Direct Modelling of Speech Emotion from Raw Speech
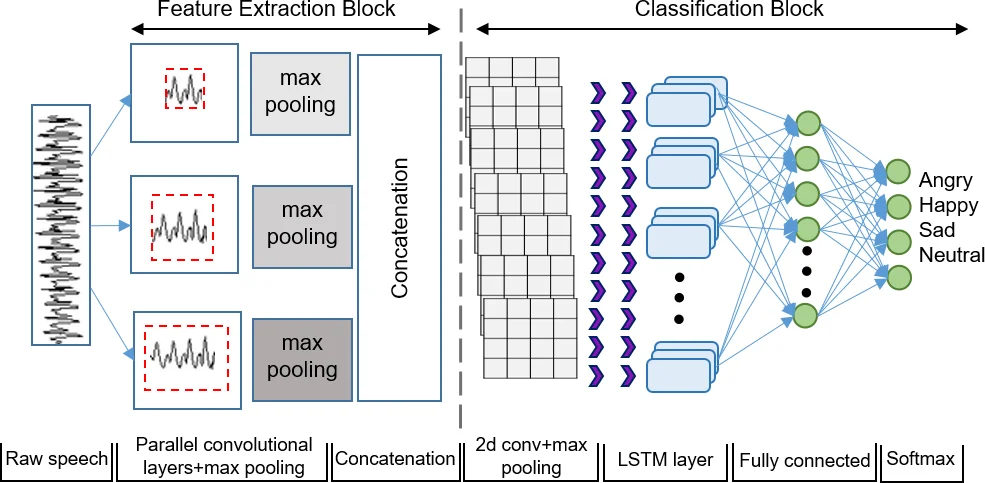
Speech emotion recognition is a challenging task and heavily depends on hand-engineered acoustic features, which are typically crafted to echo human perception of speech signals. However, a filter bank that is designed from perceptual evidence is not always guaranteed to be the best in a statistical modelling framework where the end goal is for example emotion classification. This has fuelled the emerging trend of learning representations from raw speech especially using deep learning neural networks. In particular, a combination of Convolution Neural Networks (CNNs) and Long Short Term Memory (LSTM) have gained great traction for the intrinsic property of LSTM in learning contextual information crucial for emotion recognition; and CNNs been used for its ability to overcome the scalability problem of regular neural networks. In this paper, we show that there are still opportunities to improve the performance of emotion recognition from the raw speech by exploiting the properties of CNN in modelling contextual information. We propose the use of parallel convolutional layers to harness multiple temporal resolutions in the feature extraction block that is jointly trained with the LSTM based classification network for the emotion recognition task. Our results suggest that the proposed model can reach the performance of CNN trained with hand-engineered features from both IEMOCAP and MSP-IMPROV datasets.
💡 Research Summary
The paper addresses the challenge of speech‑based emotion recognition by moving away from hand‑crafted acoustic features (e.g., MFCC, LogMel, eGeMAPS) toward an end‑to‑end deep learning approach that operates directly on raw waveforms. Recognizing that emotional cues manifest at multiple temporal scales, the authors propose a novel front‑end consisting of three parallel 1‑D convolutional layers with distinct filter lengths: 15 ms (short‑term), 25 ms (standard frame size), and 100 ms (long‑term). Each layer processes the same raw signal, producing feature maps that capture short, medium, and long temporal dependencies simultaneously. After each convolution, a max‑pooling operation reduces temporal resolution and selects the most salient activations; the pooled outputs are concatenated to form a multi‑resolution representation.
The concatenated features are fed into a classification block designed to complement the front‑end. This block begins with a 2‑D convolution (2×2 kernel, 32 filters) followed by max‑pooling, then an LSTM layer with 128 hidden cells to model long‑range contextual information, and finally a fully connected layer with 1024 units before a softmax output. Batch normalization is applied before each non‑linearity, and dropout (0.3) follows the LSTM to mitigate over‑fitting. The network is trained with RMSProp (initial learning rate 1e‑4), and learning rate decay is triggered if validation UAR does not improve for five epochs. Training stops after 20 epochs without improvement.
Data augmentation is a key component: each training utterance is duplicated twice with speed perturbations of 0.9× and 1.1× using the SOX tool, effectively tripling the training set size. Non‑speech leading and trailing silences are trimmed as in prior work. The authors evaluate the model on two widely used emotion corpora—IEMOCAP and MSP‑IMPROV—using a leave‑one‑speaker‑out protocol to ensure speaker independence. Four emotion classes (angry, happy, neutral, sad) are considered; excitement is merged with happy for IEMOCAP.
Performance is measured by unweighted average recall (UAR), which accounts for class imbalance. The proposed raw‑speech model achieves 60.23 % ± 3.2 UAR on IEMOCAP and 52.43 % ± 4.1 UAR on MSP‑IMPROV. These results are comparable to a CNN trained on Mel‑filterbank features (61.8 %/52.6 %) and substantially better than several SVM baselines using MFCC, LogMel, GeMAPS, or eGeMAPS (≈57–59 %). When data augmentation is disabled, the model’s UAR drops (≈56 % on IEMOCAP), confirming the importance of augmentation.
A series of ablation studies elucidates design choices. Varying the number of parallel convolutional layers (1–4) shows that three layers yield the best trade‑off; adding a fourth layer slightly degrades performance, suggesting diminishing returns and possible over‑parameterization. Comparing pooling strategies (max, L2, average) demonstrates that max‑pooling consistently outperforms the others, likely because it preserves the most discriminative peaks in the feature maps. Experiments on the classification block reveal that a pure DNN stack performs poorly, while LSTM alone improves UAR, and the combination of CNN‑LSTM‑DNN attains the highest scores, confirming the synergistic effect of hierarchical feature abstraction (CNN), temporal modeling (LSTM), and discriminative mapping (DNN). Finally, analysis of input utterance length indicates that performance improves with longer segments, peaking around six seconds, yet even short 1–2 second clips retain reasonable accuracy, which is encouraging for real‑time applications.
The paper acknowledges limitations: reliance on data augmentation, lack of explicit evaluation of computational cost for real‑time deployment, and restriction to four discrete emotion categories. Future work is suggested in model compression, multimodal fusion (e.g., text, video), continuous emotion regression, and cross‑lingual/generalization studies.
In summary, the study demonstrates that raw‑speech end‑to‑end models can approach the performance of traditional feature‑based systems when equipped with multi‑resolution parallel convolutions and a well‑designed CNN‑LSTM‑DNN pipeline, offering a promising direction for emotion recognition without handcrafted acoustic descriptors.
Comments & Academic Discussion
Loading comments...
Leave a Comment