iteration of the distributed optimization algorithm remains under any apriori sp ecified tolerance; existing algorithms do not pro vide such a guarantee which is required in man y practical scenarios. In this metho d, each agent during eac h iteration main tains an estimate of the optimal solution and, utilizes its lo cally av ailable gradient information along with a finite-time appro ximate consensus proto col to mov e tow ards the optimal solution (hence the name Gradien t-Consensus algorithm). W e establish that the proposed algorithm has a global R-linear rate of con vergence if the aggregate function f is strongly conv ex and Lipsc hitz differentiable. W e also sho w that under the relaxed assumption of f i ’s b eing conv ex and Lipschitz differen tiable, the ob jective function error residual decreases at a Q-linear rate (in terms of the num b er of gradient computation steps) until it reaches a small v alue, which can b e managed using the tolerance v alue sp ecified on the finite-time appro ximate consensus proto col; no existing metho d in the literature has such strong conv ergence guarantees when f i are not necessarily strongly con v ex functions. The communication ov erhead for the improv ed guarantees on meeting constraints and better conv ergence of our algorithm is O ( k log k ) iterates in comparison to O ( k ) of the traditional algorithms. F urther, we numerically ev aluate the p erformance of the prop osed algorithm by solving a distributed logistic regression problem. Key wor ds: Distributed optimization, multi-agen t netw orks, finite-time consensus, directed graphs. 1 In tro duction In this article, we consider a group of n agents connected as a directed graph, with a goal of solving the follo wing distributed optimization problem: minimize x ∈ R p f ( x ) = P n i =1 f i ( x ) , (1) ? This work was authored in part by NREL, operated by Alliance for Sustainable Energy , LLC, for the U.S. Department of Energy (DOE) under Contract No. DE-AC36-08GO28308. F unding provided by the Adv anced Research Pro jects Agency-Energy under Grant DE-AR0001016. The views expressed in the article do not necessarily represent the views of the DOE or the U.S. Gov ernment. The U.S. Governmen t retains and the publisher, by accepting the article for publication, ackno wledges that the U.S. Gov ernment retains a nonexclusive, paid-up, irrevocable, worldwide license to publish or repro duce the published form of this work, or allow others to do so, for U.S. Gov ernment purposes. Email addr esses: khata010@umn.edu (Vivek Khatana), govind.saraswat@nrel.gov (Go vind Saraswat), patel292@umn.edu (Soura v Patel), murtis@umn.edu (Murti V. Salapak a). where, x ∈ R p is a global optimization v ariable, and each function f i : R p → R is a conv ex cost function known only to agent i . Due to the underlying directed intercon- nection structure, agents can only send (receiv e) infor- mation to (from) their neigh b oring no des connected via a unidirectional link in the directed comm unication struc- ture. The study of the distributed optimization problem initiated with the seminal w orks [1], [2]. Since then, nu- merous algorithms to minimize the sum of conv ex func- tions in a distributed manner are devised; see [3]–[7]. Most of the existing first-order methods for solving (1) include the distributed gradient descent metho d [3], [8] and its modifications [9], [10]. The authors in [11] pro- p osed an exact first order metho d that conv erges to op- timal solution while using a fixed step-size in the gradi- en t up dates. The works in [12], [13] hav e dev elop ed al- gorithms based on proximal-gradien t to tackle (1) with pro ximal friendly f i ’s. Most existing w orks including, [3],[6],[8],[9],[11]–[14], imp ose restrictive conditions such as requirement of doubly-sto chastic weigh t matrices and Preprin t submitted to Automatica 27 May 2021 need of balanced undirected graphs. The first w ork to prop ose a distributed optimization metho d for directed graphs app eared in [15]. Subsequently , the authors in [9] incorp orated the push-sum proto col [16] with an earlier Distributed Gradient Descent (DGD) metho d [3] to pro- p ose the subgradient-push algorithm for time-v arying directed graphs. Recen t w orks [17] and [18] prop osed distributed optimization schemes for directed netw orks that make use of b oth row and column sto chastic ma- trices in one iteration of the algorithm. While there is a proliferating literature on developing distributed opti- mization metho ds for problem (1), most of them suffer from mismatch b et ween the estimates of the agents at an y finite time termination of the algorithm. As an il- lustration, we consider, an equiv alen t reformulation of problem (1): minimize x 1 ,...,x n P n i =1 f i ( x i ) (2) sub ject to x i = x j , for all i, j ∈ V , where, x i , x j ∈ R p are lo cal estimates (of the optimal so- lution) of agent i and j resp ectively and the equality con- strain ts enforce agreement b etw een the lo cal estimates of the agen ts. The design of existing algorithms that fo cus on finding the solution of (2) emphasize solving the unconstrained problem and reach on agreement b e- t ween the agents estimates only asymptotically . In par- ticular, at the intermediate iterations of the algorithm, the agents’ estimates often allow considerable mismatch and hence, do not provide a practically feasible solution to problem (2). The disagreemen t of agents’ estimates can b e problematic for practical applications where ob- taining a feasible solution with guarantees in finite-time is crucial for adequate p erformance and stability of the system. In order to motiv ate the discussion, we next pro- vide illustrative examples of real-world cyb er-ph ysical systems where agreement on a solution is imp erative and failing to do so can result in undesirable consequences to the system. i) Ec onomic Disp atch in p ower systems : The economic dispatc h (ED) is an optimization problem that tries to minimize the cost of dispatching n generation sources to meet the total load demand P ` while meeting gen- eration constraints in the p ow er system. Let the cost of op eration for a generation source i b e giv en as, C i ( P i ) = α i + β i P i + γ i P 2 i , where P i is the amount of p ow er generated b y source i [19]. The ED problem can b e formulated as follows: minimize P 1 ,...,P n P n i =1 C i ( P i ) sub ject to P n i =1 P i = P ` , P min i ≤ P i ≤ P max i for i = 1 , 2 , . . . , n, where, P min i and P max i are the minimum and max- im um pow er rating of generator i . The ED problem can b e solv ed in a centralized manner b y the Lagrange m ultiplier method [19]. By introducing the Lagrange m ultiplier λ , the solution of the ED problem can b e obtained b y solving the follo wing equations: d C i ( P i ) d P i = λ, ∀ i. (3) It is imp ortant while solving the ED problem distribu- tiv ely to ensure that the Lagrangian multiplier for all the generation sources should agree as required b y (3). This is also referred to as the e qual incr emental c ost optimization criterion in p ow er systems [19] which en- sures that the cost of increasing generation anywhere in the p ow er netw ork is same for all the distributed computational agents solving the economic dispatch problem. Let q i = d C i ( P i ) d P i = 2 γ i P i + β i . Using the def- inition of q i and (3), solution to the ED problem can b e obtained by solving the following equiv alent dis- tributed optimization problem: minimize q 1 ,...,q n P n i =1 q i − β i 2 γ i − P ` sub ject to q i = q j , ∀ i, j q min i ≤ q i ≤ q max i ∀ i, where, q min i = 2 γ i P min i + β i and q max i = 2 γ i P max i + β i . The ED problem needs to be solved fast as the solu- tions obtained are used to dispatc h generation sources in a real-time electricit y market as pow er system states c hange rapidly [20]. This imp oses a restriction on the a v ailable computation time and the distributed algo- rithm solving the ED problem has to pro vide esti- mates of the solution (even sub-optimal) in a short amoun t of time. Hence, it is imp erative that the dis- tributed optimization algorithm main tain constraint feasibilit y during the iterations, as an infeasible dis- patc h solution can result in economic and stabilit y is- sues (such as large frequency deviations) in the p o wer system net work. ii) R endezvous of Multi-R ob ot Systems: Consider, a group of n mobile rob ots. The control ob jective for the robots is to meet at a common agreed up on lo cation p ∗ . W e use p i and t i to denote the estimate of the p osition p ∗ and the time at whic h rob ot i considers the group should meet. It is desired to dev elop a distributed al- gorithm suc h that these estimates of meeting time and p osition should be same for all the rob ots, i.e., p i = p j and t i = t j for all i, j [21]. The rob ot rendezvous prob- lem can b e form ulated as the following distributed op- timization problem: minimize ( p 1 ,t 1 ) ,..., ( p n ,t n ) P n i =1 f i ( p i , t i ) sub ject to p i = p j , t i = t j , ∀ i u i ( p i , t i ) ≤ 0 ∀ i, where, f i is an ob jectiv e function of rob ot i (for exam- ple, a function to calculate the tra jectory of rob ot i ) 2 and u i ( p i , t i ) is the constraint function of rob ot i (for example, constrain ts on lo cal battery p ow er usage). Note that preserving the spatiotemp oral connectiv- it y among the agen ts is an imp ortan t requirement in rob ot systems [21],[22]. Hence, while solving the ren- dezv ous problem it is critical to maintain an agree- men t about the position of eac h rob ot during the in- termediate iterations of the algorithm. In this article, we introduce a new framework for design- ing distributed optimization algorithms to solv e (2). Our approac h is motiv ated tow ards reducing the inaccuracy of the consensus step in the existing distributed opti- mization algorithms in the literature. In particular, w e prop ose an optimize then agr e e framework to decouple the gradient-descen t step from the consensus step, used in tandem in most existing distributed-optimization al- gorithms (see [3],[8],[11],[18] for example) to reduce the mismatc h betw een the estimates main tained by different agen ts during each iteration of the algorithm. Based on the optimize then agr e e framework we develop a nov el first order distributed optimization metho d, termed as Gradien t-Consensus (abbreviated as GradConsensus ) algorithm for directed graph top ologies. Eac h iteration of the GradConsensus algorithm comprises tw o steps: a local gradien t-descent step at eac h agen t follow ed b y a finite-time approximate consensus proto col. The finite-time approximate consensus proto col is designed suc h that after the consensus step the up dates of all agen ts are ε -close to each other, where ε is a parameter indep enden t of the problem data and can b e chosen to get a desired level of accuracy . W e remark here that a few earlier works [23]–[25] ha ve explored the idea of utilizing multiple consensus steps. The article [25] do es not provide any conv ergence rate estimates for the pro- p osed scheme. The proto cols in [23]–[25] dep end on a symmetric double weigh t matrix, the synthesis of which requires global information of the netw ork making them unsuitable to be implemen ted in directed netw orks. The scheme prop osed in this article is amenable to di- rected netw orks and do es not rely on doubly sto chastic matrices; th us the synthesis of the algorithm and it’s implemen tation do not require centralized information of the comm unication netw ork. Moreov er, we rigorously establish conv ergence rate estimates for the prop osed algorithm. The main contributions of this article are as follo ws: (1) W e fo cus on the “disagreement” b etw een the esti- mates of different agents in the existing distributed optimization algorithms which we call the consen- sus constraint violation. W e demonstrate consensus constrain t violation for three existing algorithms in the literature while solving a distributed logistic re- gression problem (refer Section 4). F or any finite iteration, the solution obtained by the algorithms do not pro vide a feasible solution of the original distributed optimization problem. F or applications (discussed earlier) where getting a feasible solution is critical during ev ery time-instan t of op eration the existing algorithms do not provide a viable so- lution. T o address this issue, w e present a no v el optimize then agr e e framew ork with a motiv ation of decoupling the consensus and optimization steps used in tandem in existing distributed optimiza- tion sc hemes. Our framew ork pro vides a new p er- sp ectiv e on solving distributed optimization prob- lems and presents guidelines for the developmen t of new algorithms. Based on this framew ork we de- v elop a first-order distributed algorithm termed as GradConsensus to solve distributed optimization problems o ver directed graph top ologies. (2) The GradConsensus algorithm is suitable for di- rected graphs unlik e most of the existing works in the literature. It utilizes only the knowledge of the out-degree of each agent in the graph and is based on a column sto chastic matrix which is amenable for distributed synthesis scenarios where full infor- mation of the netw ork connectivity structure is not a v ailable and creating a doubly-sto c hastic matrix is not tractable. (3) W e analyze the conv ergence of the GradConsensus algorithm under t w o scenarios: (a) W e establish a global R-linear rate of conv er- gence for GradConsensus in terms of the num- b er of gradient computations p erformed by the algorithm under the assumption of aggregate function f b eing strongly-con vex and Lipsc hitz differen tiable. (b) W e show that under the relaxed assumption of individual functions f i b eing conv ex and Lipsc hitz differentiable, the ob jective function residual (defined later in the article) under the GradConsensus algorithm conv erges at a Q- linear rate (in terms of the n umber of gradient computations) un til reaching a small O ( ε 0 ) v alue, where ε 0 dep ends on the tolerance of the finite-time consensus proto col. W e remark that this stronger conv ergence guarantee, compared to the existing literature, under the assump - tion that f i are not necessarily strongly conv ex is a nov el result. The improv ed guaran tees accrue with an o verhead of O ( k log k ) (with ob jectives having uniformly bounded deriv a- tiv es) in con trast to O ( k ) communication steps b y the k th iterate for existing approaches. (4) W e present numerical tests comparing the p erfor- mance of the proposed GradConsensus in solv- ing the distributed logistic regression problem to existing algorithms in the literature. The numer- ical simulations demonstrate that the proposed GradConsensus algorithm requires significan tly less n umber of gradient calculations compared to the other algorithms and in applications where the cost of gradient computation is large our algorithm pro vides a b etter solution. W e demonstrate the con- sensus constraint violation during the intermediate iterations in other algorithms in the literature. 3 A preliminary w ork on Gradien t-Consensus b y the au- thors can b e found in [26]. In this article, we significantly extend our earlier work by in tro ducing the optimize then agr e e framew ork. W e presen t theorectical conv ergence guaran tees for the GradConsensus algorithm, account quan titatively for num b er of communication steps re- quired, provide new theoretical results and pro vide illus- trativ e examples to corrob orate the theoretical analysis. Suc h work is not present in the preliminary conference w ork. The rest of the pap er is organized as follows: Subsec- tion 1.1 provides the definitions and notations used in the article. In Section 2, we present the optimize then agr e e framework and the prop osed GradConsensus algo- rithm along with discussion on its design and supp orting results. W e establish the conv ergence guarantees for the GradConsensus algorithm under tw o different set of as- sumptions in Section 3. In Section 4, we demonstrate the resulting disagreement b et ween the agents’ estimates of the solution generated by three existing algorithms in the literature while solving a distributed logistic regres- sion problem. F urther, we compare the p erformance of the GradConsensus algorithm in solving the distributed logistic regression problem with the other existing algo- rithms in the literature. Section 5 provides the conclu- sion. 1.1 Definitions and Notations Definition 1 (Dir e cte d Gr aph) A dir e cte d gr aph G is a p air ( V , E ) wher e V is a set of vertic es (or no des) and E is a set of e dges, which ar e or der e d subsets of two distinct elements of V . If an e dge fr om j ∈ V to i ∈ V exists then it is denote d as ( i, j ) ∈ E . Definition 2 (Path) In a dir e cte d gr aph, a dir e cte d p ath fr om no de m to ` exists if ther e is a se quenc e of distinct dir e cte d e dges of G of the form ( d 1 , m ) , ( d 2 , d 1 ) , ..., ( `, d ` ) . Definition 3 (Str ongly Conne cte d Gr aph) A dir e cte d gr aph is str ongly c onne cte d if and only if it has a dir e cte d p ath b etwe en e ach p air of distinct no des k and ` . Definition 4 (Diameter of a Gr aph) The diameter of a dir e cte d gr aph G is the longest shortest dir e cte d p ath b etwe en any two no des of G . Definition 5 (In-Neighb orho o d) The set N in i = { j | ( i, j ) ∈ E } of in-neighb ors of no de i ∈ V not includ- ing the no de i , is c al le d the in-neighb orho o d of no de i with | N in i | denoting the numb er of in-neighb ors (in-de gr e e) of no de i . Definition 6 (Out-Neighb orho o d) The set N out i = { j | ( j, i ) ∈ E } of out-neighb ors of no de i ∈ V not including the no de i , is c al le d the out-neighb orho o d of no de i with | N out i | denoting the numb er of out-neighb ors (out-de gr e e) of no de i . Definition 7 (Column Sto chastic Matrix) A n × n r e al matrix P = [ p ij ] is c olumn-sto chastic matrix if P n i =1 p ij = 1 wher e, 0 ≤ p ij ≤ 1 , for 1 ≤ i, j ≤ n . Definition 8 (Irr e ducible Matrix) A n × n matrix P is irr e ducible if for al l i, j , ther e exist m ∈ N such that [ P m ] ij > 0 . Definition 9 (Primitive Matrix) A non-ne gative ma- trix P is primitive if it is irr e ducible and has only one eigenvalue of maximum mo dulus. Definition 10 (Lipschitz Differ entiability) A differ en- tiable function f is c al le d Lipschitz differ entiable with c onstant L , if ther e exists L > 0 such that the fol lowing ine quality holds: k∇ f ( x ) − ∇ f ( y ) k ≤ L k x − y k , ∀ x, y ∈ dom f . Definition 11 (Str ongly Convex F unction) A differ en- tiable function f is c al le d str ongly c onvex with p ar ameter σ , if ther e exists σ > 0 such that the fol lowing ine quality holds for al l x, y in the domain of f : h∇ f ( x ) − ∇ f ( y ) , x − y i ≥ σ k x − y k 2 , ∀ x, y ∈ dom f . Eac h agent i ∈ V maintains a lo cal estimate x i ( k ) := [ x i 1 ( k ) . . . x i p ( k )] ∈ R p at iteration k of the GradConsensus algorithm. Let, X ∗ = { x ∈ R p | P n i =1 f i ( x ) = f ∗ } de- note the set of solutions to (1), with f ∗ b eing the opti- mal ob jective function v alue. W e use a directed graph G ( V , E ) with n no des, to mo del the netw ork in tercon- nection b etw een the n agents and define D to b e an upp er b ound on the diameter of the graph G ( V , E ) . Throughout the article, we will use k x k to denote the 2-norm of the v ector x ∈ R p unless stated otherwise. F urther, we use the notation d . e to denote the least in- teger function or the ceiling function, defined as: given x ∈ R , d x e = min { m ∈ Z | m ≥ x } , where Z is the set of in tegers. 2 The Optimize then Agree F ramew ork In this section, we fo cus on problem (2) and present the prop osed optimize then agr e e framework. W e emphasize that the prop osed framew ork can b e applied to man y existing algorithms in the literature that utilize an op- timization scheme in tandem with a consensus step for the state up dates. Here we take the example of the clas- sical DGD metho d [3] for explanation. During the iter- ation k of DGD every agent i up dates its lo cal estimate x i ( k ) ∈ R p as follo ws: x i ( k ) = P j ∈ N in i ∪ i p ij x j ( k − 1) − α ∇ f i ( x i ( k − 1)) , (4) 4 where, the w eights 0 ≤ p ij ≤ 1 are such that P j p ij = P i p ij = 1 . The first term P j ∈ N in i ∪ i p ij x j ( k − 1) in (4) corresp onds to a lo cal consensus s tep and the second term − α ∇ f i ( x i ( k − 1)) denotes a lo cal gradient step. Notice that due to a lo cal consensus step the up date (4) do es not account for the agreement b etw een the esti- mates o ver the en tire netw ork of agents during iteration k . If update (4) is terminated after some finite n umber of iterations the solution estimates will hav e disagreement and will not satisfy the equalit y constrain ts in prob- lem (2) and hence the (finite-time) solution generated will not b e feasible for the original problem. T o address this issue we prop ose the optimize then agr e e frame- w ork where the optimization step (gradient-descen t in this case) and the consensus scheme are decoupled from eac h other. The optimize then agree framework enforces that the mismatch b etw een the agent estimates remain b elo w any sp ecified threshold (and hence manages the consensus constraint violation). Here, each agent em- plo ys an optimization scheme to steer tow ards the so- lution of its lo cal sub-problem and utilizes a consensus proto col to ac hiev e agreement with the lo cal estimates of all the other agents. T o describ e the optimize then agr e e framew ork mathematically we define, the optimization sc heme operator used b y agent i ∈ V as the mapping O i : R p → R p : z i ( k ) := O i ( x i ( k − 1)) . (5) Similarly , define the consensus scheme as the op erator mapping C : R p × n → R p × n : x( k ) = C (z( k )) , (6) where, z( k ) = [ z 1 ( k ) . . . z n ( k )] , x( k ) = [ x 1 ( k ) . . . x n ( k )] ∈ R p × n , such that x 1 ( k ) = x 2 ( k ) = · · · = x n ( k ) . Utilizing the ab o v e notation the optimize then agr e e framework leads to the following algorithm: Algorithm 1: Optimize then agree framework Rep eat for k = 1 , 2 , . . . /* state updates using operators (5) and (6) */ z i ( k ) = O i ( x i ( k − 1)) , ∀ i ∈ V x( k ) = C (z( k )) un til a stopping criterion is met Remark 1 W e emphasize that the up dates in Algo- rithm 1 ar e gener al and do not dep end on a p articular choic e of the optimization scheme or the c onsensus algo- rithm, thus the optimize then agr e e fr amework pr ovides a guideline for further explor ation of distribute d optimiza- tion algorithms. The fr amework of Algorithm 1 c an also b e se en as an outer optimization lo op and an inner c on- sensus lo op structur e algorithm. Thus, existing schemes [23]–[25],[27] ar e a sp e cial c ase of the optimize then agr e e fr amework with a p articular choic e of optimization scheme and a c onsensus pr oto c ol. Cho osing first-order gradient descent with a constant step-size α as the optimization scheme, Algorithm 1 at an y iteration k + 1 results in the follo wing up dates: z i ( k + 1) = x i ( k ) − α ∇ f i ( x i ( k )) , ∀ i ∈ V , x( k + 1) = C (z( k + 1)) , with, the consensus op erator implemented in a central- ized manner (with the en tire vector z( k + 1) as the in- put). How ever, in order to mak e Algorithm 1 applica- ble to distributed netw orks, we need to distributiv ely realize (6) of the consensus op erator. T o this end, one natural choice is to employ a distributed a verage con- sensus proto col [28],[16]. Although these av erage con- sensus proto cols lead to agreemen t among the agents to the initial av erage, the result holds only asymptotically whic h is a p otential problem for an efficien t implementa- tion of Algorithm 1. T o address this issue, the consensus sc heme op erator is chosen to b e a distributed finite-time appro ximate consensus proto col, whic h w e call the ε - Consensus proto col [26]. The ε - Consensus proto col pro- duces a desired level of agreement among the estimates of all agents. The accuracy in the agreement is deter- mined by a parameter ε > 0 indep enden t of problem (1) that can b e chosen arbitrarily small. In the following sec- tion, we will first discuss the ε - Consensus proto col and then introduce the prop osed GradConsensus algorithm. 2.1 ε - Consensus Pr oto c ol The ε - Consensus proto col is a distributed finite-time terminated av erage consensus algorithm. The proto col w as first prop osed in earlier works [29], [30] by the au- thors in relation to consensus on scalar v alues. Here, w e extend the proto col to higher dimensional av erage consensus protocols. Eac h agen t i ∈ V has a v ector z i = [ z i 1 z i 2 . . . z i p ] ∈ R p . The ob jective is to find an ap- pro ximate estimate of the av erage z = 1 n P n i =1 z i ∈ R p . T o achiev e this ob jectiv e an iterativ e pro cedure is de- vised where each agen t j ∈ V maintains a state v ariable s j ( k ) ∈ R p and an auxiliary v ariable t j ( k ) ∈ R , with the follo wing initialization: s j (0) = z j , t j (0) = 1 , for all j ∈ V . (7) Agen t j ∈ V up dates [16] according to: s j ( k + 1) = p j j s j ( k ) + P ` ∈ N in j p j ` s ` ( k ) (8) t j ( k + 1) = p j j t j ( k ) + P ` ∈ N in j p j ` t ` ( k ) (9) r j ( k + 1) = 1 t j ( k +1) s j ( k + 1) . (10) W e make the follo wing assu mption on the graph G ( V , E ) and the asso ciated matrix P =: [ p ij ] : Assumption 1 The dir e cte d gr aph G ( V , E ) is str ongly- c onne cte d. The asso ciate d weighte d adjac ency matrix 5 P = [ p ij ] is a primitive, c olumn-sto chastic matrix. In p articular, 0 ≤ p ij ≤ 1 and P n i =1 p ij = 1 for al l i, j ∈ V . One c hoice of weigh ts that satisfy Assumption 1 is the Out-degree based equal neighbor weigh ts rule [31]. The con vergence of the state r j ( k ) := 1 t j ( k ) s j ( k ) , j ∈ V ev olving according to (8)-(10), to the a verage z = 1 n P n i =1 z i has b een established rigorously [16], [32]. W e state the follo wing result for up dates (8)-(10): Theorem 2.1 L et Assumption 1 and the up dates (8)- (10) hold. L et the initial c onditions of the state and aux- iliary variables s j and t j , j ∈ V r esp e ctively b e given by (7). Then lim k →∞ r j ( k ) = 1 n P n i =1 z i , for al l j ∈ V . Pr o of. Refer [32], Theorem 2.1, for pro of. 2 W e now provide a criteria for determining when consen- sus is reached within a tolerance ε > 0 . Let, r i ( k ) = 1 t i ( k ) s i ( k ) and r ( k ) = [ r 1 ( k ) r 2 ( k ) . . . r n ( k )] ∈ R p × n . At an y iteration k , define the maximum r ( k ) and minimum r ( k ) state v ariable of the netw ork ov er all the agents as r ( k ) := h max 1 ≤ j ≤ n r [1 j ] ( k ) . . . max 1 ≤ j ≤ n r [ pj ] ( k ) i (11) r ( k ) := h min 1 ≤ j ≤ n r [1 j ] ( k ) . . . min 1 ≤ j ≤ n r [ pj ] ( k ) i , (12) where, r [ ij ] ( k ) is i th -ro w and j th -column en try of r ( k ) . Theorem 2.2 L et Assumption 1 and up dates (11), (12) hold. Then, { r ( u D ) } u ≥ 1 and { r ( u D ) } u ≥ 1 ar e strictly monotonic se quenc es c onver ging to z = 1 n P n i =1 z i . Pro of. Refer [32], Theorem 4.1, for Pro of. 2 T o distributively determine the sequences of global maxim um { r ( u D ) } u ≥ 1 and minim um { r ( u D ) } u ≥ 1 eac h agen t j ∈ V , maintains tw o v ariables M j ( k ) , m j ( k ) ∈ R p at any iteration k . The v ariables M j and m j are initialized as M j (0) = m j (0) = z j for all j ∈ V and are up dated as: M j ( k + 1) = h max ` ∈ N in j ∪ j M ` 1 ( k ) . . . max ` ∈ N in j ∪ j M ` p ( k ) i (13) m j ( k + 1) = h max ` ∈ N in j ∪ j m ` 1 ( k ) . . . max ` ∈ N in j ∪ j m ` p ( k ) i , (14) where, M ` i ( k ) , and m ` i ( k ) are the i th en try of M ` ( k ) and m ` ( k ) resp ectively . Prop osition 2.1 L et Assumption 1, up dates (13) and (14) hold. Then the variables M j ( k ) and m j ( k ) for al l j ∈ V , c onver ges to r (0) and r (0) r esp e ctively in finite numb er of iter ations k f ≤ D . Pr o of. Refer [33], Prop osition 2.3, for pro of. 2 Prop osition 2.1 leads to a metho d for finding the se- quences { r ( u D ) } u ≥ 1 and { r ( u D ) } u ≥ 1 distributiv ely: re- initializing the up dates (13), (14) for all agents j ∈ V , at ev ery iteration of the form k = u D , u = 1 , 2 , . . . , to the v ariable r j ( u D ) will allow the v ariables M j and m j to conv erge to r (( u − 1) D ) and r (( u − 1) D ) resp ectively , after a finite num b er of iterations k f ≤ D by Prop osi- tion 2.1. Since, b oth the sequences { r ( m D ) } m ≥ 1 and { r ( m D ) } m ≥ 1 con verge to z (Theorem 2.2), the norm of the difference b etw een the tw o, i.e., k r ( m D ) − r ( m D ) k also conv erges to zero. Therefore, given ε > 0 , the quan tity k r ( m D ) − r ( m D ) k will ev en tually b ecome less than ε . Based on the abov e observ ations w e propose an algorithm which allows all agen ts to sim ultaneously con verge to an ε -close estimate of z with ε b eing an arbitrary pre-sp ecified tolerance. F or u = 1 , 2 , . . . , let γ j ( u D ) := M j ( u D ) − m j ( u D ) . Eac h agent computes the norm k γ j ( u D ) k every D iterations and compares it with ε . If k γ j ( ˜ u D ) k := k M j ( ˜ u D ) − m j ( ˜ u D ) k < ε at an y iteration ˜ u D , then agent j , knowing its estimate r j ( ˜ u D ) is ε -close to z , terminates the consensus proto- col up dates (8)-(10) at ˜ u D . The v ariable r j ( ˜ u D ) is the ε -close estimate of z av ailable with agent j . 2.2 The GradConsensus Algorithm Here, each agent i main tains t wo estimates: an optimiza- tion v ariable x i ( k ) ∈ R p and a gradient-descen t up date v ariable z i ( k ) ∈ R p at an y iteration k . Every iteration k pro ceeds in t w o steps: first every agent i updates z i ( k ) via a gradient descen t up date based on its o wn func- tion f i at x i ( k − 1) . At the next step, the optimiza- tion v ariable x i ( k ) is up dated to an estimate whic h is ε ( k ) -close to the a v erage v alue ˆ z ( k ) := 1 n P n i =1 z i ( k ) , i.e. k x i ( k ) − ˆ z ( k ) k ≤ ε ( k ) , using the distributed ε - Consensus proto col, initialized with z i ( k ) as the initial condition for the agen t i and tolerance ε ( k ) . Thus, at each iteration k Algorithm 2: GradConsensus Algorithm Input: Cho ose consensus tolerances { ε ( k ) } k ≥ 0 and step-size α Initialize: - Eac h agen t j ∈ V initializes its estimates as x j (0) = z j (0) = 0 . Rep eat for k = 1 , 2 , . . . for j = 1 , 2 , 3 , . . . , n , ( In p ar al lel ) do outer gradient descent iteration: z i ( k ) = x i ( k − 1) − α ∇ f i ( x i ( k − 1)) inner consensus iterations: x i ( k ) ← ε ( k ) - Consensus ( z i ( k ) , i ∈ V ) end un til a stopping criterion is met of Algorithm 2, every individual agent i ∈ V p erforms 6 the follo wing up dates: z i ( k ) = x i ( k − 1) − α ∇ f i ( x i ( k − 1)) (15) x i ( k ) = r i ( k c ( k )) , with, (16) k r i ( k c ( k )) − ˆ z ( k ) k < ε ( k ) , ˆ z ( k ) := 1 n P n i =1 z i ( k ) , (17) where, k c ( k ) denotes the num b er of iterations required b y the ε - Consensus proto col to reac h the consensus ac- curacy within ε ( k ) at iteration k of Algorithm 2, and r i ( k c ( k )) is the approximate estimate of ˆ z ( k ) pro duced b y the ε - Consensus proto col. Remark 2 T o ke ep the analysis c oncise we assume the step-size α to b e the same for al l the agents. However, this do es not p ose any r estriction to scheme. Befor e the start of Algorithm 2 any agent c an cho ose a step-size α and by using the Maximum Consensus Pr oto c ol [34] (one dimensional e quivalent of up date (13)) e ach agent c an know the value of step-size α within D numb er of iter ations (se e Pr op osition 2.1). After the step-size is known e ach agent c an exe cute Algorithm 2 indep endently. Remark 3 Note that GradConsensus algorithm (up- dates (8)-(10)) utilize a c olumn sto chastic matrix which al lows for a distribute d synthesis of the pr oto c ol. This fe atur e gives an advantage over existing schemes in the liter atur e [3],[11],[23],[35] that utilize a doubly-sto chastic weight matrix and c annot achieve tr actable distribute d synthesis in dir e cte d networks. 3 Con vergence Analysis for GradConsensus This section is dedicated to the analysis of the prop osed GradConsensus algorithm. W e will analyze the conv er- gence of the GradConsensus algorithm for t w o scenar- ios: (i) when the aggregate function f is conv ex and Lip- sc hitz differen tiable and, (ii) when f is strongly conv ex and Lipschitz differentiable. In b oth the scenarios w e es- tablish the conv ergence of the iterates generated by Al- gorithm 2 to the optimal solution of problem (1). W e will pro vide estimates of the rate of con v ergence to the op- timal solution in terms of the (outer) iterations k of the Algorithm 2 and the total communication steps K . W e b egin presen ting preliminary results that we will utilize in the con v ergence analysis. 3.1 Supp orting L emmas W e make the following assumptions throughout the rest of the article: Assumption 2 F or pr oblem (1) the optimal value f ∗ is finite and the optimal solution set X ∗ is non-empty. Assumption 3 (1) F or al l i ∈ V , f i is a pr op er close d- c onvex function with a lower b ound. (2) Each function f i is Lipschitz differ entiable with c on- stant L f i > 0 . W e make the following assumption which primarily ef- fects the analysis of num b er of inner consensus iterations needed b y the Algorithm 2. Assumption 4 The gr adients of functions f i ar e b ounde d, i.e., ther e ex- ists h i < ∞ such that ∀ x ∈ R p , k∇ f i ( x ) k ≤ h i . W e establish most results with Assumption 4, ho w- ev er, the conv ergence analysis and rate estimates of the GradConsensus remains v alid without Assumption 4. Relaxing Assumption 4 only effects the n umber of it- erations required by the ε ( k ) - Consensus proto col. W e state results that hold in the absence of Assumption 4 in remarks after each Theorem. Let the av erage of the optimization v ariables at iteration k ≥ 0 b e denoted as: ˆ x ( k ) := 1 n P n i =1 x i ( k ) . W e denote the gradient of the function f ev aluated at the individual optimization v ariables of all the n agen ts and at the av erage ˆ x ( k ) at an y iteration k ≥ 0 as: g ( k ) := P n i =1 ∇ f i ( x i ( k )) , ˆ g ( k ) := P n i =1 ∇ f i ( ˆ x ( k )) . Eac h iteration of Algorithm 2 utilizes an ε - Consensus proto col. The following Lemma provides the num b er of comm unication steps required b y the ε - Consensus pro- to col to conv erge to an ε ( k ) -close solution at the k th outer gradien t descen t iteration of Algorithm 2. Lemma 3.1 L et Assumptions 1, 3 and 4 hold. Then at any outer gr adient desc ent iter ation k of Algorithm 2, after k c ( k ) = log 1 ε ( k ) − log λ + log 8 n δ ( P k − 1 s =0 ε ( s )+ αkh m ) − log λ iter ations of the c onsensus pr oto c ol (up dates (8)-(10)) with the initial c ondition s i (0) = z i ( k ) , t i (0) = 1 , ∀ i ∈ V we have: k x i ( k ) − ˆ z ( k ) k ≤ ε ( k ) , ∀ i ∈ V , wher e, ε ( k ) is the c onsensus toler anc e p ar ameter, h m := max 1 ≤ i ≤ n h i and δ > 0 , λ ∈ (0 , 1) ar e p ar ameters of the gr aph G satisfying δ ≥ 1 n n , λ ≤ 1 − 1 n n . Pro of. T o b egin, w e will present a mo dification of an existing result (Lemma 1 [9]). The result in Lemma 1 [9], with the p erturbation term b eing zero, reduces to a conv ergence result for the push-sum proto col. Using this prop ert y , we conclude that the up dates (8)-(10) con- v erges at a geometric rate to the a v erage of the initial v alues . Note that the GradConsensus algorithm at every iteration k utilizes ε - Consensus proto col (up dates (8)- (10)) with the initial v alues z i ( k ) . Hence, the estimates x i ( k ) con verges to the av erage ˆ z ( k ) (of the initial v alues) 7 at a geometric rate. Therefore, we conclude, k x i ( k ) − ˆ z ( k ) k ≤ 8 √ nλ k c ( k ) δ k z( k ) k , ∀ i ∈ V , (18) where, z( k ) := [ z 1 ( k ) , . . . , z n ( k )] ∈ R p × n and, δ > 0 , λ ∈ (0 , 1) satisfy: δ ≥ 1 n n , λ ≤ 1 − 1 n n . Here, the v ariables λ and δ are parameters of the graph G . The parameter λ measures the sp eed at which the graph G diffuses the information among the agent s ov er time. F or a regular graph G (leading to a symmetric dou- bly sto chastic P ) λ is equiv alen t to the second largest eigen v alue of P . F urther, the parameter, δ measures the im balance of influences among the in G [9]. Next, we will b ound k z( k ) k using an induction argument. Claim: Under Assumption 4, at an y k , k z i ( k ) k ≤ P k − 1 s =1 ε ( s ) + α k h m , for all i ∈ V . Pr o of: F or k = 1 , for an y i w e hav e, k z i (1) k = k x i (0) − α ∇ f i ( x i (0)) k ≤ α max 1 ≤ i ≤ n h i = αh m . Assume, for k = k, k z i ( k ) k ≤ P k − 1 s =1 ε ( s ) + αk h m , for all i ∈ V . No w, for k = k + 1 , for an y i , k z i ( k + 1) k = k x i ( k ) − α ∇ f i ( x i ( k )) k ≤ k x i ( k ) − ˆ z ( k ) k + k ˆ z ( k ) k + α k∇ f i ( x i ( k )) k ≤ ε ( k ) + P k − 1 s =1 ε ( s ) + αk h m + α max 1 ≤ i ≤ n h i = P k s =1 ε ( s ) + α ( k + 1) h m , for all i ∈ V , where w e used (17) in the last inequality . Therefore, induction holds. Using the ab ov e claim it can b e shown that k z( k ) k ≤ √ n ( P k − 1 s =0 ε ( s ) + αk h m ) . If ε ( k ) δ λ k c ( k )8 √ n = k z( k ) k ≤ √ n ( P k − 1 s =0 ε ( s )+ αk h m ) it implies that, δ ε ( k ) 8 n P k − 1 s =0 ε ( s )+ αkh m ≤ λ k c ( k ) . Therefore, w e ha v e, k c ( k ) ≤ − 1 log λ h log 1 ε ( k ) + log 8 n δ ( P k − 1 s =0 ε ( s ) + α k h m ) i := k c ( k ) . Using (18) we conclude that after k c ( k ) num b er of itera- tions at the k th outer gradient descent iteration, k x i ( k ) − ˆ z ( k ) k ≤ ε ( k ) , for all i ∈ V . Remark 4 L emma 3.1 pr ovides an upp er b ound on the numb er of c ommunic ation steps r e quir e d at the k th outer gr adient desc ent iter ation of Algorithm 2 to obtain ε ( k ) - close solution. In p articular, if P ∞ k =0 ε ( k ) < ∞ , then at the k th outer gr adient desc ent iter ation of A lgorithm 2, after O log 1 ε ( k ) + log( k ) c ommunic ation steps the es- timates of al l the agents ar e guar ante e d to b e ε ( k ) -close to e ach other. Remark 5 Note that the r esult in L emma 3.1 makes use of Assumption 4. However, this r estriction is not pr esent for a wide variety of sc enarios; her e an upp er b ound on the gr adient of the functions c an b e obtaine d if the gr adient desc ent minimization step is p erforme d over a c omp act set X with a diameter R . In p articular, sinc e, f i have Lipschitz c ontinuous gr adients, k∇ f i ( x i ( k )) − ∇ f i ( x i (0)) k ≤ max 1 ≤ i ‘ n L f i k x i ( k ) − x i (0) k = ⇒ k f i ( x i ( k )) k ≤ L h R + max 1 ≤ i ≤ n k∇ f i ( x i (0)) k := h m , wher e, R := sup x,y ∈X k x − y k is the diameter of the set X . The ε - Consensus pr oto c ol c an b e utilize d to get an ε ( k ) -close solution within finite numb er of iter ations without Assumption 4. This is establishe d in L emma 6.1 pr esente d in App endix wher e the O ( k log k ) is r eplac e d by O ( k 2 ) for the numb er of c ommunic ation iter ates. A consequence of the ε - Consensus proto col is that the difference b etw een g ( k ) and ˆ g ( k ) is b ounded for suffi- cien tly large consensus lo op iterations k c ( k ) . The next Lemma establishes this prop erty of the GradConsensus algorithm. Lemma 3.2 Under assumptions 1 and 3, at k th outer gr adient desc ent iter ation of Algorithm 2 after k c ( k ) it- er ations of the c onsensus pr oto c ol, we have: k g ( k ) − ˆ g ( k ) k ≤ 2 nL h ε ( k ) , wher e, L h = max 1 ≤ i ≤ n L f i , ε ( k ) is the c onsensus toler- anc e p ar ameter, and k c ( k ) is as define d in L emma 3.1. Pro of. Under Assumption 3, we note that, k g ( k ) − ˆ g ( k ) k = P n i =1 ∇ f i ( x i ( k )) − P n i =1 ∇ f i ( ˆ x ( k )) ≤ L h P n i =1 k x i ( k ) − ˆ x ( k ) + ˆ z ( k ) − ˆ z ( k ) k ≤ L h P n i =1 k x i ( k ) − ˆ z ( k ) k + k ˆ z ( k ) − ˆ x ( k ) k ≤ 2 nL h ε ( k ) , (19) where, in the last step follows from Lemma 3.1. 2 F rom up date (15), 1 n P n i =1 z i ( k ) = 1 n P n i =1 x i ( k − 1) − α ∇ f i ( x i ( k − 1)) = ˆ x ( k − 1) − α n P n i =1 ∇ f i ( x i ( k − 1)) . Therefore, w e ha v e ˆ z ( k ) = ˆ x ( k − 1) − ˆ αg ( k − 1) + ˆ x ( k ) − ˆ x ( k ) , = ⇒ ˆ x ( k ) = ˆ x ( k − 1) − ˆ αg ( k − 1) + v ( k ) , (20) where, v ( k ) := ˆ x ( k ) − ˆ z ( k ) , k v ( k ) k ≤ ε ( k ) due to Lemma 3.1 and ˆ α = α n . In the cen tralized setting the information ab out the gradient of the function f , i.e. ∇ f ( x ) = P n i =1 ∇ f i ( x ) = ˆ g ( x ) is known to the central serv er. Here, an iteration of the (cen tralized) gradient descen t will be of the form: ˜ x = x − α ˆ g ( x ) , where, ˜ x denotes the up dated estimate of the optimal solution. Note that due to Lemma 3.2 the up date (20) can b e view ed as an inexact centralized gradient descent up date 8 p erformed at the av erage of all the agen ts’ estimates for the function f . In particular, ˆ x ( k + 1) = ˆ x ( k ) − ˆ α ˆ g ( k ) + u ( k ) , with u ( k ) := ˆ α ( ˆ g ( k ) − g ( k )) + v ( k ) , k u ( k ) k ≤ (2 L h α + 1) ε ( k ) . Therefore, the GradConsensus algorithm p erforms an appro ximate centralized gradient descent up dates at eac h iteration. Due to this prop ert y , Algorithm 2 ex- hibits con vergence properties similar to a cen tralized gradien t descent metho d. W e define the solution residual ˆ e ( k ) and ob jectiv e v alue residual ˆ r ( k ) at iteration k as: ˆ e ( k ) := ˆ x ( k ) − x ∗ , and (21) ˆ r ( k ) := f ( ˆ x ( k )) − f ∗ = P n i =1 f i ( ˆ x ( k )) − f ∗ . (22) Under Assumption 3 since all f i are Lipschitz differen- tiable with parameter L f i , f also is Lipschitz differen- tiable with the constant L f := P n i =1 L f i . The following t wo Lemmas are prop erties of Lipschitz differentiable con vex and strongly conv ex functions that are standard results in the conv ex analysis. W e will make use of these iden tities in Theorems 3.1 and 3.2. Lemma 3.3 Under Assumption 3 for al l x, y ∈ R p , h∇ f ( y ) − ∇ f ( x ) , y − x i ≥ 1 L f k∇ f ( y ) − ∇ f ( x ) k 2 . Pro of. Refer [36], Theorem 2.1.5, for pro of. 2 Lemma 3.4 Under Assumptions 3, 5 for al l x, y ∈ R p , h x − y , ∇ f ( x ) − ∇ f ( y ) i ≥ 1 σ + L f k∇ f ( x ) − ∇ f ( y ) k 2 + σ L f σ + L f k x − y k 2 . Pro of. Refer [36], Theorem 2.1.12, for pro of. 2 3.2 Conver genc e Analysis for Convex f In this subsection, w e present the conv ergence result for the GradConsensus when the function f is con vex and Lipsc hitz differentiable. Under these assumptions Theo- rem 3.1 establishes a Q-linear rate of conv ergence to an O ( ε ) neigh b orho o d of the optimal solution. Moreov er, w e also provide a b ound on the total num b er of comm u- nication steps required by the GradConsensus algorithm to ac hieve the con vergence rate estimates. Theorem 3.1 L et assumptions 1-4 hold. L et ˆ α ≤ 2 L f and ε ( k ) = ε 0 k 1+ η , wher e, ε 0 , η ∈ (0 , 1) ar e p os- itive c onstants. Consider, the outer gr adient de- sc ent iter ation k , the total c onsensus c ommunic a- tion iter ations K := P k s =1 k c ( s ) ar e b ounde d by P k s =0 log s 1+ η ε 0 − log λ + log 8 n δ ( ε 0 ζ (1+ η )+ αsh m ) − log λ = O ( k log k ) , wher e, ζ ( . ) denotes the Riemann zeta function. At the k th outer gr adient desc ent iter ation of Algo- rithm 2, if the obje ctive function r esidual (define d in (22)), ˆ r ( k ) > 2 e q 4 αnL 2 h + L f +2 / ˆ α ˆ α ε 0 , wher e, e := k ˆ x (0) − x ∗ k + (2 αε 0 L h + 1) ζ (1 + η ) , then ˆ r ( k ) de cr e ases at a Q-line ar r ate, with r esp e ct to the outer gr adient desc ent iter ations. In p articular, ther e exists β ∈ (0 , 1) , such that at the k th outer gr adient desc ent iter ation ˆ r ( k ) ≤ β k ˆ r (0) . Pro of. W e start b y showing that the solution residual k ˆ e ( k ) k is b ounded. Consider, k ˆ x ( k ) − ˆ α ˆ g ( k ) − x ∗ k 2 = k ˆ x ( k ) − x ∗ k 2 + ˆ α 2 k ˆ g ( k ) k 2 − 2 ˆ α h ˆ g ( k ) , ˆ x ( k ) − x ∗ i ≤ k ˆ x ( k ) − x ∗ k 2 + ˆ α ˆ α − 2 L f k ˆ g ( k ) k 2 ≤ k ˆ x ( k ) − x ∗ k 2 , (23) where, w e used Lemma 3.3 and the fact ˆ g ( x ∗ ) = 0 . Us- ing (20), Lemma 3.2 and (23), k ˆ x ( k + 1) − x ∗ k = k ˆ x ( k ) − ˆ αg ( k ) − x ∗ + v ( k ) k = k ˆ x ( k ) − ˆ αg ( k ) + ˆ α ˆ g ( k ) − ˆ α ˆ g ( k ) − x ∗ + v ( k ) k ≤ k ˆ x ( k ) − ˆ α ˆ g ( k ) − x ∗ k + ˆ α k g ( k ) − ˆ g ( k ) k + ε ( k ) ≤ k ˆ x ( k ) − x ∗ k + 2 αε 0 L h +1 k 1+ η ≤ k ˆ x (0) − x ∗ k + (2 α ε 0 L h + 1) P k s =0 1 k 1+ η ≤ k ˆ x (0) − x ∗ k + (2 α ε 0 L h + 1) ζ (1 + η ) := e , (24) where, ζ ( . ) is the Riemann zeta function. F urther, f ( ˆ x ( k + 1)) ≤ f ( ˆ x ( k )) + h ˆ g ( k ) , ˆ x ( k + 1) − ˆ x ( k ) i + L f 2 k ˆ x ( k + 1) − ˆ x ( k ) k 2 = ⇒ ˆ r ( k + 1) ≤ ˆ r ( k ) + h ˆ g ( k ) , ˆ x ( k + 1) − ˆ x ( k ) i + L f 2 k ˆ x ( k + 1) − ˆ x ( k ) k 2 = ˆ r ( k ) − ˆ α h ˆ g ( k ) , g ( k ) i + ˆ α 2 L f 2 k g ( k ) k 2 + (1 − ˆ αL f ) h g ( k ) , v ( k ) i + L f 2 k v ( k ) k 2 = ˆ r ( k ) − ˆ α h ˆ g ( k ) , ˆ g ( k ) i + ˆ α 2 L f 2 k ˆ g ( k ) − g ( k ) k 2 + ˆ α 2 L f 2 k ˆ g ( k ) k 2 + ( ˆ α − ˆ α 2 L f ) h ˆ g ( k ) , ˆ g ( k ) − g ( k ) i + (1 − ˆ αL f ) h g ( k ) , v ( k ) i + L f 2 ε ( k ) 2 ≤ ˆ r ( k ) − ˆ α 2 k ˆ g ( k ) k 2 + 4 αnL 2 h + L f 2 ε ( k ) 2 , + (1 − ˆ αL f ) h g ( k ) , v ( k ) i ≤ ˆ r ( k ) − ˆ α 4 k ˆ g ( k ) k 2 + 4 αnL 2 h + L f +2 / ˆ α 2 ε ( k ) 2 (25) where, w e used the Cauc hy-Sc hw arz and AM-GM in- equalit y to get the second last inequality and inequality ± 2 h a, b i ≤ ζ k a k 2 + 1 ζ k b k 2 , a, b ∈ R p with ζ = 2 ˆ α to get the last inequality . Note that, ˆ r ( k ) = f ( ˆ x ( k )) − f ∗ ≤ h ˆ g ( k ) , ˆ x ( k ) − x ∗ i = h ˆ g ( k ) , ˆ e ( k ) i . Using (24) we obtain, k ˆ g ( k ) k ≥ k ˆ g ( k ) k k ˆ x ( k ) − x ∗ k e ≥ h ˆ g ( k ) , ˆ x ( k ) − x ∗ i e ≥ ˆ r ( k ) e . 9 This giv es, ˆ r ( k +1) ≤ ˆ r ( k ) − ˆ α 4 e 2 ˆ r 2 ( k )+ 4 αnL 2 h + L f +2 / ˆ α 2 ε ( k ) 2 . Th us, while ˆ r ( k ) > 2 e q 4 αnL 2 h + L f +2 / ˆ α ˆ α ε 0 , w e ha v e, ˆ r ( k + 1) ≤ ˆ r ( k ) − ˆ α 8 e 2 ˆ r 2 ( k ) ≤ ˆ r ( k ) − ˆ α 8 e 2 ˆ r ( k )2 n e ε 0 L h = 1 − α 4 e L h ε 0 ˆ r ( k ) = β ˆ r ( k ) = ⇒ ˆ r ( k ) ≤ β k ˆ r (0) . Note, αL h ε 0 < 4 e = ⇒ β ∈ (0 , 1) . This completes the pro of. 2 Remark 6 The or em 3.1 establishes a ge ometric r ate of c onver genc e to a smal l O ( ε 0 ) neighb orho o d of the optimal solution. Sinc e, the gr adients of functions f i ar e b ounde d, f ( x i ( k )) − f ∗ ≤ ˆ r ( k ) + h∇ f ( x i ( k )) , x i ( k ) − ˆ x ( k ) i ≤ ˆ r ( k ) + P n j =1 k∇ f ( x i ( k )) kk x i ( k ) − ˆ x ( k ) k ≤ ˆ r ( k ) + h m nε ( k ) . Henc e, using the r esult of The or em 3.1 we c onclude that f ( x i ( k )) − f ∗ , similar to ˆ r ( k ) de cr e ases ge ometric al ly, with r esp e ct to the outer gr adient desc ent iter ations of the Algorithm 2, until r e aching a smal l O ( ε 0 ) neighb or- ho o d. The p ar ameter ε 0 is a user sp e cifie d algorithm p a- r ameter which c an b e chosen appr opriately to get solu- tions arbitr arily close to the optimal solution. Note that the Algorithm 2 (in the worst c ase) utilizes O ( k log k ) numb er of c ommunic ation steps along with k gr adient de- sc ent iter ations. This is a log( k ) factor incr e ase c omp ar e d to other gr adient desc ent b ase d algorithms in the liter- atur e that typic al ly r e quir es O ( k ) c ommunic ation steps along with k gr adient iter ations. The additional c ommu- nic ation steps pr ovide impr ove d c onver genc e guar ante es for the GradConsensus algorithm over the existing algo- rithms in the liter atur e. In p articular, the Q-line ar r ate of c onver genc e with r esp e ct to the numb er of gr adient c om- putation steps (outer gr adient desc ent iter ations of Algo- rithm 2) in The or em 3.1 is str onger than the sub-line ar c onver genc e r ate pr esent in the liter atur e [3], [6], [11] un- der the assumptions 1, 2 and 3. Mor e over, empiric al ly it is se en that the total numb er of gr adient desc ent steps is smal ler with our algorithm. Thus it is is mor e suite d to situations wher e c omputations ar e exp ensive. Remark 7 W e emphasize that even if Assumption 4 is not satisfie d the r esult of The or em 3.1 stil l holds. Using, L emma 6.1, after p erforming O ( k 2 + k log ( k )) total num- b er of c ommunic ation steps (in the worst c ase) at the k th outer gr adient desc ent iter ation the GradConsensus al- gorithm c onver ges at a Q-line ar r ate until a neighb orho o d of the optimal solution. 3.3 Conver genc e Analysis for Str ongly Convex f In this subsection, we make an additional assumption: Assumption 5 f = P n i =1 f i is a str ongly c onvex func- tion with p ar ameter σ > 0 . Note, that Assumption 5 does not require all the f i ’s to b e necessarily strongly conv ex. How ever, when this is the case, assumption 5 holds naturally . W e will sho w in Theorem 3.2 that the solution estimates of every agent con verges exactly to the optimal solution of problem (1) at a R-linear rate. Similar to Theorem 3.1 we will provide the total num b er of communication steps required to ac hieve the R-linear rate of con v ergence. Theorem 3.2 L et assumptions 1-3 and 5 hold. L et ˆ α ≤ 2 σ + L f . Define, ρ := q 1 − 2 ˆ ασL f σ + L f . L et ε ( k ) = µ k , wher e, µ ∈ [ ρ, 1) . Consider, the outer gr adient de- sc ent iter ation k , the total c onsensus c ommunic a- tion iter ations K := P k s =1 k c ( s ) ar e b ounde d by P k s =0 log 1 µ s − log λ + log 8 n δ ( γ s γ γ − µ + γ s nL h αL 0 ) − log λ = O ( k 2 ) , wher e, L 0 := max 1 ≤ i ≤ n ∇k f i (0) k , γ = 1 + αL h and L h := max 1 ≤ i ≤ n L f i . Then at the k th outer gr adient desc ent iter ation of Algorithm 2, the agent estimates c onver ges at a R-line ar r ate to the optimal solution, k x i ( k ) − x ∗ k ≤ C µ k , for al l i ∈ V , wher e, C := k ˆ x (0) − x ∗ k + (2 α L h + 1) µ µ − ρ + 1 . Pro of. Consider, k ˆ x ( k ) − ˆ α ˆ g ( k ) − x ∗ k 2 = k ˆ x ( k ) − x ∗ k 2 + ˆ α 2 k ˆ g ( k ) k 2 − 2 ˆ α h ˆ g ( k ) , ˆ x ( k ) − x ∗ i ≤ 1 − 2 ˆ α σ + L f k ˆ x ( k ) − x ∗ k 2 + ˆ α ˆ α − 2 σ + L f k ˆ g ( k ) k 2 ≤ ρ 2 k ˆ x ( k ) − x ∗ k 2 , (26) where, w e used Lemma 3.4 and the fact ˆ g ( x ∗ ) = 0 . F rom (20), k ˆ x ( k + 1) − x ∗ k = k ˆ x ( k ) − ˆ αg ( k ) − x ∗ + v ( k ) k ≤ k ˆ x ( k ) − ˆ α ˆ g ( k ) − x ∗ k + ˆ α k ˆ g ( k ) − g ( k ) k + ε ( k ) . Com- bining (26) and the result of Lemma 3.2 we get, k ˆ x ( k + 1) − x ∗ k ≤ ρ k ˆ x ( k ) − x ∗ k + (2 α L h + 1) ε ( k ) = ρ k ˆ x ( k ) − x ∗ k + (2 α L h + 1) µ k . Using the triangle inequality and applying the ab ov e inequalit y recursively w e get, k x i ( k ) − x ∗ k ≤ k ˆ x ( k ) − x ∗ k + k x i ( k ) − ˆ x ( k ) k ≤ ρ k k ˆ x (0) − x ∗ k + (2 α L h + 1) P k − 1 s =0 ρ s µ k − s + µ k ≤ ρ k k ˆ x (0) − x ∗ k + (2 α L h + 1) µ k P k − 1 s =0 ρ µ s + µ k ≤ ρ k k ˆ x (0) − x ∗ k + (2 α L h + 1) µ k µ µ − ρ + µ k ≤ µ k h k ˆ x (0) − x ∗ k + (2 α L h + 1) µ µ − ρ + 1 i = C µ k . 2 10 Remark 8 Note that the Algorithm 2 (in the worst c ase) utilizes O ( k 2 ) numb er of c ommunic ation steps along with k gr adient desc ent iter ations for a glob al R-line ar r ate of c onver genc e to the exact optimal solution. Using the r e- sult in The or em 3.2 the p er no de work c omplexity (sum of total numb er of gr adient c omputations and total num- b er of c ommunic ation steps) to achieve an ac cur acy of τ > 0 , i.e., k x i ( k ) − x ∗ k ≤ τ is given by: O (log (1 /τ )) + O (log(1 /τ ) 2 ) . Thus, to obtain an η -optimal solution, Al- gorithm 2 utilizes O (log (1 /τ )) c omputation steps and O (log(1 /τ ) 2 ) c ommunic ation steps. Theorems 3.1 and 3.2 sho w that utilizing the ε - Consensus protocol also improv es the con vergence neigh b orho o d of the optimal solution. In particular, the consensus parameter ε ( k ) can be suitably c hosen to get near-optimal solutions. Theorem 3.2 shows that b y controlling the disagreement b etw een the agents (and hence the infeasibilit y of the algorithm iterates) to a small v alue using an appropriately chosen ε ( k ) , re- sults in strong con vergence guarantees (global R-linear rate of conv ergence) for the GradConsensus algorithm. Ho wev er, there exists a trade-off as tight regulation of the disagreement b et ween agents’ estimates w ould re- quire p erforming more total num b er of communication steps O ( k 2 ) un til any outer gradien t descent iteration k , compared to O ( k log k ) that giv es a Q-linear rate to the near optimal solution. 4 Numerical Sim ulations and Results W e consider a netw ork of 100 agen ts where the net- w ork in terconnection topology is generated using the Erdos-Ren yi mo del [37] with connectivit y probabilit y 0 . 2 . The weigh t matrix P is chosen using the equal neigh- b or mo del [31]. W e fo cus on solving the following dis- tributed logistic regression problem, minimize x ∈ R p P n i =1 1 n i P n i j =1 ln(1 + exp ( − ( A ij x ) y ij )) , where each agent i ∈ V has its training data ( A ij , y ij ) ∈ R p × {− 1 , +1 } , j = 1 , 2 , . . . , n i , with feature v ariables A ij and binary outcomes y ij . F or our sim ulations we generate an artificial data-set of feature vectors A ij with outcome y ij = 1 from a normal distribution with mean µ 1 and standard deviation σ 1 , and with output y ij = − 1 from another normal distribution with mean µ 2 and standard deviation σ 2 . W e will compare the p erformance of the prop osed GradConsensus algorithm with three state-of-the-art distributed approaches: Dis- tributed Gradient Descent (DGD) [3], EXTRA [11] and PushPull gradien t [18]. F or all the metho ds we use a constan t step-size. In the sim ulation results demon- strated here, we ha v e chosen a constan t ε ( k ) = 0 . 01 , ∀ k for the GradConsensus algorithm. Consensus Constraint violation: In Fig. 1 we plot the total mismatch b etw een the estimates generated b y different agents while solving the distributed logis- tic regression problem for the three algorithms. W e calculate the total mismatch at any iteration k as P n i =1 P n j =1 k x i ( k ) − x j ( k ) k P n i =1 P n j =1 k x i (0) − x j (0) k . F or all the three algorithms it can b e seen that the constraint violation has a signifi- can t v alue. Although, it decreases with the n umber of iterations but a large num b er of iterations are required to obtain a small total mismatc h among the agents. Hence, an y finite-time solution generated by the three algorithms will not provide a viable solution for appli- cations where meeting the constrain ts is critical. W e remark that the prop osed GradConsensus algorithm ensures that the agent estimates remain ε -close to each other during each iteration and any finite-time termi- nated solution results in a viable solution. Con vergence of solution residuals with resp ect to outer gradien t descent iterations: In the follow- ing discussion we present the results of comparison b e- t ween GradConsensus and other metho ds in terms of the solution residual k x i ( k ) − x ∗ k k x i (0) − x ∗ k with resp ect to the outer gradien t-descent iterations. Here, i is chosen to b e the agen t that gives the low est v alue of the solution resid- ual in the netw ork running the corresp onding algorithm. Fig. 2 gives the residual tra jectories for all the compared metho ds. Note that the GradConsensus gives a sup erior p erformance conv erging to an error less than 10 − 8 in ap- pro ximately 300 (outer) iterations. Observe that the de- crease in the residual is fastest for the GradConsensus algorithm among the compared algorithms, showing ap- plicabilit y of the prop osed scheme. EXTRA is the second b est metho d in this case requiring around 1000 iterations to achiev e a similar lev el of residual error. These results demonstrate that the total num b er of gradient compu- tation steps required by the prop osed GradConsensus algorithm (to reach the same v alue of solution residual) is significantly less compared to the other algorithms. This shows an adv antage of using the GradConsensus algorithm in applications where computation of the gra- dien ts is (computation) cost intensiv e. Fig. 1. Consensus constraint violation 11 Fig. 2. Residuals k x i ( k ) − x ∗ k k x i (0) − x ∗ k against the num b er of outer gra- dien t descent iterations (left) and the total communication and computation steps (right). Con vergence of solution residuals with resp ect to total num b er of comm unication and computation steps: As, the GradConsensus method utilizes an ap- pro ximate consensus proto col at eac h iteration the com- m unication burden of GradConsensus is larger than the other compared metho ds. T o pro vide a more compre- hensiv e comparison, w e compare the conv ergence of the solution residuals k x i ( k ) − x ∗ k k x i (0) − x ∗ k for each metho d with re- sp ect to the total num b er of communication and com- putation steps required (including the ε - Consensus pro- to col iterations). Like the previous case the agent i was c hosen as the one which gives lo west residual v alue. Fig. 2 gives the residual plots in case of all the four algo- rithms. W e observe that in terms of the communication complexit y PushPull is the b est p erforming metho d in this case requiring around 1000 communication steps to reac h a residual v alue of less than 10 − 10 . As discussed (remark 6) due to an ε - Consensus step at each itera- tion the GradConsensus algorithm tak es more n umber of communication steps to reach the same lev el of resid- ual (around 2100 iterations). How ever, it can b e seen in Fig. 2 that the prop osed GradConsensus doesn’t stall and conv erges to a smaller neigh b orho o d of the optimal solution unlik e the other algorithms. T able 1: A verage CPU time of the four metho ds (sec) GradConsensus EXTRA DGD PushPull 2.35 3.82 5.29 3.18 CPU Computation time requiremen t: The amount of time required b y a pro cessor to execute the instruc- tions of the compared algorithms denotes the CPU time of each algorithm. T able 1 provides av erage CPU time of the four metho ds to reach the residual v alue of less than 10 − 5 o ver 1000 tests with random graph realizations. T able 1 illustrates that even-though GradConsensus is more comm unication in tensiv e it tak es lesser CPU time to reach a desired solution. The reason for this observ ation is that the GradConsensus p erforms signif- ican tly less num b er of computationally exp ensive gradi- en t computation steps compared to the other metho ds (as detailed in Fig. 2). In applications where the com- putation complexity of the problems is a concern, the GradConsensus metho d provides a more efficient alter- nativ e to the existing metho ds with faster conv ergence. 5 Conclusion In this article, w e considered the problem of distribu- tiv ely minimizing the sum of n conv ex functions o ver a directed multi-agen t netw ork. W e introduced the opti- mize then agr e e framework where the optimization step and the consensus step are decoupled to improv e the con vergence prop erties of the distributed optimization algorithms b y reducing the mismatch b etw een the so- lution estimates of the agen ts. W e dev elop ed a nov el GradConsensus algorithm where each agent p erforms a gradien t-descent up date for the optimization step and utilizes a finite-time ε - Consensus proto col to achiev e ε ( k ) -close agreement b etw een the agent estimates at eac h iteration k of the algorithm. F urther, w e estab- lished strong conv ergence guaran tees for the prop osed GradConsensus algorithm under t wo different set of assumptions on the aggregate ob jective function f . In particular, w e show ed that the iterates generated b y the GradConsensus algorithm conv erges to the optimal solution at a linear rate of con vergence under these assumptions. In numerical simulations, we applied the GradConsensus to solv e the distributed logistic regres- sion problem. The results indicate the suitability of the prop osed GradConsensus algorithm in solving dis- tributed optimization problems. W e should note that the presen ted optimize then agr e e framew ork is appli- cable to other existing algorithms in the literature and pro vides a guideline for developmen t of newer algo- rithms to solv e the distributed optimization problem. 6 App endix Lemma 6.1 L et Assumptions 1 and 3 hold. Then at any outer gr adient desc ent iter ation k of Algorithm 2, after k c ( k ) = h log 1 ε ( k ) − log λ + log 8 n δ ( γ k P k − 1 s =1 ε ( s ) γ s + γ k − 1 γ − 1 αL 0 ) − log λ i , wher e, L 0 := max 1 ≤ i ≤ n ∇k f i (0) k , γ = 1 + αL h and L h := max 1 ≤ i ≤ n L f i , iter ations of the c onsensus pr o- to c ol (up dates (8)-(10)) with the initial c ondition s i (0) = z i ( k ) , t i (0) = 1 , ∀ i ∈ V we have: k x i ( k ) − ˆ z ( k ) k ≤ ε ( k ) , ∀ i ∈ V , wher e, ε ( k ) is the c onsensus toler anc e p ar ameter, L h := max 1 ≤ i ≤ n L f i and δ > 0 , λ ∈ (0 , 1) ar e p ar ameters of the gr aph G satisfying δ ≥ 1 n n , λ ≤ 1 − 1 n n . Pro of. The pro of is similar to Lemma 3.1. In particular, w e will utilize (18) to get an upp er b ound on the num b er of consensus iterations k c ( k ) . Recall, from (18) that the 12 estimates x i ( k ) generated by GradConsensus algorithm at every iteration k conv erges to the av erage ˆ z ( k ) at a geometric rate. Therefore, we conclude, k x i ( k ) − ˆ z ( k ) k ≤ 8 √ nλ k c ( k ) δ k z( k ) k , ∀ i ∈ V , (27) where, z( k ) := [ z 1 ( k ) , . . . , z n ( k )] ∈ R p × n and, δ > 0 , λ ∈ (0 , 1) satisfy: δ ≥ 1 n n , λ ≤ 1 − 1 n n . Here, the v ariables λ and δ are parameters of the graph G as de- fined in Lemma 3.1. Next, we will b ound k z( k ) k using an induction argumen t. Claim: At any k , k z i ( k ) k ≤ γ k P k − 1 s =1 ε ( s ) γ s + γ k − 1 γ − 1 αL 0 , for all i ∈ V , where, L 0 := max 1 ≤ i ≤ n ∇k f i (0) k , γ = 1 + α L h . Pr o of: F or k = 1 , for an y i w e ha ve, k z i (1) k = k x i (0) − α ∇ f i ( x i (0)) k ≤ α max 1 ≤ i ≤ n ∇k f i ( x i (0)) k = α max 1 ≤ i ≤ n ∇k f i (0) k = α L 0 . Note, x i (0) = 0 , ∀ i ∈ V due to the initialization of Algorithm 2. Assume, for k = k , k z i ( k ) k ≤ γ k P k − 1 s =1 ε ( s ) γ s + γ k − 1 γ − 1 αL 0 , for all i ∈ V . Now, for k = k + 1 , for an y i , k z i ( k + 1) k = k x i ( k ) − α ∇ f i ( x i ( k )) k ≤ k x i ( k ) − ˆ z ( k ) k + k ˆ z ( k ) k + α k∇ f i ( x i ( k )) k ≤ ε ( k ) + k ˆ z ( k ) k + α k∇ f i ( x i ( k )) − ∇ f i ( x i (0)) k + α k∇ f i ( x i (0)) k ≤ ε ( k ) + k ˆ z ( k ) k + αL h k x i ( k ) k + α k∇ f i (0) k (17) ≤ ε ( k ) + k ˆ z ( k ) k + αL h k ˆ z ( k ) k + αL h ε ( k ) + αL 0 ≤ (1 + αL h )[ γ k P k − 1 s =1 ε ( s ) γ s + γ k − 1 γ − 1 αL 0 ] + (1 + α L h ) ε ( k ) + αL 0 = γ k +1 P k s =1 ε ( s ) γ s + γ k +1 − 1 γ − 1 αL 0 , for all i ∈ V . Therefore, induction holds. Using the ab ov e claim it can b e shown that k z( k ) k ≤ √ n ( γ k P k − 1 s =1 ε ( s ) γ s + γ k − 1 γ − 1 αL 0 ) . If ε ( k ) δ λ k c ( k )8 √ n = k z( k ) k ≤ √ n ( γ k P k − 1 s =1 ε ( s ) γ s + γ k − 1 γ − 1 αL 0 ) it implies that, δ ε ( k ) 8 n ( γ k P k − 1 s =1 ε ( s ) γ s + γ k − 1 γ − 1 αL 0 ) ≤ λ k c ( k ) . Therefore, w e ha v e, k c ( k ) ≤ − 1 log λ h log 1 ε ( k ) + log 8 n δ ( γ k P k − 1 s =1 ε ( s ) γ s + γ k − 1 γ − 1 αL 0 ) i := k c ( k ) . Using (27) we conclude that after k c ( k ) num b er of itera- tions at the k th outer gradient descent iteration, k x i ( k ) − ˆ z ( k ) k ≤ ε ( k ) , for all i ∈ V . Remark 9 L emma 6.1 pr ovides an upp er b ound on the numb er of c ommunic ation steps r e quir e d at the k th outer gr adient desc ent iter ation of Algorithm 2 to obtain ε ( k ) - close solution. In p articular, if 0 < ε ( k ) < 1 , then at the k th outer gr adient desc ent iter ation of Algorithm 2, af- ter O log 1 ε ( k ) + k c ommunic ation steps the estimates of al l the agents ar e guar ante e d to b e ε ( k ) -close to e ach other. References [1] J. N. T sitsiklis, “Problems in decentralized decision making and computation.,” tech. rep., Massac husetts Inst of T ech Cambridge Lab for Information and Decision Systems, 1984. [2] D. P . Bertsek as and J. N. T sitsiklis, Par al lel and distribute d c omputation: numeric al metho ds , vol. 23. Prentice hall Englewood Cliffs, NJ, 1989. [3] A. Nedic and A. Ozdaglar, “Distributed subgradient methods for multi-agen t optimization,” IEEE T ransactions on Automatic Contr ol , vol. 54, no. 1, p. 48, 2009. [4] I. Lob el and A. Ozdaglar, “Distributed subgradient metho ds for con vex optimization o ver random netw orks,” IEEE T r ansactions on Automatic Control , vol. 56, no. 6, pp. 1291– 1306, 2010. [5] A. Nedic, “Asynchronous broadcast-based conv ex optimization ov er a netw ork,” IEEE T ransactions on Automatic Contr ol , vol. 56, no. 6, pp. 13 37–1351, 2010. [6] J. C. Duc hi, A. Agarwal, and M. J. W ainwrigh t, “Dual av eraging for distributed optimization: Conv ergence analysis and netw ork scaling,” IEEE T r ansactions on Automatic c ontr ol , vol. 57, no. 3, pp. 592–606, 2011. [7] J. Chen and A. H. Say ed, “Diffusion adaptation strategies for distributed optimization and learning ov er netw orks,” IEEE T r ans. on Signal Pro c essing , vol. 60, no. 8, pp. 4289–4305, 2012. [8] K. Y uan, Q. Ling, and W. Yin, “On the conv ergence of decentralized gradient descent,” SIAM Journal on Optimization , vol. 26, no. 3, pp. 1835–1854, 2016. [9] A. Nedić and A. Olshevsky , “Distributed optimization ov er time-v arying directed graphs,” IEEE T r ansactions on Automatic Contr ol , vol. 60, no. 3, pp. 6 01–615, 2014. [10] A. Nedić and A. Olshevsky , “Sto chastic gradient-push for strongly conv ex functions on time-v arying directed graphs,” IEEE T r ansactions on Automatic Contr ol , vol. 61, no. 12, pp. 3936–3947, 2016. [11] W. Shi, Q. Ling, G. W u, and W. Yin, “Extra: An exact first- order algorithm for decentralized consensus optimization,” SIAM Jour. on Opt. , vol. 25, no. 2, pp. 944–966, 2015. [12] W. Shi, Q. Ling, G. W u, and W. Yin, “A proximal gradient algorithm for decentralized comp osite optimization,” IEEE T r ansactions on Signal Pr oc essing , vol. 63, no. 22, pp. 6013– 6023, 2015. [13] Z. Li, W. Shi, and M. Y an, “A decentralized proximal-gradien t method with net work indep endent step-sizes and separated conv ergence rates,” IEEE T r ansactions on Signal Pr o cessing , vol. 67, no. 17, pp. 4494–4506, 2019. [14] A. Olshevsky , “Linear time av erage consensus and distributed optimization on fixed graphs,” SIAM Journal on Control and Optimization , vol. 55, no. 6, pp. 3990–4014, 2017. [15] K. I. T sianos, S. Lawlor, and M. G. Rabbat, “Push-sum distributed dual av eraging for convex optimization,” in IEEE c onf. on de cision and contr ol , pp. 5453–5458, IEEE, 2012. [16] D. Kemp e, A. Dobra, and J. Gehrk e, “Gossip-based computation of aggregate information,” in 44th Annual IEEE Symp osium on F oundations of Computer Scienc e, 2003. Pr o c ee dings. , pp. 482–491, IEEE, 2003. [17] R. Xin and U. A. Khan, “A linear algorithm for optimization ov er directed graphs with geometric conv ergence,” IEEE Contr ol Systems L etters , vol. 2, no. 3, pp. 315–320, 2018. [18] S. Pu, W. Shi, J. Xu, and A. Nedic, “Push-pull gradient methods for distributed optimization in networks,” IEEE T r ansactions on Automatic Contr ol , 2020. 13 [19] A. J. W o o d, B. F. W ollenberg, and G. B. Sheblé, Power gener ation, oper ation, and c ontrol . John Wiley & Sons, 2013. [20] S. Patel, B. Lundstrom, G. Saraswat, and M. V. Salapak a, “Distributed p ow er apportioning with early dispatch for ancillary services in renewable grids,” arXiv pr eprint arXiv:2007.11715 , 2020. [21] Z. F eng and G. Hu, “A distributed constrained optimization approach for spatiotemp oral connectivit y- preserving rendezvous of multi-robot systems,” in 2018 IEEE Confer enc e on De cision and Contr ol (CDC) , pp. 987–992, 2018. [22] J. A. F ax and R. M. Murray , “Information flo w and coop erative control of vehicle formations,” IF AC Pr o ce e dings V olumes , vol. 35, no. 1, pp. 115–120, 2002. [23] D. Jako vetić, J. Xavier, and J. M. Moura, “F ast distributed gradient methods,” IEEE T r ansactions on Automatic Contr ol , vol. 59, no. 5, pp. 1131–1146, 2014. [24] A. I.-A. Chen, F ast distributed first-or der metho ds . PhD thesis, Massach usetts Institute of T echnology , 2012. [25] B. Johansson, T. Keviczky , M. Johansson, and K. H. Johansson, “Subgradient metho ds and consensus algorithms for solving conv ex optimization problems,” in IEEE Conf. on De cision and Contr ol , pp. 4185–4190, IEEE, 2008. [26] V. Khatana, G. Saraswat, S. Patel, and M. V. Salap ak a, “Gradient-consensus metho d for distributed optimization in directed m ulti-agent netw orks,” in 2020 Americ an Contr ol Confer enc e (ACC) , pp. 4689–4694, 2020. [27] A. S. Berahas, R. Bollapragada, N. S. Kesk ar, and E. W ei, “Balancing communication and computation in distributed optimization,” IEEE T r ansactions on Automatic Contr ol , vol. 64, no. 8, pp. 3141–3155, 2018. [28] L. Xiao and S. Boyd, “F ast linear iterations for distributed av eraging,” Systems & Contr ol L etters , vol. 53, no. 1, pp. 65– 78, 2004. [29] M. Prak ash, S. T alukdar, S. Attree, V. Y adav, and M. V. Salapak a, “Distributed stopping criterion for consensus in the presence of dela ys,” IEEE T r ansactions on Control of Network Systems , 2019. [30] G. Saraswat, V. Khatana, S. Patel, and M. V. Sa lapak a, “Distributed finite-time termination for consensus algorithm in switching top ologies,” , 2019. [31] A. Olshevsky and J. N. T sitsiklis, “Conv ergence sp eed in distributed consensus and averaging,” SIAM Journal on Contr ol and Optimization , vol. 48, no. 1, pp. 33–55, 2009. [32] J. Melb ourne, G. Saraswat, V. Khatana, S. Patel, and M. V. Salapak a, “On the geometry of consensus algorithms with application to distributed termination in higher dimension,” International F e der ation of Automatic Contr ol (IF AC) , 2020. [33] V. Y adav and M. V. Salapak a, “Distributed proto col for determining when av eraging consensus is reached,” in 45th Annual Al lerton Conf , pp. 715–720, 2007. [34] M. Prak ash, S. T alukdar, S. Attree, S. Patel, and M. V. Salapak a, “Distributed stopping criterion for ratio consensus,” in 2018 56th Annual A l lerton Confer ence on Communic ation, Contr ol, and Computing (Al lerton) , pp. 131–135, IEEE, 2018. [35] G. Qu and N. Li, “Accelerated distributed nesterov gradient descent,” IEEE T r ansactions on Automatic Contr ol , 2019. [36] Y. Nesterov, Intr o ductory le ctur es on c onvex opt.: A b asic c ourse , vol. 87. Springer Science & Business Media, 2013. [37] P . Erdős and A. Rén yi, “On the ev olution of random graphs,” Publ. Math. Inst. Hung. A cad. Sci , vol. 5, no. 1, pp. 17–60, 1960. 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment