Agora: A Unified Asset Ecosystem Going Beyond Marketplaces and Cloud Services
Data, algorithms, and compute/storage infrastructure are key assets that drive data science and artificial intelligence applications. As providing all these assets requires a huge investment, data science and artificial intelligence technologies are …
Authors: Jonas Traub, Jorge-Arnulfo Quiane-Ruiz, Zoi Kaoudi
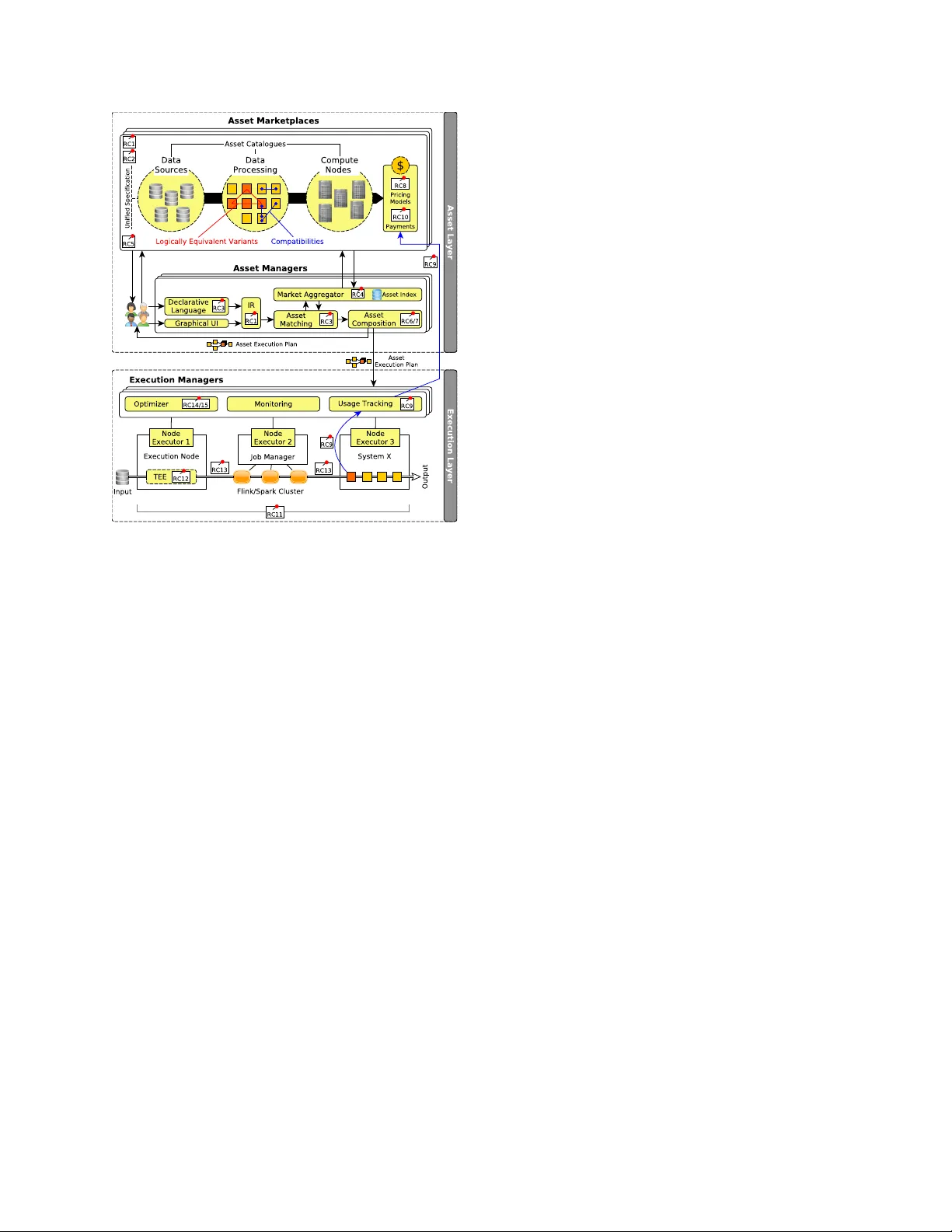
Agora: A Unified Asset Ecosystem Going Be y ond Marketplaces and Cloud Services [Vision] Jonas T raub Zoi Kaoudi Kaustubh Beedkar Sergey Redyuk Viktor Rosenf eld Jorge-Ar nulf o Quiané-Ruiz V olker Markl T echnisc he Univ ersit ¨ at Berlin DFKI Gm bH ABSTRA CT Data, algorithms, and compute/storage infrastructure are key assets that driv e data science and artificial in- telligence applications. As providing all these assets requires a huge inv estment, data science and artificial intelligence technologies are currently dominated by a small number of providers who can afford these in vest- ments. This leads to lock-in effects and hinders features that require a flexible e xchange of assets among users. In this vision paper, we present Agora, a unified as- set ecosystem. The Agora system provides the techni- cal infrastructure that allows for of fering and using data and algorithms, as well as physical infrastructure com- ponents. Agora is designed as an open ecosystem of asset mark etplaces and provides to a broad audience not only data b ut the entire data value chain (including com- putational resources and human expertise). Agora (i) lev erages a fine-grained exchange of assets, (ii) allows for combining assets to novel applications, and (iii) fle x- ibly executes such applications on av ailable resources. As a result, Agora ov ercomes lock-in ef fects and re- mov es entry barriers for ne w asset providers. In con- trast to existing data management systems, Agora op- erates in a heavily decentralized and dynamic environ- ment: Data, algorithms, and e ven compute resources are dynamically created, modified, and removed by differ - ent stakeholders. Agora presents novel research direc- tions for the data management community as a whole: It requires to combine our traditional expertise in scal- able data processing and management with infrastruc- ture provisioning as well as economic and application aspects of data, algorithms, and infrastructure. 1. INTR ODUCTION The ongoing d igitalization has a profound i mpact on industry , science, and so ciety as a whole. The access to data as well as to data science (DS) tech- nology constitute a critical point of control: Wide access to b oth of them is crucial for economic suc- cess and scientific progress, promoting a new data- cen tric economy [30]. Now ada ys, business leaders talk ab out the fourth industrial rev olution [82] . The fourth paradigm of data-in tensiv e scientific disco v- ery facilitates new insights through the analysis of large datasets that are generated from mo dern sci- en tific exp eriments [40]. Data has b ecome a fundamen tal factor of pr o- duction . In con trast to natural resources lik e oil, data can b e exploited infinitely . It can b e rep eat- edly curated and analyzed with DS technologi es to pro duce new insigh ts and solv e problems in a more efficient wa y . Data to gether with DS tech- nologies are competitive differen tiators in the data econom y . Companies that are proficient at utiliz- ing them gro w faster and p erform better than their comp etitors [88]. As a result, the data economy is quic kly develop ing a strong dependency on a small n um ber of DS proficient companies. This implicitly causes lo ck-in effects on customers, whic h, in turn, migh t cause customers to use sub optimal solutions or even to not hav e a solution at all. 1.1 T owards a Unified Asset Ecosystem As data and DS technologies pro duction factors, it is clear that they must b e accessible by everyone . In fact, the database comm unity has recently r ecog- nized that removing such lo ck-in effects will signifi- can tly b enefit all users [1]. Academia and industry ha v e made progress tow ards this goal by providing access to data [20, 43, 62], AI algorithms [2, 5, 9, 54], exp ertise (services) [28, 79], or computational resources [27]. How ev er, the users still require sig- nifican t exp ertise to combine all these data-r elate d assets (assets, for short) from differen t marketplaces and cloud p ro viders. F or instance, a social scien tist, who has no exp ertise in DS tec hniques and do es not own any data, can hardly v alidate her assump- tions ab out a social phenomenon, even if the re- quired data and tec hnology exists. W e th us need an ecosystem that provides unifie d access to all t yp es of assets: (i) high-qualit y data, (ii) state-of-the-art Bob Alice Be rl i n C ri me (BC ) Ag o ra Asse t BC data Real-Estate-Pricing ! (REP) Dataset ] REP data Elastic-Net (EN) ! Agora Asset EN ! Algorithm ] REP data EN ! Algorithm Real-Estate Forecasting ! Agora Asset search search contribute 1 2 4 3 Enriched ! Real-Estate-Pricing ! (E-REP) Dataset ] E-REP data 1 search 2 contribute 3 House-Pricing (HP) ! Dataset HP data Linear Regression ! (LR) Algorithm ] E-REP data Improved Real-Estate ! Forecasting Agora Asset LR ! Algorithm Charlie ML Algorithm ! Agora Asset ] E-REP data ML ! Alg o ri t h m x x 1 search 2 Compute Node ! Agora Asset run Figure 1: Motiv ating examples: Bob, Alice, and Charlie use Agora to discov er assets, improv e them, and con tribute them back to the ecosystem. Agora also pro vides the infrastructure to optimize and run these assets (e.g., in the case of Charlie). DS tec hnology and exp ertise, and (iii) compute and storage resources. The treatmen t of these ty p es of assets in a uniform and systematic wa y allo ws for easy creation and composition of data science pipelines, b oth with resp ect to the algorithmic and data sp ecification as well as its scalable execution. 1.2 Our V ision: The Agora Ecosystem W e envi sion A gor a , an ecosystem that brings to- gether asset providers and consumers to solve data- related problems using DS. Agora allo ws providers to offer any type of assets (e.g., data, algorithms, soft w are, computational resources, human exper- tise) to a broader audience. Also, it enables b oth the experts and the non-exp ert users to gain insights or enhance their businesses by com bining and using the assets. Ultimately , Agora aims at providing ac- cess not only to data sources but to the entire data v alue chain. W e env ision this ecosystem as a tw o-lay er ab- straction: the asset layer and the exe cution layer . The asset la yer is comp osed of a set of mark etplaces where pro viders and consumers can exchange assets. The execution lay er provides the means to users to run their tasks (comp osition of assets) in Agora instead of using their own computing infrastruc- ture. The key asp ect of Agora is the fine-grained exc hange of any asset. Each type of assets corre- sp onds to a sp ecialization of the provider, leading to differen t user roles. Agora hides the complexit y of each role. F or example, (i) a researc her can sub- scribe to a stream of even ts without knowing any detail about the infrastructure that captures those ev en ts; (ii) a company can acquire a classification pipeline without understanding the details of all in- v olv ed algorithms; (iii) researc hers and companies can b o ok a stream pro cessing cluster with uptime guaran tees without ha ving any knowledge on cluster op erations; and (iv) system op erators can fo cus on cluster monitoring and maintenance without know- ing an y detail about the tasks running on top of the cluster. Ov erall, w e see Agora as an um brella system, whic h unites all pieces of data managemen t research in an op en and collab orative ecosystem. W e, th us, b eliev e that the database communit y should drive the realization of this vision. 1.3 Motivating Examples Imagine Bob, a freelance data scien tist, who w an ts to create a machine learning (ML) mo del for real-estate price forecasting in Berlin. His dataset is missing the criminalit y rate of each area, which he kno ws also affects the prices. He, thus, go es to Agora to find data ab out the crime rates in Berlin 1 . He finds the data, augmen ts his ini- tial dataset with this feature 2 , and builds an ML mo del using the elastic-net algorithm 3 . He then decides to pro vide his composed asset in Agora 4 . Bob’s asset consists of the ‘real-estate- pricing’ dataset for Berlin and the elastic-net algo- rithm to estimate a p otential price of apartmen ts. Alice, another data scientist, finds Bob’s asset in Agora 1 and de cides to impro ve it 2 . She enriches the original ‘real-estate-prici ng’ dataset with sev- eral feature engineering techniques, adds the ‘linear- regression’ algorithm for prediction, and c on tributes it back to Agora to gain some reven ue 3 . Charlie, a consumer who is lo oking for a real- estate pricing predictor, queries Agora for a v ailable assets on price forecasting that yield the a verage er- ror rate b elo w 5,000 euros 1 . As he do es not hav e the infrastructure to run assets in his home, he de- cides to use Agora to also execute his disco v ered as- sets (e.g., train the ML pipelines he has found) 2 . Although he wan ts to complete the training as fast as p ossible, his budget is limited. T o ov ercome his budget limitation, Agora replaces the linear re- gression algorithm by a logically equiv alen t neural net w ork that achiev es b etter p erformance. Next, Agora decides to run the resulting asset on an exe- cution no de registered as an asset within Agora. Allo wing asset exchange in Agora leads to the follo wing main b enefits: (1) Se c ondary use of existing assets. Users can reuse an y (comp osed) asset (e.g., data and algo- rithms) offered in Agora. In most cases, companies o wn a plethora of highly v aluable assets. Ho w ev er, as these assets are fragmented across companies, their economical potential remains un used as sec- ondary asset usage is extremely rare. A fine-grained asset sharing w ould allo w for combining existing re- sources to derive new insights and services. (2) L ever aging sp e cializations. Agora creates an ecosystem of highly sp ecialized pro viders who pro- vide assets of a very high quality . Suc h an ecosys- tem is comparable with the automotiv e industry where many companies sp ecialize in certain parts (e.g., brakes, tires, or light s), which get combined to one high-qualit y car. Sp ecialized pro viders can only op erate efficiently if they can offer their assets without massiv e o v erhead. This enables small and medium-sized companies to offer assets that they w ould not be able to bring in the market other- wise. Agora, th us, allo ws consumers to build com- plex applications by combining high-quality assets from multiple providers. (3) Hiding c omplexity. Agora hides the complex- it y and intricacies of assets from the consumers. It is a w are of logical equiv alence of assets, i.e., assets that yield the same results (e.g., a nested lo ops join is equiv alen t with a hash join for equi-joins). Imple- men tations of logically equiv alen t assets can hav e v ery differen t prop erties: They may use differen t programming languages (e.g., C++ and Jav a), b e tailored to different systems (e.g., Flink and Spark), b e optimized for sp ecific hardw are (e.g., CPU and GPU), and run in a parallelized, distributed, or se- quen tial setting. In addition, each provider can de- fine different pricing for her implemen tation. T o optimize asset execution, Agora chooses the b est com bination out of the a v ailable implemen tations based on the requiremen ts of the incoming task or application. 1.4 Requirements and Challenges T o see the Agora vision b ecome a reality , w e m ust fulfill the following requirements: (i) asset sharing and disco v ering – users s hould be able to easily pro- vide or consume assets; (ii) asset priv acy and secu- rit y – users must b e able to set priv acy and secu- rit y constraints to their assets; (iii) asset in terop- erabilit y – users should b e able to easily combine differen t (types of ) assets; (iv) asset equiv alence – users should b e able to achiev e their desired goals without being concerned ab out the sp ecifics of the underlying algorithms; and (v) hardware indep en- dence – users should be able to run their assets on heterogeneous hardware seamlessly . Ultimately , Agora aims at consolidating informa- tion from around the w orld and executing intelli- gen t algorithms on top of it. This is a formidable c hallenge that presen ts the opportunity to in tegrate and adv ance database research in many areas, from query compilation and pro cessing to data integra- tion and mining, while dealing with asset hetero- geneit y , priv acy , security , heterogeneous hardw are, and nov el computer architect ures. Realizing this vision comes with a plethora of research questions, suc h as: How c an we sp e cify highly heter o gene ous assets in a unifie d way? Can we automatic al ly gen- er ate such a sp e cific ation? How c an we disc over and p otential ly c omp ose highly heter o gene ous assets to satisfy a c onsumer’s r e quest? What is the right pricing mo del for e ach typ e of asset? How c an we guar ante e that for a c ombination of assets every c ontributor gets p aid? How c an we sp e cify privacy and se curity c onstr aints to assets? Can we ensur e a truste d envir onment for the exe cution of assets hav- ing such c onstr aints? Can we enable assets to run on any c omputing r esour c e of the asset e c osystem? Outline. In the remainder of the pap er, w e first define an asset and introduce the differen t kinds of assets in Agora in Section 2. Next, in Section 3, we presen t the arc hitecture of and vision behind Agora. In Section 4, we p oint out the research challenges and outline p ossible solutions. W e discuss related w ork in Section 5 and conclude in Section 6. 2. ASSETS IN A GORA Before discussing the in ternals of Agora, let us first define assets as any data-r elate d unit of pr o- duction that al lows users to exploit the value of data . W e identify six ma jor categories of assets: data sour c es , algorithms , pip elines , systems , stor age and c ompute r esour c es , and applic ations . In the fol- lo wing, we explain them as well as p oint out the pro viders’ and users’ incen tives in each one of them: (1) Data sources. These include ra w data (e.g., relational data or graph data) as w ell as enric hed or curated data (e.g., kno wledge graphs and ontologies). In addition, data may b e pro- vided as data-at-rest (batch data) or data-in-motion (streams). Agora provides the platform for sp ecial- ized providers that offer high-qualit y data. Suc h data providers can bring their data to the market and benefit from resp ective reven ues. Data users b enefit from the a v ailable diverse, high-qualit y data. (2) Algorithms. Efficient algorithm implementa- tions are core building blo cks in data-driven appli- cations pro vided by developers. An algorithm im- plemen tation can b e part of a pro cessing pip eline, system, or soft w are to ol. Typical examples include database op erators, indices building, feature extrac- tion, and ML mo del training. Agora eases co de reuse as it enables secondary usage of implemen- tations. F or example, the databases communit y presen ts several new join algorithms at their lead- ing conferences ev ery year. Ho w ev er, only few of the presen ted algorithms see a wide-spread adop- tion mainly b ecause it is hard for dev elopers to sell- /put their algorithms in the mark et. Agora enables a plug-and-pla y solution: an y developer can offer a new join algorithm that is logically equiv alen t to an existing one, but more resource efficient or tailored for a sp ecific hardware or system. (3) Pipelines. Pip elines are a sequence of data sources and algorithms that manipulate data to- w ards a single goal. The v alue of a pip eline lies in a ready-to-use combination of such assets. F or exam- ple, a pip eline can combi ne data cleaning, feature extraction, and classification algorithms to trans- form raw data into labeled ev en ts. Setting up a pipeline of compatible algorithms is often a chal- lenging task. Th us, it is attractiv e to acquire a ready-to-use pip eline, which was already tested in practice and receiv ed p ositiv e user rating, instead of implementing a new pip eline from scratc h. (4) Systems. T ypical systems are relational databases, streaming engines, and ML systems. Eac h system ma y be proprietary or op en-source. With Agora, users get access to differen t systems and can access them through one federated plat- form. This allows for testing different systems and com binations with real work loads b efore making a decision for pro duction use. Moreov er, users will find supp ort and op eration services for each sys- tem. System providers can offer their systems to a large num ber of customers without the need for individual license negotiations. This makes it e asier to bring new systems to the market and to attract users to use a system that is optimized for their w orkloads. (5) Storage and compute. Agora accommo- dates storage and compute no des, which can b e of- fered b y cloud pro viders, organizations, or individu- als. Compute nodes can b e virtual machines or ded- icated serv ers. Storage resources can b e main mem- ory , disks, or net w ork-attac hed storage. As there are diverse providers, users gain access to diverse serv ers with div erse hardw are, can test differen t se- tups, and find the optimal environmen t for their ap- plication. In this wa y users a v oid lock-in effects to a particular cloud provider b ecause they can easily switc h betw een compute nodes. Users can also b en- efit from accessing spare resources in a data center that is close to their customers or sensors. (6) Applications . An application consists of systems, pip elines, algorithms, and, optionally , data sources and storage/compute no des to offer a complete ready-to-use solution. The comp onen ts that constitute the application can b e assets from the ecosystem or priv ate resources. Application pro viders benefit from a platform on which they can offer applications to users similar to an app- store for smartphones. Application pro viders can dev elop and impro v e their applications using assets that are a v ailable in Agora. F or example, one can offer a web shop as an application which integrates a pip eline for article recommendations. 3. A GORA ARCHITECTURE Agora builds around assets and consists of t w o la y ers: the Asset L ayer and the Exe cution L ayer . A ma jor strength of Agora is its seamless connection b et w een these tw o la y ers. It goes b eyond stand- alone mark etplaces, stand-alone execution engines, and cloud services with the goal of facilitating the use of DS to ols for a broader group of users. Fig- ure 2 illustrates the architecture of Agora. The asset la yer constitutes an “in telligen t” ecosystem of m ultiple asset marketplac es and en- ables not only offering and finding assets but also comp osing them in a smart w a y via asset man- agers . Recall our motiv ation example describ ed in Section 1.3. Bob, who is searc hing for a dataset, has the choice of going directly to his fav orite mar- k etplace or to an asset manager to find his desired dataset. In the former case, he either browses the mark etplace or uses keyw ords to searc h within it. In the latter case, he simply sp ecifies his request in a declarative manner and the asset manager is responsible to resp ond by accessing multiple mar- k etplaces. The execution lay er optimizes and runs asset execution plans via exe cution managers and no de exe cutors . F or instance, Charlie, in our running ex- ample, finds his pip eline via an asset manager and decides to execute it in Agora. F or this reason, the asset manager translates the p ip eline in to an execu- Figure 2: An ov erview of the architecture of Agora with 15 selected R ese ar ch Chal lenges (RCs) . tion plan together with its equiv alent assets, which are logically equiv alen t v arian ts satisfying the same request. Logically equiv alen t v arian ts can b e dif- feren t ph ysical implemen tations of the same logi- cal operator, alternative compute no des with simi- lar prop erties, or alternative data sources, such as w eather data from differen t pro viders. Next, the as- set manager passes the execution plan to an execu- tion manager, whic h is responsible to optimize the plan and find the b est p ossible equiv alen t pip eline asset that resp ects Charlie’s budget. The execu- tion manager accesses pro cessing no des through a no de exe cutor , whic h is a standardized comp onent to interface arbitrary execution environmen ts with execution managers. F or example, No deExecutor 1 in Figure 2 provides access to a T rusted Execu- tion En vironmen t (TEE), suc h as an Intel SGX En- cla v e [17], and NodeExecutor 2 pro vides access to a Flink [13] or Spark [100] Job Manager to run Flink and Spark Jobs on a cluster. It is w orth noting that all comp onen ts of Agora (asset marketplace, asset manager, execution manager, and node executor) are assets themselves. A consumer/pro vider can of- fer her o wn implemen tation for an y of these compo- nen ts and charge consumers for its use. Consumers can c ho ose betw een concrete implemen tations pro- vided by different users. W e b eliev e that this flexi- bilit y leads to a comp etition for providing the b est p ossible Agora comp onents, e.g., for providing the execution manager with the b est optimizer. In the following, we discuss the details of the tw o la y ers and p oin t out 15 researc h challenges (R Cs), whic h we further elab orate in Section 4. 3.1 Asset Layer Agora’s asset la yer consists of an ecosystem of asset marketplac es , whic h allo w providers to share their assets, and asset managers , which allo w con- sumers to easily use assets across mult iple market- places. Eac h asset marketplace contains catalogues that kee p track of the a v ailable assets and their properties. T o make this p ossible, Agora unifies as- sets under a common sp ecification. Only a unified sp ecification enables easy asset discov ery and com- p osition across all the marketplaces in the ecosys- tem. Pro viders should conform with this unified sp ecification when they offer new assets to the mar- k etplaces. This can b e a barrier for new asset pro viders. Therefore, it is crucial that Agora pro- vides the means for automatically generating asset sp ecifications from more intuitiv e user inputs, such as query and programming languages or graphical in terfaces. Defining such a sp ecification and deter- mining wa ys for its automated extraction is chal- lenging due to the the large heterogeneity of assets ( R C1 and RC2 ). Moreo v er, provider s might wan t to sp ecify usage constrain ts to their assets. F or example, lo cation requiremen ts (e.g., priv ate data may not b e mov ed out of a country) or v endor requirements (e.g., m y algorithm may not b e used by a comp etitor) may b e asset constrain ts. Identifying the b est wa y to describe constrain ts ov er assets is an intere sting re- searc h challenge b ecause of the asset heterogeneit y and different constraint granularit y ( RC5 ). Pro viders can also define a pricing mo del (e.g., subscriptions or pay-per-use) for their assets usage ( RC8 ). Ideally , Agora prop oses a pricing mo del and a price based on monitoring the current trend of the mark et. When a pro vider chooses a pa y-per-use pricing model, Agora ensures to track the asset’s usage and rep ort usage counters back to marketplace ( RC9 ). Mark etplaces then p er- form the inv oicing and initiate (micro-)pa ymen ts b et w een users ( RC10 ). Asset managers are the en try p oin t for users who w an t to declaratively: find assets across dif- feren t marketplaces; combine m ultiple assets into execution plans; and run asset execution plans. An asset manager provides a graphical user inter- face and/or a declarative language for finding and comp osing assets ( RC3 ). A user request is then con v erted to an in termediate represen tation (IR), whic h allows for matc hing asset sp ecifications with user requests ( RC 1 ). The asset manager matches user requests to assets that are compatible with eac h other and satisfy the requests ( RC3 ). F or this, it needs to aggregate the assets of all mar- k etplaces and build an asset index ( R C4 ). Next, the asset manager composes all the relev ant assets (with their equiv alen t assets) together so that they fulfill the r equest. When composing assets, it is cru- cial to satisfy usage constrain ts of the assets ( RC6 and RC7 ). As a result, the asset manager outputs an asset execution plan, which allo ws the execution la y er to further optimize, deploy , and run the plan. 3.2 Execution Layer Agora’s execution lay er consists of exe cution managers , whic h receiv e execution plans from an asset manager, and no de exe cutors , whic h allo w con- sumers to run their assets. An execution manager is a core comp onent of the execution lay er. It is resp onsible for optimizing an asset execution plan, deploying it on compute no des, and monitoring its execution. As the plan ma y con tain differen t v ariants of op erations, the ex- ecution manager can schedule an op eration of an execution plan on different execution environmen ts (node execu tors). Achieving this multi-en vironmen t execution of a plan is very c hallenging as the search space of all p ossibilities to execute a plan b ecomes v ery large ( R C14 and R C15 ). The selection of ex- isting v arian ts and the selection of node executors go es hand-in-hand with p ossible algorithm adapta- tions, which increases the p erformance on a partic- ular target system. A no de executor is Agora’s in terface compo- nen t to connect arbitrary execution environmen ts with execution managers. F or example, in Figure 2 the asset execution plan is deplo y ed to three no de executors with differen t c haracteristics: NodeEx- ecutor 1 provides access to a trusted execution en- vironmen t (TEE), which provides additional secu- rit y b ecause the owner of the node has no access to the executed source co de nor the pro cessed data ( R C12 ); NodeExecutor 2 provides access to a Flink or Spark Cluster; and No deExecutor 3 provides di- rect access to hardware resources on a dedicated serv er. When dealing with mul tiple node executors, Agora pro vides a secure wa y to transfer data among no des to v alidate data integrit y and to pay for data that is traded as an asset. This is hard to achiev e esp ecially when data is large or data streams hav e high bandwidth ( RC13 ). It is w orth noting that b oth no de executors and execution managers are resp onsible for tracking the usage of assets, which is crucial to ensure fair pa y- men ts. This is a challenging task b ecause it also as- sumes t rac king fine-gran ular op erations in a compo- sition of assets ( RC9 ). Agora adopts certificates to ensure transparency and trust b et w een consumers and providers. F or example, one can certify the ph ysical lo cation of a no de, securit y standards, com- pliance with asset usage tracking, or energy effi- ciency . The main challenge remains in the stan- dardization of certificates and assets requirements ( R C11 ). 4. RESEARCH DIRECTIONS W e now elab orate on the 15 main research chal- lenges that we b elieve are crucial to address in or- der to implement Agora. Most of the c hallenges stem from the heterogeneity of assets and the op en ecosystem setting. They deal with asset manage- men t (Section 4.1), complian t asset pro cessing (Sec- tion 4.2), pricing and paymen ts (Section 4.3), pri- v acy and securit y (Section 4.4), and efficient asset execution (Section 4.5). In the follo wing, w e discuss eac h researc h chal lenge and outline approaches to tac kle them. 4.1 Asset Management The first step to w ards Agora is enabling effective and efficien t asset management : any asset-related op eration, such as asset sharing, discov ery , and comp osition. W e identify the following four main researc h challenges that we need to tac kle to ac hieve this. (R C1) Unified sp ecification. A ma jor c hal- lenge for asset managemen t is the design of a uni- fied sp ecification (a standar d ). Such a sp ecification will allow sharing and discov ery of assets not only within a single mark etplace but also among differ- en t mark ets. It, thus , facilitates the usage of an asset searc h engine across differen t marketplaces. The difficulty in devising suc h a standardization lies in the fact that there are different types and gran ularities of assets: from datasets and stream sources to complex algorithms or data management systems. The standard should tak e all these differ- en t types of assets into consideration while keeping as muc h simplicit y as p ossible. In addition, a single asset may not b e sufficient to satisfy a consumer’s request. F or this reason, the standard should en- able interoperability among assets so that compos- ite assets, i.e., assets formed by mul tiple assets, can also b e shared. T o enable asset comp osition, such as the one required for our example in Section 1.3, 1 X _ t r a i n , X _ t e s t , y _ t r a i n , y _ t e s t = t r a i n _ t e s t _ s p l i t ( X , y , t e s t _ s i z e = . 1 ) 2 3 f e a t u r e _ t r a n s f o r m a t i o n = C o l u m n T r a n s f o r m e r ( t r a n s f o r m e r s = [ 4 ( ’ c a t e g o r i c a l _ a t t r ’ , O n e H o t E n c o d e r ( u n k n o w n = ’ i g n o r e ’ ) , [ ’ a r e a ’ , ’ f l o o r ’ ] ) , 5 ( ’ n u m e r i c _ a t t r ’ , S t a n d a r d S c a l e r ( ) , [ ’ s u r f a c e ’ , ’ c r i m e _ r a t e ’ ] ) ] ) 6 7 p i p e l i n e = P i p e l i n e ( [ 8 ( ’ f e a t u r e s ’ , f e a t u r e _ t r a n s f o r m a t i o n ) , 9 ( ’ l e a r n e r ’ , S G D C l a s s i f i e r ( m a x _ i t e r = 1 0 0 0 , t o l = 1 e - 3 ) ) ] ) 10 11 p a r a m _ g r i d = { ’ l e a r n e r _ _ a l p h a ’ : [ 0 . 0 0 0 1 , 0 . 0 0 1 , 0 . 0 1 , 0 . 1 ] } 12 s e a r c h = G r i d S e a r c h C V ( p i p e l i n e , p a r a m _ g r i d , c v = 5 ) 13 m o d e l = s e a r c h . f i t ( X _ t r a i n , y _ t r a i n ) 14 15 p r e d i c t e d = m o d e l . p r e d i c t ( X _ t e s t ) Listing 1: Excerpt of a data science pip eline asset expressed in Py thon whic h predict s real estate pricing. the sp ecification must be flexible to consider asset com binations. It should enable building complex pipelines and systems and at the same time b e gen- eral enough to supp ort all op erations and multiple query languages. Our initial efforts tow ards a unified sp ecification is a declarative intermedi ate representation of data science assets [76]. T o cope with the lack of higher- lev el declarativ e abstractions for end-to-end data science processes [80], w e ha v e defined a schema for the sp e cific ation of the exe cution of data scienc e pip elines inspired b y ML Schema [72] or Amazon’s experiment trac k er [81]. Figure 3 sho ws an example of the int ermediate represen tation of a data science pipeline asset follo wing this sc hema sp ecification. No des in the graph represent high lev el asset cate- gories, optionally accompanied by their metadata, and edges connect tw o assets by their input/out- put. Ha ving suc h a high level represen tation of as- sets allows us to mak e further optimizations and find equiv alences among different assets. (R C2) Automated sp ecification genera- tion. Providing the asset sp ecification can be error-prone and introduce significan t o verhead to asset pro viders. F or this reason, it is necessary to pro vide mechanism s to generate assets sp ecification from more intuitiv e user inputs. This opens up new research directions on automated extraction of a specification from query and programming languages as w ell as graphical user interf aces. Our first step tow ards this direction focuses on data science asset pro viders, i.e., data scientists, who are primarily familiar with writing Python Figure 3: Automated specification gene ration of the asset shown in Listing 1. The num bers next to the algorithm assets p oint to the lines of co de in List- ing 1 that represent that particular asset. scripts. Agora ext racts an in termediate repre- sen tation from data science pipelines written in Python code with little or no in volv emen t of the end-user [76]. Our approach allo ws for simple and straightforw ard use of the asset la y er, yet in tegrates it with a pow erful to ol for search and sharing, potentially across languages and domains. Automation of schema extraction is based on static co de analysis [58] and its semantic enrichmen t [67]. Listing 1 shows a real estate predictor asset, while Figure 3 shows the automatically generated in termediate represen tation of this asset. T o ac hiev e this automated extraction w e maintain a simple kno wledge base consisting of data science sub-processes (e.g., normalization). W e then map ob ject signatures that the programming language (and its ecosy stem) supp orts to the categor ies found in the kno wledge base. F or example, Python ’s sklearn.preprocessing.OneH otEncoder class signature maps to the ‘data-prepro cessing- transformation’ category , that instructs the system what meta information to extract and ho w. W e plan to further in v estigate this direction and attempt exploiting pattern mining solutions as a p oten tial replacemen t of man ually curated kno wledge bases. (R C3) Matc hmaking. The asset la y er via its as- set search engine (as well as a single marketplace) should be able to effectively and efficien tly iden- tify all assets related to a giv en consumer’s request. T o achiev e this the marketplace should provide the users with a declarative query language or graphi- cal user in terface that allo ws them to disco ver assets with the desired character istics. Using the graph- ical user in terface lay users can browse assets or use a k eyw ord search, while more adv anced users should b e able to use the declarativ e query language to quickly describ e the assets they wan t. Devising a declarative language which can express requests ab out different t ypes and granulari ties of assets is a c hallenging task. In addition, identifying the most suitable approach for matc hing a query with the a v ailable assets is not straightforw ard. T o solv e this c hallenge we are lo oking in to the direction of matc h- making and recommendation, which has b een used recen tly in multi-sided marketplaces [53]. The dif- ference with traditional recommendation systems is that in the case of mark etplaces, such as the asset la y er we envision in Agora, there is a multi-ob jective optimization problem that needs to be taken into consideration: increasing b oth pro vider and con- sumer satisfaction. W e also plan to combine recom- mendation systems with the solutions that fo cus on satisfaction-based [74, 73, 75] and economic-based query pro cessing [84]. (R C4) Mark et aggregator. The Agora ecosys- tem is comp osed of multiple asset marke tplaces. It is thus important for the asset manager to b e a w are of the different mark etplaces and their as- sets through a mark et aggregator. The c hallenge w e ha v e to face when building the mark et aggre- gator is t w ofold: (i) indexing av ailable assets in an efficien t and scalable wa y despite their num b er and div ersit y , and (ii) finding equiv alences among assets. Although the asset specification facilitates the com- parison b etw een tw o assets, it is still not straight- forw ard how exact or approximate equiv alences can b e found. W e plan to incorp orate techniques from source co de search engines [52] and program trans- lation [61], traditionally used to migrate co de from one language to another, to tackle these tw o chal- lenges. 4.2 Compliant Asset Processing In suc h an op en asset-cen tric ecosystem as Agora, it is imp ortant to allo w pro viders to provide con- strain ts to their assets. A provider might not wan t her asset to b e pro cessed in unintended wa ys and therefore may sp ecify usage p olicies that the asset consumer should comply to. F or this reason, as- set processing (i.e., satisfying a user’s request) faces unique challenges due to asset constraints and le- gal requiremen ts. F or example, a usage p olicy may prohibit o verla ying (joining) the provided data with an y other data [59] or may disallo w aggregation with other pro viders [97]. Moreov er, c om bining geo- Result 1 SHIP EU Nation (ME) 1 1 Customer (EU) SHIP EU Orders (EU) Lineitem (NA) (a) Non-compliant Result 1 SHIP NA Nation (ME) 1 Lineitem (NA) SHIP NA 1 Orders (EU) Customer (EU) (b) Compliant Figure 4: Excerpt of distributed query plans for TPC-H Query 10. The leaf no des denote base tables lo cated in Middle East (ME), North America (NA), and Europ e (EU). distributed assets ma y in v olv e transfer or shipping of assets across b orders. As a result, asset pro cess- ing must comply to regulations (suc h as GDPR [32] or CCP A [12]) that prohibit the use or flow of as- sets across geographical b orders or certain sites. F or example, pro cessing data generated by autonomous cars in three different geographies, such as Europ e, North America, and Asia, ma y face different regula- tory constraints: There ma y b e legal requirements that only aggregated or anonymized data may b e shipped from Europ e and no data whatso ev er may b e shipp ed out of Asia. This op ens up a com- pletely new dimension of c ompliant query ( “asset” ) pr o c essing that entails the follo wing tw o research c hallenges. (R C5) Constrain t sp ecification. The first chal- lenge to ov ercome is determining how to sp ecify as- set constraints declaratively . Doing so is imp ortant for easing the sp ecification of constrain ts. How ev er, it is challenging not only b ecause of the asset hetero- geneit y but also b ecause of the different constraint gran ularities. F or example, a constraint might ap- ply to an en tire asset, parts of it, or even to infor- mation derived from it. (R C6) Constrain t satisfaction. The second c hallenge is to find efficient wa ys to pro cess queries in a manner compliant with resp ect to asset con- strain ts. In our early efforts tow ards realizing Agora w e pro vide support for c ompliant ge o-distribute d query pro cessing. Our initial implemen tation al- lo ws expressing constraints on shipping data across geographical borders using our extende d -SQL state- men ts. Its query optimizer aims at finding dis- tributed query execution plans that are compliant with resp ect to shipping of intermediate data b e- t w een compute sites. T o illustrate query plans pro duced by a compli- an t query optimizer, assume TPC-H query Q 10 in a setting where data is geo-distributed: the base tables are geo-distributed across the Middle East (ME), North America (NA), and Europe (EU). Also, we set one constrain t stating that no data from NA can b e shipped to EU. Figure 4 sho ws excerpts of the query plans produced by a tradi- tional query optimizer (Figure 4(a)) and our opti- mizer (Figure 4(b)). The query plan on the left is not complian t b ecause it disregards constrain ts on shipping parts of the Lineitem table to Europe. Optimisation time (s) 0 1,75 3,5 5,25 7 TPC-H Queries Q3 Q10 T raditional Compliant C C NC C 1 Figure 5: T raditional vs complian t query (asset) pro cessing; Letters on top of bars denote if the plan w as complian t (C) or non- complian t (NC). Figure 5 sho ws the query opti- mization time for that query along with query TPC-H Q 3 . Both queries in v olv e joining data from differen t geographical sites, with a n umber of constraints on data mo v emen t across the different geographical sites. W e observe that traditional query pro cessing is not suitable for such settings as they simply disregard the data mov emen t constrain ts: they can indeed pro duce non-compliant query execution plans (denoted by NC), such as the one for Q 10 , whereas our approach alwa ys pro duces a complian t plan (denoted by C) if it exists. This sho ws that traditional query pro cessing techniques are unsuitable for dealing with asset constrain ts. Still, is it p ossible to match (or b e as close as p ossible to) the p erformance of traditional query pro cessing? This is a ma jor c hallenge w e are seeking to tackle in Agora. (R C7) Capturing asset prov enance. Another important aspect when com bining and sharing as- sets is to b e able to audit compliance with respect to data usage and its sharing p olicies. T o this end, w e also need pro venance capturing tec hnology in an asset-centric marketplace. While w ork on using pro v enance to audit compliance (e.g., [15, 93]) has receiv ed m uch traction, their applicabilit y is limited to homogeneous execution en vironmen ts or to spe- cial data pro cessing facilit y . T o supp ort auditing in Agora, we need nov el solutions that can capture pro v enance in a heterogeneous execution en viron- men t. In particular, we need prov enance mo dels that can capture relationships in comp osite assets, Marketplace billing Execution Manager Aggregation Aggregation algorithm ! tracking pipeline ! tracking asset ! code asset ! code Node Executors Marketplace billing Figure 6: Asset usage tracking and billing. deal with diverse data mo dels of assets, and cop e with large amounts of prov enance data. 4.3 Pricing and Payments In contrast to existing mark etplaces for data or algorithms and to existing cloud providers, Agora lev erages a more flexible and extremely diverse com bination of assets. This makes it c hallenging to track each stakehold er’s contributions and con- sumptions and to organize the resp ective in voice and paymen t pro cesses. In this section, we dis- cuss research directions with resp ect to pricing and billing in Agora. (R C8) Pricing mo dels. Our ecosystem should allo w prov iders to define prices of their assets based on differen t pricing mo dels. Ideally , the system should also prop ose a price based on a contin uous mark et monitoring. Ideas from query-based pric- ing [18, 46] and economic mo dels for the cloud [84] can b e the foundation, but hav e to b e extended to fit a more general data ecosystem. W e plan to sup- p ort differen t pricing mo dels. In softw are licensing, there are three common and fundamentally different pricing mo dels: pay-once, subscription, and pa y- p er-use. With p ay-onc e , a user buys a license once and can use the licensed soft w are forever. Subscrip- tion mo dels are similar to the pa y-once model, with the difference that licenses may expire and hav e to b e renew ed. The p ay-p er-use model is common for cloud services where users pay eve ry time they use a service or call a function (e.g., the Go ogle Sp eec h API, the Twitter API, and A WS Lam b da functions). A provider could adopt any of these mo dels. F or instance, pay-per-use can b e used for algorithms (e.g., pay $1 p er thousand calls) and for compute resources (e.g., pay $5 p er hour). While a pa y-per-use model seems to b e the fairest solution, it is c hallenging to realize pay-per-use in a pro cess- ing pip eline that consists of man y differen t assets including algorithms, co de, and compute resources. In the follo wing, we lay out the challenges related to usage trac king and micro-paymen ts as well as out- line a solution for each of them. (R C9) Asset usage tracking. T o ensure fair as- set paymen ts, the execution manager should b e able to track the usage of the assets. How ev er, track ing fine-gran ular op erations in a set of assets (e.g., in a pipeline), which may run in parallel, is not an easy task. It requires not only an aggregation comp o- nen t but it also dep ends on the trustw orthiness of the no des that rep ort the usage tracking. In Fig- ure 6, we depict a p ossible mec hanism for usage trac king. This mechanism provides a common API that allows for calling a trac king function from the asset source co de (to trac k the use of assets) or as an operator (to track the use of pipelines). Alterna- tiv ely , one could also track the amoun t of pro cessed data as part of our secure transmission pro cess (see Section 4.4). Because usage trackin g functions are called many times (e.g., p er pro cessed tuple), an aggregation component is required to propagate ag- gregated usage counters (e.g., once per min ute) in- stead of individual function calls. W e plan to base this aggregation comp onent on our previous work on efficien tly aggregating data streams [14, 90, 91] as well as on related work that enables distributed (pre-) aggregation [7, 51]. Still, suc h a usage track- ing mec hanism do es w ork only if compute nodes honestly r ep ort usages coun ters. W e, th us, allow for restricting the execution of op erators and pip elines to specific no des, which fulfill certification require- men ts (see Section 4.4). (R C10) P a yments. Ensuring a safe wa y for pro viders to charge and consumers to pay the use of assets is crucial for the ecosystem health. Ideally , a pa ymen t pro cess would b e distributed such that eac h comp onent can receiv e micro-paymen ts and forw ard parts of these paymen ts to sub-comp onents. F or example, an execution manager may charge $1 to process a MB of data, but has to share that money with asset pro viders. Note that comp osite- asset providers hav e to split their share again, to pa y the individual asset providers that are part of the pipeline. Recen tly , blo c k c hain-based tech- niques [50, 96] as w ell as blo ck chain-alternativ es suc h as IOT A [69] hav e b een prop osed to supp ort suc h micro-paymen ts. Ho w ev er, all these techniques ha v e been criticized for either limited scalabilit y , transaction-fees, pro of-of-w ork requirement s, secu- rit y issues, missing final settlemen t of transactions, or authorit y cen tralization. Morev oer, giv en the div ersit y of crypto currencies and their underlying tec hnologies [16], it is impossible to select a single b est paymen t system. Therefore, w e aim at inte- grating an abst raction la y er to make Agora agnostic to the details of the paymen t metho d used b etw een users. Agora will pro vide a reference implemen ta- tion for the most common pa ymen t metho ds and users ma y implemen t additional options: users will ha v e to implemen t the logic for executing a pa y- men t, including a notification ab out the completion of a transaction; Agora will trigger transactions and confirm completed transactions based on the users’ implemen tation. 4.4 Privacy and Security Another ma jor concern in an op en ecosystem is priv acy and security . Agora needs to ensure pri- v acy and security when pro cessing assets as well as secure, priv ate, and scalable data transfer among users and pro cessing no des. W e describe b oth as- p ects and present resp ective research directions in the following. In Agora, users ma y decide to run their as- sets on pro cessing nodes operated b y a diversit y of pro viders. As these pro viders hav e physical access to their pro cessing no des, they potentially gain ac- cess to the co de of assets that runs on their no des and the data these no des pro cess. Both data and co de of assets should b e protected against unau- thorized access and manipulation to ensure priv acy and to preven t attack s aiming at manipulating re- sults. W e inv estigate three approaches that com- plemen t each other: establishing trust c ertific ates , using truste d exe cution envir onments , and ensuring se cur e data tr ansfer . (R C11) Establishing trust certificates. Cer- tifications are a common wa y to establish trust b e- t w een cloud providers and users [85]. How ev er, ex- isting certifications for cloud providers assume a sin- gle provider (e.g., A WS, Microsoft Azure, or IBM Bluemix) to serve a v ery large num ber of users. Th us, the certification pro cess can be complex and users are able to chec k certificates man ually for the (only) one provider they use. Agora aims at drasti- cally increasing flexibility for asset creation and exe- cution. Consequently , the main chal lenge resides in the standardiz ation of certificates and asset requir e- men ts. Our goal is to enable the execution manager of Agora to automatically match assets with com- pute and storage resources. T o this end, our k ey idea is to democratize the certification of prop er- ties, such as securit y standards and the lo cations of no des. Ev ery one can b ecome a certification au- thorit y and decide which authorities to trust. F or example, the EU could certify that a compute no de is lo cated in the EU and therefore b ecome a certi- fication authorit y . The execution constraints of an asset (or asset execution plan) then include a set of required certificates connected with trusted au- thorities for eac h t ype of certificate. T ec hnically , we plan to use the TLS handshake proto col [57] as so- lution for authenticating compute node prop erties. In con trast to common TLS in the world wide web, eac h compute no de in Agora may hold a plethora of certificates issued b y diverse certification author- ities. The execution manager then v alidates that all required certificates are presen t at a compute no de b efore assigning an asset to that particular no de. (R C12) T rusted execution environmen ts. A T rusted Execution Environmen t (TEE) provides a solution for secure computation, which do es not re- quire to trust the owner of a compute no de. Th us, TEE-based solutions go b eyond certification-based solutions to protect assets co de and data, whic h are particularly critical for security . W e esp ecially con- sider TEEs that enable remote execution, suc h as ARM T rustZone [60] and Intel Softw are Guard Ex- tension (SGX) [17]. The k ey idea is that proces- sor vendors pro vide a secure execution environmen t within their pro cessors. The pro cessor ensures the in tegrit y of the executed co de with a remote attes- tation, whic h preven ts co de manipulations [95]. All data enters the secure environmen t encrypted, and is decrypted only within the pro cessor. The pro- cessor also encrypts all outputs b efore they lea v e the secure environmen t. Th us, the owner of a com- pute no de cannot see or manipulate any asset data or co de that runs inside the TEE, i.e., within the pro cessor. In the past, it was difficult to engineer applications for TEEs, whic h has also lead to secu- rit y vulnerabilities [39, 86]. No w ada ys, op en source framew orks, such as Asylo [70] and Keystone [48], ease the develop men t of assets that run in TEEs. This makes it feasible to leve rage TEEs in the con- text of distributed data pro cessing. Agora will sup- p ort TEEs to impro v e securit y in general and to enable secure data processing even on uncertified no des. Thereby , existing works on TEE-secured databases [71, 94, 102] and stream pro cessing sys- tems [36, 66, 89] are an important first step, but need to b e extended to be (i) scalable, (ii) generally applicable, and (iii) easy to use in the context of an asset-based ecosystem such as Agora. (R C13) Secure data transfer. It is imp ortant that users can exc hange data among them in a se- cur e w ay within Agora. In this context, ‘secure’ means that (i) all data transmission is encrypted to preven t unauthorized access, (ii) the integrit y of the data is guaranteed and can b e v alidated b y re- ceiv ers, and (iii) sender and receiver can use an es- cro w service to secure data trading. One of the c hallenges is that data can b e arbitrarily large and data streams often hav e high bandwidths. Thus, Execution Manager # key hash Sender encrypt 1 Receiver decrypt 6 send 3 2 4 5 Figure 7: Secure Data T ransfer and Escro w betw een t w o no de executors. senders need to send data directly to receiv ers and the execution manager should act as a co ordinator. W e outline our solution for secure data exchange in Figure 7. The execution manager acts as a mediator to pass th e hash v alue and key of the encryp ted data from the sender to the receiver. Th us, the execu- tion manager w orks without storing or transmitting the data itself, whic h preven ts it from b ecoming a honeypot of data for p otential attack ers. The exe- cution manager releases the key if and only if the receiv er issues the pa yment for the receiv ed data. The receiver will only issue the paymen t once it con- firmed the data in tegrity using the provided hash v alue. Existing key escro w encryption services [23] can serv e as a blueprin t for our ecosystem. How ever, w e need to adapt these tec hniques to support assets requiring stre am processing and intermediate trans- missions within assets. W e wan t to design a scalable and light-w eight escrow pro cess, whic h can be p er- formed ev en for small c h unks of data (e.g., net w ork pac k ages). This pro cess has to combine fast micro- pa ymen ts (discussed in Section 4.3) with a scalable implemen tation of the co ordination comp onent in the execution manager. 4.5 Efficient Asset Execution Giv en the high div ersity of assets in Agora, it is crucial to also provide a div erse execution en- vironmen t in order to obtain maxim um p erfor- mance. F ollowing the one-size-do es-not-fit-all dic- tum, a plethora of specialized systems ha ve emerged since almost tw o decades ago. There are rep ort- edly ov er 200 different platforms only under the um brella of NoSQL [22]. Eac h excels in sp ecific as- p ects, e.g., Spark is optimized for batch pro cess- ing (requiring full scans) and a database is very efficien t for p oin t queries (requiring index access), leading to w orks using multiple systems [8, 33, 45, 68, 92]. At the same time, pro cessor vendors ha v e turned to specialization and acceleration, i.e., build- ing pro cessors that are optimized for a sp ecific use case [10], suc h as GPUs and FPGAs. Broadly sp eaking, GPUs are optimized for highly parallel throughput appl ications [49], whereas CPUs are op- timized for single thread p erformance [10]. FPGAs, in turn, enable the design of custom hardware solu- tions to meet high demands on latency and through- put and hence are also increasingly b eing used to accelerate some data pro cessing tasks [87, 29]. In this highly heterogeneous computing land- scap e, it is crucial that Agora fully lev erages the capabilities of each data processing plat- form (databases, dataflow-based processing sys- tems, stream pro cessing systems, etc.) and comput- ing device (CPU, GPU, or/and FPGA) to get the maxim um p erformance b enefits out of them. How- ev er, fully leveraging this heterogeneous computing landscape is challenging for sev eral reasons that we explain in the following. (R C14) Heterogeneous asset deploy- men t. Agora can determine the de- plo ymen t environmen t, i.e., the process- ing system for deplo ying eac h asset. N u mb e r o f ce n t ro i d s (k) Ba t ch si ze N . o f i t e ra t i o n s Sca l e f a ct o r Sa mp l e si ze (% ) R u n t i me (s) 0 60 120 180 240 100 0 65 130 195 260 1 0 11 0 220 330 440 1 0 425 850 1275 1700 100 200 0 875 1750 2625 3500 100 200 0 250 500 750 1000 10 100 1000 0 150 300 450 600 10 100 (a ) T e x t m i n i n g (b ) R e l a ti o n a l a n a l y ti c s (c ) Ma c h i n e l e a r n i n g (d ) G r a p h m i n i n g A g g r e g a te Join Kmeans SG D C r o c o PR Wo r d C o u n t Wo r d 2 N V e c Si m W o r d s Ja va St re a ms Sp a rk Flink G i ra p h R H EEM JG ra p h 0 150 300 450 600 1 100 1000 O u t o f Me m o r y 215 31 43 29 229 30 24 23 384 31 46 31 1646 274 394 265 633 1276 617 331 1 210 152 150 392 265 265 476 149 165 149 > 1 h o u r 629 167 187 167 924 183 207 183 290 352 309 22 292 392 317 22 292 433 330 22 206 140 187 57 11 2 58 > 1 h o u r 448 329 413 Runtime (s) Batch size SGD 0 150 300 450 600 1 100 1000 290 352 309 22 292 392 317 22 292 433 330 22 JavaStreams Spark Flink Spark+JavaStreams 1 Figure 8: Benefits of heterogeneous asset de- plo ymen t for SGD. F or example, if the asset is a stream pro cessing algorithm, Agora might decide to run it on Flink [13], while if it is a rein- forcemen t learning algorithm, it may decide to run it on Ra y [56]. Iden tifying the type of assets and where they should b e executed is a very c hallenging task. W e already did the first step to w ards this direction with Rheem [3]. W e hav e sho wn that using m ultiple data pro cessing platforms significan tly decreases the execution time of a single processing task. F or instance, Figure 8 sho ws the run time of a classification training asset using sto c hastic gradien t descen t (SGD) for different batc h sizes and for the HIGGS dataset as input. W e observe that enabling heterogeneous asset deploymen t (Spark and Jav aStreams for the example) can significantly increase p erformance (more than one order of magnitude faster than using Spark, Flink, or Ja v aStreams only for the example). W e also hav e sho wn such p erformance b enefits for a large v ariet y of other tasks [3, 45]. Th us, the consumers of Agora can b enefit from suc h p erformance increase without an y kno wledge ab out th e deplo yment itself. Although Rheem is on e of Agora’s ingredien ts, considering highly diverse assets is still an op en researc h problem. (R C15) Heterogeneous asset execution. In addition to determining whic h pro cessing system to execute an asset, Agora also determines how to allocate the asset to compute resources. Given a n um ber of processor-sp ecific algorithm implemen- tations, it has to decide on whic h pro cessor to exe- cute every single asset. How ev er, achieving this in an automatic wa y is challenging for sev eral reasons. T o statically sc hedule assets, we ha v e to sp ecify the computational requiremen ts of an algorithm as metadata and match them with the computational capabilities of hardware pro viders. Scheduling as- sets dynamically at run time requires cost models and output cardinalit y estimates that capture al- gorithm b eha vior on heterogeneous computing re- sources. Although such cost models [37, 38] and cardinalit y estimates [34, 98] exist for sp ecific ap- plications, Agora requires more generic models to reflect the asset diversit y . A promising approach is to synthesize complex algorithms from basic data la y out design c hoices and data access primitiv es, whic h one can quic kly b enchmark on different pro- cessors [42]. This approach has been demonstrated only on CPUs. W e will extend these basic building blo c ks to capture the sp ecific prop erties of heteroge- neous computing resources. Still, Agora mus t adapt algorithms to the specific pro cessor they run on to exploit the full p otential of heterogeneous comput- ing resources. F or this, we must automatically gen- erate suc h pro cessor-sp ecific algorit hm implemen ta- tions. Our previous work [11, 77, 78] demonstrates that this is indeed feasible: Data processing systems can learn processor-sp ecific implemen tations dur ing installation or at runtime. The abov emen tioned research challenges present the opp ortunit y to integrate and adv ance database re- searc h in many sub-fields, from query compilation and pro cessing to information integration to data mining, while dealing with priv acy , security and billing as well as with heterogeneous hardware and other nov el computer architectures. 5. RELA TED WORK Most adv anced DS systems require huge amoun ts of data, cutting edge data science inno v ations, and p o w erful computational infrastructure. Agora aims to connect providers and users of these key assets in an op en ecosystem. In con trast, recen t works suc h as Op enAI [64], Ocean Proto col [62], ML Bazaar [83], Enigma [27], Datum [35], and Neb- ula [44] tackle only parts of the solution pro vided b y Agora. F or example, OpenAI [64] is the first non-profit research initiativ e promoting “op enness” in AI. This organization aims at ensuring that AI b enefits touc h all of h umanit y . How ev er, it pri- marily builds custom solutions and shares them via free soft w are for training, b enchmarking, and ex- p erimen ting. Ocean Protocol [62] has similar goals with Agora, i.e., democratizing AI by giving equal opp ortunities to every one to access data. T o ac hiev e this they develop a decentralized proto col and net- w ork to b e used as a foundational substrate to p o w er a new ecosystem of data marke tplaces. How- ev er, their fo cus in only on the data asp ect. Da- tum [35] fo cuses on the priv atization and secure storage of data sharing and proposes a netw ork based on blo ck c hain tech nology that allows users to tak e control of their data, b oth p ersonal and data from IoT devices they own. Enigma [27] of- fers a proto col for computations on encrypted data b y enabling computational resources to be shared securely in a decentralized manner and Nebula [44] forms a cloud of edge computers to p erform dis- tributed data-intensiv e computing. In the space of mac hine learning, ML Bazaar [83] prop oses a uni- fied ML API to ease the developmen t and sharing of ML algorithms. Although such primitiv es can b e used in our sp ecification, Agora go es beyond a sim- ple abstraction to a holistic solution for democratiz- ing AI and data science. Although all these efforts are going in the right direction for building a data ecosystem, it is still hard to combin e them for devis- ing new solutions. Our work envisions a single data ecosystem where data, DS tec hnologies, and stor- age and compute resources can easily b e com bined to give birth to new data insights or tec hnologies. There are also initiatives in pro viding mark et- places for sharing data [19, 21], data science to ols [ 5, 31, 54], AI [54, 2, 5, 9], and services [79, 28]. When it comes to matchm aking, previous solutions are in- spired b y the seman tic w eb reseac h communit y that address a similar problem for w eb services [65], in- cluding solutions for automated web service compo- sition [25]. The industry has also brought storage, computational, and cloud resources at the reach of the masses. Amazon EC2 [4], Microsoft Azure [54], and IBM Cloud [41] are just few examples of such efforts. Neverthele ss, all these efforts pro vide lo ck- in solutions: Users must stick to one provider for the entire pipeline of their solutions. W e envision an op en data ecosystem where one can combine re- sources from differen t mark etplaces without lo c k-in effects. The research comm unit y has also prop osed man y solutions to facilitate data pro cessing in general from differen t angles: such as scalable data process- ing systems [99, 6], declarativ e data querying [26, 63], intelligen t systems [47], internet-of-things sys- tems [55, 101], and cross-platform (a.k.a. polystore) pro cessing [3, 24, 33], among others. All these works are orthogonal and complemen tary to our vision: one could see them as the assets b eing offered in Agora. 6. CONCLUSION W e presented Agora, our vision tow ards a uni- fied asset ecosystem. Assets are fine-grained data- related units of pro duction, such as data, algo- rithms, and ph ysical infrastructure comp onen ts. Agora provides the technical infrastructure for of- fering, using, and comb ining assets to form nov el data-driv en applications and to deriv e new insigh ts. One can share assets through mark etplaces, use and com bine them through asset managers, and exe- cute them through execution managers. Ultimately , Agora aims at providing op en access to the entire data v alue chain, thereb y prev en ting lo c k-in effects and removing entry barriers for new asset pro viders. W e pointed out 15 open research challenge s that the database research comm unit y should address to mak e suc h an asset ecosystem a realit y . W e dis- cussed different p otential solutions with resp ect to asset management, complaint asset pro cessing, as- set pricing and billing, asset priv acy and security , as well as efficient asset execution. This pap er is a call for action as we b elieve that the database communit y is well p ositioned to lead the efforts tow ards a unified asset ecosystem. That, in turn, will hav e p ositiv e implications on so ciety , econom y , and science: • So ciety : It w ould b e used not only by economic op erators but also b y research institutions, univer - sities, schools, and citizens, which w ould ha v e a h uge b enefit in data literacy . F or example, students could be pla yfully in troduced to programming, data analysis, and even p otential business mo dels. La y p eople could also prepare chores, or even p oten tial business models, by developing on top of the ex- p osed data and analytics infrastructure. Most im- p ortan tly , data and DS technologies could remain with their o wners. Every one could contrib ute to the big asset ecosystem. • Ec onomics : It woul d pro vide a breeding ground for data-driven technology inno v ation by exp osing data and DS technologies. This w ould reduce the cost of new insigh ts or the establishmen t of new business models. In this wa y , it can b ecome an inno v ation engine for education, business mo dels, business start-ups, and data-driven v alue creation. It would also hav e a huge impact on small and medium-sized enterprises by having a lo w er entry threshold for the use of a data and analysis infras- tructure. F or example, it w ould enable a restaurant to predict ho w long they will ha v e to sta y op en on a giv en ev ening in order to b etter plan human re- sources. Additionally , it would motiv ate a consis- ten t implementation of op en standards, whic h, in turn, could break the curren t vendor lock-in effects. • Scientific : It would make to ols of the entire data v alue chain (processing, analysis, and visualization) re-usable and easy-to-use (web-based, plug & pla y , a com bination of publ ic and priv ate data in an anal- ysis). This would enable more researchers to derive insigh ts from data without deep knowledge ab out data management and algorithms. It would also foster scientific innov ation by enabling researchers to easily share their data insigh ts and technologies. Moreo v er, it w ould ignite new researc h in all sci- ences by providing scientis ts with access to a large amoun t of data and state-of-the-art DS technolo- gies. 7. REFERENCES [1] D. Abadi, A. Ailamaki, D. Andersen, P . Bailis, M. Balazinsk a, P . Bernstein, P . Boncz, S. Chaudhuri, A. Cheung, A. Doan, L. Dong, M. J. F ranklin, J. F reire, A. Halevy , J. M. Hellerstein, S. Idreos, D. Kossmann, T. Krask a, S. Krishnamurth y , V. Markl, S. Melnik, T. Milo, C. Mohan, T. Neumann, B. C. Ooi, F. Ozcan, J. Patel, A. Pa vlo, R. Popa, R. Ramakrishnan, C. Re, M. Stonebraker, and D. Suciu. The Seattle Rep ort on Database Research. h ttps://db.cs.w ashington.edu/ev ents/other/ 2018/Seattle DBResearc h Rep ort- F ull.pdf . [2] Acumos. https://www.acumos.org. [3] D. Agraw al, S. Chawla, B. Contreras-Ro jas, A. Elmagarmid, Y. Idris, Z. Kaoudi, S. Kruse, J. Lucas, E. Mansour, M. Ouzzani, P . Papotti, J.-A. Quiane-Ruiz, N. T ang, S. Thirumuruganathan, and A. T roudi. Rheem: enabling cross-platform data pro cessing – may the big data b e with you! In PVLDB , 2018. [4] Amazon EC2. https://a ws.amazon.com/ec2. [5] A WS Marketplace. https://a ws.amazon.com/ mark etplace. [6] D. Battr´ e, S. Ewen, F. Hueske, O. Kao, V. Markl, and D. W arnek e. Nephele/P A CTs: A programming mo del and execution framew ork for web-scale analytical pro cessing. In SoCC , 2010. [7] L. Benson, P . M. Grulich, S. Zeuch, V. Markl, and T. Rabl. Disco: Efficien t distributed window aggregation. In EDBT , 2020. [8] M. Bo ehm, M. W. Dusenberry , D. Eriksson, A. V. Evfimievski, F. M. Manshadi, N. Pansare, B. Reinw ald, F. R. Reiss, P . Sen, A. C. Surve, and S. T atik onda. SystemML: Declarativ e machine learning on Spark. In PVLDB , 2016. [9] Bonseyes. https://bonseyes.com/. [10] S. Bork ar and A. A. Chien. The future of microprocessors. Communic ations of the AC M , 54(5):67–77, 2011. [11] S. Breß, B. K ¨ oc her, H. F unk e, S. Zeuch, T. Rabl, and V. Markl. Generating custom co de for efficient query execution on heterogeneous pro cessors. VLDB Journal , 27(6):797–822, 2018. [12] California consumer priv acy act. h ttps://oag.ca.go v/priv acy/ccpa. [13] P . Carb one, A. Katsifo dimos, S. Ewen, V. Markl, S. Haridi, and K. Tzoumas. Apac he Flink: Stream and batch pro cessing in a single engine. Bul letin of the IEEE Computer So ciety T e chnic al Committe e on Data Engine ering , 36(4), 2015. [14] P . Carb one, J. T raub, A. Katsifodimos, S. Haridi, and V. Markl. Cutty: Aggregate sharing for user-defined windows. In CIKM , 2016. [15] Z. Chothia, J. Liagouris, F. McSherry , and T. Rosco e. Explaining outputs in mo dern data analytics. Pr o c. VLDB Endow. , 9(12):1137–1148, Aug. 2016. [16] S. Corb et, B. Lucey , A. Urquhart, and L. Y arov a y a. Crypto currencies as a financial asset: A systematic analysis. International R eview of Financial Analysis , 62:182–199, 2019. [17] V. Costan and S. Dev adas. Intel SGX explained. IACR Cryptolo gy ePrint A r chive , (086):1–118, 2016. [18] D. Dash, V. Kantere, and A. Ailamaki. An economic mo del for self-tuned cloud caching. In ICDE , 2009. [19] Data Space. https://www.datapace.io. [20] Datahub. https://datah ub.io. [21] Dataw ex. https://www.da wex.com. [22] DB Engines. Knowledge base of relational and nosql database management systems. h ttps://db- engines.com/. [23] D. E. Denning and D. K. Branstad. A taxonom y for key escrow encryption systems. Communic ations of the ACM , 39(3):34–40, 1996. [24] J. Duggan, A. J. Elmore, M. Stonebraker, M. Balazinsk a, B. How e, J. Kepner, S. Madden, D. Maier, T. Mattson, and S. Zdonik. The BigDA WG p olystore system. SIGMOD R e c or d , 44(2):11–16, 2015. [25] S. Dustdar and W. Schreiner. A survey on w eb services comp osition. International journal of web and grid servic es , 1(1):1–30, 2005. [26] C. Engle, A. Lupher, R. Xin, M. Zaharia, M. J. F ranklin, S. Shenker, and I. Stoica. Shark: F ast data analysis using coarse-grained distributed memory . In SIGMOD , 2012. [27] Enigma. https://enigma.co. [28] Exp erfy. https://www.experfy .com. [29] J. F ang, Y. T. B. Mulder, J. Hidders, J. Lee, and H. P . Hofstee. In-memory database acceleration on FPGAs: A survey . VLDB Journal . [30] F uel of the future. Data is giving rise to a new economy . The Ec onomist - The world’s most valuable r esour c e - Data and the new rules of c omp etition , 2017. h ttps://econ.st/2uRnmOw. [31] G Suite Marketplace. h ttps://gsuite.google.com/marketplace. [32] General data protection regulation. h ttps://gdpr- info.eu/. [33] I. Gog, M. Sch w arzk opf, N. Cro oks, M. P . Grosv enor, A. Clement, and S. Hand. Musk eteer: all for one, one for all in data pro cessing systems. In Eur oSys , 2015. [34] C. Gregg and K. Hazelwoo d. Where is the data? why you cannot debate CPU vs. GPU p erformance without the answer. In ISP ASS , 2011. [35] R. Haenni. Datum netw ork - the decen tralized data marketplace - white pap er v15. 2017. https://datum.org/assets/Datum- WhiteP aper.p df . [36] A. Hav et, R. Pires, P . F elb er, M. Pasin, R. Rouvo y , and V. Schia v oni. Securestreams: A reactive middleware framework for secure data stream pro cessing. In DEBS , pages 124–133, 2017. [37] B. He, M. Lu, K. Y ang, R. F ang, N. K. Go vindara ju, Q. Luo, and P . V. Sander. Relational query copro cessing on graphics pro cessors. ACM T r ansactions on Datab ase Systems , 34(4):21:1–21:39. [38] J. He, M. Lu, and B. He. Revisiting co-processing for hash joins on the coupled cpu-gpu architecture. PVLDB , 6(10):889–900. [39] W. He, W. Zhang, S. Das, and Y. Liu. Sgxlinger: A new side-channel attack v ector based on interrupt latency against enclav e execution. In ICCD , 2018. [40] T. Hey , S. T ansley , and K. T olle. The F ourth Par adigm: Data-Intensive Scientific Disc overy . 2009. [41] IBM Cloud. https://www.ibm.com/cloud. [42] S. Idreos, K. Zoumpatianos, B. Hentsc hel, M. S. Kester, and D. Guo. The data calculator: Data structure design and cost syn thesis from first principles and learned cost mo dels. In MOD , 2018. [43] IOT A Data Mark etplace. h ttps://data.iota.org. [44] A. Jonathan, M. Ryden, K. Oh, A. Chandra, and J. W eissman. Nebula: Distributed edge cloud for data intensiv e computing. IEEE T r ansactions on Par al lel and Distribute d Systems , 28(11):3229–3242, 2017. [45] Z. Kaoudi, J.-A. Quian´ e-Ruiz, S. Thirumuruganathan, S. Chawla, and D. Agraw al. A cost-based optimizer for gradien t descent optimization. In SIGMOD , 2017. [46] P . Koutris, P . Upadhy a y a, M. Balazinsk a, B. How e, and D. Suciu. Query-based data pricing. Journal of the ACM (JACM) , 62(5):1–44, 2015. [47] T. Krask a, M. Alizadeh, A. Beutel, E. H. Chi, J. Ding, A. Kristo, G. Leclerc, S. Madden, H. Mao, and V. Nathan. SageDB: A learned database system. In CIDR , 2019. [48] D. Lee, D. Kohlbrenner, S. Shinde, D. Song, and K. Asanovic. Keystone: An op en framew ork for architecting tees, 2019. [49] E. Lindholm, J. Nick olls, S. Ob erman, and J. Montrym. NVIDIA T esla: A unified graphics and computing architecture. IEEE Micr o , 28(2):39–55, 2008. [50] T. Lundqvist, A. de Blanche, and H. R. H. Andersson. Thing-to-thing electricity micro pa ymen ts using blo ck chain technology . In 2017 Glob al Internet of Things Summit (GIoTS) , pages 1–6. IEEE, 2017. [51] S. Madden, M. J. F ranklin, J. M. Hellerstein, and W. Hong. T ag: A tiny aggregation service for ad-ho c sensor netw orks. ACM SIGOPS Op er ating Systems R eview , 36(SI):131–146, 2002. [52] C. McMillan, M. Grechanik, D. Posh yv anyk, C. F u, and Q. Xie. Exemplar: A Source Co de Searc h Engine for Finding Highly Relev ant Applications. IEEE T r ansactions on Softwar e Engine ering , 38(5):1069–1087, 2012. [53] R. Mehrotra and B. Carterette. Recommendations in a marketplace (tutorial). In ACM R e c ommender Systems (R e cSys) , 2019. [54] Microsoft Azure. h ttps://azure.microsoft.com. [55] D. Miorandi, S. Sicari, F. De Pellegrin i, and I. Chlamtac. Internet of things: Vision, applications and research challenges. A d Ho c Networks , 2012. [56] P . Moritz, R. Nishihara, S. W ang, A. T umanov, R. Lia w, E. Liang, M. Elib ol, Z. Y ang, W. P aul, M. I. Jordan, and I. Stoica. Ray: A distributed framew ork for emerging AI applications. In OSDI , pages 561–577, 2018. [57] P . Morrissey , N. P . Smart, and B. W arinsc hi. The tls handshake proto col: A mo dular analysis. Journal of Cryptolo gy , 23(2):187–223, 2010. [58] M. H. Namaki, A. Floratou, F. Psallidas, S. Krishnan, A. Agraw al, and Y. W u. V amsa: T racking prov enance in data science scripts, 2020. [59] Navteq. https://here.na vigation.com/. [60] B. Ngab onziza, D. Martin, A. Bailey , H. Cho, and S. Martin. T rustzone explained: Arc hitectural features and use cases. In IEEE CIC , 2016. [61] A. T. Nguyen, Z. T u, and T. N. Nguyen. Do con texts help in phrase-based, statistical source co de migration? In ICSME , 2016. [62] Ocean Proto col. https://oceanproto col.com. [63] C. Olston, B. Reed, U. Sriv astav a, R. Kumar, and A. T omkins. Pig Latin: A not-so-foreign language for data pro cessing. In SIGMOD , 2008. [64] Op enAI. https://openai.com. [65] M. Paolucci, T. Kaw am ura, T. R. Pa yne, and K. Sycara. Semantic matching of web services capabilities. In International semantic web c onfer enc e , pages 333–347. Springer, 2002. [66] H. Park, S. Zhai, L. Lu, and F. X. Lin. StreamBo x-TZ: secure stream analytics at the edge with T rustZone. In USENIX A TC , pages 537–554, 2019. [67] E. Patterson, I. Baldini, A. Mo jsilo vic, and K. R. V arshney . T eac hing machines to understand data science co de by semanti c enric hmen t of dataflow graphs, 2018. [68] A. Pa vlo, E. Paulson, A. Rasin, D. J. Abadi, D. J. DeWitt, S. Madden, and M. Stonebraker. A comparison of approaches to large-scale data analysis. In SIGMOD , 2009. [69] S. Popov. The tangle. cit. on , 2016. [70] N. Porter, J. Garms, and S. Simako v. In troducing Asylo: an op en-source framew ork for confidential computing, 2018. h ttps://cloud.google.com/blog/pro ducts/ gcp/in troducing- asylo- an- op en- source- framew ork- for- confiden tial- computing. [71] C. Prieb e, K. V asw ani, and M. Costa. Encla v eDB: A secure database using SGX. In IEEE Symp osium on Se curity and Privacy (SP) , pages 264–278. IEEE, 2018. [72] G. C. Publio, D. Esteves, A. La wryno wicz, P . Pano v, L. Soldatov a, T. Soru, J. V anschoren, and H. Zafar. ML Schema: Exposing the semantics of machine learning with schemas and ontologies. 2018. [73] J.-A. Quian´ e-Ruiz, P . Lamarre, and P . V alduriez. A Self-Adaptable Query Allocation F ramework for Distributed Information Systems. VLDB Journal , 18(3):649–674. [74] J.-A. Quian´ e-Ruiz, P . Lamarre, and P . V alduriez. SQLB: A Query Allo cation F ramework for Autonomous Consumers and Pro viders. In VLDB , 2007. [75] J.-A. Quian´ e-Ruiz, P . Lamarre, and P . V alduriez. SbQA: A Self-Adaptable Query Allocation Pro cess. In ICDE , 2009. [76] S. Redyuk. Automated do cumentation of end-to-end exp eriments in data science. In ICDE , 2019. [77] V. Rosenfeld, S. Breß, S. Zeuch, T. Rabl, and V. Markl. Performance analysis and automatic tuning of hash aggregation on gpus. In DaMoN , 2019. [78] V. Rosenfeld, M. Heimel, C. Viebig, and V. Markl. The op erator v ariant selection problem on heterogeneous hardware. In ADMS , 2015. [79] Salesforce. https://www.salesforce.com. [80] S. Schelter, F. Biessmann, T. Janusc howski, D. Salinas, S. Seufert, G. Szarv as, M. V artak, S. Madden, H. Miao, A. Deshpande, et al. On challenges in machine learning mo del managemen t. IEEE Data Engine ering , 2018. [81] S. Schelter, J.-H. B ¨ ose, J. Kirschnic k, T. Klein, and S. Seufert. Automatically trac king metadata and prov enance of mac hine learning exp eriments. Machine L e arning Systems workshop at NIPS , 2017. [82] K. Sch w ab. Mastering the fourth industrial rev olution. F or eign Affairs , 2015. [83] M. J. Smith, C. Sala, J. M. Kanter, and K. V eeramachaneni . The machine learning bazaar: Harnessing the ml ecosystem for effectiv e system developmen t. 2019. [84] M. Stonebraker, P . M. Aoki, W. Litwin, A. Pfeffer, A. Sah, J. Sidell, C. Staelin, and A. Y u. Marip osa: A Wide-Area Distributed Database System. VLDB Journal , 5(1):48–63, 1996. [85] A. Suny aev and S. Schneider. Cloud services certification. Communic ations of the ACM , 56(2):33–36, 2013. [86] A. T ang, S. Seth umadha v an, and S. Stolfo. CLKSCREW: exp osing the p erils of securit y-oblivious energy management. In USENIX Se curity Symp osium , 2017. [87] J. T eubner and L. W o o ds. Data pro cessing on FPGAs. Synthesis L e ctur es on Data Management , 5(2):1–118, 2013. [88] The future of data: Adjusting to an opt-in econom y. Oxfor d Ec onomics R ep ort , 2018. h ttps://www.o xfordeconomics.com/recen t- releases/the- future- of- data. [89] C. Thoma, A. J. Lee, and A. Labrinidis. Behind enemy lines: Exploring trusted data stream pro cessing on untrusted systems. In AC M Confer enc e on Data and Applic ation Se curity and Privacy , pages 243–254, 2019. [90] J. T raub, P . M. Grulich, A. R. Cuellar, S. Breß, A. Katsifo dimos, T. Rabl, and V. Markl. Scotty: Efficient windo w aggregation for out-of-order stream pro cessing. In ICDE , 2018. [91] J. T raub, P . M. Grulich, A. R. Cu´ ellar, S. Breß, A. Katsifo dimos, T. Rabl, and V. Markl. Efficient window aggregation with general stream slicing. In EDBT , 2019. [92] D. Tsoumakos and C. Mantas. The case for m ulti-engine data analytics. In Eur o-Par , 2013. [93] P . Upadhy ay a, M. Balazinsk a, and D. Suciu. Automatic enforcement of data use p olicies with datalawy er. In Pr o c e e dings of the 2015 AC M SIGMOD International Confer enc e on Management of Data , SIGMOD ’15, page 213–225, 2015. [94] D. Vinay agam urth y , A. Grib ov, and S. Gorbunov. StealthDB: a scalable encrypted database with full SQL query support. Pr o c e e dings on Privacy Enhancing T e chnolo gies , 2019(3):370–388, 2019. [95] J. W ang, Z. Hong, Y. Zhang, and Y. Jin. Enabling security-enhanced attestation with in tel sgx for remote terminal and iot. IEEE T r ansactions on Computer-Aide d Design of Inte gr ate d Cir cuits and Systems , 37(1):88–96, 2017. [96] A. Xu, M. Li, X. Huang, N. Xue, J. Zhang, and Q. Sheng. A blo ck chain based micro pa ymen t system for smart devices. Signatur e , 256(4936):115, 2016. [97] Yelp display requirements. h ttps://www.y elp.com/dataset/. [98] Y. Y uan, R. Lee, and X. Zhang. The yin and y ang of pro cessing data warehousing queries on GPU devices. In PVLDB , 2013. [99] M. Zaharia, M. Chowdh ury , M. J. F ranklin, S. Shenker, and I. Stoica. Spark: Cluster computing with working sets. In USENIX HotCloud , 2010. [100] M. Zaharia, R. S. Xin, P . W endell, T. Das, M. Armbrust, A. Dav e, X. Meng, J. Rosen, S. V enk ataraman, M. J. F ranklin, et al. Apac he Spark: a unified engine for big data pro cessing. Communic ations of the ACM , 59(11):56–65, 2016. [101] S. Zeuch, A. Chaudhary , B. Del Monte, H. Gavriilidis, D. Giouroukis, P . M. Grulich, S. Breß, J. T raub, and V. Markl. The NebulaStream Platform: Data and application management for the internet of things. CIDR , 2020. [102] W. Zheng, A. Dav e, J. G. Beekman, R. A. P opa, J. E. Gonzalez, and I. Stoica. Opaque: An oblivious and encrypted distributed analytics platform. In USENIX NSDI , pages 283–298, 2017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment