CMIR-NET : A Deep Learning Based Model For Cross-Modal Retrieval In Remote Sensing
We address the problem of cross-modal information retrieval in the domain of remote sensing. In particular, we are interested in two application scenarios: i) cross-modal retrieval between panchromatic (PAN) and multi-spectral imagery, and ii) multi-…
Authors: Ushasi Chaudhuri, Biplab Banerjee, Avik Bhattacharya
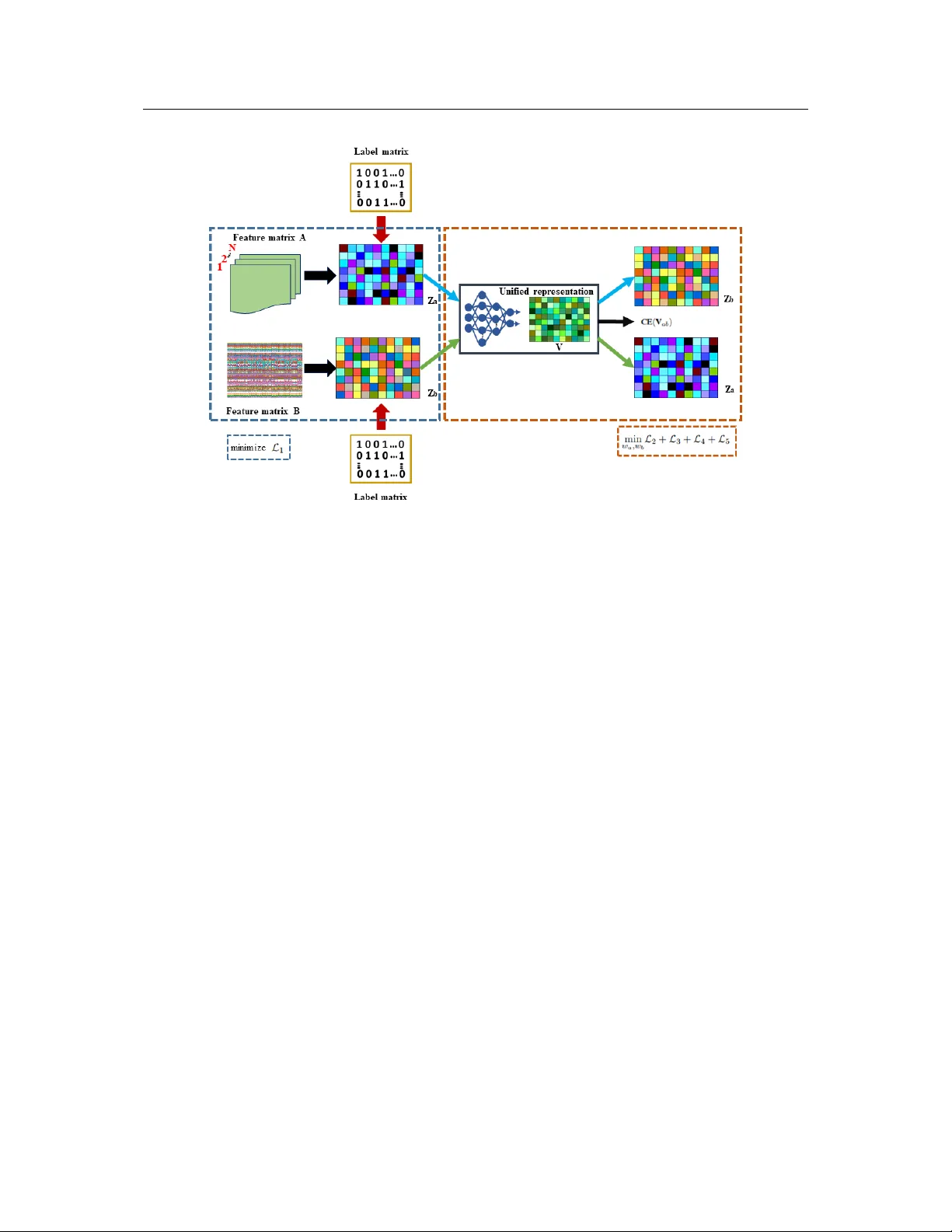
Paper is under consideration at P attern Recognition Letters CMIR-NET : A Deep Learning Based Model For Cross-Modal Retrie v al In Remote Sensing Ushasi Chaudhuri a, , Biplab Banerjee a , A vik Bhattacharya a , Mihai Datcu b a Indian Institute of T ec hnology Bombay , Mumbai-400076, India b German Aer ospace Center (DLR), Oberpfaffenhofen, Munich, Germany ABSTRA CT W e address the problem of cross-modal information retriev al in the domain of re- mote sensing. In particular , we are interested in two application scenarios: i) cross– modal retriev al between panchromatic (P AN) and multi-spectral imagery , and ii) multi-label image retriev al between very high resolution (VHR) images and speech based label annotations. These multi-modal retrie val scenarios are more challenging than the traditional uni-modal retriev al approaches giv en the inherent dif ferences in distributions between the modalities. Howe ver , with the increasing av ailability of multi-source remote sensing data and the scarcity of enough semantic annotations, the task of multi-modal retrie v al has recently become extremely important. In this regard, we propose a nov el deep neural network based architecture which is con- sidered to learn a discriminativ e shared feature space for all the input modalities, suitable for semantically coherent information retriev al. Extensi ve experiments are carried out on the benchmark large-scale P AN - multi-spectral DSRSID dataset and the multi-label UC-Merced dataset. T ogether with the Merced dataset, we generate a corpus of speech signals corresponding to the labels. Superior performance with respect to the current state-of-the-art is observed in all the cases. c 2019 Elsevier Ltd. All rights reserv ed. e-mail: ushasi@iitb.ac.in (Ushasi Chaudhuri) Paper is under consideration at P attern Recognition Letters 1. Introduction W ith the a vailability of e xtensi ve data collections, and with efficient storage facilities, the recent time has witnessed the accumulation of an enormous volume of remote sensing data. These data represent different modalities reg arding the same underlying phenomenon. This has, in turn, led to the requirement for shifting the paradigm from the traditional uni-modal to the more challenging cross-modal information extraction scenario. Ideally , given a query from one domain, the cross-modal approaches retriev e relev ant information from the other domains. In this regard, the necessity of the multi-modal approaches is especially more evident in the area of remote sensing (RS) data analysis, due to the a vailability of a large number of satellite missions. As an example, gi ven a panchromatic query image, we may want to retriev e all semantically consistent multi-spectral images captured by a different satellite sensor for better analysis in the spectral domain. In gist, the paradigm of cross-modal information retriev al is critical in the area of RS gi ven the complementary information captured in different cross-sensor acquisitions. Although the notion of image retriev al has receiv ed extensi ve attention, several other cross-modal com- binations are tried in the past, specifically in the area of computer vision and natural language processing: image - text (label) pairs [1, 2], RBG image - depth image pairs [3], etc. While most of the recent en- deav ors in this respect follo w a closed-form formulation to associate the samples from different domains directly [1, 4], others [5, 2, 6] depend on the con ventional learning-based approaches. In contrast to the single-label based image retriev al, few strategies extend the framew ork to support multiple semantic labels for each image, thus contriving the notion of multi-label image retrie val [7]. Paper is under consideration at P attern Recognition Letters In the same spirit, the notion of cross-modal information retriev al is practiced in the RS domain for many applications concerning the following modality pairs: SAR - optical, P AN - multi-spectral, image - text, to name a few . Note that these data can be made av ailable in paired or unpaired fashion, depending upon the underlying data extraction strategy . When two streams of data hav e precisely a set of data samples having the same label and re garded as a unit, we refer them as a pair ed dataset, else the y are designated as unpair ed datasets. In this respect, [6] classifies a generic cross-modal retrie val scenario into four broad categories: single-label paired, multi-label paired, single-label unpaired, and multi-label unpaired, respecti vely . By definition, the instances come as pairs in the paired case, else it is considered as unpaired. Ho wev er, in both the scenarios, the training data are considered in pairs given the modalities to learn the similarity function while the retrie val strategy may differ . While a gi ven paired dataset has the same number of instances in both the domains, the domains are of different size for the unpaired dataset. Unarguably the major challenge for designing a cross-modal retriev al framework lies in learning the unified feature space for the input data streams which is expected to be both discriminativ e and class-wise compact simultaneously . Once learned, such a common feature space can be used to compare the data from different domains ef ficiently . Ho wev er, since both the modalities hav e mostly different data distributions, learning such a feature space is inherently non-tri vial. The potentials of the deep learning techniques have been proven as far as the task of uni-modal image retriev al is concerned [8]. Despite the fact, such methods cannot be directly extended to the multi-modal case without additional constraints since it f ails to adequately capture the underlying correlation among the samples from all the domains. Paper is under consideration at P attern Recognition Letters Dataset: Query Retriv ed 1 Retriv ed 2 Retriv ed 3 Pa vement Bare Soil Buildings Grass Fig. 1: T op-3 retrieval instances from all the four combinations of cross-modal query samples (first column) are sho wn. The first two rows correspond to P AN → MUL (Aquafarm class), and MUL → P AN (High buildings class) respectively . The next two rows show the UC-Merced ↔ audio multi-label retriev al instances. Our contributions: Inspired by the discussions mentioned above, we propose a deep neural network based framew ork for cross-modal retriev al (CMIR-NET) in RS giv en a pair of data streams depicting the i) paired single-label, and ii) unpaired multi-label scenarios. In particular , we consider paired P AN- multi-spectral images for the paired case, whereas we introduce a new scenario for the multi-label unpair ed image - speech retriev al case. Specifically , we capture the speech signals of the semantic labels in different pronun- ciations/ascents which constitute our speech domain whereas the images with multiple semantic categories define our image domain (Figure 1 sho ws a fe w instances of cross-modal retriev al results obtained using the proposed framew ork). Effecti vely , the proposed model has simultaneous feature extractors for both the modalities which project Paper is under consideration at P attern Recognition Letters the data into a shared latent space. Sev eral intuitive constraints are further introduced to ensure discrimina- tiv e and domain-independence of the latent space. During inference, gi ven the query data from any of the modalities, the related data from the other modality are retriev ed as a ranked list using the nearest-neighbor search in the latent space. W e consider the large-scale DSRSID dataset [9], consisting of paired samples of singly-labelled P AN and multi-spectral data for the image to image retriev al. In contrast, the second set of experiments are performed on the very high resolution (VHR) multi-label UC-Merced [10] dataset and a ne w uncorrelated speech corpus. 2. Related W orks In this section, we primarily restrict our discussions on (i) single and multi-label image retriev al from a uni-modal RS dataset, and (ii) multi-modal image retriev al in the context of RS and computer vision. Retrieval from uni-modal data: The image retrie val frameworks can either be content-based or text-based, depending upon the nature of the query data. The applications of CBIR in RS mainly gained its motion after the Landsat thematic mapper multi-spectral satellite data were made accessible. Subsequently , sev eral techniques came up which focus on training of the retrie val models through the notion of activ e learning by incorporating the user’ s knowledge during training iterations [11]. As opposed to the real-valued feature representations, se veral techniques consider the binary features for quicker response during retrie val. In this regard, [12] proposes a hashing-based approximate nearest neighbor search for a f ast and scalable RS image Paper is under consideration at P attern Recognition Letters retriev al. V isual databases targeted by CBIR applications have been e xtended for multi-label image retrie val [7, 8]. Retrieval fr om cross-modal data: As already mentioned, cross-modal retriev al has mainly receiv ed its attention in the image to text or text to image settings [6, 4, 13, 14]. There have also been works on color image for depth perception for improv ed scene synthesis [3]. Howe ver , there e xists not much prior research regarding cross-modal retriev al in RS giv en the scarcity of multi-source images databases suitable for the retriev al task. In this respect, [9] v ery recently has proposed a large-scale dual-source remote sensing image dataset (DSRSID) which comprises of panchromatic and multi-spectral image pairs acquired from the Gaofen-1 satellite. Another attempt for cross-modal data retriev al in RS is by [15], which introduces a deep cross-modal retrie v al framew ork for image and audio data. T o the best of our kno wledge, these are the only two reported works in RS in cross-modal retrieval. Howe ver , a major limitation to these works is that both of them are modality specific and not generic, unlike ours. How we are different: In contrast to the very few previous methods like [9, 15] in cross-modal retriev al in RS, we focus on the discriminativ e and domain independence of the shared latent feature space simultane- ously . W e find that our real-valued feature learning strategy outperforms the pre vious discriminati ve hashing based feature encoding substantially . Besides, we introduce the ne w notion of cross-modal retriev al between multi-label image and speech domains to aid the visually impaired. W e also feel that the present works in cross-modal retriev al which hav e been done on image - te xt domain ha ving a single label is ef fectiv ely a classification problem as we have just a single label corresponding to any image. Hence we mov ed to a Paper is under consideration at P attern Recognition Letters more challenging problem of image - speech. This can hav e a unique application to help a visually impaired person. F or any image, a visually impaired person can hav e their corresponding audio label. Extensi ve experiments are performed to sho wcase the efficacy of the proposed frame work. 3. Methodology Preliminaries: Let A and B denote data from two dif ferent modalities/domains with shared labels from L ∈ { 1 , 2 , . . . , C } . In the paired case, both A and B ha ve the same number of instances which come as pairs while the sizes of the domains are dif ferent for the unpaired case. In this regard, we define the training labeled data triplets as X = { ( a i , b i , l i ) } where a i ∈ A , b i ∈ B , and l i ∈ L is the semantic label for both a i and b i . In the proposed scenario, A represents the image data while B can be image or speech. Ho wever , they can also be realized in terms of features extracted from the instances in which case a i ∈ R d a and b i ∈ R d b , respectiv ely . Under this setup, we aim for learning a unified feature representation space V with dimensions d v . The normalized instances from A and B are projected in such a way that i) the samples with same labels should be close to each other (irrespective of their domains) while samples from different classes should be distinctiv ely placed, ii) giv en a triplet ( a i , b i , l i ) from X , the projected a i and b i should have highly similar feature representations. In this regard, let V a i and V b i represent the projected representations corresponding to a i and b i , respectively . During inference, the query image is projected onto V , and subsequently , the corresponding ranked list is obtained using a nearest-neighbor based approach. Paper is under consideration at P attern Recognition Letters Fig. 2: Overall pipeline of the proposed CMIR-NET architecture for learning the unified embedding space from two dif ferent modality of signals. The loss functions are defined and discussed in detail in section 3.1. T o realize V , the proposed framew ork broadly consists of two parallel feature extractor networks for A and B , which are further compared in the shared V space. All the concerned loss measures are ev aluated in the V space for ensuring its discriminative and domain-independence. A detailed depiction of the proposed framew ork can be found in Figure 2. In the following, both the training and inferences stages are discussed in greater details. 3.1. T raining - modeling the unified featur e space V In order to learn V a = { V a i } and V b = { V b i } given X , we propose a two-stage training process as follows: • First, we train two separate domain specific classification networks for { ( a k , l k ) } | A | k =1 and { ( b j , l j ) } | B | j =1 Paper is under consideration at P attern Recognition Letters where both the networks consist of a feature extraction module followed by the classification module ( | · | denotes the number of samples in the respective domain). It is further ensured that the extracted features for giv en a k and b j , to be represented by Z a k and Z b j henceforth, are highly non-redundant as far as the dependencies among the indi vidual feature dimensions are concerned. • { Z a i } and { Z b i } (corresponding to X ) are further considered as the inputs to the network designed for obtaining V . The intuition behind obtaining the intermediate representations { Z a k /b j } from the original data is to ensure that the { Z a i /b i } no w contains enough class information explicitly , which subsequently helps in learning a better V . The rationale behind the two-stage training protocol is to avoid learning a tri vial solution. T o pre vent this, we take two measures, i) apply an orthogonality constraint (equation 1), and ii) initialize the weights after some pre-training. W e found that randomly initialized weights for an end-to-end framework lead to learning up of a sub-optimal V , as the remaining difference losses (discussed in equation 6) dominate the system than the classification loss. Generation of Z a k /b j : Gi ven { ( a k , l k ) } and { ( b j , l j ) } , separate neural network based architectures are deployed for both the modalities where the penultimate network layers (prior to the classification layer) represent the Z a k /b j features. T o further ensure non-redundancy in the Z a k /b j features, a soft orthogonality constraint is included in the cost function along with the standard cross-entropy based classification loss as Paper is under consideration at P attern Recognition Letters follows: L A / B = CE ( ˜ Z a/b ) + || ˜ Z T a/b ˜ Z a/b − I || 2 F (1) where ˜ Z a = { Z a k } , CE ( ˜ Z a ) denotes the cross-entropy loss for the labeled samples from A , and I is a vector of ones, respectiv ely . The network for obtaining { V a i /b i } is trained henceforth giv en the learned { Z a i /b i } . Construction of V : T o construct the unified representations { V a i } and { V b i } from { Z a i } and { Z b i } , we use a neural network based discriminati ve encoder -decoder architecture which minimizes the follo wing four loss measures: • the difference between each pair of corresponding i th samples in V a and V b : ( L 2 ) (equation 2). • a classification loss on V ab = [ V a , V b ] : ( L 3 ) (equation 3). • separate feature norm loss measures on both V a and V b , respectiv ely: ( L 4 ) . • a decoder loss which is deemed to reconstruct cross-domain samples giv en the latent representations: ( L 5 ) (equation 4). L 2 ensures that the latent feature embeddings for similar samples from both the domain turns out to be highly analogous in the V space, while imposing an inter-class separation constraint. L 3 imposes an intra-class, or within class separation constraint by minimizing the cross-entropy loss on all the samples from both the domains. L 3 is essential as it encodes the label information within the unified representation V . In addition, we penalize any unbounded modulation of the latent representations V a/b by explicitly Paper is under consideration at P attern Recognition Letters minimizing their ` 2 norm in L 4 . Finally , the decoder loss L 5 ensures the domain in variance of the space V by reconstructing the cross-domain samples giv en the latent V a/b . This difference loss between the unified representation and the corresponding cross-modal sample, effecti vely For L 2 , let w a and w b be the learnable parameters such that V a i = Z a i w a and V b i = Z b i w b , and w c denotes the parameters for the classifier block. Giv en that, we define L 2 , L 3 , and L 4 as follows: L 2 = || V a − V b || 2 F (2) L 3 = CE ( V ab ) (3) L 4 = || V a || 2 F + || V b || 2 F (4) Similarly for L 5 , let w ab and w ba denote the learnable weights for the decoder blocks. Gi ven the latent V a , we try to reconstruct Z b in the decoder and vice-versa by as follo ws: L 5 = || w ab V a − Z b || 2 F + || w ba V b − Z a || 2 F (5) where Z a/b = { Z a i /b i } . The overall objective function and optimization: W e consider a weighted combination of the loss men- tioned above measures for obtaining the latent space V . In particular , the overall loss function to be mini- mized can be mentioned as: L = λ 1 L 2 + λ 2 L 3 + λ 3 L 4 + λ 4 L 5 + λ 5 R (6) Paper is under consideration at P attern Recognition Letters giv en the non-negati ve weights λ 1 − 5 and R defines the standard ` 2 regularizer on w a and w b , respectiv ely . In general, R takes the form of: R = || w a − α || 2 F + || w b − α || 2 F (7) for α ≥ 0 . It can be seen from the equations 2 and 5 that since these loses are just a difference loss, the loss would reach a global minimum of value 0 if the system learns a tri vial solution, i.e., all the multiplicativ e weights are learned to zero. Hence we use the regularizer term R to ensure that the weight norm of the layer being learned is constrained to some value α . This step is essential to ensure that the framew ork does not end up learning a trivial solution. W e follow the standard alternate stochastic mini-batch gradient-descent based optimization strategy for minimizing L . Algorithm 1 mentions the stages for minimizing L . 3.2. Uni-modal and Cr oss-modal Retrieval During inference, gi ven a query ( a/b ) q uer y from any of the modalities, it is possible to perform i) uni- modal, ii) cross-modal, and iii) mixed-modal information retriev al in the V space. The retriev al is based on the nearest-neighbor search in V which outputs the top- K data according to their similarity with ( a/b ) q uer y in terms of the Euclidean distance measure (Algorithm 1). 4. Experiments W e discuss the performance analysis of the proposed method in the following. Paper is under consideration at P attern Recognition Letters Algorithm 1 The proposed training and inference stage Input: { ( a k , l k ) } , { ( b j , l j ) } , and X Output: Unified representations V a/b ( w a Z a and w b Z b ). 1: Normalize A and B . 2: Generate intermediate representations { Z a k } and { Z b j } by minimizing L A / B . 3: T rain the network to obtain V by optimizing L . The optimization follows the follo wing stages: 4: do 5: min w a ,w b λ 1 L 2 + λ 2 L 3 + λ 3 L 4 + λ 4 L 5 (8) 6: while until con vergence 7: retur n w a and w b (for projecting data onto V ) Input: a ∈ A or b ∈ B Output: T op- K retrieved data. 8: Uni-modal retriev al using K -NN from w a Z a or w b Z b . 9: Cross-modal retriev al using K -NN from w a Z a and w b Z b . Paper is under consideration at P attern Recognition Letters Datasets and model architecture: For the image to image retrie val case, we consider the lar ge-scale DSR- SID dataset proposed in [9]. The dataset comprises of 80,000 pairs of panchromatic and multi-spectral images from 8 major land-cover classes where both the images of a gi ven pair focus on the same geo- graphical area on the ground (Figure 3). The images are acquired by the GF-1 panchromatic and GF-1 multi-spectral sensors, respectiv ely . The panchromatic data samples are of image size 256 × 256, with a spatial resolution of 2m and single spectral channel ( A ∈ R 256 × 256 × 80 , 000 ), while the multi-spectral images are of dimensions 64 × 64, with a resolution of 8m, and 4 spectral channels ( B ∈ R 64 × 64 × 4 × 80 , 000 ). In order to learn ˜ Z a/b from the raw image data, we consider two separate con volutional netw ork architectures. For each of the networks, we use three con volution - pooling - non-linearity blocks as: ( 3 × 3 × channel × 32 ), ( 3 × 3 × 32 × 32 ), and ( 3 × 3 × 64 × 128 ) where leak y R eLU ( · ) is considered as the non-linear acti vation. Note that the batch-normalization layer is also appended after each con volution block. After the conv olution modules, we consider a fully-connected layer of size ((4 ∗ 4 ∗ 128) × 128 ), which is activ ated by a R eLU ( · ) function and a drop-out layer with probability 0 . 5 . Hence, the dimensions of Z a/b is 128 -d. For the second set of experiments, we consider the multi-label VHR UC-Merced dataset [10] (domain A ), where the B domain corresponds to speech signals. In particular , we construct a corpus of spoken speech samples for each of the land-cover semantic labels in .wav format. T o increase the diversity of the speech samples, it is ensured that the labels are pronounced with different English accents. In this way , W e gather 15 speech samples for each label, leading to 255 speech samples in total. Also, note that the multi-label UC- Merced dataset consists of 2100 VHR images of size 256 × 256 where each image has multiple associated Paper is under consideration at P attern Recognition Letters semantic labels from a set of 17 land-cover categories [7]. As opposed to the DSRSID dataset where features are directly learned from the images, we consider the features extracted from pre-trained Con vnet networks for initial feature extraction for this data. Essentially , the B space of speech signals is constructed using the vgg-ish [16] model which is pre-trained on the lar ge-scale AudioSet dataset and outputs a d b = 128 -d v ector corresponding to each input signal. On the other hand for A , the images are represented using d a = 4096 -d Imagenet pre-trained VGG-16 [17] features. In order to obtain ˜ Z a , we train a multi-label classifier for the images while the standard 17 -class multi-class classifier is trained for the speech signals in order to obtain ˜ Z b . The size of the final Z a/b space is 128-d, similar to DSRSID. Subsequently , the network responsible for obtaining V consists of three fully-connected neural network layers each coupled with ReLU ( · ) non-linearity both in the encoder as well as the decoder branches. The latent space with dimensions d v (the third encoder layer) is used as V for both the dataset. T raining protocol and evaluation: W e consider the Adam optimizer with a learning rate of 0 . 01 and batch size of 64 for training both the networks (corresponding to Z and V ), and trained both the model for 400 epochs. For performance ev aluation, we report the mAP (Mean A verage Precision) and P@10 scores. The mAP v alue is calculated by finding the mean of the a verage precisions of each class for a set of queries. Higher the mAP score, better is the framework. Also, we compare the performance on the DSRSID data with three techniques from the literature: SCM [13], DCHM [14], and SIDGCNN [9], all of which are based on discriminativ e hash-code learning. In addition, we perform extensi ve ablation study to sho wcase the importance of i) the indi vidual loss terms, ii) the hyper -parameter α , iii) comparison between V a/b and Z a/b Paper is under consideration at P attern Recognition Letters features, and iv) separate pre-training of Z features. 4.1. Results on DSRSID dataset Follo wing the protocol mentioned in [9], we consider a split of 75000-5000 for constructing the training and test sets for this dataset. The same set of samples are used for all similar techniques to avoid any bias. The λ 1 , to λ 4 parameters (Equation 6) are set to 1 since we did not find the training to be sensiti ve to the choice while we consider se veral values for λ 5 in the range [1 , 0 . 001] and consider the one giving the best performance on a validation set (considering unimodal retriev al). Similarly , the weight-norm parameter α of Equation 7 is set to 0 as a higher v alue is found to degrade the subsequent retrie val precision. W e report the performance on both uni-modal as well as cross-modal retriev al for this dataset on the V space. In this regard, we consider different dimensions of the embedding space V and report a sensiti vity analysis in T able 1. It can is found that the retriev al accuracy for this dataset is mainly in variant to the dimensionality of v , although we obtain the best performance for d v = 64 . On the other hand, we compare the performance of our technique with the literature only for the cross-modal scenarios. It can be observed from T able 2 that the proposed technique outperforms SCM and DCMH substantially by a large margin ( ≥ 13% ) in terms of the mAP score for both the cases when the query image comes from A or B (P AN ↔ MUL). Likewise for 32 -dimensional V , we observe that our method outperforms SIDHCNN for both P AN to MUL and MUL to P AN. On the other hand for 16 -dimensional V space, we surpass the performance of SIDHCNN for MUL to P AN by 2% , while we report comparable retriev al performance to SIDHCNN for the P AN to MUL case. Overall for d v = 32 and 64 , we report the new state-of-the-art performance for this Paper is under consideration at P attern Recognition Letters Fig. 3: A verage precision for top-50 retriev al for both P AN → MUL and MUL → P AN cases. T able 1: Performance of the proposed CMIR-NET framework on the DSRSID dataset in terms of mAP (%) and precision at top-10 (P@10) (%) values, under dif ferent embedding vector code lengths ( d v ). T ask d v =16 d v = 32 d v = 64 mAP P@10 mAP P@10 mAP P@10 Pan → Mul 95.52 97.10 98.96 98.99 99.05 99.40 Mul → Pan 98.77 99.00 97.95 97.99 98.93 98.60 Pan → P an 99.41 99.82 98.11 98.40 98.69 99.40 Mul → Mul 99.55 99.69 98.18 98.60 98.25 98.40 dataset. Additionally , Figure 3 shows the av erage class-wise precision both the P AN to MUL and MUL to P AN retriev al cases for the top-50 retriev al scenario. It can be observed that the proposed method produces very high precision measures for all the classes. 4.2. Results on UC Mer ced-Audio dataset As already mentioned, this dataset contains multi-label images with a different number of labels for each of the classes ranging between 100 and 1300 . Hence, while training the network for V , we feed each image with a single-label speech signal with the same label at random. As a result, the size of Z a becomes Paper is under consideration at P attern Recognition Letters T able 2: Comparison of mAP values of our proposed framew ork and other comparative algorithms based on the code length of the embedding space. T ask Model d v =16 d v = 32 mAP(%) mAP(%) Pan → Mul SCM [13] 34.72 37.67 DCMH [14] 80.76 85.09 SIDHCNN [9] 95.53 96.43 Proposed CMIR-NET 95.52 98.96 Mul → Pan SCM [13] 36.71 38.71 DCMH [14] 80.23 84.45 SIDHCNN [9] 97.25 97.89 Proposed CMIR-NET 98.77 97.95 R 7004 × 128 , owing to 7004 distinct labels corresponding to the multi-label images. W e associate each image with a randomly selected speech signal representing one of its categories which construct the features Z b . W e consider a 70%: 30% training - test split for this dataset. The parameters λ 1 , λ 3 , λ 4 , and λ 5 are set to 0.00001, 0.01, 0.01, 1, respecti vely , upon grid-search on a v alidation set (similar to DSRSID). α is set to 1 for this case (more about α in Section 4.3). W e report the mAP and the P@10 values for both the cross-modal scenarios where we vary the dimensions of V as 32, 64, and 128, respectively (T able 3). W e observe that the performance increases substantially with increasing size of the V space. On the other hand, W e find that the performance of the Image to Audio retrie v al case is substantially superior to the Audio to Image retriev al case. This can be attrib uted to the complexity of the multi-label annotations of the image space and the high intra-class variability of the speech signals. Paper is under consideration at P attern Recognition Letters T able 3: Performance of the CMIR-NET framework on UC Merced-Audio dataset in terms of mAP and P@10 values, with v ariation in embedding vector code length ( d v ). Model d v =32 d v = 64 d v = 128 mAP P@10 mAP P@10 mAP P@10 Img → Aud 29.67 60.91 41.60 63.15 62.11 64.81 Aud → Img 21.60 40.11 42.36 51.29 54.21 56.00 Fig. 4: Ablation study with different losses. Paper is under consideration at P attern Recognition Letters 4.3. Critical analysis Advantage of pre-training Z a/b over end-to-end training of the entire model : W e find that the training error abruptly modulates when only one network is considered to learn the V space directly from the input data (bypassing the modeling of Z a/b ), which further leads to a somewhat less discriminativ e V space. W e observe a steady enhancement of at least 3 − 5% in mAP values for all the experimental cases when Z a/b are separately learned. Ablation on the loss terms : Here, we analyze the effect of the specific loss terms. First, we consider the cross-modal retriev al experiments directly from the feature matrices Z a and Z b . W e find that the mAP and P@10 scores are less than 15 % for all the four experimental scenarios (for both the dataset) with Z a/b features. This illustrates precisely the reason wh y we need to hav e a unified representation for data retrie val, as the feature spaces of each data stream encode uncorrelated information. W e refer to this case as the base model, on top of which we add the proposed loss terms incrementally and showcase their ef fectiv eness. On the other hand, the model with all the loss measures (Equation 6) is henceforth termed as the full model. In particular , Figure 4 shows a bar graph based analysis, wherein we sho w the mAP v alues obtained on the two experimental cases: Image to Audio (UC-Merced) and P AN to MUL (DSRSID). After studying the base case, we consider the ef fect of the latent loss ( L 2 ) by examining the performance of the full model, e xcluding the L 2 loss in Equation 6. It is found that L 2 boosts the performance of the model quite meagerly . Although this loss is the backbone for the construction of the unified representation V , it alone does not consist of any label information in the V space. W e then in vestigate the effect of decoder Paper is under consideration at P attern Recognition Letters loss ( L 5 ) by excluding this loss from the full model. The decoder loss function is found to be essential to boost the performance of the framework as it mak es V robust for both the modalities while restricting any tri vial solution in the V space. It is observed that without the consideration of L 5 , most of the latent feature vectors rapidly approach to zero values in V . W e furthermore follow a similar protocol to study the effect of the classification loss function ( L 3 ). The classification loss help in fine-tuning the performance of the model. This is achie ved by encoding the respecti ve class information labels in the unified embedding vector . By keeping the entire loss function as in Equation 6, we see that we can achiev e a very high retriev al performance. Sensitivity to weight norm parameter α : W e show the effect of the critical parameter α , which is used in the weight regularizing term R (Equation 7). Setting α to 0 for both the cross-modal retrie val scenarios of the UC-Merced - Audio dataset leads to the learning of a trivial V where all the projected samples collapse to a single point, and hence one is unable to perform meaningful retrie val. This gi ves us a v ery useful insight as to why the regularizer term is so important in this framework. A non-zero α value helps the system to av oid learning a non-tri vial solution. The performance of the model on the UC Merced - Audio dataset with different α v alues can be obtained in T able 4. It shows that the best retriev al performance can be achie ved for α = 1 for both the combinations in this case. On the other hand, we observe that α = 0 gives the best results for the DSRSID dataset. Paper is under consideration at P attern Recognition Letters T able 4: Sensitivity to critical parameter α for the UC-Merced ↔ Audio case. Model α = 0 α = 1 α = 2 mAP P@10 mAP P@10 mAP P@10 Img → Aud 0 0 62.11 64.81 32.09 52.77 Aud → Img 0 0 54.21 56.00 33.64 45.01 5. Conclusions W e propose a novel framew ork for cross-modal information retriev al and ev aluate the same in conjunc- tion with remote sensing data. The framework focuses on learning a unified and discriminative embedding space from different input modalities. The proposed model is generic enough to handle both uni-modal and cross-modal information retriev al scenarios. W e further introduce a new e xperimental scheme of cross- modal retrie val between the multi-label image and audio domains where a v ariety of speech signals are used to represent the semantic labels. As a whole, we showcase the performance of the proposed model on the large-scale DSRSID and the image - audio dataset where improved performance can be observed. W e are currently interested in extending the model to support more than two modalities and also in exploring the possibility of using compact hash codes to learn the shared embedding space. W e are also interested to see its applicability in retrieving multi-spectral - SAR data. Howe ver , owing to the lack of av ailability of a such annotated dataset, it remains as a future work for no w . References [1] D. W ang, X.-B. Gao, X. W ang, L. He, Label consistent matrix f actorization hashing for large-scale cross-modal similarity search, IEEE T ransactions on Pattern Analysis and Machine Intelligence. [2] L. W ang, Y . Li, J. Huang, S. Lazebnik, Learning two-branch neural networks for image-text matching tasks, IEEE T ransactions on Pattern Analysis and Machine Intelligence 41 (2) (2019) 394–407. Paper is under consideration at P attern Recognition Letters [3] D. Eigen, C. Puhrsch, R. Fergus, Depth map prediction from a single image using a multi-scale deep network, in: Advances in neural information processing systems, 2014, pp. 2366–2374. [4] K. Li, G.-J. Qi, J. Y e, K. A. Hua, Linear subspace ranking hashing for cross-modal retriev al, IEEE transactions on pattern analysis and machine intelligence 39 (9) (2017) 1825–1838. [5] H. Liu, R. Ji, Y . W u, F . Huang, B. Zhang, Cross-modality binary code learning via fusion similarity hashing, in: Proceedings of the IEEE Conference on Computer V ision and Pattern Recognition, 2017, pp. 7380–7388. [6] D. Mandal, K. N. Chaudhury , S. Biswas, Generalized semantic preserving hashing for n-label cross-modal retrie val, in: Proceed- ings of the IEEE Conference on Computer V ision and Pattern Recognition, 2017, pp. 4076–4084. [7] B. Chaudhuri, B. Demir, S. Chaudhuri, L. Bruzzone, Multilabel remote sensing image retriev al using a semisupervised graph- theoretic method, IEEE T ransactions on Geoscience and Remote Sensing 56 (2) (2018) 1144–1158. [8] O. E. Dai, B. Demir, B. Sankur, L. Bruzzone, A novel system for content based retrie val of multi-label remote sensing images, in: 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), 2017, pp. 1744–1747. doi:10.1109/ IGARSS.2017.8127311 . [9] Y . Li, Y . Zhang, X. Huang, J. Ma, Learning source-in variant deep hashing con volutional neural netw orks for cross-source remote sensing image retriev al, IEEE Transactions on Geoscience and Remote Sensing (99) (2018) 1–16. [10] Y . Y ang, S. Ne wsam, Bag-of-visual-words and spatial extensions for land-use classification, in: Proceedings of the 18th SIGSP A- TIAL International Conference on Advances in Geographic Information Systems, GIS ’10, A CM, New Y ork, NY , USA, 2010, pp. 270–279. doi:10.1145/1869790.1869829 . URL http://doi.acm.org/10.1145/1869790.1869829 [11] M. Ferecatu, M. Crucianu, N. Boujemaa, Retrieval of difficult image classes using svd-based relev ance feedback, in: Proceedings of the 6th A CM SIGMM international workshop on Multimedia information retrie val, A CM, 2004, pp. 23–30. [12] B. Demir, L. Bruzzone, Hashing-based scalable remote sensing image search and retriev al in large archives, IEEE T ransactions on Geoscience and Remote Sensing 54 (2) (2016) 892–904. doi:10.1109/TGRS.2015.2469138 . [13] D. Zhang, W .-J. Li, Lar ge-scale supervised multimodal hashing with semantic correlation maximization, in: T wenty-Eighth AAAI Conference on Artificial Intelligence, 2014. [14] Q.-Y . Jiang, W .-J. Li, Deep cross-modal hashing, in: Proceedings of the IEEE Conference on Computer V ision and Pattern Recognition, 2017, pp. 3232–3240. [15] G. Mao, Y . Y uan, L. Xiaoqiang, Deep cross-modal retriev al for remote sensing image and audio, in: 2018 10th IAPR W orkshop on Pattern Recognition in Remote Sensing (PRRS), IEEE, 2018, pp. 1–7. [16] S. Hershey , S. Chaudhuri, D. P . Ellis, J. F . Gemmeke, A. Jansen, R. C. Moore, M. Plakal, D. Platt, R. A. Saurous, B. Seybold, et al., Cnn architectures for lar ge-scale audio classification, in: 2017 ieee international conference on acoustics, speech and signal processing (icassp), IEEE, 2017, pp. 131–135. [17] K. Simonyan, A. Zisserman, V ery deep conv olutional networks for lar ge-scale image recognition, arXi v preprint
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment