Reward Machines for Cooperative Multi-Agent Reinforcement Learning
💡 Research Summary
In cooperative multi‑agent reinforcement learning (MARL), a set of agents must jointly achieve a common objective while interacting with a shared environment. Two fundamental challenges arise: (1) coordination, because the correctness of an individual’s actions often depends on teammates, and (2) non‑stationarity, because each agent’s policy changes continuously during learning, making the environment appear non‑stationary from any single agent’s perspective. Traditional approaches—centralized Q‑learning, independent Q‑learning (IQL), and hierarchical independent learners (h‑IL)—either scale poorly with the number of agents or suffer from instability due to the lack of coordinated information.
The paper introduces Reward Machines (RMs) as a structured, finite‑state representation of temporally extended tasks. An RM consists of a finite set of states, an initial state, a finite event alphabet Σ, a transition function δ, and an output (reward) function σ that assigns a reward only when a transition leads to a designated “goal” state. By abstracting high‑level events (e.g., button presses, goal achievement) rather than raw low‑level observations, RMs capture the logical progression of a task in a compact form.
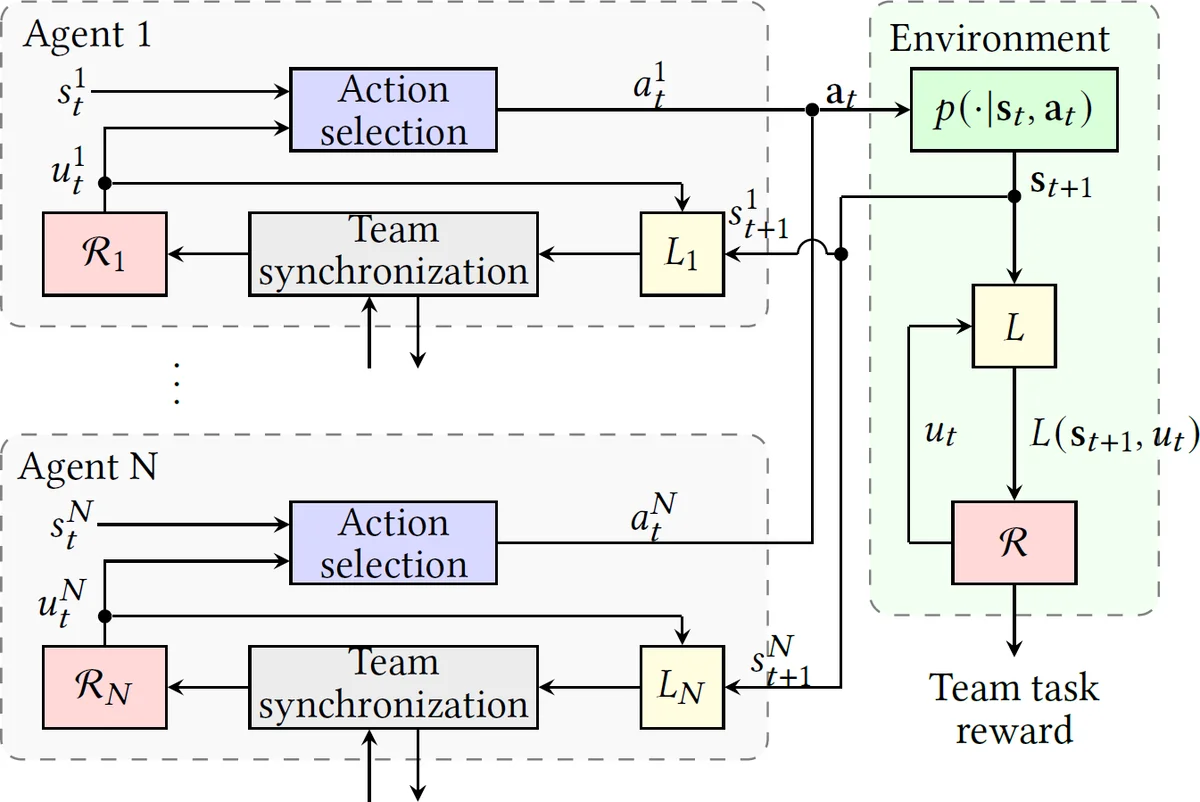
To apply RMs to MARL, the authors define a labeling function L(s, u) that maps a concrete environment state s and the current RM state u to a set of events in Σ. This function enables the RM to interact with the underlying Markov decision process (MDP) despite the RM’s abstract nature. The standard Q‑learning with Reward Machines (QRM) algorithm learns a separate Q‑function q_u(s, a) for each RM state u, updating them using temporal‑difference (TD) errors and also performing counterfactual updates for states that were not currently active.
The central contribution is a team‑task decomposition technique that transforms a single global RM describing the whole team’s objective into a collection of local RMs {R_i} for each agent i. Each agent is assigned a local event set Σ_i, a subset of the global event alphabet, representing the high‑level information that the agent can observe or influence. The authors formalize a state equivalence relation ∼_i that merges RM states indistinguishable under events outside Σ_i. Quotienting the global state space by ∼_i yields the local state space U_i of R_i. The resulting projected RM preserves the original task’s logical structure (bisimulation) while containing only the events relevant to agent i.
Under this decomposition, the authors prove two key theoretical results: (1) Completeness – if every agent successfully completes its local RM, then the joint execution necessarily satisfies the original global RM, guaranteeing that decentralized learning of sub‑tasks yields a correct team behavior; (2) Value bounds – for undiscounted rewards (γ = 1), the sum of local value functions provides provable lower and upper bounds on the global value function, quantifying how close the decentralized solution can get to the optimal centralized solution.
Building on the decomposition, the paper proposes a decentralized Q‑learning algorithm (Dec‑QRM). Each agent i runs QRM on its local RM R_i, using only its own local state s_i, its current RM state u_i, and the events returned by its local labeling function L_i(s_i, u_i). After taking an action, the agent observes the next local state, obtains the event set, updates its RM state, receives the corresponding reward, and performs a TD update on q_{u_i}. Counterfactual updates are also performed for all other RM states, mirroring the original QRM’s ability to learn from a single transition across the entire RM. Crucially, agents never need to exchange raw state or action information; they only rely on the abstract events encoded in their local RMs, thereby mitigating non‑stationarity.
Empirical evaluation is conducted in three discrete domains: (a) a two‑agent “buttons” task, (b) a ten‑agent extension of the same task, and (c) an additional grid‑world scenario with multiple goals and obstacles. Results show that Dec‑QRM converges an order of magnitude faster than a centralized QRM in the two‑agent case. In the ten‑agent setting, neither the centralized learner nor hierarchical independent learners (h‑IL) nor IQL achieve task completion within the allotted training steps, whereas Dec‑QRM quickly learns a successful joint policy. Across all domains, Dec‑QRM attains higher final success rates while requiring far less inter‑agent communication.
The paper’s contributions can be summarized as follows:
- A formal definition of RM‑based task decomposition for cooperative MARL, including an algorithmic construction of local equivalence relations and projected RMs.
- Theoretical guarantees that local RM completion implies global task completion, and that local value functions bound the global value.
- A decentralized Q‑learning algorithm that leverages counterfactual updates and operates solely on locally observable events, thereby addressing both coordination and non‑stationarity.
- Comprehensive experiments demonstrating superior learning speed and robustness compared to centralized and existing decentralized baselines.
Limitations include the focus on discrete state and action spaces, reliance on manually designed labeling functions, and the assumption of a static team composition. Future work suggested by the authors involves extending the framework to continuous domains via function approximation, automating the construction of labeling functions, and handling dynamic team membership or partial‑observable settings.
In conclusion, by integrating Reward Machines as structured, decomposable representations of team objectives, the authors provide a powerful and theoretically grounded approach to cooperative MARL. Their method enables agents to learn independently yet cooperatively, achieving faster convergence and higher reliability without the communication overhead of centralized control. This work opens promising avenues for applying formal methods to large‑scale, real‑world multi‑robot or multi‑drone systems where coordinated task execution is essential.
Comments & Academic Discussion
Loading comments...
Leave a Comment