KonVid-150k: A Dataset for No-Reference Video Quality Assessment of Videos in-the-Wild
Video quality assessment (VQA) methods focus on particular degradation types, usually artificially induced on a small set of reference videos. Hence, most traditional VQA methods under-perform in-the-wild. Deep learning approaches have had limited su…
Authors: Franz G"otz-Hahn, Vlad Hosu, Hanhe Lin
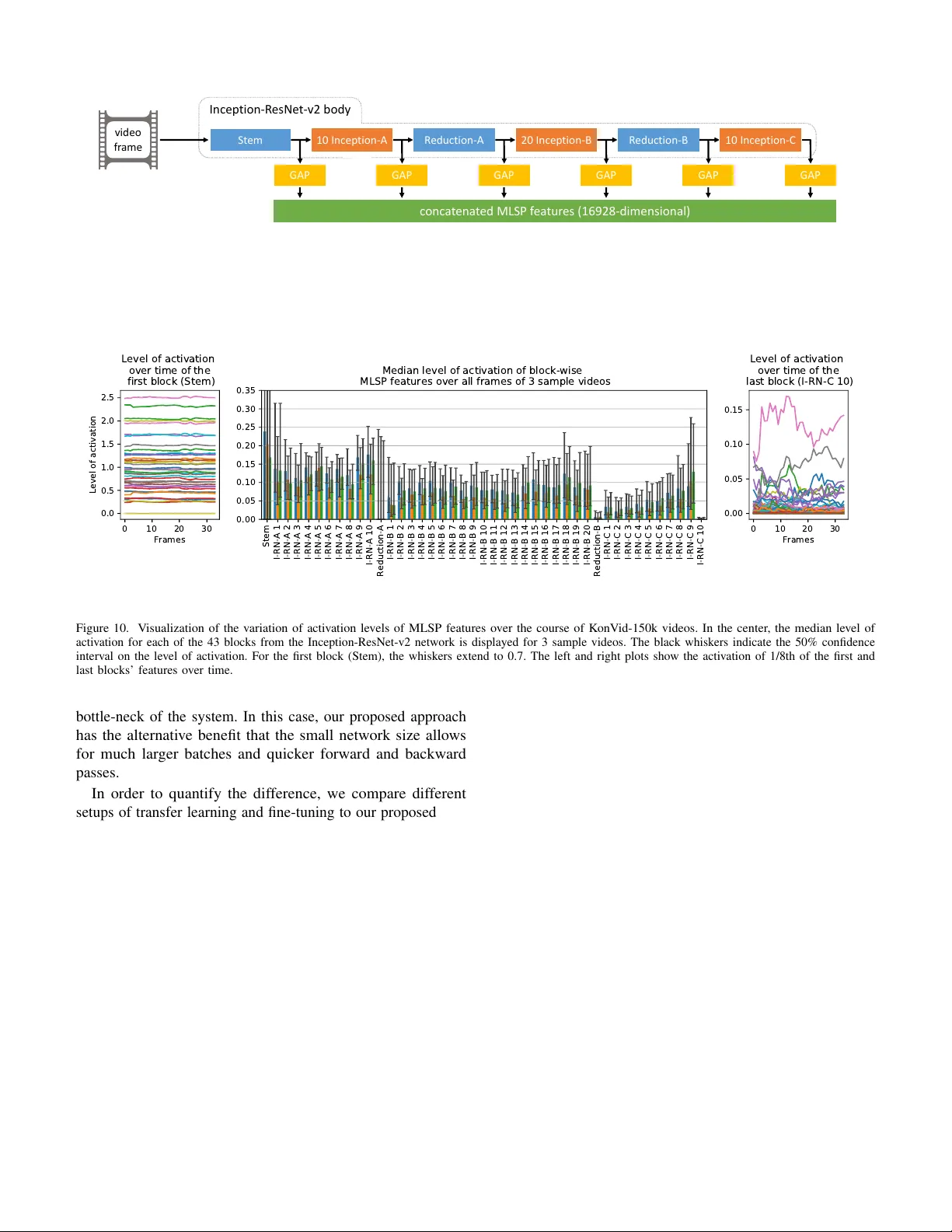
TRANSA CTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY , V OL. 21, NO. 2, FEB. 2020 1 K onV id-150k: A Dataset for No-Reference V ideo Quality Assessment of V ideos in-the-W ild Franz Götz-Hahn, Vlad Hosu, Hanhe Lin, and Dietmar Saupe Abstract —V ideo quality assessment (VQA) methods f ocus on particular degradation types, usually artificially induced on a small set of refer ence videos. Hence, most traditional VQA methods under -perf orm in-the-wild. Deep learning approaches hav e had limited success due to the small size and diversity of existing VQA datasets, either artificial or authentically distorted. W e introduce a new in-the-wild VQA dataset that is substantially larger and diverse: KonV id-150k. It consists of a coarsely annotated set of 153,841 videos having five quality ratings each, and 1,596 videos with a minimum of 89 ratings each. Additionally , we propose new efficient VQA approaches (MLSP-VQA) r elying on multi-level spatially pooled deep-features (MLSP). They are exceptionally well suited for training at scale, compared to deep transfer learning appr oaches. Our best method, MLSP-VQA- FF , improves the Spearman rank-order correlation coefficient (SRCC) performance metric on the commonly used K oNViD- 1k in-the-wild benchmark dataset to 0.82. It surpasses the best existing deep-learning model (0.80 SRCC) and hand-crafted feature-based method (0.78 SRCC). W e further in vestigate how alternativ e approaches perform under different levels of label noise, and dataset size, showing that MLSP-VQA-FF is the overall best method for videos in-the-wild. Finally , we show that the MLSP-VQA models trained on K onV id-150k sets the new state-of-the-art f or cross-test perf ormance on KoNV iD-1k, LIVE- VQC, and LIVE-Qualcomm with a 0.83, 0.75, and 0.64 SRCC, respecti vely . For both KoNV iD-1k and LIVE-VQC this inter - dataset testing outperforms intra-dataset experiments, showing excellent generalization. I . I N T RO D U C T I O N V IDEOS hav e become a central medium for business marketing [1], with over 81% of b usinesses using video as a marketing tool. Additionally , ov er 40% of businesses hav e adopted live video formats such as Facebook Live for marketing and user connection purposes [2]. For consumers, video is the primary source of media entertainment; for example the av erage US consumer spends 38 hours per week watching video content [3] and it is projected that online videos will make up more than 82% of all consumer internet traffic by 2022 [4]. Streaming platforms such as Y ouT ube report that more than a billion hours of video are watched every day [5]. The success of online videos is due in part to the consumer belief that traditional TV offers an inferior quality [3]. Additionally , increased accessibility to video content acquisition hardware, as well as improv ements in overall image quality , are a central aspect in smartphone technology advancement. Similarly , user- generated content is produced at an increasing rate, but the resulting videos often suffer from quality defects. F . Götz-Hahn, V . Hosu, H. Lin and D. Saupe are with the Department of Computer Science, University of Konstanz, 78464 K onstanz, German y (e-mail: franz.hahn@uni.kn, or firstname.lastname@uni.kn). Therefore a wide range of video producers and consumers should be able to get automated feedback on video quality . For example, user -generated video distribution platforms like Y ouT ube or V imeo may want to analyze ne w videos according to quality to separate professional from the amateur video content, instead of only inde xing by video playback resolution. Additionally , with an automated video quality assessment (VQA) system, video streaming services can adjust video encoding parameters to minimize bandwidth requirements while ensuring the delivery of satisfactory video quality . A critical emerging challenge for VQA is to handle ecolog- ically valid in-the-wild videos. In en vironmental psychology , ecological validity is defined as “the applicability of the results of laboratory analogues to non-laboratory , real life settings” [6]. In our case the term can be understood as a measure for the extent to which the data represented in a dataset can be generalized to data that would be naturally encountered in the use of a technology . Concretely , this would refer to the types and degree of distortions in visual media contents of internet videos, such as those consumed on Y ouT ube, Flickr , or V imeo. The term in-the-wild refers to datasets that are “not constructed and designed with research questions in mind” [7]. In the case of VQA this would mean datasets that are not recorded or altered with a specific research purpose in mind, such as artificially distorting videos at v ariable degrees. It comes as no surprise that no-reference VQA (NR-VQA), in particular , has been a field of intensi ve research in the past few years achieving significant performance gains [8]– [19]. Howev er, state-of-the-art NR-VQA algorithms perform worse on in-the-wild videos than on synthetically distorted ones. These methods aggregate indi vidual video frame quality characteristics that are engineered for specific purposes, such as detecting particular compression artifacts. Often, these features are a balance between precision and computational efficiency . Furthermore, since there is a lack of large-scale in-the-wild video quality datasets with authentic distortions, a thorough ev aluation of NR-VQA methods is dif ficult. Most existing databases are intended as benchmarks for the detection of those specific artificial distortions that NR-VQA algorithms hav e classically been designed to detect. Giv en the pre vious challenges, our first contrib ution is the creation of a large ecologically valid dataset, K onV id-150k. Similar to the dataset K oNV iD-1k [20], the ecological v alidity of K onV id-150k stems from its size, content div ersity , as well as naturally occurring, and thus representativ e degradations. Howe ver , being two orders of magnitude larger than existing datasets, it poses new challenges to VQA methods, requiring to train across a v ast amount of content and a wide span of TRANSA CTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY , V OL. 21, NO. 2, FEB. 2020 2 authentic distortions. Moreover , since a fix ed b udget usually constrains the development of a dataset, we needed to ensure a minimum level of annotation quality . Therefore, a part of K onV id-150k consists of 153,841 fiv e seconds long videos that are annotated by fiv e subjective opinions each. This set, from here on called KonV id-150k-A, is ov er 125 times larger than existing VQA datasets in terms of number of videos and with close to one million subjectiv e ratings ov er eight times lar ger in number of annotations [20]–[23]. The dataset is accompanied by a benchmark set of nearly 1,600 videos (K onV id-150k-B) from the same source with a minimum of 89 opinion scores each. This presents a unique opportunity to analyze the trade-off between the number of training videos and the annotation noise/precision, in terms of the performance on the KonV id-150k-B benchmark dataset. This new dataset exacerbates two problems of classical NR-VQA methods. First, the computational costs of hand- crafted feature-based approaches are increased through the sheer number of videos. Second, since hand-crafted features handle in-the-wild videos worse than con ventional databases, this dataset is very challenging for classical NR-VQA methods. An alternati ve to hand-crafted features comes with the rise of deep con volutional neural networks (DCNNs), where stacked layers of increasingly complex feature detectors are learned directly from observations of input images. These features are often relativ ely generic and ha ve been prov en to transfer well to similar tasks that are not too different from the source domain [24], [25]. This suggests considering a DCNN as a feature extractor with a benefit o ver hand-crafted features in that the features are entirely learned from data. As a second contribution, we propose to use a new way of extracting video features by aggreg ating acti vations of all layers of DCNNs, pre-trained for classification, for a selection of frames. W e adopt a strategy similar to Hosu et al. [26] and extract narrow multi-lev el spatially pooled (MLSP) features of video frames from an InceptionResNet-v2 [27] architecture to learn VQA. By global average pooling the outputs of inception module acti vation blocks, we obtain fixed sized feature representations of the frames. The third contribution of this paper consists of two network v ariants trained on the frame feature vectors that surpass state- of-the-art NR-VQA methods on in-the-wild datasets and train much faster than the baseline transfer learning approach of fine-tuning the entire source network. In a short ablation study we in vestigate the impact of architectural and hyperparameter choices of both models. Both approaches are then ev aluated on existing VQA datasets consisting of authentic videos as well as those containing artificially degraded videos and show that on in-the-wild videos the proposed method outperforms classical methods based on hand-crafted features. In particular, training and testing on K oNV iD-1k improves the state-of-the-art 0.80 to 0.82 SRCC. Finally , we show that training our proposed model on the ne w dataset of 153,841 videos with fi ve subjective opinions each achieves a 0.83 SRCC in a cross-database test on K oNV iD-1k, which outperforms state-of-the-art when training and testing on KoNV iD-1k itself, which hav e the benefit of not being affected by any domain shift [28]. In summary , our main contrib utions are: • K onV id-150k, an ecologically valid in-the-wild video quality assessment database, two orders of magnitude larger than existing ones. • The successful application of deep multi-layer spatially pooled features for video quality assessment. • Three deep neural network models (MLSP-VQA-FF , - RN, and -HYB). They surpass the state-of-the-art with 0.82 SRCC versus the best existing 0.80 SRCC in an intra-dataset scenario on KoNV iD-1k, and sho w excellent generalization in inter-dataset tests when trained on K onV id-150k, surpassing the best e xisting feature-based models. I I . R E L A T E D W O R K This paper contributes to datasets and methods for video quality assessment. In this section we summarize related work in both fields as well as research in feature extraction that was influential for our work. A. VQA Datasets There are a fe w distinguishing characteristics that di vide the field of VQA datasets which are usually governed by decisions made by their creators. W e will cover the characteristics differentiating the wide variety of relev ant related works separately . 1) V ideo sources: The first distinguishing factor that heavily influences the use of a dataset is the source of stimuli. The early works in the field of VQA datasets stem from 2009 to 2011. EPFL-PoliMI [29], [30], LIVE-VQA [31], [32], CSIQ [33], VQEG-HD [34], and IVP [35] were mostly con- cerned with particular compression or transmission distortions. Consequently , these early datasets contain few source videos that were degraded artifically to cover the different distortion domains. From today’ s standpoint the induced de gradations lack ecological validity when compared to degradations observed in ne w videos in-the-wild. W ith transmission being largely an extraneous factor , due to high-quality transmission networks, the focus of VQA datasets has been shifting towards covering a broad diversity of contents and in-the-wild distortions. Recently designed VQA databases from 2014 to 2019 (CVD2014 [21], LIVE-Qualcomm [22], K oNV iD-1k [20], and LIVE-VQC [23]) ha ve taken the first steps tow ards improving ecological validity . CVD2014 contains videos which were degraded with realistic video capture related artifacts. V ideos in LIVE-Qualcomm, LIVE-VQC, and KoNV iD-1k were either self-recorded or crawled from public domain video sharing platforms without any directed alteration of the content. An additional side-effect of this change in dataset paradigms are dif ferences in numbers of devices and formats represented in modern datasets. • CVD2014 considers videos taken by 78 different cameras with different levels of quality from low-quality camera phones to high-quality digital single-lens reflex cameras. The video sequences were captured one at a time from different scenes using different devices. They captured a total of 234 videos, three from each camera, with a mixture of in-capture distortions. While each stimulus in TRANSA CTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY , V OL. 21, NO. 2, FEB. 2020 3 CVD2014 is a unique video rather than an alteration of a source video, the dataset only co vers fiv e unique scenes, which is the smallest number of unique scenes among all VQA datasets. • LIVE-Qualcomm contains videos recorded using eight different mobile cameras at 54 scenes. Dominant fre- quently occurring distortion types such as insufficient color representation, over/under -exposure, auto-focus related distortions, blurriness, and stabilization related distortions were introduced during video capturing. In total, the 208 videos cov er six types of authentic distortions, but there is no quantification as to how common these distortions are for videos in-the-wild. • LIVE-VQC contains videos captured by 80 naïve mobile camera users, totaling 585 unique video scenes at various resolutions and orientations. • KoNV iD-1k contains 1,200 unique videos sampled from YFCC100m. It is hard to quantify the number of devi ces cov ered, b ut in terms of content and distortion v ariety , it is the lar gest existing collection of videos. The videos in K oNV iD-1k have been reproduced from Flickr , based on the highest quality do wnload option; howe ver , they are not the raw versions originally uploaded by users. The videos show compression artifacts, having been re-encoded to reduce bandwidth requirements. W e are employing a strategy similar to KoNV iD-1k, ho wev er we obtained the originally uploaded versions of the videos to re- encode them at a higher quality . W e aim to reduce the number of encoding artifacts while keeping the file size manageable for distribution in a crowdsourcing study with an av erage of 1.23 meg abytes per video. 2) Subjective assessment: The second distinguishing factor is the choice of subjective assessment en vironment. VQA has been a field of research since before the time when video could easily and reliably be transmitted o ver the Internet. Conse- quently , early datasets ha ve all been annotated by participants in a lab en vironment. This allows for assessment of quality under strictly-controlled conditions with reliable raters, giving an upper bound to discriminability . W ith dataset sizes increasing, due to a push for more content div ersity and transmission rates improving, crowdsourcing has become an affordable and fast way of annotating multimedia datasets with subjecti ve opinions. In a lab setup it is practically infeasible to handle annotation of tens of thousands of items. The do wnside of crowdsourcing is a reduced lev el of control over the en vironment, resulting in potentially lower quality of annotation. Howe ver , with careful quality control considerations a crowdsourcing setup can achieve an annotation quality comparable to lab setups [36]. Concretely , CVD2014 and LIVE-Qualcomm are annotated in a lab en vironment, while K oNV iD-1k and LIVE-VQC are both annotated using cro wdsourcing. Considering the sheer size of our dataset, we also employed a crowdsourcing campaign with rigorous quality control in the form of an initial quiz and interspersed test questions to ensure a good annotation quality . 3) Number of observers: A third factor that has been studied only very little thus far is the choice of numbers of ratings per video. With a few exceptions, early works in lab en vironments ensured at least 25 raters per stimulus. Additionally , it has 1 10 10 0 10 00 10 00 0 1 0 0 0 0 0 U ni que Cont ents Tot al V i deo s Rat i ng s per V i deo Tot al Rat i ng s (Tho usa nds) I RCCy N I V C 1 0 8 0 i ( 2 0 0 8 ) CV D201 4 ( 2 0 1 4 ) MCL -V (2015 ) LI V E-Q ua l c om m (20 1 7 ) Ko nVid- 1 k ( 2 0 1 7 ) LI V E-V Q C (201 8 ) Ko nVid- 1 5 0 k -A Ko nVid- 1 5 0 k -B Figure 1. Comparison of size characteristics of current VQA datasets. Our proposed datasets, K onV id-150k-A and KonV id-150k-B are represented by the two right most bars of the histograms. Note the logarithmic scale. been a common approach that all participants rated all stimuli. Recent works [23] have increased the number of ratings per stimulus to above 200 to ensure very high quality annotation. Howe ver , giv en a fixed, af fordable budget of annotations, one must consider the trade-off between the benefit of slightly more accurate quality scores for a small number of stimuli and the potential increase in generalizability when annotating more stimuli with fe wer votes. The 8-fold increase in numbers of ratings per stimulus when going from the generally accepted 25 to 200 ratings could just as well be in vested in an 8- fold increase of numbers of stimuli, each rated 25 times. The increase of the precision of the experimental MOS suffers from diminishing returns as the number of raters increases. Since the precision gain per vote is highest at none or few ratings, careful considerations have to be made with respect to the distribution of annotation b udgets across an unlabeled dataset. This is especially true in the wake of deep learning approaches outperforming classical methods in many computer vision tasks, as deep learning models are known to be robust to noisy labels [37] but also hungry for input data. Figure 1 shows a comparison of rele v ant VQA datasets on some of these characteristics. There is an evident progression to a wider variety of contents in the last few years. W e are attempting to push this boundary much further by exploring the trade-of f between the number of ratings per video and the total annotated stimuli. B. F eatur e Extraction There ha ve been sev eral recent works that inspired our approach for feature extraction. The BLINDER framew ork [24] was an initial work that utilized multi-le vel deep-features to predict image quality . They resized images to 224 × 224 and extracted a feature vector from each layer of a pre-trained V GG- net. Each of these features vectors was then fed into separate SVR heads and trained, such that the av erage layer-wise scores predict the quality of an image. BLINDER was ev aluated on a variety of IQA datasets, v astly impro ving the state-of-the-art. [26] went a step further by utilizing deeper architectures to extract features, such as Inception-v3 and InceptionResNet-v2. Furthermore, features were aggregated from multiple lev els and extracted from images at their original size. This retained TRANSA CTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY , V OL. 21, NO. 2, FEB. 2020 4 detailed information that would have been lost by do wn-sizing the inputs. Moreover , it allowed linking information coming from early le vels (image dependent) and general category- related information from the latter le vels in the network. W e use the same approach as presented in [26] to extract sets of features of video frames. The layers of the DNNs are a basic measure for the lev el of complexity that the feature can represent. F or e xample, first layer features resemble Gabor filters or color blobs, while features in higher levels correspond to semantic entities such as circular objects with a particular texture or e ven faces. Changes in the response of different features can, therefore, encode temporal information. For example, it is reasonable to assume that a change in the ov erall response of low-le vel Gabor-like features can indicate the rapid mov ement of an object. Consequently , learning from frame-lev el features allows to learn the effect of temporal degradations on video quality indirectly . In [38] a similar approach was used for the purpose of NR- VQA. The method extracted features for intra-frames, a veraging them along the temporal domain to obtain a video-level feature vector . The final video quality prediction is done by an SVR. In our approach we go beyond this by considering both an av erage feature vector with our MLSP-VQA-FF architecture, as well as an LSTM model that takes a set of consecutiv e features of frames as input, lev eraging temporal information of feature activ ations. C. NR-VQA Existing NR-VQA methods can be differentiated based on whether they are based solely on spatial image-le vel features or also explicitly account for temporal information. In general, howe ver , all recently developed models are learning-based. Image-based NR-VQA methods are mostly based on the- ories of human perception, with natural scene statistics (NSS) [39] being the predominant hypothesis used in se v- eral works, such as the naturalness image quality ev aluator (NIQE) [40], blind/referenceless image spatial quality ev alua- tor (BRISQUE) [41], feature-map-based referenceless image quality e v aluation engine (FRIQUEE) [42] and high dynamic- range image gradient-based ev aluator (HIGRADE) [43]. NSS hypothesizes that certain statistical distributions govern ho w the human visual system processes particular characteristics of natural images. Image quality can be deriv ed by measuring the perturbations of these statistics. The approaches above ha ve been extended to videos by ev aluating them on a representativ e sample of frames and aggregating the features by a veraging. Approaches that consider temporal features, so-called general-purpose VQA methods, are less numerous and more particular in their approach. In [11], the authors extended an image-based metric by incorporating time-frequency character- istics and temporal motion information of a given video using a motion coherence tensor that summarizes the predominant motion directions over local neighborhoods. The resulting approach, coined V -BLIINDS, has been the de facto standard that ne w NR-VQA methods are compared with. Apart from V -BLIINDS, several other machine-learning- based models for NR-VQA hav e been proposed. Re grettably , most have only been ev aluated on older datasets such as LIVE- VQA, making comparisons across multiple datasets difficult. Moreov er , their codes are not publicly av ailable, further exacerbating this issue. The three most notable e xamples are the follo wing. V -CORNIA [42] is an unsupervised frame-base feature-learning approach that uses Support V ector Regression (SVR) to predict frame-lev el quality . T emporal pooling is then applied to obtain the final video quality . SA CONV A [44] extracts feature descriptors using a 3D shearlet transform of multiple frames of a video, which are then passed to a 1D CNN to extract spatio-temporal quality features. COME [45] separated the problem of extracting spatio-temporal quality features into two parts. By fine-tuning AlexNet on the CSIQ dataset, spatial quality features are extracted for each frame by both max pooling and computing the standard deviation of acti vations in the last layer . Additionally , temporal quality features are extracted as standard de viations of motion v ectors in the video. Then, two SVR models are used in conjunction with a Bayes classifier to predict the quality score. The state-of-the-art in blind VQA is set by two recently published approaches, namely TL VQM [19] and 3D-CNN + LSTM [46]. The former is a hierarchical approach for feature extraction. It computes two types of features: low complexity features characterizing temporal aspects of the video for all video frames, and high complexity features representing spatial aspects. High complexity features relating to spatial acti vity , exposure, or sharpness, are extracted from a small representati ve subset of frames. TL VQM achiev es the best performance on LIVE-Qualcomm and CVD2014. The latter is an end-to-end DNN approach, where 32 groups of 16 224 × 224 crops of frames are extracted from the original video and individually fed into a 3D-CNN architecture that outputs a scalar frame- group quality . This is then subsequently passed to an LSTM that predicts the overall video quality . This approach sets the state-of-the-art for KoNV iD-1k, besting TL VQM slightly . There has been a body of work by another author on NR- VQA [38], [47], [48]. Ho wever , there are concerns about the v alidity of the published performance v alues [49]. Specifically , it has been shown that the performance values reported in both [47] and [48] were obtained with implementations containing some forms of data leakage. In both cases, the fine-tuning stage of the two-stage process embedded information about the test sets into the model used for feature extraction. Furthermore, in [49] it was sho wn that fine-tuning prior to feature extraction had much less impact on the final performance than claimed. Since [38] is using a similar two-stage approach inv olving fine-tuning and feature extraction, and there is a substantial improv ement in performance from the non-fine-tuned to the fine-tuned implementation, we hold some reservations as to the v alidity of the reported performance values. I I I . D A TA S ET I M P L E M E N T A T I O N D E TA I L S In this section, we introduce the video dataset in two parts. First, we discuss the design choices and gathering of the data in Section III-A alongside an ev aluation of the diversity captured by the dataset in relation to existing work in Section III-B . Then, Section III-C follows up with details regarding the crowdsourcing experiment to annotate the dataset. TRANSA CTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY , V OL. 21, NO. 2, FEB. 2020 5 o u rs o rig i n al fli c kr Figure 2. Comparison of the quality of the original (center) to the v ersion Flickr pro vides (right) and our transcoded v ersion (left). A. V ideo Dataset Our main objective was to create a video dataset that covers a wide variety of contents and quality-lev els as commonly av ailable on video sharing websites. For this reason, we took a similar approach to collect our data as was done for K oNV iD-1k, with an additional step to improve the quality of the videos. In KoNV iD-1k all collected videos had been transcoded by Flickr, to reduce their bandwidth requirements and standardizing them for playback. Consequently , noticeable degradation was introduced relative to the original uploads. Flickr allows the uploading of video files of most codec and container combinations, resolutions, and durations. Howe ver , they re-encode the uploaded videos to common resolutions such as HD, Full HD, strongly compressing them. The Flickr API allows access to metadata that links to the original, raw uploads. As these raw uploads are often very large and come in many different formats, the y cannot directly be used for crowdsourcing. Therefore, we proceeded as follows. W e downloaded authentic raw videos that had an aspect ratio of 16:9 and resolution higher than 960 × 540 pix els. Then we rescaled them to 960 × 540, if necessary , and extracted the middle fi ve seconds. Finally , we re-encoded them using FFmpeg at a constant rate factor of 23, which balances visual quality and file size. The resulting files have an av erage size of 1.23 megabytes. Figure 2 is a visual comparison of the dif ferences, sho wing a small crop of a frame of the originally uploaded video together with the two re-encodings offered by Flickr and our o wn version. Compression artifacts are clearly visible in the Flickr re-encoded version, whereas our re-encoding is very similar to the original. For each video, we extracted meta-information that identifies the original encoding, including the codec and the bit-rate. Furthermore, we collected social-network attributes such as the number of vie ws and likes and publication dates that indicate the popularity of videos. In total, this collection amounts to 153,841 videos. W e believ e that all the additional measures we ha ve taken to refine our dataset significantly improv ed its ecological validity , and thus the performance of VQA methods trained on it in the future. B. Dataset Evaluation In order to e v aluate the di versity of KonV id-150k, which is our main objecti ve with this dataset, we will now demonstrate that it is not only the largest annotated VQA dataset in terms of video items, but also the most div erse in terms of content. First, we need a measure for content div ersity . For this purpose we extract the activ ations of the last fully-connected layer of an Inception-ResNet-v2 model pre-trained on ImageNet for each frame. T o represent a giv en video, we av erage these activ ations ov er all frames to obtain a 1792-dimensional content feature. A similar approach has been used in the image quality domain before to create a subset of data that is diverse in content [50]. Figure 3 is an illustration of the usefulness of these content features to assess content similarity . Giv en a query video taken from K oNV iD-1k on the left we compute the Euclidean distance in content feature space to all other videos in the dataset. On the right we sho w still frames from the three videos with smallest distance to the query . W e can see that close proximity in content feature space seems to correspond to semantically similar video content. The images in the first ro w show flying objects in a blue sky , where the color of the object as well as the color of the sky seem to influence the distance in content feature space. In the second row we can see that crowds in front of a stage are located in close proximity in content feature space. Images in the third row show that videos containing heads, but especially babies are encoded similarly in the 1792-d content feature vectors. Light shows and underwater videos, as seen in the fourth and fifth rows, can also be retrieved by querying nearest neighbours of an appropriate video. It is to be noted that the closest videos for rows one, two and four are near duplicates. The recordings seem to be from different periods of time of the same scene. Therefore, the e xtracted features are useful as an information retriev al tool, and we make use of it to quantify the degree by which a video dataset covers the content of competing datasets. F or this purpose we represent a video dataset by its corresponding set of content feature vectors, X = { x i | i = 1 , ..., N } , where N is the number of videos in the dataset. W e consider the Euclidean distance of a point x in feature space to a (finite) point set Y , d ( x, Y ) = min { d ( x, y ) | y ∈ Y } . For two finite point sets X = { x 1 , ..., x n } , Y = { y 1 , ..., y m } and any giv en distance s ≥ 0 , we define the fraction or ratio of the first dataset X , that is covered by the dataset Y at distance s as C Y ,s ( X ) = |{ x ∈ X | d ( x, Y ) ≤ s }| | X | where | A | denotes the cardinality of a set A . For example, if X ⊆ Y , then Y cov ers X perfectly at distance zero, i.e., C Y , 0 ( X ) = 1 . Or , if C Y , 1 ( X ) = 0 . 8 , then this means that the union of all balls of radius 1 centered at the points of the set Y contain 80% of the points in X . The function s 7→ C Y ,s ( X ) thus comprises the cumulativ e histogram of the individual distances d ( x, Y ) for all x ∈ X . When comparing the coverage two datasets with respect to each other, we check the corresponding cumulativ e histograms showing the coverage of one dataset by the other . The dataset TRANSA CTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY , V OL. 21, NO. 2, FEB. 2020 6 Quer y Video Closes t Video 2nd Closes t Video 3r d Closes t Video 𝑑 = 1 . 23 𝑑 = 2 . 06 𝑑 = 2 . 62 𝑑 = 1 . 94 𝑑 = 3 . 84 𝑑 = 3 . 92 𝑑 = 2 . 04 𝑑 = 2 . 54 𝑑 = 2 . 58 𝑑 = 2 . 05 𝑑 = 2 . 82 𝑑 = 2 . 87 𝑑 = 2 . 08 𝑑 = 2 . 59 𝑑 = 2 . 89 Figure 3. Still images from videos closest to the query video on the left as measured by the Euclidean distance d in the feature space of top-layer features from Inception-ResNet-v2. This shows the utility of activ ations of layers from pre-trained DCNNs for usage in a content similarity measure. Even though only the 1792 activ ations of the last layer were used, which are commonly understood to focus on semantic entities more so than lo w lev el structures, these features encode useful information. with the topmost cumulati ve histogram then can be considered to be the dominant one that co vers the competing one. T o compare the di versity of content for sev eral given datasets X 1 , . . . , X K , let us form their union Z = X 1 ∪ · · · ∪ , X k and consider ho w well each dataset X k cov ers all the others, i.e., the complement X c k = Z \ X k . For this purpose we compute the cumulati ve histograms C X k ,s ( X c k ) for k = 1 , . . . , K . Figure 4 shows the result for the fiv e datasets K onV id-150k, K oNV iD- 1k, VQC, Qualcomm, and CVD 2014. Here, K onV id-150k clearly has the best cov erage of contents present in the other datasets, as it has the largest area under the curve. T o summarize the coverage of one dataset X by another , Y , by a single number rather than the curves of the cumulativ e histogram of distances, we define the one-sided distance of X from Y as d ( X, Y ) = f ( d ( x 1 , Y ) , d ( x 2 , Y ) , ..., d ( x n , Y )) where f is a scalar , non-negativ e function. For example, if f is the maximum function, then d ( X, Y ) is known as the one-sided Hausdorf f distance. For our purpose, the median is better suited as it is less sensitiv e to outliers. The distance d ( X, Y ) can be understood as a simplified indicator for the cov erage of X by Y . These medians are shown in Figure 4 by the bullet dots at the coverage ratio of 0.5. Figure 5 then shows d ( X, Y ) for the competing dataset pairs indi vidually . It can be seen that K onV id-150k covers the contents of competing datasets the best, as the green curves are strictly abov e the cumulati ve histograms for the other datasets. Moreov er, the other datasets cov er the content space of KonV id-150k the worst, as the solid lines depicting the cov erage of K oNV iD-1k, CVD 2014, Qualcomm, and VQC of K onV id-150k are generally to the right of the other three for the respecti ve dataset. These findings are an indication that our proposed dataset K onV id-150k is comprised of a large variety of contents with good cov erage of the contents contained in existing works. C. V ideo Annotation W e annotated all 153,841 videos for quality in a crowd- sourced setting on Figure Eight 1 . First, each participant was presented with instructions according to VQEG recommenda- tions [51], which were modified to our requirements. Here, 1 http://www .figure-eight.com/ (no w https://appen.com/) TRANSA CTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY , V OL. 21, NO. 2, FEB. 2020 7 2 3 4 5 6 7 8 d ( x c , X ) f o r x c X c 0.00 0.25 0.50 0.75 1.00 Ratio of Coverage X = K 1 5 0 k X = K 1 k X = V Q C X = Q u a l X = C V D Figure 4. This figure shows how well a video dataset covers all others together . The curves are the empirical cumulative histograms of Euclidean distances d ( x c , X ) for all x c ∈ X c , where X c is the complement to X , i.e., the union of the other datasets. The green, red, blue, yellow , and cyan lines refer to X being KonV id-150k, KoNV iD-1k, VQC, Qualcomm, and CVD 2014, respectiv ely . K onV id-150k covers the other datasets the best, as the green plot has the largest area under the curv e and it has the smallest median distance of approximately 2.3 at coverage ratio 0.5. This means that for half of the videos in all other datasets, there is a similar video in K onV id-150k that has a distance in content feature space of at most 2.3. 2 3 4 5 6 7 8 d ( x , Y ) f o r x X 0.00 0.25 0.50 0.75 1.00 Ratio of Coverage Y = K 1 5 0 k Y = K 1 k Y = V Q C Y = Q u a l Y = C V D X = K 1 5 0 k X = K 1 k X = V Q C X = Q u a l X = C V D Figure 5. Pairwise comparison of content coverage. Empirical cumulativ e histograms of d ( x, Y ) for all x ∈ X . The green, red, blue, yellow , and cyan line colors refer to the covering set Y and the dif ferent line styles refer to X being KonV id-150k, KoNV iD-1k, CVD 2014, Qualcomm, and VQC, respectiv ely . As expected from the previous figure, KonV id-150k covers the other datasets the best, indicated by the four green plots consistently falling to the left of their counterparts. The summarizing statistics, d ( X, Y ) can be taken from the intersections of the graphs with the participants were introduced to the task and provided with information about types of degradation, e.g., poor levels of detail, inconsistencies in color and brightness, or imperfections in motion. Ne xt, we provided examples of videos of a v ariety of quality le vels with a brief description of identifiable flaws and instructed the reader on the workflow of rating videos, which is illustrated in Figure 6. Finally , we informed participants about ongoing hidden test questions that were presented throughout the experiment, as well as the minimum resolution requirement that enabled them to continue participating in the experiment. This was checked before the playback of any video. During the actual annotation procedure, for each stimulus, workers were first presented with a white-box of the size of the video that also functioned as a play button. Then, the video was shown in its place with the playback controls hidden and deacti vated. After playback finished, it was hidden, and the rating scale was rev ealed below it. This setup ensured that neither the first nor the last still frame of the video were influencing the worker’ s rating, and no preemptiv e rating could be performed before the entirety of the video had been seen. An option to replay the video was not provided so as to improv e attenti veness and ensure that the obtained score is the intuiti ve response from the worker . Additionally , playback of any other video on the page was disabled until the currently playing video was finished, in order to better control viewing behavior and discourage unreliable or random answers. According to Figure Eight’ s design concept, crowd workers submit batches of multiple ratings in so-called pages. Each page has a fixed batch size of rows, where each row con ventionally represents a single item. Due to constraints on the number of rows allowed per study , we grouped 15 stimuli by random selection into each ro w , with a page size of ten ro ws per page, totaling to 150 videos per batch, respecti vely page. Moreov er , the design concept intends a two-stage testing process, where workers are first presented with a quiz of test questions follo wed by subsequent pages where test questions are randomly inserted into the data acquisition process. T est questions are not distinguishable from con ventional annotation items. In our implementation, illustrated in Figure 7, we inter- spersed three test videos with twelve videos randomly sampled from the dataset in each row with test questions. The test videos were sampled from hand-picked set of videos, which in one part was made up of very high-quality videos obtained from Pixabay 2 and in another of heavily degraded versions of them. Therefore, we defined the ground truth quality of each test video as either excellent or bad, respecti vely . W e performed a confirmation study to ensure that the percei ved quality of these videos was rated at the very top or bottom ends of the 5-point A CR scale. In the second stage, after the quiz, consisting of only test rows, workers annotated 150 videos in 10 rows per page. On each page, we included one further test row at a random position. Participants had to retain at least 70% accuracy on test ques- tions throughout the experiment. Data entered from work ers that dropped belo w this threshold were remov ed from our study , and the corresponding videos were scheduled for re-annotation. When running a study on Figure Eight, the experimenter decides the number of ratings per data row , as well as the pay per page. The latter was set such that with eight seconds per video, including fiv e seconds for viewing and three seconds for making the decision, a worker would be paid USD 3 per hour . W e had compiled 10,368 data rows of 15 data videos each. These data rows were presented to fiv e workers each, yielding 155,520 annotated video clips. From these, 152,265 2 http://pixabay .com TRANSA CTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY , V OL. 21, NO. 2, FEB. 2020 8 P l eas e click to pla y the video ! P l eas e r a t e belo w ! W ha t is the visua l qu ali ty of the video ? F air P oor Ba d Ex c ell en t Good Figure 6. Illustration of the crowdsourcing video playback workflow . A worker is first presented with a white box of 960x540 pixels. Upon clicking the box, the video plays in its place. Playback controls are disabled and hidden. Upon finishing, the video is hidden and replaced with a white box that informs the participant to rate the quality on the Absolute Category Rating (ACR) scale shown belo w . The rating scale is only sho wn upon completion of video playback. pass Q ui z P a g e Da t a P age 1 Da t a P age 2 TR TR TR TR TR DR DR DR TR DR DR DR DR DR TR DR TR DR DR DR DR DR TR DR DR Da t a P age 3 Da t a P age 4 TR 133 t es t r o w s wi th 3 t es t and 12 da t a videos each DR 10368 da t a r o w s wi th 15 da t a videos each … … … … … Figure 7. Simplified work flow diagram of the experiment. A worker is first presented with a quiz page of test rows (TR, in yello w) with three test videos and twelve data videos each. Upon passing the quiz with ≥ 70% accuracy they proceed to answer data pages with one test row per page. Data rows (DR, in white) contain 15 data videos. Data rows are annotated by five unique participants. T est rows can be answered once by each work er . were valid 3 and were retained, forming our larger dataset, called K onV id-150k-A. Each of the 10,368 data ro ws was presented to fi ve workers. There were altogether 133 test rows for presentation to all crowd workers. Howe ver , each cro wd worker could annotate any giv en test row at most once. Since 12 of the 15 videos in a test row were sampled from the set of data videos, we thus obtained far more than fiv e ratings for each of these individual videos. In total, 1,596 data videos were used in the 133 test ro ws and were rated between 89 and 175 times, due to randomness in test question distribution. W e separated 1,575 valid 3 videos of this very extensi vely annotated set in a ne w dataset and call it K onV id-150k-B. As a random subset of the entirety of our videos selected from Flickr , it is ecologically v alid and from the same domain as the other data videos. This dataset will be used as a test set for the ev aluation of our models trained on KonV id-150k-A. The choice for five individual ratings per data ro w was based on a small scale pilot study with a subset of 600 randomly sampled videos. For this subset we obtained two sets of 50 3 In some rare ( ≤ 1% ) cases users bypassed our restrictions by disabling jav ascript and were able to proceed without actually rating the videos. In that case the required 5 votes were not met, and we had to discard this video. Additionally , not all videos were readable by the Python libraries we used as feature e xtractors. Those videos were also remo ved. opinion scores for each video with a similar experimental setup as described above. W e then ev aluated the SRCC between a MOS comprised of a random sample of n votes from one set to the MOS of the other set. At 5 votes this SRCC reached 0.8, which we considered to be a good threshold. For reference, the SRCC between the two independent samplings of 50 votes settled at 0.9. Further inv estigation of the feasibility of our choice of 5 ratings is contained in more detail in Section V -C . Another common characteristic to compare the annotation quality of different studies is by ev aluating the standard deviation of opinion scores (SOS) as a function of MOS. It follows the basic idea that in experimental studies that are conducted in a quality controlled manner subjectiv e opinions will vary only to a certain extent, as the experimental setup ensures similar test conditions. In the case of the 5-point scale we used in our experimental setup, the maximum SOS is found at a MOS of 3, while the minimum will always be at the extremes of the rating scale. Howe ver , computing the av erage SOS over all videos is not an unbiased indicator, as datasets commonly do not contain a uniform distribution of videos in relation to the MOS. Instead, the variance σ 2 is modelled as a quadratic function of the MOS [52], which in the case of a 5-point scale is described as: SOS ( MOS ) 2 = a ( − x 2 + 6 x − 5) , (1) where the SOS parameter a better indicates the v ariance of subjecti ve opinions for an y particular experimental study . More- ov er , it has been shown to correlate with task dif ficulty [53] and can be used to characterise application categories. A reasonable range for the SOS parameter in the domain of VQA has been reported to be a ∈ [0 . 11 , 0 . 21] , with a K oNV iD-1k = 0 . 14 and a CVD2014 = 0 . 17 . In the case of LIVE-Qualcomm and LIVE-VQC, no SOS parameter has been reported and the publicly a v ailable annotation data does not allo w for such an analysis, as only the MOS v alues for videos in these specific datasets are available. W e hav e e v aluated the SOS hypothesis for K onV id-150k as well, howe ver we hav e limited it to the K onV id-150k-B set, as the discretized MOS values for the larger KonV id-150k-A set render it incompatible to the other datasets. Nonetheless, K onV id-150k-B is a good estimation of what can be expected in terms of annotation quality of KonV id- 150k as a whole. Figure 8 shows the comparison between K oNV iD-1k, CVD2014, and KonV id-150k-B, where the latter TRANSA CTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY , V OL. 21, NO. 2, FEB. 2020 9 1 2 3 4 5 MOS 0.0 0.5 1.0 1.5 Variance of MOS K 1 5 0 k , a = 0 . 2 1 K 1 k , a = 0 . 1 4 C V D , a = 0 . 1 7 Figure 8. Comparison of the SOS hypothesis [52] of K oNV iD-1k, CVD2014, and K onV id-150k-B. The SOS parameter for the three datasets are a = 0 . 14 , a = 0 . 17 , and a = 0 . 21 , respecti vely . For VQA the recommended range is a ∈ [0 . 11 , 0 . 21] , which shows that KonV id-150k is of sufficient annotation quality . has an SOS parameter of a K onV id-150k-B = 0 . 21 , which lies within the recommended range for VQA e xperiments. I V . V I D E O Q UA L I T Y P R E D I C T I O N The naïv e way to perform transfer learning for tasks related to visual features with small sets of data is removing the head of a pre-trained base-model and replacing it with a small fully connected head. By freezing the layers in the base-model it’ s predicti ve power can be used to perform well on the ne w task. After training this new header, it is not uncommon to unfreeze all layers and fine-tuning the entire trained network with a lo w learning rate to improve predictiv e power ev en more. Howe ver , this approach has three important do wnsides. 1) First, the new task is trained based on the highest lev el features in the base-model. These features are particularly tuned to detecting high-le vel semantic features that are useful in the detection of objects present in the image. Howe ver , for tasks such as quality , low-le vel features with a small recepti ve field are arguably more important. 2) Secondly , for each forward and backward pass the entire base-model has to be present in memory , which contain many more weights than the header network that is being trained. Consequently , training is slo wed down a lot. 3) Finally , the last fine-tuning step is prone to o verfitting, as the high capacity of the base-model alone allo ws the network to memorize training data rather than extracting useful general features. Careful hyperparameter tuning is therefore required, to ensure this step is successful in improving performance. Instead of performing fine-tuning, we trained our models on features extracted from pre-trained DCNNs. The procedure is an expansion of what we described earlier for the comparison of content div ersity , except we extracted features of all Inception modules of the network. The approach is inspired by [26], namely we extracted narrow multi-le vel spatially- pooled (MLSP) features, but for indi vidual frames of videos, as sho wn in Fig. 9. In principle, this general approach of extracting acti vations from indi vidual layers of a network can be applied to any popular architecture. Related work has shown that this approach works with an Inception-ResNet-v2 network as a feature extractor in the IQA domain [50], [54]. For the extraction process we, therefore, passed individual video frames to an InceptionResNet-v2 network, pre-trained on ImageNet [27]. W e then performed global a verage pooling on the acti vation maps of all kernels in the stem of the network, as well as on each of the 40 Inception-ResNet modules and the two reduction modules. Concatenating the results yielded our MLSP feature vector consisting of av erage activ ation levels for 16,928 kernels of the InceptionResNet-v2 network. These MLSP feature vectors were extracted for all frames of all videos. Figure 10 shows a visualization of parts of the MLSP feature vector for multiple consecuti ve frames. A. Model Implementation Details Dif ferent learning-based regression models, such as Support V ector Regression (SVR) or Random Forest Regression (RFR), hav e been employed to predict subjective quality scores from frame features, with SVR yielding generally better results [19]. Howe ver , most existing works only extract a fe w dozen to a fe w hundred features. Since SVR is sub-optimal when applied to very large dimensional features like our MLSP feature, we instead train three small-capacity DNNs (Figure 11): • MLSP-VQA-FF , a feed-forward DNN where the av erage feature vector is the input of three blocks of fully connected layers with ReLU activ ations, followed by batch normalization and dropout layers. • MLSP-VQA-RN, a deep Long Short-T erm Memory (LSTM) architecture, where each LSTM layer recei ves the feature v ector or the hidden state of the lower LSTM layer as an input and outputs its hidden state. This stacking of layers allo ws for the simultaneous representation of input series at different time scales [55]. The bottom LSTM layer can be understood as a selective memory of past feature vectors. In contrast, each additional LSTM layer represents a selectiv e memory of past hidden states of the previous layer . • MLSP-VQA-HYB, a two-channel hybrid of both the FF and RN variants. The temporal channel is a copy of the RN model’ s architecture, while the second channel is a mirror of the FF network scaled up to match the number of kernels in the temporal branch in the last layer . The outputs of the tw o channels are concatenated and a small 32 kernel fully connected layer feeds into the last prediction layer . Our tests sho wed that employing dropout of any kind within the recurrent networks, such as input/output dropout or recurrent dropout, resulted in reduced performance. W e therefore do not employ any dropout in these architectures. As mentioned before, this two-step strategy of feature extraction followed by training a regressor is much faster than transfer learning and fine-tuning an Inception-style network. It’ s dif ficult to fairly assess the difference, as a lot of factors play a role. For example, when fine-tuning an Inception-net, the speed at which the videos are read from the hard-dri ve can become a bottle-neck, if a very powerful GPU is performing the training procedure. Our proposed approach with an Inception- ResNet-v2 as a feature extraction network has a benefit for this scenario, since the input data for each frame is fixed at 16,928 floating point v alues. In contrast, if the GPU used to perform the training is not as powerful, it itself can become a TRANSA CTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY , V OL. 21, NO. 2, FEB. 2020 10 c onc a t en a t ed MLSP f ea tur es (16 928 - d i me n s i on al) In cept i on - R es Ne t - v2 body GAP GAP GAP GAP GAP GAP 1 0 I nce p ti on - A R educ ti on - A St em 2 0 I nce p ti on - B R educ ti on - B 1 0 I nce p ti on - C vi deo fr ame Figure 9. Extraction of multi-level spatially-pooled (MLSP) features from a video frame, using an InceptionResNet-v2 model pre-trained on ImageNet. The features encode quality-related information: earlier layers describe low-le vel image details, e.g. image sharpness or noise, and later layers function as object detectors or encode visual appearance information. Global A verage Pooling (GAP) is applied to the acti vations resulting from the Stem, each Inception-module, as well as the Reduction-modules, and finally concatenated to form MLSP features. For more information regarding the individual blocks please refer to the original paper [27]. 0 10 20 30 Frames 0.0 0.5 1.0 1.5 2.0 2.5 Level of activation Level of activation over time of the first block (Stem) Stem I-RN-A 1 I-RN-A 2 I-RN-A 3 I-RN-A 4 I-RN-A 5 I-RN-A 6 I-RN-A 7 I-RN-A 8 I-RN-A 9 I-RN-A 10 Reduction-A I-RN-B 1 I-RN-B 2 I-RN-B 3 I-RN-B 4 I-RN-B 5 I-RN-B 6 I-RN-B 7 I-RN-B 8 I-RN-B 9 I-RN-B 10 I-RN-B 11 I-RN-B 12 I-RN-B 13 I-RN-B 14 I-RN-B 15 I-RN-B 16 I-RN-B 17 I-RN-B 18 I-RN-B 19 I-RN-B 20 Reduction-B I-RN-C 1 I-RN-C 2 I-RN-C 3 I-RN-C 4 I-RN-C 5 I-RN-C 6 I-RN-C 7 I-RN-C 8 I-RN-C 9 I-RN-C 10 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 Median level of activation of block-wise MLSP features over all frames of 3 sample videos 0 10 20 30 Frames 0.00 0.05 0.10 0.15 Level of activation over time of the last block (I-RN-C 10) Figure 10. V isualization of the v ariation of activ ation le vels of MLSP features o ver the course of KonV id-150k videos. In the center , the median level of activ ation for each of the 43 blocks from the Inception-ResNet-v2 network is displayed for 3 sample videos. The black whiskers indicate the 50% confidence interval on the le vel of activ ation. F or the first block (Stem), the whiskers extend to 0.7. The left and right plots sho w the activation of 1/8th of the first and last blocks’ features over time. bottle-neck of the system. In this case, our proposed approach has the alternativ e benefit that the small network size allows for much larger batches and quicker forward and backward passes. In order to quantify the difference, we compare different setups of transfer learning and fine-tuning to our proposed two- step MLSP feature-based training procedure on a machine that reads from an NVMe connected SSD and trains the networks using T ensorflow 2.4.1 on an NVIDIA A100 with 40GB of VRAM. T o simplify the setup, we are ev aluating only the MLSP-VQA-FF model on the pre-extracted first frames of K onV id-150k-B. The transfer learning scenarios are all performed using an Inception-ResNet-v2 base-model with our FF model sitting on top for 40 epochs. Howe ver , we compare four slightly different scenarios: • Koncept : The FF model takes the last layer of the base- model as an input, much like the Koncept model proposed in [50]. The weights of the base-model are not frozen, so the entire model is fine-tuned over the course of the training. W e employ two training stages, one with a learning rate of 1 × 10 − 3 , and the second with a learning rate of 1 × 10 − 5 . • IRNV2 : Instead of fine-tuning the entire model throughout both stages, we freeze the layers of the Inception-ResNet- v2 base-model for the first stage, so as to avoid the large update steps caused by the random initialisation of the header network to destroy the useful features in it. For the second stage we unfreeze the weights in all layers. • IRNV2-MLSP : As stated before, one downside of the abov e approaches lies in the circumstance that the header network relies only on the top lev el features as inputs. For the third comparison we concatenate the activ ation layers of all Inception-modules and feed that as an input to the header network. Here, we also freeze the base-model weights for the first stage, and unfreeze all weights for the second stage. • MLSP : The final item in the comparison takes the MLSP features described above as an input. This means, the model is much smaller , as the base-model does not need to be loaded. Ho we ver , the model can not lev erage the spatial information about the activ ations to make it’ s prediction. No explicit weight freezing is performed in this scenario. These dif ferent cases are compared in Figure 12. The green graph, corresponding to the Koncept model, takes the longest to train in total and achie ves the worst validation performance at the end of the 80 epochs. The reason for the slow training in the first stage is that none of the weights are frozen and the backpropagation step therefore takes additional time. Both the TRANSA CTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY , V OL. 21, NO. 2, FEB. 2020 11 F C 32 M OS 𝑛 f ea t ur e v ec t or s LS TM 2 5 6 LS TM 25 6 LS TM 1 2 8 Conc a t ena t e F C 1024 F C 512 F C 128 F C 1 MOS a vg f ea t ur e v ec t or F C 512 B a t c h N or m D r op ou t 0.2 5 R eL U F C 256 B a t c h N or m D r op ou t 0.2 5 R eL U F C 64 B a t c h N or m D r op ou t 0.2 5 R eL U F C 1 MOS 𝑛 f ea t ur e v ec t or s LS TM 2 5 6 LS TM 25 6 LS TM 128 Figure 11. Left: The MLSP-VQA-FF model, that relies on average frame MLSP features and a densely connected feed forward network. Middle: The MLSP-VQA-RN recurrent model, implementing a stacked long short-term memory network. Right: The hybrid MLSP-VQA-HYB dual channel model, that has a bigger v ariant of the FF network on the left and the recurrent part of the RN network on the right. Both channels output activ ations at each timestep and are merged along the feature dimension, before feeding into a small prediction head. Both the RN and HYB models tak e corresponding frame features at each time step as an input to the network. orange IRNV2 and blue IRNV2-MLSP models train faster by approximately 22%, as the weights are frozen in the first stage. Howe ver , they differ in that the inclusion of all Inception-modules in the concatenation layer for the latter increases performance significantly . Finally , the red graph, representing the MLSP-VQA-FF model trained on extracted MLSP features achieves the best performance while beating the IRNV2-MLSP model in terms of speed by factor 74. Moreov er, peak performance is achiev ed much earlier , as the second training stage is not required, raising the speed-up to factor 171. Ho wev er, feature extraction has to be performed once as well, which for the first frames of KonV id-150k-B took 38 seconds. Including this time in the comparison still renders the MLSP- VQA-FF model faster by factor 36, when considering both training stages. This factor is dependant on input resolutions, ho wev er with videos increasing in resolution the speed-up will only change in fav or of the MLSP-based model, as its training speed will not change, while the training speed of the fine- tuning approach is in versely correlated with input resolution. This sho ws the power of using pre-extracted MLSP features. Furthermore, we have observed the success of fine-tuning an Inception-style network in this manner is very sensitive to hyperparameters, while training the small FF network on MLSP features is fairly rob ust. T able I gi ves an overvie w of some hyperparameter settings used in the training of our MLSP-based models for the compared datasets. Mean square error (MSE) was used as a loss function for a duration of 250 epochs, stopping early if 0 20 40 60 80 Epochs 0.45 0.50 0.55 0.60 0.65 0.70 0.75 0.80 Validation SROCC 28m 29s 16m 3s 16m 24s 16s 56m 50s 44m 14s 45m 39s 37s Koncept IRNV2 IRNV2-MLSP MLSP-VQA-FF full ft @ low lr Figure 12. A visualization of the conv ergence of different transfer learning techniques along with information about the training times. The solid lines show the first training stage of 40 epochs, where the IRNV2 (orange) and IRNV2-MLSP (blue) architectures hav e their weights frozen. Koncept (greeN) and IRNV2 connect the last layer to the small header network, while IRNV2- MLSP concatenates all individual Inception-module outputs to feed into the head. Finally , MLSP-VQA-FF works off of extracted MLSP features, which for this scenario took 38 seconds. the validation loss did not improve in the most recent 25 epochs at an initial learning rate of 10 − 4 . By default, the MLSP-VQA- FF model was trained with a learning rate of 10 − 2 , and both the MLSP-VQA-RN and the MLSP-VQA-HYB models were trained with a learning rate of 10 − 4 . TRANSA CTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY , V OL. 21, NO. 2, FEB. 2020 12 T able I T R AI N I N G S E TT I N G S A N D PA RA M E T ER S MLSP-VQA-FF MLSP-VQA-RN/-HYB T ype frames batch size lr frames batch size lr KoNV iD-1k all 128 10 − 2 180 128 10 − 4 LIVE-Qualcomm all 8 10 − 3 150 8 10 − 4 CVD2014 all 8 10 − 3 140 8 10 − 4 LIVE-VQC all 8 10 − 3 150 8 10 − 4 Proposed all 128 10 − 2 180 128 10 − 4 V . M O D E L E V A L U A T I O N Our proposed NR-VQA approach of extracting features from a pre-trained classification network and training DNN architectures on them hav e been designed to predict video quality in-the-wild. W e ev aluate the potential of the MLSP features when used for training the shallow feed-forward and recurrent networks by measuring their performance on four widely used datasets (K oNV iD-1k, LIVE-VQC, CVD2014, and LIVE-Qualcomm) and our newly established dataset K onV id- 150k. W e consider two basic scenarios, namely (1) intra-dataset, i.e. training and testing on the same dataset, and (2) inter- dataset, i.e., training (and v alidating) on our lar ge dataset K onV id-150k and testing on another . There are two fundamental limitations in these datasets that affect the performance of our approach. The first one relates to the video content, in the form of domain shifts between ImageNet and the videos in the datasets. The other one is due to the different types of subjecti ve video quality ratings (labels) in the datasets, that may af fect the cross-testing performance. First, the features in the pre-trained network hav e been learnt from images in ImageNet. There are situations when the information in the MLSP features may not transfer well to video quality assessment: • Some artifacts are unique to video recordings; this is the case of temporal degradations such as camera shake, which does not apply to photos. • Compression methods are dif f erent for videos in compar- ison to images. Thus, the individual frames may show encoding-specific artifacts that are not within the domain of artifacts present in ImageNet. • In-the-wild videos have different types and magnitudes of degradations compared to photos. For e xample, motion blur degradations can be more prev alent and of a higher magnitude in videos compared to photos. This could af fect how well MLSP features from networks pretrained on ImageNet transfer to VQA. Secondly , concerning the subjectiv e video quality ratings to be predicted when cross-testing, while there are similarities between the rating scales used in the subjectiv e studies corresponding to each dataset, the ratings themselves may suffer from a presentation bias. For example, in the case of a dataset with highly similar scenes, but minuscule differences in degradation lev els, as is the case for LIVE-Qualcomm and CVD2014, a human observer may become very sensitiv e to particular degradations. Con versely , video content becomes less critical for quality judgments. The attention of the human observer is di verted to parts in the video he might otherwise not hav e looked at, had he not seen the same or a very similar scene many times before. Whether the resulting subjective judgments can be regarded as fair quality values is ar guable. A human observer would rarely watch a scene multiple times before rating the quality . This bias of subjective opinions may greatly influence how the quality predictions trained in one setting generalize to others. Similarly , quality scores obtained in a lab en vironment will be much more sensitiv e to dif ferences in technical quality than a worker in a crowdsourcing experiment might be able to pick up. Therefore, it may be challenging to generalize from one experimental setup to another . While consumption of ecologically valid video content happens in a variety of en vironments and on a multitude of devices, it is arguable whether one experimental setup is superior . A. Model P erformance Comparisons W e first ev aluate the performance of the proposed model on four existing video datasets. K oNV iD-1k and LIVE-VQC both pose the unique challenge that they are in-the-wild video datasets, containing authentic distortions that are common to videos hosted on Flickr . LIVE-Qualcomm contains self- recorded scenes of different mobile phone cameras that were aimed at inducing common distortions. CVD2014 differs from the previous two, in that it is a dataset with artificially introduced acquisition-time distortions. It also contains only fi ve unique scenes depicting people. Finally , LIVE-VQC was a collaborati ve effort of friends and family of the LIVE research group that were asked to submit video files of a variety of contents to capture div ersity in capturing equipment and distortions. W e are comparing our proposed DNN models against published results for other methods that hav e been thoroughly ev aluated on these datasets using SVR and RFR. Detailed information reg arding the experimental e v aluation and results of the classical methods can be found in [19]. W e adopt a similar testing protocol by training 100 different random splits with 60% of the data used for training, 20% used for v alidation, and 20% for testing in each split. T able II summarizes the SRCC w .r .t. the ground-truth for the predictions of the classical methods (taken from [19]) alongside our DNN- based approach. It is to be noted that the random splits we used are dif ferent from the ones used to e valuate the classical methods in [19]. For brevity , we are only reporting the results for classical methods obtained using SVR, although four individual results are slightly improved using RFR. The FF network outperforms the existing works on K oNV iD- 1k, improving state-of-the-art SRCC from 0.80 to 0.82, while the RN and HYB models remain competiti ve with an SRCC of 0.78 and 0.79, respectiv ely . This shows that the proposed approaches are performing close to state-of-the-art on authentic videos with some encoding degradations. Since the feature extraction network is trained on images with natural image distortions, some of the extracted features are likely indicativ e of these distortions, which are not unlike the video encoding artifacts introduced by Flickr . Existing methods had not been ev aluated exhausti vely on LIVE-VQC at the time of writing. Our recurrent networks achie ve 0.70 (RN) and 0.69 (HYB) SRCC, while the FF model TRANSA CTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY , V OL. 21, NO. 2, FEB. 2020 13 performs at 0.72 SRCC, rendering it competitive with state- of-the-art for the dataset 4 . One of the difficulties inherent to VQC with respect to our models is the circumstance, that it is comprised of videos of various resolutions and aspect ratios. An ev aluation of the performance of the models with respect to the video resolutions can be found in the top part of Figure 13. Since 1080p, 720p, and 404p in portrait orientation are the predominant resolutions with 110, 316, and 119 videos, respectiv ely , we grouped the other resolutions into the other category . W e can see that both the FF and RN models perform worse on the 1080p and 720p videos, whereas the HYB model performs better on the higher resolution videos. In the case of LIVE-Qualcomm our best performance of 0.75 SRCC of the hybrid model is surpassed only by TL VQM with 0.78. Since the dataset is comprised of videos containing six different distortion types, we also ev aluated the performance of the models according to each degradation, as depicted in the middle plot of Figure 13. Here, we sho w the deviation of the RMSE of each model for each distortion type from the av erage performance in percent. Little de viation between all three models is observed for both Exposure and Stabilization type distortions. Ho we ver , for Artifacts and Color the RN model de viates from the other tw o drastically , performing worse on the former and better on the latter . V ideos in the focus degradation class sho w auto-focus related distortions where parts of the video are intermittently blurry or sharp ov er time and are ov erall the biggest challenge for our recurrent models, that both perform ov er 20% worse on them than av erage. Finally , the Sharpness distortion is best predicted by the recurrent networks, with the hybrid model outperforming the pure LSTM network. On CVD2014, our proposed models with SRCCs of 0.77, 0.75, and 0.79 for the FF , RN and HYB models, respecti vely , are outperformed by both FRIQUEE and TL VQM at 0.82 and 0.83 SRCC. CVD2014 is a dataset of videos of two dif ferent resolutions, with artificially introduced capturing distortions and only fi ve unique scenes of humans and human faces. The magnitude of the artifacts is at a lev el that is not commonly seen in videos in-the-wild, and the types of defects are also not within the domain of distortions present in ImageNet. Therefore, this is the most challenging dataset for our approach and, consequently , the relative performance of our approach is worse. CVD2014 is split into six subsets with partially ov erlapping scenes but distinct capturing cameras. The bottom part of Figure 13 sho ws the relati ve deviation of the RMSE from the mean performance for each of these test setups. The first two setups include videos at 640 × 480 pixels resolution, which are generally rated with a lower MOS than videos in the other test setups, which could both be an important factor in our models’ increased performance here. Although all setups include scenes 2 and 3, scene 1 is only included in test setups 1 and 2, scene 4 is only included in test setups 3 and 4, and scene 5 is solely included in test setups 5 and 6. Since the features we use are tuned to identify content, as we showed in Section III-B , inclusion or exclusion of particular scenes can have an impact on the performance of our method. Moreov er, since each test 4 Recently , a new publication on arXiv disusses a new approach called RAPIQUE that achieves an SROCC of 0.76 on LIVE-VQC ?? . Ho wev er, this work has not yet been peer revie wed. setup contains videos taken from different cameras than the rest, it is possible that the in-capture distortions caused by particular cameras in any individual test setup may be closer to the types of distortions present in ImageNet. W e now consider the performance ev aluation when training and testing on our ne w dataset, K onV id-150k-B of 1,596 videos, each with at least 89 ratings comprising the quality score. W e separate these tests from the previous ones because, in this case, we hav e the option to train the networks on the additional 150k videos in KonV id-150k-A that stem from the same domain. From the previous experiments, it is evident that TL VQM is the best performing classical metric on the similar domain, given by K oNV iD-1k, by a large margin. Therefore, we compare our MLSP-VQA models only against TL VQM and the standard V -BLIINDS. T able III summarizes the performance results. Compared to the performance on KoNV iD-1k, V -BLIINDS (ro w 1) improv es slightly , while TL VQM (ro w 2) performs significantly worse. Since the main dif ference between K oNV iD-1k and this dataset is the reduced re-encoding degradations, it appears as though the classical methods ov er-emphasize their prediction on these artifacts. The third through fifth ro w list the performance of our models, which outperform both classical methods, beating TL VQM’ s 0.71 SRCC with 0.83 (FF), 0.78 (RN) and 0.75 (HYB) when trained and tested on the B variant exclusi vely . Finally , the last three rows sho w the results from training on the large dataset, K onV id-150k-A, with 150k videos. For these last three ev aluations a random subset of 50% of KonV id- 150k-B was used for validation during training. The remaining part of K onV id-150k-B was used for testing. W e note an Figure 13. Percent de viation of the mean RMSE of the proposed models on each of the six de gradation types present in LIVE-Qualcomm (top), each of the six test scenarios in CVD2014 (middle), and the dif ferent resolutions in LIVE-VQC (bottom). TRANSA CTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY , V OL. 21, NO. 2, FEB. 2020 14 T able II R E SU LT S O F D I FF E RE N T N R - V QA M E T RI C S O N D I FF ER E N T AU T H EN T I C V Q A D A TA SE T S in-the-wild synthetic K oNV iD-1k LIVE-VQC LIVE-Qualcomm CVD2014 Name SRCC ( ± σ ) SRCC ( ± σ ) SRCC ( ± σ ) SRCC ( ± σ ) SVR NIQE (1 fps) 0.34 ( ± 0.05) 0.56 ( ± –.––) 0.46 ( ± 0.13) 0.58 ( ± 0.10) BRISQUE (1 fps) 0.56 ( ± 0.05) 1 0.61 ( ± –.––) 0.55 ( ± 0.10) 0.63 ( ± 0.10) 1 CORNIA (1 fps) 0.51 ( ± 0.04) –.–– ( ± –.––) 0.56 ( ± 0.09) 0.68 ( ± 0.09) V -BLIINDS 0.65 ( ± 0.04) 1 0.72 ( ± –.––) 0.60 ( ± 0.10) 0.70 ( ± 0.09) 1 HIGRADE (1 fps) 0.73 ( ± 0.03) –.–– ( ± –.––) 0.68 ( ± 0.08) 0.74 ( ± 0.06) FRIQUEE (1 fps) 0.74 ( ± 0.03) –.–– ( ± –.––) 0.74 ( ± 0.07) 0.82 ( ± 0.05) TL VQM 0.78 ( ± 0.02) –.–– ( ± –.––) 0.78 ( ± 0.07) 0.83 ( ± 0.04) DNN 3D-CNN + LSTM 2 0.80 ( ± –.––) –.–– ( ± –.––) 0.69 ( ± –.––) –.–– ( ± –.––) MLSP-VQA-FF 0.82 ( ± 0.02) 0.72 ( ± 0.06) 0.71 ( ± 0.08) 0.77 ( ± 0.06) MLSP-VQA-RN 0.78 ( ± 0.02) 0.70 ( ± 0.06) 0.72 ( ± 0.07) 0.75 ( ± 0.06) MLSP-VQA-HYB 0.79 ( ± 0.02) 0.69 ( ± 0.07) 0.75 ( ± 0.04) 0.79 ( ± 0.05) 1 Performance improves when using random forest regression. 2 The authors did not supply any standard de viations for the performance measures, and did not ev aluate the method on CVD2014. additional substantial performance increase for our networks. The FF model’ s performance increases from 0.81 SRCC to 0.83, while the RN model improves from 0.78 SRCC to 0.81. The largest performance gain can be observed for the HYB network, as it improves from 0.75 SRCC to 0.81 SRCC as well. This demonstrates, for the first time, the enormous potential gains that can be achiev ed by vast training datasets for VQA. Although K onV id-150k-A only has MOS scores comprised of fiv e individual v otes, by training on them and validating on the target dataset we drastically improv e performance. It is to be noted as well that the test sets in this scenario are larger than when training and testing solely on K onV id-150k-B. This renders the test performance to be ev en more representativ e. Howe ver , the change in variance of the resulting correlation coefficients can not directly be attributed to the increase in training dataset size. The dif ference likely arises from the fact that the models trained using KonV id-150k-A hav e the same training data, and are therefore more likely to learn similar features. Nonetheless, this effect should be in vestigated further . B. Inter -Dataset P erformance Considering the div ersity in content and distortions in K onV id-150k we highlight the power of KonV id-150k in combination with our MLSP-VQA models in inter-dataset testing scenarios. At the time of writing, LIVE-VQC has not been considered in any performance ev aluations across datasets. The pre viously best reported cross-test performances between the other three legacy datasets are three different combinations of NR-VQA methods and training datasets 5 . Specifically , TL VQM trained on CVD2014 performs best on K oNV iD-1k cross-testing with 0.54 SRCC. V -BLIINDS trained on K oNV iD-1k is the best combination for cross-testing on LIVE-Qualcomm with 0.49 SRCC. Finally , FRIQUEE trained on K oNV iD-1k performs best when cross-testing on CVD2014 with 0.62 SRCC. It is apparent from these results that no single NR-VQA and dataset combination generally outperforms in inter-dataset testing scenarios. 5 These results are taken from [18]. W e ev aluate the performance of our models when cross- testing on other datasets, trained on KonV id-150k-A and validated and tested on each 50% of KonV id-150k-B. The av erage SRCC performances of 10 models are reported in T able IV. For ease of comparison we also include the best within-dataset performance in the first row , as well as the previous best cross-dataset test performances as taken from [18] in the second row of the table. Although the performances between our different models do not vary much, the results rev eal some interesting findings. • The cross-dataset test performance of the FF model on K oNV iD-1k of 0.83 SRCC is higher than all other within- dataset test performances and especially any cross-test setups. This again underlines the potential power of data, ev en if it is annotated with lower precision. Although K onV id-150k does not have the Flickr video encoding artifacts present, it can predict the distorted videos of K oNV iD-1k better than training on videos taken from the same dataset. • Our models trained on KonV id-150k and cross-tested on LIVE-VQC achiev e state-of-the art performance and ev en surpass the best within-dataset performance in the case of the FF model with 0.75 SRCC 4 • On LIVE-Qualcomm the cross-dataset test performances of all our models are slightly better than V -BLIINDS (0.60), when it is trained and tested on LIVE-Qualcomm. Since V -BLIINDS has been the de facto baseline method, this is a remarkable result. Additionally , for a cross- dataset test our proposed KonV id-150k dataset shows the best generalization to LIVE-Qualcomm, improving the pre vious best 0.49 SRCC to 0.64. • Next, our models struggle with CVD2014, as none of them beat e ven the most dated classical models trained and tested on CVD2014 itself. This may be in part due to the nature of the degradations induced in the creation of the dataset, which are not nativ e to the videos present in K onV id-150k. Moreover , the domain shift between K onV id-150k and CVD2014 seems to be larger than to the other datasets, as the previous best cross-dataset TRANSA CTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY , V OL. 21, NO. 2, FEB. 2020 15 T able III R E SU LT S O F N R - V QA M E T RI C S O N K ON V I D -1 5 0 K -B . T H E B OT T OM T H R EE R OW S D E S CR I B E T H E P E R F OR M A NC E W H E N T R AI N I N G O N T H E E N T I RE T Y O F K O N V I D - 1 5 0 K - A , U S I N G H A LF O F K O N V I D - 1 5 0 K - B A S A V A L I DATI O N S E T , A N D T H E OT H E R . Name PLCC ( ± σ ) SRCC ( ± σ ) RMSE ( ± σ ) SVR V -BLIINDS (SVR) 0.68 ( ± 0.04) 0.68 ( ± 0.04) 0.27 ( ± 0.02) TL VQM (SVR) 0.68 ( ± 0.12) 0.71 ( ± 0.04) 0.26 ( ± 0.04) DNN MLSP-VQA-FF 0.83 ( ± 0.02) 0.81 ( ± 0.02) 0.26 ( ± 0.01) MLSP-VQA-RN 0.80 ( ± 0.02) 0.78 ( ± 0.02) 0.29 ( ± 0.01) MLSP-VQA-HYB 0.76 ( ± 0.04) 0.75 ( ± 0.04) 0.32 ( ± 0.03) MLSP-VQA-FF (Full) 0.86 ( ± 0.01) 0.83 ( ± 0.01) 0.19 ( ± 0.01) MLSP-VQA-RN (Full) 0.83 ( ± 0.01) 0.81 ( ± 0.01) 0.21 ( ± 0.01) MLSP-VQA-HYB (Full) 0.83 ( ± 0.01) 0.81 ( ± 0.01) 0.21 ( ± 0.01) T able IV I N TE R - DA TAS E T T E S T P E R FO R M A NC E O F O U R T H R E E M O D EL S A V E R AG ED OV E R 1 0 S P L IT S T R AI N E D O N T H E E N TI R E T Y O F K O N V I D - 15 0 K - A. T H E D I FFE R E N T S P LI T S O N LY A FF EC T T H E V A L I DA T I ON A N D T E S T S E T S , A S A LL V I D E OS O F K O N V ID - 1 5 0 K - A A R E U S ED F O R T R A I NI N G . in-the-wild synthetic K oNV iD-1k LIVE-VQC LIVE-Qualcomm CVD2014 SRCC ( ± σ ) SRCC ( ± σ ) SRCC ( ± σ ) SRCC ( ± σ ) Intra-dataset best 0.82 ( ± 0.02) 0.72 ( ± 0.06) 0.78 ( ± 0.07) 0.83 ( ± 0.04) Prev . inter-dataset best [18] 0.54 ( ± –.––) –.–– ( ± –.––) 0.49( ± –.––) 0.62 ( ± –.––) MLSP-VQA-FF 0.83 ( ± 0.01) 0.75 ( ± 0.01) 0.64 ( ± 0.01) 0.55 ( ± 0.02) MLSP-VQA-RN 0.80 ( ± 0.01) 0.71 ( ± 0.01) 0.61 ( ± 0.03) 0.52 ( ± 0.02) MLSP-VQA-HYB 0.79 ( ± 0.01) 0.71 ( ± 0.01) 0.62 ( ± 0.03) 0.52 ( ± 0.02) performance is also not achiev ed. The cross-test performance drops notably when testing on synthetic video datasets. This has already been observed in the IQA domain [54], where training and testing on the same domain resulted in much higher performance than when the source and target domains were different. The types of distortions in individual frames of videos from two different domains result in dif ferent characteristics of the activ ations of Inception-net features, resulting in reduced performance. C. Evaluation of T raining Sc hemes As described in Section II-A , the choice of the number of ratings per video is a distinguishing, yet so far unexplored f actor in the design of VQA datasets in the context of optimizing model training performance. In order to study the effect of varying the number of ratings per video, we trained a large set of corresponding models in two experiments. In the first one, we increased the number of ratings to reduce the lev el of noise in the training set. In the second one, we additionally introduced the natural constraint of a vote budget, limiting the total number of ratings to a constant. It is common to use an equal number of votes for each stimulus so that the MOS of the training, v alidation, and test sets have the same reliability , respectiv ely , the same lev el of noise. Deep learning is known to be robust to label noise [37], howe ver , this has been only studied when the same amount of noise is present for all items in all parts of the dataset (train/test/v alidation). Thus, the first question we in vestigate is: • What impact do differ ent noise levels in the training and validation sets have on test set pr ediction performance? More precisely , we are interested to know the change in prediction performance when fewer votes are used for training and v alidating deep learning models, compared to the number of v otes used for test items. In order to answer this question, we randomly sampled v = 1 , 2 , 4 , 7 , 14 , 26 , and 50 votes fiv e times for each video within K onV id-150k-B and computed the corresponding MOS values (7 × 5 MOS per video). W e then trained our MLSP- VQA-FF model by varying both training set, and validation set MOS vote counts while keeping the test set MOS vote count at 50. For each pair of training and validation MOS, we considered twenty random splits with 60% of the data for training, 20% for validation, and 20% for testing, with the abov e mentioned five versions of the MOS each. Therefore, we trained 5 × 20 × 7 × 7 = 4900 models in total. The graph in Figure 14 depicts the mean SRCC between the models’ predictions and the ground truth MOS of the test sets. Each line in this graph represents a different number of votes comprising the validation MOS, whereas the x-axis indicates the number of votes comprising the training MOS. Note that the x-axis is scaled logarithmically for better visualization. There are three key observations concerning the prediction performance: • The prediction performance improves as the number of votes comprising the training MOS increases, re gardless of the number of votes used for v alidation. • The performance impro vements scale approximately log- arithmically with the number of votes comprising the training MOS. • The test set performance varies less due to changes in the number of votes used for v alidation than it does due to the number of votes for items in the training set. The fact that performance improves with lower training label noise is not surprising. Nonetheless, the gentler slope for the performance curves beyond four votes comprising the training TRANSA CTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY , V OL. 21, NO. 2, FEB. 2020 16 1 2 4 7 14 26 50 Numbers of votes comprising training MOS 0.55 0.60 0.65 0.70 0.75 SROCC Performance analysis at different numbers of votes comprising training and validation MOS Number of votes comprising validation MOS 1 2 4 7 14 26 50 Figure 14. Noise rob ustness of MLSP feature based method. MOS is an indicator that the common policy to gather 25 votes for all stimuli in a dataset may be sub-optimal, due to diminishing returns. In fact, at approximately five v otes (1/10th of the analysed budget) the model achiev es roughly 92% of the peak performance, suggesting it to be a good trade-off between precision and cost. The comparison between data splits in this experiment is not balanced, because the data points in the graphs of Figure 14 correspond to different vote budgets, ranging from 1 rating per video in one instance on the left up to 50 per video on the right. The annotation of datasets in the lab and also in the crowd usually is constrained by a budget in terms of total hours of testing or overall cost of crowdsourcing. This translates to a maximum number of votes that can be attained for a giv en dataset. Therefore, the second question we in vestigate is: • Given a fixed vote budget, how does the allocation of votes on the training set affect test performance? In other words, is it better to collect more votes for fewer stimuli, or less votes for more videos? In order to answer this question, we first di vided KonV id- 150k-B into fiv e disjoint test sets (each with 20% of all videos) and sampled the same number of videos from the remaining set of K onV id-150k-B for validation. W e then considered three le vels of precision at 100, 5, and 1 votes comprising the MOS of videos used in training, as well as six vote budgets of 100,000, 25,000, 10,000, 2,500, and 1,000 votes. W e built the training sets accordingly , sampling from the remaining videos in KonV id-150k-B first, and then adding in videos from K onV id-150k-A, if needed, such that the smaller sets are proper subsets of the larger variants. F or the vote b udget of 100,000 votes we consequently created three training sets of 1,000, 20,000, and 100,000 videos at training MOS precision le vels of 100, 5 and 1 vote(s), respectiv ely . It is to be noted that the ov erlap between the different samples of the same sets increases as the set size increases, as the whole K onV id-150k-B set is only comprised of ≈ 150,000 videos, which in turn has an ef fect on the standard de viation of the predictions. W e trained both MLSP-VQA-FF and MLSP-VQA-RN on the fi ve dif ferent splits for all three vote budget distributions T able V P E RF O R M AN C E O F O U R F F M O D E L AT A FI XE D VO T E B UD G E T O F 1 0 0, 0 0 0 , 2 5 ,0 0 0 , 1 0 , 0 00 , 2 , 50 0 , A ND 1 , 0 0 0 V OT E S . Set PLCC SRCC RMSE 1000@100 0.76 ( ± 0.03) 0.73 ( ± 0.04) 0.24 ( ± 0.01) 20000@5 0.76 ( ± 0.02) 0.74 ( ± 0.03) 0.24 ( ± 0.01) 100000@1 0.77 ( ± 0.02) 0.74 ( ± 0.03) 0.24 ( ± 0.01) 250@100 0.75 ( ± 0.01) 0.70 ( ± 0.01) 0.26 ( ± 0.01) 5000@5 0.77 ( ± 0.02) 0.72 ( ± 0.02) 0.25 ( ± 0.01) 25000@1 0.76 ( ± 0.02) 0.72 ( ± 0.02) 0.25 ( ± 0.01) 100@100 0.68 ( ± 0.03) 0.62 ( ± 0.05) 0.28 ( ± 0.01) 2000@5 0.68 ( ± 0.02) 0.64 ( ± 0.03) 0.28 ( ± 0.02) 10000@1 0.69 ( ± 0.06) 0.66 ( ± 0.05) 0.28 ( ± 0.01) 25@100 0.56 ( ± 0.08) 0.51 ( ± 0.07) 0.32 ( ± 0.02) 500@5 0.59 ( ± 0.04) 0.54 ( ± 0.07) 0.34 ( ± 0.02) 2500@1 0.57 ( ± 0.04) 0.52 ( ± 0.05) 0.36 ( ± 0.04) 10@100 0.46 ( ± 0.07) 0.41 ( ± 0.09) 0.34 ( ± 0.02) 200@5 0.55 ( ± 0.05) 0.50 ( ± 0.07) 0.34 ( ± 0.02) 1000@1 0.46 ( ± 0.12) 0.44 ( ± 0.10) 0.45 ( ± 0.05) and reported the results in T able V. W e gi ve the av erage SRCC, PLCC, and RMSE between the models’ predicted scores and the MOS computed by using all av ailable votes. There are are few key takeaways from these results: • As one would suspect, the performance drops as the total vote budget decreases. • Surprisingly , howe ver , the performance appears to be stable across the different distribution strategies for budgets of more than 1,000 votes. • For smaller vote budgets a middle ground choice between MOS precision and numbers of videos seems to be fa vorable, as indicated by the 5 vote MOS distribution strategy outperforming the more and less precise extreme strategies. This suggests that for very small vote budgets in particular the focus should be on fewer than the commonly suggested 30 rating MOS recommendations that are found in literature. V I . C O N C L U S I O N S W e introduced a large-scale in-the-wild dataset KonV id- 150k for video quality assessment (VQA), as well as three nov el state-of-the-art no-reference VQA methods for videos in-the-wild. Our learning approach (MLSP-VQA) outperforms the best existing VQA methods trained end-to-end on sev eral datasets, and is substantially faster to train without sacrificing any predicti ve power . The large size of the database and ef ficiency of the learning approach hav e enabled us to study the ef fect of different levels of label-noise and how the v ote budget (total number of collected scores from users) affects model performance. W e were able to study the effect of dif ferent vote budget distribution strategies, meaning that the number of annotated videos was adjusted according to the desired MOS precision. Under a fixed b udget, we found that in most cases the number of votes allocated to each video is not important for the final model performance when using our MLSP-VQA approach and other feature-based approaches. K onV id-150k takes a novel approach to VQA, going far beyond the usual in the VQA community . The database is two TRANSA CTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY , V OL. 21, NO. 2, FEB. 2020 17 orders of magnitude larger than previous datasets, and it is more authentic both in terms of variety of content types and distortions, but also due to the compression settings of the videos. W e retrieved the original video files uploaded by users from Flickr , without the default re-encoding that is generally applied by any video sharing platform to reduce playback bandwidth costs. W e encoded the raw video files ourselves at a high enough quality to ensure the right balance between quality and size constraints for cro wdsourcing. The main nov elty of the proposed MLSP-VQA-HYB method is the two-channel architecture. By global average pooling the activ ation maps of all kernels in the Inception modules of an InceptionResNet-v2 network trained on ImageNet, we extract a wide variety of features, ranging from detections of oriented edges to more abstract ones related to object category . These features are input to the partially recurrent DNN architectures, which on the one hand makes use of the temporal sequence of the frame features, while on the other also considering the individual frame features as well. W e hav e trained and validated the proposed methods on the four most rele vant VQA datasets, improving state-of-the- art performance on K oNV iD-1k and LIVE-VQC. While one or two existing works outperform our proposed method on the LIVE-Qualcomm and CVD2014, this is likely due to the artificial nature of de gradations in these datasets that our feature extraction network is not trained on. W e also show that our proposed method outperforms the current state-of-the-art on K onV id-150k-B, the set of 1,596 accurately labeled videos that are part of our proposed dataset. Additionally , by training our method on the entirety of the proposed noisily annotated dataset, we can improv e the cross-dataset test performance on K oNV iD-1k, LIVE-Qualcomm, and LIVE-VQC, e ven beating within-dataset performances on K oNV iD-1k and LIVE-VQC. CVD2014 appears to be a tough challenge for our approach, both when trained in within-dataset and cross-dataset scenarios. A C K N O W L E D G M E N T Funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) – Project-ID 251654672 – TRR 161 (Project A05). R E F E R E N C E S [1] W yzowl, “W yzowl State of Video Marketing Statistics 2019, ” https: //info.wyzowl.com/state- of- video- mark eting- 2019- report, 2019, [Online; accessed 15-No vember -2019]. [2] Buffer , “State Of Social 2019 Report, ” https://buf fer.com/ state- of- social- 2019, 2019, [Online; accessed 15-Nov ember-2019]. [3] K. W estcott, J. Loucks, K. Downs, and J. W atson, “Digital Media Trends Survey , 12th edition, ” 2018. [4] Cisco, VNI, “Cisco visual networking index: F orecast and trends, 2017– 2022, ” White P aper , vol. 1, 2018. [5] C. Goodro w , “Y ou know what’ s cool? a billion hours, ” https://youtube. googleblog.com/2017/02/you- know- whats- cool- billion- hours.html, 2017, [Online; accessed 15-November-2019]. [6] G. E. McK echnie, “Simulation techniques in environmental psychology , ” in P erspectives on envir onment and behavior . Springer , 1977, pp. 169–189. [7] C. S. Ang, A. Bobrowicz, D. J. Schiano, and B. Nardi, “Data in the wild: Some reflections, ” interactions , v ol. 20, no. 2, pp. 39–43, 2013. [8] S. Argyropoulos, A. Raake, M.-N. Garcia, and P . List, “No-reference video quality assessment for SD and HD H. 264/A VC sequences based on continuous estimates of packet loss visibility , ” in 2011 Third International W orkshop on Quality of Multimedia Experience . IEEE, 2011, pp. 31–36. [9] Z. Chen and D. W u, “Prediction of transmission distortion for wireless video communication: Analysis, ” IEEE T ransactions on Ima ge Pr ocessing , vol. 21, no. 3, pp. 1123–1137, 2011. [10] G. V alenzise, S. Magni, M. T agliasacchi, and S. Tubaro, “No-reference pixel video quality monitoring of channel-induced distortion, ” IEEE T ransactions on Circuits and Systems for V ideo T echnology , vol. 22, no. 4, pp. 605–618, 2011. [11] M. A. Saad, A. C. Bo vik, and C. Charrier, “Blind prediction of natural video quality , ” IEEE T ransactions on Image Pr ocessing , v ol. 23, no. 3, pp. 1352–1365, 2014. [12] K. Pandremmenou, M. Shahid, L. P . K ondi, and B. Lövström, “ A no- reference bitstream-based perceptual model for video quality estimation of videos affected by coding artifacts and packet losses, ” in Human V ision and Electr onic Imaging XX , vol. 9394. International Society for Optics and Photonics, 2015, p. 93941F . [13] C. Keimel, J. Habigt, M. Klimpke, and K. Diepold, “Design of no- reference video quality metrics with multiway partial least squares regression, ” in 2011 Third International W orkshop on Quality of Multimedia Experience . IEEE, 2011, pp. 49–54. [14] K. Zhu, C. Li, V . Asari, and D. Saupe, “No-reference video quality assessment based on artif act measurement and statistical analysis, ” IEEE T ransactions on Circuits and Systems for V ideo T echnology , vol. 25, no. 4, pp. 533–546, 2014. [15] J. Søgaard, S. Forchhammer , and J. Korhonen, “No-reference video quality assessment using codec analysis, ” IEEE T ransactions on Circuits and Systems for V ideo T echnology , vol. 25, no. 10, pp. 1637–1650, 2015. [16] A. Mittal, M. A. Saad, and A. C. Bovik, “ A completely blind video integrity oracle, ” IEEE T ransactions on Imag e Processing , vol. 25, no. 1, pp. 289–300, 2015. [17] M. T . V ega, D. C. Mocanu, S. Stavrou, and A. Liotta, “Predictiv e no-reference assessment of video quality , ” Signal Processing: Image Communication , v ol. 52, pp. 20–32, 2017. [18] J. K orhonen, “Learning-based prediction of pack et loss artif act visibility in network ed video, ” in 2018 T enth International Conference on Quality of Multimedia Experience . IEEE, 2018, pp. 1–6. [19] J. Korhnen, “T wo-lev el approach for no-reference consumer video quality assessment, ” IEEE T ransactions on Image Processing , vol. 28, no. 12, pp. 5923–5938, 2019. [20] V . Hosu, F . Hahn, M. Jenadeleh, H. Lin, H. Men, T . Szirán yi, S. Li, and D. Saupe, “The Konstanz Natural V ideo Database KoNV iD-1k, ” in 9th International Confer ence on Quality of Multimedia Experience , 2017. [21] M. Nuutinen, T . V irtanen, M. V aahteranoksa, T . V uori, P . Oittinen, and J. Häkkinen, “CVD2014— a database for e v aluating no-reference video quality assessment algorithms, ” IEEE T ransactions on Image Processing , vol. 25, no. 7, pp. 3073–3086, 2016. [22] D. Ghadiyaram, J. Pan, A. C. Bovik, A. K. Moorthy , P . Panda, and K.-C. Y ang, “In-capture mobile video distortions: A study of subjectiv e behavior and objective algorithms, ” IEEE T ransactions on Circuits and Systems for V ideo T echnology , 2017. [23] Z. Sinno and A. C. Bovik, “Large-scale study of perceptual video quality , ” IEEE T ransactions on Ima ge Pr ocessing , vol. 28, no. 2, pp. 612–627, 2019. [24] F . Gao, J. Y u, S. Zhu, Q. Huang, and Q. Tian, “Blind image quality prediction by exploiting multi-level deep representations, ” P attern Recognition , v ol. 81, pp. 432–442, 2018. [25] R. Zhang, P . Isola, A. A. Efros, E. Shechtman, and O. W ang, “The unreasonable ef fectiveness of deep features as a perceptual metric, ” in IEEE Confer ence on Computer V ision and P attern Recognition , 2018, pp. 586–595. [26] V . Hosu, B. Goldlucke, and D. Saupe, “Ef fectiv e aesthetics prediction with multi-lev el spatially pooled features, ” in IEEE Confer ence on Computer V ision and P attern Recognition , 2019, pp. 9375–9383. [27] C. Szegedy , S. Ioffe, V . V anhoucke, and A. A. Alemi, “Inception-v4, inception-resnet and the impact of residual connections on learning, ” in Thirty-F irst AAAI Confer ence on Artificial Intelligence , 2017. [28] S. Ben-David, J. Blitzer , K. Crammer , and F . Pereira, “ Analysis of rep- resentations for domain adaptation, ” in Advances in Neural Information Pr ocessing Systems , 2007, pp. 137–144. [29] F . De Simone, M. Naccari, M. T agliasacchi, F . Duf aux, S. Tubaro, and T . Ebrahimi, “Subjective assessment of H. 264/A VC video sequences transmitted o ver a noisy channel, ” in 2009 International W orkshop on Quality of Multimedia Experience . IEEE, 2009, pp. 204–209. [30] F . De Simone, M. T agliasacchi, M. Naccari, S. T ubaro, and T . Ebrahimi, “ A H. 264/A VC video database for the ev aluation of quality metrics, ” in 2010 IEEE International Confer ence on Acoustics Speech and Signal Pr ocessing . IEEE, 2010, pp. 2430–2433. TRANSA CTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY , V OL. 21, NO. 2, FEB. 2020 18 [31] K. Seshadrinathan, R. Soundararajan, A. C. Bo vik, and L. K. Cormack, “Study of subjective and objecti ve quality assessment of video, ” IEEE T ransactions on Ima ge Pr ocessing , vol. 19, no. 6, pp. 1427–1441, 2010. [32] ——, “ A subjectiv e study to e valuate video quality assessment algorithms, ” in Human V ision and Electr onic Imaging XV , vol. 7527. International Society for Optics and Photonics, 2010, p. 75270H. [33] E. C. Larson and D. M. Chandler , “Most apparent distortion: full- reference image quality assessment and the role of strategy , ” Journal of Electr onic Imaging , v ol. 19, no. 1, p. 011006, 2010. [34] V ideo Quality Experts Group, “Report on the validation of video quality models for high definition video content, ” http://www . its. bldr doc. gov/media/4212/vqe g_hdtv_final_report_version_2. 0. zip , 2010. [35] F . Zhang, S. Li, L. Ma, Y . C. W ong, and K. N. Ngan, “IVP subjectiv e quality video database, ” The Chinese University of Hong K ong, http://ivp. ee. cuhk. edu. hk/r esearch/database/subjective , 2011. [36] D. Saupe, F . Hahn, V . Hosu, I. Zingman, M. Rana, and S. Li, “Crowd workers proven useful: A comparative study of subjecti ve video quality assessment, ” in QoMEX 2016: International Conference on Quality of Multimedia Experience , 2016. [37] D. Rolnick, A. V eit, S. Belongie, and N. Shavit, “Deep learning is robust to massi ve label noise, ” arXiv pr eprint arXiv:1705.10694 , 2017. [38] D. V arga, “Multi-pooled inception features for no-reference video quality assessment. ” in VISIGRAPP (4: VISAPP) , 2020, pp. 338–347. [39] A. Sriv astava, A. B. Lee, E. P . Simoncelli, and S.-C. Zhu, “On advances in statistical modeling of natural images, ” Journal of Mathematical Imaging and V ision , vol. 18, no. 1, pp. 17–33, 2003. [40] A. Mittal, R. Soundararajan, and A. C. Bo vik, “Making a “completely blind” image quality analyzer, ” IEEE Signal Pr ocessing Letters , v ol. 20, no. 3, pp. 209–212, 2012. [41] A. Mittal, A. K. Moorthy , and A. C. Bovik, “No-reference image quality assessment in the spatial domain, ” IEEE T ransactions on Image Pr ocessing , vol. 21, no. 12, pp. 4695–4708, 2012. [42] J. Xu, P . Y e, Y . Liu, and D. Doermann, “No-reference video quality assessment via feature learning, ” in 2014 IEEE International Confer ence on Imag e Pr ocessing . IEEE, 2014, pp. 491–495. [43] D. Kundu, D. Ghadiyaram, A. C. Bovik, and B. L. Evans, “No-reference quality assessment of tone-mapped HDR pictures, ” IEEE T ransactions on Imag e Pr ocessing , vol. 26, no. 6, pp. 2957–2971, 2017. [44] Y . Li, L.-M. Po, C.-H. Cheung, X. Xu, L. Feng, F . Y uan, and K.- W . Cheung, “No-reference video quality assessment with 3D shearlet transform and con volutional neural networks. ” IEEE T ransaction Circuits System V ideo T echnology , v ol. 26, no. 6, pp. 1044–1057, 2016. [45] C. W ang, L. Su, and W . Zhang, “COME for no-reference video quality assessment, ” in 2018 IEEE Conference on Multimedia Information Pr ocessing and Retrieval . IEEE, 2018, pp. 232–237. [46] J. Y ou and J. K orhonen, “Deep neural networks for no-reference video quality assessment, ” in 2019 IEEE International Confer ence on Image Pr ocessing (ICIP) . IEEE, 2019, pp. 2349–2353. [47] D. V arga, “No-reference video quality assessment based on the temporal pooling of deep features, ” Neural Pr ocessing Letters , v ol. 50, no. 3, pp. 2595–2608, 2019. [48] D. V arga and T . Szirányi, “No-reference video quality assessment via pretrained CNN and LSTM networks, ” Signal, Image and V ideo Pr ocessing , vol. 13, no. 8, pp. 1569–1576, 2019. [49] F . Götz-Hahn, V . Hosu, and D. Saupe, “Critical analysis on the reproducibility of visual quality assessment using deep features, ” arXiv pr eprint arXiv:2009.05369 , 2020. [50] V . Hosu, H. Lin, T . Sziranyi, and D. Saupe, “K onIQ-10k: An ecologically valid database for deep learning of blind image quality assessment, ” IEEE T ransactions on Image Pr ocessing , vol. 29, pp. 4041–4056, 2020. [51] ITU-T, “Objective perceptual assessment of video quality: Full reference television, ” T utorial, ITU-T T elecommunication Standardization Bureau, 2004. [52] T . Hoßfeld, R. Schatz, and S. Egger , “SOS: The MOS is not enough!” in Thir d International W orkshop on Quality of Multimedia Experience , 2011, pp. 131–136. [53] L. Janowski and M. Pinson, “The accuracy of subjects in a quality exper- iment: A theoretical subject model, ” IEEE Tr ansactions on Multimedia , vol. 17, no. 12, pp. 2210–2224, 2015. [54] H. Lin, V . Hosu, and D. Saupe, “Deepfl-iqa: W eak supervision for deep iqa feature learning, ” arXiv pr eprint arXiv:2001.08113 , 2020. [55] M. Hermans and B. Schrauwen, “T raining and analysing deep recurrent neural networks, ” in Advances in Neural Information Processing Systems , 2013, pp. 190–198.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment