Learning an Optimally Reduced Formulation of OPF through Meta-optimization
With increasing share of renewables in power generation mix, system operators would need to run Optimal Power Flow (OPF) problems closer to real-time to better manage uncertainty. Given that OPF is an expensive optimization problem to solve, shifting…
Authors: Alex Robson, Mahdi Jamei, Cozmin Ududec
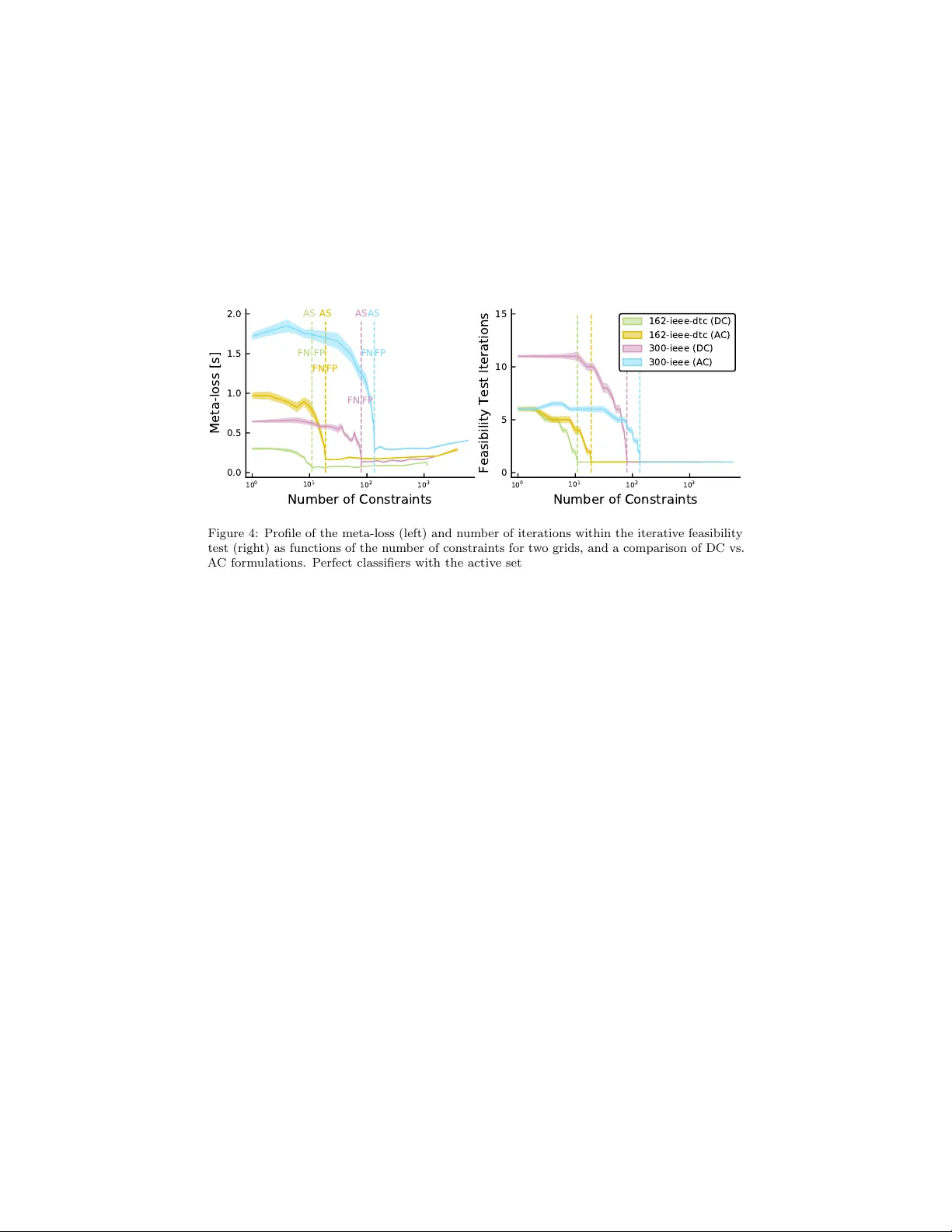
Learning an Optimally Reduced F orm ulation of OPF through Meta-optimization Alex Robson a , Mahdi Jamei a , Cozmin Ududec a , Letif Mones a, ∗ a Invenia L abs, 95 R e gent Str e et, Cambridge, CB2 1A W, Unite d Kingdom (e-mails: { firstname.lastname } @invenialabs.c o.uk). Abstract With increasing share of renew ables in p o wer generation mix, system op erators w ould need to run Optimal Po wer Flow (OPF) problems closer to real-time to better manage uncertain ty . Giv en that OPF is an exp ensiv e optimization problem to solv e, shifting computational effort aw ay from real-time to offline training by machine learning tec hniques has b ecome an in tense researc h area. In this pap er, we introduce a method for solving OPF problems, whic h can substan tially reduce solv e times of the t wo-step h ybrid techniques that comprise of a neural netw ork with a subsequent OPF step guaranteeing optimal solutions. A neural netw ork that predicts the binding status of constraints of the system is used to generate an initial reduced OPF problem, defined by removing the predicted non-binding constraints. This reduced mo del is then extended in an iterative manner un til guaranteeing an optimal solution to the full OPF problem. The classifier is trained using a meta-loss ob jective, defined by the total computational cost of solving the reduced OPF problems constructed during the iterative pro cedure. Using a wide range of DC- and AC-OPF problems, w e demonstrate that optimizing this meta-loss ob jectiv e results in a classifier that significantly outp erforms conv en tional loss functions used to train neural net work classifiers. W e also pro vide an extensiv e analysis of the inv estigated grids as well as an empirical limit of p erformance of machine learning techniques pro viding optimal OPF solutions. Keywor ds: A C-OPF, DC-OPF, Meta-optimization, Optimal Po wer Flow, Neural Net work 1. In tro duction A central task of electricit y grid operators [ 1 ] is to frequently solv e some form of Optimal P ow er Flow (OPF) [ 2 ], which is a constrained optimization ∗ Corresponding author 1 The authors thank Dr. Christian Steinrueck en and Dr. Lyndon White for their suggestions that greatly impro ved the man uscript. Pr eprint submitted to Elsevier De cemb er 22, 2020 problem. The goal of OPF is to dispatch generation in order to meet demand at minimal cost, while respecting reliability and securit y constrain ts. This is a challenging problem for several reasons. First, OPF is a non-conv ex and non-linear constrained optimization problem that can tak e a mixed-in teger form when solving the unit commitment problem. Second, it is computationally exp ensiv e due to the size of p o wer grids, requiring a large n umber of div erse constrain ts to b e satisfied. F urther, grid op erators m ust typically meet (at least) N − 1 reliability requiremen ts (e.g. North American Electric Reliabilit y Co operation requirement for the US grid op erators [ 3 ]), resulting in additional constrain ts that significan tly increase the computational complexit y of OPF. Finally , with increasing uncertaint y in grid conditions due to the integration of renew able resources (such as wind and solar), OPF problems need to b e solved near real-time to hav e the most accurate inputs reflecting the latest state of the system. This, in turn, requires the grid operators to ha v e the computational capacit y of running consecutive instances of OPF problems with fast conv ergence time. OPF problems are typically solved through interior-point metho ds [ 4 ], also kno wn as barrier metho ds (Figure 1, left panel). One of the most widely used approac hes is the primal-dual interior-point technique with a filter line-search [ 5 ]. These metho ds are robust but exp ensive, as they require the computation of the second deriv ative of the Lagrangian at eac h iteration. Nevertheless, interior- p oin t methods can b e considered as baseline approaches to solving general OPF problems. In order to reduce computational costs, v arious approximations are used. The most typical approximation, called DC-OPF [ 2 ], makes the problem conv ex and reduces the num b er of v ariables and constraints. Recent works apply the L-BF GS-B metho d [ 6 ] or the co ordinate-descent algorithm [ 7 ] to get real time appro ximations of the AC-OPF problem. A fruitful and new direction of research is to use machine learning (ML) tec hniques to solve op eration and control problems for p ow er grids. F or example, deep neural netw orks (DNN) ha ve b een deploy ed for grid state estimation and forecasting [ 8 ], and reinforcemen t learning approac hes to address the v oltage con trol problem in distribution grids [ 9 ]. Our fo cus in this pap er is on the ML approac hes that are b eing deploy ed to predict the solution of OPF or Security- Constrained Unit Commitment problems [ 10 ], shifting computational effort aw ay from real-time to offline training. These black-box techniques roughly fall into t wo categories: regression and classification metho ds. The most widely used end-to-end (or dir e ct ) approaches try to predict the optimal OPF solution based on the grid parameters through regression tec hniques. As OPF is a constrained optimization problem, the solution is not a smooth function of the grid parameters, so properly training such regression mo dels requires substantial amounts of data [ 11 , 12 ]. There is also no guarantee that the solution satisfies all constraints, and violation of imp ortan t constraints could lead to severe security issues for the grid. Nevertheless, the predicted solution can instead b e utilized as a starting p oin t to initialize an interior-point metho d [ 13 ] (Figure 1, middle panel). This approach is often called a hybrid (or indir e ct ) 2 metho d as it combines ML-based technique with a subsequent OPF calculation. Predicting a set-p oint close enough to the solution can significantly reduce the n umber of optimization iterations compared to the original problem [ 14 ], but the computational gain realized in practice is marginal for several reasons. First, b ecause only primal v ariables are initialized, the duals still need to con verge, as interior-point metho ds require a minimum n umber of iterations even if the primals are set to their optimal v alues. T rying to predict the duals as well makes the task even more challenging. Second, if the initial v alues of primals are far from optimal, the optimization can lead to a differen t lo cal minimum. Finally , ev en if the predicted v alues are close to the optimal solution, as there are no guaran tees on feasibility , this could lo cate in a region resulting in substantially longer solv e times, or even conv ergence failure. T o ov ercome this problem, one option is to attempt to obtain a feasible appro ximate solution without running a warm-start OPF optimization, but using c heap er p ost-processes instead. F or instance, for DC-OPF Pan et al. [ 15 ] use a DNN to map the load inputs to the outputs. How ever, instead of predicting the optimal v alue of all optimization v ariables, they predict only the activ e p o wer of generators. Since there is a direct linear relationship b et ween the phase angles and active p o wers via the admittance matrix, they compute the phase angles from the predicted active pow er b y solving the corresp onding linear system. Also, instead of directly predicting the active p ow er, a simple linear transformation is predicted to automatically satisfy the corresp onding minim um and maxim um inequalit y constraints. Finally , since the prediction is still not necessarily a feasible solution, a pro jection of this prediction is applied that requires solving a quadratic program. F or AC-OPF Zamzam and Baker [ 16 ] work ed out an approac h that has many similarities to the one describ ed ab o ve. They also use a DNN to map the (activ e and reactive) loads to a subset of outputs and predict only the voltage magnitudes and active p o wer outputs of generators. They also use a reparameterization of these v ariables so the b oundary constrain ts of the predicted quan tities are automatically satisfied. Finally , the voltage angles and reactiv e p o wer outputs are obtained by solving the non-linear equations of the original OPF problem using the predicted quantities. Solving a nonlinear system is m uch faster than solving a nonlinear constrained optimization problem. The ab o ve methods ha ve b een sho wn to ha ve excellent results for small synthetic grids. How ev er, for larger grids one potential drawbac k is that these approac hes migh t provide feasible but not necessarily optimal solutions. Classification black-box methods leverage the observ ation that only a fraction of constraints is actually binding at the optimum [ 17 ], so a reduced OPF problem can b e formulated by k eeping only the binding constraints. Since this reduced problem still has the same ob jective function as the original, the solution should b e equiv alent to that of the original full problem (Figure 1, right panel). This suggests a classification-based hybrid method, in whic h grid parameters are used to predict the binding status of eac h constrain t and a reduced OPF problem is solv ed. Dek a and Misra [ 18 ] iden tify all distinct active sets (i.e. all distinct structures of reduced OPFs) in the training data set and train a NN classifier (with cross-entrop y loss function) to predict the corresp onding active set given 3 the load inputs. Ho wev er, classification methods can also lead to security issues through false negativ e predictions of the binding status of imp ortan t constraints. By iterativ ely c hecking and adding violated constraints, and then solving the reduced OPF problem until all constraints of the full problem are satisfied, this issue can b e a voided [ 19 ]. As the reduced OPF problem is muc h cheaper than the full one, this pro cedure (if conv erged in few iterations) can be very efficient. This approac h is compatible with current practices of some grid operators to solv e OPF, where the transmission securit y constraints are enforced through an iterativ e pro cedure in which the solution at each iteration is chec ked against the base-case and N − 1 con tingency constraints: all violated constraints are added to the mo del, and the pro cedure contin ues until no more violations are found [ 20 ]. W e hereafter refer to this approach as the iter ative fe asibility test . F ocusing on the computational cost of obtaining an OPF solution by hybrid tec hniques suggests the use of an unconv entional loss function that directly measures this cost (instead of addressing regression or classification errors). In [ 14 ] w e combined a regression based hybrid approach with suc h an ob jective b y minimizing the total num b er of the OPF solv er iterations by predicting an appropriate warm-start for the interior-point primal v ariables. Viewing the initialization as parameters of an OPF solv er, w e refer to this ob jective as a meta-loss and its optimization as meta-optimization since it is optimization of an optimizer. 2 Inspired by recent works in predicting active constraint sets [ 18 , 21 , 22 ] and using a computational cost based meta-loss ob jective function [ 14 ], the main con tributions of this pap er are the following. W e in tro duce a classification-based h ybrid method to cop e with situations where: 1. the grid parameters ha ve a wide distribution (i.e. they hav e a large deviation compared to the samples use d in the ab ov e pap ers) resulting in a high num b er of distinct active sets. 2. the size of training data is limited compared to the space of p otential active-sets. 3. the solution guarantees feasibilit y and maintains optimality of the full problem ac hiev able b y the optimizer. First, given the high num b er of distinct active sets, instead of predicting the appropriate set (as in [ 18 ]), our metho d predicts the binding status of each inequalit y constraint and builds a reduced OPF mo del. Second, in order to obtain a feasible solution we apply the iterative feasibility test. It should b e noted that the prop osed meta-optimization pro cedure to predict the activ e sets of OPF is agnostic to the actual solver used to solve the OPF problem. In this sense, the metho d can b e used in combination with any appropriate solver b eside the ones tested in this work. Third, instead of using a 2 Although there is ov erlap, we do not refer to this as meta-learning. A meta-learning framework would typically inv olve meta-training a single model ov er different data-sets (tasks) that is capable of few-shot learning on unseen data-sets at meta-test time. In contrast, here w e hav e t wo mo dels: an interior p oin t solver that solv es OPF problems, and a DNN that learns (input) parameters for the interior p oint solver for faster conv ergence. There is, how ever, no real notion of different tasks in this framework; training and testing all operate on the same grid. 4 con ven tional loss function, we introduce a meta-loss ob jectiv e that measures the en tire computational time of obtaining a solution. The NN weigh ts are optimized b y minimizing this ob jective: w e call this meta-optimization. The meta-loss function can b e applied universally for b oth regression and classification-based h ybrid methods, which makes it p ossible to p erform a thorough quantitativ e comparison of the t wo approac hes. W e demonstrate the capability of our metho d on sev eral DC- and AC-OPF problems. T o understand the theoretical limits of h ybrid approac hes, we explore a p erfect regressor and classifier, as guides for further research. Finally , the scalabilit y of our metho d is in vestigated and a wide range of grid sizes are tested, some of whic h hav e not b een explored previously due to computational cost. In order to facilitate researc h repro ducibilit y in the field, we ha ve made the gen- erated DC- and A C-OPF samples ( https://github.com/invenia/OPFSampler. jl ), as well as our co de ( https://github.com/invenia/MetaOptOPF.jl ) pub- licly a v ailable. Figure 1: OPF solution strategies for interior-point metho ds: con ventional (left), w arm-start (middle), and reduced (right) techniques. Φ grid denotes the vector of grid parameters, C and A represent the full and active sets of constraints, resp ectively , and p ∗ and p init are the optimal and initial v alues of the optimization v ariables. ML-based end-to-end (direct) methods predict directly p ∗ using regression, while hybrid (indirect) approac hes predict either p init (using regression) or A (using classification). 2. Metho ds 2.1. DC- and A C-OPF formulations In this w ork, we fo cus on the base-case OPF using DC- and A C-OPF form ulations and do not consider any con tingency scenarios. Let G = ( V , E ) define an directed graph with V set of buses and E set of directed edges suc h that E = { ( i, j ) | i → j ; i, j ∈ V } . Also, let G and G i denote the set of generators and the set of generators at bus i , resp ectiv ely such that G = S i ∈V G i ; V s the set of slac k buses and N i the set of buses adjacent to bus i . Finally , let L p i and L q i denote the active and reactive p o wer loads at bus i ; P g and Q g the active and reactiv e p o w er outputs of generator g and F p ij and F q ij are the active and reactiv e p o wer flows on line ( i, j ), resp ectively . According to the implementation of these mo dels in Po werModels.jl [ 23 ] we used the following optimization problem for 5 DC-OPF: min X DC X g ∈G C g ( P g ) (1a) sub ject to: C eq F p ij = θ ij x ij , ∀ ( i, j ) ∈ E θ i = 0 , ∀ i ∈ V s P j ∈N i F p ij = P g ∈G i P g − L p i , ∀ i ∈ V (1b) C ineq P g ≤ P g ≤ P g , ∀ g ∈ G | F p ij | ≤ F ij , ∀ ( i, j ) ∈ E | θ ij | ≤ θ ij , ∀ ( i, j ) ∈ E (1c) where X DC denotes the vector of DC optimization v ariables, C g is the cost curv e of generator g , x ij is the reactance of line ( i, j ) and θ i and θ ij = θ i − θ j are the voltage angle at bus i and voltage angle differences b et w een bus i and j , resp ecively . Low er and upp er b ounds are denoted by the corresp onding underlined and o verlined v ariables. The sets of equalit y ( C eq ) and inequalit y ( C ineq ) constrain ts are also indicated. F or AC-OPF, the following optimization mo del is considered: min X AC X g ∈G C g ( P g ) (2a) sub ject to: C cvx eq P j ∈N i F p ij = P g ∈G i P g − L p i , ∀ i ∈ V P j ∈N i F q ij + b c ij 2 v 2 i = P g ∈G i Q g − L q i , ∀ i ∈ V θ i = 0 , ∀ i ∈ V s (2b) C ncvx eq F p ij = r ij r 2 ij + x 2 ij v 2 i τ 2 ij − v i v j ( r 2 ij + x 2 ij ) τ ij × ( r ij cos( δ ij ) − x ij sin( δ ij )) , ∀ ( i, j ) ∈ E F q ij = − x ij r 2 ij + x 2 ij + b c ij 2 v 2 i τ 2 ij − v i v j ( r 2 ij + x 2 ij ) τ ij × ( r ij sin( δ ij ) + x ij cos( δ ij )) , ∀ ( i, j ) ∈ E F p j i = r ij r 2 ij + x 2 ij v 2 j − v i v j ( r 2 ij + x 2 ij ) τ ij × ( r ij cos( δ ij ) + x ij sin( δ ij )) , ∀ ( i, j ) ∈ E F q j i = − x ij r 2 ij + x 2 ij + b c ij 2 v 2 j − v i v j ( r 2 ij + x 2 ij ) τ ij × ( − r ij sin( δ ij ) + x ij cos( δ ij )) , ∀ ( i, j ) ∈ E (2c) 6 C ineq v i ≤ v i ≤ v i , ∀ i ∈ V P g ≤ P g ≤ P g , ∀ g ∈ G Q g ≤ Q g ≤ Q g , ∀ g ∈ G | F p ij | ≤ F ij , ∀ ( i, j ) ∈ E | F q ij | ≤ F ij , ∀ ( i, j ) ∈ E | θ ij | ≤ θ ij , ∀ ( i, j ) ∈ E F p ij 2 + F q ij 2 ≤ F ij 2 , ∀ ( i, j ) ∈ E (2d) where, beside the previous definitions, X AC is the vector of A C optimization v ariables, v i denotes the magnitude of voltage at bus i , and r ij and b c ij are the resistance and shun t charging susceptance of line ( i, j ), resp ectiv ely . τ ij and θ t ij are the magnitude and angle of the phase shifter tap ratio on line ( i, j ) and for brevit y we defined δ ij = θ ij − θ t ij . If there is no phase shifter on the line, then τ ij = 1 and θ t ij = 0. F or AC-OPF, three types of constraints are distinguished: con vex equality ( C cvx eq ), non-con vex equality ( C ncvx eq ), and inequalit y ( C ineq ) sets. 2.2. Meta-optimization for R e gr ession-b ase d Hybrid Appr o aches In order to introduce the concept of a meta-loss as an alternativ e ob jectiv e function, w e briefly describ e our previous regression-based mo del [14]. Con ven tional sup ervised regression tec hniques t ypically use loss functions based on a distance betw een the training ground-truth and predicted output v alue, such as mean squared error or mean absolute error [ 24 ]. In general, each dimension of the target v ariable is treated equally in the loss function. Ho wev er, the shap e of the Lagrangian landscap e of the OPF problem as a function of the optimization v ariables is far from isotropic [ 25 ], implying that optimization under suc h an ob jective do es not necessarily minimize the w arm-started OPF solution time. The reason is that trying to derive initial v alues for optimization v ariables using empirical risk minimization techniques cannot guarantee feasibilit y , despite the accuracy of the prediction to the ground truth. Interior-point metho ds start b y first moving the system into a feasible region, thereby p oten tially altering the initial p osition significantly . Consequently , w arm-starting from an infeasible p oin t can be inefficient. Instead, we prop osed a meta-loss function that directly measures the compu- tational cost of solving the (warm-started) OPF problem [ 14 ]. One measure of the computational cost can b e defined b y the num b er of iterations required to reac h the optimal solution from the initialization p oint. This is a deterministic and noise-free measure of the computational cost. Since the warm-started OPF has exactly the same form ulation as the original OPF problem, the comparative n umber of iterations represents the impro vemen t in computational cost. W e applied a neural netw ork (NN), with parameters determined by minimizing the meta-loss function (meta-optimization) on the training set (Figure 2). As this meta-loss is a non-differentiable function with resp ect to the NN weigh ts, bac k-propagation cannot b e used. As an alternative, we employ ed the Particle Sw arm Optimization (PSO) [ 26 ] to find an optimal meta-loss in the NN weigh t 7 space. PSO is a gradien t-free meta-heuristic algorithm inspired by the concept of swarm intelligence that can b e found in nature among certain animal groups. The metho d applies a set of particles ( N p ), with the particle dynamics at each optimization step influenced by b oth the individual (b est position found by the particle) and collective (b est p osition found among all particles) knowledge. Since each optimization step of PSO requires N p computation of the meta-loss function, in this work w e used its adaptive version [ 27 ] that has an improv ed con vergence rate. W e also note that although PSO was originally in tro duced as a global optimization technique due to the high dimensionality of the w eight space, we use it here as a lo cal optimization technique. Therefore, the particles w ere initiated with a small random p erturbation from a position provided by the optimal w eights for a conv entional loss function [28]. A t each step of meta-optimization, the PSO particles try to optimize the meta-loss b y v arying the NN w eights, predict the initial v alues of the optimization v ariables, and solve the corresponding w arm-start OPFs of the training data. This requires solving OPF multiple times (as the predictor c hanges) leading to the following computational cost: with N t meta-training samples, N p PSO particles and N s meta-optimization steps, N t × N p × N s full OPF problems with w arm-start must b e solv ed. How ev er, it is a highly parallelizable problem among the PSO particles. Also, it is straigh tforward to start the meta-optimization from a pre-trained NN, under a conv entional regression loss. W e demonstrated the capabilit y of this meta-optimization for tw o syn thetic grids using DC-OPF problems [14]. Figure 2: Flow chart of the meta-optimization procedure using a NN regressor with w arm-start. The initial v alues of weigh ts θ for meta-optimization of the meta-loss are obtained from conv entional training with a regression loss. Φ grid is the v ector of grid parameters, NN θ represents the regressor with weights θ . The meta-loss is computed as the solve time or the total num b er of optimization steps of the warm-started OPF. p ∗ 0 is the initial v alue of the optimization v ariables and C denotes the full set of constraints of the problem. 8 2.3. Meta-optimization for Classific ation-b ase d Hybrid Appr o aches The first step of our new hybrid method is to train a NN-based classifier using grid parameters as features to predict the binding status of the constraints of the full OPF problem. A reduced OPF problem has the same ob jectiv e function as the full problem, but only retains those constraints that w ere predicted to b e binding by the classifier. As there may b e violated constraints not included in the reduced mo del, we use the iter ative fe asibility test to ensure conv ergence to an optimal solution of the full problem. The pro cedure has the following steps (Figure 3): 1. An initial reduced set of constraints A 1 is prop osed b y the classifier. A solution p ∗ 1 is then obtained b y solving the reduced problem. 2. In each feasibilit y iteration, k ∈ 1 . . . K , the solution p ∗ k of the reduced problem is v alidated against the constraints C of the original full formula- tion. 3. A t each step k , the violated constraints N k are added to the set of considered constrain ts to form A k +1 = A k ∪ N k . 4. This pro cedure rep eats un til no violations are found (i.e. N K = ∅ ), and the solution p ∗ K satisfies all original constraints C . At this p oin t, we hav e found a solution to the full problem ( p ∗ ). The goal is to find NN weigh ts that minimize the total computational time of the iterative feasibility test. How ev er, as we will demonstrate, minimizing a cross-en tropy loss function to obtain such weigh ts is not straightforw ard. First, the num b er of cycles in the iterative pro cedure describ ed ab o ve is muc h more sensitiv e to the false negative than false p ositiv e predictions of the binding status. Second, different constraints can b e more or less imp ortan t dep ending on the actual congestion regime and binding status. These suggest the use of a more sophisticated ob jective function, for instance a weigh ted cross-entrop y with appropriate w eights for the corresp onding terms. The w eights as h yp er- parameters then can b e optimized to achiev e an ob jective that can adapt to the ab o ve requiremen ts. How ever, an alternative ob jectiv e can be defined as the total computational time of the iterative feasibility test pro cedure. Since this directly measures the p erformance of a sequence of reduced OPF optimizations, w e call it a meta-loss function and its optimization o ver a training data set as meta-optimization. 9 Figure 3: Flow chart of meta-optimization using a NN classifier under the feasibilit y iteration procedure. Con ven tional optimization of a classification loss, which provides initial w eights θ , is follo wed by a meta-optimization of the meta-loss. Φ grid is the vector of grid parameters, NN θ represents the classifier with w eights θ . The meta-loss is computed within the iterative feasibility test, where C denotes the full set of constrain ts of the original OPF problem, A k is the actual set used in the reduced problem and N k is the set of violated constraints. p ∗ k is the solution of the corresp onding reduced problem, where k = 1 . . . K is the iteration index. The final solution p ∗ K = p ∗ at k = K is obtained when N K = ∅ . The meta-loss ob jective, therefore, includes the solution time of a sequence of reduced OPF problems. Similarly to the meta-loss defined for the regression approac h, it measures the computational cost of obtaining a solution of the full problem and unlik e w eighted cross-entrop y it do es not require additional h yp er-parameters to b e optimized. As the meta-loss is a non-differentiable function of the classifier w eights, we optimize it using the gradient-free PSO metho d. At each step of the meta-optimizations, each PSO particle v aries the NN w eights, predicts the binding status of the constraints, and p erforms the iterativ e feasibility test of the training data to optimize the meta-loss. The meta-optimization has therefore the following computational cost: with N t meta-training examples, N p particles, and N s meta-optimization steps, P N i =1 K i reduced OPF calculations are p erformed, where N = N t × N p × N s , and K i is the n umber of feasibility test iterations of the i th reduced OPF problem. Of all these parameters, N t , N p and N s are the hyperparameters we control. The v alues { K i } N i =1 , how ever, are dependent upon the classifier p erformance. In our exp erience, the pro cedure usually con verges within a few iterations to the solution of the full problem (typically 1–10 for tested grids). F urther, w e note that instead of just extending the previous set of active constraints with violations, an alternative to step 3 would b e to also discard constraints that were found to b e non-binding in A k . This alternative approach can theoretically lead to infinite lo ops when comp eting constraints switch their binding status from one to another b et ween consecutive iterations. W e also found it to hav e a slow er con vergence b ehavior in practice than the extension-only v ersion we recommend 10 in step 3. T o reduce the required num b er of steps of meta-optimization, we initialize the NN classifier b y training under a con ven tional ob jective for classification. As discussed previously for regression, optimizing such an ob jective do es not necessarily minimize the computational cost of obtaining a solution of the full problem. In practice, how ev er, we achiev e reasonable results by training with a c heap surrogate ob jective (conv en tional loss) first, follow ed by training under the more exp ensiv e meta-loss ob jective. W e summarize the differences b etw een regression- and classification-based approac hes in T able 1. T able 1: Comparison of regression- and classification-based hybrid approac hes using meta- optimization. Property Regression Classification Input Φ grid Φ grid Output p ∗ 0 A 1 OPF problem type to solve full OPF with w arm-start reduced OPF formulations Meta-loss solve time (or # iterations) total solve time Meta-optimizer PSO varying NN weigh ts PSO v arying NN weigh ts Cost of meta-optimization N t × N p × N s N t × N p × N s P i =1 K i 3. Exp erimen tal Analysis 3.1. OPF F r amework Sev eral synthetic grids from the P ow er Grid Library [ 29 ] were used. DC- and A C-OPF mo dels were solved within the Po werModels.jl [ 23 ] OPF pac k age written in Julia [30]. F or interior-point metho ds, w e used the Ip opt [5] solv er. 3.2. Input Sample Gener ation In order to explore a v ariety of distinct activ e sets of constraints for the syn thetic cases and mimic the time-v arying b eha vior of the OPF input parameters, grid parameter samples with feasible OPF solutions were generated by v arying their original v alues in the grid data-set. In particular, for eac h grid 10k DC- OPF samples w ere pro duced by rescaling each no dal load activ e p o wer by factors indep endently dra wn from uniform distribution of the form U (0 . 85 , 1 . 15), and rescaling eac h maxim um activ e pow er output of generators, line thermal ratings and line reactance v alues by scaling factors dra wn from U (0 . 9 , 1 . 1). Accordingly , the input parameter vector for DC-OPF cases w as defined as Φ DC grid = { L p i , P g , F ij , x ij } . F or AC-OPF, 1k samples were generated for the studied synthetic grids. Beside the parameters that w ere changed for DC-OPF, rescaled no dal load reactiv e p o wer, maxim um reactiv e p o wer output of generators, and line resistance v alues were pro duced by scaling factors sampled from U (0 . 9 , 1 . 1). Therefore, for A C-OPF cases the input parameter vector consisted of the following parameters: Φ AC grid = { L p i , L q i , P g , Q g , F ij , x ij , r ij } . 11 3.3. T e chnic al Details of the Mo del 3.3.1. NN Ar chite ctur e Eac h constraint was predicted to b e binding or non-binding by a multi- lab el classifier. Corresp ondingly , a binary cross-entrop y loss was used with the follo wing arc hitecture, in the Julia Flux.jl pac k age [ 31 ]. Tw o fully connected hidden lay ers w ere eac h follo wed by a BatchNorm lay er [ 32 ] and a ReLU activ ation function [ 33 ]. A Dropout la yer [ 34 ] with a dropout fraction of 0.4 was added after each BatchNorm lay er. The final output la yer had a sigmoid activ ation function. The input and output sizes of the NN were determined by the num b er of grid parameters and the cardinality of all inequality constrain ts, resp ectiv ely (see T ables 2 and 3 for details), while the middle lay er size was 50 × 50. 3.3.2. Conventional Optimization Samples w ere split randomly into training, v alidation, and test sets of 70%, 20% and 10%, resp ectiv ely . Hereafter, when referring to 10k of DC-OPF or 1k of A C-OPF samples, we refer to the total data set split as such. Mini-batch sizes of 10 and 100 were used with 1k and 10k samples, resp ectively . T raining was carried out using the ADAM optimizer [ 35 ] (with learning-rate η = 10 − 4 and parameters β 1 = 0 . 9 and β 2 = 0 . 999), using early stopping with a patience of 10 determined on a v alidation set after a 50 ep o c h burn-in p erio d. 3.3.3. Binding Status of Constr aints As the pow er flo w equalit y constrain ts are alwa ys binding, we limited the binding-state prediction to inequality constraints only . The binding status of the lo wer-bound constraints of generator output p ow er was not predicted (but force- set to b e alw ays binding) as the reduced OPF problem may b ecome unbounded with their remov al. F or similar optimization stability reasons, for AC-OPF, the binding status of low er and upp er b ound limits of voltage magnitudes were not predicted either, and alwa ys set to binding. Therefore, the follo wing inequality constrain ts were predicted: upp er limit of generator active outputs, lo wer/upper limits of real p ow er flows and voltage angle differences for DC-OPF and upp er limit of generator activ e outputs, low er/upp er limits of generator reactiv e outputs, activ e and reactive p o wer flows, voltage angle differences and upper limits of the squared of complex p o wer flo ws for AC-OPF. The binding status of the constrain ts was assigned b y c hecking each side of the inequality constraints. W e considered a constraint binding if either it was violated or the absolute v alue of the difference b et ween the tw o sides was less than a fixed threshold v alue set at 10 − 5 . 3.3.4. Meta-optimization During meta-optimization, the NN weigh ts obtained from conv entional opti- mization were further v aried to optimize the meta-loss ob jectiv e, defined as the total computational time to solve each OPF problem in the meta-training data. A t each ev aluation, the meta-training data was randomly sub-sampled from the training data with N t = 100 that improv ed the mo del to av oid ov erfitting. F or 12 eac h in vestigated grid, 10 particles and 50 iterations of PSO w ere run, using the Optim.jl pack age [ 36 ]. The pac k age was slightly mo dified to improv e the particle initialization. The starting p osition of the particles in the NN weigh t space was deriv ed from the weigh ts of the conv entionally optimized NN and eac h comp onen t was p erturbed by a random num b er drawn from a normal distribution with zero mean and standard deviation set at the absolute v alue of the comp onen t. Finally , in order to av oid conv erging to trivial minima of the meta-loss (dis- cussed in Section-4.5), a penalty term was introduced during meta-optimization: if the num b er of predicted active constrain ts was higher than a threshold defined as twice the av erage n umber of the active constrain ts in the training data, the v alue of the meta-loss function was set to infinity . 3.4. Computing R esour c es Shorter analyses with absolute computational times were run on Macb o ok Pro machines (2.9 GHz Quad-Core Intel Core i7 pro cessor for T ables 2 and 3; and 3.5 GHz Quad-Core Intel Core i7 pro cessor for Figures 4 and 5, resp ectively .) Meta-optimization exp eriments were carried out by using v arious machines on Amazon Elastic Compute Cloud. 4. Results 4.1. Distinct A ctive Sets in DC- and A C-OPF Samples Based on the generated samples, we first inv estigated the num b er of unique activ e sets (congestion regimes) of sev eral syn thetic grids. T able 2 shows the results for DC-OPF samples with 10k and a random 1k subset. It also provides the num b er of grid parameters dim (Φ grid ) (i.e., the classifier input size), the n umber of inequality constraints ( |C ineq | ), where the binding status is predicted (the classifier output size) and also the num b er of equality constrain ts ( |C eq | ) that are alw ays binding. F or the 1k subset, we compared the num b er of distinct active sets to those rep orted in [ 22 ], which w ere generated by scaling no dal load with a factor drawn from a normal distribution with µ = 1 . 0 and σ = 0 . 03. In the data presented here, the num b er of unique active sets is generally significantly higher that can b e attributed to tw o ma jor inten tional differences: 1) v arying more parameters b ey ond load, and 2) selecting a wider deviation for the load scaling v alues. It is also clear from this setup that a sample size of 1k is to o limited to co ver all p ossible distinct active sets for these grids. When extending the n umber of samples to 10k w e observe a further increase in the num b er of active sets. F or larger grids, this is capped at the num b er of samples meaning that ev ery sample has a unique active set. This indicates that under the sampling distribution of grid parameters, con vergence to the real distribution of active-sets b ecomes increasingly po or, particularly for the larger grids with realistic sampling n umbers. 13 T able 2: Grid c haracteristics and n umber of unique activ e sets for differen t DC-OPF cases, using 1K and 10K samples. Case dim(Φ grid ) |C ineq | |C eq | Num b er of active sets Ref [22] This work 1k 1k 10k 24-ieee-rts 125 208 63 5 15 18 30-ieee 105 168 72 1 1 1 39-epri 123 204 86 2 8 12 57-ieee 206 324 138 3 8 9 73-ieee-rts 387 648 194 21 8 48 118-ieee 490 768 305 2 66 122 162-ieee-dtc 693 1152 447 9 188 513 300-ieee 1080 1754 712 22 835 5145 588-sdet 1846 2916 1275 — 826 5004 1354-p egase 4915 7922 3346 — 997 9506 2853-sdet 10275 16750 6775 — 1000 10000 4661-sdet 15401 24944 10659 — 1000 10000 9241-p egase 38438 63402 25291 — 1000 10000 W e p erformed a similar analysis of grid prop erties for AC-OPF cases using 1k samples (T able 3). As exp ected, the num b er of grid parameters and num b er of constrain ts are significantly higher than those of the corresp onding DC-OPF cases. In T able 3, we split the num b er of equality constraints—that are alwa ys binding—in to tw o sets: conv ex and non-conv ex. The n umber of conv ex equality constrain ts ( |C cvx eq | ) is very similar to those of DC-OPF, but there is also a great num b er of the non-conv ex equality constraints ( |C ncvx eq | ). W e note that the computation of the non-conv ex equality constraints and their first and second deriv atives is the most exp ensive part of an interior-point optimization. Given that the systems are larger, it is not surprising that the num b er of distinct active sets is higher than those of the corresp onding DC-OPF cases. F or b oth formulations, the exp onentially increasing num b er of distinct con- gestion regimes suggests that it would b e more efficient to predict the binding status of individual constrain ts, rather than predicting the active set directly . 14 T able 3: Grid c haracteristics and num b er of unique activ e sets for different AC-OPF cases, using 1K samples. Case dim(Φ grid ) |C ineq | |C cvx eq | |C ncvx eq | Num b er of activ e sets (1k) 24-ieee-rts 214 628 49 152 39 30-ieee 177 576 61 164 8 39-epri 200 670 79 184 154 57-ieee 338 1098 115 320 7 73-ieee-rts 660 1958 147 480 523 118-ieee 864 2670 237 744 799 162-ieee-dtc 1102 3772 325 1136 812 300-ieee 1773 5804 601 1644 1000 588-sdet 3006 9770 1177 2744 1000 1354-pegase 7839 27078 2709 7964 1000 2853-sdet 16629 55462 5707 15684 1000 4.2. Maximum A chievable Gains T o compare the utility of a regression or classification approac h, w e begin with the estimation of the exp ected empirical limit of the achiev able computational gain for different solvers. In this setup, we explicitly refer to the gain ac hiev able whilst keeping the feasibility guarantees of the solvers, which is not comparable with metho ds that drop the (exp ensiv e) feasibilit y guarantee. In practice, this is equiv alent to computing the gain of computational cost of the p erfect regressor or classifier in the corresp onding framework of hybrid approaches. The p erfect regressor and classifier are hypothetical ’perfect’ predictors. Instead of a trained mo del, for a p erfect regressor-based hybrid mo del, we warm-start an OPF solver using the v alues of the primal v ariables at the solution. Similarly , for a p erfect classification-based hybrid mo del, we solve a perfectly reduced OPF problem with only the active set of binding constrain ts in the reform ulation. Therefore, we compute the av erage maximum achiev able gain for several grids using DC- and A C-OPF formulations with 1k samples. W e define the gain of the computational cost to the full OPF problem as: Gain( t ML ) = 100 t f − t ML t f (3) where t f and t ML are the computational times of the original full OPF problem and the sp ecific machine learning based approac h, respectively . Throughout, we refer to the computational solve-time, either full, reduced, or warm-started as the meta-loss. Here, we ev aluate the av erage of Gain ( t ∗ ML ) ≥ Gain ( t ML ), where t ∗ ML is the computational time of the corresp onding p erfect predictor-based hybrid approac hes. Among the in terior-p oin t solvers we used, only Ip opt had w arm-start ca- pabilit y , limited to primal v ariables only , and for consistency , the maxim um ac hiev able gain for b oth regression and classification was inv estigated with this solv er, where the v alue of its bound push and bound frac parameters were set to 10 − 9 for warm-start optimizations. F or eac h sample, w e compared the optimal 15 v alue of the ob jective of the warm-start and reduced OPF formulations to the solution of the full problem and found that they were indeed equal. This was esp ecially necessary for AC-OPF cases, where finding the same solution is less eviden t due to the non-conv ex nature of the problem. T able 4 presen ts the results for b oth form ulations. In the case of the DC form ulation, w e observe that the maximum achiev able gain of the regression-based h ybrid approach is in general somewhat low er than that of the classification approac h, esp ecially for larger grids. F urther, while the maximal gain for regression shows little correlation with the grid size, there is a muc h stronger correlation for classification, indicating a b etter scaling when moving to larger grids. Giv en the DC-OPF is a linear problem we can draw some qualitative con- clusions regarding the system size and gain. In the case of perfect regression, the size of the optimization problem is equal to the original OPF problem and the gain is determined by the conv ergence of dual v ariables that do es not seem to depend on the size. How ever, the gain of a perfect classifier-based hybrid metho d is primarily go verned b y the size of the reduced OPF problem compared to the full problem and it roughly dep ends on the ratio of the num b er of inequal- it y constrain ts and the num b er of all constrain ts of the full OPF form ulation (assuming that only a fraction of inequalit y constraints is actually active). T able 4: Maximum achiev able gains of warm-start with primal v ariables (perfect regression- based hybrid mo del) and reduced OPF formulations (p erfect classification-based hybrid mo del) methods for several grids using DC- and AC-OPF formulations and the Ipopt solver. Case DC Gain (%) A C Gain (%) Regression Classification Regression Classification 24-ieee-rts 30 . 9 ± 0 . 7 29 . 9 ± 0 . 7 27 . 0 ± 0 . 6 25 . 2 ± 0 . 6 30-ieee 33 . 9 ± 0 . 5 28 . 3 ± 0 . 5 7 . 9 ± 0 . 8 32 . 0 ± 0 . 9 39-epri 52 . 7 ± 0 . 4 28 . 0 ± 0 . 4 46 . 0 ± 0 . 6 29 . 7 ± 0 . 6 57-ieee 27 . 1 ± 0 . 6 38 . 8 ± 0 . 3 21 . 4 ± 0 . 7 30 . 6 ± 0 . 7 73-ieee-rts 29 . 7 ± 0 . 3 36 . 8 ± 0 . 3 33 . 5 ± 0 . 7 27 . 6 ± 0 . 5 118-ieee 22 . 4 ± 0 . 5 47 . 6 ± 0 . 4 15 . 8 ± 0 . 6 31 . 1 ± 0 . 4 162-ieee-dtc 55 . 4 ± 0 . 4 47 . 3 ± 0 . 3 40 . 4 ± 1 . 0 21 . 9 ± 0 . 7 300-ieee 44 . 1 ± 0 . 4 45 . 7 ± 0 . 3 37 . 2 ± 1 . 4 17 . 4 ± 0 . 6 588-sdet 28 . 5 ± 0 . 5 57 . 0 ± 0 . 3 − 18 . 3 ± 1 . 0 12 . 2 ± 0 . 8 1354-p egase 47 . 6 ± 0 . 4 47 . 0 ± 0 . 4 1 . 6 ± 1 . 3 35 . 1 ± 0 . 4 2853-sdet 34 . 8 ± 0 . 3 54 . 6 ± 0 . 2 − 9 . 9 ± 0 . 5 27 . 4 ± 0 . 3 4661-sdet 38 . 0 ± 0 . 3 45 . 1 ± 0 . 3 — — 9241-p egase 40 . 2 ± 0 . 6 52 . 7 ± 0 . 6 — — F or AC-OPF, we found that the maximum achiev able gain is more mo derate for b oth regression and classification compared to those of DC-OPF. With the A C-OPF formulation, the gain of the p erfect regression-based hybrid approac h did not show a correlation with the system size, and for some cases we observed 16 ev en negative gain with warm-started OPF. Unlike the DC-OPF case, the gain of the p erfect classification cannot b e related simply to the ratio of inequality and equality constraints anymore: the computationally most exp ensive part is the calculation of the first and second deriv atives of the non-con vex equalit y constrain ts that are alwa ys binding (see T able 3). In conclusion, we found that for DC-OPF the maxim um ac hiev able gain is significantly larger for classification ( ≈ 50%) than for regression (at least for larger grid sizes). No correlation w as found b et ween the system size and the gain of p erfect regression, while a w eak correlation was observed b etw een the grid size and the gain of p erfect classification. F or AC-OPF, the maximum ac hiev able gains are significantly lo wer than those for DC-OPF but for larger grids, classification can still provide some impro vemen t. Finally , for DC formulation w e computed the gains of the p erfect classifiers using tw o other conv ex solvers: ECOS [ 37 ] and OSQP [ 38 ]. W e found similar trends of the maximal gains to those of Ip opt and for some cases these solvers sligh tly outp erformed Ip opt. Ho wev er, we note that our meta-optimization metho d and the corresp onding gain it provides is agnostic to the applied solv er and therefore for the rest of this work w e use the Ip opt solver to b e consistent b et ween AC and DC formulations and also for other practical considerations. 4.3. Meta-loss as a F unction of F alse Ne gative and F alse Positive Pr e dictions W e extended the empirical in vestigations a wa y from p erfect p erformance and examined the asymmetric effect of error in binding-constraint classification. Sp ecifically , we inv estigated the effect of increasing false negative (i.e. binding constrain ts missing in the reduced formulation) and false p ositive (i.e. non- binding constraints predicted as binding) predictions on the meta-loss. W e demonstrate our findings on grids 162-ieee-dtc and 300-ieee with b oth DC and A C formulations using their default grid parameters. First, we solved the full OPF mo dels and determined the binding constrain ts. T o inv estigate the e ffect of false negative predictions, we randomly remov ed one, tw o, three, etc., binding inequalit y constraints from the active set and computed the meta-loss. F or false p ositiv e predictions, we extended the active set by a giv en num b er of randomly selected constrain ts from the non-binding set. F or each case, we ran 20 indep enden t exp erimen ts and the results are pre- sen ted in Figure 4. The left panel shows the actual meta-loss v alues, while the righ t panel presents the n umber of required iterations in the iterativ e feasibility test. F or all cases, vertical dashed lines indicate the p osition of the p erfect classification, i.e. the exact active set when no false p ositive or false negative predictions are present. When all active constraints are found, including false p ositiv e constraints (moving right from the p erfect classification) has a marginal effect, how ever, they slo wly but surely increase the computational cost. The iterativ e feasibility test conv erges alwa ys within a single step and the cost of the OPF problem dep ends only on its size. F alse negativ e predictions (moving left from the p erfect classification) hav e muc h more severe effect: they require more iterations in the feasibility test that significantly increases the meta-loss even in the lack of few active constraints. Since for small grids the computational cost 17 of the p erfect prediction is only ∼ 50% of the full problem (T able 4), ev en a few iterations can hav e a meta-loss exceeding that of the full OPF problem. In all cases, different constraints represented (or remov ed) can hav e a different impact on the meta-loss, particularly in the false negativ e region where the deviation is larger. 1 0 0 1 0 1 1 0 2 1 0 3 Number of Constraints 0.0 0.5 1.0 1.5 2.0 Meta-loss [s] AS FP FN AS FP FN AS FP FN AS FP FN 1 0 0 1 0 1 1 0 2 1 0 3 Number of Constraints 0 5 10 15 Feasibility Test Iterations 162-ieee-dtc (DC) 162-ieee-dtc (AC) 300-ieee (DC) 300-ieee (AC) Figure 4: Profile of the meta-loss (left) and n umber of iterations within the iterative feasibility test (right) as functions of the num b er of constrain ts for tw o grids, and a comparison of DC vs. AC formulations. Perfect classifiers with the active set (AS) are indicated by vertical dashed lines, false positive (FP) region is to the righ t and false negative (FN) region is to the left. 4.4. L oss and Meta-loss During Conventional Optimization T o demonstrate that conv entional loss optimization is not necessarily able to improv e the meta-loss, we p erformed the following exp erimen t on a smaller (73-ieee-rts), and a larger (162-ieee-dtc) grid with DC-OPF form ulations using the standard grid parameters on 1k samples. During the optimization of cross- en tropy , we sav ed the actual NN w eights every 5 epo chs and computed both the loss and meta-loss v alues on the test set. The results of 5 indep enden t exp erimen ts are collected in Figure 5. F or the smaller grid (73-ieee-rts), which has only 8 distinct active sets in the training data (see T able 2), the meta-loss also decreases progressively due to a near-p erfect p erformance of the classifier for suc h a simple system. How ev er, for the larger grid (162-ieee-dtc) the meta-loss seems to b e insensitive to the optimization of the conv entional loss, and stays at a v alue far from the empirical low er b ound. 18 r t s r t s Figure 5: Loss and meta-loss as functions of ep o c hs during the optimization of the binary cross-entrop y ob jective for a smaller (73-ieee-rts) and a larger (162-ieee-dtc) grid. LHS: each cross-entrop y loss is broken down into the constituent false positive (FP) and false negative (FN) contributions. RHS: meta-loss (computational time) ev aluated at in terv al ep ochs. The empirical low er bound is also plotted represen ting the typical low er bound for the giv en grid with p erfect reduction (see T able 4). 4.5. Impr oving the Meta-loss using Meta-optimization Finally , we presen t our results of the meta-optimization using 10k and 1k samples for the DC- and AC-OPF formulations, resp ectiv ely . W e first carried out a conv entional optimization of the cross-entrop y loss and starting from this parameterization of the NN we further optimized the meta-loss through PSO. W e computed the accumulated meta-loss of a test set b efore ( pr e ) and after ( p ost ) the meta-optimization and computed the gain in the meta-loss relative to the full OPF problem in eac h case. First, we review the results for the DC-OPF formulation. F or smaller grids up to grid 73-ieee-rts, w e found marginal improv ement using meta-optimization. The reason is similar to what we found in Section 4.4: for such small systems with a limited num b er of distinct activ e sets (T able 2), the class ifiers were able to predict binding constraints almost p erfectly and the meta-loss was already close to optimal. F or larger systems (from 118-ieee up to 1354-p egase), meta-optimization significan tly improv ed the meta-loss. Ho wev er, in many cases, we observed tw o trivial lo cal minima the meta-optimization could conv erge to. The first trivial 19 (T yp e 1) minimum mostly o ccurred with smaller training data and the classifier predicted most of the inequality constrain ts binding. This is a consequence of the fact that adding false p ositive predictions to the genuine active set only marginally increases the computational cost as it requires a single feasibility test iteration (Figure 4). This results in little signal (via the meta-loss) driving the optimization a wa y from prediction of all constraints binding to the active set. The second trivial (Type 2) minim um was observed with larger training data, and in this case, the classifier essentially memorized all p oten tially active constraints in the training set. Both are the results of a classifier that has little discriminative p o wer as in eac h case there is little sensitivity to the actual grid parameters with the optimization learning to allow only a single iteration of the iterative feasibilit y test. Recalling that the maximum ac hiev able gain of the grids w e in vestigated is around 50% (T able 4), this means that even a single false negative prediction requires an extra iteration of the feasibility test, increasing the total computational time in comparison to the full problem. F or larger grids, we exp ect a m uch higher n umber of p ossibly binding constrain ts (T able 2), and more significan t difference of the meta-loss b etw een the reduced OPF formulations and full mo del that reduce the p ossibility of the appearance of these trivial minima. T o a void the ab ov e pathological b eha vior, w e introduced the p enalty term discussed in Section-3.3.4. This strategy resulted in a meta-loss-sensitive classifier (Figure 6). Constraint 0 25 50 75 100 Binding Rate (%) Constraint 0 25 50 75 100 False Positive Rate (%) Constraint 0 25 50 75 100 True Negative Rate (%) Post Pre Figure 6: Distribution of errors pre and p ost meta-optimization. Left panel: ground truth binding rate on the test set from grid 162-ieee-dtc (using 10k samples). Middle and right panels: comparison of the false positive and true negativ e rates resp ectiv ely for pre and post meta-optimization. Constrain ts are filtered to those that appear at least 20% in the ground truth. Constraint ordering is the same in eac h subplot. The av erage gains of the meta-loss with tw o side 95% confidence interv als using 10 indep enden t runs b efore and after the meta-optimization are collected in the first tw o columns of T able 5. Gains are computed on the corresp onding test sets relative to the meta-loss of the full OPF mo dels as eq. 3 with t f = P N test i =1 t i f and t ML = P N test i =1 t i ML . F or DC-OPF cases, w e carried out exp erimen ts using 10k samples. F or 118-ieee, conv entional optimization already results in a gain (38 . 2%) that was impro ved only slightly by meta-optimization. Giv en the limited num b er of 20 distinct activ e sets (122) this training data size seems to b e sufficient to obtain a fairly goo d classifier using the conv entional loss. How ever, as the grid size increases, the gain provided by conv entional training becomes drastically worse, resulting in p oorer performance compared to that of the full problem. F or each case, meta-optimization was able to improv e the meta-loss significan tly and bring the gain in to the p ositiv e regime. F or AC-OPF formulation, 3 grids were inv estigated using 1k samples. As the system size increases, the num b er of distinct active sets is muc h larger than in the DC cases, therefore, it is not surprising that conv entional training resulted in a p oor gain for all cases. Meta-optimization again w as able to improv e all of them in to the p ositiv e regime. Finally , w e also inv estigated the effect of the p enalty term on the performance of the meta-optimization for case 162-ieee-dtc with the AC-OPF formulation. Reducing the p enalt y threshold to the av erage num b er of the active constraints in the training data (instead of the default tw ofold v alue) significan tly increased the false negative predictions resulting in a drop of the gain from 8 . 6 ± 7 . 6% to − 49 . 7 ± 4 . 7%. Using a threshold v alue of twice of the default one, how ev er, did not improv e further the gain (11 . 0 ± 5 . 9%) within the margin of error indicating that the default threshold is already sufficien t. T able 5: Average gain of classification-based hybrid mo dels in combination with meta- optimization using con ven tional and weigh ted binary cross-entrop y for pre-training the NN. Case Gain (%) Conv entional W eigh ted Cross-entrop y → Meta-loss Cross-entrop y → Meta-loss DC-OPF (10k) 118-ieee 38 . 2 ± 0 . 8 42 . 1 ± 2 . 7 43 . 0 ± 0 . 5 44 . 8 ± 1 . 2 162-ieee-dtc 8 . 9 ± 0 . 9 31 . 2 ± 1 . 3 21 . 2 ± 0 . 7 36 . 9 ± 1 . 0 300-ieee − 47 . 1 ± 0 . 5 11 . 8 ± 5 . 2 − 10 . 2 ± 0 . 8 23 . 2 ± 1 . 8 588-sdet − 56 . 0 ± 0 . 5 11 . 9 ± 9 . 2 − 11 . 8 ± 1 . 0 24 . 6 ± 2 . 0 1354-pegase − 94 . 6 ± 2 . 8 − 27 . 8 ± 4 . 7 − 54 . 9 ± 2 . 4 − 9 . 9 ± 5 . 4 AC-OPF (1k) 118-ieee − 31 . 7 ± 1 . 2 20 . 5 ± 4 . 2 − 3 . 8 ± 2 . 3 29 . 3 ± 2 . 0 162-ieee-dtc − 60 . 5 ± 2 . 7 8 . 6 ± 7 . 6 − 28 . 4 ± 3 . 0 23 . 4 ± 2 . 2 300-ieee − 56 . 0 ± 5 . 8 5 . 0 ± 6 . 4 − 30 . 9 ± 2 . 2 15 . 8 ± 2 . 3 4.6. Impr oving the Initial State of Meta-optimization Giv en the imp ortance of a go od initialization for meta-optimization we in vestigated whether further improv ement can b e attained if the NN weigh ts are initialized at a p oint closer to a lo cal minimum of the meta-loss. Moreo ver, treating the conv entional ob jective as a surrogate ob jective [ 39 ] for the meta-loss, w e inv estigated if it can b e mo dified to b etter represen t this. F or example, we can use a weigh ted cross-en tropy loss that introduces an asymmetry betw een the false negativ e and false p ositiv e p enalt y terms: − y log ( ˆ y ) w − (1 − y ) log (1 − ˆ y ) (1 − w ) , (4) 21 where ˆ y ∈ [0 , 1] is the predicted probability of an arbitrary constraint’s binding status, y ∈ { 0 , 1 } is the ground truth, and w ∈ [0 , 1] is the weigh t (note that a v alue of 0 . 5 corresp onds to the unw eighted classical cross-entrop y). As w e observed earlier, the meta-loss is muc h more sensitive to false negative predictions (Figure 4). T o reflect this in the weigh ted cross-entrop y expression, w e carried out a set of exp eriments for b oth DC and AC formulations with v arying weigh t (using the same setup for meta-optimization) and found w = 0 . 75 as an optimal v alue for the increased performance. The results are collected in the second tw o columns of T able 5. With this mo dification the gain of pre-training w as already improv ed compared to the conv entional cross-entrop y , and the corresp onding meta-optimization also resulted in further improv ement, significan tly outp erforming the previous results. F or instance, for case 118-ieee, the improv ed gains came close to the corresp onding empirical limits of 47 . 6 ± 0 . 4 and 31 . 1 ± 0 . 4 for DC and AC formulations, resp ectiv ely (T able 4). In Figure 7 we compare the gains of DC form ulations obtained b efore (circles) and after (squares) meta-optimization (using conv entional or weigh ted binary cross-en tropy losses for pre-training) as functions of the n umber of active sets in the training data. F rom the figure, it seems that reducing the cov erage (i.e. the ratio b et w een the num b er of active sets and num b er of samples approac hes 1 . 0) decreases the gain by meta-optimization. Therefore, the complexit y of the system — from learning and predictabilit y p oin t of view — is primarily determined b y the p oten tial num b er of distinct active sets rather than the system size. Although in general the system size and the num b er of distinct active sets correlate with eac h other, there are exceptions: for instance, based on T able 2, the size of case 300-ieee is appro ximately double of the size of 162-ieee-dtc and the size of case 588-sdet is double of 300-ieee. How ever, the num b er of active sets of case 300-ieee is an order of magnitude larger than that of case 162-ieee-dtc, while case 588-sdet has approximately the same. Accordingly , the ac hieved gain is v ery similar for cases 300-ieee and 588-sdet, while case 162-ieee-dtc has a muc h higher gain. 22 1 18-ieee 162-ieee-dtc 300-ieee 588-sdet 1354-pegase Figure 7: Correlation between gains of DC formulations obtained b y pre-training and subsequen t meta-optimization (using con ven tional or weigh ted binary cross-en tropy loss functions for pre-training) and the ratio of num b er of active sets and number of training samples. The empirical upp er limit of the corresponding gains (i.e. p erfect classifier, T able4) is also sho wn. Finally , we note that an even more representativ e loss function can b e constructed b y using individual weigh ts for each constrain t. These w eights can then b e optimized as hyperparameters using the meta-loss as the optimization target through a similar PSO framework. How ever, our preliminary exp eriments for DC-OPF show ed that although there is a further reduction of the meta-loss, it still required a subsequen t meta-optimization of the NN to hav e comp etitive p erformance to the ab ov e results. This suggests that under this parameterization of the classical ob jective, although the meta-loss can b e minimized to a limited exten t, in order to achiev e further improv ement, a direct meta-optimization of the NN is needed. W e leav e a more thorough exploration to future work. 5. Conclusion A promising approac h to reduce the computational time of solving OPF problems is to solve a reduced formulation, which is a considerably smaller problem. As part of a classification-based hybrid model, by training mo dels offline, predictions of the active constrain t set based on the real-time grid parameters can b e p erformed with negligible cost. Ho wev er, p ossible false negativ e predictions and the potential subsequent violation of the corresponding constrain ts can lead to infeasible points of the original (full) problem. This can 23 easily app ear for large grids, which hav e a significant num b er of distinct active sets. This issue can b e resolv ed b y the iterativ e feasibility test used b y certain grid operators. In this procedure, the solution of a reduced OPF problem is tested against all constraints of the full problem, the active set is extended by constrain ts that are violated, and a new reduced OPF problem is constructed and solved. The iteration is then terminated when no new constraint is violated, guaran teeing a solution of the full OPF problem. In this pap er, w e introduced a hybrid metho d for predicting active sets of constrain ts of OPF problems using neural netw ork based classifiers and meta- optimization. The key ingredient of our approach is to replace the conv entional loss function with an ob jective that measures the computational cost of the iterativ e feasibility test. This meta-loss function is then optimized by v arying the w eights of the NN. F or v arious syn thetic grids, using DC- and A C-OPF form ulations we demon- strated that NN classifiers optimized by meta-optimization results in a signifi- can tly shorter solv e time of the iterativ e feasibility test than those of con ven tional loss optimization. F urther, for several DC-OPF cases, the meta-loss as optimized b y meta-optimization outp erformed that of the full OPF problem. F or AC-OPF, the p erformance was more mo derate due to the large num b er of non-conv ex equalit y constraints, which are resp onsible for the ma jority of the computational cost of the OPF calculation. When comparing the p erformance for different grid sizes, meta-optimization app ears to b e an increasingly imp ortant comp onen t in iden tifying reduced formulations of OPF problems for larger grids. W e also found that the cross-entrop y ob jectiv e can b e mo dified to obtain an impro ved meta-loss after conv en tional training, b y weigh ting the con tribution of the tw o types of classification errors. How ever, particularly for larger-grids, this meta-loss is still higher than that obtained after meta-optimization of the NN parameters directly , indicating that the conv en tional classification ob jectiv e is insufficient to capture the meta-loss. Nevertheless, these approaches can b e straigh tforwardly used as initialization step for meta-optimization. Beside increasing the size of the training data set to impro ve co verage, there are additional w ays to improv e the metho d further. The simplest approac h w ould b e to use a more extensive meta-optimization that can b e carried out by increasing the n umber of meta-optimization steps, the num b er of particles of the PSO metho d and the n umber of training sub-samples. In our exp erimen ts, all these parameters had a relatively small v alue (i.e., 10 particles, 50 iterations and 100 sub-sampled training p oin t) as our inten tion was to demonstrate that ev en with this limited setup reasonable results can b e ac hieved. Using more sophisticated conv entional loss functions for pre-optimization is also a promising direction. In the current approac h, all inequality constrain ts’ binding status is predicted, including those that are alwa ys non-binding in the training data. Filtering out these constraints would p oten tially reduce the output dimensionalit y of the NN, which could improv e the predictive p o wer further. Finally , we also plan to use top ological information of the grid by applying graph neural net works for further improv ements. These c hanges can make the metho d suitable for 24 realistic grids and also for N − k con tingency problems, where w e exp ect even higher gain due to the smaller fraction of active vs. total num b er of constraints. References [1] J. T ong, Overview of PJM energy market design, op eration and exp erience, in: 2004 IEEE International Conference on Electric Utility Deregulation, Restructuring and P ow er T ec hnologies. Pro ceedings, V ol. 1, IEEE, 2004, pp. 24–27. [2] M. B. Cain, R. P . O’neill, A. Castillo, History of optimal p o wer flow and form ulations, F ederal Energy Regulatory Commission 1 (2012) 1–36. [3] NERC, NERC reliabilit y guideline, draft, september (2018). [4] A. V. Fiacco, G. P . McCormick, Nonlinear Programming: Sequential Un- constrained Minimization T ec hniques, John Wiley & Sons, New Y ork, NY, USA, 1968, reprin ted by SIAM Publications in 1990. [5] A. W¨ ac hter, L. T. Biegler, On the implementation of a primal-dual in terior p oin t filter line search algorithm for large-scale nonlinear programming, Mathematical Programming 106 (1) (2006) 25–57. [6] Y. T ang, K. Dvijotham, S. Low, Real-time optimal p o wer flow, IEEE T ransactions on Smart Grid 8 (6) (2017) 2963–2973. doi:10.1109/TSG. 2017.2704922 . [7] J. Liu, J. Marecek, A. Simonetta, M. T ak a ˇ c, A co ordinate-descen t algorithm for tracking solutions in time-v arying optimal p o wer flo ws (June 2018). doi:10.23919/PSCC.2018.8442544 . [8] L. Zhang, G. W ang, G. B. Giannakis, Real-time p ow er system state estima- tion and forecasting via deep unrolled neural netw orks, IEEE T ransactions on Signal Pro cessing 67 (15) (2019) 4069–4077. [9] Q. Y ang, G. W ang, A. Sadeghi, G. B. Giannakis, J. Sun, Two-timescale v oltage control in distribution grids using deep reinforcemen t learning, IEEE T ransactions on Smart Grid. [10] A. S. Xavier, F. Qiu, S. Ahmed, Learning to solve large-scale security- constrained unit commitmen t problems (2019). . [11] N. Guha, Z. W ang, A. Ma jumdar, Mac hine learning for AC optimal p o wer flo w, ICML, Climate Change: How Can AI Help? W orkshop. [12] F. Fioretto, T. W. K. Mak, P . V an Hentenryc k, Predicting A C Optimal P ow er Flo ws: Combining Deep Learning and Lagrangian Dual Metho ds, arXiv e-prin ts (2019) arXiv:1909.10461. 25 [13] K. Baker, Learning warm-start p oin ts for ac optimal p ow er flow, in: 2019 IEEE 29th International W orkshop on Machine Learning for Signal Pro cess- ing (MLSP), 2019, pp. 1–6. doi:10.1109/MLSP.2019.8918690 . [14] M. Jamei, L. Mones, A. Robson, L. White, J. Requeima, C. Ududec, Meta- optimization of optimal p o wer flo w, ICML, Climate Change: Ho w Can AI Help? W orkshop. [15] X. Pan, T. Zhao, M. Chen, Deep opf: Deep neural netw ork for dc op- timal p o wer flow, 2019 IEEE International Conference on Communica- tions, Control, and Computing T ec hnologies for Smart Grids (SmartGrid- Comm) doi:10.1109/smartgridcomm.2019.8909795 . URL http://dx.doi.org/10.1109/SmartGridComm.2019.8909795 [16] A. Zamzam, K. Bak er, Learning optimal solutions for extremely fast ac optimal p o wer flow (2019). . [17] Q. Zhou, L. T esfatsion, C. Liu, Short-term congestion forecasting in whole- sale pow er mark ets, IEEE T ransactions on P ow er Systems 26 (4) (2011) 2185–2196. doi:10.1109/TPWRS.2011.2123118 . [18] S. Misra, L. Roald, Y. Ng, Learning for Constrained Optimization: Identi- fying Optimal Activ e Constraint Sets, arXiv e-prints. [19] S. Pineda, J. M. Morales, A. Jim´ enez-Cordero, Data-driv en screening of net work constraints for unit commitment, IEEE T ransactions on Po wer Systems 35 (5) (2020) 3695–3705. doi:10.1109/TPWRS.2020.2980212 . [20] X. Ma, H. Song, M. Hong, J. W an, Y. Chen, E. Zak, The security-constrained commitmen t and dispatch for Midwest ISO day-ahead co-optimized energy and ancillary service mark et, in: 2009 IEEE Po wer & Energy Society General Meeting, IEEE, 2009, pp. 1–8. [21] D. Dek a, S. Misra, Learning for DC-OPF: Classifying active sets using neural nets, arXiv e-prin ts (2019) arXiv:1902.05607. [22] Y. Ng, S. Misra, L. A. Roald, S. Backhaus, Statistical Learning F or DC Optimal Po wer Flo w, arXiv e-prints (2018) arXiv:1801. 07809 . [23] C. Coffrin, R. Bent, K. Sundar, Y. Ng, M. Lubin, Po werModels.jl: An op en-source framework for exploring p o wer flo w formulations, in: 2018 P ow er Systems Computation Conference (PSCC), IEEE, 2018, pp. 1–8. [24] C. M. Bishop, Pattern Recognition and Machine Learning (Information Science and Statistics), Springer-V erlag, Berlin, Heidelb erg, 2006. [25] L. Mones, C. Ortner, G. Cs´ an yi, Preconditioners for the geometry optimisa- tion and saddle p oin t searc h of molecular systems, Scientific Rep orts 8 (1) (2018) 13991. doi:10.1038/s41598- 018- 32105- x . 26 [26] J. Kennedy, R. Eb erhart, Particle swarm optimization, in: Pro ceedings of ICNN’95 - International Conference on Neural Netw orks, V ol. 4, 1995, pp. 1942–1948 v ol.4. doi:10.1109/ICNN.1995.488968 . [27] Z. Zhan, J. Zhang, Y. Li, H. S. Chung, Adaptive particle swarm optimization, IEEE T ransactions on Systems, Man, and Cyb ernetics, Part B (Cyb ernetics) 39 (6) (2009) 1362–1381. doi:10.1109/TSMCB.2009.2015956 . [28] L. Mones, Mo dified PSO in Optim.jl, https://github.com/molet/Optim. jl (2019). [29] S. Babaeinejadsaro ok olaee, A. Birchfield, R. D. Christie, C. Coffrin, C. De- Marco, R. Diao, M. F erris, S. Fliscounakis, S. Greene, R. Huang, C. Josz, R. Korab, B. Lesieutre, J. Maegh t, D. K. Molzahn, T. J. Overb ye, P . Panci- atici, B. Park, J. Sno dgrass, R. Zimmerman, The Po wer Grid Library for Benc hmarking AC Optimal P ow er Flow Algorithms, arXiv e-prints (2019) arXiv:1908.02788. [30] J. Bezanson, S. Karpinski, V. B. Shah, A. Edelman, Julia: A fast dynamic language for tec hnical computing, arXiv preprint [31] M. Innes, Flux: Elegan t machine learning with Julia., J. Op en Source Soft ware 3 (25) (2018) 602. [32] S. Ioffe, C. Szegedy , Batch normalization: Accelerating deep netw ork train- ing by reducing in ternal cov ariate shift, in: F. Bach, D. Blei (Eds.), Pro- ceedings of the 32nd International Conference on Machine Learning, V ol. 37 of Pro ceedings of Machine Learning Research, PMLR, 2015, pp. 448–456. [33] V. Nair, G. E. Hinton, Rectified linear units improv e restricted boltzmann mac hines, in: Proceedings of the 27th In ternational Conference on Inter- national Conference on Machine Learning, ICML’10, Omnipress, Madison, WI, USA, 2010, p. 807–814. [34] N. Sriv asta v a, G. Hinton, A. Krizhevsky , I. Sutskev er, R. Salakhutdino v, Drop out: A simple w ay to preven t neural net works from o verfitting, J. Mac h. Learn. Res. 15 (1) (2014) 1929–1958. [35] D. P . Kingma, J. Ba, Adam: A metho d for sto c hastic optimization, arXiv preprin t [36] P . K. Mogensen, A. N. Riseth, Optim: A mathematical optimization pac k age for Julia, Journal of Open Source Softw are 3 (24) (2018) 615. doi:10.21105/ joss.00615 . [37] A. Domahidi, E. Chu, S. Boyd, ECOS: An SOCP solver for em b edded systems, in: 2013 European Con trol Conference (ECC), IEEE, 2013, pp. 3071–3076. 27 [38] B. Stellato, G. Banjac, P . Goulart, A. Bemp orad, S. Boyd, OSQP: An op erator splitting solver for quadratic programs, ArXiv e-prints arXiv: 1711.08013 . [39] I. Go odfellow, Y. Bengio, A. Courville, Deep Learning, MIT Press, 2016. 28
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment