Generative adversarial networks (GAN) based efficient sampling of chemical space for inverse design of inorganic materials
A major challenge in materials design is how to efficiently search the vast chemical design space to find the materials with desired properties. One effective strategy is to develop sampling algorithms that can exploit both explicit chemical knowledg…
Authors: Yabo Dan, Yong Zhao, Xiang Li
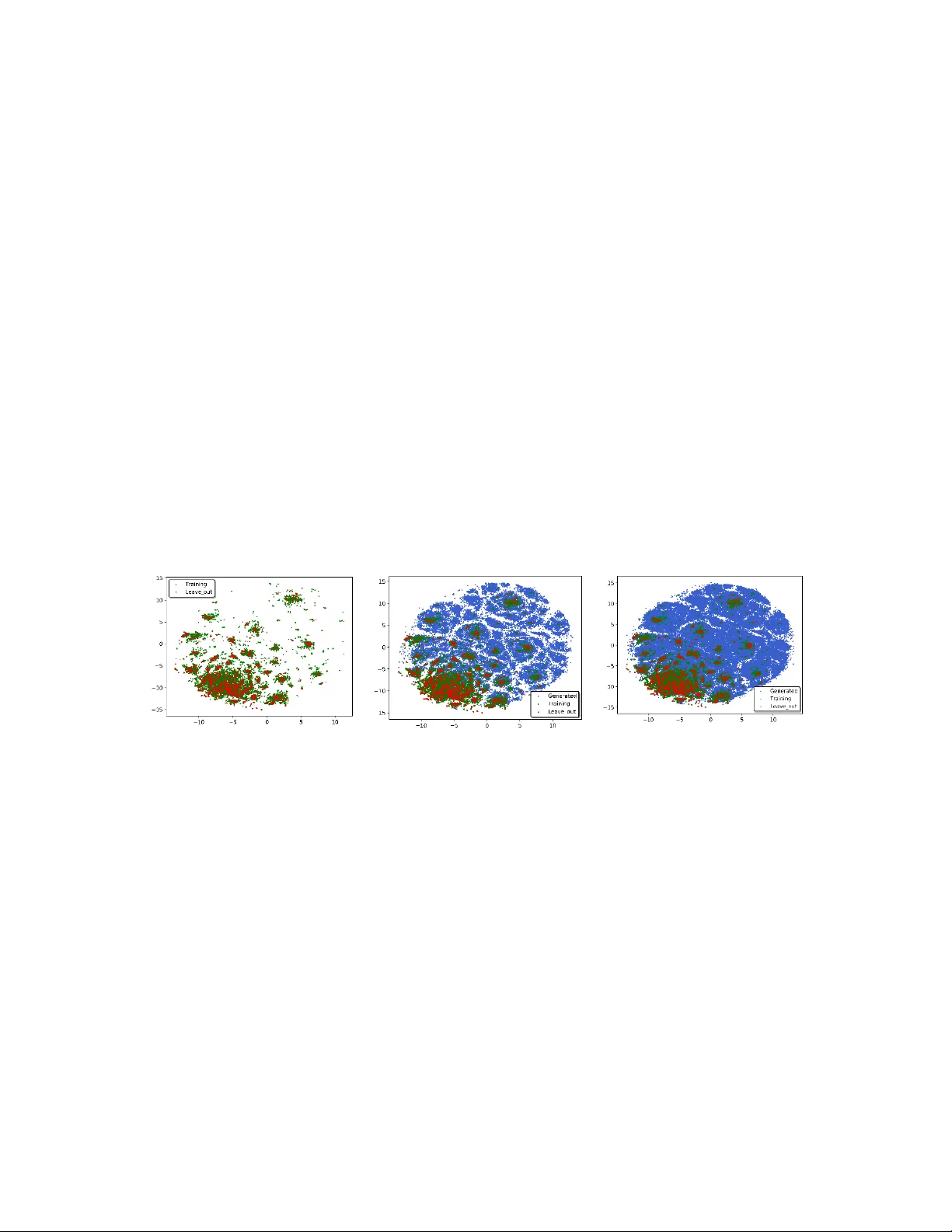
1 Generative ad versarial network s (GAN ) based efficient sam pling of chemical space f or inverse design of inorganic materi als Yabo Dan 1 Yong Zhao 2 Xiang Li 1 Shaobo Li 1 ,4 Ming Hu 3 and Jianjun Hu 1,2,* 1 School of Mechanical Eng ineering, Guizhou univ ersity, Guiyang 5 50025, China; 2 Department of Compu ter Science and Engine ering, University of South Carolina , Columbia 29201 , USA; 3 Department of Mechanica l Engineering, Universit y of South Car olina, Columbia 2 9201 , USA; 4 Key laboratory of ad vanced manufacturing t echnology, Ministry of educati on, Guiyang 550025, China; Correspondence: Jian jun Hu ( Jianjun h@cse.sc.edu ) Abstract : A major c hallenge in mate rials de sign is how to efficiently search the vast chemical design space to find the materials with desired properties. One effective strategy is to develop sampling algorithms that can ex ploit both explicit chemical knowledge and implicit composition rules embodied in the large materials da tabase. Here, w e propo se a generative machine learning model (MatGAN) based on a generative adversarial network (GAN) for efficient generation of new hypothetical inorganic materials. Trained wit h materials from the I CSD database, our GAN model can generate h ypothetical materials not existing in the training dataset, reaching a novelt y of 92.53% when generating 2 mi llion samples. The percentage of chemicall y valid (charge neutral and electronegati vity balanced) samples out of all generated ones reaches 84.5% by our GAN when trained with materials from ICSD even though no such chemi cal rules are ex plicitly enforced in our GAN model, indicating its capability to learn implicit chemical composition rules. Our algorithm could be used to speed up inverse design or computational screening of inorganic materials. Keywords : Generative adversarial networks; GAN; inverse design; materials discovery ; deep learning; composition; stoichiometry; 2 1. In tr oduction Discovering new inor ganic materials such as solid electrol y t es for lithium-ion batteries is fundamental to many industrial applications. While recent years have observed tremendous efforts on r ational materials desi gn, progress has been limited due to the challenge to find new materials that m eet diverse technical and economic constraints. From the computational perspective, brute-force molecular sim ulations or first-principles methods are computationall y too expensive for large -scale screening of the vast chemical space. A recent effort (1) to quantif y the ma gnitude of the c ompositional space for multi -component inorganic materials show ed that even after the application of chemical filters such as cha rge neutrality or electronegativity balance, the space for four-component/element materia ls exceeds 10 10 combinations and the five-component/element space ex ceeds 10 13 combinations. Indeed, a machine learning based model has been applied to screen billions of hypothetical materials to identify promising high ion -conductors (2). C onsidering the huge space of doped materials with different mixing ratios of elements and many applications such as high-temperature superconductors, where six to seven component materials are common, the number of potential materials is immense. Such combinatorial explosion calls for the need for more effective sa mpling approaches to sea rch the chemical design space that employ existing explicit chemical and physical knowledge and also implicit eleme ntal c omposition knowledge embodi ed within known s ynthesized materials. To gain more e fficient search, a variety of explicit che mical rules for assessing the feasibility of a given stoichiometry and the likelihood of particular crystal arrangements have been used in computational screening such as the Pauling’s rules (ch arge neutrality), electronegativity balance, the r adius ratio rules (3), Pettifor maps (4) and etc. How ever, such approaches sti ll fail to capture enough im plicit chemical rul es to achieve efficient chemical design space sampling. Recently, genera tive machine learning models such as autoencoders (AE) and its variants (VAE, AAE), RNNs, G enerative Adversarial Ne tworks (GANs) have be en successfull y applied to inverse desi gn of organic materials (5) (6) (7) (8) . These a lgorithms mainly exploit the sequential or graph representations of organic materials to learn the composition rules of the building blocks for generating valid and novel hypothetical materials. Given a large set of samples, a GAN is capable of learning complicated hidden rules that generate the training data, and then applies these learned rules to create new samp les with target properties. When applie d to inver se de sign, G ANs have d emonstrated their power in efficient samplin g of design space(5, 9), more e fficient than other sampling approaches such as random sampling(10), Monte Carlo sampling, and other heuristic sampling (such as genetic algorithms (11)). However, due to the radical difference in building blocks and their composition rules, such generative machine learning models have not been applied to the g eneration of inorg anic materials so far to the be st of our knowledge. Recently, variational autoencoders (11, 12) have b een proposed to generate h ypothetical cr y stal structures of inor ganic materials. However, these methods are either limited to generate new structures of a given material system such as the V-O s ystem (11) or cannot generate molecules that are physically stable (12). 3 In this pa per, we propose the first generative adversarial network mod el for ef ficient sampling of inorganic materials design space by g enerating hy potheti cal inorganic materials. Trained with materials from inorganic materials databases such as OQMD(13) , Materials Project(14), and ICSD, our GAN models are able to learn the im plicit chemical compositional rules from the known materials to g enerate hypothetical but chemically sound compounds. Without explicitly specif ying the chemical rules, our GANs trained with all charge-neutral and electronegativit y-balanced samples of the ICSD subset can generate hypothetical materials with 84.5 % reproducing the charge-neutralit y and balanced electronegativity. The analysis shows that our generative GAN c an achieve much higher efficiency in sampling the chemical composition space of inorganic materials than the exhaustive enumeration approach. 2. Results 2.1 Representation of inorganic materials Through simple statistical calculation of the materials in the OQMD dataset (15), 85 elements a re found and each element usually has less than 8 atoms in any sp ecific compound/formula. We then represent each material as a sparse matrix 8 85 ds T R d , s with 0/1 cell values. Each column represents one of the 85 elements while the column vector is a one -hot encoding of the number o f atoms of that specific element. 2.2 T he GAN generation model Generative models can be built on several mac hine learning al gorithms such as variational autoencoder (VAE), generative adversarial networks (GAN), Reinforcemen t learning (RL), Recurrent Neural netwo rks (RNN), and their hybrids (5) . Different from other generative models (16, 17) , GANs do not directly use the discrepancy of the data and model distributions to train the generator. I nstead, it uses an adve rsarial training approach: it first trains a discriminator to differentiate real samples from faked samples, which then guides the training of the generator to reduce this differ ence. These two tr aining processes are alternatively repeated. Their arm ra ce will lead to high performance of both the generator an d the discriminator. Our generative M L model for inor ganic materials (MatGAN) is based on the GAN scheme as shown in Fig.1. 4 Real samples Generated fake samples Generator(G) Discrimitor(D) z Latent space Is D correct Fine-tuning Fig.1 Architecture of Mat GAN for inorganic materials. It is composed of a generator, which maps random vectors into generated samples and a discriminator, which tries to differentiate real materials and generated one s. Detailed configuration parameters are listed in supplementary Table S1 and S2 and supplementary Fig. S1. W e choose the 8 ×85 matrix r epresentation of m aterials samples to build the GAN mod el. W e found the integ er representation of materials g reatly fac ilities the GAN training. In our GAN model, both the dis criminator (D ) and the genera tor (G ) are modeled as a deep neura l network. The generator i s composed of 1 full y connected la yer and seven deconvolution layers. The discriminator is composed of seven convolution la yers followed b y a full y connected layer . Each o f the convolution and deconvolution lay e r comes with a batch normalization la y er . The output layer of the generator uses the Sigmoid function as the activation function while all other batch normalization layers use the ReLu a s the activation function. The detailed network configuration i s shown in supplementary T able S1 and S2. In order to avoid the gradient vanishing iss ue of standard GANs, we adopt the W asserstein GAN (18), which r eplaces the JS divergence distance with the W asserstein distance. The GAN model will be trained using the W asserstein GAN approach by mi nimizing both the generator loss and discriminator loss, which are defined as () g G x P w Loss f x (1) ( ) ( ) gr D x P w x p w Loss f x f x (2) where, 𝑃 𝑔 , 𝑃 𝑟 is the distributions of generated sampl es and rea l s amples ; 𝑓 𝑤 (x) is the discriminant network. Equations (1) and (2 ) are used to guide the training process. The smaller the L oss D , the smaller the W asserstein distance between the generated samples and the real samples and the better the GAN is trained. 2.3 Variational Au toencoder for Evaluating GAN performance During our GAN generation experiments for OQMD dataset, we found that it sometimes has difficulty to generate a specific c ategory of materials. This may be caused by the li mited 5 samples to learn the required composition rules to generate those samples. To investigate this issue, we built an autoencoder (AE) (19) model as shown in Fig.2. The autoencoder is composed of an encoder with seven convolutional la yers followed by a full y conn ected layer and a decoder c omposed of a fully c onnected layer followed by seven deconvolution layers. After each of the convolution and deconvolution layer, there is a batc h normalization layer used to speed up training and reduce the influence of initial netwo rk weights (20). The ReLu is used as the activation function for all the batch normalization layers. The Si gmoid function is used as the activation function for the de coder’s output layer. The detailed configuration parameters are li sted in supple mentary Table S 3. The autoencoder are trained with 291,840 inorganic materials selected from the OQMD database. I n order to ensure the overlap between the original input matrix T and the matrix reconstructed b y the d ecoder as much as possible, we adopt the negative dice coefficient (21) commonly used in medical image semantic segmentation as the loss function of AE. The AE mod el is then trained usin g the back -propagation algorithm. The loss function is shown in the following equation: 2 2 - - - ( ) ( ) AE AB AB Loss Dice A B Sum A Sum B (3) where AB denotes the com mon elements of A and B , | g| represents the number of elements in a matrix, • denotes dot product, Sum (g) is the sum of all matr ix eleme nts. Dice coefficient essentiall y m easures the overlap of two matrix samples, with values ran ging from 0 to 1 with 1 indicating perfect overlap (22). The decoder module of t he AE model shares the same architecture o f the generator in our MatGAN model. Our h ypothesis is that if the trai ned AE model cannot decode a specific material, it is unlikely our GAN model ca n generate it. By s creening out the non -decodable materials out of the OQMD database using the AE, we may obtain a deeper understanding of the limitations of our GAN models. Encoder Decoder Conv DeConv Molecular map Molecular map MnAu MnAu Latent space Fig. 2 Architecture of Autoencoder. Detail configuration parameters are shown in supplementary Table S3 and supplementary Fig S2. 6 2.4 T he model per formance of GANs Efficient sampling of the inorganic chemical space by the GANs : We tr ained our GANs according to the procedures as detailed in Methods. For all these GANs i ncluding GAN - OQMD, GAN-MP, GAN-ICSD, we then generate d 2 million hypothetical materials using each of the se generators and evaluate their validity , uniqueness, and novelty. Mapping inorganic materials design space Out of the 2 million samples generated b y the GAN-ICSD, we filter out all sa mples that do not satisfy char ge neutrality and b alanced electronegativity leadin g to 1.69 million generated samples. To visualize how the generated ones are dist ributed co mpared to the training datasets from ICSD, we applied T-sne dimension reduction technique (23) to reduce the dimension of the matrix represe ntations of the samples from the generated set , the training set, and the leave-out validation set. The distribution of the generated samples versus the training and validation set are shown in Fig. 3. It is observed that the training samples from I CS D occu py onl y a very small portion of the whole space. The GA N- ICSD, however, has be en able to generate p otentially interesting hypothetical materials that fill the design space, which may significantly expand the range of the ICSD database. (a) (b) (c) Fig. 3. Inorganic materials space composed of existing ICSD materials and hypothetical materials generated by GAN-ICSD. The two axes correspond to the two dimensions after t-sne based dimension reduction. The I CSD mate rials only occupies a tiny portion of the chemical space of inorganic materials. (a) Training samples (green dots) and leave-out validation samples (red dots) from ICSD; (b) 50,000 generated samples (blue dots) together with training and leave-out samples (c) 200,000 generated samples together with training and leave-out samples. Validity check : charge neutrality and electronegativit y bal ance are tw o fundamental chemical rules of crystals. It is thus interesting to check how the generated samples from our GAN models satisf y these rules without explicit enforcement of such rules du ring model training. To do this, we adopt the charge-neutrality and e lectron eg ativit y check procedure as proposed in Ref. (1) to calculate the percenta ges of samples t hat obey these rules within the tr aining and generated sets of all 4 databases. The results are shown in Fig.4. First, we found that the percentages of the valid ly generated samples are very close to those of the training set. For OQMD, when the training set has 55.8 % charge-neutral 7 samples, the generated set has 56.1%. For MP and I CSD, the percenta ge of generated charge-neutral samples (84.8% and 80.3%) are als o close to those of the trai ning set s (83.5% and 84.4%). S imilar observations are found for electronegativity check. It is impressive that when we ensure al l training samples in the I CSD_filter are charge-neutral and electronegativity balanced, up to 92.1% and 84.5 % of the generated samples satisfy the two chemical rules, respectively, despite that no such rules are explicitly modeled or enforced in our GAN training model s. To de monstrate the significance of this high percentage of chemically va lid candidates, we c ompare our results to the ex haustive enumeration app roach in (Ref (1) Table 1 ). The percentage of all binar y /ternar y /qu aternary samples that satisfy both charge neutralit y and electronegativity is 0.78% with exhaustive enumeration compared to our 62.24%, which corresponds to 77 times of enrichment in terms of sampling efficiency. This strongly indicates that our GAN models have successfully learned implicit chemical rules for generating chemicall y vali d hypothetical materials. (a) (b) Fig.4 Evaluation of the validity of genera ted materials . (a) the percentages of charge- neutral (CN) and electronegativity-balanced (EN) samples of the generated samples are very close to those of the training sets for all four datasets. Train/gen CN: percentage of training/generated samples that satisfy charge neutrality; Train/gen EN: percentage of samples that satisfy balanced electronegativity. (b) Formation energy distribution of the Li -containing compound s generated by three GANs. Both G AN -ICSD and GAN-MP can generate a large percentage of hypothetical materials with low ( < 0 ) formation energy. Formation energy distribution of generated materials : another way to evaluate the quality of generated hypothetical materials is to check their stability, which can be measured b y the ir formation ene rgy (24). To do this, first, GAN -OQMD, GAN- ICSD, and GAN -MP were used to generate 2 million materials candidates each. The n, we selec ted all the materials with lithium element and then f ilter out all those materials that do not satisfy charge neutralit y and balanced electronegativity. Finally, we obtained 15591, 137948, and 281320 li thium-containing compounds, respectively, from GAN-OQMD, G AN-ICSD, and GAN -MP. We then downloaded the formation energ y prediction machine learning model (ElemNet) developed b y Jha et al. (24) and then u sed it to predict the form ation energies 55.8% 84.4% 83.5% 100.0 % 56.1% 80.3% 84.8% 92.1% 39.3% 78.1% 79.3% 100.0 % 38.4% 70.3% 73.4% 84.5% 0% 20% 40% 60% 80% 100% OQMD ICSD MP I CSD_Filter Percentage Train CN Gen CN Train EN Gen EN 8 of all these h ypothetical materials. Fig. 4(b) shows that the for mation energ y of these generated materials are mostl y less than 0, especially for those generated b y GAN -ICSD and GAN-MP, which are trained with more chemically valid samples. Also, much higher percentage of generated samples b y the GAN -OQMD are found to have hi gher formation energy scores in the figure, which is due to the fact that 68.48 % training samples of OQMD have formation energies larger than 0. Uniqueness check : To check the uniqueness of the generated samples, we calculate th e percentages of the number of unique samples out of the number of all generated samples ( 𝑛 ) as 𝑛 goes from 1 to 340,000 for all three GANs trained on the OQ MD, MP, and ICSD datasets respectively (Fig.5 (a)). First, it can be found that with the generation of more and more samples, the percentage of unique samples g oes down, showing that it is more diff icult to g enerate new hypothetical materials. However, even after generating 340,000 samples, o ur GANs still maintain a 68.09%, 85.9 0%, and 73.06% uniqu eness for GAN -OQMD, GAN-MP, and GAN -ICSD respectivel y . While all three curves decay with increasing number of generated samples, the GAN-MP maintains high er percen tage of unique samples . Actuall y, the uniqueness curve of GAN-MP dominates the one of GAN- ICSD, which further dominates the one of GAN-OQMD. After close examination of the distributions of training and generated samples in terms of their element numbers, we found that this is mainl y due to the distribution bias of the trainin g s ets of th e three GANs (See supplementary Fi g. S3) . For GAN-OQMD, the training set is dominated b y ternary compounds (84.4%) and it tends to generated ternary samples while the total number of chemicall y vali d materials as estimated by S MACT(1) (Semiconduc ting Materials from Analog y and Che mical Theory) to be around 200,000. So , it tends to generate many duplicate ternary samples. For GAN- ICSD, the ratio of binar y /ternar y/quaternary is about 2:3:1, which allows it to generate more diverse samples, leading to higher uniqueness curve . For GAN-MP, the ratio of binary/ternary/quaternary is about 0.8:2: 1, which is much more b alanced than those of GAN -OQMD and GAN -ICSD and it also has much more quaternary and quinary training samples (See supplementary Table S4). This allows it to generate most diverse samples. (a) (b) 60% 70% 80% 90% 100% 0 5 10 15 20 25 30 35 Percentage of uni que m aterias Numb er o f generated m at erial s(1E 4) OQMD ICSD MP 78.1% 30.4% 3.3% 82.7% 31.2% 5.2% 83.15% 98.68% 99.98% 0% 20% 40% 60% 80% 100% Binary Ternary Quaternary Train recover% Leave out recover% New rate% 9 Fig. 5. Uniqueness and novelty check of the generated materials. (a) Comparison of uniqueness curves of the hypothetical materials generated by thr ee GANs. GAN-MP achieves the dominating curve due to its more balanc ed distribution of binary/ternary/quaternary training sa mples. (b) Dis tribution of recovery rates of training and validation samples and also percentages of new generated hypothetica l m aterials. Novelty check : to check the capabilit y of our GA Ns to generate novel materials, we use the hold -out validation approach. We first leave out 10% samples from each of the th ree datasets OQMD, MP, and I CS D. Then we train the GANs and use them to g enerate a certain number of samples. We then examine wha t percenta ge of tr aining samples and hold-out validation samples have been recovered/re -discovered and how man y new samples have been generated. The results a re shown in Table 1. First we found that when the GANs recover/generate a certain percentage of training samples, th e approximate corresponding p ercentages of validation (hold-out novel) samples are also recovered. For example, when the GAN -MP recovered 47.36% of it s training set, about 48.82% of the hold-out samples have also been simultaneously generated. This d emonstrates that our GANs can be used to discover new materials that do not e xist in the tra ining set. To fu rther understand the generation performance, we calc ulated the recovery percentages of the training set and the lea ve-out validation set along with the perce ntages of new samples for binary, ternar y, and quaternar y samples ( Fig. 5(b)). First, by generating 2 mill ion samples, GAN -ICSD has generated 78.1% training binary samples while also generating/rediscovering 82.7% leave -out validation binar y mat erials. The recovery rates drop to 30.4% and 31.2 % respectively or ternary training and va lidation samples as the number of possible ternary samples a re larger tha n binary ones, whi ch also ex plains the recovery rates dropping to 3.3% and 5.2% for quaternary training and v alidation sets. I n addition, out of all the generated binar y /ternar y /quaternar y samples, 83.15%/98.68%/99.98% of them are novel h y pothetical materials, which strongl y shows the capabilit y of our GAN model to generate new materials candidates as a majorit y of these new c andidates satisfy the basic chemical rules as shown in Fig.4. Table 1 Novelty check of generated samples by GANs. GAN -OQMD GAN - MP GAN -ICSD Trainin g sample # 251 ,368 57 ,530 25 ,323 Leave out sample # 27 ,929 6, 392 2, 813 Generated sample # 2,000 ,0 00 2,000 ,0 00 2,000 ,0 00 Recovery % of training samples 60.26% 47.36% 59.54% Recovery % of leave o ut sample 60.43% 48.82% 60.13% New samples 1, 831 ,648 1, 969 ,633 1, 983 ,231 Conditional generation of hypothetical materials by GAN: in addition to generating valid inorganic mat erials, it is interesting to check if our GAN models can generate new materials with desired properties b y sampling from the generative distribu tion estimated by the model (25). To ve rify this, we collected 30186 inorganic materials f rom Materials 10 Project whose band gap values are lar ger than 0 . We then use these high-bandgap materials set to train a GAN -Bandgap model aiming to generate h y pothetical high-bandgap materials. To verif y the band gap values of generated samples, we trained a band gap prediction model using the Gr adient Boosted Decision T ree (GBDT) machine learning algorithm with Magpie fe atures (26) (See Methods part for its training details). We also use this model to predict the bandgap valu es of the exhaustively enumerated materials set. Fig. 6 shows the distribution of the band gaps of the generated materials set versus those of the training set and the exhaustivel y enumerated s et. The band gap distribution of g enerated samples i s much similar to that of t he training set, which de monstrates the c apability of our GAN- bandgap can generate hypothetic high-bandgap materials efficiently. Discovery of p otential new materials: To evaluate how likel y our GAN models can generate confirmed new materials, we take a cross -validation evaluation approa ch. Essentially, for all the new hypothetical materials generated b y each of ou r GAN models, we check how man y of them are confirmed/included b y the other two data sets. Table 2 lists the cross-validation confirmation re sults. I t is found that out of the 2 million g enerated materials by GAN- I CSD, 13,126 materials are confirmed b y and included in the MP dataset and 2,349 new materials are confirmed b y th e O QMD dataset. GAN -MP also has 6,880 and 3,601 generated samples confirmed by ICSD and OQMD, respectively. Table 2. Cross-validation confirmation of generated new materials by our GANs ICSD dataset MP dataset OQMD dataset GAN -ICSD N/A 13 ,126 23 , 49 GAN - MP 6, 880 N/A 3, 601 GAN -OQMD 3, 428 58 ,603 N/A Limitation of MatGAN examined by Autoencoder: Here we aim to check the relation of AE non-decodable materials and the difficult y of our G ANs to generate them. To train Fig. 6. Comparison of bandgap distributions of the generated m ate rials by GAN- Bandgap, the training set, and the enumerated set 11 the AE model, we ra ndoml y split the OQMD_L dataset with 90% samples for AE training and 10% samples as testing. The learning rat e is set as 10 −3 , batch size 1024, and Adam optimizer is used. The final AE model is picked as the model with the best performance over the test set within 1 000 epochs of training. We found that our AE m odel can decode 96.31% and 95.50% of t he samples from the training set and the test set. These samples seem to share some common chemical composition rules. To show the difference between the d ecodable samples and non -decodable ones, we applied T-sne dimension reduction technique (23) to reduce the dimension of the matrix representations of all OQMD_ L dataset to 2 and then visualiz e 20% of the samples on the 2D plot (Fig.10), in whi ch the red dots represent non-decodable samples while blue ones represent decodable ones. The apparent different distributions show that these two categories of samples have different composition rules. Our hypothesis is that the decodable s amples share well-established chemical composition rules, which allows our GAN genera tors for efficient sampling of the corresponding c hemical space. On the other hand, the non -decodable samples will be difficult to generate b y our GAN model. To verif y this, we calculated the percentage of non -decodable samples that have been generated b y the trained GAN-OQMD. It is observed that almost 95% of the non -decodable materials are out of the scope of the generated samples even after generating 2 mill ion of samples while 60.26% of the decodable training samples have been re-discovered. This shows that our GANs have limitation in generating non-decodable materials t y pe. It also means that non-decodable materials have sp ecial composition rules that either need more data or more power ful generator models to learn. Indeed, compa rison on the enriched element distribution analy sis (Suppl ementary Fig. S4) shows that the deco dable and non - decodable materials have distinct element distributions. 3. Discussion Fig.7 Distribution of decodable and non-decodable materials. X1 and X2 are the two dimensions after dimension reduction. -30 -20 -10 0 10 20 30 -30 -20 -10 0 10 20 30 X2 X1 Can decoder Can not decode r 12 The configurational phase space for new inorganic materials is immense. Forming four- component compounds from the first 103 elements of the periodic table r esults in more than 10 12 combinations. Such a vast materials design space is intractable to high-throughput experiments or first-principle computations. On the other hand, c urrent inorganic materials databases such as ICSD and Materials Projects all consist of onl y a tiny portion of the whole inorganic chemica l space, which needs expansi on for computational screening of new materials. Here we proposed a GAN based generative model for efficient sampling of the vast chemical desi gn space of inorganic materials. Systematic ex periments and validations show that our GAN models can achieve hi gh uniqueness, validity, and diversit y in terms of its generation capability. Our generative models can be used to explore the uncharted inorganic materials desi gn space b y expandin g ICDS, materials proje cts (MP ), and OQMD databases. The derived expanded databases can then be used for high-throug hput computational screening with higher e fficiency than exhaustive ly s creening billions of candidates (2). While principles of charge neutr ality a nd electronegativity balance (1) have been applied to filter out chemicall y im plausible composit ions for more effective search of new mate rials, such explicit composition rules are still too loose to ensure efficient sampling in the vast chemical design space for new materials search. Indeed, while the hypothetical materials with less than 5 elements can be enumerated (32 billion for 4 - element materials with charg e- ne utrality and balanced electronegativity), the desig n space of more elements can be challenging for which our GAN models can help a lot. Our work can be extended in multiple wa y s. First, we found that Mat GAN can learn chemical composition rules implicitl y even thou gh we did not ex plicitly enforce those rules into our GAN model. However, it is sometimes desirable to implement chemical rule filters to remove chemically invalid candidates, which can be easily implemented based on ou r matrix representation of materials. Another limitation in our current study is that we onl y considered the integer ratio s of elements in compounds in our material representation while doped materials with fractional ratios are ver y common in functional materials such as lithium ion battery material L iZn 0.01 Fe 0.99 PO 4 , w hich is a doped cathode material. Our study can be extended by allowing real numbers on the representation ma trix. However, considering the infinite possibil it y of doping ratios, our GAN method ma y need to work together with other sam pling techniques such a s genetic algorithm s (27, 28), genetic programming (29), and active mac hine lea rning for mix ed para meter search (30, 31) or the Bayesian optimization a pproach (30). In addition, our c urrent GAN models do not tell the crystal structures (lattice consta nts, space group, atomic coordinates, etc.) of the hypothesized materi als. However, with sufficient computational resources, it is possible to exploit DFT-based computational software packages such as USP EX (32) or CALYPSO (33) to determine the cr ystal structure given a mat erial composition and its stoichiometry . Our GAN models can also be used to work together with material structure generators (11). 4. Methods 4.1 Datasets 13 We use a subset of inorganic materials d eposited in the OQMD(13, 15) da tabase to train our AE and GAN models. OQMD is a widel y us ed DFT database with crystal structures either calculated from high-throughput DFT or obtained from the I CSD (34) database. Currently it has 606,115 compounds. We use a sim ilar screening criteria b y Jha et.al. (35) to choose the OQMD subset for GAN training: f or a formula with mult iple reported formation energies, we keep the lowest one to select the most stable compound. Single- element compounds are all removed along with mate rials whose formation energ y is out of the range of {u- 5σ , u+ 5σ } , where u and σ are t he average and standard deviation of the formation energies of all samples in OQMD . Our final dataset, OQMD_L, has 291,884 compounds. As comparison, we a lso tra in two GANs for the Materials Projects (MP ) and I CSD databases respectivel y. Both the MP dataset and ICSD dataset here are prepared by removing all the single-atom compounds, the compounds which has any element with more than 8 atoms in their uni t cell, and compounds containing Kr and He elements. The final MP da taset use d here has 63,922 compounds. The fina l I CS D dataset use d here has 28,137 compounds. 4.2 GAN Neural network s training We have opti mized the h y per -parameters for tr aining th e GANs b y setting the lea rning rate from 0.1 to 10 −6 (each time d ecrease b y 10 fold) and batch normalization size from 32 to 1024, and using diffe rent optimizers. We train our GA Ns using the screened samples from the OQMD, MP, and ICSD, and I CSD_filter dat abase, which is an ICSD subset with all charge-neutral and elect ronegativity balanced materials. These W asserstein GANs are trained for 1000 epochs with the Adam optimizer with learning rate of 0.001 for the generator tra ining and 0.01 for the discriminator training. The batch size for GAN training on OQMD is set to 512 while the batch sizes are set as 32 for GAN traini ng on all other datasets. The AE is trained with the Adam optimization algorithm with a learning rat e of 10 −3 and batch size of 1024. 4.3 T raining of band gap predict ion model We choose 30,186 inorganic materials whose band gaps are greater than 0 ou t of the 63 ,922 compounds in the selec ted MP dataset as the training samples to train the band gap prediction model. Gradie nt Boosted Decision Tree (GBDT) machine lea rning model is then trained with the Ma gpie f eatures. The learning rate is set a s 0.06. The maximum tree depth is set as 20. The subsample is set to 0.4. The number of estimator is set to 100. Supplementary video (published on Oct. 22, 2019) https://www.you tube.com/watch? v=psneoau1m-8 14 Acknowledgement s This work was partially supported by the National Natural Science Foundation of China under grant no. 51741101. J.H., Y.Z. and M. H. also ackn owledge the support from the National Science Foundation with grant no. 1905775, 1940099, and OIA-1655740. S.L. is partially supported by National M ajor Scientific and Technological Special Project of Ch ina under grant no: 2018AAA0101 803 and also by Guizhou P rovince Science & Technology Plan Talent Program # [2017]5788. We would like to thank Z huo Cao, Chengcheng Niu, Rongzhi Dong for helpful discussions. Author contribution : J.H. conceived the project. J.H. and Y.D. develop ed the method o logy. Y.D. imple m ented the method. Y.D. and Y. Z. performed the calculations. Y.D., X.L., and Y.Z. prepared the figures. J.H., Y.D., X.L. and M. H. interp reted the r esults. J.H and Y.D. wrote the manuscript. J.H. and S.L. supervised the pr oject. All authors r eviewed and com mented on the manu script. References 1. Davies DW , et al. (2 016) Computati onal screening of al l sto ichiometric inorgan ic materials. Chem 1 (4):617-627. 2. Cubuk ED, Sendek A D, & Reed EJ (201 9) Screening billi ons of candidates for s olid lithium-ion conduct ors: A transfer learning approach for s mall data. The Journal of chemical physics 1 50(21):21470 1. 3. Jensen WB & Jensen WB ( 2010) The origin of the ionic-rad ius ratio rules. Journal of Chemical Education 8 7(6):587-588. 4. Ranganathan S & In oue A (2006) An application of P ettifor structure maps fo r the identification of pseud o-binary quasicry stalline inter metallics . Acta materialia 54(14):3647-3656. 5. Sanchez-Lengeling B & Aspuru-Guz ik A (2018) Inverse molecular design using machine learning: Generativ e models for matter engineerin g. Science 361(64 00):360-365. 6. Xue D , et al. (2019) Ad v ances and chall enges in deep generative models f or de novo molecule generati on. Wiley Interdisciplinary Reviews: Computational Molecula r Science 9(3):e1395. 7. Xu Y , et al. (2019) D eep learnin g for molecular gener ation. Future medici nal chemistry 11(6):567-597. 8. Elton DC, Boukouvala s Z, Fuge MD, & Chu ng PW (201 9) Deep learning for molecular design-a review of the state of the a rt. Molecular Systems Design & Enginee ring . 9. Ferguson AL (2018) Machine learning and data scienc e in soft materials engineering. J Phys-Condens Mat 30 (4). 10. Arjovsky M, Chin tala S, & Bottou L (20 17) Wasserstein generative advers arial networks. International Confe rence on Machin e Learning , pp 214-2 23. 11. Noh J , et al. (2019) In v erse Design of Solid-State Mater ials v ia a Contin uous Representati on. Matter . 12. Hoffmann J , et al. (2 019) Data-Driven App roach to Encoding and Decoding 3-D C rystal Structures. arXiv p reprint arXiv :1909.00949 . 15 13. Kirklin S , et al. ( 2015) The Open Quantu m Materials Database (OQM D): assessin g the accuracy of DFT for mation energies. npj Co mputational Mate r ials 1:1501 0. 14. Jain A , et al. (2013 ) Commen tary: The Materials Project: A materials g enome approach to accelerating materials innovation. Ap l Mater 1(1):1 049. 15. Saal JE, Kirklin S, Ayk ol M, Meredig B , & Wolverton C (2013) Materials desig n and discovery with high-thr o ughput density func tio nal the ory: the open quan tum materials database (OQMD). Jo m 65(11):1501-1509. 16. Doersch C (2016) Tut o rial on variati onal autoencoders. arXiv preprint arXiv:160 6.05908 . 17. Chen X , et al. (20 16) Infogan: Interpre table representa tio n learning b y informatio n maximizing generati v e adversaria l nets. Advances in n eural information proce ss ing systems , pp 2172-21 80. 18. Arjovsky M, Chin tala S, & Bottou L (20 17) Wasserstein gan. arXiv preprint arXiv:1701.078 75 . 19. Pu Y , et al. (201 6) Variational auto encoder for deep le arning of images, labels and captions. Advances in neural information p r ocessing s ystems , pp 2352-23 60. 20. Ioffe S & Szegedy C (2015) Batch normaliz ation: Accel erating deep network training by reducing internal c ovariate shi ft. arXiv preprint a rXiv:1502.03167 . 21. Shamir RR, Duchin Y, Kim J, Sapiro G, & Harel N (2019 ) Continuous dice coefficient: a method for evaluatin g probab ilistic segmentations. ar Xiv preprint arXiv :1906.11031 . 22. Shamir RR, Duchin Y, Kim J, Sapiro G, & Harel N (2018 ) Continuous Di ce Coefficien t: a Method for Evaluatin g Probabilistic Segm entations. BioRxiv : 306977. 23. Ma aten Lvd & Hint o n G (20 08) Visualizing data using t-SNE. Journal of mac hine learning research 9(Nov):25 79-2605. 24. Ye W, Chen C, Wang Z, Chu I-H, & Ong SP (2018) Deep neural netw orks for accurate predictions of crys tal stability. Nature com munications 9(1):3800. 25. Kang S & Cho K ( 2018) Conditional molecular design with deep generative models. J Chem Inf Model 59( 1):43-52. 26. Ward L, Agrawal A, Choudhary A, & Wolverton C (2016) A general-purpose machine learning framew ork for pred icting properties of in organic materials. Npj Compu t Mater 2. 27. Atilgan E & Hu J (2 018) First-principle-based c o mputat ional doping of SrTiO $ $ _ {} $$ using combinat o rial genetic alg o rithms. Bulletin of Materials Science 41(1):1. 28. Atilgan E & Hu J (2 015) A Combinat orial Genetic Algor ithm for Computati onal Doping based Material Design. Proceedings of the Co mpanion Publica tion of the 2015 An nual Conference on Genetic and Evolution ary Computation , (ACM), pp 1349-1350. 29. Atilgan E (2016) Computational Doping for Fuel Cell Material Design Ba sed on Genetic Algorithms and Gen et ic Program ming. Ph.D. (Uni versity of South Car olina, Columbia, SC). 30. Xue D , et al. (2016) A ccelerated sea rch for materials with target ed properties by adaptive design. N ature communication s 7:11241. 31. Lo okman T, Balach andran PV, Xu e DZ, Hogden J, & Theiler J (2017 ) Statistical infe rence and adaptive desig n for materials di scovery. Curr Opin Solid St M 21(3):12 1-128. 32. Glass CW, Oganov A R, & Hansen N (2006) USPEX — Ev olutionary crystal structure prediction . Compute r physics communica tions 175(11-12):713- 720. 33. Wang Y, Lv J, Zhu L, & Ma Y (2 012) CALYPSO: A method for crystal structure predi ction. Computer Physics Com munica tions 183(10):2063-2070 . 34. Bergerhoff G, Hundt R , Sievers R, & Brown I (1983) The inorganic cr ystal structure d ata base. Journal of chemica l information and comp uter sc iences 23(2):66- 69. 16 35. Jha D , et al. (20 18) Elemnet: Deep l earning the chemi stry of mat erials from only elemental compositi o n. Sci Rep- Uk 8(1):17593.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment