Testing Neural Program Analyzers
Deep neural networks have been increasingly used in software engineering and program analysis tasks. They usually take a program and make some predictions about it, e.g., bug prediction. We call these models neural program analyzers. The reliability …
Authors: Md Rafiqul Islam Rabin, Ke Wang, Mohammad Amin Alipour
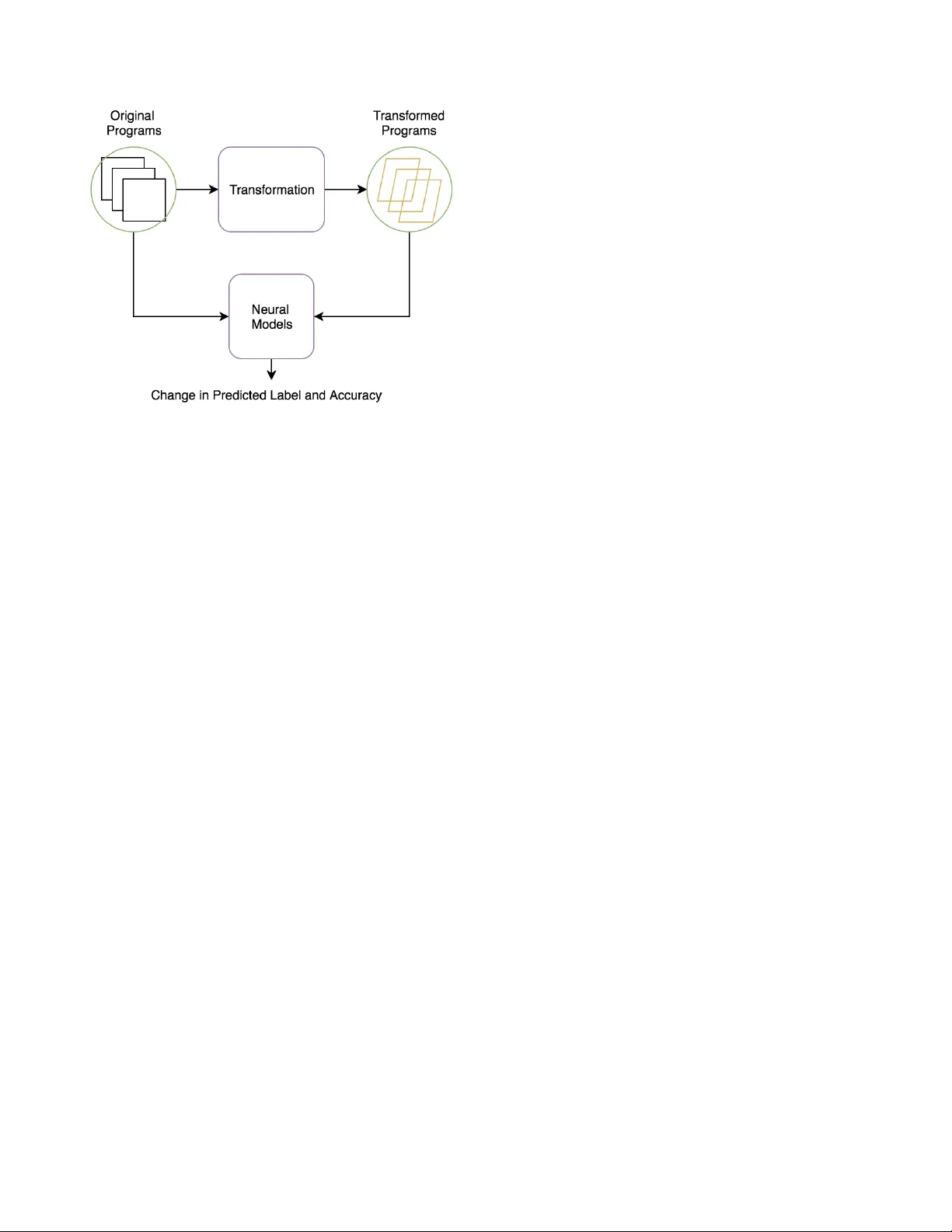
T esting Neural Program Analyzers Md Rafiqul Islam Rabin Uni versity of Houston mdrafiqulrabin@gmail.com K e W ang V isa Research ke wang ad@gmail.com Mohammad Amin Alipour Uni versity of Houston amin.alipour@gmail.com Abstract —Deep neural networks have been increasingly used in software engineering and program analysis tasks. They usually take a program and mak e some pr edictions about it, e.g., b ug prediction. W e call these models neural program analyzers . The reliability of neural pr ograms can impact the reliability of the encompassing analyses. In this paper , we describe our ongoing eff orts to dev elop effective techniques for testing neural programs. W e discuss the challenges in volved in developing such tools and our future plans. In our preliminary experiment on a neural model recently proposed in the literature, we found that the model is very brittle, and simple perturbations in the input can cause the model to make mistakes in its prediction. I . I N T R O D U C T I O N The adv ances of deep neural models in software engineering and program analysis research have recei ved significant atten- tion in recent years. Researchers ha ve already proposed v arious neural models (e.g., Tree-LSTM [11], Gemini [18], GGNN [1], Code V ectors [7], code2v ec [3], code2seq [2], D YPR O [14, 16], LIGER [17], Import2V ec [12]) to solve problems related to dif ferent program analysis or software engineering tasks. Although each neural model has been e v aluated by its authors, in practice, these neural models may be susceptible to untested test inputs. Therefore, a set of testing approaches has already been proposed to trace the unexpected corner cases. Recent neural model testing techniques include [13, 19] for models of autonomous systems, [8]–[10] for models of QA systems, and [15, 17] for models of embedding systems. Howe ver , testing neural models that work on source code has receiv ed little attention from researchers except the exploration initiated by W ang et al. [15]. Evaluating the rob ustness of neural models that process source code is of particular importance because their robust- ness would impact the correctness of the encompassing analy- ses that use them. In this paper , we propose a transformation- based testing framew ork to test the correctness of state- of-the-art neural models running on the programming task. The transformation mainly refers to the semantic changes in programs that result in similar programs. The key insight of transformation is that the transformed programs are se- mantically equi valent to their original forms of programs but hav e different syntactic representations. For e xample, one can replace a switch statement of a program with conditional if-else statements. The original program of the switch statement is semantically equi valent to the new program of if-else statements. A set of transformations can be applied to a program to generate more semantically equi valent pro- Fig. 1. A failure in the code2vec model revealed by a transformation. grams, and those ne w transformed programs can be e valuated on neural models to test the correctness of those models. The main motiv ation to apply transformation is the fact that such transformations may cause the neural model to behave differently and mispredict the input. W e are conducting a small study to assess the applicability of transformations in the testing of neural models. The preliminary results sho w that the transformations are very effecti ve in finding irrelev ant output in neural models. W e closely percei ve that the semantic- preserving transformations can change the predicted output or the prediction accuracy of neural models compared to the original test programs. I I . M O T I V A T I N G E X A M P L E W e use Figure 1 as a motiv ating e xample to highlight the usefulness of our approach. The code snippet sho wn in Figure 1 is a simple Jav a method that demonstrates the prime functionality . The functions check whether an integer is a prime number . The only dif ference between these functions is that the implementation on the left uses a for loop, while the implementation on the right uses a while loop. W e instrument the prediction of the code2vec model [5] with these two equiv alent functions. The code2vec takes a program and predicts its content. The result of the online demo [5] rev eals that the code2vec model successfully predicts the program on the left as an “isPrime” method, but cannot predict the program on the right as an “isPrime” method. The model mistakenly predicts the program on the right as a “skip” method, e ven though the “isPrime” method is not included in the top-5 predictions made by the code2vec model. I I I . P R O P O S E D M E T H O D O L O G Y In this section, we describe our ef forts for testing neural programs. Currently , we are inv estigating semantic-preserving transformations that can potentially mislead a neural model of programs. Fig. 2. The workflo w of our approach. Figure 2 depicts an ov ervie w of our approach for testing the neural models. It can broadly be divided into two main steps: (1) Generating synthetic test programs using the semantic transformation of the programs in the original dataset, and (2) Comparing the predictions for the transformed programs with those for the original programs. Semantic-Equivalent Program T ransformations W e hav e implemented multiple semantic program transformations to generate synthetic programs. Those semantic-preserving trans- formations include renaming v ariables, exchanging loops, swapping boolean values, conv erting switches and permuting the order of statements. In variable-renaming transformation, we rename all the occurrences of specific variables in program using an arbitrary name. The boolean-swapping transformation refers to sw apping true with false and vice v ersa, and we also neglect the condition so that the semantic is maintained. In the same way , the loop-exchanging transformation means replacing a while loop with a for loop, and vice v ersa. In switch-conv erting transformation, we replace the switch statements with the conditional if-else statements. Finally , we include another transformation by permuting the order of statements without any semantic violations. All these transfor- mations maintain semantic equiv alence but generate different syntactic programs. Thus far , we hav e not found any one transformation that works substantially better than others. T est Oracle W e ev aluate both the original program and the transformed program in the neural model. W e mainly look at the predicted label and the prediction accuracy of the model for both original and transformed programs. The neural model should behave similarly with both the original and the transformed program, which we define as a transformation- based metamorphic relation. The main challenge in this phase is to define a measure for the similarity of the predictions. W e are experimenting with a few ideas for this phase, for example, setting a threshold for the similarity of the predictions. Challenges Ahead There are fi v e main challenges that we are aiming to address in this project: (1) what types of transformation should be performed, (2) how to preserv e the semantic equi v alence during transformations, (3) where to apply those transformations, (4) how to control the transfor - mation strategies, and (5) how to e valuate the transformed programs. I V . O U R P L A N Thus far , we ha ve applied fi v e types of transformation. Those transformations are only capable of making basic changes in the syntactic representations of programs. Ho wever , our target is to devise more systematic transformations. W e are in v estigating the techniques and heuristics to suggest places in programs to transform, and the types of transformation that are most likely to cause the neural model to mispredict. Moreov er , we ha ve only e v aluated our transformation on the code2vec model [3], where the target task is to label the method name giv en a method body . W e also plan to ev aluate the transformation on the GGNN model [1], where the target task is to label the correct variable name based on the understanding of its usage. Additionally , we ha ve only experimented with a small set of examples [5]. Our further plan includes a detailed study with a lar ger Jav a dataset [4] for the code2vec model and a larger C# dataset [6] for the GGNN model. V . R E L A T E D W O R K Sev eral approaches for transformation-based testing have been proposed, such as DeepT est [13] and COSET [15]. T ian et al. [13] proposed DeepT est, a tool for auto- mated generation of real-world test images and testing of DNN-dri ven autonomous cars. They introduced poten- tial image transformations (e.g., blurring, scaling, fog and rain effects) that mimic real-world conditions. They applied transformation-based testing to identify the numerous corner cases that may lead to serious consequences, such as a collision in an autonomous car . Another study in this area was conducted by the authors of DeepRoad [19], who applied extreme realistic image-to-image transformations (e.g., heavy snow or hard rain) using the DNN-based UNIT method. W ang et al. [15] proposed COSET , a frame work for stan- dardizing the ev aluation of neural program embeddings. They applied transformation-based testing to measure the stability of neural models and identify the root cause of misclassifications. They also implemented and e v aluated a new neural model called LIGER [17] with COSET’ s transformations, where they embedded programs with runtime information rather than learning from the source code. R E F E R E N C E S [1] M. Allamanis, M. Brockschmidt, and M. Khademi, “Learning to represent programs with graphs, ” CoRR , vol. abs/1711.00740, 2017. [Online]. A v ailable: http://arxiv .org/abs/1711.00740 [2] U. Alon, O. Levy , and E. Y ahav , “code2seq: Generating sequences from structured representations of code, ” CoRR , vol. abs/1808.01400, 2018. [Online]. A vailable: http://arxiv .org/abs/1808.01400 [3] U. Alon, M. Zilberstein, O. Levy , and E. Y ahav , “code2v ec: Learning distributed representations of code, ” CoRR , vol. abs/1803.09473, 2018. [Online]. A v ailable: http://arxiv .org/abs/1803.09473 [4] “CODE2VEC Dataset, ” https://github.com/tech- srl/code2v ec# additional- datasets/. [5] “CODE2VEC Online Demo, ” https://code2vec.or g/. [6] “GGNN Dataset, ” https://aka.ms/iclr18- prog- graphs- dataset/. [7] J. Henkel, S. Lahiri, B. Liblit, and T . W . Reps, “Code vectors: Understanding programs through embedded abstracted symbolic traces, ” CoRR , vol. abs/1803.06686, 2018. [Online]. A vailable: http://arxiv .org/abs/1803.06686 [8] Q. Lei, L. W u, P . Chen, A. G. Dimakis, I. S. Dhillon, and M. Witbrock, “Discrete attacks and submodular optimization with applications to text classification, ” CoRR , vol. abs/1812.00151, 2018. [Online]. A v ailable: http://arxiv .org/abs/1812.00151 [9] M. T . Ribeiro, S. Singh, and C. Guestrin, “Semantically equivalent adversarial rules for debugging NLP models, ” in Pr oceedings of the 56th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) . Melbourne, Australia: Association for Computational Linguistics, Jul. 2018, pp. 856–865. [Online]. A vailable: https://www .aclweb.or g/anthology/P18- 1079 [10] B. Rychalska, D. Basaj, P . Biecek, and A. Wr ´ oblewska, “Does it care what you asked? understanding importance of verbs in deep learning QA system, ” CoRR , vol. abs/1809.03740, 2018. [Online]. A vailable: http://arxiv .org/abs/1809.03740 [11] K. S. T ai, R. Socher , and C. D. Manning, “Improved semantic representations from tree-structured long short-term memory networks, ” CoRR , vol. abs/1503.00075, 2015. [Online]. A vailable: http://arxiv .org/ abs/1503.00075 [12] B. Theeten, F . V andeputte, and T . V an Cutsem, “Import2vec learning embeddings for software libraries, ” in Proceedings of the 16th International Confer ence on Mining Softwar e Repositories , ser. MSR ’19. Piscataway , NJ, USA: IEEE Press, 2019, pp. 18–28. [Online]. A vailable: https://doi.org/10.1109/MSR.2019.00014 [13] Y . T ian, K. Pei, S. Jana, and B. Ray , “Deeptest: Automated testing of deep-neural-network-driv en autonomous cars, ” in Pr oceedings of the 40th International Confer ence on Software Engineering , ser . ICSE ’18. New Y ork, NY , USA: A CM, 2018, pp. 303–314. [Online]. A vailable: http://doi.acm.org/10.1145/3180155.3180220 [14] K. W ang, “Learning scalable and precise representation of program semantics, ” CoRR , vol. abs/1905.05251, 2019. [Online]. A vailable: http://arxiv .org/abs/1905.05251 [15] K. W ang and M. Christodorescu, “COSET : A benchmark for ev aluating neural program embeddings, ” CoRR , vol. abs/1905.11445, 2019. [Online]. A v ailable: http://arxiv .org/abs/1905.11445 [16] K. W ang, R. Singh, and Z. Su, “Dynamic neural program embedding for program repair, ” CoRR , vol. abs/1711.07163, 2017. [Online]. A vailable: http://arxiv .org/abs/1711.07163 [17] K. W ang and Z. Su, “Learning blended, precise semantic program embeddings, ” ArXiv , vol. abs/1907.02136, 2019. [18] X. Xu, C. Liu, Q. Feng, H. Y in, L. Song, and D. Song, “Neural network-based graph embedding for cross-platform binary code similarity detection, ” CoRR , vol. abs/1708.06525, 2017. [Online]. A vailable: http://arxiv .org/abs/1708.06525 [19] M. Zhang, Y . Zhang, L. Zhang, C. Liu, and S. Khurshid, “Deeproad: Gan-based metamorphic testing and input validation framew ork for autonomous driving systems, ” in Pr oceedings of the 33rd A CM/IEEE International Conference on Automated Software Engineering , ser. ASE 2018. New Y ork, NY , USA: ACM, 2018, pp. 132–142. [Online]. A vailable: http://doi.acm.org/10.1145/3238147.3238187
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment