Learning to Seek: Autonomous Source Seeking with Deep Reinforcement Learning Onboard a Nano Drone Microcontroller
We present fully autonomous source seeking onboard a highly constrained nano quadcopter, by contributing application-specific system and observation feature design to enable inference of a deep-RL policy onboard a nano quadcopter. Our deep-RL algorit…
Authors: Bardienus P. Duisterhof, Srivatsan Krishnan, Jonathan J. Cruz
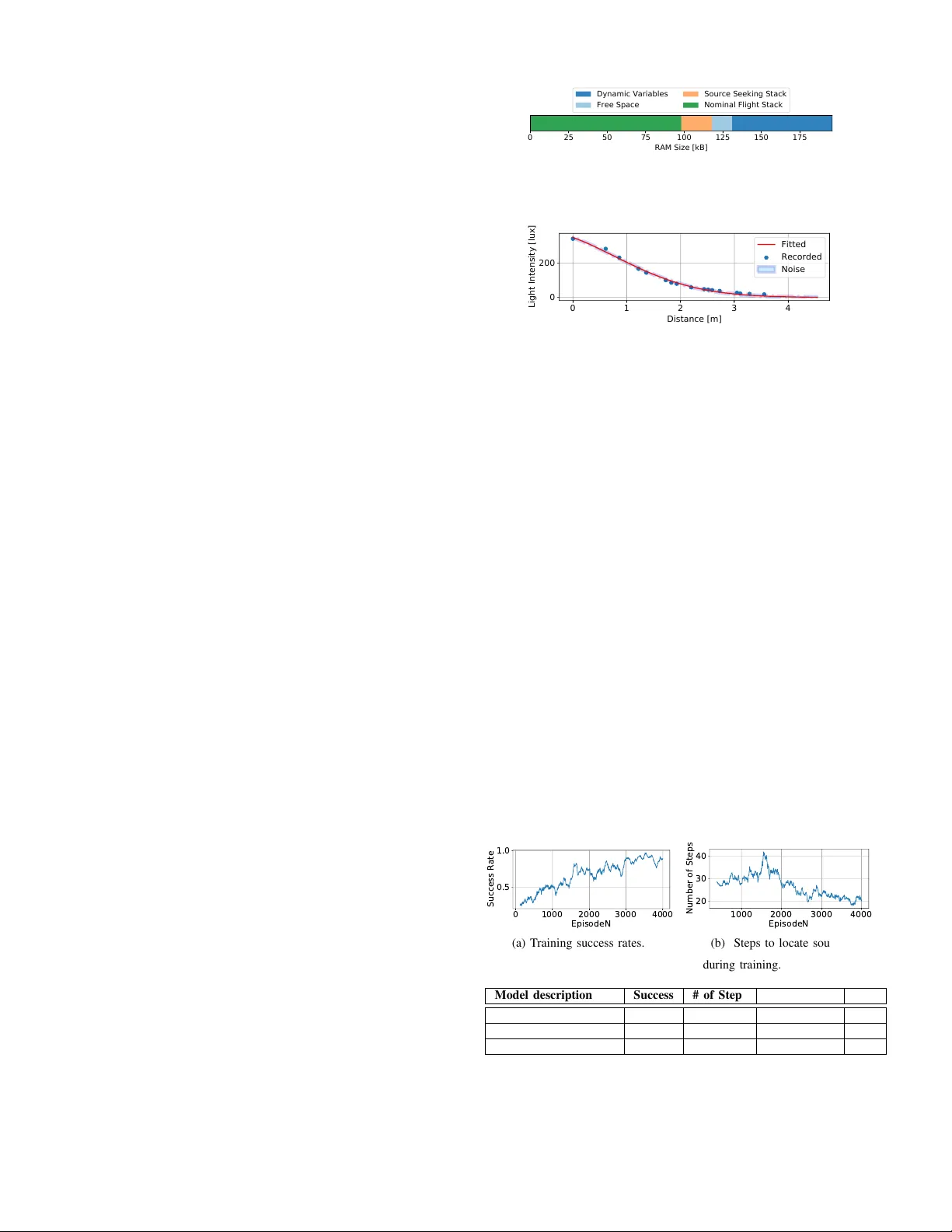
Learning to Seek: Autonomous Source Seeking with Deep Reinforcement Learning Onboard a Nano Drone Microcontroller Bardienus P . Duisterhof 1 , 3 Sri v atsan Krishnan 1 Jonathan J. Cruz 1 Colby R. Banbury 1 W illiam Fu 1 Aleksandra Faust 2 Guido C. H. E. de Croon 3 V ijay Janapa Reddi 1 Abstract —W e present fully autonomous source seeking on- board a highly constrained nano quadcopter , by contributing application-specific system and observation feature design to enable inference of a deep-RL policy onboard a nano quadcopter . Our deep-RL algorithm finds a high-performance solution to a challenging problem, ev en in presence of high noise levels and generalizes across real and simulation en vironments with different obstacle configurations. W e verify our approach with simulation and in-field testing on a Bitcraze CrazyFlie us- ing only the cheap and ubiquitous Cortex-M4 microcontroller unit. The results show that by end-to-end application-specific system design, our contribution consumes almost three times less additional power , as compared to competing learning-based navigation approach onboard a nano quadcopter . Thanks to our observation space, which we carefully design within the resource constraints, our solution achieves a 94% success rate in cluttered and randomized test en vironments, as compar ed to the previously achieved 80%. W e also compare our strategy to a simple finite state machine (FSM), geared towards efficient exploration, and demonstrate that our policy is more robust and resilient at obstacle av oidance as well as up to 70% more efficient in source seeking. T o this end, we contrib ute a cheap and lightweight end- to-end tiny robot learning (tinyRL) solution, running onboard a nano quadcopter , that proves to be robust and efficient in a challenging task using limited sensory input. Index T erms —Motion and Path Planning, Aerial Systems: Applications, Reinforcement Learning I . I N T R O D U C T I O N Source seeking is an important application for search and rescue, inspection, and other jobs that are too dangerous for humans. Imagine cheap and disposable aerial robots inspecting ship hauls for leaks, aiding search for surviv ors in mines, or seeking a source of radiation in nuclear plants. For that reality , we need small, agile, and inexpensi v e robots capable of fully- autonomous na vigation in GPS denied en vironments that can be deployed quickly , without additional set-up or training. Nano quadrotors are a lightweight, cheap, and agile hard- ware platform, and an ideal candidate for source seeking in GPS denied environments. T o make them work, we need to add appropriate sensors and navigation software. How- ev er , they are sev erely resource constrained. Their available memory , battery , and compute power is limited. Those con- straints pose challenges to the existing autonomous navigation 1 Harvard Univ ersity , 2 Robotics at Google, 3 Delft Uni versity of T echnology - bduisterhof@g.harvard.edu. The work was done while Bart was a visiting student at Harvard. Fig. 1. CrazyFlie nano quadcopter running a deep reinforcement learning policy fully onboar d with robust obstacle av oidance and source seeking. methods, and the sensor and software selection needs to be carefully designed. The memory constraints means the system cannot store large maps used in traditional planning, the battery constraints means that we need to consider energy consumption of the system [1], and the limited compute power means that lar ge neural networks cannot run. Source seeking applications needs motion planning capable of obstacle avoidance that can be deployed quickly , with- out apriori knowledge of the obstacle placement, without the need to configure or re-train for a specific condition or environment. Instead, the algorithms we deploy need to generalize to a wide range of unknown en vironments for ef fec- tiv e deployment. The currently av ailable finite state machines on nano quadcopters [2] are designed for certain conditions and en vironments, and may not generalize well. T raditional navigation solutions like SLAM cannot run, as they require more memory and compute than our nano quadcopter can offer . Instead, we need a mapless navigation solution that uses little sensory input, memory and compute, while also generalizing to dif ferent en vironments. T o address these challenges, we present a fully autonomous source-seeking nano quadcopter (Figure 1), by equipping nano U A Vs with sparse light-weight sensors, and using reinforce- ment learning (RL) to solve the problem. W e contribute POMDP formulation including source observation features, and sensor modelling. Our method operates under memory , compute, and energy constraints with zero-shot transfer from (a) Air Learning training en v . (b) 0 obstacles. (c) 3 obstacles. (d) 7 obstacles. Fig. 2. Air Learning training en vironment (2a), and three distinct trajectories in flight tests (2b-2d). Blue dot is the start and green dot is the destination. simulation to reality , and generalizes to new environments without prior training. W e fit an ultra-tiny neural network with two hidden layers, which runs at 100 Hz on a commercially av ailable off-the-shelf ARM Cortex-M4 microcontroller unit (MCU). Our source-seeking nano quadcopter, sho wn in Fig- ure 1, seeks a light source as a proxy for an y point source, such as a radiation source. W e use a light source as it allows for better understanding of behavior in real flight tests. Our nano quadcopter locates the light source in challenging conditions, with varying obstacle counts and positions, ev en beyond the en vironments presented in simulation (Figure 2a). The robot first explores, when it is far away from the source and it detects no gradient in light but just noise. It then seeks reactiv ely for the light source when it detects gradients (Figure 2). W e compare our work with baselines in three areas: 1) nano quadcopter system design, 2) source seeking performance and 3) obstacle av oidance robustness. From a systems perspecti ve, the state of the art solution for learning-based navigation onboard a nano quadcopter [3] consumes almost three times more additional po wer . From a source seeking perspective, the state of the art RL light seeking approach [4] reaches an 80% success rate in ’ simple’ simulated en vironments, and 30% in ’complex’ simulated en vironments, which we outperform by reaching a 94% success rate in real flight tests in cluttered and randomized test en vironments (Figure 2b-2d). Finally , we compare against a finite state machine (FSM) geared to wards exploration, which we outperform by more robust obstacle av oidance and ef ficient source seeking. Hereby , we show that our simulator-trained policy provides a high-performance and robust solution in a challenging task in on-robot experiments, ev en in environments beyond those presented in simulation. I I . R E L AT E D W O R K Deep reinforcement learning has proven to be a promising set of algorithms for robotics applications. The fast-moving deep reinforcement learning field is enabling more robust and accurate b ut also more ef fortless application [5]. Lower -level control has been demonstrated to be suitable to replace a rate controller [6]–[8] and was recently used to perform model- based reinforcement learning (MBRL) with a CrazyFlie [9]. High-lev el control using deep reinforcement learning for obstacle avoidance has been sho wn with different sets of sensory input [10], [11], but not yet on a nano quadcopter . Although light seeking has been demonstrated before using Q-learning [4], it used multiple light sensors and reached a success rate of 80% in simple en vironments and 30% in com- plex environments. Thanks to our observation space design and larger network, we present a deep reinfor cement learning- based model for r obust and ef ficient end-to-end navigation of a sour ce seeking nano quadcopter , including obstacle avoidance, that beats the curr ent state of the art . T raditional source seeking algorithms can be divided into four categories [12]: 1) gradient-based algorithms, 2) bio- inspired algorithms, 3) multi-robot algorithms, and 4) prob- abilistic and map-based algorithms. Even though gradient- based algorithms are easy to implement, their success in source seeking has been limited due to their unstable beha vior with noisy sensors. Pre vious algorithms hav e yielded promising results, but rarely considered obstacles [13]. Obstacles are important as they make the problem harder , not just from an av oidance perspectiv e, but also considering phenomena like shadows. W e contribute a deep RL appr oach, capable of r obust sour ce seeking and obstacle avoidance on a nano dr one. In a multi-agent setup, particle swarming [14], [15] has shown to be successful in simulation. Ho wev er , PSO swarms require a positioning system, and lack laser-based obstacle av oidance. Finally , probabilistic and map-based algorithms are more flexible but require high computational cost and accurate sensory information. In contrast to traditional methods, deep reinforcement learning can learn to deal with noisy inputs [16] and effecti vely learn (optimal) behavior for a combination of tasks (i.e., generalize). Hence, source seeking on a nano quadcopter is a suitable task for deep reinforcement learning, as it can combine obstacle avoidance with source seeking and deal with extraordinary noise levels in all sensors. W e lever ag e these advantages of deep reinfor cement learning to pr oduce a r ob ust and efficient algorithm for mapless navigation for sour ce seeking. I I I . M E T H O D W e present our application-specific system design (Sec- tion III-A), using lightweight and cheap commodity hardware. Next, we describe our simulation design (Section III-B), used to train deep-RL policies by randomizing the training en viron- ment and deploying a source model. Finally , in Section III-C, we show the POMDP formulation. A. System Design W e configure a BitCraze CrazyFlie nano quadcopter for source seeking, taking into account its physical and com- putational limitations, as visible in T able I. While adding a camera may be useful for navigation, its added weight and cost make effecti ve deployment more difficult. Instead, we Developer Bitcraze Parrot Delta V ehicle CrazyFlie 2.1 Bebop 2 T akeoff weight 27 g 500 g 18 . 5 x Max payload 15 g 70 g 4 . 6 x Battery (LiPo) 250 mAh 2700 mAh 10 . 8 x Flight time 7 min 2 5 min 3 . 6 x Size (WxHxD) 9.2 cm x 9.2 cm 32.8 cm x 38.2 cm 12 . 7 x T ABLE I C R AZ Y F L IE V S . B E BO P 2 . T H E D E L T A B E T WE E N T H E M I S S I GN I FI C AN T . use only cheap, lightweight and robust commodity hardware. W e configure our nano quadcopter with laser rangers for obstacle a voidance, an optic flo w sensor for state estimation, and a custom light sensor to seek a light source (Figure 3). The nano quadcopter carries four laser rangers with a range of approximately 5 m , facing in the negati ve and positiv e direction of the x and y axis of the robot’ body frame. W e attach an ultra-tiny PCB to the laser ranger board, fitting an upward-facing TSL2591 light sensor . B. Simulation Envir onment Source modelling is key to the success of our nano quad- copter . W e model source intensity as a function of the distance from the source. W e generate this function by capturing data in the testing environment with the light source present. W e capture the light intensity in a two-dimensional grid with our light sensor . Once captured, we use the data to fit a function with two requirements: 1) lim dist → 0 < ∞ and 2) lim dist →∞ = 0 . A Gaussian function meets both require- ments and is shown in Figure 5. The function has the form: f ( x ) = a · e − ( x − b ) 2 2 c 2 with a = 399 . 0 , b = − 2 . 6 , c = 5 . 1 . The R-squared error , measuring the goodness-of-fit, is 0.007, implying a high-quality fit. Additionally , we inject Gaussian noise with a standard deviation of 4. The noise observed in recordings had a standard deviation of 2; howe ver , in flight with unstable attitude, we e xpect more noise, so we inject more noise than recorded. In flight tests (Section V -D), we present the rob ustness of this function when shado ws and reflections are present. C. POMDP Setup T o learn to seek a point source, we choose reinforcement learning with partial state observations, which we model as a Partially Observable Markov Decision Process (POMDP). The agents is modeled as a POMDP by the tuple ( O, A, D , R, γ ) with continuous observations and discrete actions. W e train and deploy a DQN [17] algorithm, using a feedforward net- work with two hidden layers of 20 nodes each and activ ations. The observ ations, o = ( l 1 , l 2 , l 3 , l 4 , s 1 , s 2 ) ∈ O , consist of four laser ranger values in front/right/back/left directions , l 1 - l 4 ,, and two custom ‘source terms’, s 1 and s 2 . The source terms are inspired by [18], and provide an estimate for source gradient and strength. W e first compute a normalized version of the light sensor readings c , as sensor readings are dependent on sensor settings (e.g., integration time, gain). W e then add a low-pass filter and compute c f (Equation 1). W e then compute s 1 (Equation 2), which is effecti vely a normalized Fig. 3. Our BitCraze CrazyFlie with multiranger deck, custom TSL2591 light sensor board and an optic flow deck. and low-pass version of the gradient of c (i.e., it is the light gradient over time). Finally , we compute s 2 (Equation 3), a transformation of c f . c f ← 0 . 9 · c f +0 . 1 · c (1) s 1 = c − c f c f (2) s 2 = 2 · c f − 1 (3) Figure 10 shows traces of all variables onboard a source- seeking nano quadcopter . T erm s 1 is effecti vely a normalized and low-pass version of the gradient of c (i.e., it is the light gradient over time). The lo w-pass filter has a high cutoff frequency , but is useful in filtering outliers. Normalization is crucial when f ar aw ay from the source, when the gradient is small and finding the source is hard. T erm s 2 is a transfor- mation of c f . The signal provides the agent with a proxy of distance to the source, which it can use to alter behavior . W e have trained policies with non-filtered gradient inputs, leading to poor results (30% succes rate). While the direct gradient only contains information about the last time-step, c f is the weighed sum of the entire history of measurements. It is a computationally cheap way of using history information, which is necessary as the fluctuations between two time-steps ( 0 . 01 s ) are noise-dominated. T o teach the nano quadcopter to seek the source, the re ward is computed at each step (instantaneous re ward): r = 1000 · α − 100 · β − 20 · ∆ D s − 1 (4) Here, α is a binary variable whose v alue is ‘1’ if the agent reaches within 1 . 0 m from the goal else its value is ‘0’. β is a binary variable which is set to ‘1’ if the nano quadcopter collides with an y obstacle or runs out of the 300 steps. 1 Otherwise, β is ‘0’, penalizing the agent for hitting an obstacle or not finding the source in time. ∆ D s is the change in distance, compared to the previous step. A negati v e ∆ D s means the agent got closer to the source, rewarding the agent to move to the source. The agent’ s discrete actions space, a = v x , ˙ ψ 3 ∈ A , consists of three pairs of tar get states, composed of target yaw rate and the target forward velocity ( v x ). The target states are then realized by the low-le vel PID controllers. The three 1 W e set the maximum allowed steps in an episode as 300. This is to make sure the agent finds the source within some finite amount of steps and penalize a large number of steps. actions are: mov e forward , rotating left or right . The forward-moving speed is 0 . 5 m / s , and the yaw rate is 54 ◦ /s in either direction. Finally , the dynamics D of the en vironment are a simple drone model developed by AirSim [19] and γ was set to be 0.99. I V . I M P L E M E N TA T I O N D E TA I L S W e discuss the implementation details of our simulation en vironment (Section IV -A), and inference of the deep-RL policy onboard the nano quadcopter (Section IV -B) A. Simulation W e simulate an arena to train an agent to seek a point source. The agent (i.e., drone) is initialized in the middle of the room, and the point source is spawned at a random location. By randomizing the source position and obstacle positions, we arrive at a policy that generalizes to dif ferent en vironments with different obstacle configurations. W e use the Air Learning platform [11], which couples with Microsoft AirSim [19] to provide a deep reinforcement learning back end. It generates a variety of en vironments with randomly varying obstacle density , materials, and textures. B. Infer ence The CrazyFlie [20] is heavily constrained, carrying an STM32F405 MCU. Though our MCU is constrained in mem- ory and compute, it is widely deployed. In fact, more than 30 billion general-purpose MCUs are shipped e very year . 2 Their ubiquity makes them cheap, easy to use and e xpendable, and so suitable for cheap and disposable search and rescue robots. Our implementation consists of a custom lightweight C library , capable of performing the necessary inference oper- ations. The advantage of this approach is its small memory footprint and ov erhead, compared to a general inference frame- work like T ensorFlow Lite for Microcontrollers [21]. The Crazyflie has 1 MB of flash storage. The stock software stack occupies 192 kB of the av ailable storage, while the custom source seeking stack takes up an additional 6 kB. So the total flash storage used is 198 kB, which leaves an ample amount of free storage space (o v er 75%). Howe ver , the memory constraints are much more severe. RAM a v ailability during e xecution is sho wn in Figure 4. Of the 196 kB of RAM av ailable on the Cortex-M4 microcontroller , only 131 kB is a vailable for static allocation at compile time. The rest is reserved for dynamic variables (i.e., heap). During normal operation, the Bitcraze software stack uses 98 kB of RAM, leaving only 33 kB av ailable for our purposes. The entire source seeking stack takes up 20.5 kB, leaving 12.5 kB of free static memory . Our policy runs at 100 Hz in flight. V . R E S U LT S W e ev aluate simulation and flight results of our models. W e ev aluate training results (Section V -A), introduce our baselines (Section V -B) and e v aluate the models in simulation (Section V -C) and flight tests (Section V -D). Finally , we analyze robot beha vior (Section V -E) and endurance and po wer consumption (Section V -F). 2 From IC Insights, Research Bulletin. 0 25 50 75 100 125 150 175 RAM Size [kB] Dynamic Variables Free Space Source Seeking Stack Nominal Flight Stack Fig. 4. RAM usage on the Bitcraze CrazyFlie, using a custom float inference stack. T otal free space: 12.5 kB 0 1 2 3 4 Distance [m] 0 200 Light Intensity [lux] Fitted Recorded Noise Fig. 5. Light intensity describing the function as used in training with 3 σ (standard deviations) of the noise. A. T raining in Simulation T o ev aluate the learning process, we present quality metrics (success rate and number of steps) during training. As shown in Figure 6, we train our policy up to con vergence at around 3,600 episodes (or 100,000 steps). A consistent upward trend in success rate is visible, while number of steps shows a consistent decrease after an initial spike. The initial spike is caused by the agent becoming more successful, hence reaching more distant targets, instead of only finding close targets. After continued training success rate quickly drops, i.e., it ov er -trains after around 3600 episodes. W e continued training to over 8,000 episodes and nev er saw an impro vement in performance. B. Baseline Comparison W e compare our approach with three baselines: 1) nano quadcopter system design, 2) source seeking performance and 3) obstacle av oidance robustness. From a systems perspecti ve, the state of the art solution for learning-based navigation onboard a nano quadcopter [3] adds almost three times more po wer consumption (Section V -F), showing end to end application-specific system design can benefit mission metrics. 0 1000 2000 3000 4000 EpisodeN 0.5 1.0 Success Rate (a) Training success rates. 1000 2000 3000 4000 EpisodeN 20 30 40 Number of Steps (b) Steps to locate source. Fig. 6. Quality metrics during training. Model description Success # of Steps Distance [m] SPL Our deep RL algorithm 96% 30.51 4.21 0.37 FSM baseline 84% 87.73 10.40 0.16 Random actions 30% 42.13 3.55 0.13 T ABLE II M O DE L S I N S I M U LATI O N . FSM Baseline Random Actions Deep-RL Method 0 100 200 Number of Steps Fig. 7. Number of steps in simulation over 100 runs of each algorithm. FSM Baseline Random Actions Deep-RL Method 0 10 20 30 40 Path Length [m] Fig. 8. Path length (i.e. trav eled distance) in simulation ov er 100 runs. Thanks to our low-dimensional sensory input, we perform inference at 100 Hz on the stock microcontroller processor . From a source seeking perspecti ve, the state of the art RL light seeking approach [4] reaches an 80% success rate in ’ simple’ simulated en vironments, and 30% in ’complex’ simulated environments, which we beat by reaching a 94% success rate in real flight tests (Section V -D) in cluttered and randomized test environments. Our design of the observ ation space (i.e., the network inputs) has been critical in our success. Finally , we compare against a finite state machine (FSM) geared towards exploration [22], which we outperform by more robust obstacle av oidance and more efficient source seeking, as shown in T able II. As demonstrated in [22], this approach is effecti ve in exploration and often used in au- tonomous cleaning robots. This baseline serv es to understand the dif ficulty of obstacle a voidance using limited sensory input, and to sho w our polic y efficiently uses light information. W e test it in the same simulation and real test en vironments, to put our approach into perspecti ve. As a final baseline, we ha ve also tested random actions, to show the effecti veness of the finite state machine (FSM). W e cannot test the approach from [4], as, to the best of our kno wledge, no public code is av ailable. C. Infer ence in Simulation T raining data provide limited information as the model is continuously changing. So, we ev aluate our policy after training (as shown in T able II). W e compare it in terms of success rate, the av erage number of steps, and average trav eled distance. The number of steps and traveled distance are captured only when the agent succeeds. Additionally , we add the ‘SPL ’ metric: Success weighted by (normalized in v erse) Path Length [23]. W e compute the SPL metric as: S P L = 1 N X S i l i − 1 max ( p i , l i − 1) (5) Here N is the number of runs considered, l i the shortest direct path to the source, p i the actual flown path and S i a binary variable, 1 for success and 0 for failure. W e subtract l i by 1, as the simulation is terminated when the drone is within NO OBS LOW OBS HIGH OBS 0.0 0.5 1.0 Success Rate Deep-RL FSM Baseline Fig. 9. Success rate ov er 104 flight experiments, comparing our deep rein- forcement learning approach with the FSM baseline. Our solution consistently performs better, especially in high-density obstacle en vironments. 1 meter of the source. W e do not take into account obstacles in the path, making the SPL displayed a conserv ati ve estimate. W e e valuate our finite state machine (FSM) and fully random actions in simulation. T able II and Figures 7, 8 sho w the results of testing each method for 100 runs. Our deep reinforcement learning model outperforms the FSM baseline in ev ery metric. It finds the source in 65% fewer steps, with a 14% higher success rate, with 60 % shorter paths and a 131% higher SPL. Random actions yield shorter successful paths, as shorter paths hav e a higher chance of surviv al with random actions. In fact, the average path length over all (successful and f ailed) attempts for the random approach is 5 . 7 m , while 4 . 19 m for our approach. D. Flight T ests W e use a room that is approximately 5 m × 5 m in size (see Figure 2). W e use a 50 W light source attached to the roof, radiating a 120 ◦ beam onto the ground, as the light source. W e count a distance under 0 . 7 m as a successful run, while the drone is flying at 1 m / s and performs inference at 100 Hz . Figure 2 sho w four distinct trajectories during testing. W e conduct 114 flight tests in a variety of different scenar- ios, in v olving highly cluttered environments. Across a set of representativ e flight tests, we get an average success rate of 94%. This number is measured o ver a set of 32 e xperiments, 16 with no obstacles, and 16 with 3 obstacles in the room. This is representativ e to simulation as it alternates between no obstacles and sparse obstacles. All agents were initialized at different positions, at the same 4 . 6 m from the source on one axis. On the other axis, we varied drone position between 0 a nd 4 . 6 m from the source, resulting in an initial total source distance between 4 . 6 m and 6 . 5 m . Obstacle configuration, density , and source position were randomized. W e classify three distinct obstacle densities: ‘NO OBS’, ‘LOW OBS’, and ‘HIGH OBS’, featuring zero, three and sev en obstacles respectively . T o better understand the behavior of our algorithm, we decompose the results into two categories: 1) success rate and 2) mission time. Over a total of 104 flight tests, we compared success rate of our model against the FSM baseline model. As can be seen in Figure 9, our model beats the baseline in all three obstacle density groups. The baseline reaches a 75% success rate in a set of representativ e flight tests (‘NO OBS’ and ‘LO W OBS’), compared to a 84% success rate in simulation. These results demonstrate that obstacle avoidance using solely a multiranger is challenging, as drift and limited vis- ibility are the most prominent causes for crashing. In most crashes, the drone would either not see the obstacle or keep rotating close to an obstacle and ev entually crash into the obstacle due to drift. The baseline serves to put our algorithm into perspectiv e, i.e., it shows the rob ustness of our obstacle av oidance and source seeking strategy . A deteriorated success rate in the ‘HIGH OBS’ scenario is expected, as it has nev er seen such a scenario in simulation. Despite some loss in success rate when adding more obstacles, our appr oac h shows greater r esilience to task complexity when compar ed to the baselines. It generalizes better than other baselines, even beyond the simulated envir onments, showing tinyRL ’ s potential. Our objective is not only to perform successful obstacle av oidance, but also to find the source in as little time as possible. Nano drones are characterized by their limited battery life. Therefore, ef ficient flight is an important metric when ev aluating the viability of an approach for real applications. Figure 11 shows the distribution of the mission time of successful runs, demonstrating an impressiv e adv antage for our algorithm. Across the obstacle densities, from low to high, our policy was 70%, 55%, and 66% f aster , respecti vely . The baseline is again used to put our model into perspecti ve. As demonstrated in [22], the FSM is ef fectiv e in exploring an area without any source information. Because of its random character , the baseline shows a more ev en distribution of mission times. The deep reinforcement learning approach has a small number of outliers with high mission time, often caused by the agent getting stuck in a certain trajectory in the dark. As sho wn in Figure 10, the light gradient is limited far away from the source. The presence of noise makes it extremely hard for the agent to retriev e source information, at a great distance. W e often observed a more direct path in the last 2 . 5 m , compared to the initial exploration. Our appr oach performs r obust obstacle avoidance and efficient sour ce seeking using only a tiny neur al network. E. Behavior Analysis T o better understand the behavior of the nano quadcopter , we record source measurements and network inputs during flight. It can be seen that when far away from the source, extremely little information is present. In the first 20 seconds, almost no gradient is visible, forcing the agent to explore. The raw light readings are extremely noisy and unstable due to sensor noise, attitude changes and shado ws. Once the agent ’ sees’ the source, it keeps traveling up the gradient and doesn’t go back to the dark zone. Finally , the features work as imagined, s 1 is a normalized light gradient with a low-pass filter and s 2 is a transformation of c f . F . Endurance and P ower comparison W e consider endurance as a performance metric for our solution. By performing source seeking on the CrazyFlie, we add weight and CPU cycles. W e determine endurance in hover and compare a stock hov ering CrazyFlie with our source seeking solution. W e swap the multiranger deck with light sensor for the battery holder , lowering the weight from 0 20 40 Time [sec] 0.00 0.25 0.50 0.75 1.00 Signal [-] c c f (a) Normalized light measurements c and its low-pass version c f . 0 20 40 Time [sec] −1 0 1 2 Signal [-] s 1 s 2 (b) Policy inputs s 1 and s 2 , as described in Equations 2 and 3. Fig. 10. Source measurements on the nano quadcopter while seeking the source. The first 20 seconds the sensor provides little information. NO OBS LOW OBS HIGH OBS 0 100 200 Time [sec] Deep-RL FSM Baseline Fig. 11. Mission time in success over 104 flight experiments, comparing our deep RL approach with the FSM baseline. 33 . 4 g to 31 . 7 g ( − 1 . 7 g ). The endurance observed with the stock CrazyFlie is 7:06.3, while our solution hovers for 6:30.8, reducing endurance by 35 . 5 s . W ith a battery capacity of 0.925 Wh , the average power consumption increased from 7 . 81 W to 8 . 52 W (+ 0 . 71 W ). It is e xpected that the vast majority of the extra power consumption comes from the extra weight, as the maximum consumption of the Cortex-M4 is 0 . 14 W . T o put these numbers into perspectiv e, we compare them to a CrazyFlie with a camera and additional compute [3]. As shown in [3], endurance is reduced by 100 s when adding the PULP-Shield, almost 3X more than in our experiments— the state of the art methods for vision-based navigation on nano dr ones have lar ge impact on endurance, and hence differ ent sensors ar e worth in vestigating. T inyRL applications will likely make mor e use of sensors outside of the camera. V I . D I S C U S S I O N A N D C O N C L U S I O N W e show that deep reinforcement learning can be used to enable autonomous source seeking applications on nano drones, using only general-purpose, cheap, commodity MCUs. W e trained a deep reinforcement learning policy that is robust to the noise present in the real world and generalizes out- side of the simulation en vironment. W e believ e our tinyRL methodology is useful in other real-world applications too, as robots learn to adapt to noise and other implicit information. As our policy was trained on a general point source model, we believ e it will provide a high-performance solution for other sources, such as radiation. By simply swapping the sensor , the nano quadcopter may readily be deployed to seek other sources. V ersatile software and hardware will be important when deploying these robots in the real world, while exploring unknown en vironments and seeking an unkno wn source. R E F E R E N C E S [1] B. Boroujerdian, H. Genc, S. Krishnan, W . Cui, A. Faust, and V . J. Reddi, “Mavbench: Micro aerial vehicle benchmarking, ” in Pr oceedings of the 51st Annual IEEE/A CM International Symposium on Micr oar chitectur e , ser . MICRO-51. IEEE Press, 2018, p. 894–907. [Online]. A v ailable: https://doi.org/10.1109/MICR O.2018.00077 [2] K. N. McGuire, C. De W agter, K. T uyls, H. J. Kappen, and G. C. H. E. de Croon, “Minimal navigation solution for a swarm of tiny flying robots to explore an unknown environment, ” Science Robotics , vol. 4, no. 35, 2019. [Online]. A vailable: https: //robotics.sciencemag.org/content/4/35/eaa w9710 [3] D. P alossi, A. Loquercio, F . Conti, E. Flamand, D. Scaramuzza, and L. Benini, “ A 64-mw dnn-based visual navig ation engine for autonomous nano-drones, ” IEEE Internet of Things Journal , vol. 6, no. 5, pp. 8357– 8371, Oct 2019. [4] S. Dini and M. A. Serrano, “Combining q-learning with artificial neural networks in an adaptive light seeking robot, ” 2012. [5] A. Faust, A. Francis, and D. Mehta, “Evolving rewards to automate reinforcement learning, ” CoRR , vol. abs/1905.07628, 2019. [Online]. A vailable: http://arxiv .org/abs/1905.07628 [6] J. Hwangbo, I. Sa, R. Siegwart, and M. Hutter , “Control of a quadrotor with reinforcement learning, ” CoRR , vol. abs/1707.05110, 2017. [Online]. A vailable: http://arxiv .org/abs/1707.05110 [7] W . Koch, R. Mancuso, R. W est, and A. Bestavros, “Reinforcement learning for uav attitude control, ” ACM T rans. Cyber-Phys. Syst. , vol. 3, no. 2, pp. 22:1–22:21, Feb. 2019. [Online]. A vailable: http://doi.acm.org/10.1145/3301273 [8] A. Molchanov , T . Chen, W . H ¨ onig, J. A. Preiss, N. A yanian, and G. S. Sukhatme, “Sim-to-(multi)-real: Transfer of low-le vel robust control policies to multiple quadrotors, ” CoRR , vol. abs/1903.04628, 2019. [Online]. A v ailable: http://arxiv .org/abs/1903.04628 [9] N. O. Lambert, D. S. Drew , J. Y aconelli, R. Calandra, S. Levine, and K. S. J. Pister, “Low level control of a quadrotor with deep model-based reinforcement learning, ” CoRR , vol. abs/1901.03737, 2019. [Online]. A vailable: http://arxiv .org/abs/1901.03737 [10] K. Kang, S. Belkhale, G. Kahn, P . Abbeel, and S. Levine, “Generalization through simulation: Integrating simulated and real data into deep reinforcement learning for vision-based autonomous flight, ” CoRR , vol. abs/1902.03701, 2019. [Online]. A v ailable: http: //arxiv .org/abs/1902.03701 [11] S. Krishnan, B. Boroujerdian, W . Fu, A. Faust, and V . J. Reddi, “ Air learning: An AI research platform for algorithm-hardware benchmarking of autonomous aerial robots, ” CoRR , vol. abs/1906.00421, 2019. [Online]. A v ailable: http://arxiv .org/abs/1906.00421 [12] X. xing Chen and J. Huang, “Odor source localization algorithms on mobile robots: A re view and future outlook, ” Robotics and Autonomous Systems , v ol. 112, pp. 123 – 136, 2019. [Online]. A vailable: http://www .sciencedirect.com/science/article/pii/S0921889018303014 [13] J. R. Bourne, E. R. Pardyjak, and K. K. Leang, “Coordinated Bayesian- Based Bioinspired Plume Source T erm Estimation and Source Seeking for Mobile Robots, ” IEEE T ransactions on Robotics , vol. 35, no. 4, pp. 967–986, 2019. [14] R. Zou, V . Kaliv arapu, E. W iner, J. Oliver, and S. Bhattacharya, “Particle swarm optimization-based source seeking, ” IEEE T ransactions on A utomation Science and Engineering , vol. 12, no. 3, pp. 865–875, July 2015. [15] L. Parker , J. Butterworth, and S. Luo, “Fly safe: Aerial swarm robotics using force field particle swarm optimisation, ” CoRR , vol. abs/1907.07647, 2019. [Online]. A vailable: http://arxiv .org/abs/1907. 07647 [16] A. Faust, O. Ramirez, M. Fiser, K. Oslund, A. Francis, J. Davidson, and L. T apia, “PRM-RL: long-range robotic na vigation tasks by combining reinforcement learning and sampling-based planning, ” CoRR , vol. abs/1710.03937, 2017. [Online]. A vailable: http://arxiv .org/abs/1710. 03937 [17] C. J. C. H. W atkins and P . Dayan, “Q-learning, ” Machine Learning , vol. 8, no. 3, pp. 279–292, May 1992. [Online]. A vailable: https://doi.org/10.1007/BF00992698 [18] G. de Croon, L. O’Connor , C. Nicol, and D. Izzo, “Evolutionary robotics approach to odor source localization, ” Neurocomputing , v ol. 121, pp. 481 – 497, 2013, advances in Artificial Neural Networks and Machine Learning. [Online]. A vailable: http://www .sciencedirect.com/ science/article/pii/S0925231213005869 [19] S. Shah, D. Dey , C. Lovett, and A. Kapoor, “ Airsim: High-fidelity visual and ph ysical simulation for autonomous vehicles, ” CoRR , v ol. abs/1705.05065, 2017. [Online]. A vailable: http://arxiv .org/abs/1705. 05065 [20] W . Giernacki, M. Skwierczy ´ nski, W . W itwicki, P . Wro ´ nski, and P . K ozierski, “Crazyflie 2.0 quadrotor as a platform for research and education in robotics and control engineering, ” in 2017 22nd Interna- tional Conference on Methods and Models in Automation and Robotics (MMAR) , Aug 2017, pp. 37–42. [21] R. David, J. Duke, A. Jain, V . J. Reddi, N. Jeffries, J. Li, N. Kreeger , I. Nappier, M. Natraj, S. Rege v et al. , “T ensorflow lite micro: Embedded machine learning on tinyml systems, ” arXiv preprint , 2020. [22] J. Palacin, T . Palleja, I. V alganon, R. Pernia, and J. Roca, “Measuring coverage performances of a floor cleaning mobile robot using a vision system, ” in Pr oceedings of the 2005 IEEE International Conference on Robotics and Automation , April 2005, pp. 4236–4241. [23] P . Anderson, A. X. Chang, D. S. Chaplot, A. Dosovitskiy , S. Gupta, V . Koltun, J. Kosecka, J. Malik, R. Mottaghi, M. Savv a, and A. R. Zamir , “On ev aluation of embodied navigation agents, ” CoRR , vol. abs/1807.06757, 2018. [Online]. A vailable: http://arxiv .org/abs/1807. 06757
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment