HUGE2: a Highly Untangled Generative-model Engine for Edge-computing
As a type of prominent studies in deep learning, generative models have been widely investigated in research recently. Two research branches of the deep learning models, the Generative Networks (GANs, VAE) and the Semantic Segmentation, rely highly o…
Authors: Feng Shi, Ziheng Xu, Tao Yuan
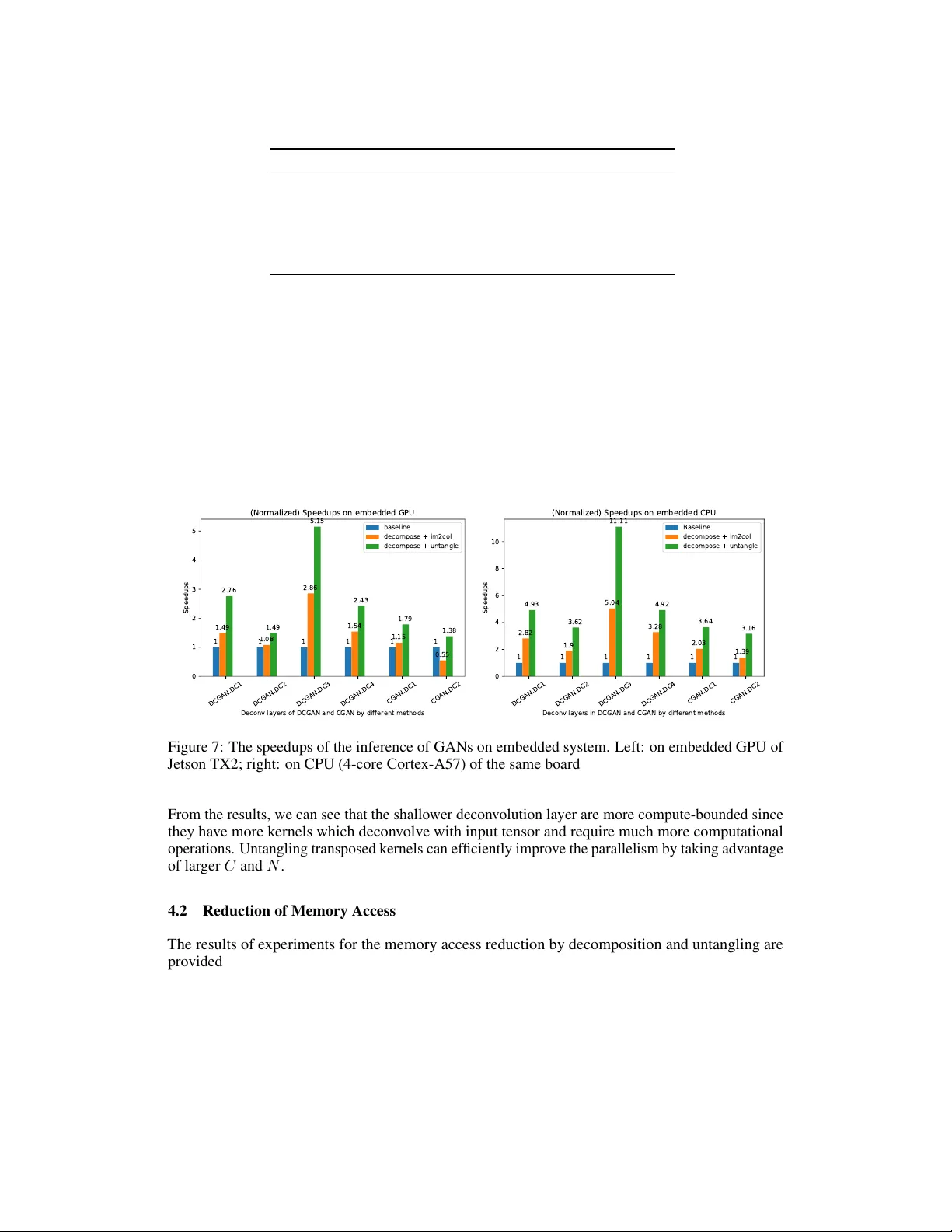
HUGE 2 : a Highly Untangled Generativ e-model Engine f or Edge-computing Feng Shi, Ziheng Xu, T ao Y uan, Song-Chun Zhu Department of Computer Science Univ ersity of California Engineering VI, Los Angeles, CA 90095 shi.feng@cs.ucla.edu, lawrencexu@g.ucla.edu Abstract As a type of prominent studies in deep learning, generative models ha ve been widely in vestig ated in research recently . T w o research branches of the deep learn- ing models, the Generative Networks (GANs, V AE) and the Semantic Segmentation , rely highly on the upsampling operations, especially the transposed con volution and the dilated con volution . Ho wev er , these two types of con v olutions are intrinsi- cally dif ferent from standard con volution regarding the insertion of zeros in input feature maps or in kernels respecti vely . This distinct nature se verely de grades the performance of the existing deep learning engine or frame works, such as Darknet, T ensorflo w , and PyT orch, which are mainly de veloped for the standard con volution. Another trend in deep learning realm is to deploy the model onto edge/ embedded devices, in which the memory resource is scarce. In this work, we propose a H ighly U ntangled G enerativ e-model E ngine for E dge-computing or HUGE 2 for accelerating these two special con volutions on the edge-computing platform by decomposing the kernels and untangling these smaller conv olutions by performing basic matrix multiplications. The methods we propose use much smaller memory footprint, hence much fe wer memory accesses, and the data access patterns also dramatically increase the reusability of the data already fetched in caches, hence increasing the localities of caches. Our engine achieves a speedup of nearly 5 × on embedded GPUs, and around 10 × on embedded CPUs, and more than 50% reduction of memory access. 1 Introduction Recently , the deep generativ e models and semantic segmentation algorithms have shown their stunning abilities in various fields, such as creating realistic images from the learned distribution of a giv en dataset, providing the robots with the ability to learn from en vironment without human input, generating the synthetic 3D objects for the scene parsing in a scenario, and so forth. These creativ e deep learning models attract great interests in research by both scholar and industry . The representativ e works include the Generati ve Neural Networks (GAN) Goodfello w et al. [2014], the V ariational Auto-encoder (V AE) Kingma and W elling [2013], and the semantic image segmentation algorithms Shelhamer et al. [2017], Chen et al. [2017]. Ho wev er , the generati ve models and semantic se gmentation algorithms rely heavily on the decon volu- tion which is an inef ficient, and both computation- and memory-intensiv e operation. The inef ficiency comes either from the zero insertions in either input tensor or kernels or from repeatedly accesses to the ov erlapped regions. Zero insertions cause wasteful computations, hence high latency . The non- consecuti ve memory access manner in decon volutions also hurts system performance drastically . The Preprint. Under revie w . ov erlapped region in outputs hinders the concurrent processing because the chained memory-writings happen to the same location. In this work, we concei ve a set of solutions from an algorithmic perspecti ve to improve the per - formance of decon volution for embedded systems. And the experiments sho w that we achiev e the speedup nearly 10 × on CPUs and 5 × on GPU, the memory storage and their accesses are reduced by more than 50 percent. 2 Background m ✕ n ✕ C H ✕ W m ✕ n ✕ C N N kernels of m ✕ n ✕ C Feature Maps of H ✕ W ✕ C N = Feature Maps of (H /2) ✕ ( W/2) ✕ N (H /2) ✕ ❨ W/2) im2col(…) & stride 2 col2im(…) (a) Standard Con v olution (e.g. stride = 2) vectorize(…) C kernels of m ✕ n ✕ N Transpose dimension N and C C m ✕ n ✕ N H ✕ W m ✕ n ✕ N col2im(…) & zero-insertion H ✕ W C col2im(…) ( b ) Trans p osed Con v olution = = skipped due to stride 2 = zero-inserted vectorize(…) Figure 1: The upper is the implementation of a strided con volution, and the bottom is its related transposed con v olution. 2.1 Decon volution The so-called decon volution used in the decon volution layers of the g enerative adversarial networks and the semantic ima ge segmentation is actually not as exact as the rev erse operation of the con volu- tion . Actually , the decon volution layers are learnable up-sampling layers. T wo categories of special con volution operations can fulfill such kind of task, they are the transposed con volution and the dilated con volution , respectiv ely . The follo wing subsections giv e details about how these operations work. 2.1.1 T ransposed Conv olution T ransposed con volution , also called F ractionally-Strided Convolution , is used not only to upsample an initial layer but also to create new features in enlar ged output feature maps. Theoretically , transposed con v olution works as a process of swapping the Forward and backward passes of a con volution, and this is where its name comes from. Algorithm 1 describes how this kind of con volution works. As it shows, when s m and s n are bigger than 1, the kernels slide on the feature maps with fractional steps. Figure 1 shows the implementations of the transposed con volution and its counterpart. It is always possible to emulate a transposed conv olution with a direct con volution. Such process first spreads the input feature map by inserting zeros (or blank lines) between each pair of ro ws and columns. The original input tensor I now becomes ˆ I . It then applies a standard conv olution, with strides of 1 (equiv alent to sliding step of 1 stride on the original input Dumoulin and V isin [2016]), on the resulting input representation, as shown in Algorithm 1. Let us tak e left hand side of Figure 2 as an example. It illustrates a 2 D transposed con volution of a zero-inserted feature map of size 6 × 6 and a 3 × 3 transposed kernel. 2 Algorithm 1 T ransposed Con v olution function C O N V 2 D T R A N S P O S E ( I , K, O , s m , s n ) . s m , s n are fraction factor also zero-insertion stride on input tensors for 0 ≤ k ≤ N − 1 do for 0 ≤ h ≤ H − R + 1 do for 0 ≤ w ≤ W − S + 1 do for 0 ≤ c ≤ C − 1 do for 0 ≤ m ≤ R − 1 , m = m + s m do for 0 ≤ n ≤ S − 1 , n = n + s n do O [ h, w, k ] += I [ h + m s m , w + n s n , c ] × K [ h mod s m + m, w mo d s n + k n , c, k ] Algorithm 2 Dilated Con v olution function C O N V 2 D D I L A T E D ( I , K, O , s m , s n ) . s m , s n are dilation factors also zero-insertion stride on kernels for 0 ≤ k ≤ N − 1 do for 0 ≤ h ≤ H − R + 1 do for 0 ≤ w ≤ W − S + 1 do for 0 ≤ c ≤ C − 1 do for 0 ≤ m ≤ R − 1 do for 0 ≤ n ≤ S − 1 do O [ h, w, k ] += I [ h + s m × m, w + s n × n, c ] × K [ m, n, c, k ] 2.1.2 Dilated Convolution Strictly speaking, despite of that dilated conv olution, also known as atrous con volution , is not acknowledged as a kind of decon volution, it has been widely explored to upsample input tensors in the semantic image se gmentation algorithms. Moreover , it shares some characteristics on which we can apply our acceleration algorithm as it does for the transposed con volution. On the contrary to transposed con volution, dilated con volution inserts zeros into kernels b ut not input tensors. The kernels are dilated so as to enlar ge their corresponding recepti ve fields. One thing needs to be noticed is that only stride bigger than 1 has the ef fect of upsampling on input tensors. Details are demonstrated in Algorithm 2 and right side of Figure 2. 2.2 Pre vious W ork T o our best kno wledge, up to this work, most of optimized solutions have been proposed are from the research of the hardware accelerator realm. These designated designs achieve much higher throughput compared with non-optimized generic hardware. Hence, our goal is to conceive an easily-accessible and cost-efficient solution for the generic hardw are. 1. Zero-Skipping : Y azdanbakhsh et al. [2018a,b] present a set of designs by sw apping zero rows and columns with non-zeros ones, and then rearranging non-zero ro ws and columns into ef fectiv e w orking groups. Howe ver , this design doesn’ t thoroughly solve the unbalanced working load problem among ef fective computation groups. Song et al. [2018] discov ers the delicate mathematical relation of indices among input tensors, kernels, and output tensors. These relations help rearrange the computations to skip zeros. But this method lacks memory access coalescing. Therefore, input tensors and kernels are accessed in a non-consecuti ve fashion with degradation in the o verall performance of the system. 2. Reverse Looping and Overlapping : Reverse Looping is introduced by both Zhang et al. [2017] and Xu et al. [2018]. This technique av oids accessing the output tensors in an ov erlapped manner with more operations, especially the accumulations and memory writings. Rev erse looping, on the contrary , uses the output space to determine corresponding input blocks, and thus eliminating the need for the additional accumulations and memory accesses. Ho wev er , the overlapped regions are not e venly distributed, hence the w ork load unbalancing issue among processing elements is still not well solved by such kind of solution. 3 Figure 2: left: the transposed con volution of a 3 × 3 kernel o ver a 6 × 6 input padded with a 1 × 1 border of zeros using 2 × 2 strides; right: dilated con volution of a 3 × 3 kernel ov er a 7 × 7 input with a kernel of the dilation factor of 2 Dumoulin and V isin [2016]. 3 Algorithm In this section, we introduce our algorithm for accelerating the deconv olution operations. Our algorithm consists of three steps: 1) kernel decomposition, 2) untangling of kernels and matrix multiplications, and 3) dispatching and combining the results to the output tensor . The following subsections pro vide the explanation for each of them. * * * * ( , , , ) Decompose Convovle (Each with Stride 2) Combine (2, 0) (0, 2) (0, 0) (0, 1) (0, 3) (2, 1) (1, 0)(1, 2) (3, 0) (1, 1) (1, 3) (3, 1) (0, 0) (0, 1) (1, 0) (1, 1) Figure 3: the kernel of the transpose conv olution is decomposed into 4 patterns, each conv olves with zero-inserted feature maps with stride 2, the final result is obtained by combining the 4 partial feature maps; the yellow , pink, and blue patches correspond to sliding windo ws at different positions. 3.1 Decompose Deconvolution Giv en an input tensor with stride 2 zero-inserted as example, and let us take a transposed kernel to slide on it. W e discover that there exists 4 kinds of patterns as shown at the bottom of Figure 3 where the nonzero elements in the kernel meet the nonzero elements in the zero-inserted input tensor ˆ I , and thus generate non-o verlapped ef fecti ve outputs as sho wn on the top of Figure 3. Mathematical description of these 4 patterns is giv en belo w: Pattern 1 : odd columns and odd r ows of k ernel con volv e with stride 2 on input tensor ˆ I and generate even columns and e ven r ows of output tensor O . O [2 h, 2 w, k ] = C X c =0 R X m =0 S X n =0 K [2 m + 1 , 2 n + 1 , k , c ] × ˆ I [2 h + 2 m, 2 w + 2 n, c ] (1) Pattern 2 : even columns and odd r ows of kernel con volv e with input tensor ˆ I and generate odd columns and even r ows of output tensor O . O [2 h, 2 w + 1 , k ] = C X c =0 R X m =0 S X n =0 K [2 m + 1 , 2 n, k , c ] × ˆ I [2 h + 2 m, 2 w + 2 n + 1 , c ] (2) Pattern 3 : odd columns and even r ows of kernel con volv e with input tensor ˆ I and generate even columns and odd r ows of output tensor . O [2 h + 1 , 2 w , k ] = C X c =0 R X m =0 S X n =0 K [2 m, 2 n + 1 , k , c ] × ˆ I [2 h + 2 m + 1 , 2 w + 2 n, c ] (3) 4 Pattern 4 : even columns and even r ows of kernel conv olve with input tensor ˆ I and generate odd columns and odd r ows of output tensor . O [2 h + 1 , 2 w + 1 , k ] = C X c =0 R X m =0 S X n =0 K [2 m, 2 n, k , c ] × ˆ I [2 h + 2 m + 1 , 2 w + 2 n + 1 , c ] (4) zero-inserted feature maps kernels Zero removal Ze ro re mo v al Decom p ose Ker nel s convolve c onvolve c onvolve c onvolve Intermediate output feature maps scatter scatter scatter scatter combine ✕ N N N C C C N output feature maps 3 ✕ 3 Convolutions Scatter and Combine Previous layer 2 ✕ 3 Convolutions 3 ✕ 2 Convolutions 2 ✕ 2 Convolutions Figure 4: left: the corresponding flow of the example; right: a simplified view One benefit of such decomposition is that the non-overlapped sparse regions on the output tensor do not cause any race conditions for writing in memory , since it will not be block ed by consecutiv e memory writings. After ha ving in vestigated the relation between indices of the nonzeros in input tensor and the decomposed kernels, we draw the conclusion that we can safely remo ve all the zero inserted in both input tensor and the decomposed kernels as shown in left side of Figure 4. The flow demonstrates the zero-remov al for all patterns where they become 4 smaller standard con volutions on input tensors without zero-insertion. Then we scatter and combine their results. The scattering of the results from each pattern follows the corresponding indices used in the zero-inserted v ersion. And the simplified flow on the right side of Figure 4 resembles the Inception module of GoogLeNet Szegedy et al. [2015] e xcept that the last step here is scattering and combination instead of stacking. 3.2 Untangling Ex t rac t Cor res p onding Rece pt i v e Fields Resha p e and cro p (Ski pp ed if DeCon v ) Poin t - w ise A cc u m u la t ion Ma t rix M u l t i p lica t ion Transfor ma t ion W - n + 1 H - m + 1 C C N N C C (H- m + 1) ✕ ( W - n + 1) N m ✕ n Receptive field of input FMs Kernel at (x, y , :) Partial output FMs N kernels of C ✕ m ✕ n Feature Maps of C ✕ H ✕ W (H- m + 1) ✕ (W - n + 1) Figure 5: untangle a standard con volution into a set of 1 × 1 con volutions T o further impro ve the parallelism of arithmetic computations, we propose an algorithm to untangle ev ery decomposed pattern of the transposed con volution into a set of 1 × 1 conv olutions. 3.2.1 Untangle standard con volution As shown in the right side of Figure 4 each pattern conv olves with input tensor as a standard con v olution. T o better understand our algorithm, let us take pattern 4 (the 3 × 3 one) as an example. 5 The process is shown in Figure 5. Giv en N decomposed kernels of pattern 4 (with zero removed) from previous subsection and the original input tensor, each kernel has dimension of m × n × C and the input tensor has dimension H × W × C . W e re group the elements of the k ernels by gathering N columns along the dimension C from ev ery kernel at position ( x, y ) (e.g. (0 , 0) at top left case, (0 , 2) for the bottom right case in the Figure 5) of the ( m, n ) plane. These columns form a matrix of dimension N × C . Then, their corresponding receptiv e fields on the input tensor can be fetched for input tensor to form another matrix of dimension ( H − m + 1)( W − n + 1) × C . Such configuration can be regarded as a 1 × 1 con volution with N 1 × 1 kernels working with a cropped tensor . The products of the m × n matrix multiplications are then accumulated together . The elements of the resultant matrix are then dispatched to the corresponding position in the output tensor . 3.2.2 Untangle dilated con volution Poin t - w ise A cc u m u la t ion Ex t rac t Cor res p onding Rece pt i v e Fields U n t ang ling (Transfor m) N dilated kernels of C ✕ R ✕ S R = ( m - 1) ✕ l + 1 , S = ( n - 1) ✕ l + 1 N C m ✕ n Feature Maps of C ✕ H ✕ W Ma t rix M u l t i p lica t ion N C C (H - R + 1) ✕ ( W - S + 1) Resha p e and cro p N Receptive field of input FMs Kernel at (x, y, :) Partial output FMs l : dilation stride C W - S + 1 H - R + 1 (H - R + 1) ✕ ( W - S + 1) l Input feature maps kernels C convolve (stride 2) N convolve (stride 1, depthwise) N C C copies Output feature maps ! outputs (derivatives) zero-insertion & copy calculat e deri v ati v e ! kernels (derivatives) subtract subtract subtract (update kernel) N N 1 2 3 4 5 Figure 6: left: untangle a dilated con volution; right: training of discriminator with dilated con volutions Dilated con volution can also take the adv antage of untangling. As it sho ws in left side of Figure 6 untangling technique is also applicable. The sliding step on input tensor is larger , and the receptiv e field shrink with multiple of stride. 3.2.3 T raining of GAN The back-propagation of the discriminator of GAN can be seen as a special case of dilated con volution. Step 3 of right side of Figure 6 depicts that, in order to propagate the deriv ativ es of the output errors, there are C × N con v olutions by C input feature maps and N deriv ative maps. Each deriv ativ e map is dilated (since discriminator uses the strided con volution) and con volves with each input feature map. Therefore, we can make C copies of each of N deri vati ve maps from output errors to form N new dilated kernels of C channels. Then the dilated kernels con volv e with input tensor to form the deriv ates of kernels and the results are subtracted from corresponding kernels. The dilated con volution in step 4 of right side of Figure 6 is actually a depth-wise v ersion. Hence, it corresponds to C = 1 in left side of Figure 6 which is seen as a outer-product of tw o vectors. The back-propagation of generator of GAN can be seen as a strided con volution of deri v ativ e maps of output errors and input tensor (not shown in this paper). 4 Experimental Results This section provides the e v aluation of our algorithms. W e use the decon volution layers of DCGAN Radford et al. [2015] and cGAN Mirza and Osindero [2014] as case study . Their configurations are shown in T able 1. In this paper, we mainly focus on the inference phase of decon volution layers, and all models are pretrained with CIF AR100 Krizhe vsky et al. dataset. The experiments for GAN’ s training are only in vestig ated at sev eral typical layers. The baseline of library we pick up is DarkNet Redmon [2013–2016] since it is open-sourced, and the commercial library such as cuDNN Chetlur et al. [2014] only deliv ers with binary code. The system used in our experiments equips with embedded CPU, 4-core ARM Cortex-A57, and a Nvidia’ s GPU (256-core NVIDIA Pascal ™ Embedded GPU). The experiments are run on both embedded CPU and embedded GPU. The metrics used for performance comparison includes the speedup and memory access reduction. W e compared our implementations of transposed con volution and dilated 6 T able 1: Configuration of deconv olution layers GAN Layer Input Ker nel Stride DCGAN DC1 4 × 4 × 1024 5 × 5 × 1024 , 512 2 × 2 DC2 8 × 8 × 512 5 × 5 × 512 , 256 2 × 2 DC3 16 × 16 × 256 5 × 5 × 256 , 128 2 × 2 DC4 32 × 32 × 128 5 × 5 × 128 , 3 2 × 2 CGAN DC1 8 × 8 × 256 4 × 4 × 256 , 128 2 × 2 DC2 16 × 16 × 128 4 × 4 × 128 , 3 2 × 2 con v olution with the baseline, which is the naiv e implementations from DarkNet for both CPU and GPU. Most 2D standard and transpose con volution implementation in modern deep learning library are based on im2col . 4.1 Speedup of Computation The speedup is obtained by the comparison of the computational runtime with the baseline. Figure 7 demonstrates the speedup gained by applying kernel decomposition and untangling for DCGAN and cGAN, respectiv ely . DCGAN.DC1 DCGAN.DC2 DCGAN.DC3 DCGAN.DC4 CGAN.DC1 CGAN.DC2 Deconv layers of DCGAN and CGAN by different methods 0 1 2 3 4 5 Speedups 1 1 1 1 1 1 1.49 1.08 2.86 1.54 1.15 0.55 2.76 1.49 5.15 2.43 1.79 1.38 (Normalized) Speedups on embedded GPU baseline decompose + im2col decompose + untangle DCGAN.DC1 DCGAN.DC2 DCGAN.DC3 DCGAN.DC4 CGAN.DC1 CGAN.DC2 Deconv layers in DCGAN and CGAN by different methods 0 2 4 6 8 10 Speedups 1 1 1 1 1 1 2.82 1.9 5.04 3.28 2.03 1.39 4.93 3.62 11.11 4.92 3.64 3.16 (Normalized) Speedups on embedded CPU Baseline decompose + im2col decompose + untangle Figure 7: The speedups of the inference of GANs on embedded system. Left: on embedded GPU of Jetson TX2; right: on CPU (4-core Cortex-A57) of the same board From the results, we can see that the shallower decon volution layer are more compute-bounded since they ha ve more k ernels which decon volve with input tensor and require much more computational operations. Untangling transposed kernels can efficiently improv e the parallelism by taking adv antage of larger C and N . 4.2 Reduction of Memory Access The results of experiments for the memory access reduction by decomposition and untangling are provided in Figure 8. One more thing we want to mention is that untangling technique we applied fa vors the C × N × R × S memory layout for the transposed kernels and C × H × W for the input tensor . This is because elements along C and N dimensions are stored consecuti vely in these layouts, and this helps with the data fetching in coalescing memory access pattern. As shown in Figure 8, it is obvious that the deeper deconv olution layers are data-bounded, the reduction can be obtained more on the deeper layers since the output tensor becomes lar ger by the unsampling ef fects. W e achie ve a memory access reduction around 30% to 70% by only applying untangling technique. 7 DC G A N . DC 1 DC G A N. DC 2 DC G A N . DC 3 DC G A N . DC 4 C G A N . DC 1 C G A N . DC 2 De c o n v l a y e r s o f DC G A N a n d C G A N b y d i f fe r e n t m e t h o d s 0 . 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 M e m o r y R e d u c t i o n 0 0 0 0 0 0 0 . 3 1 0 . 3 7 0 . 0 4 0 . 1 6 0 . 3 1 0 . 3 4 0 . 5 2 0 . 7 8 0 . 0 8 0 . 3 9 0 . 7 0 . 7 9 M e m o r y R e d u c t i o n i n DC G A N a n d C G A N b a se l i n e ( n o n m e m r e d u c t i o n ) d e c o m p o se + i m 2 c o l d e c o m p o se + u n t a n g l e DC G A N. DC 1 DC G A N . DC 2 DC G A N . DC 3 DC G A N . DC 4 C G A N . DC 1 C G A N. DC 2 De c o n v l a y e r s o f DC G A N a n d C G A N 0 . 0 0 . 5 1 . 0 1 . 5 2 . 0 2 . 5 S p e e d u p s 1 1 1 1 1 1 1 . 4 1 0 . 9 5 2 . 5 2 1 . 6 4 1 . 0 2 0 . 7 S p e e d u p s o f DC G A N a n d C G A N o n t r a i n i n g b a se l i n e u n t a n g l e Figure 8: left: the memory access reduction for GANs; right: the speedup of training GANs 4.2.1 Speedup in GAN training The right side of Figure 8 plots the speedup of training of GANs. W e select sev eral typical layers for the experiments, we want to cov er both the cases for dilated deriv ati ve maps con volving input tensor and deriv ative maps stridedly con volving input tensors. 5 Conclusion In this paper we presented a set of ef ficient algorithms and optimizations for decon volutions, these algorithms are the core components in our deep generativ e model engine " HUGE ". W e devised them as perv asiv e as possible to fit on most hardw are platforms. HUGE really accomplishes the outstanding results for our applications. It shows great impro vements in two crucial aspects, computation loads and memory access, respectiv ely . References Ian J. Goodfellow , Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David W arde-Farle y , Sherjil Ozair , Aaron Courville, and Y oshua Bengio. Generativ e adversarial nets. In Proceedings of the 27th International Confer ence on Neural Information Processing Systems - V olume 2 , NIPS’14, pages 2672–2680, Cambridge, MA, USA, 2014. MIT Press. URL http://dl.acm.org/citation.cfm?id=2969033.2969125 . Diederik P . Kingma and Max W elling. Auto-encoding variational bayes. CoRR , abs/1312.6114, 2013. E. Shelhamer, J. Long, and T . Darrell. Fully conv olutional networks for semantic segmentation. IEEE T ransactions on P attern Analysis and Machine Intelligence , 39(4):640–651, April 2017. ISSN 0162-8828. doi: 10.1109/TP AMI.2016.2572683. Liang-Chieh Chen, George Papandreou, Florian Schrof f, and Hartwig Adam. Rethinking atrous con volution for semantic image segmentation. CoRR , abs/1706.05587, 2017. URL . V incent Dumoulin and Francesco V isin. A guide to con volution arithmetic for deep learning. arXiv e-prints , art. arXiv:1603.07285, March 2016. Amir Y azdanbakhsh, Kambiz Samadi, Nam Sung Kim, and Hadi Esmaeilzadeh. Ganax: A unified mimd-simd acceleration for generativ e adversarial networks. In Proceedings of the 45th Annual International Symposium on Computer Ar chitectur e , ISCA ’18, pages 650–661, Piscata way , NJ, USA, 2018a. IEEE Press. ISBN 978-1- 5386-5984-7. doi: 10.1109/ISCA.2018.00060. URL https://doi.org/10.1109/ISCA.2018.00060 . Amir Y azdanbakhsh, Michael Brzozo wski, Behnam Khaleghi, Soroush Ghodrati, Kambiz Samadi, Nam Sung Kim, and Hadi Esmaeilzadeh. Flexigan: An end-to-end solution for fpga acceleration of generati ve adv ersarial networks. 2018 IEEE 26th Annual International Symposium on F ield-Pr ogrammable Custom Computing Machines (FCCM) , pages 65–72, 2018b. M. Song, J. Zhang, H. Chen, and T . Li. T owards efficient microarchitectural design for accelerating unsupervised gan-based deep learning. In 2018 IEEE International Symposium on High P erformance Computer Arc hitectur e (HPCA) , pages 66–77, Feb 2018. doi: 10.1109/HPCA.2018.00016. 8 Xinyu Zhang, Srinjoy Das, Ojash Neopane, and Kenneth Kreutz-Delgado. A design methodology for efficient implementation of decon volutional neural netw orks on an fpga. CoRR , abs/1705.02583, 2017. Dawen Xu, Kaijie T u, Y ing W ang, Cheng Liu, Bingsheng He, and Huawei Li. Fcn-engine: Accelerating decon volutional layers in classic cnn processors. In Pr oceedings of the International Confer ence on Computer - Aided Design , ICCAD ’18, pages 22:1–22:6, Ne w Y ork, NY , USA, 2018. A CM. ISBN 978-1-4503-5950-4. doi: 10.1145/3240765.3240810. URL http://doi.acm.org/10.1145/3240765.3240810 . Christian Szegedy , W ei Liu, Y angqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov , Dumitru Erhan, V incent V anhoucke, and Andre w Rabino vich. Going deeper with con volutions. In Computer V ision and P attern Recognition (CVPR) , 2015. URL . Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep conv olutional generativ e adversarial networks. CoRR , abs/1511.06434, 2015. Mehdi Mirza and Simon Osindero. Conditional generative adv ersarial nets. CoRR , abs/1411.1784, 2014. Alex Krizhe vsky , V inod Nair , and Geoffre y Hinton. Cifar-10 (canadian institute for adv anced research). URL http://www.cs.toronto.edu/~kriz/cifar.html . Joseph Redmon. Darknet: Open source neural networks in c. http://pjreddie.com/darknet/ , 2013–2016. Sharan Chetlur, Cliff W oolley , Philippe V andermersch, Jonathan Cohen, John Tran, Bryan Catanzaro, and Evan Shelhamer . cudnn: Efficient primitiv es for deep learning. CoRR , abs/1410.0759, 2014. URL http: //arxiv.org/abs/1410.0759 . 9
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment