MFRNet: A New CNN Architecture for Post-Processing and In-loop Filtering
💡 Research Summary
The paper introduces MFRNet, a novel convolutional neural network (CNN) architecture specifically designed to improve post‑processing (PP) and in‑loop filtering (ILF) in modern video codecs. The authors motivate the work by noting the growing demand for high‑quality video (including AR/VR) and the limitations of current standards—HEVC and the newer VVC—in handling visual artifacts such as blocking, ringing, and blurring that arise from quantisation, especially in the Random Access (RA) configuration which is the most widely used mode in practice.
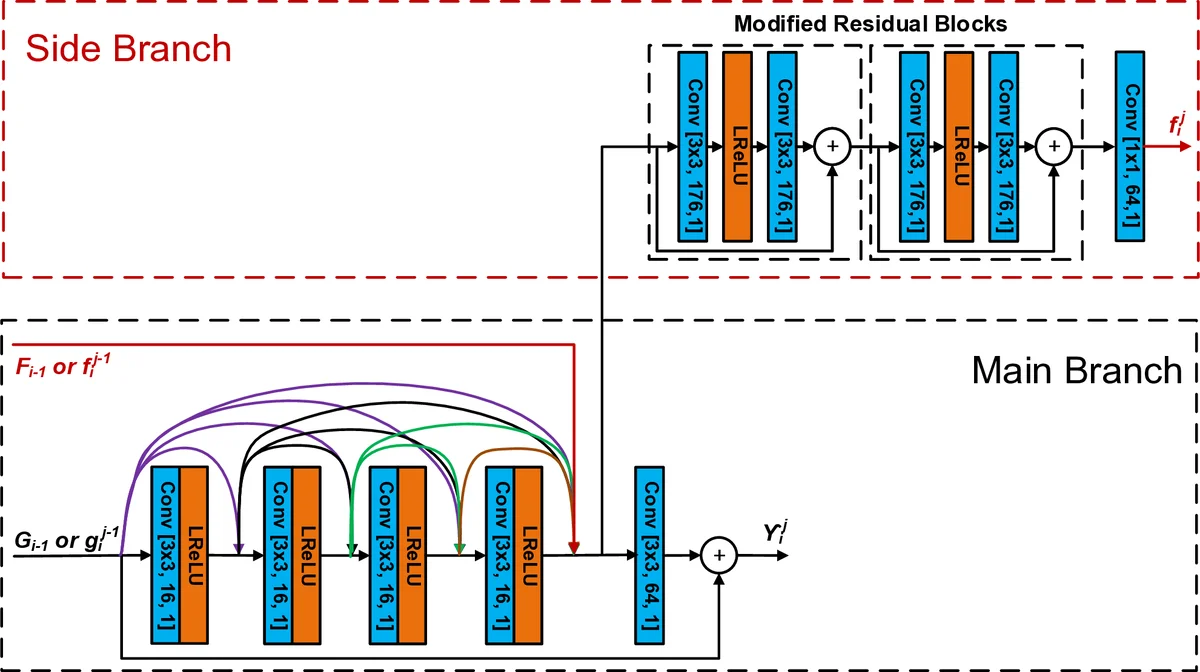
MFRNet’s core building block is the Multi‑level Feature Review Residual dense Block (MFRB). Four MFRBs are arranged in a cascading fashion, each containing three Feature Review Residual dense Blocks (FRBs). An FRB differs from conventional residual or dense blocks in that it possesses a main branch and a side branch. The main branch processes the current input together with the output of the preceding block through four densely connected 3×3 convolutions (64 channels each). The side branch receives high‑dimensional features (HDFs) propagated from the previous FRB or MFRB, concatenates them with the dense features, and passes them through a 1×1 convolution. The two branches are then merged, producing both a main‑branch output and a side‑branch output that is fed forward as HDF to the next FRB. This dual‑path design enables “feature review”, i.e., the network repeatedly revisits high‑level information generated earlier, mitigating the diminishing‑feature‑reuse problem common in deep CNNs.
The overall pipeline begins with a shallow feature extraction layer (96×96 YCbCr 4:4:4 patch, Leaky ReLU activation). The extracted shallow features are fed into the four MFRBs. Cascading connections (implemented via 1×1 convolutions) inject the original shallow features and the outputs of the first three MFRBs (G₁, G₂, G₃) into subsequent blocks, enhancing information flow while keeping the model compact. After the fourth MFRB, a reconstruction layer (RL1) is added, and a long skip connection adds the shallow features back to the RL1 output. A second reconstruction layer (RL2) and a final convolution produce a residual image, which is added to the original input through a long‑range skip connection, yielding the final filtered patch.
Training uses the BVI‑DVC video database together with additional high‑resolution sequences, employing a mixed loss that combines L1 pixel error and a perceptual VMAF‑based term. Data augmentation (flipping, rotation, colour jitter) and the Adam optimizer (initial LR 1e‑4) are applied for up to 2 M iterations. The network is trained on 96×96 patches, which matches the typical block size used in HEVC/VVC coding loops.
For evaluation, the authors integrate MFRNet into both the HM 16.20 (HEVC) and VTM 7.0 (VVC) reference software, creating four variants: HEVC‑PP, HEVC‑ILF, VVC‑PP, and VVC‑ILF. Experiments follow the JVET Common Test Conditions (CTC) Random Access configuration, covering a diverse set of test sequences. Performance is measured using Bjøntegaard Delta (BD‑Rate) reductions for both PSNR and VMAF.
Results show substantial gains. In HEVC, MFRNet‑ILF achieves up to 16.0 % BD‑Rate reduction (VMAF) and MFRNet‑PP up to 21.0 % reduction, outperforming prior CNN‑based PP/ILF methods such as VRCNN, DRN, and ResNet‑based filters. In VVC, the gains are slightly lower but still significant: up to 5.1 % (ILF) and 7.1 % (PP) BD‑Rate reductions. To isolate the contribution of the architecture, the authors retrain 13 popular CNN models (AlexNet, VGG, ResNet, DenseNet, etc.) on the same data and evaluate them under identical conditions; MFRNet consistently delivers the best trade‑off between parameter count, convergence speed, and coding efficiency.
The paper also discusses practical considerations. While MFRNet delivers impressive quality improvements, its current patch‑based design and parameter count may pose challenges for real‑time encoding/decoding on resource‑constrained devices. Future work is suggested on model pruning, quantisation‑aware training, and hardware‑friendly implementations (e.g., FPGA or ASIC accelerators). Moreover, extending the evaluation to other coding configurations (All‑Intra, Low‑Delay) and to higher resolutions (8K) would further validate the generality of the approach.
In conclusion, MFRNet introduces a sophisticated yet effective way to enhance video codec post‑processing and in‑loop filtering by leveraging multi‑level feature review and residual dense connections. The extensive experimental validation on both HEVC and VVC demonstrates that the architecture yields consistent and sizable BD‑Rate savings, establishing a new state‑of‑the‑art baseline for CNN‑based video compression enhancements.
Comments & Academic Discussion
Loading comments...
Leave a Comment