Deep Innovation Protection: Confronting the Credit Assignment Problem in Training Heterogeneous Neural Architectures
Deep reinforcement learning approaches have shown impressive results in a variety of different domains, however, more complex heterogeneous architectures such as world models require the different neural components to be trained separately instead of…
Authors: Sebastian Risi, Kenneth O. Stanley
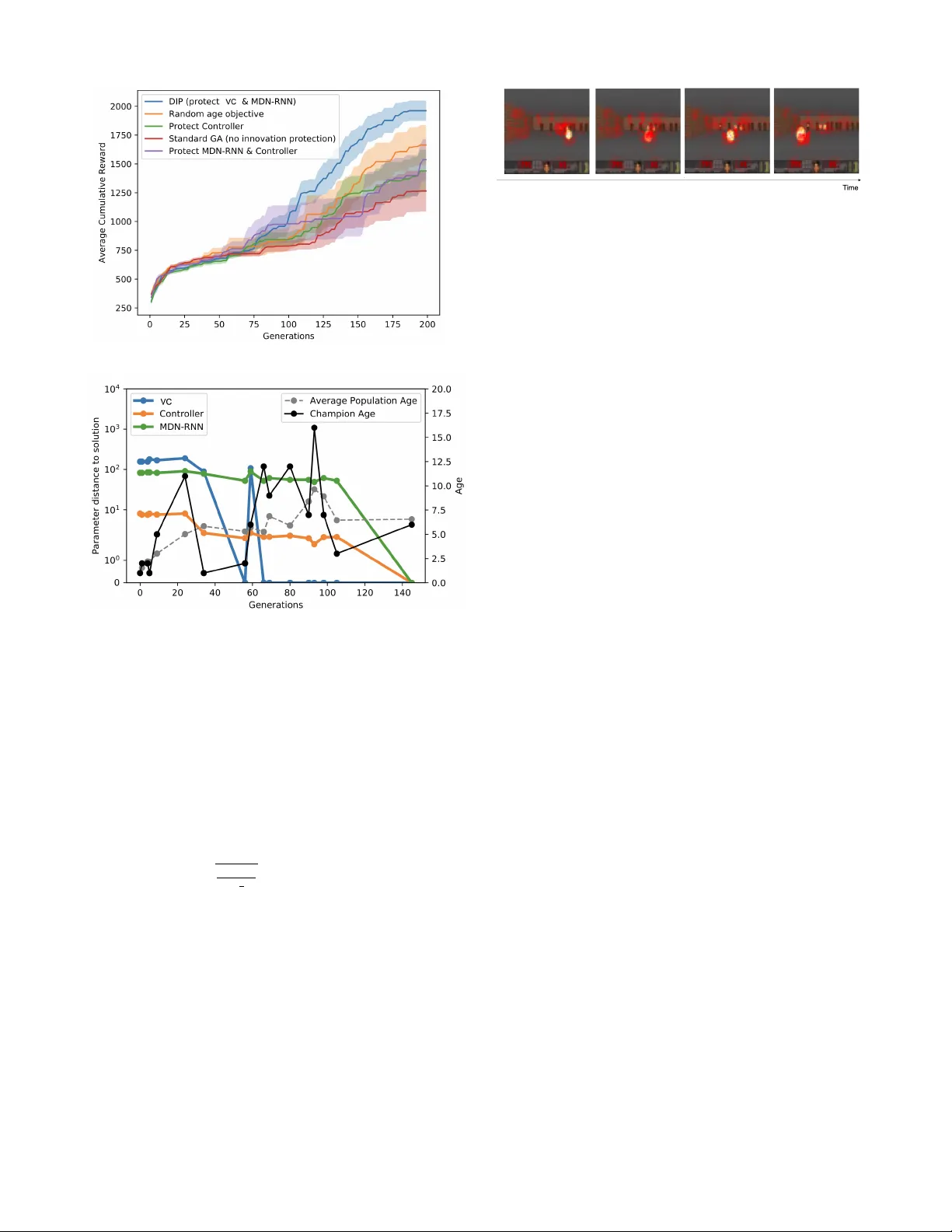
Deep Innov ation Pr otection: Confronting the Cr edit Assignment Pr oblem in T raining Heter ogeneous Neural Architectur es Sebastian Risi 1 and K enneth O. Stanley 2 1 IT Univ ersity of Copenhagen, Copenhagen, Denmark, sebr@itu.dk 2 Uber AI, San Francisco, CA 94103, kennethostanley@gmail.com Abstract Deep reinforcement learning approaches hav e sho wn impres- siv e results in a variety of different domains, howe v er , more complex heterogeneous architectures such as world models require the different neural components to be trained sepa- rately instead of end-to-end. While a simple genetic algorithm recently showed end-to-end training is possible, it failed to solve a more complex 3D task. This paper presents a method called Deep Innovation Pr otection (DIP) that addresses the credit assignment problem in training complex heterogenous neural network models end-to-end for such en vironments. The main idea behind the approach is to employ multiobjec- tiv e optimization to temporally reduce the selection pressure on specific components in multi-component network, allow- ing other components to adapt. W e inv estigate the emer gent representations of these ev olved networks, which learn to pre- dict properties important for the survi val of the agent, without the need for a specific forward-prediction loss. Introduction The ability of the brain to model the world arose from the process of e v olution. It e v olved because it helped or ganisms to survi v e and striv e in their particular en vironments and not because such forward prediction was explicitly optimized for . In contrast to the emergent neural representations in na- ture, modules of current world model approaches are often directly re w arded for their ability to predict future states of the en vironment (Schmidhuber 1990; Ha and Schmidhuber 2018; Hafner et al. 2018; W ayne et al. 2018). While it is un- doubtedly useful to be able to explicitly encourage a model to predict what will happen next, here we are interested in the harder problem of agents that should learn to predict what is important for their surviv al without being explicitly rew arded for it. A challenge in end-to-end training of complex neural models that does not require each component to be trained separately (Ha and Schmidhuber 2018), is the well-known credit assignment problem (CAP) (Minsk y 1961). While deep learning has sho wn to be in general well suited to solve the CAP for deep networks (i.e. determining how much each weight contributes to the network’ s error), evidence sug- gests that more heterogeneous networks lack the “niceness” Copyright © 2021, Association for the Advancement of Artificial Intelligence (www .aaai.org). All rights reserved. of conv entional homogeneous networks (see Section 6.1 in Schmidhuber (2015)), requiring dif ferent training setups for each neural module in combination with e volutionary meth- ods to solv e a comple x 3D task (Ha and Schmidhuber 2018). T o explore this challenge, we are building on the re- cently introduced world model architecture introduced by Ha and Schmidhuber (2018) but employ a novel neuroevo- lutionary optimization method. This agent model contains three dif ferent components: (1) a visual module, mapping high-dimensional inputs to a lower -dimensional represen- tativ e code, (2) an LSTM-based memory component, and (3) a controller component that takes input from the visual and memory module to determine the agent’ s ne xt action. In the original approach, each component of the world model was trained separately and to perform a different and spe- cialised function, such as predicting the future. While Risi and Stanley (2019) demonstrated that these models can also be trained end-to-end through a population-based genetic algorithm (GA) that exclusi vely optimizes for final perfor- mance, the approach was only applied to the simpler 2D car racing domain and it is an open question how such an ap- proach will scale to the more complex CAP in a 3D V iz- Doom task that first validated the effecti veness of the world model approach. Adding support to the hypothesis that CAP is a problem in heterogeneous networks, we show that a simple genetic algorithm fails to find a solution to solving the V izDoom task and ask the question what are the missing ingredients necessary to encourage the ev olution of better performing networks. The main insight in this paper is that we can vie w the optimization of a heterogeneous neural network (such as world models) as a co-evolving system of multiple differ ent sub-systems . The other important CAP insight is that rep- resentational innov ations discovered in one subsystem (e.g. the visual system learns to track moving objects) require the other sub-systems to adapt. In fact, if the other systems are not given time to adapt, such innov ation will likely initially hav e an adversarial ef fect on o verall performance. In order to optimize such co-e v olving heterogeneous neu- ral systems, we propose to reduce the selection pressure on individuals whose visual or memory system was recently changed, gi ven the controller component time to readapt. This Deep Innovation Pr otection (DIP) approach is able to find a solution to the VizDoom:Take Cover task, which was so far only solv ed by the original world model approach (Ha and Schmidhuber 2018) and a recent approach based on self-interpretable agents (T ang, Nguyen, and Ha 2020). More interestingly , the emergent models learned to predict ev ents important for the surviv al of the agent, ev en though they were not e xplicitly trained to predict the future. Additionally , our in vestigation into the training process shows that DIP allows e volution to carefully orchestrate the training of the components in these heterogeneous architec- tures. In other words, DIP is able to successfully credit the contributions of the dif ferent components to the o verall suc- cess of the agent. W e hope this work inspires more research that focuses on in vestigating representations emerging from approaches that do not necessarily only rely on gradient- based optimization. Deep Innovation Pr otection The hypothesis in this paper is that to optimize heteroge- neous neural models end-to-end for more complex tasks re- quires each of its components to be carefully tuned to work well together . For example, an innovation in the visual or memory component of the network could adversely impact the controller component, leading to reduced performance and a complicated CAP . In the long run, such innov ation could allow an indi vidual to outperform its predecessors. The agent’ s network design is based on the world model network introduced by Ha and Schmidhuber (2018). The network includes a visual component (VC), implemented as the encoder component of a variational autoencoder that compresses the high-dimensional sensory information into a smaller 32-dimensional representativ e code (Fig. 1). This code is fed into a memory component based on a recurrent LSTM (Hochreiter and Schmidhuber 1997), which should predict future representativ e codes based on previous infor- mation. Both the output from the sensory component and the memory component are then fed into a controller that de- cides on the action the agent should take at each time step. W e train the model end-to-end with a genetic algorithm, in which mutations add Gaussian noise to the parameter vec- tors of the networks: θ 0 = θ + σ , where ∼ N (0 , I ) . The approach introduced in this paper aims to train het- erogeneous neural systems end-to-end by temporally re- ducing the selection pressure on individuals with recently changed modules, allowing other components to adapt. For example, in a system in which a mutation can either affect the visual encoder , MDN-RNN or controller , selection pres- sure should be reduced if a mutation affects the visual com- ponent or MDN-RNN, giving the controller time to readapt to the changes in the learned representation. W e employ the well-known multiobjecti v e optimization approach NSGA-II (Deb et al. 2002), in which a second “age” objective keeps track of when a mutation changes either the visual system or the MDN-RNN. Every generation an indi vidual’ s age is increased by 1, ho wev er , if a mutation changes the VC or MDN-RNN, this age objectiv e is set to zero (lower is bet- ter). Therefore, if two neural networks reach the same per- formance (i.e. the same final reward), the one that had less time to adapt (i.e. whose age is lower) would hav e a higher chance of being selected for the next generation. The sec- ond objective is the accumulated rew ard received during an episode. Pseudocode of the approach applied to w orld mod- els is shown in Algorithm 1. It is important to note that this novel approach is differ - ent to the traditional usage of “age” in multi-objective op- timization, in which age is used to increase div ersity and keeps track of how long individuals have been in the popu- lation (Hornby 2006; Schmidt and Lipson 2011). In the ap- proach in this paper , age counts how many generations the controller component of an individual had time to adapt to an unchanged visual and memory system. Algorithm 1 Deep Innov ation Protection 1: Generate random population of size N with age objecti ves set to 0 2: for gener ation = 1 to i do 3: for Indi vidual in Population do 4: Objectiv e[1] = age 5: Objectiv e[2] = accumulated task re ward 6: Increase individual’ s age by 1 7: end for 8: Assign ranks based on Pareto fronts 9: Generate set of non-dominated solutions 10: Add solutions, starting from first front, until number solu- tion = N 11: Generate child population through binary tournament se- lection and mutations 12: Reset age to 0 for all indi viduals whose VC or MDN-RNN was mutated 13: end for In the original world model approach the visual and mem- ory component were trained separately and through unsuper- vised learning based on data from random rollouts. W e opti- mize the multi-component architecture in our work through a genetic algorithm without ev aluating each component in- dividually . In other words, the VC is not directly optimized to reconstruct the original input data and neither is the mem- ory component optimized to predict the next time step; the whole network is trained in an end-to-end fashion. Here we are interested in what type of neural representations emerge by themselves that allo w the agent to solv e the giv en task. Experiments In the experiments presented here an agent is trained to solv e the car racing tasks, and the more challenging V izDoom task (K empka et al. 2016) from 64 × 64 RGB pixel inputs (Fig. 2). These two tasks were chosen to test the general- ity of the approach, with one requiring 2D top-do wn control ( CarRacing-v0 ) and the other task requering the control of an agent from a first-person 3D view (V izDoom). In the continuous control task CarRacing-v0 (Klimov 2016) the agent is presented with a new procedurally gen- erated track ev ery episode, receiving a reward of -0.1 ev- ery frame and a re ward of +100/ N for each visited track tile, where N is the total number of tiles in the track. The network controlling the agent (Fig. 1) has three outputs to control left/right steering, acceleration and braking. T raining Observation 64 x 64 x 3 Visual Encoder Memory Controller action Environment Figure 1: Agent Model. The agent model consists of three modules. A visual component that produces a latent code z t at each time step t , which is concatenated with the hidden state h t of the LSTM-based memory component that takes z t and pre viously performed action a t − 1 as input. The combined vector ( z t , h t ) is input into the controller component to determine the next action of the agent. In this paper , the agent model is trained end-to-end with a multiobjecti ve genetic algorithm. (a) CarRacing (b) VizDoom Figure 2: In the CarRacing-v0 task the agent has to learn to driv e across many procedurally generated tracks as fast as possible from 64 × 64 RGB color images. In the VizDoom:Take Cover domain the agent has to learn to av oid fireballs and to stay ali ve as long as possible. agents in procedurally generated en vironments has shown to significantly increase their generality and avoid overfitting (Risi and T ogelius 2020; Justesen et al. 2018; Zhang et al. 2018; Cobbe et al. 2018). In the VizDoom:Take Cover task the agent has to try to stay alive for 2,100 timesteps, while av oiding fire- balls shot at it by strafing to the left or the right. The agent receiv es a +1 reward for e very frame it is alive. The net- work controlling the agent has one output a to control left ( a < − 0 . 3 ) and right strafing ( a > 0 . 3 ), or otherwise stand- ing still. In this domain, a solution is defined as surviving for o ver 750 timesteps, averaged across 100 random rollouts (Kempka et al. 2016). Follo wing the NSGA-II approach, individuals for the next generation are determined stochastically through 2-way tournament selection from the 50% highest rank ed individu- als in the population (Algorithm 1). No crossover operation was emplo yed. The population size w as 200. Because of the randomness in this domain, we ev aluate the top three indi- viduals of each generation one additional time to get a better estimate of the true elite. W e compare a total of four differ- ent approaches: 1. Deep innovation protection (DIP): The age objectiv e is reset to zero when either the VC or MDN-RNN is changed. The idea behind this approach is that the con- troller should get time to readapt if one of the components that precede it in the network change. 2. Controller innovation protection: Here the age objec- tiv e is set to zero if the controller changes. This setting tests if protecting components upstream can be effecti v e in optimizing heterogeneous neural models. 3. MDN-RNN & Controller innovation protection: This setup is the same as the controller protection approach but we additionally reset age if the MDN-RNN changes. On av erage, this treatment will reset the age objecti ve as often as DIP . 4. Random age objective: In this setup the age objectiv e is assigned a random number between [0, 20] at each ev aluation. This treatment tests if better performance can be reached just through introducing more div ersity in the population. 5. Standard GA - no innovation protection: In this non- multi-objectiv e setup, which is the same one as introduced in Risi and Stanley (2019), only the accumulated reward is taken into account when e v aluating indi viduals. For all treatments, a mutation has an equal probability to either mutate the visual, memory , or controller component of the network. Interestingly , while this approach performs similarly well to an approach that always mutates all compo- nents for the CarRacing-v0 task (Risi and Stanle y 2019), we noticed that it performs significantly worse in the more complicated V izDoom domain. This result suggests that the more complex the tasks, the more important it is to be able to selectiv ely fine-tune each different component in a complex neural architecture. Optimization and Model Details The genetic algorithm σ was determined empirically and set to 0 . 03 for the experiments in this paper . The code for the DIP approach is av ailable at: github .com/sebastianrisi/dip. The sensory model is implemented as a variational au- toencoder that compresses the high-dimensional input to a latent v ector z . The VC takes as input an RGB image of size 64 × 64 × 3 , which is passed through four conv olutional lay- ers, all with stride 2. The network’ s weights are set using the (a) (b) Figure 3: V izDoom Evolutionary T raining . Shown is (a) mean performance over generations together with one stan- dard error . For one representativ e run of DIP (b), we plot the euclidean distances of the weights of the intermediate solutions (i.e. individuals with the highest task rew ard dis- cov ered so far) compared to the final solution in addition to their age and the av erage population age. default He PyT orch initilisation (He et al. 2015), with the resulting tensor being sampled from U ( − bound, bound ) , where bound = q 1 f an in . The memory model (Ha and Schmidhuber 2018) combines a recurrent LSTM network with a mixture density Gaussian model as network out- puts, known as a MDN-RNN (Ha and Eck 2017; Grav es 2013a). The network has 256 hidden nodes and models P ( z t +1 | a t , z t , h t ) , where a t is the action taken by the agent at time t and h t is the hidden state of the recurrent net- work. Similar models hav e previously been used for gen- erating sequences of sketches (Ha and Eck 2017) and hand- writing (Grav es 2013b). The controller component is a sim- ple linear model that directly maps z t and h t to actions: a t = W c [ z t h t ] + b c , where W c and b c are weight matrix and bias vector . Figure 4: Still frames of a learned policy . The agent learned to primarily pay attention to the walls and fireballs, while ignoring the floor and ceiling. Interestingly the agent also seems to pay attention to the health and ammo indicator . Experimental Results All results are av eraged over ten independent ev olutionary runs. In the car racing domain we find that there is no no- ticeable dif ference between an approach with and without innov ation protection and both can solve the domain with a reward of 905 ± 80 and 903 ± 72, respectively . Howe ver , in the more complex V izDoom task (Fig. 3a), the DIP approach that protects innov ations in both VC and MDN-RNN, sig- nificantly outperforms all other approaches during training. The approach is able to find a solution to the task, effecti v ely av oiding fireballs and reaching an average score of 824.33 (sd ± 491.59). T o better understand the netw ork’ s behavior , we calculate perturbation-based saliency maps to determine the parts of the environment the agent is paying attention to (Fig. 4). The idea behind perturbation-based saliency maps is to measure to what extent the output of the model changes if parts of the input image are altered (Greydanus et al. 2017). Not sur- prisingly , the agent learned to pay particular attention to the walls, fireballs, and the position of the monsters. The better performance of the random age objecti ve com- pared to no innov ation protection suggests that increasing div ersity in the population improves performance but less effecti vely than selectivity resetting age as in DIP . Interest- ingly , the controller and the MDN-RNN&Controller protec- tion approach perform less well, confirming our hypothesis that it is important to protect innov ations upstream in the network for do wnstream components. Learned Representations W e further in vestigate what type of world model can emerge from an e volutionary pro- cess that does not directly optimize for forward prediction or reconstruction loss. T o gain insights into the learned rep- resentations we employ the t-SNE dimensionality reduc- tion technique (Maaten and Hinton 2008), which has pro ven valuable for visualizing the inner workings of deep neural networks (Such et al. 2018; Mnih et al. 2015). W e are par- ticularly interested in the information contained in the com- pressed 32-dimensional vector of the VC and the informa- tion stored in the hidden states of the MDN-RNN (which are both fed into the controller that decides on the agent’ s action). Different combinations of sequences of these latent vectors collected during one rollout are visualized in tw o di- mensions in Fig. 5. Interestingly , while the 32-dimensional z vector from the VC does not contain enough information to infer the correct action, either the hidden state alone or in combination with z results in grouping the states into (a) z+hidden (b) z alone (c) hidden alone Figure 5: t-SNE mapping of the latent+hidden vector (a), la- tent vector alone (b), and hidden vector alone (c). While the compressed latent vector is not enough to infer the correct action (b), the hidden LSTM vector alone contains enough information for the agent to decide on the correct action (c). Red = strafe left, blue = strafe right, black = no mov ement. two distinct classes (one for moving left and one for mov- ing right). The temporal dimension captured by the recur - rent network prov es in v aluable in deciding what action is best. For example, not getting stuck in a position that makes av oiding incoming fireballs impossible, seems to require a lev el of forward prediction by the agent. T o gain a deeper understanding of this issue we look more closely into the learned temporal representation next. Learned Forward Model Dynamics In order to analyze the learned temporal dynamics of the forw ard model, we are taking a closer look at the av erage activ ation x t of all 256 hidden nodes at time step t and how much they differ from the ov erall a verage across all time steps ¯ X = 1 N P N 1 ¯ x t . The variance of ¯ x t is thus calculated as σ t = ( ¯ X − ¯ x t ) 2 , and normalized to the range [0 , 1] before plotting. The hy- pothesis is that acti v ation le v els far from the mean might in- dicate a higher importance and should ha ve a greater impact on the agent’ s controller component. In other words, they likely indicate critical situations in which the agent needs to pay particular attention to the predictions of the MDN-RNN. Fig. 6 depicts frames from the learned policies in two differ - ent situations, which sho ws that the magnitude of LSTM ac- tiv ations are closely tied to specific situations. The forward model does not seem to react to fireballs by themselves but instead depends on the agent being in the line of impact of an approaching fireball, which is critical information for the agent to stay aliv e. Evolutionary Innovations In addition to analyzing the learned representations of the final networks, it is interest- ing to study the different stepping stones ev olution discov- ered to solve the V izDoom task. W e show one particular ev olutionary run in Fig. 7, with other ones following sim- ilar progressions. In the first 30 generations the agent starts to learn to pay attention to fireballs but only tries avoid- ing them by either standing still or moving to the right. A jump in performance happens around generation 34 when the agent starts to discov er mo ving to either the left or right; howe ver , the learned representation between moving left or right is not well defined yet. This changes around genera- tion 56, leading to another jump in fitness and some gener- ations of quick fine-tuning later the agent is able to differ - entiate well between situations requiring different actions, managing to surviv e for the whole length of the episode. Motiv ated by the approach of Raghu et al. (2017) t o analyse the gradient descent-based training of neural networks, we in v estigate the weight distances of the world model compo- nents of the best-performing netw orks found during training to the final solution representation (Fig. 3b). The VC is the component with the steepest decrease in distance with a no- ticeable jump around generation 60 due to another lineage taking over . The MDN-RNN is optimized slowest, which is likely due to the fact that the correct forward model dynam- ics are more complicated to discov er than the visual compo- nent. These results suggest that DIP is able to orchestrate the training of these heterogeneous w orld model architectures in an automated way , successfully solving the underlying CAP . Reward and Age Objective W e performed an analysis of the (1) cumulativ e reward per age and (2) the number of individuals with a certain age averaged across all ten runs and all generations (Fig. 8). While the average rew ard in- creases with age, there are fewer and fewer individuals at higher age le vels. This result suggest that the two objecti ves are in competition with each other , motiv ating the choice for a multi-objectiv e optimization approach; staying alive for longer becomes increasingly difficult and a high age needs to be compensated for by a high task rew ard. Sample Efficiency Comparison While ev olutionary al- gorithms are typically regarded as requiring many samples, DIP is surprisingly sample efficient and competitive with other solutions to the DoomT akeCov er and CarRacing task. The other reported solutions that solve both of these tasks are the world model approach by Ha and Schmidhuber (2018) and an ev olutionary self-attention approach (T ang, Nguyen, and Ha 2020). In case of the CarRacing task, T ang, Nguyen, and Ha (2020) report that they can solve the tasks reliable after 1,000 generations (with a slightly larger population size of 256 compared to our population size of 200). The world model approach uses a mix of different methods (Ha and Schmidhuber 2018), which makes comparing sample efficienc y slightly more complicated. The world model ap- proach finds a solution to the CarRacing task in 1,800 gen- erations with an already trained V AE and MDN-RNN. DIP can solve CarRacing after 1,200 generations (without re- quiring pre-training) and is thus similarly sample ef ficient to the end-to-end training approach in T ang, Nguyen, and Ha (2020). The purely ev olutionary training in T ang, Nguyen, and Ha (2020) can reliable solve the DoomT akeCov er task after around 1,000 generations. DIP solves the tasks in only 200 generations. The world model approach only trains the DoomT akeCo ver agent in a simulated dream environment and then transfers the controller to the actual en vironment. Evolutionary training of the learned world model is fast, since it doesn’ t require simulated graphics, and takes around 1,500 generations. Ho wev er , it relies on training the V AE and MDN-RNN with 10,000 random rollouts. Related W ork A variety of dif ferent RL algorithms have recently been shown to work well on a div erse set of problems when combined with the representative po wer of deep neural net- works (Mnih et al. 2015; Schulman et al. 2015, 2017). While most approaches are based on v ariations of Q-learning (a) (b) Figure 6: A vera ge activation levels of LSTM in two differ ent situations. For visualization purposes only , images are colored more or less blue depending on the LSTM activ ations. The forward model seems to hav e learned to predict if a fireball would hit the agent at the current position. In (a) the agent can take advantage of that information to av oid the fireball while the agent does not hav e enough time to escape in situation (b) and gets hit. Sho wn on top are the actions the agent takes in each frame. (Mnih et al. 2015) or policy gradient methods (Schulman et al. 2015, 2017), recently e volutionary-based methods hav e emerged as a promising alternativ e for some domains (Such et al. 2017; Salimans et al. 2017). Salimans et al. (2017) showed that a type of e volution strategy (ES) can reach competitiv e performance in the Atari benchmark and at controlling robots in MuJoCo. Additionally , Such et al. (2017) demonstrated that a simple genetic algorithm is in fact able to reach similar performance to deep RL methods such as DQN or A3C. Earlier approaches that evolv ed neu- ral networks for RL tasks worked well in complex RL tasks with lower -dimensional input spaces (Stanley and Miikku- lainen 2002; Floreano, D ¨ urr , and Mattiussi 2008; Risi and T ogelius 2017). Ev olutionary approaches solving 3D tasks directly from pixels has so far prov en dif ficult although a few notable approaches e xist (K outn ´ ık et al. 2013; Alv ernaz and T ogelius 2017; Poulsen et al. 2017; Lehman et al. 2018). For complex agent models, different network components can be trained separately (W ahlstr ¨ om, Sch ¨ on, and Deisen- roth 2015; Ha and Schmidhuber 2018). For example, in the world model approach (Ha and Schmidhuber 2018), the authors first train a variational autoencoder (V AE) on 10,000 rollouts from a random policy to compress the high- dimensional sensory data and then train a recurrent network to predict the next latent code. Only after this process is a smaller controller network trained to perform the actual task, taking information from both the V AE and recurrent network as input to determine the action the agent should perform. Evolutionary approaches solving 3D tasks directly from pixels has so far proven difficult although a few notable ap- proaches exist. Koutn ´ ık et al. (2013) evolv ed an indirectly encoded and recurrent controller for car driving in TORCS, which learned to driv e based on a raw 64 × 64 pixel im- age. The approach was based on an indirect encoding of the network’ s weights analogous to the JPEG compression in images. T o scale to 3D FPS tasks, Alvernaz and T ogelius (2017) first trained an autoencoder in an unsupervised way and then e v olved the controller gi ving the compressed repre- sentation as input. In another approach, Poulsen et al. (2017) trained an object recognizer in a supervised way and then in a separate step ev olved a controller module. More recently , Lehman et al. (2018) introduced an approach called safe mu- tations , in which the magnitude of mutations to weight con- nections is scaled based on the sensiti vity of the network’ s output to that weight. It allowed the e volution of lar ge-scale deep networks for a simple 3D maze task and is a comple- mentary approach that could be combined with DIP . The approach introduced in this paper can be viewed as a form of di versity maintenance, in which selection pressure on certain mutated neural networks is reduced. Many other methods for encouraging div ersity (Mouret and Doncieux 2012) were inv ented by the ev olutionary computation com- munity , such as nov elty search (Lehman and Stanley 2008), quality di versity (Pugh, Soros, and Stanley 2016), or speci- ation (Stanley and Miikkulainen 2002). For increasing div ersity , algorithms often introduce new individuals into the population. In the ALPS approach by Hornby (2006), the population is segregated into different Generation 0 Generation 24 Generation 34 Generation 56 Generation 145 Figure 7: De velopment of the evolved r epr esentation. Shown are t-SNE mappings of the 288-dimensional vectors (32- dimensional latent vectors + 256-dimensional hidden state vector) together with saliency maps of specific game situa- tions. Early on in ev olution the agent starts paying attention to the fireballs (generation 24) but only moves to the right (blue) or stands still (black). Starting around generation 34 the agent starts to mov e to the left and right, with the saliency maps becoming more pronounced. From generation 56 on the compressed learned representation (latent vector+hidden state vector) allows the agent to infer the correct action al- most all the time. The champion discov ered in generation 145 discov ered a visual encoder and LSTM mapping that shows a clear di vision for left and right strafing actions. layers depending on when they were introduced into the population and newly generated individuals are introduced into the ”ne west” layer to increase div ersity . Schmidt and Lipson (2011) combine this idea with a multi-objectiv e ap- proach, in which individuals are rew arded for performance and for how many generations hav e passed since they hav e been introduced into the population. Similar to the approach by Cheney et al. (2018) to co-evolv e morphologies and neural controller , and in contrast to previous approaches (Hornby 2006; Schmidt and Lipson 2011), DIP does not in- troduce new random individuals into the generation but in- stead resets the “age” of individuals whose sensory or mem- ory system have been mutated. That is, it is not a measure of how long the indi vidual has been in the population. Approaches to learning dynamical models hav e mainly focused on gradient descent-based methods, with early work on RNNs in the 1990s (Schmidhuber 1990). More recent work includes PILCO (Deisenroth and Rasmussen 2011), which is a probabilistic model-based policy search method and Black-DR OPS (Chatzilygeroudis et al. 2017) that em- ploys CMA-ES for data-efficient optimization of comple x control problems. Additionally , interest has increased in learning dynamical models directly from high-dimensional 0 5 10 15 20 25 30 35 Ag e 350 400 450 500 550 600 Cumu l a tive Re wa r d 0 1000 2000 3000 4000 5000 6000 7000 I nd i vi d ua l s Figure 8: A verage reward across ages and number of indi- viduals per age. images for robotic tasks (W atter et al. 2015; Hafner et al. 2018) and also video games (Guzdial, Li, and Riedl 2017). W ork on e v olving forward models has mainly focused on neural networks that contain orders of magnitude fe wer con- nections and lo wer -dimensional feature v ectors (Norouz- zadeh and Clune 2016) than the models in this paper . Discussion and Future W ork The paper demonstrated that a predictive representation for a 3D task can emerge under the right circumstances with- out being explicitly rew arded for it. T o encourage this emer- gence and address the inherent credit assignment problem of complex heterogeneous networks, we introduced the deep innovation pr otection approach that can dynamically reduce the selection pressure for different components in such neu- ral architectures. The main insight is that when components upstream in the network change, such as the visual or mem- ory system in a w orld model, components downstream need time to adapt to changes in those learned representations. The neural model learned to represent situations that re- quire similar actions with similar latent and hidden codes (Fig. 5 and 7). Additionally , without a specific forward- prediction loss, the agent learned to predict “useful” ev ents that are necessary for its surviv al (e.g. predicting when the agent is in the line-of-fire of a fireball). In the future it will be interesting to compare the differences and similarities of emergent representations and learning dynamics resulting from ev olutionary and gradient descent-based optimization approaches (Raghu et al. 2017). A natural extension to this work is to e volv e the neural ar- chitectures in addition to the weights of the network. Search- ing for neural architectures in RL has previously only been applied to smaller networks (Risi and Stanle y 2012; Stanle y and Miikkulainen 2002; Stanley et al. 2019; Gaier and Ha 2019; Risi and T ogelius 2017; Floreano, D ¨ urr , and Mattiussi 2008) but could potentially now be scaled to more complex tasks. While our innov ation protection approach is based on ev olution, ideas presented here could also be incorporated in gradient descent-based approaches that optimize neural systems with multiple interacting components end-to-end. Broader Impact The ethical and future societal consequences of this work are hard to predict but likely similar to other work dealing with solving complex reinforcement learning problems. Be- cause these approaches are rather task agnostic, they could potentially be used to train autonomous robots or drones in areas that have both a positiv e and negati ve impact on soci- ety . While positiv e application can include deliv ery drones than can learn from visual feedback to reach otherwise hard to access places, other more w orrisome military applications are also imaginable. The approach presented in this paper is far from being deployed in these areas, but it its important to discuss its potential long-term consequences early on. Acknowledgments W e would like to thank Nick Cheney , Jeff Clune, David Ha, and the members of Uber AI for helpful comments and dis- cussions on ideas in this paper . References Alvernaz, S.; and T ogelius, J. 2017. Autoencoder- augmented neuroe v olution for visual Doom playing. In Computational Intelligence and Games (CIG), 2017 IEEE Confer ence on , 1–8. IEEE. Chatzilygeroudis, K.; Rama, R.; Kaushik, R.; Goepp, D.; V assiliades, V .; and Mouret, J.-B. 2017. Black-box data- efficient policy search for robotics. In 2017 IEEE/RSJ In- ternational Conference on Intelligent Robots and Systems (IR OS) , 51–58. IEEE. Cheney , N.; Bongard, J.; SunSpiral, V .; and Lipson, H. 2018. Scalable co-optimization of morphology and control in embodied machines. Journal of The Royal Society In- terface 15(143). ISSN 1742-5689. doi:10.1098/rsif.2017. 0937. URL http://rsif.ro yalsocietypublishing.org/content/ 15/143/20170937. Cobbe, K.; Klimo v , O.; Hesse, C.; Kim, T .; and Schulman, J. 2018. Quantifying generalization in reinforcement learning. arXiv pr eprint arXiv:1812.02341 . Deb, K.; Pratap, A.; Agarwal, S.; and Meyariv an, T . 2002. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE transactions on evolutionary computation 6(2): 182– 197. Deisenroth, M.; and Rasmussen, C. E. 2011. PILCO: A model-based and data-efficient approach to policy search. In Pr oceedings of the 28th International Confer ence on ma- chine learning (ICML-11) , 465–472. Floreano, D.; D ¨ urr , P .; and Mattiussi, C. 2008. Neuroev o- lution: from architectures to learning. Evolutionary Intelli- gence 1(1): 47–62. Gaier , A.; and Ha, D. 2019. W eight Agnostic Neural Net- works. arXiv pr eprint arXiv:1906.04358 . Grav es, A. 2013a. Generating sequences with recurrent neu- ral networks. arXiv pr eprint arXiv:1308.0850 . Grav es, A. 2013b. Hallucination with recurrent neu- ral networks. URL https://www .youtube.com/watch?v=- yX1SY eDHbg&t=49m33s. Greydanus, S.; K oul, A.; Dodge, J.; and Fern, A. 2017. V i- sualizing and understanding atari agents. arXiv pr eprint arXiv:1711.00138 . Guzdial, M.; Li, B.; and Riedl, M. O. 2017. Game Engine Learning from V ideo. In IJCAI , 3707–3713. Ha, D.; and Eck, D. 2017. A neural representation of sk etch drawings. arXiv pr eprint arXiv:1704.03477 . Ha, D.; and Schmidhuber, J. 2018. Recurrent world models facilitate policy ev olution. In Advances in Neural Informa- tion Pr ocessing Systems , 2455–2467. Hafner , D.; Lillicrap, T .; Fischer, I.; V illegas, R.; Ha, D.; Lee, H.; and Davidson, J. 2018. Learning latent dynamics for planning from pixels. arXiv pr eprint arXiv:1811.04551 . He, K.; Zhang, X.; Ren, S.; and Sun, J. 2015. Delving deep into rectifiers: Surpassing human-level performance on im- agenet classification. In Pr oceedings of the IEEE interna- tional confer ence on computer vision , 1026–1034. Hochreiter , S.; and Schmidhuber, J. 1997. Long short-term memory . Neur al computation 9(8): 1735–1780. Hornby , G. S. 2006. ALPS: the age-layered population structure for reducing the problem of premature con v er- gence. In Proceedings of the 8th annual conference on Ge- netic and evolutionary computation , 815–822. A CM. Justesen, N.; T orrado, R. R.; Bontrager , P .; Khalifa, A.; T o- gelius, J.; and Risi, S. 2018. Illuminating Generalization in Deep Reinforcement Learning through Procedural Lev el Generation. NeurIPS 2018 W orkshop on Deep Reinfor ce- ment Learning . Kempka, M.; W ydmuch, M.; Runc, G.; T oczek, J.; and Ja ´ sko wski, W . 2016. V izdoom: A Doom-based AI re- search platform for visual reinforcement learning. In 2016 IEEE Confer ence on Computational Intelligence and Games (CIG) , 1–8. IEEE. Klimov , O. 2016. Carracing-v0. URL https://gym.openai. com/en vs/CarRacing- v0/. K outn ´ ık, J.; Cuccu, G.; Schmidhuber , J.; and Gomez, F . 2013. Evolving large-scale neural networks for vision-based reinforcement learning. In Pr oceedings of the 15th annual confer ence on Genetic and evolutionary computation , 1061– 1068. A CM. Lehman, J.; Chen, J.; Clune, J.; and Stanley , K. O. 2018. Safe mutations for deep and recurrent neural networks through output gradients. In Pr oceedings of the Genetic and Evolutionary Computation Confer ence , 117–124. A CM. Lehman, J.; and Stanley , K. O. 2008. Exploiting open- endedness to solve problems through the search for novelty . In ALIFE , 329–336. Maaten, L. v . d.; and Hinton, G. 2008. V isualizing data using t-SNE. Journal of machine learning r esear ch 9(Nov): 2579– 2605. Minsky , M. 1961. Steps tow ard artificial intelligence. Pr o- ceedings of the IRE 49(1): 8–30. Mnih, V .; Kavukcuoglu, K.; Silver , D.; Rusu, A. A.; V e- ness, J.; Bellemare, M. G.; Graves, A.; Riedmiller, M.; Fid- jeland, A. K.; Ostrovski, G.; et al. 2015. Human-le vel con- trol through deep reinforcement learning. Nature 518(7540): 529. Mouret, J.-B.; and Doncieux, S. 2012. Encouraging behav- ioral di versity in evolutionary robotics: An empirical study . Evolutionary computation 20(1): 91–133. Norouzzadeh, M. S.; and Clune, J. 2016. Neuromodulation improv es the ev olution of forward models. In Pr oceedings of the Genetic and Evolutionary Computation Conference 2016 , 157–164. A CM. Poulsen, A. P .; Thorhauge, M.; Funch, M. H.; and Risi, S. 2017. DLNE: A hybridization of deep learning and neu- roev olution for visual control. In Computational Intelli- gence and Games (CIG), 2017 IEEE Confer ence on , 256– 263. IEEE. Pugh, J. K.; Soros, L. B.; and Stanley , K. O. 2016. Qual- ity diversity: A ne w frontier for ev olutionary computation. F r ontiers in Robotics and AI 3: 40. Raghu, M.; Gilmer , J.; Y osinski, J.; and Sohl-Dickstein, J. 2017. Svcca: Singular vector canonical correlation analysis for deep learning dynamics and interpretability . In Advances in Neural Information Pr ocessing Systems , 6076–6085. Risi, S.; and Stanley , K. O. 2012. An enhanced hypercube- based encoding for e volving the placement, density , and connectivity of neurons. Artificial life 18(4): 331–363. Risi, S.; and Stanley , K. O. 2019. Deep Neuroev olution of Recurrent and Discrete W orld Models. In Pr oceedings of the Genetic and Evolutionary Computation Confer ence , GECCO ’19, 456–462. New Y ork, NY , USA: A CM. ISBN 978-1-4503-6111-8. doi:10.1145/3321707.3321817. URL http://doi.acm.org/10.1145/3321707.3321817. Risi, S.; and T ogelius, J. 2017. Neuroe v olution in games: State of the art and open challenges. IEEE T ransactions on Computational Intelligence and AI in Games 9(1): 25–41. Risi, S.; and T ogelius, J. 2020. Increasing generality in ma- chine learning through procedural content generation. Na- tur e Machine Intellig ence 2(8): 428–436. Salimans, T .; Ho, J.; Chen, X.; Sidor, S.; and Sutskev er , I. 2017. Evolution strategies as a scalable alternativ e to rein- forcement learning. arXiv preprint arXiv:1703.03864 . Schmidhuber , J. 1990. An on-line algorithm for dynamic re- inforcement learning and planning in reacti v e en vironments. In 1990 IJCNN international joint confer ence on neural net- works , 253–258. IEEE. Schmidhuber , J. 2015. Deep learning in neural networks: An ov ervie w . Neural networks 61: 85–117. Schmidt, M.; and Lipson, H. 2011. Age-fitness pareto opti- mization. In Genetic pr ogramming theory and practice VIII , 129–146. Springer . Schulman, J.; Levine, S.; Abbeel, P .; Jordan, M.; and Moritz, P . 2015. Trust region policy optimization. In International Confer ence on Machine Learning , 1889–1897. Schulman, J.; W olski, F .; Dhariwal, P .; Radford, A.; and Klimov , O. 2017. Proximal policy optimization algorithms. arXiv pr eprint arXiv:1707.06347 . Stanley , K. O.; Clune, J.; Lehman, J.; and Miikkulainen, R. 2019. Designing neural networks through neuroevolution. Natur e Machine Intellig ence 1(1): 24–35. Stanley , K. O.; and Miikkulainen, R. 2002. Evolving neu- ral networks through augmenting topologies. Evolutionary computation 10(2): 99–127. Such, F . P .; Madhav an, V .; Conti, E.; Lehman, J.; Stanley , K. O.; and Clune, J. 2017. Deep neuroev olution: genetic algorithms are a competitiv e alternativ e for training deep neural networks for reinforcement learning. arXiv pr eprint arXiv:1712.06567 . Such, F . P .; Madhav an, V .; Liu, R.; W ang, R.; Castro, P . S.; Li, Y .; Schubert, L.; Bellemare, M.; Clune, J.; and Lehman, J. 2018. An Atari model zoo for analyzing, visualizing, and comparing deep reinforcement learning agents. arXiv pr eprint arXiv:1812.07069 . T ang, Y .; Nguyen, D.; and Ha, D. 2020. Neuroev olution of self-interpretable agents. In Pr oceedings of the 2020 Genetic and Evolutionary Computation Confer ence , 414–424. W ahlstr ¨ om, N.; Sch ¨ on, T . B.; and Deisenroth, M. P . 2015. From pixels to torques: Policy learning with deep dynamical models. arXiv preprint arXiv:1502.02251 . W atter , M.; Springenberg, J.; Boedecker , J.; and Riedmiller, M. 2015. Embed to control: A locally linear latent dynamics model for control from raw images. In Advances in neural information pr ocessing systems , 2746–2754. W ayne, G.; Hung, C.-C.; Amos, D.; Mirza, M.; Ahuja, A.; Grabska-Barwinska, A.; Rae, J.; Mirowski, P .; Leibo, J. Z.; Santoro, A.; et al. 2018. Unsupervised Predictiv e Memory in a Goal-Directed Agent. arXiv:1803.10760 . Zhang, C.; V inyals, O.; Munos, R.; and Bengio, S. 2018. A study on overfitting in deep reinforcement learning. arXiv pr eprint arXiv:1804.06893 .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment