Private Set Intersection: A Multi-Message Symmetric Private Information Retrieval Perspective
We study the problem of private set intersection (PSI). In this problem, there are two entities $E_i$, for $i=1, 2$, each storing a set $\mathcal{P}_i$, whose elements are picked from a finite field $\mathbb{F}_K$, on $N_i$ replicated and non-colludi…
Authors: Zhusheng Wang, Karim Banawan, Sennur Ulukus
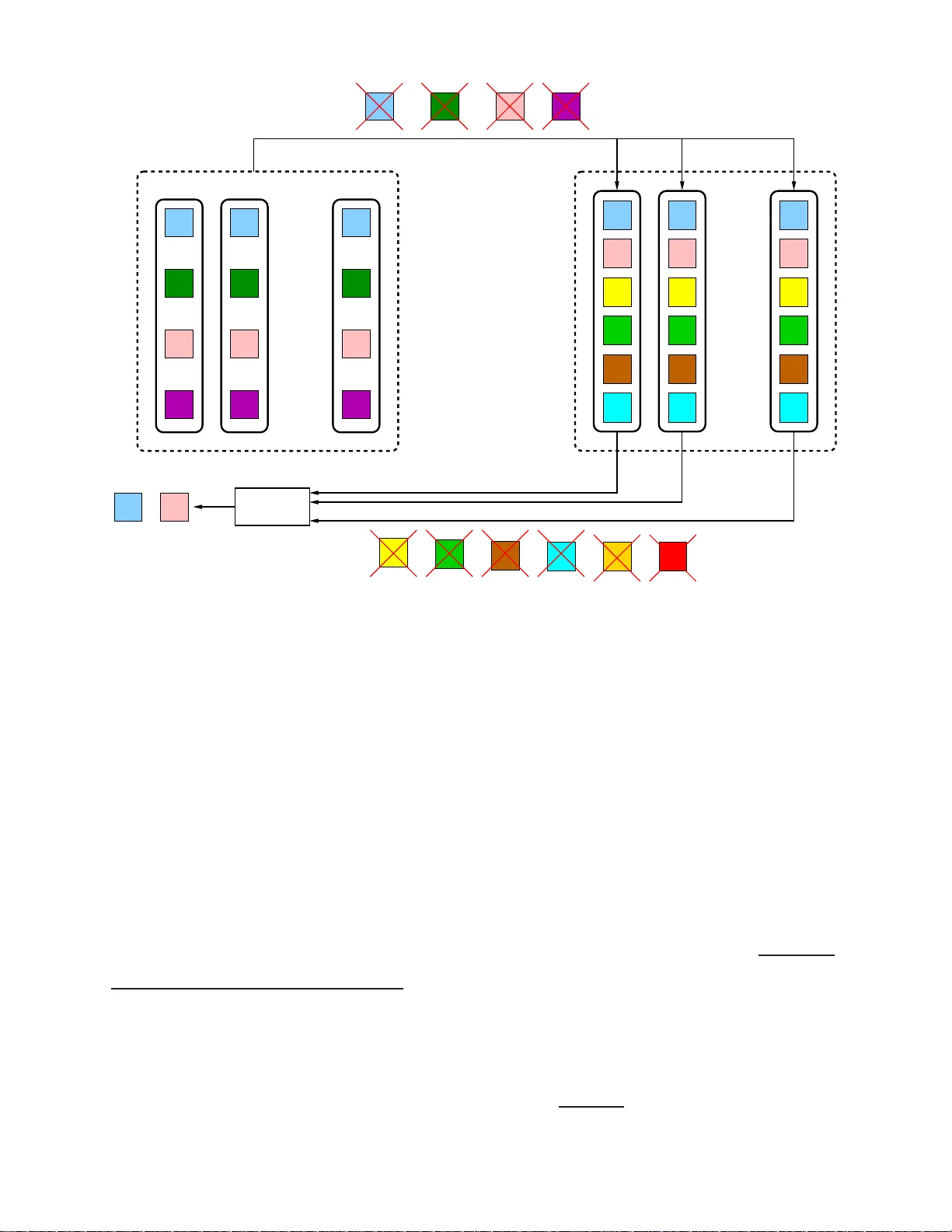
Priv ate Set In tersection: A Multi-Message Symmetric Priv ate Information Retriev al P ersp ectiv e ∗ Zh usheng W ang 1 , Kar i m Bana w an 2 , and Sennur Ulukus 1 1 Departmen t of Elec trical and Computer Engineering, Univ ersit y of Maryland 2 Electrical Engineering Departmen t, F acult y of Engineering, Alexandria Un iv ersity Decem b er 1, 202 0 Abstract W e study the problem of p riv ate set intersec tion (PSI). In this pr oblem, there are t wo en tities E i , for i = 1 , 2, eac h storing a set P i , whose elemen ts are p ic ke d from a finite set S K , on N i replicated and non-colluding databases. It is requir ed to determine the set in tersection P 1 ∩ P 2 without l eaking a n y information ab out the remaining elemen ts to the other en tit y , and to do this with the least amoun t of d o wn loaded b its. W e fi r st show that the PSI pr oblem can b e recast as a m u lti-message symmetric priv ate in f ormation retriev al (MM-SPIR) pr oblem with certain added r estrictions. Next, as a stand-alone result, we derive the information-theoretic sum capacit y of MM-SPIR, C M M − S P I R . W e sho w that with K messages, N databases, and a giv en size of the desired message set P , the exact capacit y of MM-SPIR is C M M − S P I R = 1 − 1 N when P ≤ K − 1, p ro vid ed that the en tr op y of the common randomness S satisfies H ( S ) ≥ P N − 1 p er desired sym b ol. When P = K , the MM-SPIR capacit y is trivially 1 without the need for any common rand omness S . Th is result implies that there is no gain for MM-SPIR o ver successiv e single-message SPIR (SM-SP I R). F or the MM-SPIR prob lem, we presen t a no v el capac it y-ac hieving sc heme whic h builds s eamlessly o ver the near-optimal s cheme of Bana wan-Ulukus originally prop osed for the multi-message PI R (MM-PIR) pr ob lem without an y database priv acy constrain ts. Surp r isingly , our sc h eme here is exactly optimal for the MM-SPIR problem for any P , in con tr ast to the sc h eme for the MM- PIR problem, whic h w as pro v ed only to b e near-optimal. Our sc heme is an alternativ e to th e s u ccessiv e usage of the SM-SPIR scheme of Su n-Jafar. Based on this capacit y result f or the MM-SPIR problem, and after addressing the added requir emen ts in its con version to the PS I problem, w e sho w that the optimal do w nload cost for the PSI problem is give n by min nl P 1 N 2 N 2 − 1 m , l P 2 N 1 N 1 − 1 mo , where P i is the cardin alit y of set P i . ∗ This work was supp orted by NSF Gra nts CCF 17- 13977 and ECCS 18 - 07348 . 1 1 In tro du c tion The priv ate set interse ction (PSI) problem refers to the pro blem of determining the common elemen ts in tw o sets (lists) without leaking an y further informatio n abo ut the remaining ele- men ts in the sets. This problem ha s b een a ma jor researc h topic in the field of cryptography starting with the w o r k [1] (see also [2 – 4]). In all these works , computational guarantee s are used to ensure the priv acy of the elemen ts b ey o nd the in t ersection. The PSI problem can b e motiv ated by many practical examples , for instance: Consider a n airline compan y whic h has a list of its customers, and a la w enforcemen t agency whic h has a list of susp ected terrorists. The airline compan y a nd the la w enforcemen t agency wish t o determine the in tersection of their respectiv e lists without the airline compan y rev ealing t he rest of its customers and the la w enforcemen t ag ency rev ealing the rest of the suspects in its list. As a nother example, consider a ma jor service pro vider (e.g., Whatsapp) and a new customer who wishes to join this service. The user wishes to find out which mem b ers o f his/her con tact list are already using this service without rev ealing his/her en tire contact list to the service pro vider. Sim- ilarly , the service pro vider wishes to determine the in tersection without rev ealing its en tire list of customers. F or other examples, please see [2 , 3]. Since the entities in PSI w a n t to privately r etrieve t he elemen ts that b elong to the in- tersection o f their sets P 1 ∩ P 2 , where P i is the set (list) that b elongs to the i th en tity , priv ate informa t io n retriev al (PIR) can b e used as a building blo c k for the PSI problem. In classical PIR, whic h w as intro duced by Chor et al. [5], a user w an ts to retriev e a message (file) from distributed databases without leaking an y information ab out the iden tity o f the desired file. This is desirable in the PSI problem, as one of the en t it ies wan ts to retriev e the in t ersection P 1 ∩ P 2 . Nev ertheless, it is needed to k eep the remaining elemen ts of the sets secret fro m the other en tit y , i.e., the first entit y w an ts to k eep the set P 1 \ P 2 from the second en tity a nd vice v ersa. This g ives rise naturally to the problem of symmetric PIR (SPIR), whic h was originally in tro duced in [6], where the retriev al sc heme needs to ensure that the user learns no information b ey o nd the desired message. This extra requiremen t is called the datab ase privacy constrain t, whic h is in addition to the usual user privacy constrain t in PIR. Recen tly , Sun and Jafar reformulated the problems of PIR and SPIR from an information- theoretic p oint of view, and determined the fundamen tal limits of b oth of these problems, i.e., their capacit y , in [7] and [8], respectiv ely . Subsequen tly , the fundamen tal limits of man y in t eresting v aria nts of PIR and SPIR hav e b een considered, see f or example [9 – 62]. No w, to use SPIR to implemen t PSI, the i th en tity needs to priv ately c hec k the presence of each elemen t in P i at the other entit y . That is, the i th en tity needs to retriev e the o c curr enc es of all elemen ts that b elong to its set P i from the other en tity . This implies that the i th entit y needs to retriev e multiple mess ages from the other en tit y , where the messages here corresp ond t o the incide n c e s of eac h elemen t of the set P i . This establishes the connection betw een the PSI problem and the multi-message SPIR (MM-SPIR) problem. Apart from the PSI problem, the MM-SPIR pro blem is in teresting on its o wn right and 2 has remained an op en problem until this work. Reference [23] in v estigates the problem o f m ulti- message PIR (MM-PIR) without an y database priv acy constrain ts. The results of [23] sho w that the user can impro v e the retriev al rate by jointly retrieving the desired messages instead of retrieving them one-by -one. In this pa p er, w e aim to c haracterize t he capacit y of the MM-SPIR problem as a stand- alone result, and determine whether the MM-SPIR capacit y is larger than the single-message SPIR (SM-SPIR) capacity . Second, w e aim to unify the a c hiev ability sc hemes of MM-PIR and MM-SPIR so tha t the query structure can b e maintained with and without the data base priv acy constrain ts. The pap ers that are most closely r elat ed to o ur w o rk are the o nes that fo cus on symmetry and multi-mes sage asp ects of PIR. Referenc e [8] deriv es the SPIR capacit y when the user wishes to retriev e a single message as C S M − S P I R = 1 − 1 N . Reference [2 3] considers MM-PIR and determines the exact capacit y when the nu m b er of desired messages P is at least half of the total n umber of messages K or when K/ P is an in teger; fo r all other cases [23] pro vides a nov el PIR sc heme whic h is near- optimal. Reference [35 ] studies m ulti- serv er MM-PIR with priv a t e side information. References [36, 37] study single-serv er MM-PIR with side informa- tion. Reference [13] studies SPIR fr o m MDS-co ded databases. The problem is extended to include colluding serv ers in [14] and mismatc hes b et w een message and common randomness co des in [15]. Reference [16] inv estigates SPIR in the presence of adv ersaries. Reference [17] c hara cterizes the tradeoff b et w een the minim um do wnload cost and the information leak age from undesired messages . None of these w orks considers the in terplay b et we en the data priv a cy constrain t and the joint retriev al of multiple messages, as needed in MM-SPIR. In this pap er, first fo cusing on MM-SPIR as a stand-alone problem, w e deriv e its capac- it y . Our results sho w that the sum capacit y of MM-SPIR is exactly equal to the capacit y of SM-SPIR, i.e., C S M − P I R = C M M − P I R = 1 − 1 N . W e sho w that the databases need to share a r a ndom v ar iable S suc h that H ( S ) ≥ P N − 1 p er desired sym b o l, whic h is P m ultiple of the common randomness required for SM-SPIR. This implies that, unlik e MM-PIR, there is no gain from jointly retrieving the P messages, and it suffices to down load the P messages suc - cessiv ely using the SM-SPIR sch eme in [8], provide d tha t statistically indep enden t common randomness sy m b ols are used at eac h time. F or the extreme case P = K , i.e., when the user w ants to retriev e all messages, the problem reduces to SPIR with K = 1 message, where the dat abase priv acy and the user priv acy constrain t s are trivially satisfied and full capacit y (i.e., C M M − S P I R = 1 ) is attained without the need fo r an y common randomness. F urther, fo r MM-SPIR, we pr o p ose a no vel capacit y-ac hieving sc heme for 1 ≤ P ≤ K − 1 . Compared with the one in [8], the form of this ac hiev able sc heme is muc h closer to t he ac hiev able sc heme in [7]. The query structure of t he sc heme rese m bles its coun terpart in [23], in par t icular, w e construct the greedy algorithm in [7] bac kw ards a s in [23]. The ma jor difference b et wee n our prop osed sc heme here and the MM-PIR sch eme in [23] is the fact that databases add the common randomness to the returned answ er strings to satisfy the database priv acy constrain t. O ur sche me is surprisingly optimal for all P and K in con trast 3 to the sche me in [2 3] whic h is pro v ed to b e optimal only if P is at least half of K or K /P is an in t eger. By plugg ing P = 1, our sc heme serv es as a n alternativ e capacit y-ac hieving sche me for the SM-SPIR sc heme in [8]. As an added adv an tage, our sc heme extends seamless ly the MM-PIR sc heme to satisfy the database priv acy constrain t without changing the query structure. Hence, by op erating suc h a sc heme the databa ses can supp ort SPIR and PIR sim ultaneously . Moreov er, the sc heme ma y serv e as a stepping stone t o solv e some other SPIR problems, suc h a s, SM-SPIR or MM-SPIR with side information. In this pap er, w e ultimately consider the PSI problem. There are tw o en tities E 1 and E 2 . The en tit y E i has a set (list) P i , whose elemen ts are pic k ed from a finite set S K and has a cardinality P i . The set P i is stored on N i non-colluding and replicated databases. It is required to compute the intersec tion P 1 ∩ P 2 without leaking informat io n ab o ut P 1 \ P 2 or P 2 \ P 1 with the minim um dow nload cost. W e first sho w that this problem can b e recast as an MM-SPIR problem, where a user needs to r etrieve P messages from a library containing K messages. In this MM-SPIR pro blem, messages correspo nd to i n cidenc es o f elemen ts in these sets with resp ect to the field elemen ts. Specifically , the en tit y E i constructs the incidence v ector of its elemen ts with resp ect to the field elemen ts. The incidence v ector is a binary v ector of length K that stores a 1 in the p osition of the j th elemen t of t he field if this field elemen t is in P i . This transforms eac h set in t o a library o f K binary messages (o f length 1 bit eac h). This transformation is needed since in SPIR, a user needs to know the lo cation of the file(s) in the databases. Therefore, in transforming the PSI problem into a n MM-SPIR problem, tw o restrictions arise: First, the message size is fixed and finite, whic h is 1 in this case. Second, dep ending o n the mo del assumed regarding the generation of sets P 1 and P 2 , the messages may b e correlated. In our formulation, the message size is 1, but the messages are indep enden t; see the exact problem formulation. F o llo wing these constructions, en tity E i p erforms MM-SPIR of the messages corresp onding to its set P i within the databases o f the other en tity . By deco ding these messages, the inters ection P 1 ∩ P 2 is determined without leaking any information ab out P 1 \ P 2 or P 2 \ P 1 . This is a direct consequence of satisfying the reliability , user pr iv acy , and database pr iv acy constrain ts of the MM-SPIR problem. W e sho w that the optim um dow nload cost of the PSI problem is min nl P 1 N 2 N 2 − 1 m , l P 2 N 1 N 1 − 1 mo , whic h is linear in the size of t he smaller set, i.e., min { P 1 , P 2 } . The linear scaling app ears in the problem of determining the set inte rsection ev en without any priv a cy constrain ts. 2 PSI: Proble m F orm ulatio n Consider the problem o f priv ately determining the in tersection of tw o sets (or lists) pic k ed from a finite set 1 S K . F or con venie nce, w e denote a random v ariable and its realization 1 The r estriction of generating the set fro m a finite set is without loss of gener alit y as the set elements of a n y kind can b e mapp ed into co rresp onding finite set elements for sufficiently large size. F or example, the elements of the set that contains the na mes of s uspected terrorists in the United States can b e mapp ed int o elemen ts from the finite s e t S K , where K is the populatio n size on this planet. As w e will show next, 4 b y using the same general upp ercase letter when distinction is clear from the con text. W e address this issue additionally whenev er clarification is needed. Consider a setting where there are tw o en tities E 1 and E 2 . F or i = 1 , 2, the entit y E i stores a set P i . F or eac h elemen t of t he finite set S K , the entit y E i adds 2 this elemen t to its set P i indep enden tly from the remaining field elemen ts with probability q i . In this w ork, we fo cus o n the case o f q i = 1 2 for i = 1 , 2. Aft er generation of the set P i , the cardinalit y of P i ⊆ S P i K is denoted by | P i | = P i , and is public know ledge. 3 The en tit y E i stores P i in a replicated fashion on N i replicated and non- colluding databa ses. The en tities E 1 and E 2 w ant to compute the interse ction P 1 ∩ P 2 priv a t ely ( see Fig . 1). T o that end, t he entit y 4 E 1 sends N 2 queries to t he databases asso ciated with E 2 . Sp ecifically , E 1 sends the query Q [ P 1 ] n 2 to the n 2 th database f o r all n 2 ∈ [ N 2 ], where [ N 2 ] (a nd a lso [1 : N 2 ]) denotes integers from 1 to N 2 . Since E 1 do es not know P 2 in adv ance, it generates the queries Q [ P 1 ] 1: N 2 = n Q [ P 1 ] n 2 : n 2 ∈ [ N 2 ] o indep enden tly f rom P 2 , hence, I ( Q [ P 1 ] 1: N 2 ; P 2 ) = 0 (1) The databases associat ed with E 2 resp ond truthfully with answ ers A [ P 1 ] 1: N 2 = n A [ P 1 ] n 2 : n 2 ∈ [ N 2 ] o . The n 2 th answ er A [ P 1 ] n 2 is a deterministic function of the set P 2 , the query Q [ P 1 ] n 2 and the existing common ra ndomness S , th us, H ( A [ P 1 ] n 2 | Q [ P 1 ] n 2 , P 2 , S ) = 0 , n 2 ∈ [ N 2 ] (2) Denote the cardinality o f the in tersection |P 1 ∩ P 2 | b y M . The en tit y 5 E 1 should b e able to reliably compute the in tersection P 1 ∩ P 2 based on the sen t queries Q [ P 1 ] 1: N 2 , the collected answ ers A [ P 1 ] 1: N 2 and the kno wledge of P 1 without kno wing M in adv ance. This is captured b y the following PSI reliability constraint, [PSI reliability ] H ( P 1 ∩ P 2 | Q [ P 1 ] 1: N 2 , A [ P 1 ] 1: N 2 , P 1 ) = 0 (3) the download cos t is indep endent o f K . Hence, the optimization of the alphab et size is irrelev a n t to our formulation. Nev e rtheless, it is advisable to choose K to b e the lowest in teger such that P 1 , P 2 ⊆ S K to minimize the upload cost. It suffices to hav e K > P 1 + P 2 . 2 W e note that our achiev ability scheme w orks for a ny statistical distribution imp osed on the s ets, i.e., the i.i.d. generatio n assumption presented here is not needed for the achiev a bilit y pr o of. 3 W e no te that cho osing to have P i to b e a glo bal k nowledge is for co nvenience only . This knowledge enables the entities to deter mine which en tit y should initiate the P SI pro ces s to hav e the least download cost (or if any is needed at all, as in the cas e of P i = K , for a n i ; see Remar k 1). If the car dina lities are not public kno wledge, our achiev ability works by choosing one of the entities arbitr arily to initiate the PSI pro cess assuming that the o ther entit y has sufficient common r andomness. W e no te, how ever, that k ee ping the cardinalities priv a te is indeed a challenging pr oblem a nd it is o utside the sco pe of this work. 4 The en tities E 1 , E 2 should a gree on a sp ecific order of retr iev al op eratio ns such that this order r esults in the minimal download cost. Without los s o f g enerality , w e assume he r e that the optimal order of op eration starts with entit y E 1 sending queries to the databases asso ciated with en tit y E 2 . 5 After calculating P 1 ∩ P 2 at E 1 , the entit y E 1 sends the result of P 1 ∩ P 2 directly to E 2 if needed. 5 f g h a c e f g h a e f g h Deco der a c a a a c c c b b b e j f g h i b d a c DB N 2 DB 1 DB 2 Q [ P 1 ] 1 Q [ P 1 ] 2 Q [ P 1 ] N 2 . . . c a E 2 d E 1 A [ P 1 ] 2 A [ P 1 ] N 2 A [ P 1 ] 1 DB 1 DB 2 DB N 1 . . . d d c e Figure 1: Example for the priv ate set in tersection (PSI) problem. E 1 has the set P 1 = { a, b, c, d } and E 2 has the set P 2 = { a, c, e, f , g , h } . E 1 submits queries to E 2 that do not leak information ab out P 1 , while E 2 resp onds with a nswe rs that do no t leak information ab out e, f , g , h (or non-existen ce of i, j ). By decoding the answ ers, E 1 learns that P 1 ∩ P 2 = { a, c } . The priv acy requiremen ts can b e expressed as t he f o llo wing tw o priv acy constrain ts: E 1 priv a cy and E 2 priv a cy . First, the queries sen t b y E 1 should not leak any information ab out 6 P 1 , i.e., an y individual database asso ciated with E 2 learns nothing ab out P 1 from the query Q [ P 1 ] n 2 , the a nsw er A [ P 1 ] n 2 , the knowledge of P 2 and the existing common ra ndomness S , [ E 1 priv a cy] I ( P 1 ; Q [ P 1 ] n 2 , A [ P 1 ] n 2 , P 2 , S ) = 0 , n 2 ∈ [ N 2 ] (4) Second, E 1 should not b e able to learn any thing further than P 1 ∩ P 2 , i.e., E 1 should not learn the elemen ts in P 2 other than the in tersection, P 2 \ ( P 1 ∩ P 2 ) = P 2 \ P 1 . Moreov er 7 , E 1 should not learn the absence of the remaining field eleme n ts in E 2 , i.e., the set ( P 1 ∪ P 2 ). 6 While chec k ing the presence of elemen ts of P 1 in P 2 , E 1 wan ts to protect P 1 \ P 2 . How ever, since E 1 do es not know P 2 , the queries canno t de p end on P 2 (see als o (1)), and E 1 should protect a ll of P 1 in querie s . 7 Although it is tempting to formulate the E 2 priv acy constraint as I ( P 2 \ P 1 ; A [ P 1 ] 1: N 2 ) = 0, this co nstraint per mits lea king informatio n ab out the remaining field elements that do no t exist in P 2 . More sp ecifically , if we ado pted this co ns traint in the example in Fig. 1, the answers should not leak infor mation ab out e, f , g , h , how ever, E 1 may learn tha t the elements i, j do not exist in P 2 . T o prop erly for malize the constraint that E 1 learns nothing other than the intersection, we need to pro tect ( P 1 ∪ P 2 ) as well. 6 Th us, E 1 should learn nothing ab out whethe r E 2 con ta ins ( P 2 \ P 1 ) ∪ ( P 1 ∪ P 2 ) = ¯ P 1 or not (w e denote this information by E 2 , ¯ P 1 ) from the collected answ ers A [ P 1 ] 1: N 2 giv en the generated queries Q [ P 1 ] 1: N 2 and the kno wledge of P 1 , [ E 2 priv a cy] I ( E 2 , ¯ P 1 ; Q [ P 1 ] 1: N 2 , A [ P 1 ] 1: N 2 , P 1 ) = 0 (5) F or giv en finite set size K , set sizes P 1 and P 2 , and n um b er of dat a bases N 1 and N 2 , an ac hiev able PSI sc heme is a sc heme that satisfies the PSI reliabilit y constrain t (3), the E 1 priv a cy constraint (4), and t he E 2 priv a cy constraint (5). In this pap er, w e measure the efficiency of a sc heme b y the maximal num b er of downloaded bits by o ne o f the entities E 1 or E 2 in order to compute P 1 ∩ P 2 . W e denote the maximal num b er o f downloaded bits b y D . Then, the optimal download cost is D ∗ = inf D o ve r all achiev able PSI sc hemes. 8 3 F rom PSI to MM-SPIR In this section, w e sho w tha t the PSI problem can b e reduced to an MM-SPIR problem, if the entitie s allow storing t heir sets in a sp ecific searchable format. This transformation has the same flav or as [63] and [42], where the original conten ts of the databases a re ma pp ed in t o searc ha ble lists to enable PIR, whic h assumes that the user know s the p osition of the desired file in the databases. T o tha t end, define the incidence v ector X i ∈ F K 2 as a binary v ector of size K asso ciated with the set P i . Denote the j th elemen t of the incidence v ector X i b y X i ( j ) where X i ( j ) = 1 , j ∈ P i 0 , j / ∈ P i (6) for all j ∈ S K . Hence, X i ( j ) is an i.i.d. random v aria ble for all j ∈ [ K ] suc h tha t X i ( j ) ∼ Ber( q i ). The en tit y E i constructs the incidence v ector X i corresp onding to the set P i (see Fig. 2). The en tity E i replicates the ve ctor X i at all of its N i asso ciated databases ( see Fig. 3). Note that X i is a sufficien t statistic f or P i for a giv en K . The PSI determination 8 A mo re na tur al efficiency metric is to co nsider the sum of the ma x imal num ber of uploaded bits (denoted by U ) and the maximal num be r of downloaded bits (denoted by D ) by one of the entities E 1 or E 2 to compute P 1 ∩ P 2 . In this cas e, the most efficient scheme is the scheme with the low es t communication co s t, i.e., that achiev es the optimal co mm unication cost C ∗ = inf ( U + D ) ov er all achiev a ble PSI schemes. The SPIR pro blem [8] under combined uplo ad and download cos ts is still an op en pr oblem. As we will see, our framework builds on the SPIR problem. There fore, in this work, we cons ider only the download cost. The PSI under co m bined upload and download costs is an interesting future direc tio n, which is outside the scop e of our pa per . In Section 7.2, we provide an illustrative example to s how that the upload cost can b e reduced without affecting the download cost. Nevertheless, we a rgue that if the PSI determination is repea ted (for example, if one lis t is kept the same a nd the other list is regula rly up dated, w e alwa ys use the fixed list to initiate the PSI pro cess), the queries could b e used r epea tedly without co mpromising the user priv acy as long as the databases do not co llude. In this cas e, the upload co st would not sc ale with the n umber of P SI determination rounds, unlike the download cos t. 7 d a c b f g h a c e DB 1 ⇒ X 2 E 2 1 1 0 1 1 1 0 0 0 1 a b c d e f i h j alphab et g DB 1 ⇒ X 1 E 1 1 1 1 1 0 0 0 0 0 0 Figure 2: Example f o r the transformation from sets to incidence v ectors. E 1 has the set P 1 = { a, b, c, d } and E 2 has the set P 2 = { a, c, e, f , g , h } . The alphab et is P alph = { a, b, c, d, e, f , g , h, i, j } . En tity E i constructs an incidence v ector X i to facilitate MM-SPIR. pro cess is p erformed o v er X 1 or X 2 , and not o v er the original P 1 or P 2 . T o solidify ideas, w e stat e the v ariables defined so f ar explicitly ov er a sp ecific example. Consider the example in Fig. 1. Here, the en tity E 1 has the set P 1 = { a, b, c, d } and the en tity E 2 has the set P 2 = { a, c, e, f , g , h } . Therefore, the in tersection is P 1 ∩ P 2 = { a, c } . Let us assume that the alphab et, P alph , for this example is P alph = { a, b, c, d, e, f , g , h, i, j } as sho wn in Fig. 2. Then, the incidence v ectors at t he entities are X 1 = [1 1 1 1 0 0 0 0 0 0] and X 2 = [1 0 1 0 1 1 1 1 0 0 ], whic h are also sho wn in Fig. 2. F or this example, P 1 = 4, P 2 = 6 , K = 10, and M = 2. Finally , the MM-SPIR is conducted o v er the replicated incidence v ectors at the tw o en tities as show n in Fig. 3. Without loss of generality , assume that E 1 initiates t he PSI pro cess. E 1 do es not kno w M in adv ance. The only information E 1 has is P 1 . Consequen t ly , E 1 w ants to verify the existence o f eac h elemen t of P 1 in P 2 to deduce P 1 ∩ P 2 . Th us, E 1 needs to join tly and reliably do wnload the bits W P 1 = { X 2 ( j ) : j ∈ P 1 } b y sending N 2 queries to the databases asso ciated with E 2 and collecting the corresp onding answ ers with the kno wledge of X 1 . Hence, w e can write the reliabilit y constrain t as, H ( W P 1 | Q [ P 1 ] 1: N 2 , A [ P 1 ] 1: N 2 , X 1 ) = 0 (7) 8 1 0 1 1 1 0 0 1 0 1 1 0 1 1 1 0 0 1 0 1 1 0 1 1 1 0 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 0 0 0 0 0 . . . DB 1 DB 2 DB N 1 Decod er 0 1 0 c a 1 b e j DB N 2 DB 1 DB 2 Q [ P 1 ] 1 Q [ P 1 ] 2 Q [ P 1 ] N 2 . . . E 2 E 1 d A [ P 1 ] 1 A [ P 1 ] 2 A [ P 1 ] N 2 a c f g h i 0 1 0 1 Figure 3: Example for the transformation from the PSI problem to an MM-SPIR pr o blem. E 1 needs to retriev e the elemen ts corresp onding to P 1 from the incidence v ector X 2 without rev ealing P 1 , while E 2 resp onds with answ er strings that do not leak ¯ P 1 . Since E 1 is searc hing for the existence of all elemen ts of P 1 in P 2 without leaking any in- formation ab out P 1 to an y individual databa se asso ciated with E 2 , the E 1 priv a cy constraint in (4) dictates, I ( P 1 ; Q [ P 1 ] n 2 , A [ P 1 ] n 2 , X 2 , S ) = 0 , n 2 ∈ [ N 2 ] (8) This is exactly the priv acy constrain t in the MM-PIR problem [23]. As the databases asso ciated with E 2 store X 2 no w, to ensure the E 2 priv a cy constrain t in (5), the answe rs from E 2 databases should no t leak anything ab out E 2 , ¯ P 1 , whic h can b e further mapp ed to not leaking any information a b out W ¯ P 1 = { X 2 ( j ) : j / ∈ P 1 } a s, I ( W ¯ P 1 ; Q [ P 1 ] 1: N 2 , A [ P 1 ] 1: N 2 , X 1 ) = 0 (9) This is exactly the databa se priv acy constraint in MM-SPIR; see Section 5 .1. Consequen tly , the PSI problem fo rmally reduces to MM-SPIR with i.i.d. messages of length 1 bit eac h (see Fig . 3) , when the en tities E 1 and E 2 are allo w ed to construct the cor- resp onding incidence v ectors for the original sets P 1 and P 2 . The message length constrain t of 1 bit p er message, i.e., H ( W k ) = 1 for all k ∈ [ K ], comes due to messages r epresen ting 9 incidences in the SPIR problem. The i.i.d. prop ert y of the messages that w e ha v e here in this pa p er is a consequence of the i.i.d. generatio n of the sets with probability q i , and it is not true in general. In Section 5, w e deriv e in detail the capacity of the MM-SPIR problem (see also Section 6), whic h in turn g iv es the most effic ien t infor ma t ion-theoretic PSI sc heme. 4 Main Result In this section, w e presen t our main result concerning the PSI problem. The result pro vides the optimal (minim um) download cost for the PSI pro blem under the assumptions in Sec- tions 2 and 3. The result is based on the optimal download cost of t he MM-SPIR problem, whic h is presen ted in detail in Section 5; see also Section 6 . Theorem 1 In the PSI pr o b lem, the elements o f the sets ar e adde d in dep endently with pr ob ability q i = 1 2 fr om a finite set of size K . Onc e the set gener ation i s fini s h e d , the fixe d set P 1 wher e |P 1 | = P 1 < K is stor e d among N 1 datab ases and the fixe d set P 2 wher e |P 2 | = P 2 < K is stor e d am o ng N 2 datab ases. The set c ar dinalities P 1 and P 2 ar e made public. The amount of c om mon r an d omness s a tiesfies H ( S ) ≥ min { l P 1 N 2 − 1 m , l P 2 N 1 − 1 m } . Then, the optimal downlo a d c ost with one-r ound c o m munic ation ( o ne entity sends the queries to the other entity and then r e c eives fe e d b a ck) is, D ∗ = min P 1 N 2 N 2 − 1 , P 2 N 1 N 1 − 1 (10) The pro of of Theorem 1 is a direct consequence of the capacit y result for MM-SPIR presen ted in Section 5; see also Section 6. W e hav e the follo wing remarks. Remark 1 In the sp e c ial c ase of having P i = K fo r i = 1 or i = 2 , the d o wnlo ad c ost is trivial ly z er o . This i s due to the fact that if P 1 = K for example , the entity E 2 dir e ctly c oncludes that the in terse ction P 1 ∩ P 2 = P 2 without sending any queries to E 1 or r e quiring any c om m on r a n domness. Remark 2 The min term in The or em 1 c omes fr om the fact that either entity c an initiate the PSI determination pr o c ess so that the over al l downlo ad c ost i s minim i z e d . Remark 3 We note that although our r esult is exact, i.e., the downlo ad c ost c ap a c ity (in the sense of matching achievabil i ty and c onverse pr o ofs) under the assumptions of ind e p e ndent gener ation mo del for the lists with q i = 1 2 , our sc h eme is achievable for any list gener ation mo del with arbitr ary q i (se e F o o tno te 2). Remark 4 Our r esult is p ri v ate in information-the or etic (absolute) se n se and do e s n ot ne e d any assumptions ab out the c o mputational p owe rs of the entities. F urthermor e, the a c h ievable scheme is fai rly simple and e asy to implement c omp ar e d to the ful ly ho momorphic e n cryption 10 ne e de d in [3]. A dr aw b ack of our ap p r o a ch is that it ne e ds multiple non-c ol luding datab ases ( N 1 or N 2 ne e ds to b e strictly lar ger than 1), otherwise, our scheme is infe asi b le. Remark 5 The line ar sc alability of our scheme matches the line ar sc alability of the b es t- known set interse ction algorithms without any p ri v acy c onstr aints. 5 MM-SPIR as a S t and-Alone Problem In this section, w e consider the MM-SPIR problem. W e presen t the problem in a stand-alone format, i.e., w e presen t a formal problem description in Section 5 .1, follow ed b y the main result in Section 5.2, the con v erse in Section 5.3, and a no v el achiev abilit y in Section 5.4. 5.1 MM-SPIR: F ormal P r ob lem Description There are N non-colluding databases each storing K i.i.d. messages . Eac h message is com- p osed of L 9 i.i.d. and unifo rmly c hosen sym b ols from a sufficien tly la r g e finite field F q . Then, H ( W k ) = L, k ∈ [ K ] (11) H ( W 1: K ) = K L (12) In the MM-SPIR problem, our goal is to retriev e a set of messages W P out o f the K av ail- able messages without leaking an y info r ma t ion regarding the index set P t o any individual database where P = { i 1 , i 2 , · · · , i P } ⊆ [ K ] suc h that its cardinalit y is |P | = P . 10 This is the user priv acy constrain t. In a ddition, o ur g oal is to not retriev e a n y messages beyond the desired set of messages W P . This is the database priv acy constraint. F ollowing the SPIR form ulation in [8], let F denote the randomness in the retrieving strategy adopted b y the user. Because of the user priv a cy constrain t, F is a random v ariable whose realization is o nly known to the user, but is unknow n to the databases. A necessary common ra ndomness S m ust b e shared amo ng the N da t abases to satisfy the database priv a cy constrain t. The random v a riable S is generated indep enden t o f the message set W 1: K . Similarly , F is independent of W 1: K as the user do es not know message realizations in adv ance. Moreo ve r, F a nd S are generated indep enden tly without kno wing t he desired index set P . Then, H ( F , S , P , W 1: K ) = H ( F ) + H ( S ) + H ( P ) + H ( W 1: K ) (13) 9 As in most PIR problems, the messag e length L can approa ch infinit y . 10 W e use the symbol P to deno te the random v a riable corresp onding to the desired set and its re alization with little abuse of notation. 11 T o p erform MM-SPIR, a user generates one query Q [ P ] n for eac h database a ccording to the randomness F and then sends it to the n th data base. Hence, the queries Q [ P ] 1: N are deterministic functions of F , i.e., H ( Q [ P ] 1 , Q [ P ] 2 , · · · , Q [ P ] N |F ) = 0 , ∀P (14) Com bining (13) and (14), the queries are indep enden t of the messages, i.e., I ( Q [ P ] 1: N ; W 1: K ) = 0 (15) After receiving a query from the user, each database truthfully generates an answ er string based o n the messages and the common randomness, hence, H ( A [ P ] n | Q [ P ] n , W 1: K , S ) = 0 , ∀ n, ∀P (16) After collecting all t he answ er strings from the N dat a bases, the user should b e able to deco de the desired messages W P reliably , therefore, [reliabilit y] H ( W P | A [ P ] 1: N , Q [ P ] 1: N , F ) (14) = H ( W P | A [ P ] 1: N , F ) = 0 , ∀P (17) In o rder to protect the user’s priv acy , the query generated to retriev e the set of messages W P 1 should b e statistically indistinguishable from the one g enerated to retriev e the set of messages W P 2 where |P 1 | = |P 2 | = P , i.e., [user priv acy] ( Q [ P 1 ] n , A [ P 1 ] n , W 1: K , S ) ∼ ( Q [ P 2 ] n , A [ P 2 ] n , W 1: K , S ) , ∀ n, ∀P 1 , P 2 s.t. |P i | = P (18) The user priv acy constraint in (18) is equiv alent to, [user priv acy] I ( P ; Q [ P ] n , A [ P ] n , W 1: K , S ) = 0 , ∀P (19) In order to protect the databases’ priv acy , the user should learn nothing ab out W ¯ P whic h is the complemen t of W P , i.e., W ¯ P = W 1: K \ W P , [database priv acy] I ( W ¯ P ; Q [ P ] 1: N , A [ P ] 1: N , F ) = 0 , ∀P (20) An ac hiev able MM-SPIR sche me is a sc heme that satisfies the MM-SPIR reliabilit y con- strain t (17), the user priv acy constrain t (18)-(19), and the database priv acy constrain t (20). The efficiency of the sc heme is measured in terms of the maximal n um b er of do wnloaded bits b y the user from a ll the databases, denoted by D M M − S P I R . Th us, the sum retriev al ra te 12 of MM-SPIR is giv en b y R M M − S P I R = P L D M M − S P I R (21) The sum capacity o f MM-SPIR, C M M − S P I R , is the suprem um of the sum retriev al rates R M M − S P I R o v er all ac hiev able sc hemes. 5.2 MM-SPIR: Main Results Our stand-alone result for MM-SPIR is stated in the follo wing theorem. W e only consider N ≥ 2 as SPIR is infeasible for N = 1. Theorem 2 The MM-SPIR c ap acity for N ≥ 2 , K ≥ 2 , and a fixe d P ≤ K , is g iven by, C M M − S P I R = 1 , P = K 1 − 1 N , 1 ≤ P ≤ K − 1 , H ( S ) ≥ P L N − 1 0 , otherwise (22) The con v erse pro o f is giv en is Section 5.3, and the ac hiev ability pro of is giv en in Sec- tion 5 .4. W e hav e the follo wing remarks concerning Theorem 2. Remark 6 The r esult implies that the c ap acity of MM-SPIR is exactly the sam e as the c ap acity of SM-SPI R [8]. Henc e, ther e is no ga i n fr om joint r etrieval in c omp arison to suc- c essive single-message SPIR [8]. T his in c ontr ast to the gain in MM-PIR [23] in c om p arison to suc c ess i v e single-mess a ge PIR [7]. MM-SPIR c ap acity e xpr ession in The or em 2 inheri ts al l of the structur al r e marks fr om [8] . Remark 7 Similar to the SM-SPIR pr oblem , w e o bserve a thr eshold effe ct on the size of the r e quir e d c om m on r an domness. S p e cific al ly, we no te that ther e is a mi n imal r e quir e d siz e for the c ommon r andomnes s ab ove which the pr oblem is fe asible. This thr eshold is P times the thr e s hold in SM-SPI R. Using a c ommo n r a ndomness in the amount of the thr eshold achieves the ful l c ap acity, and ther e is no ne e d to use any mor e r a n domness than the thr eshold. Remark 8 F or the extr eme c ase of P = K , the SPIR c ap acity is 1 without using any c ommon r andomn e s s. This is due to the fact that the user privacy a nd the datab ase privacy c onstr aints a r e trivial ly satisfie d, and henc e the user c an s imply downlo a d al l of the messages fr om one of the datab as es without using any c o m mon r a n domness. 5.3 MM-SPIR: Con v erse Pro of In this section, w e deriv e the conv erse for Theorem 2. In the conv erse pro of, we fo cus on the case P ≤ K − 1. Because when P = K , t he trivial upp er b ound f or the retriev al rate 13 R ≤ 1 and the trivial low er b ound f o r the common randomness H ( S ) ≥ 0 suffice. F urther, w e exclusiv ely fo cus on the case K ≥ 3. When K = 1, we hav e P = 1, a nd the conv erse trivially f o llo ws since P = K . When K = 2 : If P = 2, the con v erse trivially f o llo ws from the con vers e of P = K , and when P = 1 , the conv erse follo ws from the con v erse of SM- SPIR [8]. No w, fo cusing on the case K ≥ 3, and P ≤ K − 1, the tot a l num b er of p ossible ch oices for the index set P is β = K P ≥ 3. Th us, t here alwa ys exis t at least three no n-iden tical index sets P 1 , P 2 , P 3 suc h that |P i | = P , i = 1 , 2 , 3. T o prov e the conv erse of Theorem 2, w e first need the f o llo wing lemmas. L emmas 1 a re 2 are direct extensions to [8, Lemmas 1 and 2] to the setting of MM-SPIR. Lemma 1 simply states that an answ er string A [ P 1 ] n whic h is receiv ed a t the user to retriev e W P 1 has the same size as A [ P 2 ] n , i.e., all answ er strings are symmetric in length, ev en if we condition o v er the desired message set W P 1 . This lemma is a direct conseque nce of the use r priv a cy constrain t. Lemma 1 (Symmetry) H ( A [ P 1 ] n | W P 1 , Q [ P 1 ] n ) = H ( A [ P 2 ] n | W P 1 , Q [ P 2 ] n ) , ∀ n, ∀P 1 , P 2 s.t. P 1 6 = P 2 , |P 1 | = |P 2 | (23) H ( A [ P 1 ] n | Q [ P 1 ] n ) = H ( A [ P 2 ] n | Q [ P 2 ] n ) , ∀ n, ∀P 1 , P 2 s.t. P 1 6 = P 2 , |P 1 | = |P 2 | (24) Pro of: F rom t he user priv acy constraint (18), we ha v e H ( A [ P 1 ] n , W P 1 , Q [ P 1 ] n ) = H ( A [ P 2 ] n , W P 1 , Q [ P 2 ] n ) (25) H ( W P 1 , Q [ P 1 ] n ) = H ( W P 1 , Q [ P 2 ] n ) (26) Using the definition of conditional entrop y H ( X | Y ) = H ( X , Y ) − H ( Y ), we obtain (23). The pro of of (24) follow s from the user priv acy constraint as w ell with noting that H ( A [ P 1 ] n , Q [ P 1 ] n ) = H ( A [ P 2 ] n , Q [ P 2 ] n ) and H ( A [ P 1 ] n ) = H ( A [ P 2 ] n ). Next, Lemma 2 states that kno wing the user’s priv ate randomness F do es not help in decreasing the uncertain t y of the answ er string A [ P ] n . Lemma 2 (Effect of conditioning on user’s randomness) H ( A [ P ] n | W P , F , Q [ P ] n ) = H ( A [ P ] n | W P , Q [ P ] n ) , ∀ n, ∀P (27) Pro of: W e start with the f o llo wing m utual information, I ( A [ P ] n ; F | W P , Q [ P ] n ) ≤ I ( A [ P ] n , W 1: K , S ; F | W P , Q [ P ] n ) (28) = I ( W 1: K , S ; F | W P , Q [ P ] n ) + I ( A [ P ] n ; F | W 1: K , S, W P , Q [ P ] n ) (29) = I ( W 1: K , S ; F | W P , Q [ P ] n ) + I ( A [ P ] n ; F | W 1: K , S, Q [ P ] n ) (30) = I ( W 1: K , S ; F | W P , Q [ P ] n ) + H ( A [ P ] n | W 1: K , S, Q [ P ] n ) − H ( A [ P ] n |F , W 1: K , S, Q [ P ] n ) (31) 14 = I ( W 1: K , S ; F | W P , Q [ P ] n ) (32) ≤ I ( W 1: K , S ; F | W P , Q [ P ] n ) + I ( W P ; F | Q [ P ] n ) (33) = I ( W 1: K , W P , S ; F | Q [ P ] n ) (34) = I ( W 1: K , S ; F | Q [ P ] n ) (35) ≤ I ( W 1: K , S ; F | Q [ P ] n ) + I ( W 1: K , S ; Q [ P ] n ) (36) = I ( W 1: K , S ; F , Q [ P ] n ) (37) = 0 (38) where (32) f o llo ws fro m the fact that the answ er strings are deterministic functions of the queries and the messages, and (38) follow s from the indep endence of ( W 1: K , S, F ) and (1 4 ). Since mutual information cannot b e negative , it mu st b e equal to zero, and H ( A [ P ] n | W P , Q [ P ] n ) − H ( A [ P ] n | W P , F , Q [ P ] n ) = I ( A [ P ] n ; F | W P , Q [ P ] n ) = 0 (39) completing the pro of. Next, we need Lemma 3, whic h is an existence pro of for index sets with sp ecific prop- erties. This tec hnical lemma is nee ded in the pro ofs of up coming t wo lemmas, Lemma 4 and Lemma 5. First, w e give the definitions of relev ant index sets P a , P b , P c , P d , and a n elemen t i m . Giv en P 1 and P 2 , w e divide P 1 in t o t wo disjoin t partitions P a and P b (i.e., P a ∪ P b = P 1 and P a ∩ P b = ∅ ), where P a ⊆ P 2 (i.e., P 1 ∩ P 2 = P a ), P b ⊆ ¯ P 2 . Supp ose |P a | = M ∈ [1 : P − 1]. Note that since P 1 6 = P 2 , w e cannot ha ve M = P . W e assume that P a = { i 1 , · · · , i M } for clarit y of presen tat ion. Giv en an arbitrar y num b er m ∈ [1 : M ], w e define a new index set P c = { i 1 , · · · , i m } which consists of exactly the first m elemen ts in the index set P a . Let i m b e the last elemen t from the index set P c . W e obtain a new index set P d = { i 1 , · · · , i m − 1 } after r emoving this elemen t. That means P c = P d ∪ { i m } . The relat io n of all these men tioned index sets is sho wn in Fig. 4. Lemma 3 F or K ≥ 3 , 1 ≤ P ≤ K − 1 , g i ven index sets P 1 , P 2 such that |P i | = P for i = 1 , 2 and P 1 6 = P 2 , we c an c onstruct an index set P 3 such that, i) P 3 6 = P 1 and P 3 6 = P 2 , ii) |P 3 | = P , and iii) P 3 includes P b ∪ P d but do es n ot include the c ommon element i m in P 1 ∩ P 2 . Pro of: The k ey is to construc t an index set P e whic h satisfies the following t wo constrain ts: P e ⊆ [1 : K ] \{P b , P c } and |P e | = M − ( m − 1). As w e can see, |P a \P c | = M − m and |P 2 \P a | ≥ 1. One w ay to construct the index set P e is to include all the ( M − m ) elemen ts from the index set P a \P c and one more elemen t from the index set P 2 \P a , i.e., P e = ( P a \P c ) ∪ { i ∗ } (40) 15 P c P d P e P b P a P 1 P 2 [1 : K ] Figure 4: The relation of the index sets presen ted in Lemma 3 and use d in Lemmas 4 and 5. where i ∗ ∈ P 2 \P a . The index set P e is generally not unique (for some examples, see Exam- ples 1 and 2 b elow ). No w, w e a re ready to construct the index set P 3 as, P 3 = P b ∪ P d ∪ P e (41) Since P b , P d , P e are disjoint sets, | P 3 | = |P b | + |P d | + |P e | = ( P − M ) + ( m − 1) + ( M − m + 1) = P . Thus , w e are a ble to construct P 3 suc h that |P 3 | = P . Based on the form ula t io n of P b , P d and P e , these three index sets do not include the elemen t i m . Hence, i m / ∈ P 3 . Since b oth P 1 and P 2 ha v e the elemen t i m as i m b elongs to their inters ection P a , P 3 is not the same as P 1 or P 2 , i.e., P 3 6 = P 1 , P 3 6 = P 2 and |P 3 | = P . The following tw o examples illustrate the relations b et w een the aforemen tioned sets, whic h will b e imp ortan t f o r the conv erse pro of through the pro ofs of Lemmas 4 and 5. Example 1 Supp ose K = 3 , P = 2 an d N ≥ 2 is an arbitr ary p ositive inte ger. The total p ossible numb er of index sets is K P = 3 . Assume P 1 = { 1 , 2 } , P 2 = { 1 , 3 } without loss of gener ality. Then , P a = { 1 } , P b = { 2 } and the c orr e sp onding M is 1. Thus, m c an only take the value 1 . That me ans P c = { 1 } and P d has to b e an empty set. F or P e , we c annot take any element fr om the set P a \P c as it is empty, inste ad we c an take the element 3 fr om the set P 2 \P a . Thus, P e is forme d a s { 3 } , a n d we c onstruct P 3 = { 2 , 3 } . Example 2 Supp ose K = 6 , P = 4 an d N ≥ 2 is an arbitr ary p ositive inte ger. The total p ossible numb er of index sets i s K P = 15 . Assume P 1 = { 1 , 3 , 5 , 6 } , P 2 = { 2 , 3 , 5 , 6 } without loss of gener ality. Then, P a = { 3 , 5 , 6 } , P b = { 1 } and the c orr esp o n ding M is 3. Thus, m c an take the values 1 , 2 or 3 . T o avoid b eing r ep etitive, we only c onsi d er the c ases of m = 2 16 or m = 3 , which ar e diff er e nt fr om Exa m ple 1. When m = 2 , P c = { 3 , 5 } an d P d = { 3 } . F or P e , we c an take the element 6 fr om the set P a \P c and then take the element 2 fr om the set P 2 \P a . A lternatively, we c an pick the element 4 outside the union P 1 ∪ P 2 inste ad o f the elem ent 6 fr om the set P a \P c . Thus, P e is fo rme d as { 2 , 6 } (or { 4 , 6 } ). Ther efor e, we final ly obtain P 3 = { 1 , 2 , 3 , 6 } (or { 1 , 3 , 4 , 6 } ). When m = 3 , P c = { 3 , 5 , 6 } and P d = { 3 , 5 } . F or P e , we c a nnot take any elem ent fr om the set P a \P c sinc e it is empty. We take the element 2 fr om the set P 2 \P a or take the element 4 outside the union P 1 ∪ P 2 . T hus, P e is forme d as { 2 } (or { 4 } ), a nd we c onstruct P 3 = { 1 , 2 , 3 , 5 } (or { 1 , 3 , 4 , 5 } ). Next, w e need the follow ing lemma. Lemma 4 states that rev ealing any individual answ er giv en the messages ( W P b , W P d ) do es not leak any information ab out the message W i m . Lemma 4 (Message leak age wit hin an y individual answer string) When 1 ≤ P ≤ K − 1 and M ≥ 1 , for arbitr ary m ∈ [1 : M ] , the fol lowing e quali ty is alwa ys true, H ( W i m | W P b , W P d , A [ P 2 ] n , Q [ P 2 ] n ) = H ( W i m | W P b , W P d , Q [ P 2 ] n ) ( 4 2) Remark 9 The go al of L emma 4 is to pr ov e a key step, e quation ( 63) , in the pr o of of L emma 5. We r e mark that L emma 4 is true for any m ∈ [2 : M ] w hen M ≥ 1 as pr ove d b elow. I n the c as e w h en m = 1 , the me s sages set W i 1 : i m − 1 (i.e., P d ) is an empty set and thus L emma 4 is stil l true in this c ase. Pro of: F rom t he user priv acy constraint (18), we ha v e, H ( W P b , W P c , A [ P 2 ] n , Q [ P 2 ] n ) = H ( W P b , W P c , A [ P 3 ] n , Q [ P 3 ] n ) (43) H ( W P b , W P d , A [ P 2 ] n , Q [ P 2 ] n ) = H ( W P b , W P d , A [ P 3 ] n , Q [ P 3 ] n ) (44) Since P c = P d ∪ i m , we ha ve H ( W i m | W P b , W P d , A [ P 2 ] n , Q [ P 2 ] n ) = H ( W i m | W P b , W P d , A [ P 3 ] n , Q [ P 3 ] n ) ( 4 5) Similarly , H ( W i m | W P b , W P d , Q [ P 2 ] n ) = H ( W i m | W P b , W P d , Q [ P 3 ] n ) (46) F rom the data base priv acy constrain t (20 ) , w e hav e, 0 = I ( W ¯ P 3 ; A [ P 3 ] 1: N , Q [ P 3 ] 1: N , F ) (47) = I ( W ¯ P 3 ; A [ P 3 ] 1: N , W P 3 , Q [ P 3 ] 1: N , F ) (48) ≥ I ( W ¯ P 3 ; A [ P 3 ] 1: N , W P b , W P d , Q [ P 3 ] 1: N ) (49) ≥ I ( W i m ; A [ P 3 ] 1: N , W P b , W P d , Q [ P 3 ] 1: N ) ( 5 0) 17 ≥ I ( W i m ; A [ P 3 ] n , W P b , W P d , Q [ P 3 ] n ) ( 5 1) = I ( W i m ; A [ P 3 ] n | W P b , W P d , Q [ P 3 ] n ) (52) = H ( W i m | W P b , W P d , Q [ P 3 ] n ) − H ( W i m | A [ P 3 ] n , W P b , W P d , Q [ P 3 ] n ) (53) where (48) comes from the MM-SPIR reliabilit y constrain t (17), (49) comes from the rela- tionship P 3 = P b ∪ P d ∪ P e (i.e, P b ∪ P d ⊆ P 3 ), and (50) comes from t he relationship i m ∈ ¯ P 3 . Th us, H ( W i m | W P b , W P d , Q [ P 3 ] n ) ≤ H ( W i m | A [ P 3 ] n , W P b , W P d , Q [ P 3 ] n ). This concludes the pro of b y observing tha t H ( W i m | W P b , W P d , Q [ P 3 ] n ) ≥ H ( W i m | A [ P 3 ] n , W P b , W P d , Q [ P 3 ] n ) trivially as con- ditioning cannot increase en trop y . Finally , t he following lemma states tha t conditioning on an undesired message set do es not decrease the uncertaint y o n an y individual answ er string. This is a consequenc e of the database priv acy constrain t. Lemma 5 (Effect of conditioning on an undesired message set) H ( A [ P 2 ] n | W P 1 , Q [ P 2 ] n ) = H ( A [ P 2 ] n | Q [ P 2 ] n ) , ∀ n, ∀P 1 , P 2 s.t. P 1 6 = P 2 , |P 1 | = |P 2 | (54) Remark 10 We note that although L emma 5 has the same flavor as [8, e qn. (39)], the pr o of is much mor e involve d . The main r e ason for this difficulty is the inter-r ela tions b etwe en subsets of messages of size P . Sp e c i fi c a l ly, in SM-SPIR, al l message subsets ar e o f size P = 1 , and ther e for e, they ar e di s j o int. However, in MM-SPIR, the message subsets ar e of size P , and they interse ct in ge n er a l , i.e., for a given P 1 , P 2 such that |P 1 | = |P 2 | = P , the interse ction P 1 ∩ P 2 is not an empty set in gen e r al in c ontr ast to SM-SPIR. De aling with message subset interse ctions is the essenc e of intr o ducing and pr oving L em mas 3, 4 and 5. Pro of: F rom t he database priv a cy constrain t (20), we ha v e, 0 = I ( W ¯ P 2 ; A [ P 2 ] 1: N , Q [ P 2 ] 1: N , F ) (55) ≥ I ( W ¯ P 2 ; A [ P 2 ] n , Q [ P 2 ] n ) (56) ≥ I ( W P b ; A [ P 2 ] n , Q [ P 2 ] n ) ( 5 7) = I ( W P b ; A [ P 2 ] n | Q [ P 2 ] n ) (58) = H ( W P b | Q [ P 2 ] n ) − H ( W P b | A [ P 2 ] n , Q [ P 2 ] n ) (59) where (5 7) comes from the relationship P b ⊆ ¯ P 2 , (58) follo ws from the indep endence of messages and queries. Hence, H ( W P b | Q [ P 2 ] n ) = H ( W P b | A [ P 2 ] n , Q [ P 2 ] n ) as the rev erse implication follo ws form the fact that conditio ning cannot increase en tropy . 18 Case 1: M = 0 : In t his case, t here is no interse ction betw een P 1 and P 2 . W P a is an empty set of messages a nd then W P 1 = W P b . Hence, I ( W P 1 ; A [ P 2 ] n | Q [ P 2 ] n ) = I ( W P b ; A [ P 2 ] n | Q [ P 2 ] n ) = 0 (60) where (60) follows from (58). This prov es (54), the claim o f lemma, when M = 0. Case 2: M ≥ 1 : In this case, W P 1 = W P a ∪ W P b and W P a = { W i 1 , · · · , W i M } . H ( W P a | W P b , A [ P 2 ] n , Q [ P 2 ] n ) = H ( W i 1 : i M | W P b , A [ P 2 ] n , Q [ P 2 ] n ) (61) = H ( W i 1 | W P b , A [ P 2 ] n , Q [ P 2 ] n ) + H ( W i 2 | W i 1 , W P b , A [ P 2 ] n , Q [ P 2 ] n ) + · · · + H ( W i M | W i 1 : i M − 1 , W P b , A [ P 2 ] n , Q [ P 2 ] n ) (62) = H ( W i 1 | W P b , Q [ P 2 ] n ) + H ( W i 2 | W i 1 , W P b , Q [ P 2 ] n ) + · · · + H ( W i M | W i 1 : i M − 1 , W P b , Q [ P 2 ] n ) (63) = H ( W i 1 : i M | W P b , Q [ P 2 ] n ) (64) = H ( W P a | W P b , Q [ P 2 ] n ) (65) where (63) comes from the direct application of Lemma 4. Th us, w e ha v e, I ( W P 1 ; A [ P 2 ] n | Q [ P 2 ] n ) = H ( W P 1 | Q [ P 2 ] n ) − H ( W P 1 | A [ P 2 ] n , Q [ P 2 ] n ) (66) = H ( W P 1 | Q [ P 2 ] n ) − H ( W P a , W P b | A [ P 2 ] n , Q [ P 2 ] n ) (67) = H ( W P 1 | Q [ P 2 ] n ) − H ( W P b | A [ P 2 ] n , Q [ P 2 ] n ) − H ( W P a | W P b , A [ P 2 ] n , Q [ P 2 ] n ) (68) = H ( W P 1 | Q [ P 2 ] n ) − H ( W P b | Q [ P 2 ] n ) − H ( W P a | W P b , Q [ P 2 ] n ) (69) = H ( W P 1 | Q [ P 2 ] n ) − H ( W P a , W P b | Q [ P 2 ] n ) (70) = H ( W P 1 | Q [ P 2 ] n ) − H ( W P 1 | Q [ P 2 ] n ) (71) = 0 (72) where (69) follows from (59) a nd (65). This prov es (54), t he claim of lemma, when M ≥ 1. Com bining (60) and (72) pro v es (54 ) in all cases completing the pro o f. Remark 11 The intuition b eh i n d L emm a 5 is as f o l lows: If the p a ir ( A [ P 2 ] n , Q [ P 2 ] n ) pr ovide any in formation ab out W P 1 , they have to pr ovide some info rm ation ab out W ¯ P 1 under the user privacy c on str ain t. However, da tab a se privacy c o n str aint is thus obviously v i olate d if the user r e c eive s any information ab out W ¯ P 1 . C onse quently, the p air ( A [ P 2 ] n , Q [ P 2 ] n ) c a n nev e r pr ovide any informa tion ab out W ¯ P 1 . Ther e f o r e, we ar e abl e to de rive H ( W P 1 | A [ P 2 ] n , Q [ P 2 ] n ) = H ( W P 1 ) (15) = H ( W P 1 | Q [ P 2 ] n ) , and henc e I ( W P 1 ; A [ P 2 ] n | Q [ P 2 ] n ) = 0 . No w, we are ready to construct the main b o dy of the conv erse pro of for MM-SPIR, as 19 w ell as the minimal en trop y of common randomness required to achiev e p erfect MM-SPIR. Since w e dealt with the in ter-relatio ns b etw een message subsets in the previous lemmas and reac hed similar conclusions to those in SM-SPIR [8], the main b o dy of the con v erse pro of will b e similar in structure to it s coun terpart in SM-SPIR. The pro of for R ≤ C M M − S P I R : P L = H ( W P 1 ) (73) = H ( W P 1 |F ) (74) = H ( W P 1 |F ) − H ( W P 1 | A [ P 1 ] 1: N , F ) (75) = I ( W P 1 ; A [ P 1 ] 1: N |F ) (76) = H ( A [ P 1 ] 1: N |F ) − H ( A [ P 1 ] 1: N | W P 1 , F ) (77) = H ( A [ P 1 ] 1: N |F ) − H ( A [ P 1 ] 1: N | W P 1 , F , Q [ P 1 ] n ) (78) ≤ H ( A [ P 1 ] 1: N |F ) − H ( A [ P 1 ] n | W P 1 , F , Q [ P 1 ] n ) (79) = H ( A [ P 1 ] 1: N |F ) − H ( A [ P 1 ] n | W P 1 , Q [ P 1 ] n ) (80) = H ( A [ P 1 ] 1: N |F ) − H ( A [ P 2 ] n | W P 1 , Q [ P 2 ] n ) (81) = H ( A [ P 1 ] 1: N |F ) − H ( A [ P 2 ] n | Q [ P 2 ] n ) (82) = H ( A [ P 1 ] 1: N |F ) − H ( A [ P 1 ] n | Q [ P 1 ] n ) (83) ≤ H ( A [ P 1 ] 1: N |F ) − H ( A [ P 1 ] n | Q [ P 1 ] n , F ) (84) = H ( A [ P 1 ] 1: N |F ) − H ( A [ P 1 ] n |F ) (85) where (74) follows from the indep endence of the user’s priv ate randomness and the messages, (75) follow s f rom the MM-SPIR reliability constraint (17), (78) follo ws f r om the fact that the queries are deterministic functions o f the user’s priv ate randomness F (14), (80) follows from Lemma 2, ( 8 1) fo llo ws from the first part of Lemma 1 , (82) follo ws from Lemma 5, (83) follo ws from the sec ond part Lemma 1, and (85) a g ain follows from the fact that the queries are deterministic functions of the user’s priv a t e randomness F (14). By summing (8 5) up f o r all n ∈ [1 : N ] and letting P denote the general desired index set, w e obtain, N P L ≤ N H ( A [ P ] 1: N |F ) − N X n =1 H ( A [ P ] n |F ) (86) ≤ N H ( A [ P ] 1: N |F ) − H ( A [ P ] 1: N |F ) (87) = ( N − 1) H ( A [ P ] 1: N |F ) (88) ≤ ( N − 1) N X n =1 H ( A [ P ] n |F ) (89) ≤ ( N − 1) N X n =1 H ( A [ P ] n ) (90) 20 whic h leads to the desired con v erse result on the retriev al rate, R M M − S P I R = P L D M M − S P I R ≤ P L P N n =1 H ( A [ P ] n ) ≤ N − 1 N = 1 − 1 N (91) The pro of for H ( S ) ≥ P L N − 1 : 0 = I ( W ¯ P 1 ; A [ P 1 ] 1: N , Q [ P 1 ] 1: N , F ) (92) ≥ I ( W ¯ P 1 ; A [ P 1 ] 1: N , F ) (93) = I ( W ¯ P 1 ; A [ P 1 ] 1: N , W P 1 , F ) (94) = I ( W ¯ P 1 ; A [ P 1 ] 1: N | W P 1 , F ) (95) ≥ I ( W ¯ P 1 ; A [ P 1 ] n | W P 1 , F ) (96) = H ( A [ P 1 ] n | W P 1 , F ) − H ( A [ P 1 ] n | W 1: K , F ) (97) = H ( A [ P 1 ] n | W P 1 , F ) − H ( A [ P 1 ] n | W 1: K , F ) + H ( A [ P 1 ] n | W 1: K , F , S ) (98) = H ( A [ P 1 ] n | W P 1 , F ) − I ( S ; A [ P 1 ] n | W 1: K , F ) (99) = H ( A [ P 1 ] n | W P 1 , F ) − H ( S | W 1: K , F ) + H ( S | A [ P 1 ] n , W 1: K , F ) (100) = H ( A [ P 1 ] n | W P 1 , F ) − H ( S ) + H ( S | A [ P 1 ] n , W 1: K , F ) (101) ≥ H ( A [ P 1 ] n | W P 1 , F ) − H ( S ) (102) = H ( A [ P 1 ] n | W P 1 , F , Q [ P 1 ] n ) − H ( S ) (103) = H ( A [ P 1 ] n | Q [ P 1 ] n ) − H ( S ) (104) where (92) follows from the dat abase priv acy constraint (20), (9 4) follo ws fro m the MM-SPIR reliabilit y constraint (17), (98) follows from the fact that t he answ er strings are deterministic functions of messages and queries whic h are also functions of the randomness F as in (14) and (16 ), (101) follows from the indep endence of the common randomness, messages, and user’s priv ate randomness as in (13 ), (1 0 3) follo ws from (14), and (104) follo ws from the steps b etw een (80)-(83) by applying Lemma 1, 2 and 5 again. By summing (104) up for all n ∈ [1 : N ] and letting P denote the g eneral desired index set again, w e obtain, 0 ≥ N X n =1 H ( A [ P ] n | Q [ P ] n ) − N H ( S ) (105) ≥ H ( A [ P ] 1: N | Q [ P ] n ) − N H ( S ) (106) ≥ H ( A [ P ] 1: N | Q [ P ] n , F ) − N H ( S ) (107) = H ( A [ P ] 1: N |F ) − N H ( S ) (108) ≥ N N − 1 P L − N H ( S ) (109) 21 where (108) follow s from (14) a nd (109) follo ws from (88), whic h leads to a lo w er b ound for the minimal required en tro py of common randomness S , H ( S ) ≥ P L N − 1 (110) 5.4 MM-SPIR: Ac hiev abilit y Pro of Since the MM-SPIR capacit y is the same as the SM-SPIR capacity , and the required common randomness is P times t he required common randomness for SM-SPIR, w e can use the ac hiev able sc heme in [8] successiv ely P times in a ro w (by utilizing indep enden t common randomness eac h time) to a c hiev e the MM-SPIR capacit y . Although the query structure for the capacity -ac hieving sche me for SPIR in [8] is quite simple, it is fundamen tally differen t than the query structure for the capacit y-ac hieving sc heme fo r PIR in [7]. This means that user/databases should execute differen t query structures for differen t database priv acy lev els. In this pap er, b y combining ideas for ac hiev ability from [23] and [15], w e prop ose a n alternativ e capacity-ac hieving sc heme for MM-SPIR for any 11 P . Our ac hiev ability sc heme enables us to switc h b et wee n MM-PIR and MM-SPIR seamlessly , and therefore supp ort differen t database priv acy lev els, as the basic query structure s are similar. W e start with t w o motiv at ing examples in Section 5.4.1, giv e the general ac hiev able sc heme in Section 5.4.2, and calculate its rate and required common r a ndomness amount in Section 5.4.3. F or con v enience, w e use the k -sum nota t ion in [7, 23]. A k - sum is a sum of k sym b ols from k differen t messages. Th us, a k -sum sym b ol app ears o nly in round k . W e denote the n umber of stages in round k by α k , whic h w as originally in t r o duced in [23]. In addition, w e use ν to denote the num b er of rep etitions of the sc heme 12 in [23] w e need b efore we start assigning common randomness sym b ols. 5.4.1 Motiv ating Examples Example 3 Consider the c a s e K = 3 , P = 1 , N = 3 . Our achie v able s c h eme i s as fol lows: First, we gener ate an initial query table, which strictly fol lo w s the query table gener ation in [23]. F or this c ase, fr om [23], we obtain the numb er of stages ne e de d in e ach r ound as α 1 = 1 , α 2 = 2 , α 3 = 4 . F r om the p ersp e ctive of a datab ase , b efor e the assignment of c om mon r andomness symb ols b e gin s, the total numb er of downlo ade d de s ir e d symb o ls in r ound 1 is α 1 P = 1 × 1 = 1 . T h us, we ne e d 1 p r eviously downl o ade d c ommon r andomn ess symb ol fo r this desir e d symb ol. S inc e this c ommon r andomnes s symb ol ne e ds to c ome fr o m the other N − 1 = 2 datab a s es, the r e quir e d c ommon r and omness to b e downlo ade d fr o m e ach d atab a se 11 W e note that the ca pacity-ac hieving scheme for K = P is simply to download all mess ages fr o m one of the databases, hence, without loss of generality , we fo cus on the ca se 1 ≤ P ≤ K − 1 in this s ection. 12 When we refer to the scheme in [2 3], we refer to the near-optimal scheme in [23] which was int ro duced for K/ P ≥ 2. Reference [23] ha s a different, optimal, scheme for K/ P ≤ 2. Howev er , in this pa p er, even when K/ P ≤ 2, we still refer to (and use) the near-o ptimal scheme in [23]. 22 is 1 2 symb ols ( a ssuming a symmetric schem e that dis tributes downlo ads e qual ly over the other 2 datab ases). Thus, in or der to obtain a n inte ger numb er of c ommon r andomnes s symb ols to b e downlo ade d fr om e a ch datab a s e, we r ep e at the scheme in [23] two times (i.e . , ν = 2 ) b efor e we b e gin assigning the c om m on r andomnes s symb ols. Henc e, the numb er of stages in e ach r ound b e c o me ν α k = 2 α k , for k = 1 , 2 , 3 . That is we have 2 stages of 1 -sums, 4 stages of 2 - s ums and 8 stages of 3 -sums; se e T a ble 1. Database 1 Database 2 Database 3 s 1 s 2 s 3 a 1 + s 2 a 3 + s 1 a 5 + s 1 a 2 + s 3 a 4 + s 3 a 6 + s 2 b 1 + s 4 b 3 + s 8 b 5 + s 12 b 2 + s 5 b 4 + s 9 b 6 + s 13 c 1 + s 6 c 3 + s 10 c 5 + s 14 c 2 + s 7 c 4 + s 11 c 6 + s 15 a 7 + b 3 + s 8 a 15 + b 1 + s 4 a 23 + b 1 + s 4 a 8 + b 4 + s 9 a 16 + b 2 + s 5 a 24 + b 2 + s 5 a 9 + b 5 + s 12 a 17 + b 5 + s 12 a 25 + b 3 + s 8 a 10 + b 6 + s 13 a 18 + b 6 + s 13 a 26 + b 4 + s 9 a 11 + c 3 + s 10 a 19 + c 1 + s 6 a 27 + c 1 + s 6 a 12 + c 4 + s 11 a 20 + c 2 + s 7 a 28 + c 2 + s 7 a 13 + c 5 + s 14 a 21 + c 5 + s 14 a 29 + c 3 + s 10 a 14 + c 6 + s 15 a 22 + c 6 + s 15 a 30 + c 4 + s 11 b 7 + c 7 + s 16 b 11 + c 11 + s 20 b 15 + c 15 + s 24 b 8 + c 8 + s 17 b 12 + c 12 + s 21 b 16 + c 16 + s 25 b 9 + c 9 + s 18 b 13 + c 13 + s 22 b 17 + c 17 + s 26 b 10 + c 10 + s 19 b 14 + c 14 + s 23 b 18 + c 18 + s 27 a 31 + b 11 + c 11 + s 20 a 39 + b 7 + c 7 + s 16 a 47 + b 7 + c 7 + s 16 a 32 + b 12 + c 12 + s 21 a 40 + b 8 + c 8 + s 17 a 48 + b 8 + c 8 + s 17 a 33 + b 13 + c 13 + s 22 a 41 + b 9 + c 9 + s 18 a 49 + b 9 + c 9 + s 18 a 34 + b 13 + c 14 + s 23 a 42 + b 10 + c 10 + s 19 a 50 + b 10 + c 10 + s 19 a 35 + b 15 + c 15 + s 24 a 43 + b 15 + c 15 + s 24 a 51 + b 11 + c 11 + s 20 a 36 + b 16 + c 16 + s 25 a 44 + b 16 + c 16 + s 25 a 52 + b 12 + c 12 + s 21 a 37 + b 17 + c 17 + s 26 a 45 + b 17 + c 17 + s 26 a 53 + b 13 + c 13 + s 22 a 38 + b 18 + c 18 + s 27 a 46 + b 18 + c 18 + s 27 a 54 + b 14 + c 14 + s 23 T able 1: The query ta ble for the case K = 3 , P = 1 , N = 3. We ar e now r e ady to start assign i n g the c o m mon r andom n ess symb o ls. We first dow n - lo ad 1 c ommon r andomness symb ol fr om e ach datab ase; for instanc e, we downlo a d s 1 fr om datab ase 1 . I n r ound 1 , we mi x (i . e ., add) a c o mmon r ando mness symb ol to e ach 1 -sum. Al l the c ommon r andom ness symb ols at e ach datab a s e should b e d i s tinc t; for instanc e , observe that, we a dd s 2 , s 3 , s 4 , s 5 , s 6 , s 7 at datab a s e 1 . Se c ond, the c ommon r and o m ness symb ols add e d to the desir e d symb ols ( a symb ols in this exa m ple) must b e downlo ade d f r o m other datab ases; for instanc e, n ote that s 2 and s 3 adde d to symb ols a 1 and a 2 ar e downlo a d e d fr om datab ases 23 2 and 3 . Note that the indic e s of the c ommon r andomn e ss symb ol s adde d to the undesir e d symb ols (symb o ls b and c ) incr e ase cumulatively, e.g., s 4 , s 5 , s 6 , s 7 at datab a s e 1 in r ound 1 , and these symb ols ar e not sep ar a tely d o wnlo ade d by the user. In r ound 2 , for every 2 -sum c o n taining a desir e d m essage symb ol, we add a side informa- tion symb ol downlo ade d fr om another da tab as e whic h alr e a d y c ontains a c ommo n r and o mness symb ol; for instanc e, we add b 3 + s 8 that is a l r e ad y downlo ade d fr om da tab as e 2 , to the de- sir e d symb ol a 7 at datab ase 1 , i.e . , we downlo ad a 7 + b 3 + s 8 . On the other hand , for every 2 -sum not c on taining any desir e d message symb ols, we add a n ew dis tinct c ommo n r andom- ness symb ol w ith a cumulatively incr e as i n g index; for instanc e, for the downlo ad b 7 + c 7 fr om d a tab as e 1 , we add s 16 which is a new non- d ownlo ade d c ommon r andomness symb ol, and downlo a d b 7 + c 7 + s 16 . Final ly, in r ound 3 , wher e we downlo ad 3 -sums, an d henc e every downlo ad c ontains a desir e d symb o l, we add the side information ge n er a te d at other datab ases; fo r instanc e, w e add b 11 + c 11 + s 20 downlo ade d fr om datab ase 2 , to a 31 and down- lo ad a 31 + b 11 + c 11 + s 20 . This c om p letes the achievable scheme for this c a se. T h e c omplete query table is show n in T able 1. Now, we c alculate the r a te of this scheme. The len g th of e ach message is L = 54 , and the total numb er of downlo ad s is D = 81 . Thus, the r ate R o f this scheme is 54 81 = 2 3 = 1 − 1 3 , wh ich matches the c ap ac ity expr ession. In addition, we use d 27 c o m mon r and omness symb ols, henc e the r e quir e d c ommon r ando mness H ( S ) is 2 7 = 54 2 , whic h matches the r e quir e d minimum. Example 4 Consider the c ase K = 5 , P = 3 , N = 2 . Our achievable scheme is as fol low s : A ga in, first, we gener ate an initial query table, which strictly fol lows the query table gener- ation in [23]. Note that, we stil l use the ne ar-optimal scheme i n [23], even though for this c ase K / P ≤ 2 (se e F o otnote 12). F o r this c ase, fr om [23], w e obtain the numb er of stages ne e de d in e a c h r ound as α 1 = 3 , α 2 = 1 , α 3 = α 4 = 0 and α 5 = 1 . In this c as e, fr om the p e rs p e c tive of a d atab a se, b efo r e the assignment of c ommo n r andom ness symb ols b e gins, the total numb er of d ownlo ade d d e sir e d symb ols in r ound 1 is α 1 P = 3 × 3 = 9 . T hus, we ne e d 9 pr eviously downlo ade d c o m mon r andomness symb ols for these desir e d symb ols. These c ommon r a n domness symb ols ne e d to c om e fr om the other N − 1 = 1 datab ase. In this c as e , sinc e 9 / 1 = 9 is an inte ger alr e ady, we do not ne e d to r ep e at the scheme unlik e the c ase in Example 3. Thus, ν = 1 her e, ther e is no ne e d for r ep etition, and the underlying query structur e b efor e adding c ommon r andomn ess symb ols is exactly the same as [23]; se e T able 2. We ar e now r e a dy to start assigning the c omm on r a n domness symb ols. We first downlo ad 9 c ommon r andom ness symb ol s fr o m e a ch datab ase; for instanc e, we downl o ad s 1 , · · · , s 9 fr om datab ase 1 . In r ound 1 , we add a c ommon r andomness symb ol to e ach 1 -sum. Al l the c ommon r andomness symb ols at e ac h datab ase should b e distinct; for instan c e, observ e that, we add s 10 , · · · , s 24 at datab ase 1 . Se c on d, the c ommon r andom ness symb ols adde d to the des i r e d symb ols ( a , b , c symb ols in this exam ple) must b e downlo ade d fr om the other datab ases; for instanc e, note that s 10 , · · · , s 18 adde d to symb ols a 1 , b 1 , c 1 , a 2 , b 2 , c 2 , a 3 , b 3 , c 3 ar e d o wnlo ade d fr om datab ase 2 . Note that the indic es of the c ommon r andomn ess symb ols a d de d to the 24 undesir e d symb o ls (symb ols d and e ) incr e ase cumulatively, e.g., s 19 · · · , s 24 at datab a s e 1 in r ound 1 , and these symb o l s ar e not sep a r ately d o wnlo ade d by the user. Database 1 Database 2 s 1 , s 2 , s 3 s 10 , s 11 , s 12 s 4 , s 5 , s 6 s 13 , s 14 , s 15 s 7 , s 8 , s 9 s 16 , s 17 , s 18 s 31 , s 32 , s 33 s 34 , s 35 , s 36 a 1 + s 10 a 4 + s 1 b 1 + s 11 b 4 + s 2 c 1 + s 12 c 4 + s 3 d 1 + s 19 d 4 + s 25 e 1 + s 20 e 4 + s 26 a 2 + s 13 a 5 + s 4 b 2 + s 14 b 5 + s 5 c 2 + s 15 c 5 + s 6 d 2 + s 21 d 5 + s 27 e 2 + s 22 e 5 + s 28 a 3 + s 16 a 6 + s 7 b 3 + s 17 b 6 + s 8 c 3 + s 18 c 6 + s 9 d 3 + s 23 d 6 + s 29 e 3 + s 24 e 6 + s 30 a 7 + b 4 + s 34 a 10 + b 1 + s 31 a 4 + c 7 + s 35 a 1 + c 10 + s 32 a 8 + d 4 + s 25 a 11 + d 1 + s 19 a 9 + e 4 + s 26 a 12 + e 1 + s 20 b 7 + c 4 + s 36 b 10 + c 1 + s 33 b 8 + d 5 + s 27 b 11 + d 2 + s 21 b 9 + e 5 + s 28 b 12 + e 2 + s 22 c 8 + d 6 + s 29 c 11 + d 3 + s 23 c 9 + e 6 + s 30 c 12 + e 3 + s 24 d 7 + e 7 + s 37 d 8 + e 8 + s 38 a 13 + b 5 + c 5 + d 8 + e 8 + s 38 a 2 + b 13 + c 2 + d 7 + e 7 + s 37 T able 2: The query ta ble for the case K = 5 , P = 3 , N = 2. In r ound 2 , for every 2 -sum c ontaining only one desir e d message symb ol, we add a side information symb ol downlo ade d f r om the other datab ase which alr e ady c o n tains a c ommon r andomness symb ol; for instanc e, we add d 4 + s 25 that is alr e ady downlo ade d fr om datab ase 2 , to the d e s ir e d bit a 8 at datab a s e 1 , i.e., we dow nlo ad a 8 + d 4 + s 25 . O n the other hand, for every 2 -sum c on taining two of the desir e d message symb ols, we add a n ew distinct c ommon r andomness symb ol and downlo ad it sep ar ately fr om the other datab ase; for instanc e, for the downlo ad a 7 + b 4 fr om d atab a s e 1 , we add s 34 and d o wnlo ad s 34 sep ar ately fr o m datab as e 2 , and downl o ad a 7 + b 4 + s 34 . T her efor e, for this, we ne e d to downl o ad 3 c om mon r andom ness symb ols ( s 34 , s 35 , s 36 ) fr om datab ase 2 . F urther, for every 2 -sum not c o n taining any desir e d 25 message symb o l s , we add a n ew di stinct c ommon r andomness symb o l with a cumulatively incr e asing index; for instanc e, for the downlo ad d 7 + e 7 fr om datab ase 1 , we a dd s 37 which is a new non-d o wnlo ade d c ommo n r and omness symb ol , and d o wnlo ad b 7 + c 7 + s 37 . We skip r ounds 3 and 4 b e c a use α 3 = α 4 = 0 . Final l y, in r ound 5 , wher e we downlo ad 5 -sums, we add the side information gener ate d at the other datab ases; for instanc e, we add d 8 + e 8 + s 38 downlo ade d fr om datab ase 2 , to a 13 + b 5 + c 5 and downl o ad a 13 + b 5 + c 5 + d 8 + e 8 + s 38 . T his c ompletes the achievable scheme for this c ase . The c omplete query table is shown in T abl e 2. Now, we c alculate the r ate of this s c h eme. We downlo ade d 13 a symb ols, 13 b symb ols and 12 c symb o ls, henc e a total of L = 38 desir e d symb ols. The total numb er of downlo a ds is D = 76 . T hus, the r ate R of this scheme is 38 76 = 1 2 = 1 − 1 2 , which matches the c ap acity expr ession. In addition, we use d 38 c ommon r andom n ess symb ols , henc e the r e quir e d c ommon r andomness H ( S ) is 38 = 38 1 , whic h matches the r e quir e d minimum. We final ly note that, sin c e we downlo ade d asymmetric numb er of symb ols fr o m desir e d messages, i.e., 1 3 a symb ols, 13 b symb o ls and 12 c symb ols, we c an r ep e at this scheme 3 times c hanging the r oles of a , b and c , a n d have a symmetric scheme wher e we downlo ad 38 a s ymb ols, 38 b symb ols and 38 c symb ols. T his wil l not c h ange the normalize d d ownlo ad c ost and no rm alize d d o w nlo ade d c omm on r ando m ness symb ol numb ers, henc e, al l the c alc ulation s (r ate and c o mmon r andom n ess c a lculations) wil l r em ain the sa me. 5.4.2 General A c hiev able Sch eme Our ac hiev ability sc heme is primarily based on the one in [23], with the addition o f down- loading and/or mixing common randomness v ariables into sym b ol downloads appropriately . W e note that, here we extend the ne ar-optimal algor ithm in [23], whic h w as originally pro - p osed for P ≤ K 2 , to the case of P ≥ K 2 , and therefore, use it for all 1 ≤ P ≤ K − 1 (see F o otnote 12). Our achie v a bilit y sc heme comprises the f ollo wing steps: 1. Initial MM-PIR Query Gener ation: Generate an initial query table strictly following the near-o ptimal pro cedure in [2 3] for a rbitrary K , P and N . 2. R ep e tition: Rep eat Step 1 for a to tal of ν times. The purp ose of the r ep etitio n is to i) get an in t eger n umber of common randomness generated at each database b y a symmetric algorithm (as exemplified in Example 3), and ii) get equal num b er of sym b ols do wnloaded from each des ired message (as exemplified in Example 4). Let ν 0 b e the smallest in teger suc h that ( N − 1) K − P N ν 0 P (i.e., α K N ν 0 P ) is an in teger. Similar ly , for 1 ≤ k ≤ min { P, K − P } , let ν k b e the smallest in teger suc h that ( P k ) α k ν k N − 1 is an integer ( k ≤ K − P comes from α K − P +1 = · · · = α P − 1 = 0 in [23, eqn. (51 ) ]) . Then, ch o ose ν as the lo w est common m ultiple of these ν k , where k ∈ [0 : min { P , K − P } ]. 3. Common R andomness Assignment: Assign the common randomness as follo ws: 26 (a) In round 1, assign ν P α 1 N − 1 indep enden t common randomness sym b ols to eac h database, and do wnload them. At eac h database, mix eve ry 1- sum sym b ol con- taining a desired message sym b ol with an arbitrary common ra ndo mness sym b ol already do wnloaded f r o m a nother database, making sure that ev ery 1-sum sym- b ol at eac h database is mixed with a different common randomness sym b ol. Mix all other 1- sum sym b ols not con taining a desired sym b o l with a new common randomness sym b ol whic h is not dow nloaded b y the user. (b) In round k ( k ≥ 2), assign ν ( P k ) α k N − 1 indep enden t common randomness symbols to eac h database, and download them. A t each da t abase: Mix ev ery k -sum sym b ol con ta ining only desired message sym b ols with an arbit r a ry common randomness sym b ol already downloaded from another database. Mix ev ery k -sum sym b ol con- taining p desired message sym b ols (1 ≤ p ≤ k − 1) with the common randomness sym b ol from the ( k − p )- sum sym b ol hav ing the same k − p undesired message sym b ols downloaded at an y other data base. Mix ev ery k -sum sym b ol not con tain- ing an y desired message sym b o ls with a new common randomness sym b ol whic h is not dow nloaded b y the user. (c) R ep eat Step 3b un til k reach es K . Note tha t if α k = 0, nothing is done. This sc heme inherits the user priv acy prop ert y from t he underlying sc heme in [23], as the new common randomness sym b ols, whic h are separately do wnloaded and subtracted out, mak e no difference. Due to the pro cedure in Step 3, where no n- do wnloaded common randomness sym b ols are added to the do wnloads, no undesired sym b ol is deco dable because of the added unknow n common randomness, ensuring the database priv acy constraint. 5.4.3 Rate and Common Randomness Amoun t Calculation W e calculate the ac hiev able rate a nd t he minimal required common randomness for only one rep etition of the sc heme. The reason fo r this is that, in ev ery rep etition, ev ery in v olv ed term w ould b e m ultiplied b y T , and th us T can b e cancelled in the nu merator and the denominator of the normalized rate and normalized r equired common randomness expressions. F or eac h database, b efore the assignmen t of common randomness, let D 1 b e the total n umber of downloaded sym b ols, U 1 b e the total n umber of downloaded undesired sym b ols, U 2 b e the total n um b er of do wnloaded sym b ols including only desired message sym b o ls, and D 2 b e the total num b er of downloaded common randomness sym b ols. The achie v a ble rate is then giv en by , R = D 1 − U 1 D 1 + D 2 (111) 27 Using the resp ectiv e results in [23, eqns. (6 6 )-(69) and (7 0 )-(72)], w e ha v e D 1 = K X k =1 K k α k = P X i =1 γ i r K − P i " 1 + 1 r i K − 1 # (112) U 1 = K − P X k =1 K − P k α k = P X i =1 γ i r K − P i " 1 + 1 r i K − P − 1 # (113) In the prop o sed new achie v a ble sc heme, eve ry k -sum symbol (1 ≤ k ≤ min { P , K − P } ) con ta ining only desired message sym b ols is mixed with an arbitrary common r a ndomness sym b ol whic h is do wnloaded from another database. In a ddition, these down loaded common randomness sym b ols are uniformly requested from the other ( N − 1 ) databases. Thus, U 2 = min { K − P ,P } X k =1 P k α k (114) D 2 = 1 N − 1 U 2 = 1 N − 1 min { K − P ,P } X k =1 P k α k (115) With these observ a t io ns we hav e the follo wing tw o lemmas where w e compute the MM- SPIR rate and the required common randomness a moun t. Lemma 6 The r ate of the pr op ose d achievabl e scheme is, R = 1 − 1 N (116) Pro of: W e first calculate D 2 in tw o p ossible settings. When P ≤ K 2 , i.e., P ≤ K − P , D 2 = 1 N − 1 P X k =1 P k α k (117) = 1 N − 1 P X k =1 P k P X i =1 γ i r K − P − k i (118) = 1 N − 1 P X k =1 P X i =1 P k γ i r K − P − k i (119) = 1 N − 1 P X i =1 P X k =1 P k γ i r K − P − k i (120) = 1 N − 1 P X i =1 γ i r K − 2 P i P X k =1 P k r P − k i (121) = 1 N − 1 P X i =1 γ i r K − 2 P i ( N − 1) r P i (122) 28 = 1 N − 1 P X i =1 γ i r K − P i ( N − 1) (123 ) where (12 2) follows b ecause r i is a ro ot o f the c haracteristic equation [23, eqn. (5 9)]. When K 2 ≤ P ≤ K − 1, i.e., K − P ≤ P , D 2 = 1 N − 1 K − P X k =1 P k α k (124) = 1 N − 1 P X k =1 P k α k − P X k = K − P +1 P k α k (125) = 1 N − 1 P X k =1 P k α k (126) = 1 N − 1 P X i =1 γ i r K − P i ( N − 1) (127) where (126) follows b ecause α K − P +1 = · · · = α P − 1 = 0 due to [23, eqn. (51)], and (127) follo ws from (123). Therefore, f r o m (123) a nd (127), for all P , where 1 ≤ P ≤ K − 1, w e a lwa ys ha v e D 2 = 1 N − 1 P X k =1 P k α k = 1 N − 1 P X i =1 γ i r K − P i ( N − 1) (128) No w, in order to sho w that R = D 1 − U 1 D 1 + D 2 = 1 − 1 N , w e need to equiv alen tly sho w that D 1 = N U 1 + ( N − 1) D 2 . Thus , w e pro ceed as, N U 1 + ( N − 1) D 2 = N P X i =1 γ i r K − P i " 1 + 1 r i K − P − 1 # + P X i =1 γ i r K − P i ( N − 1) (129) = P X i =1 γ i r K − P i " N 1 + 1 r i K − P − N + N − 1 # (130) = P X i =1 γ i r K − P i " N 1 + 1 r i K − P − 1 # (131) = P X i =1 γ i r K − P i " N 1 + 1 r i − P 1 + 1 r i K − 1 # (132) = P X i =1 γ i r K − P i " 1 + 1 r i K − 1 # (133) = D 1 (134) where (13 3) follows b ecause N (1 + 1 r i ) − P = 1, whic h comes fr o m [23, eqn. (62)]. 29 Lemma 7 The m inimal r e quir e d c ommon r andomn ess in the pr op ose d achi e v able sche m e is, H ( S ) = P L N − 1 (135) Pro of: In our pro p osed sc heme, a t eac h database, a new common randomness sym b ol is emplo yed only in tw o cases. The first case is when a new common randomness sym b ol is added to a k -sum sym b ol that contains only desired message sym b ols. In this case, the common randomness symbols are equally distributed o ve r the ( N − 1) databases and do wnloaded f r om them. The second case is when a new common randomness sym b o l is assigned to a k -sum sym b ol that do es no t contain an y desired mes sage sym b ol. In this case, the common ra ndomness sym b ols are not do wnloaded. Therefore, we count the total n umber of distinct common randomness sym b ols as H ( S ) = U 1 + D 2 . W e note t ha t L can b e written as 1 P ( D 1 − U 1 ). Th us, P L N − 1 = P P ( D 1 − U 1 ) N − 1 (136) = D 1 − U 1 N − 1 (137) = N U 1 + ( N − 1) D 2 − U 1 N − 1 (138) = ( N − 1) U 1 + ( N − 1) D 2 N − 1 (139) = U 1 + D 2 (140) = H ( S ) (141) where (13 8) comes fro m (134), i.e., D 1 = N U 1 + ( N − 1) D 2 . 6 MM-LSPIR: Arbit rary Message Lengt hs Since the message sizes in the PSI problem are given and fixed, in particular, t hey a r e fixed to b e 1 (a s the incidence v ectors are comp osed 0s and 1s), w e need to determine the capacity of MM-SPIR with a giv en a nd fixed message size L . W e call this setting MM-LSPIR. The capacit y o f MM-LSPIR is giv en in the next theorem. Theorem 3 The MM-LSPIR c ap acity for N ≥ 2 , K ≥ 2 , and P ≤ K , for a n arbitr a ry message len g th L is given by, C M M − LS P I R = 1 , P = K P L ⌈ N P L N − 1 ⌉ , 1 ≤ P ≤ K − 1 , H ( S ) ≥ P L N − 1 0 , otherwise (142) 30 W e give the conv erse of Theorem 3 in Section 6.1, the a c hiev ability in Section 6.2, and map MM-LSPIR bac k to PSI in Section 6.3. 6.1 MM-LSPIR: Con v erse Pro of F rom the conv erse pro of of Theorem 2, using (21) and (91), we ha v e R M M − LS P I R = P L D M M − LS P I R ≤ P L P N n =1 H ( A [ P ] n ) ≤ N − 1 N = 1 − 1 N (143) Note that, for an a rbitrary finite fixed mess age length L , the do wnload cost D M M − LS P I R m ust b e a p ositiv e integer. Th us, we ha v e, D M M − LS P I R ≥ N P L N − 1 (144) and therefore, the con vers e result for a finite and fixed L , is R M M − LS P I R = P L D M M − LS P I R ≤ P L N P L N − 1 (145) Similarly , the en tro p y of common rando mness m ust also b e a p ositiv e in t eger, as the common randomness sym b o ls are pic k ed uniformly and indep enden tly from the same field as the message symbols. Th us, with a careful lo ok at going from (109) to (1 1 0), w e hav e, H ( S ) ≥ P L N − 1 (146) Therefore, (1 45) and (1 46) constitute the con vers e for Theorem 3. 6.2 MM-LSPIR: Ac hiev abilit y Pro of F or simplicit y , w e follow the a c hiev ability sc heme in [8, Section IV.B.1]. By setting the v alue of l K to b e 1 and using t he total length of m ulti-messages P L to replace the length of a single message L , w e get t he achiev abilit y of MM-LSPIR directly with D = N P L N − 1 and H ( S ) = P L N − 1 . These constitute the ac hiev ability f or Theorem 3. The ac hiev a bilit y can also b e done by using an extension of o ur prop o sed alternativ e achie v able sc heme. 6.3 Mapping MM-LS P IR Bac k to PSI Finally , w e map our MM-SPIR results bac k to the PSI problem to o bt a in Theorem 1. Recall that, in the PSI problem, by generating the sets P 1 and P 2 b y i.i.d. dra wing the elemen ts from the alphab et P alph , w e obtain i.i.d. messages in the corresp onding MM-SPIR problem. F urther, b y c ho osing the probabilit y q i of choosing eac h eleme n t to be included in the set P i 31 to b e q i = 1 2 , for i = 1 , 2, we obtain uniformly distributed messages, with message size L = 1. Therefore, the PSI problem is equiv alent to an MM-LSPIR pro blem with L = 1. No w, using Theorem 3 with L = 1 , w e obtain the ultimat e r esult of this pap er in Theorem 1. 7 Conclus ion and D iscussi o n W e in v estigated the PSI problem o ve r a finite set S K from an information-theoretic p oin t of view. W e sho wed that the problem can b e recast as an MM-SPIR problem with a message size 1. This is under the assum ption that the sets (or their corresponding incidence v ectors) can b e stored in replicated and non-colluding databases. F urther, the set elemen ts are generated in an i.i.d. fa shion with a pro babilit y 1 2 of adding any elemen t to an y of the sets. T o that end, w e explored the information-theoretic capacity of MM-SPIR as a stand-alone problem. W e sho wed that join t m ulti- message retriev al do es not outp erfor m the success iv e application of single-message SPIR. This is unlike the case of MM-PIR, where significan t p erformance gains can b e obtained due to join t retriev al. W e remark that SM-SPIR is a sp ecial case of the problem studied in this pap er b y plugging P = 1. F or the conv erse pro of, w e extended the pro of tech niques of [8] t o the setting of m ulti-messages. In particular, the pro of of Lemma 5 is significan tly more in v olv ed than the pro of in [8]. This is due to the fact that the desired message subsets in the case of MM-SPIR may no t b e disjoin t. T o unify the query structures of MM-PIR a nd MM-SPIR, w e prop o sed a new capacity-ac hieving sch eme for an y P as an alternative to the successiv e usage of the sc heme in [8]. Our sche me primarily consists of three steps: Exploiting the achie v a ble sc heme in [23], making necessary rep etitio ns to symmetrize the sc heme, and adding the needed common randomness prop erly . The last step is inspired by [15]. Based on these results, w e show ed that the optimal down load cost for PSI is min nl P 1 N 2 N 2 − 1 m , l P 2 N 1 N 1 − 1 mo . In the follow ing subsections, we mak e a few remarks ab out assumptions made in this pap er, a nd directions for further researc h. 7.1 Data Generation Mo del In this w o r k, w e add elemen ts to eac h set in an i.i.d. manner and with probability 1 2 . This assumption is made for t w o reasons, first, to hav e i.i.d. incidence vec tors, therefore, i.i.d. mes- sages in the MM-SPIR problem, and second, to hav e uniform messages to a v oid the need for compressing the messages W 1: K b efore/within retriev al. How ev er, this assumption may b e restrictiv e, as with this a ssumption, the exp ected sizes of b oth sets are K 2 . Ev en with ke ep- ing the i.i.d. generation assumption, the pro babilit y of adding eac h elemen t to set i could b e generalized to b e an arbitrar y q i . In this more general case, the expected sizes of the sets, K q 1 and K q 2 , could b e arbitrary . This may b e done b y using appropriate compression b efore/during retriev al, but needs to b e studied f urt her. Regarding the i.i.d. selection of 32 elemen ts, while this assumption is not needed from the ac hiev ability side, it is needed for the conv erse pro of. T o ov ercome these restrictions, as future w ork, it may b e w orth while to in ves tigate t he MM-SPIR pro blem with correlated messages. 7.2 Upload Cost Reduction In this pa p er, w e hav e fo cused on the do wnload cost a s the sole p erformance metric. A more natural p erformance metric is to consider the com bined uploa d a nd download cost. In this section, w e provide an illustrativ e example, whic h sho ws that the upload cost may b e reduced without sacrificing the do wnload cost. Nev ertheless, the characterization of t he optimal com bined upload and dow nload cost is an in teresting future direction that is outside the scop e of this pap er. Example 5 Consider the SPIR pr oblem with K = 3 , N = 2 , P = 1 , L = 1 . The original SPIR s c heme in [8] achieves the optimal d o wnlo ad c ost of D = 2 bits, while the uplo ad c ost is U = 6 bits. I nspir e d by [64], we show that the uplo ad c os t c an b e r e duc e d to just 4 bits without incr e as i n g the dow n lo ad c ost. Our new achievable scheme is as fol lows: F or any one of the two datab ases, ther e ar e four p o s sible answers A ( q ) n , wh er e n ∈ [2] , q ∈ [4] and c ommon r and omness S is a uniformly distribute d bit: A (1) 1 = W 1 + W 2 + W 3 + S, A (1) 2 = W 2 + W 3 + S (147) A (2) 1 = W 1 + S, A (2) 2 = S (148) A (3) 1 = W 2 + S, A (3) 2 = W 1 + W 2 + S (149) A (4) 1 = W 3 + S, A (4) 2 = W 1 + W 3 + S (150) The c orr esp o n ding q uerie s for di ff er e n t desir e d messages ar e gener a te d ac c or din g to the fol lowing distributions: W 1 : ( Q [1] 1 , Q [1] 2 ) i s uniform ove r { (1 , 1) , (2 , 2) , (3 , 3) , (4 , 4) } , (151) W 2 : ( Q [2] 1 , Q [2] 2 ) i s uniform ove r { (1 , 4) , (2 , 3) , (3 , 2) , (4 , 1) } , (152) W 3 : ( Q [3] 1 , Q [3] 2 ) i s uniform ove r { (1 , 3) , (2 , 4) , (3 , 1) , (4 , 2) } . (153) The r eliab ility c onstr aint fol lows fr om the fact for every query p a ir, the user c an c an - c el the interferi n g messa g es and the c o m mon r an domness S fr om the other datab ase. F or the datab ase-privacy c o n str ain t, we note that the undesir e d m essages ar e always mixe d with S . Henc e, the information le akage fr om undesir e d messages is zer o. F o r the user-privacy c onstr aint, we have P ( Q [ k ] n = q ) = P ( Q [ k ′ ] n = q ) , ∀ k , k ′ ∈ [3] , ∀ n ∈ [2] , ∀ q ∈ [4] (154) 33 i.e., fr om the p oint of view of any d a tab as e, the same set of queries is use d for an y desir e d message W i , wher e i = 1 , 2 , 3 with the same pr ob ability distribution. F or the pr op ose d scheme, the r e quir e d downlo ad c ost is D = 2 bits and the r e quir e d uplo ad c ost is U = 4 bits, whic h outp erfo rm s the one in [8] in terms of uplo ad c ost. 7.3 Comm unication Mo del W e note that our optimalit y result is restricted to the presen t ed comm unication scenario, where a sender submits queries to a receiv er in one round. An in teresting future direction is to in v estigate whether there is a more efficien t comm unication sc heme or whether there can b e an imp ossibilit y result t ha t can assert that no other comm unicatio n sc heme can outp erform our presen ted sc heme. 7.4 Single Database Assumption Our sc heme is infeasible for N 1 = N 2 = 1 due to the capacity result fo r MM-SPIR. It w ould b e interesting to see if MM-SPIR can b e made feasible with certain mo difications to the pr o blem, e.g., side information, or alternativ ely , if PSI can b e transformed in to other problems, in the case of a single-serv er. References [1] M. F reedman, K. Niss im, and B. Pink as. Efficien t priv ate matching and set inters ec- tion. In In ternational Conf e r en c e on the The ory and Applic ations of Crypto gr ap h ic T e chniques , pages 1– 1 9. Springer, 2004 . [2] E. De Cristofaro and G. Tsudik . Practical priv ate set in tersection proto cols with linear complexit y . In Interna tional Confer enc e on Fi n ancial Crypto gr aphy and Data Se curity , pages 143 –159. Springer, 2 010. [3] H. Chen, K. Laine, and P . Rindal. F ast priv ate set intersec tion fro m homomorphic encryption. In ACM SIGSAC Confer e nc e on Co m puter a nd Co mmunic ations Se c urity , pages 124 3–1255. A CM, 20 1 7. [4] D. D ac hman- Soled, T. Malkin, M. Ra yk ov a, and M. Y ung. Efficien t robust priv ate set in tersection. In International Confer enc e on Applie d Crypto gr aphy and Network Se curity , pages 125–14 2 . Springer, 2009 . [5] B. Chor, E. Kushilevitz, O. Goldreic h, and M. Sudan. Priv ate information retriev al. Journal of the ACM , 45(6):965–981 , No ve m b er 1998. 34 [6] Y. Gertner, Y. Ishai, E. Kushilevitz , and T. Malkin. Protecting data priv a cy in priv ate information retriev al sch emes. In Thirtieth A nnual ACM Symp osium on The o ry of Computing , pages 15 1–160. ACM, Ma y 19 9 8. [7] H. Sun and S. A. Jaf a r. The capacity of priv ate informat io n r etriev al. I EEE T r ansactions on Informa tion The ory , 63(7) :4 075–4088, July 20 17. [8] H. Sun and S. A. Jafar. The capacity of symmetric priv a te infor ma t ion r etriev al. IEEE T r ans. on Info. The ory , 65(1):322– 3 29, Jan uary 2019. [9] H. Sun and S. A. Jafar . The capacity of robust priv at e info r mation retriev al with colluding databases. IEEE T r ansactions on Inform ation The ory , 64(4):236 1–2370, April 2018. [10] R. T a jeddine, O. W. Gnilk e, D. Karpuk, R. F reij-Holla n ti, C. Hollanti, and S. El Rouay- heb. Priv a te information retriev al sc hemes for co ded data with arbitrary collusion pat- terns. In IEEE ISI T , June 2 0 17. [11] R. T a jeddine and S. El Roua yheb. Robust priv ate information retriev al o n co ded data. In IEEE ISIT , June 2017. [12] R. Bitar and S. El Rouayhe b. Staircase-PIR: Univ ersally robust priv ate information retriev al. In IEEE ITW , pages 1–5, No v em b er 201 8. [13] Q. W ang and M. Sk oglund. Symmetric priv ate information retriev al for MDS co ded distributed stora ge. In I EEE ICC , Ma y 201 7 . [14] Q. W ang a nd M. Sk o glund. L inear symmetric priv a te info rmation retriev al for MDS co ded distributed storage with colluding serv ers. In IEEE IT W , pages 71– 75, Nov em b er 2017. [15] Q. W a ng, H. Sun, and M. Skoglund. Symmetric priv ate informat io n retriev al with mismatc hed co ded messages and randomness. In IEEE I SIT , pages 365–3 69, July 2019 . [16] Q. W ang and M. Sk oglund. Secure symmetric priv ate info rmation retriev al from col- luding data bases with advers aries. In A l lerton Confer e n c e , Octob er 201 7. [17] T. G uo, R. Zho u, and C. Tian. O n t he information leak age in priv ate information retriev al systems. Av ailable a t arXiv: 1909.11605 . [18] K. Bana wan and S. Ulukus. The capacity of priv at e information retriev al fr o m co ded databases. IEEE T r ansactions on Information The ory , 64(3):194 5 –1956, Marc h 2018. [19] R. F reij-Hollanti, O. Gnilk e, C. Hollan ti, and D. Karpuk. Priv at e information retriev a l from co ded databases with colluding serv ers. SIAM Journal on Applie d Algebr a and Ge o metry , 1(1):6 47–664, 2017. 35 [20] Y. Zhang and G. Ge. A general priv ate info rmation retriev al sche me f o r MDS co ded databases with colluding serv ers. D e signs, Co des and Crypto gr ap hy , 87(1 1), Nov em b er 2019. [21] S. Kumar, H.-Y. Lin, E. Rosnes, and A. G . i Amat. Ac hieving maxim um distance separable priv at e infor mation retriev al capa city with linear co des. IEEE T r ansactions on Informa tion The ory , 65(7) :4 243–4273, July 20 19. [22] H. Sun and S. A. Jafa r . Priv a t e information retriev al from MDS co ded data with colluding serv ers: Settling a conjecture b y Freij- Ho lla n ti et al. IEEE T r ansactions on Information The ory , 64(2):1000 – 1022, F ebruary 2018. [23] K. Bana wan and S. Ulukus. Multi-message priv ate infor mation retriev al: Capac- it y results and near-optimal sc hemes. IEEE T r ansactions on Information The ory , 64(10):684 2–6862, Octob er 2018 . [24] Y. Zhang and G. Ge. Multi-file priv at e information retriev al from MDS co ded databases with colluding serv ers. Av aila ble at a rXiv: 1705 .03186. [25] K. Banaw an and S. Ulukus. The capacit y o f priv ate informat ion retriev al from Byzan tine and colluding databases. IEEE T r ansactions on Information Th e ory , 65(2 ) :1 206–1219, F ebruary 2 019. [26] R. T a jeddine, O. W. Gnilk e, D. Karpuk, R. F reij- Hollan ti, and C. Hollanti. Priv ate information retriev al from co ded storage sys tems with colluding, Byzantine , and un- resp onsiv e serv ers. IEEE T r ansactions on I nformation The o ry , 65(6 ):3898–3906 , June 2019. [27] R. T a ndon. The capacity of cac he aided priv ate information retriev al. In Al lerton Confer enc e , Octob er 2017. [28] M. Kim, H. Y ang, and J. Lee. Cac he-aided priv ate information retriev al. In Asilomar Confer enc e , Octob er 2017. [29] Y.-P . W ei, K. Banaw an, and S. Ulukus. F undamen tal limits of cac he-aided priv ate information retriev al with unknown and unco ded prefetchin g. IEEE T r ansactions on Information The ory , 65(5):3215 – 3232, Ma y 201 9. [30] Y.-P . W ei, K. Banaw an, and S. Ulukus. Cac he-aided priv ate information retriev al with partially kno wn unco ded prefetc hing: F undamen tal limits. IEEE JSA C , 36(6):1126 – 1139, June 2018. [31] S. Kumar, A. G. i Amat, E. R o snes, and L. Senigagliesi. Priv a te information retriev al from a cellular net work with cac hing at the edge. IEEE T r an s a ctions on Communic a- tions , 67(7) :4 900–4912, July 20 19. 36 [32] S. Ka dhe, B. Garcia, A. Heidarzadeh, S. El Roua yheb, and A. Sprin t son. Priv ate infor- mation retriev al with side info rmation: The single serv er case. In Al lerton Conf e r en c e , pages 109 9–1106, Octob er 2017. [33] Z. Chen, Z. W ang, and S. Jafa r. The capacity o f t -priv ate information retriev al with priv a t e side info rmation. Av ailable at arXiv:1709.0302 2 . [34] Y.-P . W ei, K. Banaw an, and S. Ulukus. The capacit y of priv ate information retriev al with partially kno wn priv ate side informa t io n. I EEE T r ansactions on Information The- ory , 65(12):8 222–8231, Decem b er 2019. [35] S. P . Shariat panahi, M. J. Siav oshani, and M. A. Maddah-Ali. Multi-message priv at e information retriev al with priv ate side information. In IEEE I TW , pages 1–5, No v em b er 2018. [36] A. Heidarzadeh, B. G arcia, S. Kadhe, S. E. Rouay heb, a nd A. Sprin tson. On the capacit y of single-serv er m ulti-message priv a te info rmation retriev al with side information. In A l lerton Confer en c e , pages 180–1 8 7, Octob er 20 18. [37] S. L i and M. Ga stpar. Single-serv er multi-mes sage priv ate information retriev al with side information. In Al lerton Confer enc e , pag es 173–17 9, Octob er 20 18. [38] S. Li and M. Ga stpar. Con v erse for m ulti-serv er single-message PIR with side informa- tion. Av ailable at arXiv:180 9 .09861. [39] Y.-P . W ei and S. Ulukus. The capacity of priv at e infor ma t io n retriev al with priv ate side informatio n under storage constrain ts. IEEE T r ansa ctions on Information The ory , 2019. Early Access. [40] H. Sun and S. A. Jafar. The capacity of priv ate computation. I EEE T r an s a ctions on Information The ory , 65(6):3880 – 3897, June 2019. [41] M. Mirmohseni and M. A. Maddah-Ali. Priv ate function retriev al. In IWCIT , pages 1–6, April 2018. [42] Z. Chen, Z. W a ng , and S. Jafar. The asymptotic capacit y of priv ate searc h. In IEEE ISIT , June 2018. [43] M. Ab dul-W ahid, F. Almoualem, D. K umar , and R. T andon. Priv ate information retriev al from storag e constrained da tabases – co ded caching meets PIR. Av ailable at arXiv:1711 .0 5244. [44] M. A. A ttia, D . Kumar, and R. T andon. The capacity of priv ate informatio n retriev al from unco ded storage constrained da t a bases. Av ailable a t arXiv:1805.041 04v2. 37 [45] K. Banaw an, B. Arasli, and S. Ulukus. Impro v ed storage for efficien t priv ate information retriev al. In IEEE ITW , August 2019. [46] C. Tian. On the storage cost of priv ate information retriev al. Av ailable at arXiv:1910.1197 3 . [47] Y.-P . W ei, B. Arasli, K. Banaw an, and S. Ulukus. The capa city of priv ate information retriev al f rom decen tralized unco ded caching databases. Informa tion , 10, Decem b er 2019. [48] K. Bana w an, B. Arasli, Y.-P . W ei, a nd S. Ulukus. The capa city of priv ate informa - tion retriev al from heterogeneous unco ded caching da tabases. IEEE T r ansactions on Information The ory . Early Access. Av a ilable at arXiv: 1 9 02.09512. [49] N. Raviv and I. T amo. Priv ate information retriev a l in graph based replication systems. In IEEE ISIT , June 2018. [50] K. Ba na wan and S. Ulukus. Priv a t e informa t io n r etriev al from non-replicated databases. In IEEE ISIT , pages 1 272–1276, July 2019. [51] K. Banaw an and S. Ulukus. Priv ate information retriev al through wiretap c hannel I I: Priv acy meets securit y . IEEE T r an s a ctions on Information The ory . Submitted Jan uary 2018. Also a v ailable at a rXiv:1801.06171. [52] Q. W ang and M. Sk oglund. On PIR and symme tric PIR from colluding databa ses with adv ersaries and ea ves dropp ers. IEEE T r a n sactions on I nformation T he ory , 65(5) :3 183– 3197, Ma y 2019. [53] Q. W ang, H. Sun, and M. Sk oglund. The capacit y of priv ate information retriev al with ea ves dropp ers. IEEE T r ansac tions on Information The ory , 65 (5):3198–32 14, Ma y 2019. [54] H. Y a ng, W. Shin, and J. Lee. Priv a te info r mation retriev al for secure distributed stora ge systems . IEEE T r ansactions on Information F or ensics and Se curity , 13(12):2953–2 964, Decem b er 2018. [55] Z. Jia, H. Sun, and S. Jafar. Cross subspace alignmen t and t he asymptotic capacit y of X -secure T -priv ate info rmation retriev al. IEEE T r ansaction s on Info rm ation The ory , 65(9):5783 –5798, Septem b er 201 9 . [56] H. Sun a nd S. A. Jafar. Optimal dow nload cost of priv ate information retriev al for arbitrary message length. IEEE T r ansactions on I nformation F or ensics and Se curity , 12(12):292 0–2932, Decem b er 2017 . 38 [57] R. Zhou, C. Tian, H. Sun, and T. Liu. Capacit y-ac hieving priv a t e informa t io n re- triev al co des from mds-co ded dat abases with minim um message size. Av a ilable at arXiv: 1903.0822 9. [58] H. Sun and S. A. Jafar. Multiround priv ate info rmation retriev al: Capacit y and storage o v erhead. IEEE T r ansactions on Information The ory , 6 4 (8):5743–57 54, August 201 8 . [59] K. Banaw an and S. Ulukus. Asymmetry hurts : Priv a t e information retriev al under asymmetric-traffic constrain ts. IEEE T r ansactions on I n formation Th e ory , 65(11):7 628– 7645, Nov ember 2019. [60] K. Banaw a n and S. Ulukus. Noisy priv ate information retriev al: O n separability of c hannel co ding and information retriev al. IEEE T r ansactions on Information The ory , 65(12):823 2–8249, Dec 2019. [61] R. G. L. D’Oliv eira and S. El Rouayheb. One-shot PIR: Refinemen t and lift ing . IEEE T r ansactions on I nformation The ory , 2019. Early Access. [62] R. T a jeddine, A. W ac h ter-Z eh, and C. Holla n ti. Priv ate inf o rmation retriev al o v er random linear net w orks. Av ailable at a rXiv:1810.08941. [63] B. Chor, N. Gilb o a, and M. Naor. Priv ate information retriev al by key w or ds. I A CR Cryptolo gy ePrint Ar chi v e , 1998:3, 1997. [64] Y. Zhou, Q. W ang, H. Sun, and S. F u. The minim um upload cost of symme tric priv ate information retriev al. In I EEE ISIT , pages 103 0–1034, June 2 020. 39
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment