Adversary-resilient Distributed and Decentralized Statistical Inference and Machine Learning: An Overview of Recent Advances Under the Byzantine Threat Model
While the last few decades have witnessed a huge body of work devoted to inference and learning in distributed and decentralized setups, much of this work assumes a non-adversarial setting in which individual nodes---apart from occasional statistical…
Authors: Zhixiong Yang, Arpita Gang, Waheed U. Bajwa
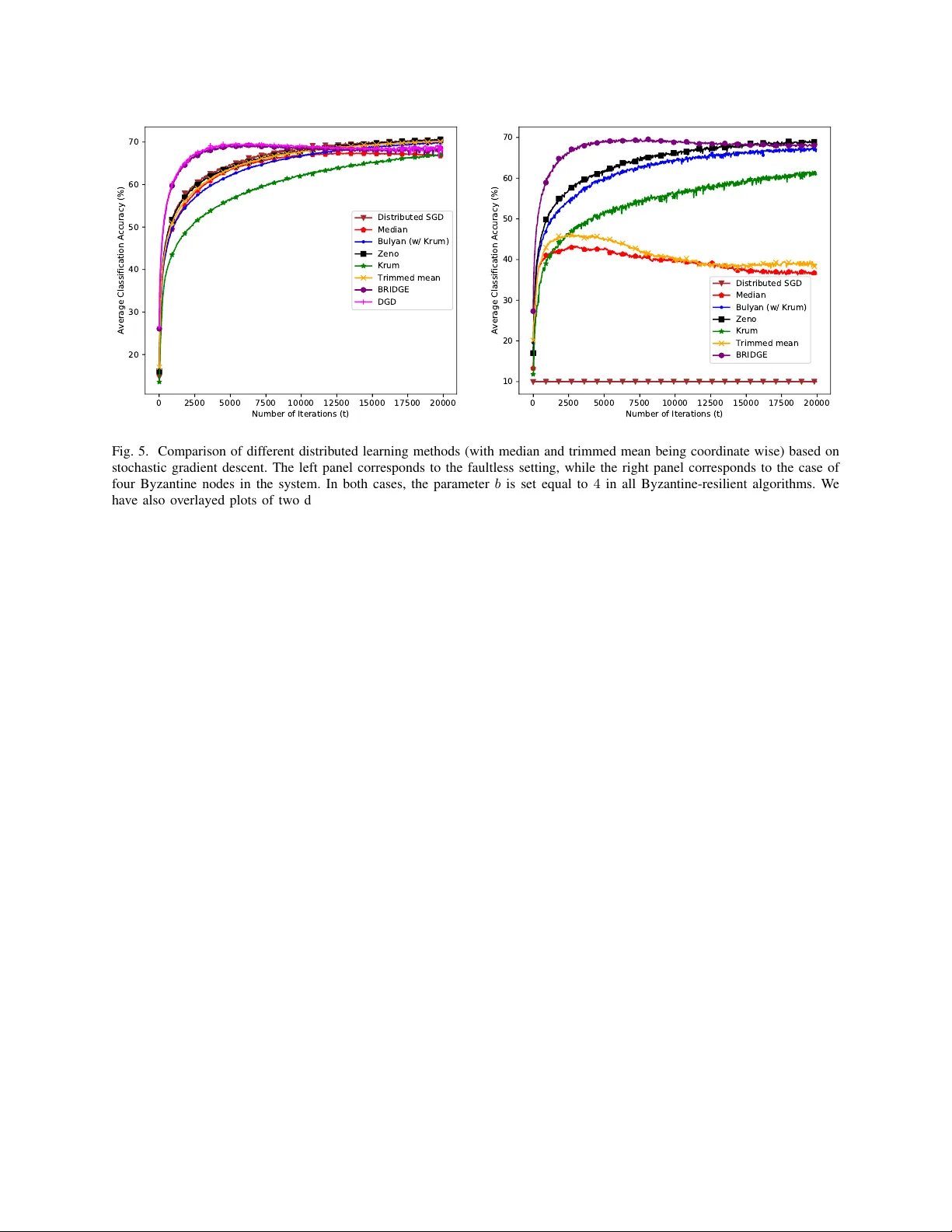
1 Adv ersary-resilient Distrib uted and Decentralized Statistical Inference and Machine Learning [An Overvie w of Recent Adv ances Under the Byzantine Threat Model] Zhixiong Y ang, Arpita Gang, and W aheed U. Bajwa Statistical inference and machine learning algorithms hav e traditionally been dev eloped for data av ail- able at a single location. Unlike this centralized setting , modern datasets are increasingly being distributed across multiple physical entities (sensors, devices, machines, data centers, etc.) for a multitude of reasons that range from storage, memory , and computational constraints to pri vac y concerns and engineering needs. This has necessitated the de velopment of inference and learning algorithms capable of operating on non-collocated data. W e divide such algorithms into two broad categories in this article, namely , distributed algorithms and decentr alized algorithms . Distributed Algorithms: Distributed algorithms correspond to setups in which the data-bearing entities (henceforth referred to as “nodes”) require some form of coordination through a specially designated entity in the system in order to generate the final result. Depending on the application, this special entity is referred to as master node, central server , parameter server , fusion center , etc., in the literature. While distributed setups can take a number of forms, this exposition mostly re volves around the so-called master – worker distributed ar chitectur e in which data-bearing nodes only communicate with a single master node that is tasked with generating the final result. Among other applications, such distributed architectures arise in the context of parallel computing, where the focus is computational speedups and/or overcoming memory/storage bottlenecks, and federated systems, where “raw” data collected by indi vidual nodes cannot be shared with the master node due to either communication constraints (e.g., sensor networks) or pri vac y concerns (e.g., smartphone data). Decentralized Algorithms: Decentralized algorithms correspond to setups that lack central servers; instead, data-bearing nodes in a decentralized system are collectively tasked with generating the final result. In particular , individual nodes in a decentralized setup typically communicate among themselves ov er a netw ork (often ad hoc) to reach a common solution (i.e., achie ve consensus ) at all nodes. Decentralized setups arise either out of the need to eliminate single points of failure in distributed setups or due to practical engineering constraints, as in the internet of things and autonomous systems. 2 Fig. 1. Inference and machine learning algorithms in volving non-collocated data can be broadly divided into the categories of ( i ) distributed algorithms and ( ii ) decentralized algorithms. The former category includes master–worker distributed setups such as parallel computing and federated systems in which a single entity is tasked with generating the final result. The latter category deals with decentralized setups in which entities cooperate among themselves to produce the final result. Is it distributed or is it decentralized? Inference and learning from non-collocated data hav e been stud- ied for decades in computer science, control, signal processing, and statistics. Both among and within these disciplines, howe ver , there is no consensus on use of the terms “distributed” and “decentralized. ” Though many works share the definitions provided in here, there are numerous authors who use these two terms interchangeably , while there are some other authors who reverse these definitions. The last fe w decades hav e witnessed the emergence of a plethora of applications that necessitate adv ances in inference and learning in distributed and decentralized setups. Indeed, distributed and de- centralized statistical inference methods are increasingly being relied upon in urban traffic monitoring, en vironmental sensing, management of smart grids, distributed spectrum sensing, and homeland security , among other applications. Similarly , distributed and decentralized machine learning algorithms are in- creasingly being utilized in the context of networks of self-driving cars, control of robot swarms, pattern recognition in large-scale datasets, and federated learning systems for healthcare data. Collectively , these applications hav e resulted in the development of a huge body of work de voted to understanding the algorithmic and theoretical underpinnings of distributed and decentralized inference and learning. But much of this work assumes a non-adversarial setting in which indi vidual nodes—apart from occasional statistical failures—operate as intended within the algorithmic frame work. In recent years, howe ver , cybersecurity threats from malicious non-state actors and rogue entities—and the potentially disastrous consequences of these threats for the aforementioned applications—have forced 3 practitioners and researchers to rethink the robustness of distributed and decentralized algorithms against adversarial attacks. As a result, we now hav e an abundance of algorithmic approaches that guarantee robustness of distributed and/or decentralized inference and learning under dif ferent adversarial threat models; see, e.g., recent surve y articles [1]–[3]. Driven in part by the world’ s growing appetite for data- dri ven decision making, ho wev er , securing of distributed/decentralized frame works for inference and learning against adversarial threats remains a rapidly ev olving research area. In this article, we provide an overvie w of some of the most recent developments in this area under the threat model of Byzantine attacks . This threat model—which subsumes the case of malfunctioning nodes, referred to as Byzantine faults/failur es —is one of the hardest to safeguard against since it allo ws for undetected takeo ver of nodes by the adversary . In particular, nodes affected under this threat model—termed Byzantine nodes —are assumed to hav e the potential to arbitrarily bias the outputs of the underlying algorithms by colluding among themselves, injecting false data and information into the distributed/decentralized system, etc. This is in stark contrast to the relativ ely simpler threat model of crash faults , in which individual nodes in the distributed/decentralized system continue to operate as intended till a crash fault occurs, at which point the faulty node ceases to interact with the system (rather then potentially injecting false information into the system). W e refer the reader to [4], and the references within, for further discussion on both the generality and the hardness of the Byzantine threat model in relation to the crash-fault model. Fig. 2. A Byzantine army led by three generals, one of whom (General 3) is a traitor , surrounding an enemy city . The loyal generals are trying to reach a consen- sus on the plan of action against the enemy , while the traitor is trying to mislead them. Origination of the Byzantine thr eat model: The threat model of Byzantine attacks/faults/failures in its most general form w as introduced and analyzed in [5] within the context of reliability of computer systems with potentially malfunctioning components. The o verarching problem in [5] was abstracted as the Byzantine Generals Pr oblem , in which sev eral generals of the Byzantine army—some of whom are likely to be traitors—need to agree on attacking or retreating from an enemy city through exchange of messages via a messenger; see, e.g., Figure 2. The authors reported two k ey results in [5] for this problem. First, the y established the impossibility of safeguarding against Byzantine nodes (traitor generals) when the number of uncompromised nodes (loyal generals) is not more than two-thirds of the total number of nodes. The threat from General 3 in Figure 2, therefore, cannot be neutralized by any algorithm since the number of loyal generals is only two in this scenario. Second, the authors proposed two 4 algorithms for complete and r e gular graphs that provably counter the actions of Byzantine nodes in the case of binary (e.g., attack/retreat) decisions as long as the number of uncompromised nodes exceeds two-thirds of the total number of nodes. The Byzantine threat model, since its introduction in 1982, has been extensi vely studied in the context of statistical inference from non-collocated data [1], [2]. Ho wever , its potential impact on more general decentralized consensus and distributed/decentralized machine learning problems has only been recently studied. It is against this backdrop that this article summarizes recent developments in Byzantine-resilient processing of non-collocated data, with a majority of the discussion focused on machine learning problems in distrib uted and decentralized settings. I . A DV E R S A RY - R E S I L I E N T D I S T R I B U T E D P R O C E S S I N G O F D A TA In the classic master–work er setting of distributed systems tasked with processing of non-collocated data, there is one central server—referred to as master node, parameter server , fusion center, etc.—that coordinates with M data-bearing nodes (sensors, smartphones, worker nodes, etc.) for final decision making. While all nodes in this setting communicate with the server , they usually cannot communicate with each other (see “Distributed Setups” in Figure 1). The Byzantine threat model in this setting assumes at most b nodes in the system have been compromised. This parameter b , which typically corresponds to a crude upper bound on the exact number of Byzantine nodes, often plays an important role in both the analysis and the performance of Byzantine-resilient algorithms. W e summarize some of these algorithms and their theoretical guarantees in the following for statistical inference and machine learning problems. A. Distributed Statistical Inference Statistical inference le verages data samples in order to draw conclusions about the underlying proba- bility distribution(s) generating the data. While statistical inference can take many forms, we limit our discussion in this article to Byzantine-resilient distributed detection and distributed estimation. Distributed Detection: Distributed detection under both the Neyman–P earson (NP) and the Bayesian frame works has a rich history . Given two hypotheses H 0 and H 1 , a typical distributed detection algorithm first in volv es each node taking a local decision in fav or of either H 0 or H 1 based on its own data samples. The nodes then send their decisions to the central server , which applies a fusion rule to the local decisions in order to reach the final (global) decision. Unfortunately , distributed detection algorithms designed without consideration of potential Byzantine failures break do wn in the presence of Byzantine nodes. Despite the brittleness of traditional distributed detection techniques, in vestigation of Byzantine-resilient distributed detection only took off in the last decade. The survey article [1] provides an ov erview of many 5 T ABLE I S U M M A RY O F R E C E N T R E S U LT S C O N C E R N I N G B Y Z A N T I N E - R E S I L I E N T D I S T R I B U T E D D E T E C T I O N Reference Hypothesis T est Detection Setup Critical Fraction α ∗ Distributed Architecture Nadendla et al. [6] Q -ary Neyman–Pearson α ∗ = Q − 1 Q Star topology Kailkhura et al. [7] Binary Bayesian α ∗ = 0 . 5 Star topology Hashlamoun et al. [8] Binary Bayesian Can have α ∗ = 1 Quasi-star topology Kailkhura et al. [9] Binary Neyman–Pearson b 1 = d M 1 2 e T ree topology of the resulting methods and asymptotically characterizes the respectiv e critical fraction α ∗ of Byzantine nodes, defined as α ∗ := b M , at (or beyond) which the central server cannot do better than random guessing for its final decision. An important insight from the earliest works on Byzantine-resilient distributed detection is that (asymptotically) α ∗ can be 1 2 or higher [1]; in contrast, recall that α ∗ = 1 3 for the original Byzantine Generals Problem [5]. Since the appearance of [1] in 2013, a fe w other works on Byzantine-resilient distributed detection hav e appeared in the literature. It is shown in [6] that distributed detection can be more resilient to Byzantine failures in the case of a general Q -ary hypothesis testing problem, with the critical fraction gi ven by α ∗ = Q − 1 Q . Byzantine-resilient distrib uted binary hypothesis testing is in vestigated for the first time under the Bayesian framework in [7], with the critical fraction also giv en by α ∗ = 1 2 in this case. Finally , it is established in [8] that—under certain conditions—it is possible to have α ∗ = 1 in the case of Bayesian distributed binary detection as long as each node is allowed to replicate its message to the central server through one other node in the system. Strictly speaking, howe ver , this coordination among pairs of nodes leads to a distributed architecture that differs from the distributed master–w orker (star topology) architecture of prior works. W e conclude by noting that a tree topology in which the central server sits at the root of the tree (Depth 0) and nodes in the distributed system route their messages to the server through their parent nodes is another distributed architecture that does not fall under the distributed master–worker setup. Byzantine resilience of such architectures in distributed detection tasks is in vestigated in [9], with the critical fraction of Byzantine nodes defined in terms of the number of Byzantine nodes b 1 and the total number of nodes M 1 at Depth 1 of the tree. W e also refer the reader to T able I for a summary of all the results that have been discussed in this article in relation to Byzantine- resilient distrib uted detection. Distributed Estimation: Byzantine-resilient distributed estimation has receiv ed significant attention lately in the context of state estimation in cyberphysical systems. Much of the developments in this regard hav e been limited to linear models, with a typical observation model at any giv en time at node 6 j expressed as y j = h T j w + η j , j = 1 , . . . , M , where h j ∈ R d denotes a kno wn vector , w ∈ R d is the unknown state vector that needs to be estimated at the central server , and η j denotes the observation noise at node j . T raditionally , distributed estimation has inv olved the nodes transmitting y j ’ s (or their quantized versions) to the central server and the server estimating w using some v ariant of the following least-squares formulation [10] (or a maximum likelihood one in the case of quantized transmissions): b w = arg min e w y − H e w 2 , (1) where the matrix H ∈ R M × d has h j ’ s as its rows. The quality of such solutions are assessed in terms of gap of their mean squared err or (MSE), E [ k b w − w k 2 2 ] , from either the minimum mean squar ed error (MMSE) or the Cramer –Rao lower bound (CRLB) for unbiased estimators. In the presence of Byzantine nodes, in which case the y j ’ s corresponding to the b Byzantine nodes can be arbitrarily dif ferent from h T j w , solutions of distributed estimation techniques based on (1) can be pushed far from the optimal (in terms of MMSE/CRLB); see, e.g., Figure 3. In this setting, one can again characterize the critical fraction α ∗ of Byzantine nodes at (or beyond) which the server can do no better than relying on prior knowledge about w . It is, for instance, established in [6] that—under certain assumptions—it is possible to hav e α ∗ = Q − 1 Q when nodes utilize Q -ary quantization in order to transmit their data to the server . The survey articles [1]–[3] provide additional discussion of works on Byzantine-resilient distributed estimation, man y of which are based on the idea of either detection of Byzantine attacks and/or identification of individual Byzantine nodes as part of their mitigation strategy . Finally , while much of the focus in Byzantine-resilient distrib uted estimation has been on linear models, there are works like [11] that focus on nonlinear models. Since there is a significant overlap between statistical estimation and machine learning problems, we do not indulge in discussion of such works; instead, we mov e towards our revie w of recent results on Byzantine-resilient distributed machine learning. Fig. 3. The impact of Byzantine failures on traditional least-squares estimation. Distributed estimation and Byzantine failur es: W e illustrate the impact of Byzantine nodes on distributed estimation through a simple example of two-dimensional parameter estimation, in which the linear observation model corresponds to a line in ( x, y ) plane, using M = 8 nodes. The observations at each node in this example correspond to y j = h T j w + η j with h T j := [ x j 1] and the two-dimensional vector w describing the slope and y -intercept of the line. It can be seen from Figure 3 that Byzantine failures of just two nodes returns a least-squares solution that results in a model h T j b w that significantly dif fers from the true model h T j w . 7 B. Distributed Mac hine Learning A typical challenge in machine learning is to statistically minimize a function f , referred to as loss function or risk function , with respect to a candidate model w ∈ R d that describes the data, i.e., min w E z ∼P f ( w , z ) , (2) where z denotes data living in some Hilbert space that is drawn from an unknown probability distribution P . T o solve (2) without kno wledge of P , distrib uted machine learning focuses on minimizing an empirical v ariant of E z ∼P f ( w , z ) using samples of z —termed training data —distributed across different nodes. The resulting objectiv e, aptly termed distributed empirical risk minimization (ERM), can be expressed as min w 1 M M P j =1 f ( w , Z j ) , with Z j denoting the local training data at node j that comprises multiple samples drawn from P and w referred to as the global optimization variable. The model/variable w in distributed machine learning is stored at the central server , which iterati vely updates it based on messages recei ved from individual nodes and subsequently sends the updated w to all nodes. Each node, in turns, performs some computation according to its local data and the receiv ed w , and sends a message back to the server . Distributed Stochastic Gradient Descent: Similar to distrib uted statistical inference, Byzantine fail- ures can lead to breakdo wns of distributed machine learning methods. Motiv ated in part by the widespread adoption of deep neural networks and variance-reduction techniques like mini batching by the practition- ers, we mainly focus here on robustification of synchronous distributed stochastic gradient descent (SGD) against Byzantine attacks. A typical distributed SGD algorithm proceeds iterativ ely . In each iteration, nodes compute the gradient of the loss function on their local data with respect to the current model and send their gradients to the server . The server , in turn, takes the a verage of all the gradients and updates the global variable according to the av eraged gradient. In a faultless en vironment, distributed SGD—with proper choices of step size and batch size—has a linear con ver gence rate for strongly con vex functions. Ho wev er , a single Byzantine node can force the algorithm to con ver ge to any model using a simple strategy . Suppose, for instance, the summation of gradients of faultless nodes is g and the Byzantine node wishes the server to operate on an alternate gradient g 0 . The Byzantine node can accomplish this by sending M g 0 − g as its gradient to the server , thereby controlling the update step at the server . Of course, as simple as this strategy is, it is not an optimal one for the Byzantine node; indeed, a large M will result in a large gradient, which is likely to make the malicious message detectable. W e refer the reader to [12]–[14] for more sophisticated strategies that can be employed by Byzantine nodes. Se veral algorithms ha ve been put forth recently to safeguard distrib uted SGD against Byzantine failures. The central idea in all these approaches that imparts Byzantine resilience to distributed SGD in volves the use of a scr eening procedure at the server while it aggregates the local gradients. Using an appropriate 8 screening rule, the screened aggregated gradient can be shown to be close to the true av erage gradient, thereby enabling the server to approximately solve the distributed ERM problem. Algorithm 1 provides a general framework for Byzantine-resilient distributed SGD that is based on this idea of screening. While some algorithms alter this frame work a little bit, the general idea remains the same. Note that if one were to remove the screening procedure in Step 10 of the algorithm, it becomes vanilla distributed SGD. Algorithm 1 A General Frame work for Byzantine-resilient Distributed SGD 1: for t = 1 , 2 , . . . do 2: Server : 3: Send the global optimization v ariable to all nodes 4: Node : 5: Recei ve the global optimization variable from the server 6: Calculate gradient with respect to the local training set 7: Send the local gradient to the server 8: Server : 9: Recei ve local gradients from all nodes 10: Screen the receiv ed gradients for Byzantine resilience and aggregate them 11: Update the global variable by taking a gradient step using the aggregated gradient 12: end for The State of the Art: W e now discuss the various screening (and aggregation) procedures adopted in dif ferent algorithms. The algorithm introduced in [15], termed r obust distributed gr adient descent , uses two screening methods: coor dinate-wise median and coor dinate-wise trimmed mean . In coordinate-wise median, the server aggreg ates the local gradients by taking the median in each dimension of the gradients. Coordinate-wise trimmed mean, on the other hand, in volves the server eliminating the smallest and the largest b values in each dimension of the gradients and coordinate-wise averaging the remaining values for aggregation. The GeoMed algorithm [16], in contrast, uses the geometric median of local gradients as the screening and aggregation rule. The Krum [17] algorithm, on the other hand, finds the local gradient that has the smallest distance to its M − b − 2 closest gradients and uses this gradient for the update step. There is also a variant of the Krum algorithm, termed Multi-Krum [17], which finds m ∈ { 1 , . . . , M } local gradients using the Krum principle and uses an a verage of these gradients for update. The Bulyan algorithm [18], [19] is a two-stage algorithm. In the first stage, it recursively uses vector median methods such as Geometric median and Krum to select M − 2 b local gradients. In the second stage, it carries out a coordinate-wise operation on the M − 2 b selected gradients in which M − 4 b 9 v alues in each coordinate are retained (and then averaged for aggregation) by eliminating 2 b values that are farthest from the coordinate-wise median. Zeno/Zeno++ [20], [21] are related algorithms that require an oracle at the server , which can generate an estimate of the true gradient in each iteration, for screening/aggregation purposes. In particular , the screening procedure in volves calculating a score for each local gradient based on its difference from the oracle gradient, with the survi ving gradients being the ones that are the most similar to the oracle gradient. The Byzantine-resilient distrib uted SGD framework of Algorithm 1 has also been inv estigated in [22] under a gener alized Byzantine threat model. The basic assumption underlying this threat model is that the set of nodes under Byzantine attacks can change in each iteration of the algorithm, but the attackers can only inject malicious information in some dimensions of their respecti ve gradients. Similar to [15], [16], the work in [22] puts forth the use of coordinate-wise median, a variant of coordinate-wise trimmed mean, and geometric median for screening purposes, and establishes resilience of the resulting methods under the assumption that less than half of the gradients in each dimension are attacked in each iteration. W e conclude by discussing a few methods that somewhat deviate from the distributed frame work of Algorithm 1. In contrast to [15]–[22], the RSA algorithm of [23] robustifies distributed SGD by making indi vidual nodes store and update local versions of the global optimization variable w , which are then aggregated at the server in each iteration in a Byzantine-resilient manner . In order to reduce the communications overhead of Byzantine-resilient distributed SGD, [24] discusses the signSGD algorithm, which only uses the element-wise sign of the gradient—rather than the gradient itself—for the update step. In particular , it is established in [24] that signSGD with an element-wise majority vote on the signs of the local gradients as a screening/aggregation rule is a Byzantine-resilient learning method. Finally , [25] proposes and analyzes a variant of distributed SGD that requires only one pass over the entire training data. Unlike other works, howe ver , resilience in this work is accomplished through explicit labeling of nodes as Byzantine, which are then excluded from all future computations at the server . W e next summarize key aspects of some of the Byzantine-resilient distributed learning algorithms in T able II in terms of the number of nodes M , the number of Byzantine nodes b , and the number of independent and identically distributed (i.i.d.) samples per node N . The con vergence rates in the table correspond to the gap between the learned model after t iterations and the minimizer of the statistical risk (cf. (2)) in the limit of large N . The parameter c denotes a constant that may change from one algorithm to the other , the O ( · ) scaling hides dependence on problem parameters (including dimension d in the top part of the table), N/A signifies an algorithm lacks a particular result, and — means guarantees for an algorithm are not directly comparable to other algorithms. The last column in the top part of the table 10 T ABLE II S U M M A RY O F S O M E R E C E N T R E S U LT S C O N C E R N I N G B Y Z A N T I N E - R E S I L I E N T D I S T R I B U T E D M A C H I N E L E A R N I N G Algorithm Con vergence Rate Statistical Learning Rate Condition on ( M , b ) Coordinate-wise Median (CM) [15] O c t O b M √ N + 1 √ M N + 1 N M ≥ 2 b + 1 Coordinate-wise Trimmed Mean (CTM) [15] O c t O b M √ N + 1 √ M N M ≥ 2 b + 1 GeoMed [16] O c t O √ b √ M N M ≥ 2 b + 1 Krum [17] N/A N/A M ≥ 2 b + 3 Multi-Krum [17] N/A N/A M ≥ 2 b + m + 2 Bulyan [18] N/A N/A M ≥ 4 b + 3 Zeno/Zeno++ [20], [21] O c t + O (1) N/A M ≥ b + 1 RSA [23] O 1 t + O (1) N/A M ≥ b + 1 signSGD [24] — N/A M ≥ 2 b + 1 Algorithm CM, CTM, Zeno/Zeno++ GeoMed Krum, Multi-Krum Bulyan Screening Complexity O ( M d ) O M d + bd log 3 ( 1 γ ) ? O ( M 2 d ) O ( M 2 d + M d ) ? Screening computational complexity for GeoMed is for computing (1 + γ ) -approximate geometric median [16]. lists conditions on M and b necessary for well-posedness of different algorithms. The bottom part of the table lists per -iteration computational complexity of the screening procedure for algorithms that inv olve an explicit screening step at the server . While the conv ergence/learning rates in the table are for strongly con vex and smooth loss functions, some of the works require further assumptions and/or also provide results under a relaxed set of assumptions on the loss function and training data. W e refer the reader to the referenced works for further details. -2 0 2 4 6 8 10 50 g 1 -1 1 3 5 7 9 11 50 g 2 Byzantine point Nonfaulty points True average Average Median Trimmed mean Krum Bulyan Fig. 4. An illustration of the effects of data falsified by Byzantine nodes on screening methods. Scr eening and ag gre gation in two dimensions: W e il- lustrate the robustness of different screening/aggregation methods against Byzantine attacks through a simple two- dimensional example. Consider a total of se ven two- dimensional points ( g 1 , g 2 ) , out of which six represent correct data (black discs in Figure 4) and one of which has been falsified by a Byzantine node (red disc in Figure 4). It can be seen from Figure 4, which is displayed with non- uniform g 1 - and g 2 -axes to capture the effect of the Byzantine node, that the ordinary av erage operation is highly susceptible to the falsified data point. On the other hand, screening and aggregation rules such as coordinate-wise median, coordinate-wise trimmed mean, Krum and Bulyan (using Krum in Figure 4) all produce final results that stay close to the true a verage of the faultless data points. 11 Numerical Experiments: It can be seen from T able II that (coordinate-wise) median, (coordinate- wise) trimmed mean, and GeoMed have some of the best theoretical guarantees for strongly conv ex and smooth loss functions in terms of conv ergence and learning rates. W e now numerically compare the performance of most of the algorithms listed in T able II on noncon vex loss functions. Our comparison excludes GeoMed, since it lacks an algorithm for computing the exact geometric median of a set of high- dimensional gradients, as well as signSGD and RSA, since they differ from the rest of the algorithms in terms of their approach to Byzantine resilience. The noncon vex learning task in the experiments corresponds to classification of the ten classes in CIF AR-10 dataset using a conv olutional neural network with three con volution layers followed by two fully connected layers. Each of the three con volution layers are follo wed by ReLU acti vation and max pooling, while the output layer uses softmax activ ation. The distrib uted setup corresponds to one server and M = 20 nodes, with the 50 , 000 sample training set uniformly at random distributed across the system (i.e., each node has N = 2 , 500 training samples). W e run two rounds of experiments for each algorithm, where each round is repeated 10 times—with each trial corresponding to 20,000 algorithmic iterations—and the results on the CIF AR-10 test set are a veraged over these 10 trials. In the first round, none of the nodes are taken to be Byzantine nodes. In the second round, four nodes are randomly selected as Byzantine nodes, with each one sending a random vector to the server in each iteration whose elements uniformly take values in the range (0 , 10 − 5 ) for odd-numbered iterations and (0 , 20) for e ven-numbered iterations. W e limit ourselves to four Byzantine nodes in order to provide a fairer comparison between dif ferent algorithms, since fiv e Byzantine nodes exceeds the theoretical limit of some algorithms (e.g., Bulyan). In both rounds of experiments, the algorithms operate under the assumption of b = 4 . W e conclude our discussion of the experimental setup by noting that the optimal Byzantine attack strategy that adv ersely af fects all distrib uted learning algorithms in a uniform manner remains an open problem. Nonetheless, the attack strategy being employed in our experiments has been carefully designed in light of the discussions in prior works (see, e.g., [12]); in particular , it appears to be the uniformly most potent strategy for the distrib uted learning algorithms under consideration in this article. The results of the experiments in terms of average classification accuracy are shown in Figure 5, which highlight some trade-offs that should help the practitioners select algorithms that best fit their needs. W e first note from T able II that the computational complexity of screening steps in Krum and Bulyan scales quadratically with the number of nodes M , whereas it scales only linearly with M in median, trimmed mean, and Zeno/Zeno++. Next, it can be seen from Figure 5 that all screening-based methods fall short of distributed SGD’ s performance in the faultless setting. This is in line with the con ventional wisdom 12 0 2500 5000 7500 10000 12500 15000 17500 20000 Number of Iterations (t) 20 30 40 50 60 70 Average Classification Accuracy (%) Distributed SGD Median Bulyan (w/ Krum) Zeno Krum Trimmed mean BRIDGE DGD 0 2500 5000 7500 10000 12500 15000 17500 20000 Number of Iterations (t) 10 20 30 40 50 60 70 Average Classification Accuracy (%) Distributed SGD Median Bulyan (w/ Krum) Zeno Krum Trimmed mean BRIDGE Fig. 5. Comparison of different distributed learning methods (with median and trimmed mean being coordinate wise) based on stochastic gradient descent. The left panel corresponds to the faultless setting, while the right panel corresponds to the case of four Byzantine nodes in the system. In both cases, the parameter b is set equal to 4 in all Byzantine-resilient algorithms. W e hav e also overlayed plots of two decentralized machine learning methods, namely , BRIDGE and DGD, on top of the ones for distributed learning methods; these two methods are discussed later in the article (see “Decentralized Machine Learning”). that robustness often comes at the expense of correctness, with median and Krum paying the highest price in terms of correctness, while Bulyan, trimmed mean, and Zeno paying the least (and somewhat insignificant) price. In the presence of Byzantine nodes, on the other hand, the vanilla distrib uted SGD completely falls apart. In contrast, while varying degrees of reduction in the performance of screening- based methods are observed under Byzantine attacks, none of them breaks down to the lev el of distributed SGD. Nonetheless, median, trimmed mean, and Krum (in this particular order) are affected the most in terms of performance by the aggressive Byzantine attack strate gy employed in our e xperiments. Bulyan and Zeno, on the other hand, seem to be the most stable under Byzantine attacks. In addition, both these methods offer a competitive tradeoff between correctness (in a faultless setting) and robustness (under attack). Howe ver , it is worth pointing out that Zeno’ s resilience comes at the expense of an oracle that can provide it with some knowledge of the true gradient. Similarly , since Bulyan screens four times the number of Byzantine nodes in each iteration, its resilience comes at the expense of a limited number of Byzantine nodes that it can handle (cf. T able II). I I . A D V E R S A RY - R E S I L I E N T D E C E N T R A L I Z E D P R O C E S S I N G O F D A TA Distributed systems in general, and distributed master–work er architectures in particular , hav e become the workhorse framework for non-centralized processing of data. The reasons for this range from relativ e ease of implementation and subsequent scaling up or scaling down of the system through addition or 13 remov al of nodes to relativ e simplicity of synchronization and communication protocols. Despite these and other related advantages, decentralized setups for inference and learning are increasingly being in ves- tigated in lieu of distributed setups for a multitude of reasons. Unlike the distributed setup, a decentralized system lacks a central server that is connected to every node (see “Decentralized Setup” in Figure 1). Instead, all nodes in a decentralized system maintain local copies of the decision v ariable/machine learning model and reach (approximate) consensus on a common solution through periodic exchange of messages ov er a network with a subset of other nodes, termed neighbors . Because of this reason, and unlike distributed systems, there is no single point of failure in decentralized systems. In the same vein, whereas the star communications topology in distributed master–w orker architectures can create a communications bottleneck at the central server (see “Distributed Setups” in Figure 1), the network/communications topologies in decentralized systems can be carefully designed to av oid such bottlenecks. One of the biggest reasons for the study of Byzantine-resilient inference and learning in decentralized systems, ho wev er , is the emergence of inherently decentralized applications such as networks of self-dri ving cars and robot swarms. Both centralized and distributed setups typically cannot be engineered in a cost-effecti ve manner in such applications, which are generally studied under the moniker of multiag ent systems . This necessitates the use of decentralized framew orks, often with ad-hoc network topologies, for statistical inference and machine learning. Since no single node in decentralized setups gets access to the entire set of local variables, ensuring robustness against Byzantine failures is generally harder in decentralized systems. In particular , unlike simple characterizations of the feasible and/or necessary relationships between the number of nodes M and the number of Byzantine nodes b in T able I and T able II, the necessary and/or suf ficient conditions for Byzantine-resilient decentralized algorithms are stated in terms of topology of the underlying network graph. In addition, while practical benefits of asynchronous update rules for and impact of time-varying network topologies on decentralized processing of data hav e long been in vestigated by researchers, the literature on Byzantine-resilient decentralized processing is relativ ely sparse in this regard. Because of this reason, and due to space constraints, our discussion in this article is mostly limited to synchronous algorithms on decentralized networks whose topology does not change with time (i.e., static graphs ). W e begin by engaging in discussion of an algorithmic process, aptly termed consensus , that often forms the basis of algorithms for decentralized inference and machine learning. A. Decentralized Consensus Many decentralized inference and learning algorithms require a subprocess that ensures (approximate) agreement, i.e., consensus, among all nodes. In the conte xt of Byzantine-resilient decentralized processing, 14 therefore, it is instructive to understand the fundamentals of Byzantine-resilient consensus. Our discussion in this reg ard will be limited to linear strate gies for consensus, which form the basis for Byzantine-resilient decision consensus, averaging consensus, con vex consensus, etc. [26], [27]. Suppose each node j in the decentralized system has a local variable w 0 j and it is desired to reach consensus on the av erage of these variables at each node through in-network message passing, i.e., w j ≈ 1 M M P i =1 w 0 i for every node j . Consensus algorithms usually proceed by having each node iterati vely take a weighted av erage of their neighbors’ variables. Mathematically , therefore, a consensus algorithm is associated with an M × M weight matrix whose ( j, i ) -th entry corresponds to the weight assigned by node j to the variable it receiv es from node i . In the absence of Byzantine nodes, a well-known result says that a doubly stochastic weight matrix whose smallest nonzero entry is lower bounded guarantees con vergence of all w j ’ s to the av erage 1 M M P i =1 w 0 i . Suppose, howe ver , that node k in the system is Byzantine and it transmits w k = w 0 to its neighbors in each iteration. This simple “lazy” Byzantine strategy is enough for all nodes to con ver ge to w 0 . And if there were another Byzantine node k 0 in the system that alw ays transmitted the same w k 0 6 = w 0 , nodes in the system will not reach consensus at all. The main idea behind ensuring robustness of (averaging) consensus to Byzantine nodes is to screen potential outliers at each node before the weighting step in each iteration. Since av eraging of finite- dimensional vectors is equiv alent to av eraging of their individual respecti ve (scalar) coordinates, much of the discussion in Byzantine-resilient consensus has focused on scalar-v alued problems. Some variant of the trimmed mean, in which a node removes the largest b and the smallest b values received from its neighbors (including itself), is in particular a common screening method used in scalar consensus. Clearly , each node has to have enough neighbors (e.g., more than 2 b for trimmed mean) for screening- based consensus to be well defined. Ho wev er , since the network must not become disconnected after screening, the exact constraint on network topology for different algorithms tends to be more in volved; see [26], [27] for further discussion of different screening methods and the corresponding topology constraints. Note that decentralized inference and learning algorithms utilizing similar screening ideas for Byzantine resilience tend to ha ve similar topology constraints. In terms of the performance of Byzantine-resilient consensus, ev en the best screening/aggregation method cannot guarantee remov al of all falsified data. Howe ver , equipped with a reasonable strategy , a Byzantine-resilient scalar consensus algorithm can guarantee two things in each iteration: ( i ) the retained v alues are between the smallest and the largest scalars at all nonfaulty nodes; and ( ii ) the difference between the largest and the smallest nonfaulty values decreases. T ogether , these two conditions can ensure that the nonfaulty nodes con ver ge to a common value. Howe ver , since a node can also retain falsified data 15 and/or eliminate nonfaulty data, consensus to the true a verage is no longer possible. Instead, guarantees can only be given to an approximate average such as a con ve x combination of initial values. This in particular is what makes Byzantine-resilient decentralized inference and learning so challenging. W e conclude by noting that asynchronous v ariants of decentralized consensus in the presence of Byzantine attacks have been in vestigated in [28], [29]. The asynchronicity in [29] comes through the use of randomized gossip algorithms, but the focus in that work is primarily on detection of Byzan- tine nodes. In contrast, [28] extends the synchronous (screening) frame work and analysis of [26] to asynchronous settings (and time-varying network topologies). A noteworth y implication of [28] is that asynchronicity does not impose additional topology constraints required for resilience of decentralized consensus algorithms. This is important since synchronous algorithms often incur additional latency; indeed, a synchronous algorithm can only be as fast as the slo west connection/node in the system. B. Decentralized Statistical Inference Similar to the case of distributed inference, we limit ourselves in here to decentralized detection and estimation. In both problems, decentralized consensus makes an integral part of the de veloped algorithms. Decentralized Detection: Similar to distributed detection, a typical setup in decentralized detection in volv es nodes in the system making observ ations under one of tw o (or more) hypotheses. Unlike distributed detection, ho we ver , nodes must collaborate among themselves to reach consensus in fa vor of one of the hypotheses. V ulnerability of the vanilla consensus framew ork to Byzantine nodes, therefore, also makes decentralized detection highly susceptible to Byzantine attacks. While sev eral application scenarios call for Byzantine-resilient decentralized detection, it has recei ved less attention compared to its distributed counterpart. Some of the most relev ant works in this regard include [30]–[32], all of which focus on scalar-v alued problems. In the spirit of Byzantine-resilient scalar consensus, an adaptive threshold-based screening method is utilized in [30] to mitigate the impact of Byzantine nodes on the final decision. Similarly , a robust variant of distributed alternating direction method of multipliers (ADMM) is proposed in [31] that uses trimmed mean to eliminate 2 b scalars at each node in every iteration. But other than the trivial topology constraint imposed by the trimmed mean (i.e., in-degree of nodes being greater than 2 b ), this work lacks guarantees. In contrast, [32] proposes and analyzes a robust detection scheme that in volves identification of Byzantine nodes and use of a weighted av erage consensus algorithm. Ho wev er , this work focuses on a particular variant of Byzantine attacks and does not characterize topology constraints as a function of the number of Byzantine nodes. Decentralized Estimation: Decentralized estimation, in which nodes use local observations and mes- sages from neighbors to reach consensus on the estimate of an unknown parameter w ∈ R d , is often 16 also studied under the linear model. Similar to decentralized detection, Byzantine-resilient decentralized estimation is a relatively recent topic of interest. Among relev ant works, [33] focuses on a specialized estimation problem in which node j need only estimate the j -th entry of w and there are three types of nodes in the system: reliable nodes, which are special nodes having perfect knowledge of the entry of w associated with them, ordinary (normal) nodes, and Byzantine nodes. Under this setup and the assumption of a time-varying directed graph, [33] proposes and analyzes a trimmed mean-type (scalar- v alued) screening procedure for Byzantine resilience. The works [34], [35] study vector -valued dynamic estimation under the noiseless observ ation model of y j [ n ] = w , n = 1 , . . . , for nonfaulty nodes. While the threat model in [34], [35] is a specialized v ariant of the Byzantine model, it allows the indices of the nodes under attack to change from one time instance to the ne xt one. Both [34], [35] use similar consensus+innov ations algorithms coupled with time-v arying gains to achiev e resilience. The main difference in these works is that [35] can achie ve linear conv ergence, as opposed to sublinear con vergence for [34], but it can only tolerate less than 30% of the nodes being under attack, in contrast to 50% for [34]. Finally , [36] accomplishes Byzantine-resilient decentralized dynamic estimation under the general linear model y j [ n ] = H j w + η j [ n ] by focusing on explicit detection of adversaries. W e conclude by noting that the re view article [2] provides more detailed o vervie w of [33], [34], [36]. C. Decentralized Machine Learning Decentralized machine learning algorithms, which can be considered a combination of consensus and distributed learning frame works, approximately solve (2) by minimizing a global loss function on the non-collocated data in a decentralized manner while reaching an agreement among all nodes, i.e., min { w 1 ,..., w M } 1 M M X j =1 f ( w j , Z j ) subject to w i = w j ∀ i, j, (3) where w j ∈ R d denotes the model learned at node j in the system. W e refer to (3) as the decentr alized ERM problem, which approximately solves the statistical risk minimization problem (2). W e focus here on synchronous gradient descent-based methods for solving (3). The classic decentralized gradient descent (DGD) method [37], for instance, in v olves each node j exchanging its current local iterate in ev ery iteration t with all nodes in its neighborhood N j and then updating the local iterate using a consensus-type weighted averaging step and a local gradient descent step, i.e., w t +1 j = α j j w t j + X i ∈N j α j i w t i | {z } consensus − ρ ( t ) g j ( w t j ) | {z } local gradient descent , (4) 17 where { α j i } is the collection of averaging weights, ρ ( t ) denotes the step size, and g j ( w ) := ∇ w f ( w , Z j ) denotes the local gradient. Similar to the case of “Decentralized Consensus, ” howe ver , a simple lazy Byzantine strate gy at one or more nodes will lead to breakdo wn of DGD-based learning methods. Scalar -valued Pr oblems: Robustification of decentralized ERM-based learning in the presence of Byzantine attacks requires resilient variants of DGD. The works in [4], [38] focus on this for scalar- v alued (i.e., d = 1 ) decentralized optimization. Similar to distributed learning and decentralized consensus, resilience in these methods is also achie ved through the use of a screening-based aggregation procedure within the consensus step in (4). The works [4], [38] in particular focus on trimmed-mean screening: after node j recei ves w i ∈ R from its neighbors, it removes the largest b and the smallest b w i ’ s and takes average of the remaining scalars for consensus. This leads to the following update rule: w t +1 j = 1 |N t j ∗ | X i ∈N t j ∗ w t i − ρ ( t ) g j ( w t j ) , (5) where N t j ∗ is the set of nodes (possibly including node j itself) that surviv e the screening at node j . This update can be shown to be Byzantine resilient in the sense that the w t j ’ s con verge to the minimizer of some con vex combination of local losses f ( w , Z j ) . W e also have a result from [4] that the minimum of the decentralized ERM in (3), e ven when restricted to the set of nonfaulty nodes, cannot be achie ved in the presence of Byzantine nodes. Despite this negati ve result, it can be sho wn that any con vex combination of local losses will con ver ge in probability to the global statistical risk in the case of i.i.d. training samples. This can then be le veraged to establish the robustness of (5) for scalar-v alued decentralized learning [39]. V ector -valued Problems: The algorithms in [4], [38] cannot be directly utilized in vector -valued problems (i.e., w ∈ R d for d > 1 ). On the one hand, unless a problem decouples o ver different coordinates of the optimization variable w , minimizing the objective function along one coordinate independent of the other coordinates does not yield the right solution. On the other hand, since the trimmed-mean procedure of [4], [38] requires sorting of values recei ved from one’ s neighbors, it cannot be directly applied to members of an unorder ed space like R d . This limitation of [4], [38] is ov ercome in [39], which proposes an algorithm termed Byzantine-r esilient decentralized coor dinate descent (ByRDiE) for vector -valued decentralized learning in the presence of Byzantine nodes. ByRDiE, fundamentally being a coordinate descent method, cyclically updates one coordinate at a time in a decentralized manner . And since each subproblem in coordinate descent becomes a scalar-v alued problem, ByRDiE uses trimmed- mean screening in each inner (coordinate-wise) iteration for Byzantine resilience. The final update rule in each coordinate-wise iteration of ByRDiE takes a form similar to (5), except that the gradient term also depends on other coordinates of w . For strictly con vex and smooth loss functions, [39] guarantees 18 (algorithmic and statistical) con vergence of the iterates of ByRDiE to the statistical minimizer , with the algorithmic con vergence rate being sublinear and the statistical learning rate being O a/ √ M N ; here, N again denotes the number of i.i.d. training samples per node, while the parameter a differs from one problem setup (and Byzantine attack model) to another and satisfies 1 ≤ a ≤ √ M . Despite these guarantees, which establish that ByRDiE can result in robust and (sample-wise) fast statistical learning in decentralized setups that exceeds the local learning rate of O 1 / √ N [39], the one-coordinate-at-a- time update of ByRDiE can be inefficient for high-dimensional (i.e., d 1 ) problems. Indeed, since the coordinate-wise gradient update step depends on the updates of other coordinates, the iterates in ByRDiE cannot be updated in a coordinate-wise parallel fashion, leading to high network coordination and local computation o verheads in decentralized learning. T o curtail the high ov erheads of ByRDiE, [40] presents another algorithm—termed Byzantine-r esilient decentralized gradient descent (BRIDGE)—that is based on gradient descent and coordinate-wise trimmed mean. Similar to DGD, each node j in BRIDGE also exchanges its entir e current iterate w t j in e very iteration t with all nodes in its neighborhood N j . The update step in BRIDGE, howe ver , inv olves coordinate-wise screening/aggregation of w t j ’ s using trimmed mean with parameter 2 b , which is follo wed by a local gradient descent step. Mathematically , the (parallel) update of the k -th coordinate is giv en by ∀ k ∈ { 1 , . . . , d } (in parallel) , w t +1 j ( k ) = 1 |N t,k j ∗ | X i ∈N t,k j ∗ w t i ( k ) − ρ ( t ) g k j ( w t j ) , (6) where N t,k j ∗ is the set of nodes whose k -th coordinates surviv e the screening at node j and g k j ( w ) denotes the k -th coordinate of the local gradient g j ( w ) . In the case of strongly conv ex and smooth loss functions, theoretical guarantees for BRIDGE match those for ByRDiE. T opology Constraints: W e noted earlier (see “Decentralized Consensus”) that Byzantine resilience in decentralized setups depends on network topology . W e no w describe two related topology constraints for trimmed mean-based decentralized learning. The constraint in [4] requires that, after removing all b Byzantine nodes and any combination of remaining b (incoming) edges from each node, there is always a group of nodes—termed sour ce component —of cardinality at least ( b + 1) that has a directed path to ev ery other node. In words, this constraint means ev ery nonfaulty node, ev en after trimmed-mean screening, can always receiv e information—directly or indirectly—from the source component. The topology constraints for ByRDiE and BRIDGE are also based on this condition. The constraint in [38], on the other hand, is based on the idea that any two arbitrary partitions of the network must result in one of the partitions having at least one node with (2 b + 1) neighbors outside the partition. This, in turn, guarantees that b Byzantine nodes cannot isolate any subset of nonfaulty nodes during trimmed-mean screening. 19 Bey ond T rimmed-mean Screening: Unlike distributed learning, where se veral screening methods and aggregation rules hav e been proposed and analyzed for Byzantine resilience (T able II), utilization of screening methods in decentralized learning has been limited to (coordinate-wise) trimmed mean. The main reason for this is the need for iterate consensus in decentralized learning, which makes analysis of other screening/aggregation methods challenging. (It is also worth noting that our focus here is on iterate screening, as opposed to gradient screening in distributed learning.) In practice, it is possible to merge the ideas behind BRIDGE and screening methods such as coordinate-wise median, Krum, and Bulyan to de velop other Byzantine-resilient decentralized learning methods. This is indeed the approach we hav e taken in the numerical experiments discussed in the following. Consensus, con vergence analysis, and statistical learning rates of such methods, howe ver , remain an open problem. Numerical Experiments: W e first compare the performance of DGD, ByRDiE, BRIDGE and three v ariants of BRIDGE that come about from incorporation of the screening principles of (coordinate-wise) median, Krum, and Bulyan (with Krum) within the BRIDGE framework. The computational inefficiency of ByRDiE for high-dimensional datasets and machine learning models necessitates an experimental setup, both in terms of the dataset and the learning task, that differs from the one utilized as part of our discussion on Byzantine-resilient distrib uted machine learning. Specifically , note that each (colored) image in the CIF AR-10 dataset is 3 , 072 -dimensional and the corresponding con volutional neural network used earlier in our discussion for this dataset giv es rise to a model with d = 122 , 410 . In contrast, we resort to a computationally tractable experimental setup in here that corresponds to multiclass classification of MNSIT dataset ( 784 -dimensional data samples) using a linear one-layer neural network (i.e., d = 7 , 840 ). In addition to being computationally manageable for ByRDiE, this setup also results in a loss function that satisfies the theoretical conditions for con ver gence of ByRDiE and BRIDGE. The decentralized system in our experimental setup in volv es a total of M = 20 nodes in the network, with a communications link (edge) between two nodes decided by a random coin flip. Once a random topology is generated, we ensure each node has at least 4 b + 1 nodes in its neighborhood (a condition imposed due to Bulyan screening). The training data at each node corresponds to N = 2 , 000 samples randomly selected from the MNIST dataset. The performance of each method is reported in terms of classification accuracy , averaged ov er ( M − b ) nodes and a total of 10 independent Monte Carlo trials, as a function of the number of scalars broadcast per node. The final results, shown in Figure 6, correspond to two sets of experiments: ( i ) the faultless setting in which none of the nodes actually behav es maliciously; and ( ii ) the setting in which two of the 20 nodes are Byzantine, with each Byzantine node broadcasting e very coordinate of the iterate as a uniform random variable between − 1 and 0 . Note that this Byzantine 20 0 100000 200000 300000 400000 500000 600000 700000 800000 Number of Scalars Broadcast per Node 10 20 30 40 50 60 70 80 90 Average Classification Accuracy (%) DGD ByRDiE BRIDGE Median Krum Bulyan 0 100000 200000 300000 400000 500000 600000 700000 800000 Number of Scalars Broadcast per Node 10 20 30 40 50 60 70 80 90 Average Classification Accuracy (%) DGD ByRDiE BRIDGE Median Krum Bulyan Fig. 6. Performance comparison of different decentralized learning methods in both faultless (left panel) and Byzantine settings (right panel). Byzantine-resilient algorithms in both settings operate under the assumption of b = 2 . The algorithms entitled Median , Krum , and Bulyan are effectiv ely BRIDGE combined with the screening procedures advocated in distributed learning. attack strategy is by no means the most potent in all decentralized settings. Howe ver , similar to the attack strate gy utilized in our earlier discussion on distributed learning, this particular strate gy has been selected after careful ev aluation of the impact of different strategies proposed in works such as [12]–[14] on our particular experimental setup. Finally , with the exception of DGD, all methods are initialized with parameter b = 2 in both faultless and faulty scenarios. It can be seen from Figure 6 that, other than ByRDiE and Krum-based screening, all methods perform almost as well as DGD in the f aultless case. In the presence of Byzantine nodes, ho we ver , DGD completely falls apart, whereas the performances of all screening methods remain comparable to the faultless setting. It is also worth comparing these results to those for Byzantine-resilient distributed learning (see Figure 5). While (coordinate-wise) median and trimmed mean appear to be the worst performers in Figure 5, Krum- based screening is the least effecti ve in Figure 6. In both cases, ho we ver , Bulyan is quite effecti ve, except that it has stringent topology requirements. W e conclude by explicitly comparing the performance of DGD and BRIDGE in decentralized settings to that of (Byzantine-resilient) learning methods in distrib uted settings. Since DGD and BRIDGE are scalable to high-dimensional learning tasks, our experimental setup, dataset, data distribution, learning task, and Byzantine attack strategy for this comparison are identical to the ones described earlier for Byzantine- resilient distributed learning methods. In order to ensure the decentralized setup in the case of BRIDGE satisfies the topology constraints corresponding to four Byzantine nodes in the system, we use 0 . 7 as the probability of random connectivity between any two nodes. The final results for DGD and BRIDGE, 21 which are overlayed on top of the ones for distributed learning methods in Figure 5, show that BRIDGE of fers competitiv e performance in both faultless and faulty systems. In fact, BRIDGE (and DGD) have faster con vergence rates than the distributed learning methods for this particular nonconv ex problem, decentralized setup, and Byzantine strategy . While this could be partly attributable to higher network connecti vity of 0 . 7 in the decentralized setting, a careful head-to-head comparison and understanding of distributed and decentralized learning methods in both faultless and faulty settings is an open problem. I I I . S O M E O P E N R E S E A R C H P R O B L E M S Despite recent advances, Byzantine-resilient inference and learning remains an active area of research with sev eral open problems. Much of the focus in distributed inference has been on the some what restricti ve model in which Byzantine nodes do not collude. Collaborativ e Byzantine attacks, on the other hand, can be much more potent than independent ones. A fundamental understanding of mechanisms for safeguarding against such attacks remains a relativ ely open problem in distributed inference. Byzantine- resilient distributed estimation under nonlinear models is another problem that has been relati vely un- explored. In the case of Byzantine-resilient distributed learning, existing works have only scratched the surface. Con ver gence and/or learning rates of many of the proposed methods remain unknown (T able II). In addition, while SGD is a workhorse of machine learning, approaches such as accelerated first-order methods (e.g., accelerated gradient descent), first-order dual methods (e.g., ADMM), and second-order methods (e.g., Newton’ s method) do play important roles in machine learning. Howe ver , resilience of distributed variants of such methods to Byzantine attacks has not been in vestigated in the literature. The lack of a central server , the need for consensus, and an ad-hoc topology make it ev en more challenging to de velop and analyze Byzantine-resilient methods for decentralized inference and learning. Much of the work in this regard is based on screening methods such as trimmed mean and median that originated in the literature on Byzantine-resilient scalar-v alued consensus. This has left open the question of how other screening methods, such as the ones explored within distributed learning, might handle Byzantine attacks—both in theory and in practice—in various decentralized problems. Unlike distributed learning, any such efforts will also hav e to characterize the interplay between network topology and effec- ti veness of the screening procedure. The fundamental tradeof fs between the robustness and the (faultless) performance of Byzantine-resilient methods also remain lar gely unknown for decentralized setups. Finally , existing works on decentralized learning only guarantee sublinear con ver gence for strictly/strongly con vex and smooth functions. Whether this can be improv ed by taking advantage of faster distrib uted optimization frame works or different screening methods also remains an open question. 22 I V . C O N C L U S I O N S In this article, we hav e presented an ov erview of latest advances in Byzantine-resilient inference and learning. In the distributed master–w orker setting, which is characterized by the presence of a central server that computes the final solution, we discussed recent results concerning resilience of distributed detection, estimation, and machine learning against Byzantine attacks. Within distributed machine learning, we focused on Byzantine-resilient v ariants of distributed stochastic gradient descent, whose performances were compared using numerical experiments. In the decentralized setting, which typically requires consensus due to lack of a central server , we first discussed the principles behind Byzantine-resilient consensus. This was followed by a discussion of latest results on decentralized detection, estimation, and learning in the presence of Byzantine nodes. W e also compared and contrasted dif ferent Byzantine-resilient decentralized learning methods using numerical experiments, and discussed similarities and differences between them and distributed learning methods. Byzantine-resilient inference and learning has a number of research challenges that remain unaddressed, some of which are also briefly discussed in the article. A C K N O W L E D G E M E N T S The authors gratefully acknowledge the support of the NSF (CCF-1453073, CCF-1907658), the ARO (W911NF-17-1-0546), and the D ARP A Lagrange Program (ONR/SP A W AR contract N660011824020). S H O RT B I O G R A P H I E S Zhixiong Y ang (zhixing.yang@rutgers.edu) recei ved BS degree from Beijing Jiaotong Uni versity , China in 2011, MS degree from Northeastern Uni versity , MA in 2013, and PhD in electrical engineering from Rutgers Univ ersity–New Brunswick, NJ in 2020. He is currently a system engineer at Blue Danube Systems. His research interests are distributed processing, machine learning, and massiv e MIMO systems. Arpita Gang (arpita.gang@rutgers.edu) receiv ed BT ech degree from the National Institute Of T echnology , Silchar , India, and MT ech degree from IIIT -Delhi, India. Since 2017, she has been pursuing PhD in electrical engineering from Rutgers Univ ersity–New Brunswick, NJ. Her research interests are distributed optimization and signal processing. She is a graduate student member of the IEEE. W aheed U. Bajwa (waheed.bajwa@rutgers.edu) has been with Rutgers Univ ersity–New Brunswick, NJ since 2011, where he is currently an associate professor in the Departments of Electrical & Computer Engineering and Statistics. His research interests include statistical signal processing, high-dimensional statistics, and machine learning. He is a senior member of the IEEE. 23 R E F E R E N C E S [1] A. V empaty , L. T ong, and P . V arshney , “Distributed inference with Byzantine data: State-of-the-art revie w on data falsification attacks, ” IEEE Signal Pr ocess. Mag. , v ol. 30, no. 5, pp. 65–75, 2013. [2] Y . Chen, S. Kar, and J. M. F . Moura, “The Internet of Things: Secure distributed inference, ” IEEE Signal Pr ocess. Mag. , vol. 35, no. 5, pp. 64–75, 2018. [3] J. Zhang, R. S. Blum, and H. V . Poor, “ Approaches to secure inference in the Internet of Things: Performance bounds, algorithms, and effecti ve attacks on IoT sensor networks, ” IEEE Signal Pr ocess. Mag. , v ol. 35, no. 5, pp. 50–63, 2018. [4] L. Su and N. V aidya, “Fault-tolerant distributed optimization (Part IV): Constrained optimization with arbitrary directed networks, ” arXiv preprint , 2015. [5] L. Lamport, R. Shostak, and M. Pease, “The Byzantine generals problem, ” ACM T rans. Pr ogramming Languages and Syst. , vol. 4, no. 3, pp. 382–401, 1982. [6] V . S. S. Nadendla, Y . S. Han, and P . K. V arshney, “Distributed inference with M-ary quantized data in the presence of Byzantine attacks, ” IEEE T rans. Signal Process. , vol. 62, no. 10, pp. 2681–2695, 2014. [7] B. Kailkhura, Y . S. Han, S. Brahma, and P . K. V arshney, “Distributed Bayesian detection in the presence of Byzantine data, ” IEEE T rans. Signal Pr ocess. , vol. 63, no. 19, pp. 5250–5263, 2015. [8] W . Hashlamoun, S. Brahma, and P . K. V arshney, “ Audit bit based distributed Bayesian detection in the presence of Byzantines, ” IEEE T rans. Signal Inform. Proc. over Netw . , vol. 4, no. 4, pp. 643–655, 2018. [9] B. Kailkhura, S. Brahma, B. Dulek, Y . S. Han, and P . K. V arshney, “Distributed detection in tree networks: Byzantines and mitigation techniques, ” IEEE T rans. Inf. F or ens. Security , vol. 10, no. 7, pp. 1499–1512, 2015. [10] J. Haupt, W . U. Bajwa, M. Rabbat, and R. Nowak, “Compressed sensing for networked data, ” IEEE Signal Pr ocess. Mag. , vol. 25, no. 2, pp. 92–101, 2008. [11] A. V empaty, O. Ozdemir, K. Agrawal, H. Chen, and P . K. V arshney, “Localization in wireless sensor networks: Byzantines and mitigation techniques, ” IEEE T rans. Signal Process. , v ol. 61, no. 6, pp. 1495–1508, 2013. [12] C. Xie, S. Koyejo, and I. Gupta, “Fall of empires: Breaking Byzantine-tolerant SGD by inner product manipulation, ” arXiv pr eprint arXiv:1903.03936 , 2019. [13] M. Fang, X. Cao, J. Jia, and N. Z. Gong, “Local model poisoning attacks to Byzantine-robust federated learning, ” arXiv pr eprint arXiv:1911.11815 , 2019. [14] G. Baruch, M. Baruch, and Y . Goldberg, “ A little is enough: Circumventing defenses for distributed learning, ” in Pr oc. Advances in Neural Inf. Pr ocess. Syst. (NeurIPS’19) , 2019, pp. 8632–8642. [15] D. Y in, Y . Chen, K. Ramchandran, and P . Bartlett, “Byzantine-robust distributed learning: To wards optimal statistical rates, ” in Pr oc. 35th Int. Conf. Machine Learning (ICML’18) , 2018, vol. 80, pp. 5650–5659. [16] Y . Chen, L. Su, and J. Xu, “Distributed statistical machine learning in adversarial settings: Byzantine gradient descent, ” in Pr oc. ACM Measur ement and Analysis of Computing Systems , Dec. 2017, vol. 1, pp. 44:1–44:25. [17] P . Blanchard, R. Guerraoui, and J. Stainer , “Machine learning with adversaries: Byzantine tolerant gradient descent, ” in Pr oc. Advances in Neural Inf. Pr ocess. Syst. (NeurIPS’17) , 2017, pp. 118–128. [18] E. El-Mhamdi, R. Guerraoui, and S. Rouault, “The hidden vulnerability of distributed learning in Byzantium, ” in Pr oc. 35th Int. Conf. Machine Learning (ICML’18) , 2018, vol. 80, pp. 3521–3530. [19] E. El-Mhamdi and R. Guerraoui, “Fast and secure distrib uted learning in high dimension, ” arXiv preprint , 2019. [20] C. Xie, O. K oyejo, and I. Gupta, “Zeno: Byzantine-suspicious stochastic gradient descent, ” arXiv pr eprint arXiv:1805.10032 , 2018. 24 [21] C. Xie, O. Koyejo, and I. Gupta, “Zeno++: Robust asynchronous SGD with arbitrary number of Byzantine workers, ” arXiv pr eprint arXiv:1903.07020 , 2019. [22] C. Xie, O. Koyejo, and I. Gupta, “Generalized Byzantine-tolerant SGD, ” arXiv preprint , 2018. [23] L. Li, W . Xu, T . Chen, G. Giannakis, and Q. Ling, “RSA: Byzantine-robust stochastic aggregation methods for distributed learning from heterogeneous datasets, ” in Pr oc. AAAI Conf. on Artificial Intelligence (AAAI’19) , 2019, vol. 33, pp. 1544– 1551. [24] J. Bernstein, J. Zhao, K. Azizzadenesheli, and A. Anandkumar , “signSGD with majority vote is communication efficient and Byzantine fault tolerant, ” arXiv preprint , 2018. [25] D. Alistarh, Z. Allen-Zhu, and J. Li, “Byzantine stochastic gradient descent, ” in Pr oc. Advances in Neural Inf. Pr ocess. Syst. (NeurIPS’18) , 2018, pp. 4618–4628. [26] H. J. LeBlanc, H. Zhang, X. Koutsouk os, and S. Sundaram, “Resilient asymptotic consensus in robust networks, ” IEEE J. Sel. Ar eas Commun. , vol. 31, no. 4, pp. 766–781, 2013. [27] N. V aidya, “Matrix representation of iterativ e approximate Byzantine consensus in directed graphs, ” arXiv pr eprint arXiv:1203.1888 , 2012. [28] L. Haseltalab and M. Akar , “ Approximate Byzantine consensus in faulty asynchronous networks, ” in Pr oc. American Contr ol Conf. (ACC’15) . IEEE, 2015, pp. 1591–1596. [29] D. Silvestre, P . Rosa, J. P . Hespanha, and C. Silvestre, “Stochastic and deterministic fault detection for randomized gossip algorithms, ” Automatica , vol. 78, pp. 46–60, 2017. [30] S. Liu, H. Zhu, S. Li, C. Chen, and X. Guan, “ An adaptive deviation-tolerant secure scheme for distributed cooperative spectrum sensing, ” in Pr oc. IEEE Global Commun. Conf. (GLOBECOM’12) , 2012, pp. 603–608. [31] B. Kailkhura, P . Ray, D. Rajan, A. Y en, P . Barnes, and R. Goldhahn, “Byzantine-resilient locally optimum detection using collaborativ e autonomous networks, ” in Proc. IEEE 7th Int. W orkshop Computational Advances Multi-Sensor Adaptive Pr ocess. (CAMSAP’17) , 2017, pp. 1–5. [32] B. Kailkhura, S. Brahma, and P . K. V arshney, “Data falsification attacks on consensus-based detection systems, ” IEEE T rans. Signal Inform. Proc. over Netw . , vol. 3, no. 1, pp. 145–158, 2017. [33] H. J. LeBlanc and F . Hassan, “Resilient distributed parameter estimation in heterogeneous time-varying networks, ” in Pr oc. 3rd Int. Conf. High Confidence Networked Syst. (HiCoNS’14) , 2014, pp. 19–28. [34] Y . Chen, S. Kar, and J. M. F . Moura, “Resilient distributed estimation: Sensor attacks, ” IEEE T rans. Automat. Contr ol , vol. 64, no. 9, pp. 3772–3779, 2018. [35] Y . Chen, S. Kar, and J. M. F . Moura, “Resilient distributed estimation: Exponential con vergence under sensor attacks, ” in Pr oc. IEEE Conf. Decision Contr ol (CDC’18) , 2018, pp. 7275–7282. [36] Y . Chen, S. Kar, and J. M. F . Moura, “Resilient distributed estimation through adversary detection, ” IEEE T rans. Signal Pr ocess. , vol. 66, no. 9, pp. 2455–2469, 2018. [37] A. Nedi ´ c and A. Ozdaglar , “Distributed subgradient methods for multi-agent optimization, ” IEEE T rans. Automat. Control , vol. 54, no. 1, pp. 48–61, 2009. [38] S. Sundaram and B. Gharesifard, “Distributed optimization under adversarial nodes, ” IEEE T rans. Automat. Control , vol. 64, no. 3, pp. 1063–1076, 2019. [39] Z. Y ang and W . U. Bajwa, “ByRDiE: Byzantine-resilient distributed coordinate descent for decentralized learning, ” IEEE T rans. Signal Inform. Proc. over Netw . , vol. 5, no. 4, pp. 611–627, 2019. [40] Z. Y ang and W . U. Bajwa, “BRIDGE: Byzantine-resilient decentralized gradient descent, ” arXiv pr eprint arXiv:1908.08098 , 2019.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment