A Combinatorial Design for Cascaded Coded Distributed Computing on General Networks
Coding theoretic approached have been developed to significantly reduce the communication load in modern distributed computing system. In particular, coded distributed computing (CDC) introduced by Li et al. can efficiently trade computation resources to reduce the communication load in MapReduce like computing systems. For the more general cascaded CDC, Map computations are repeated at r nodes to significantly reduce the communication load among nodes tasked with computing Q Reduce functions s times. In this paper, we propose a novel low-complexity combinatorial design for cascaded CDC which 1) determines both input file and output function assignments, 2) requires significantly less number of input files and output functions, and 3) operates on heterogeneous networks where nodes have varying storage and computing capabilities. We provide an analytical characterization of the computation-communication tradeoff, from which we show the proposed scheme can outperform the state-of-the-art scheme proposed by Li et al. for the homogeneous networks. Further, when the network is heterogeneous, we show that the performance of the proposed scheme can be better than its homogeneous counterpart. In addition, the proposed scheme is optimal within a constant factor of the information theoretic converse bound while fixing the input file and the output function assignments.
💡 Research Summary
The paper addresses a fundamental bottleneck in modern distributed computing systems: the data‑shuffling phase of MapReduce‑style workloads, which often dominates overall execution time due to massive traffic. Building on the coded distributed computing (CDC) framework introduced by Li et al., the authors focus on the more general “cascaded” setting where each Reduce function is computed at s > 1 nodes (instead of the traditional single‑node case). In cascaded CDC the Map phase is repeated at r nodes, creating coding opportunities that can reduce the shuffle traffic by roughly a factor of r.
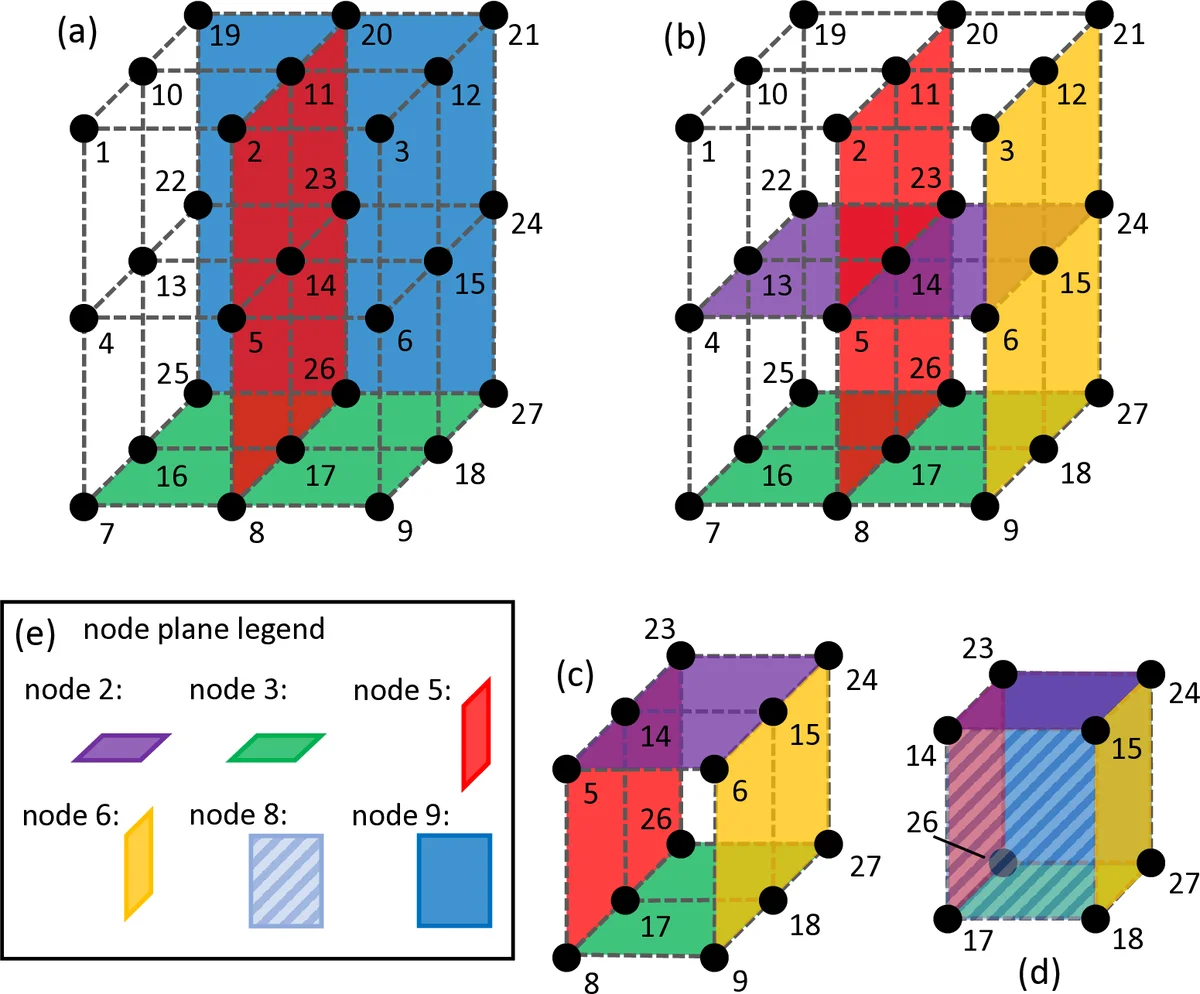
While prior work on CDC (including the original cascaded scheme) assumes a homogeneous cluster—identical storage, compute, and communication capabilities for all nodes—and requires a large number of input files N and output functions Q, this paper proposes a low‑complexity combinatorial design that works for both homogeneous and heterogeneous networks. The core of the design is a “hyper‑cuboid” construction: nodes are placed on a d‑dimensional lattice, each lattice point representing a pair (input file, Reduce function). Horizontal, vertical, or higher‑dimensional “lines” through the lattice define which files a node stores and which functions it is responsible for. Consequently, the replication factors r (number of nodes storing each file) and s (number of nodes executing each Reduce function) are directly dictated by the dimensions of the lattice, and can be chosen independently of K (the total number of nodes).
A novel two‑round shuffle protocol is introduced. In the first round, intermediate values (IVs) that are requested by exactly one other node are paired and XOR‑coded; each transmission simultaneously satisfies two distinct requests, halving the required bandwidth for that class of IVs. In the second round, IVs requested by two nodes are split into three equal packets. Each node then broadcasts two linear combinations of the packets it holds. The set of received combinations at any node forms a full‑rank matrix (denoted A in the paper), allowing the node to solve for all missing packets via a simple matrix inversion. This multi‑round approach eliminates the need for large random linear combinations that appear in earlier CDC schemes, dramatically reducing encoding/decoding complexity.
The authors analytically characterize the computation‑communication trade‑off L = L(r, s) for their scheme. They prove that, for any fixed (r, s) and given assignments of files and functions, the achieved communication load L_c is within a constant factor c (of order 2) of the information‑theoretic optimum L*. Notably, even in the homogeneous case the proposed design can beat the previously believed optimal bound L₁ derived in Li et al.’s cascaded CDC paper. A concrete example with K = 4, r = s = 2 yields L_c ≈ 0.417 versus L₁ ≈ 0.444, demonstrating that relaxing the implicit assumption about Reduce‑function assignment (i.e., allowing flexible placement of functions across nodes) can “break” the earlier bound.
The heterogeneous extension is achieved by allowing nodes to occupy different numbers of lattice dimensions according to their storage capacity M_k and compute power. Nodes with larger storage take part in more dimensions, thereby storing more files (higher local r) and reducing the amount of data they need to request. Nodes with limited storage participate in fewer dimensions, keeping the global average replication factor r unchanged while still benefiting from the same coding opportunities. Simulations show that, for the same total numbers of files and functions, the heterogeneous hyper‑cuboid design attains a lower communication load than any homogeneous allocation with identical average resources.
Another practical advantage is the drastic reduction in required numbers of files and functions. Traditional cascaded CDC needs on the order of r·s·K distinct files and functions to realize the coding gain, which grows linearly with the number of nodes. The hyper‑cuboid construction reduces this requirement to roughly K^{1/2} (for a 2‑dimensional lattice) or more generally K^{1/d}, an exponential saving that eases storage provisioning and system configuration.
Finally, the paper proves optimality (up to a constant factor) when the file‑to‑node and function‑to‑node assignments are fixed, positioning the work as a bridge between combinatorial design theory and practical distributed‑system engineering. The authors outline four key contributions: (1) a unified combinatorial framework for simultaneous file and function placement, (2) a multi‑round coded shuffle that cuts both communication volume and coding complexity, (3) explicit support for heterogeneous node capabilities, and (4) provable near‑optimality with respect to the fundamental information‑theoretic bound.
In summary, this work advances CDC by delivering a scalable, low‑complexity, and heterogeneity‑aware coding scheme that reduces shuffle traffic, lowers the number of required files/functions, and achieves near‑optimal performance. It opens new avenues for deploying CDC in large‑scale cloud and edge environments where resources are unevenly distributed and communication costs dominate.
Comments & Academic Discussion
Loading comments...
Leave a Comment