Mastering high-dimensional dynamics with Hamiltonian neural networks
We detail how incorporating physics into neural network design can significantly improve the learning and forecasting of dynamical systems, even nonlinear systems of many dimensions. A map building perspective elucidates the superiority of Hamiltonian neural networks over conventional neural networks. The results clarify the critical relation between data, dimension, and neural network learning performance.
💡 Research Summary
The paper investigates how embedding the Hamiltonian formalism—a fundamental principle of classical mechanics—into neural network architecture yields a powerful model for learning and forecasting high‑dimensional dynamical systems. The authors contrast conventional feed‑forward neural networks (NNs), which directly map positions and velocities to velocities and accelerations, with Hamiltonian neural networks (HNNs) that map positions and momenta to a single scalar energy function, the Hamiltonian H(q,p). By differentiating H according to Hamilton’s equations, the network automatically generates the full phase‑space dynamics. This “single‑function” learning dramatically reduces the effective dimensionality of the learning problem, because regardless of the number of degrees of freedom the network only needs to approximate one scalar field rather than a separate derivative for each coordinate.
The study proceeds through a series of controlled experiments. First, a one‑dimensional linear oscillator (H = ½(p²+q²)) demonstrates that HNNs learn a smooth paraboloidal energy surface, yielding closed circular orbits and energy conservation to within 0.01 % over long integration times. In contrast, a conventional NN learns two intersecting planes (velocity and acceleration) and exhibits a spiralling loss of energy (~10 % after the same time).
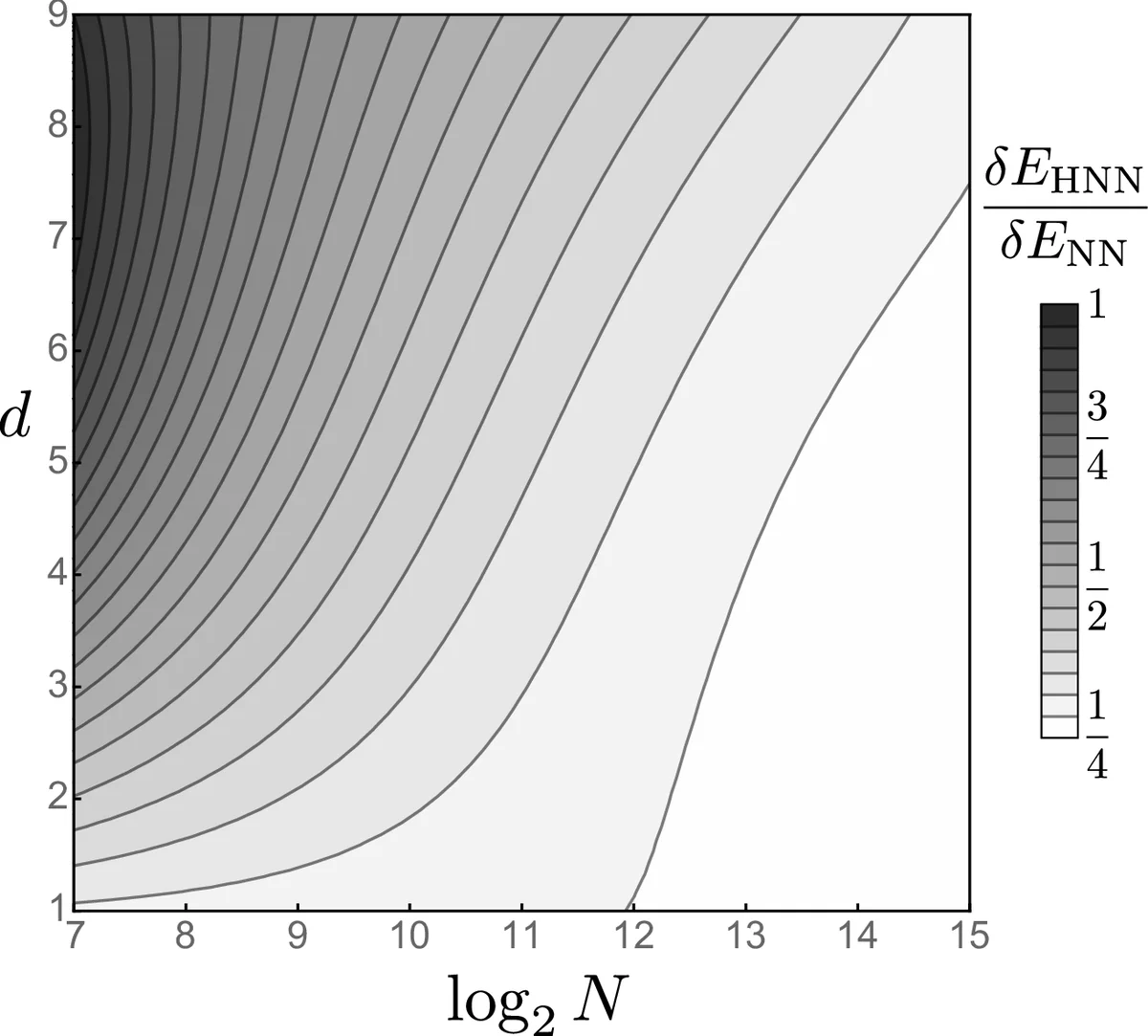
Next, the authors scale to multi‑dimensional systems. For linear oscillators with up to d = 9 degrees of freedom, HNNs achieve a mean relative energy error that decays as a power law δE/E ∝ N⁻⁰·²² with the number of training pairs N, while NNs suffer rapidly increasing error and variance as d grows. The advantage persists for nonlinear quartic oscillators (H = ½p² + ¼q⁴), where HNNs still outperform NNs by roughly a factor of 20 in energy error when sufficient data are provided.
The most demanding test is a chain of coupled bistable oscillators, each described by a double‑well potential V(q)=−½aq² + ¼bq⁴ and coupled by linear springs. The Hamiltonian for the chain includes kinetic energy, on‑site potential, and nearest‑neighbor coupling terms. Even for chain lengths up to d = 9, HNNs consistently achieve lower energy errors than NNs, especially when the training set contains enough samples (N ≈ 10³ or more). In regimes with very few samples and high dimensionality, both models perform poorly, but the trend remains that increasing data benefits HNNs more dramatically.
Three performance metrics are examined: the training loss C, the mean relative energy error δE/E, and the state error δr (distance in phase space). The authors argue that δE/E is the most informative indicator because it directly reflects the preservation of the symplectic structure, which is essential for long‑term forecasting. They also note that a low loss C does not guarantee energy conservation, underscoring the importance of physics‑aware loss design.
Overall, the paper demonstrates that Hamiltonian neural networks, by learning a single energy surface, sidestep the curse of dimensionality that plagues conventional networks. The symplectic constraint enforces energy conservation, leading to stable long‑term predictions even for chaotic trajectories. The authors suggest future work on scaling network depth and width, exploring the relationship between chaos intensity (Lyapunov exponents) and data requirements, and extending the approach to dissipative or driven systems. The findings provide a compelling case for integrating fundamental physical structures into machine‑learning models to tackle real‑world, high‑dimensional dynamical problems.
Comments & Academic Discussion
Loading comments...
Leave a Comment