gpuRIR: A Python Library for Room Impulse Response Simulation with GPU Acceleration
The Image Source Method (ISM) is one of the most employed techniques to calculate acoustic Room Impulse Responses (RIRs), however, its computational complexity grows fast with the reverberation time of the room and its computation time can be prohibi…
Authors: David Diaz-Guerra, Antonio Miguel, Jose R. Beltran
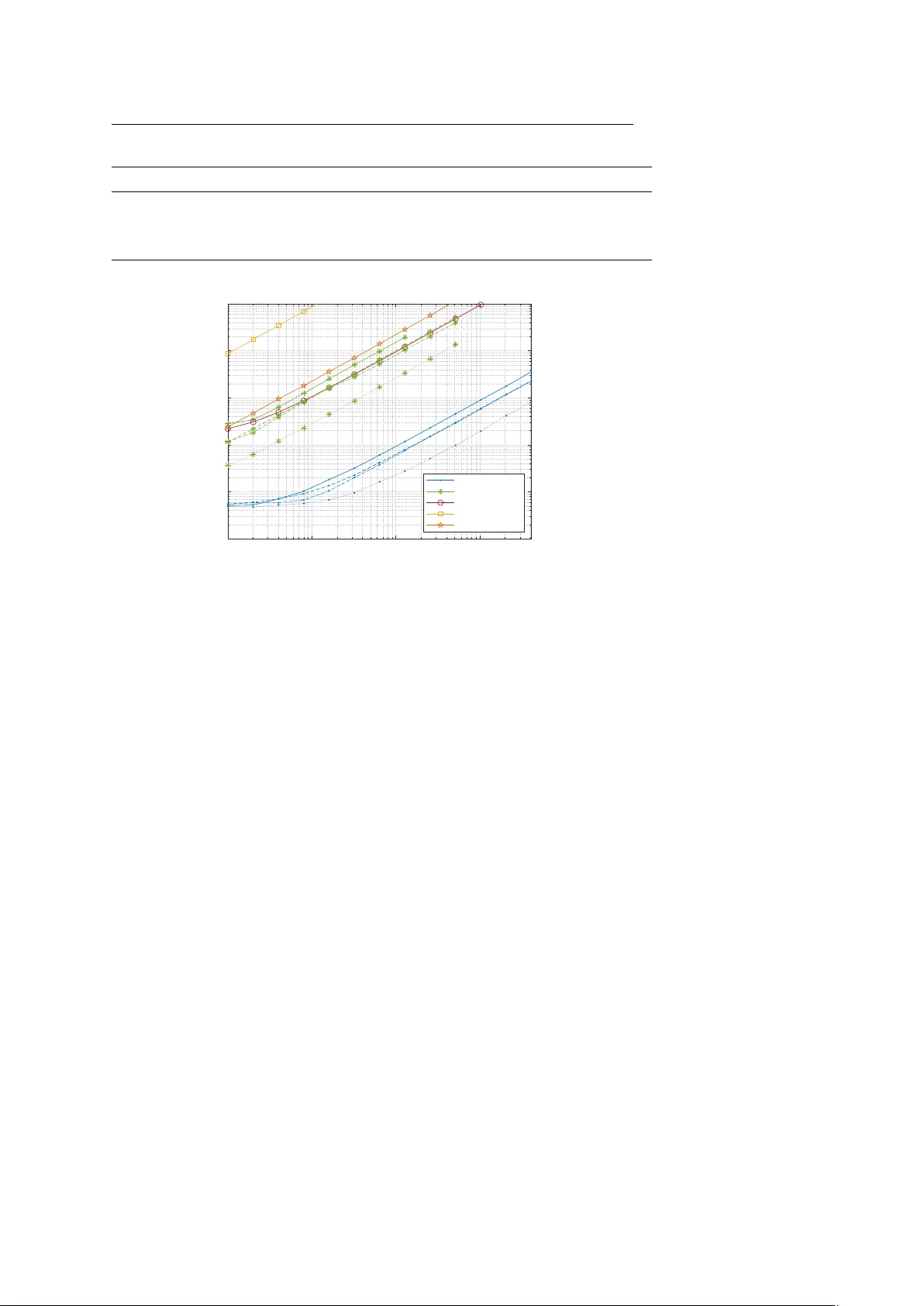
Noname man uscript No. (will b e inserted b y the editor) gpuRIR: A Python Library for Ro om Impulse Resp onse Sim ulation with GPU Acceleration Da vid Diaz-Guerra · Antonio Miguel · Jose R. Beltran Received: date / Accepted: date Abstract The Image Source Metho d (ISM) is one of the most emplo y ed tec h- niques to calculate acoustic Ro om Impulse Resp onses (RIRs), how ev er, its computational complexity grows fast with the reverberation time of the ro om and its computation time can b e prohibitiv e for some applications where a h uge num ber of RIRs are needed. In this pap er, w e present a new implemen- tation that dramatically improv es the computation sp eed of the ISM by using Graphic Pro cessing Units (GPUs) to parallelize b oth the simulation of mul- tiple RIRs and the computation of the images inside eac h RIR. Additional sp eedups were ac hiev ed b y exploiting the mixed precision capabilities of the new er GPUs and b y using lookup tables. W e provide a Python library under GNU license that can b e easily used without any knowledge ab out GPU pro- gramming and w e sho w that it is ab out 100 times faster than other state of the art CPU libraries. It may become a p ow erful tool for man y applications that need to p erform a large num ber of acoustic sim ulations, suc h as training mac hine learning systems for audio signal pro cessing, or for real-time ro om acoustics simulations for immersiv e m ultimedia systems, suc h as augmen ted or virtual realit y . Keyw ords Ro om Impulse Response (RIR) · Image Source Method (ISM) · Ro om Acoustics · Graphic Pro cessing Units (GPUs) This work was supp orted in part b y the Regional Go vernment of Aragon (Spain) with a grant for postgraduate research contracts (2017-2021) co-funded by the Op erative Program FSE Aragon 2014-2020. This material is based up on work supp orted by Go ogle Cloud. David Diaz-Guerra, Antonio Miguel and Jose R. Beltran Department of Electronic Engineering and Comm unications Universit y of Zaragoza, Spain David Diaz-Guerra E-mail: ddga@unizar.es This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3 2 David Diaz-Guerra et al. 1 In tro duction The sim ulation of the acoustics of a room is needed in man y fields and ap- plications of audio engineering and acoustic signal pro cessing, such as train- ing robust Sp eech Recognition systems [1] or training and ev aluating Sound Source Localization [2] or Sp eech Enhancement [3] algorithms. Although there are man y lo w complexity techniques to sim ulate the rev erb eration effect of a ro om in real time, as the classic Schroeder Reverberator [4], some applications require an accurate simulation of the reflections causing the rev erberation. The information of all those reflections is gathered in the Ro om Impulse Resp onse (RIR) betw een the source and the receiver p ositions, which allows to simulate the rev erb eration process by filtering the source signal with it. Our goal in this w ork is to provide a fast metho d to obtain these RIRs. The Image Source Metho d (ISM) is probably the most used technique for RIR simulation due its conceptual simplicit y and its flexibilit y to modify parameters suc h as the ro om size, the absorption co efficients of the walls, and the source and receiv er positions. W e can simulate any level of reverberation b y mo difying the ro om size and the absorption co efficients, but the computational complexit y of the algorithm gro ws fast as the num b er of reflections to sim ulate increases. In addition, many applications require the computation of multiple RIRs for sev eral source and receiver positions, e.g. to simulate a mo ving source recorded with a microphone array . F urthermore, with the increasing p opularity of Machine Learning techniques, the need for computing randomly generated RIRs on the fly for h uge datasets in a reasonable time is constantly increasing. Firstly developed to supp ort the graphics computations of video-games, Graphics Pro cessing Units (GPUs) are to day one of the b est and cheapest w ays to increase the sp eed of man y algorithms that can b e expressed in a parallel form. Despite parallelizing most of the stages of the ISM is quite straigh tforward, to the b est of our knowledge, only [5] prop osed to implement it in GPUs. Although they show ed that using GPUs it was p ossible to sp eed- up the RIR sim ulations, they did not pro vide the code of their implemen tation and the acoustic signal pro cessing and audio engineering comm unities hav e not em braced their approac h. In addition, they used an ov erlap-add strategy with atomic op erations to combine the con tributions of each image source, which strongly reduces the level of parallelism. In this pap er, we presen t a new GPU implemen tation with a higher degree of parallelism, which allo ws us to achiev e higher sp eed-ups with cheaper GPUs. Motiv ated by the p erformance b o ost obtained with the use of lookup tables (LUTs) in the CPU implemen tations, w e also study its use in our GPU implementation. Finally , w e prop ose a 16-bit precision implementation which can increase even more the simulation sp eed in the new er GPUs with mixed precision supp ort. T able 1 shows some state of the art implementations of the ISM and com- pare some of their main characteristics. W e can see how our implemen tation is the only one with GPU acceleration that is av ailable as a free and open source This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3 gpuRIR: A Python Library for RIR Simulation with GPU Acceleration 3 T able 1 Comparison of some state of the art ISM implementation RIR generator [6] pyroomacoustics [7] [8] [5] gpuRIR Open source library (language) 3 (Matlab and Python) 3 (Python) 3 (Matlab) 7 3 (Python) Implementation language C++ Python and C++ Matlab CUDA CUDA F ractional dela ys 3 3 3 3 3 Negative reflection coefficients 7 7 3 7 3 Diffuse reverberation mo del 7 7 3 7 3 GPU acceleration 7 7 7 3 3 Lookup table implementation 7 3 7 7 3 Mixed precision implementation 7 7 7 7 3 library 1 and ho w it includes some features (further explained in section 2.2) that are not included in other Python libraries. Using our library does not require an y knowledge about GPU programming, but just having a CUD A compatible GPU and the CUD A T oolkit, and it can b e installed and used as an y CPU RIR simulation library . The contributions of the pap er are the follo wing: (i) we present a new parallel implemen tation of the ISM whic h fits b etter with the new er GPUs arc hitectures than the only alternative a v ailable in the literature, (ii) we discuss ho w to increase the p erformance of GPU programs with several tec hniques suc h as using Lo okup T ables or 16-bit precision floating point arithmetics, (iii) w e presen t a new F ree and Op en Source Python library exploiting this implemen tation, and (iv) w e compare it against sev eral state of the art ISM implemen tations and show how ours is tw o orders of magnitude faster than them. The reminder of this pap er is structured as follows. W e review the ISM in section 2, section 3 explains ho w we ha ve parallelized it, and section 4 presents the Python library . Finally , in section 5, w e compare the p erformance of our library against three of the most commonly used RIR simulation libraries and section 6 concludes the pap er. 2 The Image Source Metho d (ISM) The Metho d of Images has b een widely used in many fields of ph ysics to solv e differen tial equations with boundary conditions, but its application for RIR es- timations was originally prop osed b y Allen and Berkley [9]. In this section, w e first review their original algorithm and then explain some of the impro v emen ts that hav e b een prop osed to improv e b oth its accuracy and computational p er- formance. 1 The co de, the do cumentation, the installation instructions, and examples can b e found in https://github.com/DavidDiazGuerra/gpuRIR This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3 4 David Diaz-Guerra et al. n : x n : y -4 -3 -2 -1 0 12 3 -2 -1 0 1 β y0 β y1 β x1 β x0 Fig. 1 Image sources for a t wo dimensional room. The red square and the blue dot represents the receiv er and the source and the blue circumferences represents the image sources. The solid green line represents one of the m ultiple reflection paths and the dashed green line the direct path of the equiv alen t image source. The black dot is the origin of the co ordinates system. 2.1 Original Allen and Berkley algorithm The main idea b ehind the ISM is to compute each wa v e-front that arriv es to the receiver from each reflection off the walls as the direct path received from an equiv alent (or image) source. In order to get the positions of these image sources, we need to create a 3D grid of mirrored ro oms with the reflections of the room in each dimension; as sho wn in Fig. 1 simplified to 2D for an example. If the num ber of images we wan t to compute for each dimension are N x , N y and N z , then w e define a grid N of image sources n = ( n x , n y , n z ) : d− N x / 2 e ≤ n x < d N x / 2 e , d− N y / 2 e ≤ n y < d N y / 2 e and d− N z / 2 e ≤ n z < d N z / 2 e (where d·e stands for the round tow ard p ositiv e infinit y op erator). The co ordinates of the position of each image p n = ( x n , y n , z n ) are calculated using its grid indices, the p osition of the source and the dimensions of the ro om; as an example, the comp onen t x would b e calculated as x n = ( n x L x + x s if n x is ev en ( n x + 1) L x − x s if n x is o dd , (1) where L = ( L x , L y , L z ) is the size of the ro om and p s = ( x s , y s , z s ) is the p osition of the original source. The y and the z coordinates can be obtained similartly . This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3 gpuRIR: A Python Library for RIR Simulation with GPU Acceleration 5 The distance d n from the image source n to a receiver in the p osition p r = ( x r , y r , z r ), and therefore the delay of arriv al τ n , is trivial if we know the image source p osition: d n = || p r − p s || , (2) τ n = d n c , (3) where || · || denotes the Euclidean norm and c is the sp eed of sound. In order to calculate the amplitude with which the signals from eac h im- age source arriv e to the receiv er, we need to take in to accoun t the reflection co efficien ts of the w alls of the ro om. W e define β x 0 as the reflection coefficient of the wall parallel to the x axis closest to the origin of the co ordinates system and β x 1 as the farthest; β y 0 , β y 1 , β z 0 and β z 1 are defined equiv alen tly . Finally , if we define β n as the pro duct of the reflection co efficients of each wall crossed b y the path from the image source n to the receiver, its amplitude factor will b e A n = β n 4 π · d n . (4) Kno wing the amplitude and the dela y for each image, w e can easily obtain the RIR as the sum of the contribut ion of each image source: h ( t ) = X n ∈N A n · δ ( t − τ n ) , (5) where δ ( t ) is the Dirac impulse function. 2.2 Impro vemen ts to the original algorithm 2.2.1 F r actional delays In order to implement (5) in the digital domain, we need to deal with the fact that the v alues of τ n ma y not be m ultiples of the sampling p erio d. The original algorithm proposed to just approximate the fractional dela ys b y the closest sample, how ever, the error in troduced b y this appro ximation is too high for some applications, suc h as Sound Source Localization with microphone arra ys. In [10], Paterson prop osed to substitute the Dirac impulse function b y a sinc windo wed b y a Hanning function: δ 0 ( t ) = ( 1 2 1 + cos 2 π t T ω sinc(2 π f c t ) if − T ω 2 < t < T ω 2 0 otherwise , (6) where f c is the cut-off frequency , T ω is the windo w length, and the sinc function is defined as sinc( x ) = sin( x ) /x . This is motiv ated b y the lo w pass anti-aliasing filter that would b e used if the RIR w as recorded with a microphone in the real ro om. A window duration of T ω = 4 ms and a cut-off frequency equal to the Nyquist frequency , i.e. f s / 2, are t ypically used. This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3 6 David Diaz-Guerra et al. Using the P aterson approac h with T ω = ∞ is equiv alent to compute (5) in the frequency domain as the sum of complex exp onential functions as pro- p osed in [11] [12], but using shorter windo w lengths reduces the computational complexit y of the algorithm. 2.2.2 Ne gative r efle ction c o efficients Using p ositive reflection co efficien ts as prop osed in [9] generates a low fre- quency artifact that must be remo v ed using a high-pass filter. In addition, while a RIR recorded in a real ro om has both positive and negative peaks, all peaks generated by the ISM are p ositiv e. Using negativ e reflection coeffi- cien ts as proposed in [12] solve b oth problems without the need for adding an y p osterior filter to the ISM algorithm. 2.2.3 Diffuse r everb er ation In order to prop erly simulate a RIR, we need to use v alues of N x , N y and N z high enough to get all the reflections which arrive in the desired reverberation time. Since the delays of the signals of each image source are prop ortional to their distance to the receiv er, and the distance is to the image index, the n umber of images to calculate for each dimension gro ws linearly with the rev erb eration time, and, therefore, the num b er of op erations in (5) grows in a cubic w ay . A popular solution to allow the simulation of long rev erberation times in a reasonable time is decomp osing the RIR in tw o parts: the early reflections and the late, or diffuse, reverberation. While the early reflections need to b e correctly simulated with the ISM metho d to av oid lo osing spatial information, the diffuse reverberation can b e mo deled as a noise tail with the correct p ow er en velope. In [8], Lehmann and Johansson prop ose using noise with logistic distribution and the tec hnique introduced in [13] to predict the pow er env elop e. Although the tec hnique presented i n [13] generates better predictions of the pow er env elop e obtained in real ro oms, its computational complexity is quite high. Therefore, for the sak e of computational efficiency , we decided to use a simple exp onential env elop e follo wing the popular Sabine formula [14]. According to this mo del, the reverberation time T 60 that takes for a sound to deca y by 60 dB in a ro om, is T 60 = 0 . 161 V P S i α i , (7) where V is the v olume of the room and S i and α i = 1 − β 2 i are the surface area and the absorpti on co efficient of each w all 2 ; and the pow er env elop e of 2 It should b e noted that, as done in [9], we are defining the absorption ratio α as a quotient of sound intensities (energies) while the reflection co efficient β is defined as a quotien t of pressures (amplitudes). This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3 gpuRIR: A Python Library for RIR Simulation with GPU Acceleration 7 T able 2 Kernels and functions of the CUDA implementation CUDA functions Description Time (%) calcAmpT au kernel Equations (3) and (4) 0.68 generateRIR kernel Sincs computation and initial sum (5) 90.34 reduceRIR kernel Parallel sum (5) 1.07 envPred kernel Po wer env elop e prediction 0.03 generate seed pseudo cuRAND function (diffuse reverberation) 7.78 gen sequenced cuRAND function (diffuse rev erberation) 0.01 diffRev kernel Diffuse reverberation computation 0.01 CUDA memcpy [CPU to GPU] 0.00 CUDA memcpy [GPU to CPU] 0.06 the RIR is P ( t ) = ( A exp log 10 T 60 20 ( t − t 0 ) if t > t 0 0 otherwise . (8) Therefore, kno wing T 60 , w e can easily estimate A from the early reflections sim ulated with the ISM and then multiply the logistic-distributed noise by p P ( t ) to sim ulate the diffuse reverberation. 3 P arallel implemen tation As shown in Fig.2, the parallel computation of the delays and the ampli- tudes of arriv al for the signals from eac h image source and their sinc functions is straightforw ard since there are not an y dependencies b etw een each image source, and computing RIRs for different source or receiver p ositions in paral- lel is also trivial. Ho wev er, the parallelization of (5) in volv es more problems, as the contributions of all the image sources need to b e added to the same RIR. It is worth mentioning that, though it w ould b e p ossible to compute RIRs from different ro oms in parallel, we choose to implement only the paralleliza- tion of RIRs corresponding to the same room. This w as b ecause the num b er of image sources to b e computed depends on the room dimensions and the rev erb eration time and to compute different ro oms in parallel we would hav e needed to use the w orst case scenario (i.e. the smallest room and higher re- v erb eration time) for all of them, which would hav e decreased the av erage p erformance. In order to implemen t the ISM in GPUs, w e decided to use CUDA [15] and divide our co de in to the kernels 3 listed in T able 2. F or illustrative purposes, w e show in T able 2 the av erage prop ortion of time employ ed by eac h k ernel to compute a standard case of 6 RIRs with T 60 = 1 s using the ISM metho d 3 A CUDA kernel is a function that, when is called, is executed N times in parallel by N different CUDA threads in the GPU. F or more details, see the CUDA programming guide: https://docs.nvidia.com/cuda/cuda- c- programming- guide/ This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3 8 David Diaz-Guerra et al. Fig. 2 ISM parallel implementation. Our library actually computes some of the sincs se- quentially , which leads to a more efficient memory use. The reduction sum is detailed in Fig.3 for the 250 first milliseconds and the diffuse model for the follo wing 750ms using a Nvidia ™ GTX 980Ti. It can be seen how the b ottleneck is located at the b eginning of the computation of (5), whic h is due to the high amoun t of sinc functions that are needed to b e computed. The follo wing sections provide further details ab out the implementation of the different parts of the algorithm. 3.1 Amplitudes and dela ys computation F or computing (3) and (4), w e use calcAmpTau kernel , whic h computes se- quen tially each RIR but parallelizes the computation for e ac h image source. Although parallelizing the computations for each RIR would ha ve b een p ossi- ble, since N x · N y · N z is generally greater than the num b er of RIRs to compute, the level of parallelization is already quite high and, as s ho wn in T able 2, fur- ther optimizations of this kernel would ha ve had a sligh t impact on the final p erformance of the sim ulation. This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3 gpuRIR: A Python Library for RIR Simulation with GPU Acceleration 9 3.2 Computation and sum of the con tribution of each image source The computation of (5) is the most complex part of the implementation as it implies a reduction operation (the sum of the contributions of eac h image source into the final RIR), whic h is hard to parallelize since it w ould imply sev eral threads writing in the same memory address, and the calculation of a high n umber of trigonometric functions. W e can see it as creating a tensor with 3 axis (eac h RIR, eac h image source, and eac h time sample) and summing it along the image sources axis. How ev er, the size of this tensor w ould be h uge and it w ould not fit in the memory of most GPUs. T o solve this problem, we first compute and sum a fraction of the sources con tributions sequentially , so the size of the tensor we need to allocate in the GPU memory is reduced; we do that through generateRIR kernel . Specifi- cally , each parallel thread of this kernel p erforms sequentially the sum of 512 images for a time sample of a RIR. This sequential sum reduces the degree of parallelism of the implemen tation but, since the num b er of threads is already high enough to keep the GPU alwa ys busy , it does not decrease the p erfor- mance. It should be noted that, although all the threads can p otentially run in parallel, the num b er of threads which actually run in parallel is limited by the n umber of CUDA cores of the GPU and, if w e ha ve more threads than CUD A cores, many threads will b e queued and will run sequentially . After that, w e use reduceRIR kernel recursively to p erform the reduction in parallel by pairwise summing the contribution of eac h group of images as sho wn in Fig.3. Performing the whole sum in parallel would lead to all the threads concurrently writing in the same memory positions, which would corrupt the result. It can be seen in T able 2 ho w most of the simulation time is exp ended in generateRIR kernel , this is due to the high amoun t of sinc functions that need to b e computed and it also happens in the sequential implementations. Ho wev er, thanks to the computing pow er of mo dern GPUs, w e can compute man y sinc functions in parallel and therefore reduce the time we would hav e needed to sequentially compute them in a CPU. W e analyze the implementa- tion of these sinc functions using lo okup tables (LUTs) in section 3.5 and its p erformance in section 5.2. 3.3 Diffuse rev erb eration computation F or the diffuse reverberation, w e first use envPred kernel to predict in par- allel the amplitude and the time constan t of eac h RIR. After that, w e use the cuRAND library included in the CUDA T oolkit to generate a uniformly distributed noise (the functions generate seed pseudo and gen sequenced in T able 2 b elong to this library) and w e finally transform it to a logis- tic distributed noise and apply the pow er en velope through diffRev kernel , whic h parallelizes the computations of each sample of each RIR. The function generate seed pseudo generates the seed for the cuRAND random n um b er This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3 10 David Diaz-Guerra et al. Fig. 3 Parallel reduction sum of the sincs (each level is p erformed by a call to reduceRIR kernel ). The sum must b e p erformed pairwise to av oid several threads to con- currently write in the same variable. The sums of each time sample are also p erformed in parallel. generator and it is only c alled when the library is imp orted, not every time a new RIR is calculated. 3.4 Sim ulating moving sources As an application example of the library , it is p ossible to sim ulate a mo ving source recorded by a microphone arra y . In this case, w e w ould need to compute the RIR b etw een eac h point of the tra jectory and each microphone of the arra y and filter the sound source by them using the ov erlap-add metho d. In sequen tial libraries, the complexity of the filtering is negligible compared to the RIR simulation; ho wev er, in our library , thanks to the p erformance of the GPUs, we found that we also needed to parallelize the filtering process if we did not wan t to b e limited by it (sp ecially for short reverberation times). T o solve this problem, our library is able to compute m ultiple conv olutions in parallel using the cuFFT library (included in the CUD A T o olkit) and a custom CUD A k ernel to p erform the p oint wise complex multiplication of the FFTs. This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3 gpuRIR: A Python Library for RIR Simulation with GPU Acceleration 11 3.5 Lo okup T ables (LUTs) Motiv ated b y the p erformance increase that the CPU implemen tations ac hiev e b y using lo okup tables (LUTs) to calculate the sinc functions (see section 5), w e also implemented it in our GPU library . Our LUT stores the v alues of a sinc ov ersampled in a factor Q = 16 m ul- tiplied b y a Hanning window: LU T [ n ] = 1 2 1 + cos 2 π n QT ω sinc π n Q for n ∈ − T ω 2 Qf s , ..., T ω 2 Qf s (9) and then we use linear in terp olation b etw een the closest en tries of the table to compute eac h sample of the sinc functions of each image source. The main design c hoice we m ust make is to define the t ype of memory that will b e used to place the LUT. CUDA GPUs hav e, in addition to the regis- ters of eac h thread, 4 differen t memories: shared, global, constant and texture memory . On the one hand, shared memory is shared only b etw een threads of the same blo ck and it has the fastest access, how ev er it is generally low er than 100KB. On the other hand, global memory is shared b y all the threads and usually has several gigabytes, but it has the low er bandwidth and the higher la- tency . Finally , constan t and texture memories are read-only cac hed memories, constan t memory b eing optimized for several threads accessing to the same address and texture memory b eing optimized for memory access with spatial lo calit y . Although constan t memory has a low er latency than texture memory , texture memory implements some features like several accessing mo des and hardw are interpolation, which are extremely useful for the implementation of LUTs. W e implemen ted the window ed sinc LUT both in shared memory and texture memory and obtained b etter performance with the texture memory thanks to the hardw are interpolation. 3.6 Mixed precision Since the P ascal arc hitecture, the Nvidia TM GPUs include support for 16- bit precision floats and are able to p erform t wo 16 bit operations at a time. T o exploit this feature, we dev elop ed the kernels generateRIR mp kernel and reduceRIR mp kernel , whic h compute t w o consecutiv e time samples at a time so we can halv e the num b er of threads needed. W e fo cused on these kernels and did not optimise the others b ecause, as shown in T able 2, most of the sim ulation time is sp ent in them. CUD A provides the data type half2 , whic h contains 2 floating p oint n um- b ers of 16 bits, and several intrinsics to op erate with it. These in trinsics allow to double the n umber of arithmetic op erations that w e can perform p er sec- ond; how ever, we found that the functions pro vided to compute tw o 16-bit trigonometric functions were not as fast as computing one 32-bit function. T o increase the simulation sp eed, we dev elop ed our own sinpi(half2) and cospi(half2) functions. F or the sine function w e first reduce the argument This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3 12 David Diaz-Guerra et al. to the range [-0.5, 0.5], then we appro ximate the sine function in this range b y sin( π x ) ≈ 2 . 326171875 x 5 − 5 . 14453125 x 3 + 3 . 140625 x (10) and finally , multiply the result b y -1 if the angle was in the second or the third quadran t. The co efficients of the p olynomial are the closest num bers that can b e represented with half precision floats to those of the optimal p olynomial in a least-squares sense. Equiv alently , for the cosine function, we used the p olynomial: cos( π x ) ≈ − 1 . 2294921875 x 6 + 4 . 04296875 x 4 − 4 . 93359375 x 2 + 1 (11) with the adv antage that, since w e only used it for computing the Hanning win- do w in (5), we do not need to p erform argument reduction or sign correction. The p olynomial ev aluation can b e efficien tly p erformed with the Horner’s metho d: b n = a n b n − 1 = a n − 1 + b n x ... p ( x ) = b 0 = a 0 + b 1 x (12) where a i are the coefficient of the n degree p olynomial p ( x ) w e w an t to ev aluate and the computation of b i can b e done in parallel for tw o differen t v alues of x using the CUDA intrinsic hfma2(half2) that p erforms the fused m ultiply- add op eration of the tw o elements of three half2 v ariables at a time. More information ab out p olynomial approximation of transcendental functions can b e found in [16]. Ob viously , working with half precision represen tation reduces the accuracy of the results. W e found that the most critical part was in subtracting t − τ n . W orking with 16-bit precision floats, w e can only represen t 3 significan t figures accurately , so, when t grows, we lose precision in the argument of the sinc function which leads to an error which increases with the time; when t grows w e exp end the precision in the integer part and we don’t represent accurately the fractional part. T o solve this issue, w e p erform the subtraction with 32 bits arithmetic and then we transform the result to 16-bit precision. W orking this wa y , we hav e alw ays maximum precision in the centre of the sinc and the lo wer accuracy is outside the Hanning window. Unfortunately , the hardware interpolation of the texture memory do es not supp ort 16-bit arithmetic, so the mixed precision implemen tation is not com- patible with the LUT. 4 Python library W e ha ve included the previous implemen tation in a Python library that can b e easily compiled and installed using the Python pac ket manager (pip) and This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3 gpuRIR: A Python Library for RIR Simulation with GPU Acceleration 13 b e used as any CPU library . The library provides a function which tak es as parameters the room dimensions, the reflections co efficients of the walls, the p osition of the source and the receiv ers, the n umber of images to sim ulate for each dimension, the duration of the RIR in seconds, the time to switch from the ISM metho d to the diffuse reverberation mo del, and the sampling frequency and it returns a 3D tensor with the RIR for eac h pair of source and receiv er p ositions. Information ab out the p olar pattern of the receivers and their orien tation can b e also included in the simulation. W e also pro vide some p ython functions to predict the time when some level of attenuation will b e reached, to get the reflections co efficients needed to get the desired reverberation time (expressed in terms of T 60 , i.e. the time needed to get an attenuation of 60 dB), and to get the n umber of image sources to sim ulate in eac h dimension to get the desired simulation time without loss reflections. Finally , w e include a function to filter a sound signal by several RIRs in order to simulate a mo ving source recorded by a microphone array . In the rep ository of the library some examples can b e found ab out how to sim ulate b oth isolated RIRs and moving sources. Since the use of the LUT to compute the sinc function impro v es the p er- formance in most of the cases and the precision loss is negligible (see section 5.2), its use is activ ated by default, but the library provides a function to deactiv ate it and use the CUDA trigonometric functions instead. In order to exploit the mixed precision capabilities of the new er GPUs, it has a function to activ ate it and use the 16-bit precision k ernels instead of the 32-bit; activ ating it automatically deactiv ates the use of the LUT. Since the library was dev elop ed, we ha ve used it to train a sound source trac king system based on a 3D Conv olutional Neural Netw ork simulating the training signals as they w ere needed instead of creating a pre-simulated dataset [17]; this approac h has the adv antage of being equiv alen t to ha v e an infinite- size dataset, but it would ha v e b een unfeasible with the simulation times of previous libraries. Other authors hav e also used it to train deep learning sys- tems [18, 19, 20, 21] and to ev aluate signal pro cessing techniques [22, 23]. 5 Results 5.1 Base implemen tation In order to show the b enefits of using GPUs for RIR simulation, w e hav e compared our library against three of the most employ ed libraries for this purp ose: the Python version of the RIR Generator library presented in [6], whose co de is freely av ailable in [24] and has b een used, for example, in [3, 25, 26]; the Python pack age pyroomacoustics presented in [7] that has b een emplo yed in [27, 28, 29] among others; and the Matlab ™ library presented in [8], whose co de is freely av ailable in [30], and that has b een used, for example, in [2, 31, 32]. Since all the libraries are based on the ISM, whose acoustical accuracy is w ell known, we fo cus on the computation time of each library . This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3 14 David Diaz-Guerra et al. T able 3 GPUs employ ed for the p erformance analysis GPU mo del Architecture Memory Single Precision FLOP/s Memory Bandwidth GTX 980 Ti Maxwell 6GB 5.6 T eraFLOP/s 337 GB/s T esla P100 Pascal 16GB 9.5 T eraFLOP/s 732 GB/s T esla V100 V olta 16GB 14.9 T eraFLOP/s 900 GB/s T esla T4 T uring 16GB 8.1 T eraFLOP/s 320 GB/s 10 0 10 1 10 2 10 3 M scr 10 -3 10 -2 10 -1 10 0 10 1 10 2 runtime [s] Runtime vs number of RIRs gpuRIR gpuRIR (full ISM) Matlab library RIRgenerator pyroomacoustics Fig. 4 Runtime of eac h library for computing different num b ers of RIRs (M src ) in a room with size 3 m × 4 m × 2 . 5 m and T 60 = 0 . 7 s. F or the gpuRIR library , the solid line times were obtained with the GTX 980 Ti GPU, the dashed lines with the T esla P100, the dotted lines with the T esla V100, and the dash-dot lines with the T esla T4. Neither RIR Generator nor p yroomacoustics implement an y kind of diffuse rev erb eration mo del, so they are exp ected to hav e w orse p erformance than the Matlab ™ library and our GPU library if w e use it. The Matlab ™ library uses the form ula presen ted in [13] to mo del the pow er en velope of the diffuse rev erb eration, which is more complex than our exponential env elop e model, so, for the sake of a fairer comparison, we mo dified the Matlab ™ implementation to use a exp onential mo del. The simulations with the sequential libraries and the ones with the Nvidia ™ GTX 980Ti were p erformed in a computer with an In tel ™ Core i7-6700 CPU and 16 GB of RAM, while the simulations with the Nvidia ™ T esla P100 and V100 and T4 were p erformed in a n1-highmem-4 instance in the Go ogle Cloud Platform ™ with 4 virtual CPUs cores and 26 GB of RAM memory; more details ab out the GPUs employ ed for the simulations can b e found in T able 3. Fig.4 represents the runtime of the different libraries for computing differ- en t num b ers of RIRs in a ro om with size 3 m × 4 m × 2 . 5 m and T 60 = 0 . 7 s. It can be seen ho w our library can simulate a h undred times more RIRs in a second than the Matlab ™ library ev en with a GPU designed for gaming (the This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3 gpuRIR: A Python Library for RIR Simulation with GPU Acceleration 15 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 T60 [s] 10 -3 10 -2 10 -1 10 0 10 1 10 2 runtime [s] Runtime vs reverberation time gpuRIR gpuRIR (full ISM) Matlab library RIRgenerator pyroomacoustics Fig. 5 Runtime of each library for computing 128 RIRs in a ro om with size 3 m × 4 m × 2 . 5 m and different rev erb eration times. F or the gpuRIR library , the solid line times were obtained with the GTX 980 Ti GPU, the dashed lines with the T esla P100, the dotted lines with the T esla V100, and the dash-dot lines with the T esla T4. Nvidia ™ GTX 980 Ti). Using our library without any kind of diffuse reverber- ation mo deling, w e hav e a similar execution time than the Matlab ™ library , whic h only computes the ISM until the RIR has an attenuation of 13 dB, and w e are also ab out a hundred times faster than the RIR Generator library . Fi- nally , it is w orth noting ho w pyroomacoustics p erforms quite similarly to our library when w e use a GTX 980 Ti and compute the whole RIR with the ISM without using any diffuse reverberation mo del; this is due to the use of LUTs to compute the sinc functions by p yro omacoustics (to confirm this hypothe- sis we mo dified the co de of pyroomacoustics to av oid the use of LUTs and its p erformance degraded to the same results than RIR Generator). How ev er, using a faster GPU, i.e. the T esla V100, our library can compute ten times more RIRs in a second than pyroomacoustics even without using LUTs, since w e can set at full p erformance all the parallelization mechanisms presen ted in section 3. Comparing the p erformance of our library using different GPUs, we can see how the low er results are obtained using the GTX 980 Ti, the T esla P100 and T4 hav e a quite similar performance (b eing the T4 sligh tly faster), and the b etter results are obtained with the T esla V100 (b eing more than 5 times faster than the GTX 980 Ti). This results are what we could expect for an algorithm whose computation time is mostly limited by the n umber of op erations that w e can p erform p er second, but it is worth noting how the T esla T4 (with the newer Nvidia ™ GPU arc hitecture) can outp erform the T esla P100 ha ving lo wer FLOP/s, memory bandwidth and p ow er consumption. This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3 16 David Diaz-Guerra et al. In Fig.5 w e sho w the run time of the differen t libraries for computing 128 RIRs in a ro om with size 3x4x2.5m and differen t reverberation times. W e can see again how our library is ab out tw o orders of magnitude faster than the sequen tial alternativ es whic h do not use LUTs. It m ust b e said that our library has some limitations b ecause calculating a large n umber of RIRs with high reverberation times may require more memory than it is av ailable in the GPU; how ever, using the diffuse reverberation mo del, this limitation app ears only for really high num b er of RIRs and reverberation times. F urthermore, it would b e alwa ys p ossible to batch the RIRs in several function calls to circum ven t this problem. 5.2 Lo okup tables Motiv ated by the h uge sp eedup generated by the use of LUTs in the CPU implemen tations (a factor 5 in Fig. 4) we replaced the trigonometric compu- tations by a LUT as describ ed in section 3.5. T ables 4 and 5 show the sp eedup (defined as the runtime without using the LUT divided by the runtime using it) for several num b ers of RIRs and rev erb eration times using different GPUs. W e can see how our library obtains a sp eedup muc h low er than the obtained b y pyroomacoustics ov er CPU. This is due to the high computation p ow er of the GPUs, whic h makes the computation of trigonometric functions quite efficien t and therefore they are not so b enefited by replacing computation tasks b y memory calls. Despite that, we can see ho w using LUTs is faster than computing the trigonometric functions, i.e. the sp eedup is higher than 1.0, in most of the cases, esp ecially when the num ber of RIRs or the reverberation time increases. Among the studied GPUs, the T esla P100 obtains the higher sp eedups since it has a higher memory bandwidth compared with its computing p ow er. The GTX 980 Ti gets really hum ble sp eedups due it lo w memory bandwidth and the T esla V100, though it has the higher bandwidth, do es not reach the sp eedups obtained by the T esla P100 due to its h uge computing p ow er. Finally , it is interesting how the T esla T4 obtains higher sp eedups than the GTX 980 Ti despite ha ving a low er memory bandwidth; this might b e due to some optimizations in tro duced in the newer T uring architecture. Fig. 6 shows the first 0.5 seconds of the RIR of a room with T 60 = 1 s computed with our GPU implemen tation working with single (32-bit) precision trigonometric functions and the error introduced by replacing them b y out LUT. W e can see how, as it could be exp ected, the error introduced by the use of the LUT is negligible: three orders of magnitude lo wer than the amplitude of the RIR. 5.3 Mixed precision In case of using the 16-bit precision k ernels, w e are reducing the accuracy of the simulation, so we need to analyze its impact. Fig. 6 also shows the This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3 gpuRIR: A Python Library for RIR Simulation with GPU Acceleration 17 T able 4 Lo okup T able (LUT) and Mixed Precision (MP) simulation times and sp eedups for computing different num b ers of RIRs with T 60 = 0 . 7 s Number of RIRs Diffuse reverberation mo del F ull ISM 1 16 128 1024 1 16 128 Matlab Library 221,52 1,643.20 12,252.67 96,208.58 - - - pyroomacoustics - - - - 242.35 3,6409.16 28,646.86 GTX 980 Ti Base [ms] 4.98 17.43 117.60 898.54 283.88 2,601.82 19,630.60 LUT [ms] speedup 5.19 x0.96 16.64 x1.05 109.38 x1.08 834.38 x1.08 279.28 x1.02 2,434.33 x1.07 18,547.03 x1.06 MP [ms] speedup - - - - - - - T esla P100 Base [ms] 5.81 13.86 79.28 596.02 115.5 7 1,661.35 12,879.31 LUT [ms] speedup 5.97 x0.97 12.14 x1.14 63.90 x1.24 471.16 x1.27 86.86 x1.33 1,235.64 x1.35 9,397.40 x1.37 MP [ms] speedup 5.52 x1.05 9.45 x1.47 45.49 x1.74 324.12 x1.84 59.46 x1.94 847.74 x1.96 6,493.92 x1.98 T esla V100 Base [ms] 4.76 7.13 28.14 195.69 37.62 447.04 3,403.60 LUT [ms] speedup 5.01 x0.95 6.79 x1.05 23.66 x1.19 156.91 x1.25 30.66 x1.23 394.54 x1.13 2,595.97 x1.31 MP [ms] speedup 4.55 x1.05 6.29 x1.13 19.57 x1.44 128.72 x1.52 21.76 x1.73 253.03 x1.77 1,900.52 x1.79 T esla T4 Base [ms] 5.80 10.95 73.49 582.79 117.00 1,612.79 10,188.68 LUT [ms] speedup 5.63 x1.03 10.14 x1.08 63.75 x1.15 503.91 x1.16 81.37 x1.44 1,433.60 x1.13 8,870.68 x1.15 MP [ms] speedup 4.80 x1.21 7.37 x1.43 43.28 x1.76 351.78 x1.66 58.45 x2.00 860.43 x1.87 5,693.29 x1.79 error in tro duced by computing the same RIR using our half (16-bit) precision k ernels. W e can see ho w the error is 3 orders of magnitude low er than the amplitude of the RIR at the b eginning, whic h should be acceptable for most of the applications; how ever, since the error does not decrease with the time as muc h as the RIR do es, the signal-to-error ratio deteriorates with the time. Hop efully , this higher error corresp ond with the diffuse rev erb eration, where its p erceptual imp ortance is lo wer. Theoretically , a tw ofold sp eedup could b e exp ected from working with 16- bit precision floats instead of 32-bit floats, ho wev er, this sp eedup is generally not reachable as the num b er of op erations is not the only limiting factor of man y GPU kernels and some half2 functions are not as fast as its equiv alen t single functions. T ables 4 and 5 sho w the sp eedup that our mixed precision implemen tation ac hieve for several num b ers of RIRs computed in parallel and sev eral rev erb eration times. W e can see how the speedup is higher when the w orkload increases, esp ecially for long reverberation times where the op era- tions p er second are the main limiting factor of its p erformance and ho w the This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3 18 David Diaz-Guerra et al. T able 5 Lo okup T able (LUT) and Mixed Precision (MP) simulation times and sp eedups for computing different num b ers of RIRs with T 60 = 0 . 7 s T 60 [s] Diffuse reverberation mo del F ull ISM 0.3 0.7 1.1 1.5 1.9 0.3 0.7 1.1 Matlab Library 2,573.67 12,078.52 39,330.40 94,946.73 136,522.39 - - - pyroomacoustics - - - - - 1,854.08 23,253.22 90,960.54 GTX 980 Ti Base [ms] 8.90 118.00 627.15 2,016.40 5,073.48 731.59 19,657.05 - LUT [ms] speedup 8.62 x1.03 109.89 x1.07 588.90 x1.06 1,896.48 x1.06 4,769.68 x1.06 694.10 x1.05 18,466.15 x1.06 - MP [ms] speedup - - - - - - - - T esla P100 Base [ms] 8.97 80.78 416.57 1,349.47 3,289.13 494.33 12,875.14 76,383.87 LUT [ms] speedup 7.39 x1.21 64.90 x1.25 321.97 x1.29 1,023.39 x1.32 2,452.18 x1.34 391.39 x1.26 9,406.31 x1.37 55,402.08 x1.38 MP [ms] speedup 6.64 x1.35 45.18 x1.79 218.18 x1.91 699.95 x1.93 1,698.17 x1.94 258.96 x1.91 6,484.46 x1.99 38,393.03 x1.99 T esla V100 Base [ms] 5.80 28.81 125.02 379.13 896.97 141.86 3,400.95 19,935.71 LUT [ms] speedup 5.95 x0.97 24.43 x1.18 101.85 x1.23 332.35 x1.14 690.02 x1.30 117.55 x1.22 2,594.15 x1.31 15,363.05 x1.30 MP [ms] speedup 5.08 x1.14 19.80 x1.46 76.71 x1.63 220.66 x1.72 519.46 x1.73 87.48 x1.62 1,901.21 x1.79 11,052.52 x1.80 T esla T4 Base [ms] 6.43 73.22 385.88 1,376.26 2,862.44 465.76 10,139.45 57,596.94 LUT [ms] speedup 6.59 x0.97 63.20 x1.16 344.66 x1.12 1,122.22 x1.23 2,406.75 x1.19 407.88 x1.14 8,812.73 x1.15 49,612.01 x1.16 MP [ms] speedup 5.80 x1.11 43.93 x1.66 230.89 x1.67 770.90 x1.79 1,841.16 x1.55 270.88 x1.72 5,693.18 x1.78 31,377.01 x1.84 sp eedup ac hieved with the mixed precision implementation is alwa ys higher than the ac hieved with the LUTs. The mixed precision supp ort was introduced with the Pascal architecture, so it is not a v ailable in older mo dels like the GTX 980 Ti. The T esla P100 ac hieves sp eedups really close to 2 for high workloads. The sp eedups obtained with the T esla T4 are quite erratic and its increase with the workload is no so clear than with other GPUs, but it is generally higher than the sp eedup obtained with the T esla V100. 6 Conclusions W e ha ve presented a new free and open-source library to simulate RIRs that uses GPUs to dramatically reduce the simulation time and it has b een prov ed that it is ab out one hundred times faster than other state of the art CPU li- braries. T o the b est of out knowledge, it is the first library with these features This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3 gpuRIR: A Python Library for RIR Simulation with GPU Acceleration 19 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 time [s] -0.05 0 0.05 0.1 RIR computed with 32-bit trigonometric functions 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 time [s] -5 0 5 10 -5 Error whith the LUT implementation 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 time [s] -5 0 5 10 -5 Error whith the Mixed Precision implementation Fig. 6 RIR computed with single (32-bit) precision trigonometric functions and the er- ror introduced due to compute it using a lookup table (LUT) and half (16-bit) precision functions (Mixed Precision). freely av ailable on the In ternet, and it could allow to the acoustic signal pro- cessing communit y , for example, to generate huge datasets of mo ving sp eak er sp eec h signals in a reasonable computation time or to compute the acoustics of a Virtual Realit y (VR) scene in real time. W e ha v e studied different metho ds to increase the sp eed of our GPU im- plemen tation, concluding that the b est strategy is using 16-bit arithmetic, but this is only compatible with the newer GPUs. On the other hand, using LUTs stored in the GPU’s texture memory , though it generates lo wer speedups, is compatible with most of the CUD A GPUs, so we ha ve chosen to use this implemen tation as our library default. W e exp ect this library to be a useful to ol for the audio signal processing comm unity , esp ecially for those who need to simulate large audio datasets to train their mo dels. Since it has been published as free and op en-source soft ware, it can b e easily upgraded to exploit the new features that future generations of GPUs may bring, b oth by us as the original authors or by any other researc her interested in it. This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3 20 David Diaz-Guerra et al. Ac knowledgemen ts Authors would like to thank Norb ert Juffa for his advises and assis- tance in the Nvidia ™ Developer F orums. References 1. C. W eng, D. Y u, S. W atanab e, B.F. Juang, in 2014 IEEE International Confer enc e on Ac oustics, Spe e ch and Signal Pr o ce ssing (ICASSP) (2014), pp. 5532–5536. DOI 10.1109/ICASSP .2014.6854661 2. A. Griffin, A. Alexandridis, D. Pa vlidi, Y. Mastorakis, A. Mouch taris, Lo calizing Mul- tiple Audio Sources in a Wireless Acoustic Sensor Net work, Signal Processing 107 , 54 (2015). DOI 10.1016/j.sigpro.2014.08.013 3. D.S. Williamson, D. W ang, Time-F requency Masking in the Complex Domain for Sp eech Dereverberation and Denoising, IEEE/ACM T ransactions on Audio, Speech, and Lan- guage Pro cessing 25 (7), 1492 (2017). DOI 10.1109/T ASLP .2017.2696307 4. M.R. Schroeder, Natural Sounding Artificial Reverberation, Journal of the Audio En- gineering So ciety 10 (3), 219 (1962) 5. Z.h. F u, J.w. Li, GPU-based image metho d for ro om impulse resp onse calculation, Multimedia T o ols and Applications 75 (9), 5205 (2016). DOI 10.1007/s11042- 015- 2943- 4 6. E.A. Hab ets, Ro om Impulse Response Generator. T ech. rep. (2010) 7. R. Scheibler, E. Bezzam, I. Dokmani´ c, in 2018 IEEE International Confer enc e on A coustics, Sp e e ch and Signal Pr o cessing (ICASSP) (2018), pp. 351–355. DOI 10.1109/ICASSP .2018.8461310 8. E.A. Lehmann, A.M. Johansson, Diffuse Reverberation Mo del for Efficient Image-Source Simulation of Ro om Impulse Resp onses, IEEE T ransactions on Audio, Sp eec h, and Language Pro cessing 18 (6), 1429 (2010). DOI 10.1109/T ASL.2009.2035038 9. J.B. Allen, D.A. Berkley , Image metho d for efficiently simulating small-ro om acoustics, The Journal of the Acoustical So ciety of America 65 (4), 943 (1979). DOI 10.1121/1. 382599 10. P .M. Peterson, Sim ulating the response of m ultiple microphones to a single acoustic source in a reverberant ro om, The Journal of the Acoustical So ciety of America 80 (5), 1527 (1986). DOI 10.1121/1.394357 11. B.D. Radlo vic, R.C. Williamson, R.A. Kennedy , Equalization in an acoustic rev erb erant environmen t: Robustness results, IEEE T ransactions on Sp eech and Audio Pro cessing 8 (3), 311 (2000). DOI 10.1109/89.841213 12. J. Antonio, L. Go dinho, A. T adeu, Reverberation Times Obtained Using a Numerical Model V ersus Those Given by Simplified F ormulas and Measurements, A CT A ACUS- TICA UNITED WITH A CUSTICA 88 , 10 (2002) 13. E.A. Lehmann, A.M. Johansson, Prediction of Energy Decay in Ro om Impulse Re- sponses Simulated with an Image-Source Mo del, The Journal of the Acoustical So ciety of America 124 (1), 269 (2008). DOI 10.1121/1.2936367 14. W.C. Sabine, Col le cte d Pap ers on A coustics (Cambridge : Harvard University Press, 1922) 15. J. Nic kolls, I. Buck, M. Garland, K. Sk adron, in A CM SIGGRAPH 2008 Classes (A CM, New Y ork, NY, USA, 2008), SIGGRAPH ’08, pp. 16:1–16:14. DOI 10.1145/1401132. 1401152 16. T.G.J. Myklebust, Computing accurate Horner form approximations to sp ecial functions in finite precision arithmetic, arXiv:1508.03211 [cs, math] (2015) 17. D. Diaz-Guerra, A. Miguel, J.R. Beltran, Robust Sound Source T racking Using SRP- PHA T and 3D Conv olutional Neural Netw orks, arXiv:2006.09006 [cs, eess] (2020) 18. Y. Luo, C. Han, N. Mesgarani, E. Ceolini, S.C. Liu, in 2019 IEEE Automatic Sp e e ch R ec o gnition and Understanding Workshop (ASRU) (2019), pp. 260–267. DOI 10.1109/ ASRU46091.2019.9003849 19. Y. Luo, Z. Chen, N. Mesgarani, T. Y oshioka, in ICASSP 2020 - 2020 IEEE International Confer ence on A c oustics, Sp e ech and Signal Pr o c essing (ICASSP) (2020), pp. 6394– 6398. DOI 10.1109/ICASSP40776.2020.9054177 20. D. W ang, Z. Chen, T. Y oshiok a, Neural Sp eech Separation Using Spatially Distributed Microphones, arXiv:2004.13670 [cs, eess] (2020) This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3 gpuRIR: A Python Library for RIR Simulation with GPU Acceleration 21 21. M. Mirbagheri, B. Do osti, C-SL: Contrastiv e Sound Lo calization with Inertial-Acoustic Sensors, arXiv:2006.05071 [cs, eess] (2020) 22. E. Ceolini, I. Kiselev, S.C. Liu, Ev aluating Multi-Channel Multi-Device Sp eech Separa- tion Algorithms in the Wild: A Hardware-Soft w are Solution, IEEE/ACM T ransactions on Audio, Sp eech, and Language Processing 28 , 1428 (2020). DOI 10.1109/T ASLP . 2020.2989545 23. J.D. Ziegler, H. Pa ukert, A.K.a.A. Schilling, in Audio Engine ering So ciety Convention 148 (Audio Engineering Society, 2020) 24. Marvin182. Room Impulse Response Generator. h ttps://github.com/Marvin182/rir- generator (2018) 25. A. Hassani, J. Plata-Chav es, M.H . Bahari, M. Mo onen, A. Bertrand, Multi-T ask Wire- less Sensor Net work for Join t Distributed No de-Sp ecific Signal Enhancement, LCMV Beamforming and DOA Estimation, IEEE Journal of Selected T opics in Signal Pro cess- ing 11 (3), 518 (2017). DOI 10.1109/JSTSP .2017.2676982 26. S. Mark ovic h, S. Gannot, I. Cohen, Multichannel Eigenspace Beamforming in a Re- verberant Noisy Environmen t With Multiple Interfering Sp eech Signals, IEEE T rans- actions on Audio, Speech, and Language Pro cessing 17 (6), 1071 (2009). DOI 10.1109/T ASL.2009.2016395 27. X. Qin, D. Cai, M. Li, in Intersp e ech 2019 (ISCA, 2019), pp. 4045–4049. DOI 10.21437/ Interspeech.2019- 1542 28. L. Mosner, M. W u, A. Ra ju, S.H. Krishnan Parthasarathi, K. Kumatani, S. Sundaram, R. Maas, B. Hoffmeister, in ICASSP 2019 - 2019 IEEE International Confer enc e on A coustics, Sp e e ch and Signal Pr o cessing (ICASSP) (IEEE, Brighton, United Kingdom, 2019), pp. 6475–6479. DOI 10.1109/ICASSP .2019.8683422 29. M. Sev erini, D. F erretti, E. Principi, S. Squartini, Automatic Detection of Cry Sounds in Neonatal Intensiv e Care Units by Using Deep Learning and Acoustic Scene Simulation, IEEE Access 7 , 51982 (2019). DOI 10.1109/ACCESS.2019.2911427 30. E.A. Lehmann, Matlab Implemen tation of F ast Image-Source Mo del for Ro om Acoustics (2018) 31. D. P avlidi, M. Puigt, A. Griffin, A. Mouch taris, in 2012 IEEE International Conferenc e on Ac oustics, Spe e ch and Signal Pr o ce ssing (ICASSP) (2012), pp. 2625–2628. DOI 10.1109/ICASSP .2012.6288455 32. A. Alexandridis, A. Griffin, A. Mouch taris, Capturing and Reproducing Spatial Audio Based on a Circular Microphone Array, Journal of Electrical and Computer Engineering 2013 , 1 (2013). DOI 10.1155/2013/718574 This is a pre-print of an article published in Multimedia Tools and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s11042-020-09905-3
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment