A domain-specific language and matrix-free stencil code for investigating electronic properties of Dirac and topological materials
We introduce PVSC-DTM (Parallel Vectorized Stencil Code for Dirac and Topological Materials), a library and code generator based on a domain-specific language tailored to implement the specific stencil-like algorithms that can describe Dirac and topological materials such as graphene and topological insulators in a matrix-free way. The generated hybrid-parallel (MPI+OpenMP) code is fully vectorized using Single Instruction Multiple Data (SIMD) extensions. It is significantly faster than matrix-based approaches on the node level and performs in accordance with the roofline model. We demonstrate the chip-level performance and distributed-memory scalability of basic building blocks such as sparse matrix-(multiple-) vector multiplication on modern multicore CPUs. As an application example, we use the PVSC-DTM scheme to (i) explore the scattering of a Dirac wave on an array of gate-defined quantum dots, to (ii) calculate a bunch of interior eigenvalues for strong topological insulators, and to (iii) discuss the photoemission spectra of a disordered Weyl semimetal.
💡 Research Summary
The paper presents PVSC‑DTM (Parallel Vectorized Stencil Code for Dirac and Topological Materials), a software framework that combines a domain‑specific language (DSL) with an automated code generator to implement matrix‑free stencil algorithms for Dirac and topological systems such as graphene, three‑dimensional topological insulators, and Weyl semimetals. Traditional sparse‑matrix approaches store the Hamiltonian explicitly, leading to high memory traffic and limited performance on modern multi‑core CPUs. PVSC‑DTM eliminates the explicit matrix by expressing the Hamiltonian as a stencil that updates each lattice site using only a small, fixed set of neighboring sites.
The DSL allows users to describe the lattice geometry, spin‑orbital degrees of freedom, hopping terms, on‑site potentials, and disorder in a high‑level, physics‑oriented syntax. During code generation the DSL is parsed, and a C++ source file is produced that incorporates optimal blocking factors, data layout, and vectorization directives. Blocking sizes are derived automatically from the target machine’s cache hierarchy and memory bandwidth, removing the need for manual autotuning. The generated code is hybrid‑parallel: MPI distributes sub‑domains across nodes, while OpenMP threads handle intra‑node parallelism. SIMD extensions (AVX2 or AVX‑512) are used to vectorize the innermost loops, achieving 4‑ to 8‑fold data parallelism.
Performance measurements were carried out on two Intel Xeon platforms (Ivy Bridge and Broadwell) and on a 500‑node InfiniBand cluster (“Emmy”). For the core operation of sparse matrix‑vector multiplication (spMVM) and its multi‑vector extensions, PVSC‑DTM reaches 85‑95 % of the theoretical memory bandwidth, matching the roofline model predictions. Compared with the matrix‑based GHOST library, the matrix‑free implementation is up to 2.5× faster on a single node, and strong scaling on the cluster retains >90 % parallel efficiency up to hundreds of nodes, indicating that communication overhead is negligible relative to computation.
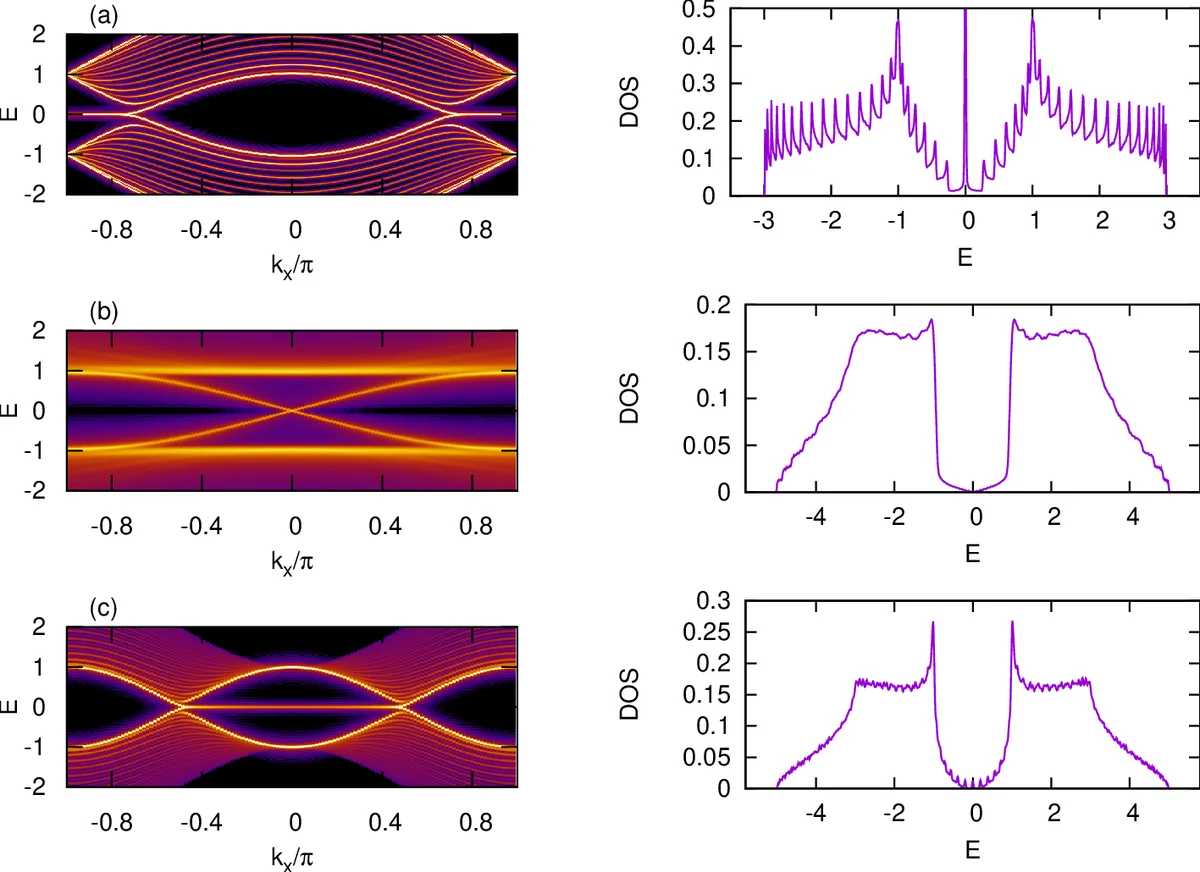
Three scientific applications demonstrate the framework’s versatility. (i) Scattering of a Dirac wave on a gate‑defined array of quantum dots in a graphene nanoribbon is simulated, yielding detailed transmission spectra and interference patterns that would be costly with a matrix formulation. (ii) Interior eigenvalues of a strong three‑dimensional topological insulator are computed using a kernel polynomial method combined with the stencil code, providing access to thousands of states and enabling analysis of surface Dirac cones versus bulk bands across the topological phase transition. (iii) Photo‑emission spectra of a disordered Weyl semimetal are obtained; the matrix‑free stencil efficiently handles random on‑site potentials and reproduces characteristic Fermi‑arc features and bulk Weyl node signatures.
The authors conclude that the combination of a physics‑oriented DSL, automatic generation of highly optimized matrix‑free stencil kernels, and hybrid MPI‑OpenMP‑SIMD parallelism delivers a powerful, portable tool for large‑scale simulations of topological quantum materials. The code is released under an open‑source license, facilitating further extensions to other lattice models, higher‑order interactions, and emerging hardware such as GPUs or many‑core accelerators.
Comments & Academic Discussion
Loading comments...
Leave a Comment