BasicBlocker: ISA Redesign to Make Spectre-Immune CPUs Faster
Recent research has revealed an ever-growing class of microarchitectural attacks that exploit speculative execution, a standard feature in modern processors. Proposed and deployed countermeasures involve a variety of compiler updates, firmware updates, and hardware updates. None of the deployed countermeasures have convincing security arguments, and many of them have already been broken. The obvious way to simplify the analysis of speculative-execution attacks is to eliminate speculative execution. This is normally dismissed as being unacceptably expensive, but the underlying cost analyses consider only software written for current instruction-set architectures, so they do not rule out the possibility of a new instruction-set architecture providing acceptable performance without speculative execution. A new ISA requires compiler and hardware updates, but these are happening in any case. This paper introduces BasicBlocker, a generic ISA modification that works for all common ISAs and that allows non-speculative CPUs to obtain most of the performance benefit that would have been provided by speculative execution. To demonstrate the feasibility of BasicBlocker, this paper defines a variant of the RISC-V ISA called BBRISC-V and provides a thorough evaluation on both a 5-stage in-order soft core and a superscalar out-of-order processor using an associated compiler and a variety of benchmark programs.
💡 Research Summary
The paper “BasicBlocker: ISA Redesign to Make Spectre‑Immune CPUs Faster” proposes a radical yet practical solution to the Spectre‑style speculative‑execution attacks: eliminate speculative execution entirely and recover the lost performance through a modest ISA extension called BasicBlocker. The authors begin by reviewing the historical role of branch prediction and speculative fetching in modern CPUs, noting that the performance argument for speculation assumes that a branch takes effect immediately after it is decoded. This assumption leads to the classic cost model where every branch incurs a penalty of P × I cycles (P = pipeline depth, I = instructions‑per‑cycle), which, when multiplied by the typical branch frequency (one every 4–6 instructions), yields a severe performance hit if speculation is disabled.
BasicBlocker breaks this assumption by introducing a new instruction, “basic‑block N” (abbreviated as bb N), which tells the processor that the next N instructions will be executed consecutively, regardless of where a branch appears inside the block. The ISA therefore supports all possible values of N simultaneously; the hardware simply reads the size field and fetches the whole block without speculative fetching. The compiler, modified in the LLVM backend, groups instructions into maximal basic blocks, moves branches as far forward as possible within the block (the classic branch‑delay‑slot technique generalized), and can combine the construct with hardware loop counters for tight loops. Because the processor knows the exact block length, it can fetch the entire block in one go, stall only when the block ends, and resume fetching the next block without any branch prediction or rollback logic.
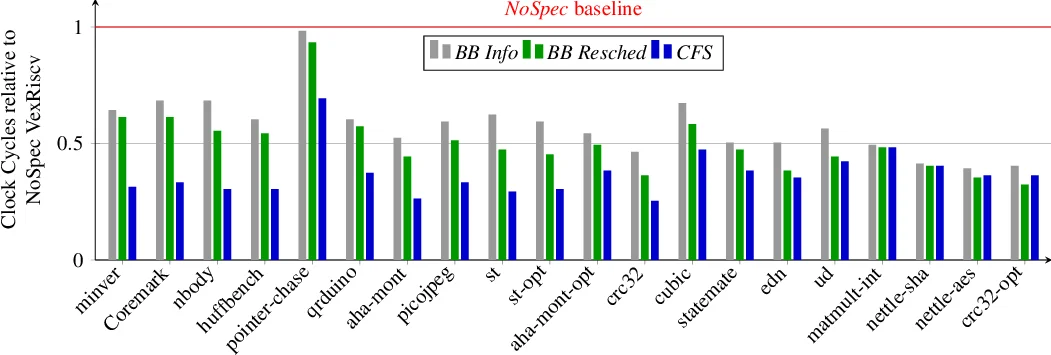
Two hardware platforms are used for evaluation: a 5‑stage in‑order soft core (implemented on an FPGA) and a simulated superscalar out‑of‑order processor. Both are extended with a small “bb‑size” register and control logic that disables all forms of speculation (including speculative fetching). The authors show that the added hardware is simple, incurs negligible area overhead, and eliminates the need for complex branch predictors and rollback buffers.
Security analysis demonstrates that, with speculation completely disabled, the processor is immune to the entire class of control‑flow‑based transient‑execution attacks (Spectre‑V1, V2, V4, etc.). Since no instructions are ever executed speculatively, there is no microarchitectural state that can be observed by an attacker after a mispredicted branch, and standard memory‑protection checks remain effective.
Performance results are presented on a suite of 30 benchmarks (SPEC‑CPU2017, PARSEC, real‑time workloads). On the in‑order core, the average slowdown relative to the speculative baseline is about 9 %; on the out‑of‑order core it is about 8 %. Notably, for loop‑intensive kernels the BasicBlocker design actually yields a modest speed‑up (3–5 %) because the hardware loop counter and large basic blocks reduce branch frequency. These figures contrast sharply with the >20 % slowdown typically reported when speculation is simply turned off without any ISA support.
The paper acknowledges limitations: the current study focuses on single‑threaded, single‑core execution. Extending the approach to multi‑core systems will require careful handling of cache‑coherency, memory‑ordering, and other forms of speculation such as store‑load forwarding. Moreover, while BasicBlocker eliminates control‑flow speculation, other speculative mechanisms (e.g., speculative memory loads) would still need to be disabled or mitigated for a fully Spectre‑proof design.
In conclusion, BasicBlocker demonstrates that a modest, backward‑compatible ISA extension can enable non‑speculative CPUs to retain most of the performance benefits traditionally attributed to speculative execution, while providing a clean, provable defense against a wide class of transient‑execution attacks. This work offers a concrete pathway for hardware designers and compiler developers to build future processors that are both fast and secure.
Comments & Academic Discussion
Loading comments...
Leave a Comment