Touche: Towards Ideal and Efficient Cache Compression By Mitigating Tag Area Overheads
Compression is seen as a simple technique to increase the effective cache capacity. Unfortunately, compression techniques either incur tag area overheads or restrict data placement to only include neighboring compressed cache blocks to mitigate tag a…
Authors: Seokin Hong, Bulent Abali, Alper Buyuktosunoglu
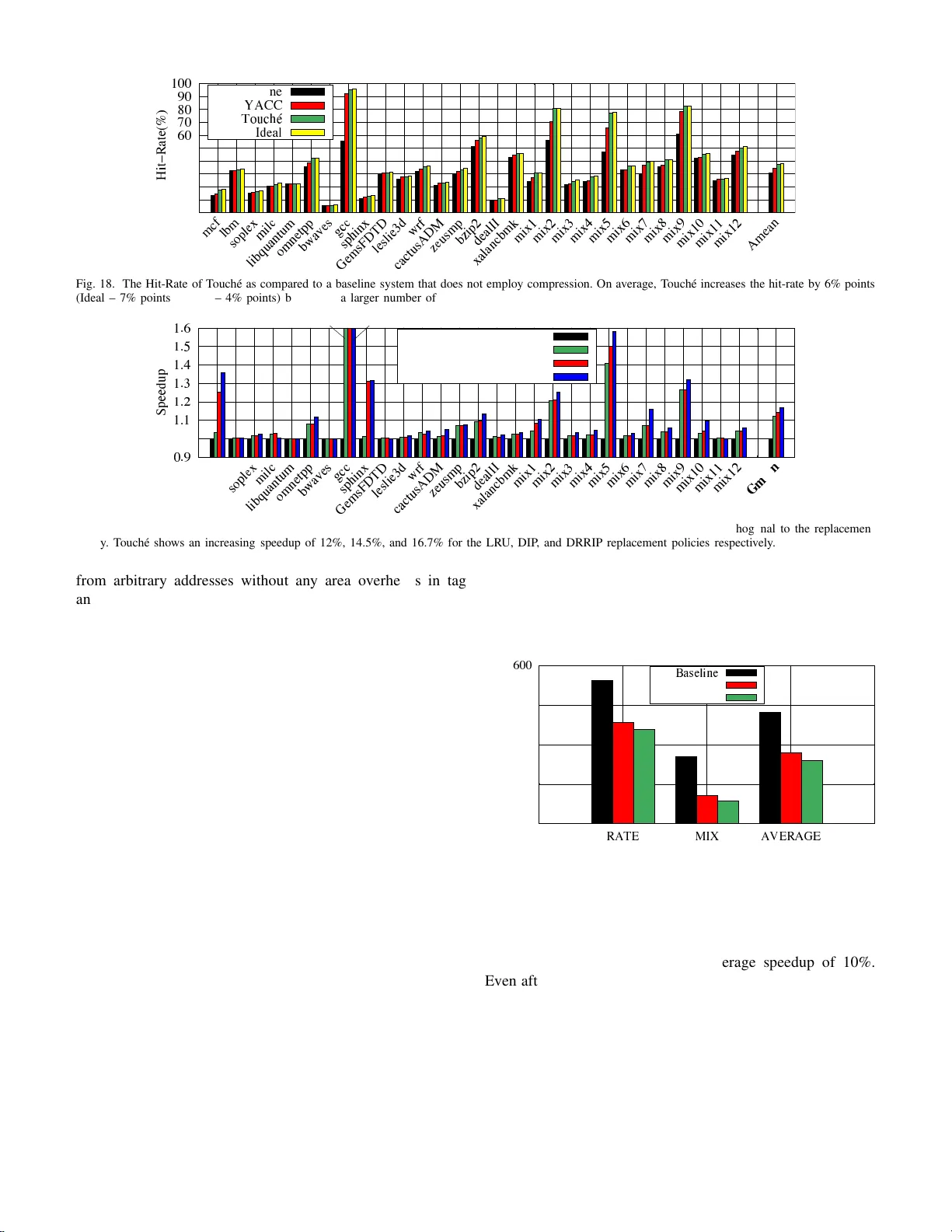
T ouch ´ e: T o wa rds Ideal and E f ficient Cache Compression By Mitigating T ag Area Ov erheads Seokin Hong ∗ , Bulent Abali † , Alper Buyuktosun o glu † , Michael B. Healy † , and Prashant J. Nair ‡ ∗ Kyungpook National University † IBM T . J. W atson Research Center ‡ The Un iv ersity of British Columb ia seokin@knu.a c.kr [ abali,a lperb,mbh e a ly ] @us.ibm.com prashantnair@ece.ubc.c a Abstract —Compression is seen as a simple techniq ue to in- crease th e effective cache capacity . Unfortunately , compression techniques either incur tag area ov erh eads or restrict data placement to only i nclude neighboring compressed cache blocks to mitigate tag area ov erheads. Ideally , we should be able to place arbitrary co mpressed cache blocks without any p l acement restrictions and tag area overheads. This paper proposes T ouch ´ e, a framewor k that enables storing multiple arbitrary compressed cache blocks withi n a physical cacheline without any tag ar ea ov erheads. The T ouch ´ e framew ork consists of three componen t s. Th e first component , called the “Signature” (SIGN) engine, cre ates shortened signatures from the tag addresses of compressed blocks. Due to this, the SIGN engine can store mu l tiple signatures in each tag entry . On a cache access, the physical cacheline is a ccessed only if t h ere is a signature match ( w h ich has a negligible p robability o f false positive). The second component, called the “T ag A ppended Data” (T ADA) mechanism, stores the fu l l tag addresses with data. T ADA enables T ouch ´ e to detect false positive signature matches b y ensurin g that the actual tag address is av ailabl e fo r comparison. The third component, called the “Superblock Marker” (S MARK) mechani sm, uses a u n ique marker in the tag entry to in dicate th e occurrence of compressed cache bl ocks from neighboring physical addresses in the same cacheline. T ouch ´ e is completely hardware-based and achieves an aver age speedu p of 12% (ideal 13%) when compared to an u ncompressed b aselin e. I . I N T RO D U CT I O N As M oore’ s Law slows down, the n umber of transistors-per- core for L ast-Lev el cach e s (L L C) ten ds to be stagn ating [ 1], [2], [3], [4], [5]. For instance, in moving from Ivy Brid ge (i7- 4930K p rocessor at 22nm ) to Bro adwell ( i5 -5675 C pr ocessor at 1 4nm), th e L L C cap acity per cor e (thre a d) has stagnated at 1MB [6], [7]. One can employ d ata compression to increase the effecti ve LLC cap acity [ 8], [ 9], [10], [11]. Un fortun ately , data compression may a lso incur sig n ificant tag area over- heads [ 1 2], [13], [ 14]. This is because, in conv e ntional caches each block n eeds a separate tag. W e can redu ce the tag area overheads by storing comp ressed blocks only from neig hbor- ing addresses [15], [16], [17], [18]. This en ables u s to use a single overlapping tag fo r all com pressed blocks. Howe ver, such an ap p roach restricts data compression only to regions that con tain contigu ous compressed blo cks. Ideally , we would like to em ploy LLC co mpression withou t any data p la c ement restrictions a nd tag area overhe ads. T ag overheads are a key road block for ca c he compr ession. For instance, if w e stor e 4 x mor e block s, the effective LLC capacity can be in c r eased by 4 x. But we will also incur the area overheads for maintain in g 4x unique tags. Furthermo re, it is likely that these unique tags hav e no locality , cannot be combine d tog ether, an d therefor e incu r sign ificant area overheads [17], [18]. One can reduce the tag area overhead with placemen t re strictions. For instance, if we set a rule that only compr essed bloc k s fro m neig hborin g memory addr esses can reside in a physical cach eline, then we can overlap their tag s. These con tiguous comp ressed blocks ar e called “superblo ck” an d their tag is called a “sup e r block-tag ” [15], [16]. For a 4MB 8-way cach e, super b lock-tag s can track 4 compressed b locks p er cac h eline with 1.3 5x tag area. Restricting block place ment by using superb locks reduce s the ben e fits of compre ssion. Figu re 1 shows the effective LLC capacity for four designs executing 2 9 memory-in tensiv e SPEC worklo ads in mixed an d rate modes o n a 4MB shar ed LLC [1 9]. Th e first design is a b aseline L LC witho u t da ta compression . Th e second design employs data compre ssion in LLC while using sup erblocks. While su c h a design ha s a tag area of 1.35 x as com pared to the baseline, it also increases the effective LL C capacity only b y 20 %. Th is is because only block s fro m n eighbo ring ad dresses can be co mpressed and stored in the cacheline. T he third design en a bles da ta compression to place arbitrary tags in the same cacheline. While this design increases the effectiv e LLC capacity by 38%, it also requ ires 3. 7x the tag area. The fourth d e sign is an ideal desig n which places arbitr ary tags in the same ca cheline without any area overheads. This paper presents T ouch ´ e, a framework that helps achieve the fou r th design to enable ne a r- ideal LL C co m pression. Fig. 1. The ef fecti ve capaci ty and tag area overhe ads for a 4MB last-le vel cache employing compression. Superblock-ta gs uses 1.35x tag area while provi ding 20% higher effect i ve capacit y . Arbitrary-t ags uses 3.7x tag area while pro viding 38% higher ef fecti ve capacit y . The goal of this paper is to obtain 38% higher ef fecti ve capacity with no tag overhe ad. T ouch ´ e mitigates the tag area overheads by u sing a short- ened signature of th e full tag ad dress for each co mpressed block. This has two key benefits. First, short signatures requir e fewer bits as compa r ed to full tag addresses. Due to this, multiple signatures fro m d ifferent tags add r esses can be plac ed in the sp ace that was origin ally reserved for only a sing le tag address. Seco nd, by enabling arbitrar y signatures to reside next to each other, we can overcom e restrictions of pr ior work th a t require co mpressed b lo cks to b e fro m ne ig hborin g add resses. Furthermo re, as compression creates unused space in the data array , tag ad dresses can b e appen d ed to compressed b locks and stored in this unused space. The T ouc h ´ e framework consists o f three co mpone n ts. The first com ponent, called th e “Signatur e” (SIGN) e ngine, cre- ates shortened sig n atures from the tag addresses and places them in the tag array . The second com ponen t, called the “T ag Ap pended Data” (T AD A) mechan ism, appends full tag addresses to the c ompressed blocks an d stores them in th e data array . The third compon ent, c a lled the “ Superb lock Marker” ( SMA RK) m e chanism, uses a u nique marker in the tag-bits to enab le T o uch ´ e to identify su perblock s tha t co ntain 4 contiguo us comp r essed b lo cks from neighbo ring phy sical addresses. W e describ e each m echanism below: 1) Signature (SIGN) Engine : The T ou c h ´ e f ramework is implemented with in th e LLC contr o ller . The core provides the LLC controller with a 48 -bit physical a d dress f or each request 1 . Th e LL C controller uses th is physical addr ess to index into the appropr iate set. At the same time, T o uch ´ e in vokes the SIGN eng ine to create a shortened 9 -bit signature of the tag and looks u p all the ways f or a matchin g signature. On a sign a tu re m atch, the cor respond ing com pressed blo ck is acce ssed from the da ta array . As these sign atures ar e o nly 9-bits long, sev eral signa tures, each belon ging to a different tag addre ss, can co- r eside in a tag entr y . For instance, a 4MB 8-way LLC with 64 Byte cachelines has tag entries that store 29-bit tag addr e ss. The SIGN en gine ca n sto r e up to three 9-bit signatures in the space th a t was designed for a single 29-b it tag add ress. This enables T ouch ´ e to store u p to three arbitrar y compressed b locks with out a ny ta g area overheads. Unfortu n ately , simply using shortened 9- b it signatu res can lead to false positi ve tag matches (signature collision s). Signa- ture co llisions cause the LLC con tr oller to incorrectly access blocks th at do not have matching tag addresses fo r each acc e ss. For instance, in a workload that h as a 0% cach e hit- r ate (worst case scena rio), a 9-bit signatu r e has an average signature collision r a te of 0. 1 9% (i.e., 1 2 9 ). Fur th ermore, as each way in a set can hav e up to thr ee 9-bit signatures, T ouch ´ e pote n tially needs to check twenty-four 9-bit signatur e s in an 8-way LLC (worst case scenario) which results in a signature-collision rate of 4 .58%. Therefore, it is essential to a lso ch eck th e full tag address o n a sign ature collision . 1 Processor vendors have already proposed schemes lik e the Intel 5-le vel paging for enabling 57-bit physica l addresses to increase the physical address space from 256 TB to 128 P B [20]. This would increase the tag addre ss bits within an LL C tag entry by 9. 2) T ag Appended Data (T ADA) Mechanism : The full tag addresses o f the comp ressed block s can be stor ed in th e data array . T ouch ´ e re-provisions a portion of the ad ditional space that is obtained by compression to store the f ull tag addresses. T o this end, T ouc h ´ e uses the “T ag Append e d Data” (T AD A) mechanism to append full tags beside the comp ressed blo cks. The T AD A me chanism ap pends metadata inform ation on com- pressibility ( 3-bits), dirty and valid state (2-bits), and the fu ll tag add ress (29-bits) to each compressed block. Overall, T AD A increases th e block size by only 34 bits (4.25 Bytes) an d ou r experiments show tha t it o nly m in imally re duces the effecti ve LLC capacity . On an access, T AD A in ter prets the la st few bits in a compr essed cacheline as metad ata and tag addresses. As T ADA checks the fu ll tags on all sign ature m a tches and collisions, it g uarantees the co rrectness of each LL C access. 3) Superblock Marker (SMARK) Mechanism : Sho rtened 9-bit sig n atures enable storing up to three co m pressed block s. Howe ver, there can be in stances o f f o ur co mpressed b locks from neig hborin g addresses (supe r block). T o address th is sce- nario, T ouch ´ e uses a “Su perblock Marker” ( SMARK) m ech- anism to gener ate a unique 1 6-bit marker . T ouch ´ e stores this 16-bit marker in th e tag bits, and uses this marker to ind icate the pr esence o f a sup erblock within the cache lin e. W ith a negligible probab ility (0.01 2 %), the un ique 1 6-bit marker can flag a m atch with the signatu res that are stored by the SIGN engine. W e call these scenarios as SMARK col- lisions. Fortunately , SMARK collisions cau se no corr ectness problem s. This is b ecause ev en afte r a ma r ker collision, the T AD A mechanism will r ead the data ar ray and check for full tag matche s. During a collision, the tag addresses will not match and th e comp r essed b locks are n ot pro cessed b y the LLC. The SMARK m echanism enables T ouch ´ e to derive all the benefits of super blocks wh ile also enabling the sto rage of up to three arb itr ary compressed b locks. T ouch ´ e provides a speedup of 12% (ideal 13%) witho ut any area overheads. T ouch ´ e requires comp arators and lookup tables within the LLC con troller . T ouch ´ e is a completely hardware- based f ramework that en ables nea r-ideal com pression. I I . B AC K G RO U N D A N D M O T I V A T I O N W e provide a brief b ackgro und on last-le vel cache o rgani- zation and highligh t the po tential o f data comp ression. A. La st-Level Caches: Why Size Matters Processors tend to have sev eral levels o f on-chip cach es. Caches are design e d to exp lo it spatial and tempo ral locality of accesses. Due to this, caches help improve the perfo rmance of pro c e ssors as they re d uce th e nu m ber of o ff-chip accesses and reduce the latency of memor y req uests. Cach es are usually designed such that each level is pr ogressively larger th an its previous level. Co nsequently , the Last-L ev el Cach e (LLC) tends to have the largest size, is typically sh a r ed, and occu pies significant on-c hip real-estate. Due to th is, it is ben eficial to increase the LLC capacity per core as this would e nable the designers to fit a larger numbe r of b locks on-chip and fu rther reduce th e n umber of o ff-chip a c c esses [2 1]. B. La st-Level Caches: Capa city Stagna tion Figure 2 shows the LLC capacity pe r core for com mercial Intel an d AMD processors fro m 2009 un til 2018 . On average, as the numb er of co res has increased, the LLC capacity per core has r educed. In current m ulti-core system s, the L LC capacity per c o re tends to be less than 1MB. Th erefore, going into th e future, it is b eneficial to look at techniq u es to improve the effecti ve cap acity of the LLC [22]. LLC Size (MB)/Core 0 1 2 3 4 5 5 10 15 20 25 30 Number of (logical) Cores MEAN Intel AMD Fig. 2. The L ast-Lev el Cache (LL C) capac ity per (logical) core for Inte l and AMD processors from 2009 to 2018. On av erage, as the number of cores has increa sed, the LLC capac ity per core has reduced. C. Last-Level Caches: Or g anization A Last-Level Cache (LLC) is organized into d ata arrays and tag arrays. Each cacheline in the data arr ay has a cor- respond in g tag entry in th e ta g array . Fur thermor e , gr oups o f cachelines form “sets” and eac h cacheline in a set corresponds to a separate “way”. As the size of th e LLC is sign ificantly smaller than the total physical address space, sev eral blo c ks can m ap in to the same set. Because of this, the LLC co n troller stores a tag add ress in th e tag entry to un iquely identify the block in th e cach eline. For instan ce, as shown in Figu re 3, a 4MB 8- way LLC with 64-b yte lines, uses 29 bits of tag address. On a cache a c cess, all th e tag entries for each of the ways in a set is searche d in parallel by the LLC con troller . LLC Controller (4MB Cac he) Tag Arrays Data Arrays 8 Ways Set To/From L2 Cache To/From Main Memory Tag Entry Cacheline 29-bit Tag 64 Byte 8192 Sets Fig. 3. The orga nizati on of a 4MB Last-Le vel Cache (LLC). The LLC consists of data arrays, tag arrays, and an L LC controller . The tags are 29-bits long and all tag entries across the ways in a set are searc hed in paral lel. D. Comp r ession: High e r Effective Capa city Sev eral prior works have pro posed using efficient and low- latency algorithms to co mpress blocks, the r eby storing mor e blocks and improving th e effecti ve LLC c apacity . T ypically , LLC co mpression tech niques ar e ty pically imp lemented within the LLC co ntroller . 1) Efficient Da ta Compr ession Algorithms: The Base Delta Immediate (BDI) and Frequen t Pattern Compression (FPC) are two state-of- the-art low-latency compression alg orithms [8 ], [23]. BDI u ses the insight th at data values tend to be similar within a block and therefo re can be compressed by repre- senting them using small offsets. FPC uses the insight th at blocks contain frequ ent patter n s like all-zer os, all- ones, etc. FPC represents frequent patterns with fe wer bits. Prior work has shown that both BDI an d FPC can be implem ented to execute with a a single- cycle delay and can b e im plemented within th e L LC contr oller [8], [2 3]. LLC Controller Dat a Arrays To/From L2 Cache To/From Main Memory D E Tag Manager C Compressed? Compressed? Tag Arrays Fig. 4. The LLC compression-deco mpression engine. The compression- decompressio n engine taps the data bus and stores compressibili ty information in the tag entries. 2) Compr ession-Deco mpr e ssion Engine: As shown in Fig- ure 4, the LLC co n troller implements a compression - decomp r ession engine that taps the bus g oing into the cache data array . T he LL C controller co ntains a sepa r ate “tag m an- ager” to manag e tag en tries. Th e com p ression-dec o mpression engine imp lements bo th BDI and FPC and ch ooses the best algorithm . The tag m anager maintains the co mpressibility informa tio n in th e tag en tries. 3) Distrib ution of Comp r essed Data S ize: Figu r e 5 shows the distribution of the size of blocks after compr ession for 29 SPEC work loads. On average, 55% of th e block s can be compressed to less than 48 bytes in size. Fur thermor e, 17% of the lines can b e compr essed to be less than 1 6 bytes in size. Th erefore, several workloads tend to have b locks with low entropy and can benefit from com p ression. 0 20 40 6 ! 8 " 1 # $ m % & lbm s ' ( ) * + milc l , - . / 0 2 3 4 5 o 7 9 : ; < = b > ? @ A B gcc F G H I J K L M N O P Q R S T U V W X Y Z [ w \ ] c ^ _ ` a d e f g z h i j k n p q r t u v x y { | } ~ ¡ ¢ £ ¤ ¥ ¦ § ¨ © ª « ¬ ® ¯ ° ± ² ³ ´ µ ¶ · ¸ ¹ AM EAN º » ¼ ½ ¾ ¿ À Á Â Ã Ä Å Æ Ç È É Ê Ë Ì Í Î Ï Ð Ñ Ò Ó Ô Õ Ö× Ø Ù Ú Û Ü ÝÞ ß à á â ã äå æ ç è é ê ëì í Fig. 5. The distri buti on of block-si ze for 29 SPEC w orkloads (rate and mix modes). On av erage, up to 55% of the blocks can be compressed to 48 Bytes. E. LLC Compr ession: T ag Ar ea Overhead s Modern computing systems tend to operate on 64-by te blocks. Fig u re 6 ( a) shows th e desig n of the tag entry an d the cachelin e in the data array for a 4MB 8-way LLC that does not em ploy com pression. The tag en try fo r each blo ck requires a valid bit an d a d irty bit. Further more, we assume that r eplacement policy is m aintained at the cacheline-level and the largest block in th e selected cach e line is evicted. T o reduce the number of encoding b its in the tag ar ray , blocks are co mpressed into 16 b yte, 32 b yte, or 64 b yte bound aries. T o reduce the num ber of bits in the tag en try further, on e can restric t cacheline s to store blocks only fro m contiguo us add r esses. Such a co ntiguou s set o f block s is called a superb lock. Prior work has shown that super blocks with 4 compressed blo cks can redu ce the tag ar ea overheads to 8 bits. A s shown in Figure 6 ( b ), a 4MB 8-way LLC that stores up to four blocks p er c a cheline will r e quire 46 b its of tag entry . While su p erblock s help red uce tag ar ea overheads, they limit the p otential ben efits of LLC compression as they r estrict block placemen t to inclu de only neighbor ing addresses. If one can store blocks from arbitrary addr esses, we can u nlock all the be n efits o f LLC compression . Howev er , the disadvantage of this approach is th at, as sh own in Figur e 6 (c) , a 4MB 8-way LLC th a t stores up to fo u r blocks p er cachelin e will require 1 27 bits o f tag e ntry (3. 7x high er than the baseline) . A Cacheline in Data Array A Tag Entry in Tag Array Valid-Bit Dirty-Bit Tag Address Bits Replacement Policy Bits (3-bits) 64 Bytes 29-bits 34-bits (a) Baseline (No Compression) Memory Block 1 35-bits 46-bits (b) Compression with Superblock Tag Addresses Memory Block 2 Memory Block 4 Memory Block 3 116-bits 127-bits (c) Compression with Arbitrary Tag Addresses Block 1 1 2 3 4 Compressed Blocks Compressed Blocks 1 43 233 129 Fig. 6. The tag area ov erheads for differe nt technique s. (a) The baseline techni que that does not employ any compre ssion has no tag area overhea ds. (b) The superblock technique increases the tag area to 1.35x. (c) Storing arbitra ry tags increase s the tag area to 3.7x. F . LLC Comp r ession: P otentia l Figure 7 shows the overheads and b enefits o f LLC com- pression for three technique s. The baseline techniqu e does n ot employ compression, has no tag ov erheads and has an average hit-rate of 31.5%. The second technique employs su perblock s for co mpression, has a tag are a of 1.35x and increa ses the av erage hit-rate to 36%. The third technique highligh ts the potential hit-r a te with comp ression when each ca cheline can store up to 4 com pressed blocks. Un f ortunately , the third 20 25 30 35 40 45 50 55 60 RATE MIX AVERAGE Hit Rate (%) Baseline Superblock (1.35x Tag Area) Ideal (3.7x Tag Area in Practice) Fig. 7. The poten tial of LLC compression. Enabling blocks from arbitra ry addresses incre ases the av erage hit-rate of the LLC from 31.5% to 38.5%. technique uses a tag area of 3 .7x while also increasing the av erage LLC hit-r ate to 38.5 %. I I I . T H E T O U C H ´ E F R A M E W O R K A. A n Overview Figure 8 shows an overvie w o f the T ou ch ´ e framework. T ouch ´ e consists of three co mponen ts. The first co mpon e nt, called the Signatu re (SI GN) Engine, gen erates sho r tened sig- natures o f the tag ad dresses. The SIGN en gine is designed within the tag manager . The second compo n ent, called the T ag Ap pended Data (T AD A ) mechan ism, attaches fu ll tag ad- dresses to c ompressed memo ry blocks. T he T AD A mechanism taps th e data bus after the comp ression-deco mpression e n gine and obtain s th e full tag addr ess f rom the tag manager . Th e third compon ent, called Superblock Marker (SMARK) mechan ism, keeps trac k o f superblo cks by using a u n ique 16- bit m arker in the tag entry . T he SMARK mech anism is implemented in the tag m anager . T ou ch ´ e requ ires ch anges only in the LLC controller . LLC Controller Dat a Arrays To/From L2 Cache To/From Main Memory îï ð ñ ò ó ô õ ö ÷ ø ù ú û ü ý þ ÿ E Tag Manager C Compressed? Compressed? Tag Arrays SIGN Engine SMARK TADA Full Tag Address Fig. 8. An overvi e w of T ouch ´ e. T ouch ´ e consists of three components. The Signat ure (SIGN) Engine, the T ag Appended Data (T AD A) mechanism, and the Superblock Mark er (SMARK) mechani sm. All components are implement ed in the LLC controller with no changes to the LLC. B. S ignature (S IGN) Engin e The Signature (SIGN) E ngine is implemented in th e tag manager . The SIGN Engin e gen erates sho rtened signatures from the full tag a ddresses supp lied du ring the read an d write accesses to the LLC. 1) Identifying Compres sed b locks: On a LLC write, the compression -decomp ression en gine infor ms th e tag ma nager if the block is compr essible; a block can be com p ressed to 16B, 32B or 48B. T he tag manager uses the original valid bit and th e d irty bit in its tag entr y to enco de this infor mation. W e use the insight that, f or uncomp r essed b locks, the v alid bit and the d irty bit can only exist in th ree states. For instance, a cach eline cann ot be m arked both in valid and d ir ty at the same time. The tag man ager uses th is u nused state to flag cachelines that con tains com pressed block s. Ther eafter, f or a cacheline that stores c ompressed b locks, th e 1 st and 2 nd bits of th e tag ad dress enc o des its valid bit and dirty bit. As shown in T able I, on a read, th e tag manager checks the original dirty b it and the valid b it in the tag e n try to iden tify if the cach eline contain s compr essed blo c ks. If the cache line is deemed to contain compr essed blocks, th e ta g man ager read s the 1 st and 2 nd bits f rom the tag add ress to deter mine if any of the cacheline co ntains blocks that are valid, dirty or b oth. T ABLE I I D E N T I F Y I N G C O M P R E S S E D BL O C K S Cachel ine Stat us V alid Dirty T ag Address T ag Address Bit Bit 1 st Bit 2 nd Bit In valid 0 0 N/A N/A Uncompressed: V alid 1 0 N/A N/A Uncompressed: V alid and Dirty 1 1 N/A N/A Compre ssed: V alid 0 1 1 0 Compre ssed: V alid and Dirty 0 1 1 1 2) Using Shortened Sign a tur e s: T o store multiple signa- tures within a single tag entry , the SIGN en gine shor ten s th e full tag addr ess into a 9-b it sig n ature. For a 4MB 8-way LLC, the full tag address is 29-bits long. For a co mpressed block, as th e top 2 b its of the tag address spa c e in its tag entry a re already used fo r valid and dirty bits, we have 27 unused bits remaining in the tag addr ess space of its tag entry . T herefor e, we ca n stor e u p to th r ee 9 -bit sign atures cor respond in g to thr ee compressed b locks. Figure 9 shows th e d esign of the signa ture ge nerator in the SIGN engin e. The signature gener a tor uses th e least 2 7-bits of the full tag ad dress and divides it into three 9-bit segments. Each bit of th ese 9-bit segments is then XORed tog ether to generate a 9-b it outpu t. Th e 9-bit output is then p artitioned into a 4-bit segment co n taining its lowest bits and a 5-bit segment that con tain its high est bits. These 4- bit an d 5-bit p artitions then in dex into a 1 6 entry lookup table and a 3 2 entr y loo k up table r espectiv ely . Each entry in lo okup tables are pop ulated at boot-time with u nique numb ers. The indexed 4 -bit and 5-b it number s fr o m the loo kup ta b les are the n a ppende d togeth er to form a 9- b it signatur e . The overall latency of gener ating signatures is the delay o f one 3-bit XOR g a te and one parallel table loo kup. For a hig h-perf ormance p rocessor executing at 3.2GHz, we estimate the signa ture generatio n to in c ur only 1 cycle. Furtherm ore, th e latency of signature gener ation is masked by the latency o f reading the tag entries for each LLC access ( up to 5 cycles). 3) Chec kin g fo r Matching Signatures: On a n LLC read, the tag m anager rea ds th e tag en tr ies fr om all the ways of the L t he ! " # $ % & ' ( ) 9 * + , - s . / 0 1 2 s 3 4 5 6 7 s X 8 : ; < = > ? s @ A BD F s G H IJ K s 4-Bits 5-Bits M N OP Q S R T U V W Y Z [ \ ] ^ _ ` a b c d e f g h i j k l m n o p q r s u v w x y z { | } ~ Fig. 9. The signature generator within the SIGN E ngine. The signature generat or only requires one XOR operation and two paralle l tabl e lookups for eac h LLC acc ess. indexed set. At the same time, th e SIGN engine fo rwards its 9-bit sig n ature to the tag manager . The tag m anager identifies if the cach eline contains co m pressed blocks using th e orig inal valid and dir ty bits. For an uncom pressed cacheline, the tag manager ig nores the signatur e a n d uses the full tag add ress to check fo r a match . If the cacheline contains compressed block s, the tag man- ager igno res th e first two b its of the tag address as they are valid an d dirty bits. Th ereafter, th e remainin g 27 bits in th e tag address space of the tag entry are p a r titioned into th ree 9-bit entries. The tag manag er then c o mpares each of these thr ee 9-bit entries with the 9-bit signature from the SIGN Engine . If th e 9-bit entry does not match the 9-bit sign ature, then the block is g uaranteed to be a b sent. On the oth er hand , if the 9-bit signature matches in any o ne of the ways, then th e block is likely to be present. As a 9-b it sign ature is smaller than its full 29 -bit tag add r ess, there is a small chance of 0.19 % ( 1 512 ) that each 9-bit entry comparison with th e 9-b it signatu r e can result in a false positive match. W e call th ese false positive matches o f sign a tures as “signa tu re collisions”. 4) Collision Rate of Sign atur es: As each tag en try can store up to thre e 9-bit signatu res, an 8-way LLC would requ ir e up to twen ty-fou r 9 -bit sign ature comparison s for each access. As signatures ar e sh orter th an full tags, several tags may map into the same sign ature. As we perf orm twenty - four sign a ture checks (in the worst-case), it is likely that some of LLC accesses will resu lt in signature collisions. Figu re 10 shows the probab ility of collisions as the numb er of sign atures present in the 8-ways varies from zero (all ways ar e unco mpressed) to twenty- f our ( all ways have th ree compressed blo cks) for different LLC hit-rates. 5% 8 Probability of Signature Collision Per Access Number of 9-Bit Signature Entries in a Set 0% Hit Rate 25% Hit Rate 50% Hit Rate 75% Hit Rate 100% Hit Rate Worst-Case = 4.58% Fig. 10. The probability of collisi on for a 9-bit s ignatu re as the number of signature entrie s vary in a set. In the worst-case, for a 8-way LLC, we expect a signat ure colli sion 4.58% of the time for each acc ess. In the worst case, we can expect a co llision 4.5 8% of the time and this occurs for a workload that has 0 % hit-rate. As signature collisions can cause the LLC to forward blocks with incorrect tag addresses to the pr ocessing cor e s, it is essential to check f u ll ta g s. C. T ag Appen ded Data (T A DA) Mechanism The T ag Ap pended Da ta (T ADA) m echanism is imple- mented in the LLC contro ller and taps the data- bus between the compr ession-deco m pression engine an d th e data array . 1) Appending Full T ag Add r esses to Data: During an L LC write, the T AD A m echanism uses the fu ll tag s that are su p plied by th e tag m a nager . Th e T AD A mechanism th en ap pends the full tag add resses (29 bits), the valid-bit, the dirty-bit, an d the compressibility info rmation (3 bits) to th e end of the cacheline (total 34 bits or 4.2 5 Bytes). Figure 11 shows a cacheline storing th r ee comp ressed b locks and the T ADA m echanism append ing the inform ation for each of these block s at the end of th e cacheline. A Cacheline in Data Array A Tag Entry in Tag Array s ¡ ¢ £ ¤ ¥ ¦ § ¨ © ª « ¬ ® ¯ 1 9-Bit Signatures ° ± ² ³ ´ µ ement Policy ¶ · ¸ ¹ º » ¼ bit ½ ¾ ¿À Á Â Ã Ä ÅÆ Ç È É Ê Ë Ì ÍÎ Ï Ð Ñ Ò Ó Ô Õ Ö ×Ø Ù Ú Û Ü Ý Þ ß à áâã ä åæ ç è é ê ëì íî ï ð t a ñ ò ó ô õ ö ÷ ø ù ú ûü ýþÿ C y F V D t a n ! "# $%&' y ( ) *+ , - . / 0 1 2 3 456 7 89 : ; < = >? @A B E t a G H I J K L M N O P QR STUW y X YZ [ \ ] ^ _ ` Fig. 11. A cache line storing compressed blocks with T ADA m echani sm. The T AD A mechanism appends full tag addresses, v alid bit, dirty bit, and compressibil ity information for eac h block at the end of the ca chelin e. 2) Appending Full T ag Address es to Data : The T ADA mechanism appen ds 34 bits (4.25 Bytes) of info rmation to the end of the cacheline con taining compre ssed bloc k s. As a result, T AD A redu ces the space a vailable to store the compr essed block. W e can store th ree 16B com pressed b locks or a pair of a 32B an d a 16B compressed bloc k s in the d ata arr a y; the block size is stored in th e co mpressibility info rmation field. Fortunately , this a d ditional lo ss of space on ly ca u ses a few lines to reduc e their effectiv e capacity . Figure 12 shows th e reduction in effecti ve LLC cap a city due to T ADA for an LLC that can store up to 3 arbitrar y compressed blocks. T ADA decreases the effective cach e capacity by only 4.1 5% points as co mpared to an ideal sche m e that can store th ree ar bitrary compressed b locks with out a ny sto rage overhe a ds. 3) Detecting Collisions of Signatures : T AD A helps detect signature co llisions. This is beca u se, on a signature co llision, the cachelines fr o m the selected way(s) in the d a ta ar ray a r e read b y the tag man ager . The T ADA mec hanism extracts th e full tag add ress from the cach e lines an d checks if they m atch the full tag address o f the LLC access. If there is no match, a b c 1 d e f g h i j k l m o p q r st u v w x y z{ | } ~ Baseline TADA based Block Storage (3 Compressed Blocks) 4.15 % Points Effecti ci ¡ LC Fig. 12. The reducti on in the ef fecti ve LLC capacity by the T AD A storage ov erhead . While T ADA uses 4.25 Bytes per compressed block, it decrease s the effe cti ve LLC capacity only by 4.15% points as compared to an ideal scheme that does not requi re the metadat a storage in the data array . T AD A flags a signature collision. Theref ore, T AD A g u arantees the de tec tion of signature co llisions and thereby ensur e s cor- rectness. Fu rthermor e, T AD A extracts the the com pressibility informa tio n a nd supplies to the decomp ression engine. The valid and dirty bits of comp ressed b locks a re also stored usin g T AD A. Theref ore, T AD A help s to av oid u sing any additio nal bits in the tag entry to store addition al informa tion. D. Late n cy Overhe ads As the data array need s to be accessed during a signatu re collision, it c an incr ease the LL C acce ss latency . 1) Additional Accesses to Data Arrays: In the baseline system, a n L LC access p r obes all the ways in the indexed set from the tag array . Th e ca c heline fr om the d ata ar ray is read-on ly in case of an LLC h it. As a tag access occur s for ev ery ac c ess, irrespective of whether the access is a h it or a miss, th e tag array is d esigned with lower access latency as compare d to th e d ata array . T yp ic a lly , accessing th e LLC tag array incu rs a laten cy overhead of only 5 cycles. On the other hand, read ing the LL C data array incu r s an overhead of 3 0 cycles in mod ern processors [24]. In the T ou c h ´ e fram ew o rk, the d ata array s are likely to be accessed even in case of an LL C miss. This is bec a use the SIGN engine may incur signature collisions and may in voke the T AD A mechanism to access th e data array to detect signature c o llisions. I n the worst-case, fo r a workload with 0% hit-rate, this scenario may o ccur o nly 4 .58% o f the times. Therefo re, signa tu re collisions will in c rease th e overall laten cy of LL C access. T a ble II shows the average latency of an LLC access d uring a c o llision. T ABLE II A D D I T I O NA L D AT A A RR A Y S A C C E S S E D O N A C O L L I S I O N Number of Data Arrays Acce ssed Probabili ty Latenc y (cycl es) 1 0.9768 35 2 0.0229 70 3+ 0.0003 105+ A verag e: 1.0235 1 35.82 In the worst-case, all accesses can be a ca c h e miss an d a collision can oc cur 4 .58% o f the times. As shown in T able II, collisions incr e a se the access laten cy to 35.82 cycles. For a worst-case worklo ad with a 0% hit-rate, the increa se in the LLC tag acc e ss latency is denoted by E quation 1. New T ag Access Latency = (1 − 0 . 045 8) × Old Latency + 0 . 0458 × Collision Latency (1) As the o ld tag access latency is 5 cycles an d the collision latency is 3 5.82 cycles, the new tag access latency of T ouch ´ e is 6 . 4 cycles. 2) Mitigate Latency Overheads: Dyn amic T ouch ´ e: One can mitigate signatur e -collision latency overheads b y com pressing only wh en it is useful. T o this end , T ou ch ´ e co ntinuou sly monitors the average mem ory latency at th e LLC co ntroller . The av erage memo ry latency is d efined as the total laten cy that is experience d by each request and this can eman ate from the LLC an d main mem ory . T ouch ´ e enables compression only wh en the av erage memory access laten cy is 100x greater than the latency overheads of signature co llisions. As sig n ature collision s in c r ease the LLC tag access latency b y 1. 4 cycles, T ouch ´ e enables compression only when the average memo r y latency is greater than 140 cycles. This has two key a d vantages. First, T ouch ´ e is enabled for workload s that sho wcase a large mem ory latency and benefit from LLC compression. Second, the latency overheads from T o uch ´ e are c a p ped at 1 %. As shown in Figur e 13, fo r memory intensive bench m arks, the a verage mem ory latency for reads is 541 cycles (sign ificantly h igher than 14 0 cycles). Therefo re, the latency overhead of T ouch ´ e is only 0.2 6%. 200 400 ¢ £ ¤ ¥ ¦ § ¨ © ª « ¬ ® ¯ ° ± ² ³ ´ µ ¶ lbm · ¸ ¹ º » ¼ milc ½ ¾ ¿ À Á Â Ã Ä Å Æ Ç È É Ê Ë Ì Í Î Ï Ð Ñ Ò Ó gcc Ô Õ Ö × Ø Ù Ú Û Ü Ý Þ ß à á â ã ä å æ ç è é ê ë ì í î ï ð ñ ò ó ô õ ö ÷ ø ù ú û ü ý þ ÿ b d x m ! " # $ % & ' ( ) * + , - . / 0 1 2 3 4 5 6 7 8 9 : ; < = > Amean A ? @ B C D E F G H I J K L M N O P Q R S T U V 140 cycles Fig. 13. The ave rage memory latency for reads. On av erage, the ave rage memory access latency is 541 cyc les. Theref ore, T ouch ´ e has a latenc y ov erhead of only 0.26%. E. S uperblock Marker (SMA R K) Mechanism The SIGN Engine enab les storage o f up to three blocks. Howe ver, some cachelines may co ntain sup e rblocks (fou r compressed b locks f rom neig hborin g addresses). 1) Benefits of In cluding Sup erblocks: Figure 1 4 shows the hit-rate of T ouch ´ e while maintainin g up to three compressed blocks an d comp ares this against a sch eme th at also stores superbloc ks (up to four blo cks). For a superblock , T ouch ´ e tries to com press each bloc k to 15Bytes. T his en ables T ouch ´ e to g et the benefits of storing b oth the superblock- ta g s and the arbitr ary tag s. If we can store superb lo cks and ar bitrary blocks at the same tim e, we can increa se th e average hit-ra te of T ouch ´ e fro m 31.5 % to 37.5%. 20 25 30 35 40 45 50 W X Y Z [ \ ] ^ _ ` a c e f g h i j k l n o p q Touché: 3 Arbitrary Blocks Touché: 3 Arbitrary Blocks + Superblocks Fig. 14. The avera ge hit-rate of T ouch ´ e with 3 blocks versus 3 blocks with superblocks. On avera ge, the hit-rat e increases to 37.5% by combining superbloc ks. 2) Identifying P otentia l Cachelines: Du ring an LLC install, if the block is comp ressible an d if the candid ate cacheline already co ntains compr essed blocks from its neighborin g ad- dresses, then th is cachelin e is also a su perblock candid ate. The T AD A mechan ism is used to iden tify supe r block can d idates by extracting the full tag addresses for all the block s in a cach eline during an L L C install. 3) Generating Markers : T ouch ´ e imp le m ents a “Sup erblock Marker” (SMARK) mechanism in the tag manager . SMARK mechanism gen erates a random 16-b it mar ker at boot- time a nd uses th is m arker thro ughou t the op e r ational time of the system. Once the T ADA mechanism id entifies a superblock cach e- line, it inform s the tag man ager . The tag manage r then retrieves the 1 6-bit marker from the SMARK mech anism. It then informs the SIGN engine to igno r e the last 2 - bits (correspo nding to four n eighbor ing ad dresses) o f the fu ll tag address to generate a unique 9 -bit sign a tu re. This en sures that neighbo ring ad dresses in the super block gen erate the sam e 9-bit signature. Thereafter, the tag mana g er app ends th e 9- bit sign ature to the 16-b it marker an d writes the 29-b it full tag of the first b lock within the superb lock at the end of the co mpressed blocks in th e data ar ray . Figure 15 shows the superbloc k-tag generation. A Cacheline in Data Array A Tag Entry in Tag Array r s t u v w s y z { | } ~ 12 13 14 SMARK SIGN Tag Manager s ¡ ¢ £ ¤ ¥ ¦ Fig. 15. The Superblock Marker (SMARK) mechani sm. The SMARK mechanism gene rates a unique 16-bit mark er to iden tify superblocks. It then appends this marker with the 9-bit signature from the SIGN engine. 4) Chec kin g for Matching Mark ers: On a read, the tag manager will check fo r matching 16-bit ma r ker values in all the ways that sto r e c ompressed blo cks within a set. If there is a m arker match, then the tag manager uses the 9 -bit sign ature (genera ted from b y ignorin g th e least two significant bits) and checks for a match. If the signature m a tches, th e n the ca cheline is r e ad from the data array . T he T AD A mechan ism extracts the full tag address and ch e cks if the tag address o f the LL C a c c ess is one of Process Request § ¨ © ª « ¬ ® ¯ ° ± ² ³ ´ µ ¶ · ¸ ¹ º » ¼ ½ ¾ ¿ À Á Â Ã Ä Å Æ Ç È É Ê Ë Ì Í Î Ï Ð Ñ Ò Ó Ô Õ Ö × Ø Ù Ú Û Ü Ý Þ ß à á â ã ä å æ ç è é ê ë ì í î ï ð ñ ò ó ô õ ö ÷ ø ù ú û ü ý þÿ W t C ! " # $ % & ' ( ) * + , - . / 0 1 2 3 4 5 6 7 8 9 N : I ; < = > ? @ A B D R E F G H J K L M O like Baseline P Q ST U V X Y Z [ \ ] ^ _ ` a b c d e f g h i j k l m no p q r s u v w x y z { | } ~ Superblock ¡ ¢ £ ¤ ¥ ¦ § ¨ © ª « ¬ ® ¯ ° ± ² ³ ´ µ ¶ · ¸ ¹º » ¼ ½ ¾ ¿ À Á Â Ã Ä Å Æ Ç È É Ê Ë Ì ÍÎ Ï Ð Ñ Ò Ó Ô Õ Ö × Ø Ù Ú Û Ü Ý Þ ß à á â ã ä å æ ç è Install é ê ë ì í î ï ð Access ñ ò ó ô õ ö ÷ ø ù ú û ü ý þ ÿ R Y I S M ! " # $ % & ' ( ) * + , - . / 0 1 2 3 4 5 6 7 8 9 : ; < = > N ? @ A B C D E F G H J K L O P Q T U V W X Z [ \ ] ^ _ ` a b c d e f Write Superblock Tag Fig. 16. The flowchart detail ing the high-le vel operati ons of T ouch ´ e for install and acce ss requests. (a) Shows the flowc hart for install reque sts. (b) Shows the fl owchart for acc ess requests. the supe rblocks. If there is a match, the block is proce ssed by the LLC co ntroller . It is likely , the cachelin e m ay not co n tain the requested b lock and it may simply be a false positive match. Similar to signature co llision s, we c a ll this scen ario as a m arker co llision . 5) Effect of Marker Collisions: Marker co llision s are ex- tremely r are. Th is is because, we use mar kers which a re 16 bits long . For in stance, in a n 8- way cach e, the pro bability of a m arker collision for each access is only 0.012 % and their impact on LLC latency is n egligible. Furthermo re, even in the case of marker collision s, the T ADA m echanism ensures that the full tag address is ch ecked b efore forwardin g th e compressed b lock. Th e refore, SMARK works with T AD A to guarantee correctn ess while storing superblo cks. F . T ouch ´ e Operation: Rea d s and Writes Figure 16 (a) and Figure 16 (b) sho w the flowchart for T ouch ´ e for LLC accesses and install r equests respectively . T ouch ´ e inv okes the SIGN, T ADA, an d SMARK mechanisms only for com pressed d a ta . For unco mpressible d ata, T ouch ´ e works just like the baseline. Furthermor e , T AD A mechanism is always in voked for LLC h its of com pressed block s. This enables T ouch ´ e to guar antee corr e c tness. G. Discussion : Cohe rence and Repla cement In the b aseline LLC, the tag entry con tains metad ata su ch as the replacement policy bits an d coherenc e states (for private LLCs). W e discuss how these affect the design of T ouch ´ e. 1) Handling Cache Coher ence:: T ouch ´ e assumes a shared LLC and therefor e does not enco unter co herence concerns. Howe ver, in case the LLC is pr i vate, T ouch ´ e would need to maintain coher e n ce states with m inimal overheads. T ou ch ´ e stores the coh erence state as well as the full tag for each compressed b lock in the data ar ray . Thus, the LL C contro ller needs to access da ta array for tag match in g a nd checking the coherence state. This operation would likely in crease the latency of tag matching for the coh e rence request. Howe ver, such an operation would likely incur low per- forman ce overheads. This is because, handling most of the coheren ce requ ests tends to b e off in the cr itical path and the coheren ce state ca n be upda ted after the critical requests are serviced. In addition , if the coheren ce req uest is the “BusRd” which is a read request made by ano th er c o re, the cur rent core might need to send the entire block to the requesting core anyway . In th is case, the ad ditional access to the data array do es n ot ad d any overhead s. Furthermo re, we ca n elim inate th e performan ce im pact of snoop ing-ba sed cohere nce p rotoco ls, by simply using a directory -based coher ence pr otocol a s implemented in com- mercial p rocessors [2 5]. 2) Handling Cache Re placement P olicy:: Each tag en try in the baselin e system is already equ ipped with replacem e nt informa tio n bits. As T ouch ´ e stores m ultiple co m pressed b locks per cach eline, ideally , it would be prefer able to equip each of these bloc k s with additiona l rep lacement bits in the tag entry . Howe ver, this would req uire us to add 3 ∼ 4 bits pe r compressed b lock in the tag entry . T o minimize the overheads for storing the replacem ent informa tio n, whe never a cachelin e is accessed, T ouch ´ e o nly updates th e o riginal replacemen t bits. T o uch ´ e does not keep track of individual replaceme nt b its for each b lock. Du ring replacemen t, T o uch ´ e selects the v ic tim cacheline based on the original replacemen t b its and ran domly evicts o ne block f rom within th e v ictim cach eline. I V . E X P E R I M E N TA L M E T H O D O L O G Y T o ev aluate the performanc e benefits of T ouch ´ e, we de- velop a trac e -based simu lator based on th e USIMM [26] which is a detailed memo r y system simu lator . W e extend ed the USI MM to model the pro c essor core and a detailed g h i 1 j k l m n o p q r s t u v w x mcf lbm y z { | } ~ milc libquantum gcc ¡ ¢ £ ¤ cactusADM ¥ ¦ § ¨ © ª « ¬ ® ¯ ° ± ² ³ ´ µ ¶ · ¸ ¹ º » ¼ ½ ¾ ¿ À Á Â Ã Ä Å Æ Ç È É Ê Ë Ì Í Î Ï Ð Ñ Ò Ó Ô Õ Ö × Ø Ù Ú Û Ü Ý Þ ß à á â ã ä å æ ç è é ê ë ì í î ï ð ñ ò ó ô õ ö ÷ ø ù ú û ü ý þ ÿ B Y T I 1.88 1.95 1.91 Fig. 17. S peedup of T ouch ´ e as compar ed to a baseline system that does not employ compression. On a vera ge, T ouch ´ e achie ves a speedup of 12% (Ideal – 13%, Y AC C – 10.3%) by enabling compressed blocks from arbitrary addresses to be pla ced nex t to each other while also all o wing superbloc ks to be stored. cache hiera r chy . Our processor mod el supports the ou t-of- order (OoO) execution. Our detailed cache mo del supp orts various rep lacement po licies such as LR U, DRRIP [27], and DIP [ 2 8]. The baseline system configu ration is describ e d in T able III. T o en able ef ficient co mpression, the com pression engine modeled in the cache model employs the BDI [8], [29] and FPC [23] compression alg orithms and uses the o ne with the best compr ession ratio for each cache lin e. As per prior work in BDI and FPC, we assume that co mpression and decomp r ession of data incur s o nly a single-cycle latency . W e compare T ou ch ´ e to th e previous state-of-the-art scheme called Y A CC that uses on ly “superblo c k s” [16]. W e also co mpare our scheme against an “Ideal” scheme that ca n store either thre e arbitrary blo c ks or a super block (fou r neighbor ing blo cks) without any area overheads. The Id eal scheme uses the same replacemen t policy as T ouch ´ e (described in Sectio n II I -G2). T ABLE III B A S E L I N E S Y S T E M C O N FI G U R ATI O N Number of cores (OoO) 4 Processor clock speed 3.2 GHz Issue width 8 L1 Cache (Pri va te) 32KB, 8-W ay , 64B lines, 4 cycle s L2 Cache (Pri va te) 256KB, 8-W ay , 64B lines, 12 cycl es Last Level Cache (Shared) 4MB, 8-W ay , 64B lines LLC T ag Access Latency 5 cycles LLC Data Access latency 30 cycles Memory bus frequency 160 0MHz (DDR 3200MHz) [30] Memory channels 2 Ranks per channel 1 Banks Groups 4 Banks per Bank Group 4 Ro ws per bank 64K Columns (cache lines) per row 128 DRAM Access Timings: T RC D - T RP - T C AS 22-22-22 [31] DRAM Refresh Timings: T RF C 420ns [32], [33] W e ch ose memory in tensiv e benchma rks, which have greater than 1 MPKI (LLC Misses Per 1 000 I nstructions), from the SPEC CPU2006 ben c hmarks. W e warm up the cac h es for 2 Billion instru ctions and execute 4 Billion instru ctions. T o ensur e ad equate representation of regions of compressibil- ity [ 34] and perfo rmance [35], the 4 Billion instru c tions are collected by samp ling 400 Millio n instructions per 1 Billion instructions over a 4 0 Billion instruction wind ow . W e execute all ben chmarks in rate mode. W e also create twelve 4-th readed mixed work loads by for ming two categories of SPEC2 0 06 Benchmark s, low MPKI, and hig h MPKI. As described in T able IV, we rando mly p ick on e ben chmark fro m each c a te- gory to fo r m high MPKI mixed workloads and medium MPKI mixed worklo ads. W e perform timing simu lation u ntil all the benchm a rks in th e workloa d finish execution. T ABLE IV W O RK L O A D M I X E S mix1 mcf, libquan tum, GemsFDTD, wrf mix2 lbm, gcc , bzip2, bwav es mix3 milc , sphinx, leslie 3d, zeusmp mix4 sople x, omnetpp, cactusADM, dealII mix5 xalanc bmk, mcf, gcc, sphinx mix6 omnetpp, lbm, milc, xalancbmk mix7 astar , mcf, milc, calcul ix mix8 omnetpp, gobmk, sjeng, libquantum mix9 namd, gcc, lbm, deal II mix10 sople x, tonto, hmmer , perlb ench mix11 GemsFDTD, bwa ves, povray , zeusmp mix12 wrf, xal ancbmk, h264, gamess V . R E S U LT S This section discusses the perfo rmance, hit-rate, and sensi- ti vity r esults o f T o uch ´ e. A. P erformance Impact Figure 17 sh ows the speedu p of T ouch ´ e whe n co mpared to a baseline system th at does not emp loy comp r ession. On av erage, T ouch ´ e has a speedup of 1 2%. Ideally , wh en we can place compressed m e mory blocks witho ut any area overheads in tag and data arrays, we get a speed up of 1 3%. On the other hand, Y A CC achieves 1 0.3% speedup b y capturing the superbloc ks. Ou r an alysis shows that gcc benefits the mo st from LLC compr ession. g cc is extremely sensitiv e to the LLC capacity and as the miss rate of g cc drops from 45% to 5% (by 9 x) du e to T ouch ´ e, gcc exper iences very low memory access latency . This is becau se, at 5% miss-rate, almo st all of its working set n ow fits in the LLC. Therefo re, gcc shows a speedup o f 91% d ue to T ouch ´ e. For all oth er worklo ads, the drop in miss-rate is at most 2 .4x (see Figu re 18), hence they show up to 50% speedu p. B. E ffect on La st-Level Cache Hit-Ra te Figure 18 sh ows the speedu p of T ouch ´ e whe n co mpared to a baseline system th at does not emp loy comp r ession. On av erage, T ouch ´ e increases the hit rate by 6 % po ints. I n th e ideal case, when we c a n p lace compressed memory b locks 0 10 20 30 40 50 6 7 8 9 1 mcf lbm s m l ! " # $ % & ' o ( ) * + , - b . / 0 2 3 g 4 5 : ; < = > ? G @ A C D E F H J K L M N O P Q w R S c U V W X Z [ \ ] z ^ _ ` a d e f h i j k n p q r t x u v y { | } ~ ¡ ¢ £ ¤ ¥ ¦ § ¨ © ª « ¬ ® ¯ ° ± ² Amean ³ ´ µ ¶ · ¸ ¹ º » ¼ ½ Baseline ¾¿À Á Â Ã Ä Å Æ Ç È É Ê Ë Ì Fig. 18. The Hit-Rate of T ouch ´ e as compared to a baseline system that does not employ compression. On av erage, T ouch ´ e increa ses the hit-rate by 6% points (Ideal – 7% points, Y A CC – 4% points) by storin g a larg er number of blo cks withi n the LLC. Í Î Ï 1 Ð Ñ Ò Ó Ô Õ Ö × Ø Ù Ú Û Ü Ý Þ ß à á mcf lbm â ã ä å æ ç è é ê ë ì í î ï ð ñ ò ó ô õ ö ÷ ø ù ú û ü ý þ ÿ b g s G l w c z ! " # $ % & ' ( ) * d + , - . / x 0 1 2 3 4 5 6 7 m 8 9 : ; < = > ? @ A B C D E F H I J K L M N O P Q R S T U V W X Y Z [ \ ] ^ _ ` a e f h i j k n o p q r ea t u v y { | } ~ Baseline Touché with LRU Touché with DIP Touché with DRRIP 1.91 1.98 2.04 Fig. 19. The sensiti vity of T ouch ´ e to differe nt replac ement polici es. As T ouch ´ e is only a LLC compression framew ork, it is orthogona l to the replace ment polic y . T ouch ´ e shows an incre asing speedup of 12%, 14.5%, and 16.7% for the LR U, DIP , and DRRIP replac ement policie s respecti vel y . from arbitrary addresses without any area overheads in tag and d ata array s, the hit-r ate incre a ses 7% poin ts. On the other hand, Y A CC increases the hit-rate by 4% points. Furthermo re, some workloads like gcc , mix 2 , mix5 , and mix9 get significant increase in hit rate. W e a lso observe that hit-rates either increase or remain the same for ben chmark s. Furth ermore, T ouch ´ e closely follows the hit-rate o f an ideal LLC co mpression tec hnique. Th e slight loss in hit-r ate fro m the id eal LLC com pression is due to the capacity loss in the d ata arr ay fr om th e T AD A mechanism. C. Sensitivity to Repla cement P olicy As T ouch ´ e is a LLC compression techniq u e, it do es not interfere with th e replace m ent policy . T ypically , the LLC con- troller will choose a cacheline based on its r eplacement policy . T ouch ´ e th e n evicts a blo ck from within the selected ca cheline random ly . Ther efore, rep lacement p o licies are or thogon al to the T ouc h ´ e fra mew ork. Figure 19 shows the speedup of T ou ch ´ e for different cache repla c e ment p o licies. On average, T o uch ´ e in creases the speedup from 12 % wh ile u sin g L R U, to 1 4.5% while using DIP . The speed up is incr eased to 16.7% wh ile using DRRIP replacemen t policy . Therefo r e, irrespectiv e of th e replaceme n t policy , T ouch ´ e co ntinues to provide high perfor m ance by enabling efficient compression . D. I mp act o n Memory La te n cy Figure 2 0 shows the impact of T ouch ´ e on the average memory latency for re ads. As T o u ch ´ e provides a h igher LL C hit rate, it also r educes the average mem ory rea d latency . On av erage, T o u ch ´ e reduce s the memor y read laten cy from 5 41 cycles to 489 cycles. In th e ide a l case, we can redu ce the av erage memor y r ead latency to 478 cycles as this scheme provides slightly high er hit-rate . 400 450 500 550 Touché Ideal Average Memory Latency (Reads) Fig. 20. T he a vera ge memory read latenc y for T ouch ´ e. On av erage, T ouch ´ e reduces the memory read lat enc y from 541 cycles to 489 cycle s. E. S ensitivity to Last-Level Cache Size Figure 2 1 shows the impact of LLC size on th e effectiv eness of T ouch ´ e. T ouch ´ e is robust to different LLC sizes an d continues to be ef f ectiv e. For in stan ce, ev en while using a 2MB cache, T ou ch ´ e provid es an a verag e spee d up o f 10%. Even after d oubling the LLC size from 4 MB to 8 MB, T ouch ´ e still pr ovides a 9% average speedup. F . Im p act on Low-MPKI Benchmarks Until now , we have presente d results only for h igh MPKI benchm a rks. Howe ver , for implementation purpo ses, it is vital that T ouch ´ e d oes not hu rt the performan ce of low MPKI benchm a rks. Figur e 2 2 shows th e impact o f T ou ch ´ e o n the 0.95 1 1.05 1.1 1.15 1.2 2MB 4MB 8MB Speedup Baseline Touché Fig. 21. The sensiti vity of T ouch ´ e to the size of the L LC. Even after va rying the L LC size , T ouch ´ e conti nues to provi de at lea st 9% av erage speedup. perfor mance of Low MPKI workloads fr o m the SPEC2006 suite. Overall, T ou c h ´ e do es not ca u se slowdown fo r any Low MPKI workload. On the contrar y , T ouc h ´ e pr ovides an average speedup o f 1. 9% fo r these worklo ads. 0.9 1.0 1.1 hmmer ¡ ¢ £ ¤ ¥ ¦ § astar gromacs ¨ © ª « ¬ ® ¯ ° ± namd tonto ² ³ ´ µ ¶ · ¸ ¹ gamess º » ¼ ½ ¾ ¿ À Á ea Â Ã Ä Å Æ Ç È É Ê Ë Ì Í Î Ï Ð Ñ Ò Ó Ô Õ Ö × Ø Ù Ú Û Ü Fig. 22. Impact of T ouch ´ e on low MPKI workl oads. T ouch ´ e does not hurt the performance of any low MPKI workloa d. T ouch ´ e provides an av erage speedup of 1. 9% for these workloa ds. V I . R E L AT E D W O R K In this section, we describe prior work that is closely r e lated to the id eas d iscussed in th is pa per . A. E fficient Compr ession Algo rithms Cache co m pression algo rithms like Frequ ent Pattern Com- pression (FPC) [23], Base-Delta- Immediate (BDI) [ 8 ], and Cache Packer ( C-P A CK) [36] have low d ecompression laten cy and require low imp le m entation co st (i.e., area overhead). The C-P A CK algorith m can be improved further by detecting zero cache line s [15]. Recently , Kim et al. [37] introduce a bit-p lane compression algorith m that u ses a bit-p lane tr ansformatio n to achiev e a h igh compression ratio. T ouch ´ e is o r thogon al to all o f these compression algorithms. T ouch ´ e can select any of these algorithm s to meet th e har d ware budget, latency constraints, and application ’ s requirem ents. B. Cache Compress ion with T ag Management Prior works h av e propo sed compr essed cache arch itectures to imp rove the effective cache cap acity [12], [ 15], [16], [17], [1 8]. For instance, a variable-size co mpressed cache architecture using FPC was pro posed [12]. This architecture doubles the c ache size whe n all cache lines are compr essed while requir ing twice a s m a ny tag entries. T o redu ce tag overhead of the compressed cache, DCC [17] and SCC [15] use super blocks to track multiple neigh bor blocks with a single tag entry . Recently , Y A CC [16] was propo sed to reduce th e co mplexity of SCC by exploitin g the compr e ssion and spatial locality . Y AC C still restricts the mapping of compressed ca c helines as it requ ires superblo cks that contain ca c helines only f rom n eighbo ring addresses. Fur- thermor e , Y A CC requir e s th at those cachelines be of the same compressed size. T o uch ´ e eliminates this fu n damental limita- tion o f the sup er b lock-based com pressed cache . On average, Y A CC p r ovides 10.3 % speedu p while requirin g addition al bits in the tag area resulting in 1.35 x tag area. T ouch ´ e p rovides 12% speed up without any a r ea overhead s. T o increase LL C efficiency , Am oeba-Cache [ 38], prop oses storing tag a n d data together while eliminating the tag area. Howe ver, to create space for tags, Amoeb a-Cache stores on ly parts o f the memor y block within the cache. As DRAM caches do no t en counter tag storage problem s an d tend to be ban dwidth sensiti ve, Y oung et. al. [39] use compression in DRAM caches to improve both capacity and ban dwidth d y namically . C. Compression using Dedu plication Data dedu plication explo its the observation that several memory blocks in the LLC con tain the same identical value [40], [41], [4 2]. T o improve ef ficiency , these techniques store only a single value of these mem ory blocks within the LLC and design technique s to maintain tags that point to such memory blocks. Exploit the presen ce of identical m e mory blocks in th e LLC, Dedup [40] changes the LLC to enab le se veral tags to point to the same da ta. T o this end, the tag array is deco upled from th e d ata arr ay . Each tag entry is then equip ped with pointers to enab le them to p oint to arbitrar y memory blocks in the data array . T ou ch ´ e is o r thogon al to Dedup, as T o uch ´ e is comp ression tech nique th at compr esses arbitr a r y memo ry blocks indep endently an d enables Dedup to be applied over it. D. Main Memory Comp r ession T echniques Compression can also be used for main mem ory . Memzip compresses data for improving the bandw id th of the main memory [43]. Pekhimenko et. al. [ 29] and Abali et. al [44] have prop osed ef ficient techn iques to improve the ef f ectiv e capacity of m ain mem o ry using c o mpression. Compression can also be used in No n-V olatile Memories (NVM) to re- duce energy a n d improve p erforma n ce [45]. As compr ession increases the nu mber of bit- toggles o n the bus, Pek himenko et. al. [46] m inimizes bit- toggles and reduces the bus energy consump tion. Recently , Compresso [47] memory system was propo sed to red u ce the addition a l d ata m ovemen t cau sed by metadata accesses for a dditional translation, chan ges in co m- pressibility of the cach eline, and compression across cacheline bound aries. Similarly , DMC [48] was prop osed to improve memory capacity . Compression ca n u se software suppo rt an d increa se the main mem o ry cap acity . Products like IBM MXT and VMW are ESX use “Balloon Driv ers” to allocate and hold unu sed memory when data becomes incompressible or when V irtual Machines exceed cap acity thresholds [49], [50], [51], [ 52], [53]. On e can also use com p ression in the co ntext of mem ory security . Morphab le Counters [54] compr e ss integrity tree and encryptio n counter s to redu ce the size a n d height o f the integrity tree within the main mem ory . E. Meta data Man agement for Ma in Memory T o re duce metadata b andwidth overheads fro m compr e ssion, Attach ´ e [55] and PTM C [5 6] en a bles data and me ta d ata to be accessed togethe r . De b et. al. [57] describe s th e challenges in maintaining metad ata in main m emory and r ecommen d using ECC to store Metadata. While this technique is useful for memory mo dules that h av e ECC in them, LLC uses tag entries and does not have to rely on ECC to store metadata [58], [ 59], [60], [ 61], [6 2], [63], [64], [65], [66], [67]. Howev er , T ouch ´ e can be expand e d to include the ECC within LLC to stor e metadata. F . Oth e r Relevan t W ork Sardashti and W o od [68] ob served th at cachelines in the same p age may n o t have similar comp ressibility . Hallnor et. al. [6 9] proposed using comp ressed data throug hout the memory hierarchy . Th is ap proach reduces the overheads of compression and decomp r ession a t every le vel of memory hierarchy . Sath ish et al. [70] try to sav e m emory band w id th by using both lossy and lossless compression fo r GPUs. Recent work fr om Ha n et. al. [71] and Kadetotad et. al. [72] used compr ession with deep neural networks to significantly improve perfo rmance and reduce en ergy . These prior work are orthog onal to T o uch ´ e. Cache co mpression has a lso been used to reduce cache power con sumption . Residue cache architec ture [10] reduces the last-level cache area by half, resu lting in p ower saving. Other prior works have b een proposed to lower the negativ e impacts of co m pression on the replacemen t. ECM [ 1 4] re duces the cache misses using Size-A ware In sertion and Size-A ware Replacement. CAMP [ 73] exploits the c o mpressed cache b lock size as a reuse in d icator . Base-V ictim [74] was also pro posed to a void performan ce degradation du e to com pression on the replacemen t. T h e p ower-performa n ce efficiency o f T ouch ´ e can be imp roved u sing th e se p rior work. V I I . S U M M A RY The Last-Level Cache (LLC) capacity pe r core ha s stagnated over the past decade. One way to increase th e effectiv e capacity of LL C is b y emp loying data compr ession. Data compression enables th e LLC co ntroller to pac k m ore memory blocks within the LLC. Unfortunate ly , th e add itional com- pressed memo ry blocks req uire add itio nal tag entr ie s. T he LLC designer needs to provision add itional tag area to store the tag entries of com pressed blo cks. W e c an also restrict data placem e nt with in each cachelin e to neighborin g addresses (superblo cks) and red uce the tag area overheads. Ide ally , we would like to get the be n efits of LLC comp ression witho ut incurrin g any tag area overheads. T o this end, this paper proposes T ouc h ´ e, a framework that enables L LC compression without a ny area overheads in th e tag or data arrays. T o uch ´ e uses shortened sign atures to represent f u ll tag add ress an d appends the fu ll tag s to th e compressed memor y block s in the data arra y . This enab les T ouch ´ e to stor e arbitrar y m e mory blo cks as ne ig hbors. Further- more, T ouch ´ e can be enhanced further to includ e superbloc k s. T ouch ´ e is completely hard ware based an d a c hiev es a n ear- ideal speedup of 12% (ideal 13 %) without any ch anges or area overhead s to th e tag an d d a ta array . A C K N OW L E D G E M E N T W e than k the anonymou s revie w e r s for their feed back. W e thank Amin Azar his feed back o n com pression. This work was p artially supported by the Natura l Sciences and Engineer ing Research Council of Canada (NSERC) [funding referenc e number RGPIN-2 0 19-05 059] an d by the National Research Foundation of Korea (NRF) grant funded by the K o rea governme nt (MSIT) [fu nding referen ce num ber NRF- 2019R1G 1 A1011 403]. R E F E R E N C E S [1] T he Economist, “T echnolo gy Quarte rly: After Moore’ s Law, ” 2019, accesse d: 2019-03-07. [2] T he V er ge, “Inte l is forced to do less with Moore , ” 2019, acce ssed: 2019-03-08. [3] BBC Science, “The End of Moore ’ s Law: What Happens Next , ” 2019, accesse d: 2019-03-08. [4] H. Es maeilz adeh et al. , “Dark silicon and the end of multicore scalin g, ” IEEE Mic r o , vol. 32, no. 3, pp. 122–134, May 2012. [5] H. Es maeilz adeh et al. , “Dark silicon and the end of multicore scalin g, ” in Pro ceedin gs of the 38th Annual Internati onal Symposium on Com- puter A rc hitectur e , ser . ISCA ’11. New Y ork, NY , USA: A CM, 2011, pp. 365–3 76. [6] Intel Inc., “Ivy Bridge: Intel Core X-series Processors, ” 2019, accessed: 2019-03-07. [7] ——, “Broadwell : 5th Generation Intel Core i5 Processors, ” 2019, accesse d: 2019-03-07. [8] G. Pekhimenko et al. , “Base-de lta-immedi ate compression: Practic al data compression for on-chi p caches, ” in 2012 21st International Con- fer ence on P arallel Arc hitectur es and Compilation T echniqu es (P AC T) , Sept 2012 , pp. 377–388 . [9] A. Arelakis and P . Stenst rom, “Sc2: A statisti cal compression cache scheme , ” in Pr oceeding of the 41st Annual Inte rnational Symposium on Computer Arc hitecutur e , ser . ISCA ’14. Piscataw ay , NJ, US A : IEEE Press, 2014, pp. 145–156. [Online]. A vail able: http:/ /dl.acm.or g/cita tion.cfm?id=2665671.2665696 [10] S. Kim, J. Kim, J. Lee, and S. Hong, “Residue cache: A lo w-ener gy lo w-area l2 cache architecture via compression and partial hits, ” in 2011 44th Annual IEEE/AC M Internati onal Symposium on Micr oarc hitectur e (MICR O) , Dec 2011, pp. 420–429. [11] J. Dusser , T . Piquet , and A. Seznec, “Zero-co ntent augmented caches, ” in Pro ceedin gs of the 23r d International Confere nce on Super computing , ser . ICS ’09. New Y ork, NY , USA: A CM, 2009, pp. 46–55 . [Online ]. A v aila ble: http://doi .acm.org/10 .1145/1542275.1542288 [12] A. R. Alameldeen and D. A. W ood, “ Adapti ve cache compression for high-perf ormance processors, ” in Proc eeding s. 31st Annual Internation al Symposium on Computer Arc hitectur e, 2004. , J une 2004, pp. 212–223. [13] N. S. K im, T . Austin, and T . Mudge, “Low-ener gy data cache using sign compression and cache line bisec tion. ” Citeseer . [14] S. Baek, H. G. Lee, C. Nicopoulos, J. Lee, and J. Kim, “Ecm: Effec ti ve capac ity maximizer for high-performan ce compressed cachi ng, ” in 2013 IEEE 19th Internation al Symposium on High P erformance Computer Arc hitectur e (HP CA) , Feb 2013, pp. 131–142. [15] S. Sardashti, A. Seznec, and D. A. W ood, “Ske wed compressed caches, ” in 2014 47th Annual IEEE/ACM Internat ional Symposium on Micr oar- chi tectur e , Dec 2014, pp. 331–342. [16] ——, “Y et another compressed cache: A lo w-cost yet ef fecti ve compressed cache, ” ACM T rans. Archi t. Code Optim. , vol. 13, no. 3 , pp. 27:1–27:25 , Sep. 2016. [Online]. A v ailabl e: http:/ /doi.acm.or g/10.1145/ 2976740 [17] S. Sardashti and D. A. W ood, “Decoupl ed compressed cache: Exploiting spatial locality for energy optimizatio n, ” IEE E Micr o , vol. 34, no. 3, pp. 91–99, May 2014. [18] S. Sardashti and D. A. W ood, “Decoupl ed compressed cache: Exploiting spatial local ity for ener gy-optimized compressed cac hing, ” in 2013 46th Annual IEEE/AC M International Symposium on Micr oarc hitec tur e (MICR O) , Dec 2013, pp. 62–73. [19] www.spe c.org, “The SPEC2006 Benc hmark Suite, ” 2006. [20] Intel Inc., “Intel 5-Lev el Paging and 5-Leve l EPT, ” 2019, accessed: 2019-03-07. [21] D. W eiss, M. Dreesen, M. Ciraula, C. Henrion, C. Helt, R. Freese, T . Miles, A. Karega r , R. Schreiber, B. Schneller, and J. Wuu, “ An 8mb le vel-3 cache in 32nm soi with column-select aliasing, ” in 2011 IEEE Internati onal Solid-State Circ uits Confer ence , Feb 2011, pp. 258–260. [22] P . J. Nair, B. Asgari, and M. K. Qureshi, “Sudok u: T olerati ng high- rate of transient failures for enabli ng scalabl e sttram, ” in 2019 49th Annual IEEE/IFIP International Confere nce on Dependable Systems and Network s (DSN) , June 2019, pp. 388–400. [23] A. R. Alameldeen and D. A. W ood, “Frequent pattern compression: A significance -based compression scheme for l2 cache s, ” Dept. Comp. Scie . , Univ . W isconsin-Madison, T ech. R ep , vol. 1500, 2004. [24] Intel Inc., “Intel 64 and IA-32 Archit ecture s Optimizati on Referen ce Manual, ” 2016, accessed: 2019-04-08. [25] ——, “Intel Ultra Path Interc onnect : Directory-B ased Protocol, ” 2019, accesse d: 2019-05-08. [26] N. Chatterjee et al. , “Usimm: the utah simulated memory module a s im- ulati on infrastruct ure for the jwac memory s cheduling championshi p, ” 2012. [27] A. Jaleel, K. B. Theobald, S. C. Steely , Jr ., and J. Emer , “High perf ormance cache replacemen t using re-re ference interv al predict ion (rrip), ” in Proce edings of the 37th Annual Internat ional Symposium on Computer A rc hitectur e , ser . ISCA ’10. Ne w Y ork, NY , USA: A CM, 2010, pp. 60–71. [Online]. A vaila ble: http:/ /doi.acm.or g/10.1145/ 1815961.1815971 [28] M. K. Qureshi et al. , “ Adapti ve insertion policies for high performanc e caching, ” in Proce edings of the 34th Annual Interna tional Symposium on Computer A rc hitectur e , ser . ISCA ’07. Ne w Y ork, NY , USA: A CM, 2007, pp. 381–391. [Online]. A vail able: http:/ /doi.acm.or g/10.1145/ 1250662.1250709 [29] G. Pekhimenk o et al. , “Linearly compressed pages: A low- comple xity , lo w-latenc y main memory compression frame work, ” in P r oceedings of the 46th A nnual IEEE/ACM Internat ional Symposium on Micr oarch itect ure , ser . MICR O-46. Ne w Y ork, NY , USA: ACM, 2013, pp. 172–184. [Online]. A vaila ble: http:/ /doi.acm.or g/10.1145/ 2540708.2540724 [30] JE DEC Stand ard, “DDR4 Standa rd, ” in JESD79-4 , 2015. [31] K. K. Chang, P . J. Nair, D. L ee, S. Ghose, M. K. Qureshi, and O. Mutlu, “Lo w-cost inter- link ed subarrays (lisa): Enabling fast inter-subarr ay data mov ement in dram, ” in 2016 IEEE International Symposium on High P erformance Computer Archit ectur e (HPCA) , March 2016, pp. 568–580. [32] P . Nair , C.-C. Chou, and M. Qureshi, “ A case for refresh pausin g in dram memory systems, ” in High P erformance Compute r Arc hitectur e (HPCA2013), 2013 IEEE 19th Internati onal Symposium on , Feb 2013, pp. 627–6 38. [33] M. K . Qureshi , D. Kim, S. Khan, P . J. Nair, and O. Mutlu, “ A va tar: A varia ble-ret ention-time (vrt) aware refresh for dram systems, ” in 2015 45th Annual IEEE/IFIP Internat ional Confer ence on Dependable Systems and Ne tworks , June 2015, pp. 427–437. [34] E . Choukse, M. Erez, and A. Alame ldeen, “Compresspo ints: An e valu- ation m ethodol ogy for compressed memory s ystems, ” IEEE Computer Arc hitectur e Letter s , vol. 17, no. 2, pp. 126–129, July 2018. [35] E . Perelman et al. , “Using SimPoint for accura te and efficien t simula- tion, ” ACM SIGMETRICS P erformance Evaluati on Revie w , 2003. [36] X. Chen, L . Y ang, R. P . Dick, L. Shang, and H. Lekatsas, “C-pack: A high-perf ormance microprocessor cache compression algori thm, ” IEEE T ransactio ns on V ery Large Scale Inte gration (VLSI) Systems , vol. 18, no. 8, pp. 1196–1208, Aug 2010 . [37] J. Kim, M. Sulliv an, E. Choukse, and M. Erez, “Bit-pla ne compre ssion: Tra nsforming data for better compression in many-core archi tectu res, ” in 2016 ACM/IEEE 43rd Annual International Symposium on Compute r Arc hitectur e (ISCA) , June 2016, pp. 329–340. [38] S. Kumar, H. Zhao, A. Shriraman, E. Matthe ws, S. Dwarkada s, and L. Shannon, “ Amoeba-c ache: Adapti ve blocks for elimina ting waste in the memory hierarch y , ” in 2012 45th A nnual IEEE/ACM Internati onal Symposium on Micr oarc hitect ur e , Dec 2012, pp. 376–388. [39] V . Y oung, P . J. Nair , and M. K. Qureshi , “Dice: Compressing dram cache s for bandwid th and capa city , ” in Proce edings of the 44th Annual Internati onal Symposium on Computer A rc hitectur e , ser . ISCA ’17. Ne w Y ork, NY , USA: AC M, 2017, pp. 627–638. [Online]. A vaila ble: http:/ /doi.acm.or g/10.1145/ 3079856.3080243 [40] Y . Ti an, S. M. Khan, D. A. Jim ´ enez, and G. H. Loh, “Last- le vel cache deduplica tion, ” in P r oceedings of the 28th ACM Internati onal Confer ence on Supercompu ting , ser . ICS ’14. Ne w Y ork, NY , USA: A CM, 2014, pp. 53–62. [Online]. A vaila ble: http:/ /doi.acm.or g/10.1145/ 2597652.2597655 [41] B. Hong, D. Plantenbe rg, D. D. E. Long, and M. Siv an-Zimet, “Duplic ate data eli mination in a san file system, ” in MSST , 2004. [42] T . E. Denehy , W . W . Hsu, T . E. Denehy , and W . W . Hsu, “Duplica te management for reference data, ” in Researc h Report RJ10305, IBM , 2003. [43] A. Shafiee et al. , “Memzip: Exploring uncon venti onal benefits from memory compression, ” in 2014 IEEE 20th Internat ional Symposi um on High P erformance Computer A rc hitectur e (HPCA) , Feb 2014, pp. 638– 649. [44] B. Abali et al. , “Performance of hardware compressed main mem- ory , ” in Pr oceedi ngs HPCA Se venth Internation al Symposium on High- P erformance Computer Archi tectu re , 2001, pp. 73–81. [45] P . M. Pal angappa and K. Mohanram, “Compex: Compression-e xpansion coding for ener gy , lat ency , and life time improvement s in mlc/tlc n vm, ” in 2016 IE EE International Symposium on High P erformance Computer Arc hitectur e (HP CA) , March 2016, pp. 90–101. [46] G. Pekhimenko et al. , “ A case for toggle-a ware compression for gpu systems, ” in 2016 IEEE Internat ional Symposium on High P erformance Computer Ar chi tectur e (HPCA) , March 2016, pp. 188–200. [47] E . Choukse, M. Erez, and A. R. Alameldeen, “Compresso: Pragmatic main memory compression , ” in 2018 51st Annual IEEE/ACM Interna- tional Symposium on Micr oarc hitectur e (MICRO) , Oct 2018, pp. 546– 558. [48] S. Kim, S. Lee, T . Kim, and J. Huh, “T ransparent dual memory compression archit ecture , ” in 2017 26th Internatio nal Confer ence on P arall el Arc hitectur es and Compila tion T echni ques (P ACT) , Sept 2017, pp. 206–2 18. [49] P . Franaszek and J. Robinson, “Design and analy sis of internal organi- zatio ns for compressed random access memories, ” in IBM R eport, RC 21146, year=19 98 . [50] C. D. Ben veniste, P . A. Frana szek, and J. T . Robinson, “Cache-memory interf aces in compressed memory systems, ” IEE E T ransacti ons on Computer s , vol. 50, no. 11, pp. 1106–1116, Nov 2001. [51] T . B. Smith, B. Abali, D . E. Poff, and R. B. Trema ine, “Memory expa nsion tec hnology (mxt): Competiti ve impact, ” IBM Journal of Resear ch and Devel opment , vol. 45, no. 2, pp. 303–309, March 2001. [52] R. B. Tre maine, T . B. Smith, M. W azlo wski, D. Har , K.-K. Mak, and S. Arramreddy , “Pinnacle: Ibm mxt in a memory controller chip, ” IEEE Micr o , vol. 21, no. 2, pp. 56–68, Mar 2001. [53] E . VMware, “Underst anding memory resource management in vmware esx 4.1, ” 2010. [54] G. Saile shwar et al. , “Morphable counters: Enablin g compact in- teg rity trees for low-o verhead secure memories, ” in 2018 51st Annual IEEE/ACM Internati onal Symposium on Micr oarchi tectu re (MICR O) , Oct 2018, pp. 416–427. [55] S. Hong, P . J . Nair, B. Abali, A. Buyuktosunoglu, K. Kim, and M. Healy, “ Attach ´ e: T owards ideal m emory compression by mitigating m etada ta bandwidt h ove rheads, ” in 2018 51st A nnual IEE E/ACM Internat ional Symposium on Micr oarc hitect ur e (MICR O) , Oct 2018, pp. 326–33 8. [56] V . Y oung, S. Kariyappa , and M. Qureshi, “Enabling transparent memory- compression for commodity m emory systems, ” in 2019 IEEE Interna- tional Symposium on High P erformance Computer Archi tectu re (HPCA) , Feb 2019, pp. 570–581. [57] A. Deb et al. , “Enabling technol ogies for memory compre ssion: Meta- data, mapping, and predicti on, ” in 2016 IEEE 34th Internat ional Con- fer ence on Computer Design (ICCD) , Oct 2016, pp. 17–24. [58] D. H. Y oon, M. K. Jeong, and M. Erez, “ Adapti ve granularity memory systems: A tradeof f between storage ef ficienc y and throughput, ” in Pr oceedi ngs of the 38th Annual International Symposium on Computer Arc hitectur e , ser . ISCA ’11. New Y ork, NY , USA: AC M, 2011, pp. 295–306. [59] P . J. Nair , D.-H. Kim, and M. K. Qureshi, “ Archshie ld: Architectural frame work for assisting dram sca ling by tolera ting high error rate s, ” in Pr oceedi ngs of the 40th Annual International Symposium on Computer Arc hitectur e , ser . ISCA ’13. New Y ork, NY , USA: AC M, 2013, pp. 72–83. [60] P . J. Nair , D. A. Roberts, and M. K. Qureshi, “Fault sim: A fast, configurable m emory-reli abili ty s imulator for con vent ional and 3d-stack ed systems, ” ACM T rans. Arc hit. Code Optim. , vol. 12, no. 4, pp. 44:1–44:24, Dec. 2015. [Online]. A vail able: http:/ /doi.acm.or g/10.1145/ 2831234 [61] D. Roberts and P . Nair, “Fa ultsim: A fast, configurabl e memory- resilie nce s imulato r , ” in The Memory F orum: In conjunction with ISCA , vol. 41, 2014. [62] S. Khan et al. , “The efficac y of error mitigation techni ques for dram retent ion fail ures: A comparati ve experimen tal study , ” in The 2014 AC M Internati onal Confer ence on Measur ement and Modeli ng of Computer Systems , s er . SIGMET RICS ’14. Ne w Y ork, NY , USA: A CM, 2014, pp. 519–5 32. [63] P . J. Nair , V . Sridharan, and M. K. Qureshi, “Xed: Exposing on-die error detec tion information for strong memory reliabilit y , ” in 2016 ACM/IEEE 43r d Annual Internatio nal Symposium on Computer A rc hitectur e (ISCA) , June 2016, pp. 341–353. [64] C. Chou, P . Nair , and M. K. Qureshi, “Reduci ng refresh po wer in mobile de vices with morphable ecc, ” in 2015 45th Annual IE EE/IFIP Internati onal Confere nce on Dependabl e Syste ms and Networks , June 2015, pp. 355–366. [65] P . J . Nair , D. A. Roberts, and M. K. Qureshi, “Citadel : Efficien tly protect ing stacked memory from large granularit y fail ures, ” in 2014 47th Annual IEEE/ACM International Symposium on Micr oar chi tectu re , Dec 2014, pp. 51–62. [66] ——, “Citadel : Effici ently protect ing stacked memory from tsv and lar ge granula rity fail ures, ” ACM T rans. A rc hit. Code Optim. , vol. 12, no. 4, pp. 49:1 –49:24, Jan. 2016. [Online]. A vaila ble: http:/ /doi.acm.or g/10.1145/ 2840807 [67] G. Saileshwa r et al. , “Synergy: Rethinking secure-memory design for error- correct ing memories, ” in 2018 IEEE Internatio nal Symposium on High P erformance Computer A rc hitectur e (HPCA) , Feb 2018, pp. 454– 465. [68] S. Sardashti and D. A. W ood, “Could compressio n be of general use? e v aluat ing memory compression across domains, ” ACM Tr ans. Arch it. Code Optim. , vol. 14, no. 4, pp. 44:1–44:24, Dec. 2017. [Online]. A v aila ble: http://doi .acm.org/10 .1145/3138805 [69] E . G. Hallnor and S. K. Reinhardt, “ A unified compressed memory hierarc hy , ” in 11th Internatio nal Symposium on High-P erformance Com- puter A rc hitectur e , Feb 2005, pp. 201–212. [70] V . Sathish, M. J. Schulte, and N. S. Kim, “Lossless and lossy memory i/o link compressio n for improvin g performa nce of gpgpu worklo ads, ” in Pro ceedin gs of the 21st Internatio nal Confer ence on P arall el Arc hitect ur es and Compilation T ech niques , ser . P A CT ’12. Ne w Y ork, NY , USA: AC M, 2012, pp. 325–334. [Online]. A vaila ble: http:/ /doi.acm.or g/10.1145/ 2370816.2370864 [71] S. Han, H. Mao, and W . J. Dally , “Dee p compression: Compressi ng deep neural netw ork with pruning, trained quantizati on and huffman coding, ” CoRR , vol. abs/1510.00149, 2015. [Online]. A vai lable: http:/ /arxi v .org/abs/1510.00 149 [72] D. Kadetotad et al. , “Effic ient m emory compression in deep neural netw orks using coarse-grain sparsification for speech applicat ions, ” in Pr oceedi ngs of the 35th Internatio nal Conf er ence on Computer-Aided Design , s er . ICCAD ’16. Ne w Y ork, NY , USA: A CM, 2016, pp. 78:1– 78:8. [Onli ne]. A va ilabl e: http://doi.ac m.org/10.1145/ 2966986.2967028 [73] G. Pekhimenko et al. , “Exploiting compressed block size as an indicato r of future reuse, ” in 2015 IEEE 21st Internat ional Symposium on High P erformance Computer Archi tectu re (HP CA) , Feb 2015, pp. 51–63. [74] J. Gaur, A. R. Alameldeen, and S. Subramoney , “Base-victi m com- pression: An opportuni stic cache compression archite cture, ” in 2016 ACM /IEEE 43rd Annual Internat ional Symposium on Computer Archi - tectu re (ISCA) , June 2016, pp. 317–328.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment