Perfect match: Improved cross-modal embeddings for audio-visual synchronisation
This paper proposes a new strategy for learning powerful cross-modal embeddings for audio-to-video synchronization. Here, we set up the problem as one of cross-modal retrieval, where the objective is to find the most relevant audio segment given a sh…
Authors: Soo-Whan Chung, Joon Son Chung, Hong-Goo Kang
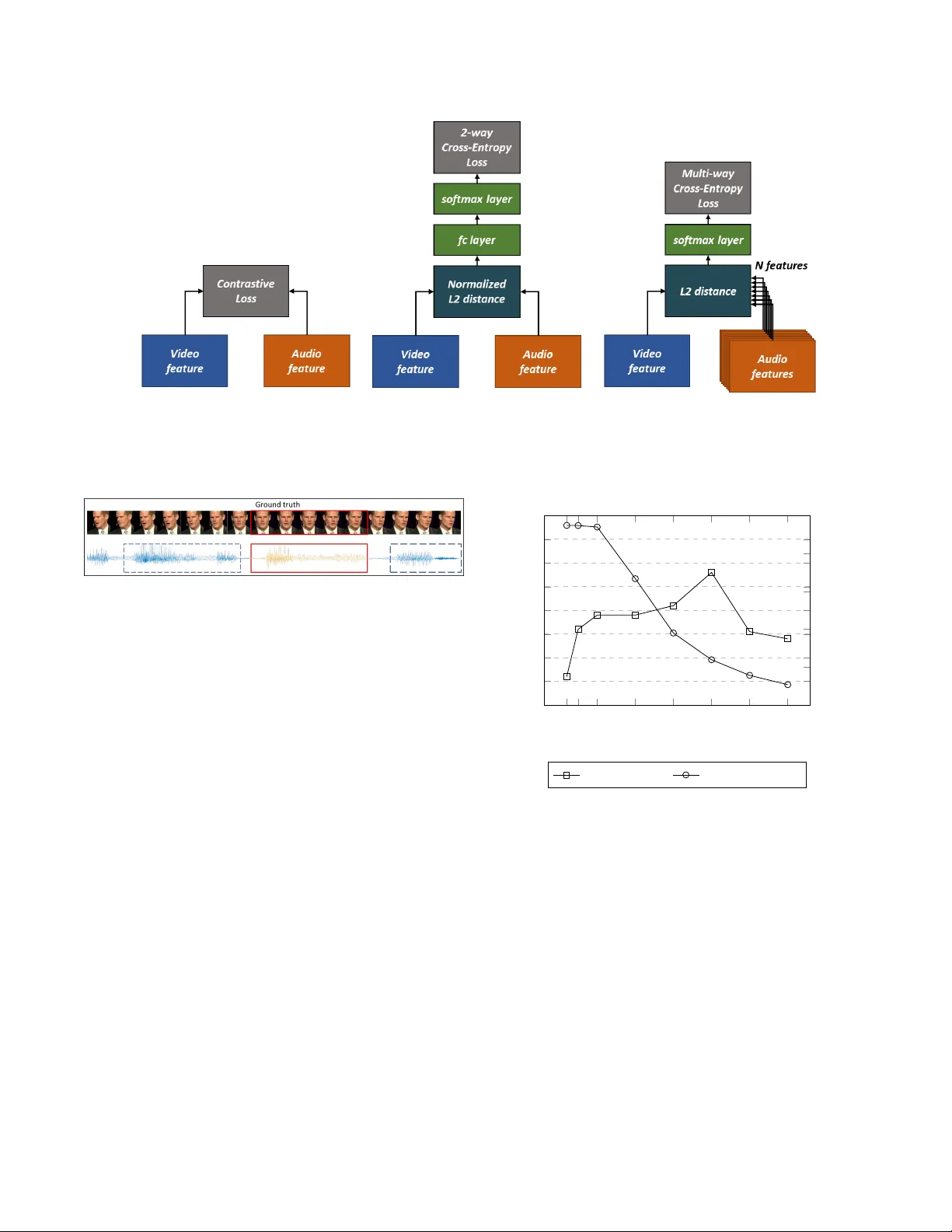
PERFECT MA TCH: IMPR O VED CR OSS-MOD AL EMBEDDINGS FOR A UDIO-VISU AL SYNCHR ONISA TION Soo-Whan Chung 1 , 2 , J oon Son Chung 2 and Hong-Goo Kang 1 1 Department of Electrical & Electronic Engineering, Y onsei Uni versity , Seoul, South K orea 2 Nav er Corp., Seongnam-si, Gyeonggi-do, South Korea ABSTRA CT This paper proposes a new strate gy for learning power ful cross-modal embeddings for audio-to-video synchronisation. Here, we set up the problem as one of cross-modal retriev al, where the objecti ve is to find the most rele vant audio se g- ment giv en a short video clip. The method builds on the recent adv ances in learning representations from cross-modal self-supervision. The main contrib utions of this paper are as follows: (1) we propose a new learning strategy where the embeddings are learnt via a multi-way matching problem, as opposed to a binary classification (matching or non-matching) problem as proposed by recent papers; (2) we demonstrate that performance of this method far e xceeds the existing baselines on the synchronisation task; (3) we use the learnt embeddings for visual speech recognition in self-supervision, and show that the performance matches the representations learnt end-to-end in a fully-supervised manner . Index T erms — Cross-modal supervision, cross-modal embedding, audio-visual synchronisation, self-supervised learning 1. INTR ODUCTION There has been a growing amount of interest in self-supervised learning, which has a significant advantage o ver fully super - vised methods that has been prev alent ov er the past years, in that one can capitalize on the huge amount of data freely av ailable on the Internet without the need for manual annota- tions. One of the earlier adaptations of such idea is the work on auto-encoders [1]; there are recent work on learning represen- tations via data imputation such as predicting context by in- painting [2] or RGB images from only grey-scale images [3]. Recently , the use of cr oss-modal self-supervision has prov ed particularly popular, where the supervision comes from the correspondence between two or more naturally co-occurring streams, such as sound and images. Previous work of particular rele vance is [4], which uses a con volution neural network (CNN) model called SyncNet to learn a joint embedding of face image sequence and cor - responding audio signal for lip synchronisation. The method learns po werful audio-visual features that are ef fectiv e for ac- tiv e speaker detection and lip reading. [5] has shown that the SyncNet features can also be used to achie ve a dynamic temporal alignment between speech and video sequences for synchronising re-recorded speech segments to a pre-recorded video. More recent (concurrent) papers hav e proposed meth- ods for co-training audio and video representations using two-stream architectures for source localization [6, 7], cross- modal retrie val [6], A V synchronisation and action recogni- tion [8, 9] in videos of general domain. All these train two- stream networks to predict whether the audio and the video inputs are matching or not. The models are trained either with contrastiv e loss [8] or as a binary classification [6, 7, 9]. Similar strategies have also been used for cross-modal bio- metric matching between faces and v oices [10, 11]. Although these works show great promise on the cross-modal learning task, the question remains as whether these objectiv es are suitable for the proposed applications such as recognition and retriev al. In this paper , we propose a novel training strategy for cross-modal learning, where we learn powerful cross-modal embeddings through a multi-w ay matching task. In particular , we combine the similarity-based methods ( e .g. L2 distance loss) used to learn joint embeddings across modalities, with a multi-class cross-entropy loss; this way , the training objectiv e naturally lends itself to cross-modal retriev al, where the task is to find the most relev ant sample in one domain to a query in another modality . W e propose a new training strategy in which the network is trained for the multi-way matching task without explicit class labels, whilst still benefiting from the fa vourable learning characteristics of the cross-entropy loss. The effecti veness of this solution is demonstrated for audio-visual synchronisation, where the objecti ve is to locate the most relev ant audio segment giv en a short video clip. The models trained for multi-way matching is able to produce powerful representations of the auditory and visual informa- tion that can be applied to other tasks – we also demonstrate that the learnt embeddings sho w better performance on a vi- sual speech recognition task compared to the representations learnt via pairwise objectiv es. (a) Audio stream (b) V isual stream Fig. 1 . T runk architecture for audio and visual stream 2. ARCHITECTURE AND TRAINING In this section, we describe the architecture and training strat- egy for the audio-visual matching task, and compare it to the existing state-of-the-art methods for audio-visual correspon- dence, including A VE-Net [6] and SyncNet [4]. 2.1. T runk ar chitecture The architecture of the audio and the video streams is de- scribed in this section. The inputs and the layer configura- tions are the same as SyncNet [4], so that the performance using the ne w training strate gy can be compared to the e xist- ing methods. The netw ork ingests 0.2-second clips of both audio and video inputs. A udio stream. The inputs to the audio stream are the 13- dimensional Mel-frequency cepstral coefficients (MFCCs), extracted at ev ery 10ms with 25ms frame length. Since the audio data is extracted from the video, there are natural en- vironmental factors such as background noise and distortions in speech. The input size is 20 frames in the time-direction, and 13 cepstral coefficients in the other direction (so the in- put image is 13 × 20 pixels). The network is based on the VGG-M [12] CNN model, b ut the filter sizes are modified for the audio input size as shown in Figure 1(a). V isual stream. The input to the visual stream is a video of a cropped f ace, with a resolution of 224 × 224 and a frame rate of 25 fps. The network ingests 5 stacked RGB frames at once, containing the visual information over the 0.2-second time frame. The visual stream is also based on the VGG-M [12], but the first layer has a filter size of 5 × 7 × 7 instead of 7 × 7 of the regular V GG-M, in order to capture the motion information ov er the 5 frames. The detailed visual stream is described in Figure 1(b). 2.2. T raining strategies The objectiv e is to learn cross-modal embeddings of the au- dio and the visual information using self-supervision. The two baselines are trained as a pair -wise correspondence task, whereas the proposed method is set up as a multi-way match- ing task. Baseline - SyncNet. The original SyncNet [4] is trained with a contrasti ve loss, which is designed to maximise the distance between features for non-matching pairs of inputs, and min- imise the distance for matching pairs. The audio and the video for non-matching pairs are sampled from the same face track, but from different points in time. The method requires man- ual tuning of the margin hyper -parameter . Baseline - A VE-Net. The Audio-V isual Embedding Network (A VE-Net) [6], designed for cross-modal retrie val, also takes the outputs from the audio and the video networks as inputs. The input vectors are L2 normalised, then the Euclidean dis- tance between the tw o normalised embeddings are computed, before being passed through a fully-connected layer and a softmax layer . The fully-connected layer essentially learns the threshold on the distance above which the features are deemed not to correspond. Proposed - Multi-way classification. Unlike previous meth- ods that use pairwise losses, the proposed embeddings are learnt here via a multi-way matching task. Since pairwise losses are only used for the binary matching, they do not use context information. Ho wev er , the multi-way matching strat- egy controls not only the distance between pairs but also uses relev ant information among sequential data to train the model. The learning criterion takes one input feature from the visual stream and multiple features from the audio stream. This can be set up as any N -way feature matching task. Euclidean dis- tances between the audio and video features are computed, resulting in N distances. The network is then trained with a cross-entropy loss on the in verse of this distance after passing through a softmax layer , so that the similarity between match- ing pairs are greater than that of non-matching pairs. Training strategies described here are summarised in Figure 2. All N audio frames are sampled from the same face track as the video clip, b ut only one corresponds to the video clip in time. This is to force the network to learn the content of what is being said, rather than the identity or other utterance char- acteristics. The sampling strategy is illustrated in Figure 3. 3. EXPERIMENTS In this section, we compare the performance of the proposed system to existing method for lip synchronisation and a re- lated audio-visual application. (a) SyncNet (b) A VE-Net (c) Proposed model Fig. 2 . Comparison between the existing and proposed training strate gies. Fig. 3 . Sampling strategy for self-supervised learning. The red rectangle highlights the audio segments that corresponds to the talking face above, the blue dotted rectangles sho w non- matching audio segments. 3.1. A udio-to-video synchronisation Audio-to-video synchronisation can be seen as a cross-modal retriev al task, where the temporal offset is found by selecting an audio segment from a set, gi ven a video segment. This is done by computing the distance between a learnt video fea- ture (from a 5-frame window) and a set of audio features. W e assume that the two streams are synchronised when the dis- tances between features are minimised. Howe ver as [4] sug- gests, one visual feature might not be enough to determine the correct offset, since not all samples contain discrimina- tiv e information – for instance, there may be some 5-frame video segments in which nothing is said. Therefore, we also conduct experiments with the context window of more than 5 video frames, in which case we av erage the distances across multiple video samples (with a temporal stride of 1 frame). Dataset. The network is trained on the pre-train set of the Lip Reading Sentences 2 (LRS2) [13] dataset. The LRS2 dataset contains 96,318 clips for training, and 1,243 for test. There is a trade-of f between the number of classes (or candidate audio features) N and the number of av ailable video clips for train- ing, since longer video clips are required to train networks 2 5 10 20 30 40 50 60 84 85 86 87 88 89 90 91 92 0 0 . 2 0 . 4 0 . 6 0 . 8 1 The number of audio features ( N ) Accuracy (%) · 10 5 # of video clips Accurac y (%) Accuracy (%) # of video clips Fig. 4 . Synchronisation accuracy according to N with larger N (the candidate audio clips are sampled without ov erlap). W e run experiments with dif ferent v alues of N in order to find the optimal value, and report the accuracy and the number of av ailable video clips in Figure 4. Evaluation pr otocol. The task is to determine the correct synchronisation within a ± 15 frame windo w , and the syn- chronisation is determined to be correct if the predicted of fset is within 1 video frame of the ground truth. A random pre- diction would therefore yield 9.7% accuracy . Since there are non-informativ e frames, we also compute the sync offset over various numbers of input visual frames, using the a verage dis- tances between features for input length K > 5 . Results. The results of experiments are gi ven using the net- T able 1 . Synchronization accuracy . # Frames : the number of visual frames for which the distances are av eraged ov er . # Frames SyncNet A VE-Net Proposed 5 75.8% 74.1% 89.5% 7 82.3% 80.4% 92.1% 9 87.6% 86.1% 94.7% 11 91.8% 90.6% 96.1% 13 94.5% 93.7% 97.5% 15 96.1% 95.5% 98.1% Fig. 5 . Architecture of the TC-5 lip reading network. work trained with N = 40 in T able 1. The performance of the proposed method far exceeds the baseline trained with a pair-wise objectiv es. In particular , for # frames = 5 ( i.e. no context beyond the receptive field), there is a significant in- crease in synchronisation performance from 75.8% to 89.5%. 3.2. V isual speech recognition The netw ork learns a po werful embedding of the visual infor- mation contained in the input video. The objectiv e of this ex- periment is to show that the embeddings learnt by the match- ing network are effecti ve for other applications, in this case, visual speech recognition. This is demonstrated on a word- lev el recognition task, and we compare the performance us- ing the embeddings learnt by the proposed self-supervised method to networks trained end-to-end with full supervision. Dataset. W e train and ev aluate the models on the Lip Read- ing in the W ild (LR W) [14] dataset, which consists of word- lev el speech and video segments extracted from the British television. The dataset has a v ocabulary size of 500, and con- tains o ver 500,000 utterances, of which 25,000 are reserved for testing. T able 2 . W ord accuracy of visual speech recognition using various architectures and training methods. Architectur e Method T op-1 (%) MT -5 [15] E2E 66.8 LF-5 [15] E2E 66.0 LSTM-5 [15] E2E 65.4 TC-5 E2E 71.5 TC-5 PT - SyncNet 67.8 TC-5 PT - A VE-Net 66.7 TC-5 PT - Proposed 71.6 Architectur e. The front-end architecture is taken from the vi- sual stream of the network described in Section 2.1. W e pro- pose a 2-layer temporal con volution back-end, followed by a 500-way softmax classification layer . This netw ork struc- ture is summarised in Figure 5 and is referred to as TC-5 in T able 2. The ‘5’ refers to the receptiv e field of the feature extractor in the temporal dimension, in line with the naming con vention of the networks in [15]. The performance of the TC-5 model exceeds the network designs proposed in [15] when trained end-to-end (E2E). The visual features are e x- tracted in advance for the ‘pre-trained’ e xperiments (PT), and only the back-end layers are trained for the 500-way classifi- cation task – the feature extractor is not fine-tuned with full supervision. Results. W e report the results on the visual speech recogni- tion task in T able 2. The results are compared to existing lip reading networks based on the VGG-M base architecture, and also to a model with the identical TC-5 architecture trained end-to-end on the large-scale LR W dataset in a full supervi- sion. It is notew orthy that the performance of the feature ex- tractor trained with the self-supervised method matches that of the end-to-end trained network without any fine-tuning. 4. CONCLUSION W e proposed a ne w training strategy for cross-modal match- ing and retriev al, which enables netw orks to be trained for matching without explicit class labels, whilst benefiting from fa vourable learning characteristics of the cross entropy loss. The experimental results sho w superior performance on the audio-visual synchronisation task compared to the existing state-of-the-art. The proposed embedding strategy also gi ves a significant improvement on the visual speech recognition task, and the performance matches that of a fully-supervised method with the same architecture. The method should also be applicable to other cross-modal tasks. Acknowledgements. W e would like to thank Bong-Jin Lee, Dongyoon Han, Jaesung Huh, Min-Seok Choi and Y ouna Ji at Nav er Clov a AI for their helpful advice. 5. REFERENCES [1] G. E. Hinton and R. R. Salakhutdinov , “Reducing the dimensionality of data with neural networks, ” science , vol. 313, no. 5786, pp. 504–507, 2006. [2] D. Pathak, P . Krahenbuhl, J. Donahue, T . Darrell, and A. A. Efros, “Context encoders: Feature learning by inpainting, ” in Pr oceedings of the IEEE Conference on Computer V ision and P attern Recognition , 2016, pp. 2536–2544. [3] R. Zhang, P . Isola, and A. A. Efros, “Colorful image col- orization, ” in Pr oceedings of the Eur opean Confer ence on Computer V ision . Springer, 2016, pp. 649–666. [4] J. S. Chung and A. Zisserman, “Out of time: automated lip sync in the wild, ” in W orkshop on Multi-view Lip- r eading, ACCV , 2016. [5] T . Halperin, A. Ephrat, and S. Peleg, “Dynamic tem- poral alignment of speech to lips, ” arXiv preprint arXiv:1808.06250 , 2018. [6] R. Arandjelovi ´ c and A. Zisserman, “Objects that sound, ” in Pr oceedings of the Eur opean Conference on Computer V ision , 2018. [7] A. Senocak, T .-H. Oh, J. Kim, M.-H. Y ang, and I. S. Kweon, “Learning to localize sound source in visual scenes, ” in Pr oceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , 2018, pp. 4358–4366. [8] B. K orbar , D. T ran, and L. T orresani, “Co- training of audio and video representations from self- supervised temporal synchronization, ” arXiv pr eprint arXiv:1807.00230 , 2018. [9] A. Owens and A. A. Efros, “ Audio-visual scene analy- sis with self-supervised multisensory features, ” in Pr o- ceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , 2018. [10] A. Nagrani, S. Albanie, and A. Zisserman, “Seeing voices and hearing faces: Cross-modal biometric match- ing, ” in Pr oceedings of the IEEE Confer ence on Com- puter V ision and P attern Reco gnition , 2018, pp. 8427– 8436. [11] C. Kim, H. V . Shin, T .-H. Oh, A. Kaspar , M. Elgharib, and W . Matusik, “On learning associations of faces and voices, ” arXiv preprint , 2018. [12] K. Chatfield, K. Simonyan, A. V edaldi, and A. Zisser - man, “Return of the devil in the details: Delving deep into con volutional nets, ” in British Mac hine V ision Con- fer ence , 2014. [13] J. S. Chung, A. Senior , O. V inyals, and A. Zisserman, “Lip reading sentences in the wild, ” in IEEE Conference on Computer V ision and P attern Recognition , 2017. [14] J. S. Chung and A. Zisserman, “Lip reading in the wild, ” in Pr oceedings of the Asian Confer ence on Computer V ision , 2016. [15] J. S. Chung and A. Zisserman, “Learning to lip read words by w atching videos, ” Computer V ision and Ima ge Understanding , 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment