Stochastic Dispatch of Energy Storage in Microgrids: An Augmented Reinforcement Learning Approach
The dynamic dispatch (DD) of battery energy storage systems (BESSs) in microgrids integrated with volatile energy resources is essentially a multiperiod stochastic optimization problem (MSOP). Because the life span of a BESS is significantly affected…
Authors: Yuwei Shang, Wenchuan Wu, Jianbo Guo
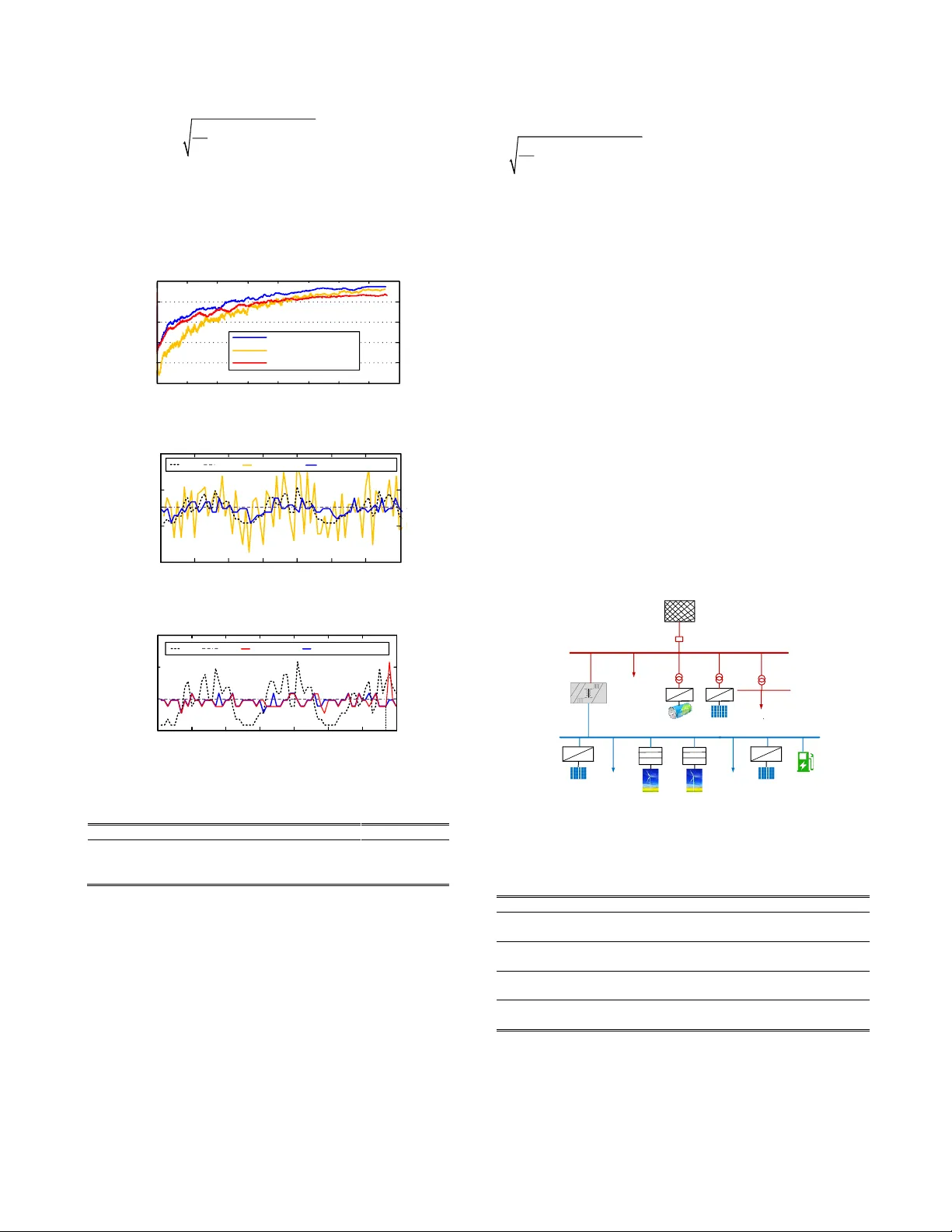
1 Abstract — T he dynamic dispatch (D D) of battery energy storage systems (BESS s ) in m icrogrids integrated w ith volatile energy resources is essenti ally a mu ltiperiod stochastic optimization problem (M SOP) . Because the li fe span of a B ESS is significantly affected by its charging and discharging behavior s , its lifecycle degradation costs should be incorporated in to the DD model of BESS s, which mak es it non-convex. In general, th is MSOP is in tractable. To solve this problem , we propose a reinforcement learning (R L) solution augmented with Monte-Carlo tree search (M CTS) and do ma in knowledge expressed as dispatching rules. In th is solution , the Q-learning with func tion approxi m ation is employed as the basic learning architecture that allows multist ep bootstrapping and continuous policy learning. To i mprove the c omputation efficiency of randomized m ultist ep simulations, w e employed the M CTS to estimate the expected maximum action values. M oreov er, we embedded a few dispatching ru les in RL as probabilistic l ogics to reduce infeasible action ex plorations , w hich can improve the quality of the data-driven solution. N umerical test results sho w the prop osed algorithm outper for ms other baseline RL algorithms in all cases tested. Index Ter ms — m icrogrid, energy storage, vo latile energy resource, dynamic dispatch, reinforcement learning. N OMENCLAT URE For the management of battery ener gy storage systems : SOC Battery state of charge battery self-dischar ge rate B battery charging/disc harging ef ficiency P B charging/discharging p ower of the batter y Ca capacity of the batter y V B-nom rated voltage of the b attery li fetime throughput of the battery N f number of cycles unti l failure o f the battery min ma x , BB PP minimum, maximu m power of the b attery min ma x , SO C SO C minimum, maximu m state of char ge c electricity tariff Manuscript received XX, 2019. This work was sup ported in part by the National Scie nce Foundation of China under G rant 5172570 3. Y. Shang, W. Wu are with Tsinghua University, 100084 Beijing, China (Corresponding A uthor: Wenchua n Wu, email: w uwench@tsinghua.edu.c n ). J. Guo, Z. M a, W. Sheng a re with China Electric Power Research Institute, 100192 Beijing, China. Z. Lv, C. Fu are with North C hina Electric Power University, 1 02206 Beijing, Ch ina. min ma x , PCC PCC PP minimum, maximu m power at PCC DOD Depth of discharge In the Markov dec ision process: a , s , R action, state, immediate re ward , , set of all actions, state s, rewards Pr probability transition function policy (action selectio n rule) Q(s,a) value function for taking action a in state s step-size para meter discount-rate para meter tn t G + cumulative rewards from t to t+n | as potential function for the domain knowledge f set of feasible action s I. I NTRODUCTI ON A. Backgrou nd olatile energ y resources, such as loads from r enewable energy based distributed generato rs (DGs) and electric vehicles (EV s), significantly affect the operation of power systems . In microgrids, we can coordinate volatile energy resources and energy storage to mitigate power f luctuatio ns [1] . Hence, battery energy storage systems ( BESSs ) are w idely us ed to balance the power and shave peaks in microgrids [ 2] . Furthermore , BESSs can b e scheduled to increa se the electricity revenue for microgr id entities by chargi ng energy in low-price per iods and dischar ging energy in h igh-price per iods [3] . Therefore , ho w to dy na mically d ispatch the B ESS suc h that the o peration al costs of the microgrids are minimized while satisfying the operational constraints of the distributio n network is a key challenge. Many studies have focused on the dynamic d ispatch of BESSs. Som e w orks em ploy deter ministic o ptimization models. However, d ue to the stoc hastic nature of DGs and EV s , t he dynamic dispatch o f BESSs is essentia lly a multiperi od st ochastic op timization problem (M SOP). One way to so lve MSOPs is to app ly scenario -based stocha stic progra mming (SP). In this approach, Monte Carlo simulations are employed to repeatedly generate scenarios across a m ultist ep process. The computational b urden increases exponentially with the numb er of scenarios investigated. Add itionally, the life span of a BE SS is significa ntly influenced by its chargin g and d ischarging behavior. When incorporating th e lifecycle degradation costs of Y uwei Shang, Wenchuan Wu, Sen ior Member, IEEE , Ji anbo Guo, Zhao Ma, Wa nxing Sheng, Zhe Lv , Chenran Fu S tochastic Dispatch of Ener gy S torage in Microgrids: An Augmented Reinforcement Learning Approach V 2 BESSs into the microgrid op timization objectives, considerable cost red uction may be achie ved in different applications, e.g., the microgrid p lanning and o peration [4], and the co ordinated operation of the B ESS and renewable ener gy [5]. However, most of the existin g SP models either assu me zero degrad ation costs for the B ESS, or simpli fy the batter y cycle life to a linear function of the Depth of Discharge ( DOD ), which may introduce additional estimation erro r on the BESS d egradation cost [ 6]. W hen a more accurate d egradation cost model is used for BESSs, the MSOP generall y beco mes no nconvex and computationally challen ging [7 ]. Reinforcement lear ning (RL) may be a viable alternative for tackling an MSOP with a non-co nvex o bjective f unction [8] . RL arose fro m dynamical systems theory, a nd is for malized by the B ellman Equation and Ma rkov decision process (MDP ). A fundamental issue in RL is the balance of exploration and exploitation, which facil itates action-value es timation and policy improvement . It i s common for a RL agent to occasionally e xplore some rando m ac tions and lear n fro m experience. In Q-learnin g, this tr i al -and-error learning proce ss is guaranteed with asymptotic convergence. A s the bootstrapping steps increa se, the er ror o f actio n va lue estimation decreases ( i.e., the error reduction prop erty); yet t he conventional RL algorithm suffers from increased computation complexity. To reduce th e co mputation burden of the multi-step RL for tackli ng MSOPs, th e Monte-Carlo tr ee sear ch (MCTS) method may b e a viable so lution that shows remarkable success recently [9 ]. Motivated b y these achievements , we stud y how to incor porate MCTS in to Q-learning t o sol ve t he s tochastic dispatc h o f BESS in microgrids. B. Related work The ear ly r elated resear ch er s mainly employ deter ministic models for scheduling BESSs . Reference [1 0 ] in troduces linear programing (LP) to mitigate fluctuations i n p hotovoltaic (P V) output and increase t he elec tricity revenue in the microgrid . In addition to increasing the electricity r evenue, the e fficiency o f the BE SS is cons idered in [ 11 ], in which a non-linea r optimization m o del is formulated and solved by a meta-heuristic algorit hm. Re fere nce [ 12 ] formulates a quadratic p rogramming (QP) to achieve economic microgrid dispatch. A different objec tive i s considered in [ 13 ] , namely to satisfy the constraints o f the distribution net work by tracking the po wer profile e stablished on a day-ahead basis. The y formulate a QP and employ mo del predictive control (MPC) to schedule th e BESS. These deterministic models n eglect th e intermittency and variabilit y of volatile energy resources. Some other researcher s formulate the B ESS schedulin g problem as stochastic o ptimization models, which tackle the uncertainties associated with volatile energy resources. In [ 14 ] , a two-stage stochastic mixed-integer programming (SMI P) i s formulated to optimize the d ispatching p olicy for m icrogrids. In [ 15 ], the problem o f storage co -optimization i s add ressed by formulating a two-stage SMIP using piecewise-linear approximation of the value function. I n [ 16 ], the da y-ahead scheduling o f the BESS in the microgrid is studied. The optimization model incorpo rates the batter y degradation cost using the rain flow al gorithm. Yet this work assu mes unlimited energy e xchange with the d istribution network. I n [1 7], a two-stage stochastic mixed-integer nonlinear model i s formulated, and the battery degradation cost was considered by si mplifying its cycle li fe as a linear function o f the DOD. A similar battery cycle life mode l is considered i n [18]. This work formulates t he BESS degradation cost model as an eq uivalent fuel-run generator, which e nables it to be incorporated into a unit commitment problem. In addition to the tw o -stage SP models, a multistage SP m odel i s formulated in [ 19], and solved by a customized stoc hastic dual dynamic p rogramming algorithm. Besides the above methods, so me works have explored RL methods for scheduling B ESSs. A deep reinforcement lear ning method is used in [ 20 ] to provide th e energy management results f or the microgrid. In [ 21], the Q-learning method is used to optimize t he energy mana gement i n the microgrid, which considers the variabilit y o f stochastic e ntities. A coop erative RL algorithm i s proposed i n [7 ], whose dispatch ob jectives incorporate a non -convex BESS d egradation cost model. In [8], a dual Q-iterative lear ning al gorithm i s propo sed to minimize the microgrid operation co st . In ad dition to the se studies, RL based solutions are seen in other related prob lems or fields with promising results. [2 2] studies a dynamic pricing problem in the microgrid, wh ere the basic Q-learning model is ad opted an d improved by defini ng the energ y co nsumption -based approximate state and ado pting the virtual experience updates. [2 3] develops a RL method for the optimal management o f the operation and maintenance o f p ower grids . In this sol ution t he tabular Q-learning is used to lear n the o ptim al p olicy and the neural network then rep laces the tabular representatio n of t he state-action value function. H owever, the RL methods used in these works ignor e the uncertainties between state transitio ns along the multist ep b ootstrapping trajecto ries [19 ]. In the field of machine learning, combining the MCTS method and embedding domain knowledge into data-driven solutions can enha nce the ir perfor mances, which inspire us on tackling MSOPs . For the MCTS algorithms, [24 ] introduces its basic idea, in which tree search polic ies are use d to asymptotically foc us the M onte Carlo trials on multist ep bootstrapp ing trajectories that are promising to high-retur n rewards. [25] p resents a s urvey of di fferent variants of M CTS. [26 ] adop ts the MCTS to achieve fast multistep simulations in the co mputationally intensive game GO. In the studies of incorporating do main knowledge , [27 , 28] demonstrate the performance enhancement of RL solutions by leveraging different kinds of do main knowledge. To numerically e xpress the rule based domain kno wledge, t he pr obabilistic so ft logic (PSL) is for malized in [ 2 9] . In [30 ], the PSL is used to map knowledge rules i nto neural networks. In [31 ] , the PSL is employed to s upervise t he lear ning process by knowledge rules. Contributions We formulate a multiperiod s tochastic model for dispatching the BESS in microgrids. The degradation co st model of BESSs adopted in this work is a benchmark model e mployed in the microgrid si mulation tool HO MER [3 2] and other applications [33, 34]. In our RL based solution , the key for identifying statistically optimal dispatching policies is the esti mation of 3 expected maximum action values. This may be achieved by na ively co mputing the opti mal val ue function in the scenario based search trees containing b d possible sequences o f actions, where b is the number of d iscretized actions p er state ( tree’s breadth) and d is the number o f steps (tree’s depth) . So , its computation complexity i ncreases rapidly a s t he number of scenarios increases . To reduce the computation burden, we employ the MCTS al gori thm that has made prolific achievements in pla ying Go . However, from t he perspective of game theory, the M CTS in Go tackles t wo-player zero-s um deterministic game [2 5] , yet in our case it tackles single -player stochastic po wer dispatching . Ho w to integrate the M CTS into the Q -learning for solving t he MSOP is a key challe nge in t his work . Moreover, in order to in co rporate the domain knowledge for performance e nhancement, a kno wledge i ncorporation scheme is needed to numerically express different knowledg e rules a nd co mbine the m for reducing infeasible acti on explorations. T he novelty and contribution s of our work are two-fold: 1) We propose a RL solutio n incor porated with M CTS to tackle the MSOP. In this solut ion, the Q-learning with function approximation is emplo yed as the basic learning architecture that allows multistep bootstrap ping and continuou s polic y learning . To alleviate the co mputation burden of rando mized multist ep simulations, a M CTS algorithm is develo ped to efficient ly estimat e the expected maximum action value s in the iterative learning proce ss. 2) W e d evelop a knowledge incorpor ation sche me to embed the rules into the learning process. In this scheme, the probabilistic soft logic is ado pted to map knowledge rule s i nto potential functions. T he potential functio ns are then co mbined by so ft logic oper ations to co nf ine the state -wise feasible acti on space and enhance t he performance of the learn ed po licy. As far as we know, this is t he first work of incorporating MCTS and domain knowledge into RL methods in po wer system applicatio ns. The remainder of the paper is organized as follows. T he problem is f ormulated in Se ction II . I ts solut ion is given i n Section III . The results in cas e studies are rep orted in Section IV and the paper concludes in Se ctio n V. II. P ROBL EM F ORMULATI ON Figure 1 p resents a si mplified configuration of t he problem. The microgrid is co nnect ed to the d istribution network at the point o f co mmon coupli ng ( PCC) . Co mponents of t he microgrid include DG, EV, other loads, and the BESS . T he active p ower of t hese compo nents is marked with a positi ve power flow directio n in t he figure . For notational conve nience , we introduce P SUM to represen t ( P DG - P EV - P OL ). Other Lo a d P DG P EV P OL P B P PCC P SUM + + DG Distr ibutio n Ne two r k Po sitive Power f l o w Disp atchab le r eso u r ce No n-d ispat ch a b le r e sourc e EV BESS Fig. 1. Simplified architec ture of a grid-connected microgrid ; da shed arrow s define the positive direction of power fl ow. A. Constraints Let t be the time index. The active power constraint imposed by the distribution utility at t he PCC is mi n ma x , , , , , () PCC t PCC t SUM t B t PCC t P P P P P = − + (1) The branch p ower flow model developed in [ 35] is ad opted for the po w er flo w calculation of the microgrid , 22 2 () ( ) ( ) () ij ij gd ij j ij jj j j j i pq p p r p p v + + − = + (2) 22 2 () ( ) ( ) () ij ij gd ij j ij jj j j j i pq q q x q q v + + − = + (3 ) 22 2 2 2 2 2 ( ) ( ) ( ) ( ) 2( ) [( ) ( ) ] () ij ij j i ij ij ij ij ij i j i pq v v r p x q r x v + = − + + + (4) where i , j represent nodes of a line in the m icrgor id . ij p and ij q are active a nd reactive p ower delivered through the line . i v and j v are voltage m ag nitudes. ij r and ij x are resistance and reactance of the line . g i p and g i q are active and reactive po wer generation at node i . d j p and d j q are active a nd reacti ve p ower demand at no d e j . () j is the set of all child nodes of nod e j . The operational constraints in micro grid are given b y (5)-(8), min ma x i v v v (5 ) 2 2 m ax 2 ( ) ( ) ( ) ij ij ij p q AP + (6) min ma x DG DG DG P P P (7) min ma x B B B P P P (8) where the node v oltage amplitude, power f low of lines, power generation of DG s, and power ch arging/dischargi ng of BESSs are constrained by the ir thresholds. Variable max ij AP denotes the maximum apparent po wer of the line. The SOC of the BESS is given by , 1 , ( 1 ) Bt t t B t B nom PT SOC SOC Ca V − = − − (9) I n the char ging mode, B 1 and P B ,t 0 . In the discharg ing mode, B 1 and P B ,t 0. T is the time interval . To prevent d amages caused by overcharge/overdisc harge , the SOC t is restricted by min ma x t SO C SO C SOC ( 10 ) The life-cycle throughput of a BESS is related to the num ber of operation cycles, SOC in individual cycles , etc. [32] , , ( ) ( 1 ) 1000 / t nom B nom SOC t f t Ca V N e SOC W kW = − ( 11 ) where is an empirical p arameter . The level o f BESS degradation is measured by | P B ,t | /2 t [ 33 ]. B. Objective fun ction Assume t is the decisio n t ime ( which means all state variables are known up to t ). In order t o maximize the operation al profits of the B ESS, w e can formulate t he follo wing multiperiod sto chastic optimization model, 1 2 1 1 2 Pr 1 1 Pr | Pr 2 2 Pr | Pr 1 1 max ( , ) [ m a x ( , ) [max ( , ) ... [ m a x ( , ) ] ... ] ] t t t t n t n t t t t a a t t t n t n aa z R s a R s a R s a R s a + + + + − + − ++ + + + − + − = + + ++ ( 12 ) 4 where ( , ) t i t i R s a ++ is the i mmediate re ward o f taking action a t+i in state s t+i . Pr is the probability meas ure of state transitio ns and 1 P r | P r t i t i + + − denotes the expectation taken co rresponding to the conditional prob ability measure ( 1 Pr | Pr t i t i + + − ). is the discount factor. T he superscript is used to distinguish stochastic variables fro m deterministic variab les. This notati on is also used herei nafter for vectors contai ning stochastic variables. In our case, a t and s t are given by , set ,, ( , , , ) t B t t t SUM t t PCC t aP s SOC P c P = = ( 13 ) where t c and set , PCC t P are the ti me- of - use tariff (T OU) and the active p ower at PCC e xpected by the di stribution utility , respectively . T he B ESS is considered as the only dispatchable component. B ecause s t+ i is an unknown future state at d ecision time t , , SUM t i P + is modeled as a stochastic variable o wing to the volatile energy resources. Because our focus of uncertainty is the p ower generation/con sumption in volatile energy resources, c t+i and set , PCC t i P + are modelled as deter ministic variables. The immediate re ward, R , co ntains three factors, d efined as 1 1, 2 2, 3 3, + t t t t R R R R =+ ( 14 ) where w i ( i =1,2,3) are the weights of the different factors. Individual factors are specified as 1, , , 1, 2, , , ,0 = ,0 t B t B t t t B t B t c P T P R c P T P ( 15 ) , 2, , 2 Bt t life t PT RC Q =− (16) set 3, , , = t P CC t PC C t R P P −− (1 7) where R 1 is the electricit y rev enue generated by leveraging the TOU tariff. R 2 is minus the de gradation cost of the BESS due to lifecycle degradation. C is th e investment cost of BESS [6 , 33 ]. R 3 is minus the penalty cost for power tr acking erro rs at the PCC. The optimal solution to the above MSOP is a dynamic schedule of multistep charging/disc harging actions o f BESS. This solution maximizes the microgrid oper ational benefits indicated by (12 )-(17). A t the d ecision time t , althoug h only a t is actually p erfor med , the follo w- up scheduled actions can estimate the expected future rewards of a t more accurately. III. P ROPOSED M ETHO D The basic for m of R L algorithm is modeled by a tuple ( , , , ) in the frame w ork of MDP . is the state space containing all sta te variables, is the action space involving all decisions of B ESS charging/disc harging power, : is the reward function of the state-action pair, : [0 , 1 ] → is the transitio n pr obability fro m a state-action pair to a successor state, which defi nes the dynamics o f the environment. In deter ministic proble ms, = 1 and s t+1 is a d eterministic function of state -action p air ( s t , a t ). However, in stochastic problems such as our case, there is some Pr that measures the transition pr obability. Because predicting the p recise transition p robabilities of volatile energ y is challenging, we d evelop a RL based approximate solution. A. Basic Q-learning architecture with function approximation To b alance the explo ration a nd exploitation i n Q-learnin g, the ε -greedy action selection polic y is commonly used, arg max ( ( , )) with probabil ity 1- random action with pr obability tt a Q s a = (1 8) where ε is a smal l positive value. ( ( , )) tt Q s a is t he expected value of taking action a t in state s t . Assume action a t has been selected in state s t , to estimate its long-term r eward we employ n - st ep bootstrapping to update the action value estimates. The cumulative n - st ep future rewards in a bootstrap ping trajectory is given by 1 12 ( , ) t n n t t t t t t n G s a R R R + − + + + = + + + ( 19 ) where ( , ) tn t t t G s a + is th e cumulative action v alues from s t to s t+n . It is a function of seq uential a ctions 1, 1 ( ,..., ) t t n aa + + − conditioned on ( s t , a t ). To f urther incorporate uncertainties for action value updating , we calculate the e xpectation o f tn t G + , i.e. () tn t G + . T he law for updating the expected action value is 11 , .. ., ( ( , ) ) ( ( , ) ) [ m a x ( ( , ) ) ( ( , ) ) ] t t n tn t t t t t t t t t aa Q s a Q s a G s a Q s a + + − + + − (20) where 11 ,..., max ( ( , )) t t n tn t t t aa G s a + + − + is the e xpected maximum action value obtained b y taking the best -performing acti ons ( a t+ 1 ,…, a t+n- 1 ), following ( s t , a t ). T o allow continuo us policy learnin g, the function approximation is e mployed in the above tabular Q-learning architecture that achieves a parametric approximation of t he action value functio n, ( , ; ) ( ( , ) ) Q s a Q s a θ (21) where d θ is a fin ite -dimensiona l weight vector. In this work , t he basic neural netwo rk in [ 36] is adop ted as the function appro ximator, whose w eig hts can be updat ed following the gradien t descent rule. The for mulation of (2 0) distinguis hes our Q -learning model from [7 , 8] that d o not incorpo rate the mechanis m of multistep bootstrapping under uncertainty . Ho wever, thi s formulation makes the conventional Q-leaning suffer fro m increas ed computation complexity, as m or e si mulation step s and scenarios need to be addressed for estimating the stochastical ly optimal rewards. We tackle this is sue by developing the MCTS algorithm in subsection B . B. MCTS algorith m Different from t he MCTS algorithms developed in deterministic games, the MCTS em ployed in t his w or k n eeds to incorporate stochastic scenarios into the estimation pro cedure of expected maximum actio n values. Here we outline t he key ideas of the develop ed alg orithm . More details of th is algor ithm is explained in t he Appendix. At decision time t , the MCTS is applied to estimate 11 ,..., max ( ( , )) t t n tn t t t aa G s a + + − + , wh ere the seq uential s tates are represented as tree nodes, a nd the actio ns ar e tree ed ges connecting different nodes . Let { } tn t + be a stochastic vector for the p robability distributio n of stochastic variab les over a 5 planning horizon n , we refer to a scenario 1 tn t t t n + ++ as a realizatio n (or sampling trajectory) of the stochastic process { } tn t + . W e then u se the notion o f S SP t as a scenario sa mpling pool for p roviding t he generative scenarios, i n f s u p i n f s u p , 1 , 1 , , SSP {[ , ]. ..,[ , ]} t SU M t SUM t SUM t n SUM t n P P P P + + + + = (22) where i n f s u p , SUM SUM PP are lo wer and upper bounds for the confidence interval o f SUM P . Fr om SSP t , the generative sce narios containing n sto chastic variables , 1 , { ,..., } SUM t SUM t n PP ++ are seque ntially sampled that forms different po ssible scenarios . Let , 1 , SSP { ,..., } m m m t SUM t SUM t n PP ++ = be the m th sce nario , a sear ch tree is built incrementally that s tems fro m the root nod e 1 m t s + and expands from a father nodes ti s + to some child node 1 ti s ++ ( 1 m t s + is transitioned fro m s t , a t in the m t h scenario) . T he tree expansion follo ws the UC T (upper co nfidence bound for trees) policy 1 1 1 c h i l d e r n o f 11 ( ) l n ( ) ar g max ( ) ( ) ( ) t i t i tn t i t i t i s s t i t i G s N s N s N s + + + + + + + + + + + + + + (23) where ( ) ti Ns + and 1 ( ) ti Ns ++ are the visit co unts of the father and child nodes, respectivel y . is a constant variable determining t he le vel of explo ration. I nitially, ( 23 ) prefers nodes with low visit co unts. Asymptotically , the nodes that are promising with high values ar e identified . T his policy balances the exploitatio n of learned val ue functio n and the exploration of unvisited nodes. When a child node is selected in th e m th scenario , the Monte Carlo rollout policy r begins at th is node and en ds at the terminal node m tn s + . Each ro llout per forms a seque ntial simulation a nd co nstitutes n state variable s , we use { , 1 ml t s + ,…, , ml tn s + } to denote the simulation trajectory in th e l th rollout. Then the rollout statistics of all tra versed ed ges are b acked up, , 1 ( , ) ( , ) L m m l t i t i t i t i l N s a s a + + + + = = ( 24) , 1 1 ( , ) ( , ) ( , ) L m m l t n t i t i t i t i m l t i t i ti Q s a s a G N s a + + + + + = ++ + = (25) where is the indicator function. If edge , ( , ) ml t i t i s a ++ was traversed, , ( , ) 1 ml t i t i sa ++ = ; Otherwise , ( , ) 0 ml t i t i sa ++ = . tn ti G + + is the accumulated reward fro m the node ti s + to the end node tn s + . ( 24 )-( 25 ) updates the visit counts and mean ac tion value function in all si mulations passing thro ugh that edge. After L rollouts are executed in the m th s cenario, we identify the set of best-perfor ming actions and obtain the n - st ep maximum action value for ( s t , a t ), 11 1 1 1 1 1 ,..., ( , | SSP ) ( , , ) m a x ( , | S S P ) t t n t n m m t n m m t t t t t t t t t t t t aa G s a R s a s G s a + + − + + + + + + + = + (26) By repeating the above pr ocess i n different scenarios, the expected maximum action values is approxi mated as 11 , . . . , 1 1 ma x ( ( , ) ) m a x ( ( , | SSP ) ) t t n M t n t n m t t t t t t t m aa M G s a G s a + + − ++ = (27) where M is the nu mber of scenarios investigated. There are two difference s that distinguish the ab ove MCTS and the M CTS deployed in deter ministic games su ch as Go [25] . The f irst difference is that in Go o nly a deterministic scenario is investigated for esti mating the value fu nction. In our case, we incorporate d ifferent po ssible scenarios for deriving the expected v alue f unction. This is ach ieved by u sing th e notion of SSP in ( 22 ) to allow s cenarios generation based on any explicit or implicit pr obability function , and the expected optimal value are accumulated from individ ual scenarios by (2 6)-(27). The second difference is that i n Go only the e stimated value of the last-stage state (i.e. th e terminal node) in each rollout is backed up for updating the value function, which is not an accur ate estimation in our case. Thereb y, we te mporally memorize and accumulate the action values of each transition b etween father and child nodes by ( 24 )-( 25 ) for updating the value function in each rollout. C. Sch eme for incorpo rating knowledge ru les Two definitions are given below to leverag e dispatching rules for red ucing in f easible explo rations in the RL algorithm. Definition 1 . Let 1 { , ( | )} Y y y y k a s = = be a set of weighted rule sets , w here ( | ) y k a s is the y th rule estimating th e feasibility of action a co nditioned on state s, y is the weight of k y . In practice t he knowled ge rules ca n b e classified as hard rules and soft rules. Here we c onsider three rule s in the rule set (if desired additio nal rules can also be included ), inf sup 1 1 1 inf sup 2 1 , 1 3 1 , 1 , , ( | , ) : ( | , ) : ( | , ) : t t t t t t t PCC PCC t PCC t t t PCC t PCC t Threshold t SOC SOC SOC k a s s k a s s P P P k a s s P P P ++ ++ ++ − ( 28 ) where k 1 and k 2 are hard rules that require SOC and P PCC to remain within allowable ranges when taking action a t in state s t and transitioned to a successor state s t+ 1 . The hard rules are definitely not violated, otherwise th e security of the po wer distribution network or the B ESS will b e da maged . k 3 is a so ft rule that expects the ac tual P PCC to have small fluctuations between success ive states when tak ing an act ion . Ho w to use a soft ru le d epends on actual needs. For exa mple, when the BESS is funded by an end user who focuse s o nly on electri city revenue, k 3 can be relaxed because otherwise some candidate actions with higher re wards will be excluded. Definition 2 . Let ( | ) y k as be an individual p otential function of ac tion a conditione d on state s and examined by r ule k y . Let ( | ) as be the total potential functio n of action a conditioned on s and exa mined by the rule set . Also, let f be the set of feasible action spaces eval uated by ( | ) as . ( | ) y k as can be see n a s the numerical expression of rule k y . However, when there exi sts multiple rule s, the logic inferences among them are needed for deriving a final result of t he feasibility of ca ndidate actions, especially when these rules a re not consistent in e valuating the feasibilit y o f a n action. Therefore, w e i ntroduce PSL to m ap knowled ge ru les into t he scalar values tak en in the interval [0, 1 ] . The m ap ping of k y into an individual potential function is typically of t he form (m ax { 0, }) yy kk d = , w here y k d is a measure of t he distance to satisfiability of k y [29]- [3 0] . For hard rules k y ( l =1, 2), 1 y k d = 6 when the candidate action i s e valuated as feasible according to k y , o therwise 0 y k d = . For the soft rule k 3 , an expo nential operator is used to measure i ts d istance to satisfiabil ity, i.e., 3 , 1 , , exp( ) PCC t PCC t k Threshold t PP d P + − =− . We then derive the total p otential function ( | ) as from all individual p otential functions using cer tain logic operators. Because we ha ve soft rules th at take truth values in [ 0, 1 ] , the classic Boo lean logic is replac ed by t he Lukasie wicz logic that allows co ntinuous truth values take n fro m the interval [0 , 1]. The logic oper ators suc h as AND ( ), OR ( ), NOT ( ) are redefined as [29 ]- [3 0] max{ 1 , 0 } max{ 1 , 0 } 1 y j y j y j y j yy k k k k k k k k kk = + − = + − = − ( 29 ) This redefinition allows a simple and fle xible inference among different rules. In this work, let be the total po tential function of all hard rules, and be the potential function of all soft r ules, we have 12 kk = , 3 k = , and = . Hence f is decided by { | ( | ) } f a a s = ( 30 ) where is the threshold. D. The dev eloped RL algorithm Fig. 2 disp lays the episod ic learning i mplementations of o ur RL algorithm. 1 tt =+ A gen t f o r m ul a t es st ate Sta r t 1 t = Env iron ment mu ltis tage B o o tstr a p ping (st och asti c simul a tio n ) for m = 1 : M do 1 . Randomiz e d s c ena ri o generation 3 . Rewards estimated by MCTS End for Derive expected maximum value A g en t s elect act i o n s ra n d () < ε Ex plo r a tion Ran d om ac tio n in Ex plo it a tio n Knowledge i n c orporati on for reducing infeasi b l e explor ation 2 . R e d u c e g l ob a l a c t i o n s p a c e 11 1 1 into fea sibl e a c ti on s pace t s t a Observe new sta t es ( , ) tt sa 11 ( , ) tt sa ++ ... 1 . Map different knowledge rule s into potential function Obta in the c urrent state ve ctor and f or eca st e d fu t ur e s t a t e v ar i a bl e s over a planning horizon of n Stochastic l ea rni ng envi ronm ent with explicit re w a rd funct i ons arg max ( , ) f a Q s a 2 . n -stage bootstrappi ng 11 ,..., max ( ( , | SSP )) t t n t n m t t t t aa G s a + + − + f , 1 , SSP ( ,..., ) m m m t SUM t SUM t n PP ++ = f 1 t R + 2 t R + tn R + tn s + 11 ,..., max ( ( , )) t t n tn t t t aa G s a + + − + Fig .2 Flow chart of the p roposed RL algorithm; two gray boxes highlight the novelty o f this algorithm. At decision time t , the RL agent observes its state vector and n stochastic variables , 1 , { , ... , } SUM t SUM t n PP ++ . Conditioned o n these variables, the i ncorporated knowledge rules are then mapp ed into the potential function for confining the global action spac e into fea sible actio n space f . T hen, based on the basic Q-learning frame work, the agent selects either an e xploitative action a t with prob ability 1- ε , or an explorator y actio n a t with probability ε from , ft . Next, the age nt interacts with the stochastic environment and estimates the expected rewards that can b e obtained over a n -step bootstrapping trajector ies. Note that this trajector y starts from the state -actio n pair ( s t , a t ), and the MCTS is u sed to sequentially select the remaining n - 1 actions fro m a t+1 to a t+n-1 and estimate t he expected maximum cumulative rewards. After si mulations o f a number o f sce narios, the estimated rewards an d the parameters of the neural networ k are updated . The RL agent t hen conti nues its learning fro m the current decisio n time t to wards the next decis ion time t+ 1, and the above co mputation process are repeated . IV. C ASE S TUDY In this sec tion , two microgrid systems are provided to conduct ca se studie s. In Subs ection A, a microgrid in [33 ] is us ed to verify i n detail the perfor mance of the proposed algorithm. In Subsection B, a real microgrid s ystem in China is used to show the ef fectiveness o f the method. A. Test case 1 Fig ure 3 presents t he modified microgrid system from [ 33] , which contains two PV systems, two EV charging statio ns, one BESS, and other load s conn ected to each node . T he rated capacity of the two PV systems, i.e. PV1 and P V2, are 40kW and 20kW, respectively. T wo EV charging sta tions, i.e. EVCS1 and EVCS2, contain 5 AC charging posts and 1 0 AC char ging posts, respectively. T he rated power of each c harging post is 7 kW. Typical charging modes of EVs include constant current charging, co nstant voltage char ging, etc. T he BESS is a 5 00 kWh lead -acid batter y pack. Figure 4 depicts the hourly ac tive power of different co mponents in the microgrid, which shows the high volatilit y of DGs and EVs. In t he stochastic sce narios, t he 95% confidence level of SUM P is ass umed . For simplicity, set PCC P is set as 50 kW, and t he T OU tar iffs are refere nced fro m the actual tariffs i n China . For the thresholds of the knowled ge rules , we restrict the S OC in rule k 1 to be within [3 0%, 90%], P PCC in rule k 2 is set to [0, 100 kW], and the variation bet w een the P PCC of two consecutive s tates in rule k 3 is maintained below 50 kW. The training and testing procedure s of our algor ithm follow [7], [2 3]. The parameters ε in (18) and in ( 22 ) are set to 1% and 0.7, respectively. The bootstrap ping stage is set to 4. Circuit breaker 1 2 3 4 5 6 7 8 9 L2 L6 L7 L5 L4 L9 Distribu t ion gri d PV 1 PV 2 Transformer BESS EVCS1 E VCS2 Fig. 3 Tested microgrid system; it contai ns two PV systems, two EV ch arging stations, one BESS , and 6 residential lo ad points. 7 10 20 30 40 50 60 70 80 90 100 Power (kW) PV1 PV2 EVCS1 EVCS2 Fig. 4 Hourly active power of the microgrid ; d iffere nt curves are shown in different colo rs. We f irst test the f easibility of the p roposed algorithm in realizing its obj ectives expressed in (12). Figure 5 sho ws the power m a nagement results of BESS in n early th ree consecutive days. I n s ub -figure (a) , P SUM fluct uats significantly because of the volatile resources DGs and EVs. In contrast, th e dispatching of BESS r egulates P PCC f or a close tracking of set PCC P . S ub -figure (b) s hows that the disp atching solution o f BESS in general procures energy durin g low- price lo w-load per iods and s el ls energy duri ng high-price high -load per iods, which increass the electricity reve nues . Mo reover, a regular chargi ng/discharging behavior of BE SS is showed by t he SOC cur ve, th us p reventing the accelerated d egradation rate caused b y over -charging or over-discharging. 0 10 20 30 40 50 60 70 - 50 0 50 100 P B ( kW ) 70 80 90 100 SOC (%) 0 10 20 30 40 50 60 70 0 50 100 Power ( kW ) P SUM P PCC Time ( hour ) (a) Time ( hour ) (b) Disch a r g i n g C harg in g SOC o f Batte ry set PCC P Fig. 5 Power management results of the proposed algorithm . (a) sh ows the power regulation result at PCC; (b) shows the charging/d ischarging behavior and the correspo nding SOC of the BESS. W e then a nalyze the comp utation performance o f the developed MCTS algorithm, whose role is mainly to give efficient esti mations of the maximum action values over multistep bootstrap ping traj ectories. To evaluate the degree of accomplishment o f this role, we compare the num erical results of MCTS and t hree algorithms by var ying the n umber of iterations while fixing the investigated scenarios . As listed in Table 1, the compared algorithms include a random sear ch algorithm (RS) th at used a random polic y during bootstrapping, an exhaustive search algorithm (ES) enumerating candidate actions, and a heuristic search algorithm based on the genetic algorithm (GA) . The num ber of iteratio ns in the numerical tests is varied from 1 0 1 to 1 0 4 . In each iterati on b udget, we repeat the computations of t hese algorithms for 10 times and record the mean a nd variance of di fferent algorithms . The m ean v alues are normalized by the min-max normalization. The variances of BS are omitted b ecause they are zero . Table 1 Performances of diffe rent alg orithms in estimating the maxim um action value s. Number of iterations Mean of maxim um action value Variance of estim ation MCTS RS GA ES MCTS RS GA 10 1 0.81 0. 34 0.17 0 0.62 0.99 0.49 10 2 0.92 0.42 0.26 0.18 0.34 1.56 0.11 10 3 0.97 0.38 0.34 0.42 0.10 2.00 0.01 10 4 1 0.39 0.38 0.74 0.02 2.17 0 The mean val ue indicates th at MCT S is the most e fficient algorithm in discoveri ng the maximum multi-step action valu es. The v ariance of MCTS is asym ptoticall y reduced as the number of iterations increase , which ju stifies the robustness and asymptotic co nvergence of th is algorithm. However , ES is the least efficient in esti mating the action v alues. RS is highly stochastic w ithout convergence guarantees regardless o f the increase of iterations. For GA, althoug h its variance is the smallest a nd reached almost 0 after 10 4 iteratio ns, its estimations of t he maxi mum action value improve s slowl y when the co mputation ef fort increases. One possible explanation is that the iter ative searching in GA is stuck in some local optimum after 10 4 iterations. From abo ve comparisons, w e can conclude that the MCT S is the best-performing algorith m for achievin g the computation task (20) . We f urther de monstrate the p erformance of incorpo rating the knowledge rule s in to supervising the Q - le arning p rocess. In this test, we co mpare the p roposed algor ithm (kno wledge incorporation, 4- st age bootstrapp ing) with two o ther algorit hms , namely Algorith m 1 (no kno wledge i ncorporatio n, 4 - st age bootstrapping) and Algorithm 2 ( knowledge incorporation , 1-stage bootstrapping) in terms of the rewards obtained and the actual dispatchi ng results. T o increase the learnin g efficiency when extending the boo tstrapping depth fro m 1 to 4, in our algorithm the immediate rewar d of one-step state tra nsition is set as the i nitial value for the follow -up action value updating. Figure 6 depicts the accu mulated r ewards ob tained b y th e se algorithms along t he learning tr ajectory. It sho ws o ur algorithm is th e most e ffective one in maximizing t he cumulative rewards . Specifically , the advantages in the estimating re wards o f our algorithm over Algorith m 1 a nd 2 are highlighted in the earlier and later lear ning trajectories , respectively. T his result s hows th at knowledge incorporat ion is useful when the agent has insufficient experiences . Moreover, extending the bootstrapping depth in conjunction with kno wledge incorporation can facilitate t he agent to increase its rewards in the long run. Figures 7 and 8 present furt her comparison results regardin g the ac tual dispatching per formance o f the se algor ithms . I n Fig ure 7, the explor ative policy of Algorithm 1 is poor that exacerbate the fluctuatio ns i n P PCC , but our explor ative polic y always pr ovide f easible policies that red uce power fluctuatio ns . In Figure 8, Algorith m 2 overdraws the B ESS capacity at 6 7 h, which forces the BESS to charge e nergy afterwar ds . Consequently, the power trac king result at the P CC is w orsen thereafter . In co ntrast , our algorithm appropriately manages the SOC and al ways maintains t he power trac king at the PCC. Table 2 compared the actual power management resul ts obtained using t he prop osed algorithm a nd Algorithm 2 . T he results are calc ulated based on the 72 -hour power manageme nt results p resented in Fig.8. Specifically, the electr icity reve nue 8 is ca lculated by e quation (15), the BESS degradatio n co st is calculated by equation (16), and the Standard deviation of P PCC is ca lculated by 71 set 2 ,, 0 1 () 72 PCC t PCC t t PP = − , which measures the level of po wer fluct uation at PCC. Fo r simplicit y, t he results are shown in p er u nit values and the results of Algorithm 2 are used as base values . Ob viously , our algorithm achieves power tracking with smaller power fluctuations (evidenced by th e standard deviation of P PCC ), and th e m icrogrid gains more tariff revenue with lo wer BESS degrad ation costs. Numbe r of It era t ions ( N ) Accumulat ed Re w ards 0 1000 2000 3000 4000 5000 6000 7000 8000 200 300 400 500 100 0 Proposed Al gori thm Algorithm 1 Algorithm 2 Fig. 6 Comparison of accum ulated rewards obtained by three algorithms. The higher the rew ard, the better the algorithm performance. 0 10 20 30 40 50 60 70 -100 0 100 200 Power ( kW ) Time (hour) 50 Pr o po s e d Algorit h m SUM P set PCC P Alg o rithm 1 Fig. 7 P PCC regulation results using the explorative policies generated by the proposed algor ithm and Algo rithm 1. 0 10 20 30 40 50 60 67 0 50 100 150 Power ( kW ) Alg orith m 2 Pr o p o s e d Alg o r ithm Time ( hour ) 70 SUM P set PCC P Fig. 8 P PCC regulation results obtained u sing the optimal policies of the proposed algor ithm and Algo rithm 2. Table 2 Dispatch results comp arisons of the propose d algorithm and al gorithm 2. Proposed alg orithm Algorithm 2 Electricity revenue 1.05 1 BESS degradation cost 0.92 1 Standard deviatio n of P PCC 0.79 1 B. Test case 2 This test i s referenced from a real grid -connected microgrid system installed in Zhejiang, China. Figure 9 shows the configuration and parameters o f the test s ystem. It is a hybrid AC/DC microgrid con nected to the medium -volta ge distribution g rid. The AC b us o f the microgrid contains 200 kW solar power, 300 kW residential/com mercial load, and 500 kW× 2 h lead-carbon BESS. The AC bus links th e DC bus via a power electronic transformer. The DC bus contains 25 0 kW solar po wer,10 kW wind power,25 0 kW residential/co mmercial load and 60 kW× 2 EV fast c harging facilitie s. We then train and compare the proposed RL algorithm and the baseli ne RL algorithm (i.e. 1-stage bootstrapping) for dispatching the BESS based on realistic hi storical l oad profiles. T he ai m of t he RL agent is to increase the net o peration revenue of the microgrid (i.e. the TOU revenue minus the degradation cost of the BESS) while reducin g the po wer fluctuations at the PCC (i.e . measur ed by 23 set 2 ,, 0 1 () 24 PCC t PCC t t PP = − ). The investment cost of the BESS is ¥ 2/Wh. T he T OU tariffs are referenced fro m the actual tariffs in Zhejiang P rovince ( i.e. ¥ 1 .02/kWh from 8 :00-22:00 ; ¥ 0.51/kWh for the rest of the day). Other para meters re main the same as in the test case 1 . Table 3 lists the dispatching results of the two algorithms based on the daily po wer profiles. The net o peration r evenue and the s tandard deviation of P P CC in f our days ar e g iven. These four d ays repr esent di fferent r enewable power ge neration and load consumption patterns in t he spr ing, summer, autumn, and winter, respectively. As can be seen, the proposed method obtains higher reven ue w it h lo wer po wer fluctuation at the PCC in all seasons. The biggest gap in revenues is in t he autumn, i.e. our method gains ¥ 300.3 more than the baseli ne method. The largest gap regarding the po wer fluctuation at the PCC is in the summer, i.e. our meth od achie ves 3% les s po wer fluctuation at the PCC than the b aseline method. On average, the daily revenues of our method and the baseline method are ¥ 71 0.3 and ¥ 560.9, respectivel y. I n the long run, using the pr oposed method can considerabl y shor ten t he c ost recovery p eriod for the BESS investor. T he above tests provide a first necessa ry step to pro ve the e ffectiveness of the pro posed algorithm. Future research efforts will be devoted to test the p roposed method on additio nal numerical models of microgrids . 10kV AC BUS 1MWh Distribution grid ~ = 100kW = = = = ~ 5kW 150kW = = 100kW = = ~ 5kW AC 400V 100kW 60kW× 2 150kW 560V DC BUS ~ = = 200kW Power electric transformer Circuit breaker ~ = 200kW Fig. 9 Configuration o f the h ybrid A C /DC micro grid sy stem; the par ameters o f the BESS, distri buted energy r esources and loa ds are prese nted. Table 3 Result compariso ns using based on daily power profile s in different season s. Ty pical da y Proposed me thod Baseline RL Spring Net revenue (¥ ) 473.6 400.8 SD of P PCC 0. 161 0. 169 Autumn Net revenue (¥ ) 873.5 543.2 SD of P PCC 0.39 0. 419 Summer Net revenue (¥ ) 1223.7 1134.0 SD of P PCC 0. 138 0. 168 Winter Net revenue ( ¥) 270 .3 165.4 SD of P PCC 0. 242 0. 266 SD : standard dev iation V. C ONCLUSION In this paper, we present a multiperiod stochastic optimization model for the d ynamic management o f battery in microgrids . T he model is develop ed to minimize the 9 operational costs of the microgrid, taking into account the nonconvex d egradation co st function of t he batter y energ y storage system. Then , we provide a reinforcement learning solution aug mented with Monte-Carlo Tree Sear ch and knowledge rules . W e first exp ress the knowledge rules into the potential function in the for m of soft logic . The se knowled ge rules are used to co nfine the state-wise action space, which can reduce the nu mber of infea sible actions e xplored by the learning age nt. T o alleviate the co mputation burden o f multistep bootstrap ping under uncertainty, the Monte- Carlo Tree search algorithm is modified to increase the esti mation efficiency o f the expected maximum action values . The r esults of o ur numerical te sts s how that the pr oposed algorithm asymptotically optimiz es the dispatch policy and o utperforms other algorithms. A PPENDIX The appendix explains how the R L agent learns the dispatching policy i n more d etail . First, t he key steps of the modified MCTS method is explained . T hen, the full algorith m of the proposed meth od is pr esent ed . A. The MCTS algo rithm To incorporate uncertainties when estimating the cumulative action value for an y state action pair, e.g., ( s t , a t ), five steps are needed when perfor ming the MCT S, as shown in Fig. A.1. a. Generation . This step provides randomized sequences containing n seq uential stochastic variables, i.e. , 1 , [ , ..., ] SUM t SUM t n PP ++ . T he realization of , SUM t i P + can be expressed as , , , f o r e c a s t SUM t i SUM t i SU M t i P P P + + + = + , where , SUM t i P + is t he forecast error . W e use the tr uncated normal distrib ution (TN) with predefined confidence inter vals (CI s) to construct SUM P based on the maximum likelihood estimator (MLE ), i.e ., , , + , ˆ ~ ( , ) SUM t i SUM t i SUM t i P TN P P ++ , where , SUM t i P + and , ˆ SUM t i P + are the sa mple mean and varia nce (T he details of the TN refer to [9]). T hen the Mo nte Carlo sa mpling met hod is used to generate scenarios (the m t h scenario denotes by SSP m t ), and (30) is used to form the feasible actio n space m f . b. Selection. T his stage selec ts explorati ve policies in t he generated sce narios. Given the m th scenario, assume t he current in -tree simulation step begins at node 1 m t s + and ends at m tn s + , each node s of the tree stores the state-action pair ( , ) s a , and each edge stores the statistics { ( , ) , ( , ) } G s a N s a , where ( , ) N s a is the visit count and ( , ) G s a is the mean action value for that edge. c. Expansion. This stage incr ementally expa nds the tree until the ter minal nodes in a generati ve scenario . The UCT criterion is used to decide which child nod e to be expand ed. Then the Monte Carlo rollout policy r begins at this node and ends at a ter minal node. Du ring tree ex pansion, t he successiv ely joined leaf nodes result in different combinations of seq uential state-action pairs. d. Backpropaga tion. T his stage upd ates the rollout statistic s of each in-tree node b ackwards fro m the ter minal node to the root node by (24) and (25) . After reaching the computation budget (e.g. constrai nt of iteration, time o r memory), the set of state-action p airs with t he highest expected re wards is identified as marked in the red rectangle i n Fig. A.1. e. Up date. This stage updates the actio n val ue estimation results for each scenario b y (26), and finally acc umulate the expected action value esti mations of all scenarios b y (27). 1 m t s + SS P t a . G ener a t i o n b . Sel ec t i o n c . Ex p an si o n d . Ba ckP rop agation e . U pda te m a x , tt sa , tt sa m a x { G , N } { G , N } { G , N } { G , N } max , tt sa m a x { G , N } { G , N } { G , N } { G , N } ~ r , tt sa { G , N } { G , N } { G , N } ~ r , tt sa .. . . . . SSP m t ,1 m SUM t P + , m SUM t i P + , m SUM t n P + 1 m t s + 1 m t s + m ti s + m tn s + ,1 m tn s + , mL tn s + , mL ti s + 1 1 t s + 1 ti s + 1 tn s + tn t G + 1 SSP t 1 m t s + m ti s + m tn s + tn t G + SSP m t 1 M t s + M ti s + M tn s + tn t G + SSP M t 1 SSP t SSP M t .. . . . . m ti s + Fig. A .1 Diagram of the modified Mo n te-Carlo tre e search method. B. The full a lgorithm The propo sed approach is shown in Algorithm 1. T he main part of this algorithm is shown from line 1 to lin e 13, wh ere the MCTS method is denoted as the function M CTS S EARCH and realized fro m line 14 to line 45 . In the main part of the Algorithm 1, given ti me t , the state s t is observed and th e ε -greedy policy is used to select an action a t from the feasib le action space f . T he SSP t is then generated to provide different possible scenarios for the future n time stamps. Given the m th scenario , the M CTS S EARCH is performed , whose inp ut parameter 1 m t s + is transitioned from ( s t , a t ). W hen M scenarios have been evaluated , the expected maximum action val ue for ( s t , a t ) can be app roximated. This approximated value is m arked as the label of a training exa mple, corresponding to input p arameters s t , a t , i n f s u p i n f s u p , 1 , 1 , , ( , ), ..., ( , ) SUM t SUM t SUM t n SUM t n P P P P + + + + . In total , T training examples are provided for learning the weights of the parameterized action -value function (i.e. the neural network) following the gradien t descent law. In the function M CTS S EARCH 1 ( m t s + ) , the subfunction s T REE P OLICY, D EFAULT P OLICY and B ACKUP are iteratively executed. In one iteration, th e T REE P OLICY determ ines how to expand the tree from a father node to a child node. In this 10 subfunction, the unvisited nodes ar e assigned high er pr iority for node expansion tha n the visited node selected by the subfunction B EST C HILD . The subfunction D EFAULT P OLICY then perfor ms fa st si mulations from a current node, e.g. m ti s + to the ter minal node, and r Q records the cu mulative re wards of the si mulated trajecto ry. Afterwards, the sub function B ACKUP updates the c umulative re wards of nod es 1 , . . . , mm t i t s s ++ given b y the T REE P OLICY and the D EFAULT P OLICY. When the computation budget is reac hed (e.g., co nstraint of ti me, iteration or memory), we identify a complete path of the search tree, with tree edges representing the o ptimal actions { 1 m t a + ,…, 1 m tn a +− } and tree nodes representi ng the corresponding states { 1 m t s + ,…, m tn s + }. No te that in line 31, f deno tes the state transition fu nction; i n the subfunction D EFAULT P OLICY , the variable r Q is used to sum up th e sequential rewards of a simulation trajecto ry rather than only the terminal re ward. Algorithm 1 M ultistep Q-lea rning incorporated w ith MCTS 1: Initialize action-value f unction ( , ; ) Q s a θ arbitrarily 2: for t =1, T do 3: o bserve s t 4: select a t from f using the ε -greed y policy 5: generate SSP t according to (22) 6: fo r m =1, M do 7: sample scenario , 1 , SSP { , ..., } m m m t SUM t SUM t n PP ++ = 8: perf orm M CTS S EARCH ( 1 m t s + ) 9: estimate the maximum action val ue by (26) 10: end f or 11: estimate the e xpected maximum actio n value b y (27) 12: upd ate (20) and the weights θ of the neural network 13: end fo r 14: function M CTS S EARCH ( 1 m t s + ) 15: crea te root node as 1 m t s + 16: w hile within computational budget do 17: 1 R E E O L I C Y ( ) TP mm t i t s s ++ 18: EF AU L T OL ICY ( ) DP r m ti Qs + 19: B ACKUP ( , r m ti s Q + ) 20: return a (B EST C HIL D ( 1 m t s + )) 21: function T REE P OLICY ( s ) 22: while s is nonterminal do 23: if s not fully expanded t hen 24: return E XPAND ( s ) 25: else EST HI LD ( ) BC ss 26: return s 27: function E XPAND ( s ) 28: choose a untried actions from () s 29: add a ne w ch ild s to s 30: Initialize ( ) =0 Gs 31: ( , ) s f s a and () a s a 32: return s 33: function B EST C HILD ( s ) 34: re turn chil der n of ( ) ln ( ) ar g max ( ) ( ) ( ) ss G s N s N s N s + 35: function D EFAULT P OLICY ( s ) 36: Initialize ( , )= (0, 0) r Qj 37: while s is non -terminal do 38: choose rand om action a 39: ( , ) s f s a , ( , ) rr j Q Q R s a + and 1 jj =+ 40: re turn r Q for state s 41: function B ACKUP ( s, r Q ) 42: while s is not n ull do 43: ( ) ( ) 1 N s N s + 44: ( ) ( ) r G s G s Q + 45: pa re nt o f ss R EFERENCES [1] Mu hammad FZ, Elhoussin E, Mohamed B. Microgrids energy manageme nt systems: A critical review on methods, solutions, and prospects. A ppl Energy 2018;222:1033-1055. [2] L uo X, Wang J, Mark D, Jo nathan C . Overview of current dev elopment in electrical energy st orage technologies and the appl ication pote ntial in power syste m operation. A ppl Energy 2015;1 37:511-536. [3] Z hang C, Wu J, Z hou Y, Cheng M, Long C. Pee r- to -Pee r ener gy trading in a Microgrid. A ppl Energy 2 018;220:1- 12. [4] G onç alo C , T homas B, Nicholas D, Wang D, Miguel H, L eander K . Battery aging in multi-energy microgrid design using mixed integ er linear programming. A p pl Energy 2 018;231: 1059 -106 9. [5] W ang Y, Zhou Z, Botterud A, Zhang K, Din g Q. Stochastic coordinated operation of wind and battery energy storage system considering battery degradation. J Mod Power Sys Clean Energy 2016;4(4):581 – 592. [6] L iu C, Wang X, Wu X, Guo J. Economic scheduli ng model of microgrid considering the lifetime of batterie s. I ET Ge ner Transm Distrib 2017;11(3):7 59-767. [7] Li u W, Zhuang P, L ian g H, Peng J, Huang Z. Distributed Eco n omic Dispatch in Microgrids Ba sed on Cooper ative Reinforceme nt Learning. IEEE Tr ans Neural Netw orks & Learning Sy s 2 018;29(6): 2192-2203. [8] W ei Q, L i u D, Shi G. A novel dual iterative Q-learning method for optimal battery management in smart residential environments. I EEE Trans I nd Electron 2015; 62 (4 ): 2509-251 8. [9] Su tton RS, B arto AG. Reinforceme n t L earning: An I ntroduction . M IT Press, Lo ndon;2018. [10] Hopkins MD, P ahwa A , Easton T . Intelligent d ispatch for distributed renewable resources. IEEE Tr ans Smart Grid 2012;3(2 ): 10 47-1054. [11] K arami H, Sanjari M, Hosse inian SH, Gharehpet ian GB. An optimal dispatch algorithm for man aging residential distributed energy resources . IEEE Tr ans Smart Grid 2014;5(5 ): 23 60-236 7. [12] Mahmoodi M, Shamsi P, Fahimi B. Economic dispatch of a hybrid microgrid with distributed energy storage. I EEE Trans Smart Grid 2015;6(6 ): 2607-261 4. [13] G iorgio AD, L iberati F, Lanna A, Pie trabissa A, Pris coli FD. Model Predictive Cont rol of Energy Storage S ystems for Power Trackin g and Shaving in Distribution Grids. IEEE Trans Sustain Energy 2017;8( 99 ): 496-504. [14] Tal ari S, Yazda ninejad M, Haghifam MR . Stochastic-based scheduling of the m i crogrid operation including wind turbines, photovoltaic cells, energy storages and re sponsive loads. IET Gener T ransm Distrib 2015;9( 12 ): 1498-1509. [15] Xi X, Sioshansi R, Marano V . A stochastic dynamic programming model for c o-optimization o f distr ibuted ene rgy st orage. Energy Sys 2014;5(3 ): 475 -505. [16] Alamg ir Hossain Md, Hemanshu RP, Stefano S, Forhad Z, Josep MG. Energy scheduling of community mic rog rid with battery cost using particle swarm optimiza tion. Appl Ener gy 2019;254:5 11 -536. [17] Su W, Wang J, Roh J. Stochasti c energy scheduling in microgrids with intermittent renewable energy r esources. IEEE Trans Smart Grid 2014;5(4 ): 1876-188 3. 11 [18] Nguye n TA , Crow ML. Stochastic Optimizatio n of Renewable-Based Microgrid Operation Incorporating Battery Operating Cost . IEEE Trans Pow Sys 2016; 31 (3 ): 2289-2296. [19] Bhattachary a A, K h aroufeh JP , Zen g B. Managing Energy Storage in Microgrids: A Multistage Stochas tic Prog ramming Approach. IEEE T rans Smart Grid 2018;9(1 ): 483 -496. [20] Shirajum Munir Md, Sarder FA, Ngu ye n HT, Choong SH. When Edge Computing Meets Microgrid: A Deep Reinforceme nt L earning Approach. IEEE IoT Journal 2019; 6(5): 7360-7374. [21] Elham F, Leen-Kiat S, Sohrab A. Reinforcement Learning Approach for Optimal Dis tributed Energy Management in a Micro grid. I EEE Trans Pow Sys 2018;33(5): 5749-5758. [22] K im BG, Zhan g Y, Van der Schaar M, Lee JW. Dynamic pricin g and energy consu mption scheduli ng with reinforcement learning . IEEE Trans Smart Grid 2016; 7(5):2187-2198. [23] Rocchetta Bellanib RL, Compare M, Ziob E, Patellia E. A reinforceme n t learning framew ork for opti mal operation and mai ntenance of pow er grids. Appl Energy 2019;241:291-301. [24] Coulom R. Efficient Selectivity and B ackup Operators in M onte-Carlo Tree Se arch. In: Proc 5th I nt Conf Comput and Game s;2006. p. 72-83. [25] Brow n e C, Po wley E, Whitehouse D , Lucas S, Cowling PI, Rohlfshagen P, Tavene r S, Perez D, Samothrakis S, Colton S. A Survey of Monte Carlo Tree Search Methods. IEEE Trans Comput Intel and AI in Games 2012;4(1):1-49. [26] Silve r D, Huang A, Maddison C J, Guez A, Sifre L, Dri essche G, Schrittwiese r J, Antonogou I, Pannee rshelvam V, Lanctot M, Diele man S, Grewe D, Nham J, Kalchbrenner N, Sutskever I, Lillicrap T, Leach M, Kavukcuoglu K, Grae pel T, Hassabi s D. Mastering the game of go with deep neural ne tworks and tre e search. Nature 2016;529(75 87):484-489. [27] Christia no P, Leike J, Brown TB, Martic M, Legg S, Amodel D. Deep reinforceme n t learning from human prefere nces. In: the Annual Conference on Neural Information Processing Systems (N IPS ); 2017. p. 1-17. [28] Huang J, Wu F, Precup D, Cai Y. Learning Safe Policies with Expert Guidance. I n: 32nd Conference on Neural I nformation P rocessing Systems (NeurIPS ); 2018. p. 1-10. [29] Bach S, Broecheler M , Huang B, Getoor L. Hin ge-L oss Markov R andom Fields a nd P robabilistic S oft L ogic. Jo urnal of Mach ine L earning Researc h 2017; 18 : 1-67. [30] Hu Z, Ma X, Liu Z, Hovy E, Xing E. Harnessing Deep Neural Networks with Logic Rules. In: Proc. 54th An nual M eeti ng of the Asso ciation for Computational L in guistics; 20 16. p. 2410-2420. [31] Sachan M, Dubey A, Mitchell T, Rot h D, Xing E . Lear ning Pipelines with Limited Data and Domain Know ledge: A Stud y in Parsing Physics Problems. I n: 32nd Co nference o n Neural Information P rocessing Systems (NeurIPS ); 2018. p. 1-12. [32] L a mbert T, Gilman P, Lilienthal P. Micropower s ystem modeling with ho mer, 2006. www .homerenergy . com/documents/Micro powerSy stemModel ingWithHOME R.pdf. [33] Ma T, Yang H, Lu L . A f easibility study of a stand -alone hybrid solar-wind-batte ry s ystem for a remote island . Appl Energy 2014; 12 1: 149 -158,. [34] Zhao B, Zhang X, Chen J, Wang C, Guo L. Operation optimization of standalone microgrids conside ring lifetime characteristics of battery energy storage system. I EEE Trans Sustain E nergy 2013;4(4):934-943. [35] Baran ME , Wu FF. Optimal capacitor placement on radial distribution systems . IEEE Trans Powe r Del 1989;4(1 ): 725-734. [36] Si J, Wang Y. On-line learning control by association and reinforceme nt. IEEE Tr ans Neural Netw 2001;12(2): 264 - 276 .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment