Sequential Skip Prediction with Few-shot in Streamed Music Contents
This paper provides an outline of the algorithms submitted for the WSDM Cup 2019 Spotify Sequential Skip Prediction Challenge (team name: mimbres). In the challenge, complete information including acoustic features and user interaction logs for the f…
Authors: Sungkyun Chang, Seungjin Lee, Kyogu Lee
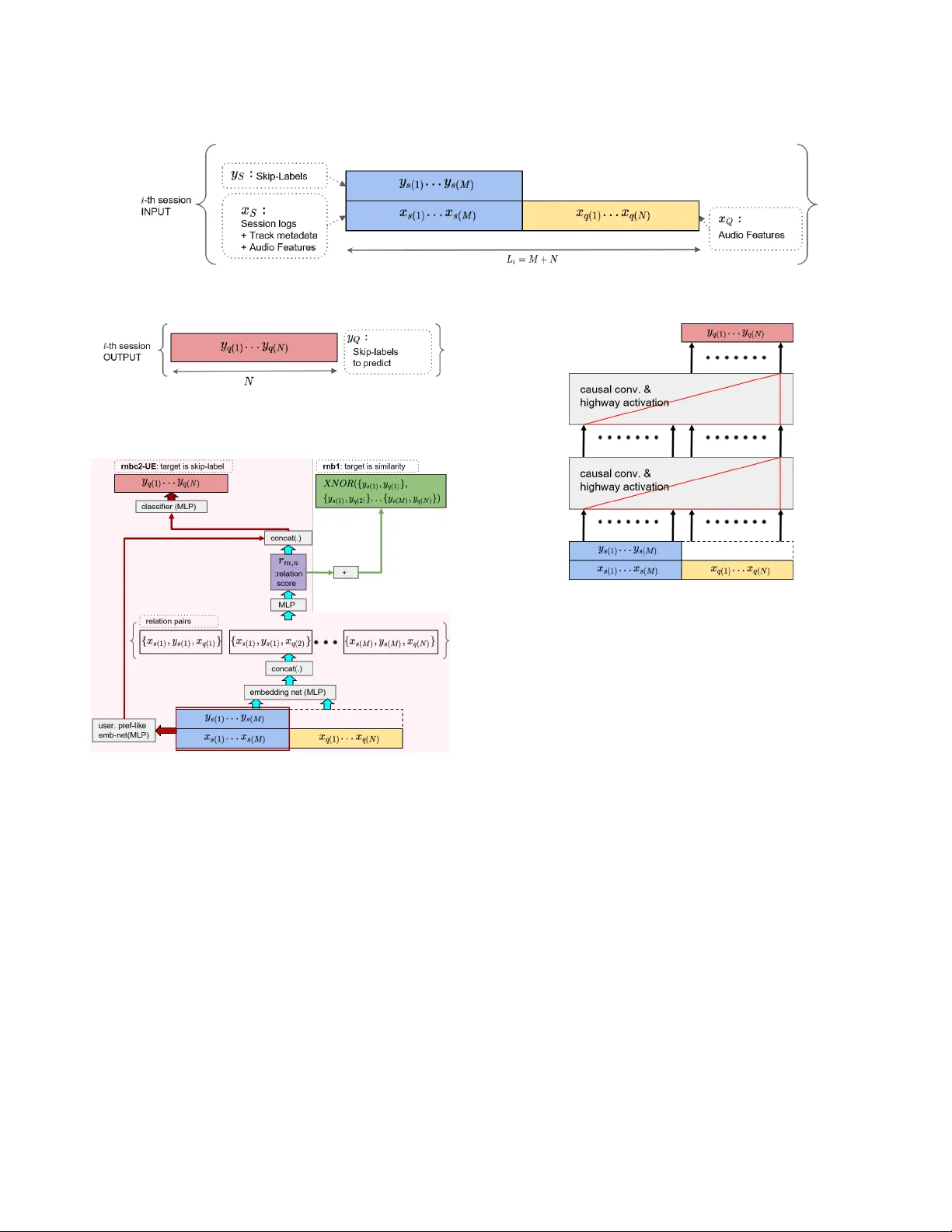
Sequential Skip Pr ediction with Fe w-shot in Str eamed Music Contents Sungkyun Chang ∗ Music and A udio Research Group Center for Super Intelligence Seoul National University rayno1@snu.ac.kr Seungjin Lee Music and A udio Research Group Seoul National University joshua77@snu.ac.kr K y ogu Lee Music and A udio Research Group Center for Super Intelligence Seoul National University kglee@snu.ac.kr ABSTRA CT This paper provides an outline of the algorithms submitted for the WSDM Cup 2019 Spotify Sequential Skip Prediction Challenge (team name: mimbr es). In the challenge, complete information including acoustic features and user interaction logs for the rst half of a listening session is provided. Our goal is to predict whether the individual tracks in the second half of the session will be skipped or not, only given acous- tic features. W e proposed two dierent kinds of algorithms that were based on metric learning and sequence learning. The experimental results showed that the se quence learn- ing approach performed signicantly b etter than the metric learning approach. Moreover , we conducted additional ex- periments to nd that signicant performance gain can be achieved using complete user log information. CCS CONCEPTS • Information systems → Information retrieval ; Per- sonalization ; KEYWORDS Music Information Retrieval, Sequence Learning, Few-shot Learning, Personalization, Music A CM Reference Format: Sungkyun Chang, Seungjin Lee, and K yogu Lee. 2019. Sequential Skip Prediction with Few-shot in Streamed Music Contents. In Proceedings of A CM International Conference on W eb Search and Data Mining (WSDM Cup 2019 W orkshop) . ACM, New Y ork, N Y , USA, 4 pages. 1 INTRODUCTION In online music streaming services such as Spotify 1 , a huge number of active users are interacting with a librar y of over 40 million audio tracks. Her e, an important challenge is to recommend the right music item to each user . T o this end, ∗ Sungkyun Chang is also with the Institute for Industrial Systems Innova- tion, Seoul National University , Seoul, Korea. 1 https://www.spotify .com/ WSDM Cup 2019 W orkshop, February 2019, Melbourne, A ustrailia 2019. there has b een a large related body of works in music rec- ommender systems. A standard approach was to construct a global model based on user’s play counts[ 2 , 12 ] and acoustic features[ 12 ]. Howev er , a signicant aspect missing in these works is how a particular user sequentially interacts with the streamed contents. This can be thought as a problem of personalization[ 3 ] with few-shot, or meta-learning[ 6 ] with external memor y[ 7 ]. The WSDM Cup 2019 tackles this is- sue by dening a new task with a real dataset[ 1 ]. W e can summarize the task as follows: • The length 𝐿 𝑖 of an 𝑖 -th listening session for a blinded- particular user varies in the range fr om 10 to 20. W e omit 𝑖 for readability from ne xt page. • W e denote the input sequence (Figure 1) from the rst half ( = supp ort ) and second half( = query ) of each session 𝑖 as 𝑋 𝑖 𝑠 and 𝑋 𝑖 𝑞 , respectively . • 𝑋 𝑖 𝑠 contains complete information including session logs and acoustic features. • 𝑋 𝑖 𝑞 contains only acoustic features. • 𝑌 𝑖 𝑠 is the labels representing whether the supports wer e skipped ( = 1 ) or not ( = 0 ) . • Given a set of inputs { 𝑋 𝑖 𝑠 , 𝑌 𝑖 𝑠 , 𝑋 𝑖 𝑞 } , our task is to pr edict 𝑌 𝑖 𝑞 (Figure 2). One limitation of our research was that we did not make use of any external dataset nor pr e-trained model from them. The code 2 and evaluation results 3 are available online. 2 MODEL ARCHITECT URES In this se ction, we explain two dierent branches of algo- rithms based on 1) metric learning, and 2) sequence learning. In metric learning-based approach, one key feature is that we do not assume the presence of orders in a sequence. This allows us to formulate the skip prediction problem in a simi- lar way with the pre vious works[ 10 ] on few-shot learning that learns to compare . In sequence learning-based approach, we employ temporal convolution layers that can learn or memorize information by assuming the presence of orders in a se quence. In this 2 https://github.com/mimbres/SeqSkip 3 https://www.cr owdai.org/challenges/spotify-sequential-skip-prediction- challenge WSDM Cup 2019 W orkshop, February 2019, Melbourne, Austrailia S. Chang et al. Figure 1: Input structure; The blue and yellow blocks represent the inputs of supports and queries for prediction, respectively . Figure 2: Output structure; The red block represents the skip-labels to b e predicted for the 𝑖 -th session. Figure 3: “rnb1” is a relation network-based few-shot metric learner . It can predict a pair-wise similarity (green arrows) by learnt latent metric space: it constructs all possible rela- tion pairs from the few-shot features and labels. “rnbc2-UE” (pink) shares the structure of “rnb1” , and it can be trained as a few-shot classier that directly predicts skip-lab els. fashion, we formulate the skip pr ediction problem as a meta- learning[6] that learns to refer past experience . Metric Learning This model aims to learn how to compare a pair of input acoustic features, through a latent metric space , within the context given from the supports. Pre viously , Sung et al.[ 10 ] proposed a metric learning for few-shot classication. The relation score 𝑟 𝑚,𝑛 for a pair of support and quer y inputs, { 𝑥 𝑠 ( 𝑚 ) , 𝑥 𝑞 ( 𝑛 ) } and the lab el 𝑦 𝑠 ( 𝑚 ) can be dened by: 𝑟 𝑚,𝑛 = RN ( 𝐶 ( 𝑓 𝜃 ( 𝑥 𝑠 ( 𝑚 ) , 𝑓 𝜃 ( 𝑥 𝑞 ( 𝑛 ) ) , 𝑦 𝑠 ( 𝑚 ) ) ) , (1) Figure 4: “seq1HL” has 2-stack of causal encoders. A red right triangle represents causal encoder , that is not allowed to observe future inputs. where RN ( . ) is the relation networks[ 8 ], 𝑓 𝜃 is an MLP for embedding network, and 𝐶 ( . ) is a concatenation operator . In the original model[ 10 ] denoted by rnb1 , the sum of the relation score is trained to match the binary target similarity . The target similarity can be computed with XNOR op eration for each relation pair . For example, a pair of items that has same labels will have a target similarity 1 ; otherwise 0 . The nal model is denoted as rnbc2-UE (Figure 3) with: (1) training the classier to predict the skip-labels directly , instead of similarity . (2) trainable parameters to calculate weighted sum of the relation score 𝑟 , (3) additional embedding layers (the red arrows in Figure 3) to capture the user preference-like . Sequence Learning In Figure 4, this model consists of dilated convolution layers followed by highway[ 9 ]-activations or GLUs (gated linear units[ 4 ]). A similar architecture can b e found in the text encoder part of a recent T TS (T ext-to-speech) system[ 11 ]. In practice, we found that non-auto-regressive (non-AR)- models performed consistently better than the AR-models. This was explainable as the noisy outputs of the previous WSDM Cup 2019 W orkshop, February 2019, Melbourne, Austrailia Figure 5: “att(seq1eH(S), seq1eH(Q))” has non-causal en- coder for the supports. This allows mo del to obser ve future inputs, as represented with a red isosceles triangle. steps degraded the outputs of the next steps cumulatively . The nal model, seq1HL , has the following features: (1) a non- AR mo del, (2) highway-activations with instance norm[ 14 ], instead of using GLUs, (3) 1 - 𝑑 causal convolution layers with a set of dilation parameters 𝑑 = { 1 , 2 , 4 , 8 , 16 } and kernel size 𝑘 = 2 , (4) in train, parameters are updated using the loss of 𝑌 𝑞 , instead of the entire loss of { 𝑌 𝑞 , 𝑌 𝑞 } . W e have two variants of the sequence learning model with attention modules. The model in Figure 5 has separate en- coders for supports and queries. The support encoder has 1 - stack of non-causal convolution with a set of dilation parame- ters 𝑑 = { 1 , 3 , 9 } and kernel size 𝑘 = 3 . The quer y encoder has 1 -stack of causal convolution with a set of dilation parame- ters 𝑑 = { 1 , 2 , 4 } and kernel size 𝑘 = { 2 , 2 , 3 } . These encoders are followed by a dot product attention operation[13]. In contrast with the models mentioned above, SNAIL[ 6 ] (in Figure 6) has attention module at the bottom, and the causal convolution layer follo ws. For the multi-head attention, we set the number of head to 8. 3 EXPERIMENTS Pre-processing From the Spotify dataset[ 1 ], we decoded the categorical text labels in session logs into one-hot vectors. Other integer values from the logs, such as “number of times the user did a seek forward within track” were min-max normalized after taking logarithm. W e didn’t make use of dates. The acoustic features were standar dized to have mean= 0 with std= 1 . Evaluation Metric The primary metric for the challenge was Mean A verage Ac- curacy (MAA), with the av erage accuracy dened by 𝐴𝐴 = Figure 6: SNAIL[6]-like model. W e remov ed the rst embed- ding layer , and trained it as a non-AR mo del. Í 𝑇 𝑖 = 1 𝐴 ( 𝑖 ) 𝐿 ( 𝑖 ) / 𝑇 , where 𝑇 is the number of tracks to be pre- dicted for the given session, 𝐴 ( 𝑖 ) is the accuracy at position 𝑖 of the sequence, and 𝐿 ( 𝑖 ) is the boolean indicator for if the 𝑖 -th prediction was correct. Training In all experiments displayed in T able 1, we trained the mod- els using 80 % of train set. The rest of train set was used for validation. rnb1 and rnb2-UE was traine d with MSE loss. All other models were traine d with binary cross entropy loss. W e use d Adam[ 5 ] optimizer with learning rate 10 − 3 , annealed by 30% for every 99,965,071 sessions (= 1 epoch). Every training was stoppe d within 10 epochs, and the train- ing hour varie d from 20 to 48. W e uniformly applied the batch-size 2,048. For the baseline algorithms that have not been submitted, we display the validation MAA instead. The total size of trainable parameters for each model can var y . For comparison of model architectures, w e maintained the in-/output dimensions of every repeated linear units in met- ric learning as 256. In se quence learning, we maintained the size of in-/output channels as 256 for every encoder units. Main Results and Discussion Note that we only discuss here the results from non- AR setting. The main results are displayed in T able 1. W e can compare the metric learning-based algorithms in the rst three rows. rnb1 was the rstly implemented algorithm. rnb2-UE had two additional embedding layers. It achieved 2.4%p improvements ov er rnb1 . The nal model, rnbc2-UE additionally achieved 1%p improvements by changing the target label from similarity to skip-labels. The v e ro ws fr om the bottom display the performance of sequence learning-based algorithms. seq1eH and seq1HL WSDM Cup 2019 W orkshop, February 2019, Melbourne, Austrailia S. Chang et al. T able 1: Main Results Model Category MAA(ofc) MAA(val) rnb1 M - 0.540 rnb2-UE M - 0.564 rnbc2-UE M 0.574 0.574 seq1eH (1-stack) S 0.633 0.633 seq1HL (2-stack) S 0.637 0.638 att(seq1eH(S), seq1eH(Q)) S - 0.633 self-att. transformer S - 0.631 replicated-SNAIL S - 0.630 MAA(ofc) from ocial evaluation; MAA(val) from our validation; M and S denote metric and sequence learning, respectively; rnb1 was the replication of “learning to compare”[ 10 ]; rnbc2-UE and seq1HL were our nal model for metric and sequence learning, respectively; T able 2: The eect of complete information provided to query Model User-logs Acoustic feat. Skip-label MAA(val) T eacher use use - 0.849 seq1HL - use - 0.638 shared the same architecture , but diered in the depth of the networks. seq1HL achieved the best result, and it sho wed 0.5%p improv ement ov er seq1eH . att(seq1eH(S), seq1eH(Q )) showed a comparable performance with seq1eH . The trans- former[ 13 ] and SNAIL[ 6 ] were also attention-based models. Howev er , we could obser ve that sequence learning-based model without attention unit worked better . Overall, the sequence learning-based approaches outper- formed the metric learning-based approaches by at least 5.9%p. The large dierence in performance implied that se- quence learning was more ecient, and the metric learning- based models were missing crucial information from the sequence data. How helpful would it be if complete information was provided to quer y sets? So far , the input query set 𝑋 𝑞 has been dene d as acoustic features (see Figure 1). In this experiment, we trained a new model T eacher using both user-logs and acoustic features that were available in dataset. In T able 2, the performance of the T eacher was 21.1%p higher than our b est model seq1HL . This revealed that the user-logs for 𝑋 𝑞 might contain very useful information for sequential skip prediction. In future work, we will discov er how to distill the knowledge. 4 CONCLUSIONS In this paper , we have describe d two dierent approaches to solve the sequential skip prediction task with few-shot in online music service. The rst approach was based on metric learning, which aimed to learn how to compare the music contents repr esented by a set of acoustic features and user in- teraction logs. The second approach was base d on sequence learning, which has b een widely used for capturing tem- poral information or learning how to refer past e xperience. In experiments, our models were evaluated in WSDM Cup 2019, using the real dataset provided by Spotify . The main results rev ealed that the sequence learning approach worked consistently better than metric learning. In the additional experiment, we veried that giving a complete information to the query set could improve the prediction accuracy . In future work, we will discov er how to generate or distill these knowledge by the model itself. A CKNO WLEDGMENTS This work was supported by Kakao and Kakao Brain corporations, and by National Research Foundation (NRF2017R1E1A1A01076284). REFERENCES [1] Brian Brost, Rishabh Mehrotra, and Tristan Jehan. 2019. The Music Streaming Sessions Dataset. In Proc. the 2019 W eb Conference . A CM. [2] Oscar Celma. 2010. Music recommendation. In Music recommendation and discovery . Springer , 43–85. [3] Y oon Ho Cho, Jae K yeong Kim, and Soung Hie Kim. 2002. A personal- ized recommender system based on web usage mining and decision tree induction. Exp ert systems with A pplications 23, 3 (2002), 329–342. [4] Y ann N Dauphin, Angela Fan, Michael Auli, and David Grangier . 2016. Language modeling with gated conv olutional netw orks. arXiv preprint arXiv:1612.08083 (2016). [5] Diederik P Kingma and Jimmy Ba. 2014. A dam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014). [6] Nikhil Mishra, Mostafa Rohaninejad, Xi Chen, and Pieter Abbeel. 2018. A simple neural attentive meta-learner . In Proc. ICLR 2018 . [7] Adam Santoro , Sergey Bartunov , Matthew Botvinick, Daan Wierstra, and Timothy Lillicrap. 2016. Meta-learning with memor y-augmented neural networks. In Proc. ICML 2016 . 1842–1850. [8] Adam Santoro, David Raposo, David G Barrett, Mateusz Malino wski, Razvan Pascanu, Peter Battaglia, and Timothy Lillicrap. 2017. A simple neural network module for relational reasoning. In Proc. NIPS 2017 . 4967–4976. [9] Rupesh Kumar Srivastava, Klaus Gre, and Jürgen Schmidhub er . 2015. Highway networks. arXiv preprint arXiv:1505.00387 (2015). [10] Flood Sung, Y ong xin Y ang, Li Zhang, T ao Xiang, Philip HS T orr , and Timothy M Hospedales. 2018. Learning to compare: Relation network for few-shot learning. In Proc. CVPR 2018 . 1199–1208. [11] Hideyuki T achibana, Katsuya Uenoyama, and Shunsuke Aihara. 2018. Eciently trainable text-to-speech system based on deep convolutional networks with guided attention. In Proc. ICASSP 2018 . IEEE, 4784–4788. [12] Aaron V an den Oord, Sander Dieleman, and Benjamin Schrauwen. 2013. Deep content-based music recommendation. In Proc. NIPS 2013 . 2643–2651. [13] Ashish V aswani, Noam Shazeer , Niki Parmar , Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser , and Illia Polosukhin. 2017. At- tention is all you need. In Proc. NIPS 2017 . 5998–6008. [14] Victor Lempitsky Dmitry Ulyanov Andrea V edaldi. 2016. Instance Normalization: The Missing Ingredient for Fast Stylization. arXiv preprint arXiv:1607.08022 (2016).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment