Regressor: A C program for Combinatorial Regressions
In statistics, researchers use Regression models for data analysis and prediction in many productive sectors (industry, business, academy, etc.). Regression models are mathematical functions representing an approximation of dependent variable $Y$ from n independent variables $X_i \in X$. The literature presents many regression methods divided into single and multiple regressions. There are several procedures to generate regression models and sets of commercial and academic tools that implement these procedures. This work presents one open-source program called Regressor that makes models from a specific variation of polynomial regression. These models relate the independent variables to generate an approximation of the original output dependent data. In many tests, Regressor was able to build models five times more accurate than commercial tools.
💡 Research Summary
The paper introduces Regressor, an open‑source C program that implements a variant of polynomial regression called combinatorial regression. Traditional polynomial regression models consist of independent powers of each predictor variable, which limits their ability to capture nonlinear interactions among variables. Combinatorial regression augments the model with product terms that combine different predictors (e.g., an extra β₃·X₁·X₂ term in a first‑order model). This simple extension dramatically improves the fit: in a synthetic compound‑interest example, the R² jumps from 0.34 (linear) to 0.61 (first‑order combinatorial), and higher‑order combinatorial models achieve R² values of 0.99 and even 1.0, whereas a 50‑degree ordinary polynomial only reaches 0.46.
The core algorithm follows the ordinary least‑squares formulation B = (MᵀM)⁻¹MᵀY, but the design of matrix M differs. For a regression of degree d with v variables, the number of columns of M is (d + 1)ᵛ, which grows exponentially. To keep the computation tractable, the authors store Mᵀ (the transpose) and generate its columns on the fly, limiting the number of variables involved in each column using a logarithmic bound. They also replace the direct matrix inversion with a QR‑factorization routine (a modified version of the Java‑based Jama library) that works on columns rather than rows, improving cache locality and reducing numerical error caused by floating‑point rounding in large matrices. Benchmarks on a 4‑core DDR3 system show the modified QR factorization solving a 45 000 × 625 matrix in 150 seconds versus 650 seconds for the original implementation.
The command‑line tool accepts two arguments: the polynomial degree and the path to a CSV file. The first column of the CSV is treated as the dependent variable Y; the remaining columns are independent variables X. The program automatically lowers the degree if the number of rows is insufficient for the generated number of columns, thereby avoiding an under‑determined system. After building the design matrix, it calls the QR routine to obtain the coefficient vector β, writes the R² value and a spreadsheet‑compatible formula to a .txt file, and outputs residuals to a separate CSV.
Four real‑world datasets were used for evaluation:
- Protein tertiary structure (9 variables, 45 730 samples).
- Heart failure clinical records (13 variables, 399 samples; reduced to 4 variables after correlation‑based selection).
- Cancer prediction (26 variables, 3 048 samples; reduced to 7 variables).
- COVID‑19 testing results (111 variables, 5 644 samples; reduced to 14 and then 9 variables).
For each dataset, the authors compared three models: LibreOffice Calc’s built‑in multiple linear regression, a polynomial‑only version of Regressor (RegressorPolynomial), and the full combinatorial regression. Results (summarized in Table 1) show that combinatorial regression consistently yields higher R² values. Notably, the heart‑failure model with only four variables achieved an R² of 0.948, more than double the 0.3998 obtained by LibreOffice Calc using all eleven original variables. The COVID‑19 binary classification model reached an R² of 0.8815, compared with 0.1743 from the spreadsheet tool, and produced only two misclassifications out of 598 cases.
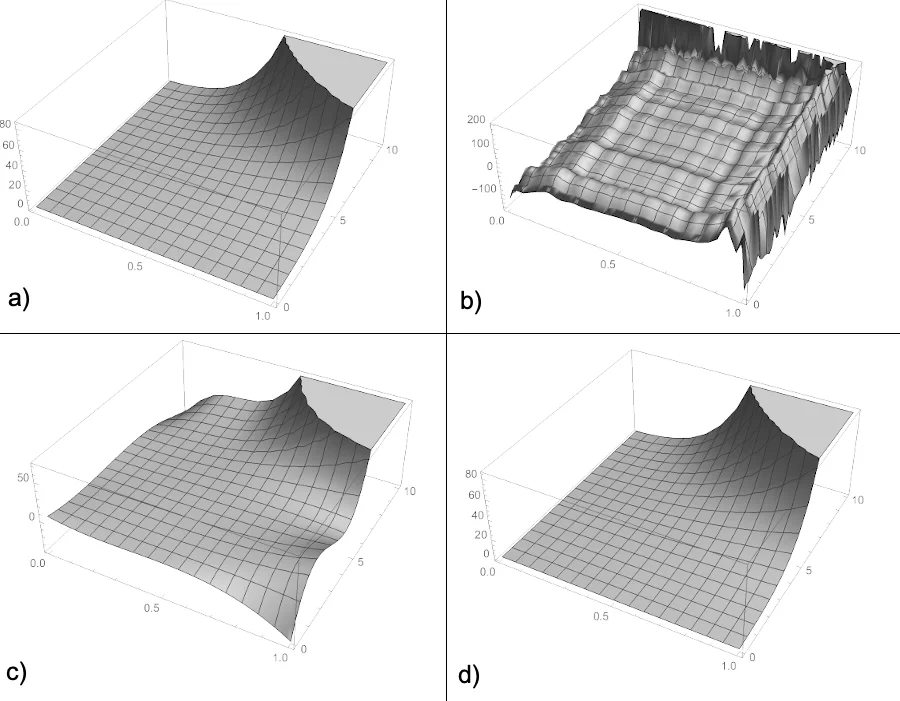
The authors acknowledge two major limitations of combinatorial regression. First, the exponential growth of columns makes memory consumption prohibitive for many variables or high degrees. Second, very high‑degree models tend to diverge at the edges of the data domain, reducing predictive stability. They also note that the method performs poorly on functions with strong trigonometric components, though they argue that many practical problems (e.g., economics, engineering) involve limited trigonometric behavior.
In conclusion, Regressor demonstrates that adding interaction terms in a systematic combinatorial fashion can substantially improve model fit over traditional polynomial regression, especially for datasets where variable interactions are important. The open‑source implementation provides a practical tool for researchers and engineers, while future work is needed to develop mathematical techniques for reliable prediction with high‑degree combinatorial models and to address the computational scalability challenges.
Comments & Academic Discussion
Loading comments...
Leave a Comment