Exploratory Landscape Analysis is Strongly Sensitive to the Sampling Strategy
💡 Research Summary
**
The paper investigates how the sampling strategy and sample size affect the quality of feature value approximations in Exploratory Landscape Analysis (ELA) and, consequently, the performance of supervised learning models that rely on these features for algorithm selection and configuration. ELA transforms a black‑box optimization problem f into a vector of statistical descriptors (e.g., skewness, multimodality, linear‑fit quality). When the function is not analytically available, these descriptors must be estimated from a limited set of evaluated points (x, f(x)).
Experimental Setup
The authors use the 24 noiseless BBOB functions in five dimensions, mirroring previous work for comparability. For each function they generate three different sample sizes n = 30, 300, 3125 and five distinct sampling designs: (1) uniform random sampling with the Mersenne Twister generator, (2) uniform random sampling with the historically flawed RANDU generator, (3) standard Latin Hypercube Sampling (LHS) via pyDOE, (4) an improved LHS (iLHS) implemented in flacco, and (5) Sobol low‑discrepancy sequences. Each design is repeated 100 times, producing 100 independent feature vectors per function (46 features per vector, as returned by the flacco package).
From each set of 100 vectors, 50 are randomly selected for training a classifier and the remaining 50 for testing. This split is repeated 50 times to obtain robust average accuracies. Two off‑the‑shelf classifiers are employed without hyper‑parameter tuning: 5‑Nearest Neighbours (K = 5) and decision trees. A random‑forest experiment is also reported as a sanity check, showing similar trends.
Key Findings
-
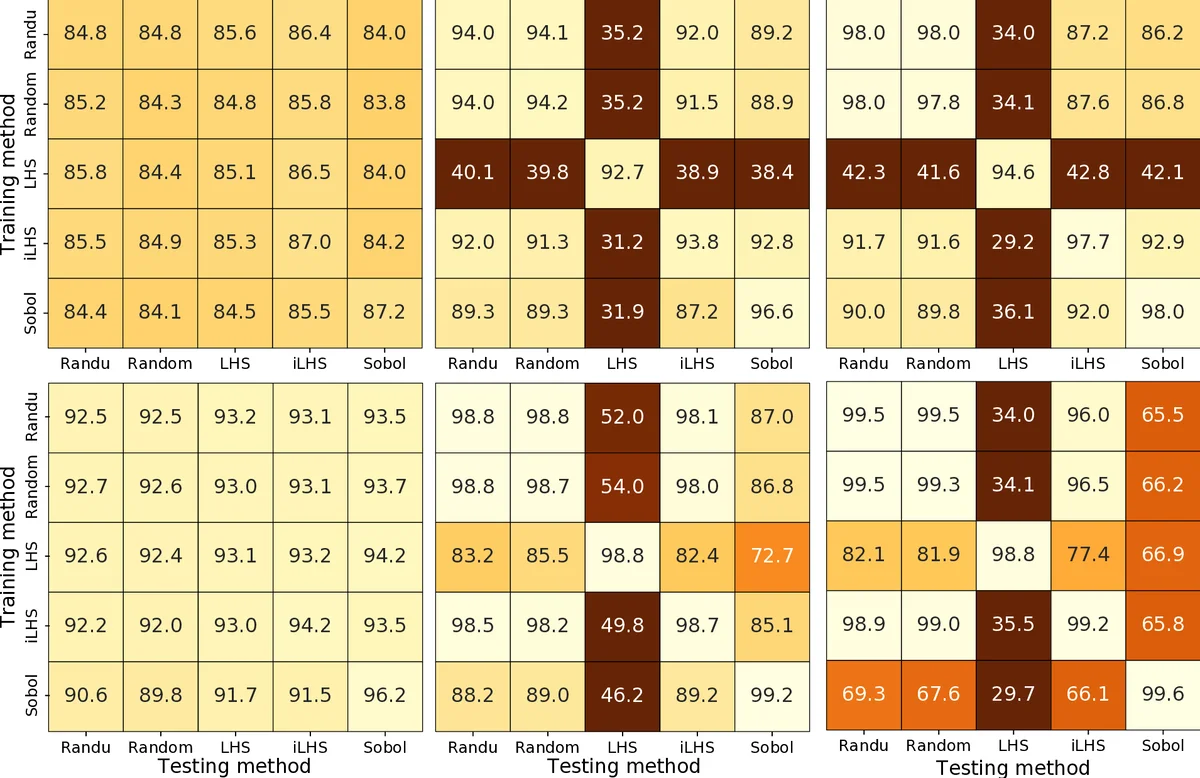
Sample Size Effect – As expected, larger n reduces the dispersion of the estimated features and improves classification accuracy for all sampling strategies.
-
Strategy‑Dependent Feature Values – Crucially, the approximated feature values do not converge to a single “true” value when n → ∞. Different sampling distributions produce systematically different feature vectors for the same underlying function. This contradicts earlier claims in the ELA literature that feature estimates become invariant with infinite samples.
-
Training‑Testing Consistency – Classifiers achieve high accuracy only when the sampling strategy used for training matches the one used for testing. Mixing strategies (e.g., training on LHS, testing on uniform) leads to a marked drop in performance, indicating that the learned models are tightly coupled to the sampling distribution.
-
Impact of Random Number Generators – Using two very different pseudo‑random generators (Mersenne Twister vs. RANDU) for uniform sampling yields virtually identical results, suggesting that generator quality is not a critical factor for ELA feature estimation.
-
Superiority of Sobol Sequences – Among all designs, Sobol low‑discrepancy sequences consistently deliver the highest classification accuracies. For n = 300, Sobol‑based features achieve ≈ 0.92–0.95 accuracy, and for n = 3125 they reach ≈ 0.96–0.98, outperforming both uniform and LHS variants. The authors attribute this to the small star discrepancy of Sobol sequences, which provides a more uniform space‑filling property and reduces sampling bias.
Implications
-
Model Transferability – When deploying ELA‑trained machine‑learning models to new problems, practitioners must either replicate the exact sampling strategy used during training or retrain the model with data generated by the new sampling distribution. Failure to do so can degrade performance dramatically.
-
Benchmark Reporting – Researchers should always disclose the sampling method (including the random seed or generator) when publishing ELA feature datasets, as comparisons across studies are otherwise unreliable.
-
Sampling Strategy Choice – The findings encourage a shift away from the default uniform or LHS designs toward low‑discrepancy quasi‑random sequences (e.g., Sobol, Halton, Faure) for ELA, especially when evaluation budgets are limited.
-
Future Research Directions – The paper suggests exploring other low‑discrepancy families, assessing the effect of dimensionality beyond five, and investigating hybrid approaches that combine trajectory‑based sampling (i.e., using points generated by an optimizer) with quasi‑random designs. Additionally, theoretical work to model the relationship between discrepancy, sample size, and feature estimation error would deepen understanding.
Conclusion
The study demonstrates that ELA feature values are not absolute descriptors but are intrinsically tied to the sampling distribution from which they are estimated. This sensitivity has practical consequences: supervised learning models built on ELA features are only as robust as the consistency of the underlying sampling strategy. Moreover, Sobol low‑discrepancy sequences provide a clear empirical advantage over traditional uniform and Latin Hypercube sampling, suggesting that the community should reconsider standard sampling practices in ELA‑based algorithm selection and configuration pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment