Mish: A Self Regularized Non-Monotonic Activation Function
We propose $\textit{Mish}$, a novel self-regularized non-monotonic activation function which can be mathematically defined as: $f(x)=x\tanh(softplus(x))$. As activation functions play a crucial role in the performance and training dynamics in neural …
Authors: Diganta Misra
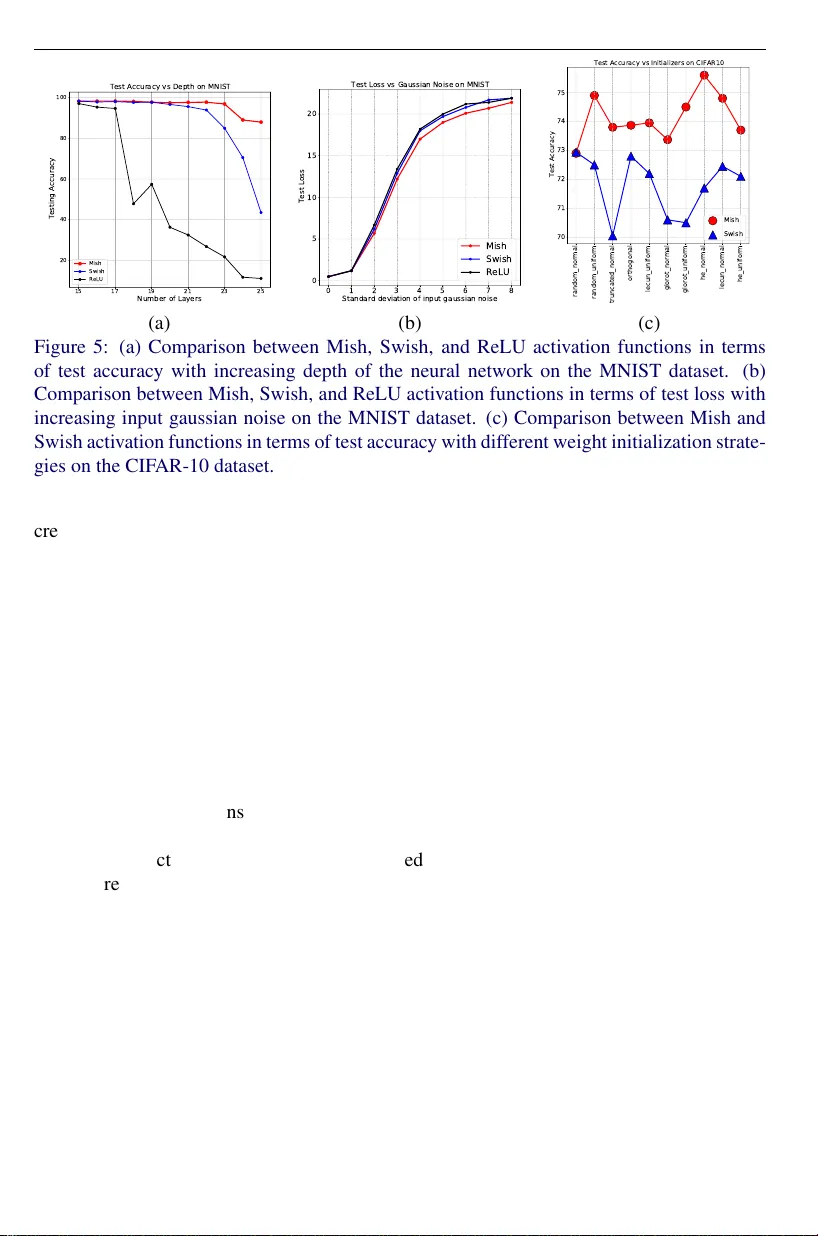
MISRA: MISH A CTIV A TION FUNCTION 1 Mish: A Self Regularized Non-Monotonic Activ ation Function Diganta Misra mishradiganta91@gmail.com Landskape KIIT , Bhubanes war , India Abstract W e propose Mish , a nov el self-regularized non-monotonic activ ation function which can be mathematically defined as: f ( x ) = x tanh ( so f t pl us ( x )) . As activ ation functions play a crucial role in the performance and training dynamics in neural networks, we v al- idated experimentally on se veral well-kno wn benchmarks against the best combinations of architectures and activ ation functions. W e also observe that data augmentation tech- niques have a fav orable effect on benchmarks like ImageNet-1k and MS-COCO across multiple architectures. For example, Mish outperformed Leaky ReLU on YOLOv4 with a CSP-DarkNet-53 backbone on av erage precision (AP 50 val ) by 2.1% in MS-COCO ob- ject detection and ReLU on ResNet-50 on ImageNet-1k in T op-1 accuracy by ≈ 1% while keeping all other netw ork parameters and hyperparameters constant. Furthermore, we explore the mathematical formulation of Mish in relation with the Swish family of func- tions and propose an intuitiv e understanding on how the first deri vati ve beha vior may be acting as a regularizer helping the optimization of deep neural networks. Code is publicly av ailable at https://github.com/digantamisra98/Mish . 1 Intr oduction Activ ation functions are non-linear point-wise functions responsible for introducing non- linearity to the linear transformed input in a layer of a neural network. The choice of activ a- tion function is imperativ e for understanding the performance of a neural network. The pro- cess of applying an activ ation function in a layer of a neural network can be mathematically realized as z = g ( y ) = g ( ∑ i w i x i + b ) where z is the output of the acti vation function g ( y ) . In early literature, Sigmoid and T anH activ ation functions were extensi vely used, which subse- quently became inef fecti ve in deep neural networks. A less probability inspired, unsaturated piece-wise linear activ ation known as Rectified Linear Unit (ReLU) [ 25 , 34 ] became more relev ant and sho wed better generalization and improved speed of con vergence compared to Sigmoid and T anH. Although ReLU demonstrates better performance and stability compared to T anH and Sigmoid, it is not without weaknesses. One of which is popularly known as Dying ReLU, which is experienced through a gradient information loss caused by collapsing the negati ve inputs to zero. Over the years, many activ ation functions have been proposed which improv e performance and address the shortcomings of ReLU, which include Leaky ReLU [ 32 ], ELU [ 6 ], and SELU [ 23 ]. Swish [ 37 ], which can be defined as f ( x ) = xsigmoid ( β x ) , pro ved to be a more robust acti v ation function sho wcasing strong improvements in results as compared to c 2020. The copyright of this document resides with its authors. It may be distributed unchanged freely in print or electronic forms. 2 MISRA: MISH A CTIV A TION FUNCTION 3 2 1 0 1 2 3 0.0 0.5 1.0 1.5 2.0 2.5 3.0 Mish ReLU SoftPlus Swish 3 2 1 0 1 2 3 0.0 0.2 0.4 0.6 0.8 1.0 Derivatives of Mish and Swish 1st Derivative of Mish 2nd Derivative of Mish 1st Derivative of Swish 2nd Derivative of Swish (a) (b) Figure 1: (a) Graph of Mish, ReLU, SoftPlus, and Swish acti vation functions. As illustrated, Mish and Swish are closely related with both having a distincti ve ne gativ e concavity un- like ReLU, which accounts for preserv ation of small negati ve weights. (b) The 1 st and 2 nd deriv atives of Mish and Swish acti v ation functions. that of ReLU. The smooth, continuous profile of Swish prov ed essential in better information propagation as compared to ReLU in deep neural network architectures. In this work, we propose Mish , a novel self regularized non-monotonic activ ation func- tion inspired by the self gating property of Swish. Mish is mathematically defined as: f ( x ) = x tanh ( so f t pl us ( x )) . W e ev aluate and find that Mish tends to match or improve the performance of neural netw ork architectures as compared to that of Swish, ReLU, and Leak y ReLU across different tasks in Computer V ision. 2 Motiv ation Across theoretical research into activ ation functions, those sharing properties similar to Swish, which includes non-monotonicity , ability to preserve small negativ e weights, and a smooth profile, have been a recurring discussion. For instance, Gaussian Error Linear Units (GELU) [ 16 ] is a popular acti vation function which has similar properties to that of Swish and is actively used in the GPT -2 architecture [ 36 ] for synthetic text generation. Swish was discov ered by a Neural Architecture Search (N AS) [ 52 ] ov er the space of the non-linear func- tions by a controlled search agent. An RNN-controller was used as the agent which generated a ne w candidate function at each step, for a total of 10K steps, which were then e v aluated on CIF AR-10 classification task using a ResNet-20 defined with that candidate function as its activ ation function. The design of Mish, while influenced by the work performed by Swish, was found by systematic analysis and experimentation over the characteristics that made Swish so effecti ve. When studying similarly behaved functions like Swish, as illustrated in Fig. 2 (a), which include arctan ( x ) so f t pl us ( x ) , tanh ( x ) so f t pl us ( x ) , x log ( 1 + arctan ( e x )) and x log ( 1 + tanh ( e x )) , where so f t pl us ( x ) = ln ( 1 + e x ) , from our ablation study we determined Mish consistently outperforms the aforementioned functions along with Swish and ReLU. W e used a standard six-layered deep conv olution neural network architecture to validate each of the experimental activ ation functions earlier defined on the CIF AR-10 image classi- MISRA: MISH A CTIV A TION FUNCTION 3 4 3 2 1 0 1 2 3 4 0 1 2 3 4 5 Swish Mish a r c t a n ( x ) s o f t p l u s ( x ) t a n h ( x ) s o f t p l u s ( x ) x l o g ( 1 + a r c t a n ( e x ) ) x l o g ( 1 + t a n h ( e x ) ) 0 10 20 30 40 50 Epochs 0.4 0.5 0.5 0.6 0.6 0.7 0.7 0.8 Validation Accuracy Swish x l o g ( 1 + t a n h ( e x ) ) x l o g ( 1 + a r c t a n ( e x ) ) Mish (a) (b) Figure 2: (a) Graph of Mish, Swish, and similar v alidated e xperimental functions. (b) T rain- ing curve of a six-layered CNN on CIF AR-10 on dif ferent v alidated activ ation functions. fication task. The networks were trained for three runs, each for 50 epochs with RMSProp as the optimizer . As sho wn in Fig. 2 (b), we found that Mish performed better than the other validated functions. Although it can be observ ed that x log ( 1 + tanh ( e x )) performed at par to Mish, we noted that its training is often unstable and, in many cases, leads to div ergence in deeper architectures. W e observed similar unstable training issues for arctan ( x ) so f t pl us ( x ) and tanh ( x ) so f t pl us ( x ) . While all of the validated functions hav e a similar shape, Mish prov es to be consistently better in terms of performance and stability . While not evident at first sight, Mish is closely related to Swish, as it can be observed in the first deriv ative: f 0 ( x ) = sech 2 ( so f t pl us ( x )) xsigmoid ( x ) + f ( x ) x (1) = ∆ ( x ) swish ( x ) + f ( x ) x (2) where so f t pl us ( x ) = ln ( 1 + e x ) and sigmoid ( x ) = 1 / ( 1 + e − x ) . From experimental observations, we speculate that the ∆ ( x ) parameter acts like a precon- ditioner , making the gradient smoother . Preconditioning has been extensi vely discussed and used in general optimization problems where the preconditioner, in case of gradient descent [ 3 , 29 ] is the in verse of a symmetric positi ve definite matrix ( H − 1 k ) which is applied to mod- ify the geometry of the objecti ve function to increase the rate of con vergence [ 1 ]. Intuitiv ely , preconditioning makes the objective function much smoother and thus making it easier to optimize. The ∆ ( x ) parameter mimics the behavior of a preconditioner . It provides a strong regularization effect and helps make gradients smoother, which corresponds to easier to opti- mize function contour , which is possibly why Mish outperforms Swish in increasingly deep and complex neural net architectures. Mish, additionally , similar to Swish, is non-monotonic, smooth, and preserv es a small amount of negati ve weights. These properties account for the consistent performance and improv ement when using Mish in-place of Swish in deep neural networks. 4 MISRA: MISH A CTIV A TION FUNCTION ReLU: Sharp T ran sitions, Rough P rofile Mish: Smooth T ran sitions, Sm ooth Profile Figure 3: Comparison between the output landscapes of ReLU and Mish acti v ation function 3 Mish Mish, as visualized in Fig. 1 (a), is a smooth, continuous, self regularized, non-monotonic activ ation function mathematically defined as: f ( x ) = x tanh ( so f t pl us ( x )) = x tanh ( ln ( 1 + e x )) (3) Similar to Swish, Mish is bounded belo w and unbounded abov e with a range of [ ≈ -0.31, ∞ ). The 1 st deriv ative of Mish, as sho wn in Fig. 1 (b), can be defined as: f 0 ( x ) = e x ω δ 2 (4) where, ω = 4 ( x + 1 ) + 4 e 2 x + e 3 x + e x ( 4 x + 6 ) and δ = 2 e x + e 2 x + 2. Inspired by Swish, Mish uses the Self-Gating property where the non-modulated input is multiplied with the output of a non-linear function of the input. Due to the preservation of a small amount of negati ve information, Mish eliminated by design the preconditions necessary for the Dying ReLU phenomenon. This property helps in better expressi vity and information flow . Being unbounded abov e, Mish avoids saturation, which generally causes training to slo w do wn due to near -zero gradients [ 11 ] drastically . Being bounded below is also advantageous since it results in strong re gularization effects. Unlike ReLU, Mish is continuously dif ferentiable, a property that is preferable because it av oids singularities and, therefore, undesired side effects when performing gradient-based optimization. Having a smooth profile also plays a role in better gradient flow , as shown in Fig. 3 , where the output landscapes of a fiv e-layered randomly initialized neural network with ReLU and Mish are visualized. The landscapes were generated by passing in the co-ordinates to a fiv e-layered randomly initialized neural network which outputs the corresponding scalar magnitude. The output landscape of ReLU has a lot of sharp transitions as compared to the smooth profile of the output landscape of Mish. Smoother output landscapes suggest smooth loss landscapes [ 28 ], which help in easier optimization and better generalization, as demonstrated in Fig. 4 . MISRA: MISH A CTIV A TION FUNCTION 5 Figure 4: Comparison between the loss landscapes of (from left to right): (a) ReLU, (b) Mish and (c) Swish activ ation function for a ResNet-20 trained for 200 epochs on CIF AR-10. W e observed the loss landscapes [ 28 ] of a ResNet-20 [ 15 ] equipped with ReLU, Mish, and Swish activ ation functions with each trained for 200 epochs for the image classifica- tion task on the CIF AR-10 dataset. W e used a multi-step learning rate policy with the SGD optimizer for training the networks. As shown in Fig. 4 , the loss landscape for the ResNet- 20 equipped with Mish is much smoother and conditioned as compared to that of ReLU and Swish activ ation function. Mish has a wider minima which improv es generalization compared to that of ReLU and Swish, with the former ha ving multiple local minimas. Ad- ditionally , Mish obtained the lowest loss as compared to the networks equipped with ReLU and Swish, and thus, validated the preconditioning ef fect of Mish on the loss surface. 3.1 Ablation Study on CIF AR-10 and MNIST Hyperparameters, including the depth of the network, type of weight initialization, batch size, learning rate, and optimizer used in the training process, ha ve significant unique effects. W e manipulate different hyper-parameters to observe their effects on the performance of ReLU, Swish, and Mish acti vation functions. Firstly , we observe the ef fect of increasing the number of layers of a neural network with ReLU, Swish, and Mish on the test accuracy . For the task, we used the MNIST dataset [ 26 ] and trained fully connected networks of linearly increasing depth. Each layer was initialized with 500 neurons, while Residual Units [ 15 ] were not used since they allo w the training of arbitrary deep networks. W e used Batch Normalization [ 20 ] layers to decrease the dependence on initialization along with Dropout [ 41 ] of 25%. The network was optimized using SGD [ 3 ] with a batch size of 128. For a fair comparison, the same learning rate was maintained for the three networks with ReLU, Swish, and Mish. As sho wn in Fig. 5 (a), post fifteen layers, there was a sharp decrease in accuracy for both Swish and ReLU, while Mish maintained a significantly higher accuracy in large models where optimization becomes dif ficult. This property was later v alidated in ImageNet-1k [ 7 ] experiments in Section 4.3 , where Mish performed superior to Swish in increasingly large netw orks. W e also ev aluated the robustness of Mish in noisy input conditions where the input MNIST data was corrupted with additive zero-centered Gaussian Noise with linearly in- 6 MISRA: MISH A CTIV A TION FUNCTION 15 17 19 21 23 25 Number of Layers 20 40 60 80 100 Testing Accuracy Test Accuracy vs Depth on MNIST Mish Swish ReLU 0 1 2 3 4 5 6 7 8 Standard deviation of input gaussian noise 0 5 10 15 20 Test Loss Test Loss vs Gaussian Noise on MNIST Mish Swish ReLU random_normal random_uniform truncated_normal orthogonal lecun_uniform glorot_normal glorot_uniform he_normal lecun_normal he_uniform 70 71 72 73 74 75 Test Accuracy Test Accuracy vs Initializers on CIFAR10 Mish Swish (a) (b) (c) Figure 5: (a) Comparison between Mish, Swish, and ReLU activ ation functions in terms of test accuracy with increasing depth of the neural network on the MNIST dataset. (b) Comparison between Mish, Swish, and ReLU activ ation functions in terms of test loss with increasing input gaussian noise on the MNIST dataset. (c) Comparison between Mish and Swish activ ation functions in terms of test accurac y with different weight initialization strate- gies on the CIF AR-10 dataset. creasing standard de viation. W e used a fi ve-layered con volution neural netw ork architecture optimized using SGD for this task. Fig. 5 (b) demonstrates the consistently better loss with varying intensity of Input Gaussian Noise with Mish as compared to ReLU and Swish. Initializers [ 11 ] play a crucial role in the performance of a neural network. W e observ ed the performance of Mish and Swish using different weight initializers, including Glorot ini- tializer [ 11 ], LeCun normal initializer [ 27 ], and He uniform v ariance scaling initializer [ 13 ], in a six-layered con volution neural netw ork. Fig. 5 (c) demonstrates the consistent positi ve difference in the performance of Mish compared to Swish while using dif ferent initializers. 4 Benchmarks W e ev aluated Mish against more than ten standard acti vation functions on dif ferent models and datasets. Our results show , especially in computer vision tasks like image classification and object detection, Mish consistently matched or exceeded the best performing network. W e also recorded multiple runs to observe the statistical significance of our results. Along with the vanilla settings, we also validated the performance of Mish when coupled with various state of the art data augmentation techniques lik e CutMix and label smoothing. 4.1 Statistical Analysis T o e v aluate the statistical significance and consistenc y of the performance obtained by Mish activ ation function compared to baseline activ ation functions, we calculate and compare the mean test accuracy , mean test loss, and standard deviation of test accuracy for CIF AR-10 [ 24 ] classification task using a Squeeze Net [ 18 ]. W e experimented for 23 runs, each for 50 epochs using the Adam optimizer [ 22 ] and changing the acti vation functions while keeping ev ery other network parameter constant. T able. 1 shows Mish outperforms other activ ation functions with the highest mean accuracy ( µ acc ), second-lo west mean loss ( µ l oss ), and third- lowest standard de viation of accuracy ( σ acc ). MISRA: MISH A CTIV A TION FUNCTION 7 Activ ation µ acc µ l oss σ acc Mish 87.48 % 4.13% 0.3967 Swish [ 37 ] 87.32% 4.22% 0.414 GELU [ 16 ] 87.37% 4.339% 0.472 ReLU [ 25 , 34 ] 86.66% 4.398% 0.584 ELU [ 6 ] 86.41% 4.211% 0.3371 Leaky ReLU [ 32 ] 86.85% 4.112 % 0.4569 SELU [ 23 ] 83.91% 4.831% 0.5995 SoftPlus 83% 5.546% 1.4015 SReLU [ 21 ] 85.05% 4.541% 0.5826 ISR U [ 4 ] 86.85% 4.669% 0.1106 T anH 82.72% 5.322% 0.5826 RReLU [ 48 ] 86.87% 4.138% 0.4478 T able 1: Statistical results of different activ ation functions on image classification of CIF AR- 10 dataset using a Squeeze Net for 23 runs. 4.2 CIF AR-10 W e compare the performance of different baseline activ ation functions on the image classi- fication task of CIF AR-10 dataset [ 24 ] using different standard neural network architectures by just swapping the acti v ation functions and keeping e very other network parameter and training parameter constant. W e ev aluate the performance of Mish as compared to ReLU and Swish on various standard network architectures, including Residual Networks [ 15 ], W ide Residual Networks [ 50 ], Shuffle Net [ 51 ], Mobile Nets [ 17 ], Inception Network [ 42 ], and Efficient Networks [ 43 ]. T able. 2 shows that Mish activ ation function consistently out- performs ReLU and Swish activ ation functions across all the standard architectures used in the experiment, with often providing 1% to 3% performance impro vement ov er the baseline ReLU enabled network architectures. Architecture Mish Swish ReLU ResNet-20 [ 15 ] 92.02 % 91.61% 91.71% WRN-10-2 [ 50 ] 86.83 % 86.56% 84.56% SimpleNet [ 12 ] 91.70 % 91.44% 91.16% Xception Net [ 5 ] 88.73 % 88.56% 88.38% Capsule Net [ 40 ] 83.15 % 82.48% 82.19% Inception ResNet v2 [ 42 ] 85.21 % 84.96% 82.22% DenseNet-121 [ 19 ] 91.27 % 90.92% 91.09% MobileNet-v2 [ 17 ] 86.25 % 86.08% 86.05% ShuffleNet-v1 [ 51 ] 87.31 % 86.95% 87.04% Inception v3 [ 42 ] 91.19 % 91.17% 90.84% Efficient Net B0 [ 43 ] 80.73 % 79.37% 79.31% T able 2: Comparison between Mish, Swish, and ReLU activ ation functions based on test accuracy on image classification of CIF AR-10 across v arious network architectures. 8 MISRA: MISH A CTIV A TION FUNCTION 4.3 ImageNet-1k Additionally , we compare Mish with Leaky ReLU [ 32 ] and Swish for ImageNet 2012 dataset classification task. ImageNet [ 7 ] is considered to be one of the most challenging and signif- icant classification tasks in the domain of computer vision. ImageNet comprises of 1.28 million training images distributed across 1,000 classes. W e use the validation set compris- ing of 50,000 images to e valuate the performance of the trained networks. W e trained the networks using the DarkNet frame work [ 38 ] on an A WS EC2 p3.16xlarge instance compris- ing of 8 T esla V100 GPUs for a total number of 8 million training steps with batch size, mini-batch size, initial learning rate, momentum, and weight decay set at 128, 32, 0.01, 0.9, and 5e-4 respectiv ely . Model Data Augmentation LReLU/ ReLU † Swish Mish T op-1 T op- 5 T op-1 T op- 5 T op-1 T op- 5 ResNet-18 [ 15 ] No 69.8% † 89.1% † 71.2 % 90.1 % 71.2 % 89.9% ResNet-50 [ 15 ] No 75.2% † 92.6% † 75.9% 92.8% 76.1 % 92.8 % SpineNet-49 [ 8 ] Y es 77.0% † 93.3% † 78.1% 94% 78.3 % 94.6 % PeleeNet [ 46 ] No 70.7% 90.0% 71.5 % 90.7 % 71.4% 90.4% CSP-ResNet-50 [ 45 ] Y es 77.1% 94.1% - - 78.1 % 94.2 % CSP-DarkNet-53 [ 2 ] Y es 77.8% 94.4% - - 78.7 % 94.8 % CSP-ResNext-50 [ 45 ] No 77.9% 94.0% 64.5% 86% 78.9 % 94.5 % CSP-ResNext-50 [ 45 ] Y es 78.5% 94.8% - - 79.8 % 95.2 % T able 3: Comparison between Mish, Swish, ReLU and Leaky ReLU activ ation functions on image classification of ImageNet-1k dataset across various standard architectures. Data Augmentation indicates the use of CutMix, Mosaic, and Label Smoothing. † indicate scores for ReLU. In T able. 3 , we compare the T op-1 and T op-5 accuracy of Mish against ReLU, Leaky ReLU, and Swish on PeleeNet [ 46 ] , Cross Stage Partial ResNet-50 [ 45 ], and ResNet-18/50 [ 15 ]. Mish consistently outperforms the default Leak y ReLU/ ReLU on all the four network architectures with a 1% increase in T op-1 Accuracy ov er Leaky ReLU in CSP-ResNet-50 architecture. Although Swish provides marginally stronger result in PeleeNet as compared to Mish, we inv estigate further of the inconsistency of the performance of Swish in a larger model where we compare Swish, Mish and ReLU in a CSP-ResNext-50 model [ 45 , 47 ] where Swish decreases the T op-1 accuracy by 13.4% as compared to Leak y ReLU while Mish impro ves the accurac y by 1%. This sho ws that Swish cannot be used in e very architec- ture and has drawbacks in especially large complex models like ResNe xt based models. W e also combine dif ferent data augmentation techniques like CutMix [ 49 ] and Label Smooth- ing (LS) [ 33 ] to improve the baseline scores of CSP-ResNet-50, CSP-DarkNet-53 [ 2 ] and CSP-ResNext-50 models. The results suggest that Mish is more consistent and generally guarantees performance increase in almost any neural network for ImageNet classification. 4.4 MS-COCO Object Detection Object detection [ 10 ] is a fundamental branch of computer vision that can be categorized as one of the tasks under visual scene understanding. In this section, we present our exper- imental results on the challenging Common Objects in Context (MS-COCO) dataset [ 30 ]. W e report the mean av erage precision (mAP-50/ mAP@0.5) on the COCO test-dev split, as demonstrated in T able. 4 . W e report our results for two models, namely , CSP-DarkNet-53 MISRA: MISH A CTIV A TION FUNCTION 9 [ 2 ] and CSP-DarkNet-53+P ANet+SPP [ 2 , 14 ], where we retrained the backbone network from scratch by replacing the activ ation function from ReLU to Mish. W e also v alidate our results by using various data augmentation strategies, including Cut- Mix [ 49 ] , Mosaic [ 2 ], self adversarial training (SA T) [ 2 ], Dropblock regularization [ 9 ] and Label Smoothing [ 33 ] along with Mish. As per the results demonstrated in T able. 4 , simply replacing ReLU with Mish in the backbone improv ed the mAP@0.5 for CSP-DarkNet-53 and CSP-DarkNet-53+P ANet+SPP by 0 . 4%. For CSP-DarkNet-53, we achiev e state of the art mAP@0.5 of 65.7% at a real-time speed of 65 FPS on T esla V100. Additionally , CSP- DarkNet-53 was used as the backbone with a Y olo v3 detector [ 39 ] as its object detection head. W e use multi-input weighted residual connections (MiWRC) [ 44 ] in the backbone and train the model with a cosine annealing scheduler [ 31 ]. W e also eliminate grid sensitivity and use multiple anchors for single ground truth for the detector . Experiments were done on a single GPU to enable multi-scale training with default parameters, including epochs, initial learning rate, weight decay , and momentum set at 500500, 0.01, 5e-4, and 0.9, respectiv ely . Model Size Data Augmentation ReLU Mish CSP-DarkNet-53 [ 2 ] (512 x 512) No 64.5% 64.9 % CSP-DarkNet-53 [ 2 ] (608 x 608) No - 65.7 % CSP-DarkNet53+P ANet+SPP [ 2 , 14 ] (512 x 512) Y es 64.5% 64.9 % T able 4: Comparison between ReLU and Mish activ ation functions on object detection on MS-COCO dataset. W e pro vide further comparati ve results using the Y OLOv4 [ 2 ] detector , as demonstrated in T able. 5 . Using Mish, we observed a consistent 0.9% to 2.1% improvement in the AP 50 val on test size of 736. W e ev aluated three variants of YOLOv4, which are: Y OLOv4 pacsp , Y OLOv4 pacsp-s , and YOLOv4 pacsp-x . All three variants use a CSP-DarkNet-53 [ 45 ] and CSP- P ANet in the backbone coupled with a CSP-SPP [ 14 ] (Spatial Pyramid Pool) module where the latter two v ariants denote the tiny and e xtra-large v ariant of Y OLOv4 pacsp . Detector Acti vation AP val AP 50 val AP 75 val AP S val AP M val AP L val Y OLOv4 pacsp-s Leaky ReLU 36.0% 54.2% 39.4% 18.7% 41.2% 48.0% Mish 37.4 % 56.3 % 40.0 % 20.9 % 43.0 % 49.3 % Y OLOv4 pacsp Leaky ReLU 46.4% 64.8% 51.0 % 28.5% 51.9% 59.5 % Mish 46.5 % 65.7 % 50.2% 30.0 % 52.0 % 59.4% Y OLOv4 pacsp-x Leaky ReLU 47.6% 66.1% 52.2% 29.9% 53.3% 61.5% Mish 48.5 % 67.4 % 52.7 % 30.9 % 54.0 % 62.0 % T able 5: Comparison between Leaky ReLU and Mish activ ation functions on object detection on MS-COCO 2017 dataset with a test image size of 736 x 736. 4.5 Stability , Accuracy , and Efficiency T rade-off Mish is a novel combination of three acti vation functions, which are T anH, SoftPlus, and the identity function. In practical implementation, a threshold of 20 is enforced on Softplus, which makes the training more stable and prevents gradient overflo w . Due to the increased complexity , there is a trade-off between the increase in accuracy while using Mish and the 10 MISRA: MISH A CTIV A TION FUNCTION increase in computational cost. W e address this concern by optimizing Mish using a CUD A based implementation, which we call Mish-CUD A which is based on PyT orch [ 35 ]. Activ ation Data T ype Forward Pass Backward Pass ReLU fp16 223.7 µ s ± 1.026 µ s 312.1 µ s ± 2.308 µ s SoftPlus fp16 342.2 µ s ± 38.08 µ s 488.5 µ s ± 53.75 µ s Mish fp16 658.8 µ s ± 1.467 µ s 1.135 ms ± 4.785 µ s Mish-CUD A fp16 267.3 µ s ± 1.852 µ s 345.6 µ s ± 1.875 µ s ReLU fp32 234.2 µ s ± 621.8 ns 419.3 µ s ± 1.238 µ s SoftPlus fp32 255.1 µ s ± 753.6 ns 420.2 µ s ± 631.4 ns Mish fp32 797.4 µ s ± 1.094 µ s 1.689 ms ± 1.222 µ s Mish-CUD A fp32 282.9 µ s ± 876.1 ns 496.3 µ s ± 1.781 µ s T able 6: Comparison between the runtime for the forw ard and backward passes for ReLU, SoftPlus, Mish and Mish-CUD A activ ation functions for floating point-16 and floating point- 32 data. In T able. 6 , we sho w the speed profile comparison between the forw ard pass (FWD) and backward pass (BWD) on floating-point 16 (FP16) and floating-point 32 (FP32) data for ReLU, SoftPlus, Mish, and Mish-CUD A. All runs were performed on an NVIDIA GeForce R TX-2070 GPU using standard benchmarking practices o ver 100 runs, including warm-up and removing outliers. T able. 6 shows the significant reduction in computational overhead of Mish by using the optimized version Mish-CUD A which shows no stability issues, mirrors the learning performance of the original baseline Mish implementation and is ev en faster than nativ e PyT orch Softplus implementation in single precision, making it more feasible to use Mish in deep neural networks. Mish can be further optimized using the e xponential equi v alent of the T anH term to accelerate the backward pass, which in volves the deri v ativ e computation. 5 Conclusion In this work, we propose a nov el acti vation function, which we call Mish. Even though Mish shares many properties with Swish and GELU like unbounded positiv e domain, bounded negati ve domain, non-monotonic shape, and smooth deriv ativ e, Mish still provides under most experimental conditions, better empirical results than Swish, ReLU, and Leaky ReLU. W e expect that a h yperparameter search with Mish as a tar get may improv e upon our results. W e also observ ed that the state of the art data augmentation techniques like CutMix and other prov en ones like Label Smoothing behav e consistently with the expectations. Future work includes optimizing Mish-CUD A to reduce the computational ov erhead fur- ther , e valuating the performance of the Mish acti v ation function in other state of the art mod- els on various tasks in the domain of computer vision, and obtaining a normalizing constant as a parameter for Mish which can reduce the dependency on using Batch Normalization layers. W e believ e it is of theoretical importance to inv estigate the contribution of the ∆ ( x ) parameter at the first deri vati ve and understand the underlying mechanism on ho w it may be acting as a regularizer . A clear understanding of the behavior and conditions govern- ing this regularizing term could moti vate a more principled approach to constructing better performing activ ation functions. MISRA: MISH A CTIV A TION FUNCTION 11 6 Acknowledgements The author would like to dedicate this work to the memory of his late grandfather , Prof. Dr . Fakir Mohan Misra. The author would also like to of fer sincere gratitude to e veryone who supported during the timeline of this project including Sparsha Mishra, Alexandra Deis from X â ˘ A ¸ S The Moonshot Factory , Ajay Uppili Arasanipalai from Uni versity of Illinois - Ur- bana Champaign (UIUC), Himanshu Arora from Montreal Institute for Learning Algorithms (MILA), Javier Ideami, Federico Andres Lois from Epsilon, Alexe y Bochkovskiy , Chien- Y ao W ang, Thomas Brandon, Soumik Rakshit from DeepWrex, Less Wright, Manjunath Bhat from Indian Institute of T echnology - Kharagpur (IIT -KGP), Miklos T oth and many more including the Fast.ai team, W eights and Biases community and e veryone at Landskape. Refer ences [1] Owe Axelsson and Gunhild Lindskog. On the rate of conv ergence of the preconditioned conjugate gradient method. Numerische Mathematik , 48(5):499–523, 1986. [2] Alexe y Bochkovskiy , Chien-Y ao W ang, and Hong-Y uan Mark Liao. Y olo v4: Optimal speed and accuracy of object detection. arXiv preprint , 2020. [3] Léon Bottou. Large-scale machine learning with stochastic gradient descent. In Pr o- ceedings of COMPST AT’2010 , pages 177–186. Springer , 2010. [4] Brad Carlile, Guy Delamarter , Paul Kinney , Akiko Marti, and Brian Whitney . Im- proving deep learning by inv erse square root linear units (isrlus). arXiv pr eprint arXiv:1710.09967 , 2017. [5] François Chollet. Xception: Deep learning with depthwise separable con volutions. In Pr oceedings of the IEEE confer ence on computer vision and pattern r ecognition , pages 1251–1258, 2017. [6] Djork-Arné Clev ert, Thomas Unterthiner , and Sepp Hochreiter . Fast and accurate deep network learning by exponential linear units (elus). arXiv pr eprint arXiv:1511.07289 , 2015. [7] Jia Deng, W ei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern r ecognition , pages 248–255. Ieee, 2009. [8] Xianzhi Du, Tsung-Y i Lin, Pengchong Jin, Golnaz Ghiasi, Mingxing T an, Y in Cui, Quoc V Le, and Xiaodan Song. Spinenet: Learning scale-permuted backbone for recognition and localization. arXiv pr eprint arXiv:1912.05027 , 2019. [9] Golnaz Ghiasi, Tsung-Y i Lin, and Quoc V Le. Dropblock: A re gularization method for con volutional networks. In Advances in Neural Information Pr ocessing Systems , pages 10727–10737, 2018. [10] Ross Girshick, Jef f Donahue, Tre vor Darrell, and Jitendra Malik. Rich feature hierar- chies for accurate object detection and semantic segmentation. In Pr oceedings of the IEEE confer ence on computer vision and pattern r ecognition , pages 580–587, 2014. 12 MISRA: MISH A CTIV A TION FUNCTION [11] Xavier Glorot and Y oshua Bengio. Understanding the difficulty of training deep feed- forward neural networks. In Proceedings of the thirteenth international confer ence on artificial intelligence and statistics , pages 249–256, 2010. [12] Seyyed Hossein HasanPour , Mohammad Rouhani, Mohsen Fayyaz, and Mohammad Sabokrou. Lets keep it simple, using simple architectures to outperform deeper and more complex architectures. arXiv preprint , 2016. [13] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-le vel performance on imagenet classification. In Pr oceedings of the IEEE international confer ence on computer vision , pages 1026–1034, 2015. [14] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Spatial pyramid pooling in deep con v olutional networks for visual recognition. IEEE transactions on pattern analysis and machine intelligence , 37(9):1904–1916, 2015. [15] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Pr oceedings of the IEEE conference on computer vision and pattern r ecognition , pages 770–778, 2016. [16] Dan Hendrycks and Ke vin Gimpel. Gaussian error linear units (gelus). arXiv pr eprint arXiv:1606.08415 , 2016. [17] Andrew G How ard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, W eijun W ang, T obias W eyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Ef fi- cient conv olutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861 , 2017. [18] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In Proceedings of the IEEE confer ence on computer vision and pattern r ecognition , pages 7132–7141, 2018. [19] Gao Huang, Zhuang Liu, Laurens V an Der Maaten, and Kilian Q W einber ger . Densely connected conv olutional networks. In Proceedings of the IEEE confer ence on computer vision and pattern r ecognition , pages 4700–4708, 2017. [20] Sergey Ioffe and Christian Szegedy . Batch normalization: Accelerating deep network training by reducing internal cov ariate shift. arXiv pr eprint arXiv:1502.03167 , 2015. [21] Xiaojie Jin, Chunyan Xu, Jiashi Feng, Y unchao W ei, Junjun Xiong, and Shuicheng Y an. Deep learning with s-shaped rectified linear activ ation units. In Thirtieth AAAI Confer ence on Artificial Intelligence , 2016. [22] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv pr eprint arXiv:1412.6980 , 2014. [23] Günter Klambauer , Thomas Unterthiner , Andreas Mayr , and Sepp Hochreiter . Self- normalizing neural networks. In Advances in neural information pr ocessing systems , pages 971–980, 2017. [24] Alex Krizhe vsk y , Geof frey Hinton, et al. Learning multiple layers of features from tin y images. 2009. MISRA: MISH A CTIV A TION FUNCTION 13 [25] Alex Krizhevsky , Ilya Sutske ver , and Geoffre y E Hinton. Imagenet classification with deep conv olutional neural networks. In Advances in neural information pr ocessing systems , pages 1097–1105, 2012. [26] Y ann LeCun, Corinna Cortes, and CJ Burges. Mnist handwritten digit database. ATT Labs [Online]. A vailable: http://yann. lecun. com/exdb/mnist , 2, 2010. [27] Y ann A LeCun, Léon Bottou, Genevie ve B Orr , and Klaus-Robert Müller . Efficient backprop. In Neural networks: T ricks of the tr ade , pages 9–48. Springer , 2012. [28] Hao Li, Zheng Xu, Gavin T aylor , Christoph Studer, and T om Goldstein. V isualizing the loss landscape of neural nets. In Advances in Neural Information Pr ocessing Systems , pages 6389–6399, 2018. [29] Xi-Lin Li. Preconditioned stochastic gradient descent. IEEE transactions on neural networks and learning systems , 29(5):1454–1466, 2017. [30] Tsung-Y i Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Dev a Ra- manan, Piotr Dollár , and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European confer ence on computer vision , pages 740–755. Springer , 2014. [31] Ilya Loshchilo v and Frank Hutter . Sgdr: Stochastic gradient descent with warm restarts. arXiv pr eprint arXiv:1608.03983 , 2016. [32] Andrew L Maas, A wni Y Hannun, and Andre w Y Ng. Rectifier nonlinearities improve neural network acoustic models. In Pr oc. icml , volume 30, page 3, 2013. [33] Rafael Müller , Simon Kornblith, and Geof frey E Hinton. When does label smoothing help? In Advances in Neural Information Processing Systems , pages 4696–4705, 2019. [34] V inod Nair and Geof frey E Hinton. Rectified linear units improve restricted boltzmann machines. In Pr oceedings of the 27th international confer ence on mac hine learning (ICML-10) , pages 807–814, 2010. [35] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury , Gregory Chanan, T rev or Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperativ e style, high-performance deep learning library . In Advances in Neural Information Pr ocessing Systems , pages 8024–8035, 2019. [36] Alec Radford, Jeffrey W u, Rewon Child, David Luan, Dario Amodei, and Ilya Sutske ver . Language models are unsupervised multitask learners. OpenAI Blog , 1 (8):9, 2019. [37] Prajit Ramachandran, Barret Zoph, and Quoc V Le. Searching for activ ation functions. arXiv pr eprint arXiv:1710.05941 , 2017. [38] Joseph Redmon. Darknet: Open source neural networks in c. http://pjreddie. com/darknet/ , 2013–2016. [39] Joseph Redmon and Ali Farhadi. Y olov3: An incremental improv ement. arXiv pr eprint arXiv:1804.02767 , 2018. 14 MISRA: MISH A CTIV A TION FUNCTION [40] Sara Sabour, Nicholas Frosst, and Geoffrey E Hinton. Dynamic routing between cap- sules. In Advances in neural information pr ocessing systems , pages 3856–3866, 2017. [41] Nitish Sri v astav a, Geoffre y Hinton, Alex Krizhe vsky , Ilya Sutskev er , and Ruslan Salakhutdinov . Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning r esearc h , 15(1):1929–1958, 2014. [42] Christian Szegedy , W ei Liu, Y angqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov , Dumitru Erhan, V incent V anhouck e, and Andrew Rabinovich. Going deeper with con volutions. In Pr oceedings of the IEEE confer ence on computer vision and pat- tern r ecognition , pages 1–9, 2015. [43] Mingxing T an and Quoc V Le. Ef ficientnet: Rethinking model scaling for con v olu- tional neural networks. arXiv pr eprint arXiv:1905.11946 , 2019. [44] Mingxing T an, Ruoming P ang, and Quoc V Le. Efficientdet: Scalable and efficient object detection. arXiv pr eprint arXiv:1911.09070 , 2019. [45] Chien-Y ao W ang, Hong-Y uan Mark Liao, I-Hau Y eh, Y ueh-Hua W u, Ping-Y ang Chen, and Jun-W ei Hsieh. Cspnet: A ne w backbone that can enhance learning capability of cnn. arXiv pr eprint arXiv:1911.11929 , 2019. [46] Robert J W ang, Xiang Li, and Charles X Ling. Pelee: A real-time object detection system on mobile devices. In Advances in Neural Information Pr ocessing Systems , pages 1963–1972, 2018. [47] Saining Xie, Ross Girshick, Piotr Dollár , Zhuowen T u, and Kaiming He. Aggre gated residual transformations for deep neural networks. In Pr oceedings of the IEEE confer- ence on computer vision and pattern r ecognition , pages 1492–1500, 2017. [48] Bing Xu, Naiyan W ang, T ianqi Chen, and Mu Li. Empirical ev aluation of rectified activ ations in conv olutional network. arXiv pr eprint arXiv:1505.00853 , 2015. [49] Sangdoo Y un, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Y oungjoon Y oo. Cutmix: Regularization strategy to train strong classifiers with lo- calizable features. In Proceedings of the IEEE International Conference on Computer V ision , pages 6023–6032, 2019. [50] Sergey Zagoruyko and Nikos Komodakis. W ide residual networks. arXiv pr eprint arXiv:1605.07146 , 2016. [51] Xiangyu Zhang, Xin yu Zhou, Mengxiao Lin, and Jian Sun. Shuf flenet: An extremely efficient con volutional neural network for mobile devices. In Proceedings of the IEEE confer ence on computer vision and pattern r ecognition , pages 6848–6856, 2018. [52] Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning. arXiv pr eprint arXiv:1611.01578 , 2016.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment