A Robust Score-Driven Filter for Multivariate Time Series
A multivariate score-driven filter is developed to extract signals from noisy vector processes. By assuming that the conditional location vector from a multivariate Student’s t distribution changes over time, we construct a robust filter which is able to overcome several issues that naturally arise when modeling heavy-tailed phenomena and, more in general, vectors of dependent non-Gaussian time series. We derive conditions for stationarity and invertibility and estimate the unknown parameters by maximum likelihood (ML). Strong consistency and asymptotic normality of the estimator are proved and the finite sample properties are illustrated by a Monte-Carlo study. From a computational point of view, analytical formulae are derived, which consent to develop estimation procedures based on the Fisher scoring method. The theory is supported by a novel empirical illustration that shows how the model can be effectively applied to estimate consumer prices from home scanner data.
💡 Research Summary
The paper introduces a robust, observation‑driven, score‑driven filter for multivariate time‑series whose conditional distribution is assumed to be a multivariate Student’s t with time‑varying location (mean) vector. By letting the location evolve according to a stochastic recurrence equation driven by the score of the conditional likelihood, the authors obtain a filter that automatically down‑weights extreme observations through a scalar weight that depends on the Mahalanobis distance. When the degrees‑of‑freedom parameter ν is finite, this weight shrinks large deviations, providing robustness against outliers and heavy‑tailed shocks; as ν → ∞ the model collapses to the familiar linear Gaussian state‑space filter, guaranteeing a smooth bridge between robust and classical settings.
The model is specified as
yₜ = μₜ + Ω^{1/2} εₜ, εₜ ~ t_ν(0, I_N),
with the conditional density of yₜ given past information F_{t‑1} written in closed form. The score with respect to μₜ is proportional to uₜ = (yₜ‑μₜ)/wₜ, where wₜ = 1 + (yₜ‑μₜ)′Ω⁻¹(yₜ‑μₜ)/ν. The updating equation for the filtered location is
μ_{t+1|t} = ω + Φ(μ_{t|t‑1}‑ω) + K·uₜ,
where ω, Φ and K are static N‑dimensional vector and N×N matrices, respectively. This recursion mirrors a Gauss‑Newton step: it moves the location estimate in the direction that most increases the conditional likelihood.
The authors establish the stochastic properties of the filter. Lemma 1 proves that the score‑driven term uₜ is an i.i.d. zero‑mean sequence with all moments finite, and provides explicit expressions for its even‑order moments. Lemma 2 shows that, under the standard spectral radius condition ρ(Φ) < 1, there exists a unique strictly stationary and ergodic solution to the recursion. Lemma 3 introduces a contraction condition on the expected logarithm of the product of Jacobian matrices, guaranteeing that the filtered sequence converges exponentially fast to the stationary solution, regardless of the initial value. These results extend the theory of linear state‑space models to the nonlinear, heavy‑tailed multivariate context.
For inference, the conditional log‑likelihood is available analytically, enabling maximum‑likelihood estimation of the static parameters θ = (ω, Φ, K, Ω, ν). The authors derive the Fisher information matrix in closed form and propose a Fisher‑scoring algorithm that updates θ using the observed information, offering computational efficiency comparable to Newton‑Raphson while preserving the desirable convergence properties of Fisher scoring. Under standard regularity conditions, they prove strong consistency and asymptotic normality of the ML estimator.
A Monte‑Carlo simulation study evaluates finite‑sample performance across different dimensions (N) and degrees of freedom (ν). Results indicate that the robust filter dramatically reduces bias and mean‑square error relative to a Gaussian Kalman filter when the data are heavy‑tailed, while retaining comparable efficiency when ν is large. The weight wₜ effectively winsorizes outliers without any ad‑hoc trimming.
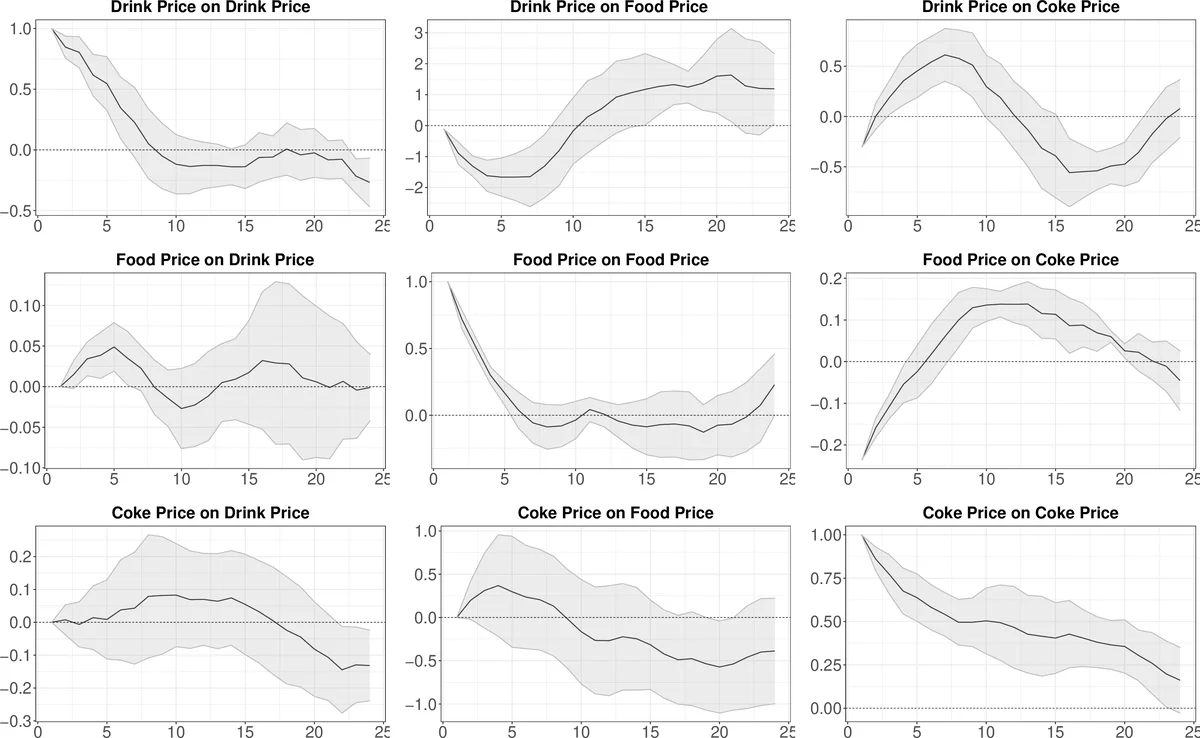
The empirical application focuses on regional consumer price indices derived from home‑scanner (Homescan) data. Such data are high‑frequency, highly granular, but notoriously noisy and prone to extreme price spikes. Applying the proposed filter yields smoothed price series that exhibit lower volatility and clearer inter‑regional dynamics. The estimated ν values confirm substantial heavy‑tailed behavior, justifying the need for a robust approach. Moreover, the filtered series retain enough information for policy‑relevant analysis while mitigating the distortion caused by outliers.
In summary, the paper makes three main contributions: (1) it extends the score‑driven filtering framework to multivariate Student‑t locations, providing rigorous proofs of stationarity, invertibility, and statistical properties; (2) it supplies analytical expressions for the likelihood and Fisher information, facilitating fast, matrix‑oriented implementation via Fisher scoring; and (3) it demonstrates practical relevance through a novel application to scanner‑based price indices, showing that the method can extract reliable signals from noisy, heavy‑tailed multivariate data. Potential extensions include spatial dependence, time‑varying degrees of freedom, and applications to high‑frequency financial returns.
Comments & Academic Discussion
Loading comments...
Leave a Comment