Extracting dispersion curves from ambient noise correlations using deep learning
We present a machine-learning approach to classifying the phases of surface wave dispersion curves. Standard FTAN analysis of surfaces observed on an array of receivers is converted to an image, of which, each pixel is classified as fundamental mode,…
Authors: Xiaotian Zhang, Zhe Jia, Zachary E. Ross
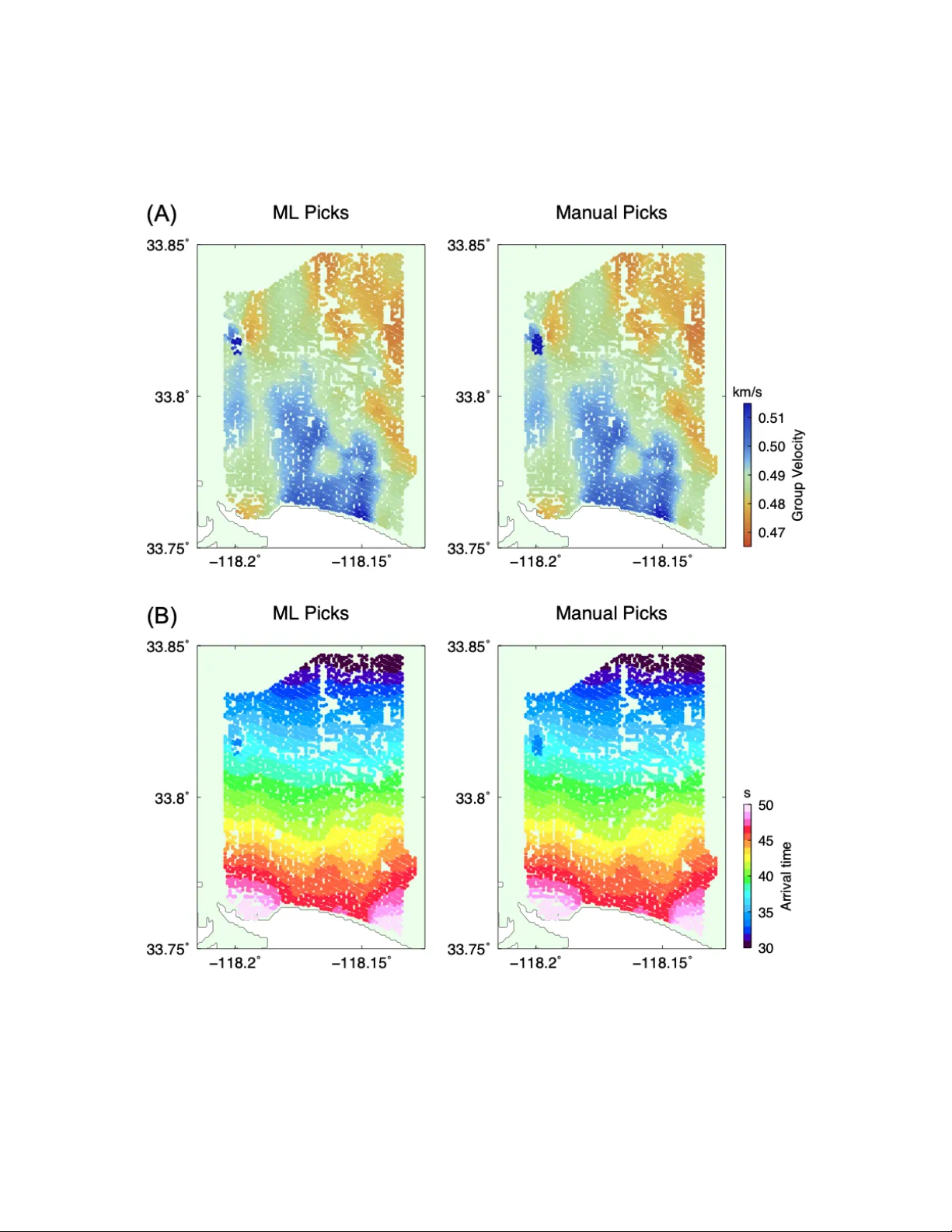
IEEE TRANSA CTIONS ON GEOSCIENCE AND REMO TE SENSING 1 Extracting dispersion curv es from ambient noise correlations using deep learning Xiaotian Zhang, Zhe Jia, Zachary E. Ross, and Robert W . Clayton California Institute of T echnology Abstract —W e present a machine-learning approach to classify- ing the phases of surface wave dispersion curves. Standard FT AN analysis of surfaces observed on an array of r eceivers is con verted to an image, of which, each pixel is classified as fundamental mode, first overtone, or noise. W e use a con volutional neural network (U-net) ar chitecture with a supervised learning objec- tive and incorporate transfer learning . The training is initially performed with synthetic data to learn coarse structure, followed by fine-tuning of the netw ork using appr oximately 10% of the real data based on human classification. The results show that the machine classification is nearly identical to the human picked phases. Expanding the method to process multiple images at once did not impro ve the perf ormance. The developed technique will faciliate automated processing of large dispersion curve datasets. Index T erms —Dispersion curves, surface waves, deep learning, con volutional networks. I . I N T RO D U C T I O N The inv ersion of surface waves has become a standard method for determining the near-surface shear velocity . One reason for this is that surface w aves can be relativ ely easily extracted from ambient noise correlations, and hence are not dependent on a suitable distribution of earthquakes. Another reason is that surface wa ves only require cov erage over a 2D plane and not a 3D volume, which is what would be required for body wav es (S-w av es). This becomes important when dealing with dense seismic arrays that typically ha ve a short deployment time. The method usually consists of three steps, with the first being the determination of dispersion curv es, which are mea- surements of the velocity as a function of frequency . Once this is done, a tomographic method is used to conv ert these line measurements into maps of the phase or group v elocity as a function of frequency [1]. The final step is to then con vert velocity as a function of frequency at each (x,y)-point, to velocity as a function of depth, thus making a 3D model of the subsurface velocity . In this paper we will focus on applying machine learning to the first step in the process determining the dispersion curves. A commonly used procedure to e xtract the dispersion curves is the FT AN (Frequenc y-Time Analysis) method [2], [3], in which the correlated signal between two stations is filtered by a sequence of zero-phase narro wband filters to determine the travel time of the surface waves as a function of fre- quency . Knowing the separation distance of the stations allows these measurements to be con verted to phase velocity . If the en velope of the signal is used instead of the seismograms themselves then the group velocity is determined. At a giv en frequency , there may be a number of modes present that correspond to different eigenfunctions (dependen- cies with depth). The fundamental mode is the slowest mode with the ov er-tones increasing in velocity as the eigenfunctions penetrate deeper in depth. A key part of determining the dispersion curve is picking the trav el time or equiv alently the velocity since the distance is kno wn. This is similar to problem of picking P- and S-wa ves in determining earthquake locations, but here, the various surface-wav e modes need to be classified for the inv ersion process. W e typically pick the fundamental and 1st-ov ertone modes, and occasionally the 2nd-ov ertone if it can be seen. The more that are picked, the better the resolution of the resulting shear velocity model. Picking the dispersion curves is v ery labor intensiv e, par - ticularly when dealing with dense arrays. The moti vation for automating this procedure is not only the large volume of data that is now a vailable (an example of which is shown in Figure 1), but also the increased precision that is now required because of the density of stations. The process can be machine-assisted by defining target zones for the curv es, but the output needs to be checked and adjusted because of spurious noise within these zones. Dev eloping an automatic method to determine the dispersion curves is the subject of this paper . In recent years, deep learning has become state-of-the-art in numerous areas of artificial intelligence, which has quickly translated into major advances within seismology . Such appli- cations include detection and picking of seismic wav es [4], [5], signal denoising [6], and phase association [7]. These problems can all be cast as supervised learning objectiv es and benefit from the wealth of labeled datasets that exist in the seismological community . They bear structural similarities to that of dispersion curve picking, moti v ating the application of deep neural netw orks. In this study , we de velop a deep learning approach to the dispersion picking problem with the goal of classifying tentati ve picks as fundamental mode, 1st ov ertone, or noise. Our approach uses deep conv olutional networks to learn a lo w dimensional representation of the data which can be used for pix elwise segmentation of dispersion curves. W e show that our approach can reliably and efficiently classify picks, which will greatly facilitate automated processing of large seismic datasets. I I . D A TA : R E A L A N D S Y N T H E T I C In this study , we use data from a temporary dense seismic network of 5340 stations in Long Beach, California [8] that IEEE TRANSA CTIONS ON GEOSCIENCE AND REMO TE SENSING 2 Fig. 1: Location and Correlations. The left panel shows the location of the industry arrays (shaded polygons) and the SCSN broadband stations (black circles). The Long Beach array with 5300 stations (red dots) and the broadband station LGB (big red dot) that are used to create the correlations shown on the right. The correlations are done for approximately 500 hours, and are bandpassed 0.1-3.0 Hz. were originally used for an e xploration survey conducted by an oil company . The broadband station LGB is part of the permanent earthquak e monitoring array in the re gion (Southern California Seismic Network) and is cross-correlated with this array to form 5340 station pairs, from which we wish to determine the dispersion curves. The geometry of the array and a sample cross-correlation are sho wn in Figure 1. The FT AN method was applied to each correlation pair for a range of frequencies between 0.2 and 5 Hz to construct images of dispersion curves. The band pass filter is a Gaussian filter H ( ω ) = exp( − α ( ω − ω 0 ) 2 /ω 2 0 ) where we set filter parameter α = 25 for a compromise between the narrow-band assumption and filtering robustness, These were then hand- picked (labor -intensiv e) to create a set of labeled dispersion curves. W e set aside 4340 of the curve images to be used as a testing set, and the rest (1000) were used as a training set for the method. In a production environment, we would hand- label only the 1000 training images and allow the algorithm to determine all remaining 4340 correlation pairs (testing set) without interv ention. Here, we need to hand-label the testing set in order to assess our models final performance. T o limit the amount of labeled data necessary to train a model to pick dispersion curves, we designed an approach to generate realistic synthetic training data, with the ultimate goal of applying transfer learning to the trained model. T o generate synthetic dispersion curves, we started with a 1D layered velocity model (Fig. 2) that matched the av erage dispersion curve for the region of the survey . This function was then perturbed both in velocities and layer thicknesses by a random amount up to 10% of the original v elocity function, forming an ensemble of different velocity models. The random variations on the layer thicknesses and velocities for this ensemble were drawn from a uniform distribution that centered at the starting 1D v elocity model. For each instance, the dispersion curv es were determined by a numerical solution of the eigen-problem [9], [3]. The resulting curves were then altered by random variations of up to +/-2.5% in the frequencies and velocities and by adding random noise to the curves. In total, 100,000 synthetic curves were generated. The synthetic and real dispersion curves are first pre- processed into image representations to make them suitable for con volutional networks. Initially , each curve is a collection of points with (frequency , velocity , amplitude) values such as shown in Figure 3. Each point also has an associated label from one of the three classes: fundamental mode, 1st ov ertone, and noise. W e de-trend each curve in the frequency-velocity domain and transform the frequenc y axis to the logarithmic domain. Then, we create a 64-by-64 pixel greyscale image with pixel values between 0 and 255 representing the am- plitude (Figure 3). T o map individual points to the pixels, we treat each pixel as a discretized bin and fill its greyscale value as the amplitude of points that fall into the bin (post- IEEE TRANSA CTIONS ON GEOSCIENCE AND REMO TE SENSING 3 Fig. 2: V elocity Model. The P- and S-wav e models used to construct the synthetic training set is shown along with the variations in velocity and layer depths. detrending and log transform). The variable transforms are done to compact the information, thus reducing computational requirements. Similarly , the ground truth labels for each point of the dispersion curv es are mapped to indi vidual pixels by discretization and subsequent binning. I I I . M E T H O D S A. Overview Our approach to picking dispersion curves uses deep con vo- lutional networks in a supervised manner to perform pixelwise segmentation of the images. It consists of two main steps: (1) a U-Net architecture is trained first on the entirely synthetic dataset to learn coarse features, and (2) the best model is then fine-tuned to the limited amount of real data using a transfer learning approach. Belo w we describe each of these steps in detail. The use of con volutional networks is well-motiv ated by the structure of our data, as the dispersion curve images exhibit spatially coherent geometric structure [10]. Our problem is set up as one of fully-supervised image segmentation, since we ha ve pix elwise labels for all images. The model used in this study is the U-Net architecture [11], which is a deep con volutional network that has been successful for image segmentation tasks. In particular , the network applies a series of con volution and pooling layers to an input image to learn a sparse representation of it, and then applies a series of transpose conv olution layers to finally output an image with the same lateral dimensions as the input. The depth of the output image is equal to the number of classes, which in our case is 3: fundamental mode, 1st-overtone, and noise. Figure 4 provides a summary of the model used in this study . The network takes in a 64x64x1 image and outputs a stack of three images of equiv alent dimension, with a softmax activ ation function applied to the outputs. In our case, the output of the neural netw ork is a 64-by-64-by-3 array , with each pixel having 3 probabilities: [noise, fundamental mode curve, 1st o vertone curve] associated with it. An e xample of an input image and the corresponding labels are shown in Figure 5 (upper panels). T o ov ercome the discretization error due to the 64x64 pixelization of the images, we post-process the picks by finding the corresponding closest frequency-time energy peaks in the original FT AN maps. The lar gely eliminates the errors introduced by the image formation process. Theoretically this could also be done by using finer grained images such as 128x128 pixels, but this would increase the computational requirements by a factor of 4. B. Con volutional Neur al Network T raining Starting the training process using data from a simulation (a sim2real approach) av oids the need for extensiv e human labelling. W e set aside 10% of the synthetic images for model validation purposes and train the network on the remainder using the Adam optimizer [12] using mini-batches of size 32. After each epoch of training, we check the models perfor- mance on the 10,000 unseen images in the v alidation set. If performance does not improv e for 3 epochs in a row , we save the model after the best epoch. Next, we proceed to fine-tune the best model on the syn- thetic data to the real Long Beach data using a transfer learning approach. Of the 5340 images from the Long Beach data set, we take a random subset of 1000 images for use in transfer learning. Of these 1000 images, 100 are used for validation (checking when to stop training the model) and 900 are used for updating model weights, which results in a 90%-10% train- validation split. For these 1000 images, we followed the same training procedure as with the synthetic data. The remaining 4340 stations are reserved for e valuation of our models we pretend that we hav e no access to their correct labels until after the final model is sav ed, as the y are used only to determine whether our method is suitable for real usage. Example output predictions are shown in Figure 5 along with the raw feature input and labels. It is clear that the model performs well for this examined image, correctly reco vering nearly all fundamental and 1st overtone picks. Quantitati ve performance results on the validation set are provided in Figure 6, where precision and recall are computed for each of the three classes. The noise class has the highest precision and recall of the three classes (¿99%), which probably reflects the fact that the composition of the training dataset is heavily ske wed tow ard noise. The fundamental and 1st-order modes hav e around 99% and 98% median precision, respectiv ely , demonstrating that the model can accurately classify individual pixels. The median recalls for these classes are about 95% and 94%, respecti vely . The application of ML to this problem is able to substantially reduce the human-labor in analyzing surface wa ve data. C. Multi-station input The analysis described above was done for each station pair . W e also explored the possibility of including neighboring stations into the feature set to better facilitate separation IEEE TRANSA CTIONS ON GEOSCIENCE AND REMO TE SENSING 4 Fig. 3: Example of a hand-labeled dispersion curve for the path shown in Figure 1. The right panel sho ws the compacted image with logarithmic period axis and the linear trend removed. Fig. 4: A cartoon flowchart of ho w our data is processed throughout the paper . In the plots, the [X, Y , Size] axes represent [Period (s), Group V elocity (km/s), Amplitude], respectively . The center of the figure represents the con volutional neural network (CNN) structure that we emplo yed. The goal of the paper is to tak e in a noisy plot and pick out points inside it that belong to the fundamental (red) and first-order (blue) ov ertones, while discarding e verything else as noise. of genuine signal from noise. While the velocity structure may v ary between different pairs, here we assume that these changes are small enough that the general characteristics from one dispersion curve to another are o verall similar . The motiv ation is to use all of the av ailable information together to make a decision, rather than examining one station pair at a time. T o do this, we include the images for K nearest neighbor stations by concatenating them in the depth dimension to create a 3D input volume. Thus, the inputs are 64x64x K . W e repeat the entire training procedure starting from generating synthetic data, as well as the transfer learning part. An e xample of a model using K = 8 is shown in Figure 5, which can be compared with the results for the K = 1 model seen previously . Figure 6 shows the median performance while increasing K from 1 to 8. After accounting for the variability introduced by the stochastic nature of the training process (examining the 107 best training runs out of 215 total), we find that the performance does not improve significantly when adding in additional stations. W e hoped that noise seen in one station might not be seen in a neighboring station, so a neural network might be able to combine multi-channel IEEE TRANSA CTIONS ON GEOSCIENCE AND REMO TE SENSING 5 Fig. 5: Results for different algorithms. The top-left is the input data, which is conv erted to greyscale pixels. The top-right is a hand-picked classification of the dispersion curves. The bottom-left is the conv olutional network prediction of labels using only one station input. The bottom-right is the results using 8 stations input. information to determine that this idiosyncratic noise is indeed noise. Howe ver , this unfortunately is not the case. I V . D I S C U S S I O N The approach developed in this paper provides a means to train deep neural networks to perform dispersion curve picking using a hybrid simulation + real data scheme. The transfer learning step enables the neural network to learn coarse features from the simulation data that are also present in the real data, with the benefit that as much simulated data can be generated as needed. By then fine-tuning the model to the real data, the network learns finer scale features that are unique to these data, while only needing a relatively small amount of it. Here, we sho wed that just 1000 images are enough to adapt the initial model to the real data, although if more is av ailable, the performance may improve further . This type of sim2real approach will likely be rele vant to other problems in seismology where labeled data can be initially obtained from simulations. W e attempted many tweaks to the model hyperparameters as well as the randomization of workflow (same synthetic + model man y real models, man y synthetic models + many real models, varying learning rates, varying image dimensions, fixed vs. variable terminating epoch numbers, zero-padded empty channels vs. completely deleted empty channels, chang- ing the probability threshold for picks, etc.) but failed to see any meaningful increase in performance as we increased station count. Therefore, it appears that there is no need to use more than 1 station for the proposed method, which also requires the least amount of training data. W e also tried to frame the problem as one of sequential classification, treating the picks as a sequence rather than conv erting to an image and using bidirectional Gated Recurrent Units (similar to Ross et al. [4]). The sequences of floating-point tuples (period, group velocity , amplitude) directly extracted from the FT AN analysis were sorted by amplitude and presented to the neural network. This approach did not perform nearly as well as the con volutional network approach described abo ve. V . C O N C L U S I O N S W e ha ve dev eloped a machine learning method for ex- tracting dispersions curves from velocity-frequenc y images. The procedure was training with a combination of synthetic examples and labelled real data. T esting on real data shows the method works with a median per-class precision of at least 98% and a per-class recall rate of at least 94%. W e achie ved an IEEE TRANSA CTIONS ON GEOSCIENCE AND REMO TE SENSING 6 Fig. 6: Precision and Recall. Median precision and recall compared with the number of stations presented to the neural network simultaneously . N = 23 (top 10% of N = 239 models in validation error) of synthetically trained, then Long-Beach trained models. V ariations are due to changes in random seed for the model training, which changes the weight initializations and the order of training data sho wn. 80% reduction in human labor using this extraction technique on a dataset of 5340 curve sets, and we expect this efficienc y to improve further if applications on future datasets start with this pretrained model. The value of this method is its ability to be applied in bulk, and will be more apparent as more datasets are used. W ith this new method to classify points for dispersion curve fitting, it is now possible to ingest large volumes of recorded sensor data with minimal human input, and then systematically calculate tra vel times as shown in Figure 7. Pre viously , this data ingestion step for each dataset would take hours of human work consisting of point selection by heuristics and experience, b ut it can no w be taken care of with a pipeline designed to separate noise from dispersion curve. A C K N O W L E D G M E N T W e thank Signal Hill Petroleum for permission to use the Long Beach Array , and the Southern California Seismic Network for providing data from the broadband stations. W e also thank Y isong Y ue for helpful discussions. This study was partially supported by NSF/EAR 1520081. R E F E R E N C E S [1] N. M. Shapiro, M. Campillo, L. Stehly , and M. H. Ritzwoller, “High- resolution surface-wave tomography from ambient seismic noise, ” Sci- ence , vol. 307, no. 5715, pp. 1615–1618, 2005. [2] A. L. Levshin, V . Pisarenko, and G. Pogrebinsky , “On a frequenc y- time analysis of oscillations, ” in Annales de geophysique , vol. 28, no. 2. Centre National de la Recherche Scientifique, 1972, pp. 211–218. [3] R. B. Herrmann, “Computer programs in seismology: An ev olving tool for instruction and research, ” Seismological Researc h Letters , vol. 84, no. 6, pp. 1081–1088, 2013. [4] Z. E. Ross, M.-A. Meier , and E. Hauksson, “P wav e arri val picking and first-motion polarity determination with deep learning, ” Journal of Geophysical Resear ch: Solid Earth , vol. 123, no. 6, pp. 5120–5129, 2018. [5] W . Zhu and G. C. Beroza, “Phasenet: a deep-neural-network-based seis- mic arri val-time picking method, ” Geophysical Journal International , vol. 216, no. 1, pp. 261–273, 2019. [6] W . Zhu, S. M. Mousavi, and G. C. Beroza, “Seismic signal denoising and decomposition using deep neural networks, ” IEEE T ransactions on Geoscience and Remote Sensing , vol. 57, no. 11, pp. 9476–9488, 2019. [7] Z. E. Ross, Y . Y ue, M.-A. Meier , E. Hauksson, and T . H. Heaton, “Phaselink: A deep learning approach to seismic phase association, ” Journal of Geophysical Research: Solid Earth , vol. 124, no. 1, pp. 856– 869, 2019. [8] F .-C. Lin, D. Li, R. W . Clayton, and D. Hollis, “High-resolution 3d shallo w crustal structure in long beach, california: Application of ambient noise tomography on a dense seismic arraynoise tomography with a dense array , ” Geophysics , vol. 78, no. 4, pp. Q45–Q56, 2013. [9] K. Aki and P . G. Richards, “Quantitative seismology , sausalito, ” 2002. [10] Y . LeCun, Y . Bengio, and G. Hinton, “Deep learning, ” natur e , vol. 521, no. 7553, pp. 436–444, 2015. [11] O. Ronneberger , P . Fischer, and T . Brox, “U-net: Con volutional networks for biomedical image segmentation, ” in International Confer ence on Medical ima ge computing and computer-assisted intervention . Springer , 2015, pp. 234–241. [12] D. P . Kingma and J. Ba, “ Adam: A method for stochastic optimization, ” arXiv pr eprint arXiv:1412.6980 , 2014. IEEE TRANSA CTIONS ON GEOSCIENCE AND REMO TE SENSING 7 Fig. 7: Results for Long Beach Example. Shown are the group velocity maps (A) and the trav el time picks (B) for the Long Beach data for the machine-learning processing (ML), and manual processing. That the two types of processing produce nearly identical results indicates that the machine-learning approach is working. IEEE TRANSA CTIONS ON GEOSCIENCE AND REMO TE SENSING 8 Xiaotian (Jim) Zhang is a student of the Com- puting and Mathematical Sciences Department who works in the areas of machine learning applications and probability models. He has created models and performed research at Caltech as well as various industry firms. Zhe Jia is a graduate student in geophysics at the Seismological Laboratory , Caltech. He major interests lie in characterizing rupture processes of complex earthquakes and studying the shallow struc- ture with ambient noise tomography . Zachary E. Ross is an Assistant Professor of Geo- physics who uses machine learning and signal pro- cessing techniques to better understand earthquakes and fault zones. He is interested in seismicity , earth- quake source properties, and fault zone imaging. Robert W . Clayton is a Prof. of Geophysics who works in the areas of seismic wa ve propagation, earth structure and tectonics. He has applied imaging methods to the Los Angeles re gion and to subduction zones around the world.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment