Efficient crowdsourcing of crowd-generated microtasks
Allowing members of the crowd to propose novel microtasks for one another is an effective way to combine the efficiencies of traditional microtask work with the inventiveness and hypothesis generation potential of human workers. However, microtask pr…
Authors: Abigail Hotaling, James P. Bagrow
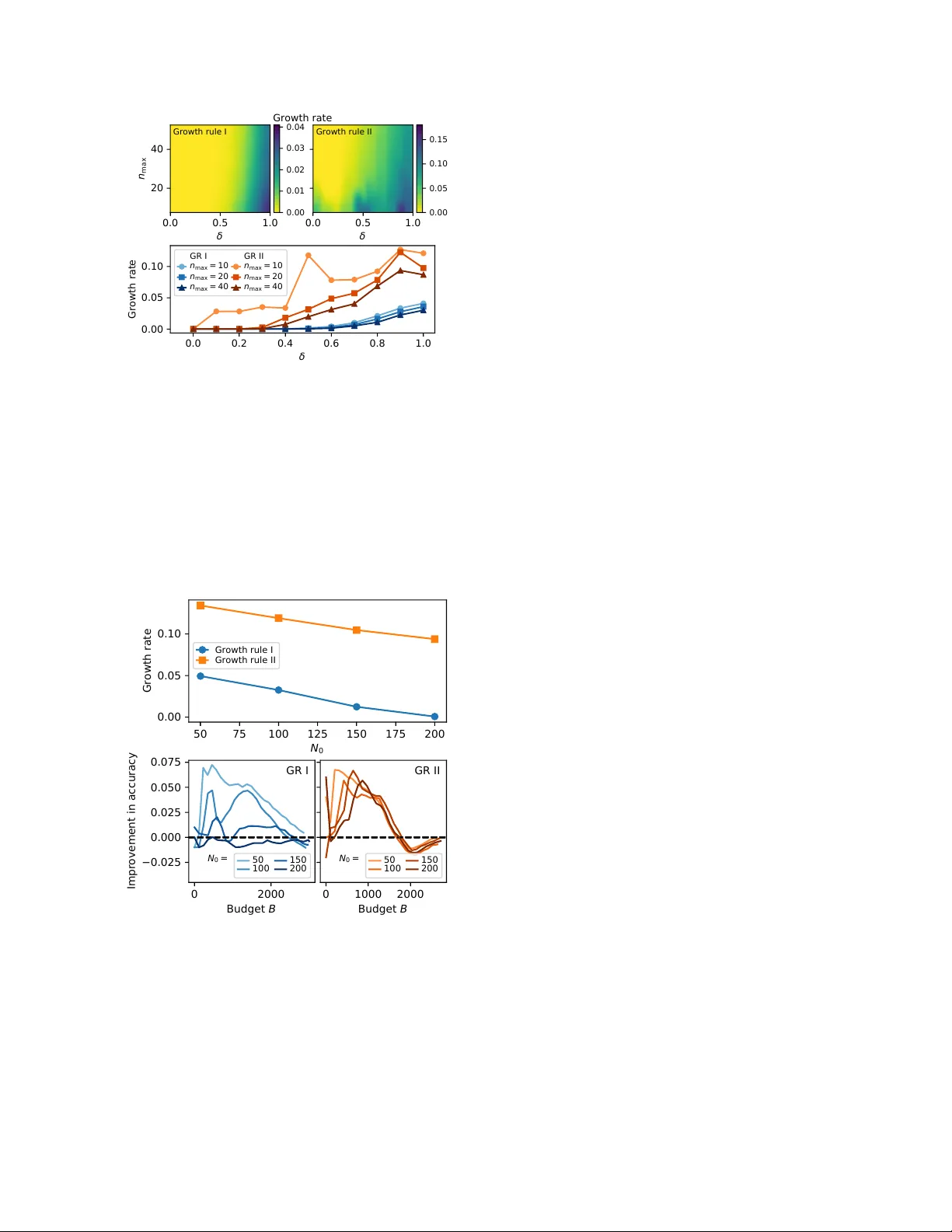
Efficient crowdsourcing of cro wd-generated microtasks Abigail Hotaling 1,2 and James P . Bagro w 1,2,* 1 Depar tment of Mathematics & Statistics, Univ ersity of V ermont, Bur lington, VT , United States 2 V ermont Complex Systems Center , Univ ersity of V ermont, Bur lington, VT , United States * Corresponding author . Email: james.bag row@uvm.edu , Homepage: bagrow .com December 23, 2020 Abstract Allo wing members of the crowd to propose no vel microtasks for one another is an effectiv e wa y to combine the efficiencies of traditional microtask w ork with the inv entiv eness and hypothesis g eneration potential of human w orkers. Ho we v er , microtask proposal leads to a g ro wing set of tasks that may o v er whelm limited cro wdsourcer resources. Cro wdsourcers can emplo y methods to utilize their resources efficiently , but algorithmic approaches to efficient cro wdsourcing generall y require a fixed task set of kno wn size. In this paper , w e introduce cost f orecasting as a means f or a cro wdsourcer to use efficient crowdsourcing algor ithms with a g ro wing set of microtasks. Cost f orecasting allo ws the crowdsourcer to decide between eliciting new tasks from the cro wd or receiving responses to e xisting tasks based on whether or not ne w tasks will cost less to complete than exis ting tasks, efficiently balancing resources as cro wdsourcing occurs. Experiments with real and synthetic crowdsourcing data sho w that cost forecas ting leads to impro ved accuracy . A ccuracy and efficiency gains f or cro wd-generated microtasks hold the promise to further le verag e the creativity and wisdom of the cro wd, with applications such as g enerating more inf or mativ e and diverse training data f or machine lear ning applications and improving the performance of user -generated content and question-answ ering platforms. Keyw ords— algor ithmic crowdsourcing; s tatistical decision process; budget allocation methods; budg et-uncer tain cro wdsourcing; cro wd ideation; question-answ er ing; user -generated content. 1 Introduction Cro wdsourcing platf or ms enable large g roups of individ- ual cro wd members to collectivel y provide a cro wdsourcer with ne w information f or many problems [ 1 , 2 ] such as completing user surv ey s [ 3 ], generating training data for machine lear ning models [ 4 , 5 ], or pow ering citizen sci- ence programs [ 6 , 7 ]. The work per f or med by the cro wd is often used by researchers and fir ms to address problems that remain computationally challenging. Y et incor porat- ing humans into a problem domain introduces ne w c hal- lenges: w orkers must be paid and ev en volunteers should be properl y incentivized, bad actors or unreliable crowd members should be identified, and care must be taken to efficiently and accurately agg reg ate the response of the cro wd. Algorithmic crowdsourcing f ocuses on compu- tational approac hes to these challenges, allowing crowd- sourcers to maximize the accuracy of the data generated b y the crowd while also efficiently managing the costs of emplo ying the cro wd. Despite the potential challenges, engaging a crowd is often inv aluable, as crowd participants are capable of cre- ativ e ideation in a wa y that computational methods are not, and the y can g enerate no vel ideas or ne w tasks be yond those designed b y the cro wdsourcer . Cro wd-g enerat ed micro tasks are an impor tant a venue f or this creativity to manif est [ 8 , 9 ]: The members of the cro wd ma y be asked to not simply pro vide responses to giv en tasks, but also to propose new tasks to give to other crowd members. Combining task proposal with microtask w ork pro vides the cro wd a simple v ehicle to introduce their own new ideas and h ypotheses [ 8 ], while still le veraging the kno wn efficiency of microtask work [ 10 ]. Cro wd-generated microtasks ha ve been used for a num- 1 ber of practical cro wdsourcing applications. Ex amples include f eature generation for machine learning meth- ods [ 11 , 5 ], used to explore no vel predictors of childhood obesity and home energy use; the ‘verify’ step of So y- lent ’ s Find-Fix- V erify algor ithm [ 12 ], enabling prose writ- ing to lev erage microtask w ork within a crowd-po wered w ord processor; cro wdsourced creation of kno wledg e net- w orks [ 8 , 13 ], allowing f or an impro ved understanding of causal attr ibution; and contr ibuting new questions to a growing user sur v ey [ 14 ], used to generate and vote upon no vel ideas f or Ne w Y ork City’ s gov ernment to impro ve the w elfare of its citizens. In all these e xamples, as ne w content are generated, the crowdsourcer is left to manage a gro wing set of simple, associated microtasks such as an- sw er ing multiple-choice questions or v oting for proposed ideas. Another popular application of cro wd-generated micro- tasks is question-answ ering (QA) w ebsites, online com- munities where members can pose ne w questions they wish answ ered and provide answ ers to questions posed by other members [ 15 , 16 ]. Although asking and answering questions are often open-ended tasks, microtasks are a ke y component of administrating a QA platform, with the platf or m pro vider instantiating an y number of additional microtasks f or pur poses such as labeling or classifying content [ 9 ]. One e xample of such a microtask, which is often embedded as par t of other tasks, is a y es/no surv ey sho wing members a question paired with a user -submitted answ er and asking if this question is no w sufficientl y an- sw ered. Allo wing the cro wd to generate tasks can lead to a growing set of tasks and this gro wth, ev en slo w growth, can ev entually o verwhelm the cro wdsourcer’ s resources and the majority of tasks will remain unseen by the cro wd [ 8 ]. Thus a crowdsourcer using cro wd-generated microtasks must use resources efficiently . Algorithmic cro wdsourcing addresses efficiency with methods f or the cro wdsourcer to allocate tasks to the crowd and efficiently and accurately inf er answers f or given microtasks [ 17 , 18 ]. Ho we v er, most allocation algor ithms assume a fixed set of tasks to distribute to the crowd. Our goal here is to study ho w algor ithmic cro wdsourcing methods can best be used f or crowdsourcing problems with crowd-g enerated mi- crotasks. W e introduce a decision process— cost for e- casting —that enables a cro wdsourcer to decide online whether to grow the set of tasks or receiv e responses to e xisting tasks. For problems where the crowdsourcer can make this choice, this pro vides a means to apply efficient algorithms to cro wd-generated microtasks, allo wing the cro wdsourcer to achie ve high quality w ork on tasks ev en when the set of tasks is open-ended. The res t of this paper is or ganized as f ollo ws. In Sec. 2 w e provide background describing the cro wd- sourcing problem model we consider , e xisting methods f or crowdsourcing cro wd-generated microtasks, and pr ior w ork on efficient crowdsourcing (budg et allocation) algo- rithms. W e introduce cost f orecasting in Sec. 3 and der iv e probabilistic estimators using it on our problem model. W e repor t in Sec. 4 (Materials and Methods) and Sec. 5 (Experiments) our results using real and synthetic crowd- sourcing data to inv estig ate the accuracy of collected data when crowdsourcing with cost f orecasting. W e also de- scribe in Sec. 4 ho w to simulate crowd-g enerated micro- tasks using pre-e xisting cro wdsourced datasets. Lastl y , w e conclude in Sec. 6 with a discussion of this work and its applications, including the limitations of our study and promising directions for future research. 2 Bac kground Here we descr ibe the problem model we emplo y in our study to represent crowdsourcing tasks, describe pr ior re- search on crowd-g enerated microtask crowdsourcing, as w ell as provide details on e xisting methods f or cro wd- sourcing microtask data under budget constraints. 2.1 Problem model and e xisting w ork W e f ocus on problems where cro wd members propose binary labeling tasks as a representativ e model for indi- vidual microtasks, as is standard practice in algorithmic cro wdsourcing. In the conte xt of cro wd-generated micro- tasks, w orkers can introduce no vel microtasks f or other w orkers to label, leading, perhaps after appropr iate vali- dation, to a g ro wing set of labeling tasks. F or e xample, when crowdsourcing causal attributions [ 13 ], a w orker ma y introduce a no vel microtask by posing a new ques- tion ( Do you think that viruses cause sic kness? ) which then becomes a new y es/no binar y labeling microtask f or other cro wd work ers. While binar y labeling is a simpli- fication of the nuance of many real-wor ld crowdsourcing tasks, binary labeling can represent image categorization tasks or ev en basic sur v ey questions, and can be readil y generalized to categor ical labeling tasks such as multiple choice ques tions, although those tasks can also be bina- rized (see [ 19 ]). Let 𝑧 𝑖 ∈ { 0 , 1 } be the true but unkno wn label f or task 𝑖 and let 𝑦 𝑖 𝑗 be the response provided by work er 𝑗 when giv en task 𝑖 . W e define the associated task parameter 𝜃 𝑖 ≡ Pr ( 𝑧 𝑖 = 1 ) as the unknown probability that the tr ue label f or task 𝑖 is 1. Multiple work ers are typically asked to respond to a giv en task, allo wing us to aggregate their 2 responses f or impro ved accuracy; we assume that work ers respond independently so that the { 𝑦 𝑖 𝑗 } are iid for a giv en 𝑖 . T o trac k the response tallies f or task 𝑖 , let 𝑎 𝑖 and 𝑏 𝑖 be the total number of ‘ + 1 ’ and ‘ 0 ’ responses, respectiv ely , f or 𝑖 , and let 𝑛 𝑖 = 𝑎 𝑖 + 𝑏 𝑖 be the total number of responses receiv ed f or 𝑖 . As responses are g athered, these tallies will chang e, so 𝑎 𝑖 , 𝑏 𝑖 , and 𝑛 𝑖 are considered functions of time 𝑡 , where we track ‘time’ as the number of responses receiv ed across all work ers and tasks ( 𝑡 = Í 𝑖 𝑛 𝑖 ( 𝑡 ) ). W e can estimate 𝜃 with ˆ 𝜃 = 𝑎 𝑖 / 𝑛 𝑖 . The final goal is to inf er the true label of the task accurately , i.e., dev elop ˆ 𝑧 𝑖 ≈ 𝑧 𝑖 using the responses { 𝑦 𝑖 𝑗 } for task 𝑖 . Most work on efficient crowdsourcing assumes a fixed set of tasks but some studies ha v e considered task g ro wth. The work of Sheng, Pro vos t & Ipeirotos [ 20 ] considers the idea of soliciting new training e xamples (labeling tasks) from the crowd, and discusses strategies f or ho w often to request new tasks depending on the cost of receiving a new task relativ e to the cost of receiving a response to an e xist- ing task. How ev er, the focus on their w ork is on ho w man y responses a single task requires, as multiple responses are typically used to o vercome noisy work ers, and they do not consider the cost to complete a task (something we will f ocus on; Sec. 3 ), only the cost on a per -response basis. Like wise, the recent w ork of Liu and Ho [ 9 ] studies task growth using a multi-ar med bandit approach, where the arms of the bandit increase o ver time. The y assume the cro wdsourcer is not able to control when ne w tasks are generated, how ev er, and neither study considers the use of efficient allocation methods f or guiding w orkers to tasks when costs are constrained by a budget. Of course, re- turning to the ex ample of a QA platf or m, users typically submit questions on their o wn, but an y QA site can im- plement an approv al process allo wing the site to control the rate of ne w ques tions. T o the best of our kno wledg e, cro wdsourcing a growing set of tasks when efficient allo- cation methods are used to complete those tasks has not been studied. 2.2 Efficient allocation methods Often a cro wdsourcer must accurately inf er the 𝑧 𝑖 labels under budget constraints, as only finite resources (such as time or mone y) will be a vailable to suppor t the cro wd. For simplicity , we assume a crowdsourcer has a total budget of 𝐵 reques ts that can be elicited from the cro wd. The budget then imposes the constraint Í 𝑖 𝑛 𝑖 ( 𝑡 ) ≤ 𝐵 f or all 𝑡 ≤ 𝐵 . This cons traint becomes especially challenging f or a growing set of tasks, since the finite budget must be spread out ov er an increasing number of individual tasks. Cro wdsourcing allocation methods [ 18 , 21 , 19 ] ha ve been dev eloped to efficiently and accuratel y inf er labels f or tasks under a finite budg et. These methods choose which tasks to giv e to w orkers with a goal of maximizing the efficiency and accuracy of the task labels the cro wd- sourcer will inf er from the work er responses. In this work, w e appl y the Optimistic Know ledg e Gradient (Opt-K G) method [ 18 ]. Opt-K G works to optimize accuracy by im- plementing a Marko v Decision Process that chooses tasks with the lar gest e xpected impro v ement in accuracy . This method has sho wn improv ement in accuracy when applied to finite budget crowdsourcings [ 18 ]. Opt-K G f ocuses on optimizing ov erall accuracy , which makes it par ticularl y beneficial f or appl ying to cro wd-generated microtasks and is the reason we focus on it in this work (see also our dis- cussion of Opt-KG and other methods in Sec. 6 ). Fur ther , Opt-K G has no parameters that need to be tuned or chosen b y the cro wdsourcer . Opt-K G and other allocation methods assume a fixed set of 𝑁 tasks. The goal of our w ork here is to enable an efficient allocation method to suppor t crowdsourcing problems where the crowd can pro vide new tasks to the cro wdsourcer , leading to a set of tasks that grow s ov er the duration of the crowdsourcing. 3 Cost F orecasting Here we introduce a method to enable efficient allocation methods such as Opt-K G to work with crowd-g enerated microtasks. Firs t, w e e xtend the traditional binar y label- ing model for a fix ed set of tasks to an open-ended prob- lem where the cro wdsourcer begins with a small seed of tasks that gro ws as the crowd generates no v el tasks. W e then descr ibe the components of cost f orecasting includ- ing cost estimators for ho w many responses are needed to complete tasks and a decision rule (Growth R ule) based on those costs that allow s the crowdsourcer to choose whether a cro wd w orker should w ork on an exis ting task or propose a new task. 3.1 Model f or cro wd-generated micro t asks The problem model given abo v e (Sec. 2.1 ) descr ibes each of a fix ed set of 𝑁 tasks. T ypicall y , allocation methods assume there is a fix ed number of tasks that a cro wd- sourcer wishes to distribute to w orkers. Ho we ver , in this w ork we consider task gr owth where the number of tasks grow s as new tasks are g enerated by the cro wd. Gro wing tasks can represent the submission of ne w questions to a question-answ er ing site, f or e xample, while responding to a task represents a user answ er ing an exis ting question 3 or more simply flagging an exis ting question-answ er pair as cor rect. Let 𝑁 𝑡 be the total number of tasks that exis t at time 𝑡 , where 𝑁 0 initial seed tasks are used to begin the crowd- sourcing and w e track time such that each timestep repre- sents one request made b y the crowdsourcer . When a new task is desired at timestep 𝑡 , a work er will be prompted to propose a new task, which is then added to the set of all tasks, and 𝑁 𝑡 + 1 = 𝑁 𝑡 + 1 . Later , other w orkers can submit responses to this ne w task so that a label for that task can be inferred. In this model, the cost of a new task generated by the cro wd and the cost of a response is defined to be 𝑓 𝑡 and 𝑓 𝑟 units, respectivel y . Depend- ing on problem-specific considerations, the crowdsourcer can set 𝑓 𝑡 = 𝑓 𝑟 or let the costs differ (see also [ 20 ]). In this w ork, we define cos t units in number of responses, taking 𝑓 𝑡 = 𝑓 𝑟 = 1 ; we discuss 𝑓 𝑡 ≠ 𝑓 𝑟 in our discussion. In practice, an approv al process may also be needed to guarantee requirements f or the new task such as appropri- ateness, no velty , or impor tance. F or simplicity , here we assume this process has already been implemented. 3.2 F orecasting the cost to comple te a task Suppose at some time 𝑡 dur ing the cro wdsourcing that task 𝑖 has already received 𝑛 𝑖 ( 𝑡 ) independent ( 0 , + 1 ) responses, of which 𝑎 𝑖 ( 𝑡 ) are +1 responses. Our cur - rent estimate of the task’ s associated parameter 𝜃 𝑖 is ˆ 𝜃 𝑖 ( 𝑡 ) = 𝑎 𝑖 ( 𝑡 ) / 𝑛 𝑖 ( 𝑡 ) . W e can decide if task 𝑖 should be labeled + 1 or labeled 0 based on whether ˆ 𝜃 𝑖 > 1 / 2 or ˆ 𝜃 𝑖 < 1 / 2 , but we want to minimize the probability of giv- ing 𝑖 the wrong label. This may require w aiting until more responses to 𝑖 are gathered, so a conclusion can be drawn more safel y , but w e also want to av oid wasting additional responses on tasks that we can already label 𝑖 with an acceptable accuracy or on tasks that are too difficult (or too e xpensiv e) to answ er accurately . Thus, we need to incorporate our uncer tainty in ˆ 𝜃 giv en the collected data. In g eneral, for 𝑛 independent samples of a Bernoulli random variable, the probability that our estimate ˆ 𝜃 dif- f ers from the true value 𝜃 by at leas t 𝜖 is bounded b y Hoeffding’ s Inequality : Pr ˆ 𝜃 − 𝜃 ≥ 𝜖 ≤ 2 𝑒 − 2 𝑛 𝜖 2 . (1) This ineq uality allo ws us to decide a v alue f or this prob- ability and then es timate the minimum number of labels needed to ensure that probability . Suppose we want the probability that we are off by more than 𝜖 to be no more than 𝛿 . Then at least 𝑛 ≥ ln ( 2 / 𝛿 ) 2 𝜖 2 (2) responses are needed to provide a bound on 𝛿 . (Note that tighter bounds than Hoeffding’ s may be used, but for simplicity here we f ocus on Eq. ( 1 ); see the discussion for more.) Our cro wdsourcing goal for a giv en task is to deter mine if the unknown label 𝑧 is 1 or 0 (f or no w w e suppress the dependence on task index 𝑖 and timestep 𝑡 ). The differ - ence betw een our cur rent estimate ˆ 𝜃 and 1 / 2 represents our w eight of e vidence tow ards this decision. If we are confident to some degree that our estimate ˆ 𝜃 is different from 1 / 2 , then we are able to conclude the label of the task based on whether ˆ 𝜃 > 1 / 2 or ˆ 𝜃 < 1 / 2 and when w e can dra w that conclusion we can also deem the task complete. Using Eq. ( 2 ) and our current es timate with 𝑛 responses, w e can then estimate how many additional responses 𝑚 w e need until our confidence inter val (or margin of er ror) does not include 1 / 2 : 𝑚 ≥ ln ( 2 / 𝛿 ) 2 𝑎 𝑛 − 1 2 2 − 𝑛 . (3) Equation ( 3 ) show s us that the closer the task’ s parameter 𝜃 is to 1 / 2 , the more costl y the task will be in terms of requiring more responses to distinguish if the label should be 0 or 1. Of course, this estimate may be inaccurate as it relies on the current value of ˆ 𝜃 = 𝑎 / 𝑛 at 𝑛 responses. In reality , as more responses are gathered, ˆ 𝜃 will be revised. These updated estimates can be automaticall y incor po- rated into this equation as new responses are receiv ed, yielding improv ed forecas ts f or 𝑚 . Ho we v er, Eq. 3 is not valid when ˆ 𝜃 = 1 / 2 . In this scenario, we can ask: what if w e receiv e our ne xt response and it is + 1 or it is 0 ? Since all we cur rentl y know in this scenario is ˆ 𝜃 = 1 / 2 , we should assume either outcome is equall y likel y , giving a revised estimate ˆ 𝜃 = 𝑎 / ( 𝑛 + 1 ) (if the new response is 0) or ˆ 𝜃 = ( 𝑎 + 1 ) / ( 𝑛 + 1 ) (if the new response is + 1 ). Thankfully , ( ˆ 𝜃 − 1 / 2 ) 2 is the same in both cases, and so plugging either into Eq. ( 3 ) will giv e the same estimate f or 𝑚 : 𝑚 ≥ ln ( 2 / 𝛿 ) 2 𝑎 𝑛 + 1 − 1 2 2 − 𝑛 − 1 , (4) where the − 1 counts the additional label w e assume w e will receive. In summary , w e can estimate the number of additional 4 responses 𝑚 needed to complete a task using 𝑚 ≥ ln ( 2 / 𝛿 ) 2 ( 𝑎 𝑛 − 1 2 ) 2 − 𝑛 if 𝑎 / 𝑛 ≠ 1 / 2 , ln ( 2 / 𝛿 ) 2 ( 𝑎 𝑛 + 1 − 1 2 ) 2 − 𝑛 − 1 if 𝑎 / 𝑛 = 1 / 2 . (5) Once a task’ s ˆ 𝜃 has been shown to be different statisti- cally from 1 / 2 , the additional cost is 𝑚 ≤ 0 (no additional responses are needed). T o use in subsequent sections, w e define the set of available tasks 𝑀 ( 𝑡 ) as those where additional responses are needed: 𝑀 ( 𝑡 ) = { 𝑖 : 𝑚 𝑖 ( 𝑡 ) > 0 } , where (suppressing the dependence on 𝑖 and 𝑡 ) 𝑚 𝑖 ( 𝑡 ) is giv en by Eq. ( 5 ). 3.3 Deciding when to req uest a new task The ability to es timate the cost to complete a task allow s us to introduce a simple decision r ule f or when to request ne w tasks: reques t a new task when the expected cost to complete a new task is less than the estimat ed cost to complete the curr ently av ailable task that is closest to completion . Specifically , let 𝑖 ∈ [ 1 , . . . , 𝑁 𝑡 ] inde x the 𝑁 𝑡 currently a vailable tasks, and let 𝑚 𝑖 be our cur rent estimate for the cost to complete task 𝑖 . Let the expected cost to complete a ne w , unseen task be E 𝑛 𝑗 (w e compute this belo w). Comparing the { 𝑚 𝑖 } with E 𝑛 𝑗 then informs our decision r ule f or growing the set of tasks. T o decide whether or not to request a new task at some time 𝑡 , w e study tw o specific Gro wth Rules (GRs): Re- quest a new task when E 𝑛 𝑗 < min { 𝑚 𝑖 } Gro wth Rule I (GR I) (6) E 𝑛 𝑗 < median { 𝑚 𝑖 } Gro wth Rule II (GR II) , (7) where the minimum and the median are taken o ver the set of tasks for which additional responses are needed at time 𝑡 , 𝑀 ( 𝑡 ) . W e include the second rule (GR II) to pro vide a potentially less e xtreme counter point to GR I in that using the median as a decision point ma y be less influenced by outlier tasks than the minimum. The intuition behind these gro wth r ules is as f ollow s. As the cro wd w orks on completing the cur rentl y av ailable tasks, ine xpensive tasks (those with 𝜃 far from 1/2) will finish first, and soon only e xpensiv e tasks (those with 𝜃 close to 1/2) will remain. Ev entually , the remaining tasks will be costly enough that the cro wdsourcer will be better off taking the chance on a brand ne w task. Our experi- ments (Secs. 4 and 5 ) inv estigate using these r ules to elicit ne w tasks dur ing cro wd-generated microtask cro wdsourc- ing. 3.4 Estimating the cost to complete an un- seen task Giv en the g ro wth r ules introduced in Eqs. ( 6 ) and ( 7 ), a question remains: ho w can we estimate the expected cost to complete a task 𝑗 when the task is unseen or has no responses (i.e., 𝑎 𝑗 = 𝑛 𝑗 = 0 )? One option is to track the mean completion cost of previousl y completed tasks and use that f or E 𝑛 𝑗 . Another option is to track the mean par ameter ˆ 𝜃 of pre viously completed tasks E ˆ 𝜃 and use that mean within Eq. ( 5 ) to estimate the com- pletion cos t. The f or mer uses more data, but the latter option may be preferable as the GRs are then comparing tw o estimated costs instead of one observ ed cost and one estimated cost—if the estimates are biased then compar - ing two estimates may prev ent or at leas t limit the bias from ha ving a harmful impact. How ev er , here we take a simpler approach focused on computing the expected cost from only a given prior distribution of 𝜃 . Giv en a pr ior distribution 𝑃 ( 𝜃 ) f or task parameters, w e can estimate the e xpected minimum cost to complete unseen tasks if they are sampled from that pr ior: 𝐸 [ 𝑛 ] ≈ ∫ ∞ 𝑛 min 𝑛 𝑃 ( 𝑛 ) 𝑑𝑛 , (8) where 𝑛 min ≡ 2 ln ( 2 / 𝛿 ) is the e xpected minimum cost f or the ideal case of 𝜃 = 0 or 𝜃 = 1 . Here 𝑃 ( 𝑛 ) can be derived by performing a change-of-v ar iables on the pr ior distribution 𝑃 ( 𝜃 ) . U nfortunately , 𝐸 [ 𝑛 ] div erges for an y 𝑃 ( 𝜃 ) that assigns sufficient probability at or near 𝜃 = 1 / 2 , as tasks at that 𝜃 will on a verag e nev er be completed. T o ensure con ver gence, we assume a bound is used f or the maxi- mum amount of responses 𝑛 max that should be spent on a giv en task, and tasks 𝑖 that reach 𝑛 𝑖 ≥ 𝑛 max without be- ing deemed complete are abandoned. Although here w e used this bound only theoretically (when computing 𝐸 [ 𝑛 ] ) since Opt-K G itself helps to prev ent ov er-spending [ 18 ], in practice this bound can prev ent a g ro wth in sunk cos ts where e xpensive tasks consume an inordinate amount of the crowdsourcer ’ s budget. W e explore the effects of this bound below . Using this bound, the e xpected minimum cost to com- plete unseen tasks can be estimated: 𝐸 [ 𝑛 ] = 𝑛 max 𝜂 √ 2 + 2 1 − 𝜂 √ 2 ∫ 𝑛 max 𝑛 min 𝑛 𝑃 ( 𝑛 ) 𝑑𝑛 (9) = √ 𝑛 min 𝑛 max ( 2 − 𝜂 ) − 𝑛 min ( 1 − 𝜂 ) , (10) where 𝜂 ≡ 𝑛 min / 𝑛 max and the second line holds f or a unif or m (pr ior) distribution of 𝜃 . 5 Finall y , Eq. ( 10 ) f or 𝐸 [ 𝑛 ] (or Eq. ( 9 ) f or a different prior) and Eq. ( 5 ) f or additional costs { 𝑚 𝑖 } can be used in our Gro wth Rules, Eqs. ( 6 )–( 7 ), to per f or m cost forecas t- ing for cro wd-generated microtask crowdsourcing. 4 Materials and Methods Here w e descr ibe the real and synthetic cro wdsourcing datasets we apply cost f orecasting to, ho w to perform cro wd-generated cro wdsourcing on these data, and w e introduce a non-gro wth baseline control to understand the per f or mance of cost f orecasting. 4.1 Datasets W e study three crowdsourcing datasets. These data were not generated using an efficient allocation algor ithm, and so it has become standard practice to ev aluate such al- gorithms with these data [ 19 , 8 ]— since labels were col- lected independently , one can use an allocation algor ithm to choose what order to rev eal labels from the full set of labels, essentially “rerunning” the crowdsourcing after the fact. Due to g enerally small number of responses f or each task in these datasets, to simulate a response from a w orker to a task we sample from a Ber noulli distribution with a probability ˆ 𝜃 that is es timated from the responses f or that task given in the original data. Belo w w e describe eac h dataset and how to use these data with cro wd-generated microtask cro wdsourc- ing, where the set of tasks chang es throughout the cro wd- sourcing. RTE R ecognizing T extual Entailment [ 4 ]. P aired wr it- ten statements from the P ASCAL RTE-1 data c hal- lenge [ 22 ]. W orkers were asked if one written statement entailed the other . These data consist of 𝑁 = 800 tasks and 8 , 000 responses, with each task receiving 10 responses. Data are a vailable at https://sites.google.com/site/ nlpannotations/ . Bluebirds Identifying Bluebirds [ 23 ]. Eac h task is a photograph of either a Blue Grosbeak or an In- digo Bunting, W orkers were asked if the photograph contains an Indigo Bunting. There are 𝑁 = 108 tasks and 4 , 212 responses, with 39 responses for each task. Data are av ailable at https://github.com/ w elinder/ cubam . Games This dataset contains cro wdsourcing tasks gener - ated from an app based on a TV g ame show , “Who W ants to Be a Millionaire” [ 24 ]. When a question is first rev ealed on the sho w , the app sends a task containing the ques tion and 4 possible answers to the users. R esponses from users and cor rect an- sw ers were collected. Data were preprocessed and responses binar ized f ollowing the procedure used by Li et al. [ 19 ]. The dataset contains 𝑁 = 1 , 682 tasks and 179 , 162 responses. Data are av ailable at https://github.com/bahadir i/Millionaire . T o study cro wd-generated microtask cro wdsourcing on these datasets, w e first sample 𝑁 0 tasks from the 𝑁 tasks in the dataset to constr uct the initial seed tasks f or the cro wdsourcer to use. T o replicate reques ting a ne w task, w e simply dra w from the set of tasks remaining in the dataset that ha ve not y et been requested. In other words, at the star t of crowdsourcing there are 𝑁 0 tasks av ailable to the cro wdsourcer and 𝑁 − 𝑁 0 tasks which are in the data but not yet requested. The gro wth rule in use deter- mines when new tasks should be g enerated, simulating the cro wdsourcer’ s decision process. Crowdsourcing contin- ues until the budg et 𝐵 is e xhausted or all 𝑁 tasks ha v e been req uested. Budget is used to reques t ne w tasks and to receive responses to e xisting tasks. 4.2 Synthetic cr o wdsourcing W e supplement our results from real crowdsourcing data b y performing controlled simulations. W e generate datasets f ollowing the model defined abo ve by assum- ing each work er response to task 𝑖 f ollow s a Bernoulli distribution with parameter 𝜃 𝑖 . This controls f or the cost of the task and the amount of responses needed to ac- curately label ˆ 𝑧 𝑖 = 0 or ˆ 𝑧 𝑖 = 1 . This assumes work ers are reliable; see the discussion f or incor porating work er reliability . N ote also that 𝜃 𝑖 is used onl y to simulate w orker responses—all subsequent calculations are per - f or med using the estimate ˆ 𝜃 𝑖 as 𝜃 𝑖 itself is unknown to the cro wdsourcer . When tasks are created, we draw 𝜃 𝑖 from a unif or m pr ior distribution but w e can also dra w from other probability distributions such as the Beta distr ibution. T o begin each r un of crowdsourcing, we generate a set of 𝑁 0 seed tasks. T o simulate requesting a new task 𝑗 from a w orker at time 𝑡 , we dra w a new 𝜃 𝑗 from the underl ying prior distribution, add 𝑗 to the set of tasks, increment the number of tasks 𝑁 ( 𝑡 + 1 ) = 𝑁 ( 𝑡 ) + 1 , and so forth. Unless otherwise noted, in simulations, w e used 𝑁 0 = 100 and a total budget (Sec. 2.2 ) of 𝐵 = 3000 ; we e xplore the effects of these and other parameters in our experiments belo w . Using this model, w e can apply efficient budget allocation techniques such as Opt-K G and implement the growth r ules defined abo ve. 6 Baseline control T o understand better the per f or mance of cost f orecasting, f or each Gro wth R ule, w e compare to a non-g ro wth baseline that controls for the number of tasks and total budg et spent on responses to those tasks. In this baseline, the number of tasks av ailable at the star t matches the final number of tasks generated when using cost f orecasting, no new tasks are proposed by the crowd, and the budg et av ailable to the baseline is equal to the number of labeling responses receiv ed when using cost f orecasting. Specificall y , the budg et f or responses 𝐵 𝑟 a vailable to the baseline is 𝐵 𝑟 = 𝐵 − ( 𝑁 − 𝑁 0 ) where 𝐵 is the total budget used by cost f orecasting and 𝑁 is the final number of tasks generated by the cro wdsourcing we are comparing against. W e per f orm one matching realization of the baseline for each realization of cost f orecasting, as randomness in w orker responses leads to variability in the total number of tasks proposed across different realizations of cost f orecasting. Note that this baseline is equivalent to a growth r ule that perf or ms all gro wth at the star t of the cro wdsourcing, then receiv es all w orker responses to those tasks until the budg et is e xhausted. This contrasts with cost f orecasting which dynamicall y alternates between g ro wing tasks and responding to tasks using a given Gro wth Rule. 5 Experiments 5.1 Real and synthetic data W e e valuate the performance of cost forecas ting on sim- ulated and real crowdsourcing data (Fig. 1 ). Solid lines correspond to cost forecas ting while dashed lines cor re- spond to the non-g ro wth baseline. For these results w e used cos t f orecasting parameters (Sec. 3.2 ) 𝛿 = 0 . 9 f or GR I, 𝛿 = 0 . 5 f or GR II (which e xhibits faster gro wth than GR I), and 𝑛 max = 10 (Sec. 3.4 ) f or both; w e fur ther e xplore the dependence on 𝛿 and 𝑛 max belo w . (Bluebirds, a smaller, noisier dataset, used 𝛿 = 0 . 5 (GR I), 𝛿 = 0 . 1 (GR II), 𝑁 0 = 10 , 𝐵 = 600 .) Cost f orecasting leads to slo wer growth at the beginning of crowdsourcing, visible in the long pause bef ore the number of tasks begins to grow (Fig. 1 ). Our method does not begin to gro w until the crowd has pro vided enough responses about the seed tasks to ac hiev e accurate labels. In contrast, the non- growth baseline begins with all tasks initially a vailable. Examining the accuracy , or proportion of correct tasks, sho ws that cost f orecasting achie ves higher accuracy than the baseline f or most data, especially f or earlier in the bud- get, with Bluebirds (a difficult task with a global accuracy of only ≈ 0 . 65 ) being a possible ex ception. Note that b y controlling f or the o verall g ro wth rate and budg et of cost 0 2000 200 400 Synthetic Number of tasks 0 2000 0.75 0.80 0.85 Accuracy GR I GR II 0 2000 200 400 RTE 0 2000 0.70 0.75 200 400 600 25 50 75 Bluebirds 200 400 600 0.60 0.65 0 2000 B u d g e t B 200 400 Games 0 2000 B u d g e t B 0.85 0.90 0.95 Figure 1: Cost forecas ting applied to synthetic and real w orld cro wdsourcing data. A ccuracy of inferred labels is generally higher at given total budget for both growth r ules (solid lines; blue: Gro wth R ule I, orang e: Gro wth R ule II) than if all tasks w ere a vailable to star t (control, dashed lines). Higher accuracy at tight budgets allow s cost f orecasting to handle cro wd-generated sets of tasks and to handle budge t-uncertain scenarios (see dis- cussion), helping the crowdsourcer to ensure the g athered data is high-quality ev en if the budget is suddenly cut. f orecasting in the baseline (see abo ve), the final accuracy (at high budgets) of both methods will on av erage alwa ys be the same, as both methods use the same Opt-K G allo- cation method. Y et, cos t f orecasting can achiev e higher accuracy at low budg ets (often up to ≈ 5% ) by dynami- cally determining the gro wth rate based on the past and current state of the crowdsourcing. 5.2 Dynamics of cost f orecasting Cost forecas ting decides between requesting responses to e xisting tasks and requesting ne w tasks. The dynamics of this decision process will vary as the responses are gathered f or e xisting tasks, leading to a dynamical patter n distinctl y different from that exhibited by , e.g., constant random g ro wth (Fig. 2 , top). A w ell-established w ay to s tudy these dynamics is 7 through the interev ent times Δ 𝑡 , the number of non-growth requests that occur betw een gro wth reques ts. If a discrete- time process is memoryless, where each reques t is equall y likel y to be a gro wth request, Δ 𝑡 will follo w a g eomet- ric distribution 𝑃 ( Δ 𝑡 = 𝑘 ) = 𝑝 ( 1 − 𝑝 ) 𝑘 where 𝑝 is the probability for a gro wth ev ent. This conv erges to an e xponential distribution f or a continuous-time process, 𝑃 ( Δ 𝑡 ) = 𝜆𝑒 − 𝜆 Δ 𝑡 , with rate parameter 𝜆 . In contrast, bur sty processes e xhibit hea vy-tailed, often po wer -law distribu- tions of Δ 𝑡 : 𝑃 ( Δ 𝑡 ) ∝ ( Δ 𝑡 ) − 𝛼 f or pow er-la w e xponent 𝛼 > 1 [ 25 ]. Po wer -law distr ibutions sho w higher proba- bilities relative to exponentials for both v er y shor t Δ 𝑡 and v er y long Δ 𝑡 , captur ing the long pauses of non-activity punctuated by sudden bursts of activity that are character - istic of bursty processes. Figure 2 sho ws the interev ent distribution for both cost f orecasting growth r ules. At top, we use a “spike train” to illustrate the gro wth ev ents around one r un of simulated cro wdsourcing, with another random g ro wth spike train demonstrating a memoryless process where g ro wth ev ents occur at the same rate as the cost forecas ting g ro wth r ule. Belo w , w e sho w po w er-la w and g eometr ic dis tr ibutions fitted to the Δ 𝑡 obser v ed ov er 50 runs [ 26 ]. Indeed, w e see that cost f orecasting is hea vy-tailed and at least ap- pro ximately well e xplained by a pow er-la w dis tr ibution, indicating it is a bursty process. Fur thermore, likelihood- ratio tests [ 26 ] show ed significant evidence ( 𝑝 < 10 − 14 ) f or po wer -law s o ver e xponentials (the continuous analog of the geometric distr ibution) f or both gro wth r ules. The burstiness of cost forecas ting sho ws that the algor ithm tends to alter nate betw een suddenly requesting multiple ne w tasks (shor t interev ent times) and then focusing f or some time on receiving responses to e xisting tasks (long interev ent times). In other w ords, it is reactive to the cur - rent state of the cro wdsourcing, trading off expected cos ts giv en by responses to the cur rent tasks with the potential cost a ne w , unseen task will require to be completed. 5.3 Parame ter dependence The cost f orecasting procedure introduced in Eqs. ( 3 )– ( 10 ) depends on parameters 𝛿 and 𝑛 max . Here w e explore some effects of these parameters. Fur ther , we assume each cro wd-generate microtask cro wdsourcing begins with an initial seed of 𝑁 0 kno wn tasks (and no responses), so w e also study how cost forecas ting behav es f or different size seeds. Figure 3 uses simulated crowdsourcing to e xplore the dependence of the a verag e gro wth rate of tasks on 𝛿 and 𝑛 max . Examining Fig. 3 , 𝑛 max has little effect on GR I’s growth rate while increasing 𝛿 pro vides the researcher Cost-forecasting (GR I) Cost-forecasting (GR II) Ran dom gro wth Ran dom gro wth Δ t Figure 2: Cos t f orecasting leads to a burs ty pattern of growth. ( T op ) Example “spike trains” highlighting when new tasks are requested for one r un of eac h growth r ule. F or context, we sho w f or each an e xample of a spik e train with the same av er - age growth rate where growth is eq ually likely to occur at an y point. ( Bottom ) Cost forecas ting leads to a heavy -tailed, ap- pro ximately pow er -law distribution of Δ 𝑡 , the waiting times or interev ent times betw een growth requests. This distribution is characteristic of a bursty process, unlike the g eometr ic distribu- tion of Δ 𝑡 displa yed by a memoryless random g ro wth process. with some ability to tune a giv en growth r ule ’s growth rate. In par ticular , using GR I and varying 𝛿 from 1/2 to 1 increases the typical growth rate by about 4% (Fig. 3 , bot- tom) essentially independently of 𝑛 max . GR II, in contrast, e xhibits a higher o verall gro wth rate, a slightly g reater de- pendence on 𝑛 max than GR I, and the g ro wth rate increases b y ≈ 8% f or 𝛿 = 1 compared with 𝛿 = 0 . 1 (Fig. 3 , bot- tom). These results sho w that the choice of 𝑛 max does not ha ve a large impact on g ro wth rate for GR I, while GR II sho ws increased growth rate f or small v alues of 𝑛 max . W e ne xt inv estig ate how g ro wth rate depends on the initial number of av ailable tasks 𝑁 0 . When man y tasks are a vailable to start, w e anticipate that cost f orecasting will spend more time exploring the a vailable tasks be- f ore it begins to g ro w , which will lead to a lo wer ov erall growth rate f or a fixed budget. Indeed, Fig. 4 (top) show s that larger 𝑁 0 cro wdsourcings ha ve lo wer gro wth rates 8 0.0 0.5 1.0 δ 20 40 n m a x Growth rule I 0.0 0.5 1.0 δ Growth rule II 0.0 0.2 0.4 0.6 0.8 1.0 δ 0.00 0.05 0.10 Growth rate GR I n m a x = 1 0 n m a x = 2 0 n m a x = 4 0 GR II n m a x = 1 0 n m a x = 2 0 n m a x = 4 0 0.00 0.01 0.02 0.03 0.04 0.00 0.05 0.10 0.15 Growth rate Figure 3: How av erage growth rate depends on cost forecas ting parameters 𝛿 and 𝑛 max (Sec. 3 ) for simulated crowdsourcing. Generally , 𝛿 has a strong er effect than 𝑛 max on gro wth rate, especially GR I. than smaller 𝑁 0 cro wdsourcings f or a given Gro wth Rule. For e xample, when 𝑁 0 = 200 , the g ro wth rate is appro x- imately 5% lo wer (f or GR I) or 3% lo wer (f or GR II) than when 𝑁 0 = 50 , indicating a small but potentiall y important affect on the o verall cro wdsourcing. 50 75 100 125 150 175 200 N 0 0.00 0.05 0.10 Growth rate Growth rule I Growth rule II 0 2000 B u d g e t B −0.025 0.000 0.025 0.050 0.075 Improvement in accuracy N 0 = GR I 5 0 1 0 0 1 5 0 2 0 0 0 1000 2000 B u d g e t B N 0 = GR II 5 0 1 0 0 1 5 0 2 0 0 Figure 4: Effect of initial number of tasks 𝑁 0 on g ro wth rate and impro vement in accuracy f or simulated crowdsourcing. Gener - ally , larg er 𝑁 0 leads to less gro wth and less impro vement in accuracy , since v er y larg e 𝑁 0 effectiv ely acts like a fix ed set of tasks. Giv en that larg er 𝑁 0 giv es lo wer gro wth rates, what effect does 𝑁 0 ha ve on accuracy? The bottom panels of Fig. 4 e xplore ho w accuracy improv ement (accuracy of cost f orecasting minus accuracy of corresponding base- line) depends on different v alues of 𝑁 0 . Generally , ac- curacy is impro v ed at tight budgets using cos t f orecast- ing, but this improv ement is lessened to some extent as 𝑁 0 increases—this is plausible as very lar ge v alues of 𝑁 0 are effectiv ely fixed-size traditional microtask cro wd- sourcings, meaning larg e 𝑁 0 are scenarios where there is less advantage f or a crowdsourcer to appl y cos t f orecast- ing. Smaller 𝑁 0 , how ev er , sho w the advantag es at tight budgets in ter ms of accuracy f or cost f orecasting. W e also note that (as in Fig. 1 ) there is a consis tent trend f or GR II to briefly per f orm worse than the baseline at high values of 𝐵 ( ≈ 2000 ) before higher v alues of 𝐵 lead to comparable per f or mance betw een the tw o approaches. 5.4 Non-stationary cro wdsourcing— increasing com pletion costs Our cost f orecasting approach assumes the expected min- imum cost to complete an unseen task is cons tant ov er the course of the cro wdsourcing. Y et, is this a realis- tic assumption? One can imagine a scenar io where the cro wd initiall y proposes “easy” tasks (where consensus is reached quickl y and the label can be inf er red with f ew responses) then the crowd runs out of “low -hanging fr uit” and later tasks will tend to be more expensiv e. An e x- ample scenar io is a question-answ er ing site where all the easy-to-answ er questions ha ve already been proposed and subsequentl y proposed questions tend to be polarizing f or the community . If this occurs, how will it affect the per - f or mance of crowdsourcing using cost f orecasting? T o explore ho w cost f orecasting beha ves under an increasing-cost scenar io, w e augment our crowdsourcing model by enabling the prior dis tr ibution for 𝜃 𝑖 , the prob- ability of a 1-label f or task 𝑖 , to v ar y as more tasks are proposed b y the cro wd. When this distribution becomes more shar ply peaked at 𝜃 = 1 / 2 , tasks will tend to be more costl y to complete. Then, to capture an increasing-cos t scenario, we take a Beta distribution B ( 𝛼 , 𝛽 ) f or the pr ior of 𝜃 and make the parameters linearl y increasing func- tions: 𝛼 ( 𝑁 𝑡 ) = 𝛽 ( 𝑁 𝑡 ) = 1 + 𝑠 ( 𝑁 𝑡 − 𝑁 0 ) , where 𝑁 𝑡 − 𝑁 0 is the number of tasks proposed so far , 𝑠 parameter izes the rate at which tasks become more costl y (as increasing 𝛼 = 𝛽 leads to a pr ior more sharply peaked at 𝜃 = 1 / 2 ), and the intercept 1 ensures the initial pr ior is a unif or m distribution. W e illustrate the changing pr ior of the increasing-cost model in the left panel of Fig. 5 . In the inset of this panel w e sho w how the Beta distribution parameters change as budget 𝐵 increases (and more new tasks are proposed), 9 0.00 0.25 0.50 0.75 1.00 θ 0 1 2 3 4 Probability Density 100 200 300 Number of tasks GR I s = 0 . 0 s = 0 . 1 s = 0 . 2 GR II s = 0 . 0 s = 0 . 1 s = 0 . 2 0 1000 2000 3000 B u d g e t B 0.7 0.8 Accuracy 0 2500 B 5 10 α , β Figure 5: Increasing completion costs. ( Left ) The prior 𝑃 ( 𝜃 ) f or new tasks’ 1-label probability 𝜃 . The cost to complete tasks grow s as this distribution become more shar ply peaked around 𝜃 = 1 / 2 where it req uires the most responses to distinguish 1- and 0-labels. ( Inset ) The change in prior distribution parameters as cro wdsourcing occurs. The colored points cor respond to the distributions shown in the main plot. ( Right ) Accuracy f or different rates of increasing cost 𝑠 . Accuracy drops at high budgets for 𝑠 > 0 , as expected, but both gro wth r ules ac hiev e similar accuracy for 𝑠 = 0 . 2 as the y do f or the less costl y 𝑠 = 0 . 1 . with the colored points in the inset cor responding to the distributions shown in the main plot. In the r ight of Fig. 5 w e illustrate ho w the growth rules perf or m as tasks of increasing cost are proposed—note that the cost f orecast- ing method used here is not made aw are of these changing costs. Here w e used 𝛿 = 0 . 5 ( 0 . 1 ) f or GR I (GR II). As we also saw in Fig. 1 , GRII generall y exhibits more gro wth and low er accuracy than GRI, and we expect higher ac- curacy when there is low er gro wth as there will be more responses f or f ew er tasks. This growth-accuracy tradeoff effect is e xacerbated further here, when later tasks are more difficult than ear lier tasks, as less gro wth leads to more responses to ear lier, easier tasks. Indeed, accuracy drops at larg er 𝐵 f or higher 𝑠 , as tasks become more dif- ficult, but both growth r ules handle the chang e in 𝑠 rather w ell, sho wing similar drops in accuracy f or both 𝑠 = 0 . 1 and the more costl y 𝑠 = 0 . 2 . Y et GR II show s a faster growth rate f or 𝑠 = 0 . 1 than 𝑠 = 0 . 2 , demonstrating ho w , despite incorrectly assuming new tasks are alw ay s equall y costl y to complete, cost f orecasting can still react to some e xtent to non-stationary task sets. 6 Discussion In this work, w e introduced cost forecas ting as a means to cro wdsource cro wd-generated microtasks where the cro wd both completes tasks but also proposes new tasks to the cro wdsourcer . Cro wdsourcing of cro wd-generated microtasks can be used for question-answ er ing sites, the design of ne w sur v ey s, and in general can enable cro wds to combine creative task proposal with traditional micro- task w ork. W e demonstrated f or binary labeling tasks on both synthetic and real-w orld cro wdsourcing data that cost f orecasting can lev erage the perf or mance of an efficient cro wd allocation method and lead to improv ed accuracy . Cost f orecasting can also help budget-uncertain cro wd- sourcing. If a cro wdsourcer does not kno w how many responses they will be able to gather , they will w ant to achie v e and maintain a high accuracy as soon as possible, so that, whenev er cro wdsourcing terminates, the labels receiv ed f or tasks are of as high a quality as possible. One application of such budg et-uncer tain crowdsourcing is large-scale, automated A/B/n testing, where stopping rules ma y be ev aluated online f or man y concurrent cro wd- sourcings. There are many fur ther directions to e xplore and ex- tend this researc h. One direction is the integration of cost forecas ting with different crowd allocation methods. W e f ocused our validation on applying cost f orecasting to Opt-K G, a popular and effectiv e cro wd allocation method f or fix ed sets of microtasks, free of parameters and fo- cused on the ov erall accuracy of the generated task labels. Like wise, the statis tical decision process of cost f orecast- ing brings to mind Mark ov decision processes (MDP) and POMDP , and MDP and POMDP are common approaches to algor ithmic crowdsourcing [ 27 ]. Indeed, Opt-K G it- self defines a policy using MDP [ 18 ]; thus our results here demonstrate that cost forecas ting can be fruitfully interfaced with MDPs. More generall y , as improv ed allo- cation methods are de v eloped, it is impor tant to examine if and how they can benefit from cost f orecasting or other methods g eared to wards applying an allocation s trategy to a set of cro wd-generated microtasks. Dev eloping meth- ods that can directly allocate work ers without assuming a fix ed and kno wn number of tasks w ould be an especially useful area of research. Another direction for future research is to better under - stand ho w a cro wdsourcer can integrate information about a par ticular crowdsourcing problem of interest. For ex am- ple, a cro wdsourcer ma y already ha ve a good idea about the difficulties of ne w tasks, perhaps from per f or ming a pilot study . This information can be integrated into cost f orecasting b y c hoosing a non-unif orm pr ior dis tr ibution f or 𝜃 . What about other cost f orecasting parameters such as 𝛿 , 𝑛 max or a different gro wth r ule? A crowdsourcer will wish to balance their needs f or accuracy and budget con- straints when choosing these parameters. Lo w-budg et, pilot crowdsourcings ma y again be fruitful to help select these parameters and it is worth studying procedures for estimating their values. 10 Our f ormulation of cost forecas ting is simple in sev - eral wa ys, but can be fruitfully e xtended. W e based our cost f orecasting calculations on the Hoeffding bound f or simplicity . This lea ves considerable room f or impro ve- ment as the Hoeffding bound is not par ticularl y tight, and better results may be achie ved using a tighter bound such as the empirical Ber nst ein inequality [ 28 , 29 ]. Further impro vements include using a lear ning procedure where the estimated unseen task completion cost is dynami- cally lear ned as cro wdsourcing is performed, although w e found some suppor t (Sec. 5.4 ) using an increasing- cost model that our basic cost f orecasting procedure can already handle some changing costliness of ne w tasks. W e assume reliable w orkers, but w orker reliability can be readil y incor porating b y using the w orker reliability (or “one-coin ”) variant of Opt-K G or b y incorporating w orker reliability into whate ver allocation method the cro wdsourcer wishes to use. W e also assume the cos ts to request new tasks or request responses to exis ting tasks are the same, but of course in practice these ma y be dif- f erent [ 20 ]. Ho we ver , cost f orecasting can automaticall y capture an y task cos t differential b y modifying 𝐸 [ 𝑛 ] to in- clude a different proposal cost. Lik ewise, the completion costs of unseen tasks are lik ely to vary o ver the course of a cro wdsourcing, a phenomena w e in ves tigated using an increasing-cost model. While such models are useful, it is also impor tant to understand ho w these costs ma y vary in practice (see [ 30 ]). Do work ers really run out of lo w-hanging fr uit when perf or ming cro wd-generated microtask cro wdsourcing? Exper iments are needed to understand better ho w the set of tasks c hanges ov er time as the crowd proposes ne w tasks. Finall y , our cost f orecasting Gro wth Rules f ocus on completion costs of tasks, as probabilistic cost estimators can be applied. Y et it w ould be especially interesting to use other quantities f or growth r ules. For example, if one can estimate the expected g ain of no v el inf or mation when requesting a new task, then a crowdsourcer can de- sign cro wd-generated microtask cro wdsourcing to achie ve goals such as crowdsourcing until a certain number of in- teresting or no vel tasks are generated. A ckno wledgments W e thank Paul Hines and Hamid Ossareh for helpful com- ments. This material is based upon w ork suppor ted b y the N ational Science Foundation under Grant No. IIS- 1447634. R efer ences [1] D. C. Brabham, “Cro wdsourcing as a model f or prob- lem sol ving: An introduction and cases, ” Conv erg ence , v ol. 14, no. 1, pp. 75–90, 2008. 1 [2] A. Kittur, J. V . Nickerson, M. Bernstein, E. Gerber, A. Shaw , J. Zimmer man, M. Lease, and J. Horton, “The future of cro wd work, ” in Proceedings of the 2013 Confer - ence on Computer Supported Cooper ative W ork , CSCW ’13, (Ne w Y ork, NY , USA), pp. 1301–1318, A CM, 2013. 1 [3] T . S. Behrend, D. J. Sharek, A. W . Meade, and E. N . Wiebe, “The viability of cro wdsourcing f or sur v ey re- search, ” Behavior resear ch methods , v ol. 43, no. 3, p. 800, 2011. 1 [4] R. Sno w , B. O’Connor , D. Jurafsky , and A. Ng, “Cheap and f ast – but is it good? ev aluating non-e xper t annota- tions f or natural language tasks, ” in Proceedings of the 2008 Confer ence on Empirical Met hods in Natural Lan- guag e Processing , (Honolulu, Haw aii), pp. 254–263, As- sociation f or Computational Linguistics, Oct. 2008. 1 , 6 [5] M. D. W agy , J. C. Bongard, J. P . Bagrow , and P . D. Hines, “Cro wdsourcing predictors of residential electr ic energy usage, ” IEEE Syst ems Journal , v ol. 12, no. 4, pp. 3151– 3160, 2018. 1 , 2 [6] E. Kamar, S. Hack er, and E. Hor vitz, “Combining human and machine intellig ence in larg e-scale cro wdsourcing, ” in Proceedings of the 11th International Confer ence on Autonomous Ag ents and Multiag ent Sys tems- V olume 1 , pp. 467–474, International F oundation for A utonomous Ag ents and Multiagent Sys tems, 2012. 1 [7] C. Franzoni and H. Sauer mann, “Cro wd science: The org anization of scientific research in open collaborative projects, ” Researc h policy , vol. 43, no. 1, pp. 1–20, 2014. 1 [8] T . C. McAndrew , E. A. Gusev a, and J. P . Bag ro w , “R e- ply & Supply : Efficient cro wdsourcing when w orkers do more than answ er questions, ” PloS one , v ol. 12, no. 8, p. e0182662, 2017. 1 , 2 , 6 [9] Y . Liu and C.-J. Ho, “Incentivizing high quality user con- tributions: New ar m g eneration in bandit lear ning, ” in Thirty-Second AAAI Confer ence on Ar tificial Intellig ence , 2018. 1 , 2 , 3 [10] A. Kittur, B. Smus, S. Khamkar , and R. E. Kraut, “Crowd- f orge: Crowdsourcing complex work, ” in Proceedings of the 24th annual ACM symposium on User int er face sof t- war e and technology , pp. 43–52, A CM, 2011. 1 [11] J. C. Bong ard, P . D. Hines, D. Conger , P . Hurd, and Z. Lu, “Crowdsourcing predictors of beha vioral out- comes, ” IEEE T ransactions on Systems, Man, and Cy- bernetics: Syst ems , vol. 43, no. 1, pp. 176–185, 2013. 2 11 [12] M. S. Bernstein, G. Little, R. C. Miller, B. Hartmann, M. S. A ckerman, D. R. Karg er, D. Crow ell, and K. Pano vich, “So ylent: a w ord processor with a crowd inside, ” in Pro- ceedings of the 23nd annual A CM symposium on User interface sof tw are and tec hnology , pp. 313–322, 2010. 2 [13] D. Berenberg and J. P . Bagrow , “Efficient crowd e xplo- ration of large networks: The case of causal attribution, ” Proc. A CM Hum.-Comput. Inter act. , vol. 2, pp. 24:1– 24:25, No v . 2018. 2 [14] M. J. Salganik and K. E. Levy , “W iki Sur v ey s: Open and quantifiable social data collection, ” PloS one , vol. 10, no. 5, p. e0123483, 2015. 2 [15] J. Zhang, M. S. Ac kerman, and L. Adamic, “Expertise net- w orks in online communities: Structure and algorithms, ” in Proceedings of the 16th International Confer ence on W orld W ide W eb , WWW ’07, (Ne w Y ork, NY , US A), pp. 221–230, A CM, 2007. 2 [16] J. Bian, Y . Liu, E. Agichtein, and H. Zha, “Finding the right facts in the crowd: F actoid question answering ov er social media, ” in Proceedings of the 17th International Conf erence on W orld Wide W eb , WWW ’08, (Ne w Y ork, NY , USA), pp. 467–476, A CM, 2008. 2 [17] A. P . Dawid and A. M. Skene, “Maximum likelihood es- timation of observer er ror -rates using the EM algor ithm, ” Applied statistics , pp. 20–28, 1979. 2 [18] X. Chen, Q. Lin, and D. Zhou, “Optimis tic know ledge gra- dient policy f or optimal budget allocation in crowdsourc- ing, ” in Proceedings of the 30th Int er national Confer ence on Machine Learning (S. Dasgupta and D. McAlles ter, eds.), v ol. 28 of Pr oceedings of Mac hine Learning Re- searc h , (Atlanta, Georgia, USA), pp. 64–72, PMLR, 17– 19 Jun 2013. 2 , 3 , 5 , 10 [19] Q. Li, F . Ma, J. Gao, L. Su, and C. J. Quinn, “Crowd- sourcing high quality labels with a tight budget, ” in Pro- ceedings of t he Ninth A CM International Confer ence on W eb Searc h and Data Mining , W SDM ’16, (Ne w Y ork, NY , USA), pp. 237–246, A CM, 2016. 2 , 3 , 6 [20] V . S. Sheng, F . Prov ost, and P . G. Ipeirotis, “Get another label? improving data quality and data mining using mul- tiple, noisy labelers, ” in Pr oceedings of the 14th A CM SIGKDD International Conf erence on Know ledge Discov- er y and Data Mining , KDD ’08, (N ew Y ork, NY , USA), pp. 614–622, A CM, 2008. 3 , 4 , 11 [21] D. R. Karg er , S. Oh, and D. Shah, “Budg et-optimal task allocation for reliable crowdsourcing sy stems, ” Oper . Res. , v ol. 62, pp. 1–24, Feb. 2014. 3 [22] I. Dag an, O. Glickman, and B. Magnini, “ The P ASCAL recognising textual entailment challeng e, ” in Machine learning c hallenges. ev aluating predictiv e uncer tainty , vi- sual object classification, and recognising tectual entail- ment , pp. 177–190, Spr inger , 2006. 6 [23] P . W elinder , S. Branson, P . Perona, and S. J. Belongie, “The multidimensional wisdom of cro wds, ” in Adv ances in Neur al Inf ormation Pr ocessing Sy stems 23 (J. D. Laf- f er ty , C. K. I. Williams, J. Sha we- T a ylor , R. S. Zemel, and A. Culotta, eds.), pp. 2424–2432, Curran Associates, Inc., 2010. 6 [24] B. I. A ydin, Y . S. Yilmaz, and M. Demirbas, “ A cro wd- sourced “who wants to be a millionaire?” pla yer , ” Con- curr ency and Computation: Pr actice and Experience , p. e4168, 2017. 6 [25] K.-I. Goh and A.-L. Barabási, “Burstiness and memory in complex sys tems, ” EPL (Europhy sics Letter s) , vol. 81, no. 4, p. 48002, 2008. 8 [26] J. Alstott, E. Bullmore, and D. Plenz, “pow erla w: a python packag e for anal ysis of heavy -tailed distributions, ” PloS one , vol. 9, no. 1, p. e85777, 2014. 8 [27] P . Dai, C. H. Lin, Mausam, and D. S. W eld, “P omdp- based control of workflo ws f or cro wdsourcing, ” Ar tificial Intellig ence , vol. 202, pp. 52 – 85, 2013. 10 [28] J.- Y . Audibert, R. Munos, and C. Szepesvár i, “Exploration–e xploitation tradeoff using v ar iance esti- mates in multi-ar med bandits, ” Theor etical Computer Sci- ence , vol. 410, no. 19, pp. 1876–1902, 2009. 11 [29] A. Maurer and M. Pontil, “Empirical Ber nstein bounds and sample variance penalization, ” in Proceedings of 22nd Annual Conf erence on Learning Theor y (COL T) , 2009. 11 [30] A. Shtok, G. Dror , Y . Maarek, and I. Szpektor , “Learn- ing from the past: Answering ne w ques tions with past answ ers, ” in Proceedings of t he 21st International Con- f erence on W orld Wide W eb , WWW ’12, (New Y ork, NY , US A), pp. 759–768, A CM, 2012. 11 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment