Deep learning for magnitude prediction in earthquake early warning
Fast and accurate magnitude prediction is the key to the success of earthquake early warning. We have proposed a new approach based on deep learning for P-wave magnitude prediction (EEWNet), which takes time series data as input instead of feature pa…
Authors: Yanwei Wang, Zifa Wang, Zhenzhong Cao
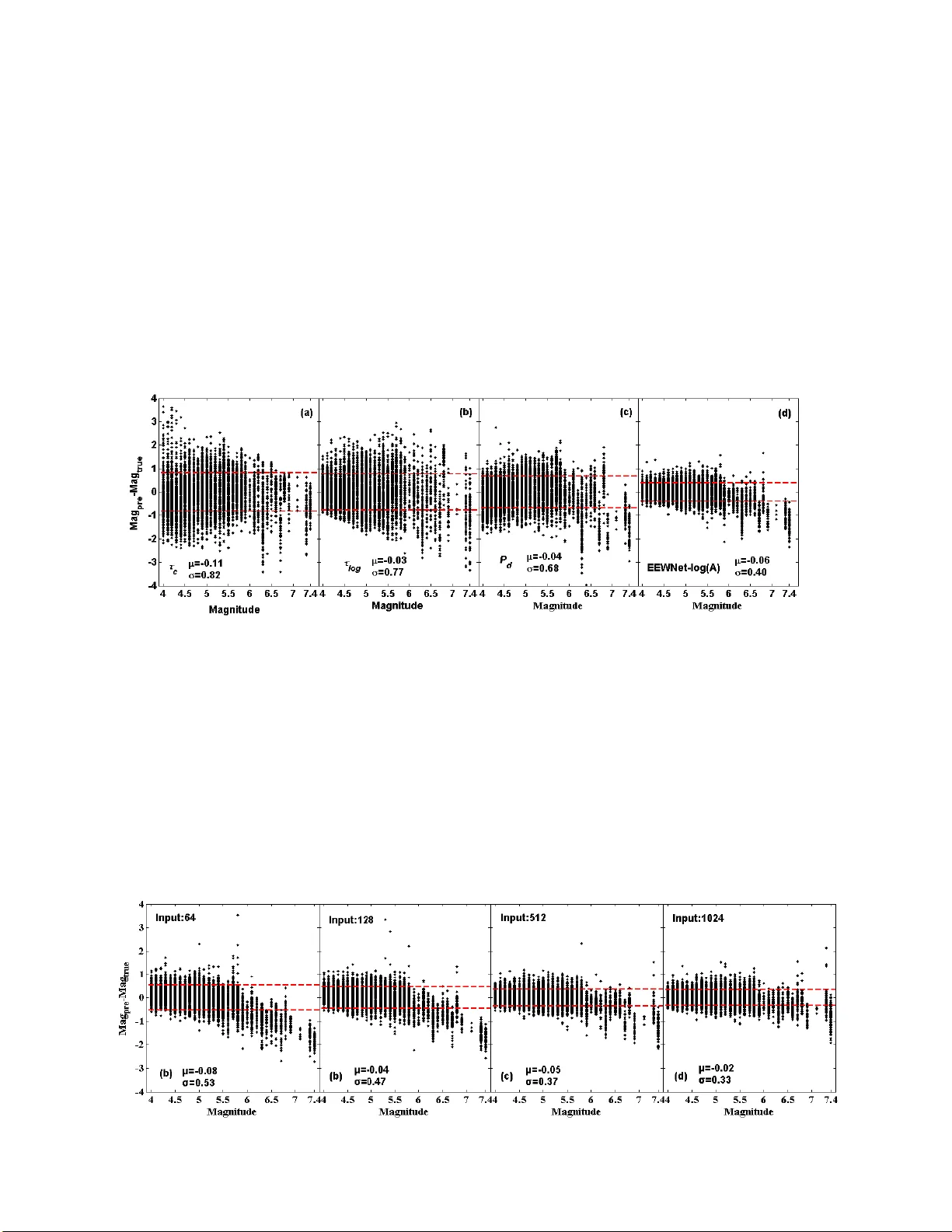
D e e p l e a r n i n g f o r m a g n i t u d e p r e di c t i o n i n e a r t h q u a k e e a r l y w a r n i n g Yanwei Wang 1 , Z ifa Wang 2 ,3 , Zhenzhong Cao 1 , and Jingyan Lan 1 1 Guangxi Key Laboratory of Geomechanics and Geotechnical Engineering, Guilin University of Technology, Guilin, China. 2 College of Architecture and Civil Engineering, Henan University, Kaifeng, China 3 Institute of Engineering Mechanics, China Earthquake Administration , Harbin, China. Corresponding author: Z. F. Wang ( zifa@iem.ac.cn) Key Points: • A self-adaptive deep learning approach is proposed for magnitude prediction. • The approach is trained on a moderate-size data set and achieves better performance than other approach es . • The research suggests that deep learning has great potential application in EEW . Abstract Fast and accurate magnitude prediction is the key to the success of earthqu ake early warning . We have proposed a new approach based on deep learning for P-wave magnitude prediction (EEWNet), which takes ti me series data as input instead of feature parameters. The architecture of EEWNet is adaptively adjusted according to the length of the input, t hus eli minates the need of complicated tuning of hyperparameters for deep learning. Only the unfiltered accelerograms of vertical components are used. EEWNet is trained on a moderate number of data set (10,000s of rec ords), but it achieves excellent result s in magni tude pre diction compared with approaches using parameters τ log , τ c and P d . Plain Language Summary After an earthquake occurs, earthquake early warning (EEW) sends warni ng information to service areas by using the first-arriving P- wave before the destructive S-wave arrives. Accurate earthquake magnitude prediction is the key challenge in EEW. In this paper, we applied the deep learning method in designing a neural network approach (EEWNet) to address those the challenge. Afte r testing, EEWNet trained with a moderate number of data set (less than 20,000) has obvious advantages over traditional algorithms, with great application potential in future EEW systems. 1 Introduction Most of magnitude prediction algorit hms rely on relations between magnitude and manually defined parameters of initial P-wave(e.g. 3s), such as predominant period τ p (Nakamura,1988), max pre dominant period τ p max (Allen & Kanamori, 2003), average period τ c (Wu & Kanamori, 2005), the log -average period τ log (Ziv, 2014), and peak displacement P d (Wu & Zhao, 2006). While many approaches have been attempted, the probl em of magnitude prediction has not been well re solved probably due to the lack of whole fractu re information and the limitations of the parameters themselves. Magnitude is a manually defined parameter related to the ground displacement. Using the initial P-wave as the input of deep learning to pre dict the maximum displacement of the complete record used to calculate magnitude seems to be an attractive proposal because of its direct applicability . The disadvantage of deep learning is that it usually requires a large labelled data set for training, which limits its application. In earthquake studies, there are millions of seismic records (seismograms and accelerograms) for sma ll earthquakes ( M < 4) , while the records for medium to large earthquakes ( M >= 4) applicable to EEW are limited in size , especially with added conditions defined by hypocentral distance, signal to noise ratio (SNR), peak amplitude and others. The challenge we fac e is, can deep learning approach trained by a moderate labelled data set be used to predict magnitude? In this paper, we have developed a new deep learning approach (EEWNet) for magnitude prediction in EEW. EEWNet is built on convolution neural network, which automatically adjusts its architecture according to the length of input. The vertical accelerogram without any preprocessing is used as the input to EEWNet and the final maximum displacement is predicted. The magnitude can be calculated by the displacement. Tens of thous ands of accelerograms labeled were used to train, validate and test EEWNet instead of a large data set in th e order of millions that is often required by comparable approaches. 2 Data and Methods 2.1 Data sets In this study, we used a high-quality data set that consists of 30,75 6 accelerograms recorded by 688 strong motion borehole sensors of the Kiban Kyoshin network (KiK-net) (10/1997~03/2019), with magnitude from 4 to 9 (3,648 earthquakes) and hypocentral distance between 25km and 200km. All acce lerograms were vertical components and resampled to 100Hz. Two selection criteria were used to guarantee the high-quality of these accelerograms. One was the peak ground acceleration (PGA) over 2 gal, and the other was to check the data to avoid incomplete records, baseline drift records, and records containing multiple events (Figure S1). After that the signal to noise ratio (SNR) (Perol et al., 2018) of the data set is mostly greater than 10. We manually picked the P-wave arrival time to ensure accuracy. Each accelerogram was labeled for P-wave arrival time and the logarithm of the maximu m displacement in the horizontal components. Selected accelerograms were divided into three data sets: 17,717 accelerograms from 10/1997 to 12/2011 were used as the training data set, 6,106 accelerograms fr om 01/2012 to 12/2014 were used as the validation data set, and 6,933 accelerograms from 01/2015 to 03/2019 were used as the test data set. The training and validation data sets were used for training and tuning hyperparameters of deep learning. The test data set was used to assess the performance of the deep learning after training. 2.2 EEWNet The architecture of EEWNet is developed based on the one-dimensional convolution neural network, which is used to deal with the regression of a sequential data set. The architecture of EEWNet is composed of an input, multiple hidden layers, a fully connected layer and an output, as shown in Figure 1. For predicting magnitude, the input is the initial P-wave, and the output is the logarithm of the maximum displ acement in the horizontal components of the complete records. EEWNet was trained by the training data set through optimization of the loss function defined as mean square error of output values. The self-adaptive architecture of the EEWNet were obtai ned by the performance of the tr aining and validation data sets. For 2 N lengt h of input, the total number of hidden layers is N , and each hidden layer is compos ed of a standard convolution operation consisting of 2 L +3 filters and a pooling operation. L is the serial number of hidden layer and equals to 1, 2, 3, …, N . For each filter, kernel size is 2, stride is 1 and padding type is ‘same’. The activation function of convolutional layer uses rectified linear units (ReLUs) (Nair & Hinton, 2010). For each pooli ng opti mization, method=”max pooling”, size=2 and stride=2. The keep probability of dropout for the last pooling layer is 0.5. The fully connected layer is a vector with 2 N +3 . The Adam stoch astic optimization algorithm (Kingma & Ba, 2015) was used for the optimization with a learning rate of 0.0001. The batch size and epochs can be adjusted according to computer memory and computational convergence res pectively. Here each batch consists of 200 accelerograms and epochs are 400. The architecture of EEWNet has four characteristics: the number of layer and filter siz e are adaptive to input; the length of input time series data can be less than 2 N , but 2 N is recommended; each feature map in the last hidden layer is a value (1× 1 dimension); and there are no normaliza tion and regularization operations. EEWNet repeats convolution and pooling operations to achi eve desired performance. For this study, EEWNet was programmed with TensorFlow GPU 1.6. Figure 1 . The architecture of EEWNet 3 Results Magnitude of Kik -net given by Japan Meteorological Agency (JMA) is based on the maximum amplitudes of seismograms as shown into the following (Doi, 2014). log 10 (𝐴) = 𝑎 × 𝑀 + 𝑏 × log 10 (𝑅 ) + 𝑐 (1) where A is maximum velocity or displacement of the complete record, M is magnitude, R is hypocentral dist ance, a , b and c are fitting coefficients. In EEW, magnitude is pre dicted by using formulas similar to equation (1), but it is based on the ini tial P-wave instead of the complete record , using parameters such as τ c , τ log and P d . τ c and τ log are frequency-based parameters that do not need to be corrected by hypocentral distance (Zi v, 2014). P d needs be corrected by hypocentral distance (Wu & Zhao, 2006). Her e, initial P-wave of vertical accelerogram is used as the input of EEWNet to predict log 10 ( A ). A is the maximum displacement (μm, 1e -6m) in the horizontal components of the complete records (Doi, 2014). Magnitude can be then calculated by equation (1). To evaluate the per formance of EEWNet, τ log , τ c and P d , were als o used to predict magnitude for comparison. The first 2.56s (2 8 samples) P-waves were used for the training, vali dation and test of EEWNet. The arch it ecture of EEWNet was determined by N =8. The fitting coefficients a , b and c of τ c , τ log , P d and log 10 ( A ) were estimated based on the training and validation data sets. T he prediction errors of the test data set as a function of magnitude was shown in Figure 3. The standard deviation σ for τ c , τ log , P d and EEWNet was 0.82, 0.77,0.68, and 0.40, respectively. The percentage of magnitude errors between -0.5 and 0.5 was 46.86%, 50.78%, 55.65% and 84.21% for τ c , τ log , P d and EEWNet, res pectively, indicating EEWNet having much better magnitude prediction accuracy. Figure 3 . Magnitude prediction errors as a function of magnitude for τ c, τ log , P d a nd EEWNet. τ log , τ c and P d were filtered using a 0.075Hz casual Butterworth high-pass filter with two poles. The calculation of τ log was ba sed on power spectrum of acceleration instead of velocity. μ and σ were mean and standard deviation of errors. The black points indicated the errors of each prediction, and the red dashed lines were for 0 ± σ . In EEW, magnitude needs to be continuously updated. To evaluate the performance of EEWNet with different lengths of initial P-wave, 64, 128, 512 and 1024 samples of initial P-wave were used to train and test respectively. The prediction error s of the test data set as a function of magnitude with different length of P-wave was shown in Fi gure 4. It is obvious that the standard deviation of prediction errors decreased with increasing input le ngth, and the magnitude prediction of large earthquakes improved with the incr eased length of P -wave. T o test for sample size other than 2 N , 50, 100, 200 and 300 samples of initial P-wave were als o used to train and test EEWNet, whose architecture was determined by inputs of length 64, 128, 256 and 512, respectively, and EEWNet achieved similar results. Figure 4 . Magnitude prediction errors as a function of magnitude for EEWNet wi th different length of P -wave. The black points indicate the errors of each prediction, and the red dashed lines are the 0 ± σ. 4 Conclusions We have proposed a new approach, EEWNet, based on convolutional neural ne twork to predict magnitude for EEW. EEWNet used verti cal accelerogram directly as an input without any preprocessing. The architecture of EEWNet is self-adaptive and it adjusts according to different length of inputs. This feature avoids hyperparameter tuning when the input length varies as in the case of mag nit ude prediction in EEW where P- wave length is increasing over time. For magnitude prediction, EEWNet was used to predict th e maximum displacement in the horizontal components of the complete rec ords to calculate the magnitude. The result was compared against those based on parameters τ log , τ c and P d using the different lengths of initial P-wave. The comparison demonstrated that EEWNet achieved the highest precision with the smallest standard deviation. Moreover, the accuracy of magnitude prediction of EEWNet increased with increasing length of P-wave. The excellent performance of EEWNet shows its great application potential in EEW. Acknowledgments We would like to thank KiK-net online database for the recorded data (last accessed in March 2019). We are grateful to A. Ziv for sharing his source code of τ log . This research has been supported by the National Natural Scienc e Foundation of China (Grant No. 51968016 and No. 51978634) and the Guangxi Innovation Driven Development Project (Science and Technology Major Project, Grant No. Guike AA18118008). References Allen, R. M., & H. Kanamori (2003). The potential for earthquake early warning in Southern California, Science 300, 685 – 848. https://doi.org/10.1126/science.1080912 Doi, K., Seismic Network and Routine Data Processing - Japan Meteorological Agency, In Summary of the Bulletin of the International Seismological Centre, July - December 2010, 47 (7 – 12), 25 – 42, Thatcham, United Kingdom, 2014. Kingma, D. P., & Ba, J. L. (2015). Adam: a method for stochastic optimization. The 3rd International Conference for Learning Representations, May 7-9, 2015, San Diego. Nair, V., & Hinton, G. E. (2010). Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th international conference on machine learning (ICML-10), 807 – 814. Nakamura, Y. (1988), On the urgent earthquake detection and alarm system (UrEDAS), paper presented at 9th World Conference on Earthquake Engineering VII, Tokyo, 673 – 678. Perol, T., Gharbi, M., & Denolle, M. (2018). Convolutional neural network for earthquake detection and location. Science Advances, 4(2), e1700578. https://doi.org/10.1126/sciadv.1700578 Wu, Y. M., and H. Kanamori (2005), Experiment on an onsite early warning method for the Taiwan early warning system, Bulletin of the Seismological Society of America, 95(1), 347 – 353. https://doi.org/10.1785/0120040097 Wu, Y. M., and Zhao, L. (2006), Magnitude estimation using the first three seconds p ‐ wave amplitude in earthquake early warning. Geophysical Research Letters, 33(16). https://doi.org/10.1029/2006GL026871 Ziv, A. (2014). New frequency ‐ based real ‐ time magnitude proxy for earthquake early warning. Geophysical Research Letters, 41(20), 7035 – 7040. https://doi.org/10.1002/2014GL061564
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment