A Decision-Theoretic Approach for Model Interpretability in Bayesian Framework
A salient approach to interpretable machine learning is to restrict modeling to simple models. In the Bayesian framework, this can be pursued by restricting the model structure and prior to favor interpretable models. Fundamentally, however, interpre…
Authors: Homayun Afrab, pey, Tomi Peltola
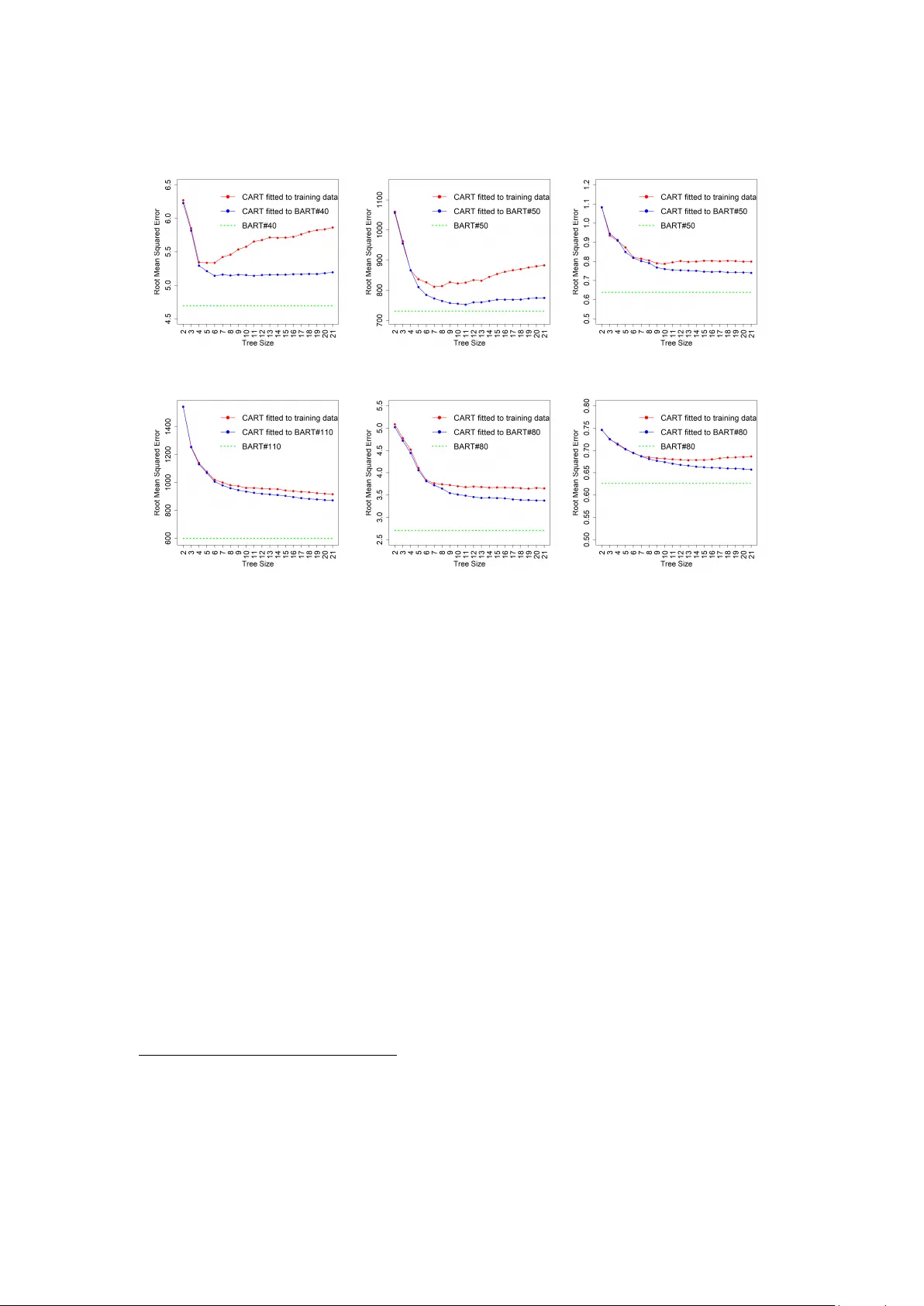
A Decision-Theoretic Approac h for Mo del In terpretabilit y in Ba y esian F ramew ork Homa yun Afrabandp ey 1 , T omi P eltola 1,2, © , Juho Piironen 2, ¨ , Aki V eh tari 1 , and Sam uel Kaski 1,3 1 Helsinki Institute for Information T ec hnology HI IT, Departmen t of Computer Science, Aalto Universit y 2 Curious AI 3 Univ ersity of Manc hester, UK 1 firstname.lastname@aalto.fi , © tomi.peltola@tmpl.fi , ¨ juho.t.piironen@gmail.com Abstract A salient approac h to in terpretable machine learning is to restrict mo deling to simple mo dels. In the Bay esian framew ork, this can b e pursued b y restricting the mo del struc- ture and prior to fa vor interpretable mo dels. F undamentally , ho wev er, interpretabilit y is ab out users’ preferences, not the data generation mechanism; it is more natural to for- m ulate in terpretability as a utilit y function. In this work, w e prop ose an in terpretability utilit y , which explicates the trade-off betw een explanation fidelity and in terpretability in the Ba yesian framew ork. The metho d consists of tw o steps. First, a reference mo del, possibly a blac k-b o x Bay esian predictive mo del which do es not compromise accuracy , is fitted to the training data. Second, a pro xy model from an interpretable mo del family that b est mimics the predictive behaviour of the reference mo del is found by optimizing the in terpretability utilit y function. The approac h is mo del agnostic – neither the interpretable mo del nor the reference mo del are restricted to a certain class of mo dels – and the optimization problem can b e solved using standard tools. Through exp erimen ts on real-word data sets, using decision trees as in terpretable mo dels and Ba yesian additive regression mo dels as reference mo dels, we show that for the same lev el of interpretabilit y , our approach generates more accurate models than the alternativ e of restricting the prior. W e also prop ose a systematic w ay to measure stability of interpretabile mo dels constructed b y differen t interpretabilit y approac hes and show that our proposed approac h generates more stable mo dels. 1 In tro duction and Bac kground Accurate machine learning (ML) mo dels are usually complex and opaque, even to the mo delers who built them [ 32 ]. This lack of in terpretability remains a k ey barrier to the adoption of ML mo dels in some applications including health care and econom y . T o bridge this gap, there is gro wing in terest among the ML comm unity to interpretabilit y methods. Suc h m ethods can b e divided into (i) interpretable mo del construction, and (ii) p ost-hoc in terpretation. The former aims at constructing mo dels that are understandable. P ost-ho c interpretation approaches can b e categorized further into (i) mo del-lev el in terpretation (a.k.a. global in terpretation), and (ii) 1 prediction-lev el in terpretation (a.k.a. lo cal interpretation) [ 12 ]. Mo del-lev el interpretation aims at making existing blac k-b o x mo dels interpretable. Prediction-lev el interpretation aims at ex- plaining each individual prediction made b y the mo del [ 11 ]. In this pap er, we fo cus mostly on p ost-hoc interpretation. Prior research on the construction of in terpretable mo dels has mainly fo cused on restricting mo deling to simple and easy-to-understand mo dels. Examples of suc h mo dels include sparse linear mo dels [ 42 ], generalized additiv e mo dels [ 33 ], decision sets [ 28 ], and rule lists [ 22 ]. In the Ba yesian framew ork, this approac h maps to defining mo del structure and prior distributions that fa vor in terpretable models [ 31 , 37 , 44 , 45 ]. W e call this approach interpr etability prior . Letham et al. [ 31 ] established an in terpretabilit y prior approac h for classification by use of decision lists. In terpretability measures used to define the priors were (i) the num b er of rules in the list and (ii) the size of the rules (num b er of statements in the left-hand side of rules). A prior distribution w as defined o ver rule lists to fav or decision lists with a small num b er of short rules. W ang et al. [ 45 ] developed tw o probabilistic mo dels for interpretable classification b y constructing rule sets in the form of Disjunctiv e Normal F orms (DNFs). In this work, interpretabil ity is ac hieved similar to [ 31 ], using prior distributions which fa vor rule sets with a smaller num ber of short rules. In [ 44 ], the authors extended [ 45 ] by presen ting a multi-v alue rule set for in terpretable classification, whic h allo ws m ultiple v alues per condition and thereby induces more concise rules compared to single-v alue rules. As in [ 45 ], in terpretabilit y is characterized b y a prior distribution that fav ors a smaller n um b er of short rules. Popk es et al. [ 37 ] built up an interpretable Bay esian neural net work for clinical decision-making tasks, where in terpretability is attained by employing a sparsity-inducing prior o v er feature w eights. F or more examples, see [ 16 , 17 , 24 , 47 ]. A common practice in mo del-lev el interpretabilit y is to use simple models as interpretable sur- rogates to highly predictiv e blac k-b o x mo dels [ 1 , 8 , 26 , 29 , 48 ]. Crav en and Shavlik [ 8 ] w ere among the first to adopt this approac h for explaining neural net works. They used decision trees as surrogates and trained them to approximate predictions of a neural netw ork. In [ 48 ], the authors presented an approac h to appro ximate the predictive b eha vior of a random forest by use of a single decision tree. With the same ob jective as [ 48 ], Bastani et al. [ 1 ] dev elop ed an approac h to in terpret random forests using simple decision trees as surrogates. They employ ed activ e learning to construct more accurate decision trees with help from a h uman. Lakk ara ju et al. [ 29 ] established an approac h to in terpret black-box classifiers by highligh ting the b eha vior of the blac k-b o x mo del in subspaces c haracterized by features of user in terest. In [ 26 ], the authors used decision trees to extract rules to describ e the decision-making b eha vior of black-box mo d- els. F or more examples of this approac h, see [ 3 , 9 , 34 , 46 ]. The common c haracteristic of these approac hes is that they seek an optimal trade-off b etw een interpretabilit y of the surrogate mo del and its faithfulness to the blac k-b o x model. T o the b est of our knowledge, there is no Bay esian coun terpart for this approac h in the interpretabilit y literature. W e argue that an interpretabilit y prior is not the best wa y to optimize in terpretability in the Ba yesian framew ork for the following reasons: 1. In terpretability is about users’ preferences, not about our assumptions about the data. The prior is meant for the latter. One should distinguish the data generation mec hanism from the decision-making pro cess, whic h in this case includes optimization of in terpretability . 2. Optimizing interpretabilit y may sacrifice some of the accuracy of the mo del. If inter- pretabilit y is pursued by revising the prior, there is no reason why the trade-off b et ween accuracy and in terpretability w ould b e optimal. This has b een sho wn for a differen t but re- lated scenario in [ 36 ] where the authors sho wed that fitting a model using sparsit y-inducing 2 T able 1: Characteristics of differen t intereptation approaches. G – global, L – lo cal, DT – Decision T ree, DR – Decision Rules, M/A – Mo del Agnostic, TE – T ree Ensem ble, NN – Neural Net work, C – Classification, R – Regression Approac h Ref. Domain In terp. Mo del Blac k-Box Model T ask Bay esian T repan [ 8 ] G DT NN C 8 – [ 1 ] G DT TE C 8 BA T rees [ 3 ] G DT TE C/R 8 inT rees [ 9 ] G DR TE C 8 – [ 26 ] G M/A M/A C/R 8 No de Harv est [ 34 ] G TE TE R 8 Our Approach – G/L M/A M/A C/R 4 priors that fav or simpler mo dels results in p erformance loss. 3. F orm ulating an interpretabilit y prior for certain classes of mo dels suc h as neural netw orks could b e difficult. T o address these concerns, we develop a general principle for interpretabilit y in the Bay esian framew ork, formalizing the idea of approximating black-box models with interpretable surro- gates. The approach can b e used to both constructing, from scratch, interpretable Bay esian pre- dictiv e mo dels, or to interpreting existing black-box Bay esian predictive mo dels. The approac h consists of t w o steps: first, a highly accurate Ba yesian predictiv e model, called a reference mo del, is fitted to the training data without compromising the accuracy . In the second step, an inter- pretable surrogate model is constructed which b est describ es lo cally or globally the b eha vior of the reference mo del. The proxy mo del is obtained b y optimizing a utilit y function, referred to as interpr etability utility , whic h consists of t wo terms: (i) a term to minimize the discrepancy of the proxy mo del from the reference model, and (ii) a term to penalize the complexit y of the mo del to make the proxy model as interpretable as possible. T erm (i) corresp onds to selection of reference predictive model in the Bay esian framework [ 43 , Section 3.3]. The prop osed approach can b e used b oth for constructing interpretable Ba yesian predictive mo dels and to generate p ost-ho c in terpretation for black-box Bay esian predictive mo dels. When using the approach for p ost-ho c interpretabilit y , it can be used to generate b oth global or lo- cal in terpretation. The approach is mo del-agnostic, meaning that neither the reference mo del nor the interpretable proxy are constrained to a particular mo del family . Ho wev er, when using the approac h to construct in terpretable Ba yesian predictive models, the surrogate model should b e from the family of Ba yesian predictive mo dels. W e also emphasize that the prop osed ap- proac h is feasible for non-Bay esian mo dels as w ell, whic h can b e interpreted to pro duce point estimates of the parameters of the mo del instead of p osterior distributions. T able 1 compares the characteristics of the proposed approach with some of the related works from literature. W e demonstrate with exp erimen ts on real-world data sets that the prop osed approach generates more accurate and more stable in terpretable mo dels than the alternativ e of fitting an a priori in terpretable mo del to the data, i.e., using the in terpretability prior approac h. F or the exp eri- men ts in this pap er, decision trees and logistic regression were used as interpretable pro xies, and Ba yesian additive regression tree (BAR T) models [ 6 ], Bay esian neural netw orks, and Gaussian Pro cesses (GP) w ere used as reference mo dels. 3 1.1 Our Con tributions: Main contributions of this paper are: • W e prop ose a principle for interpretable Ba yesian predictive mo deling. It combines a reference mo del with interpretabilit y utilit y to pro duce more interpretable mo dels in a decision-theoretically justified wa y . The prop osed approac h is model agnostic and can be used with different notions of in terpretability . • F or the sp ecial case of classification and regression tree (CAR T) [ 2 ] as interpretable mo dels and BAR T as the black-box Ba yesian predictiv e mo del, w e show that the prop osed approach outp erforms the earlier interpretabilit y prior approac h in accuracy , explicating the trade- off b et ween explanation fidelit y and in terpretability . F urther, through exp erimen ts with differen t reference mo dels, i.e., GP and BAR T, w e demonstrate that the predictive p o w er of the reference model p ositiv ely affects the accuracy of the in terpretable mo del. W e also demonstrate that our prop osed approac h can find a better trade-off b et ween accuracy and in terpretability when compared to its non-Bay esian coun terparts, i.e., BA T rees [ 3 ] and no de harv est [ 34 ]. • W e prop ose a systematic approach to compare stability of interpretable mo dels and sho w that the prop osed method pro duces more stable mo dels. 2 Motiv ation In this section, w e discuss the motiv ation for formulating interpretabilit y optimization in the Ba yesian framew ork as a utility function. W e also discuss how this form ulation allows to accoun t for mo del uncertaint y in the explanation. Both discussions are accompanied with illustrativ e examples. 2.1 In terpretabilit y as a Decision-Making Problem Ba yesian mo deling allo ws encoding prior information in to the prior probabilit y distribution (simi- larly , one might use regularization in maxim um likelihoo d based inference). This might b e tempt- ing to c hange the prior distribution to fa vor mo dels that are easier for h umans to understand, as has b een done in earlier works, using some measure of interpretabilit y . A simple example is to use shrink age priors in linear regression to find a smaller set of practically imp ortan t cov ariates. Ho wev er, w e argue that based on the observ ation, in terpretability is not an inherent character- istic of data generation pro cesses. The approach can b e misleading and results in leaking user preferences ab out in terpretability in to the mo del of the data generation pro cess. W e suggest to separate the construction of a model for the data generating process from c onstruc- tion of an in terpretable proxy mo del. In a prediction task, the former corresp onds to building a model that predicts as accurately as p ossible, without restricting it to b e in terpretable. Inter- pretabilit y is introduced in the second stage by building an interpretable proxy to explain the b eha vior of the predictiv e mo del. W e consider the second step as a decision-making problem, where the task is to choose a proxy model that trades off b et ween human in terpretability and fidelit y (w.r.t. the original model). 4 2.2 The Issue with Interpretabilit y in the Prior Let M denote the assumptions ab out the data generating pro cess and I the preferences tow ard in terpretability . Consider an observ ation model for data y , p ( y | θ , M ), and alternativ e prior distributions p ( θ | M ) and p ( θ | M , I ). Here, θ can, for example, b e con tinuous model parameters (e.g., w eights in a regression or classification mo del) or it can index a set of alternative mo dels (e.g., each configuration of θ could corresp ond to using some subset of input v ariables in a predictiv e mo del). Clearly , the p osterior distributions p ( θ | D , M ) and p ( θ | D , M , I ) (and their corresp onding posterior predictive distributions) are in general different and the latter includes a bias tow ards interpretable mo dels. In particular, when I do es not corresp ond to prior information ab out the data generation pro cess, there is no guaran tee that p ( θ | D , M , I ) pro vides a reasonable quan tification of our kno wledge of θ giv en the observ ations D , or that, p ( ˜ y | D , M , I ) provides go od predictions. W e will give an example of this b elo w. In the special case, where I does describ e the data generation process, it can directly b e included in M . Lage et al [ 27 ] prop ose to find interpretable mo dels in t wo steps: (1) fit a set of models to data and take ones that giv e high enough predictiv e accuracy , (2) build a prior ov er these models, based on an indirect measure of user interpretabilit y (human interpretabilit y score). In practice, the pro cess requires the set of mo dels for step 1 to contain in terpretable mo dels, which means that there is still the p ossibilit y of leaking user preferences for in terpretability in to the knowledge ab out the data generation process. This ma y lead to an unreasonable trade-off b et ween accuracy and interpretabilit y . 2.2.1 Illustrativ e Example W e give an example to illustrate the effect of adding in terpretability constraints to the prior distribution when these constrain ts do not match data generating pro cess. F or simplicity , we define a single in terpretability constrain t whic h is o ver the structure of the model: regression tree with a fixed depth of 4. The in terpretability prior approac h corresp onds to fitting an in terpretable mo del with the ab o v e constraint directly to the training data. In the alternative approac h, first a reference mo del is fitted to the data, and then the reference model is approximated with a pro xy mo del that satisfies the interpretabilit y constraint, using the in terpretability utilit y introduced in Section 3 . F or simplicit y of visualization, we use a one-dimensional smo oth function as the data-generating pro cess, with Gaussian noise added to observ ations (Figure 1 :left, black curve and red dots). Regression tree is a piece-wise constant function whic h do es not correspond to the true prior knowledge ab out the ground-truth function, i.e. b eing a 1D smo oth function. A Gaussian pro cess with the MLP kernel function is used as a reference mo del for the tw o-stage approac h (Figure 1 :left, magen ta). The regression tree of depth 4 fitted directly to the data (blue line) ov erfits and does not give an accurate represen tation of the underlying data generation pro cess (blac k line). The tw o-stage approac h, on the other hand, gives a clearly b etter represen tation of the smo oth, increasing function. This is because the reference mo del (green line) captures the smo othness of the un- derlying data generation pro cess and this is transferred to the regression tree (magen ta line). The choice of the complexit y of the interpretable mo del is also easier b ecause the tree can only “o verfit” to the reference model, meaning that it becomes a more accurate (but p ossibly less easy to interpret) represen tation of the reference mo del as shown in Figure 1 :righ t. 5 1.0 0.5 0.0 0.5 1.0 x 4 3 2 1 0 1 2 y true function training data ref.model tree fit to training data tree fit to ref.model 2 4 6 8 Tree depth 0.2 0.3 0.4 0.5 0.6 0.7 0.8 RMSE ref.model tree fit to training data tree fit to ref.model Figure 1: Left : T he reference mo del (green) is a highly predictive non-in terpretable model that appro ximates the true function (black) w ell. The interpretable model fitted to the reference mo del (magenta) appro ximates the reference mo del (and consequen tly the true function) well, while the interpretable mo del fitted to the training data (blue) fails to appro ximate the predictiv e b eha vior of the true function. Righ t : Ro ot Mean Squared Errors (RMSE) compared to the true underlying function as the tree depth is v aried. By increasing the complexity of the in terpretable mo del (decreasing its in terpretability), predictive performance of the reference mo del and its corresp onding in terpretable mo del con verge; the in terpretable mo del o v erfits to the reference mo del. 2.3 In terpreting Uncertaint y In man y applications, such as medical treatmen t effectiveness prediction [ 41 ], knowing the uncer- tain ty in the prediction is imp ortant. Any explanation of the predictive mo del should also pro vide insigh t ab out the uncertainties and their sources. The p osterior predictiv e distribution of the reference model contains b oth the aleatoric (predictive uncertaint y giv en the model parameter, i.e., noise in the output) and the epistemic uncertaint y (uncertain ty ab out mo del parameters). W e can capture b oth of these in to our interpretable model, since it is fitted to match the refer- ence p osterior predictiv e distribution. The former is captured by conditioning the interpretable mo del on a posterior draw from the reference mo del, while the latter is captured b y fitting the in terpretable mo del on m ultiple p osterior draws. Details will be given later in Section 3 . Here, w e demonstrate with an example that the proposed method can pro vide useful information about mo del uncertain ty . 2.3.1 Practical Example W e demonstrate uncertaint y interpretation in lo cally explaining a prediction of a Ba yesian deep con volutional neural net work in the MNIST dataset of images of digits [ 30 ]. The reference mo del is classifying betw een digits 3 and 8. W e use the Bernoulli drop out method [ 14 , 15 ], with a 6 Mean V arianc e Sample 1 Sample 2 Sample 3 Image Early t raining F ully tra ined Figure 2: Mean explanation, explanation v ariance, and three sample explanations for a con- v olutional neural netw ork 3-vs-8 MNIST-digit classifier early in the training and fully trained. Colored pixels show linear explanation mo del weigh ts, with red b eing positive for 3 and blue for 8. drop out probabilit y of 0.2 and 20 Mon te Carlo samples at test time, to appro ximate Bay esian neural netw ork inference (the posterior predictiv e distribution). Logistic regression is used as the interpretable model family 1 . Since w e are classifying images, we can conv eniently visualize the explanation mo del. Figure 2 sho ws visually the logistic regression weigh ts for a digit, comparing the reference mo del in an early training phase (upp er row) and fully trained (low er row). The mean explanations show that the fully trained model has spatially smo oth con tributions to the class probabilit y , while the mo del in early training is noisy . Moreov er, being able to look at the explanations of individual p osterior predictive samples illustrates the epistemic uncertaint y . F or example, the reference mo del in early training has not yet been able to confiden tly assign the upp er lo op to either indicate a 3 or an 8 (samples 1 and 2 hav e reddish loop, while sample 3 has bluish). Indeed, the v ariance plot shows that the mo del v ariance spreads evenly ov er the digit. On the other hand, the fully trained mo del has little uncertaint y about which parts of the digit indicate a 3 or an 8, with most mo del uncertain ty being ab out the magnitude of the contributions. 3 Metho d: Interpretabilit y Utilit y for Ba y esian Predictiv e Mo dels Here w e first explain the pro cedure to obtain interpretabilit y utility for regression tasks. The case of classification mo dels is similar and is explained in Section 3.3 . 1 The optimization of the in terpretable model follo ws the general framework explained in Section 3, with logistic regression used as the interpretable mo del family instead of CAR T. No penalty for complexity wa s used here, since the logistic regression model weights are easy to visualize as pseudo-colored pixels 7 3.1 Regression mo dels Let D = { ( x n , y n ) } N n =1 denote a training set of size N , where x i = [ x i 1 , · · · , x id ] T is a d - dimensional feature vector and y i ∈ R is the target v ariable. Assume that a highly predictive (reference) mo del M is fitted to the training data without concerning interpretabilit y constrain ts. Denote the likelihoo d of the reference mo del by p ( y | x , θ , M ) and the p osterior distribution p ( θ | D , M ). Posterior predictive distribution of the reference mo del obtains as p ( ˜ y | D ) = R θ p ( ˜ y | θ ) p ( θ | D ) dθ . Our goal is to find an interpretable model that best explains the b ehavior of the reference mo del lo cally or globally . W e introduce an interpretable model family T with lik eliho o d p ( y | x , η , T ) and po sterior p ( η | D , T ), b elongs to a probabilistic model family with parameters η . The b est in terpretable model is the one closest to the reference mo del prediction– wise, and at the same time easily interpretable. T o measure the closeness of the predictiv e b eha vior of the interpretable model to the reference mo del, we compute the Kullbac k-Leibler (KL) div ergence b et ween their posterior predictiv e distribution. Assuming w e wan t to locally in terpret the reference mo del, and following simplifications of [ 36 ] for computing the KL div ergence of p osterior predictive distributions, the best interpretable model can b e found b y optimizing the follo wing utility function: ˆ η = arg min η Z π x ( z )KL [ p ( ˜ y | z , θ , M ) k p ( ˜ y | z , η , T )] d z + Ω( η ) (1) where KL denotes the KL divergence, Ω is the penalty function for the complexit y of the inter- pretable model, and π x ( z ) is a probabilit y distribution defining the lo cal neighborho o d around x , data p oin t the prediction of whic h is to b e explained. Minimization of the KL divergence v erifies that the interpretable mo del has similar predictiv e p erformance to the reference model while the complexity penalty cares for the in terpretability of the mo del. W e compute the exp ectation in Eq. 1 with Mon te Carlo approximation by drawing { z s } S s =1 samples from π x ( z ): ˆ η ( l ) = arg min η 1 S S X s =1 KL h p ( ˜ y s | z s , θ ( l ) , M ) k p ( ˜ y s | z s , η , T ) i + Ω( η ) , (2) for l = 1 , . . . , L p osterior draws from p ( θ | D , M ). Eq. 2 can b e solv ed by first drawing a sample θ ( l ) from the p osterior of the reference mo del and then finding a sample η ( l ) from the p osterior of the interpretable mo del that minimizes the ob jective function. It has b een shown in [ 36 ] that minimization of the KL-div ergence in Eq. 2 is equiv alent to maximizing the exp ected log-lik eliho o d of the interpretable model ov er the likelihoo d obtained by a posterior draw from the reference mo del: arg max η 1 S S X s =1 E ˜ y s | z s , θ ( l ) [log p ( ˜ y s | z s , η )] . (3) Using this equiv alen t form and b y adding the complexit y p enalt y term, the in terpretability utilit y obtains as arg max η 1 S S X s =1 E ˜ y s | z s , θ ( l ) [log p ( ˜ y s | z s , η )] − Ω ( η ) . (4) The complexity p enalt y term should b e chosen to matc h the resulting model; possible options are the num b er of leaf no des for decision trees, num b er of rules and/or size of the rules for rule list mo dels, num b er of non-zero weigh ts for linear regression mo dels, etc. Although the prop osed approach is general and can b e used for an y family of in terpretable mo dels, in the 8 follo wing, we use CAR T mo dels with tree size (the n umber of leaf no des) as the measure of in terpretability . With this assumption, similar to the illustrative example in Section 2.2.1 , the in terpretability constraint is defined o ver the mo del space; it could also b e defined o ver the parameter space of a particular model, suc h as tree shap e parameters of Bay esian CAR T models [ 5 ]. The interpretabilit y prior approac h corresp onds to fitting a CAR T mo del to the training data, i.e. samples drawn from the neigh b orhoo d distribution of x . A CAR T model describes p ( y | z , η ) with t wo main comp onents η = ( T , φ ): a binary tree T with b terminal nodes and a parameter v ector φ = ( φ 1 , φ 2 , · · · , φ b ) that asso ciates the parameter v alue φ i with the i th terminal no de. If z lies in the region corresponding to the i th terminal no de, then y | z , η has distribution f ( y | φ i ), where f denotes a parametric probabilit y distribution with parameter φ i . F or CAR T mo dels, it is t ypically assumed that, conditionally on η , v alues y within a terminal no de are independently and identically distributed, and y v alues across terminal nodes are indep enden t. In this case, the corresponding likelihoo d of the interpretable mo del for the l th dra w from the posterior of θ has the form p y | Z , η ( l ) = b Y i =1 f y i | φ ( l ) i = b Y i =1 n i Y j =1 f y ij | φ ( l ) i , (5) where y i ≡ ( y i 1 , · · · , y in i ) denotes the set of the n i observ ations assigned to the partition gen- erated by the i th terminal no de with parameter φ ( l ) i , and Z is the matrix of all the z s . F or regression problems, assuming a mean-shift normal mo del for each terminal node i , 2 the lik eli- ho od of the interpretable model is defined as f y | φ ( l ) = b Y i =1 n i Y j =1 N y ij | µ ( l ) i , σ 2 ( l ) , (6) where φ ( l ) = ( µ ( l ) = { µ ( l ) i } b i =1 , σ 2 ( l ) ). With this formulation, the task of finding an in terpretable pro xy to the reference mo del M is reformed to find a tree structure T with parameters φ ( l ) suc h that its predictiv e performance is as close as p ossible to M , while b eing as interpretable as p ossible. Interpretabilit y is measured by the complexity term Ω. The log-likelihoo d of the tree with the S samples dra wn from the neigh b orhoo d of x is L = − S 2 log(2 π σ 2 ) − 1 2 σ 2 b X i =1 n i X j =1 ( y ij − µ i ) 2 . (7) Pro jecting this into Eq. 4 , the in terpretability utilit y has the following form: arg max η − 1 2 log(2 π σ 2 ) − 1 2 S σ 2 b X i =1 n i X j =1 E y ij | θ ( l ) h ( y ij − µ i ) 2 i − Ω( T ) ∝ arg max η − 1 2 log(2 π σ 2 ) − 1 2 S σ 2 b X i =1 n i X j =1 h σ 2 ij + ( ¯ y ij − µ i ) 2 i − Ω( T ) , (8) where ¯ y ij and σ 2 ij are resp ectiv ely the mean and v ariance of the reference mo del for the j th sample in the i th terminal no de. Ω( T ) is a function of the in terpretability of the CAR T mo del. Here we set it to α b using α as a regularization parameter. The pseudo co de of the prop osed approac h is sho wn in Algorithm 1 . 2 In the mean-v ariance shift mo del, eac h terminal no de has its own σ 2 i v ariable and the n umber of parameters is 2 × b . 9 Algorithm 1: Decision–theoretic approach for lo cal in terpretability in the Bay esian framework Input: training data D = { ( x n , y n ) } N n =1 , a test sample x test to b e explained Output: a decision tree explaining the prediction for the test sample x test /* REFERENCE MODEL CONSTRUCTION */ fit the Bay esian predictiv e mo del to D without concerning interpretabilit y constraints; dra w { z s } S s =1 from the neighborho od of x test defined by π x ; for e ach dr aw z s do get the mean ¯ y s and v ariance σ 2 s of the Bay esian predictiv e distribution; end /* INTERPRETABILITY OPTIMIZATION */ fit a CAR T mo del to { ( z s , ¯ y s ) } S s =1 b y optimizing Eq. 8 When fitting a global in terpretable mo del, instead of dra wing samples from π x , we use training inputs { x n } N n =1 with their corresp onding output computed by the reference model { y ref n } N n =1 as the target v alue. The next subsection explains how to solv e Eq. 8 for CAR T mo dels. 3.2 Optimization Approac h W e optimize Eq. 8 b y using the backw ard fitting idea which inv olves first growing a large tree and then pruning it bac k to obtain a smaller tree with b etter generalization. F or this goal, w e use the formulation of maxim um likelihoo d regression tree (MLR T) [ 40 ]. 3.2.1 Gro wing a large tree Giv en the training data 3 , MLR T automatically decides on the splitting v ariable x j and split p oin t (a.k.a. piv ot) c using a greedy search algorithm that aims to maximize the log-lik eliho od of the tree b y splitting the data in the curren t node in to t wo parts: the left child no de satisfying x j ≤ c and the right c hild no de satisfying x j > c . The pro cedure of gro wing the tree is as follo ws: 1. F or each node i , determine the maximum lik eliho od estimate of its mean parameter µ i giv en observ ations asso ciated with the no de, and then compute the v ariance parameter of the tree given { µ i } b i =1 : ˆ µ i = 1 n i n i X j =1 ¯ y ij ˆ σ 2 = P b i =1 P n i j =1 h σ 2 ij + ( ¯ y ij − ˆ µ i ) 2 i S . The log-likelihoo d score of the no de is then computed, up to a constan t, b y L i ∝ − n i log( ˆ σ 2 ). 3 Here, for local in terpretation, training data refers to the S samples (with their corresponding predictions made by the reference mo del) taken from the neighborho od distribution to fit the explainable mo del. 10 2. F or each v ariable x j , determine the amoun t of increase in the log-likelihoo d of the node i caused by a split r as ∆ ( r,x j ,i ) = L i R + L i L − L i , where L i R and L i L are the log-likelihoo d scores of the righ t and left c hild no des of the paren t no de i generated by the split r on the v ariable x j , resp ectiv ely . 3. F or eac h v ariable x j , select the b est split r ∗ j with largest increase to the log-likelihoo d. 4. Among the b est splits, the one that causes the global maximum increase in the log- lik eliho o d score will b e selected as the global b est split, r ∗ , for the curren t no de, i.e. r ∗ = max r ∗ j , j =1 , ··· ,d ∆ ( r ∗ j ,x j ,i ) . 5. Iterate steps 1 to 4 until reac hing the stopping criteria. In our implemen tation, w e used the minimum size of a terminal no de (the n umber of samples lie in the region generated by the terminal no de) as the stopping condition. 3.2.2 Pruning W e adopt the cost-complexit y pruning using the follo wing cost function: C α ( T ) = log( ˆ σ 2 ) + αb. (9) Pruning is done iteratively; in each iteration i , the in ternal no de h that minimizes α = ( C ( h ) − C ( T i )) ( | lea ves ( T h ) |− 1 ) is selected for pruning, where C ( h ) refers to the cost of the decision tree with h as terminal no de, C ( T i ) denote the cost of the full decision tree in iteration i , and T h denotes the subtree with h as its ro ot. The output is a sequence of decision trees and a sequence of α v alues. The best α and its corresp onding subtree are selected using 5-fold cross-v alidation. 3.3 Classification mo dels F or classification problems, assuming the CAR T mo dels as the interpretable model family , the form of the interpretabilit y utility is the same as Equation 4 except that the likelihoo d of the in terpretable mo del follows a m ultinomial distribution with the following log-lik eliho od: L = b X i =1 n i X j =1 K X k =1 I ( y ij ∈ C k ) log p ik s.t. p ik ≥ 0 , K X k =1 p ik = 1 (10) where I ( y j k ∈ C k ) is the indicator function determining wheter or not the j th sample of the i th no de belongs to the k th category assuming that there are in total K categories. The p ik denote the probabilit y of the o ccurrence of the k th category in the i th terminal node and the set of parameters are φ = { p i = ( p i 1 , . . . , p ik ) } b i =1 . Therefore, the final form of the in terpretability utilit y for Ba yesian classification models is arg max η 1 S b X i =1 K X k =1 n k log p ik + Ω( T ) s.t. p ik ≥ 0 , K X k =1 p ik = 1 (11) where η = ( T , φ ) and n k = P n i j =1 I ( y j k ∈ C k ). The optimization approach is again similar to the pro cess explained in Section 3.2 with the difference that the maximum likelihoo d estimate of 11 the parameters of each no de i obtains as ˆ p ik = n k n i . Finally , the log-lik eliho o d score of eac h node i is determined by L i = P K k =1 n k log ˆ p ik . 3.4 Connection With Lo cal In terpretable Mo del-agnostic Explanation (LIME) LIME [ 39 ] is a prediction-level interpretation approach that fits a sparse linear model to the blac k-b o x mo del’s prediction via drawing samples from the neighborho od of the data p oin t to b e explained. Our prop osed approac h extends LIME to KL div ergence based in terpretation of Ba yesian predictive mo dels (although it can also b e used for non-Bay esian probabilistic mo dels as well). This is achiev ed by combining the idea of LIME with the idea of pro jection predictive v ariable selection [ 36 ]. The approac h is able to handle differen t types of predictions (con tinuous v alued, class labels, coun ts, censored and truncated data, etc.) and interpretations (model-level or prediction-level) as long as we can compute KL div ergence betw een the predictive distribu- tions of the original mo del and the explanation mo del. F or a more detailed explanation of the connection, chec k the preliminary w ork of [ 35 ]. 4 Exp erimen ts W e demonstrate the efficacy of the proposed approach through experiments on several real-w orld data sets. Subsection 4.1 discusses the exp erimen ts related to global intepretation. W e first in- v estigate the effect of reference mo dels with different predictiv e p o wers on the p erformance of the final in terpretable mo del. Secondly , w e compare our approach with the interpretabilit y prior alternativ e, of fitting directly an in terpretable mo del to the data, in terms of their capability to trade off betw een accuracy and interpretabilit y . W e also compare the p erformance of our approac h with non-Bay esian counterparts introduced in Section 1 . F urther, w e inv estigate the stabilit y of our approach and the in terpretability prior approac h. Section 4.2 examines lo cal in ter- pretation, where we compare our approach with LIME. Our co des and data are a v ailable online at gith ub.com/homayunafra/Decision Theoretic Approach for Interpretabilit y in Bay esian F ramew ork . 4.1 Global In terpretation 4.1.1 Data In our exp erimen ts, we use the following data sets: b ody fat [ 21 ], baseball pla yers [ 20 ], auto risk [ 23 ], bike rental [ 13 ], auto mpg [ 38 ], red wine quality [ 7 ], and Boston housing [ 18 ]. Eac h data set is divided into training and test set con taining 75% and 25% of samples, resp ectiv ely . 4.1.2 Effect of Reference Mo del The purpose of this test is to ev aluate how the predictive p o wer of the reference model affects the p erformance of the in terpretable mo del when it is used to globally explain the reference mo del. Three data sets are adopted for this test: bo dy fat, baseball play ers, and auto risk. F urthermore, 12 (a) Body fat (b) Baseball (c) Auto risk Figure 3: Effect of reference models with different predictive p erformance on the performance of the interpretable mo dels fitted to them. More accurate reference mo dels result in interpretable mo dels with higher predictiv e p erformance. The v alues of “ntree” used for the BAR T mo dels are shown b y “#”. three reference mo dels with differen t predictive p o wers are adopted: tw o BAR T models, and a Gaussian pro cess (GP). F or the BAR T models, w e used the BAR T pack age in R with tw o differen t v alues for the “ntree” (n umber of trees) parameter. F or one mo del, “n tree” is set to the v alue that gives the highest predictiv e performance on the v alidation set (blue dotted line in Figure 3 ), while for another one, this parameter is set to 3, a lo w v alue, whic h giv es po or predictive p erformance (red-dotted line in Figure 3 ). The rest of the parameters are set to their default v alues except “nskip” and “ndpost”, which are set to 2000 and 4000, resp ectiv ely . F or the BAR T mo dels, mean of the predictions of the posterior dra ws is used as their output. F or the GP (green-dotted line in Figure 3 ), “Matern52” is used as the kernel with v ariance and length scales obtained by cross-v alidation o ver a small grid of v alues 4 . CAR T models are used as the in terpretable mo del family . The size of the tree, i.e., the total num b er of leaf no des, is used as the measure of in terpretability [ 1 , 17 ]. Figure 3 demonstrates the results, which are av eraged ov e r 50 runs. The difference in the predictiv e p erformance of the in terpretable mo dels fitted to different reference models suggests that using more accurate reference mo dels (BAR T in Baseball and Auto risk data sets, and GP in Bo dy fat data set) can generate more accurate interpretable mo dels as well. This is exp ected since by the p erformance of the interpretable mo del con verges to the p erformance of the reference mo del; therefore the in terp etable mo del will b e more accurate when fitted to a more accurate reference mo del. The gap b etw een the predictive p erformance of the in terpretable mo dels and their corresp onding reference mo dels is due to the limited predictiv e capabilit y of the in terpretable mo del. F or some tasks, this gap can be made narrow er by increasing the complexit y of the interpretable mo del, while for others, a differen t family of interpretable mo dels ma y b e needed. Finally , in Figure 3 .c, the p erformance of the in terpretable mo del fitted to the GP reference mo del is b etter than the reference mo del itself, for some complexities. This may b e because of differen t extrapolation behavior of CAR T and GP . In the high-dimensional space, the test data 4 This may not be the best setting for the GP . W e did not attempt to optimize that since our ob jectiv e is not to compare the p erformance of GP with BAR T, but instead to compare the p erformance of the interpretable mo dels fitted to them. 13 (a) Body fat (b) Baseball (c) Auto risk (d) Bik e (e) Auto mpg (f ) Wine qualit y Figure 4: Comparison of interpretabilit y prior (red) and interpretabilit y utility (blue) approach in trading off betw een accuracy and in terpretability when using CAR T as explainable mo dels and BAR T as reference mo del. The v alues of “n tree” used for the BAR T mo dels are shown by “#”. ma y be outside the supp ort of the training data; thus, extrapolation b ehavior matters. Simpler mo dels can mak e more conserv ative extrapolations which ma y b e helpful in this case. 4.1.3 In terpretability Prior vs In terpretabilit y Utilit y In this subsection, we compare our approach with the interpretabilit y prior approach, in terms of the capability of the metho ds to trade off betw een accuracy and interpretabilit yr. BAR T is used as the reference model, and CAR T is used as the in terpretable model family . The interpretabilit y prior approach fits a CAR T mo del directly to the training data where the prior assumption is that CAR T mo dels are simple to interpret. On the other hand, our approach fits the CAR T mo del to the reference model, b y optimization of the interpretabilit y utility . Figure 4 demonstrates the results using all the data sets introduced in Subsection 4.1.1 . The results are av eraged o ver 50 runs. It can b e seen that the most accurate mo dels with any lev el of complexity (in terpretabilit y) are obtained with our proposed approac h 5 . T o test the significance of the differences in the results, we performed the Ba yes t -test [ 25 ]. The approac h w orks by building up a complete distributional information for the mean and standard 5 The single exception happened in auto risk data set with tree size of 3. 14 (a) Body fat (b) Baseball (c) Auto risk (d) Bik e (e) Auto mpg (f ) Wine qualit y Figure 5: Results of Bay esian t-test that sho ws the mean and 95% highest densit y interv al of the distribution of difference of means. µ 1 and µ 2 refer to the means of the distributions obtained for the interpretabilit y prior and interpretabilit y utilit y approach, resp ectiv ely deviation of each group 6 and constructing a probability distribution ov er their differences using MCMC estimation. F rom this distribution, the mean credible v alue as the b est guess of the actual difference and the 95% Highest Densit y In terv al (HDI) as the range were the actual difference is with 95% credibility are sho wn in Figure 5 . When the 95% HDI do es not include zero, there is a credible difference b etw een the t wo groups. As sho wn in the figure, for all data sets and for highly in terpretable models (highly inaccurate), the difference b et ween the tw o approaches is not significant (HDI contains zero). This is expected since by increasing the in terpretability , the abilit y of the interpretable mo del to explain v ariabilit y of the data or of the reference mo del decreases, and both approac hes provide almost equally p o or p erformance. How ever, b y increasing the complexit y (equiv alently decreasing interpretabilit y) to a reasonable level, w e see that the differences of the tw o approaches become significant for all data sets. Finally , w e further compared the p erformance of our prop osed approac h with tw o non-Ba yesian coun terparts, i.e., BA T rees [ 3 ] and node harv est [ 34 ]. BA T rees emplo ys a single decision tree that b est mimics the predictive b eha vior of a tree ensemble. Random forest is used as the reference mo del for BA T rees. No de harv est simplifies a tree ensem ble, i.e., random forest, b y use of the shallo w parts of the trees. W e chose these approac hes with random forest as their black-box mo del for the comparison for t wo reasons: 6 F or each tree size, there are tw o groups of 50 RMSE v alues: one for the in terpretability prior approach, and one interpretabilit y utilit y approach. 15 T able 2: Comparison of our approach with t wo non-Ba yesian counterparts: no de harv est and BA T rees. The RMSE v alues are sho wn in terms of mean ± sd. Sizes are shown in terms of mean ± sd of num b er of leaf nodes for BA T rees and n umber of no des with non-zero co efficien ts for no de harvest. F or BA T rees, the predictive p erformance of its reference mo del is sho wn in the paran theses. F or node harvest, it w as not possible to obtain the performance of the reference mo del since the R pac k age provides no means for that. Best RMSE v alues are bolded. RMSE Size No de Harv est BA T rees Our Approach No de Harv est BA T rees size = 10 size = 15 Bo dy fat 5 . 14 ± 0 . 37 5 . 26 ± 0 . 42 5 . 15 ± 0 . 36 5 . 16 ± 0 . 37 34 . 4 ± 6 . 5 19 . 5 ± 5 . 7 * (4 . 84 ± 0 . 38) Baseball 783 . 1 ± 72 . 5 1020 . 1 ± 69 . 9 755 ± 81 . 1 768 . 6 ± 92 . 5 35 . 5 ± 5 . 4 15 . 3 ± 6 . 5 * (755 . 9 ± 67 . 8) Auto risk 0 . 78 ± 0 . 06 0 . 79 ± 0 . 1 0 . 76 ± 0 . 1 0 . 75 ± 0 . 1 37 . 2 ± 12 . 4 20 . 4 ± 4 . 8 * (0 . 64 ± 0 . 09) Bik e 913 . 3 ± 67 . 2 907 . 4 ± 71 . 5 934 . 4 ± 68 . 9 904 . 2 ± 60 . 6 47 . 6 ± 9 . 1 33 . 5 ± 6 . 3 * (681 . 8 ± 60 . 7) Auto mpg 3 . 47 ± 0 . 33 3 . 39 ± 0 . 27 3 . 51 ± 0 . 31 3 . 43 ± 0 . 33 58 . 8 ± 8 . 1 28 ± 4 . 4 * (2 . 83 ± 0 . 34) Wine quality 0 . 67 ± 0 . 03 0 . 66 ± 0 . 02 0 . 67 ± 0 . 02 0 . 66 ± 0 . 02 51 . 3 ± 7 43 ± 13 . 2 * (0 . 6 ± 0 . 02) i. to the best of our knowledge, there is no approach particularly established for explaining Ba yesian tree ensemble mo dels, i.e., BAR T. The approach of Hara and Hay ashi [ 17 ] can b e modified for this ob jective; ho w ever, it requires inputs in terms of rules extracted from the tree ensemble, whic h calls for considerable of extra work. ii. BAR T can b e considered as a Bay esian in terpretation of random forest, and it has been rev ealed with some syn thetic and real-data exp erimen t that they hav e similar predictiv e p erformances [ 19 ]. F or no de harv est, we used the R implemen tation with default setting. F or BA T rees, the Python implemen tation in [ 17 ] is used with the depth of BA T rees chosen from { 3 , 4 , 5 , 6 } using 5-fold cross v alidation. The measure of complexit y for no de harvest is the total num b er of nodes with non-zero co efficien ts. T able 2 demonstrates the results. The results are av eraged o ver 50 runs with the same seed v alue used for the exp erimen ts in Figure 4 . The table shows that our prop osed approach attained muc h b etter trade-off b et ween accuracy and interpretabilit y compared to BA T rees and no de harvest. F or 4 data sets, our approach pro vides higher accuracies even with smaller sizes. F or the rest, still our approac h pro vides comparable predictiv e p erformance with a complexit y of ab out half of the complexities of no de harv est and BA T rees. The differences b etw een the b olded RMSE v alues with the rest of the RMSEs in Baseball, Auto risk and Wine quality data sets are significan t using the Ba yes t -test, while for other data sets the differences are not significant. According to the table, no de harv est tends to generate more complex surrogate models. This is exp ected since in no de harv est, the surrogate mo del is still an ensemble of shallo w trees. 16 T able 3: Bootstrap instabilit y v alues in the form of mean ± std. Best v alues are bolded. In terpretability Body fat Baseball Auto risk Bik e Auto mpg Wine qualit y Prior 0 . 71 ± 0 . 11 0 . 84 ± 0 . 08 0 . 79 ± 0 . 19 0 . 79 ± 0 . 19 0 . 79 ± 0 . 19 0 . 68 ± 0 . 09 0 . 68 ± 0 . 09 0 . 68 ± 0 . 09 0 . 70 ± 0 . 14 0 . 74 ± 0 . 11 Utilit y 0 . 62 ± 0 . 19 0 . 62 ± 0 . 19 0 . 62 ± 0 . 19 0 . 83 ± 0 . 07 0 . 83 ± 0 . 07 0 . 83 ± 0 . 07 0 . 81 ± 0 . 16 0 . 68 ± 0 . 09 0 . 68 ± 0 . 09 0 . 68 ± 0 . 09 0 . 64 ± 0 . 14 0 . 64 ± 0 . 14 0 . 64 ± 0 . 14 0 . 70 ± 0 . 13 0 . 70 ± 0 . 13 0 . 70 ± 0 . 13 4.1.4 Stabilit y Analysis The goal of interpretable ML is to provide a comprehensiv e explanation of the predictive b ehavior of the black-box model to the decision maker. How ever, p erturbation in the data or adding new samples may affect the learned interpretable mo del and lead to a very differen t explanation. This instability can cause problems for decision mak ers. Thereb y , it is imp ortan t to ev aluate the stabilit y of different interpretable ML approac hes. F or this ob jectiv e, we propose the following pro cedure for stabilit y analysis of interpretable ML approac h. Using a b ootstrapping procedure with 10 iterations, we compute pairwise dissimilarities of the in terpretable models obtained using each approach and report the mean and standard deviation of the dissimilarity v alues as their instability measure (smaller is b etter). W e used the dissimilarity measure prop osed in [ 4 ]. Assuming we are given tw o regression trees T 1 and T 2 , for eac h internal no de t , the similarit y of the trees at node t is computed b y S t (1 , 2) = I t k = k 0 1 − | δ t 1 − δ t 2 | range( X k ) (12) where I t k = k 0 is the indicator that determines whether the feature used to gro w node t in T 1 is iden tical to the one used in T 2 ( I t k = k 0 = 1) or not, δ t 1 and δ t 2 are pivots used to grow the no de t in T 1 and T 2 , resp ectiv ely , and range( X k ) is the range of v alues of feature k . Finally , the dissimilarit y of the t wo decision trees is computed as d ( T 1 , T 2 ) = 1 − P t ∈ in ternal no des q t S t (1 , 2) where q t are user sp ecified w eight v alue whic h we set to 1 /b where b is the n umber of terminal no des. The reported v alues are a veraged ov er 45 v alues (10 b ootstraping iterations result in (10 × 9) / 2 = 45 pairs of explainable mo dels). T able 3 compares the t wo approac hes o ver the data sets introduced in Section 4.1.1 . The inter- pretabilit y utilit y approac h generated on av erage more stable models for most data sets; how ever, dra wing a general conclusion is not p ossible b ecause except bo dy fat, for the rest of the data sets, the differences are not significant according to the Bay es t -test. 4.2 Lo cal In terpretation W e next demonstrate the ability of the proposed approac h in locally in terpreting the predictions of a Bay esian predictiv e mo del. BAR T 7 is used as the blac k b o x mo del and CAR T is used as the in terpretable mo del family . F or the CAR T model, we set the maxim um depth of the decision trees to 3 to obtain more interpretable lo cal explanations. W e compare with LIME 8 whic h is a commonly used baseline for lo cal interpretation approaches. Decision trees obtained b y our approach to lo cally explain predictions of the BAR T mo del, used on a v erage 2 . 03 and 7 In this experiment, we set the num b er of trees to 50 with nskip and ndpost set to 1000 and 2000 resp ectiv ely , for faster run. 8 W e use the ‘lime’ pac k age in R ( h ttps://cran.r-pro ject.org/web/pac k ages/lime/lime.p df ) for the implementa- tion. 17 T able 4: Comparison of the lo cal fidelit y of LIME and In terp ertabilit y utilit y when b eing used to explain predictions of BAR T. Best v alues are b olded. Dataset LIME In terpretability Utilit y Boston housing 4 . 86 2 . 94 Auto risk 0 . 014 0 . 010 2 . 4 features for the Boston housing and the auto risk data sets, resp ectiv ely . Therefore, to maximize comparabilit y , w e set the feature selection approac h of LIME to ridge regression and select the 2 features with the highest absolute w eights to b e used in the explanation 9 . W e use the standard quantitativ e metric for lo cal fidelit y: E x [loss (interp x ( x ) , pred( x ))] where given a test data x , interp x ( x ) refers to the prediction of the lo cal in terpretable mo del (fitted locally to the neigh b orhoo d of x ) for x , and pred( x ) refers to the prediction of the black-box mo del for x . W e used lo cally w eigh ted square loss as the loss function with π x = N x , σ 2 I where σ = 1. Eac h data set is divided into 90%/10% training/test split. F or each test data, we dra w 200 samples from the neigh b orhoo d distribution. T able 4 shows that our approach pro duces more accurate lo cal explanation for both data sets. Figure 6 shows, as an example, a decision tree constructed by our prop osed approach to locally explain the prediction of the BAR T mo del for the particular test data sho wn in the figure from Boston housing data set. It can b e seen that using only t wo features, our prop osed approach obtains go o d lo cal fidelit y while main taining in terpretability with a decision tree with only 3 leaf no des. 5 Conclusion W e presented a nov el approac h to construct in terpretable explanations in the Bay esian framew ork b y formulating the task as optimizing a utility function instead of c hanging the priors. This is obtained b y first fitting a Bay esian predictiv e mo del which do es not compromise accuracy , termed as a reference mo del, to the training data, and then pro ject the information in the predictive distribution of the reference mo del to an interpretable mo del. The approac h is mo del agnostic, implying that neither the reference mo del nor the interpretable mo del is restricted to a certain mo del. In the current implemen tation, the interpretable mo del, i.e., CAR T, is not a Bay esian predictiv e mo del; how ever, it is straightforw ard to extend the form ulation to the case where a Ba yesian predictiv e mo del, e.g., Ba yesian CAR T [ 10 ], is used as the in terpretable model. This re- mains for future. The approac h also allo ws accoun ting for mo del uncertaint y in the explanations. Through exp erimen ts, w e demonstrated that the prop osed approach outp erforms the alternative approac h of restricting the prior, in terms of accuracy , in terpretability and stability . F urther- more, we sho wed that the prop osed approac h p erforms comparable to non-Bay esian counterparts suc h as BA T rees and no de harvest even when they hav e higher complexities (equiv alently less in terpretability). 6 Ac kno wledgmen ts This work was supp orted b y the Academy of Finland (Flagship programme: Finnish Cen ter for Artificial In telligence F CAI, grants 294238, 319264 and 313195), by the Vilho, Y rj¨ o and Kalle 9 MSEs of LIME with 3 features are, respectively , 2 . 48 and 0 . 006 for Boston housing and Auto risk data sets. 18 Figure 6: Example of a decision tree obtained by the in terpretability utilit y approach to locally explain the prediction of the BAR T mo del ( y ref is the mean of the predictions of the 2000 p osterior dra ws) for the particular test data x test . Using only 2 features, our approac h predicts the output 10 . 76. LIME with 2 features predicts the output to b e 14 . 06, and with 3 features, LIME prediction is 13 . 18. V¨ ais¨ al¨ a F oundation of the Finnish Academy of Science and Letters, b y the F oundation for Aalto Univ ersity Science and T echnology , and by the Finnish F oundation for T ec hnology Promotion (T ekniik an Edist¨ amiss¨ a¨ ati¨ o). W e ac kno wledge the computational resources pro vided b y the Aalto Science-IT Pro ject. References [1] Hamsa Bastani, Osb ert Bastani, and Carolyn Kim. In terpreting predictive mo dels for h uman-in-the-lo op analytics. arXiv pr eprint arXiv:1705.08504 , pages 1–45, 2018. [2] L Breiman, J F riedman, R Olshen, and C Stone. Classification and regression trees, 1999. [3] Leo Breiman and Nong Shang. Born again trees. University of California, Berkeley, Berke- ley, CA, T e chnic al R ep ort , 1:2, 1996. [4] B ´ en´ edicte Briand, Gilles R Ducharme, V anessa P arache, and Catherine Mercat-Rommens. A similarity measure to assess the stability of classification trees. Computational Statistics & Data Analysis , 53(4):1208–1217, 2009. [5] Hugh A Chipman, Edward I George, and Rob ert E McCullo c h. Ba yesian CAR T mo del searc h. Journal of the A meric an Statistic al Asso ciation , 93(443):935–948, 1998. [6] Hugh A. Chipman, Edw ard I. George, and Rob ert E McCulloch. BAR T: Ba yesian additive regression trees. The A nnals of Applie d Statistics , 4(1):266–298, 2010. 19 [7] P aulo Cortez, An t´ onio Cerdeira, F ernando Almeida, T elmo Matos, and Jos´ e Reis. Mo deling wine preferences b y data mining from physicochemical properties. De cision Supp ort Systems , 47(4):547–553, 2009. [8] Mark Crav en and Jude W Sha vlik. Extracting tree-structured represen tations of trained net works. In A dvanc es in neur al information pr o c essing systems , pages 24–30, 1996. [9] Houtao Deng. In terpreting tree ensem bles with intrees. International Journal of Data Scienc e and Analytics , 7(4):277–287, 2019. [10] Da vid GT Denison, Bani K Mallic k, and Adrian FM Smith. A Ba yesian CAR T algorithm. Biometrika , 85(2):363–377, 1998. [11] Finale Doshi-V elez and Been Kim. T o wards a rigorous science of in terpretable mac hine learning. arXiv pr eprint arXiv:1702.08608 , 2017. [12] Mengnan Du, Ninghao Liu, and Xia Hu. T ec hniques for interpretable machine learning. arXiv pr eprint arXiv:1808.00033 , 2018. [13] Hadi F anaee-T and Joao Gama. Even t labeling com bining ensemble detectors and bac k- ground knowledge. Pr o gr ess in Artificial Intel ligenc e , 2(2-3):113–127, 2014. [14] Y arin Gal and Zoubin Ghahramani. Ba yesian conv olutional neural netw orks with Bernoulli appro ximate v ariational inference. In 4th International Confer enc e on L e arning R epr esen- tations (ICLR) workshop tr ack , 2016. [15] Y arin Gal and Zoubin Ghahramani. Drop out as a Bay esian approximation: Represen ting mo del uncertaint y in deep learning. In Pr o c e e dings of the 33r d International Confer enc e on Machine L e arning , pages 1050–1059, 2016. [16] Jingyi Guo, Andrea Riebler, and H ˚ av ard Rue. Bay esian biv ariate meta-analysis of diagnostic test studies with interpretable priors. Statistics in me dicine , 36(19):3039–3058, 2017. [17] Satoshi Hara and Kohei Ha yashi. Making tree ensem bles in terpretable: A Bay esian model selection approach. In International Confer enc e on Artificial Intel ligenc e and Statistics , pages 77–85, 2018. [18] Da vid Harrison Jr and Daniel L Rubinfeld. Hedonic housing prices and the demand for clean air. Journal of envir onmental e c onomics and management , 5(1):81–102, 1978. [19] Belinda Hern´ andez, Adrian E Raftery , Stephen R Pennington, and Andrew C Parnell. Ba yesian additive regression trees using ba yesian model a veraging. Statistics and c omputing , 28(4):869–890, 2018. [20] Da vid C Hoaglin and P aul F V elleman. A critical lo ok at some analyses of ma jor league baseball salaries. The A meric an Statistician , 49(3):277–285, 1995. [21] Roger W Johnson. Fitting p ercen tage of b o dy fat to simple bo dy measuremen ts. Journal of Statistics Educ ation , 4(1), 1996. [22] Jongbin Jung, Connor Concannon, Ravi Shroff, Sharad Go el, and Daniel G Goldstein. Simple rules for complex decisions. arXiv pr eprint arXiv:1702.04690 , 2017. [23] Dennis Kibler, Da vid W Aha, and Marc K Albert. Instance-based prediction of real-v alued attributes. Computational Intel ligenc e , 5(2):51–57, 1989. 20 [24] Been Kim, Elena Glassman, Brittney Johnson, and Julie Shah. ib cm: In teractive Ba yesian case mo del emp o wering humans via intuitiv e in teraction. T e chnic al R ep ort: MIT-CSAIL- TR , 2015. [25] John K Krusc hke. Ba y esian estimation sup ersedes the t test. Journal of Exp erimental Psycholo gy: Gener al , 142(2):573, 2013. [26] Deepthi Prav eenlal Kuttic hira, Sunil Gupta, Cheng Li, Santu Rana, and Svetha V enk atesh. Explaining black-box mo dels us ing in terpretable surrogates. In Pacific Rim International Confer enc e on A rtificial Intel ligenc e , pages 3–15. Springer, 2019. [27] Isaac Lage, Andrew Slavin Ross, Been Kim, Sam uel J Gershman, and Finale Doshi-V elez. Human-in-the-lo op in terpretabilit y prior. arXiv pr eprint arXiv:1805.11571 , 2018. [28] Himabindu Lakk ara ju, Stephen H Bac h, and Jure Lesk ov ec. Interpretable decision sets: A join t framew ork for description and prediction. In Pr o c e e dings of the 22nd ACM SIGKDD international c onfer enc e on know le dge disc overy and data mining , pages 1675–1684, 2016. [29] Himabindu Lakk ara ju, Ece Kamar, Ric h Caruana, and Jure Lesko v ec. F aithful and cus- tomizable explanations of black b o x mo dels. In Pr o c e e dings of the 2019 AAAI/A CM Con- fer enc e on AI, Ethics, and So ciety , pages 131–138, 2019. [30] Y ann LeCun, L ´ eon Bottou, Y osh ua Bengio, Patric k Haffner, et al. Gradient-based learning applied to do cumen t recognition. Pr o c e e dings of the IEEE , 86(11):2278–2324, 1998. [31] Benjamin Letham, Cyn thia Rudin, Tyler H McCormic k, Da vid Madigan, et al. Interpretable classifiers using rules and Ba yesian analysis: Building a better strok e prediction model. The A nnals of Applie d Statistics , 9(3):1350–1371, 2015. [32] Zac hary C Lipton. The m ythos of mo del in terpretability . Communic ations of the ACM , 61 (10):36–43, 2018. [33] Yin Lou, Rich Caruana, and Johannes Gehrke. In telligible mo dels for classification and regression. In Pr o c e e dings of the 18th ACM SIGKDD international c onfer enc e on Know le dge disc overy and data mining , pages 150–158, 2012. [34] Nicolai Meinshausen. Node harvest. The Annals of Applie d Statistics , pages 2049–2072, 2010. [35] T omi Peltola. Lo cal interpretable mo del-agnostic explanations of Ba yesian predictive mo dels via kullback-leibler pro jections. arXiv pr eprint arXiv:1810.02678 , 2018. [36] Juho Piironen, Markus P aasiniemi, and Aki V eh tari. Pro jective inference in high- dimensional problems: Prediction and feature selection. arXiv pr eprint arXiv:1810.02406 , 2018. [37] Anna-Lena Popk es, Hisk e Overw eg, Ari Ercole, Yingzhen Li, Jos ´ e Miguel Hern´ andez-Lobato, Y ordan Zayk o v, and Cheng Zhang. Interpretable outcome prediction with sparse Ba yesian neural netw orks in in tensive care. arXiv pr eprint arXiv:1905.02599 , 2019. [38] J Ross Quinlan. Combining instance-based and model-based learning. In Pr o c e e dings of the tenth international c onfer enc e on machine le arning , pages 236–243, 1993. 21 [39] Marco T ulio Ribeiro, Sameer Singh, and Carlos Guestrin. Why should i trust you?: Explain- ing the predictions of an y classifier. In Pr o c e e dings of the 22nd A CM SIGKDD international c onfer enc e on know le dge disc overy and data mining , pages 1135–1144. ACM, 2016. [40] Xiaogang Su, Morgan W ang, and Juanjuan F an. Maxim um likelihoo d regression trees. Journal of Computational and Gr aphic al Statistics , 13(3):586–598, 2004. [41] Iiris Sundin, T omi P eltola, Luana Micallef, Homa yun Afrabandp ey , Marta Soare, Mun tasir Mam un Ma jumder, Pedram Daee, Chen He, Baris Serim, Aki Ha vulinna, et al. Improv- ing genomics-based predictions for precision medicine through active elicitation of exp ert kno wledge. Bioinformatics , 34(13):i395–i403, 2018. [42] Berk Ustun and Cyn thia Rudin. Sup ersparse linear integer mo dels for optimized medical scoring systems. Machine L e arning , 102(3):349–391, 2016. [43] Aki V eh tari and Janne Ojanen. A surv ey of Ba yesian predictiv e metho ds for mo del assess- men t, selection and comparison. Statistics Surveys , 6:142–228, 2012. [44] T ong W ang. Multi-v alue rule sets for in terpretable classification with feature-efficien t rep- resen tations. In A dvanc es in Neur al Information Pr o c essing Systems , pages 10835–10845, 2018. [45] T ong W ang, Cynthia Rudin, Finale Doshi-V elez, Yimin Liu, Erica Klampfl, and Perry Mac- Neille. A Ba yesian framew ork for learning rule sets for interpretable classification. The Journal of Machine L e arning R ese ar ch , 18(1):2357–2393, 2017. [46] Mik e W u, Michael C Hughes, Sonali Parbhoo, Maurizio Zazzi, V olk er Roth, and Finale Doshi-V elez. Beyond sparsit y: T ree regularization of deep mo dels for interpretabilit y . In Thirty-Se c ond AAAI Confer enc e on A rtificial Intel ligenc e , 2018. [47] Hongyu Y ang, Cyn thia Rudin, and Margo Seltzer. Scalable Ba yesian rule lists. In Pr o c e e d- ings of the 34th International Confer enc e on Machine L e arning-V olume 70 , pages 3921–3930. JMLR. org, 2017. [48] Yic hen Zhou and Giles Ho ok er. In terpreting models via single tree approximation. arXiv pr eprint arXiv:1610.09036 , 2016. 22
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment