Variational Autoencoders for Learning Latent Representations of Speech Emotion: A Preliminary Study
Learning the latent representation of data in unsupervised fashion is a very interesting process that provides relevant features for enhancing the performance of a classifier. For speech emotion recognition tasks, generating effective features is cru…
Authors: Siddique Latif, Rajib Rana, Junaid Qadir
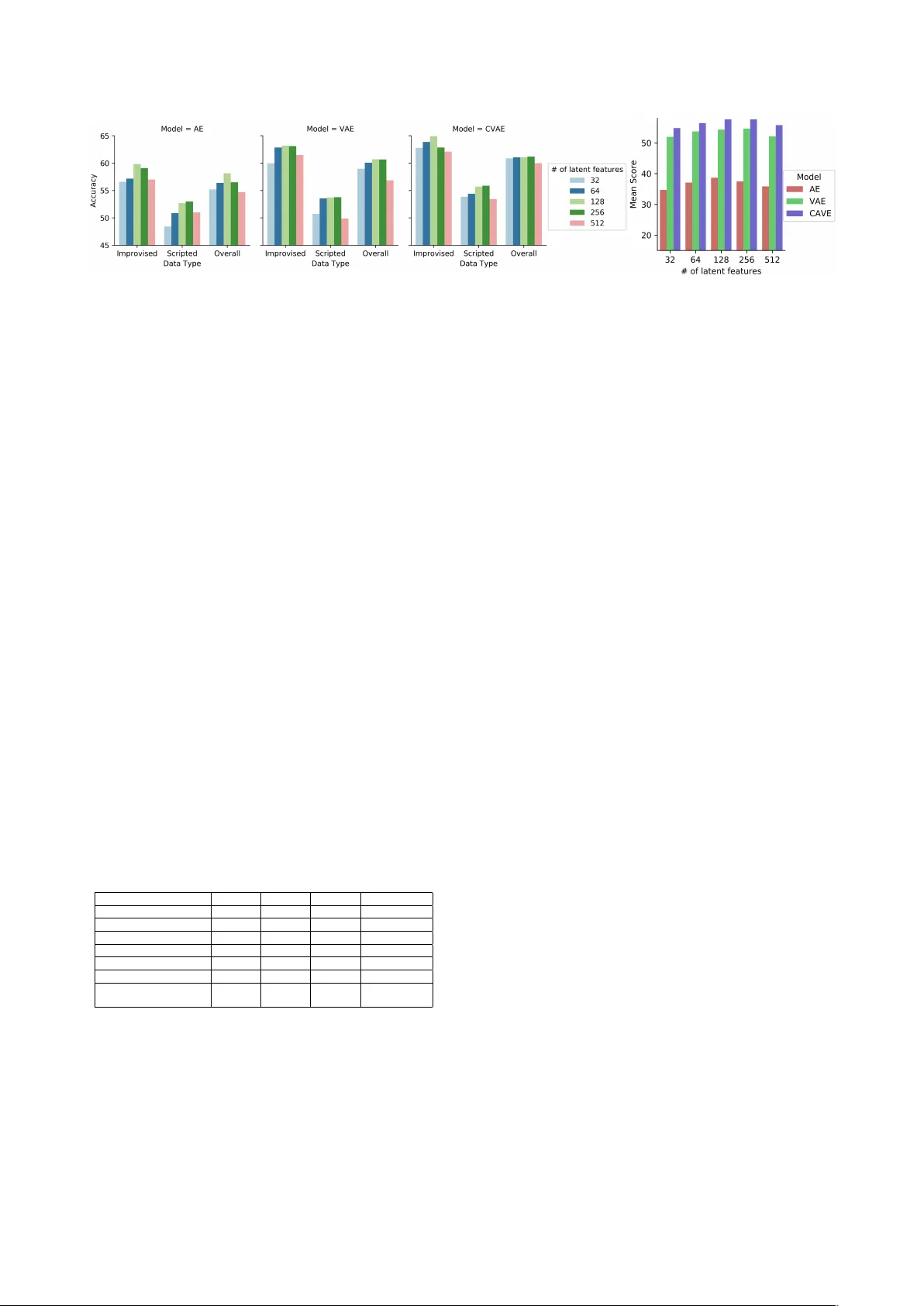
V ariational A utoencoders f or Learning Latent Repr esentations of Speech Emotion: A Pr eliminary Study Siddique Latif 1 , Rajib Rana 2 , J unaid Qadir 1 , J ulien Epps 3 1 Information T echnology Uni versity (ITU)-Punjab, P akistan 2 Uni versity of Southern Queensland, Australia 3 Uni versity of Ne w South W ales, Sydney , Australia siddique.latif@itu.edu.pk, rajib.rana@usq.edu.au, junaid.qadir@itu.edu.pk, j.epps@unsw.edu.au Abstract Learning the latent representation of data in unsupervised fash- ion is a very interesting process that provides relev ant features for enhancing the performance of a classifier . For speech emo- tion recognition tasks, generating effectiv e features is crucial. Currently , handcrafted features are mostly used for speech emo- tion recognition, howe ver , features learned automatically using deep learning hav e shown strong success in many problems, especially in image processing. In particular , deep generati ve models such as V ariational Autoencoders (V AEs) have gained enormous success for generating features for natural images. Inspired by this, we propose V AEs for deri ving the latent repre- sentation of speech signals and use this representation to clas- sify emotions. T o the best of our kno wledge, we are the first to propose V AEs for speech emotion classification. Evaluations on the IEMOCAP dataset demonstrate that features learned by V AEs can produce state-of-the-art results for speech emotion classification. Index T erms : speech emotion classification, V ariational Au- toencoders, deep learning, feature learning 1. Introduction Recently speech emotion recognition has received significant attention from both industry and academia. It has various appli- cations in human-computer interaction and analysis of human- human interactions. The speech signal has complex distribu- tions with high v ariance due to v arious factors such as speaking style, age, gender , linguistic content, en vironmental and chan- nel effects, emotional state. Understanding the influence of these factors on the speech signal is a crucial problem for speech emotion recognition. Although considerable attempts have fo- cused on handcrafting features to capture these factors [1], au- tomatic learning of features that are sensitive to emotion needs more exploration. Deep generativ e models are recently becoming immensely popular in the deep learning community due to the fact that un- like discriminativ e approaches, they try to learn the true distri- bution of the training data and generate new data points (with some v ariations). In this paper , we are not focused on gener- ating new data but on capitalising the capacity of generativ e models to learn the true distribution of the data and hence create powerful features, automatically . The most commonly used and efficient generativ e models are currently Generative Adversar- ial Nets (GANs) [2] and V ariational Autoencoders (V AEs) [3]. While GANs are optimised for generati ve tasks, V AEs are prob- abilistic graphical models which are optimised for latent mod- elling. W e therefore focus on V AEs. There hav e been many at- tempts to model natural images using generative models [4–6], but only some research has been conducted into learning latent representations of speech generation [7, 8], conv ersion [9], and speaker identification [10]. Most importantly , the feasibility of V AEs for speech emotion recognition is largely unexplored. In this paper, we conduct a preliminary study to under- stand the feasibility of V AE for learning the latent represen- tation of speech emotion. W e also in vestigate the performance of a variant of V AE known as Conditional V ariational Autoen- coder (CV AE) for learning the latent representation of speech emotion. T o objectively measure the performance of this latent representation, we use Long Short T erm Memory (LSTM) to classify speech emotion using the latent representation as fea- tures. This simultaneously of fers the opportunity to validate the performance of V AE for learning latent representation, and de- liv ers a new V AE-LSTM classification frame work. Giv en that Autoencoders (AE) hav e been widely used for speech emotion, we implement an AE-LSTM model to compare its classifica- tion performance with V AE-LSTM. W e also compare its clas- sification performance of V AE-LSTM with the recent results in the literature. Our comparisons show that latent representation learned by V AE and its v ariant CV AE (For bre vity we often use the term “V AEs” to represent the pair .) can help achieve state- of-the-art speech emotion classification performance. 2. Related W ork Autoencoders hav e been extensiv ely used for emotion recog- nition (e.g., [11, 12]), howe ver to date, V ariational Autoen- coders hav e mainly been used for natural image generation (e.g., [13, 14]). Use of V AEs for speech processing and recog- nition is very limited. In the speech and audio domain, V AEs hav e mainly been used for speech generation and transforma- tion [8]. They have also been used to learn phonetic con- tent or speaker identity in speech segments without supervisory data [7, 8]. Moreov er , a framework based on V AE was used in [15] to learn both frame-level and utterance-le vel robust rep- resentations. The authors used these salient features along with the other speech features for robust speech recognition. Hsu et al. [9] proposed a V AE based framework for modelling of spectral con version with unaligned corpora. In this study , the encoder learned the phonetic representation for the speaker , and the decoder reconstructed the designated speaker by removing the demand of parallel corpora for the model training on spec- tral con version. Finally , Blaauw et al. [7] used a fully-connected V AE to model the frame-level spectral en velopes of the speech signal. Based on their experiments, the authors found that V AE can achiev e similar or comparativ ely better reconstruction er- rors than related competitive models like the Restricted Boltz- mann machine (RBM). Many researchers hav e used LSTMs for speech emotion recognition (e.g., [16, 17]). In many scenarios, LSTMs are more effectiv e than conv entionally-employed support vector machines [18]. Researchers have also used LSTM networks on the IEMOCAP speech corpus and hav e shown that the y per- form better than po werful methods like Hidden Markov Mod- els [19, 20]. Chernykh et al. [16] used a Connectionist T em- poral Classification (CTC) loss function with LSTM networks for emotion classification, and ev aluated it on the IEMOCAP dataset. In her worth mentioning work [21], Emily et al. also employed the IEMOCAP database for speech emotion recogni- tion. Ho wev er , the authors have used transfer learning to lever - age information from another database to improve the speech emotion accuracy . T ransfer learning is out of the scope of this paper , b ut in future we would in vestigate if transfer learning can further enhance the accuracy achie ved by our approach. 3. Methods 3.1. Generating Speech Featur es using V AE V ariational Autoencoder (V AE) is a combination of Graphical Models and Neural Networks. It has a similar structure as an Autoencoder (AE) b ut functions differently . An AE learns a compressed representation of the input and then reconstructs the input from the compressed representation. On the other hand, V AE learns the parameters of a probability distrib ution repre- senting the input in a latent space. This is done by making the latent distribution as close as possible to a “prior” on the latent variable. The key adv antages of the V AE over an AE is that the “prior” allows the injection of domain knowledge, enabling estimation of the uncertainty in the prediction, and making it more suitable for speech emotion recognition. Formally speaking, giv en any emotion data X the aim of V AE is to find the probability of X with respect to its latent representation z : P ( X ) = Z P ( X | z ) P ( z ) dz . (1) Howe ver , the quantities P ( X | z ) and P ( z ) both are unknown. The idea of V AE is to infer P ( z ) using P ( z | X ) , where P ( z | X ) is determined using V ariational Inference (VI). In VI, P ( z | X ) is inferred upon minimising the di ver gence with a kno wn distri- bution Q ( z | X ) . It becomes [3], log P ( X ) = −{| X − ˆ X | 2 + K L [ Q ( z | X ) || P ( z )] } (2) As can be seen in (2), the aim of VI is to eventually reduce the reconstruction error and to train the encoder Q ( z | X ) in such a way that it produces the parameters of the probability distri- bution for the latent space z based on a known distribution of choice. This will minimise the div ergence between Q ( z | X ) and P ( z ) . For example, if we assume that the latent space will ha ve a normal distribution, we need to train the encoder to generate the mean and cov ariance. Samples of P ( z | X ) will be generated using these parameters, which the decoder will use to generate the approximation of X . Conditional V ariational A utoencoder (CV AE) : In con ven- tional V AE there is no way to generate specific data, for exam- ple a picture of an elephant, if the user inputs an elephant image. This is because the V AE models the latent variable and image directly . T o eliminate this problem, the Conditional V ariational Autoencoder (CV AE) models both latent variables and the emo- tion data conditioned on some random v ariables, c . The encoder is therefore conditioned on two variables X and c : Q ( z | X , c ) and the decoder is also conditioned to two variables, z and c : P ( X | z , c ) . There are many possibilities for the conditional variable: it could have a categorical distribution expressing the label, or ev en could hav e the same distribution as the data. Despite the capabilities of V AE, we are not particularly in- terested in generating speech emotion ˆ X . Ho we ver , when the distance ( | X − ˆ X | 2 ) between the original and the generated emotion becomes smaller than our predefined threshold, we use the parameters of the probability distribution P ( z | X ) as the features for emotion X . For imposing conditions on the P ( z | X ) (i.e. to emulate CV AE), we simply concatenate the speech frame representation in LogMel for any particular emo- tion X with its emotion class label ( c ) and pass this into the encoder . 3.2. Speech Emotion Classification using LSTM LSTM can model a long range of contexts due to the presence of a special structure called the memory cell. Emotions in speech are conte xt-dependent, therefore the ability to model contextual information makes LSTM suitable for speech emotion recogni- tion [22]. The LSTM memory cell is built into a memory block, which constitutes the hidden layers of LSTM. There are three gate units in the memory cell - the input, output, and forget gate, which are used to perform reading, writing, and resetting of information, respectively . When the feature representations from the V AE are input to the LSTM, the input gate enables a memory block to selecti vely control the incoming information and store in the internal memory . The output gate decides what part of the information will be output, and a forget gate selec- tiv ely clears the speech emotional contents from the memory cell. T o use LSTM for emotion classification, its output vector (end layer) is projected onto a vector with a length of the num- ber of emotion classes. Projection is done using simple func- tions Q = W x , where x ∈ R n is the LSTM output vector , W ∈ R m × n is a weight vector and Q ∈ R m is the vector having the same length as the number of classes m . The vec- tor Q is then mapped onto a probability vector with values in [0 , 1] ha ving sum of the probabilities equates to 1 . The highest probability indicates the identified class. The ov erall classification framework has been shown in Figure 1. Previous studies ha ve concluded that the performance of the LSTM model can be enhanced by using more predictive and knowledge-inspired features despite the limited training ex- amples [18, 22, 23]. Therefore, LSTM is a natural choice for us to use with features generated by V AEs. 4. Experimental Setup 4.1. Speech Corpus For experimentation, we selected the Interacti ve Emotional Dyadic Motion Capture (IEMOCAP) [25] dataset, which is widely used for speech emotion recognition. IEMOCAP is a multimodal corpus containing recordings of ten actors ov er fiv e sessions. Each session contains one female and one male speaker . The data includes two types of dialogues: scripted and non-scripted. In the non-scripted dialogue, the speakers were instructed to act without pre-written scripts. For the scripted di- alogue data, the actors follo wed a pre-written script. Annotation Figure 1: Overall Classification F ramework. was performed by 3-4 assessors based on both video and au- dio streams. Each utterance was annotated using 10 categories: neutral, happiness, sadness, anger , surprise, fear , disgust frus- tration, excited, and other . T o better compare the results with related work, we computed our results for improvised, scripted and complete data (including both improvised and scripted). W e considered four emotions: neutral, happiness, sadness, and anger , by combining happiness and excited as one emotion, fol- lowing the state-of-the-art studies on this corpus [24, 26]. IEMOCAP data were also annotated on three continuous dimensions: Arousal (A), Power (P), and V alence (V). F or com- parison of our classification results with the state-of-the-art ap- proaches in [18, 22], we also consider the above emotion di- mensions. Ho wev er , to maintain it as a classification problem, like [18, 22], within each dimension we created three categories: low (v alues less than 3), mid (v alues equal to 3) and high (values greater than 3). 4.2. Speech Data Processing W e consider the LogMel speech frame representation, as used in [24, 27]. Again follo wing the above studies, a Hamming win- dow of length 25ms with 10ms frame-shift was applied to the speech signal, and the discrete Fourier transform coefficients were computed. W e then computed 80 mel-frequency filter- banks. The feature set was formulated by taking the logarithmic power of each mel-frequenc y band energy . 4.3. Configuration of V AE and LSTM W e input speech se gments of length 100ms into the V AE for la- tent representation of data. This speech segment of 800 features is represented in a latent space of 128. W e used two encoding layers with 512 and 256 hidden units respectively . The number of hidden units were chosen based on intuition from prior work on autoencoders [3] and on speech recognition using V AEs [8]. W e used the Adam (adaptive moment estimation) optimiser , which is a Stochastic Optimisation Algorithm widely used to update network weights iteratively based on the training data [28]. The values of the various parameters used in the Adam optimiser were as follows: β 1 =0.999 and β 2 =0.99, = 10 − 8 and learning rate = 10 − 3 . These values were chosen in an iterati ve manner to obtain the minimum reconstruction loss of the au- toencoder networks. W e used the reparameterization trick [3] to approximate the latent space z with normally distributed δ by setting z = µ + δ σ , where denotes element-wise mul- tiplication, δ ∼ N (0 , 1) , and z ∼ N ( µ, σ ) . In CV AE we conditioned the V AE on the categorical emo- tion labels. T o benchmark the performance of V AE, we also used a conv entional autoencoder (AE) having the same archi- tecture (i.e., hidden units, layers and model parameters), e xcept for the Gaussian layer , which was replaced with a fully con- nected layer . Our LSTM model consisted of two consecuti ve LSTM lay- ers with the activ ation of the hyperbolic tangent. The hidden states of the second LSTM layer were connected to the dense layer and the outputs of the dense layer were fed into the soft- max layer for classification of both categorical and dimensional class labels. The network parameters were chosen through cross-validation e xperiments. As a common setup, we used the Adam optimiser [28] with default learning rate of 10 − 3 by fol- lowing [29]. T o av oid overfitting, we used early stopping cri- teria with the maximum number of epochs equal to 20. All the experiments were performed using an Nvidia Quadro M5000 with 8 GB memory . 5. Results The latent representations generated by both V AEs and AE were input to an LSTM network for classification. The segment- lev el latent representations obtained by autoencoder networks were merged into the whole utterance-level features for clas- sification of emotions as in [30, 31]. Because the IEMOCAP corpus did not have a have a split of training and testing data, we inv estigated the performance of our model by training it in the speaker-independent manner . This also allowed us to com- pare our results with pre vious studies. W e adopted a leav e-one- session-out cross-validation approach and ev aluated the mod- els for both weighted accuracy (W A) and unweighted accuracy (U A) for categorical dimensions. For dimensional annotations, we follo wed e v aluations strategies in [18, 22] to be able to com- pare with these studies. W e report the F-measures scores over the test dataset. The models were trained using 90% of data and testing was performed on the remaining 10% of unseen data. 5.1. Classification Perf ormance f or Categorical Emotions T able 1 sho ws the fiv e-fold classification results on dif fer- ent subsets of the IEMOCAP data. It can be noted that the features learned by V AE produces better classification perfor- mance when compared with the con ventional autoencoder . The representations learned by CV AE are highly predictiv e, which further outperform that learned by V AE. In T able 1, we also compare different approaches on IEMO- CAP used in the literature with our proposed approach. Lee et al. [17] proposed an extreme learning machine (ELM) based T able 1: Accuracy (%) comparison amongst dif fer ent models for cate gorical classification. Data AE-LSTM V AE-LSTM CV AE-LSTM Attentiv e CNN [24] (W A) BLSTM [16] (W A) BLSTM [17] (W A) W A U A W A U A W A U A LogMel MFCC eGeMAPS Improvised 59.84 58.32 63.21 60.91 64.93 62.81 61.716 61.35 61.27 54 62.85 Scripted 52.68 48.52 53.74 52.23 55.71 53.50 52.64 53.19 53.19 NA NA Complete Data 58.16 55.42 60.71 56.08 61.08 58.10 54.86 55.12 54.78 NA NA (a) (b) Figure 2: Results using differ ent number of latent featur es both on cate gorical and dimensional annotations. F igur e 2a shows the effect of differ ent number of features on cate gorical classification accuracy and 2b presents the corr esponding tr end of mean scor e for dimensional annotation. RNN model using bidirectional-LSTM (BLSTM) model and achiev ed 62.85% accuracy . The authors used low-lev el acous- tic features and MFCC along with their deriv ati ves, as a fea- ture set to the model. In [24], authors used different types of features and ev aluated single vie w (SV) as well as multi-view (MV) attentiv e CNN on IEMOCAP data using four emotions (as we used). W e mention their best results (SV or MV) in the table. Chernykh et al. [16] used three different type of fea- tures (MFCC, chromagram, and spectrum properties) and report 54% accuracy using BLSTM. Using CV AE deri ved features, we achiev e 64.93% accuracy , which is very competitive with re- spect to the literature. 5.2. Classification Perf ormance f or Dimensional Emotions T able 2 presents the 10-fold cross-validation results on dimen- sional annotation using IEMOCAP data, where “Mean” repre- sents the arithmetic mean of all three emotional dimensions: Arousal (“ A ”), Power (“P”), and V alence (“V”). The results are calculated on the basis of classifying the three subcategories: low , mid and high within each emotion dimension. W e com- pare the performance of our proposed methods with an autoen- coder model and also with some recent studies in the literature. Both V AE-LSTM and CV AE-LSTM significantly outperform the AE-LSTM model, while CV AE-LSTM producing the best performance. T able 2: Results on IEMOCAP data for dimensional annota- tions. Method A (%) P (%) V (%) Mean (%) AE-LSTM 42.21 38.25 35.58 38.68 V AE-LSTM 61.35 53.18 48.46 54.33 CV AE-LSTM 62.73 53.84 52.69 56.42 DN features [18] 41.6 37.8 34.0 37.8 DN+LLD features [18] 53.9 51.6 39.5 48.3 eGeMAPS [22] 60.1 52.2 46.6 53 Hierarchical Feature Fusion [22] 61.7 52.8 51.2 55.3 Studies [18, 22] that we ha ve compared with in T able 2 used different types of features, such as kno wledge-inspired disflu- ency and non verbal vocalization (DN) features, and statistical Low-Le vel Descriptor (LLD) features, as an input to the LSTM model. The highest score they achieve is 55.3% (Mean score), which we closely outperform using our proposed CV AE-LSTM model (Mean score 56.42%). 5.3. Number of Latent Featur es V ersus Accuracy In all the results reported abov e, we have used a latent space size 128, which essentially means we hav e used 128 set of mean and variances (since, z = µ + δ σ ) of a normal distribution as latent features. Howe ver , we also in vestigate the impact of a higher and lower number of latent features. Figure 2a and 2b show the trend of results using different number of latent features for categorical and dimensional emo- tions, respectiv ely . Across all of AE, and V AEs, a very small number of features (32) perform poorly . Howev er , a very large number of features (512) does not produce the best performance as well. W ithin this lower and higher bound, only an insignifi- cant improv ement can be observed with the increase of number of features. Based on these results we conclude that a suitable number of latent features needs to be determined empirically to av oid selecting a very small or a v ery lar ge number of features. 6. Conclusion In this paper we demonstrate that V AEs can effecti vely learn la- tent representation of speech emotion, which offers great poten- tial for learning po werful features, automatically . W e show that this helps achiev e high classification accuracy when combined with a classifier of natural choice, LSTM, as LSTM has the intrinsic capacity to model contextual information like speech emotion, also an LSTM model can be enhanced by using more predictiv e and kno wledge-inspired features. W e analyse both categorical and dimensional emotions and comparing the emo- tion classification results with that of a widely used AE-LSTM model, we show that V AEs offer great promise by producing state-of-the-art results. W e also analyse the impact of the num- ber of latent features on classification accuracy with a view to determining the optimal number of features. Howe ver , we conclude that the suitable number of features needs to deter- mined empirically . Overall, the preliminary results presented in this paper demonstrate that it is highly feasible to automati- cally learn features for speech emotion classification using deep learning techniques, which will potentially moti vate researchers to further innov ate in this space. 7. Acknowledgements This research is partly supported by Advance Queensland Re- search Fellowship, reference A QRF05616-17RD2. 8. References [1] F . Eyben, K. R. Scherer, B. W . Schuller, J. Sundberg, E. Andr ´ e, C. Busso, L. Y . Devillers, J. Epps, P . Laukka, S. S. Narayanan et al. , “The genev a minimalistic acoustic parameter set (gemaps) for voice research and affectiv e computing, ” IEEE T ransactions on Affective Computing , v ol. 7, no. 2, pp. 190–202, 2016. [2] I. Goodfellow , J. Pouget-Abadie, M. Mirza, B. Xu, D. W arde- Farley , S. Ozair, A. Courville, and Y . Bengio, “Generative adver- sarial nets, ” in Advances in neural information processing sys- tems , 2014, pp. 2672–2680. [3] D. P . Kingma and M. W elling, “ Auto-encoding variational bayes, ” arXiv pr eprint arXiv:1312.6114 , 2013. [4] A. Radford, L. Metz, and S. Chintala, “Unsupervised representa- tion learning with deep conv olutional generative adversarial net- works, ” arXiv preprint , 2015. [5] A. B. L. Larsen, S. K. Sønderby , H. Larochelle, and O. Winther , “ Autoencoding beyond pixels using a learned similarity metric, ” arXiv pr eprint arXiv:1512.09300 , 2015. [6] E. L. Denton, S. Chintala, R. Fergus et al. , “Deep generative im- age models using a laplacian pyramid of adversarial networks, ” in Advances in neural information pr ocessing systems , 2015, pp. 1486–1494. [7] M. Blaauw and J. Bonada, “Modeling and transforming speech using variational autoencoders. ” in INTERSPEECH , 2016, pp. 1770–1774. [8] W .-N. Hsu, Y . Zhang, and J. Glass, “Learning latent representa- tions for speech generation and transformation, ” arXiv pr eprint arXiv:1704.04222 , 2017. [9] C.-C. Hsu, H.-T . Hwang, Y .-C. Wu, Y . Tsao, and H.-M. W ang, “V oice con version from non-parallel corpora using variational auto-encoder , ” in Signal and Information Pr ocessing Associa- tion Annual Summit and Confer ence (APSIP A), 2016 Asia-P acific . IEEE, 2016, pp. 1–6. [10] J. V illalba, N. Br ¨ ummer , and N. Dehak, “Tied variational au- toencoder backends for i-vector speaker recognition, ” Pr oc. In- terspeech 2017 , pp. 1004–1008, 2017. [11] J. Deng, Z. Zhang, E. Marchi, and B. Schuller , “Sparse autoencoder-based feature transfer learning for speech emotion recognition, ” in Affective Computing and Intelligent Interaction (ACII), 2013 Humaine Association Confer ence on . IEEE, 2013, pp. 511–516. [12] J. Deng, X. Xu, Z. Zhang, S. Fr ¨ uhholz, and B. Schuller , “Semisupervised autoencoders for speech emotion recognition, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr o- cessing , vol. 26, no. 1, pp. 31–43, 2018. [13] X. Hou, L. Shen, K. Sun, and G. Qiu, “Deep feature consis- tent variational autoencoder , ” in Applications of Computer V ision (W ACV), 2017 IEEE W inter Confer ence on . IEEE, 2017, pp. 1133–1141. [14] C. K. Sønderby , T . Raiko, L. Maaløe, S. K. Sønderby , and O. Winther , “Ladder variational autoencoders, ” in Advances in Neural Information Pr ocessing Systems , 2016, pp. 3738–3746. [15] S. T an and K. C. Sim, “Learning utterance-level normalisation using v ariational autoencoders for rob ust automatic speech recog- nition, ” in Spoken Language T echnology W orkshop (SLT), 2016 IEEE . IEEE, 2016, pp. 43–49. [16] V . Chernykh, G. Sterling, and P . Prihodko, “Emotion recogni- tion from speech with recurrent neural networks, ” arXiv preprint arXiv:1701.08071 , 2017. [17] J. Lee and I. T ashev , “High-lev el feature representation using re- current neural network for speech emotion recognition. ” in IN- TERSPEECH , 2015, pp. 1537–1540. [18] L. Tian, J. D. Moore, and C. Lai, “Emotion recognition in spon- taneous and acted dialogues, ” in Affective Computing and In- telligent Interaction (A CII), 2015 International Conference on . IEEE, 2015, pp. 698–704. [19] M. W ¨ ollmer , A. Metallinou, N. Katsamanis, B. Schuller , and S. Narayanan, “ Analyzing the memory of blstm neural networks for enhanced emotion classification in dyadic spoken interac- tions, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2012 IEEE International Confer ence on . IEEE, 2012, pp. 4157– 4160. [20] M. W ¨ ollmer , A. Metallinou, F . Eyben, B. Schuller , and S. S. Narayanan, “Context-sensiti ve multimodal emotion recognition from speech and facial expression using bidirectional lstm model- ing, ” in Eleventh Annual Conference of the International Speech Communication Association , 2010. [21] J. Gideon, S. Khorram, Z. Aldeneh, D. Dimitriadis, and E. M. Prov ost, “Progressive neural networks for transfer learning in emotion recognition, ” arXiv preprint , 2017. [22] L. Tian, J. Moore, and C. Lai, “Recognizing emotions in spo- ken dialogue with hierarchically fused acoustic and lexical fea- tures, ” in Spoken Language T echnology W orkshop (SLT), 2016 IEEE . IEEE, 2016, pp. 565–572. [23] L. Chao, J. T ao, M. Y ang, Y . Li, and Z. W en, “Long short term memory recurrent neural network based multimodal dimensional emotion recognition, ” in Pr oceedings of the 5th International W orkshop on A udio/V isual Emotion Challenge . ACM, 2015, pp. 65–72. [24] M. Neumann and N. T . V u, “ Attentive con volutional neural net- work based speech emotion recognition: A study on the impact of input features, signal length, and acted speech, ” arXiv preprint arXiv:1706.00612 , 2017. [25] C. Busso, M. Bulut, C.-C. Lee, A. Kazemzadeh, E. Mower , S. Kim, J. N. Chang, S. Lee, and S. S. Narayanan, “Iemocap: Interactiv e emotional dyadic motion capture database, ” Language r esources and e valuation , vol. 42, no. 4, p. 335, 2008. [26] R. Xia and Y . Liu, “ A multi-task learning framew ork for emotion recognition using 2d continuous space, ” IEEE T ransactions on Af- fective Computing , vol. 8, no. 1, pp. 3–14, 2017. [27] O. Abdel-Hamid, A.-r . Mohamed, H. Jiang, L. Deng, G. Penn, and D. Y u, “Con volutional neural networks for speech recogni- tion, ” IEEE/ACM T ransactions on audio, speech, and language pr ocessing , vol. 22, no. 10, pp. 1533–1545, 2014. [28] D. P . Kingma and J. Ba, “ Adam: A method for stochastic opti- mization, ” arXiv preprint , 2014. [29] J. Kim, K. P . T ruong, G. Englebienne, and V . Evers, “Learning spectro-temporal features with 3d cnns for speech emotion recog- nition, ” arXiv preprint , 2017. [30] K. Han, D. Y u, and I. T ashe v , “Speech emotion recognition using deep neural network and extreme learning machine, ” in Fifteenth Annual Conference of the International Speech Communication Association , 2014. [31] Y . Zhao, X. Jin, and X. Hu, “Recurrent con volutional neural net- work for speech processing, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2017 IEEE International Confer ence on . IEEE, 2017, pp. 5300–5304.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment