Lineage Evolution Reinforcement Learning
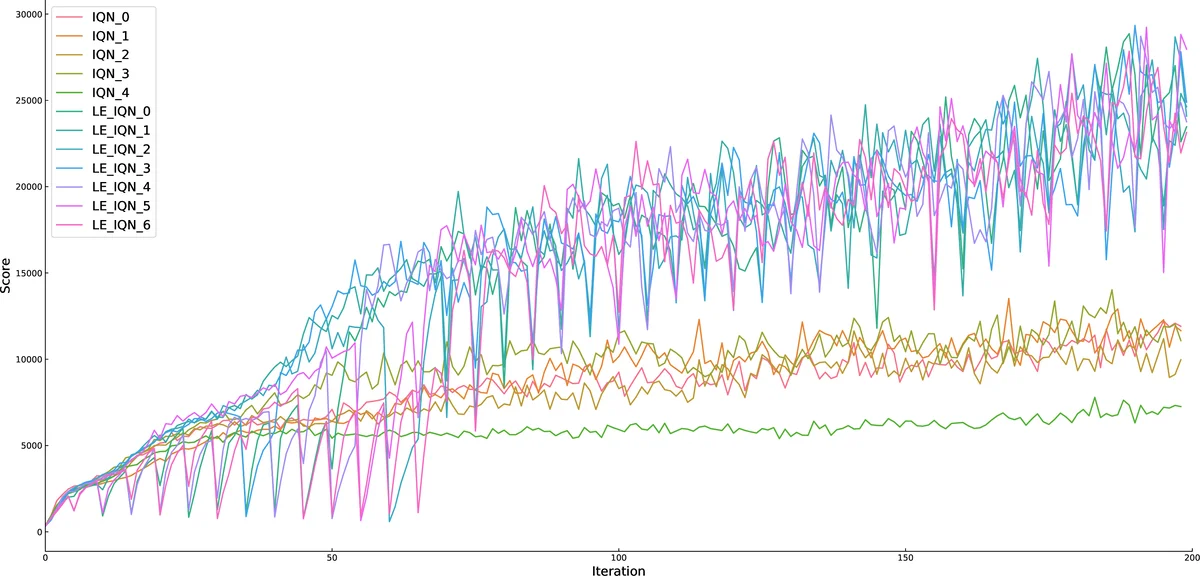
We propose a general agent population learning system, and on this basis, we propose lineage evolution reinforcement learning algorithm. Lineage evolution reinforcement learning is a kind of derivative algorithm which accords with the general agent population learning system. We take the agents in DQN and its related variants as the basic agents in the population, and add the selection, mutation and crossover modules in the genetic algorithm to the reinforcement learning algorithm. In the process of agent evolution, we refer to the characteristics of natural genetic behavior, add lineage factor to ensure the retention of potential performance of agent, and comprehensively consider the current performance and lineage value when evaluating the performance of agent. Without changing the parameters of the original reinforcement learning algorithm, lineage evolution reinforcement learning can optimize different reinforcement learning algorithms. Our experiments show that the idea of evolution with lineage improves the performance of original reinforcement learning algorithm in some games in Atari 2600.
💡 Research Summary
The paper introduces Lineage Evolution Reinforcement Learning (LERL), a framework that blends deep reinforcement learning (RL) with evolutionary computation to create a population‑based learning system. The authors observe that while deep Q‑network (DQN) variants (Double DQN, Prioritized Replay, Dueling DQN, A3C, Noisy DQN, Rainbow, etc.) have achieved impressive results on Atari 2600 games, they still suffer from issues such as premature convergence and inefficient exploration. Conversely, genetic algorithms (GAs) excel at exploring large search spaces but lack the fine‑grained policy optimization that gradient‑based RL provides. LERL aims to combine the strengths of both paradigms without altering the underlying RL algorithm’s parameters.
Core Architecture – General Agent Population Learning System (GAPLS)
GAPLS is organized into three hierarchical layers:
- Perception Layer – extracts raw sensory data (e.g., pixel frames) into high‑level features using a neural network. This layer is analogous to a biological sensory organ and is trained (often semi‑supervised) to produce reusable representations.
- Thinking Layer – receives the feature vectors from the perception layer and implements the decision‑making policy/value function. This layer corresponds to the “brain” and can be any standard RL algorithm (DQN, C51, Rainbow, IQN, etc.).
- Population Layer – treats each complete agent (perception + thinking) as an individual in a population. Evolutionary operators (selection, crossover, mutation) are applied at this level, allowing a set of agents to co‑evolve.
The population layer is the primary driver of exploration. By employing an elite strategy, high‑performing agents are preserved, while the rest of the population undergoes genetic variation to discover new policies.
Evolutionary Mechanism with a “Lineage” Factor
Traditional GAs evaluate individuals solely on current fitness. LERL introduces a lineage factor (φ) that captures an agent’s historical performance. The evaluation score for agent i at generation g is:
\
Comments & Academic Discussion
Loading comments...
Leave a Comment