Attributed Sequence Embedding
Mining tasks over sequential data, such as clickstreams and gene sequences, require a careful design of embeddings usable by learning algorithms. Recent research in feature learning has been extended to sequential data, where each instance consists o…
Authors: Zhongfang Zhuang, Xiangnan Kong, Elke Rundensteiner
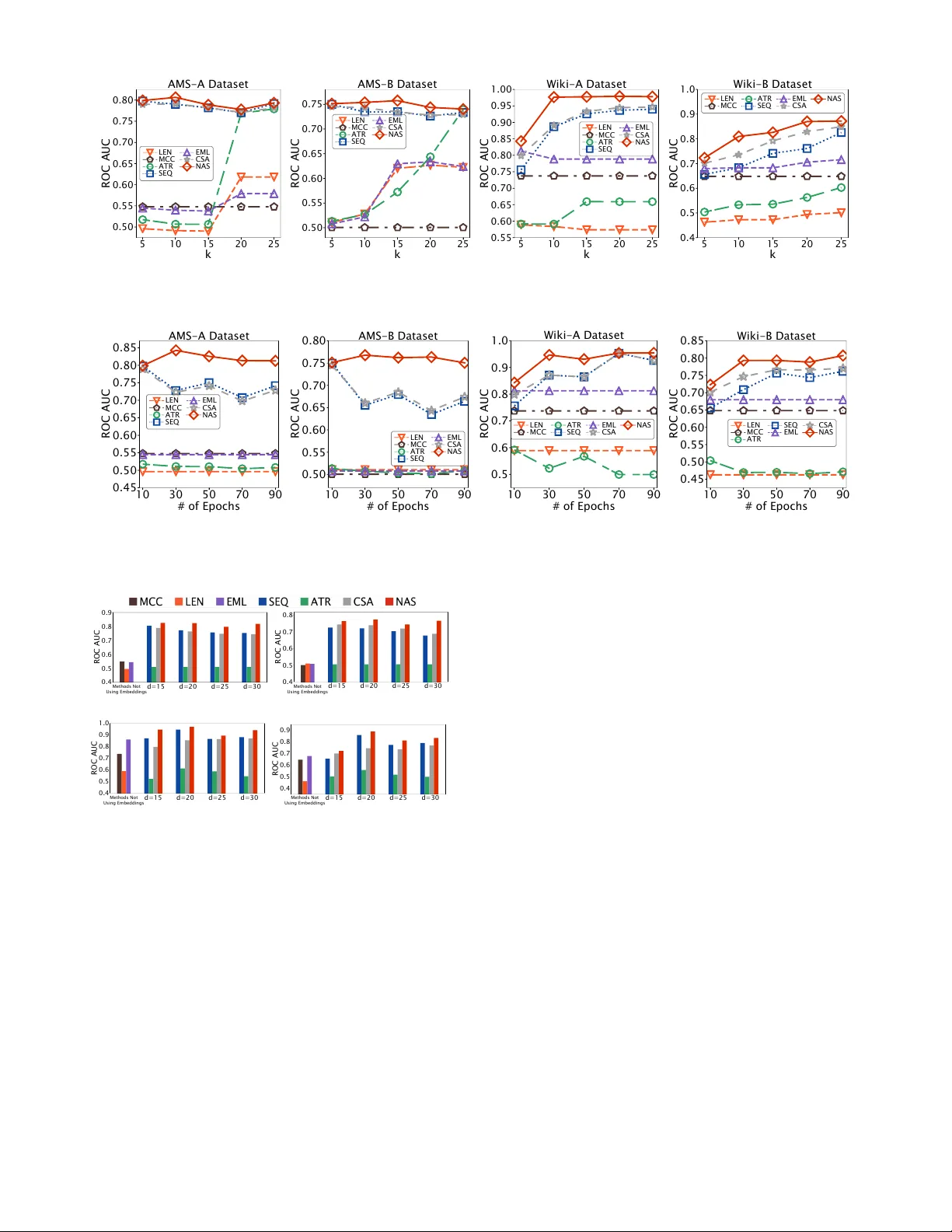
Attrib uted Sequence Embedding Zhongfang Zhuang, Xiangnan Kong, Elke, Rundensteiner W orcester Polytechnic Institute { zzhuang, xkong, rundenst } @wpi.edu Jihane Zouaoui, Aditya Arora Amadeus IT Group { jihane.zouaoui, aditya.arora } @amadeus.com Abstract —Mining tasks over sequential data, such as click- streams and gene sequences, r equire a careful design of em- beddings usable by learning algorithms. Recent r esearch in feature learning has been extended to sequential data, where each instance consists of a sequence of heter ogeneous items with a variable length. Howev er , many real-w orld applications often in volve attrib uted sequences , where each instance is composed of both a sequence of categorical items and a set of attributes. In this paper , we study this new problem of attributed sequence embed- ding , wher e the goal is to learn the repr esentations of attrib uted sequences in an unsupervised fashion. This problem is core to many important data mining tasks ranging from user behavior analysis to the clustering of gene sequences. This problem is challenging due to the dependencies between sequences and their associated attributes. W e propose a deep multimodal learning framework, called NAS , to produce embeddings of attributed sequences. The embeddings are task independent and can be used on various mining tasks of attributed sequences. W e demonstrate the effectiveness of our embeddings of attributed sequences in various unsupervised learning tasks on r eal-world datasets. Index T erms —Sequence, Embedding, Attrib uted sequence. I . I N T RO D U C T I O N Sequential data arise naturally in a wide range of applica- tions [1], [2], [3], [4]. Examples of sequential data include click streams of web users, purchase histories of online customers, and DN A sequences of genes. Different from con ventional multidimensional data [5], the sequential data [6] are not represented as feature vectors of continuous values, but as sequences of categorical items with v ariable-lengths. Many real-world applications inv olve mining tasks ov er sequential data [4], [7], [3]. For example, in online ticketing systems, administrators are interested in finding fraudulent sequences from the clickstreams of users. In user profiling systems, researchers are interested in grouping purchase his- tories of customers into clusters. Motiv ated by these real-world applications, sequential data mining has recei ved considerable attention in recent years [2], [1]. Sequential data usually requires a careful design of its embedding before being fed to data mining algorithms. One of the feature learning problems on sequential data is called sequence embedding [8], [9], where the goal is to transform a sequence into a fixed-length embedding. Con ventional methods on sequence embedding focus on learning from sequential data alone [10], [8], [9], [11]. How- ev er , in man y real-world applications, sequences are often associated with a set of attributes. W e define such data as attributed sequences , where each instance is represented by a book se arch se arch se arch login Fig. 1: An example of attributed sequences. The three types of dependencies in an attrib uted sequence: item dependencies, attribute dependencies and attribute - sequence dependencies. set of attributes associated with a sequence . For example, in online ticketing systems as shown in Fig. 1, each user transac- tion includes both a sequence of user actions ( e.g. , “ login ”, “ search ” and “ pick seats ”) and a set of attrib utes ( e.g . , “ user name ”, “ browser ” and “ IP address ”) indicat- ing the context of the transaction. In gene function analysis, each gene can be represented by both a DN A sequence and a set of attrib utes indicating the expression lev els of the gene in different types of cells. Moti vated by the recent success in attributed graph embedding [12], [13], in this paper , we study the problem of attributed sequence embedding. Building embedding for attributed sequences (as shown in Fig. 2d corresponds to transforming an attrib uted sequence into a fixed-length embedding with continuous values. Different from the work in [14], [15], we do not hav e labels for any attributed sequence instances in the embedding task. Sequence embedding problems are particularly challenging with additional attributes. In sequence embedding problems (as shown in Fig. 2a, con ventional methods focus on modeling the item dependencies , i.e. , the dependencies between different items within a sequence. Howe ver , in attributed sequences, the dependencies between items can be dif ferent if the sequence is observed under dif ferent contexts (attributes). Even the same ordering of the items can ha ve different meanings if associ- ated with different attribute values. In this paper , instead of building embeddings to model only the dependencies between items in each single sequence, we aim to model three types of dependencies in an attrib uted sequence jointly: (1) item dependencies , (2) attribute dependencies ( i.e. , the dependen- cies between different attributes) and (3) attribute-sequence dependencies ( i.e. , the dependencies between attrib utes and items in a sequence). Despite its relev ance, the problem of producing attributed sequence embeddings in an unsupervised setting remains open. W e summarize the major research challenges as follows: 1) Heterogeneous Dependencies. The bipartite structure of attributed sequences poses unique challenges in feature 978-1-7281-0858-2/19/$31.00 c 2019 IEEE (a)Sequence embedding [9]. J 1 J 2 J 3 J 4 J 5 (b) Attribute embedding[16]. (c) Time series embedding [17]. (d) Attrib uted sequence em- bedding (this paper). Fig. 2: Comparison of different embedding problems. learning. As shown in Fig. 1, there exist three types of possible dependencies in an attributed sequence: item dependencies, attribute dependencies and attribute- sequence dependencies. Motivating Example 1. In Fig. 3, we present an example of fraud detection from a user privilege management system in Amadeus [18]. This system logs each user session as an attrib uted sequence (denoted as J 1 ∼ J 5 ). Each attributed sequence consists of a sequence of user’ s acti vities and a set of attributes deri ved from metadata values. The attributes ( e.g . , “ IP ”, “ OS ” and “ Browser ”) are recorded when a user logs into the system and remain unchanged during each user session. W e use different shapes and colors to denote dif ferent user acti vities, e.g. , “ Reset password ”, “ Delete a user ”. In real-world applications like this, the at- tributes and the associated sequences are already sav ed within one integrated record. An important step in this fraud detection system is to “ r ed flag ” suspicious user sessions for potential security breaches. In Fig. 3, we observe three groups of embeddings learned from the Amadeus application logs. For each group, we use a dendrogram to demonstrate the similarities between embeddings within that group. Neither of the embed- dings using only sequences or only attributes detects any outliers due to the lacking of considerations of attrib ute- sequence dependencies. Howe ver , user session J 5 is discov ered to be fraudulent using a learning algorithm that incorporates all three types of dependencies. 2) Lack of Labeled Data. W ith the continuously incoming volume of data and the high labor cost of manually labeling data, it is rare to find attributed sequences from many real-world applications with labels ( e.g . , fraud , Fraud J 1 J 2 J 3 J 4 J 5 J 1 J 2 J 3 J 4 J 5 J 1 J 2 J 3 J 4 J 5 J 1 J 2 J 3 J 4 J 5 Fig. 3: Dendrograms of embeddings learned from attributed sequences for fraud detection tasks. J 5 is a user committing fraud. Howe ver , it is considered a normal user session by the embedding generated using either only attributes or only sequences. J 5 can only be caught as a fraud instance using the embedding learned using both attributes and sequences. normal ) attached. W ithout proper labels, it is challenging to learn an embedding function that is capable of trans- forming attributed sequences into compact embeddings concerning the three types of dependencies. Motivating Example 2. Continuing with our Motiv ating Example 1, the Amadeus records user activities and their session metadata in the log files. Due to the large volume of entries and complex user sessions, the log files do not ha ve labels depicting whether one user session is fraudulent or not. Only when an embedding function that is capable of transforming unlabeled user sessions J 1 ∼ J 5 respecting the differences between them, an anomaly detection algorithm can identify J 5 as a fraudulent session. In this paper , we focus on the g eneric problem of embedding attributed sequences in an unsupervised fashion. W e propose a nov el framework (called NAS ) using deep learning models to address the abo ve challenges. This paper of fers the follo wing contributions: • W e study the problem of attributed sequence embedding without any labels av ailable. • W e propose a framew ork and a training strategy to e xploit the dependencies among the attributed sequences. • W e ev aluate the embeddings generated by NAS frame- work on real-world datasets using outlier detection tasks. W e also conduct case studies of user behavior analysis and demonstrate the usefulness of NAS in real-world applications. I I . P RO B L E M F O R M U L A T I O N A. Pr eliminaries Definition 1 (Sequence): Given a set of r categorical items I = { e 1 , · · · , e r } , the k -th sequence in the dataset S k = α (1) k , · · · , α ( l k ) k is an ordered list of items, where α ( t ) k ∈ I , ∀ t = 1 , · · · , l k . Different sequences can ha ve a v arying number of items. For example, the number of user click activities varies between different user sessions. The meanings of items are dif ferent in different datasets. For example, in user behavior analysis from clickstreams, each item represents one action in user’ s click stream ( e.g . , I = { search , select } , where r = 2 ). Simi- larly in DN A sequencing, each item represents one canonical base ( e.g. , I = { A , T , G , C } , where r = 4 ). There are dependencies between items in a sequence. With- out loss of generality , we use the one-hot encoding of S k , denoted as S k = ( α (1) k , · · · , α ( l k ) k ) ∈ R l k × r where each item α ( t ) k ∈ R r in S k is a one-hot vector corresponding to the original item α ( t ) k in the sequence S k . Additionally , each sequence is associated with a set of attributes . Each attrib ute v alue can be either categorical or numerical. The attrib ute values are denoted using a vector x k ∈ R u , where u is the number of attrib utes in x k . For example, in a dataset where each instance has two attributes “ IP ” and “ OS ”, u = 2 . W ith the attributes and sequences, we now formally define the attributed sequences (Def. 2) and the attribute-sequence dependencies (Def. 3). Definition 2 (Attributed Sequence): Giv en a vector of at- tribute values x k and a sequence S k , an attributed sequence J k = ( x k , S k ) is an ordered pair of the attribute value vector x k and the sequence S k . Definition 3 (Attrib ute-Sequence Dependencies): Giv en an attributed sequence J k = ( x k , S k ) , the log likelihood of J k is log Pr( x k , S k ) . B. Pr oblem Definition The goal of attributed sequence embedding is to learn an embedding function that transforms each attributed sequence with a v ariable-length sequence of categorical items and a set of attrib utes into a compact representation in the form of a vector . Howe ver , these representations are only valuable if an embedding function is capable of learning all three types of dependencies. Hence, gi ven a set of attrib uted sequences, we define the learning objective of the embedding function as a minimization of the aggre gated negati ve log likelihood of all three types of dependencies. Definition 4 ( Attributed Sequence Embedding.): Giv en a dataset of attributed sequences J = { J 1 , · · · , J n } , the problem of attributed sequence embedding is to find an embedding func- tion Θ with a set of parameters (denoted as θ ) that produces embeddings for J k in the form of vectors. The problem is formulated as: minimize θ n X k =1 l k X t =1 − log Pr α ( t ) k | β ( t ) k , x k (1) where β ( t ) k = α ( t − 1) k , · · · , α (1) k , ∀ t = 2 , · · · ,l k represents the items prior to α ( t ) k in the sequence. Our problem can be interpreted as: we want to minimize the prediction error of the α ( t ) k in each attributed sequence given the attribute v alues x k and all the items prior to α ( t ) k . I I I . T H E N A S F R A M E W O R K A. Attrib ute Network Fully connected neural network [19] is capable of modeling the dependencies of the inputs and at the same time reduce the dimensionality . Fully connected neural network has been widely used [20], [19], [21] for unsupervised data represen- tations learning, including tasks such as dimensionality reduc- tion and generative data modeling. W ith the high-dimensional sparse input attribute v alues x k ∈ R u , it is ideal to use such a network to learn the attribute dependencies. W e design our attribute network as: V (1) k = ρ W (1) A x k + b (1) A . . . V ( M +1) k = σ W ( M +1) A V ( M ) k + b ( M +1) A . . . c x k = σ W (2 M ) A V (2 M − 1) k + b (2 M ) A (2) where ρ and σ are two activ ation functions. In this attribute network, we use the ReLU function proposed in [22] (defined as ρ ( z ) = max(0 , z ) ) and sigmoid function (defined as σ ( z ) = 1 1+ e − z ). The attribute network is an encoder -decoder stack with 2 M layers, where the first M layers composed of the encoder while the next M layers work as the decoder . With d M hidden units in the M -th layer , the input attribute vector x k ∈ R u is first transformed to V ( M ) k ∈ R d M , d M u by the encoder . Then the decoder attempts to reconstruct the input and produce the reconstruction result c x k ∈ R u . An ideal attrib ute network should be able to reconstruct the input from the V ( M ) k . The smallest attribute network is built with M = 1 , where there are one layer of encoder and one layer of decoder . B. Sequence Network The proposed sequence network is a v ariation of the long short-term memory model (LSTM) [23]. The sequence net- work takes advantage of the con ventional LSTM to learn the dependencies between items in sequences. [23] defines the con ventional LSTM model is defined as i ( t ) k = σ W i α ( t ) k + U i h ( t − 1) k + b i f ( t ) k = σ W f α ( t ) k + U f h ( t − 1) k + b f o ( t ) k = σ W o α ( t ) k + U o h ( t − 1) k + b o g ( t ) k = σ W g α ( t ) k + U g h ( t − 1) k + b g c ( t ) k = f ( t ) k c ( t − 1) k + i ( t ) k g ( t ) k h ( t ) k = o ( t ) k tanh c ( t ) k (3) where denotes element-wise product, σ is a sigmoid activ ation function, i ( t ) k , f ( t ) k , o ( t ) k and g ( t ) k are the internal gates of an LSTM. The cell states (denoted as c ( t ) k ) and hidden states (denoted as h ( t ) k ), which store the information of the sequential data, are two important components in the LSTM model. W ithout loss of generality , we denote the dimension of the cell states and the hidden states as d . Integration of Attrib ute Network and Sequence Net- work. Dif ferent from the conv entional LSTM, our proposed sequence network also accepts the output from the attrib ute network to condition the sequence network. In particular, we hav e redesigned the function of the hidden states to inte grate the information from the attribute network by conditioning the sequence network at the first time step as h ( t ) k = o ( t ) k tanh c ( t ) k + 1 ( t = 1) V ( M ) k (4) This integration requires the attribute network and the se- quence network hav e the same number of the hidden units ( i.e. , d M = d ). Since the attributed sequences are unlabeled, we designed the sequence network to predict the next item in the sequence as the training strategy . The prediction is carried out by designing an output layer applying a softmax function on the hidden states as y ( t ) k = δ W y h ( t ) k + b y (5) where y ( t ) k ∈ R r is the predicted next item in sequence computed using softmax function, W y and b y are the weights and bias of this output layer . W ith the softmax ac- tiv ation function, the y ( t ) k can be interpreted as the probability distribution ov er r items. C. T raining 1) T raining Objectives: W e use two different learning ob- jectiv es for attrib ute network and sequence network targeting at the unique characteristics of attribute and sequence data. 1) Attribute network aims at minimizing the dif ferences between the input and reconstructed attribute values. The learning objectiv e function of attribute network is defined as L A = k x k − c x k k 2 2 (6) 2) Sequence network aims at minimizing log likelihood of incorrect prediction of the next item at each time step. Thus, the sequence network learning objecti ve function can be formulated using categorical cross-entropy as L S = − l k X t =1 α ( t ) k log y ( t ) k (7) 2) Embedding: After the model is trained, we use the parameters in attribute network and sequence network to embed each attributed sequence. Specifically , the attrib uted sequences are used as inputs to the trained model only with the one forw ard pass, where the parameters within the model remain unchanged. After the last time step for an attrib uted sequence S k , the cell state of sequence netw ork, namely c ( l k ) k , is used as the embedding of S k . I V . E X P E R I M E N T A L E V A L U A T I O N In this section, we ev aluate NAS frame work using real- world application logs from Amadeus and public datasets from Wikispeedia [24], [25]. W e ev aluate the quality of embeddings generated by different methods by measuring the performance of outlier detection algorithms using different embeddings. A. Experimental Setup 1) Data Collection: W e use four datasets in our experi- ments: two from Amadeus application log files and two from W ikispeedia 1 . The numbers of attributed sequences in all four datasets vary between ∼ 58k and ∼ 106k. • A M S - A / B : W e extract ∼ 164k instances from log files of an Amadeus internal application. Each record is com- posed of a profile containing information ranging from system configurations to of fice name, and a sequence of functions inv oked by click activities on the web interface. There are 288 distinct functions, 57,270 distinct profiles in this dataset. The av erage length of the sequences is 18. • W I K I - A / B : This dataset is sampled from W ikispeedia dataset. Wikispeedia dataset originated from a human- computation game, called W ikispeedia [25]. W e use a subset of ∼ 3.5k paths from W ikispeedia with the a verage length of the path as 6. W e also extract 11 sequence context ( e.g. , the category of the source page, av erage time spent on each page) as attributes. 2) Compar ed Methods: T o study NAS performance on attributed sequences in real-world applications, we use the following compared methods in our experiments. • L E N [26]: The attributes are encoded and directly used in the mining algorithm. • M C C [27]: M C C uses the sequence component of at- tributed sequence as input and produces log likelihood for each sequence. • S E Q [9]: Only the sequence inputs are used by an LSTM to generate fixed-length embeddings. • A T R [16]: A tw o-layered fully connected neural network is used to generate attribute embeddings. • E M L [28]: Aggregate M C C and L E N scores. • C S A [29]: The attribute embedding and the sequence embedding are independently generated by A T R and S E Q, then concatenated together . 3) Network P arameters: Follo wing the previous work in [30], we initialize weight matrices W A and W S using the uniform distribution. The recurrent matrix U S is initialized using the orthogonal matrix as suggested by [31]. All the bias vectors are initialized with zero vector 0 0 0 . W e use stochastic gradient descent as optimizer with the learning rate of 0.01. W e use a tw o-layer encoder-decoder stack as our attribute network. B. Outlier Detection T asks W e use outlier detection tasks to ev aluate the quality of embeddings produced by NAS . W e select k -NN outlier de- tection algorithm as it has only one important parameter ( i.e . , the k value). W e use R OC A UC as the metric in this set of experiments. For each of the A M S - A and A M S - B datasets, we ask domain e xperts to select two users as inlier and outlier . These 1 Personal identity information is not collected for priv acy reasons. 5 10 15 20 25 k 0.50 0.55 0.60 0.65 0.70 0.75 0.80 ROC AUC AMS-A Dataset LEN MCC ATR SEQ EML CSA NAS 5 10 15 20 25 k 0.50 0.55 0.60 0.65 0.70 0.75 ROC AUC AMS-B Dataset LEN MCC ATR SEQ EML CSA NAS 5 10 15 20 25 k 0.55 0.60 0.65 0.70 0.75 0.80 0.85 0.90 0.95 1.00 ROC AUC Wiki-A Dataset LEN MCC ATR SEQ EML CSA NAS 5 10 15 20 25 k 0.4 0.5 0.6 0.7 0.8 0.9 1.0 ROC AUC Wiki-B Dataset LEN MCC ATR SEQ EML CSA NAS Fig. 4: Parameter sensiti vity to different k values. It is shown that the embeddings generated by NAS always have the best performance under different k values. 10 30 50 70 90 # of Epochs 0.45 0.50 0.55 0.60 0.65 0.70 0.75 0.80 0.85 ROC AUC AMS-A Dataset LEN MCC ATR SEQ EML CSA NAS 10 30 50 70 90 # of Epochs 0.50 0.55 0.60 0.65 0.70 0.75 0.80 ROC AUC AMS-B Dataset LEN MCC ATR SEQ EML CSA NAS 10 30 50 70 90 # of Epochs 0.5 0.6 0.7 0.8 0.9 1.0 ROC AUC Wiki-A Dataset LEN MCC ATR SEQ EML CSA NAS 10 30 50 70 90 # of Epochs 0.45 0.50 0.55 0.60 0.65 0.70 0.75 0.80 0.85 ROC AUC Wiki-B Dataset LEN MCC ATR SEQ EML CSA NAS Fig. 5: Performance comparisons using outlier detection tasks. The embeddings generated by NAS can alw ays achie ve the best performance compared to baseline methods when the number of training epochs increases. 0.4 0.5 0.6 0.7 0.8 0.9 ROC AUC Methods Not Using Embeddings d=15 d=20 d=25 d=30 (a) A M S - A Dataset 0.4 0.5 0.6 0.7 0.8 ROC AUC Methods Not Using Embeddings d=15 d=20 d=25 d=30 (b) A M S - B Dataset 0.4 0.5 0.6 0.7 0.8 0.9 1.0 ROC AUC Methods Not Using Embeddings d=15 d=20 d=25 d=30 (c) W I K I - A Dataset 0.4 0.5 0.6 0.7 0.8 0.9 ROC AUC Methods Not Using Embeddings d=15 d=20 d=25 d=30 (d) W I K I - B Dataset Fig. 6: The performance of k -NN outlier detection ( k = 5 ). The methods not using embeddings are placed on the left. W e vary the number of dimensions on the right. The higher score is better . W e observ e that the combinations of k -NN and NAS embeddings have the best performance on the four datasets. two users hav e completely different behaviors ( i.e. , sequences) and metadata ( i.e. , attributes). The percentages of outliers in A M S - A and A M S - B are 1.5% and 2.5% of all attributed sequences, respecti vely . For the W I K I - A and W I K I - B datasets, each path is labeled based on the category of the source page. Similarly to the pre vious tw o datasets, we select paths with tw o labels as inliers and outliers where the percentage of outlier paths is 2%. The feature used to label paths is excluded from the learning and embedding process. Perf ormance. The goal of this set of experiments is to demonstrate the performance of outlier detection using all our compared methods. Each method is trained with all the instances. For S E Q, A T R and NAS , the number of learning epochs is set to 10 and we vary the number of embedding dimensions d from 15 to 30. W e set k = 5 for outlier detection tasks for L E N , S E Q , A T R , C S A and NAS . Choosing the optimal k value in the outlier detection tasks is beyond the scope of this work, thus we omit its discussions. W e summarize the performance results in Fig. 6. Analysis. W e find that the results based on the embeddings generated by NAS are superior to other methods. That is, NAS maximally outperforms other state-of-the-art algorithms by 32.9%, 27.5%, 44.8% and 48% on A M S - A, A M S - B, W I K I - A and W I K I - B datasets, respectiv ely . It is worth mentioning that NAS outperforms a similar baseline method C S A by incor- porating the information of attribute-sequence dependencies. Parameter Study There are two key parameters in our ev aluations, i.e. , k value for the k -NN algorithm and the learning epochs. In Fig. 4, we first show that the embeddings (dimension d = 15 ) generated by our NAS assist k -NN outlier detection algorithm to achieve superior performance under a wide range of k values ( k = 5 , 10 , 15 , 20 , 25 ). W e omit the detailed discussions of selecting the optimal k v alues due to the scope of this work. Fig. 5 presents the results when we fix k = 5 , d = 15 and vary the number of epochs in the learning phase. W e notice that compared to its competitor, the embeddings generated by NAS can achie ve a higher A UC e ven with a relativ ely fewer number of learning epochs. Compared to other neural network- based methods ( i.e. , S E Q, A T R and C S A ), NAS have a more stable performance. The NAS performance gain is not due to the advantage of using both attributes and sequences, but because of taking the various dependencies into account, as the other two competitors ( i.e. , C S A and E M L ) also utilize the information from both attributes and sequences. V . R E L A T E D W O R K Sequence Mining . Many sequence mining work focuses on frequent sequence pattern mining. Recent work in [2] targets finding subsequences of possible non-consecutiv e ac- tions constrained by a gap within sequences. [32] aims at solving pattern-based sequence classification problems using a parameter-free algorithm from the model space. It defines rule pattern models and a prior distribution on the model space. [33] builds a subsequence interleaving model for mining the most relev ant sequential patterns. Deep Learning. Sequence-to-sequence learning in [9] uses long short-term memory model in machine translation. The hidden representations of sentences in the source language are transferred to a decoder to reconstruct in the target language. The idea is that the hidden representation can be used as a compact representation to transfer sequence similarities between two sequences. Multi-task learning in [11] examines three multi-task learning settings for sequence-to- sequence models that aim at sharing either an encoder or decoder in an encoder-decoder model setting. Although the abov e work is capable of learning the dependencies within a sequence, none of them focuses on learning the dependencies between attributes and sequences. This new bipartite data type of attributed sequence has posed new challenges of heterogeneous dependencies to sequence models, such as RNN and LSTM. Multimodal deep neural netw orks [34], [29], [35] is designed for information sharing across multiple neural networks, b ut none of these work focuses on our attributed sequence embedding problem. V I . C O N C L U S I O N In this paper , we study the problem of unsupervised at- tributed sequences embedding . Different from conv entional feature learning approaches, which w ork on either sequences or attrib utes without considering the attribute-sequence de- pendencies , we identify the three types of dependencies in attributed sequences. W e propose a nov el frame work, called NAS , to learn the heterogeneous dependencies and embed unlabeled attributed sequences. Empirical studies on real- world tasks demonstrate that the proposed NAS ef fectiv ely boosts the performance of outlier detection tasks compared to baseline methods. R E F E R E N C E S [1] N. B ´ echet, P . Cellier et al. , “Sequence mining under multiple con- straints, ” in SAC . A CM, 2015. [2] I. Miliaraki, K. Berberich et al. , “Mind the g ap: Lar ge-scale frequent sequence mining, ” in SIGMOD . ACM, 2013. [3] G. W ang, X. Zhang et al. , “Unsupervised clickstream clustering for user behavior analysis, ” in CHI . A CM, 2016. [4] W . W ei, J. Li et al. , “Effecti ve detection of sophisticated online banking fraud on extremely imbalanced data, ” WWW , 2013. [5] T . B. Pedersen and C. S. Jensen, “Multidimensional data modeling for complex data, ” in ICDE . IEEE, 1999. [6] J. Y ang and W . W ang, “Cluseq: Efficient and effecti ve sequence clus- tering, ” in ICDE . IEEE, 2003. [7] A. T ajer , V . V . V eerav alli, and H. V . Poor , “Outlying sequence detection in large data sets: A data-driven approach, ” IEEE Signal Pr ocessing Magazine , 2014. [8] K. Cho, B. V an Merri ¨ enboer et al. , “Learning phrase representations using rnn encoder-decoder for statistical machine translation, ” arXiv pr eprint arXiv:1406.1078 , 2014. [9] I. Sutskev er, O. V inyals, and Q. V . Le, “Sequence to sequence learning with neural networks, ” in NIPS , 2014. [10] N. Kalchbrenner and P . Blunsom, “Recurrent continuous translation models. ” in EMNLP , 2013. [11] M.-T . Luong, Q. V . Le et al. , “Multi-task sequence to sequence learning, ” arXiv pr eprint arXiv:1511.06114 , 2015. [12] J. Gibert, E. V alveny , and H. Bunke, “Graph embedding in vector spaces by node attribute statistics, ” P attern Recognition , 2012. [13] B. Perozzi, R. Al-Rfou, and S. Skiena, “Deepw alk: Online learning of social representations, ” in SIGKDD . ACM, 2014. [14] Z. Zhuang, X. Kong et al. , “One-shot learning on attributed sequences, ” in Big Data . IEEE, 2018, pp. 921–930. [15] Z. Zhuang, X. K ong, and E. Rundensteiner , “ Amas: A ttention m odel for a ttributed s equence classification, ” in SDM , 2019, pp. 109–117. [16] W . W ang, Y . Huang et al. , “Generalized autoencoder: A neural network framew ork for dimensionality reduction, ” in CVPR W orkshops , 2014. [17] A. Khale ghi, D. Ryabko et al. , “Consistent algorithms for clustering time series, ” JMLR , 2016. [18] Amadeus, “ Amadeus IT Group, ” http://www .amadeus.com, 2017, ac- cessed: 2017-09-23. [19] C.-Y . Liou, W .-C. Cheng et al. , “ Autoencoder for w ords, ” Neur ocom- puting , 2014. [20] C.-Y . Liou, J.-C. Huang, and W .-C. Y ang, “Modeling word perception using the elman network, ” Neurocomputing , 2008. [21] N. Phan, Y . W ang et al. , “Differential priv acy preservation for deep auto-encoders: an application of human beha vior prediction. ” in AAAI , 2016. [22] V . Nair and G. E. Hinton, “Rectified linear units improve restricted boltzmann machines, ” in ICML , 2010. [23] S. Hochreiter and J. Schmidhuber , “Long short-term memory , ” Neural Computation , 1997. [24] R. W est and J. Leskovec, “Human wayfinding in information networks, ” in WWW . ACM, 2012. [25] R. W est, J. Pineau, and D. Precup, “Wikispeedia: An online game for inferring semantic distances between concepts, ” in IJCAI , 2009. [26] Z. Akata, F . Perronnin et al. , “Label-embedding for attribute-based classification, ” in CVPR , 2013. [27] S. D. Bernhard, C. K. Leung et al. , “Clickstream prediction using sequential stream mining techniques with markov chains, ” in IDEAS . A CM, 2016. [28] R. R. Y ager and N. Alajlan, “Probabilistically weighted ow a aggrega- tion, ” IEEE T ransactions on Fuzzy Systems , 2014. [29] J. Ngiam, A. Khosla et al. , “Multimodal deep learning, ” in ICML , 2011. [30] X. Glorot and Y . Bengio, “Understanding the difficulty of training deep feedforward neural networks, ” in AISTA TS , 2010. [31] A. M. Saxe, J. L. McClelland, and S. Ganguli, “Exact solutions to the nonlinear dynamics of learning in deep linear neural networks, ” arXiv pr eprint arXiv:1312.6120 , 2013. [32] E. Egho, D. Gay et al. , “ A parameter-free approach for mining robust sequential classification rules, ” in ICDM . IEEE, 2015. [33] J. Fowkes and C. Sutton, “ A subsequence interleaving model for sequential pattern mining, ” arXiv pr eprint arXiv:1602.05012 , 2016. [34] A. Karpathy and L. Fei-Fei, “Deep visual-semantic alignments for generating image descriptions, ” in CVPR , 2015. [35] K. Xu, J. Ba et al. , “Show , attend and tell: Neural image caption generation with visual attention, ” in ICML , 2015.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment